
Abstract
Primary prevention focuses on ensuring that healthy people remain healthy. As it is practically difficult to provide intervention for an entire healthy population, it is essential to identify and target the at risk of risks population. We aimed to distinguish at risk of risks population using data envelopment analysis (DEA). Efficiency score was calculated from the DEA using a cohort sample and its association with the onset of hypertension and dyslipidemia was analyzed. A stratification analysis was performed according to the number of conventional risk factors in participants. The adjusted odds ratios (aORs) of the incidence of hypertension and dyslipidemia according to a 0.1-point increase in efficiency score were 0.66 (90% confidence interval [CI] 0.55–0.78, p < 0.0001) and 0.84 (90% CI 0.75–0.94, p = 0.01), respectively. In the stratification analysis, aOR of the incidence of hypertension according to a 0.1-point increase in efficiency score was 0.57 (90% CI 0.37–0.89, p = 0.04) in participants with no conventional risk factors. Participants with lower efficiency score were suggested to be at high risk for future onset of hypertension and dyslipidemia. The DEA might enable us to identify the risk of hypertension where conventional methods might fail.
Similar content being viewed by others


Introduction
Lifestyle diseases, such as hypertension, dyslipidemia, and obesity can be prevented to some extent by adhering to a healthy lifestyle. The high-risk approach and the population approach are two interventional approaches that aim to prevent lifestyle diseases. The former involves providing interventions for individuals with risk factors, while the latter provides an opportunity to increase the health level of the entire population1. For example, the specific health checkups conducted in Japan are one of the high-risk approach interventions, which focus on metabolic syndrome, whereby individuals whose body mass index (BMI) or waist circumference exceed the cut-offs are targeted2,3. This approach, however, cannot prevent healthy individuals from being at high risk for lifestyle diseases; the population-approach covers such healthy individuals. However, providing high-quality intervention to an entire population is impractical due to limited medical resources, and even if we could, the population-approach might increase the health inequality, which would hinder us from providing interventions for those who really need them4.
To prevent healthy individuals from being at high risk for lifestyle diseases, the population at risk of risks should be identified (Fig. 1). Targeting primary preventive interventions in the at risk of risks population would make disease prevention more efficient. One possible strategy to distinguish the at risk of risks population is to use genomic information for risk stratification; however, such methods that can be applied in clinical practice to prevent lifestyle disease in the general population are not yet available. Another strategy, known as the vulnerable population approach, uses socio-economic status to identify the at risk of risks population4. However, there is no established indicator of socio-economic status that has generally been accepted.

Conceptual diagram of population at risk of lifestyle diseases. The at risk of risks population refers to those who are at risk of a certain disease, although the results of their health-checkup are within the normal range. aPopulation whose results of the health-checkup was within the normal range. bPopulation identified as high-risk based on the results of the health-checkup.
Data envelopment analysis (DEA) is a method in operations research, mainly in business engineering and economics, to measure productive efficiency in a decision-making unit (DMU), such as business entities5,6,7. The greater the output to the input (higher output/input value) and the greater the profit to the required cost, the more efficient the DMU is8. Given that DMU is an individual factor and efficiency is a constitutional factor, efficiency could be considered as a risk factor for the disease of interest for each individual (DMU). We hypothesized that the DEA could be applied to identify the at risk of risks population for a certain lifestyle disease.
We previously tested this hypothesis and reported the findings with regard to evaluating the risk of obesity9. Considering each individual as a DMU, lifestyle practices (physical activity and energy intake) as input, and BMI as output, each individual’s efficiency score for BMI according to their lifestyle was calculated by the DEA. We observed an increased risk of obesity (higher BMI) in less efficient individuals. The DEA allowed us to evaluate the risk of obesity, without using unobserved confounders such as genetic information and socioeconomic status. Therefore, we sought to apply this method to other lifestyle diseases, such as hypertension and dyslipidemia.
In this study, we performed the DEA for healthy individuals and calculated their efficiency scores for blood pressure and serum cholesterol, as the risk factors for hypertension and dyslipidemia, respectively. We analyzed the association between the efficiency score and onset of hypertension and dyslipidemia using the data from a population-based prospective cohort study. Assuming that DEA can distinguish the at risk of risks population for hypertension and dyslipidemia, we might be able to provide more effective preventive interventions, which would ensure that healthy individuals remain healthy for longer, without being at risk for diseases.
