
Abstract
A deep-neural-network (DNN) was successfully used to predict clinically-acceptable dose distributions from organ contours for intensity-modulated radiotherapy (IMRT). To provide the next step in the DNN-based plan automation, we propose a DNN that directly generates beam fluence maps from the organ contours and volumetric dose distributions, without inverse planning. We collected 240 prostate IMRT plans and used to train a DNN using organ contours and dose distributions. After training was done, we made 45 synthetic plans (SPs) using the generated fluence-maps and compared them with clinical plans (CP) using various plan quality metrics including homogeneity and conformity indices for the target and dose constraints for organs at risk, including rectum, bladder, and bowel. The network was able to generate fluence maps with small errors. The qualities of the SPs were comparable to the corresponding CPs. The homogeneity index of the target was slightly worse in the SPs, but there was no difference in conformity index of the target, V60Gy of rectum, the V60Gy of bladder and the V45Gy of bowel. The time taken for generating fluence maps and qualities of SPs demonstrated the proposed method will improve efficiency of the treatment planning and help maintain the quality of plans.
Similar content being viewed by others

Introduction
Radiotherapy is an essential in cancer treatment and is used for approximately 50% of all cancer patients1. The radiotherapy works by delivering high-energy radiation to the tumour. Since the radiation cannot distinguish cancer cells from normal tissues, it is important to create plans that can deliver a high dose to cancer cells while minimising the dose to normal cells. One of the methods to accomplish the goal is using intensity modulation in the delivery. This method utilises a multi-leaf collimator (MLC) located between the patient and radiation source to modulate and shape the high energy photon beam2. The shape and delivery intensity of the photon beam is determined by an optimisation process called inverse planning. Therefore, it is important to create high quality plans. However, differences in planning skills between planners can influence plan quality3, which means that patients may undergo different quality of treatments. Many studies have attempted to automate treatment planning to maintain plan quality, including those that have predicted dose-volume-histograms (DVH) for treatments4,5,6. The DVH is a common criterion for the inverse planning procedure; however, it does not provide spatial information of the dose7. In automated treatment planning, optimisation based on dose volume objectives on DVH may lead to unwanted plans. To improve the quality of automated plans, some studies have predicted the spatial dose distribution from patient images or contour data7,8,9. Those studies predicting DVHs4 or spatial dose distributions9 by using hand-crafted features from statistical analysis, such as the distance from the target or organs-at-risk (OARs), and the volume of the target and learning-based methods trained by the hand-crafted features.
Recently, deep-neural-networks (DNNs) have shown outstanding results in various fields including radiotherapy10,11,12, and there are studies using DNNs to predict the dose distribution of treatments13,14. Deep learning-based dose prediction methods do not require the hand-crafted features used in previous studies. A network typically consists of convolution, pooling and fully-connected layers with activation functions, and takes patient images or contour data as input data. In the training phase, the layers and activation functions learn high dimensional features that can predict dose distributions from given input data.
In previous studies, the predicted dose distributions or DVHs were used to identify suboptimal plans or to guide the plan optimisation process, to reduce time consumption and help planners to improve their plans and maintain quality between different planners. Some studies have generated deliverable plans from predicted dose distributions using dose mimicking15 or fluence-map optimisation methods constrained by the spatial dose distribution16. These studies utilised methods that can perform optimisation based on voxel dose constraints. This requires an optimisation step to determine the delivery parameters, which is one of the most time-consuming steps in the creation of treatment plans, as it is performed in an iterative manner to figure out the optimal solution meeting the criteria. Furthermore, different parameters for the optimisation algorithm influence the quality of plans.
Following the success of previous studies predicting dose-maps from contour data, we here focus on generating optimal fluence maps directly from organ contours and the dose-map. We assumed that dose-maps obtained from previous studies were clinically acceptable, and used a DNN to generate fluence maps from organ contours and dose distributions without an optimisation step. Direct generation of fluence maps can reduce the time and effort required in performing optimisation. Moreover, it will help to reduce variation between planners and therefore help to maintain the quality of treatment plans.
Materials and Methods
Proposed method
In conventional IMRT planning, the planning target volume (PTV) and OARs are determined on the planning CT images and the dose is prescribed. Using the prescription and organ contours, optimisation algorithms determine the optimal fluence maps to meet the optimisation objectives for the PTV and OARs, which are imposed on the DVH, as summarised in Fig. 1(a). In Fig. 1, the items inside circles are processes and the items inside the rectangles are products. In the optimisation step, various parameters are tuned to achieve the optimal solution and this process is continued until an acceptable fluence map is achieved.

