
Abstract
Faba bean (Vicia faba L.) is a pulse crop of high nutritional value and high importance for sustainable agriculture and soil protection. With the objective of identifying gene-based SNPs, transcriptome sequencing was performed in order to reduce faba bean genome complexity. A set of 1,819 gene-based SNP markers polymorphic in three recombinant line populations was selected to enable the construction of a high-density consensus genetic map encompassing 1,728 markers well distributed in six linkage groups and spanning 1,547.71 cM with an average inter-marker distance of 0.89 cM. Orthology-based comparison of the faba bean consensus map with legume genome assemblies highlighted synteny patterns that partly reflected the phylogenetic relationships among species. Solid blocks of macrosynteny were observed between faba bean and the most closely-related sequenced legume species such as pea, barrel medic or chickpea. Numerous blocks could also be identified in more divergent species such as common bean or cowpea. The genetic tools developed in this work can be used in association mapping, genetic diversity, linkage disequilibrium or comparative genomics and provide a backbone for map-based cloning. This will make the identification of candidate genes of interest more efficient and will accelerate marker-assisted selection (MAS) and genomic-assisted breeding (GAB) in faba bean.
Similar content being viewed by others


Introduction
Legume crops serve as a source of food and feed. They also play an important role in sustainable agriculture because of their ability to improve soil fertility by fixing atmospheric nitrogen and increasing crop yield when used in crop rotation with cereals or intercropping1. In particular, faba bean (Vicia faba L.; Vf) is a primary ingredient of daily meals in both developing and industrialized countries due to its high content in proteins, carbohydrates, dietary fibers and micronutrients2,3. It is the most yielding pulse crop after field pea. However, its yield is still about half that of wheat, indicating that great breeding efforts are still needed4. Faba bean yield is greatly affected by environmental conditions, especially extreme temperatures, drought and acidity5,6. In addition, diseases such as chocolate spot (Botrytis fabae S. or B. cinerea P.) or ascochyta blight (Ascochyta fabae S.), viruses such as faba bean necrotic viruses, parasitic weeds of Orobanche genus and pests such as leaf weevil (Sitona lineatus L.), aphids (Aphis fabae S., A. craccivora K., Acyrthosiphon pisum H., Myzus persicae S.) or seed weevils (Bruchus rufimanus B.) considerably reduce its yield and affect the commercialization of the grains5,7. Other factors limiting the production of faba bean include the overproduction of flowers resulting in a variable fertilization rate and abortion of ovules2, the need for pollinators for outcrossing and fertilization of ovules8 and the strong influence of symbiosis for optimal concentration of nitrogen (N) in the grain and for N soil fertility9.
Faba bean is a diploid outcrossing species (2n = 12) with a “giant genome”10 of approximately 13 Gb distributed on six chromosomes. The high content in transposable elements11 complexifies the faba bean genome assembly and map-based cloning. Most of the linkage maps generated so far have a low to medium saturation and are based on morphological, isozyme, restriction fragment length polymorphism (RFLP), random amplified polymorphic DNA (RAPD), sequence characterized amplified region (SCAR), intron targeted amplified polymorphism (ITAP), simple sequence repeat (SSR) and low-density single-nucleotide polymorphism (SNP) markers12,13,14,15,16,17,18,19,20,21. SNP-based genetic maps have been recently developed21. To date, the most saturated map is the one reported by Webb et al.21 consisting of 687 SNPs. This map provided a first glimpse of synteny of faba bean with other legumes such as barrel medic (Medicago truncatula L.; Mt), lupine (Lupinus albus L.), soybean (Glycine max (L.) M.; Gm) or lentil (Lens culinaris M.)16,21. In fact, the SNPs used to construct the consensus map of Webb et al.21 were designed based on orthologous sequences in M. truncatula with the objective of physically anchoring the faba bean consensus map to the Medicago genome. Webb et al.21 also took advantage of the macrosynteny between these two species to discern the level of conservation of the genetic organization between faba bean and lentil, one of its most closely related crop species. A high conservation of genomic blocks between V. faba and these legume species was reported.
The development of dense and robust genetic maps that involve multiple populations and gene-based markers is a prerequisite for marker-assisted selection (MAS) and paves the way to V. faba genome assembly. Now that pulse genomes are becoming available, it is important to implement more accurate comparative genomic approaches that will reinforce faba bean breeding programs through a faster and more efficient identification of candidate genes. Transcriptome sequencing has been intensively used in the development of SNP markers for genetic mapping and diversity panel structuration of model species and crops with large genomes21,22,23,24,25,26,27,28. In addition, Illumina MiSeq.29 has made possible the identification, location and functional characterization of genes that control traits of interest and has been used to provide a more comprehensive view of diversity and gene function in plants30,31,32. The design of SNP markers is strongly recommended for the construction of genetic linkage maps, as they stand out for their uniform distribution throughout the genome, for being numerous and for their tendency to be biallelic and codominant33,34. Therefore, we chose to exploit next-generation sequencing (NGS) technologies and transcriptome sequencing to specifically address the expressed gene fraction (exome) for the discovery of gene-based SNPs. The objective of our work was to develop high-resolution genetic linkage maps in three interconnected faba bean recombinant line populations and build a high-density consensus map. Our work also took advantage of macrosynteny among legume relatives to locate faba bean genomic regions conserved in different sequenced species. A comparative alignment and mapping between the faba bean consensus map developed herein and the genomes of barrel medic, birdsfoot trefoil (Lotus japonicus L.; Lj), chickpea (Cicer arietinum L.; Ca), common bean (Phaseolus vulgaris L., Pv), cowpea (Vigna unguiculata (L.) W.; Vu), pea (Pisum sativum L.; Ps) and soybean has been performed. The identification of highly syntenic and collinear areas between faba bean and already sequenced species will facilitate candidate gene discovery. In this way, SNP markers developed in genes resulting from the present work will be very useful in MAS and in map-based isolation of candidate genes.