Methods
Study population
We used data from the Yamagata Study (Takahata), a population-based prospective cohort study. The study design has been detailed elsewhere10. In brief, this cohort study was based on a health checkup, and data on the results of the checkup, such as anthropometric traits and laboratory data from the blood sample, were obtained. The baseline survey was conducted from 2004 to 2006. The follow-up survey was conducted from 2011 to 2012, 5–8 years after the baseline survey. This study was approved by the Ethics Committee of the Yamagata University Faculty of Medicine.
Assessment of lifestyles and diseases
Nutritional intake was assessed using the brief self-administered diet history questionnaire, and information on daily intake of salt in grams, potassium in milligrams, and total energy in kilocalories (kcal) were also obtained11. Additionally, salt intake was estimated by Tanaka’s formula using urinary sodium and urinary creatinine; these were evaluated from the urine collected at the baseline survey and were used for sensitivity analysis12. Physical activity was assessed using the Japan Arteriosclerosis Longitudinal Study Physical Activity Questionnaire, by which the total energy and activity-specific energy can be quantified as metabolic equivalents-hours per day (METs-h/day)13.
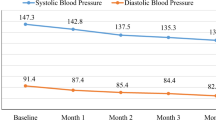
Participants who had hypertension or dyslipidemia at baseline, or who had previously been diagnosed with either disease and were receiving treatment were excluded from the analysis. Undiagnosed participants meeting the following criteria at baseline were excluded from the analysis: presence of hypertension defined as systolic blood pressure ≥18.67 kPa (140 mmHg) or diastolic blood pressure ≥12.00 kPa (90 mmHg); presence of dyslipidemia defined as triglyceride (TG) ≥1.69 mmol/L (150 mg/dL), low-density lipoprotein cholesterol (LDL-C) ≥3.63 mmol/L (140 mg/dL), or high-density lipoprotein cholesterol (HDL-C) <1.04 mmol/L (40 mg/dL). The onset of hypertension or dyslipidemia was determined by the questionnaire or meeting the above diagnostic criteria at the follow-up survey.
DEA analysis
We used the input-oriented constant returns-to-scale Charnes-Cooper-Rhodes model of DEA, given its ability to include multiple inputs and outputs without requiring an a priori function specification14. In this context, a DMU was defined as an entity, which is responsible for converting the inputs into outputs15; therefore, we defined the DMUs as each individual. In the model for hypertension, the inputs were the inverse of salt intake, the inverse of total energy intake, and physical activity, and the outputs were the inverse of systolic and diastolic blood pressure. In the model for dyslipidemia, the inputs were physical activity and the inverse of total energy intake, and the outputs were HDL-C, the inverse of TG, and the inverse of LDL-C. The inverse values were used to fit them into the definition of efficiency in DEA; efficiency is high when input is minimized while the outputs are held constant, or when the output is maximized while the inputs are held constant16. Each participant’s efficiency score was calculated using DEA-Solver-Pro Software (Saitech, Inc., Tokyo, Japan)6. Higher scores indicated higher efficiency17.
Assessment of conventional risk
We also calculated risk based on the conventional method; we adopted the method used in specific health checkups2. This method was modified because waist circumference was not measured until the start of the specific health checkups in 2008, which was conducted following the baseline survey. The definitions of the conventional risk factors in this study are shown in Table 1. We counted the number of factors that fulfilled these criteria for each participant. As participants with a pre-existing disease were excluded, factor 3 and factor 9 were excluded for assessing conventional risk for hypertension and dyslipidemia, respectively.
