
Abstract
Syntax is a species-specific component of human language combining a finite set of words in a potentially infinite number of sentences. Since words are by definition expressed by sound, factoring out syntactic information is normally impossible. Here, we circumvented this problem in a novel way by designing phrases with exactly the same acoustic content but different syntactic structures depending on the other words they occur with. In particular, we used phrases merging an article with a noun yielding a Noun Phrase (NP) or a clitic with a verb yielding a Verb Phrase (VP). We performed stereo-electroencephalographic (SEEG) recordings in epileptic patients. We measured a different electrophysiological correlates of verb phrases vs. noun phrases in multiple cortical areas in both hemispheres, including language areas and their homologous in the non-dominant hemisphere. The high gamma band activity (150-300 Hz frequency), which plays a crucial role in inter-regional cortical communications, showed a significant difference during the presentation of the homophonous phrases, depending on whether the phrase was a verb phrase or a noun phrase. Our findings contribute to the ultimate goal of a complete neural decoding of linguistic structures from the brain.
Similar content being viewed by others
Introduction
Human language is a complex system evolved to store, elaborate and communicate information among individuals. Traditionally, it is analyzed as constituted by three major domains: the physical support which is necessary for communication (the acoustic level), the archive of words isolating concepts and logical operators (the lexicon) and a set of rules combining words into larger units (syntax). Meaning is computed by interpreting syntactic structures but it is not strictly necessary to generate well-formed linguistics expressions, given the possibility to construe meaningless structures such as this triangle is a circle1,2. The role of syntax in this complex system is crucial for at least three distinct empirical and theoretical reasons: first, syntax can generate new meaning by permuting the same set of words (so for example, Abel killed Cain is different from Cain killed Abel); second, there is no upper limit to the number of words that can enter the syntactic composition: syntax can potentially generate an infinite set of structures; third, it appears to be the real species-specific boundary distinguishing human language from that of all other animals3. Unfortunately, given this integrated and complex design characterizing language, isolating electrophysiological information solely related to syntax seems to be impossible by definition, since sound is inevitably intertwined with syntactic information4,5 even during inner speech6: in fact, sound representation is already associated to the words in the lexicon before entering the syntactic computation. The current research has provided three major advancements in the comprehension of syntax: a preliminary distinction between single words in isolation, basically nouns and verbs7; the demonstration that the severely restricted formal properties of syntax “are not arbitrary and culturally conventions” – to put it in Lenneberg’s seminal perspective but rather the expression of the morphological and functional architecture of the brain8,9,10; third, the combination of an increasing number of words in sequences correlates with an increasing electrophysiological activity11. However, the origin of electrophysiological correlates of the syntactic operation as related to specific and different types of words is yet unclear. We still lack the distinction of basic syntactic structures, such as what correlates with merging of an article with a noun yielding a Noun Phrase (NP) or a verb yielding a Verb Phrase (VP).
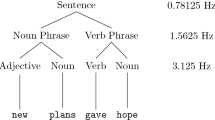
Here, we addressed this issue by designing a novel protocol to circumvent this problem and measure the specific electrophysiological correlates of two basic and core syntactic structures factoring out sound representation. As recording technique we used Invasive intracranial electroencephalography (SEEG) which offers a unique opportunity to observe human brain activity with an unparalleled combination of spatial and temporal resolution. In fact, SEEG allows artifact-free recordings, having an internal (white matter) reference. Furthermore, contrary to other techniques such as electroencephalography (EEG), magnetoencephalography (MEG), and even electrocorticography (ECoG), SEEG data do not require source localization as each contact is already perfectly source-localized and surgically mapped. Finally, SEEG has higher bandwidth which allows to explore data also in the high gamma range. High gamma activity (>100 Hz) is receiving a growing interest to understand and characterize inter-regional cortical communications12. This band is one of the most used indices of cortical activity associated to cognitive function, and has been shown to be correlated with the neuronal spiking rate and to the hemodynamic BOLD response measured with functional magnetic resonance in both animal models13 and in human cortex14,15. Many works from Lachaux’s research group underline the importance of gamma-band activity modulations as a robust correlate of local neural activation which would be masked by the time-domain averaging of the data typically used to compute event-related potentials (ERPs)16. A large body of studies have indicated its value in tracking cortical activity during language perception and production17, supporting its use as a safer alternative to cortical stimulation for the presurgical mapping of cortical language areas18. For example, Gamma-band energy increase above 50 Hz was, specific to Broca pars triangularis, Broca pars opercularis and Ventral Lateral Prefrontal was differently modulated in a word recognition experiment according to whether patients performed a Semantic or Phonological task based on visually presented written words or pseudo-words19. We hypothesize that Broca’s areas and superior temporal gyrus high gamma activity can be related to the syntactic processing yielding a Noun Phrase (NP) or yielding a Verb Phrase (VP). The stimuli were pairs of different sentences containing strings of two words with exactly the same acoustic information but completely different syntax (homophonous strings). More specifically, each pair contained an NP, resulting from syntactic combination of two lexical elements (a definite article and a noun), and a VP, resulting from the syntactic combination of two different types of lexical elements (a verb and a pronominal complement): the NP and the VP were pronounced in exactly the same way. In addition, each VP included a further crucial difference: the object of the verb, realized as a pronoun, was moved from its canonical position on the right of the verb to the left of the verb, a syntactic operation called “cliticization”. This novel strategy was made possible by relying on Italian language. For example, the sequence [laˈpɔrta], could be interpreted either as a noun phrase (“the door”) or a verb phrase (“brings her”; lit.: her brings) depending on the syntactic context within the sentence where they were pronounced (Fig. 1). As for the acoustic information concerning the homophonous phrases, it must be noticed that for each pair of sentences containing the same homophonous phrase, either phrase was deleted and substituted with a copy of the other one: this strategy was exploited to avoid the possibility that the structure of the two phrases could be distinguished by subtle intonational or prosodic clues: practically, the relevant part of the stimuli constituting the homophonous phrase was physically exactly the same. Although these results were based on a peculiar property of Italian language, our results are generalizable to other languages because the basic distinction of nouns vs. verbs is universally attested across-languages20,43. As for other variables constituting the homophonous phrases, words were balanced for major semantic features (such as abstract vs. concrete) and length (number of syllables).

