
Abstract
Lobar cerebral microbleeds (CMBs) and localized non-hemorrhage iron deposits in the basal ganglia have been associated with brain aging, vascular disease and neurodegenerative disorders. Particularly, CMBs are small lesions and require multiple neuroimaging modalities for accurate detection. Quantitative susceptibility mapping (QSM) derived from in vivo magnetic resonance imaging (MRI) is necessary to differentiate between iron content and mineralization. We set out to develop a deep learning-based segmentation method suitable for segmenting both CMBs and iron deposits. We included a convenience sample of 24 participants from the MESA cohort and used T2-weighted images, susceptibility weighted imaging (SWI), and QSM to segment the two types of lesions. We developed a protocol for simultaneous manual annotation of CMBs and non-hemorrhage iron deposits in the basal ganglia. This manual annotation was then used to train a deep convolution neural network (CNN). Specifically, we adapted the U-Net model with a higher number of resolution layers to be able to detect small lesions such as CMBs from standard resolution MRI. We tested different combinations of the three modalities to determine the most informative data sources for the detection tasks. In the detection of CMBs using single class and multiclass models, we achieved an average sensitivity and precision of between 0.84–0.88 and 0.40–0.59, respectively. The same framework detected non-hemorrhage iron deposits with an average sensitivity and precision of about 0.75–0.81 and 0.62–0.75, respectively. Our results showed that deep learning could automate the detection of small vessel disease lesions and including multimodal MR data (particularly QSM) can improve the detection of CMB and non-hemorrhage iron deposits with sensitivity and precision that is compatible with use in large-scale research studies.
Similar content being viewed by others
Introduction
The aging brain is subject to various irreversible changes, some driven by the aging process itself and others that are associated with various pathologies, including vascular lesions and neurodegeneration1,2,3,4. On magnetic resonance imaging (MRI), particularly tuned to be sensitive for differences in magnetic susceptibility, focal accumulations of iron content can be visible. This includes lesions with iron content such as cerebral microbleeds (CMBs) and non-hemorrhage iron deposits in the basal ganglia. CMBs are small hemorrhages that can occur sporadically throughout the brain5. CMBs have been associated with cognitive decline and dementia6, and are considered a biomarker for small vessel diseases. The presence of lobar CMBs is also a marker for cerebral amyloid angiopathy7,8,9. Non-hemorrhage iron deposits are located in the deep structures of the brain, particularly in the basal ganglia. While an increase in iron concentration in the basal ganglia is expected in healthy aging10, focal accumulation of iron has been associated with neurodegenerative disorders in small scale studies11,12,13.
Most of our knowledge on the iron toxicity in the aging brain is limited by the fact that both CMBs and iron deposits could be difficult to distinguish from each other and from other similar lesions including calcification using conventional MRI techniques14. T2* gradient-recalled echo (GRE) and susceptibility-weighted imaging (SWI) are often used to clinically characterize CMBs, with the latter being more sensitive for detecting CMBs15,16. CMBs can occur anywhere and appear as small rounded or ellipsoidal hypo-intense regions with a diameter of ten millimeters or less7,14,17. Non-hemorrhage iron deposits in the basal ganglia have irregular shapes and could be larger than CMBs14. Because hypo-intensities in SWI are not specific to CMBs and non-hemorrhage iron deposits, images with other tissue contrasts are required in order to identify other lesion types that can have similar low susceptibility signal on SWI, such as calcification5,18,19. The specificity for CMB detection can be increased by post-processing SWI-magnitude and phase data to derive quantitative susceptibility maps (QSM)20,21. In QSM paramagnetic tissue appears different from diamagnetic materials, and therefore this contrast is particularly useful for distinguishing non-hemorrhage iron deposits from calcifications22,23. While previous efforts have been made to automate the detection of microbleeds, all previous work neglected the detection of non-hemorrhage iron deposits in such automated frameworks24,25,26,27,28,29,30.
No work has been published to date on segmenting iron deposits in the brain using QSM with either a semi- or a fully automatic method. The advances made in MRI technology with QSM for iron content recognition are gaining more attention as cohort-based studies such as The Multi-Ethnic Study of Atherosclerosis (MESA)31,32,33 include QSM in their imaging protocol, and thus exploit its advantages in delivering specific insights on iron toxicity in the aging brain. The focus in MESA is utilizing non-invasive methods to investigate common risk factors, preclinical disease states and manifest diseases using a standardized imaging protocol, which is applied to all participants34. On one hand, this is providing a unique opportunity to study widely ignored lesions such as iron deposits in vivo using MRI but on the other hand, this comes with additional challenges as such cohorts naturally include largely cognitively normal participants with a low lesion load, resulting in a very challenging task to automate.
In order to tackle the challenges inherent in the detection of these lesions, we developed a robust and fully automated deep learning-based method to detect CMBs and non-hemorrhage iron deposits in a cohort without extensive apparent brain tissue damage and having a low load of CMBs and non-hemorrhage basal ganglia iron deposits. We experimented with both single class and multiclass segmentation models using multiple MR sequences. Our experiments show that using multi-sequence MRI (especially QSM) improves the overall accuracy of detection. The main contributions of this study include the following:
We tackled the challenging problem of simultaneously detecting CMBs and non-hemorrhage iron deposits. To our knowledge, this is one of the first reports to detect both types of lesions simultaneously. Often iron accumulation in the brain has been understudied due to the lack of appropriate techniques for detecting them in vivo in large-scale epidemiological studies;
We found out the most suitable pulse sequence combination to automate the detection tasks by exploiting imaging information jointly;
We developed an effective and flexible neural network model that is specially tailored to the differential detection task. The proposed model can be easily adapted to segment additional lesions;
We achieved highly competitive detection performance on real-life data, demonstrating the effectiveness of the proposed approach in practical applications;
We also provide access to our source code and a few trained models via the GitHub link https://github.com/NAL-UTHSCSA/CMB_NHID_Segmentation.