Materials and Methods
Plant material
Three connected bi-parental mapping populations have been built using cultivar (cv.) HIVERNA as a common female parent, and the accessions NOVA GRADISKA, SILIAN, and QUASAR as male parents for Pop1, Pop2 and Pop3, respectively. The winter type cv. HIVERNA of German origin was selected as a common parent between the three populations. The parents NOVA GRADISKA (originated in Croatia) and SILIAN (originated in Northern Sudan) are both minor type landraces sown in late and early spring, respectively; while QUASAR (originated in United Kingdom) is a winter type cultivar adapted to oceanic climate (cool winters with abundant rainfall). NOVA GRADISKA and QUASAR have previously been reported as resistant to the faba bean weevil (Bruchus spp.) attack35. All segregating recombinant populations used for mapping were made of F3 plants produced by single seed descent (SSD) of F2 plants. Pop1 includes 102 F3 individuals, Pop2 147 F3 plants derived from two F1s and Pop3 96 F3 plants. Samples were collected from the leaves of an F3 plant for each recombinant line. Tissues were flash-frozen in liquid nitrogen and stored at −80 °C until DNA extraction for genotyping.
For SNP discovery, the parental lines were grown in a growth chamber (photoperiod of 16 h light/day, 15 °C night, 20 °C day, hygrometry 60% min) for 15 days. Samples of whole plant per parental line were collected. Tissues were flash-frozen in liquid nitrogen and stored at −80 °C until RNA extraction.
Transcript assembly and SNP Discovery
SNP discovery was carried out as described by Duarte et al.28 with slight modifications. Total RNAs were extracted from the parental lines and checked for quality and integrity. RNAs were then converted to full-length double-stranded cDNA and normalized with the Mint-2 and Trimmer-2 kits (Evrogen, Moscow, Russia), respectively. Later, q-RT-PCR assays were developed on a set of genes of different abundances to assess the efficiency of normalization. Normalized double-stranded cDNAs were sheared into 450 bp fragment size using the Covaris E220 system (Covaris Inc., Massachusetts, USA). Individual indexed NGS libraries were then produced with the SPRIworks HT reagent kit (Beckman Coulter, Indianapolis, USA). An equimolar pool of the four libraries was sequenced on the Illumina MiSeq platform (V2 chemistry, PE 2 × 250 nt, 12 million of clusters) (Illumina, California, USA). FastQC was used to check raw data quality. Then, sequencing adaptor removal and quality trimming were performed using trim_galore and SMART oligos (normalization primers) that were masked in the raw sequence readings using an in house script. MIRA 4.0 (http://mira-assembler.sourceforge.net) software was used to perform a de novo assembly of all samples at once. Reads of parental genotypes were remapped on the assembly using BWA36 and only contigs with more than 10x coverage were kept for further analysis. Transdecoder37 was used to predict open reading frames in contigs. BUSCO v3.0.138 was used on viridiplantae odb10 database to assess completeness of the dataset. Functional annotation was performed using eggNOG-mapper39 on eggNOG database 5.040.
The SNP discovery was then performed with SAMtools mpileup36 and BCFtools call41. Only homozygous SNPs were retained.
Genotyping F3 populations
DNA samples were extracted from leaf tissues of the parents and the individuals of the three populations using the NucleoSpin Plant II Mini kit (https://www.mn-net.com/, Hoerdt, France) following the manufacturer’s protocol. DNAs were normalized before being fragmented with Adaptive Focused Acoustics Technology (Covaris Inc., Massachusetts, USA). A 250 bp target size value was obtained by using a Covaris E220 system, according to the manufacture’s instructions. Then DNA fragments underwent a NGS library preparation procedure consisting in end repair and Illumina adaptor ligation using the KAPA HTP kit (Roche, Basel, Switzerland). Individual index sequences were added to each library for identifying reads and sorting them according to their initial origin. Two thousand SNPs were targeted to design capture probes. The Sequence Capture was done by using SeqCap EZ Developer kit from Roche according to the manufacture’s instructions. The sequence capture reaction efficiency was evaluated by measuring, with a qPCR assessment, a relative fold enrichment and loss of respectively targeted and non-targeted regions before and after the sequence capture reaction.
The captured samples were sequenced on HiSeq sequencing platform (Illumina, California, USA) with a Paired End sequencing strategy of 2 reads of 100 bases. The objective was to produce around 3 Million sequencing clusters per sample.
Raw reads were trimmed for adaptor sequence using cutadapt 1.8.342 and then aligned on the targeted regions with Novoalign (http://www.novocraft.com, Selangor, Malaysia). Genotype at each position of interest was determined using SAMtools mpileup36 and in house Perl scripts to filter out low quality positions, call the SNPs, and to produce a genotyping matrix for all 2000 selected markers.
Genetic maps construction for each population
Markers were first filtered for deviation from Mendelian segregation (37.5:25:37.5) using the following index \(Distortion=\frac{1}{2}\cdot \frac{{\sum }_{i=1}^{{N}_{genotypicclasses}}|{f}_{i,observed}-{f}_{i,expected}|}{1-min({f}_{expected})}\) with threshold of 0.8. Then, markers were assigned to linkage groups by estimating the pairwise recombination frequencies within each population using the maximum likelihood procedure with the forward-backward algorithm and a LOD score of 5.0 as the threshold for significant linkage in the software JoinMap V5.043. In a second stage, markers were ordered and assigned to their positions in each linkage group by likelihood maximization. Candidate orders’ likelihoods were computed as for F2 populations using Spell-QTL Bayesian inference44 and heuristic local maximization was performed using custom R scripts implementing the algorithm described earlier in Ganal et al.45. This heuristic was based on the serial inference of marker orders, proceeding according to the following steps. First, 10 “seed” markers were randomly chosen in each chromosome, and one statistically robust scaffold map replicate was constructed from each seed marker, by iteratively choosing the most strongly linked neighbour with at least 10 cM between adjacent markers. Then given these scaffold maps, marker density was increased to produce framework maps containing as many markers as possible while keeping a LOD score >3.0 for the robustness of marker orders. Finally, the complete maps were obtained by placement of additional markers using bin-mapping45. As a post-processing step, it was necessary to calculate the distance between pairs of markers taking into account that the recombination rates estimated by the algorithm assumed that the populations were F2 whereas they were in fact F3. For that, we first determined the correspondence between rF2, the recombination rate estimated assuming an F2 population, and the true recombination rate, r. That correspondence was obtained in two steps. In the first step we used the explicit formula relating rF2 to the two-locus genotype frequencies fAaBb, fAaBB = fAABb, fAABB = faabb, and fAAbb=faaBB where the two parental types are denoted A (respectively a) and B (respectively b) and the labels refer to unphased genotypes. Then in the second step we inferred r from those 7 frequencies by maximum likelihood using the formulas for those frequencies in F3 as a function of r. Finally, centiMorgan (cM) distances were calculated using Haldane’s mapping function46.