Example of auditory l stimuli presented to the subject. Languages may contain homophonous sequences. i.e. strings of words with the same sound and different syntactic structure. For example, in Italian, the very same sequence of phonems [laˈpɔrta] may have two completely different meanings and two different syntactic structures: (i) LA (the) PORTA (door) as in PULISCE LA PORTA CON L’ACQUA (s/he cleans the door with water). (ii) LA (her) PORTA (brings) as in DOMANI LA PORTA A CASA (tomorrow s/he brings her home). In the first sequence [laˈpɔrta] (written here as: la porta) is a Noun Phrase: the article la (the) precedes the noun porta (door). In the second sequence, instead, the very same sequence is a Verb Phrase: the object clitic pronoun la (her) precedes the verb porta (brings) which governs it. The difference is not only reflected in the distinct lexical classes, there is also a major syntactic difference: in the case of the noun phrase the element preceding the noun, namely the article, is base generated in that position; in the case of the verb phrase, instead, the element preceding the verb in the acoustic stimulus, namely the clitic pronoun, is based generated on the right of the verb occupying the canonical position of complements and then displaced to a preverbal position. This fundamental syntactic difference is represented in the syntactic trees in the picture: “t” indicates the position where the pronoun is base generated in the VP. Notably, to exclude phonological or prosodical factors which may distinguish the two types of phrases, in our experiment the exact copy of the pronunciation of one phrase replaced the other in either sentence in the acoustic stimuli. In other words, subjects heard the very same acoustic stimulus for each homophonous phrase.
Results
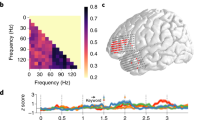
We investigated the electrophysiological correlates of exposure to these NPs vs. VPs with intracranial electrodes for stereo-electro-encephalography (SEEG) monitoring (see Ext. Data Fig. 1 with the visualization information for one subject for the assessment of anatomical electrical sources). The contacts that exhibited a significantly different response according to whether the homophonous words belonged to VPs or NPs were considered “responsive contacts” (RC). An example of RC is shown in Fig. 2.

Surprisal analysis. Scatter plot of ITWAC surprisal values related to the Art/Cl (x axis) and Verb/Noun (y axis) position in the phrase. The gray line optimally separates (Support Vector Machine analysis) the Verb and Noun surprisal values with a Score of 86%. The bars represent the average and standard deviations of the surprisal values distribution for VPs (orange) and NPs (blue), tested for significance (ANOVA, 1 way). ***=p < 0.001.
The event related spectral perturbation (ERSP) analysis indicated that 242 (16.2%) of the leads exploring grey matter exhibited a significant high gamma (150 Hz – 300 Hz) power increase during the presentation of the VP with respect to both the baseline and the other words (113 DH, 129 NDH). The percentage of RCs in the DH was significantly higher compared to that in the NDH (19.3% vs. 15.1%) (p = 0.044, Fisher’s exact test). We found higher ERSP for VPs with respect to NPs in 74% of RCs (6 subjects).
The majority of RCs was found in the temporal lobe (133; 54.9%; 62DH; 71NDH), in particular in the middle temporal gyrus (55; 22.7%; 29 DH; 26 NDH) and in the superior temporal gyrus (9; 3.7%; 7 DH; 2 NDH). Out of 44 RCs (18.2%; 10 DH; 34 NDH) found in the frontal lobe, the majority were in the inferior frontal gyrus (13; 29.5%; 3 DH; 10 NDH) and in the frontal part of cingulate gyrus (20; 45,5%; 2 DH; 18 NDH). A detailed description of the localization of RCs for each patient can be found in Ext. Data Table 1. Figure 3 shows all RCs positioned and template-matched after warping each patient’s MRI scan21.

Main Responsive Contacts. Responsive contacts in the dominant (left panel) and non-dominant (right panel) hemispheres, merged across subjects over an average MRI template group level. Responsive contacts are represented in red, black otherwise.