Statistical analysis
We performed a logistic regression analysis to calculate the odds ratio (OR) of the incidence of hypertension and dyslipidemia. Four univariate models were analyzed, and explanatory variables were efficiency scores in 2 models and conventional risk factors in 2 models. We adjusted the models with the efficiency scores by conventional risk factors, baseline age, sex, and baseline BMI. As a sensitivity analysis for the models in hypertension, we also included daily potassium intake as an adjustment factor. Further, we performed a stratification analysis according to the 4 groups stratified by the number of conventional risk factors; participants with no conventional risk factors (low-risk), those with one risk factor (moderate-risk), those with two risk factors (high-risk), and those with three or more risk factors (extreme-risk). In the logistic regression analysis, we assessed whether the continuous variables were linear on the logit using a generalized additive model with a smoothing spline using the gam function of the mgcv package in R18 and a Box-Tidwell test19. Any variable that could not achieve linearity on the logit as a continuous variable was categorized into that model (Supplementary Figs S1, S2). Age was categorized into ten-year groups (40–49, 50–59, 60–69, over 70 years), and body mass index (BMI) was categorized into two groups (<23, ≥23 kg/m2). Multicollinearity was assessed using the variance inflation factor (VIF) with the vif function of the DAAG package20, and receiver operating characteristic (ROC) curves after multivariate logistic regression models were illustrated using the roc function of the pROC package in R21. Statistical analyses were performed using R software (version 3.4.1)22.
Results
Baseline characteristics
As shown in Fig. 2, of the 3522 participants of the Yamagata Study (Takahata), the efficiency scores by DEA were calculated for 790 participants for hypertension and 915 for hypertension and dyslipidemia. Data on the incidence of hypertension was available from 520 participants, and incidence of dyslipidemia was available from 584 participants.

Flow diagram of the study participants. DEA, data envelopment analysis.
Participant characteristics are shown in Table 2. The mean follow-up time of the participants was 5.6 (standard deviation [SD] 1.2) and 5.7 (SD 1.2) years, for hypertension and dyslipidemia, respectively. Hypertension and dyslipidemia was observed in 173/520 (33.3%) and 207/584 (35.4%) participants, respectively. The efficiency score of hypertension ranged from 0.45 to 1.0 (Mean 0.68; SD 0.11), and of dyslipidemia ranged from 0.33 to 1.0 (Mean 0.59; SD 0.13). Details of the results from the DEA (lambda values and assessment of excess use) and sensitivity analysis between the two estimating methods for salt intake are described in the Supplementary Information (Supplementary Text, Supplementary Figs. S3, S4, and Tables S1–S4).
Logistic regression analysis
The ORs of the incidence of hypertension and dyslipidemia are shown in Table 3. The adjusted ORs of the incidence of hypertension and dyslipidemia according to a 0.1-point increase in efficiency score were 0.66 (90% confidence interval [CI] 0.55–0.78, p < 0.0001) and 0.84 (90% CI 0.75–0.94, p = 0.01), respectively. The evidence for association between the conventional risk and onset of the diseases appeared to be weak compared to that of the efficiency score, especially in the low-risk group of hypertension (OR 1.42 [90% CI 0.87–2.34, p = 0.24]). Results of the sensitivity analysis of adjusting the model with potassium intake are shown in the Supplementary Information (Supplementary Text and Supplementary Table S5).
Stratification analysis
The results of the stratification analysis are shown in Table 4. In the models for hypertension, the efficiency score was highest in the low-risk group (0.72 [SD 0.10]) and lowest in extreme-risk group of participants having three or more conventional risk factors (0.65 [SD 0.10]). A higher efficiency score was associated with a decreased risk of hypertension; adjusted ORs of the incidence of hypertension according to a 0.1-point increase in efficiency score were 0.57 (90% CI 0.37–0.89, p = 0.04), 0.65 (90% CI 0.48–0.88, p = 0.02), 0.50 (90% CI 0.34–0.72, p = 0.002), and 0.82 (90% CI 0.59–1.13, p = 0.32) in low-, moderate-, high-, and extreme-risk groups, respectively. Evidence for the association between the efficiency score and dyslipidemia was weak; adjusted ORs of the incidence of dyslipidemia according to a 0.1-point increase in efficiency score were 0.79 (90% CI 0.60–1.05, p = 0.18), 0.80 (90% CI 0.65–0.99, p = 0.08), 0.93 (90% CI 0.77–1.13, p = 0.53), and 0.86 (95% CI 0.63–1.17, p = 0.41) in low-, moderate-, high-, and extreme-risk groups, respectively.
