
Abstract
We stated and solved three successive problems concerning automatization of geological mapping using the case of the Bolshetroitskoe high-grade iron ore deposit in weathered crust of Banded Iron Formation (Kursk Magnetic Anomaly, Belgorod Region, Russia). (1) Selecting a classification (clustering) method of geochemical data without reference sampling, i.e., solution of an “unsupervised clustering task”. We developed 5 rock classifications based on different principles, i.e., classification by visual description, by distribution of economic component (Fe2O3), by cluster analysis of raw data and centered log-ratio transformation of the raw data, and by artificial neural network (Kohonnen’s self-organized map). (2) Non-parametric comparison of quality of the classifications and revealing the best one. (3) Automatic 3D geological mapping in accordance with the best classification. The developed approach of automatic 3D geological mapping seems to be rather simple and plausible.
Similar content being viewed by others


Introduction
Theory and practice of spatial analysis in geosciences have been developing rapidly since the 1990s. However, geological maps and cross-sections are usually built manually. So, they significantly depend on a ‘human factor’. Recently, there is a trend to automatize a creation of geological maps and 3D models1,2,3,4,5. However, the ‘human factor’ takes place here too, e.g., it is required to create a priori rules, manually draw reference cross-section, etc. Plus, these methods are applied to relatively simple geological objects, i.e., gentle sedimentary strata or monotonous magmatic bodies.
Earlier, we proposed an approach of automatic 3D geological mapping based on interpolation and chemistry-to-mineral conversion and implicated it for an intricate magmatic (carbonatite-phoscorite) body6. A rock type in each cell of 3D space was ‘recognized’ on a basis of reference sampling, i.e., we had a set of samples with conjunct bulk-rock chemistry analyses and accurately determined mineral composition. So, it was a type of ‘supervised learning’ task. However, in geological practice, such reference sampling is often absent since it is impossible to exactly determine mineral composition of rocks (fine-grained or cryptocrystalline rocks, or strongly weathered rocks, etc.). In this work, we try to apply our approach to automatically map a geological object of this type without a reference sampling, i.e., it is an ‘unsupervised learning’ task. Furthermore, here we are studying a geological object of fundamentally another genesis, composition, structure, etc., namely, a high-grade iron ore deposit in weathered crust developed by banded iron formation (BIF).
Rocks inside a weathered crust formation are one of the most difficult rocks for mapping. These rocks are usually fine-grained (typical grain size is tens micrometers), in different physical state (from loose to rocky), significantly altered, complicated by relics and breccias, etc. So, these rocks are hard to classify by mineral (modal) composition, using both visual and microscopic investigation. Similar problems for volcanic rocks are solved in a general form, namely, classification by chemical composition by the TAS (total alkali–silica) diagram plus norm calculation by the CIPW7,8. There is no similar standard solution for sedimentary rocks in general and specifically for weathered crusts. So, we are forced to develop a classification ad hoc for such objects. On the analogy of the classification for volcanic rocks by chemical composition, we suggest that classification of the weathered crust rocks by chemical composition would be more relevant than by visual/optic microscopy investigation.
In statistics, this kind of problems is known as an “unsupervised clustering task”. For this task, a problem of quantitative comparison of different classifications quality is not solved in general form9, in contrast to a supervised learning task, where the clustering quality is estimated by cross-validation, bootstrap, etc.10. In this work, we suggest a particular method of quantitative comparison of classifications quality, however, we did not solve a problem of optimal quantity of clusters (i.e., rock types, in our case)—we used quantity of clusters defined by a visual geological description of drill core.
We developed the method on the Bolshetroitskoe high-grade iron ore deposit in weathered crust of banded iron formation (BIF), Belgorod Region, Russia (Figs. 1, 2). In this paper, we developed several geochemical classifications of the deposit rocks based on different principles, i.e., visual description, one-dimensional statistics, multiple regression, and artificial neural networks. Then we introduced a method of quantitative comparison of classifications. Based on the best classification, we automatically built a 3D geological map of the deposit.

