
Abstract
The prevalence of childhood obesity in China has recently become increasingly severe, and intervention measures are needed to stop its growth. Currently, there is a lack of assessment and prediction methods for childhood obesity. We develop a predictive model that uses currently measured predictors [gender, age, urban/rural, height and body mass index (BMI)] to quantify children’s probabilities of belonging to one of four BMI category 5 years later and identify the high-risk group for possible intervention. A total of 88,980 students underwent a routine standard physical examination and were reexamined 5 years later to complete the study. The full model shows that boys, urban residence and height have positive effects and that age has a negative effect on transition to the overweight or obese category along with significant BMI effects. Our model correctly predicts BMI categories 5 years later for 70% of the students. From 2018 to 2023, the prevalence of obesity in rural boys and girls is expected to increase by 4% and 2%, respectively, while that in urban boys and girls is expected to remain unchanged. Predictive models help us assess the severity of childhood obesity and take targeted interventions and treatments to prevent it.
Similar content being viewed by others


Background
With the rapid growth of the social economy and lifestyle changes, childhood overweight and/or obesity prevalence is increasing globally at an alarming pace, which has greatly increased public health concerns.1,2 The prevalence of childhood obesity in China has increased rapidly in the past two decades. According to statistics on overweight in Chinese children and adults, from 1985 to 2014, the overweight rate among schoolchildren (over 7 years old) increased from 2.1 to 12.2%, and the obesity rate increased from 0.5 to 7.3%. Without effective interventions, the overweight and obesity rates will reach 28.0% by 2030, with a total of 49.48 million overweight and/or obese children.3 Childhood obesity is an important predictor of several adulthood chronic diseases, such as hypertension, type 2 diabetes mellitus, obstructive sleep apnea, and psychological and behavioral problems.4 It has been shown that 72% and 63% of children in kindergarten and the following three years of school (between ages 11 and 14 years old), respectively, are obese.5 Thus, BMI trajectories from childhood to adulthood could improve our understanding of the evolution of the prevalence of childhood obesity. In addition, estimating age-specific morbidity rates would facilitate the development future intervention strategies.6,7 Moreover, if we can target children at high risk of future or continuing obesity based on a set of significant factors, personalized interventions would be feasible to prevent and/or decrease the incidence of obesity. Although a number of studies on the prevalence of childhood obesity are available,4,5,8 few studies have quantified the joint impacts of recognized predictors of obesity after a specified number of years (the time window for implementing an intervention). Therefore, we conducted a 5-year follow-up study on primary school students in Yantai, China, to establish a reliable predictive model to quantify the probability of each student being in a certain BMI category after 5 years. Our study mainly aimed to (1) study the transition rates (from the beginning to the end of the study) across four BMI categories; (2) establish an efficient overweight/obesity probability model with improved predictive performance (e.g., compared to that using only the BMI categories form the beginning of the study); and (3) identify the high-risk group through the definition of a joint high-risk domain based on the significant predictors.
Methods
Data collection and processing
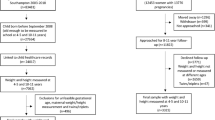
The human research ethics committee at our institute (Yantai Center for Disease Control and Prevention) approved this study after confirming that all the procedures, including the anthropometric procedures and data collection, were performed in accordance with the relevant guidelines and regulations. Students’ written informed consent was obtained from parents, legal guardians, or both. The participants of the current cohort were recruited randomly from primary and junior high schools (in Yantai) in September 2013 during a physical examination conducted by our institute. All participants were followed up five years later (in September 2018). A total of 96,264 individuals were enrolled when the study began, and 88,980 completed the study (with a small proportion missing completely at random due to irrelevant issues).
Description of anthropometric measures: All researchers participated in training on anthropometric procedures and data collection, and all instruments were calibrated. The children were asked to take off thick clothing, shoes and socks during the measurement process, and their weight and height were measured to the nearest 0.1 cm and 0.1 kg, respectively. In addition, the children’s name, gender, date of birth, grade, and area or residence (urban or rural) were collected.
Body mass index (BMI) is calculated as weight (kg)/height (m)2; the evaluation criteria for underweight, normal, overweight and obese vary for different genders and age groups per Chinese national criteria specifically designed to provide a comprehensive evaluation standard for school-aged children and adolescent development.9,10 The large sample size is sufficient to accurately estimate the small group of parameters [point estimate and 95% confidence interval (CI)] and test the significance of each predictor.