Discussion
In this study, we found that the higher the efficiency scores calculated by the DEA, the lower the risk of hypertension and dyslipidemia. This suggests that efficiency scores could be useful for assessing the risk of both diseases. The efficiency scores were higher in the low-risk group than in the higher risk groups, which is consistent with the defined concept of performing DEA to evaluate the risk; the results of the DEA showed equivalent validity to the conventional method in assessing the risk of hypertension and dyslipidemia.
The results of the stratification analysis indicated the potential of the DEA to distinguish the at risk of risks population for hypertension. An increase in the efficiency score was associated with a decrease in the risk for hypertension in the low- to high-risk groups, whereas, the efficiency score could not predict the onset of hypertension in the extreme-risk group. In other words, the efficiency score calculated by the DEA could not distinguish the inequality in the level of risk among the participants in the extreme-risk group, who had three or more than three conventional risk factors. Accumulations of conventional risk factors seemed to surpass the risks that could be distinguished by the efficiency score. However, participants in the extreme-risk group can be regarded as at risk rather than at risk of risks, and it is more likely for them to be identified by the conventional secondary-prevention method heretofore, such as the specific health check-ups carried out in Japan2,3. On the other hand, the conventional method is inadequate to precisely classify the at risk of risks population in low- to high-risk groups, especially in the low-risk, thereby making it difficult to provide adequate intervention owing to insufficient resources (manpower). Taken together, the efficiency score calculated by the DEA may serve as a risk stratification measure to classify the at risk of risks population, thus enabling us to provide primary preventive intervention.
Contrary to the findings observed for hypertension, we did not observe a clinically meaningful association between the risk of dyslipidemia and the efficiency score calculated by the DEA in the subgroups stratified by the number of conventional risk factors. Moreover, the relationship between the risk of these diseases and conventional risk factors appeared to be different from that observed for hypertension. The ORs for the onset of hypertension were higher in the higher risk groups. On the other hand, the ORs for the onset of dyslipidemia appeared to be equivalent in the three groups stratified by the conventional risk factors compared to low-risk group (Table 3). Having one conventional risk factor increased the risk of the onset of dyslipidemia; however, additional risk factors did not further increase the risk. One explanation for this finding is that dyslipidemia is a spectrum of diseases with various subtypes according to the type of lipoproteins. Further, some conventional risk factors, such as diabetes, obesity, and smoking, are known to affect the level of blood cholesterol; part of which is referred to as secondary dyslipidemia. We assumed that clinically irrelevant findings observed in the stratification analysis for dyslipidemia were due to the imprecise stratification of the risk for dyslipidemia by conventional risk factors. Nevertheless, we cannot currently provide an explanation that goes beyond our speculation regarding those discrepancies in observed results between hypertension and dyslipidemia; future research should explore this topic further.
Our results suggest that the efficiency score from the DEA and conventional risk factors could be used in a mutually-complementary manner in an actual healthcare setting. Combining both strategies for risk stratification would enable us to provide the primary prevention more efficiently, as we would be able to distinguish the at risk of risks population. In the domain of business administration, where DEA originates, efficiency score is used as a benchmark to improve the management of each DMU by targeting the efficiency frontier (those whose efficiency score is 1). However, our premise for applying the findings of this study is to use efficiency score as a cross-sectional risk to relatively evaluate inequality in the risk for hypertension and dyslipidemia. In this way, the efficiency score could encompass the effect of unobserved factors, such as genetic and socio-economic factors, lean body mass, renal function and so on. A a more specific example is a genetic variation rs8022678, a single nucleotide variant that has been suggested as affecting the sodium sensitivity of an individual (further discussion can be found in Supplementary Text)23. This difference is caused by the discrepancy between the efficient state and healthy state of the individual. For example, an efficient individual is someone who leads a sedentary lifestyle and consumes excessive energy (calories) and salt, although their blood pressure is under control. On the other hand, even if their blood pressure is well-controlled, leading a healthy lifestyle is still ideal because there are many other diseases that a healthy lifestyle could prevent. Being efficient does not indicate being excluded from the recommended healthy lifestyle habits. The efficiency score and conventional risk factors can be used together to determine whether interventions are needed. As an example for hypertension, those at an extreme risk according to the conventional risk factors require intervention regardless of their efficiency score, but for individuals at low- to high-risk, who are often deemed normal, we can provide intervention with priority to those with a low efficiency score. With respect to dyslipidemia, we can put priority in those with moderate- to extreme-risk. Combining the efficiency score from the DEA and conventional risk factor might enable us to identify the at risk of risk population before they become at risk, especially for hypertension.
