
Abstract
Genome-wide association studies (GWAS) have identified thousands of genetic loci associated with cross-sectional blood pressure (BP) traits; however, GWAS based on longitudinal BP have been underexplored. We performed ethnic-specific and trans-ethnic GWAS meta-analysis using longitudinal and cross-sectional BP data of 33,720 individuals from five cohorts in the US and one in Brazil. In addition to identifying several known loci, we identified thirteen novel loci with nine based on longitudinal and four on cross-sectional BP traits. Most of the novel loci were ethnic- or study-specific, with the majority identified in African Americans (AA). Four of these discoveries showed additional evidence of association in independent datasets, including an intergenic variant (rs4060030, p = 7.3 × 10–9) with reported regulatory function. We observed a high correlation between the meta-analysis results for baseline and longitudinal average BP (rho = 0.48). BP trajectory results were more correlated with those of average BP (rho = 0.35) than baseline BP(rho = 0.18). Heritability estimates trended higher for longitudinal traits than for cross-sectional traits, providing evidence for different genetic architectures. Furthermore, the longitudinal data identified up to 20% more BP known associations than did cross-sectional data. Our analyses of longitudinal BP data in diverse ethnic groups identified novel BP loci associated with BP trajectory, indicating a need for further longitudinal GWAS on BP and other age-related traits.
Similar content being viewed by others

Introduction
High blood pressure (BP) is a major risk factor for cardiovascular diseases (CVD), which are leading causes of premature death worldwide1,2. BP has high familial clustering3 with heritability estimates ranging from 30 to 60%2, pointing to genetic association studies as valuable tools for discovering genetic determinants of BP. To date, genome-wide association studies (GWAS) have identified more than 2,000 variants significantly associated with BP (p < 5 × 10–8)4; however, these genetic variants explain only approximately 3.5% of BP variance2,5. This suggests a need to go beyond the common designs for BP GWAS, which use cross-sectional data almost exclusively and are enriched for European-ancestry individuals.
Longitudinal data recording BP trajectory have shown progressive upward trends from childhood to middle age, with some evidence of plateauing at older ages6,7, and, as expected, individuals who experience higher rates of BP increase are more likely to reach the elevated BP levels associated with increased risk of cardiovascular disease8,9,10. Despite this clear correlation between BP trajectory and cardiovascular-related outcomes, GWAS using empirical longitudinal BP data are currently lacking.
Longitudinal designs for BP genetic associations can identify variants associated with BP trajectory11 and may outperform the commonly used cross-sectional designs12,13. Simulations suggest that longitudinal data can more accurately identify diastolic BP loci compared to baseline data, which performs better for systolic blood pressure13. These findings indicate that using longitudinal BP in GWAS may enable the discovery of loci14 that play key roles in BP trajectory and the risk of developing CVD. Furthermore, the vast majority of BP GWAS include only or mostly individuals of European ancestry. The inclusion of multiple ethnic groups in BP GWAS has allowed the discovery of novel loci that were not detected in Europeans1,2.
To identify novel BP loci, we performed a series of ethnic-specific and trans-ethnic GWAS meta-analyses of longitudinal and cross-sectional data using 33,720 individuals from five longitudinal studies in the US and one in Brazil.
Results
Populations included and blood pressure (BP) observations
We analyzed 21,900 individuals (discovery dataset) from different ethnic backgrounds: 5304 African Americans (AA); 1439 Brazilians; 13,137 European Americans (EA); 703 Chinese Americans; and 1317 Hispanic Americans. These individuals were included from four longitudinal cohorts: (i) Atherosclerosis Risk in Communities (ARIC) Study15; (ii) the Bambui-Epigen Cohort Study of Aging (Bambui)16; (iii) the Health, Aging and Body Composition (HABC) Study17 and (iv) the Multi-Ethnic Study of Atherosclerosis (MESA)18. The studied individuals showed ancestry profiles consistent with expectations given their self-reported ethnic backgrounds (Fig. S1). Interestingly, the average diastolic BP (DBP) in the Bambui-Brazil Aging Cohort is 83.41 mm Hg (SD = 12.72), similar to the average DBP in the Brazilian general population of similar age19, but considerably higher than the average in the HABC study, also a study of older adults (71.30, SD = 11.76), and higher by ~ 10 mm Hg compared to the other analyzed groups (Table 1). We observed higher levels of BP and hypertension in African Americans (AA) compared with other ethnicities (Table 1), which is in agreement with previous reports20. However, for the older individuals (Bambui-Brazil and HABC), the mean BP and prevalence of hypertension (> 65%) were similar even among different ethnicities. Furthermore, the longitudinal data showed that increasing baseline age is correlated with a lower slope of systolic and diastolic blood pressure (SBP and DBP) in European- and African-ancestry populations (Fig. S2), consistent with previous studies21,22. Most of the baseline and follow-up ages in the cohorts included in our meta-analysis were after the expected inflection point in DBP (Table 1), as shown in Fig. S2B. Consistently, after adjustment for age2 (our study model) or age + age2, as separate covariates, there was no difference between DBP trajectory estimates (Fig. S2D).
Meta-analysis of longitudinal and cross-sectional data
We performed GWAS by ethnic group and cohort, followed by ethnic-specific and trans-ethnic meta-analysis for each longitudinal BP outcome: the trajectories (i.e. rate of change of BP per year) of (i) systolic and (ii) diastolic BP, and the averages (i.e. mean of longitudinal BP measurements) of (iii) systolic and (iv) diastolic BP. To facilitate comparisons between the longitudinal BP analyses and analyses conducted using a more standard cross-sectional approach, we also performed meta-analysis for cross-sectional SBP and DBP at baseline using the individuals included in the longitudinal analyses. We present associations from the discovery data that reached the standard genome-wide statistical significance (p < 5 × 10–8) and borderline genome-wide statistical significance (p < 9 × 10–8). For the statistically significant associations, we present the statistical significance for the three outcomes analyzed: trajectory, average, and baseline (Table 2 and Table S1).
