
Abstract
Herein, we aim to assess mortality risk prediction in peritoneal dialysis patients using machine-learning algorithms for proper prognosis prediction. A total of 1,730 peritoneal dialysis patients in the CRC for ESRD prospective cohort from 2008 to 2014 were enrolled in this study. Classification algorithms were used for prediction of N-year mortality including neural network. The survival hazard ratio was presented by machine-learning algorithms using survival statistics and was compared to conventional algorithms. A survival-tree algorithm presented the most accurate prediction model and outperformed a conventional method such as Cox regression (concordance index 0.769 vs 0.745). Among various survival decision-tree models, the modified Charlson Comorbidity index (mCCI) was selected as the best predictor of mortality. If peritoneal dialysis patients with high mCCI (>4) were aged ≥70.5 years old, the survival hazard ratio was predicted as 4.61 compared to the overall study population. Among the various algorithm using longitudinal data, the AUC value of logistic regression was augmented at 0.804. In addition, the deep neural network significantly improved performance to 0.841. We propose machine learning-based final model, mCCI and age were interrelated as notable risk factors for mortality in Korean peritoneal dialysis patients.
Similar content being viewed by others

Introduction
The prevalence of dialysis was calculated as 296 per million people (pmp), and that of renal replacement therapy (RRT) was assumed to be 709 pmp worldwide in 20101; moreover, the incidence of end-stage renal disease (ESRD) is increasing steadily. Peritoneal dialysis (PD), a well-established RRT modality for patients with ESRD, varies greatly from country to country2. The prevalence of PD has been influenced by national policies of reimbursement, and there are differences in prevalence rates between countries3. Despite its clinical advantages, PD has been declining globally3, including in the Republic of Korea, where the proportion of PD decreased from 15% in 1990 to 7% in 20164. PD versus hemodialysis (HD) has traditionally been of major benefit regarding residual renal function5,6,7, and recent studies showed that cognitive dysfunction improved relative to HD8. In addition, recent studies attempted remote monitoring with automated PD for home dialysis9. Even though it has many advantages, PD use has been limited in elderly debilitated patients and in those with comorbid diseases. To achieve the benefits of PD, it is necessary to accurately upgrade predictive risk factors for hard outcomes in PD patients.
Artificial intelligence algorithms in ESRD patients for predicting prognosis have been designed mainly to understand allograft outcomes in kidney transplant recipients10,11,12,13, because the immunologic and non-epidemiologic risks of renal transplant patients are complicated and affect prognosis14. Initially, attempts were made to predict early death in dialysis patients using a scoring system15. Subsequently, the number of studies for dialysis patients increased with the development of forecasting algorithms16,17. Most attempts were made to predict treatment responses to erythropoietin (EPO), an agent used to treat renal anemia in HD patients18, and these efforts were supported in multinational studies19. The reasons suggested were that EPO is relatively uniform in its capacity, treatment guidelines are clear-cut, and the artificial intelligence algorithm is easy to apply.
However, there is little use of artificial intelligence for diagnostic, therapeutic, and prognostic purposes in PD. In a recent report, three different machine-learning models, support vector machine (SVM), random forest (RF), and single-hidden-layer artificial neural network (ANN), were used to find immunologic biomarkers and report outperforming results20. Further, studies published in the Republic of Korea attempted to improve the discrimination index by using the modified Charlson-comorbidity index (mCCI) in incident PD patients21. In a later study, recalibration of mCCI was validated in incident PD patients and showed a different prognostic factor than in HD patients22. Therefore, in our study, we propose a novel prediction approach to PD patients’ survival, based on machine-learning techniques using nationwide prospective observational data for the augmentation of treatment strategies for PD patients in the Republic of Korea. In this study, we tried to demonstrate a novel data-driven approach using survival statistics to predict mortality.
Results
Baseline characteristics
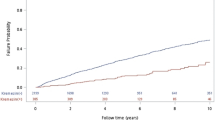
Attributes used for modeling were presented according to mortality in PD patients (Table 1). Of the total 5223 dialysis patients, final analysis included 1,730 PD patients. A total of 343 patients (19.8%) died during the mean observation period of 30.18 ± 18.25 months (Fig. 1). The mean age was 62.3 ± 10.8 years for the non-survivor group and 50.3 ± 11.8 years for the survivor group (p < 0.001). Male patients in the non-survivor group were 63.3% (N = 217), and 55.2% of patients started dialysis due to diabetes (Table 1). Patients in the non-survivor versus survivor group had a significantly greater history of cardiovascular disease, diabetes, and increased mCCI scores. There were no differences between groups in body mass index (BMI), systolic blood pressure (SBP), and use of renin-angiotensin-aldosterone system blockade. Regarding laboratory findings at dialysis initiation, blood urea nitrogen (BUN), creatinine, phosphorus, and uric acid concentrations were all significantly lower in non-survivors than survivors (Table 1). Tables S1 and S2 presented the detailed protocol for missing data and follow-up patients’ data in online supplemental material.