We previously investigated the association between efficiency score from the DEA and obesity9; the results showed no association between the efficiency score and change in BMI (difference in the BMI in the follow-up period). The following reasons might explain the inconsistent finding; first, the prevalence of obesity is known to reach its peak at 50–60 years of age, and the majority of the study participants were around this age range24. Thus, the average BMI converged to zero, and only a slight change in the BMI was observed for most participants. Contrary to our previous findings, in this study, we observed the onset of the disease in more than 30% of the participants. This might have contributed to our findings that efficiency score could predict the onset of hypertension and dyslipidemia. Second, the gene-environment interaction is known to affect the onset of obesity25. Input used for the DEA regarding obesity might have been affected by the gene-environment interaction, to a certain extent; thus, the efficiency score from the DEA could become insufficient for identifying the inequalities in the risk levels. However, the efficiency score calculated for the risk evaluation of hypertension was useful even for the population with no conventional risk factors in the stratified analysis. This indicates that the application of the efficiency score might be more efficient for the primary prevention of hypertension, in a population with no conventional risk factor. There are several other limitations that need to be acknowledged. We could not assess the change in the efficiency score; the efficiency score might change according to aging or because of some of the factors assumed to be encompassed by the DEA as mentioned above. In addition, because the detailed questionnaires on the lifestyle were only obtained during the baseline survey, we could not assess the alteration in the participants’ lifestyles during the follow-up period. Although we used a validated method to assess nutritional intake and physical activity11,13, self-reported nature of our study hindered us from avoiding bias caused by measurement error. Furthermore, while our results demonstrate the potential of DEA to be applied to the domain of healthcare, there are only limited available data to support our findings in the field of primary preventive medicine. To determine the practicality of the efficiency score from the DEA for primary preventive intervention, we need to demonstrate that targeting the at risk of risks population segregated by efficiency score can prevent the disease onset. We aim to conduct an interventional study from 2019, based on the hypothesis that the at risk of risks population can be identified using the efficiency score from the DEA.
Conclusions
Efficiency score calculated by the DEA could be used to identify those at risk of risks for a particular disease among healthy individuals at baseline. Notably, the efficiency score distinguished the inequality in the risk of hypertension in the low-risk group. Efficiency score has the potential to be applied to primary preventive intervention.
Data availability
The data analyzed during the current study are not publicly available for ethical reasons. The data that support the findings of this study can be made available after approval for data access by application to Yamagata University.
References
Rose, G.A. et al. Rose’s Strategy of Preventive Medicine (Oxford University Press, 2008).
Ministry of Health, Labour and Welfare. Specific Health Checkups and Specific Health Guidance. Ministry of Health, Labour and Welfare Website, https://www.mhlw.go.jp/english/wp/wp-hw3/dl/2-007.pdf (In English), https://www.mhlw.go.jp/stf/seisakunitsuite/bunya/0000161103.html (In Japanese, 2008).
Kobayashi, A. Launch of a national mandatory chronic disease prevention program in Japan. Dis. Manag. Health. Out. 16, 217–225 (2008).
Frohlich, K. L. & Potvin, L. Transcending the known in public health practice: the inequality paradox: the population approach and vulnerable populations. Am. J. Public. Health. 98, 216–221 (2008).
Bogetoft, P. & Otto, L. Benchmarking with DEA, SFA, and R. (Springer, 2011).
Cooper, W. W., Seilford, L. M. & Tone, K. Data Envelopment Analysis: A Comprehensive Text with Models, Applications, References and DEA-Solver Software. 2 nd ed. (ed. Cooper, W.W., Seilford, L.M. & Tone, K.) 21-40 (Springer, 2007).
Coelli, T. J. An Introduction to Efficiency and Productivity Analysis. 2nd ed. (Springer, 2005).
Farrell, M. J. The measurement of productive efficiency. J. R. Stat. Soc. Ser. A. Gen. 120, 253–281 (1957).