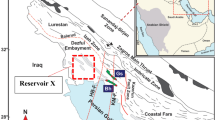
Geological map of the Belgorod iron ore district modified after11,12,13. Drawn by Adobe Illustrator CS6 (https://www.adobe.com).

Geological map of the Bolshetroitskoe high-grade iron deposit, a surface under the sedimentary Phanerozoic cover modified after17. Orange lines are cross-sections in Figs. 5 and 6. Drawn by Adobe Illustrator CS6 (https://www.adobe.com).
Geological setting
The Bolshetroitskoe high-grade iron deposit is a part of the Belgorod ore district (Fig. 1). The Belgorod district is a world’s largest iron ore district. Beside the Bolshetroitskoe, there are the Yakovlevskoe, Gostishchevskoe, Shemraevskoe, Vislovskoe (measured resources), Razumenskoe, Olimpiyskoe, Melikhovo-Shebekinskoe, Olkhovatskoe (indicated and inferred resources) high-grade iron deposits in the district. All these deposits are large and unique.
High-grade iron ore of the Belgorod metallogenic district is considered to be a weathered crust of Banded Iron Formation (BIF) and, to a lesser degree, ferriferous schists of the pre-Visean age, the Carboniferous system, 346 ± 1 Ma11. The weathered crust rocks usually preserve structures and partly mineral composition of maternal rocks.
Main minerals of the high-grade ores are hematite (including martite—pseudomorph after magnetite, and microplaty hematite), goetite–limonite, magnetite, siderite, Fe-rich micas and hydromicas, quartz, clay minerals, boxites. When described visually, ore types are classified by proportions of these minerals, as well as by mechanical properties.
The Bolshetroitskoe high-grade iron deposit (Fig. 2) is located in the SW part of the Belgorod ore district and confined to a sharp bend of the Korochan–Mukhin regional magnetic anomaly. The Bolshetroitskoe deposit is considered to be a syncline, a part of the Belgorod regional graben-syncline. In a core of the Bolshetroitskoe syncline, there are Early Proterozoic BIF (Kursk series), and in limbs of the syncline, there are Archean rocks. High-grade iron ores of the Bolshetroitskoe deposit are considered to be formed in the Carboniferous weathered crust (pre-Visean age, 346 ± 1 Ma) after BIF of the Kursk series14.
The Bolshetroitskoe deposit was discovered in 1947 as a part of the Korochan–Mukhin regional magnetic anomaly. Research and development of a hydraulic borehole mining of the deposit was performed in 1988–1991. A detailed exploration was carried out in 2006–2013, and hydraulic borehole mining of the deposit took place by “Belgorodskaya GDK” (Belgorod, Russia) in 2008–2014. This innovative method allows mining loose rock from under a thick (~ 500 m) sedimentary cover15,16. Measured resources of the Bolshetroitskoe deposit are 410 Mt of ore and indicated resources are 2150 Mt of ore at Fetotal = 62.4%.
Description of the approach
The 3D automatic mapping of ore deposits without reference sampling consists in three general tasks: (1) Selecting a classification (clustering) method of geochemical data (“unsupervised clustering task”). (2) Interpolation of the input data. (3) Joining the results of the first two tasks, i.e., applying the selected clustering method to an interpolation block model. This block model will be a 3D geological map of a deposit. The more detailed approach is applied as follows (a flowchart is shown in Fig. 3).
-
1. Collecting and preparing representative data on whole-rock chemistry of a deposit in 3D.
-
2. Finding functions of data clustering by whole-rock chemistry (i.e., finding parameters of determination of rock type).
-
3. Choosing the best clustering function, if the best way of clustering is unknown beforehand.
-
4. Interpolation of whole-rock chemistry data taking part in the clustering. Joining the interpolation models in a single block model.
-
5. Applying the clustering function found in step 2 to each block of the single block model built in step 3, i.e., computation of rock type.
-
6. Visualization the computed rock type as a set of cross-sections, a 3D body, or a grid, etc.

Flowchart of the automatic 3D geological mapping based on geochemical data without reference sampling.
Clustering and interpolation are different mathematical tasks, and comparison of classification is a task without a general solution, so we have placed solutions of the tasks for the Bolshetroitskoe deposit in separate subsections of the Results section. For usability, we have placed the number of the steps in the subsection titles.
