
Abstract
Single cell transcriptome profiling has emerged as a breakthrough technology for the high-resolution understanding of complex cellular systems. Here we report a flexible, cost-effective and user-friendly droplet-based microfluidics system, called the Nadia Instrument, that can allow 3′ mRNA capture of ~ 50,000 single cells or individual nuclei in a single run. The precise pressure-based system demonstrates highly reproducible droplet size, low doublet rates and high mRNA capture efficiencies that compare favorably in the field. Moreover, when combined with the Nadia Innovate, the system can be transformed into an adaptable setup that enables use of different buffers and barcoded bead configurations to facilitate diverse applications. Finally, by 3′ mRNA profiling asynchronous human and mouse cells at different phases of the cell cycle, we demonstrate the system's ability to readily distinguish distinct cell populations and infer underlying transcriptional regulatory networks. Notably this provided supportive evidence for multiple transcription factors that had little or no known link to the cell cycle (e.g. DRAP1, ZKSCAN1 and CEBPZ). In summary, the Nadia platform represents a promising and flexible technology for future transcriptomic studies, and other related applications, at cell resolution.
Similar content being viewed by others

Introduction
Single cell transcriptome profiling has recently emerged as a breakthrough technology for understanding how cellular heterogeneity contributes to complex biological systems. Indeed, cultured cells, microorganisms, biopsies, blood and other tissues can be rapidly profiled for quantification of gene expression at cell resolution. Among a wealth of notable findings, this has led to the unprecedented discovery of new cell populations such as CFTR-expressing pulmonary ionocytes1, new cell subtypes such as the distinct disease-associated microglia found in both mice2 and humans3, and the single-cell profiling of a whole multicellular organism4.
Several technology platforms have been devised for single cell transcriptome profiling that principally differ in amplification method, capture method, scalability and transcriptome coverage (reviewed in5). Methods with lower cell throughput (< 103) can provide full transcript coverage permitting analysis of post-transcriptional processing at cell resolution6,7,8. Meanwhile, 3′-digital gene expression (3′-DGE) based technologies focus on the 3′ end of mRNA transcripts to allow a higher throughput (> 104) at reduced cost4,9,10,11. A caveat is that such 3′-DGE methods principally report gene-level rather than isoform-level expression. However, recent adaptations allow membrane-bound proteins to be simultaneously monitored alongside the transcriptome via use of antibody-derived barcoded tags that are captured and concomitantly sequenced12,13.
Relevant to this study, droplet-based single-cell RNA-seq is a popular 3′-DGE method that involves the microfluidics encapsulation of single cells alongside barcoded beads in aqueous droplets in oil9,10. Cells are subsequently lysed within the droplets and the released polyadenylated RNA captured by oligos coating9 or embedded10 within the beads for 3′-DGE. Since all oligos associated with a single bead contain the same cellular barcode, an index is provided to the RNA that later reports on its cellular identity during computational analysis. Meanwhile, unique molecular identifier (UMI) sequences within the oligos provide each captured RNA with a transcript barcode such that PCR duplicates can be collapsed following library amplification. Both custom fabricated9,10,14,15 and commercial16,17 microfluidics setups have been developed for droplet-based workflows. However, user flexibility of these systems remains limited.
Here we report a new automated and pressure-based microfluidic droplet-based platform, called the Nadia Instrument, that encapsulates up to 8 samples, in parallel, in under 20 min. Accordingly, this allows 3′ mRNA capture of ~ 50,000 single cells or individual nuclei in a single run. The Nadia Instrument guides users through all relevant steps of the cell encapsulation via an easy-to-use touchscreen interface, whilst it maintains complete flexibility to modify parameters such as droplet size, buffer types, incubation temperatures and bead composition when combined with the Nadia Innovate. We subsequently demonstrate highly reproducible droplet size, low doublet capture rates and high mRNA capture efficiencies relative to alternative technologies. Further, we leverage our high quality datasets to elucidate active transcriptional regulatory networks at different phases of the cell cycle. This provided supportive evidence for transcription factors such as DRAP1, ZKSCAN1 and CEBPZ, among others, that had little or no previous association with distinct phases of the cell cycle. Taken together, the integrity and adaptability of the Nadia platform makes it an attractive and versatile platform for future single cell applications in which fine-tuning of experimental parameters can lead to improved data quality.
Results
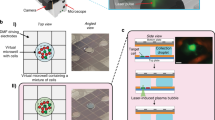
An open-platform for flexible single-cell microfluidics
Droplet-based single-cell RNA-seq is a scalable and cost-effective method for the simultaneous transcriptome profiling of 100–1000 s of cells. Here we present the flexible, user-friendly and open Nadia platform that facilitates high integrity co-encapsulation of single cells in aqueous droplets in oil together with barcoded beads (Fig. 1a–c). Unlike other custom or commercial systems that depend on mechanical injection, the Nadia employs three pressure-driven pumps to deliver pulseless and readily manipulated liquid flows of cell suspensions, barcoded beads and oil into the platform’s microfluidics cartridges (Fig. 1b,c). Successful co-encapsulation of single cells with individual beads subsequently represents the start point for cDNA library preparation. Between 1–8 samples can be processed in parallel on the Nadia due to the flexible configuration of the machines inserted cartridge (Supplementary Figure 1), whilst fully suspended magnetic stir bars and cooling elements ensure samples remain evenly in suspension and temperature controlled throughout. A U-tube geometry further prevents the oil phase flowing through the channel network before pressure is applied, which is a cause of jetting streams in some custom devices. A touch interface guides the user through all essential experimental steps, whilst optional integration of the paired ‘Innovate’ device provides the user with total flexibility to modify all parameters of each run (Fig. 1a). Accordingly, new protocols can subsequently be rapidly developed, saved and shared for future application by both the user and the wider research community. Further, like other commercial platforms16, no wetted parts and disposable cartridges mean that it is not necessary to clean and inspect the microfluidic channel networks between sample runs.

An open platform for single cell transcriptome profiling. (a) The Nadia Instrument (right) and Nadia Innovate (left) benchtop platform for single-cell transcriptomics. (b) Design of the disposable microfluidics cartridge used in the Nadia. (c) Schematic of the droplet sequencing workflow used in the Nadia platform. In brief, single cells or nuclei are encapsulated in aqueous droplets in oil together with barcoded beads. Following lysis within droplets the released mRNA is captured upon the bead and provided both a cell barcode and a unique molecular identifier. Beads are subsequently pooled prior to reverse-transcription and generation of cDNA libraries called “single-cell transcriptomes attached to microparticles” (STAMPs). The barcoded STAMPs are then amplified in pools for high-throughput RNA-seq. (d) Theoretical variation of droplet size by changing oil and liquid stream pressures. (e) Experimental variation of droplet size by changing oil and liquid stream pressures. White scale bars represent 100 μm. (f) Stable droplet diameters at different oil pressures. Inset shows example droplets containing non-deformable beads. (g) Bioanalyser traces of full-length transcript PCRs amplified from identical bead numbers but different droplet dimensions. (h) Example image of deformable beads captured with the Nadia system. Upper left panel shows crowding of deformable beads behind microfluidics junction, lower left panel shows droplet occupancy following sychronised deformable bead loading. For reader guidance, outlines of three deformable beads are indicated with dashed lines, and droplets containing beads are marked by black arrowheads. Right panel shows zoomed out image revealing > 70% droplet occupancy of deformable beads. For reader guidance, all droplets containing a deformable bead are marked by a black asterik.