Statistical analysis
The mean height and BMI in the population show different increasing trends with age. The increases also depend on both gender and district. We first use bar charts to present the exploratory analysis results of the distributions of follow-up BMI categories by making marginal comparisons between groups (e.g., boys and girls). Our primary analysis uses a baseline-category logit model to quantify the final BMI category probabilities based on the set of predictors measured at the beginning of the study. The prediction of the BMI category (in 2023) can be made based on the new data, and the high-risk (high probability of obesity) group can be identified. Data analysis and model fitting are implemented by using R 3.5.0. and SAS 9.2.
Model fitting
We apply the following baseline-category logit model:
Here the baseline category is J = 2 (“normal”), and three other categories (j = 1, 3, 4) represent “underweight”, “overweight” and “obese” with the following category probabilities:
Here predictor x is a vector of variables (xi, i = 1…,5), i.e., gender, district, age, height and BMI13 [weight is omitted due to the relationship of BMI = weight(kg)/height(m)2]. We calculate the empirical probabilities of being in the “obese” and “normal” categories for each age group, and the log(probability ratio) profiles (Fig. 1) indicate no interactions (between age, BMI, height and gender); similar observations are found for the district variable. Thus, a linear age effect in Eq. (1) applies.

The empirical log(probability ratio [obese:normal]) versus age and BMI.
The interactions found in this preliminary study are either nonsignificant or of little interest to us and are excluded from the model. The large sample size is sufficient for our parameter significance test given the small set of predictors.
To efficiently estimate the parameters, we employ the separate maximum likelihood estimation (SMLE) approach by fitting a separate logistic model to each subpopulation (response (Y) = {j, 2} in Eq. (2)), where \(p_{j}^{*} \left( x \right)\) represents the event (Y = j) probability with parameter values identical to those in Eqs. (1–2), i.e.,
ROC curves, the 5-year-later multi-category prediction outcome classification table and comparison with other model fitting algorithms (e.g., global maximum likelihood estimation (GMLE) using Newton–Raphson iteration) are made to evaluate our approach. The high-risk group is determined to enable possible intervention. We restrict BMI13 to be within [10,35] (n = 88,879) to avoid program running errors.
Results
Descriptive statistics
The general characteristics of the children at baseline are listed in Table 1. The initial sample includes 96,264 children (49,220 boys and 47,044 girls aged 6–11 at 2013). Students of Han nationality account for 99.86% of the sample, while those of other nationalities account for 0.14%. A total of 55.66% of the sample comes from urban areas.
Cross-category analysis
Cross-category changes (from 2013 to 2018) are summarized in Table 2. In 2013, the most prevalent BMI category among the children is normal weight (55%), followed by obese (25%), overweight (17%) and underweight (3%). The prevalence of obesity decreases significantly from 2013 to 2018 (95% CI 0.02, 0.03). A total of 3%, 4% and 20% of the children in the underweight, normal and overweight groups in 2013, respectively, transition to the obese group in 2018. Sixty-five percent of the 2013 obese group is still the obese group in 2018. Seventy-three percent of the 2018 obese group had been obese in 2013. Among the children in the obese group in 2013, 13% and 22% transition into the normal and overweight groups in 2018, respectively. The prevalence rates are plotted in Fig. 2 (stratified and grouped by age and BMI13 category). The majority of the normal-weight or obese students in 2018 are in the same category that they were in in 2013. Boys in all four BMI13 categories are more likely than girls to be obese in 2018 [p < 0.001, 95% CI of the odds ratio (OR) 1.66, 3.90; 1.66, 1.99; 1.28, 1.50; and 1.46, 1.64, respectively]. Girls from the 2013 obese group are more likely be overweight in 2018 than boys (p < 0.001, 95% CI of the OR 1.12, 1.28). Urban students are more likely than rural students be obese in 2018 only among those students who had been in the obese group in 2013 (p < 0.001, 95% CI of the OR 1.08, 1.21). The obesity prevalence rate generally decreases as age (in 2013) increases (Fig. 1).

BMI category (2018) proportions (stratified by age in 2013).
