
Abstract
In vestibular schwannoma patients with functional hearing status, surgical resection while preserving the hearing is feasible. Hearing levels, tumor size, and location of the tumor have been known to be candidates of predictors. We used a machine learning approach to predict hearing outcomes in vestibular schwannoma patients who underwent hearing preservation surgery: middle cranial fossa, or retrosigmoid approach. After reviewing the medical records of 52 patients with a pathologically confirmed vestibular schwannoma, we included 50 patient’s records in the study. Hearing preservation was regarded as positive if the postoperative hearing was within serviceable hearing (50/50 rule). The categorical variable included the surgical approach, and the continuous variable covered audiometric and vestibular function tests, and the largest diameter of the tumor. Four different algorithms were lined up for comparison of accuracy: support vector machine(SVM), gradient boosting machine(GBM), deep neural network(DNN), and diffuse random forest(DRF). The average accuracy of predicting hearing preservation ranged from 62% (SVM) to 90% (DNN). The current study is the first to incorporate machine learning methodology into a prediction of successful hearing preservation surgery. Although a larger population may be needed for better generalization, this study could aid the surgeon’s decision to perform a hearing preservation approach for vestibular schwannoma surgery.
Similar content being viewed by others
Introduction
Vestibular schwannomas (VSs), or acoustic neuromas are benign tumors arising from the cochleovestibular nerve, which grows slowly1. It accounts for 6–8% of all intracranial tumors and is the most common cerebellopontine angle tumor2. Recently, with the help of better access to magnetic resonance imaging, the incidence has been increased, and the tumor size at the time of diagnosis has decreased3,4. With more early detection rates, more patients are asymptomatic when diagnosed. In these patients, the following management options may all be feasible: watchful waiting, surgery, or stereotactic radiosurgery(SRS). However, there are no clear guidelines or consensus on the optimal management of small VSs, and the optimal treatment is still under debate5,6. Treatment options differ individually and are dependent upon the physician’s experience, the size and growth rate of the tumor, age, patient’s preference, and hearing status. If the tumor is too big, or hearing is below serviceable hearing, hearing preservation is not essential in treatment7. Nevertheless, in small to medium-sized tumors with serviceable hearing, hearing preservation surgeries can be offered. Currently, middle cranial fossa approach(MCFA) and retrosigmoid approach(RSA) are the two most commonly used approaches to remove VSs.
The selection between the two approaches depends on the size and location of the tumor, and the surgeon’s preference, as each procedure has its strengths in exposing regions of the internal auditory canal or cerebellopontine angle. The preservation rate of MCFA and RSA varies among studies, ranging from 2% to as high as 93%8. The heterogenicity of the result makes it difficult to rate one strategy superior to another. Because hearing preservation operation takes longer and is more complex, leading to more post-surgical complications, it is reasonable to select the patients that are likely to have a decent postoperative hearing.
Recent advances in machine learning are being adopted to medical fields, especially in image recognition, including radiology, ophthalmology, histology, and dermatology9,10,11,12,13,14. In otology, there are relatively few, but recently, there were studies focused on the automated diagnosis of ear disease using otoendoscopy15, deep-learning-based noise reduction for improvement of speech recognition in cochlear implant patients16, and predicting the outcome of hearing in patients with sudden sensorineural hearing loss17. To our knowledge, despite studies focusing on predictive factors of hearing preservation surgeries18,19,20, it is hard to predict the patient’s probability of preserving auditory function following such surgery. We present a new system based on machine learning having input parameters based on preoperative data to predict the outcome of hearing preservation surgery in patients with VSs.
Results
Fifty patients were in the cohort; 19 men and 31 women. Patient demographics are described in Table 1. The mean age at operation was 47.42 ± 11.46 years. The mean pure-tone-average(PTA) of the patients was 26.61 ± 15.64 dB HL preoperatively and 62.53 ± 41.71 dB HL postoperatively. 28 of 50 patients (56%) were able to preserve hearing following vestibular schwannoma surgery.
Four machine learning models (support vector machine; SVM, gradient boosting machine; GBM, deep neural network; DNN, diffuse random forest; DRF) were compared regarding accuracy. The SVM based model showed approximately 62% percent, which is poor performance compared to the other three models. Three models (GBM, DRF, and DNN based models) exhibited a reasonable accuracy of near 90% in 5-fold-cross-validation. The comparison between the four models is summarized in Table 2. Additionally, we also explored feature importance to determine factors affecting the prediction of postoperative hearing preservation. Although feature importance tends to vary among different models, preoperative word recognition score(WRS) was the universally important feature, which was the most crucial factor in DNN and GBM models and fourth in the DRF model (Table 3).