As with related microfluidic setups, single cell suspensions and barcoded beads are loaded at limiting dilutions to ensure minimal occurrence of more than one cell in the same droplet with a bead (Fig. 1c). Following cell and bead co-encapsulation, the aqueous droplets in oil act as chambers for cell lysis and mRNA capture. The size of droplets generated with the standard Nadia settings is 85 μm. This contrasts to 125 μm with the original custom fabricated Drop-seq setup9, and 85 μm with a modified setup used for single nuclei sequencing14. Most injection-based microfluidics systems have been restricted to single droplet sizes16, or require custom microfluidics chips designed for purpose9,14. However, retaining the ability to fine-tune droplet volumes could concentrate RNA around oligo bound capture beads for increased mRNA capture, and allow droplet parameters to be optimised according to cell dimensions, buffers or the capture beads used. Exemplifying this, whilst original reports used ~ 125 μm diameter droplets for transcriptome profiling whole cells9, Habib et al. optimised a microfluidics chip for ~ 85 μm diameter droplet generation that facilitated single-nuclei sequencing of archived mouse and human brain tissue14. Notably, the change in droplet dimensions from ~ 125 to ~ 85 μm lead to impressive 2- to 4-fold increases in the number of nuclei that provided > 1000 UMI counts when different mouse brain regions were profiled. Conversely, increasing droplet dimensions is expected to be beneficial for particularly large cells, such as adult cardiomyctes (~ 100 μM), that have so far required specialised scRNA-seq setups that preclude massively parallal studies18,19. Due to the smooth pressure-based pump system employed, and like selective other custom9 and commercial10 platforms, droplet manipulation is readily achieved with the Nadia and accompanying Innovate. Indeed, droplets can be generated over a range of sizes from as little as ~ 40 μm (Fig. 1d,e). Moreover, this can be achieved using the same microfluidics cartridge for all droplet sizes, thus negating the need for custom chip design between experiments. Crucially, resulting droplets are uniform in size (Fig. 1e,f). Meanwhile, reducing droplet size from ~ 85 to ~ 60 μm (p < 0.05, Fig. 1f) resulted in increased RNA capture from mouse 3T3 nuclei (Fig. 1g).
Beyond droplet size control, current droplet-sequencing protocols have principally reported use of two oligonucleotide bound beads; non-deformable beads9, and deformable hydrogels16,20. Non-deformable beads have the advantage that mRNA-bound beads can be pooled prior to reverse transcription and minimise reagent costs. In contrast, deformable beads, including those used in commercial platforms16, require the reverse transcription reaction to be performed within the droplets to ensure cellular barcodes remain specific to a single cell following oligo release from the hydrogel surface. A reverse transcription mix must thus constitute one of the three streams entering the microfluidics setup which can increase reagent usage. However, whilst droplet-sequencing with non-deformable beads is dependent on double Poisson loading constraints that restricts bead encapsulation to < 20%, deformable hydrogels can be efficiently synchronized such that 70–100% of droplets contain a single bead16,20. Whilst the bead configuration is dependent on the application in question, the Nadia importantly retains flexibility to use both non-deformable and deformable beads unlike other platforms16. Indeed, whilst non-deformable beads have been used for datasets presented herein, acrylamide/bis-acrylamide deformable beads are fully compatible and allow successful bead stacking behind the microfluidics junction to facilitate synchronised loading of > 70% of droplets (Fig. 1h).
Similar flexibility is provided in the ability to incorporate different buffers, a feature incorporated into some10, but not all, commercial droplet-based scRNA-seq platforms. Indeed, stable and mono-dispersed aqueous droplets in oil are created with a cell/nuclei lysis buffer containing 0.2% sarkosyl and 6% of the Ficoll PM-400 sucrose-polymer, and a cytoplasmic lysis buffer containing 0.5% Igepal CA-630 (Supplementary Figure 1). Meanwhile, in an alternative application, use of hyrdogel liquid precursors in replace of the bead-containing lysis buffer can allow hydrogel based capture of the cell suspension to create miniaturized and biocompatible niches for three dimensional in vitro cell culture (Supplementary Figure 1)21. Taken together then, the Nadia provides a flexible setup that allows the user to optimise experimental parameters for specific purpose.
Technical performance for single cell and single nuclei sequencing
In order to test the integrity of the Nadia platform, we performed a mixed-species experiment in which a 3:1 mix of human HEK293 cells and mouse 3T3 cells were subject to droplet capture using the standard machine parameters. During cDNA library preparation, 2000 beads were processed into a final library for sequencing. This number would theoretically equate to profiling of 100 cells under double Poisson loading constraints, and just ~ 1.25% of the total cells collected in this run. Following sequencing at > 100 k reads per cell, our analysis with Drop-Seq tools9, implemented through the DropSeqPipe pipeline22, revealed we had collected precisely 100 single cell transcriptomes attached to microparticles (STAMPs). Of these, 75 had mappings primarily to the human genome, and 24 to the mouse genome (Fig. 2a). Just 1% had mixed mappings that implied capture of more than two mixed species cells during the microfluidics element of the workflow. Meanwhile, each single species cell had a mean of 1.52% reads from the alternative species to imply a low-level of barcode swapping during library preparation. A low doublet capture rate was maintained when the number of beads used for cDNA library preparation was increased, whilst increasing the loading density of cells revealed an increase in doublets consistent with the double Poisson loading of the platform (Supplementary Figure 2).

Technical performance for single cell and single nuclei sequencing. (a) Mixed species barnyard plot of transcripts after profiling 2,000 collected beads (i.e. 100 expected STAMPs) representing a mix of human HEK293 cells and mouse 3T3 cells input at platform recommended cell loading density of 3 × 105 cells per ml. (b) Cumulative frequency plots reporting sequencing reads associated with individual barcodes when using indicated starting bead inputs for cDNA library construction. Dashed red lines indicate expected STAMPs for each experiment. Larger panel represents dataset used in (a). “Nadia 2k” generated cDNA libraries from 2,000 beads, “Nadia 0.5k” from 500 beads, and “Nadia 12k” from 12,000 beads. (c) Number of UMIs detected relative to individual STAMP read counts for indicated mixed-species whole cell experiments (see “Methods” section). “Nadia 2k” profiled 2000 collected beads and expected 100 STAMPs, “Nadia 12k” profiled 12,000 beads and expected 600 STAMPs, “Macosko et al.9” expected 100 STAMPs, “Chromium v3” expected 1400 STAMPs. Dashed line represents maximal point at which each sequencing read would report a unique UMI. (d) Same as C but with detected genes reported rather than UMIs. (e) Number of UMIs detected relative to individual STAMP read counts for indicated mouse 3T3 experiments (see “Methods” section). Dashed line represents maximal point at which each sequencing read would report a unique UMI. (f) Same as E but with detected genes reported rather than UMIs.
We next produced cDNA libraries from different amounts of barcoded beads to determine whether STAMP estimates matched the theoretical cell capture of the system. To assess we evaluated the number of UMI counts associated with cell barcodes, and used subsequent graph inflection points to estimate the cells captured. Across multiple experiments performed by independent users at different locations, we saw that the predicted STAMP capture was well matched to expected cell capture (Fig. 2b). Further, by comparing UMI and gene counts to the total read counts for each library, we found that using the Nadia platform resulted in a high RNA capture efficiency. Indeed this resulted in complex cDNA libraries that had favorable metrics relative to other custom fabricated9 and commercial16 droplet sequencing platforms for which comparable human HEK293 and mouse 3T3 mixed-species datasets are available (Fig. 2c,d). Specifically, quantification of the regression slopes between UMI counts and total read counts determined that for every additional thousand sequencing reads the Nadia would capture a further ~ 270–310 unique transcripts per cell. This was markedly improved from the original Drop-seq custom fabricated setup (~ 76–81 unique transcripts)9, and comparable to an alternative commercial platform (~ 370–460 unique transcripts)16. This implies that the unique design of the Nadia cartridge (Fig. 1b) is well suited for scRNA-seq applications.