Consensus genetic map construction
SNP sequences anchored to the sequences of the SNPs previously mapped by Webb et al.21 were used to assign each linkage group (defined by the initial seed used in the map construction) to one chromosome number. For each chromosome, we produce a consensus map that summarizes the recombination information within the three populations. Our method is quite general and in particular it does not assume collinearity of the individual maps. Its key feature is the minimization of an index ID which measures the differences between the (unknown) consensus map M* and all of the individual maps M1, M2. We forced our consensus map to include all the markers present in the individual maps. M* is to be specified by assigning a genetic position for each marker and of course that will also define the marker ordering in M*. Without loss of generality, the genetic position of the first marker of M* can be considered as the origin of genetic coordinates. The task is then to estimate the genetic positions of the rest of the markers.
In our framework based on the minimization of the index ID, we first define a “distance” between two maps via the formula:
where i labels the markers that are common in the two maps and j(i) labels the markers that are not only in common in the two maps but also meet a criterion for their distance to marker i. Specifically, if marker j(i) is quite far from marker i, that corresponding interval does not provide much information, so it is better to exclude it from the sum. In general, there are many of these markers and thus it is also computationally efficient to exclude them. Inversely, if a marker j(i) is very close to i, the corresponding distance is often not very well determined and so again it is better to exclude it. Therefore, our criterion imposes both a minimum and maximum distance between j(i) and i. In addition, to avoid having many j(i) markers for some i and only a few for others, we keep only a subset of the possible markers j(i) for a given i. As a result, all the is are treated on an equal footing and have the same importance in D(M, M′). Given this definition for the distance D(M, M′) between two arbitrary maps, we numerically search for the positions of the markers in M* to minimize the index
where n runs through all the individual maps from which the consensus is being built. If the maps have been determined using very different population sizes, we weight each term of this sum by the corresponding population size. In this way, if a map has a much smaller population than the other maps, it will have little influence on the construction of M* which is justified since its marker positions are not very accurate. On the contrary, if a map has a much larger population than the other maps, it will have a strong influence on the construction of M*, which is again justified since its marker positions are rather precisely determined.
Synteny with other legume crops
The flanking sequences of the SNP markers placed in the consensus map were searched against C. arietinum (v1)47 (https://www.ncbi.nlm.nih.gov/assembly/GCF_000331145.1/), P. sativum (v.1)48 (https://urgi.versailles.inra.fr/Species/Pisum/Pea-Genome-project), M. truncatula (Mt5.0)49 (https://medicago.toulouse.inra.fr/MtrunA17r5.0-ANR/), L. japonicus (v 2.5)50 (http://www.kazusa.or.jp/lotus/), G. max (v2.0)51 (http://www.plantgdb.org/GmGDB/), Phaseolus vulgaris (v2.1)52 (https://phytozome.jgi.doe.gov/pz/portal.html#!info?alias=Org_Pvulgaris) and Vigna unguiculata (v1.1)53 (https://phytozome.jgi.doe.gov/pz/portal.html#!info?alias=Org_Vunguiculata_er) genomes assemblies using the BLASTn function in order to identify the corresponding orthologous genes and their position in those genomes.
Results
Transcriptome assembly and gene annotation
A total of 1.1 million RNA-seq reads from 4 faba bean accessions, i.e. HIVERNA, NOVA GRADISKA, SILIAN and QUASAR, were assembled into 164,529 contigs (Table S1). After filtering on coverage (see Materials and Methods section), a transcriptome resource of 39,423 high-quality contigs with a N50 of 1460 bp (Table S2) and a BUSCO completeness score of 84.8% was built (Table S3). Functional annotation was obtained for 24,507 contigs (Fig. S1). Each contig of the unigene set was assigned, if possible, to the categories of biological processes, molecular functions and cellular components (Fig. S1). Among the biological processes, the metabolism of nucleobase, nucleoside, nucleotide and nucleic acid (10.26%), biosynthesis (9.67%) and cell organization and biogenesis (8.02%) were the main classes represented (Fig. S1A). Catalytic (36.49%) and transferase (13.17%) activities contributed in greater proportion to the category of molecular function (Fig. S1B). The cytoplasmic (31.68%) and nucleus (15.91%) cellular components were the most represented classes within the annotation (Fig. S1C).
SNP discovery, selection, genotyping and individual genetic linkage of the three F3 populations
A total of 105,828 homozygous SNPs (Fig. S2) were detected on 19,190 contigs (5.5 SNP/contig) with an average coverage of 47.7×. In total, 64.77% of the SNPs were transitions while 35.23% were transversions. Out of these robust SNPs, 2,000 were selected based on the following parameters: SNP quality score, polymorphism in more than one population (see Materials and Methods section), potential synteny with pea and Medicago truncatula and 1 SNP maximum per contig. Capture probes were then designed to allow large-scale targeted genotyping. Of the 2,000 gene-based SNP markers selected above, 1,911 markers were successfully scored on the progenies of three F3 inbred populations, i.e., Pop1-3 (Table S4). Of them, 95.2% (1,819 SNPs) were polymorphic in at least one population. Altogether, 1,446 SNPs were polymorphic in Pop1, 1,499 in Pop2 and 1,409 in Pop3 (Table S4).