Results
A general characteristic of the sample set (step 1)
1029 samples with an average length of 4 m were sampled along 28 drill holes (see details in the “Materials and methods” section). In the sample set, there are both ore of different quality and host rocks, so the set is obviously heterogeneous. Descriptive statistics of the sample set are given in Table 1, and correlations are shown in Fig. 4.

Scatterplots and histograms of the sampled population. Numbers are correlation coefficient r > 0.5 (p < 0.02).
Strong verifiable correlation relationships are typical of Fe2O3 (with SiO2, Al2O3, MgO, TiO2). It is clear that these relationships are negative, i.e., the richer ore, the less impurities. Beside the component of interest, Fe2O3, there is a strong positive correlation of Al2O3 vs TiO2 (r = 0.97) and FeO vs MgO (r = 0.61). Nearly all scatterplots (even highly correlated Al2O3 vs TiO2) have minimum two trends, which is typical of heterogeneous samples.
Distribution of Fe2O3 is left-asymmetric (Q-normal), and the rest of the components have right-asymmetric distribution (lognormal or exponential).
Geochemical classification of rocks (step 2)
To define the best approach to geochemical classification of the deposit rocks, we used four different methods, plus visual (‘manual’) geological classification as a basis for comparison.
1. Geological classification of rock via visual description of a drill core by geologists of the “Belgorodskaya GDK” (Belgorod, Russia). They picked out 13 rock types: appreciably martite ore; banded martite ore; martite with magnetite and platy-hematite ore; appreciably platy-hematite limonitized ore; banded platy hematite limonitized ore with carbonate cement; martite with magnetite and platy-hematite ore with carbonate cement; appreciably limonite with hematite and martite ore; banded limonitized ore with silicates and carbonates; martite limonitized and sideritized ore with magnetite and platy-hematite; weathered intra-ore schist and allite; weathered above-ore schist; banded iron formation (BIF); breccia. In this work, we excluded the last rock type because it has no geochemical and mineralogical sense. So, we have 12 rock types, and in other classification, we picked out the same number of rock types.
2. Classification by content of the principal economic component, Fe2O3, based on its multimodal distribution (Fig. 5). We accepted local minima in the histogram as borders between rock types. This approach to ore classification is common since it suits for economic (technological) ore classification of single-component deposits (e.g., rich, intermediate, poor ores).

Histogram of Fe2O3 distribution in rocks of the Bolshetroitskoe deposit. Red lines are the borders of classes (local minima) of the Classification #2 (column 2 of the Table 2).
3. Cluster analysis of raw chemical composition. We used five rock-forming components: Fe2O3, FeO, SiO2, Al2O3, CaO. Method: k-means clustering. Initial cluster centers were taken by choosing observations to maximize initial between-cluster distances. Cluster: cases (rows). Number of clusters was 12, solution was obtained after three iterations. Missing data were casewise deleted.
4. Cluster analysis of chemical composition with centered log-ratio transformation of the raw data to avoid spurious correlation in closure numerical systems18,19. We used five rock-forming components: Fe2O3, FeO, SiO2, Al2O3, CaO. Method: k-means clustering. Initial cluster centers were taken by choosing observations to maximize initial between-cluster distances. k-means clustering. Initial cluster centers were taken by choosing observations to maximize initial between-cluster distances. Number of clusters was 12, solution was obtained after six iterations. Missing data were casewise deleted.
5. Clustering by artificial neural network (ANN). 5 rock-forming components were used: Fe2O3, FeO, SiO2, Al2O3, CaO. Type of ANN: Kohonnen’s network. Number of clusters was 12. Learning parameters: random sample sizes, train 70%, test 15%, validation 15%, seed for sampling is 1000, missing deleting handling (inputs) is casewise. Topological height 2, topological width 6. Comparison measure: Euclidian distance. 1000 training cycles. Learning rates: start 0.1, end 0.02. Neighborhoods: start 3, end 0. Normal randomization of network.
Table 2 shows results of the classifications: conventional name, and chemical composition of rock types. Rock types of different classifications (i.e., cells of a row of the table) did not correspond to each other.