High RNA capture efficiency will be critical for profiling low input material such as single nuclei. Applying such a strategy is necessary when profiling heterogeneous cell samples that cannot be readily dissociated into single cell suspensions (e.g. due to long cellular projections), or when profiling archived samples not robust to freeze–thaw conditions. As such, single-nuclei sequencing is emerging as a method of choice for study of archived human brain tissue3,14,23,24. With such future applications in mind, we evaluated the ability of the Nadia platform to profile single nuclei suspensions of mouse 3T3 cells and human HEK293 cells, or mouse 3T3 cells alone. As with whole cell suspensions, mixed-species plots revealed a low doublet rate of 3.7% that was slightly higher than whole cells (Supplementary Figure 2). This slight increase in doublets is expected to be due to the sticky nature of extracted nuclei, but remains below the 5% expected doublets based on loading and flow parameters. In agreement with previous single nuclei sequencing studies14,25, a higher level of intronic reads were reported relative to whole cells (Supplementary Figure 3). Meanwhile, we found the Nadia platform had nuclear RNA capture rates that compared favourably to limited publically available single nuclei RNA-seq data and approached whole-cell datasets (Fig. 2e,f)14. Specifically, quantification of the regression slopes between UMI counts and total read counts determined that for every additional thousand sequencing reads the Nadia would capture a further ~ 240 unique transcripts per nuclei. This was improved from the original droplet based single nuclei RNA-seq custom fabricated setup (~ 210 unique transcripts) which had similar droplet dimensions (~ 85 μm)14. Whilst capture was marginally reduced relative to whole-cell profiling, the ability to fine-tune droplet dimensions with the Innovate has potential to improve nuclear RNA capture in future (e.g. 14.). Indeed, we observed an increase in cDNA generated when droplets were reduced from ~ 85 to ~ 60 μm (Fig. 1h).
Taken together these experiments demonstrate the reliability of the Nadia platform in delivering expected theoretical performance, and the efficiency of the system for both single cell and single nuclei capture.
Elucidating transcriptional regulatory networks of the cell cycle
To demonstrate the ability of the Nadia platform to distinguish closely related cell populations, we evaluated gene expression profiles linked to cell-cycle progression in 233 human and 277 mouse cells from our “Nadia 12k” mixed-species experiment. Similar to a previous Drop-seq study9, and despite the dataset being generated from two asynchronous cell populations, in both species we were able to use gene expression profiles to infer five phases of the cell cycle that matched previous stages of chemically synchronized cells (Fig. 3a)26. Despite not being based on cell cycle ground truth, this phase assignment was supported by the cycling expression of certain established and recently defined novel cell cycle-associated genes9, but not housekeeper genes (Supplementary Figure 4).

Elucidating transcriptional regulatory networks of the cell cycle. (a) Inferred cell cycle states of 233 human HEK293 cells (left panel) and 277 mouse 3T3 cells (right panel) based on the gene expression profiles of individual cells relative to stage-specific gene sets (see “Methods” section). Cells are ordered by the combination of phases switched on in each individual cell. (b) Inferred activity of indicated transcription factors based on TRRUST defined regulon expression in individual human HEK293 cells. Dashed lines highlight cell cycle phase assignments used to determine correlation to transcription factor activity. Normalised scores for each transcription factor have been mean centred across all cells. (c) Same as (b) but for mouse transcription factors and individual mouse 3T3 cells. (d) Inferred activity of indicated transcription factors in individual human HEK293 cells based on the summarised expression of regulons that had been inferred from 24 TCGA human cancer tissue sets. Dashed lines highlight cell cycle phase assignments used to determine correlation to transcription factor activity. Normalised scores for each transcription factor have been mean centred across all cells. (e) Boxplots showing normalised inferred activity and normalised gene expression across different phases for selective transcription factors shown in (d). Normalised activity and expression scores for each transcription factor were mean centred across all cells before being summarised by assigned cell cycle phase. (f) Boxplots showing CRISPR scores in four independent cell lines when using control sgRNA (n = 953) or sgRNA targeting CEBPZ (n = 7). CRISPR scores reflect the log2 fold change of each sgRNA detected in the cell lines between the start and end (~ 14 population doublings) of pooled CRISPR depletion experiments.
Analysis of single cell gene expression profiles at different stages has previously been used to identify novel genes correlated to cell cycle phases9, but the identity of the master regulators that drive coordinated cell-cycle gene-expression programmes remains incompletely understood. Accordingly, we took an alternative approach and questioned whether summarised expression of transcription factor target networks, herein referred to as regulons, could be leveraged to infer the transcriptional regulators active in specific cell cycle phases. Such an analysis has not previously been performed in previous cell cycle studies. Indeed, low depths of sequencing and the absence of mRNA capture for many genes in individual cells (dropouts) can make single cell datasets ineffective in precisely quantitating the expression of individual genes. Meanwhile, many transcription factors can be regulated post-transcriptionally such that their mRNA abundance is not a reliable proxy for protein activity. In contrast, regulon enrichments evaluate differential expression of many transcriptional targets such that these biological and measurement sources of noise are effectively averaged out.
To apply this strategy to the cell cycle we first turned to the manually curated TRRUST database of human and mouse regulons that have been determined from sentence-based text mining27. After filtering 800 human and 828 mouse regulons to those expressed in our datasets together with > 10 targets, summarised expression profiles were generated for regulons of 77 human and 78 mouse transcription factors across the human and mouse single cells. This revealed select transcriptional regulators whose activity correlated with distinct cell cycle phase scores in both species (p < 0.01, Fig. 3b,c). Crucially, phase-specific activity aligned with previous studies of these regulators and the cell cycle; KLF5 accelerates mitotic entry and promotes cell proliferation by accelerating G2/M progression28, BRCA1 regulates key effectors controlling the G2/M checkpoint29, PTTG is active in G2/M phase30, MYCN stimulates cell cycle progression by reducing G1 phase31, Nr5a2/Lrh-1 knockdown leads to G1 arrest32,33, Myc is a potent inductor of the transition from G1 to S-phase34, and Sox2 is a mitotic bookmarking transcription factor active at the M/G1 phase35. Notably, E2F1 was found active in G2/M phase of human HEK293 cells and at S-phase of mouse 3T3 cells. This is consistent with its’ control of both G1/S- and G2/M-regulated genes36, and E2F1’s role in S-phase progression in mouse 3T3 cells37.
Whilst TRRUST reports high confidence and experimentally validated regulons, representation of most transcription factors is limited to few targets. As an alternative, and to further characterise the transcriptional responses of each phase of the human cells in this study, we reasoned regulons inferred by data-driven reverse-engineering methods may offer enhanced opportunity for discovering cell cycle master regulators. Here, VIPER (Virtual Inference of Protein-activity by Enriched Regulon analysis) has recently been developed for the accurate assessment of protein activity from regulon activity38, and has recently been extended to single cell analysis via the metaVIPER adaptation39. In the absence of previous regulons assembled from HEK293 gene expression profiles, we accordingly evaluated expression of regulons assembled from 24 TCGA human cancer tissue sets using metaVIPER. Indeed, the metaVIPER workflow previously established the utility and integrity of leveraging multiple non-tissue-matched regulons39. Encouragingly, this analysis extended our previous findings to reveal a further 72 transcription factors that correlated with one or more phases of cell cycle (r > 0.35, FDR < 0.05, Fig. 3d–e, Supplementary Figure 5).