(a) The conventional IMRT inverse planning process and (b) the proposed framework based on a deep-neural-network.
In this study, we propose a framework to generate fluence maps directly from the organ contours and dose distributions. The proposed framework for deep-learning based IMRT planning is summarised in Fig. 1(b). As shown in the figure, we trained a neural network to directly find the optimal fluence maps of beams from organ contours and dose distributions.
By generating fluence maps, we can create deliverable treatment plans without a parameter tuning process and faster than can be done using optimisation algorithms; therefore, we can increase the efficiency of the planning process. As noted in the introduction, we assumed that volumetric dose distributions with clinically acceptable qualities were obtained from the previous studies and regarded the clinical dose distributions as prediction results.
Training data collection
For training purposes, we collected data from 285 prostate cancer patients under the approval of the Institutional Review Board (IRB) of Asan Medical Center for a retrospective study in accordance with guidelines for protecting patients’ private information. The informed consent was waived based on the nature of a retrospective study. There are two phases in the training process of a DNN: training and validation phases. In the training phase, the weights in the DNN are updated based on the input and its associated desirable output by use of the training dataset. The validation phase checks generality of the trained weights using separate and unused set of input and desirable output data from the dataset. After the training is done, we provide test input data to the network for evaluation. We compared the output from the network to the clinical data for evaluating the performance of the network. Among the 285 patients’ data, 240 patients’ data were used for the training and validation, and the remaining 45 patients’ data were used for the evaluation. The data were randomly selected in the entire study.
Patients were instructed to empty their bowels and bladder immediately before the planning CT scan. An endorectal balloon was used to improve the position of the rectum, and after insertion and inflation with 60 cc of air, the balloon was fixed in place with an individual adjustable stopper. Details on the planning CT acquisitions have been described elsewhere17,18. All of the patients underwent 15 megavolt (MV) 7-field IMRT. For most of the plans, the radiotherapy intention was to treat the tumour or tumour bed and the regional pelvic nodes. Based on the institutional protocol, the patients underwent the initial treatment of 44 Gy in 20 fractions to the tumour or tumour bed including the regional pelvic nodes, and were followed by the boost treatment of 28.6 Gy in 13 fractions to the prostate/bed. In this study, we only used the initial treatment plans. Treatments were performed on Clinac, TrueBeam, or VitalBeam machines (Varian Medical Systems, Inc., Palo Alto, CA, USA). The beam directions and corresponding dose distributions for a typical case are shown in Fig. 2. The dose distributions are presented in Gy and their values are indicated by the colour bar on the right of the figure.

Organ contours, directions of treatment beams and dose distributions per beam.
For the organ contour data, we labelled ten organs/structures in the patients with ten different integer values for use in training. These ten labels were ‘Body’, ‘Virtual avoiding structures’, ‘Bowel’, ‘Right femoral head’, ‘Left femoral head’, ‘Penile bulb’, ‘Rectum’, ‘Prostate’, ‘Bladder’ and ‘PTV’. Virtual avoiding structures are structures used to add detailed dose constraints to OARs, like bladder, bowel or rectum. Two virtual avoiding structures were generated for inverse planning purposes; one included the intestinal and pelvic cavity area that was not specified by bowel, bladder or rectum, and the other one included the regions posterior to the rectum. We labelled the same values for the both virtual avoiding structures.
We normalised the dose distributions to a single fraction to utilise the dose distributions for training.
Training of the DNN
For the training, we used organ contours, containing PTV and OARs, and dose distributions, viewed from the beam’s eye view (BEV) of a single beam, as input data and used fluence map at each corresponding beam direction as desired output data. As every treatment had seven fields, we had seven different input data for each individual patient. We matched the dimensions of organ contours and dose distributions to those of the fluence maps by resampling the data to the dimensions of the fluence maps. We also divided the input data into 64 different slices according to the distance from the beam source and considered the cone characteristics of the source, as shown in Fig. 3 and each slice was considered as different channel of input data. In Fig. 3, the target and OARs are located inside the black rectangle, the plane surrounded by the red dashed-lines depicts a plane located on the central axis and normal to the photon source, and the rectangles surrounded by green dashed-lines indicate slices used for resampling. After resampling, the input data was the same size as the fluence maps, with 64 channels on the direction of beams, each having a 10 mm thickness. We divided the contours into channels to provide 3D positional information to the network. Because of the attenuation characteristics of the photon beam, the dose decreases as the beam penetrates. Therefore, a beamlet incident on any OAR prior to the PTV would be less encouraged compared with a beamlet firstly incident on the PTV. Increasing the number of slices increases the resolution of the data; however, it also requires more memory for training because of the increased size of the input data. Some organs may overlap in a single channel because of the coarse pixel size of the channels; in such cases, we preserved the organs with a higher label number. In Fig. 4(a,b), the images of the organ contour data and dose distributions for the 32nd channel of a treatment beam at 180° are presented as an example of the input data with corresponding desired fluence maps in Fig. 4(c).