Model-based analysis
The SMLE parameter estimates are summarized in Table 3; all the predictors in Eq. (1) were significant (p < 0.05). Gender and district both have positive effects on the transition of students to the other three BMI categories from the “normal” category. Age has a positive (negative) effect on the transition of students to the “underweight” (“overweight” or “obese”) category from the “normal” category, and the effect of height is opposite to that of age. The linear BMI13 effect has opposite signs for the “underweight” versus “overweight” and “obese” categories. The ROC curves from the three logistic models have areas under the curve of 0.77, 0.78 and 0.92 (the left panel, Fig. 3). Height is also a significant predictor in addition to BMI13. The estimated probabilities of students being overweight and obese in the year 2023 using the recently collected 2018 physical examination data (n = 300,733) indicate that the obesity rates of boys and girls at all ages (6–11) in 2023 are higher than those in 2018. Specifically, among students aged 6 to 11, the obesity rates for boys in 2018 versus 2023 are 32 versus 34%, 27 versus 29%, 25 versus 27%, 23 versus 27%, 22 versus 26%, and 19 versus 24%, and the obesity rates for girls in 2013 versus 2018 are 22 versus 23%, 17 versus 19%, 15 versus 17%, 14 versus 16%, 13 versus 15%, and 9 versus 14%, respectively. The obesity rates among rural students (boys and girls) in 2023 appear to increase substantially compared to those of their 2018 peers (boys: 22–26%, girls: 14–16%). The overweight rates among urban students (boys and girls) and the overall sample (stratified by gender and district) show negligible changes from 2018 to 2023.

ROC curves from SMLE and GMLE model fitting approaches.
Evaluating the SMLE approach
A bootstrap study provides the correlation structure among three sets of estimated regression parameters [Eq. (1)], where the true parameter values are those point estimates (SMLE) in Table 3 and the predictor (X) population is identical to that one from which the model is fitted (Table 3). The bootstrapped SML estimates have means highly close to the true values and variances highly consistent with the confidence intervals in Table 3. The correlation coefficients among these estimated 18 (3 × 6) parameters are useful for further inference (e.g., apply multiplicity adjustment to control false discovery). For instance, the estimated “age” and “height” coefficients are highly negatively correlated for each nutrition category [j = 1, 3, 4 in Eqs. (1–3)]:
There are some other moderately correlated coefficient estimates. In comparison, SAS procedure Logistic employs GMLE (global maximal likelihood estimation) to fit models. The score test rejects the proportional odds model (p < 0.0001). For fitting the baseline-category logit model, SAS output (GMLE) highly agrees with SMLE for both point estimates and 95% CIs (Table 3) and SMLE (GMLE) has a log-likelihood of − 69,913 (− 69,806). ROC curves from GMLE (the right panel, Fig. 3) have under-the-curve areas equal to SMLE. SMLE appears to work efficiently without the need of complicated algorithms or expensive software packages.
Model-based prediction
Based on Table 3, the predicted BMI category 5 years later is that with the largest probability cross j = {1:4} (a linear discriminant rule targeting the maximal element from {\(x\beta _{1}\), 0, \(x\beta _{3}\), \(x\beta _{4}\)}). A crude prediction by assigning all students to be “normal” in 2018 only has 57% (= 50,600/88,980, Table 2) of all students being correctly predicted. We are interested in comparing the prediction performance of the full model [Eqs. (1–2)] with that of Table 1 (only based on the BMI13 category). The full model correctly predicts the 5-year BMI category for 70% of students. The model-based prediction generally has a higher specificity (for predicting “overweight” and/or “obese”) than Table 1. Since the overall obesity (normal) prevalence rates naturally decreases (increases) from 2013 to 2018 (Table 2), the prediction of the prevalence of obesity (normal weight) using only the BMI13 category tends to inherently inflate (deflate) the sensitivity. To verify the prediction improvement, we randomly divide the data set into a training set and a testing set (fivefold cross-validation) 100 times. At each time, the fitted model from the training set is used to make BMI category predictions on the testing set. On average, 70% (SD 0.3%) of students are correctly predicted, the sensitivity means are (0.2, 94, 6, 68)% and the specificity means are (15, 71, 38, 69)%. These are very close to Table 4.
Based upon the preceding procedures, the identification of a high-obesity-risk group is feasible. The joint high-risk decision domain is developed based on the following crude ranges of various predictors: 6–11 (age), 110–170 (height (cm)) and 10–35 (BMI). For illustration purposes, given a threshold of 0.9, we calculate the obesity probability (Pr(O)) for each student recorded in 2018 (stratified by gender and district, age = 6–11).
Students with a Pr(O) > 0.9 would be included in the high-risk group with the joint (height, BMI) region (i.e., lower BMI boundary) calculated and plotted (e.g., for boys in the city) in Fig. 4. As age increases, the high-risk group boundary moves towards the upper-right corner.

High-risk groups defined by height and BMI (urban boys, stratified by age).