Many of the identified transcription factors have previously been identified as master regulators of cell cycle. Among others this included ATF1, SATB2, FOXM1 and MYBL1/B-MYB. Several candidates displayed differential activity in the absence of clear phased-correlated changes in gene expression, thus suggesting activity is regulated by post-translational protein modifications or regulated protein clearance (Fig. 3e, Supplementary Figure 5). Indeed, only 9/72 were determined as phase-specific genes in previous studies9,26, thus demonstrating the merit of our alternative analysis strategy. Differentially active regulators in the absence of phased gene expression changes included YY1 which is subject to regulatory phosphorylation by various cell cycle associated kinases including Aurora A40 and PLK141, FOXM1 that is regulated by SUMOylation42 and PLK1 phosphorylation43, and REST which is regulated by phosphorylation and USP15 limited polyubiquitination44. However, certain transcription factors such as PITX1, SATB2, FOXO3 and MYBL1/B-MYB were regulated at the level of gene expression, likely due to coordinated upstream activity of other master regulators in the cell cycle regulatory gene network.
In addition to known cell-cycle regulated master regulators, we importantly provide supporting evidence for multiple differentially active transcription factors that had little or no known link to the cell cycle. This included RFXANK, DRAP1 and HES4 which were correlated with G1/S phase, ZNF33A and ZKSCAN1 which correlated with G2/M phase, and both ZNF146 and CEBPZ that were maximally correlated with mitosis (Supplementary Table). Unlike the others, RFXANK, DRAP1, ZKSCAN1 and CEBPZ had no clear relationship between cycling expression levels and activity (Fig. 3e, Supplementary Figure 5). Accordingly, it will now be important to determine how the phased-activity of these novel cell cycle associated transcription factors manifests in the absence of regulation at the level of gene expression. Indeed, the recent findings that levels of ZKSCAN1 modulate hepatocellular carcinoma progression in vivo and in vitro45, and that HES4 expression is linked to osteosarcoma prognosis46, suggests such understanding could have translational potential.
Providing independent computational support for the role of certain novel candidates in cell cycle biology, applying our strategy to a 358 human HEK293 cell dataset profiled with an alternative commercial platform (see “Data availability”)16 again supported the phased activity of RFXANK, DRAP1 and CEPBZ (Supplementary Figure 6), among other established cell cycle regulators. In agreement with Nadia generated datasets, the maximally correlated phases were G1/S phase for RFXANK and DRAP1, and mitosis for CEPBZ. Moreover, providing independent experimental support based on the recovery of gene-specific gRNAs, CRISPR deletion of CEBPZ leads to proliferation defects in four independent cell types (FDR < 0.05, Fig. 3f)47. Meanwhile, the CRISPR silencing of DRAP1 and CEBPZ in hundreds of cancer cell lines identifies them as common essential genes for proliferating cancer cell survival in general, whilst depletion of others such as ZKSCAN1 and ZNF146 reveal them as essential for certain cancer lineages (p < 0.0005, Supplementary Figure 6)48. Taken together, our regulon analysis thus confirms, and in several cases extends, understanding of the phase-correlated activity of many transcription factors across cell cycle.
Discussion
Droplet-based single cell transcriptomics is a more scalable and cost-effective strategy than individual well49, FACS50,51 or fluidic circuit-based52 alternatives. Here we present a new pressure-controlled and user-friendly microfluidics system that can rapidly enable this powerful strategy to even the inexperienced user. Using pre-fabricated and disposable microfluidics cartridges, the Nadia guides the experimenter through a simple-to-follow workflow that encapsulates ~ 6,000 cells or nuclei per sample, and up to 8 samples in parallel all in under 20 min. The paired Innovate add-on provides further opportunity to customise all experimental parameters according to the research question requirements. We present evidence of this experimental adaptability, and report high quality sequencing metrics that compare favourably in the field. We finally demonstrate potential utility of the platform by integrating single-cell transcriptomics with systems biology workflows to extend mechanistic characterisation of the cell cycle. Notably, and among others, we provided supporting evidence that DRAP1, ZKSCAN1 and CEPBZ are novel transcription factors with phased-specific activity across G1/S, G2/M and mitosis, respectively.
The user flexibility of commercial platforms for droplet-based single cell transcriptomics has been limited due to the early need for streamlined and uniform workflows that encourage new entrants to the novel field. However, as single cell transcriptomics has evolved, numerous custom adaptations have emerged of droplet-based workflows employing different microchips to profile small cells/nuclei14, using different buffers to profile diverse starting material53, employing variable experimental conditions (e.g. temperatures) to improve lysis and/or mRNA capture54, and using droplet generators to create miniaturized and biocompatible niches for three dimensional in vitro cultures53. Whilst, certain commercial platforms can provide individual elements of this adaptability (e.g.10), the flexibility provided by both the Nadia Instrument and the Nadia Innovate is unrivalled by other single-cell microfluidics platforms for droplet-based sequencing. Indeed, all parameters of the microfluidics capture process can be modified, including droplet size, stir speeds, incubation temperatures, buffer types and bead composition. The scalability that is achievable through the multiplexed and parallel processing of up to 8 samples can further match or exceed that of other comparable platforms10,16. Last, the ease-of-use and speed of microfluidics capture will ensure experiment start-to-finish times are kept to a minimum. Accordingly, unintended sample lysis and RNA degradation due to extended protocols is mitigated.
Technically speaking, we demonstrate a high integrity and quality of the transcriptome profiles generated when using the Nadia. Indeed, with standard settings we report a low doublet rate of ~ 1% using recommended bead and cell loading densities (Fig. 2a, Supplementary Figure 2), and favorable RNA capture efficiencies for both single cell and single nuclei sequencing compared to other reports and commercial platforms9,14,16. Meanwhile, the library preparation cost of ~ 5 UK pence per cell when preparing 6000 STAMPs and using user-supplied reagents is equivalent to the ~ 5 UK pence per cell with the original custom Drop-seq setup9. This equates to just 23% the cost of some other commercial platforms when preparing the same STAMP number, whilst a pre-prepared reagent kit for the Nadia platform still comes in at ~ 74% of the alternative platform library preparation costs (Supplementary Figure 2).
We used the Nadia platform and droplet sequencing workflow to profile the transcriptomes of asynchronous human and mouse cells that subsequently allowed us to infer the different phases of the cell cycle. Notably, the high complexity cDNA libraries allowed us to characterise the cells by transcription factor activity using recently developed systems biology approaches. Our analysis uncovered 77 human transcription factors with inferred activity correlated with one or more cell cycle phase. Despite this, and as noted previously39, the employed metaVIPER approach cannot accurately measure activity of proteins whose regulons are not represented adequately in one of the interactomes used for regulon inference. Accordingly, this may explain the absence of overlap between TRRUST curated regulons and those derived from 24 TCGA human cancer tissue sets. However, the expected phase-specific activity of multiple transcription factors (e.g. KLF5, BRCA1, Sox2, Nr5a2, ATF1, SATB2, FOXM1 and MYBL1/B-MYB) when using each source of regulons provides strong support for the validity of the workflow using both sets. The limitation may be mitigated in future as more cell-type specific interactomes are produced.