Patients’ follow up after peritoneal dialysis initiation. (A) Number of patients at the year of follow up at 1 year after peritoneal dialysis (PD) initiation (B) Ratio of non-survivor and survivor at 1 year after PD initiation.
Results of a conventional algorithm for predicting 5-year patients’ survival
In this study, we presented the results chosen for model parameters, including imputation method, weighting methods, validation method and ratio, test-set size, training and test performance of the test set, and validation of the mixed dataset (Fig. 2). The performance of the machine-learning algorithm for classification is compared in Table 2, Table S3, and S4, according to test performance using the area under the curve (AUC) with different settings. These tables show predictive performances of the binary classification tree, derived from the dataset with the conventional multiple-learning method, for the expected probability of death after 5 years (%).

Model structure.
Figure 3 presents findings from the clinical decision model for the probability of death. From a range attribute of an existing decision-tree model, mCCI in the first node was the most important risk factor for mortality in PD patients. This revealed that the 5-year estimated mortality rate was only 10.5%, if mCCI was <2 and was used in preference to age at dialysis initiation and various other risk factors. Age at the start of PD was chosen as the next node. If PD was started at 56.5 years, the 5-year mortality rate was expected to be 37.5% if starting creatinine value was ≥11.35 mg/dL. If it was <11.35 mg/dL, BMI was determined to be the next node. If BMI was ≥ 22.85 kg/m2, the 5-year mortality rate was expected to be as high as 100% (Fig. 3). If age at the start of PD was >56.5 years, and if SBP at the start of dialysis was ≥153 mmHg, the expected 5-year mortality rate was 63.6%. For SBP < 153 mmHg, hemoglobin (Hb) value affected SBP. If Hb at the start of dialysis was <12.25 mg/dL, there was a high expected mortality risk of 95.5%.

The 5-year mortality prediction after PD initiation using a decision tree (DT) model. The 5-year mortality of prediction rate is reported as a percentage (%). Decision tree for the training, test and validation data set, after stratified sampling, with ‘Y’ indicating a positive conclusion and ‘N’ a negative conclusion.
Results of Survival decision tree modeling for predicting patients’ survival hazard ratio
We applied additional machine-learning algorithms such as SDT, bagging, random forest, and ridge and lasso models. These models used survival analysis statistics instead of Gini indexes or entropy indexes in partitioning rules for existing tree algorithms. Table 3, and S5 show the final results for survival model parameters as concordance index (C-index). The survival tree algorithm performed better than the conventional survival modeling such as a Cox regression (0.769 vs. 0.745) (Table 3). The predicted death risk in the SDT model was a survival risk HR, compared to mean survival hazards for the entire patient population.
The most important factor in our additional analysis model was mCCI (Fig. 4). Companion comorbidities were divided into ≤4 and >4 (Fig. 4). Mortality was lowest, at HR 0.104, for all patients, regardless of other factors, in the mCCI ≤2 group. Conversely, there was a significant correlation with age from mCCI score ≥5 points. When mCCI score was ≥5 points and patients were aged >70.5 years of age, the HR for death was 4.614 times greater than that for overall mortality.

The patients’ survival prediction after PD initiation using survival hazard ratio modeling. The relative mortality risk is presented as a survival hazard ratio (HR). The survival decision tree for the training, test and validation data set, after stratified sampling, with ‘Y’ indicating a positive conclusion and ‘N’ a negative conclusion.
In patients with an mCCI score ≥5 but who were aged <70.5 years, uric acid level at the start of dialysis was the next decision node. If uric acid was >7.75 mg/dL, the survival HR was relatively low at 0.197 (for mCCI score of 5–6) but increased to 1.888 (for mCCI score ≥7.0). If uric acid levels in these patients were <7.75 mg/dL, the next node was age 44.5 years (Fig. 4). When age was <44.5 years and mCCI score was >5, there was a low mortality HR of 0.326, even when uric acid was <7.75 mg/dL at PD initiation. If patients were aged >44.5 years, the next node was Hb. If Hb was >9.55 g/dL, the HR of death was 1.47, but this increased to 3.182 if Hb was <9.55 g/dL (Fig. 4).