Comparison of the classifications (step 3)
As we obtained five classifications of the same object, and these classifications are based on different principles, a problem to choose the best classification raised.
Method of comparison of approximation and interpolation is known in statistics, e.g., cross-validation20 and bootstrap10. However, approximation and interpolation problem differs from clustering (classification) problem. It has a reference sample set, and measure of fitting quality is based on comparison of the reference sample set and approximation/interpolation model. Sometimes there is a reference set for classification problems, it is known as a supervised learning task, see review in21. However, we did not have a reference set, i.e., we had an unsupervised learning task. For such type of problems, there is no general solution, and the method of quantitative comparison of classifications is usually developed for a specific problem, see review in9. Statement of the problem in a general form and an approach to its solution were introduced in22. Our case was simpler because we did not take into account the problem of selection of cluster number. We took 12 rock types since this number of rock types (excluding the ‘breccia’ type) is used for the Bolshetroitskoe deposit, and the approximately same number of rock types is used for other high-grade iron ore deposits of the region.
In accordance with the approach suggested by Dy and Brodley22, we supposed that a sum of ‘inhomogeneity’ of all classes (from 1 to 12) of the classification m could be a measure of negative quality Qm. I.e., the less sum of ‘inhomogeneity’ of all classes, the better a classification under the condition that a number of classes is equal in all compared classifications. Thus, the optimal classification has a minimal sum of ‘inhomogeneity’ Q*:
This approach is in agreement with a definition of clustering as grouping of similar objects23. We used the standard deviation σ as a measure of inhomogeneity.
A flowsheet for comparing the quality of classifications (in our case) is as follows.
-
1.
Calculate standard deviation \(\sigma_{ij}^{m}\) of each component j (\(j = \overline{1,\,5}\)) in each class i (\(i = \overline{1,\,12}\)) of each classification m (\(m = \overline{1,\,5}\)).
-
2.
Calculate sum \(Q_{j}^{m}\) of the standard deviations of all components for each class of each classification:
$$Q_{j}^{m} = \sum\limits_{i = 1}^{12} {\sigma_{ij}^{m} }$$(2) -
3.
Based on the sum \(Q_{j}^{m}\) of the standard deviations, determine rate \(r_{j}^{m}\) of each classification for each component: the less sum, the higher rate (in our case, \(r_{j}^{m}\) = 1 for minimum \(Q_{j}^{m}\), and \(r_{j}^{m}\) = 5 for maximum).
-
4.
Calculate sum of rates \(S^{m}\) of all components for each classification:
$$S^{m} = \sum\limits_{j = 1}^{5} {r_{j}^{m} }$$(3) -
5.
Determine final rates Rm of the classifications: the less sum, the higher rate (in our case, Rm = 1 for minimum Sm, and Rm = 5 for maximum). These final rates reflect comparative quality of the classifications.
A result of application of the flowsheet to the sample set of the Bolshetroitskoe deposit is shown in Table 3.
The result shows that the classification by neural network is the best. The neural network is available online in Supplementary Materials 1. So, this classification became a basis for a 3D automatic geological mapping of the Bolshetroitskoe deposit. A chemical composition of the rock types picked out by this classification is shown in Table 4.
Interpolation, rock type evaluation, and visualization of the 3D geological model (steps 4–6)
Application of the automatic 3D geological modelling method to the Bolshetroitskoe deposit (steps 4–6 in accordance with the flowchart, Fig. 3) is described below.
Step 4.1. Interpolation of the determinative components: Fe2O3, FeO, Al2O3, SiO2, and CaO.
The interpolation was conducted using the anisotropic inverse distance weighted method, power = 2. Search ellipsoid was determined by variography (set of directional semivariograms) of the dominant component Fe2O3, taking into account distances between boreholes. Interpolation of each component was carried out in three runs with a successive increase in the search radius (130, 270, and 560 m) and a decrease in the threshold number of points falling into the search ellipsoid (4, 3, and 1). A number of sectors of the search ellipsoid is 4, a maximum number of points in a sector is 5. Parameters of the search ellipsoid: azimuth of the 1st axis is 90°, dip is 0°, factor is 1; azimuth of the 2nd axis is 180°, dip is 0°, factor is 1; azimuth of the 3rd axis is 0°, dip is 90°, factor is 0.1. Sections of the interpolation block models of the five components across the line I–I’ (Fig. 2) are shown in Fig. 6.