In addition to confirming phased-activity of many transcription factors such as ATF1, SATB2, FOXM1 and MYBL1/B-MYB, our analysis uncovered several others not previously connected to the cell cycle. This included RFXANK, DRAP1 and HES4 which were correlated with G1/S phase, ZNF33A and ZKSCAN1 which correlated with G2/M phase, and both ZNF146 and CEBPZ that were maximally correlated with mitosis. Accordingly, our analysis exemplifies how single-cell transcriptome profiling can be used to further the mechanistic understanding of basic cellular biology. There remains a paucity of knowledge about each of these factors (Supplementary Table). It will now be important to experimentally dissect the roles and importance of these novel factors to proliferating cells, how their activity is precisely controlled across phases, and determine their roles in disease. Supportive evidence based on independent gene-silencing experiments for five of these candidates was available. Notably here, CEBPZ was confirmed in an independent dataset, was identified as an essential gene for 797 cancer cell lines evaluated as part of the DepMap consortia48, and displayed proliferation defects in four mammalian cell lines targeted in genome-wide CRISPR screens47. CEBPZ has been demonstrated to recruit METTL3 to genes essential for acute myeloid leukaemia such that it can induce m6A modifications that aid their translation55. METTL3 is known to promote proliferation and regulates cell cycle genes such as cyclin A2 and cyclin D156. It will now be important to dissect the role, if any, that CEBPZ plays in these METTL3-depenendent events in greater detail. Meanwhile, the aforementioned links between ZKSCAN1 levels and hepatocellular carcinoma45, and HES4 levels and osteosarcoma46 suggests enhanced understanding of these additional factors in the context of the cell cycle could have translational potential.
In summary then, and as evidenced by our analysis of the cell cycle, the Nadia platforms’s high quality output coupled with its’ flexibility across different buffers, workflows and user-determined parameters suggest it will be an attractive technology for future transcriptomic studies at cell resolution.
Methods
Cell preparation
HEK293 and 3T3 cells were cultured in DMEM with 10% fetal bovine serum (Life Techologies) and 1 × penicillin–streptomycin (Life Technologies). Cells were trypsinised for 5 min with TrypLE (Life Technologies) before being collected and spun down for 5 min at 300 g. The pellet was resuspended in 1 ml of PBS-BSA (1 × PBS, 0.01% BSA) and spun again for 3 min at 300 g. The cells were resuspended in 1 ml of PBS, passed through a 40 μm cell strainer and counted. A concentration of 300 cells/μl in 250 μl of PBS-BSA was subsequently used to allow for the encapsulation of ~ 1 cell in every 20 droplets.
Nuclei suspension preparation
In brief, nuclei isolation media (NIM) was prepared in advance (250 mM sucrose, 25 mM KCl, 5 mM MgCl2, 10 mM Tris pH8) and pre-chilled. Cells were trypsinised for 5 min with TrypLE (Life Technologies) before being collected and spun down for 5 min at 300 g. The pellet was resuspended in 1 ml of PBS-BSA (1 × PBS, 0.01% BSA, 0.02 U/μl supernasin) and spun again for 3 min at 300 g. The cells were resuspended in 1 ml of nuclei homogenisation buffer (NIM, 1 μM DTT, 1 × Protease inhibitor, 0.1% Triton X-100, 0.04 U/μl RNasin, 0.02 U/μl Superasin) and mixed by gentle pipetting. Sample was then spun at 300 g and 4 °C for 5 min. Supernatant was discarded and the pellet was resuspended in 1 ml of PBS-BSA (0.01% BSA, 0.02 U/μl supernasin). Finally, sample was vortexed and filtered through a 40 μm strainer before nuclei quality was assessed with trypan blue and Hoechst staining and diluted to desired concentration for Nadia loading.
Microfluidics capture
Cell or nuclei suspensions were captured using the Nadia system according to pre-programmed instrument protocols for drop-seq or sNuc-seq that were accessed through the instruments touch-screen interface. In brief, the Nadia is a fully-automated, bench-top and microfluidic droplet-based platform that can encapsulate up to 8 separate samples in parallel. Each experiment used disposable microfluidic cartridges (covering 1, 2, 4 or 8 samples) with no wetted parts to avoid cross contamination. For each sample, 250 μl of 40 μM-filtered barcoded bead (Chemgene, USA) suspension was loaded into one of the cartridge’s chambers, 250 μl of sample into the second, and 3 ml of oil loaded into the third. Where deformable beads were used, beads were non-barcoded gel beads. Unless specified, cartridge integrated stir bars were set at 75 rpm (cells), 35 rpm (nuclei) and 200 rpm (beads) to ensure that the samples and beads remained in suspension throughout microfluidics capture. Each pre-programmed run lasted 16 min and involved bead, sample and oil channels being merged to form aqueous droplets in oil that co-encapsulated beads together with single cells/nuclei. During each run, three independent pressure pumps controlled the oil, sample and bead channels at pressures up to 1 bar. This ensured consistent conditions and droplet dimensions during each run, whilst providing greatest flexibility to manipulate droplet size and frequency. The standard pressures used were; beads 140 mBar, samples 130 mBar, oil 450 mBar. Double Poisson loading constraints determine that ~ 6000 cells/nuclei from a single sample are co-encapsulated with beads when using these default run parameters. Accordingly, 8 samples run in parallel can capture ~ 48,000 cells/nuclei during a single run. Additional manipulations of pressure to alter droplet sizes were controlled by the connected Innovate system; an open configurable system used to develop new protocols and applications. Corresponding pressure values are indicated in the text where relevant. Of note, the innovate was connected to a high-speed microscope and camera for real-time droplet formation at the microfluidics junction. Following sample capture in each run, the Nadia’s integrated cooling device was used to chill the samples at 4 °C before commencement of library preparation.
Library preparation
cDNA libraries for 3′ mRNA profiling were prepared using the previously described protocol of Macosko et al. with minor modifications9. In summary, mRNA bound beads were removed from the Nadia Instrument’s collection chamber and transferred to a 50 ml falcon tube. Next, 30 mls of 6 × SSC buffer (Life Technologies) and 1 ml of 1H,1H,2H,2H-Perfluorooctan-1-ol (Sigma Aldrich) were added before mixing via inversion. After spinning at 1000 g for 2 min the supernatant was removed and retained in a separate falcon whilst being careful not to disturb the beads at the oil–water interface. A further 30 mls of 6 × SSC buffer were added to the original sample to disturb the beads before mixing via inversion. Oil was allowed to settle to the bottom before bead containing suspension was transferred to a new falcon tube. After disturbing the oil fraction with a 1 ml pipette to collect any missed beads, both falcons containing ~ 30 mls of bead containing SSC buffer were spun at 1000 g and 4 °C for 2 min. At this stage, ~ 26 mls of supernatant was carefully removed from each tube whilst being careful not to disturb the beads. Beads were subsequently resuspended with retained buffer and transferred to a 1.5 ml eppendorf. Beads were spun down in a desktop micro-centrifuge and buffer removed. Additional bead fractions were added and the process repeated until all beads were collected. At this stage the buffer was removed and all beads washed by pipetting in 1 ml of 6 × SSC buffer. Buffer was removed and beads were subsequently washed in 200 μl of 5 × Maxima RT buffer (Life Technologies).
Reverse transcription was performed in 200 μl of a 1 × RT mix (80 μl nuclease free water, 40 μl of 5 × Maxima RT buffer, 40 μl of 20% Ficoll PM-400, 20 μl of 10 mM dNTP mix, 5 μl of RNasin, 10 μl of Maxima H-RT enzyme, 5 μl of 100 μM TSO-RT primer) with the following conditions; 30 min at 23 °C, 2 h at 42 °C. Throughout the process the sample was set to shake at 1100 rpm. Beads were subsequently spun down, RT mix removed and the beads washed in once in TE-SDS buffer (10 mM Tris pH 8, 1 mM EDTA, 0.5% SDS), twice in TE-TW buffer (10 mM Tris pH 8, 1 mM EDTA, 0.01% Tween-20) and once in 300 μl of 10 mM Tris pH 8. Beads were subsequently incubated for 45 min at 37 °C and 1100 rpm in Exonuclease I mix (170 μl nuclease free water, 20 μl 10 × Exonuclease I buffer, 10 μl Exonuclease I—Life Technologies). Beads were then washed once in TE-SDS buffer, twice in TE-TW buffer and then re-suspended in 300 μl of nuclease free water. Beads were subsequently counted with a haemocytometer after mixing 20 μl of beads with 20 μl of 20% PEG400 (Sigma Aldrich). An average of 4 counts were taken before test PCRs at different cycle numbers were performed with desired bead aliquots for each experiment (~ 2000–5000) to gauge optimal cycles for final PCRs on subsequent beads. Specifically, PCR mix included 24.6 μl of nuclease free water, 0.4 μl of 100 μM TSO-PCR primer, and 25 μl of Kapa HiFi readymix (Roche Diagnostics). Cycling conditions were 95 °C for 3 min, four cycles of 98 °C for 20 s, 65 °C for 45 s, 72 °C for 3 min, followed by variable cycles (~ 9–14) of 98 °C for 20 s, 67 °C for 20 s, 72 °C for 3 min. A final extension of 72 °C for 3 min completed the PCR. At the end of elongation steps during the first four cycles, PCR tubes were removed from machine and beads suspended by gentle agitation.