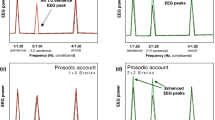
To validate the setup processing pipeline we analyzed the ERPImage and event related spectral perturbation (ERSP) of contacts responsive to the auditory stimuli (i.e., Heschl) and highlighted clear auditory event-related potentials (ERPs) and power increase time locked to the stimuli presentations (Ext. Data Fig. 2). Also, we retained in the RCs pools only the contacts where the different response between VPs and NPs was specific to the time region of interest (tROI, time interval that spans from the beginning of Art/Cl to the end of Noun/Verb). Incidentally, the high gamma frequency interval (150 – 300 Hz) showed the greatest tROI specificity in RCs. As an example, a RC (B13) is compared to a Heschl contact in Ext. Data Fig. 3. Only B13 shows (i) significantly higher power in the VP high gamma [150 - 300] time ROI (S) with respect to NP (Panel C, 4th row, bottom right) and (ii) a significant power difference between VP and NP high gamma in the time ROI (ΔS) with respect to other time periods in the phrase, e.g., from the beginning of the phrase to Art/Cl, ΔA1 (Panel C, 4th row, bottom left).
The two sentence types were also differentiated by the level of “surprisal”, an information-theoretic concept reflecting the expectedness of each word given its preceding context, which is defined as the negative log probability of a certain word in a sentence, given the words that precede it in that sentence22. The analysis shows that whereas there is no significant surprisal difference for the Verb/Noun position in the phrase, the values related to the article/clitic position were significantly different (Fig. 4). In fact, the more complex syntactic structure, i.e. the VP involving movement of the object from the right to the left position of the verb, resulted in a higher surprisal level when the same auditory input was interpreted as a clitic rather than an article, as indicated by classical statistics and by decoding in the feature space with a Support Vector Machine (SVM) analysis. Ext. Data Table 2 reports the number of valid cases, the percentage of missing, the mean and the standard deviation relative to the surprisal value, separately for the two experimental conditions. As reported in Ext. Data Table 3, 84% (n = 26) of the sentences with low surprisal were NPs and 84% (n = 26) of the sentences with high surprisal were VPs.

Example of event-related spectral perturbation and decoding for a responsive contact (channel). The first row represents the Event-Related Spectral Perturbation (ERSP) for VPs (left) and NPs (right) respectively. The four vertical lines respectively represent the beginning of the phrase, the beginning of the Art/Cl (homophonous phrase), the beginning of the first word after Art/Cl (i.e., Verb/Noun), the beginning of the word after that. The high gamma time Region of Interest (tROI) is highlighted by a superimposed square over the ERSP plots. The second row shows the baseline-normalized power in the [150–300] Hz spectrum interval. The four vertical bars have the same meaning as in the ERSP plots. The third row shows on the left a comparison between the VP tROI (orange) and NP tROI (blue) high gamma power. Similarly, the scatter plot on the right represents the tROI normalized power (y axis) and surprisal (x axis). The gray line optimally separates (Support Vector Machine analysis) the Verb and Noun classes in the surprisal/power feature space with a Score of 83%.
Discussion
In this manuscript, we defined and exploited a novel protocol to better understand the neural correlates of syntactic structure. In the sEEG signals we found higher ERSP for VPs with respect to NPs in 74% of RCs (6 subjects). This was true in particular for the verb/noun segment (see Fig. 2, middle panel, after the dotted line) but it was also true - even if with less evidence - for the article/clitic segment preceding the verb/noun one (see Fig. 2, middle panel, before the dotted line): this strongly supports the conclusion that the observed difference cannot be reduced to the morphological properties of nouns vs. verbs but that it rather pertains to the syntactic operations yielding a VP and a NP.
The different activity observed in our experiment reflects the syntactic structure of the stimuli. In particular, given that the physical stimuli where the same and that we did not observe the typical correlates distinguishing distinct lexical categories, such as noun and verbs, the higher activity of VPs can reasonably be correlated with the surviving difference, namely syntactic structure involving the operation of displacement of the object clitic from the right to the left side of the verb. In the present study, a significant increase of high gamma event related spectral perturbation23 (ERSP) was a specific index of the exposure to the syntactic contrast between clitic-verb phrases as compared to homophonous article-noun phrases.
This specific impact of syntactic structure on high gamma activity was not limited to the Broca’s area and left posterior temporo-parietal cortex, traditionally associated with syntactic processing on the basis of lesion effects and functional magnetic resonance evidence24,25. These results suggest that, while syntactic impairment is known to be caused by focal lesions affecting nodal structures in a dedicated network, syntactic processing must involve a much more integrated pattern of brain activity than expected26,27,28.