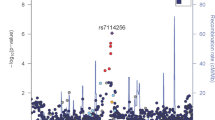
We found 19 loci that were significantly (or borderline) associated with BP outcomes (Table 2, Tables S1–S4, Fig. 1 and Figs. S3–S10), of which 14 were significantly associated and five were borderline significantly associated. Out of these 19 loci, 10 were associated with longitudinal outcomes and nine with baseline. Of these 19 loci, 17 were ethnic- or study-specific, with the majority (11) found in African Americans (AA). We observed significant heterogeneity across studies (ethnic-specific meta-analyses) or ethnicities (trans-ethnic meta-analyses) for only one locus in AA populations (Table S2). This variant (rs145522449) showed significant heterogeneity in effect sizes in MESA and ARIC even though the direction of effect was the same in both studies. Interestingly, 9 out of 10 BP loci detected using longitudinal outcomes were novel, whereas only 4 of 9 BP loci using the cross-sectional outcomes were novel (Tables 2 and S1). This suggests that longitudinal data allow for discovery of novel associations that could not be identified using baseline data alone. All signals based on average BP also had some evidence of association (p < 0.05) in the cross-sectional analyses, consistent with the fact that the cross-sectional data are included in the calculation of average BP. This trend of overlapping associations was not observed for BP trajectory (Tables 2 and S1). To evaluate the overall correlation between the ability of longitudinal and cross-sectional data to identify BP associations, we compared the statistical significance of all tested genetic variants (Fig. 2). We identified at least twofold higher correlation between average and cross-sectional findings (rho = 0.48 in African Americans, Fig. 2A, and rho = 0.50 in European Americans, Fig. 2B) compared to the correlation between trajectory and cross-sectional findings (rho = 0.06 in African Americans, Fig. 2A, and rho = 0.19 in European Americans, Fig. 2B). Consistently, we observed the highest correlation between the results using baseline and average BP outcomes, and trajectory was more correlated with average than with baseline outcomes (Fig. S11).

Forest plots of the genome-wide statistically significant associations of longitudinal and baseline BP data with additional evidence of association in independent datasets. Forest plots show β values (95% confidence intervals) and P-values from the linear regression of longitudinal outcomes (BP trajectory or BP average) adjusted for age2, sex, BMI, principal components (PC1 and PC2), and the use of antihypertensive medications. Populations not shown in the plots did not have the genetic variant to perform association analyses due to low allele frequency or because the variant was pruned during quality control.

Comparison between longitudinal and cross-sectional SBP data. Correlation between the meta-analysis results using (A) African American and (B) European American data. We combined 5293 African Americans and 13,120 European Americans from the ARIC, MESA, and HABC studies (Table 1). We used ~ 20 million variants tested for association among African Americans and ~ 10 million variants for European-Americans. The blue lines represent the fitted linear regressions and the red lines represent the x = y line. All correlations had p ≤ 2.2 × 10−16.
Discovery findings with additional evidence of association
Out of the 19 variants with a GWAS statistically significant association (or borderline) in the discovery analysis, 10, 11, and eight variants were available (passed frequency and QC criteria) in the EA, AA, and Latinos/Brazilians datasets, respectively (Fig. 1 and Table S1). We identified four variants with additional evidence of association with BP in two replication datasets (same direction and p-value < 0.05, Tables 2 and S3) and we did not identify statistically significant local replications. While some discovery associations did not show additional evidence of association in the replication datasets (Table S3), in some cases because of the absence of the variant in the replication dataset due to filtering for minor allele frequency and quality control procedures, these were still described (SI text) as promising variants based on our comprehensive annotation (Table S4).
The C allele of an intronic variant (rs4060030) in the RNA gene C8orf37-AS1 was associated (β = − 0.125, SE = 0.023, p = 5.9 × 10–8) with decreasing DBP trajectory in AA populations (Fig. 1A, Table 2, Tables S1-S4, and Fig. S8). This association was replicated using longitudinal BP data of Brazilians (Bambui-Brazil) (p = 7.3 × 10–9, after meta-analysis including AA and Brazilians). This variant was also associated in AA with decreasing SBP trajectory (β = − 0.102, SE = 0.023, p = 7.1 × 10–5) and decreasing SBP average (β = − 0.748, SE = 0.203, p = 2.2 × 10–4), and associated with decreasing SBP average (β = − 0.512 mm Hg, SE = 0.243, p = 0.03) in Hispanic women from the Women's Health Initiative (WHI). The rs4060030 variant is involved in epigenetic regulation in several tissues, including cardiac, and differentially binds 14 regulatory motifs, including YY1, for which expression is increased in hypertensive elastic arteries23. Furthermore, this variant is a statistically significant eQTL of an uncharacterized gene (LOC101927039) in the heart atrial appendage24.
The SNP rs74838709 was genome-wide associated with baseline SBP (β = 16.5 mm Hg , SE = 3.0, p = 4.2 × 10–8) in the AA meta-analysis with replication observed in Hispanics from the WHI study (p = 1 × 10–8, after meta-analysis including AA and Hispanics) (Fig. 1B, Table 2, Tables S1-S4, and Fig. S7). rs74838709 is an intergenic variant located ~ 7 kb downstream of the GABRG3 gene, which has been reported associated with several traits including coronary artery calcification25, cognition26, and weight measures27. This variant has a regulatory motif altered in the ZEB1 transcription factor (ZEB1 is located in an “obesity” locus28), which regulates the accumulation of adipose tissue29.