Results of subgroup analysis for high risk patients
Next, additional analysis was performed in high risk subgroup using conventional Cox regression to find the effect of MCCI risk on each subgroup. We divide MCCI to groups according to the result of Figs. 3 and 4, and the risk group was collected into three groups, Low group MCCI 0–2; Moderate group 3–5; High group, MCCI score 6. Table 4 presented the results of Cox regression analysis. Multivariate analysis was performed with adjustment confounding, including such as age, sex, primary renal disease, smoking history, dialysis duration, BUN, systolic BP, BMI, Hb, calcium, history of DM, CVD, usage of RAAS blockade, and serum albumin. Table 4 showed that high MCCI group is an independent risk factor for PD patients after adjustment confoundings. Univariate analysis showed that high MCCI group have increased for the mortality risk in low albumin group and male gender. However, in old age group, there was no significant association of MCCI group and mortality risk.
Results of deep learning algorithm for predicting 5-year patients’ survival
We finally performed additional analysis to apply deep learning algorithm using longitudinal data to further enhance the prediction model. Mortality risk model was validated by the deep neural network algorithms, compare to conventional algorithms. Our proposed deep learning model is composed of Long Short-Term Memory networks (LSTM) and autoencoder. LSTM was introduced to deal with time-series data and autoencoder to deal with missing data.
We analyze records of 1,127 prevalent and 603 incident PD patients, among which we use 26 independent attributes to learn this deep learning models including. The repeated measured data include 24-hour urine volume, RAAS blockade use, and dialysis efficiency (weekly KT/V). The study protocol of this study cohort was measured KT/V after 3 months of study enrollment, and the detailed protocol was presented in Table S2. Among the various conventional algorithms, the AUC value of logistic regression was the best at 0.804. Using these longitudinal data, the AUC of DT was also improved to 0.801 (Fig. 5). Our proposed deep learning model showed 0.840 when using only LSTM, and 0.858 when combined with an autoencoder (Table 5). Figure 5 presented the result of DT using longitudinal data (AUC 0.801). The most important factor in our additional analysis model was also found as mCCI (Fig. 5). Companion comorbidities were divided into ≤6 and >6 (Fig. 5), and age at the start of dialysis was the next decision node.

The 5-year mortality prediction after PD initiation using a decision tree (DT) model with repeated measured data. The repeated measured data include 24-hour urine volume, RAAS blockade use, and dialysis efficiency (weekly KT/V). The 5-year mortality of prediction rate is reported as a percentage (%). Decision tree for the training, test and validation data set, after stratified sampling, with ‘Y’ indicating a positive conclusion and ‘N’ a negative conclusion.
Discussion
The purpose of this study was to accurately evaluate prognosis in PD patients using a nationwide prospective cohort and to select a machine-learning algorithm and neural network as novel tools. To the best of our knowledge, this is the first study to predict prognosis in PD patients using various machine-learning algorithms. The main conclusion of our study is that the presence and severity of comorbid diseases using mCCI is the first decision aid in determining future mortality risk in PD patients. Until now, studies attempting to predict prognosis using comorbidity index have been limited to HD patients and have lacked information about the predictive performance of specific score cutoffs and risk thresholds that could affect clinical applications23. According to the final conclusion of this study using survival statistics, the HR of death was only 0.104 for all patients with two or less comorbidities, regardless of age (Fig. 3). If there were two or less comorbidities at PD initiation, the predicted 5-year risk of death was only 10.5%, according to the decision-tree analysis (Fig. 2).
PD and HD each have advantages and disadvantages, and the survival rate in PD patients is comparable to that in HD patients in the Republic of Korea. However, there were inconsistent results in recent studies: for example, one report revealed better survival with PD than HD in the early period24, whereas another documented comparable mortality rates in PD and HD patients25. In elderly patients, there was no survival benefit for PD over HD in either study24,25. In the United States, there were at least 6,538 PD patients in 2007, and increased to 12,095 by 201626,27,28; in the Republic of Korea, the corresponding at 2016 was 6,842 patients, only 7% of the total RRT population4,29,30. The rapid decline in PD patients in the Republic of Korea is probably due to the aging of patients with ESRD. PD is a patient-centered treatment, so it is difficult to attempt in elderly patients31,32 or those with a rapid decline in functional status33. Thus, updated prognostic tools are urgently needed and have not been tried in Korean patients. In particular, the absence of such prognostic tools has led to a reluctance of nephrologists to discuss post-dialysis prognosis with their patients34,35. Therefore, accurate prognostic tools are required, not only for PD patients, but also for patients with advanced chronic kidney disease and renal physicians, to facilitate shared-decision making.