Discussion
Our study is an observational population cohort study. We develop a baseline-category logit model to quantify the probabilities of future BMI categories with the purpose of generating new evidence to reform policy based on the most effective ways to reduce childhood obesity. The high-risk group can be identified by BMI category prediction. The model is substantively accountable in predicting obesity incidence given the currently recognized set of factors. The estimated overweight and obese prevalence rates in 2023 indicate that the obesity rates of both boys and girls at all ages in 2023 appear to be substantially higher than those in 2018. The obesity rates among rural students in 2023 appear to increase substantially compared to those of their 2018 peers.
Our study shows that the probability of becoming obese decreases as age increases and that most high-risk students become high risk earlier (age ≤ 9) rather than later during childhood. Children who entered the study with a normal BMI were less likely to be obese 5 years later than those who entered with an overweight or obese BMI. Generally, a weight development trend is established in early childhood that lasts into adulthood, and it is better to prevent childhood obesity before its onset since transitioning to a normal weight from being obese is difficult, and persistent obesity is common.11,12,13 For example, two cohort studies in the United States showed that 65% of 5th-grade obese patients remained obese in 10th grade, 75% of 7-year-old obese patients were still obese at the age of 11, and 16% of overweight people became obese.14,15 The study helps to identify how individuals’ BMI categories change within 5 years and whether these changes are consistent across populations. Boys are more likely to become obese than girls, and the chance of obesity is higher in urban areas than in rural areas. The gender imbalance [35% of boys and 22% of girls (age = 6) were obese at baseline in 2013] may be representative of the obesity distribution among preschool children. The patterns of transitions among BMI categories observed in our study are consistent with those reported in previous studies8,16 that also found that nearly 50% of participants had been overweight and 75% had been above the 70th percentile for body-mass index at baseline. Personalized interventions in high-risk primary school children may effectively reduce the incidence of obesity during puberty and adulthood, and some cohort studies on adolescent obesity have also confirmed this view.17,18,19 Preventive and proactive interventions would likely be highly cost-effective.
To our knowledge, this is the first model-based longitudinal study in China to quantify the predictive mechanism linking the predictors to obesity incidence 5 years later, and baseline height appears to be a significant predictor. In the study, we used data collected at a 5-year interval and assessed whether participants were obese at the time of observation. Our study benefits from efficient statistical models and algorithms and 70% students are correctly predicted [higher than another study20 (55–60%)]. The predicted obesity rate in 2023 indicates that the childhood obesity epidemic may worsen and require prompt prevention. Obesity rates among older boys and girls, as well as rural students, were predicted to be higher in 2023 than 2018. We expect that obesity prevention efforts for younger children and children in rural areas may be effective for these children who are most likely to become obese during childhood and adolescence.
However, our study is not without limitations. The Chinese national standard only applies to children in China. The criteria for determining overweight and obesity may differ from those of the WHO; thus, the direct application of the results of this study in other countries may result in bias. Our study followed-up the cohort only after 5 years and thus lacked information before elementary school enrollment and after high school graduation. This model is only valid for primary school students. The established predictive model using survey data from 2013 and 2018 may be subject to modifications in predictions for different years (e.g., 2023) due to the temporary evolution of the model parameters and other unmeasured confounding factors. We make the independence assumption between individual students in our study simply because no clustering effects (e.g., among different schools) or spatial correlations (e.g., among different locations) can be conceived and incorporating these factors will take time in our future study. A small proportion of students are missing due to issues irrelevant to our study and we do not involve missing mechanism into our modeling for the time being. However, the procedures we propose and the results we obtained are valuable for studying trends in the prevalence of childhood obesity and proposing interventions in Shandong Province and even other parts of China.
Our study provides support for the strong prospective association of baseline BMI and height with future BMI category. Other studies have shown that children with healthy behavioral habits have lower BMI at follow-up and a lower risk of overweight and obesity.21 Therefore, our future research will investigate the factors that influence BMI and determine the relevant factors for weight gain as the focus of intervention. Furthermore, long-term longitudinal studies are warranted to monitor trends in BMI changes and provide more data to validate the predictive model. Finally, this study can provide more epidemiological information for improving childhood and adolescent obesity surveillance and insights into the nature of the obesity epidemic; however, we could not completely rule out residual confounding factors due to unmeasured potential confounders.
Data availability
The data used during the current study are not publicly available but are available from the corresponding author upon reasonable request.
References
Lobstein, T. et al. Child and adolescent obesity: part of a bigger picture. Lancet 385, 2510–2520 (2015).
Ng, M. et al. Global, regional, and national prevalence of overweight and obesity in children and adults during 1980–2013: a systematic analysis for the global burden of disease study 2013. Lancet 384, 766–781 (2014).
Gordon-Larsen, P., Wang, H. & Popkin, B. M. Overweight dynamics in Chinese children and adults. Obes. Rev. 15, 37–48 (2014).