An intronic deletion rs565370904 was associated with SBP trajectory in EA populations (β = 0.088, SE = 0.016, p = 3.9 × 10–8) (Fig. 1C, Table 2, Tables S1-S4). The rs565370904 variant was associated with cross-sectional SBP in the Hispanics from WHI (p = 0.03) and was borderline in the UK BioBank (p = 0.051; Table S3. This deletion is in the gene LRP12 (LDL Receptor Related Protein 12), which has low-density lipoprotein particle receptor activity30.
We also identified an intergenic insertion (rs199848402) associated with DBP trajectory in EA (β = 0.079, SE = 0.014, p = 4.3 × 10–8) (Fig. 1D, Table 2, Tables S1-S4). rs199848402 was associated with cross-sectional DBP in AADM (p = 0.045) and was borderline in the Framingham study (p = 0.06) (Table S3). rs199848402 is in a genomic region downstream of HCN1, previously associated with electrocardiographic P Wave duration in European-ancestry individuals31.
Meta-analyses of discovery and replication studies
In addition to our discovery and replication design, we also conducted meta-analyses of discovery and replication studies together. All statistically significant and suggestive results (p < 1 × 10–6) are shown in Table S5. Notably, the trans-ethnic meta-analysis of average BP outcomes, including all studied individuals, identified (p < 5 × 10–8) two common frequency loci, represented by the variants rs6599176 and rs11105368 in the genes ULK4 and ATB2B1, respectively. These two loci have been consistently reported to be associated with BP and hypertension20,32.
SNP heritability of the longitudinal and cross-sectional BP traits
To calculate SNP heritability (h2), we used European American (EA) individuals from the ARIC and MESA studies. Regardless of antihypertensive medication use, DBP outcomes tended to have higher h2 than SBP outcomes (Table 3). Notably, the h2 of average DBP (h2 = 0.47, SE = 0.04) was higher than the h2 of baseline DBP (h2 = 0.28, SE = 0.04). The use of antihypertensive medication appeared to systematically decrease h2. We did not evaluate h2 in AA individuals due to limited sample size.
Identifying previous GWAS BP associations in longitudinal and cross-sectional BP datasets
The power of longitudinal compared to cross-sectional data to identify known BP loci was evaluated in GWAS Catalog associated BP traits4 (Methods). From those associations with reported risk alleles, 1957 variants (all associated with cross-sectional BP traits) were present in our combined data and 317 associations had the risk allele associated in the same direction reported in the GWAS Catalog (Fig. S12 and Tables S7 and S8). Consistent with the level of correlation between longitudinal and baseline results (Fig. 2), for both SBP and DBP, the highest number of shared identifications (associations using different BP outcomes) were found using average and the baseline (85), followed by average and trajectory (40), and then trajectory and baseline (25) (Fig. S12). The longitudinal outcomes identified similar numbers of previous associations: 185 using average and 177 using trajectory, but more (20% and 15%) than baseline (154). Considering the exclusive identifications (i.e., identified by only one outcome), the highest number (132) was identified by the trajectory, followed by average (80) and baseline (64). These results suggest that the BP longitudinal outcomes may have greater power to identify variants associated with BP.
Sensitivity analyses
We performed three additional analyses to assess sensitivity to assumptions for the five variants discovered using BP trajectories. First, adjusting for the top five principal components, instead of the top two principal components, did not change the estimates of either effect sizes or standard errors (Table S6). This analysis is consistent with a lack of confounding by weaker components of population structure. Second, adjusting trajectories for baseline BP values led to small reductions in both effect sizes and standard errors, resulting in minor increases in p-values (Table S6), as expected given correlation between trajectories and baseline values. This analysis indicates that trajectories are capturing substantive information beyond baseline values. Third, adjusting for the BMI trajectory did not change effect sizes or standard errors (Table S6), consistent with a lack of confounding between BMI and BP trajectories.
Discussion
We report the first GWAS meta-analysis using longitudinal BP data from diverse populations. By performing ethnic-specific and trans-ethnic meta-analyses, we showed that: (i) longitudinal data identified novel BP loci not identified using cross-sectional data; (ii) despite the correlation between longitudinal and cross-sectional BP outcomes, there is evidence for different genetic associations underlying these traits; (iii) longitudinal BP outcomes identified more of the previously published BP associations than cross-sectional outcomes identified; (iv) as was found with cross-sectional associations, most of the associations identified using longitudinal outcomes were ethnic-specific; and (v) longitudinal BP traits had higher heritability than baseline BP traits.
Our findings indicate that longitudinal data allows for the identification of novel BP associations as well as replication of known BP loci, suggesting a higher statistical power of longitudinal data for identifying GWAS BP loci, in agreement with a previous report13. We identified three novel BP trajectory associations with additional evidence of association in replication datasets (Table 2) with likely biological implications. Notably, one variant (rs4060030) in the RNA gene C8orf37-AS1 was associated with decreasing DBP trajectory in AA populations and Brazilians (Fig. 1A and Fig. S8, Table 2, Tables S1-S4). Interestingly, rs4060030 was also associated with decreasing SBP trajectory in AA and Hispanic women, suggesting that this locus affects both DBP and SBP trajectory. This variant differentially binds 14 regulatory motifs, including YY1, for which expression is increased in hypertensive elastic arteries23. This variant is a statistically significant eQTL of LOC101927039 in the heart atrial appendage24. C8orf37-AS1 has been reported to be associated with heart rate response to beta-blockers33.