In this study, we suggest that age itself is not the only important prognostic factor. We also suggest a cutoff in comorbidity index, related to age, which may help in selecting patients for PD. In a recent meta-analysis23, CCI was the best predictor of mortality, and CCI can be easily calculated in the clinical setting and provide meaningful information. CCI is a method of classifying patient complications based on ICD (International Classification of Diseases) diagnostic codes found in administrative data, such as hospital summary data36. Each complication category has associated weighting (from 1–6) based on the adjusted risk of death or resource use, and the sum of all weightings is each patient’s single complication score.
The CCI was originally developed in 1987. Charlson et al.36 identified 19 categories of associated diseases and weights for each category based on the adjusted 1-year relative risk of mortality. The sum of each weight is summed to yield a single equality score for each patient. However, this method has been criticized for applying CCI values directly to ESRD patients. Among the chronic disease indices validated in the dialysis population, CCI has been most widely used in statistical analyses due to its simplicity and ability to predict mortality; the original CCI has been validated in PD patients37,38. However, use of the original CCI has been questioned in patients with ESRD because of the proportion of complications within the CCI: there has been criticism that death in ESRD patients will not reflect the differences in effectiveness due to complications. In previous studies, a modification of CCI based on the proportion of relapsed complications, called mCCI, improved the predictability of mortality in dialysis populations. In these studies, complications such as cerebrovascular disease, congestive heart failure, diabetes, and myocardial infarction were reassigned to higher proportions of patients38,39. These patterns were observed in studies performed between 1999 and 2001 that applied mCCI in both HD and PD patients39. However, this study involved HD39, and studies involving only incident patients with PD in the Republic of Korea had a lower risk of comorbidities associated with cardiovascular disease21. This reflects the fact that PD patients have lower cardiovascular risk than HD patients.
One important meaning of our study is that machine-learning has increased usefulness of the mCCI, because the original CCI was designed to include only combinations identified from ICD-10 codes; however, there could have been clinical situations where it was necessary to consider all diagnoses of items not covered by the original CCI36. Because the original CCI was designed for use with very specific ICD coding found in hospital abstracts data, the medical conditions not covered in ICD coding could be overlooked. However, in our study cohort of ESRD patients, mCCI was calculated more accurately by the clinical research coordinator interviewing patients individually and then checking comorbidities. For example, if the cause of ESRD was diabetes, two points were allocated, as before, but if diabetes developed after ESRD, one point was allocated and two points were assigned for moderate or severe renal disease.
In the final SDT model (Fig. 4), the group with mCCI score >4 had the highest mortality among patients aged ≥70.5 years, as we expected (HR 4.614). Interestingly, uric acid level was determined as the next decision node in the group with mCCI score >4 points and aged <70.5 years. In this group, patients with the higher the concentration of uric acid at the start of dialysis (cutoff 7.75 mg/dL) showed the lower the risk of death (HR 0.197–1.888). In a previous study from the CRC for ESRD cohort, low uric acid level was associated with higher mortality in Korean dialysis patients, including PD and HD patients, after adjustment for nutritional markers, albumin, phosphorus, BMI, and subjective global assessment40. These results are consistent with our study findings. Intermediate-risk patients (mCCI score 3 or 4) were evaluated as the next decision node, according to serum BUN level. These patients had an increased risk of death (HR 2.517) if BUN level at the start of dialysis was low (cutoff 35.55 mg/dL). Taken together, our study results implicate that the mortality of PD patients might be related to nutritional and performance status at the dialysis initiation, irrespective of age itself.