Results
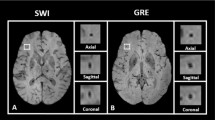
We performed leave-one-out cross-validated evaluations for both single class and multiclass segmentation experiments using the 24 participants listed in Supplementary Table 2.1. Panel A in Figure 1 shows an example of the automated segmentation of a CMB (indicated by the red arrow). Panel B in Fig. 1 shows the segmentation of the focal iron deposits in the basal ganglia. In this figure, the model correctly segmented the iron deposit lesions (indicated by the green arrow) while rejecting an instance of calcification (indicated by the yellow arrow). The results of these experiments are reported in Tables 1 and 2. Pearson correlation and Bland–Altman mean difference and confidence intervals for single class and multiclass experiments are reported in Tables 1 and 2 respectively, for the experiments with 24 participants. Overall, our experiments show that incorporating QSM in model training can increase the overall accuracy of CMB and iron deposit detection.

(A) Segmentations of CMBs by a model trained with SWI, QSM and T2w. (Top) An example of the correct segmentation of a small microbleed (red arrow). (Bottom) Magnified view of microbleed with segmentation mask (single red pixel). (B) An example of QSM being used to distinguish iron deposits from calcifications in the basal ganglia. (Top row) The SWI for TE = 7.5 ms, SWI for TE = 22.5 ms and QSM of the basal ganglia. The yellow arrow points to hypo-intense voxels which are likely calcifications and the green arrow points to basal ganglia iron deposits. (Bottom row) The segmentation mask (green labels) of the iron deposits. For both (A, B), the segmentations were generated by the multiclass model trained with SWI, QSM and T2w.
In the case of segmenting CMBs, the best performance in terms of average magnitude accuracy was seen with the model trained with SWI and QSM in both single class and multiclass experiments. The correlation coefficient between the prediction and ground truth was also high (r = 0.97 and r = 0.99, for single class and multiclass results, respectively) when QSM was included in the training. For non-hemorrhage iron deposits, the single class model trained with all three modalities had the highest average magnitude accuracy and the multiclass model trained with SWI and QSM had the highest average magnitude accuracy. The correlation coefficient was also highest for models that included QSM for training (r = 0.92 and r = 0.91 for single class and multiclass results, respectively). Figure 2 shows a joint scatterplot of the single class experimental results and Fig. 3 shows a joint scatterplot of the multiclass experiments.

Joint scatterplots of the sensitivity vs precision of all single class experiments predicting CMBs and non-hemorrhage iron deposits. (Left) all CMB only experiments and (Right) all iron deposits only experiments. In each subplot, the round points indicate the individual participants’ sensitivity and precision evaluated with leave-one-out cross-validation, and the X indicates the mean sensitivity and precision. The legend at the upper left corner of each subplot shows the coordinates of X. In each subplot, histograms of the sensitivity and precision are displayed along the upper and right axes.

Joint scatterplots of the sensitivity vs precision of all multiclass experiments predicting CMBs and non-hemorrhage iron deposits. (Left) all evaluations for CMBs and (Right) all evaluations for iron deposits. In each subplot, the round points indicate the individual participants’ sensitivity and precision evaluated with leave-one-out cross-validation, and the X indicates the mean sensitivity and precision. The legend at the upper left corner of each subplot shows the coordinates of X. In each subplot, histograms of the sensitivity and precision are displayed along the upper and right axes.
In our dataset, we identified as an outlier a single individual with exceptionally many CMBs. A comparative analysis was done by removing this outlier from the dataset and repeating a similar cross-validated evaluation by retraining both single class and multiclass models. The results are detailed in Supplementary Tables 3.1 and 3.2 in Sect. 3 of the “Supplementary materials”. With the exception of multiclass CMBs, we note that the best result in terms of magnitude accuracy was seen when the model training includes QSM. This is also reflected by the correlation coefficients. Models which included QSM showed a higher correlation between the number of predicted lesions and reference annotation. For CMBs, the correlation r = 0.51 and r = 0.69, for single class and multiclass results, respectively. For iron deposits, the correlation r = 0.94 and r = 0.97 for single class and multiclass results, respectively.
We have conducted another experiment where we modified the proposed DEEPMIR architecture by removing one layer. The results of this experiment are reported in Supplementary Table 4.2 in Sect. 4 of the “Supplementary materials”. For detecting CMBs, the model trained with SWI, QSM and T2w has the highest magnitude accuracy. For detecting iron deposits, the model trained with SWI and QSM showed the highest magnitude accuracy but having a lower correlation coefficient (r = 0.75), while the model trained with SWI, QSM and T2w reports similar magnitude accuracy and higher correlation coefficient (r = 0.93).
An additional leave-one-out cross-validated evaluation was done for the 24 participants using an implementation of the original U-Net35. The results of this experiment are reported in Supplementary Table 4.1 in Sect. 4 of the “Supplementary materials”. In these experiments, we note that the models trained with SWI, QSM and T2w had the best performance in terms of magnitude accuracy for both CMBs and iron deposits. However, in terms of the correlation coefficient, we note that the model trained with SWI and QSM had the highest correlation (r = 0.98 and r = 0.93, for CMBs and iron deposits, respectively).
We investigated the performance of the proposed DEEPMIR architecture for the simultaneous differentiation and labeling of both CMB and iron deposit labels against the performance of the original U-Net and a modified DEEPMIR architecture (having the same number of resolution layers as the original U-Net). We note that the proposed DEEPMIR model with 6 resolution layers has better overall sensitivity for detecting small lesions such as CMBs. Supplementary Figs. 12 and 13 show examples of small lesions that the original U-Net and the modified DEEPMIR models were unable to detect, compared to the accurate detection by the proposed DEEPMIR architecture.