Linkage mapping of the three F3 populations
Individual genetic maps were constructed for the three F3 populations after filtering markers for distortion and missing data (see Materials and Methods section). Two hundred thirty-three (Pop1), 189 (Pop2) and 175 (Pop3) SNP markers were placed on the individual scaffold maps (Fig. S3). The framework maps included 350 (Pop1), 209 (Pop2) and 326 (Pop3) markers (Fig. S4). The full maps had 1,438 markers for Pop1, 1,312 markers for Pop2 and 1,406 markers for Pop3 that covered all six faba bean LGs (Table 1; Figs. 1, 2 and S5, Tables S5–S7). The number of markers per LG ranged between 141 (Pop3, LGV) and 401 (Pop1, LGI) SNP markers (Table 1). Total map lengths were: 1,426 (Pop1), 1,832 (Pop2) and 1,697 (Pop3) cM. The density of markers was high for all LGs in the three populations. Pop1 had an average marker density of 1.01 markers per cM, while in Pop2 this density was 0.72 markers/cM and in Pop3 it was 0.83 markers/cM. The average gap size between pairs of non-colocalized markers was 1.16 cM in Pop1, 1.47 cM in Pop2 and 1.36 cM in Pop3 (Table 1). Only a few large gaps (>10 cM) were observed: three gaps on the linkage map for Pop1 (LGII and LGV), nine gaps on the map from Pop2 (LGI, LGIII, LGIV, LGV and LGVI) and eight gaps on the map from Pop3 (LGI, LGII, LGIII and LGV) (Table 1). Nine hundred twenty-eight markers were common to the three populations (Fig. 2). One thousand five hundred and four SNPs were mapped onto at least two of the three linkage maps. Pairwise comparisons of the positions and the orders of common markers were performed among the three populations to assess synteny and collinearity (Fig. 3). The positions of the marker were consistent in the LGs of the three populations. High positive correlations (Spearman test) between map orders were obtained: Pop1-Pop2, r = 0.98; Pop1-Pop3, r = 0.99 and Pop2-Pop3, r = 0.98; P < 0.001).

Faba bean individual genetic linkage maps constructed from three populations of (A) 102 F3 recombinant lines derived from the cross between Vicia faba cv. Nova Gradiska and Hiverna; (B) 147 F3 derived from the cross between cv. Silian and Hiverna and (C) 96 F3 derived from the cross between cv. Quasar and Hiverna.

Venn diagram showing the SNP markers shared between the individual genetic maps of the three populations presented in this study.

Order comparison of the marker assignments by linkage group between the individual linkage maps of the threee recombinant populations presented in this study. Marker positions are normalized.
Segregation distortion of the individual maps
There was a significant distortion of segregation (χ2 test, P < 0.05) with respect to the expected Mendelian segregation ratio (37.5:25:37.5) for a minority of markers in the three populations (5.57% in Pop1, 9.14% in Pop2, 8.52% in Pop3). Only a few markers exceeded the index distortion threshold of 0.8 used for mapping (see Materials and Methods section).
Pop2 presented a region with segregation distortion towards SILIAN alleles at the bottom of LGI (Figs. 4 and S6). Although with less intensity, LGI of Pop1 also displayed a region in which segregation favoured the alleles of the male parent NOVA GRADISKA (Figs. 4 and S6). Outside of this region, the segregation distortion slightly favoured NOVA GRADISKA alleles in Pop1 (except in LGIII where HIVERNA alleles were over-represented) and SILIAN alleles in Pop2 (except in LGVI where HIVERNA alleles were favoured) while in Pop3 HIVERNA alleles were favoured (except in LGIII and LGIV where QUASAR alleles were more frequent) (Fig. S6).

Distribution of the segregation distortion (χ2 test, P = 0,05) of the SNPs used to contruct the three faba bean individual maps in the recombinant populations studied throughout the six linkage groups. (A) Pop1; (B) Pop2 and; (C) Pop3. Red dashed line indicates the threshold above which segregation distorsion is significant.
Integration of the individual maps into a consensus map of faba bean
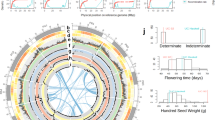
General collinearity among the individual genetic linkage maps (Fig. 3) helped to construct a dense consensus map of 1,547.71 cM that included 1,728 markers (95% of the polymorphic SNPs) (Table 1, Fig. 5, Table S8). The number of markers per LG varied from a minimum of 153 (LGV) to a maximum of 375 (LGI) SNPs (Table 1). The density of markers in this consensus map was high in all LGs, with an average density of 1.12 markers/cM. The average distance between two markers was 1.17 cM (Table 1). Nonetheless, 9 intervals were found with a distance between two markers greater than 10 cM, the largest gap being 21.51 cM (Table 1). The position and order of markers on the individual and consensus maps was overall conserved (r = 0.99 for Pop1-consensus, Pop2-consensus Pop3-consensus, P < 0.001) (Figs. 6 and S7). A few local inversions of the order of markers were observed (Fig. S7).

Faba bean consensus genetic linkage map generated after the integration of three individual maps originated from three populations consisting of (A) 102 F3 recombinant lines derived from the cross between Vicia faba cv. Nova Gradiska and Hiverna; (B) 147 F3 derived from the cross between cv. Silian and Hiverna and (C) 96 F3 derived from the cross between cv. Quasar and Hiverna.

Comparison of the marker assignments by position between the individual maps of the three populations and the consensus map.
Comparison between the faba bean consensus map SNP marker sequences reported here and those presented in the Webb et al.21 consensus map using BLASTn search highlighted markers located in the same genes. Eighty-eight common markers (e.g. markers corresponding to the same Medicago truncatula gene sequence) were found. The distribution and position of these common markers between both maps showed highly conserved collinearity between them in the six LGs, although a few marker inversions were also observed (Fig. S8), which is another evidence of the reliability of the data presented here.