Following optimised PCRs of desired bead numbers, we enriched cDNA products longer than 300 base pairs using select-a-size spin columns (Zymogen) according to the manufacturer protocol. After bioanalyser evaluation and quantification of products, 550 pg of DNA was used as input for an Illumina Nextera tagmentation reaction according to manufacturer's protocol (15 μl Nextera PCR mastermix, 8 μl nuclease free water, 1 μl of 10 μM TSO-hybrid oligo, 1 μl of 10 μM Nextera N70X indexed oligo). This reaction reduced cDNA libraries to a size distribution suitable for Illumina sequencing, and added a common PCR handle for 12 cycles of final library amplification (95 °C for 30 s, twelve cycles of 95 °C for 10 s, 55 °C for 30 s, 72 °C for 30 s, final extension of 72 °C for 3 min). Last, as shorter cDNA inserts are more likely to be overlap variable length poly-A tails, we again enriched for cDNA products longer than 300 base pairs using select-a-size spin columns (Zymogen) according to the manufacturer protocol. The final library profiles were then evaluated and quantified with a Bioanalyser, Qubit and Tapestation prior to sequencing.
Next generation sequencing
All high throughput sequencing was performed using an Illumina NextSeq 500 sequencer at the Imperial BRC genomics facility. Samples were run using a custom read 1 primer (Read1customSeq). Read 1 was set at > 20 base pairs to read through the cellular and molecular barcodes, and read 2 set at > 25 base pairs to read cDNA inserts. Additional 8 base pair index reads were used to determine libraries within multiplexed runs. Each run had 5–10% PhiX spiked in to the library to ensure suitable complexity at low diversity sequencing cycles.
Oligonucleotides
The following oligonucleotides were used for library preparation and sequencing:
TSO-RT: | AAGCAGTGGTATCAACGCAGAGTGAATrGrGrG |
TSO-PCR: | AAGCAGTGGTATCAACGCAGAGT |
TSO-hybrid: | AATGATACGGCGACCACCGAGATCTACACGCCTGTCCGCGGAAGCAGTGGTATCAACGCAGAGT*A*C |
Nextera N70X: | CAAGCAGAAGACGGCATACGAGAT[XXXXXXXX]GTCTCGTGGGCTCGG |
Read1customSeq: | GCCTGTCCGCGGAAGCAGTGGTATCAACGCAGAGTAC |
Data processing
Raw fastq files were processed with the Drop-seq toolkit established in Macosko et al.9 according to recommended guidelines. The pipeline was implemented via the DropSeqPipe v0.4 workflow22. In brief, Cutadapt v1.16 was used for adapter trimming, with trimming and filtering was performed on both fastq files separately. STAR v2.5.3 was used for mapping to annotation release v.94 and genome build v.38 for Mus musculus, or annotation release v.91 and genome build v.38 for Homo sapiens. Multimapped reads were discarded. Dropseq_tools v2 was used for demultiplexing and file manipulation according to recommended guidelines, and technology-specific positions of the cell barcodes and unique molecular identifiers (UMI) were used. A whitelist of cells barcodes with minimum distance of 3 bases was used. Cell barcodes and UMI with a hamming distance of 1 and 2 respectively were corrected.
For cell cycle phase determination, gene expression profiles of individual cells were related to adapted gene sets used in Macosko et al. that represent distinct phases of the cell cycle9. Specifically, phase scores for each cell-cycle stage were determined for individual cells by averaging the log normalised expression levels, derived using Seurat (v3.1.1)57, of the genes in each gene-set. The mean scores for each phase were then mean centred and standard deviation normalised across all cells, before phases for each individual cell were mean centred and standard deviation normalised. Cells were subsequently ordered according to the combination of phases determined to be switched on in each individual cell.
Regulatory transcriptional networks
Datasets were initially filtered to those genes expressed in at least 10% of cells of each single-cell library. Raw counts were subsequently log normalised and scaled with Seurat. For Fig. 3b,c, human and mouse transcription factor targets were downloaded from the TRRUST v2 database27. Regulons were subsequently filtered to those expressed in respective human and mouse cell datasets alongside > 10 identified targets. Transcription factor activity was subsequently scored in individual cells by averaging the normalised expression levels of the genes in each regulon. The mean scores for each regulon were mean centred and standard deviation normalised across all cells. Normalised inferred regulon activity of individual cells was subsequently correlated with the previously inferred phase-specific scores, with those having a significant (p < 0.01) pearson correlation of > 0.3 with one or more phases being used for presentation. For Fig. 3d,e, regulons used were previously derived from 24 TCGA human cancer RNA-seq datasets and accessed from the ‘aracne.networks’ R package. VIPER (v.1.18.1)38,39 was used to score all regulons from the 24 TCGA human cancers in all individual human HEK293 cells, before the average of all normalised enrichment scores (i.e. avgScore) for each specific master regulator was used to integrate scores into a single metric. The mean scores for each regulon were mean centred and standard deviation normalised across all cells. Inferred regulon activity of individual cells was subsequently correlated with the previously inferred phase-specific scores, with those having a pearson correlation of > 0.35 with one or more phases being used for presentation. The cor.test function of the stats (v. 3.6.1) R package was used for calculation of Pearson correlation and test statistics. The test statistic is based on Pearson's product moment correlation coefficient cor(x, y) and follows a t distribution with length(x)-2 degrees of freedom. The p.adjust function of the stats (v. 3.6.1) R package was used for calculation of adjusted p values using the Bonferroni method.
Gene depletion analysis
Analysis of gRNA fold changes to assess gene essentiality for proliferation was carried out as per Wang et al.47. In brief, sgRNA counts detected from the initial populations of KBM7, K562 and two Burkitt's lymphoma (Jiyoye and Raji) cell lines were combined to generate an initial reference set. Those sgRNAs with less than 400 counts across this set were removed from subsequent analysis. The log2 fold change in abundance of each sgRNA was then calculated for the final population samples for each of the lines after adding a count of one as a pseudocount. Gene-based CRISPR scores were defined as the average log2 fold change of all sgRNAs targeting a given gene in each line. The scores reported for the KBM7 cell line were the average of two independent replicate experiments. In total, the analysis summarised 953 control sgRNAs and seven gRNAs targeting CPEBZ.
Gene essentiality in multiple cancer lines were summarised using data collected as part of the Dependency Map (DepMap) project. CERES48 scores and DEMETER58 scores were accessed using the R Bioconductor packages of depmap (v.1.2.0) and ExperimentHub (v.1.14.2). CERES scores report gene-dependency levels from CRISPR–Cas9 essentiality screens while accounting for the copy number–specific effects. DEMETER2 correspondingly scores gene essentiality within RNAi screens. A lower score of either means that a gene is more likely to be dependent in a given cell line. Accordingly, a cell line was considered dependent on a gene if it had a probability of dependency less than -0.5, whilst a score of − 1 corresponded to the median of all common essential genes. As outlined by DepMap, a common essential gene was considered a gene which ranked in the top X most depleting genes in at least 90% of the cell lines in the large, pan-cancer screen. X was chosen empirically using the minimum of the distribution of gene ranks in their 90th percentile least depleting cancer lines. Enriched lineages were those with p values < 0.0005.
