
Abstract
Studies have shown that there is a certain correlation between air pollution and various human diseases, especially lung diseases, so it is very meaningful to monitor the concentration of pollutants in the air. Compared with the national air quality monitoring station (national control point), the micro air quality detector has the advantage that it can monitor the concentration of pollutants in real time and grid, but its measurement accuracy needs to be improved. This paper proposes a model combining the least absolute selection and shrinkage operator (LASSO) regression and nonlinear autoregressive models with exogenous inputs (NARX) to calibrate the data measured by the micro air quality detector. Before establishing the LASSO-NARX model, correlation analysis is used to test whether the correlation between the concentration of air pollutants and its influencing factors is significant, and to find out the main factors that affect the concentration of pollutants. Due to the multicollinearity between various influencing factors, LASSO regression is used to further screen the influencing factors and give the quantitative relationship between the pollutant concentration and various influencing factors. In order to improve the prediction accuracy of pollutant concentration, the predicted value of each pollutant concentration in the LASSO regression model and the measurement data of the micro air quality detector are used as input variables, and the LASSO-NARX model is constructed using the NARX neural network. Several indicators such as goodness of fit, root mean square error, mean absolute error and relative mean absolute percent error are used to compare various air quality models. The results show that the prediction results of the LASSO-NARX model are not only better than the LASSO model alone and the NARX model alone, but also better than the commonly used multilayer perceptron and radial basis function neural network. Using this model to calibrate the measurement data of the micro air quality detector can increase the accuracy by 61.3–91.7%.
Similar content being viewed by others


Introduction
With the development of science and technology, the progress of industry and the rapid increase of the global population, the environment that people depend on has been greatly destroyed. Many areas have experienced environmental problems such as acid rain, species extinction, and land desertification. Environmental issues have become one of the common concerns of all countries in the world today, and they are also a major challenge facing humanity in the twenty-first century. Air pollution is an especially concerning environmental issue, which can easily lead to respiratory diseases such as acute and chronic bronchitis, asthma, pneumonia, and even lung cancer1,2,3. According to estimates by the World Health Organization, 7 million people die each year from diseases caused by air pollution4,5.
The pollutants in the air are mainly inhalable particles, SO2, NO2 and other substances. The commonly used index to measure the quality of air is AQI, which is the Air Quality Index. The larger the AQI value, the more serious the air pollution, and the greater the harm to human health. AQI (GB3095-2012) is calculated based on six air pollutants: PM2.5, PM10, CO, NO2, SO2 and O3 (“two dusts and four gases"). As air quality is getting more and more attention, it is particularly important to monitor air quality.
In order to monitor the air, several national air quality monitoring stations (national control points) are generally set up in a key environmental protection city. Multi-parameter automatic monitoring equipment is installed in the air quality monitoring station for continuous automatic monitoring, and the monitoring results are stored in real time and analyzed to obtain relevant data. The construction and maintenance costs of national control points are relatively high, so the number of national control points is very small, which makes it difficult to conduct comprehensive monitoring of an area. In addition, although the national control point data is relatively accurate, it is often not released in real time, so it is difficult to realize real-time monitoring of air quality. In order to overcome the deficiencies of grid monitoring and real-time monitoring of pollutant concentration at national control points, some companies have developed miniature air quality detectors, which have the advantages of low cost, convenient installation, and convenient data reading. It can be deployed more intensively than national control points, and can also be evenly grid-arranged in key areas, which has achieved the purpose of grid-based monitoring6,7,8. However, since the electrochemical sensor used in the micro air quality detector is susceptible to external influences, the range drift and zero point drift will occur after a period of use, and the data measured by the self-built point will have a certain error. How to use the national control point data to calibrate the self-built point data is a problem worthy of study.
The commonly used pollutant concentration prediction models are mainly divided into two categories. The first type is the atmospheric chemistry transmission model, which uses the theory of the atmospheric system to simulate the physical and chemical processes of pollutants in a specific area, and uses the generated pollutant grid data to predict air quality9,10. The mechanism of the atmospheric chemistry transmission model is complex, and is limited by the accuracy of the ground emission inventory, and its pollutant forecast effect is not very good.