Discussion
Management of VSs depends on the individual patient’s status and often relies on the experience of physicians between observation, surgery, or stereotactic radiosurgery(SRS). Since increased usage of magnetic resonance imaging led to earlier diagnosis, more patients are now asymptomatic, and watchful observation is often the choice. When it comes to SRS, the tumor control rate is comparable to conventional microsurgery21. It was able to maintain serviceable hearing at four years in 72.2% of the total patient in a study22. However, in a study that observed for a longer time, only 23% of the patient’s hearing was preserved following ten years of treatment23.
When it comes to surgical resection of VSs, not all hearing preservation approaches of VS microsurgery could spare hearing. The preservation rate ranges from as low as 2% to 93%8. Therefore, it is reasonable to select the patient preoperatively who could benefit from such hearing approaches. Previous studies established a possibility for prediction of the prognosis of hearing preservation surgery in VSs18,19,20. Also, there are studies on intraoperative findings of tumor origin, SVN(superior vestibular nerve), and IVN (inferior vestibular nerve), and concludes SVN originating tumors is associated with better hearing preservation19,20,24. Preoperative determination of tumor origin (SVN or IVN) has some controversies; a study by Ushio et al. demonstrates no significant correlation of localizing tumor origin25. On the other hand, other papers show the usefulness of caloric and vestibular-evoked myogenic potential(VEMP) for determining tumor origin24,26.
In terms of evidence, this study focuses on previous findings that exhibited the correlation of preoperative tests with hearing outcomes. Preoperative PTA of each frequency, speech reception test results, caloric test results, VEMP asymmetry, and size and location of the tumor are all put into the input parameter of the proposed system. There is also a research with an emphasis on TEOAE (transient evoked otoacoustic emissions) pattern as a prognostic factor, where patients with preserved hearing tend to have TEOAE response in all five frequency (1, 1.5, 2, 3, 4 kHz) bands27.
This study is, in a sense, an ensemble of several studies on predictive factors in hearing preserving VS surgery. With feature importance search, the most important factor seems to be WRS, which consistently was among the top essential features (Table 3), and it is in line with previous studies. Better preoperative WRS implies better hearing function and may indicate less vestibulocochlear nerve degeneration due to VSs. In retrocochlear lesions, WRS is usually lower than expected compared to PTA, which is commonly due to vascular compromise or toxic protein secretion by the tumor28, and better WRS indicates less damage to the nerve, which increases the chance of sparing nerve function in surgery.
Several efforts were made to increase the accuracy of the model. Although there are still debates on whether caloric tests can represent SVN function and VEMP tests can reflect IVN function, at least in some studies, they tend to correlate. These factors were calculated in the model and contributed to increased accuracy. In contrast, training with TEOAEs as input parameters did not improve accuracy. Instead, overall accuracy was decreased, and the gap between training loss and validation loss was increased, which indicates a more overfitting tendency in machine learning. As more input parameters are put, the system becomes vulnerable to overfitting, leading to reduced overall accuracy. In the DNN model, the number of hidden layers was 50 and 20 layers. Increasing the number of hidden layers to 200, 200, and 50 layers (wider and deeper network) led to a broader gap between training loss and validation loss, and lead to worse results, the accuracy of 0.8; again, implying overfitting.
Besides machine learning strategies, conventional methods using simple logistic regression with ROC analysis were tried to predict the outcome of VS surgery. Using WRS as a cutoff, we were able to get 82% accuracy with 92.86% sensitivity and 68.18% specificity. Using PTA(3 K) yielded 86% accuracy with 89.29% sensitivity and 81.82% specificity (optimal values were chosen using Youden’s J metrics).
Although the accuracy difference between DNN model and other classical machine learning models (SVM, GBM, linear regression) is somewhat small, there are still potential benefits of the DNN model. There are studies on the application of combining multi-omics data into individual subnetworks, then merging altogether for a prediction model29,30. A similar approach could be applied to this study in the future by combining the current study’s data with radiologic and genomic data subnetworks, possibly gaining more accuracy and reliability.
The design of the study is based on domain-specific knowledge. Results of the previous studies to predict hearing preservation in VS surgery were utilized for feature engineering. In the current machine learning model, feature engineering of input variables was based on previous studies on possible predictors of hearing preservation. Likewise, this study’s design could be applied to other fields of medicine, possibly yielding high accuracy of prediction.