As expected, we observed correlation between the meta-analyses results using longitudinal and cross-sectional BP data, with the cross-sectional results more correlated with average than trajectory results. Although most of the statistically significant associations using longitudinal data showed some evidence of association (p-value < 0.05) using cross-sectional data, they did not reach genome-wide statistical significance (Table S1). In contrast, two variants (rs199848402 and rs140355897) that were significantly associated with DBP trajectory showed no evidence of association using the cross-sectional data (p-values = 0.71 and 0.77, respectively). These results indicate that novel variants identified by the longitudinal analysis could not be identified using the standard cross-sectional design alone and that, despite some degree of overlap between longitudinal and cross-sectional data, there is evidence for different genetic associations underlying these traits. Genetic variants associated with BP trajectory but not with cross-sectional measurements may be of particular significance, as understanding the underlying biological mechanisms could give us new insight into causes of steeper declines in BP over time and could potentially lead to new therapies for hypertension prevention. Furthermore, our results warrant new studies to address the question of whether BP trajectory-associated variants, singly or in aggregate, are also associated with the development of cardiovascular diseases such as myocardial infarction and stroke.
Among the 19 loci that were significantly or borderline associated with BP outcomes, 11 were identified in African-ancestry individuals (Table S1 and S7), despite smaller sample sizes compared with European-ancestry populations in the discovery analysis. This is in accordance with the higher than expected contribution of AA to genome-wide statistically significant associations compared with those of European or Asian ancestry given the proportion of GWAS that include those of African ancestry34. These results highlight the importance of including diverse ethnic populations to identify associations for variants absent or with very low frequency in European populations.
The h2 of average DBP was higher than the h2 of cross-sectional DBP in EA populations, suggesting that it may be easier to identify genetic determinants of DBP using average compared to cross-sectional DBP data in EA (Table 3), in agreement with previous reports13. Higher heritability after excluding those on antihypertensive medications was observed in EA (Table 3), but limited sample size in AA precluded this analysis among AA. Considering the ethnic-specific nature of BP heritability35, similar analyses should be performed to compare longitudinal and cross-sectional BP outcomes using AA and other ethnic groups.
Although most of the individuals (65%) included in our discovery data were not using antihypertensive medications, we recognize their potential effect on modeling BP trajectory. The effects of BP-lowering treatment and regimen adherence and compliance on BP outcomes are problematic, not only for longitudinal studies but also for cross-sectional BP studies36. To model the effect of the use of antihypertensive medication on the BP trajectories, visit-specific information on medication use was incorporated into the mixed model analysis.
DBP rises essentially linearly until around the sixth decade of life and then tends to flatten or decline37. Furthermore, our longitudinal data showed that BP trajectories show more non-linear (quadratic) behavior on an individual basis (Fig. S2B) than at the population level (Fig. S2C). We adjusted for age2 to account for this tendency. However, given that most of the baseline and follow-up ages were after the expected inflection point in DBP (Fig. S2B and Table 1), our DBP trajectories estimated in older individuals do not capture the trajectory in early life, prior to the inflection point.
In conclusion, these results show that GWAS and meta-analysis using longitudinal data enable the discovery of novel genetic variants that may have an important role in disease progression and age-related traits. More longitudinal data may facilitate the discovery of variants associated with the progression of hypertension, as well as other traits highly affected by age, such as type 2 diabetes, chronic kidney disease, metabolic syndrome, body mass index, and cognition.
Methods
Discovery datasets: study participants and longitudinal blood pressure data
Four studies were included in the discovery analyses: (i) the Atherosclerosis Risk in Communities (ARIC) Study15; (ii) the Bambui-Epigen Cohort Study of Aging (Bambui)16; (iii) the Health, Aging and Body Composition (HABC) Study17 and (iv) the Multi-Ethnic Study of Atherosclerosis (MESA)18.
The ARIC study15 is a prospective cohort study of atherosclerosis (dbGaP Study Accession: phs000090.v1.p1) including 15,792 African Americans (AA) and European Americans (EA) aged 45–64 at baseline, residing in four communities in the United States (Forsyth County, NC; Jackson, MS; the northwest suburbs of Minneapolis, MN; and Washington County, MD). The ARIC study participants were examined up to four times, with visits occurring in 1987–1989 (baseline), 1990–1992, 1993–1995, and 1996–1998.
The Bambui study38 is a population-based cohort study of aging in the city of Bambui in Southeast Brazil. The population eligible for the cohort comprised all residents aged 60 years and over on 1 January 1997 (1,742 inhabitants) and 92% of the eligible population participated in the study16. BP was measured at baseline (1997) and in three subsequent waves (2000, 2002, and 2008)38. This cohort is composed of admixed individuals with European (78.5%), African (14.7%), and Amerindian (6.7%) ancestries39.
HABC17 is a cohort study of aging (dbGaP Study Accession: phs000169.v1.p1) comprising AA and EA (3,075 men and women, aged 70–79 at baseline) who were recruited in 1997–1998 and had annual clinical follow-up for six years.
MESA18 is a prospective study of atherosclerosis (dbGaP Study Accession: phs000209.v13.p3) involving a population-based sample of 6,814 asymptomatic men and women aged 45–84. Participants included African Americans, Hispanic Americans, Chinese Americans, and European Americans from six field centers in the United States (Wake Forest University, Columbia University, Johns Hopkins University, University of Minnesota, Northwestern University, and University of California, Los Angeles). The first examination (baseline) took place from July 2000 to July 2002 and was followed by three examination periods that were 17–20 months in length.