Macrosynteny between the faba bean consensus map and the genomes of related legume species
Syntenic and collinear relationships between the faba bean consensus map presented in this study and the genomes of related legume species are summarized in Fig. 7. As expected, the degree of synteny and collinearity between faba bean and the legume species compared here increased when the phylogenetic distance decreased and vice versa. The genomes of P. sativum, C. arietinum and M. truncatula showed high levels of macrosynteny with our consensus map (Fig. 7). The best blast hits on the M. truncatula and P. sativum genomes for the faba bean markers’ flanking sequences are described in Table S4, including their annotations and positions. There was a high conservation of synteny and collinearity between LGs II, IV, V and VI of faba bean and PsChr5, PsChr4, PsChr3 and PsChr7 of P. sativum and LGs II, III, IV and V of faba bean and MtChr3, MtChr1, MtChr4 and MtChr7 of M. truncatula, respectively (Fig. 7). LGs III, IV, V and VI of faba bean turned out to be almost completely collinear to the chromosomes CaChr4, CaChr7, CaChr3 and CaChr6 of C. arietinum, respectively (Fig. 7). However, syntenic regions were associated with several chromosomes of the sequenced legumes in the rest of the LGs of faba bean. The most striking case was that of LGI, which was the longest LG. Syntenic blocks corresponding to V. faba LGI were found in CaChr1, CaChr2 and CaChr8, in PsChr1, PsChr2 and PsChr5, and also in MtChr2 and MtChr5 (Fig. 7). Substantial collinear blocks were also found between V. faba and P. vulgaris, V. unguiculata and L. japonicus, despite their greater phylogenetic distance from faba bean (Fig. 7). The same was observed between faba bean and L. japonicus: VfLGI-LjChr2 and -LjChr6, VfLGII-LjChr1, VfLGIII-LjChr5, VfLGV-LjChr1, VfLGVI-LjChr3 and -LjChr4; faba bean and P. vulgaris: VfLGI-PvChr6, VfLGII-PvChr6 and -PvChr9, VfLGIII-PvChr7, VfLGIV-PvChr3, VfLGV-PvChr1 and -PvChr8, VfLGVI-PvChr2 and -PvChr11; faba bean and V. unguiculata: VfLGI-VuChr2, -VuChr7 and -VuCVhr9, VfLGII-VuChr6 and -VuChr9, VfLGIII-VuChr7 and -VuChr8, VfLGIV-VuChr3, VfLGV-VuChr1 and VfLGVI-VuChr3 (Fig. 7). In the case of soybean, conservation patterns can be intuited between VfLGI-GmChr13, VfLGII-GmChr4 and -GmChr6, VfLGIII-GmChr10, -GmChr14 and -GmChr20, VfLGIV-GmChr17, VfLGV-GmChr19 and VfLGVI-GmChr5, -GmChr8, -Gm12 and -Gm13 (Fig. 7).

Dot-plots for synteny and collinearity comparisons between the faba bean consensus map (cM) and the genomes (bp) of (A) Pisum sativum; (B) Medicago truncatula; (C) Cicer arietinum; (D) Vigna unguiculata (E) Phaseolus vulgaris; (F) Glycine max and (G) Lotus japonicas.
Discussion
New faba bean genetic resources: transcriptome, gene-based SNPs, gene-based SNP markers and a consensus map
Europe suffers a significant deficit of plant proteins that makes it necessary to import up to 70% of the plant-based proteins consumed54. Grain legumes including faba bean are good candidates to boost EU plant protein production due to the high protein content of their seeds. Despite this potential and the important environmental services related to grain legume production, these crops represent only 3–4% of the arable land. The low investment in breeding programs has limited the development of stable high-yielding varieties, resistant to biotic and abiotic stresses55. The future of the faba bean crop depends on efficient breeding programs including MAS and/or genomic-assisted breeding (GAB), in which the development of improved varieties is accelerated. For this, new faba bean genetic resources are needed. Fortunately, the progress and cheapening of NGS and assembly technologies in recent years are allowing the development of new genetic resources. The suitability and effectiveness of the transcriptome sequencing approach for the generation of gene-based SNP markers resulted in a transcriptomic resource of 39,423 faba bean transcripts obtained after de novo assembly (File S1), of which 24,507 contigs were annotated. Although this amount is lower than that of other studies56,57, it is a sufficiently high number for the discovery of robust SNP markers well distributed throughout the faba bean genome. These data are also available for use in transcriptome comparisons with other faba bean genotypes and between faba bean and other species. In addition, the faba bean transcriptome was used to identify 105,828 gene-based SNPs (File S2). The present work makes this new source of SNPs available to the faba bean community, who can develop additional SNP markers useful in other genetic backgrounds. Two thousand non-redundant loci (Table S4) from the 105,828 SNPs were selected to develop the molecular markers for genotyping 245 recombinant lines from three populations and the four parental lines that originated them. One thousand nine hundred eleven SNP markers (95.5%) were validated after a successful genotyping (Table S4). Our set of 1,819 polymorphic gene-based SNPs is a valuable tool for the faba bean community and particularly for breeders. Since the markers were designed in genes, they are highly informative and allow establishing syntenic relationships with other species32,58,59. The high quality of this set of markers was confirmed after the construction of three individual genetic maps derived from three different populations.