Thanks to the nature of the prediction system based on machine learning, each patient can be individually predicted whether he/she could preserve hearing after VS surgery with an accuracy of 90 percent. However, we believe this accuracy does not mean that physicians could rely solely on algorithms, while our prediction system’s result may provide an important reference in the decision-making process. We think the treatment of VS should be based on individualized care. It requires a delicate assessment of risks and benefits when it comes to selection between watchful observation, surgical resection, and stereotactic radiosurgery. The attending physician should undergo a comprehensive review of the surgeon’s skills, patient’s preference, symptoms, tumor characteristics, and make a decision, putting it altogether. Our prediction system’s result may provide an additional factor in the decision-making process.
There are limitations to this study. The total number of patients is only 50, and the deep learning system can not reach its potential performance, and it may be prone to overfit. Overfitting may cause lower accuracy in the test set or unseen data. Although the current number is small in the field of machine learning, it is relatively big considering the rarity of VSs and even more rarity of hearing preservation surgery candidates in the medical field. In the future, if we have more data, we may reinforce the system to generalize better, and thus, predict better.
Conclusion
This is the first study to incorporate machine learning methodology into a prediction of hearing preservation surgery. The system is built based on evidence from previous studies and could aid physicians in deciding whether to perform hearing preservation surgery on patients with VSs with a serviceable hearing status. With better patient selection using our system, individualized medical care may result in better patient outcomes.
Materials and Methods
Study approval
This retrospective study was approved by the Severance Hospital Institutional Review Boards (IRB number 2019-1867-001). The need for written informed consent was waived by the approval process of the review boards, owing to the retrospective nature of the study. All methods were performed complying with the Declaration of Helsinki.
Patient selection
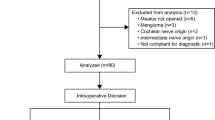
Among patients diagnosed with VSs from 2007 to 2017, 52 patients underwent hearing preservation surgery, either via MCFA or RSA. While all patients were included in the analysis, two patients were excluded. One patient was initially considered as VS but later revealed to be facial nerve schwannoma, which is not relevant to hearing abilities. Another patient was diagnosed as Neurofibromatosis type II. Therefore, we included a total of 50 patient’s data in the machine learning model. The detailed patient characteristics are described in Table 1.
Data acquisition, selection, and patient classification
Electronic medical records of 50 pathologically confirmed vestibular schwannoma patients via MCFA or RSA for excision were obtained. After reviewing previous literature for possible predictors of postoperative hearing8,18,19,20,24,27, the following preoperative measures were put into the learning model: 1) Pure-tone threshold of each frequency, 2) maximal word recognition score(WRS), speech detection threshold(SDT), most comfortable level of hearing(MCL), 3) Auditory brainstem response(ABR) latency of wave I-V interval, 4) asymmetry ratio of vestibular-evoked myogenic potential (VEMP), 5) canal paresis(CP) in caloric test of affected site, 6) maximum diameter of the tumor, and 7) type of approach (RSA or MCFA). Since the model was aimed to predict postoperative hearing preservation with preoperative tests, all intraoperative factors were not taken into account. Since RSA and MCFA are preferable in VSs in the cerebellopontine angle: porus and fundus, respectively, it was treated as the relative tumor location and included in preoperative measures.
We used a binary classification for prediction modeling. The result of the patient’s postoperative hearing was classified as preserved if the patient was able to maintain the pure-tone average better than 50 decibels, and the word recognition score was above 50% (50/50 rule) at six months postoperative audiology test.
Feature engineering, machine learning models
Some of the patient’s data were not available. VEMP asymmetry data was not available in 22 patients; CP in 1 patient; and I-V interval of ABR latency in 10 patients. In these cases, the median value was filled up for the machine learning model to minimize the missing effects. If the I-V interval of ABR latency was not countable, ten milliseconds were used. The VEMP asymmetry was calculated as the difference ratio of peak-to-peak amplitude between normal and pathologic P13 and N23 wave amplitude:
where Ah is the amplitude of P13 and N23 wave on the healthy side, and Ap is on the pathologic side. All variables were classified as continuous variables, except approach type (RSA and MCFA), which was the only categorical variable in the model.