In this process, we have not been satisfied with the performance of the model despite the analysis process, so we tried to strengthen the model by solving two problems after our CRC-ESRD cohort through deep learning algorithm i) Time-sequential longitudinal observational nature of data was attempted for overcome and performed deep learning algorism such as recurrent neural network (RNN) and Long Short Term Memory networks (LSTM) (ii) missing data was managed by Auto encoder (AE) were used to strengthen the model (Table 5). (i) The first feature of longitudinal observational cohort is the presence of time-variable attributes. The changing of those attributes might have played an important role in predicting the target variable. The recurrent neural networks (RNN) is a type of artificial neural network, and the connection between units has a cyclic structure41. These structures allow states to be stored inside the neural network to model time-variable dynamic attributes, while, unlike the conventional feed-forward artificial neural network, the RNN can process sequence-type inputs using internal memory. Thus, the RNN can process data with time-variable characteristics. In the case of vanilla RNN, gradients cannot be propagated normally, either vanished or exploded if the input sequence is long during the training process. This is called the problem of Long-Term Dependencies (LTD)42. To solve this problem, the special case of RNN, Long Short Term Memory networks (LSTM), was introduced. LSTM unit consists of an input gate, an output gate, a forget gate and a memory cell. The process is as follows in Figure S1. Figure S1 shows the structure of applying RNN/LSTM to the classification model, X is a static variable, and Xt is a time-dependent variable. In the study protocol of our cohort as Figure S1, time-dependent variables such as 24-hour urine volume, RAAS blockade use, and dialysis efficiency (weekly KT/V) were traced at 0/3/12 months (Table S2) and expressed the use of them as input values of RNN/LSTM units according to time order. (ii) The second feature of inevitable nature for observational cohort is the existence of various type of missing data. To solve these problems, we used Auto-Encoder (AE), which is a neural network that simply predicts the input value as an output value. If we set the number of nodes in the hidden layer to less than the input layer, AE can learn the compact representation of the input. This constraint enables us to learn how to express data efficiently, and it is possible to use this AE to express information including missing values as shown in Figure S2. In the training process, some input variable values are removed randomly, and AE is trained to restore them as the original values. In the inference process, the encoding value of the input is utilized regardless of the existence of the missing value.
Among the various algorithms using repeated measurement data, the AUC value of logistic regression was increased to 0.804. Using these longitudinal data, the AUC of DT was also improved to 0.801 (Fig. 5). Our proposed deep learning model showed 0.840 when using only LSTM, and 0.858 when combined with an autoencoder (Table 5). Finally, deep learning algorithm such as our proposed deep learning model with LSTM and autoencoder, especially repeated measured parameters, showed that the mortality risk of PD patients could be utilized more effectively.
Recently, the use of artificial intelligence in medical research has advanced rapidly43, and the feasibility of a machine-learning approach has increased, especially in diseases influenced by various prognostic factors, such as in ESRD, where application of a machine-learning approach can now be further expanded. The purpose of this study was to accurately predict prognosis in PD patients by focusing on comorbidities and clinical information at dialysis initiation. An elderly patient with high mCCI (≥5) on PD was associated with a 4.61-fold increase in the risk of death, while low mCCI patients (≤2) were associated with a 0.10 hazard ratio. We suggest information about the predictive performance of specific score cutoffs and risk thresholds that could be feasible for clinical PD applications. In conclusion, older adults are not unconditionally incapable of undergoing PD, and it may be helpful to calculate mCCI by accurately assessing comorbidities.
Materials and Methods
Data source and study patients
We conducted our analyses with data obtained from the database in the Clinical Research Center for ESRD (CRC for ESRD, NCT00931970), which is the only nationwide multicenter and prospective cohort of Korean ESRD. Data are collected from 36 general and teaching hospitals in the Republic of Korea. Our study included a total of 5,223 patients enrolled in the CRC for ESRD study, with 1,730 patients undergoing PD. All patients were aged ≥18 years and had received dialysis between August 2008 and December 2014. We have previously described the methods used to identify dialysis patients and their enrollment in the CRC for ESRD cohort24,44,45. Data were collected using a web-based platform (http://webdb.crc-esrd.or.kr) following the methods described in previous studies24,44,45. Out of 72 attributes in total, we analyzed 1,730 PD patient records using machine-learning algorithms with more than 50 attributes. Among these 50 attributes, we chose 23 independent attributes, which could affect all-cause mortality, to build our models. The attributes selected to build our models are specified in Table 1. The mCCI, which has been validated for dialysis patients36, was derived by reviewing patients’ medical histories and interviewing each patients by clinical research coordinator at enrollment.