Our results concerning syntactic structures converge with parsing as shown by the surprisal analysis. Syntactic surprisal is related to the expectedness of a given word’s syntactic category given its preceding context29 and is associated with widespread bilateral activity indexed by the BOLD signal30. In fact, the position of the object to the left of the verb is reflected in the higher surprisal, showing that this measure is sensitive to syntactic structure, although some bearing of surprisal or other phenomena on the results cannot be excluded. The position of the clitic object to the left of the verb as opposed to the canonical position on the right is indeed reflected in the higher surprisal, showing that this measure is also sensitive to syntactic structure, but surprisal alone cannot account for structural differentiations. Surprisal, in fact, is based on the frequency of the occurrence within a Corpus and regards natural language organization as modelled by Markovian chains. These models, however, have been proved to be unable to capture syntactic dependencies: other models involving hierarchical relations such as those expressed in phrases must be exploited to capture the complexity of syntax in natural languages31. As shown in Fig. 2, VPs and NPs surprisal values could be separated by means of Support Vector Machine Analysis with a score of 86%; on the other hand, while surprisal differences could be seen along the x axis (Art./Cl.), no significant difference in surprisal could be seen along the y axis (Verb/Noun), indicating that surprisal alone cannot explain the whole phenomenon observed. Moreover, it is indeed possible that the higher ratio of RCs in the gamma frequency in temporal cortex reflects a more demanding semantic processing triggered by unexpected VP structures, since the middle/posterior temporal cortex is typically involved in the semantic/interpretative re-analysis as required by the entire linguistic processing.
All in all, the results found in confronting homophonous VPs and NPs allow us to factor out sound from the electrophysiological stimulus and consequently highlight a specific syntactic information distinguishing these universal linguistic structures. Notice that this separation could by no means be obtained by analyzing the electrophysiological correlates of silent linguistic expressions produced during inner speech since it has been proved that acoustic information is also represented in higher language areas even when words are simply thought6. Further works are needed to definitely factor out possible contributions of other factors (namely predictability of syntactic structure and surprisal) to the results. However, this first step provided here opens up to a deeper understanding of the structure and nature of human language and contributes to the ultimate far reaching goal of a complete neural decoding of linguistic structures from the brain32.
Materials and Methods
Stimuli
A novel set of stimuli which capitalizes on three special characteristics of Italian has been provided. First, some definite articles (such as [la] written as la; “the fem.sing.”) are pronounced exactly like some object clitic pronouns (such as [la] written as la; “her fem.sing.”): both items are monosyllabic morphemes inflected by gender and number. Second, the syntax of articles and clitic pronouns is very different: like in English, articles precede nouns whereas complements follow verbs but, crucially, object clitics are obligatorily displaced the left of the verb with finite tenses. Third, the Italian lexicon contains several homophonous pairs of verb and nouns, such as [ˈpɔrta] (written porta), which can either mean “door” or “brings”. Combining these facts together, a set of pairs of words such as [la ˈpɔrta] (written as la porta) has been construed which could be interpreted either as noun phrases (“the door”) or verb phrases (“brings it”) depending on the syntactic context (homophonous phrases) they are inserted in. Moreover, in order to be sure that no phonological or prosodical factors distinguish the two types of phrases, the exact copy of the pronunciation of one phrase replaced the other in either sentence in the acoustic stimuli. No other semantic or lexical distinction differentiated the two types of phrases which were balanced for major semantic features (such as abstract vs. concrete).
The acoustic stimuli were recorded using a Sennheiser Microphone MH40P48, Sound Card: Motu Ultralight Mk3, Connection: Firewire 400, Computer: Apple OSX 10.5.8. The stimuli were edited using Audiodesk 3.02 and mastered using Peak Pro7. Files were generated in 16 bit, 44.1 kHz (Sampling Frequency); intensity was normalized to 0 Db and rendered in.wav format. All sentences were read by the same person: Italian native speaker, male, 53 years old.
Surprisal value computation
The value of surprisal (S) generally indicates how unexpected a given word is on the bases of the preceding words33. In order to calculate the surprisal value associated to a word of the sentence, it is possible to use the algorithms developed by Roark34 with a model of Probabilistic Context Free Grammar (PCFG): \(S=-\,log[\frac{P({w}_{i})}{P({w}_{1,2,\ldots ,i-1})}],\) where \(P({w}_{i})\) corresponds to the probability of occurrence of the target word/words and .. to the probability of occurrence of the preceding words. Similarly, it is possible also to calculate the surprisal of more than one word (e.g., a bigram). Here we computed the surprisal as the logarithm of the ratio between the probability of occurrence of the bigram containing the target word (i.e., \(Bigram\_{w}_{i}\)) and the probability of occurrence of the word immediately preceding the target word (i.e., \(Unigram\_{w}_{i-1}\)). The formula is as follows: \(S{w}_{i}=-\,log[\frac{P(Bigra{m}_{{w}_{i}})}{P(Unigra{m}_{{w}_{i-1}})}]\). For instance, in the sentence pulisce la porta con l’acqua (“s/he cleans the door with water”) the value of surprisal associated with the Italian word la (the definite article preceding the noun) is: \(S(la)=-\,\log \,[\frac{P\,(pulisce+la)}{P(pulisce)}]\)
In order to obtain the frequency of unigrams (i.e., single words) and bigrams (i.e., pairs of words), we initially considered the online databases “La Repubblica”, a corpus derived from Italian newspaper texts written between 1985 and 2000 and containing about 380 million words and of the Italian WEB Corpus (ITWAC35, obtained from Italian texts on the Internet, composed by about 1.5 billion words. For each unigram and bigram, we reported both the occurrence of the form, i.e. word’s frequency considering the specific category (e.g. article vs pronoun), and of the lemma, i.e. word’s frequency without taking into account the differentiation into categories. We then calculated the value of surprisal (both derived from the occurrence of the form and the lemma, for both databases) associated with all the elements of the sentences belonging to the two experimental conditions (i.e., clitic + verb and article + noun).