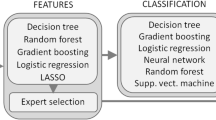
The machine learning was performed in a supervised manner. Currently, boosting and bagging are the most popular methods among tabular datasets, choosing GBM and DRF as one of the models’ lineup. SVMs are somewhat classical and were included in the study for comparison of accuracy. Lastly, neural network models have shown to be effective not only in computer visions, but also in tabular datasets, and were added to our models’ lineup. Totally, four learning models (SVM, GBM, DNN, DRF) were trained, and a comparison between the models was performed regarding accuracy. MATLAB2019a® (MathWorks, Inc., Natick, Massachusetts, United States) was used for SVM based model. For DRF, GBM, and DNN models, we built the system with Pytorch (www.pytorch.org) in Python programming language. In the training process, 80% of the patient’s data were used for training; 20% were left out for validation. We conducted five-fold-cross-validation for each model to rule out selection bias. The detailed composition of the model is described in Table 4.
Data availability
Patient data are not available for public access regarding patient privacy concerns but are available from the corresponding author on reasonable request if approved by the institutional review boards of Yonsei university college of medicine. DNN based machine learning model will be available with a reasonable request for testing purposes.
References
Kanzaki, J. et al. New and modified reporting systems from the consensus meeting on systems for reporting results in vestibular schwannoma. Otology & neurotology: official publication of the American Otological Society, American Neurotology Society [and] European Academy of Otology and Neurotology 24, 642–648 (2003). discussion 648-649.
Mahaley, M. S. Jr., Mettlin, C., Natarajan, N., Laws, E. R. Jr. & Peace, B. B. Analysis of patterns of care of brain tumor patients in the United States: a study of the Brain Tumor Section of the AANS and the CNS and the Commission on Cancer of the ACS. Clinical neurosurgery 36, 347–352 (1990).
Stangerup, S. E. et al. Increasing annual incidence of vestibular schwannoma and age at diagnosis. The Journal of laryngology and otology 118, 622–627 (2004).
Stangerup, S. E., Tos, M., Thomsen, J. & Caye-Thomasen, P. True incidence of vestibular schwannoma? Neurosurgery 67, 1335–1340 (2010). discussion 1340.
Thakur, J. D. et al. An update on unilateral sporadic small vestibular schwannoma. Neurosurgical focus 33, E1 (2012).
Meyer, T. A. et al. Small acoustic neuromas: surgical outcomes versus observation or radiation. Otology & neurotology: official publication of the American Otological Society, American Neurotology Society [and] European Academy of Otology and Neurotology 27, 380–392 (2006).
Moon, I. S., Cha, D., Nam, S. I., Lee, H. J. & Choi, J. Y. The Feasibility of a Modified Exclusive Endoscopic Transcanal Transpromontorial Approach for Vestibular Schwannomas. Journal of neurological surgery. Part B, Skull base 80, 82–87 (2019).
Kari, E. & Friedman, R. A. Hearing preservation: microsurgery. Curr Opin Otolaryngol Head Neck Surg 20, 358–366 (2012).
Mazo, C., Bernal, J., Trujillo, M. & Alegre, E. Transfer learning for classification of cardiovascular tissues in histological images. Computer methods and programs in biomedicine 165, 69–76 (2018).
Karri, S. P., Chakraborty, D. & Chatterjee, J. Transfer learning based classification of optical coherence tomography images with diabetic macular edema and dry age-related macular degeneration. Biomedical optics express 8, 579–592 (2017).
Gulshan, V. et al. Development and Validation of a Deep Learning Algorithm for Detection of Diabetic Retinopathy in Retinal Fundus Photographs. JAMA 316, 2402–2410 (2016).
Kermany, D. S. et al. Identifying Medical Diagnoses and Treatable Diseases by Image-Based Deep Learning. Cell 172, 1122–1131 e1129 (2018).
Hood, D. C. & De Moraes, C. G. Efficacy of a Deep Learning System for Detecting Glaucomatous Optic Neuropathy Based on Color Fundus Photographs. Ophthalmology 125, 1207–1208 (2018).
Tschandl, P. et al. Comparison of the accuracy of human readers versus machine-learning algorithms for pigmented skin lesion classification: an open, web-based, international, diagnostic study. Lancet Oncol 20, 938–947 (2019).
Cha, D., Pae, C., Seong, S.-B., Choi, J. Y. & Park, H.-J. Automated diagnosis of ear disease using ensemble deep learning with a big otoendoscopy image database. EBioMedicine 45, 606–614 (2019).
Lai, Y. H. et al. Deep Learning-Based Noise Reduction Approach to Improve Speech Intelligibility for Cochlear Implant Recipients. Ear and hearing 39, 795–809 (2018).