Another commonly used pollutant concentration prediction model is a statistical model based on machine learning algorithms. The multiple linear regression model is a relatively classic statistical model, which can give a quantitative relationship between the concentration of pollutants and various influencing factors. The regression equation established based on these quantitative relationships can effectively predict the concentration of pollutants. If necessary, the concentration of pollutants can be effectively controlled or dealt with according to these factors. Because the multiple linear regression model has good interpretability, the construction of multiple linear regression equation is still a common air quality prediction modeling idea11,12. Lei et al. used meteorological and air quality data from 2013 to 2017 for five years to establish a statistical model based on linear multiple regression (MR) and classification regression tree (CART) analysis. The model successfully predicted the concentrations of NO2, PM10, PM2.5 and O3 in Macau on the second day13. For the multicollinearity problem that may exist in the construction of multiple regression model, least absolute selection and shrinkage operator (LASSO) regression is one of the methods often used to solve it. Sethi et al. proposed an adaptive LASSO regression method based on correlation, successfully identified the important factors affecting the air quality index, and completed the forecast of air quality in Delhi14. It is difficult for multiple linear regression models to detect the complex and potentially non-linear relationship between predictor variables and response variables, so machine learning algorithms such as artificial neural networks15,16,17,18, support vector machines19,20,21,22, random forest23,24,25,26 and extreme gradient boosting27,28,29 have become the mainstream of pollutant concentration prediction. The nonlinear autoregressive models with exogenous inputs (NARX) increases the delay and feedback mechanism, so it enhances the ability to remember historical data. In recent years, it is often used for air quality prediction. Moursi et al. used the PM2.5 concentration, cumulative wind speed and cumulative rainfall hours in the past 24 h as independent variables, and successfully predicted the PM2.5 concentration in the next hour using the NARX model30. Mohebbi et al. successfully simulated the carbon monoxide concentration in Shiraz using the NARX neural network model without traffic data. The results show that the dynamic neural network is better than the static neural network in the prediction accuracy of CO concentration in this area31.
There are many factors that affect the concentration of pollutants, and each factor has a mutual influence. If all factors are directly introduced into the multiple linear regression model, multicollinearity may occur. LASSO regression can improve the multicollinearity of the model and retain the interpretability of the multiple linear regression model. The advantage of NARX neural network over LASSO model is that it can find out the nonlinear relationship between pollutant concentration and various influencing factors. Therefore, the NARX neural network has higher prediction accuracy than the LASSO model. Combining the LASSO regression model and NARX neural network can not only retain the advantages of the two models, but also make full use of the data measured by the micro air quality detector. This combined model is called the LASSO-NARX model in this paper. The empirical results show that the LASSO-NARX model can not only improve the interpretability of the NARX model, but also improve the prediction accuracy of the LASSO model. Figure 1 shows the construction process of the LASSO-NARX model.

The flux diagram of the regression process, where NCP represents the concentration of pollutants measured at the national control point.
Material and methods
Data source and preprocessing
The appearance of the micro air quality detector makes it possible to monitor the concentration of pollutants in real time, but the accuracy of its measurement needs to be improved. The two sets of data are collected in this paper to build the data calibration model of the micro air quality detector. The first set of data is measured by a national monitoring station in Nanjing, which provides the concentration of two dusts and four gases from November 14, 2018 to June 11, 2019. It has a total of 4200 pieces of data, and the interval of each group of data is mostly 1 h. The second set of data is measured by a self-built point equipped with a micro air quality detector. It contains 234,717 pieces of data whose time interval does not exceed 5 min. The location of the self-built point is within 10 m from the national control point. It not only measures the concentration of the two dust and four gases in the same period, but also provides five meteorological parameters of wind speed, pressure, precipitation, temperature and humidity.
Preprocessing of data is a prerequisite for building statistical models. The first step is to delete duplicate data and obviously abnormal data (greater than three times the average value of the left and right neighbors) in the data. In the second step, the self-built point data is averaged on an hourly basis, and the averaged self-built point data is used to correspond to the national control point data, and the data that cannot be corresponding is deleted. The summary table of self-built point data and national control point data after preprocessing is shown in Table 1.