Problem statement and attributes used for modeling
In this study, we conducted a thorough analysis of different machine-learning algorithms to predict a survival rate at N years after PD initiation. In this section, we explain our data in detail and describe our models in Fig. 2. Finally, we provide comprehensive results of our experiments using different machine-learning methods. Outcome measurements for detecting mortality events, we had an approach to the mortality event and cause of death within 1 month after the event by the study protocol24 via clinical research coordinator (CRC), and re-assured by merging data from Statistics Korea with informed consents every end-of-year in study observation46. In our study patients’, a total of 156 patients were dropped out for kidney transplantation, and censored. When estimating the survival prediction at N years later, using data from people who have not been followed up after N years results in distortion. We tried to overcome the disadvantages with various methods. The previous study of our research had presented for detailed methods for using survival statics13. In brief, if the patient has already experienced an event (mortality) even though the follow-up period is short, it is used as a positive example. If the patient’s follow-up period is short, they are used both as positive and negative examples and give different weights to each, so-called instance weighting method (Fig. 2).
Statistical analysis
In the present study, continuous and categorical variables were compared between the groups using the t-test and chi-square test, respectively. For the multivariate Cox model, we did not include MCCI as an adjusting covariate because of multicollinearity issues. We performed a stratified subgroup analysis using Cox regression model by age (>60 years), sex, and high risk groups (history of diabetes mellitus, low albumin level at dialysis initiation).
For extended methods related to the treatment of missing values, modeling process with data splitting, weighting method for classification, and detailed algorithm process including logistic regression, decision-tree, neural network, and deep learning algorithm process including recurrent neural network with autoencoder imputation, please refer to online supplemental data.
All of the statistical analyses were conducted using R statistical language (Version R 3.0.2, The Comprehensive R Archive Network: http://cran.r-project.org), and the MICE package was used as features for imputing missing values on continuous and categorical data. To implement the deep learning models, we use Python 3.6.5 and TensorFlow 1.14.0.
Ethic statement
All patients were informed about the study, participated voluntarily, and provided written informed consent. Also, the institutional review board of each center approved the study. All investigators conducted this study in accordance with guidelines of the 2008 Declaration of Helsinki. Seoul National University Hospital Institutional Review Board approved the study (IRB number H-0905–047–281). The study was approved by the institutional review board at each center as follows [The Catholic University of Korea, Bucheon St. Mary’s Hospital; The Catholic University of Korea, Incheon St. Mary’s Hospital; The Catholic University of Korea, Seoul St. Mary’s Hospital; The Catholic University of Korea, St. Mary’s Hospital; The Catholic University of Korea, St. Vincent’s Hospital; The Catholic University of Korea, Uijeongbu St. Mary’s Hospital; Cheju Halla General Hospital; Chonbuk National University Hospital; Chonnam National University Hospital; Chung-Ang University Medical Center; Chungbuk National University Hospital; Chungnam National University Hospital; Dong-A University Medical Center; Ehwa Womens University Medical Center; Fatima Hospital, Daegu; Gachon University Gil Medical Center; Inje University Pusan Paik Hospital; Kyungpook National University Hospital; Kwandong University College of Medicine, Myongji Hospital; National Health Insurance Corporation Ilsan Hospital; National Medical Center; Pusan National University Hospital; Samsung Medical Center, Seoul; Seoul Metropolitan Government, Seoul National University, Boramae Medical Center; Seoul National University Hospital; Seoul National University, Bundang Hospital; Yeungnam University Medical Center; Yonsei University, Severance Hospital; Yonsei University, Gangnam Severance Hospital; Ulsan University Hospital; Wonju Christian Hospital (in alphabetical order)].
References
Liyanage, T. et al. Worldwide access to treatment for end-stage kidney disease: a systematic review. The Lancet 385, 1975–1982 (2015).
Briggs, V., Davies, S. & Wilkie, M. International Variations in Peritoneal Dialysis Utilization and Implications for Practice. Am J Kidney Dis 74, 101–110 (2019).
Li, P.K., et al. Changes in the worldwide epidemiology of peritoneal dialysis. Nat Rev Nephrol (2016).
Jin, D. C. et al. Current characteristics of dialysis therapy in Korea: 2016 registry data focusing on diabetic patients. Kidney Res Clin Pract 37, 20–29 (2018).
Louise, M. MOIST, e.a. Predictors of Loss of Residual Renal Function among New Dialysis Patients. J Am Soc Nephrol 11, 556–564 (2000).
Jansen MA, et al. Predictors of the rate of decline of residual renal function in incident dialysis patients. Kidney Int 62 (2002).
Wang, A. Y. & Lai, K. N. The importance of residual renal function in dialysis patients. Kidney Int 69, 1726–1732 (2006).
Neumann, D., Mau, W., Wienke, A. & Girndt, M. Peritoneal dialysis is associated with better cognitive function than hemodialysis over a one-year course. Kidney Int 93, 430–438 (2018).