Distribution of rock-forming components in the cross-section I–I’ in Fig. 2. Red lines are drill holes.
Step 4.2. Conjugation of the interpolation block models into one table. As a result, we have a block model with value of each chemical component for each block.
Step 5. Evaluation of a rock type for each block using the previously created classification [see the sections ”Geochemical classification of rocks (step 2)” and ”Comparison of the classifications (step 3)”], i.e., clustering by artificial neural network (Kohonnen’s self-organized map), the program code of which is presented in the Supplementary Material file.
Step 6. Visualization of the block model. The final result is shown in Fig. 7.

Discussion
Model of the Bolshetroitskoe deposit
We got the 3D geological model of the deposit without human decisions. It is based only on structure of spatial variation of rock-forming components (Fe2O3, FeO, Al2O3, SiO2, CaO). The spatial variation cannot be utilized during manual drawing of geological model or cross-section of a deposit. Plus, geologists usually have a priori model of genesis and a structure of a deposit that can influence on a geological model. For example, there are two manually built cross-sections of the Bolshetroitskoe deposit (Fig. 8)15,24. We can see that the authors of the first cross-section had a conception that the regional folding formed the deposit, and the authors of the second one supposed subhorizontal bedding with tectonically induced permeability, which resulted in a thick zone of the high-grade ore. An automatic mapping approach is data-driven and free of any a priori conception. These two circumstances (basing on spatial variation and absence of a priori conception) forced us to suggest that the automatic approach can be more precise than the manual one. A general agreement of our automatic model and the most recent manual cross-section (Fig. 8b) supports this suggestion.

However, the automatically built geological model has some constrains or shortcomings.
– Some rock types are named as formation, viz. BIF, and moderately weathered BIF. Of course, they are conditional names since they should be referred to a certain formation based on textural, structural, and mineral properties. Yet, in our case, we use these names for more lucidity because it usually coincides with a visual description of drill cores.
– Most of rock types are named in accordance with their chemical composition, and these names does not have geological sense of the rock types. We suppose that it is the main shortcoming of the developed geological model. However, the shortcoming arises from quality of input data, in this case. If we obtained an exactly determined mineral composition and quantitative description of textural/structural properties throughout the drill cores, we would build a geologically interpretable model, as we did in the works25,26.
– Classification of some blocks seems to be wrong from the geological point of view. E.g., near the bottom of the drill hole 26p (Fig. 6), there is a block of BIF surrounded by a moderately weathered BIF above high-grade ore blocks.
In general, the automatically built structure of the deposit seems to be geologically correct: BIF and moderately weathered BIF are in the bottom of the cross-section; there are iron ores of different grades above maternal BIF; and, finally, iron ores are overburden by silica- and alumina-rich rocks; the highest-grade ore (rock type #1) forms the central bulge (around drill hole 2p).
Comparison of the classifications of rocks of the Bolshetroitskoe deposit
It was foreseeable that the one-parameter classification by Fe2O3 histogram became the worst one, its rate sum is twice worse than the leader’s, the classification by ANN (21 vs 10, Table 3). Surprisingly, the manual classification became the worst too (rate sum is 20), and logratio transformation of raw data did not enhance the classification: rate sum of the classification by cluster analysis of raw data is 12, and logratio transformed is 12, too (Table 3). Clustering of the data by artificial neural network became the best (rate sum is 10). It is expectable because it is known that multiparametric non-linear methods of clustering are better than k-means cluster analysis, see e.g.27,28.
We used standard deviation as σ in Eq. (2) since it is the most common measure that is used to quantify the degree of variation of a data value set, although other measures such as interquartile range, median absolute deviation, mean absolute difference, average absolute deviation, etc. can be used. In our case, we tested other ‘measures of unhomogenity’ (interquartile range and weighted standard deviation) and found that the classification by artificial neural network is still a leader. Justification of the best ‘measure of unhomogenity’ and its usability condition is an independent mathematical problem and is outside the scope of this work. Rigorous mathematical investigation and generalization of the approach are in our future plans.