Data exploratory analysis
Due to the influence of internal factors and external factors, there are certain errors in the data measured by the micro air quality detector. This article draws a time series chart to show the difference between self-built point and national control point20,32. The discussion method of the two dusts and four gases is similar. We randomly select O3 for analysis.
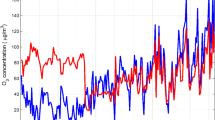
It can be seen from Fig. 2 that the change trend of O3 concentration at the self-built point is roughly the same as that at the national control point. However, there is a certain difference between the O3 concentration of the self-built point and the national control point. In the first 1500 h, the O3 concentration of self-built point was generally higher than that of national control points. After 1500 h, the fluctuation degree of O3 concentration at the national control point is generally greater than the fluctuation degree of the O3 concentration at the self-built point.

Comparison of hourly average O3 concentration data between national control points and self-built points. Figures are generated using Matlab (Version R2016a, https://www.mat- hworks.com/) [Software].
Since there are certain differences in meteorological parameters in each month, in order to reflect the influence of meteorological parameters on the concentration of pollutants, we have drawn a box plot33 as shown in Fig. 3. It can be seen that the difference in O3 concentration between self-built point and national control point is different every month. In November, December, January and February, the O3 concentration difference between the self-built point and the nationally controlled point is large. The reason is that the low temperature and low humidity during this period affect the accuracy of the electrochemical sensor. It can be seen that meteorological parameters are also factors that affect the concentration of pollutants.

Compare the O3 concentration of national control points (Ncp) and self-built points (Sbp) on a monthly basis. Note that there is no data from July to October.
Correlation analysis
The key to air quality prediction is the prediction of the concentration of pollutants such as two dusts and four gases. Predicting the concentration of pollutants must find out the main factors that affect it10. Because the factors that affect the concentration of pollutants in the air are more complex, and the factors themselves also affect each other, quantitative indicators are needed to describe them. Pearson correlation coefficient (Eq. (1)) is a statistical indicator used to reflect the degree of correlation between variables13,29.
Table 2 shows the correlation between the concentration of six types of pollutants and meteorological parameters. It can be seen that at a significant level of 0.05, all variables have a significant correlation with each other except for the NO2 concentration and temperature. The absolute value of the correlation coefficient between many of these variables exceeds 0.8, indicating that they are highly correlated.
Establishment of sensor calibration model
Introduction to basic principles
Least absolute selection and shrinkage operator was first proposed by Tibshirani in 1996. This method is a compression estimation. It constructs a penalty function to obtain a more refined model, so that it can compress some coefficients, and at the same time set some coefficients to zero, to achieve the effect of subset shrinkage29,34.
In a general regression model, the observed values of each data are generally considered to be independent of each other. Because there are many variables in the model, their dimensions are often different. In order to eliminate the interference of dimensions, all independent variables \({X}_{i}=({x}_{i1},{x}_{i2},\cdots ,{x}_{im})\) need to be standardized via a linear transformation. The standardized \({X}_{i}^{*}=({x}_{i1}^{*},{x}_{i2}^{*},\cdots ,{x}_{im}^{*})\) mean is 0, and the variance is 1. Equation (2) is the LASSO estimate of the regression model, where the second term is the L1 penalty, \(k\) is a nonnegative regularization parameter. When \(\mathrm{k}=0\), LASSO regression is ordinary least squares regression. With the increase of \(\mathrm{k}\), the LASSO can compress the coefficients of unimportant variables to 0, thus realizing variable selection. The larger the value of k, the more parameters are compressed to 0, and the smaller the model complexity, which solves the problem of poor model interpretability14,35,36.
A typical NARX neural network is mainly composed of input layer, hidden layer, output layer and input and output delay. NARX neural network model is a kind of nonlinear discrete system, which can be represented by a nonlinear difference equation (Eq. (3)), where \(y\) represents the output variable; \(x\) represents the external input variable; \(d\) represents the delay step. Different delay steps can be set for output variables and input variables to control the time step of continuous prediction.