Geometry of the contour resampling.

Images from the 32nd channel of input (on the isocentre plane perpendicular to the beam axis) and output data for a beam at 180°. (a) Organ contours, (b) dose distribution for the beam direction and (c) corresponding fluence-map.
As mentioned above, we considered each treatment field as an individual data. Although this gave us a total of 1680 (7 × 240) data for training and validation, this is still rather a small amount of data for training a DNN. Therefore, we augmented the data by translating the data in 80 different sets of directions, with each set having different values for x- and y-shift values. We only used translation for augmentation to avoid pixel value changes due to interpolation while rotating the data and excluded data if truncation occurred in dose distribution or PTV contours after translation. After the augmentation, we had 128,666 data. The numbers of training and validation datasets after the augmentation are shown in Table 1.
The network used for training is shown in Fig. 5. We modified the structure of the dual frame U-Net19 to suit our purpose. This network is an alternative implementation of the tight frame U-Net, which showed better performance in preserving high frequency components while training. We used the structural similarity (SSIM)20 index and the mean-absolute error with equal weighting factors as cost functions. To use the SSIM for training, we used a convolution operation with a Gaussian kernel to calculate the mean and standard deviation21. For faster convergence of the network, we used a residual learning scheme. We gave the central slice of the dose as an initial guess, and then trained the network to learn the difference between the initial guess and the ground truth data. In the training phase, three different input data were provided to the network: 3D organ contours, the corresponding 3D dose distribution and the central channel of the dose distribution, as shown in Fig. 5 (at the beginning of the network and outlined with a red box). At the end of the network, the central channel of the dose distributions, the third input data, was added to the output of the network for residual learning and the summation result was compared with the fluence maps to update the kernels. We used strided-convolution with 2*2 sized kernels and stride 2 for down-sampling and transposed convolution (also called deconvolution) for up-sampling with the same kernel size and stride used for the strided-convolution. For the last transposed-convolution, the size of the data was not changed, while the number of channels was reduced by half.

Structure of the network used for training.
Details of the training parameters are summarised in Table 1. While training, we reduced the learning rate by 0.8 every 10 epochs to increase the convergence of the network. In addition, we used a gradient clipping method22 to avoid a gradient exploding problem. This method calculates the norm of the gradient of each kernel and multiplies the ratio of the calculated norm and predefined value to the gradients if the calculated norm is bigger than a predefined value. We set the predefined value to \(1{{\rm{e}}}^{-4}\). If the norm of the gradients of a kernel was larger than the value, the gradients were scaled down to make their norm the same as the value. If the norm was smaller than the value, normalisation was not performed and the original gradients were used for the update. For the update, we used an Adam optimizer23.
We trained the network on a workstation with an Intel Xeon E5 2.4 GHz processor, 256 GB of RAM and a GTX 1080 Ti with 11 GB of GPU memory.
Results
Training results
We performed validation every ten epochs and the results are shown in Fig. 6 with the training loss. The validation loss curve was acceptably agreeing with the training loss curve as the iteration increases.