High collinearity between individual maps led to the construction of the densest faba bean consensus map known to date. The map includes 1,728 well-distributed markers along six LGs that correspond to the six faba bean chromosomes and covers 1,547.71 cM with a dense marker placement (0.89 cM between adjacent pairs of markers on average) (Fig. 5). In accordance with previous cytogenetic studies LGI, corresponding to chromosome 1, was the largest linkage group60,61. The total map size is consistent with the 1,403.8 cM size of the consensus map previously published by Webb et al.21. Despite having different genetic backgrounds, both consensus maps showed a good collinearity (Fig. S8), which confirming the good quality of both maps. Consensus gene-based genetic linkage maps are useful in meta-QTL analysis, phylogenetic and comparative genomic studies, map-based cloning and GAB, especially in the absence of a genome sequence. The phenotypic characteristics of the parents of the recombinant lines make these populations and maps useful resources. The next steps in our research will be to perform Quantitative Trait Locus (QTL) analyses to identify potential candidate genes for resistance to faba bean seed weevils in Pop1 and Pop3. In a previous work35, we reported that the male parents NOVA GRADISKA and QUASAR present partial resistance to the attack of bruchids. Differences in parental responses to bruchids attacks suggested distinct resistance mechanisms in the two accessions. This would be of great advantage in breeding since different genes could be pyramided and introgressed simultaneously in cultivars, making the resistance to faba bean weevils more durable and contributing to agriculture with less need for pesticides. In the case of Pop2, a distorted region was located on the top of LGI (Figs. 4 and S6). Knowledge about this area is of great importance for MAS because the genes located in this part of LGI of Pop2 seem to segregate together in favour of the genetic background of SILIAN. If favourable alleles of a gene of interest were located in this area of the LGI but at the same time there were nearby genes that carried unfavourable alleles, most likely, they would all segregate together. Thus, the introgression of favourable agronomic traits will be quite difficult in such a situation. Other previously published faba bean maps have also noted the presence of distorted regions throughout the different linkage groups62,63,64.
Syntenic regions shared between faba bean and other legumes will facilitate future comparative genomic studies
Exploitation of the syntenic relationships between the faba bean consensus map developed in this work and available legume genomes will make the identification of candidate genes of important traits easier in the future and will enable forthcoming synteny-based gene cloning approaches. As expected, robust macrosyntenic blocks that sometimes nearly cover a complete chromosome were found between faba bean LGs and pea, barrel medic and chickpea chromosomes since their phylogenetic proximity is greater than that of the rest of the compared sequenced legumes (Fig. 7). In accordance with our results, Webb et al.21 also reported good levels of synteny between their consensus map, the genome of M. truncatula and the genetic map of lentil developed by Sharpe et al.27. In addition, we have been able to locate abundant blocks of macrosynteny between faba bean and common bean, cowpea or birdsfoot trefoil despite their greater evolutionary distances (Fig. 7), providing further evidence of the mapping accuracy. By contrast, the number of markers in our consensus map may not be enough to clarify the macrosynteny between faba bean and soybean due to the extensive chromosomal rearrangements and polyploidization of the soybean genome. Hopefully, gene conservation with soybean will be more evident once the faba bean genome is available, as has happened in the case of the pea48. Although duplication of the soybean genome and chromosomal rearrangement are a limitation for translational genomics with faba bean, synteny in duplicate regions would be a good resource to exploit. Despite the large size of the faba bean genome, synteny data reflects a globally conserved organization with respect to the genome of the legumes studied here. There is of course a certain amount of reorganization that can be easily observed, for example, in the condensed LGI of faba bean that gathers the genes located on chromosomes 1, 2 and 5 of pea. These results include V. faba as an additional syntenic species in the paleogenomic scheme described in Kreplak et al.48.
In conclusion, this work provides to faba bean researchers and breeders a new faba bean exome assembly originated from transcriptome data of four accessions (HIVERNA, NOVA GRADISKA, SILIAN and QUASAR), a set of 105,828 gene-based SNPs and 1,819 mapped SNP markers on three individual linkage maps and one consensus map. The high quality of the assembly resulted in the identification of a large number of SNPs of the most informative type due to their location in genes. The molecular markers designed from this set of SNPs were validated in three recombinant populations, resulting in the densest faba bean consensus map to date. The SNP markers designed here are available for genotyping other inbred populations that could be integrated later into our consensus map. These robust resources will be useful for trait mapping, genetic diversity and linkage disequilibrium studies or map-based cloning, and will enable faba bean MAS and GAB as well as the identification of candidate genes of agronomic interest through synteny-based approaches.
References
Stagnari, F., Maggio, A., Galieni, A. & Pisante, M. Multiple benefits of legumes for agriculture sustainability: an overview. Chemical and Biological Technologies in Agriculture 4 (2017).
O’Sullivan, D. M. & Angra, D. Advances in Faba Bean Genetics and Genomics. Front. Genet. 7, 150 (2016).
Mulualem, T., Dessalegn, T. & Dessalegn, Y. Participatory varietal selection of faba bean (Vicia faba L.) for yield and yield components in Dabat district, Ethiopia. Wudpecker. J. Agric. Res 7, 270–274 (2012).
Food and Agriculture Organization of the United Nations (FAO). FAOSTAT. Available at, http://www.fao.org/faostat (2017).
Kharrat, M., Le Guen, J. & Tivoli, B. Genetics of resistance to 3 isolates of Ascochyta fabae on Faba bean (Vicia faba L.) in controlled conditions. Euphytica 151, 49–61 (2006).
Cernay, C., Ben-Ari, T., Pelzer, E., Meynard, J.-M. & Makowski, D. Estimating variability in grain legume yields across Europe and the Americas. Sci. Rep. 5, 11171 (2015).
Maalouf, F. et al. Development of faba bean productivity and production in the Nile Valley, Red Sea and Sub-Saharan region. (2009).
Nayak, G. K. et al. Interactive effect of floral abundance and semi-natural habitats on pollinators in field beans (Vicia faba). Agric. Ecosyst. Environ. 199, 58–66 (2015).
Denton, M. D., Pearce, D. J. & Peoples, M. B. Nitrogen contributions from faba bean (Vicia faba L.) reliant on soil rhizobia or inoculation. Plant Soil 365, 363–374 (2013).
Cooper, J. W. et al. Enhancing faba bean (Vicia faba L.) genome resources. J. Exp. Bot. 68, 1941–1953 (2017).
Negruk, V. Mitochondrial Genome Sequence of the Legume Vicia faba. Front. Plant Sci. 4, 128 (2013).