Equation (4) is the calculation formula for the output of each layer, where \({x}_{i}\) represents the input of each layer of neurons, that is, the output of the previous layer of neurons; \({a}_{i,j}\) represents the weight between layers;\({b}_{j}\) represents the threshold of the layer; \(f\) represents the activation function. The activation function of the hidden layer of the NARX neural network uses the hyperbolic tangent function (Eq. (5)), and the output layer uses the linear function (Eq. (6)).
LASSO regression model construction
From the correlation analysis, we can see that there is a strong correlation between the concentration of various pollutants, and between the pollutants and meteorological parameters. In this paper, the pollutant concentration at the national control point is used as the dependent variable, and the pollutant concentration and meteorological parameters measured at the self-built point are used as independent variables to establish a multiple linear regression model. An important requirement of multiple linear regression models is that the independent variables are independent of each other. The variance inflation factor is often used to determine whether the variables of a model are independent of each other. Let the standardized independent variable be \({X}^{*}\), then X*′X*=(rij) is the correlation matrix of the independent variable. The main diagonal element of the (X*′X*)−1 is defined as the variance inflation factor of the independent variable. Through the multicollinearity diagnosis of the model, we can see that the maximum variance inflation factor of the multiple linear regression model is 26.631, which is greater than 10. Therefore, the multiple linear regression model has serious multicollinearity. Multicollinearity will make the air quality prediction model very unstable and cause over-fitting problems.
Commonly used methods to solve multicollinearity in practical problems are: (i) Selecting the independent variables, and the representative methods include forward regression, backward regression and stepwise regression. (ii) Perform dimensionality reduction processing on independent variables. Representative methods include principal component regression and partial least squares regression. (iii) Biased estimation of regression coefficients, representative methods include ridge regression and LASSO regression. This study uses LASSO regression to solve the problem of multicollinearity. Compared with ridge regression, LASSO regression can select variables and eliminate some variables that have no significant influence on the dependent variable. Compared with stepwise regression, LASSO regression can retain those variables that are between significant and non-significant effects on the dependent variable, so the estimation deviation is not too large.
In the process of establishing the LASSO regression model with the help of SPSSAU (https://spssau.com/) software, in order to facilitate comparison with other models, we randomly selected 85% of the data to build the model, and the remaining 15% of the data for model verification. The analysis of LASSO regression using SPSSAU software is divided into two steps: (i) Find the best k value based on the trajectory graph. The selection principle of k value is the minimum k value when the standardized regression coefficient of each independent variable becomes stable. The smaller the k value, the smaller the deviation, when the k value is 0, it is an ordinary linear OLS regression. (ii) Manually input k value for regression modeling. For the k value, generally the smaller the better, and it is generally recommended to be less than 1.After determining the k value, we can manually enter the k value to get the LASSO regression model estimate.
For the LASSO regression model of O3 concentration prediction, it can be seen from Fig. 4 that when k = 0.05, the standardized regression coefficients of each independent variable tend to be stable, so this paper takes k = 0.05 to establish the LASSO regression model. In the model, PM2.5 concentration, CO concentration, SO2 concentration, pressure and precipitation have no effect on O3 concentration, so they are excluded from the model.

The trace diagram of all input variables, where the dependent variable is the O3 concentration measured by the national control point.
After the LASSO model is established, the model needs to be tested. Equations (7)–(9) are the definitions of F value in F test, where s represents the number of introduced model variables, n represents the total number of samples, \({y}_{i}\) represents the true value, \({w}_{i}\) represents the model fitted value, and \(\overline{y }\) represents the average value of the true value. P value is more convenient for model verification. The P value is the probability of a sample observation or extreme result when the null hypothesis is true (the null hypothesis here is that the variables introduced into the model have no significant effect on the dependent variable as a whole). Equation (10) is the formula of the model’s goodness of fit, which reflects the degree of fit of the regression line to the observed value. The F value in the model test is 1123.756, and the corresponding p value is less than 0.01, indicating that at the significance level of 0.01, the overall variables introduced into the model have a significant impact on the pollutant concentration. The coefficient of determination of the LASSO model is 0.750, indicating that 75% of the change in O3 concentration can be explained by the change in the independent variables introduced into the model. The results of the remaining pollutants LASSO regression model are shown in Table 3.