Discussion
We developed a deep learning framework for simultaneous segmentation of cerebral microbleeds and non-hemorrhage iron deposits using multi-modal MRI. To date, previously published methods for automated or semi-automated CMB detection have ignored iron deposits. In this study, we consider the iron deposit in the basal ganglia seen as hypo-intense lesions on SWI and confirmed by QSM to be iron-specific rather than mineralization. Those lesions may typically be labeled as possible or uncertain microbleeds on MARS18 and BOMBS19 mainly because of the limitation that T2* and SWI cannot differentiate iron content from mineralization. We overcome this limitation by including QSM in our study, which has shown to improve the overall accuracy for automated detection. To our knowledge, there are no studies that attempted to segment these focal iron deposits using SWI and/or QSM automatically. Our deep learning-based segmentation method presented here is filling in this gap. We have undertaken several experiments using both single class and multiclass models with different combinations of the available MR pulse sequences. We noted that the models which included QSM in training consistently performed better and the resulting predictions had statistically high correlations when compared to the reference annotation.
Our approach has several advantages over the current state-of-the-art methods for CMB detection. First, by using deep learning our model is capable of learning and generalizing features rather than rely on feature vectors derived with conventional image processing algorithms28,29,30, Fourier shape descriptors36 or probabilistic models27. Second, we employ end-to-end learning by using a single model (or network). Previously published methods that used deep learning employed multiple stages consisting of (a) a candidate generation stage which use either conventional image processing methods24,26 or an initial (and separate) deep learning-based model25 for identifying possible CMBs, and (b) a false positive reduction stage in the form of a CNN-based network24,25,26. Our single-stage design allows for greater flexibility, for example in retraining with different or larger data sets, adding additional class labels, or using different modalities, while achieving sensitivity and precision comparable to published results. Third, we trained with different sets of input imaging modalities. Combinations of imaging modalities allowed our models to reject mimics such as calcifications without explicit provisions (as shown in Fig. 1B). Supplementary Fig. 9 in the “Supplementary materials” (Supplementary Sect. 5) shows an example of mineralization being segmented as iron deposits when the model was trained with only SWI. The models in publications25,26 used SWI only and therefore may not be capable of recognizing and rejecting mimics. The method in publication24 utilizes SWI-phase and magnitude images along with QSM, but did not consider iron deposits in the basal ganglia. Fourth, we experimented with a reduced number of layers (five instead of six spatial resolution layers) and noted that having more layers can improve the overall results for detecting small lesions such as CMBs.
Our framework has achieved an excellent sensitivity of 89%. However, other studies24,25,26 have reported higher precision in detecting CMBs in their samples. We would like to note that it is impossible to directly compare reported numbers from various machine learning models, due to differences in populations included, study settings and imaging and scanner charactherisitcs37. Of particular importance is the fact that our sample was drawn from a relatively healthy population without significant brain trauma, injuries, or pre-existing neuro-pathologies whereas the studies in publications24,25,26 had hundreds if not thousands of CMB lesions related to or caused by radiation therapy, stroke and traumatic brain injury.
One of the major challenges was the small size of the lesions and their potential presence throughout the brain. The average size of four voxels (or 6 mm3) per CMB together with the generally low lesion burden of the study participants resulted in including only two CMB lesions/4 voxels on average per participant, resulting in a higher weight of a single lesion or error in the evaluation. In other words, missing a single lesion would result in a drop of sensitivity from one to 0.5 and a single false positive for a given participant would result in a drop of that participant’s precision from one to 0.5 or 0.66. Similarly, a small number of false positives, in absolute terms, can lower the average precision substantially. In general, our models over-segmented the data in terms of detecting more CMBs than were actually present (Supplementary Figs. 10 and 11 in the “Supplementary materials” show examples of false positive CMBs). In all experiments using the aforementioned combinations of available imaging modalities, most of the lesions were detected and the average sensitivity was consistently above 0.75.
Notably the sample used to train the model was a convenience sample from participants of the MESA study without particular clinical profile and without apparent brain disorders such as dementia, depression, or traumatic brain injury. Given the low number of lesions on average, our method achieved sensitivities that are comparable to state-of-the-art CMB segmentation/detection methods trained with large datasets. We expect that including more samples with more lesions would improve the precision. In general, most studies incorporating automated methods for large-scale abnormality detection or brain region segmentation incorporate a segmentation quality control step that could result in corrections or exclusions1,38,39. Thanks to the flexibility of our method, it is straightforward to increase the sample size.
In clinical terms, a larger number of CMBs is more likely to be clinically relevant. The proposed DEEPMIR method was trained and evaluated on a relatively small population and outputs the number of lesions and lesion segmentation maps for each participant. The next step would be to rigorously test and evaluate the proposed model on a larger sample size to ensure viable sensitivity, precision and overall accuracy, before applying it to a large cohort to determine the prevalence of lesions in the population. An adequately trained model can be used as a screening tool to flag participants with a high lesion load. DEEPMIR can also be used to generate an initial segmentation of lesions to accelerate manual annotation.
QSM is a good, non-invasive technique to distinguish between iron content and mineralization in the brain and showed a great advantage in improving the overall accuracy of CMB and iron deposit detection in the current study. While QSM is being recognized and is being integrated in more population-based studies, large studies with QSM data acquisition such as MESA is still ongoing. This left us with a relatively small number of imaging data used for training. For our experiment, we had a ratio of validation to training data (25:75), which showed to be reasonable to ensure that a maximal amount of the available data is used in model training, while at the same time a sufficient amount is reserved for within-training validation. The use of similar sample sizes for training and evaluation is not unprecedented in such small lesion detection27,29,40,41. One limitation of using such a small sample size is a reduction in study statistical power. For our experiments, we noted that none of the multiple comparisons were statistically significant, and this could likely be due to the small sample size. Finally, the limited access to QSM from other studies left us to perform cross-validation37 with samples from only the MESA AFib cohort for evaluating our model. We were therefore not able to test the generalizability of our model with images generated in other studies with different parameters and characteristics. This line of work should be considered in future research efforts, ultimately building machine learning models and benefiting from pooling imaging data from multiple cohort-based studies42.