Patto, M. C. V., Torres, A. M., Koblizkova, A., Macas, J. & Cubero, J. I. Development of a genetic composite map of Vicia faba using F 2 populations derived from trisomic plants. TAG. Theor. Appl. Genet. 98, 736–743 (1999).
Román, B., Torres, A. M., Rubiales, D., Cubero, J. I. & Satovic, Z. Mapping of quantitative trait loci controlling broomrape (Orobanche crenata Forsk.) resistance in faba bean (Vicia faba L.). Genome 45, 1057–1063 (2002).
Avila, C. M. et al. Isolate and organ-specific QTLs for ascochyta blight resistance in faba bean (Vicia faba L). TAG. Theor. Appl. Genet. 108, 1071–1078 (2004).
Gutierrez, M. V. et al. Cross-species amplification of Medicago truncatula microsatellites across three major pulse crops. Theor. Appl. Genet. 110, 1210–1217 (2005).
Ellwood, S. R. et al. Construction of a comparative genetic map in faba bean (Vicia faba L.); conservation of genome structure with Lens culinaris. BMC Genomics 9, (2008).
Zeid, M. et al. Simple sequence repeats (SSRs) in faba bean: new loci from Orobanche -resistant cultivar ‘Giza 402’. Plant Breed. 128, 149–155 (2009).
Díaz-Ruiz, R. et al. Confirmation of QTLs controlling Ascochyta fabae resistance in different generations of faba bean (Vicia faba L.). Crop Pasture Sci. 60, 353 (2009).
Satovic, Z. et al. A reference consensus genetic map for molecular markers and economically important traits in faba bean (Vicia faba L.). BMC Genomics 14 (2013).
Kaur, S. et al. SNP discovery and high-density genetic mapping in faba bean (Vicia faba L.) permits identification of QTLs for ascochyta blight resistance. Plant Sci. 217–218, 47–55 (2014).
Webb, A. et al. A SNP-based consensus genetic map for synteny-based trait targeting in faba bean (Vicia faba L.). Plant Biotechnol. J. 14, 177–185 (2016).
Barbazuk, W. B., Emrich, S. J., Chen, H. D., Li, L. & Schnable, P. S. SNP discovery via 454 transcriptome sequencing. Plant J. 51, 910–918 (2007).
Ma, Y. et al. Development and characterization of 21 EST-derived microsatellite markers in Vicia faba (fava bean). Am. J. Bot. 98, e22–4 (2011).
Galeano, C. H. et al. Saturation of an Intra-Gene Pool Linkage Map: Towards a Unified Consensus Linkage Map for Fine Mapping and Synteny Analysis in Common Bean. PLoS One 6, e28135 (2011).
Kaur, S. et al. Transcriptome sequencing of field pea and faba bean for discovery and validation of SSR genetic markers. BMC Genomics 13, 104 (2012).
Loridon, K. et al. Single-nucleotide polymorphism discovery and diversity in the model legume Medicago truncatula. Mol. Ecol. Resour. 13, 84–95 (2013).
Sharpe, A. G. et al. Ancient orphan crop joins modern era: Gene-based SNP discovery and mapping in lentil. BMC Genomics 14, 192 (2013).
Duarte, J. et al. Transcriptome sequencing for high throughput SNP development and genetic mapping in Pea. BMC Genomics 15, 126 (2014).
Kim, C. et al. Application of genotyping by sequencing technology to a variety of crop breeding programs. Plant Sci. 242, 14–22 (2016).
Davey, J. W. et al. Genome-wide genetic marker discovery and genotyping using next-generation sequencing. Nat. Rev. Genet. 12, 499–510 (2011).
Rothberg, J. M. et al. An integrated semiconductor device enabling non-optical genome sequencing. Nature 475, 348–352 (2011).
Tayeh, N. et al. Development of two major resources for pea genomics: The GenoPea 13.2K SNP Array and a high-density, high-resolution consensus genetic map. Plant J. 84, 1257–1273 (2015).
Schlötterer, C. Opinion: The evolution of molecular markers — just a matter of fashion? Nat. Rev. Genet. 5, 63–69 (2004).
Gupta, P. K., Rustgi, S. & Mir, R. R. Array-based high-throughput DNA markers for crop improvement. Heredity (Edinb). 101, 5–18 (2008).
Carrillo-Perdomo, E. et al. Identification of Novel Sources of Resistance to Seed Weevils (Bruchus spp.) in a Faba Bean Germplasm Collection. Front. Plant Sci. 9, 1914 (2019).
Li, H. et al. The Sequence Alignment/Map format and SAMtools. Bioinformatics 25, 2078–2079 (2009).
Haas, B. J. et al. De novo transcript sequence reconstruction from RNA-seq using the Trinity platform for reference generation and analysis. Nat. Protoc. 8, 1494–1512 (2013).
Waterhouse, R. M. et al. BUSCO Applications from Quality Assessments to Gene Prediction and Phylogenomics. Mol. Biol. Evol. 35, 543–548 (2018).
Huerta-Cepas, J. et al. Fast Genome-Wide Functional Annotation through Orthology Assignment by eggNOG-Mapper. Mol. Biol. Evol. 34, 2115–2122 (2017).
Huerta-Cepas, J. et al. eggNOG 5.0: a hierarchical, functionally and phylogenetically annotated orthology resource based on 5090 organisms and 2502 viruses. Nucleic Acids Res. 47, D309–D314 (2019).
Li, H. A statistical framework for SNP calling, mutation discovery, association mapping and population genetical parameter estimation from sequencing data. Bioinformatics 27, 2987–2993 (2011).
Martin, M. Cutadapt removes adapter sequences from high-throughput sequencing reads. EMBnet.journal 17, 10 (2011).
Van Ooijen, J. W. In Kyazma BV 33, 1371 (2006).
Leroux, D. & Jasson, S. Spell-QTL, a New Tool for QTL Analysis on Modern Datasets. in PAG XXV - Plant and Animal Genome Conference (2017).