LASSO-NARX model construction
The LASSO regression model gives a quantitative linear relationship between the pollutant concentration and various influencing factors31. However, there may be a nonlinear relationship between pollutant concentration and influencing factors, and the prediction accuracy of the LASSO model needs to be improved. Taking into account the time sequence of pollutant concentration, this paper uses NARX neural network to improve the accuracy of pollutant concentration prediction. We take the predicted value of LASSO regression and the data measured by self-built points as input, and the concentration of six pollutants as output to establish the NARX neural network model. The structure of the NARX neural network is shown in Fig. 5.

The frame structure of the LASSO-NARX model, where the input is the predicted value of the LASSO regression model and the measured value of the self-built point. This network has 12 inputs, 1 hidden layer with 10 hidden neurons, 2 input delay orders, and 1 linear output layer leading to 1 output.
In the NARX neural network, it can be known from the Kolmogorov theorem that at most two hidden layers can identify arbitrary nonlinear characteristics, so this paper selects the default one hidden layer in Matlab. The number of nodes in the hidden layer of the neural network is determined by considering the training effect and training time. For the delay order in the model, determine the order change range based on experience, and find out the order when it no longer changes significantly as the model delay order according to the change of the mean square error of the model under different orders.
In the NARX model, the input is the predicted value of the LASSO regression model of O3, the concentration of six types of pollutants and five meteorological parameters measured by the self-built point, and the output is the O3 concentration measured by the national control point. 4135 samples are randomly divided into training set, validation set and test set at a ratio of 7:1.5:1.5. For comprehensive comparison, the input delay of NARX neural network is selected as 2, and the number of hidden layer nodes is 10. The training algorithm adopts the Levenberg–Marquardt algorithm with shorter training time, and the LASSO-NARX model is established with the help of Matlab software.
In order to visually show the prediction effect of the LASSO-NARX model, we have drawn the O3 concentration regression effect diagram. It can be seen from Fig. 6 that whether it is the training set, the validation set or the test set, the correlation coefficient between the predicted value of the model and the true value of the national control point exceeds 0.95, and the coefficients of each regression model are close to 1. It shows that the LASSO-NARX model has achieved good results in prediction. It can be seen from the box plot in Fig. 7 that regardless of the median, quantile, or outlier, the measured value of the national control point is roughly the same as the fitted value of the LASSO-NARX model. In addition, the boxplots of the training set, validation set and test set are also roughly the same. We conclude that the prediction and generalization ability of the LASSO-NARX model is good. It is worth noting that the output of the model is negative at several points where the concentration of O3 is particularly low at the national control point. In actual use, it can be considered that the O3 concentration is extremely low at this moment. It can be seen from the residual histogram that the error term roughly obeys the normal distribution, and the residual values are mostly distributed in [− 40, 40]. In this way, the LASSO-NARX model has been validated.

The prediction effect of O3’s LASSO-NARX model on the training set, validation set, test set and all sets.

Residual test of LASSO-NARX model. Compare the national control point (NCP) measurement value and the model fit value (MFV) on the training set (TNG), validation set (VLD) and test set (TES) is seen on the left. The histogram of the residuals is seen on the right.
Discussion
In the data calibration problem of the micro air quality detector, the LASSO model alone and the NARX neural network model alone can predict the concentration of pollutants. This paper also chooses a multilayer perceptron (MLP) and a radial basis function (RBF) neural network to compare with the LASSO-NARX model. Multilayer perceptron is a feedforward artificial neural network model that maps multiple input data sets to a single output data set. It introduces one or more hidden layers on the basis of a single-layer neural network, and the hidden layer is located between the input layer and the output layer. MLP is a neural network composed of fully connected layers, and the output of each hidden layer is transformed by an activation function. Radial basis function neural network is a type of forward network. It is based on the function approximation theory. It mainly contains input layer, radial base layer and output layer. Its hidden layer uses the radial basis function as the excitation function, which is an effective tool for identifying nonlinear systems37,38.