Approach of automatic 3D geological mapping
In general, the approach consists of the following three steps: (1) interpolation of variables required for rock type determination in a single block model; (2) rock type determination for each block of the block model by a certain classification algorithm; (3) visualization. The most difficult problem is step 2. A classification algorithm depends on available data. The ideal (or simplest) case is when a directly determined mineral composition and quantified textural properties of rocks are available25,26, the classification algorithm will be just a logical evaluation of rock type in accordance with the commonly accepted classification (as in our aforementioned works) or any local classification. The case is more complex when a mineral composition is calculated from a chemical composition of rocks6, i.e., a chemistry-to-mineral conversion problem29,30 should be taken into account. The most complex case—rock classification by “plain” rock chemistry—is investigated here. In all these cases, the principal workflow is the same. It suggests that the developed approach is sufficiently universal. It seems that the most difficult problem (rock classification algorithm) can be reduced by total determination of mineral composition during a deposit exploration, e.g., by automatized mineralogical systems like QEMSCAN29,31. The second important source of errors of the geostatistical-based approach is interpolation. However, this field of knowledge is being actively developed now, and nearly all problems of uncertainty usually have an acceptable solution, general or special (see review e.g., in32,33).
Except for a chemistry-to-mineral conversion problem, the developed approach does not require a specially developed mathematical software or code. Commonly used mining or geographical information systems (e.g., Micromine, Datamine, Mineframe, or ArcGIS, etc.) are suitable for implementing the approach.
One more feature of the approach is a requirement of quantified data (mineral and chemical composition of rock, quantified structural/textural properties, etc.), and qualitative data (e.g., visually described textural properties) cannot be used since such type of data cannot be interpolated. We suppose that it is an advantage because an interpolation-based analysis of spatial structure of a deposit is more founded than intuitively drawn manual cross-section (see the example in Fig. 8). Besides, the approach can be used for a geometallurgical modelling: in this case, technological ore types should be taken into account (determined by mineral processing or metallurgical technology) instead of common geological rock typessup34.
Conclusions
-
1. We developed an approach of rock type classification and 3D automatic mapping of ore deposits without reference sampling (i.e., by unsupervised learning). Methods of non-linear clustering are preferable for rock type classification without reference sampling (e.g., Kohonnen’s self-organizing map).
-
2. We introduced a method of non-parametric comparison of quality of classifications based on different principles. The method is to rank classifications by a sum of standard deviations within classes.
-
3. Interpolation of rock-determining parameters in a single block model and their recalculation in rock types (method of the recalculation depends on data type, classification type, etc.) seem to be a universal approach to automatic geological mapping. The approach is rather simple and its results seem to be geologically correct and plausible.
Materials and methods
28 drill holes with an average depth of 580 m were sampled (Fig. 2). The sampling began at 420–500 m. A sample of the sedimentary cover was not taken. In total, there were 1029 samples of the drill cores with an average length of 4 m. Fetot, Fe2O3, FeO, SiO2, Al2O3, P2O5, CaO, MgO, MnO, Stot, TiO2 were analyzed in the samples by spectrophotometric, atomic absorption spectrometric, and titration methods using the Agilent 8567, DL-22, SF-26, S-302 equipment at JSC “Belgorodgeologiya” (Belgorod, Russia) and “Voronezhgeologiya Ltd.” (Voronezh, Russia). Statistical investigations were carried out by the STATISTICA 12 program (StatSoft, https://www.statsoft.ru). Geostatistical studies, interpolation, and 3D modelling were conducted by the MINEFRAME 8 program (Mining Institute of Kola Science Centre, Russian Academy of Sciences, https://www.mineframe.ru) and Micromine 2016.1 (Micromine Pty Ltd., Australia, https://www.micromine.com; commercial license). Vector graphics were drawn by the Adobe Illustrator CS6, https://ww.adobe.com.