Replication datasets: study participants and longitudinal blood pressure data
We used two additional longitudinal datasets to perform exact and local40 replication analysis: the Framingham Heart Study (FHS) (dbGaP Study Accession: phs000007.v30.p11) and the Women's Health Initiative (WHI) (dbGaP Study Accession: phs000200.v1.p1). Exact replication is when the replication dataset replicates (same direction and p-value < 0.05) the same (“exact”) variant and trait identified during the discovery analysis. Local replication accounts for possible differences in LD patterns between studies and therefore interrogates a set of variants in LD (r2 > 0.3 in the discovery dataset) with the exact variant. The p-values for the associations of these correlated variants are adjusted for the effective number of tests, following the example in40. In addition, we performed in silico replication by looking up the BP results (summary statistics) in public cross-sectional studies: UK BioBank41, The Uganda Genome Resource42 and The Africa America Diabetes Mellitus study43.
Genotyping and quality control
We used the genotype data (Illumina Infinium Omni2.5) from 1442 participants from the Bambui Study in the context of the EPIGEN project39. For the ARIC and MESA studies, we used the genotype data (Affymetrix Genome-Wide Human SNP Array 6.0) from 12,773 and 6814 participants, respectively. For the HABC study, we used the genotype data (Illumina Human1M-Duo) from 2870 individuals. We split all genotype study datasets by ethnicity (i.e., African Americans, European Americans, Hispanic Americans, and Chinese Americans) before quality control, phasing, imputation, and downstream analyses. The Brazilian Bambui Study could not be meaningfully subdivided by ethnicity because this population is highly admixed39.
For all genotype datasets, we applied standard data quality control and imputation procedures. Quality control was performed using PLINK software44 by applying the following filters: minor allele frequency (–maf 0.01), missing rate per variant (–geno 0.05), missing rate per individual (–mind 0.05), and Hardy–Weinberg equilibrium (–hwe 0.000001).
Population structure and relatedness
Before inference of population structure and relatedness, we pruned strand-ambiguous SNPs and SNPs in linkage disequilibrium (r2 > 0.2, PLINK filter—indep-pairwise 50 10 0.2). Considering that the datasets included in this study have multiple ethnicities, we performed principal component analysis (PCA) to assess population structure. We merged each study genotype dataset with the 1000 Genomes Project Phase 3 data45 and performed PCA using EIGENSTRAT46. To infer the level of relatedness among individuals, we calculated the pairwise kinship matrix for each dataset using EPACTS47.
Phasing and imputation
To generate valid VCF files before imputation and association tests, we used the tool checkVCF.py (https://genome.sph.umich.edu/wiki/CheckVCF.py) and bcftools48 to check and correct for monomorphic sites, consistency of reference alleles with the reference genome, variants with invalid genotypes, and non-SNP sites.
For the ARIC, Bambui, and MESA studies, we used the Sanger server (https://imputation.sanger.ac.uk/) for phasing and imputation of the genotype data, using the EAGLE249 and PBWT50 software, respectively. For Chinese, European, and Hispanic Americans, we used the 1000 Genomes Phase 3 reference panel, and for African Americans and Brazilians, we used the African Genome Resources panel51. For the HABC genotype data, we used the Michigan Imputation Server (https://imputationserver.sph.umich.edu/) with EAGLE2 phasing49. The HABC African Americans were imputed with the CAAPA African American reference panel and the European Americans were imputed using the Haplotype Reference Consortium (HRC r1.1 2016) panel.
Assessing blood pressure longitudinal measurements
We used two different longitudinal blood pressure (BP) outcomes, trajectory and average, obtained for systolic and diastolic BP (SBP and DBP) measurements across consecutive exams of each participant. To reduce the bias known as the white coat syndrome52, we calculated the average of the second and third measurements (discarding the first) to obtain the SBP and DBP measurements for each exam. For the exams with no data for the third BP measurement, we included only the second measurement. All the BP outcomes were obtained or calculated by study and ethnic group.
To assess the BP trajectory outcome, we followed the methodology used in Gouveia et al.53 to assess cognitive trajectory in Brazilians. We used the linear mixed models function implemented in the R package lme454 to fit and assess the per-individual systolic and diastolic BP trajectories (i.e., rate of change per year) for individuals with at least two BP measurements during follow-up. Specifically, we fitted the mixed effects model (1) below for individual j at visit i, where Xk (k = 1, 2, 3, …, n) are n covariates with fixed-effects βk (k = 1, 2, 3, …,n).
where u0j is a random variable that allows variation around the intercept β00 for each individual j, u1j allows for variation around the coefficient β1, and eij is the subject-level residual. In line with standard practice, we assumed each of the random effects to be independent and normally distributed with unstructured correlation between u0j and u1j. We then used the predicted random effect u1j from model (1) as the phenotype for GWAS. Models were adjusted for age2, sex, BMI, use of antihypertensive drugs as a binary covariate, and population structure using the two first principal components (PCs). We used visit-specific covariates for those (age2, BMI, and use of antihypertensives) that may vary over time.
The BP average outcome was obtained by calculating the average of blood pressure measurements (SBP and DBP) over time. Then, we used the BP longitudinal trajectory and average values as outcomes for our analyses. To compare the longitudinal BP outcomes with cross-sectional BP outcomes, we also performed the analyses using the baseline BP measurements as a cross-sectional outcome using the same set of individuals included in the longitudinal analysis (Table 1).