Wallace, E. L. et al. Remote Patient Management for Home Dialysis Patients. Kidney Int Rep 2, 1009–1017 (2017).
Krikov, S. et al. Predicting kidney transplant survival using tree-based modeling. ASAIO J 53, 592–600 (2007).
Decruyenaere, A. et al. Prediction of delayed graft function after kidney transplantation: comparison between logistic regression and machine learning methods. BMC Med Inform Decis Mak 15, 83 (2015).
Goldfarb-Rumyantzev, A. S., Scandling, J. D., Pappas, L., Smout, R. J. & Horn, S. Prediction of 3-year cadaveric graft survival based on pre-transplant variables in a large national dataset. Clin. Transplant. 17, 485–497 (2003).
Yoo, K. D. et al. A Machine Learning Approach Using Survival Statistics to Predict Graft Survival in Kidney Transplant Recipients: A Multicenter Cohort Study. Sci Rep 7, 8904 (2017).
Nankivell, B. J. & Kuypers, D. R. J. Diagnosis and prevention of chronic kidney allograft loss. The Lancet 378, 1428–1437 (2011).
Barrett, B. J. et al. Prediction of early death in end-stage renal disease patients starting dialysis. Am J Kidney Dis 29, 214–222 (1997).
Barbieri, C. et al. Development of an Artificial Intelligence Model to Guide the Management of Blood Pressure, Fluid Volume, and Dialysis Dose in End-Stage Kidney Disease Patients: Proof of Concept and First Clinical Assessment. Kidney Dis (Basel) 5, 28–33 (2019).
Hueso, M. & Vellido, A. Artificial Intelligence and Dialysis. Kidney Dis (Basel) 5, 1–2 (2019).
Barbieri, C. et al. A new machine learning approach for predicting the response to anemia treatment in a large cohort of End Stage Renal Disease patients undergoing dialysis. Comput Biol Med 61, 56–61 (2015).
Barbieri, C. et al. An international observational study suggests that artificial intelligence for clinical decision support optimizes anemia management in hemodialysis patients. Kidney Int 90, 422–429 (2016).
Zhang, J. et al. Machine-learning algorithms define pathogen-specific local immune fingerprints in peritoneal dialysis patients with bacterial infections. Kidney Int 92, 179–191 (2017).
Cho, H. et al. Development and Validation of the Modified Charlson Comorbidity Index in Incident Peritoneal Dialysis Patients: A National Population-Based Approach. Perit Dial Int 37, 94–102 (2017).
Park, J. Y. et al. Recalibration and validation of the charlson comorbidity index in korean incident hemodialysis patients. PLoS One 10, e0127240 (2015).
Anderson, R. T. et al. Prediction of Risk of Death for Patients Starting Dialysis: A Systematic Review and Meta-Analysis. Clin J Am Soc Nephrol 14, 1213–1227 (2019).
Choi, J. Y. et al. Survival advantage of peritoneal dialysis relative to hemodialysis in the early period of incident dialysis patients: a nationwide prospective propensity-matched study in Korea. PLoS One 8, e84257 (2013).
Kim, H. et al. A population-based approach indicates an overall higher patient mortality with peritoneal dialysis compared to hemodialysis in Korea. Kidney Int 86, 991–1000 (2014).
Collins, A. J. et al. US Renal Data System 2013 Annual Data Report. Am J Kidney Dis 63, A7 (2014).
Jin, D. C. & Han, J. S. Renal replacement therapy in Korea, 2012. Kidney Research and Clinical Practice 33, 9–18 (2014).
Saran, R. et al. US renal data system 2016 annual data report: epidemiology of kidney disease in the United States. American journal of kidney diseases 69, A7–A8 (2017).
Jin, D. C. et al. Lessons from 30 years’ data of Korean end-stage renal disease registry, 1985-2015. Kidney Res Clin Pract 34, 132–139 (2015).
Jin, D. C. Analysis of mortality risk from Korean hemodialysis registry data 2017. Kidney Res Clin Pract 38, 169–175 (2019).
Anand, S., M.K.T. & Chertow, G. M. The elderly patients on hemodialysis. Minerva Urol Nefrol. 62, 87–101 (2010).
Thorsteinsdottir, B., Montori, V. M., Prokop, L. J. & Murad, M. H. Ageism vs. the technical imperative, applying the GRADE framework to the evidence on hemodialysis in very elderly patients. Clin Interv Aging 8, 797–807 (2013).