Taylor diagrams are often used to visually compare the accuracy of various models8. The scattered points in the Taylor diagram represent the model, the radial line represents the correlation coefficient (Eq. (1)), the horizontal and vertical axis represents the standard deviation (Eq. (11)), and the dashed line represents the center root mean square error (Eq. (12)). Figure 8 is a Taylor analysis chart of O3 concentration. It should be noted that the indicators of each prediction model in the figure are based on the test set, but the self-built point (SBP) indicator is for the entire data set. It can be seen that compared with the O3 concentration measured by the national control point, the O3 concentration measured by the self-built point has the lowest accuracy, the LASSO model and the RBF neural network model have good accuracy, and the MLP neural network and NARX model have higher accuracy. The LASSO-NARX model proposed in this article performs best in comparison with other models.

Taylor diagrams of predicted values of five models and measured values of self-built points, where SBP stands for self-built points.
Goodness of fit (R2), Root Mean Square Error (RMSE), Mean Absolute Error (MAE) and Relative Mean Absolute Percent Error (MAPE) can also be used to compare various air quality prediction models. Equation (10) and Eqs. (13)-(15) are specific formulas, where \({y}_{i}\) is the measured value at the national control point, \(\overline{y }\) is the average value of the national control point, and \({w}_{i}\) is the regression value of the model25,28.
It can be seen from Tables 4, 5, 6 and 7 that in the comparison with the data of the national air quality monitoring station, the measurement data of the micro air quality detector has a large error, so it needs to be calibrated. The LASSO regression model and RBF neural network model can calibrate self-built point data, but the effect needs to be improved. The MLP neural network and NARX model have a good effect on the calibration of self-built point data, and the LASSO-NARX model given in this article is the best in each evaluation index. In the index of goodness of fit, several self-built points are negative, which is caused by the large error of self-built points. Among the other three indexes, the most improved is the MAPE of NO2, which is an increase of 91.7%, and the least improved is the RMSE of PM2.5, which is an increase of 61.3%.
Conclusions
Low-cost micro air quality detectors can help humans conduct real-time and grid monitoring of the concentration of pollutants in the air. However, since the electrochemical sensor used by the micro air quality detector is susceptible to external influences, and after a period of use, it will exhibit range drift and zero point drift, so its measurement accuracy needs to be improved. The LASSO regression model can calibrate the data measured by the micro air quality detector and give the quantitative relationship between the pollutant concentration and each influencing factor, but it cannot find the nonlinear relationship between the pollutant concentration and each influencing factor. The NARX model can find the nonlinear relationship between the pollutant concentration and various influencing factors, and the prediction accuracy is significantly higher than the LASSO regression model. However, it cannot give a quantitative relationship between pollutant concentration and various influencing factors. The LASSO-NARX air quality combined model proposed in this study combines the advantages of the two models. It can not only reflect the quantitative relationship between the pollutant concentration and the influencing factors, but also has a higher prediction accuracy than the NARX neural network model alone. Using this model to calibrate the measurement data of the micro air quality detector can increase the accuracy by 61.3–91.7%. The LASSO-NARX model performs very well on the training set and test set, indicating that it has a strong generalization ability. The model uses a total of 4135 sets of data, and the data of the four seasons are all covered in the model, which also shows that the model is relatively stable. However, due to the different climatic conditions in different regions, this model may not be applicable to other regions. In the future, our team will try to collect data from other regions to further validate the model.
References
Qiu, H. et al. Differential effects of fine and coarse particles on daily emergency cardiovascular hospitalizations in Hong Kong. Atmos. Environ. 64, 296–302 (2013).
Poloniecki, J. D., Atkinson, R. W., Deleon, A. P. & Anderson, H. R. Daily time series for cardiovascular hospital admissions and previous day’s air pollution in London, UK. Occup. Environ. Med. 54, 535–540 (1997).
Johanna, L., Francine, L., Douglas, D. & Joel, S. Chronic exposure to fine particles and mortality: An extended follow-up of the Harvard six cities study from 1974 to 2009. Environ. Health. Persp. 120, 965–970 (2012).
Akimoto, H. Global air quality and pollution. Science 302, 1716–1719 (2004).
Brauer, M. et al. Exposure assessment for estimation of the global burden of disease attributable to outdoor air pollution. Environ. Sci. Technol. 46, 652–660 (2012).