GWAS and meta-analysis
We performed genome-wide association studies (GWAS) by cohort and by ethnic group (Table 1) followed by ethnic-specific meta-analysis and trans-ethnic meta-analysis (including all discovery datasets). Association analyses were performed for longitudinal (trajectory and average) and baseline BP outcomes, using linear mixed models as implemented in EPACTS47. For cross-sectional and average BP, models were adjusted for baseline age2, sex, BMI (except for average BP), use of antihypertensive drugs, and population structure using the two first principal components (PCs). We used average BMI in the average BP models. To avoid over-adjustment, models previously adjusted during the estimation of BP trajectory (see previous section) were not adjusted in the association analysis. To account for relatedness among samples, kinship matrices were incorporated as random effects in association analyses. Markers with minor allele frequency > 0.01 and imputation info score > 0.3 were retained for the GWAS analyses. We used genotype dosages instead of hard genotype calls to allow for the uncertainty of the imputed calls to be considered within the association model. From each GWAS results, we extracted summary statistics (standard errors, sample size, and direction of effect) to perform fixed-effect meta-analysis weighted by sample size of each study using METAL55. We set the mode HETEROGENEITY to determine whether observed effect sizes (or test statistics) were homogeneous across samples. Genome-wide statistical significance for the meta-analysis was set at a p-value of 5 × 10–8 and borderline statistical significance was set at a p-value of < 9 × 10–8. We considered an association from meta-analysis to be novel if no previous BP genome-wide associations with cross-sectional BP were reported in the GWAS Catalog (reference file “All associations v1.0.2”) within ± 250 kb of our detected association.
Annotation
For our comprehensive annotation of the statistically significant associations, we utilized a series of sources: dbSNP56, Ensembl24, the human genome browser at UCSC57, GTEx Portal release V758, HaploReg v4.159, GWAS catalog4, PANTHER60, STRING61, International Mouse Phenotyping Consortium (IMPC)62 and Rat Genome Database63.
Identification of previous BP associations from the GWAS catalog
To test if our ethnic-specific and trans-ethnic meta-analysis approaches using longitudinal and cross-sectional data identify previously published associations with BP, we used the GWAS Catalog4 (reference file “All associations v1.0.2”, downloaded 08/13/2019). From this database, we considered only the statistically significant associations (p < 5 × 10–8) for which the risk allele was reported, with the following disease/trait terms: (i) “blood pressure”, (ii) “systolic blood pressure”, (iii) “diastolic blood pressure”, (iv) “systolic blood pressure change trajectories”, or (v) “pulse pressure”. Then, we evaluated 1957 GWAS Catalog associations for association using our meta-analysis data. We considered identification successful for associations with p < 0.05 for the same risk allele and the same direction of effect as reported in the GWAS Catalog.
Heritability analysis
For the heritability analysis, we used the European Americans (EA) and African Americans (AA) from the ARIC and MESA studies, since these samples have similar BP characteristics (Table 1). The genotype data were merged by ethnic group followed by pruning SNPs with missing data > 0.05 (PLINK filter –geno 0.05) and the SNPs in high linkage disequilibrium (r2 > 0.8, PLINK filter –indep-pairwise 50 10 0.8). We used the GCTA-GREML method64 to estimate the heritability of the longitudinal and cross-sectional BP outcomes adjusted for age2, sex, BMI, medication, and study. Because this method assumes unrelated individuals, we removed one of a pair of individuals with estimated relatedness > 0.2, maximizing the samples remaining for analysis64.
Ethics statement
All dbGaP studies (dbGaP Study Accession described in the Methods section) obtained ethical approval from the relevant institutions and written informed consent from each participant prior to participation. We obtained approval for controlled access (protocol number: 12-HG-N185) of each of the dbGaP studies. Brazil’s national research ethics committee approved genotyping as part of the Epigen-Brazil protocol (Brazilian National Ethics Research Council (CONEP), resolution 15,895). All methods were performed in accordance with the CONEP guidelines and regulations.
References
Giri, A. et al. Trans-ethnic association study of blood pressure determinants in over 750,000 individuals. Nat. Genet. 51, 51–62 (2019).
Sung, Y. J. et al. A Large-Scale multi-ancestry genome-wide study accounting for smoking behavior identifies multiple significant loci for blood pressure. Am. J. Hum. Genet. 102, 375–400 (2018).
Fuentes, R. M., Notkola, I. L., Shemeikka, S., Tuomilehto, J. & Nissinen, A. Familial aggregation of blood pressure: a population-based family study in eastern Finland. J. Hum. Hypertens. 14, 441–445 (2000).
Buniello, A. et al. The NHGRI-EBI GWAS Catalog of published genome-wide association studies, targeted arrays and summary statistics 2019. Nucleic Acids Res. 47, D1005–D1012 (2019).
Manolio, T. A. et al. Finding the missing heritability of complex diseases. Nature 461, 747–753 (2009).
Wills, A. K. et al. Life course trajectories of systolic blood pressure using longitudinal data from eight UK cohorts. PLoS Med. 8, e1000440 (2011).
Delgado, J. et al. Blood Pressure trajectories in the 20 years before death. JAMA Intern. Med. 178, 93–99 (2018).
Paffenbarger, R. S., Jr & Wing, A. L. Chronic disease in former college students. X. The effects of single and multiple characteristics on risk of fatal coronary heart disease. Am. J. Epidemiol. 90, 527–535 (1969).
Sundström, J., Neovius, M., Tynelius, P. & Rasmussen, F. Association of blood pressure in late adolescence with subsequent mortality: cohort study of Swedish male conscripts. BMJ 342, d643 (2011).
Poveda, A. et al. Association of established blood pressure loci with 10-year change in blood pressure and their ability to predict incident hypertension. J. Am. Heart Assoc. 9, e014513 (2020).
Justice, A. E. et al. Genome-wide association of trajectories of systolic blood pressure change. BMC Proc. 10, 321–327 (2016).
Das, K., Li, J., Fu, G., Wang, Z. & Wu, R. Genome-wide association studies for bivariate sparse longitudinal data. Hum. Hered. 72, 110–120 (2011).
Hossain, A. & Beyene, J. Analysis of baseline, average, and longitudinally measured blood pressure data using linear mixed models. BMC Proc. 8, S80 (2014).