Ma, G. S. Report on Childhood Obesity in China (People’s Medical Publishing House, Beijing, 2017).
Cunningham, S. A., Datar, A., Narayan, K. M. V. & Kramer, M. R. Entrenched obesity in childhood: findings from a national cohort study. Ann. Epidemiol. 27, 435–441 (2017).
Luttikhuis, O. H. et al. Interventions for treating obesity in children. Cochrane Syst. Rev. 3, CD001872. https://doi.org/10.1002/14651858.CD001872.pub3 (2019).
Singh, A. S., Mulder, C., Twisk, J. W., Van Mechelen, W. & Chinapaw, M. J. M. Tracking of childhood overweight into adulthood: a systematic review of the literature. Obes. Rev. 9, 474–488 (2008).
Cunningham, S. A., Kramer, M. R. & Narayan, K. M. V. Incidence of childhood obesity in the United States. N. Engl. J. Med. 370, 403–411 (2014).
Screening for overweight and obesity among school-age children and adolescents. National Health and Family Planning Commission of the People's Republic of China (WS/T586-2018).
China National Standardization Administration. Comprehensive evaluation of children and adolescents development. National Health and Family Planning Commission of the People's Republic of China (GB/T31178-2014).
Cheung, P. C., Cunningham, S. A., Naryan, K. M. V. & Kramer, M. R. Childhood obesity incidence in the United States: a systematic review. Childh. Obes. 12, 1–11 (2016).
Kamath, C. C. et al. Clinical review: behavioral interventions to prevent childhood obesity: a systematic review and meta analyses of randomized trials. J. Clin. Endocrinol. Metab. 93, 4606–4615 (2008).
Hernandez, R. G., Marcell, A. V., Garcia, J., Amankwah, E. K. & Cheng, T. L. Predictors of favorable growth patterns during the obesity epidemic among US school children. Clin. Pediatr. 54, 458–468 (2015).
Franzese, A. et al. Onset of obesity in children through the recall of parents: relationship to parental obesity and life events. J. Pediatr. Endocrinol. Metab. 11, 63–67 (1998).
Gordon, L. P., Adair, L. S., Nelson, M. C. & Popkin, B. M. Five-year obesity incidence in the transition period between adolescence and adulthood: the National Longitudinal Study of Adolescent Health. Am. J. Clin. Nutr. 80, 569–575 (2004).
Zhang, T. et al. The prevalence of obesity and influence of early life and behavioral factors on obesity in Chinese children in Guangzhou. BMC Public Health 16, 954. https://doi.org/10.1186/s12889-016-3599-3 (2016).
Sutin, A. R. & Terracciano, A. Body weight misperception in adolescence and incident obesity in young adulthood. Psychol. Sci. 26, 507 (2015).
Liechty, J. M. & Lee, M.-J. Body size estimation and other psychosocial risk factors for obesity onset among US adolescents: findings from a longitudinal population level study. Int. J. Obes. 39, 601–607 (2015).
Shirasawa, T. et al. Association between distorted body image and changes in weight status among normal weight preadolescents in Japan: a population-based cohort study. Arch. Public Health https://doi.org/10.1186/s13690-016-0151-y (2016).
Zhang, S. et al. Comparing data mining methods with logistic regression in childhood obesity prediction. Inf. Syst. Front. 11, 449–460 (2009).
Bel-Serrat, S. et al. Predictors of weight status in school-aged children: a prospective cohort study. Eur. J. Clin. Nutr. 73(1299), 1306 (2019).
Acknowledgements
We are very grateful to three anonymous reviewers whose insightful comments have substantially improved our work and knowledge in the related fields. Surveys on students' physical examination are conducted under the auspices of the department of education in Shandong Province, China. We acknowledge support from all of the study participants, the staff involved in the student health checkups and the staff responsible for data collection.
Author information
Authors and Affiliations
Contributions
Y.S. and Y.X. developed the study design and acquired the data. J.L. and X.Z. developed the statistical model and the fitting algorithm, J.L. and Z.W. contributed to the discussion. J.B., X.P. and Q.S. performed the data analysis. Z.Z. modified the equations and adjusted the prediction model. Y.S., Y.X. and J.X. drafted the manuscript. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the articleΓÇÖs Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the articleΓÇÖs Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Sun, Y., Xing, Y., Liu, J. et al. Five-year change in body mass index category of childhood and the establishment of an obesity prediction model. Sci Rep 10, 10309 (2020). https://doi.org/10.1038/s41598-020-67366-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-020-67366-y
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