Of note, sentences n.4 and n.63 were excluded from the analyses since they were not organized with the same structure as the other stimuli, i.e. article + noun or clitic + verb. Sentences n.51 and n.52 were excluded because both belonged to clitic + verb condition, namely containing the same target word. The data discussed were therefore related to 31 verb-phrases and 31 noun-phrases.
Statistical analyses were performed both on the form and on the lemma for both databases. Due to the presence of missing values (see the Ext. Data Table 2 for the percentages of misses, divided by condition) we considered only the analyses based on ITWAC lemma values.
We compared the value of surprisal associated to the two target elements of the two types of experimental phrases by means of paired samples t-test. Specifically, we compared the value of surprisal associated with the article with that associated with the pronoun and the value of surprisal associated with the noun with that associated with the verb. Since sentences n.4 and n.63 were excluded (see previous paragraphs), the corresponding sentences, respectively, noun-phrase n.3 and verb-phrase n.64 were considered as the two paired elements in the analysis.
The analyses showed significant differences between the value of surprisal of the article compared to that of the pronoun (t(30)= −6.794, p < .001), with a higher surprisal value found for pronouns than for articles. No significant differences were found between the value of surprisal associated to nouns and that associated to verbs (t(30)= 1.357, p =.185).
In order to dichotomize the surprisal variable, we divided the distribution of the surprisal values of articles and clitics on the basis of the median (M = 1.9097) obtained from the occurrence of the lemma in the ITWAC database. The values were divided, respectively, into high and low surprisal.
Patients
A total of 23 patients were recruited for the present study among those who underwent on surgical implantation of multi leads intracerebral electrodes for refractory epilepsy in the “Claudio Munari” Epilepsy Surgery Center of Milan in Italy36,37. Only patients with negative MRI and with no neurological and/or neuropsychological deficits were included. Based on anatomo–electro–clinical correlations, each patient-specific strategy of implantation was defined purely on clinical needs, in order to define the 3D shape of the epileptogenic zone (EZ).
A total of 23 patients undergoing surgical implantation of electrodes for the treatment of refractory epilepsy38 completed all experimental sessions. Only patients without anatomical alterations, as evident on MR, were included. No seizure occurred, no alterations in the sleep/wake cycle were observed, and no additional pharmacological treatments were applied during the 24 h before the experimental recording. Neurological examination was unremarkable in all cases; in particular, no neuropsychological and language deficits were found in any patient. In all patients, language dominance was assessed with high frequency stimulation (50 Hz, 3 mA, 5 sec) during SEEG monitoring. Two patients also underwent a fMRI study during a language task before the electrodes implantation.
Eight patients were excluded after analysis as they exhibited pathological EEG findings. Five patients were also excluded because no explored recording contact showed a task-related significant activation. Demographic data are shown in Ext Data Table 4. In the remaining 10 subjects, a total of 164 electrodes were implanted (median 16.5 range 13-19), corresponding to 2186 recording contacts (median 210; range 168-272). The number of contacts in the grey matter was 1439 (65.8%); 586 recording contacts in the language dominant hemisphere (DH). The DH was explored in 5 subjects (median electrodes 16, range 3-18; median contacts 210, range 25-225). The non-dominant hemisphere (NDH) was explored in 6 subjects (median electrodes 15, range 14-19; median contacts 208, range 182-272). SEEG exploration involved both hemispheres with a preference for the non-dominant side in 1 patient.
The temporal lobe was the most explored brain region, with 26 electrodes in DH and 42 electrodes in NDH, followed by frontal lobe (22 electrodes in DH and 21 in NDH).
The central lobe was implanted with a total of 22 electrodes (9 in DH). The Parieto-Occipital region was studied with a total of 9 electrodes in DH and 21 in NDH.
The present study received the approval of the Ethics Committee of ASST Grande Ospedale Metropolitano Niguarda (ID 939-2.12.2013) and informed consent was obtained. All research was performed in accordance with relevant guidelines/regulations and informed consent was obtained from all participants.
Surgical procedure and recording equipment
All trajectories of patient-related implantation strategy are planned on 3D multimodal imaging and the electrodes are stereotactically implanted with robotic assistance. The whole workflow was detailed elsewhere39. SEEG electrodes are probes with a diameter of 0.8 mm, comprising 5 to 18 2 mm long leads, 1.5 mm apart. A post-implantation Cone-Beam-CT, obtained with the O-arm scanner (Medtronic, Minneapolis, Minnesota), is subsequently registered to pre-implantation 3D T1W MR, in order to assess accurately the position of every recording lead. Finally, a multimodal scene is assembled with 3D Slicer40, aimed at providing the epileptologist with interactive images for the best assessment of anatomical electrical sources (Ext. Data Fig. 1).
During the experiment the SEEG was continuously sampled at 1000 Hz (patients 1-12) and 2000Hz (patients 12-23) by means of a 192 channels SEEG device (EEG-1200 Neurofax, Nihon Kohden). In each patient, all leads from all electrodes were referenced to two contiguous leads in the white matter, in which electrical stimulations did not produce any subjective or objective manifestation (neutral reference).