Tam, V. et al. Benefits and limitations of genome-wide association studies. Nat. Rev. Genet. https://doi.org/10.1038/s41576-019-0127-1 (2019).
The Atherosclerosis Risk in Communities (ARIC) Study: design and objectives: the ARIC investigators. Am. J. Epidemiol. 129, 687–702 (1989).
Lima-Costa, M. F., Firmo, J. O. A. & Uchoa, E. Cohort profile: the Bambui (Brazil) cohort study of ageing. Int. J. Epidemiol. 40, 862–867 (2011).
Simonsick, E. M. et al. Measuring higher level physical function in well-functioning older adults: expanding familiar approaches in the health ABC study. J. Gerontol. A Biol. Sci. Med. Sci. 56, M644–9 (2001).
Bild, D. E. et al. Multi-ethnic study of atherosclerosis: objectives and design. Am. J. Epidemiol. 156, 871–881 (2002).
Lima-Costa, M. F. et al. The Brazilian longitudinal study of aging (ELSI-Brazil): objectives and design. Am. J. Epidemiol. 187, 1345–1353 (2018).
Franceschini, N. et al. Genome-wide association analysis of blood-pressure traits in African-Ancestry individuals reveals common associated genes in African and non-African populations. Am. J. Hum. Genet. 93, 545–554 (2013).
Hakala, S. M. & Tilvis, R. S. Determinants and significance of declining blood pressure in old age: a prospective birth cohort study. Eur. Heart J. 19, 1872–1878 (1998).
Pearson, J. D., Morrell, C. H., Brant, L. J., Landis, P. K. & Fleg, J. L. Age-associated changes in blood pressure in a longitudinal study of healthy men and women. J. Gerontol. A Biol. Sci. Med. Sci. 52, M177–83 (1997).
Favot, L., Hall, S. M., Haworth, S. G. & Kemp, P. R. Cytoplasmic YY1 is associated with increased smooth muscle-specific gene expression: implications for neonatal pulmonary hypertension. Am. J. Pathol. 167, 1497–1509 (2005).
Hunt, S. E. et al. Ensembl variation resources. Database (2018).
Divers, J. et al. Genome-wide association study of coronary artery calcified atherosclerotic plaque in African Americans with type 2 diabetes. BMC Genet. 18, 105 (2017).
Mitchell-Olds, T., Mojica, J. & Wang, B. Faculty of 1000 evaluation for Gene discovery and polygenic prediction from a genome-wide association study of educational attainment in 1.1 million individuals. F1000 Post Public.ation Peer Rev. Biomed. Lit. (2018). https://doi.org/10.3410/f.733675894.793549439.
Galván-Femenía, I. et al. Multitrait genome association analysis identifies new susceptibility genes for human anthropometric variation in the GCAT cohort. J. Med. Genet. 55, 765–778 (2018).
Dong, C. et al. Possible genomic imprinting of three human obesity–related genetic loci. Am. J. Hum. Genet. 76, 427–437 (2005).
Saykally, J. N., Dogan, S., Cleary, M. P. & Sanders, M. M. The ZEB1 transcription factor is a novel repressor of adiposity in female mice. PLoS ONE 4, e8460 (2009).
Battle, M. A., Maher, V. M. & McCormick, J. J. ST7 is a novel low-density lipoprotein receptor-related protein (LRP) with a cytoplasmic tail that interacts with proteins related to signal transduction pathways. Biochemistry 42, 7270–7282 (2003).
Christophersen, I. E. et al. Fifteen genetic loci associated with the electrocardiographic P wave. Circ. Cardiovasc. Genet. 10, e001667 (2017).
Levy, D. et al. Genome-wide association study of blood pressure and hypertension. Nat. Genet. 41, 677–687 (2009).
Shahin, M. H. et al. Genome-wide association approach identified novel genetic predictors of heart rate response to β-blockers. J. Am. Heart Assoc. 7, e006463 (2018).
Gurdasani, D., Barroso, I., Zeggini, E. & Sandhu, M. S. Genomics of disease risk in globally diverse populations. Nat. Rev. Genet. 20, 520–535 (2019).
Kolifarhood, G. et al. Heritability of blood pressure traits in diverse populations: a systematic review and meta-analysis. J. Hum. Hypertens. https://doi.org/10.1038/s41371-019-0253-4 (2019).
Evangelou, E. et al. Genetic analysis of over 1 million people identifies 535 new loci associated with blood pressure traits. Nat. Genet. 50, 1412–1425 (2018).
Burt, V. L. et al. Prevalence of hypertension in the US adult population: results from the third national health and nutrition examination survey, 1988–1991. Hypertension 25, 305–313 (1995).
Lima-Costa, M. F. et al. Socioeconomic position, but not African genomic ancestry, is associated with blood pressure in the Bambui-Epigen (Brazil) cohort study of aging. Hypertension 67, 349–355 (2016).
Kehdy, F. S. G. et al. Origin and dynamics of admixture in Brazilians and its effect on the pattern of deleterious mutations. Proc. Natl. Acad. Sci. USA 112, 8696–8701 (2015).
Ramos, E. et al. Replication of genome-wide association studies (GWAS) loci for fasting plasma glucose in African-Americans. Diabetologia 54, 783–788 (2011).
Bycroft, C. et al. The UK Biobank resource with deep phenotyping and genomic data. Nature 562, 203–209 (2018).
Gurdasani, D. et al. Uganda genome resource enables insights into population history and genomic discovery in Africa. Cell 179, 984-1002.e36 (2019).
Rotimi, C. N. et al. A genome-wide search for type 2 diabetes susceptibility genes in West Africans: the Africa America Diabetes Mellitus (AADM) Study. Diabetes 53, 838–841 (2004).