We have presented a framework for the automated detection of cerebral microbleeds and non-hemorrhage iron deposits in the basal ganglia. While SWI remains the preferred modality of choice for CMB detection, few studies have leveraged QSM as an additional source of information to improve overall detection accuracy, and to date there have been no attempts to include iron deposits in the basal ganglia as an item of interest. We have utilized QSM in this study to confirm that these focal lesions in the basal ganglia are in fact iron depositions, rather than mineralization such as calcifications. Our deep learning neural network model is flexible and at the same time scalable to include additional modalities and/or class labels while maintaining comparably high sensitivity and precision. We aim in our future work to automatically detect other small vessel disease lesions in our framework such as enlarged perivascular spaces. We also aim to investigate possible advantages of expanding our network to a three-dimensional variant.
Methods
MRI acquisition and pre-processing
The MESA Exam 6 Atrial Fibrillation (AFib) Ancillary Study’s34 brain MRI protocol included T1-weighted (T1w) and T2-weighted (T2w) sequences, and a susceptibility weighted imaging (SWI) sequence with 4 different, equally spaced echo times. SWI is a high-resolution, 3D imaging sequence where the image contrast is enhanced by combining magnitude and phase image data43,44. The scans were acquired at 6 sites using the same acquisition parameters. All scans were performed on Siemens MR scanners (2 Skyra with a 20-channel head coil and 4 Prisma Fit with a 32-channel head coil) at a static magnetic field strength of 3 Tesla and identical imaging sequence parameters, as shown in Supplementary Table 1.1 in Sect. 1 of the “Supplementary materials”.
Multiple SWI phase and magnitude images were acquired with varying echo times (Supplementary Table 1.1 in the “Supplementary materials”). SWI data were generated following the method of Haacke et al.43,45. A homodyne high-pass filter with k-space window size of 64 × 64 was applied to the raw phase image to generate the negative phase mask (with values between 0 and 1). The phase mask was then raised to power 4 and multiplied with the magnitude image to generate the SWI. For creation of the reference annotation and subsequent deep learning-based inferencing, only the SWI image with the shortest echo time (TE = 7.5 ms) was used because longer echo times have more noise due to increasingly pronounced blooming effects near the sinus cavity and cerebellum. In addition, SWI with longer echo times are also more prone to showing false positive CMBs, especially when veins are perpendicular to the imaging plane. Section 2 in the “Supplementary materials” discuss this issue in more detail.
The T1w and T2w images underwent N4 bias correction46 with default parameters using the implementation in the Advanced Normalization Tools (ANTs) (http://stnava.github.io/ANTs) suite and were rigidly registered to the participants’ SWI image using FSL’s FLIRT47,48,49 (https://fsl.fmrib.ox.ac.uk). Anatomical parcellation and brain masks were generated with a multi-atlas segmentation method using the bias-corrected T1w images50. These brain masks were used in the generation of the QSM images. QSM maps were generated using the entire multi-echo SWI dataset using the Morphology Enabled Dipole Inversion (MEDI) method21,51 implemented in MATLAB (http://weill.cornell.edu/mri/pages/qsm.html). Briefly, a non-linear fitting52 was used to estimate the total field followed by region-growing based spatial unwrapping. Then the Projection onto Dipole Fields (PDF) method53 was used to remove background fields and the final susceptibility map was calculated with the Morphology Enabled Dipole Inversion with zero referencing using CSF (MEDI + 0) method54.
Manual annotation
Manual annotation was performed according to a protocol developed with the focus on highly specific differential detection of CMBs and non-hemorrhage iron deposits based on multiple modalities including QSM. The detailed protocol is described in Sect. 2 in the “Supplementary materials”, and a flowchart of the manual annotation process is shown in Supplementary Fig. 4 in the “Supplementary materials”. Panel A in Fig. 4 shows an example of a CMB in the thalamus and non-hemorrhage iron deposits in the interior section of the globus pallidus on SWI (for TE = 7.5 ms and 22.5 ms), QSM and T2w MRI, and Panel B shows the expert segmentation of the lesions based on the annotation protocol. Panel C shows an example of a larger CMB located in the occipital lobe and Panel D shows its respective expert segmentation.

This figure shows examples of cerebral microbleeds and basal ganglia iron deposition in SWI for TE = 7.5 ms (left column), SWI for TE = 22.5 ms (middle left column), QSM (middle right column) and T2w (right column). (A, C) Show the lesions in two different brains, and (B, D) show the corresponding human expert labeling of the CMBs (red) and iron deposits (green).
Study participants
We included imaging data from participants in the MESA Exam 6 Atrial Fibrillation Ancillary Study31,32,33. This study was approved by the Institutional Review Boards at the MESA Coordinating Center and at each participating institution. Written informed consent was obtained by all participants. All participant data collection was performed in accordance with relevant guidelines and regulations.