Spinelle, L., Gerboles, M., Villani, M. G., Aleixandre, M. & Bonavitacola, F. Field calibration of a cluster of low-cost available sensors for air quality monitoring. Part A: Ozone and nitrogen dioxide. Sensor. Actuator B-Chem. 215, 249–257 (2015).
Masson, N., Piedrahita, R. & Hannigan, M. Approach for quantification of metal oxide type semiconductor gas sensors used for ambient air quality monitoring. Sensor. Actuator B-Chem. 208, 339–345 (2015).
Cordero, J. M., Borge, R. & Narros, A. Using statistical methods to carry out in field calibrations of low cost air quality sensors. Sensor. Actuator. B Chem. 267, 245–254 (2018).
Azid, A. et al. Assessing indoor air quality using chemometric models. Pol. J. Environ. Stud. 6, 2443–2450 (2018).
Tai, A. P. K., Mickley, L. J. & Jacob, D. J. Correlations between fine particulate matter (PM2.5) and meteorological variables in the United States: Implications for the sensitivity of PM2.5 to climate change. Atmos. Environ. 44, 3976–3984 (2010).
Spinelle, L., Gerboles, M., Villani, M. G., Aleixandre, M. & Bonavitacola, F. Field calibration of a cluster of low-cost commercially available sensors for air quality monitoring. Part B: NO, CO and CO2. Sensor. Actuator B-Chem. 238, 706–715 (2016).
Elbayoumi, M., Ramli, N. A. & Faizah, F. M. Y. N. Development and comparison of regression models and feedforward backpropagation neural network models to predict seasonal indoor PM2.5–10 and PM2.5 concentrations in naturally ventilated schools. Atmos. Pollut. Res. 6, 1013–1023 (2015).
Lei, M. T., Monjardino, J., Mendes, L. & Ferreira, F. Macao air quality forecast using statistical methods. Air. Qual. Atmos. Hlth. 2, 249–258 (2019).
Sethi, J. K. & Mittal, M. An efficient correlation based adaptive lasso regression method for air quality index prediction. Earth Sci. Inform. https://doi.org/10.1007/s12145-021-00618-1 (2021).
Feng, X. et al. Artificial neural networks forecasting of PM2.5 pollution using air mass trajectory based geographic model and wavelet transformation. Atmos. Environ. 107, 118–128 (2015).
Wang, Z., Feng, J., Fu, Q. & Gao, S. Quality control of online monitoring data of air pollutants using artificial neural networks. Air Qual. Atmos. Health 12, 1189–1196 (2019).
Reich, S. L., Gomez, D. R. & Dawidowski, L. E. Artificial neural network for the identification of unknown air pollution sources. Atmos. Environ. 33, 3045–3052 (1999).
Samia, A., Kaouther, N. & Abdelwahed, T. A hybrid ARIMA and artificial neural networks model to forecast air quality in urban areas: Case of Tunisia. Adv. Mater. 518, 2969–2979 (2012).
Dun, M., Xu, Z., Chen, Y. & Wu, L. Short-term air quality prediction based on fractional grey linear regression and support vector machine. Math. Problems Eng. 2020, 1–13 (2020).
Liu, B., Jin, Y. & Li, C. Analysis and prediction of air quality in Nanjing from autumn 2018 to summer 2019 using PCR-SVR-ARMA combined model. Sci. Rep 11, 1–14 (2021).
Deo, R. C., Wen, X. & Qi, F. A wavelet-coupled support vector machine model for forecasting global incident solar radiation using limited meteorological dataset. Appl. Energy 168, 568–593 (2016).
Liu, B. et al. Urban air quality forecasting based on multi-dimensional collaborative support vector regression (SVR): A case study of Beijing-Tianjin-Shijiazhuang. PLoS ONE 7, 1–17 (2017).
Kamińska, J. A. The use of random forests in modelling short-term air pollution effects based on traffic and meteorological conditions: A case study in wrocaw. J. Environ. Manag. 217, 164–174 (2018).
Ding, H. J., Liu, J. Y., Zhang, C. M. & Wang, Q. Predicting optimal parameters with random forest for quantum key distribution. Quantum Inf. Process. 2, 1–8 (2020).