Narimatsu, H. et al. Applying data envelopment analysis to preventive medicine: a novel method for constructing a personalized risk model of obesity. PLoS One. 10, e0126443 (2015).
Yamagata University Genomic Cohort Consortium & Narimatsu, H. Constructing a contemporary gene-environmental cohort: study design of the Yamagata Molecular Epidemiological Cohort Study. J. Hum. Genet. 58, 54–56 (2013).
Sasaki, S., Yanagibori, R. & Amano, K. Self-administered diet history questionnaire developed for health education: a relative validation of the test-version by comparison with 3-day diet record in women. J. Epidemiol. 8, 203–215 (1998).
Tanaka, T. et al. A simple method to estimate populational 24-h urinary sodium and potassium excretion using a causal urine specimen. J. Hum. Hypertens. 16, 97–103 (2002).
Harada, A. et al. Validity of a questionnaire for assessment of physical activity in the Japan Arteriosclerosis Longitudinal Study. Med. Sci. Sports. Exerc. 35, S340 (2003).
Charnes, A., Cooper, W. W. & Rhodes, E. Measuring the efficiency of decision making units. Eur. J. Oper. Res. 2, 429–444 (1987).
Thanassoulis, E., Portela M. C. S. & Despić, O. The Measurement of Productive Efficiency and Productivity Growth (eds Fried, H. O., Lovell, C. A. K. & Schmidt, S. S.) 251–420 (Oxford University Press, 2008).
Cooper, W. W., Seilford, L. M. & Tone, K. Data Envelopment Analysis: A Comprehensive Text with Models, Applications, References and DEA-Solver Software. (eds Cooper, W. W., Seilford, L. M. & Tone, K.) 114–115 (Springer, 2007).
Hollingsworth, B. The measurement of efficiency and productivity of health care delivery. Health Econ. 17, 1107–1128 (2008).
Wood, S. N. Fast stable restricted maximum likelihood and marginal likelihood estimation of semiparametric generalized linear models. J. R. Stat. Soc. Series. B. Stat. Methodol. 73, 3–36 (2011).
Hilbe, J.M. Logistic Regression Models (Chapman & Hall/CRC, 2017).
Maindonald, J. & Braun, W.J. DAAG: Data Analysis and Graphics Data and Functions [Software] (2015).
Robin, X. et al. pROC: an open-source package for R and S+ to analyze and compare ROC curves. BMC Bioinformatics. 12, 77 (2011).
R Core Team. R: A language and environment for statistical computing. (R Foundation for Statistical Computing, 2018).
Hachiya, T. et al. Genome-wide analysis of polymorphism x sodium interaction effect on blood pressure identifies a novel 3’-BCL11B gene desert locus. Sci. Rep. 8, 14162 (2018).
Ng, M. et al. Global, regional, and national prevalence of overweight and obesity in children and adults during 1980-2013: a systematic analysis for the Global Burden of Disease Study 2013. Lancet. 384, 766–781 (2014).
Castillo, J. J., Orlando, R. A. & Garver, W. S. Gene-nutrient interactions and susceptibility to human obesity. Genes. Nutr. 12, 29 (2017).
Acknowledgements
We would like to thank Editage (www.editage.jp) for English-language editing.
Author information
Authors and Affiliations
Contributions
S.N. and H.N. conceived and designed this study. H.N., T.K., M.W., Y.U., K.I., H.Y., T.K. and T.Y. contributed to data acquisition. S.N., H.N., Y.N. and M.S. analyzed the data. S.N., H.N. and M.S. contributed to data interpretation. S.N. and H.N. drafted the manuscript. All authors have read and approved the submitted version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
H.N. has received research grants from Chugai Pharmaceutical Co. Ltd. S.N., Y.N., M.S., T.K., M.W., Y.U., K.I., H.Y., T.K. and T.Y. declare no potential conflict of interest.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Nakamura, S., Narimatsu, H., Nakata, Y. et al. Efficiency score from data envelopment analysis can predict the future onset of hypertension and dyslipidemia: A cohort study. Sci Rep 9, 16309 (2019). https://doi.org/10.1038/s41598-019-52898-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-019-52898-9
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