Data availability
Study generated transcriptomic data has been deposited in the ArrayExpress with accession number E-MTAB-10296. External datasets were collected from following sources: Macasko et al. 2015 mixed species from GEO accession GSE63473 (SRR1748412), Chromium v3 from 10 × Genomics (https://www.10xgenomics.com), Habib et al. 2017 mouse 3T3 nuclei from the Broad Institutes Single Cell portal (https://portals.broadinstitute.org/single_cell).
References
Montoro, D. T. et al. A revised airway epithelial hierarchy includes CFTR-expressing ionocytes. Nature 560, 319–324. https://doi.org/10.1038/s41586-018-0393-7 (2018).
Keren-Shaul, H. et al. A unique microglia type associated with restricting development of Alzheimer’s disease. Cell 169, 1276-1290 e1217. https://doi.org/10.1016/j.cell.2017.05.018 (2017).
Mathys, H. et al. Single-cell transcriptomic analysis of Alzheimer’s disease. Nature 570, 332–337. https://doi.org/10.1038/s41586-019-1195-2 (2019).
Cao, J. et al. Comprehensive single-cell transcriptional profiling of a multicellular organism. Science 357, 661–667. https://doi.org/10.1126/science.aam8940 (2017).
Cardona-Alberich, A., Tourbez, M., Pearce, F. S. & Sibley, C. R. Elucidating the cellular dynamics of the brain with single-cell RNA sequencing. RNA Biol. https://doi.org/10.1080/15476286.2020.1870362 (2021).
Ramskold, D. et al. Full-length mRNA-Seq from single-cell levels of RNA and individual circulating tumor cells. Nat. Biotechnol. 30, 777–782. https://doi.org/10.1038/nbt.2282 (2012).
Shalek, A. K. et al. Single-cell transcriptomics reveals bimodality in expression and splicing in immune cells. Nature 498, 236–240. https://doi.org/10.1038/nature12172 (2013).
Huang, Y. & Sanguinetti, G. BRIE: Transcriptome-wide splicing quantification in single cells. Genome Biol 18, 123. https://doi.org/10.1186/s13059-017-1248-5 (2017).
Macosko, E. Z. et al. Highly parallel genome-wide expression profiling of individual cells using nanoliter droplets. Cell 161, 1202–1214. https://doi.org/10.1016/j.cell.2015.05.002 (2015).
Klein, A. M. et al. Droplet barcoding for single-cell transcriptomics applied to embryonic stem cells. Cell 161, 1187–1201. https://doi.org/10.1016/j.cell.2015.04.044 (2015).
Rosenberg, A. B. et al. Single-cell profiling of the developing mouse brain and spinal cord with split-pool barcoding. Science 360, 176–182. https://doi.org/10.1126/science.aam8999 (2018).
Stoeckius, M. et al. Simultaneous epitope and transcriptome measurement in single cells. Nat Methods 14, 865–868. https://doi.org/10.1038/nmeth.4380 (2017).
Peterson, V. M. et al. Multiplexed quantification of proteins and transcripts in single cells. Nat. Biotechnol. 35, 936–939. https://doi.org/10.1038/nbt.3973 (2017).
Habib, N. et al. Massively parallel single-nucleus RNA-seq with DroNc-seq. Nat. Methods 14, 955–958. https://doi.org/10.1038/nmeth.4407 (2017).
Zhang, Q. et al. Development of a facile droplet-based single-cell isolation platform for cultivation and genomic analysis in microorganisms. Sci. Rep. 7, 41192. https://doi.org/10.1038/srep41192 (2017).
Zheng, G. X. et al. Massively parallel digital transcriptional profiling of single cells. Nat. Commun. 8, 14049. https://doi.org/10.1038/ncomms14049 (2017).
Khan, S. & Kaihara, K. A. Single-cell RNA-sequencing of peripheral blood mononuclear cells with ddSEQ. Methods Mol. Biol. 155–176, 2019. https://doi.org/10.1007/978-1-4939-9240-9_10 (1979).
Yamada, S. & Nomura, S. Review of single-cell RNA sequencing in the heart. Int. J. Mol. Sci. 21, 8345. https://doi.org/10.3390/ijms21218345 (2020).
Goldstein, L. D. et al. Massively parallel nanowell-based single-cell gene expression profiling. BMC Genomics 18, 519. https://doi.org/10.1186/s12864-017-3893-1 (2017).
Zilionis, R. et al. Single-cell barcoding and sequencing using droplet microfluidics. Nat. Protoc. 12, 44–73. https://doi.org/10.1038/nprot.2016.154 (2017).
Caliari, S. R. & Burdick, J. A. A practical guide to hydrogels for cell culture. Nat. Methods 13, 405–414. https://doi.org/10.1038/nmeth.3839 (2016).
Kanev, K. et al. Proliferation-competent Tcf1+ CD8 T cells in dysfunctional populations are CD4 T cell help independent. Proc. Natl. Acad. Sci. USA 116, 20070–20076. https://doi.org/10.1073/pnas.1902701116 (2019).
Lake, B. B. et al. Integrative single-cell analysis of transcriptional and epigenetic states in the human adult brain. Nat. Biotechnol. 36, 70–80. https://doi.org/10.1038/nbt.4038 (2018).
Jakel, S. et al. Altered human oligodendrocyte heterogeneity in multiple sclerosis. Nature 566, 543–547. https://doi.org/10.1038/s41586-019-0903-2 (2019).
Lake, B. B. et al. A comparative strategy for single-nucleus and single-cell transcriptomes confirms accuracy in predicted cell-type expression from nuclear RNA. Sci. Rep. 7, 6031. https://doi.org/10.1038/s41598-017-04426-w (2017).
Whitfield, M. L. et al. Identification of genes periodically expressed in the human cell cycle and their expression in tumors. Mol. Biol. Cell 13, 1977–2000. https://doi.org/10.1091/mbc.02-02-0030 (2002).
Han, H. et al. TRRUST v2: An expanded reference database of human and mouse transcriptional regulatory interactions. Nucleic Acids Res. 46, D380–D386. https://doi.org/10.1093/nar/gkx1013 (2018).
Nandan, M. O., Chanchevalap, S., Dalton, W. B. & Yang, V. W. Kruppel-like factor 5 promotes mitosis by activating the cyclin B1/Cdc2 complex during oncogenic Ras-mediated transformation. FEBS Lett. 579, 4757–4762. https://doi.org/10.1016/j.febslet.2005.07.053 (2005).
Yarden, R. I., Pardo-Reoyo, S., Sgagias, M., Cowan, K. H. & Brody, L. C. BRCA1 regulates the G2/M checkpoint by activating Chk1 kinase upon DNA damage. Nat. Genet. 30, 285–289. https://doi.org/10.1038/ng837 (2002).
Su, X. et al. Inhibition of PTTG1 expression by microRNA suppresses proliferation and induces apoptosis of malignant glioma cells. Oncol. Lett. 12, 3463–3471. https://doi.org/10.3892/ol.2016.5035 (2016).
Gherardi, S., Valli, E., Erriquez, D. & Perini, G. MYCN-mediated transcriptional repression in neuroblastoma: The other side of the coin. Front. Oncol. 3, 42. https://doi.org/10.3389/fonc.2013.00042 (2013).