Training and validation losses in training of the network.
To evaluate the performance of the network, we used the network parameters after the last update to generate the fluence maps. We compared the generated fluence maps and the dose distribution calculated from the fluence map to the clinical fluence maps and the clinical dose distribution, respectively.
Fluence map generation results
As explained in Training data collection section, we had 45 patients’ data reserved for evaluation. We provided organ contours and dose distributions to the network and obtained fluence maps from the network. We calculated the mean-absolute error (MAE) and structural similarity index (SSIM), and performed gamma evaluation with 3 mm/3% criteria between the generated fluence maps and clinical fluence maps. The results are summarised in Fig. 7. The median values of the MAE, SSIM and gamma pass rate were \(9.95\times {10}^{-4}\), 0.994 and 0.999, respectively.

Quantitative comparison results between the generated and clinical fluence maps: (a) mean-absolute-error (MAE), and (b) structural similarity (SSIM) and gamma pass rate.
Examples of the generated fluence maps are shown in Fig. 8, alongside corresponding clinical fluence maps and their differences. The pixel values of the fluence maps and the differences are presented in fractional monitor units (fMU).

Comparison of the clinical fluence maps with generated fluence maps using the trained network. (a) A 230° field for patient #35, (b) a 130° field for patient #13 and (c) a 330° field for patient #22. fMU stands for fractional MU, which is the delivered MU for a pixel in a fluence map divided by the total MU delivered by a single beam.
Synthetic dose distribution results
We calculated dose distributions from the generated fluence maps by feeding them into an Eclipse treatment planning system (Varian Medical Systems, Inc., Palo Alto, CA, USA) as optimal fluence maps, and calculated leaf motion. We calculated volumetric dose distributions of patients using the same treatment planning system based on the calculated leaf sequence. After the dose distributions were calculated, we normalised the plans to have the same mean PTV dose as the clinical plans. In the rest of this paper, we refer to the plans from the generated fluence maps as ‘synthetic plans’ and the dose distributions from these plans as ‘synthetic dose distributions’. We compared the synthetic dose distributions and clinical dose distributions according to the constraints used in our institution24, which are homogeneity index (HI), conformity index (CI), V72.6Gy of the PTV, V60Gy of rectum, V60Gy of bladder, Dmax of femoral heads, Dmean of penile bulb and absolute volume of bowel receiving 45 Gy. To calculate HI25 and CI26, we used Eqs (1) and (2), respectively. In equation (1), D95%, D5% and DPX are the dose that 95% of the volume of the PTV is receiving, a dose that 5% of the volume of the PTV is receiving and the prescription dose, respectively. In Eq. (2), VRI is the volume of the reference isodose and VPTV is the volume of the PTV. We used 95% of the prescription dose as the reference isodose, so the volume receiving more than 95% of the prescription dose is divided by the volume of the PTV to calculate CI.
We would like to point out that the criteria were designed for summation of 44 Gy/20 fx of initial treatment including the pelvic nodes and 28.6 Gy/13 fx of boost treatments for the prostate/bed. Since we only considered the initial treatment in this study, we scaled up the initial 44 Gy dose distribution to the total 72.6 Gy to apply the constraints.
We showed results of two patients in Figs 9 and 10. The dose distributions and DVH curves in Fig. 9 represent the results with the smallest average MAE in the fluence maps. The synthetic dose distributions and its DVH curves show small discrepancies from the clinical ones. In Fig. 10, a result with the largest average MAE in the fluence maps is shown. The larger error in the fluence maps led to a larger error in the dose distributions and a less homogeneous dose being delivered to the PTV.

Clinical and synthesised dose distributions, their differences, corresponding contours and DVHs of patient #33 which has the smallest average MAE in the fluence maps.

Clinical and synthesised dose distributions, their differences, corresponding contours and DVHs of patient #43 which has the largest average MAE in the fluence maps.
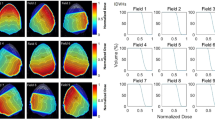
The plan quality metrics are summarised in Fig. 11, with a line indicating identical values. The mean and standard deviation of each criterion of the synthetic and clinical plans are summarised in Table 2, along with the mean and standard deviation of differences of the criteria.