Recording protocol
Each subject rested in a comfortable armchair. Constant feedback was sought from the patient to ensure the overall comfort of the setup for the whole duration experiment. Stimuli were delivered in the auditory modality (see also Fig. 1) using Presentation from Neurobehavioral Systems software. Phrases were delivered via audio amplifiers at a comfortable volume for the subject (minimum volume for words to be perceived with ease, according to the subject) while gazing at a little cross on a screen (27 inches). A synchronization TTL trigger spike was sent to the SEEG trigger port at the beginning of auditory presentation (sentence). Jitter and delays were tested and verified to be negligible (less than 1 ms). The whole experiment lasted around 30 minutes to maximize engagement. At the end of each task, subjects were asked to answer a few short questions on the content of the stimuli. Indeed, patients were always able to provide correct answers to the questions, thus demonstrating their continuous engagement to the task.
A camera, synchronized to the SEEG recording at source, was used to control for excessive blinking, maintenance of fixation with no eye movement, silence and any unexpected behavior from the patients.
Control experiment
As a further control for the analysis, the first three subjects underwent an extra auditory task. The modalities remained the same, however the sounds were substituted with beeps (auditory presentation) not carrying any meaning at all. We performed the same analyses outlined in the paper and verified that none of the results we reported (e.g., significant VP/NP high gamma power) could be ascribed to plain auditory processing.
Data analysis
A band-pass filter (0.015–500 Hz) applied at hardware level prevented any aliasing effect from altering SEEG data. Recordings were visually inspected by clinicians and scientists in order to ensure the absence of artifacts or any pathological interictal activity. Pathological channels were discarded. Further analyses were carried out using custom routines based on Matlab, Python and the EEGlab toolbox41. Data were annotated with the events triggered by the beginning of each stimulus. Events were time locked to the beginning of each word (initial syllable of the word for auditory presentation).
Epochs were extracted in the intervals [-1.5 4.5] s, time-locked to the initial presentation (i.e., beginning of the phrase). The length of the epoch was selected so as to always include the complete stimulus presentation (trial). Epochs with prominent artifacts (e.g. spikes) over significant channels were rejected. To determine significant responsive sites, analyses were performed both in the time and frequency domains. Epochs were then sorted into two classes based on the surprisal value (low or high).
Analyses in the time domain
In the time domain, single-trial data epochs were color-coded by amplitude to form a ERPImage 2D view41, without any smoothing over trials (Ext. data Fig. 2, panel C). The ERPImage allowed to assess the presence of Event-Related Potentials (ERPs) and their significance over time (e.g., to verify the presence of any habituation phenomena) with respect to the baseline. The ERPImage analysis was performed both (i) after time-warping the trials so as to temporally align the other events and (ii) after aligning the trials to the beginning of the beginning of Art/Cl position in the phrase and annotating the relative position of the other events (i.e., beginning of the sentence, beginning of the first and second words after Art/Cl).
Analyses in the frequency domain
Time-frequency transforms of each trial were normalized to the baseline (divisive baseline, ranging from -1500ms to -5ms time-locked to the beginning of the sentence), time-warped to the beginning of the sentence, beginning of Art/Cl, beginning of the first and second word after, then they were averaged across trials to obtain the event-related spectral perturbations (ERSPs) a generalization of ERD/ERS analyses to a wider range of frequencies42 (Ext. Data Fig. 2, Panel B), i.e., from theta (1-4 Hz) to high gamma (150–300 Hz). A bootstrap distribution over the trials baseline was used to determine significance (p < 0.05) of the time-frequency voxels. We considered the average ERSP across the Gamma ([50 – 150] Hz) and High Gamma ([150–300 Hz]) frequency bands to obtain band-specific ERSP (bERSP) and compared it over time between low and high suprisal (Ext. Data Fig. 2, Panel A). These bands were selected after a preliminary analysis of data related to Heschl gyrus in real and control experiments, which highlighted the presence of significant bERSP up to 300 Hz (see Ext. Data Fig. 2 panel B). The preliminary analysis also showed that several contacts reported a significant time-specific differentiation in high gamma ([150–300] Hz) bERSP between VPs and NPs and we used that frequency band to highlight responsive contacts (see next paragraph).
Identification of responsive contacts
Each contact (i.e., channel) for each subject underwent a series of screenings to determine its significance. A contact was deemed responsive if either low or high surprisal high gamma bERSP had significant amplitude specifically in the tROI (interval that spans from the beginning of Art/Cl to the end of Noun/Verb), for a significant time span. The amplitude was deemed significant if and only if greater than 95% of the distribution of amplitudes across frequencies for a significant time span. A time span was deemed significant if longer than the 95% of significant intervals in the baseline. The rationale of this test was to exclude those contacts that did not reach significance in the time ROI and ensure specificity in frequency (i.e., statistically different low and high surprisal high gamma time courses - only one of them being over threshold, or both being over threshold but statistically different – p < 0.05), and time, (i.e., no significance when performing the same analysis at other time intervals such as from the second word after Art/Cl to the end of the sentence or from the beginning of the sentence to the beginning of the Art/Cl). Significant contacts were then ranked from high to low \(sig\) values according to the formula \(sig=a\ast t/{\sum }^{}{a}_{i}{t}_{i}\) where \(a\) is the maximum amplitude over the time ROI, \(t\) is the length of the interval within the time ROI the amplitude is significant, \({a}_{i}\) and \({t}_{i}\) respectively the maximum amplitude and length of the interval at the other positions (i) in the phrase (i.e., outside the tROI). The rationale of this formula was to determine the contacts that highlighted the maximum time-specific significant difference.