References
Ming, J., Pan, M., Qu, H. & Ge, Z. GSIS: A 3D geological multi-body modeling system from netty cross-sections with topology. Comput. Geosci. 36, 756–767 (2010).
Kessler, H., Mathers, S. & Sobisch, H.-G. The capture and dissemination of integrated 3D geospatial knowledge at the British Geological Survey using GSI3D software and methodology. Comput. Geosci. 35, 1311–1321 (2009).
Calcagno, P., Chilès, J. P., Courrioux, G. & Guillen, A. Geological modelling from field data and geological knowledge. Part I. Modelling method coupling 3D potential-field interpolation and geological rules. Phys. Earth Planet. Int.171, 147–157 (2008).
Hajsadeghi, S., Asghari, O., Mirmohammadi, M. & Meshkani, S. A. Indirect rock type modeling using geostatistical simulation of independent components in Nohkouhi volcanogenic massive sulfide deposit, Iran. J. Geochem. Explor. 168, 137–149 (2016).
Talebi, H., Asghari, O. & Emery, X. Stochastic rock type modeling in a porphyry copper deposit and its application to copper grade evaluation. J. Geochem. Explor. 157, 162–168 (2015).
Kalashnikov, A. O., Ivanyuk, G. Y., Mikhailova, J. A. & Sokharev, V. A. Approach of automatic 3D geological mapping: The case of the Kovdor phoscorite-carbonatite complex, NW Russia. Sci. Rep. 7, 6893 (2017).
Le Bas, M. J., Maitre, R. W. L., Streckeisen, A. & Zanettin, B. A chemical classification of volcanic rocks based on the total alkali-silica diagram. J. Petrol. 27, 745–750 (1986).
Igneous Rocks. A Classification and Glossary of Terms. Recommendations of the International Union of Geological Sciences Subcommission on the Systematics of Igneous Rocks. (Cambridge University Press, 2002).
Dash, M. & Koot, P. W. Feature Selection for Clustering. in Encyclopedia of Database Systems 1119–1125 (Springer, 2009). https://doi.org/10.1007/978-0-387-39940-9_613
Efron, B. & Tibshirani, R. An Introduction to the Bootstrap. (CRC Press, 1994).
Nikulin, I. I. & Savko, A. D. Iron-Rich Weathering Crusts of the Belgorod District of the Kursk Magnetic Anomaly (in Russian with English abstract). (Voronezh State University, 2015).
Sokolov, N. A., Romanov, I. I. & Ponomarev, V. N. Drawing Up a Geological and Economic Map of Kursk Magnetic Anomaly of Scale 1: 500000 for Ferrous Metallurgy (in Russian). (JSC Belgorodgeologia, 1998).
Molotkov, S. P. Geological Map of the Kursk Greenstone Area, Scale 1:1 000 000. (Voronezh State University, 1999).
Nikulin, I. I., Savko, A. D. & Merkushova, M. Y. Types of hypergenic high-grade iron ores of the Belgorod region of the Kursk Magnetic Anomaly (in Russian with English abstract). Proc. Vor. State Univ. Ser. Geol. 3, 71–82 (2015).
Bezugly, M. M. & Nikulin, I. I. New information on the geological structure and nature of ores of the Bolshetroitskoe deposit (the Belgorod district of the Kursk Magnetic Anomaly) (in Russian with English abstract). Proc. Vor. State Univ. Ser. Geol. 2, 171–179 (2010).
Nikulin, I. I. Geological aspects in the development of deep-seated watered high-grade iron ore deposits (in Russian with English abstract). Belgorod State Univ. Sci. Bull. Nat. Sci.160, 148–154 (2013).
Nikulin, I. I. Rare-earth elements in the weathering crust of ferruginous quartzite of the Bolshetroitskoe deposit, the Kursk Magnetic Anomaly (in Russian with English abstract). Proc. Vor. State Univ. Ser. Geol. 1, 54–61 (2014).
Aitchison, J. The statistical analysis of compositional data. J. R. Stat. Soc. Ser. B 44, 139–177 (1982).