Ganal, M. W. et al. A Large Maize (Zea mays L.) SNP Genotyping Array: Development and Germplasm Genotyping, and Genetic Mapping to Compare with the B73 Reference Genome. PLoS One 6, e28334 (2011).
Haldane, J. The combination of linkage values, and the calculation of distances between the loci of linked factors. J. Genet. 8, 299–309 (1919).
Varshney, R. K. et al. Genetic dissection of drought tolerance in chickpea (Cicer arietinum L.). Theor. Appl. Genet. 127, 445–462 (2014).
Kreplak, J. et al. A reference genome for pea provides insight into legume genome evolution. Nat. Genet. 51, 1411–1422 (2019).
Pecrix, Y. et al. Whole-genome landscape of Medicago truncatula symbiotic genes. Nature Plants 4, 1017–1025 (2018).
Sato, S. et al. Genome structure of the legume, Lotus japonicus. DNA Res. 15, 227–239 (2008).
Schmutz, J. et al. Genome sequence of the palaeopolyploid soybean. Nature 463, 178–183 (2010).
Schmutz, J. et al. A reference genome for common bean and genome-wide analysis of dual domestications. Nat. Genet. 46, 707–713 (2014).
Lonardi, S. et al. The genome of cowpea (Vigna unguiculata [L.] Walp.). Plant J. 98, 767–782 (2019).
Rubiales, D. & Mikic, A. Introduction: Legumes in Sustainable Agriculture. CRC. Crit. Rev. Plant Sci. 34, 2–3 (2015).
Magrini, M.-B. et al. Pulses for Sustainability: Breaking Agriculture and Food Sectors Out of Lock-In. Front. Sustain. Food Syst. 2 (2018).
Khan, M. A. et al. Transcriptome profiling of faba bean (Vicia faba L.) drought-tolerant variety hassawi-2 under drought stress using RNA sequencing. Electron. J. Biotechnol. 39, 15–29 (2019).
Gao, B. et al. Comprehensive transcriptome analysis of faba bean in response to vernalization. Planta 251 (2020).
Choi, H., Mun, J. & Kim, D. … H. Z.-P. of the & 2004, U. Estimating genome conservation between crop and model legume species. Natl. Acad Sci. 101, 15289–15294 (2004).
Aubert, G. et al. Functional mapping in pea, as an aid to the candidate gene selection and for investigating synteny with the model legume Medicago truncatula. Theor. Appl. Genet. 112, 1024–1041 (2006).
Lucretti, S., Doležel, J., Schubert, I. & Fuchs, J. Flow karyotyping and sorting of Vicia faba chromosomes. Theor. Appl. Genet. 85, 665–672 (1993).
Doležel, J. & Lucretti, S. High-resolution flow karyotyping and chromosome sorting in Vicia faba lines with standard and reconstructed karyotypes. Theor. Appl. Genet. 90, 797–802 (1995).
Ellwood, S. R. et al. Construction of a comparative genetic map in faba bean (Vicia faba L.); conservation of genome structure with Lens culinaris. BMC Genomics 9, 1–11 (2008).
Cruz-Izquierdo, S. et al. Comparative genomics to bridge Vicia faba with model and closely-related legume species: Stability of QTLs for flowering and yield-related traits. Theor. Appl. Genet. 125, 1767–1782 (2012).
Khazaei, H., O’Sullivan, D. M., Sillanpää, M. J. & Stoddard, F. L. Use of synteny to identify candidate genes underlying QTL controlling stomatal traits in faba bean (Vicia faba L.). Theor. Appl. Genet. 127, 2371–2385 (2014).
Acknowledgements
Authors thank the field and laboratory staff for technical assistance, especially Philippe Declerck and Dominique Notteau (RAGT Semences), Gilles Furet and Corie Dekker (Limagrain) and Matthieu Floriot (Agri Obtentions) for their participation in the production of the recombinant populations. In addition, authors are grateful to Nathalie Rivière (Biogemma) for useful advice in the choice of the genotyping technology. This work was supported by the Project Investissements d’Avenir PeaMUST under the grant number ANR-11-BTBR-0002. GQE - Le Moulon benefited from the support of Saclay Plant Sciences-SPS (ANR-17-EUR-0007).
Author information
Authors and Affiliations
Contributions
Estefania Carrillo-Perdomo analysed the data, built the genetic maps and wrote the manuscript; Adrien Vidal developed the mapping codes, built the maps and critically reviewed the manuscript; Jonathan Kreplak filtered the contig sequences of the SNPs and contributed to transcriptome and synteny analyses; Hervé Duborjal, Magalie Leveugle, Jorge Duarte, Jean Philippe Pichon and Catherine Desmetz conducted experiments; Chrystel Deulvot, Blandine Raffiot and Pascal Marget developed the recombinant populations; Nadim Tayeh contributed to map comparisons and synteny analyses and critically reviewed the manuscript; Matthieu Falque and Olivier C. Martin designed the mapping algorithm, specified the software, followed the developments and critically reviewed the manuscript; Judith Burstin conceived the experiments and critically reviewed the manuscript; Grégoire Aubert conceived and supervised the experiments, edited and reviewed the manuscript. All authors read and approved the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Carrillo-Perdomo, E., Vidal, A., Kreplak, J. et al. Development of new genetic resources for faba bean (Vicia faba L.) breeding through the discovery of gene-based SNP markers and the construction of a high-density consensus map. Sci Rep 10, 6790 (2020). https://doi.org/10.1038/s41598-020-63664-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-020-63664-7
This article is cited by
-
High-quality faba bean reference transcripts generated using PacBio and Illumina RNA-seq data
Scientific Data (2024)
-
The giant diploid faba genome unlocks variation in a global protein crop
Nature (2023)
-
SeSAM: software for automatic construction of order-robust linkage maps
BMC Bioinformatics (2022)
-
Genomic regions associated with herbicide tolerance in a worldwide faba bean (Vicia faba L.) collection
Scientific Reports (2022)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