A subset of the MESA cohort participated in an ancillary study of cardiac arrhythmias and brain imaging during the 2016–2018 exam (Exam 6)34. From 1061 participants who underwent MR brain scans, we selected a convenience sample of 34 scans based on visual identification of possible CMBs by two experienced readers (IMN and TR). These 34 participants are not representative of the MESA cohort in terms of prevalence of CMBs and non-hemorrhage iron deposits, and additional participants in the MESA cohort likely have CMBs and/or non-hemorrhage iron deposits. A total of ten participants’ scans were excluded due to poor image quality (n = 4) and the presence of distortions/artifacts or motion-related effects (n = 6). The demographics summary and lesion loads for the 24 included participants are presented in Supplementary Table 2.1. Of these 24 participants, there were 13 males and 11 females with age range 65–94 years. Based on the expert annotation of these 24 participants, 4 participants had no microbleeds, 13 participants had 1 or 2 microbleeds (with an average size of 10.85 mm3), 6 participants had between 3 and 8 microbleeds (with an average size of 10.21 mm3) and 1 participant had more than 100 microbleeds (with an average size of 4.76 mm3). In certain circumstances, the participant with more than 100 microbleeds may be considered an outlier in terms of the number of CMBs. An examination of this is presented in Sect. 3 of the “Supplementary materials”. Of the 24 participants, 5 participants did not have any voxels labeled as non-hemorrhage iron deposits and the remaining had between 2 (each having a single voxel or 1.5 mm3) and 13 lesions (one participant had 4 non-hemorrhage iron deposit lesions with a total of 326 voxels or 489 mm3) labeled as non-hemorrhage iron deposits in the basal ganglia.
The distribution of CMBs and iron deposits pooled over all participants is illustrated in Supplementary Fig. 5. The average size (± SEM, or standard error of the mean) of CMB lesions in this sample was 6.27 ± 0.51 mm3 (4.18 ± 0.34 voxels). Among the 20 participants with CMB, 70% (n = 14) had two or fewer CMBs, 25% (n = 5) had between three and eight CMBs, and the remaining participant had 120 CMBs. The average size of non-hemorrhage iron deposit labels (± SEM) was 26.15 ± 4.76 mm3 (17.43 ± 3.17 voxels). Approximately 21% (n = 5) had no discernable basal ganglia non-hemorrhage iron deposits and half (n = 12) had fewer than 100 voxels (150 mm3) labeled as non-hemorrhage iron deposits. The remaining 29% (n = 7) had more than 100 voxels labeled as non-hemorrhage iron deposits.
Method overview for automated processing
We developed a deep learning framework for automatic segmentation of CMBs and non-hemorrhage iron deposits based on the U-Net35,55, a widely used deep learning architecture for image segmentation. Our architecture, however, employed padded instead of unpadded convolutions and operated on six instead of five spatial resolutions, and was used for both single class and multiclass segmentation experiments. The larger number of resolution layers enabled the model to detect small CMBs. A detailed description of our implementation is presented in the following sections. The overall system pipeline is shown in Fig. 5. After the initial step of co-registration, the MR volumes were preprocessed to have zero mean and unit variance, as detailed in “Image preprocessing”. The normalized MR volumes were then sliced along the z-axis (axial slices) and edge-padded to obtain 2D slices with 256 × 256 voxels. We evaluated the performance using leave-one-out cross-validation for the 24 participants listed in Supplementary Table 2.1 to ensure generalization of results. In each fold, a single participant’s data was kept separate for testing (test dataset), and the MR data and labels from the remaining 23 participants were randomly split into training dataset (75%, consisting of 17 participants) and validation datasets (25%, consisting of 6 participants). Both training and validation datasets were augmented to improve the robustness of the deep learning models (for more details on data augmentation see “Data augmentation”). The training dataset was used to train the model for a single epoch, after which the validation dataset was used to compute a commonly used evaluation metric known as intersection-over-union (IoU) which quantifies the amount of overlap between the predicted and ground truth segmentations. Each model was trained for a maximum of 30 epochs, and the best model was determined as the model with the maximum IoU. This best model was then used to predict the labels of the test dataset. The set of predictions used for evaluating model performance thus consisted of 24 segmentation masks that were predicted with 24 different models with no overlap between training, validation and testing datasets. These cross-validated evaluations were done for both single class and multiclass experiments. For all experiments, four permutations of MR modalities were considered: (1) SWI only, (2) SWI and QSM, (3) SWI and T2w, and (4) SWI, QSM and T2w.

Overview of the cross-validation process (one-fold) that is repeated n times. In each fold, the model that was used to predict the test participant was trained on the remaining n − 1 samples in order to avoid data leakage. Within the training stage, 25% of the n − 1 participants were used as the validation set. The model with the highest validation accuracy was chosen to predict the left-out participant sample.
For single class experiments, separate models were trained and evaluated for (1) CMBs only and (2) non-hemorrhage iron deposits only. For multiclass experiments, both CMBs and iron deposits had separate labels and were segmented simultaneously. For multiclass segmentations, a larger number of augmentations were used than for single class segmentations.
2D U-Net with padded convolutions
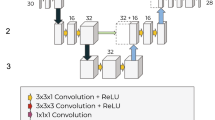
Our lesion prediction models are based on the U-Net35. Both single and multiclass models consist of an analysis path (down-sampling operations) with five stages of convolution blocks and pooling, followed by a five-synthesis path (up-sampling) with five stages of up-convolutions, plus a convolutional block. Each downsampling block consists of two layers of a 2D padded convolution layer having kernel size of 3 × 3 and stride of 1 × 1, followed by Batch Normalization and ReLU activation. The downsampling block ends with a 2 × 2 max pooling layer which reduces the resolution feature map by half in every spatial direction. The central block consists of two instances of padded 2D convolution with kernel size 3 × 3 and stride 1 × 1, followed by Batch Normalization and ReLU activation. Each upsampling block passes its input data through a 2D transpose convolution with kernel size of 2 × 2 and stride 2 × 2 in order to double the size of the feature map. This doubled feature map is then concatenated with the feature map (same size) of the corresponding analysis stage (i.e. the feature map before max pooling layer), followed by two instances of a padded 2D convolution layer having kernel size 3 × 3 and stride 1 × 1, followed by Batch Normalization and ReLU activation. Due to the use of padded convolutions throughout the model, the input and output image sizes are the same (256 × 256). The smallest downsampled image size is 8 × 8 in the central convolution block.