Liu, B., Yu, W., Wang, Y., Lv, Q. & Li, C. Research on data correction method of micro air quality detector based on combination of partial least squares and random forest regression. IEEE Access 9, 99143–99154 (2021).
Zimmerman, N. et al. A machine learning calibration model using random forests to improve sensor performance for lower-cost air quality monitoring. Atmos. Meas. Technol. 11, 291–313 (2018).
Joharestani, M. Z., Cao, C., Ni, X., Bashir, B. & Talebiesfandarani, S. PM2.5 prediction based on random forest, XGBoost, and deep learning using multisource remote sensing data. Atmosphere 10, 373 (2019).
Liu, B., Tan, X., Jin, Y. & Li, C. Application of RR-XGBoost combined model in data calibration of micro air quality detector. Sci. Rep. 11, 1–14 (2021).
Zhai, B. & Chen, J. Development of a stacked ensemble model for forecasting and analyzing daily average PM2.5 concentrations in Beijing, China. Sci. Total Environ. 635, 644–658 (2018).
Moursi, A. S., El-Fishawy, N., Djahel, S. & Shouman, M. A. An IoT enabled system for enhanced air quality monitoring and prediction on the edge. Complex Intell. Syst. https://doi.org/10.1007/s40747-021-00476-w (2021).
Mohebbi, M. R., Jashni, A. K., Dehghani, M. & Hadad, K. Short-term prediction of carbon monoxide concentration using artificial neural network (NARX) without traffic data: Case study: Shiraz City. IJST-Trans. Civ. Eng. 3, 533–540 (2019).
Liu, Q., Liu, Y., Yang, Z., Zhang, T. & Zhong, Z. Daily variations of chemical properties in airborne particulate matter during a high pollution winter episode in Beijing. Acta Sci. Circumst. 34, 12–18 (2014).
Wang, X. & Lu, W. Seasonal variation of air pollution index: Hong kong case study. Chemosphere 63, 1261–1272 (2006).
Tibshirani, T. The lasso method for variable selection in the Cox model. Stat. Med. 4, 385–395 (1997).
Sun, H., Cui, Y., Gao, Q. & Wang, T. Trimmed lasso regression estimator for binary response data. Stat. Probab. Lett. https://doi.org/10.1016/j.spl.2019.108679 (2020).
Zou, H. The adaptive lasso and its oracle properties. J. Am. Stat. Assoc. 101, 1418–1429 (2006).
Liu, B., Zhao, Q., Jin, Y., Shen, J. & Li, C. Application of combined model of stepwise regression analysis and artificial neural network in data calibration of miniature air quality detector. Sci. Rep. 11, 1–12 (2021).
Gang, S., Hoff, S. J., Zelle, B. C. & Nelson, M. A. Forecasting daily source air quality using multivariate statistical analysis and radial basis function networks. J. Air Waste Manag. 58, 1571–1578 (2008).
Acknowledgements
This work was supported by the Youth Program of National Natural Science Foundation of China (No.71602051) and Research Project of Higher Vocational Education in Nanjing Vocational University of Industry Technology (No. GJ20-30).
Author information
Authors and Affiliations
Contributions
B.L., Y.J., D.X. and Y.W. wrote the main manuscript text, and C.L. is responsible for data processing and model verification.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Liu, B., Jin, Y., Xu, D. et al. A data calibration method for micro air quality detectors based on a LASSO regression and NARX neural network combined model. Sci Rep 11, 21173 (2021). https://doi.org/10.1038/s41598-021-00804-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-021-00804-7
This article is cited by
-
Elucidating hepatocellular carcinoma progression: a novel prognostic miRNA–mRNA network and signature analysis
Scientific Reports (2024)
-
Perceived parenting styles and incidence of major depressive disorder: results from a 6985 freshmen cohort study
BMC Psychiatry (2023)
-
Regression model and method settings for air pollution status analysis based on air quality data in Beijing (2017–2021)
International Journal of Data Science and Analytics (2023)
-
Chemiresistor gas sensors based on conductive copolymer and ZnO blend – prototype fabrication, experimental testing, and response prediction by artificial neural networks
Journal of Materials Science: Materials in Electronics (2022)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