Kurella Tamura, M., C.K., Chertow, G. M., Yaffe, K., Landefeld, C. S. & McCulloch, C. E. Functional status of elderly adults before and after initiation of dialysis. N Engl J Med 15, 1539–1547 (2009).
Wachterman, M. W. et al. Relationship between the prognostic expectations of seriously ill patients undergoing hemodialysis and their nephrologists. JAMA Intern Med 173, 1206–1214 (2013).
Schell, J. O., Patel, U. D., Steinhauser, K. E., Ammarell, N. & Tulsky, J. A. Discussions of the kidney disease trajectory by elderly patients and nephrologists: a qualitative study. Am J Kidney Dis 59, 495–503 (2012).
Charlson, M. E., P.P., Ales, K. L. & MacKenzie, C. R. A new method of classifying prognostic comorbidity in longitudinal studies: development and validation. J Chronic Dis 40, 373–383 (1987).
Fried, L., Bernardini, J. & Piraino, B. Charlson comorbidity index as a predictor of outcomes in incident peritoneal dialysis patients. Am J Kidney Dis 37, 337–342 (2001).
van Manen, J. G. et al. How to adjust for comorbidity in survival studies in ESRD patients: a comparison of different indices. Am J Kidney Dis 40, 82–89 (2002).
Hemmelgarn, B. R., Manns, B. J., Quan, H. & Ghali, W. A. Adapting the charlson comorbidity index for use in patients with ESRD. American Journal of Kidney Diseases 42, 125–132 (2003).
Bae, E. et al. Lower serum uric acid level predicts mortality in dialysis patients. Medicine (Baltimore) 95, e3701 (2016).
Mikolov, T., et al. Recurrent neural network based language model. International speech communication association (2010).
Hochreiter, S., and Jürgen S. Long short-term memory Neural computation 1735-1780 (1997).
Topol, E. J. High-performance medicine: the convergence of human and artificial intelligence. Nat Med 25, 44–56 (2019).
Yoo, K. D. et al. Effect of Renin-Angiotensin-Aldosterone System Blockade on Outcomes in Patients With ESRD: A Prospective Cohort Study in Korea. Kidney Int Rep 3, 1385–1393 (2018).
Lee, M. J. et al. Prognostic Value of Residual Urine Volume, GFR by 24-hour Urine Collection, and eGFR in Patients Receiving Dialysis. Clin J Am Soc Nephrol 12, 426–434 (2017).
Oh, H. J. et al. Exploring Mortality Rates for Major Causes of Death in Korea. The Open Public Health Journal 12, 16–25 (2019).
Acknowledgements
We express our huge gratitude to all of the Clinical Research Center for End-Stage Renal Disease investigators. This research was supported by a grant of the Korea Health Technology R&D Project through the Korea Health Industry Development Institute (KHIDI), funded by the Ministry of Health & Welfare, Republic of Korea (grant number: HC15C1129 and HI15C0001).
Author information
Authors and Affiliations
Contributions
Junhyug Noh and Kyung Don Yoo analyzed the data and drafted and revised the paper; Junhyug Noh, Kyung Don Yoo, Jung Pyo Lee and Gunhee Kim collected the data, drafted and revised the paper; Jong Soo Lee, Jang-Hee Cho, Hajeong Lee, Dong Ki Kim, Chun Soo Lim, Shin-Wook Kang, Yong-Lim Kim, and Yon Su Kim collected the data and construct the observational cohort; Wonho Bae and Kangil Kim provided critical comments on method for computational prediction; Junhyug Noh, Kyung Don Yoo, W Bae, Kangil Kim, Gunhee Kim and Jung Pyo Lee conceived the study, participated in its design and coordination, and helped draft the manuscript. All authors approved the final version of the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Noh, J., Yoo, K.D., Bae, W. et al. Prediction of the Mortality Risk in Peritoneal Dialysis Patients using Machine Learning Models: A Nation-wide Prospective Cohort in Korea. Sci Rep 10, 7470 (2020). https://doi.org/10.1038/s41598-020-64184-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-020-64184-0
This article is cited by
-
Machine learning algorithms for the prediction of adverse prognosis in patients undergoing peritoneal dialysis
BMC Medical Informatics and Decision Making (2024)
-
Predict, diagnose, and treat chronic kidney disease with machine learning: a systematic literature review
Journal of Nephrology (2023)
-
Precision medicine and machine learning towards the prediction of the outcome of potential celiac disease
Scientific Reports (2021)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