In the case of the single class prediction model, the output of the final upsampling stage passes through a 2D convolution layer with kernel size 1 × 1, stride 1 × 1 and Sigmoid activation function. For the multiclass prediction model, the output of the final upsampling block is passed through a 2D convolution layer with kernel size 1 × 1, stride 1 × 1 and ReLU activation function, and then through a SoftMax layer to generate class probabilities. The model architecture is depicted in Fig. 6. We employed random translations, random rotation, and flipping along the left–right axis during training. The network was trained with the cross-entropy loss.

U-Net architecture using padded convolutions for both single class and multiclass predictions.
Image preprocessing
Each input image was normalized to have zero mean and unit variance. For QSM images, an additional prior step truncated the overall intensity such that the voxel value (VQSM) was within the range [\(-k\mathrm{*}{\sigma }_{QSM}\le \le k\mathrm{*}{\sigma }_{QSM}\)], where k = 5 and \({\sigma }_{QSM}\) is the standard deviation for the QSM image. This step is necessary because QSM images contain high-intensity noise (especially around the boundary of the brain and the region proximate to the sinus cavity) which may de-emphasize the intensity of the rest of the brain.
Data augmentation
To improve the robustness of the deep learning network and include more training data we enriched the training and validation datasets with augmentation. Axial slices containing CMBs and iron deposits are, for the most part, few compared to the remaining slices in a given brain volume. This type of class imbalance may bias the training process. To address this, data augmentation was performed on slices selectively instead of all slices, inspired from the concept of random over-sampling (ROS) and random under-sampling (RUS)56. First, all slices containing the labels of interest (i.e. CMBs and/or iron deposits) are augmented. Then a number of the remaining slices are randomly selected and augmented in the same manner until the total number of slices containing the labels of interest and the total number of slices that do not contain any labels of interest is similar.
Data augmentation consisted of geometric transforms such as translations, rotations and image mirroring. In each experiment, the axial SWI slice (along with the corresponding axial QSM and T2w slices) and corresponding axial reference annotation slice were augmented. For translations, a set of two random integers tx and ty (representing the amount of shift per axis) were generated within the range [− 45, 45] and used to translate the image slice(s) and the corresponding slice of the reference annotation. This range was chosen empirically so that most of the brain would be visible in the translated image. A total of ten random integers per axis were generated for multiclass experiments.
For rotations, a set of random integers d (representing the rotation in degree) were generated within the range [1, 60], and the image slice(s) and the slices with reference annotations were rotated using both + d and − d. The regions of the crops that were located outside the image matrix were padded with edge values. A total of 16 random integers were used for multiclass experiments.
Evaluation of performance
In single class models, the segmentation output map was in the range [0, 1]. Segmentations were accepted or rejected by applying a threshold value of 0.5 to the output map. In multiclass models, the model output was passed through a SoftMax function and segmentation labels were determined based on the class having the highest probability.
We evaluated the performance in terms of the rate of detected/missed CMBs and non-hemorrhage iron deposit lesions. For each participant, the number of true positives (TP), false positives (FP) and false negatives (FN) were counted. A connected-component filter with 3D connectivity was applied to both the predicted segmentation and the reference segmentation in order to identify clusters of voxels. The centroid of the lesion in both the predicted segmentation and reference annotation was computed. TP, FP and FN were determined on whether the Euclidean distance between the centroid of each predicted lesion and a reference lesion was below a specified tolerance. Since CMBs are generally assumed to be relatively small in size, a tolerance of 3 was used for evaluating CMBs, and a tolerance of 5 was used for evaluating non-hemorrhage iron deposits since iron deposits have a larger size and more dispersed pattern than CMBs which are spherical. The sensitivity \(S\) (or true positive rate) was computed as the ratio of TP and number of lesions in the ground truth (TP + FN) for each participant:
The precision (or positive predictive value) \(P\) was computed as the ratio of TP and the number of lesions in the predicted mask:
When the true negative (TN) is available, the typical measure of performance is the overall accuracy, determined by
To evaluate the performance of each model, we report the average sensitivity across all participants and average precision across all participants, as well as a combined metric (magnitude accuracy) computed as \(\sqrt{{\stackrel{-}{S}}^{2}+{\stackrel{-}{P}}^{2}}\), where \(\stackrel{-}{S}\) and \(\stackrel{-}{P}\) are the average sensitivity and precision respectively.
Statistical analysis
Due to the small sample size and potentially non-uniform distribution of the models’ sensitivity, precision and magnitude accuracy, we utilized the non-parametric two-tailed Wilcoxon signed rank test57 to check for any difference between the performance of the various models. In all experimental evaluations, the model trained with only SWI was considered as the baseline model for comparison. Statistical significance was considered at a p < 0.05. Correlation (Pearson) between the prediction and reference annotation is also calculated. For CMBs, the correlation was calculated using the number of lesions, and for non-hemorrhage iron deposits, the volume was used. All statistical analyses were performed in MATLAB R2017b.
References
Habes, M. et al. White matter hyperintensities and imaging patterns of brain ageing in the general population. Brain 139, 1164–1179 (2016).
Debette, S. et al. Association of MRI markers of vascular brain injury with incident stroke, mild cognitive impairment, dementia, and mortality: The Framingham Offspring Study. Stroke 41, 600–606 (2010).
Ge, Y. et al. Age-related total gray matter and white matter changes in normal adult brain. Part I: Volumetric MR imaging analysis. Am. J. Neuroradiol. 23, 1327–1333 (2002).
Scahill, R. I. et al. A longitudinal study of brain volume changes in normal aging using serial registered magnetic resonance imaging. Arch. Neurol. 60, 989–994 (2003).
Charidimou, A., Jäger, H. R. & Werring, D. J. Cerebral microbleed detection and mapping: principles, methodological aspects and rationale in vascular dementia. Exp. Gerontol. 47, 843–852 (2012).