Pawlowsky-Glahn, V. & Egozcue, J. J. Compositional data and their analysis: An introduction. in Compositional Data Analysis in the Geosciences: From Theory to Practice. (eds. Buccianti, A., Mateu-Figueras, G. & Pawlowsky-Glahn, V.) 1–10 (Geological Society, Special Publications, 2006).
Stone, M. Cross-validatory choice and assessment of statistical predictions. J. R. Stat. Soc. Ser. B 36, 111–147 (1974).
Dash, M. & Liu, H. Feature selection for classification. Intell. Data Anal. 1, 131–156 (1997).
Dy, J. G. & Brodley, C. E. Feature selection for unsupervised learning. J. Mach. Learn. Res. 5, 845–889 (2004).
Gunopulos, D. Clustering overview and applications. in Encyclopedia of Database Systems 383–387 (Springer, New York, 2009). https://doi.org/10.1007/978-0-387-39940-9_602
Leonenko, I. N., Rusinovich, I. A. & Chaykin, S. I. Geology, Hydrogeology and Iron Ores of the Kursk Magnetic Anomaly. Volume III. Iron Ores (in Russian). (Nedra, 1969).
Pakhomovsky, Y. A. et al. Selivanovaite, NaTi3(Ti, Na, Fe, Mn)4[(Si2O7)2O4(OH, H2O)4]·nH2O, a new rock-forming mineral from the eudialyte-rich malignite of the Lovozero alkaline massif (Kola Peninsula, Russia). Eur. J. Miner. 30, 525–535 (2018).
Mikhailova, J. A. et al. Petrogenesis of the eudialyte complex of the Lovozero alkaline massif (Kola Peninsula, Russia). Minerals 9, 581 (2019).
Mangiameli, P., Chen, S. K. & West, D. A comparison of SOM neural network and hierarchical clustering methods. Eur. J. Oper. Res. 93, 402–417 (1996).
Schoof, J. T. & Pryor, S. C. Downscaling temperature and precipitation: A comparison of regression-based methods and artificial neural networks. Int. J. Climatol. 21, 773–790 (2001).
Parian, M., Lamberg, P., Möckel, R. & Rosenkranz, J. Analysis of mineral grades for geometallurgy: Combined element-to-mineral conversion and quantitative X-ray diffraction. Miner. Eng. 82, 25–35 (2015).
Ntlhabane, S. et al. Towards the development of an integrated modelling framework underpinned by mineralogy. Miner. Eng. 116, 123–131 (2018).
Mackay, D. A. R., Simandl, G. J., Ma, W., Redfearn, M. & Gravel, J. Indicator mineral-based exploration for carbonatites and related specialty metal deposits—A QEMSCAN® orientation survey, British Columbia, Canada. J. Geochem. Explor. 165, 159–173 (2016).
Abzalov, M. Applied Mining Geology. (Springer, 2016). https://doi.org/10.1007/978-3-319-39264-6
Oliver, M. A. & Webster, R. Basic Steps in Geostatistics: The Variogram and Kriging. (Springer, 2016). https://doi.org/10.1007/978-3-319-15865-5
Rajabinasab, B. & Asghari, O. Geometallurgical domaining by cluster analysis: Iron ore deposit case study. Nat. Resour. Res. 28, 665–684 (2019).
Acknowledgements
Drilling and chemical analyses were carried out by “Belgorodskaya GDK” (Belgorod, Russia) in the framework of exploration of the deposit in 2006–2013. The research was supported by the Russian Science Foundation, grant No. 16-17-10173 and Ministry of Science and Higher Education of the Russian Federation, NIR 0226-2019-0051.
Author information
Authors and Affiliations
Contributions
A.O.K. developed the approach, performed all calculations, drew figures and wrote the manuscript. I.I.N. dealt with drill core and chemical analyses, and described geology. D.G.S. wrote mathematical parts and revised computations. All authors discussed and reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Kalashnikov, A.O., Nikulin, I.I. & Stepenshchikov, D.G. Unsupervised geochemical classification and automatic 3D mapping of the Bolshetroitskoe high-grade iron ore deposit (Belgorod Region, Russia). Sci Rep 10, 17861 (2020). https://doi.org/10.1038/s41598-020-74505-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-020-74505-y
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