Bayrer, J. R., Mukkamala, S., Sablin, E. P., Webb, P. & Fletterick, R. J. Silencing LRH-1 in colon cancer cell lines impairs proliferation and alters gene expression programs. Proc. Natl. Acad. Sci. USA 112, 2467–2472. https://doi.org/10.1073/pnas.1500978112 (2015).
Jin, J. et al. Targeting LRH1 in hepatoblastoma cell lines causes decreased proliferation. Oncol. Rep. 41, 143–153. https://doi.org/10.3892/or.2018.6793 (2019).
Garcia-Gutierrez, L., Delgado, M. D. & Leon, J. MYC oncogene contributions to release of cell cycle brakes. Genes (Basel) 10, 244. https://doi.org/10.3390/genes10030244 (2019).
Deluz, C. et al. A role for mitotic bookmarking of SOX2 in pluripotency and differentiation. Genes Dev. 30, 2538–2550. https://doi.org/10.1101/gad.289256.116 (2016).
Zhu, W., Giangrande, P. H. & Nevins, J. R. E2Fs link the control of G1/S and G2/M transcription. EMBO J. 23, 4615–4626. https://doi.org/10.1038/sj.emboj.7600459 (2004).
Hoog, G., Zarrizi, R., von Stedingk, K., Jonsson, K. & Alvarado-Kristensson, M. Nuclear localization of gamma-tubulin affects E2F transcriptional activity and S-phase progression. FASEB J. 25, 3815–3827. https://doi.org/10.1096/fj.11-187484 (2011).
Alvarez, M. J. et al. Functional characterization of somatic mutations in cancer using network-based inference of protein activity. Nat. Genet. 48, 838–847. https://doi.org/10.1038/ng.3593 (2016).
Ding, H. et al. Quantitative assessment of protein activity in orphan tissues and single cells using the metaVIPER algorithm. Nat. Commun. 9, 1471. https://doi.org/10.1038/s41467-018-03843-3 (2018).
Alexander, K. E. & Rizkallah, R. Aurora A Phosphorylation of YY1 during mitosis inactivates its DNA binding activity. Sci. Rep. 7, 10084. https://doi.org/10.1038/s41598-017-10935-5 (2017).
Rizkallah, R., Alexander, K. E., Kassardjian, A., Luscher, B. & Hurt, M. M. The transcription factor YY1 is a substrate for Polo-like kinase 1 at the G2/M transition of the cell cycle. PLoS ONE 6, e15928. https://doi.org/10.1371/journal.pone.0015928 (2011).
Schimmel, J. et al. Uncovering SUMOylation dynamics during cell-cycle progression reveals FoxM1 as a key mitotic SUMO target protein. Mol. Cell 53, 1053–1066. https://doi.org/10.1016/j.molcel.2014.02.001 (2014).
Fu, Z. et al. Plk1-dependent phosphorylation of FoxM1 regulates a transcriptional programme required for mitotic progression. Nat. Cell. Biol. 10, 1076–1082. https://doi.org/10.1038/ncb1767 (2008).
Faronato, M. et al. The deubiquitylase USP15 stabilizes newly synthesized REST and rescues its expression at mitotic exit. Cell Cycle 12, 1964–1977. https://doi.org/10.4161/cc.25035 (2013).
Yao, Z. et al. ZKSCAN1 gene and its related circular RNA (circZKSCAN1) both inhibit hepatocellular carcinoma cell growth, migration, and invasion but through different signaling pathways. Mol Oncol 11, 422–437. https://doi.org/10.1002/1878-0261.12045 (2017).
McManus, M. et al. Hes4: A potential prognostic biomarker for newly diagnosed patients with high-grade osteosarcoma. Pediatr. Blood Cancer https://doi.org/10.1002/pbc.26318 (2017).
Wang, T. et al. Identification and characterization of essential genes in the human genome. Science 350, 1096–1101. https://doi.org/10.1126/science.aac7041 (2015).
Meyers, R. M. et al. Computational correction of copy number effect improves specificity of CRISPR-Cas9 essentiality screens in cancer cells. Nat. Genet. 49, 1779–1784. https://doi.org/10.1038/ng.3984 (2017).
Islam, S. et al. Characterization of the single-cell transcriptional landscape by highly multiplex RNA-seq. Genome Res. 21, 1160–1167. https://doi.org/10.1101/gr.110882.110 (2011).
Jaitin, D. A. et al. Massively parallel single-cell RNA-seq for marker-free decomposition of tissues into cell types. Science 343, 776–779. https://doi.org/10.1126/science.1247651 (2014).
Habib, N. et al. Div-Seq: Single-nucleus RNA-Seq reveals dynamics of rare adult newborn neurons. Science 353, 925–928. https://doi.org/10.1126/science.aad7038 (2016).
Lake, B. B. et al. Neuronal subtypes and diversity revealed by single-nucleus RNA sequencing of the human brain. Science 352, 1586–1590. https://doi.org/10.1126/science.aaf1204 (2016).
Liu, L., Dalal, C. K., Heineike, B. M. & Abate, A. R. High throughput gene expression profiling of yeast colonies with microgel-culture Drop-seq. Lab Chip 19, 1838–1849. https://doi.org/10.1039/c9lc00084d (2019).
Chen, S., Lake, B. B. & Zhang, K. High-throughput sequencing of the transcriptome and chromatin accessibility in the same cell. Nat Biotechnol. 37, 1452–1457. https://doi.org/10.1038/s41587-019-0290-0 (2019).
Barbieri, I. et al. Promoter-bound METTL3 maintains myeloid leukaemia by m(6)A-dependent translation control. Nature 552, 126–131. https://doi.org/10.1038/nature24678 (2017).
Liu, S. et al. METTL3 plays multiple functions in biological processes. Am. J. Cancer Res. 10, 1631–1646 (2020).
Butler, A., Hoffman, P., Smibert, P., Papalexi, E. & Satija, R. Integrating single-cell transcriptomic data across different conditions, technologies, and species. Nat. Biotechnol. 36, 411–420. https://doi.org/10.1038/nbt.4096 (2018).
McFarland, J. M. et al. Improved estimation of cancer dependencies from large-scale RNAi screens using model-based normalization and data integration. Nat. Commun. 9, 4610. https://doi.org/10.1038/s41467-018-06916-5 (2018).
Acknowledgements
This work was supported by an Edmond Lily Safra fellowship and a Sir Henry Dale fellowship jointly funded by the Wellcome Trust and the Royal Society (grant no. 215454/Z/19/Z) to CRS, a Wellcome Trust Seed award to CRS (205990/Z/17/Z), and funding to CRS from the National Institute for Health Research (NIHR) Biomedical Research Centre based at Imperial College Healthcare NHS Trust and Imperial College London. The views expressed are those of the authors and not necessarily those of the NHS, the NIHR or the Department of Health. All sequencing was performed by the Imperial BRC genomics facility.
Author information
Authors and Affiliations
Contributions
D.W., H.F., and C.R.S. designed experiments. KD and DW performed experiments with contributions from E.K., F.K. and C.R.S. C.R.S. analysed the data with contribution from T.L. C.R.S. wrote the manuscript.
Corresponding author
Ethics declarations
Competing interests
D.W., F.K. and H.F. were employees for Dolomite Bio at time of study.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Davey, K., Wong, D., Konopacki, F. et al. A flexible microfluidic system for single-cell transcriptome profiling elucidates phased transcriptional regulators of cell cycle. Sci Rep 11, 7918 (2021). https://doi.org/10.1038/s41598-021-86070-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-021-86070-z
This article is cited by
-
High-throughput transcriptomics
Scientific Reports (2022)
-
Optimization of library preparation based on SMART for ultralow RNA-seq in mice brain tissues
BMC Genomics (2021)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