Purcell, S. et al. PLINK: A tool set for whole-genome association and population-based linkage analyses. Am. J. Hum. Genet. 81, 559–575 (2007).
1000 Genomes Project Consortium et al. A global reference for human genetic variation. Nature 526, 68–74 (2015).
Price, A. L. et al. Principal components analysis corrects for stratification in genome-wide association studies. Nat. Genet. 38, 904–909 (2006).
EPACTS: Efficient and parallelizable association container toolbox. http://genome.sph.umich.edu/wiki/EPACTShttp://genome.sph.umich.edu/wiki/EPACTS.
Li, H. et al. The sequence alignment/map format and SAMtools. Bioinformatics 25, 2078–2079 (2009).
Loh, P.-R. et al. Reference-based phasing using the haplotype reference consortium panel. Nat. Genet. 48, 1443–1448 (2016).
Durbin, R. Efficient haplotype matching and storage using the positional Burrows-Wheeler transform (PBWT). Bioinformatics 30, 1266–1272 (2014).
McCarthy, S. et al. A reference panel of 64,976 haplotypes for genotype imputation. Nat. Genet. 48, 1279–1283 (2016).
Oladipo, I. & Ayoade, A. The effect of the first office blood pressure reading on hypertension-related clinical decisions. Cardiovasc. J. Afr. 23, 456–462 (2012).
Gouveia, M. H. et al. Genetics of cognitive trajectory in Brazilians: 15 years of follow-up from the Bambuí-Epigen Cohort Study of Aging. Sci. Rep. 9, 18085 (2019).
Bates, D., Mächler, M., Bolker, B. & Walker, S. Fitting linear mixed-effects models using lme4. J. Stat. Softw. 67, 1–48 (2015).
Willer, C. J., Li, Y. & Abecasis, G. R. METAL: fast and efficient meta-analysis of genomewide association scans. Bioinformatics 26, 2190–2191 (2010).
Sherry, S. T. et al. dbSNP: the NCBI database of genetic variation. Nucleic Acids Res. 29, 308–311 (2001).
Wang, K., Li, M. & Hakonarson, H. ANNOVAR: functional annotation of genetic variants from high-throughput sequencing data. Nucleic Acids Res. 38, e164 (2010).
Carithers, L. J. et al. A novel approach to high-quality postmortem tissue procurement: the GTEx project. Biopreserv. Biobank. 13, 311–319 (2015).
Ward, L. D. & Kellis, M. HaploReg: a resource for exploring chromatin states, conservation, and regulatory motif alterations within sets of genetically linked variants. Nucleic Acids Res. 40, D930–D934 (2012).
Thomas, P. D. et al. PANTHER: a library of protein families and subfamilies indexed by function. Genome Res. 13, 2129–2141 (2003).
Szklarczyk, D. et al. STRING v11: protein–protein association networks with increased coverage, supporting functional discovery in genome-wide experimental datasets. Nucleic Acids Res. 47, D607–D613 (2019).
Koscielny, G. et al. The International Mouse Phenotyping Consortium Web Portal, a unified point of access for knockout mice and related phenotyping data. Nucleic Acids Res. 42, D802–D809 (2014).
Shimoyama, M. et al. The rat genome database 2015: genomic, phenotypic and environmental variations and disease. Nucleic Acids Res. 43, D743–D750 (2015).
Jiang, L. et al. A resource-efficient tool for mixed model association analysis of large-scale data. bioRxiv (2019). https://doi.org/10.1101/598110.
Acknowledgements
We are thankful to the participants in the ARIC, Bambui, HABC, MESA, WHI, and Framingham studies, their families, and their physicians. The views expressed in this manuscript are those of the authors and do not necessarily represent the views of the NIH.
Funding
Open Access funding provided by the National Institutes of Health (NIH). This project is supported by the Intramural Research Program of the National Human Genome Research Institute of the National Institutes of Health (NIH) through the Center for Research on Genomics and Global Health (CRGGH). The CRGGH is also supported by the National Institute of Diabetes and Digestive and Kidney Diseases and the Office of the Director at the NIH (Z01HG200362). The EPIGEN-Brazil Initiative is funded by the Brazilian Ministry of Health (Department of Science and Technology from the Secretaria de Ciência, Tecnologia e Insumos Estratégicos) through Financiadora de Estudos e Projetos. The EPIGEN-Brazil investigators received funding from the Brazilian Ministry of Education (CAPES Agency). MFLC and ETS were supported by Brazilian National Research Council (CNPq), Minas Gerais Research Agency (FAPEMIG) and Pró-Reitoria de Pesquisa da Universidade Federal de Minas Gerais.
Author information
Authors and Affiliations
Contributions
The project was conceived by M.H.G., D.S. and C.N.R. M.H.G. and D.S. assembled datasets. M.H.G., L.H., G.C. and D.S. analyzed genetic data. M.A.N., E.M.S., E.T.S., M.F.L.C. and C.N.R. contributed with data. M.H.G., A.R.B., K.A.C.M, K.E., M.A.N., E.T.S. A.A., D.S. and C.N.R. contributed to data interpretation. M.H.G., A.R.B., D.S. and C.N.R. wrote the manuscript. All authors read the manuscripts and contributed with suggestions.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Gouveia, M.H., Bentley, A.R., Leonard, H. et al. Trans-ethnic meta-analysis identifies new loci associated with longitudinal blood pressure traits. Sci Rep 11, 4075 (2021). https://doi.org/10.1038/s41598-021-83450-3
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-021-83450-3
This article is cited by
-
Disease clusters subsequent to anxiety and stress-related disorders and their genetic determinants
Nature Communications (2024)
-
Misuse of the term ‘trans-ethnic’ in genomics research
Nature Genetics (2021)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