Bing, D. et al. Predicting the hearing outcome in sudden sensorineural hearing loss via machine learning models. Clinical Otolaryngology 43, 868–874 (2018).
Hochet, B. et al. Preoperative Assessment of Cervical Vestibular Evoked Myogenic Potentials (cVEMPs) Help in Predicting Hearing Preservation After Removal of Vestibular Schwannomas Through a Middle Fossa Craniotomy. Otology & neurotology: official publication of the American Otological Society, American Neurotology Society [and] European Academy of Otology and Neurotology 39, e1143–e1149 (2018).
Huo, Z., Chen, J., Wang, Z., Zhang, Z. & Wu, H. Prognostic Factors of Long-Term Hearing Preservation in Small and Medium-Sized Vestibular Schwannomas After Microsurgery. Otology & neurotology: official publication of the American Otological Society, American Neurotology Society [and] European Academy of Otology and Neurotology 40, 957–964 (2019).
Brackmann, D. E. et al. Prognostic factors for hearing preservation in vestibular schwannoma surgery. The American journal of otology 21, 417–424 (2000).
Tucker, D. W. et al. Long-Term Tumor Control Rates Following Gamma Knife Radiosurgery for Acoustic Neuroma. World neurosurgery 122, 366–371 (2019).
Smith, D. R. et al. Treatment Outcomes and Dose Rate Effects Following Gamma Knife Stereotactic Radiosurgery for Vestibular Schwannomas. Neurosurgery (2019).
Carlson, M. L. et al. Long-term hearing outcomes following stereotactic radiosurgery for vestibular schwannoma: patterns of hearing loss and variables influencing audiometric decline. Journal of Neurosurgery 118, 579 (2013).
He, Y. B., Yu, C. J., Ji, H. M., Qu, Y. M. & Chen, N. Significance of Vestibular Testing on Distinguishing the Nerve of Origin for Vestibular Schwannoma and Predicting the Preservation of Hearing. Chinese medical journal 129, 799–803 (2016).
Ushio, M. et al. Is the nerve origin of the vestibular schwannoma correlated with vestibular evoked myogenic potential, caloric test, and auditory brainstem response? Acta Otolaryngol 129, 1095–1100 (2009).
Tsutsumi, T., Tsunoda, A., Noguchi, Y. & Komatsuzaki, A. Prediction of the nerves of origin of vestibular schwannomas with vestibular evoked myogenic potentials. The American journal of otology 21, 712–715 (2000).
Kim, A. H., Edwards, B. M., Telian, S. A., Kileny, P. R. & Arts, H. A. Transient evoked otoacoustic emissions pattern as a prognostic indicator for hearing preservation in acoustic neuroma surgery. Otology & neurotology: official publication of the American Otological Society, American Neurotology Society [and] European Academy of Otology and Neurotology 27, 372–379 (2006).
Dilwali, S., Landegger, L. D., Soares, V. Y. R., Deschler, D. G. & Stankovic, K. M. Secreted Factors from Human Vestibular Schwannomas Can Cause Cochlear Damage. Scientific reports 5, 18599 (2015).
Chaudhary, K., Poirion, O. B., Lu, L. & Garmire, L. X. Deep Learning-Based Multi-Omics Integration Robustly Predicts Survival in Liver Cancer. Clin Cancer Res 24, 1248–1259 (2018).
Sharifi-Noghabi, H., Zolotareva, O., Collins, C. C. & Ester, M. MOLI: multi-omics late integration with deep neural networks for drug response prediction. Bioinformatics 35, i501–i509 (2019).
Acknowledgements
This study was supported by the National Research Foundation of Korea (NRF) grant funded by the Korea government (MSIP)(NRF-2018R1D1A1A02085472) to I.S.M.
Author information
Authors and Affiliations
Contributions
D.C. designed the study and collected data. D.C. wrote the machine learning code and performed training with S.H.S., S.H.K. J.Y.C. and I.S.M. performed the operations on the patients. D.C. drafted the manuscript with I.S.M. and all authors revised the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Cha, D., Shin, S.H., Kim, S.H. et al. Machine learning approach for prediction of hearing preservation in vestibular schwannoma surgery. Sci Rep 10, 7136 (2020). https://doi.org/10.1038/s41598-020-64175-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-020-64175-1
This article is cited by
-
Decision making on vestibular schwannoma treatment: predictions based on machine-learning analysis
Scientific Reports (2021)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