Akoudad, S. et al. Association of cerebral microbleeds with cognitive decline and dementia. JAMA Neurol. 73, 934–943 (2016).
Haller, S. et al. Cerebral microbleeds: Imaging and clinical significance. Radiology 287, 11–28 (2018).
Vernooij, M. et al. Prevalence and risk factors of cerebral microbleeds: The Rotterdam Scan Study. Neurology 70, 1208–1214 (2008).
Cordonnier, C. & van der Flier, W. M. Brain microbleeds and Alzheimer’s disease: Innocent observation or key player?. Brain 134, 335–344 (2011).
Acosta-Cabronero, J., Betts, M. J., Cardenas-Blanco, A., Yang, S. & Nestor, P. J. In vivo MRI mapping of brain iron deposition across the adult lifespan. J. Neurosci. 36, 364–374 (2016).
Ward, R. J., Zucca, F. A., Duyn, J. H., Crichton, R. R. & Zecca, L. The role of iron in brain ageing and neurodegenerative disorders. Lancet Neurol. 13, 1045–1060 (2014).
Bartzokis, G. et al. Brain ferritin iron may influence age-and gender-related risks of neurodegeneration. Neurobiol. Aging 28, 414–423 (2007).
House, M. J., Pierre, T. S., Foster, J., Martins, R. & Clarnette, R. Quantitative MR imaging R2 relaxometry in elderly participants reporting memory loss. Am. J. Neuroradiol. 27, 430–439 (2006).
Greenberg, S. M. et al. Cerebral microbleeds: A guide to detection and interpretation. Lancet Neurol. 8, 165–174 (2009).
Nandigam, R. et al. MR imaging detection of cerebral microbleeds: Effect of susceptibility-weighted imaging, section thickness, and field strength. Am. J. Neuroradiol. 30, 338–343 (2009).
Ayaz, M., Boikov, A. S., Haacke, E. M., Kido, D. K. & Kirsch, W. M. Imaging cerebral microbleeds using susceptibility weighted imaging: One step toward detecting vascular dementia. J. Magn. Reson. Imaging 31, 142–148 (2010).
Cordonnier, C., Al-Shahi Salman, R. & Wardlaw, J. Spontaneous brain microbleeds: Systematic review, subgroup analyses and standards for study design and reporting. Brain 130, 1988–2003 (2007).
Gregoire, S. et al. The Microbleed Anatomical Rating Scale (MARS): Reliability of a tool to map brain microbleeds. Neurology 73, 1759–1766 (2009).
Cordonnier, C. et al. Improving interrater agreement about brain microbleeds: Development of the Brain Observer MicroBleed Scale (BOMBS). Stroke 40, 94–99 (2009).
de Rochefort, L. et al. Quantitative susceptibility map reconstruction from MR phase data using bayesian regularization: Validation and application to brain imaging. Magn. Reson. Med. 63, 194–206 (2010).
Wang, Y. & Liu, T. Quantitative susceptibility mapping (QSM): Decoding MRI data for a tissue magnetic biomarker. Magn. Reson. Med. 73, 82–101 (2015).
Liu, T. et al. Cerebral microbleeds: Burden assessment by using quantitative susceptibility mapping. Radiology 262, 269–278 (2012).
Schweser, F., Deistung, A., Lehr, B. W. & Reichenbach, J. R. Differentiation between diamagnetic and paramagnetic cerebral lesions based on magnetic susceptibility mapping. Med. Phys. 37, 5165–5178 (2010).
Liu, S. et al. Cerebral microbleed detection using Susceptibility Weighted Imaging and deep learning. Neuroimage 198, 271–282 (2019).
Dou, Q. et al. Automatic detection of cerebral microbleeds from MR images via 3D convolutional neural networks. IEEE Trans. Med. Imaging 35, 1182–1195 (2016).
Chen, Y., Villanueva-Meyer, J. E., Morrison, M. A. & Lupo, J. M. Toward automatic detection of radiation-induced cerebral microbleeds using a 3D deep residual network. J. Digital Imaging 1–7 (2018).
Seghier, M. L. et al. Microbleed detection using automated segmentation (MIDAS): A new method applicable to standard clinical MR images. PLoS ONE 6, e17547 (2011).
Bian, W., Hess, C. P., Chang, S. M., Nelson, S. J. & Lupo, J. M. Computer-aided detection of radiation-induced cerebral microbleeds on susceptibility-weighted MR images. NeuroImage Clin. 2, 282–290 (2013).
Kuijf, H. J. et al. Efficient detection of cerebral microbleeds on 7.0 T MR images using the radial symmetry transform. Neuroimage 59, 2266–2273 (2012).
Roy, S., Jog, A., Magrath, E., Butman, J. A. & Pham, D. L. Medical Imaging 2015: Image Processing 94131E (International Society for Optics and Photonics, 2015).
Bild, D. E. et al. Multi-ethnic study of atherosclerosis: Objectives and design. Am. J. Epidemiol. 156, 871–881 (2002).
Olson, J. L., Bild, D. E., Kronmal, R. A. & Burke, G. L. Legacy of MESA. Glob. Heart 11, 269–274 (2016).
Winston-Salem, N. & Irvine, C. The multiethnic study of atherosclerosis. Glob. Heart 11, 267 (2016).
Heckbert, S. R. et al. Yield and consistency of arrhythmia detection with patch electrocardiographic monitoring: The Multi-Ethnic Study of Atherosclerosis. J. Electrocardiol. 51, 997–1002 (2018).
Ronneberger, O., Fischer, P. & Brox, T. in International Conference on Medical Image Computing and Computer-Assisted Intervention, 234–241 (Springer).
Liu, H., Rashid, T. & Habes, M. in 2020 IEEE 17th International Symposium on Biomedical Imaging Workshops (ISBI Workshops). 1–4 (IEEE).