An inspection of all the contacts was also visually performed by expert clinicians and results were compared to the data-driven analysis in a double-blind fashion. The concordance was 84%. This analysis provided both validation to the data-driven analysis and also provided an extra control that selected responsive contacts (i) were not located in the white matter, (ii) were not located in affected regions of the brain, (iii) exhibited similar behaviour (e.g., high gamma time course waveform shape) if anatomically close and referring to the same brain region.
Decoding
Decoding of the phrase type (noun and verb phrases) was first performed based on the surprisal relative to the Art/Cl and Verb/Noun parts of the phrases (Fig. 4). After testing for normality (Kolmogorov-Smirnov), VP and NP surprisal values were also statistically compared (ANOVA, 1-Way). Decoding of the two classes was also performed on the feature space formed, for each trial, by the Art/Cl surprisal value and the power amplitude in the time ROI (Fig. 2). In both cases a Support Vector Machine (SVM) algorithm with leave-one-out cross validation (LOOCV) was implemented to ensure the generalizability of the model.
References
Akmajian, A., Demers, R. A., Farmer, A. K. & Harnish, R. M. An Introduction to Language and Communication, 2001 (1995).
Kandel, E. R. et al. Principles of neural science. Vol. 4 (McGraw-hill New York, 2000).
Friederici, A. D., Chomsky, N., Berwick, R. C., Moro, A. & Bolhuis, J. J. Language, mind and brain. Nature Human Behaviour 1, 713 (2017).
Ding, N., Melloni, L., Zhang, H., Tian, X. & Poeppel, D. Cortical tracking of hierarchical linguistic structures in connected speech. Nature neuroscience 19, 158 (2016).
Kayne, R. S. What is Suppletive Allomorphy? On went and on* goed in English. lingbuzz/003241 (2016).
Magrassi, L., Aromataris, G., Cabrini, A., Annovazzi-Lodi, V. & Moro, A. Sound representation in higher language areas during language generation. Proceedings of the National Academy of Sciences 112, 1868–1873 (2015).
Vigliocco, G., Vinson, D. P., Druks, J., Barber, H. & Cappa, S. F. Nouns and verbs in the brain: a review of behavioural, electrophysiological, neuropsychological and imaging studies. Neuroscience & Biobehavioral Reviews 35, 407–426 (2011).
Lenneberg, E. H. The biological foundations of language. Hospital Practice 2, 59–67 (1967).
Musso, M. et al. Broca’s area and the language instinct. Nature neuroscience 6, 774 (2003).
Rizzi, L. The discovery of language invariance and variation, and its relevance for the cognitive sciences. Behavioral and Brain Sciences 32, 467–468 (2009).
Nelson, M. J. et al. Neurophysiological dynamics of phrase-structure building during sentence processing. Proceedings of the National Academy of Sciences 114, E3669–E3678 (2017).
Buzsáki, G. & Schomburg, E. W. What does gamma coherence tell us about inter-regional neural communication? Nature neuroscience 18, 484 (2015).
Ray, S., Hsiao, S. S., Crone, N. E., Franaszczuk, P. J. & Niebur, E. Effect of stimulus intensity on the spike–local field potential relationship in the secondary somatosensory cortex. Journal of Neuroscience 28, 7334–7343 (2008).
Gaona, C. M. et al. Nonuniform high-gamma (60–500 Hz) power changes dissociate cognitive task and anatomy in human cortex. Journal of Neuroscience 31, 2091–2100 (2011).
Kucewicz, M. T. et al. High frequency oscillations are associated with cognitive processing in human recognition memory. Brain 137, 2231–2244 (2014).
Jerbi, K. et al. Task‐related gamma‐band dynamics from an intracerebral perspective: Review and implications for surface EEG and MEG. Human brain mapping 30, 1758–1771 (2009).
Flinker, A., Piai, V., Knight, R. T., Rueschemeyer, S. & Gaskell, G. Intracranial electrophysiology in language research. Rueschemeyer, S.; Gaskell, G.(ed.), The Oxford handbook of psycholinguistics (2nd ed.), chapter-43 (2018).
Arya, R., Horn, P. S. & Crone, N. E. ECoG high-gamma modulation versus electrical stimulation for presurgical language mapping. Epilepsy & Behavior 79, 26–33 (2018).
Mainy, N. et al. Cortical dynamics of word recognition. Human brain mapping 29, 1215–1230 (2008).
Moro, A. The boundaries of Babel: The brain and the enigma of impossible languages. II edn, (MIT press, 2015).
Avanzini, P. et al. Four-dimensional maps of the human somatosensory system. Proceedings of the National Academy of Sciences, 201601889 (2016).