Rathore, S., Habes, M., Iftikhar, M. A., Shacklett, A. & Davatzikos, C. A review on neuroimaging-based classification studies and associated feature extraction methods for Alzheimer’s disease and its prodromal stages. Neuroimage 155, 530–548 (2017).
Habes, M. et al. White matter lesions: Spatial heterogeneity, links to risk factors, cognition, genetics, and atrophy. Neurology 91, e964–e975 (2018).
Nasrallah, I. M. et al. Association of intensive vs standard blood pressure control with cerebral white matter lesions. JAMA 322, 524–534 (2019).
Barnes, S. R. et al. Semiautomated detection of cerebral microbleeds in magnetic resonance images. Magn. Reson. Imaging 29, 844–852 (2011).
Fazlollahi, A. et al. in 2014 IEEE 11th international symposium on biomedical imaging (ISBI). 113–116 (IEEE).
Habes, M. et al. The Brain Chart of Aging: Machine-learning analytics reveals links between brain aging, white matter disease, amyloid burden, and cognition in the iSTAGING consortium of 10,216 harmonized MR scans. Alzheimers Dement. 17, 89–102 (2021).
Haacke, E. M., Mittal, S., Wu, Z., Neelavalli, J. & Cheng, Y.-C. Susceptibility-weighted imaging: Technical aspects and clinical applications, part 1. Am. J. Neuroradiol. 30, 19–30 (2009).
Mittal, S., Wu, Z., Neelavalli, J. & Haacke, E. M. Susceptibility-weighted imaging: Technical aspects and clinical applications, part 2. Am. J. Neuroradiol. 30, 232–252 (2009).
Haacke, E. M., Xu, Y., Cheng, Y. C. N. & Reichenbach, J. R. Susceptibility weighted imaging (SWI). Magnet. Resonance Med. Off. J. Int. Soc. Magnet. Resonance Med. 52, 612–618 (2004).
Tustison, N. J. et al. N4ITK: Improved N3 bias correction. IEEE Trans. Med. Imaging 29, 1310 (2010).
Jenkinson, M., Bannister, P., Brady, M. & Smith, S. Improved optimization for the robust and accurate linear registration and motion correction of brain images. Neuroimage 17, 825–841 (2002).
Jenkinson, M. & Smith, S. A global optimisation method for robust affine registration of brain images. Med. Image Anal. 5, 143–156 (2001).
Greve, D. N. & Fischl, B. Accurate and robust brain image alignment using boundary-based registration. Neuroimage 48, 63–72 (2009).
Doshi, J. et al. MUSE: MUlti-atlas region Segmentation utilizing Ensembles of registration algorithms and parameters, and locally optimal atlas selection. Neuroimage 127, 186–195 (2016).
Liu, J. et al. Morphology enabled dipole inversion for quantitative susceptibility mapping using structural consistency between the magnitude image and the susceptibility map. Neuroimage 59, 2560–2568 (2012).
Liu, T. et al. Nonlinear formulation of the magnetic field to source relationship for robust quantitative susceptibility mapping. Magn. Reson. Med. 69, 467–476 (2013).
Liu, T. et al. A novel background field removal method for MRI using projection onto dipole fields. NMR Biomed. 24, 1129–1136 (2011).
Liu, Z., Spincemaille, P., Yao, Y., Zhang, Y. & Wang, Y. MEDI+ 0: Morphology enabled dipole inversion with automatic uniform cerebrospinal fluid zero reference for quantitative susceptibility mapping. Magn. Reson. Med. 79, 2795–2803 (2018).
Çiçek, Ö., Abdulkadir, A., Lienkamp, S. S., Brox, T. & Ronneberger, O. in International conference on medical image computing and computer-assisted intervention. 424–432 (Springer).
Van Hulse, J., Khoshgoftaar, T. M. & Napolitano, A. in Proceedings of the 24th international conference on Machine learning. 935–942 (ACM).
Wilcoxon, F. Breakthroughs in Statistics 196–202 (Springer, 1992).
Acknowledgements
This research was supported by contracts 75N92020D00001, HHSN268201500003I, N01-HC-95159, 75N92020D00005, N01-HC-95160, 75N92020D00002, N01-HC-95161, 75N92020D00003, N01-HC-95162, 75N92020D00006, N01-HC-95163, 75N92020D00004, N01-HC-95164, 75N92020D00007, N01-HC-95165, N01-HC-95166, N01-HC-95167, N01-HC-95168 and N01-HC-95169 and Grant HL127659 from the National Heart, Lung, and Blood Institute, and by Grants UL1-TR-000040, UL1-TR-001079, and UL1-TR-001420 from the National Center for Advancing Translational Sciences (NCATS). The content is solely the responsibility of the authors and does not necessarily represent the official views of the National Institutes of Health. The authors thank the other investigators, the staff, and the participants of the MESA study for their valuable contributions. A full list of participating MESA investigators and institutions can be found at http://www.mesa-nhlbi.org.
Author information
Authors and Affiliations
Contributions
T.R. wrote the manuscript and was responsible for code development and statistical analysis. A.A. contributed to code development, writing and editing. H.L. contributed to writing and editing. P.S. contributed code and critical review. I.M.N., J.B.W., J.R.R., S.R.H. provided critical review of the manuscript. M.H. and S.R.H. acquired funding for the study. M.H. contributed to study planning, experimental design, supervision, writing and critical review of the manuscript. All authors contributed critical review and approval.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Rashid, T., Abdulkadir, A., Nasrallah, I.M. et al. DEEPMIR: a deep neural network for differential detection of cerebral microbleeds and iron deposits in MRI. Sci Rep 11, 14124 (2021). https://doi.org/10.1038/s41598-021-93427-x
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-021-93427-x
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