Hale, J. A probabilistic Earley parser as a psycholinguistic model, In Proceedings of the second meeting of the North American Chapter of the Association for Computational Linguistics on Language technologies. 1-8 (Association for Computational Linguistics), (2001).
Makeig, S., Debener, S., Onton, J. & Delorme, A. Mining event-related brain dynamics. Trends in cognitive sciences 8, 204–210 (2004).
Cappa, S. F. In Perspectives on agrammatism 63–73 (Psychology Press, 2012).
Dronkers, N. F. & Ludy, C. A. In Handbook of neurolinguistics 173–187 (Elsevier, 1998).
Friederici, A. D. The neural basis for human syntax: Broca’s area and beyond. Current opinion in behavioral sciences 21, 88–92 (2018).
Pylkkänen, L. The neural basis of combinatory syntax and semantics. Science 366, 62–66 (2019).
Griffiths, J. D., Marslen-Wilson, W. D., Stamatakis, E. A. & Tyler, L. K. Functional organization of the neural language system: dorsal and ventral pathways are critical for syntax. Cerebral Cortex 23, 139–147 (2013).
Roark, B., Bachrach, A., Cardenas, C. & Pallier, C. In Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing: Volume 1-Volume 1. 324–333 (Association for Computational Linguistics).
Henderson, J. M., Choi, W., Lowder, M. W. & Ferreira, F. Language structure in the brain: A fixation-related fMRI study of syntactic surprisal in reading. Neuroimage 132, 293–300 (2016).
Chomsky, N. (New York: John Wiley and Sons, 1956).
Anumanchipalli, G. K., Chartier, J. & Chang, E. F. Speech synthesis from neural decoding of spoken sentences. Nature 568, 493 (2019).
Armeni, K., Willems, R. M. & Frank, S. L. Probabilistic language models in cognitive neuroscience: Promises and pitfalls. Neuroscience & Biobehavioral Reviews 83, 579–588 (2017).
Roark, B. Probabilistic top-down parsing and language modeling. Computational Linguistics 27, 249–276, https://doi.org/10.1162/089120101750300526 (2001).
Baroni, M. & Kilgarriff, A. In EACL 2006 - 11th Conference of the European Chapter of the Association for Computational Linguistics, Proceedings of the Conference. 87–90.
Munari, C. et al. Stereo‐electroencephalography methodology: advantages and limits. Acta Neurologica Scandinavica 89, 56–67 (1994).
Cossu, M. et al. Stereoelectroencephalography in the presurgical evaluation of focal epilepsy: a retrospective analysis of 215 procedures. Neurosurgery 57, 706–718, https://doi.org/10.1093/neurosurgery/57.4.706 (2005). discussion 706–718.
Cossu, M. et al. Stereoelectroencephalography-guided radiofrequency thermocoagulation in the epileptogenic zone: a retrospective study on 89 cases. Journal of neurosurgery 123, 1358–1367 (2015).
Cardinale, F., Casaceli, G., Raneri, F., Miller, J. & Russo, G. L. Implantation of stereoelectroencephalography electrodes: a systematic review. Journal of Clinical Neurophysiology 33, 490–502 (2016).
Fedorov, A. et al. 3D Slicer as an image computing platform for the Quantitative Imaging Network. Magnetic Resonance Imaging 30, 1323–1341, https://doi.org/10.1016/j.mri.2012.05.001 (2012).
Delorme, A. & Makeig, S. EEGLAB: an open source toolbox for analysis of single-trial EEG dynamics including independent component analysis. Journal of neuroscience methods 134, 9–21, https://doi.org/10.1016/j.jneumeth.2003.10.009 (2004).
Makeig, S. & Onton, J. ERP features and EEG dynamics: an ICA perspective. Oxford Handbook of Event-Related Potential Components. New York, NY: Oxford (2009).
Moro, A. (2016). Impossible languages. MIT Press.
Acknowledgements
We thank Elia Zanin for his help during the preparation of the stimuli and Robert Frank for discussion about the computational aspects of surprisal. This work was partly funded by the Bertarelli Foundation, by the Ministero Istruzione Università e Ricerca (MIUR) DM 610/2017 and by the European Union’s Horizon 2020 research and innovation programme under Marie Skłodowska Curie grant agreement No. 750947 (project BIREHAB).
Author information
Authors and Affiliations
Contributions
A.M. conceived the theoretical linguistic paradigm. F.A., S.C., S.M., A.M. designed the experiment. A.M. construed the auditory stimuli. F.A. developed and integrated the experiment setup for stimuli presentation and synchronized recordings and developed the data processing algorithms. F.A., P.d.O., V.P., I.S. and G.L.R. performed the recordings of the electrophysiological data. F.A., I.S., P.d.O. analysed the data, critically reviewed the results at each analysis step and wrote the results. E.C. and F.C. elaborated the lexical and frequency statistics. F.B. recorded and edited the stimuli. S.M. supervised the processing activities. F.A., S.C., S.M., A.M. wrote the paper. All the other authors provided comments to the manuscript and approved it.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Artoni, F., d’Orio, P., Catricalà, E. et al. High gamma response tracks different syntactic structures in homophonous phrases. Sci Rep 10, 7537 (2020). https://doi.org/10.1038/s41598-020-64375-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-020-64375-9
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