Plan quality comparison results between synthetic plans and clinical plans.
As shown in Fig. 11 and Table 2, the synthetic plans have comparable quality to clinical plans in terms of saving OARs; however, the dose delivered to the PTV is less homogeneous than that delivered with the clinical plans.
For a further comparison, we calculated the residual sum of squares (RSS) of the DVHs using Eq. (3) to quantify the discrepancies between the synthetic and clinical plans, and the results are shown in Fig. 12. In Eq. (3), D is the relative dose, \(DV{H}_{clinical,organ}(D)\) the relative volume of an organ receiving dose D in the clinical DVH and \(DV{H}_{synthetic,organ}(D)\) is the relative volume of an organ receiving dose D in the DVH of synthetic plan.

Box plot of RSS of the DVHs of all organs. Left y-axis for PTV, CTV, rectum, bladder, small bowel, right femoral head, and left femoral head and right y-axis for penile bulb.
The right y-axis of the Fig. 12 indicates RSS value of penile bulb and the left y-axis indicates RSS value of the other organs. We think that large discrepancies in the penile bulb are caused by the small volume of the organ, which makes the DVH for the organ sensitive to small changes in the dose distribution. Apart from the penile bulb DVHs, the other organs show only small discrepancies to the clinical plans.
Discussion
To our knowledge, this is the first attempt to use a neural network to generate fluence maps from organ contours and dose distributions.
We think major reasons for the errors in the results are that each treatment field is considered as an individual data in the training and that the input data channels have a rather coarse pixel size of 10 mm in this study. By considering each field as an individual data item, the network is not able to take care of influences coming from the other fields, which should be considered in the real world. Training a network with patient-based data (seven treatment fields as an individual data) is expected to increase the performance of the network; however, it simultaneously decreases the number of training datasets, and increases memory requirement for training. Moreover, 3-dimensional positioning of the treatment target makes it difficult to augment the data. Furthermore, some pixels containing multiple organ labels are considered to represent a single organ with higher priority: the PTV in our case, because of the coarse pixel size of the data. If rectum and PTV were to overlap in a channel, all the overlapping pixels would be considered as PTV. Reducing the pixel size of channels or separating different organ contours into different dimensions could help alleviate this problem and should increase the performance of the network; however, this will increase the memory requirements and the time required for training.
As mentioned in the results section, we normalised the plans to have the same mean dose as the clinical plans. In real cases, the reference plan used to adjust the normalisation factor would not exist and physicists should decide on the normalisation factor required to meet the criteria of their institute. We believe that improving the performance of the network will reduce errors of generated fluence maps and lead to the creation of plans without any human interaction.
In order to investigate the contribution of the input data: contour vs. dose distribution, we trained a network using the dose distributions only and compared results with the current network using the contour and dose distributions as input data. The overall performance of both networks was similar. However, fluence maps generated from the network trained with dose distribution only had larger errors of the outliers. Through the comparison, the performance of the network primarily comes from the dose distribution, and the organ contours help to reduce the errors of outliers. One may ask whether labelling order of organ contour affects the network performance. It happened that the PTV had the highest label, OARs close to the PTV had next high, and the tissue away from the target had the smallest label in this study. To check the effect of labelling order, we reversed the order of contour labels and trained the network. The performance of the network trained with a reversed labelling order did not show a noticeable difference from the original network.
The current network took about 10 days to complete 100 epochs, while it takes about a second to generate the fluence maps for each patient. This provides a much faster way than the expert-based manual optimisation methods for fluence map generation. A recent study reported that the manual optimization took 80 minutes on average for the 5-field IMRT plans in 20 prostate cancer patients27. Therefore, the proposed method would be particularly helpful for generating adaptive radiotherapy plans and optimising dose delivery for patients while minimising the workload for human practitioners.
We assumed that the dose distributions could be obtained from the aforementioned prediction methods and would be close to the clinical dose distribution in quality. To create a plan for a new patient with our framework, it is important to make a predicted dose distribution in clinical quality. We plan to develop a dose prediction module within the proposed work scope in our future study. Additionally, we are going to build a network that provides the fluence map directly from the organ contour, without dose calculation explicitly, given that a prescribed dose to the target is the same among the patients.
Conclusion
We propose a framework to generate fluence maps for prostate IMRT using a DNN. The network was trained to generate fluence maps directly from dose distributions and organ contours. The trained network was able to generate fluence maps in a second. This will increase the efficiency of the treatment planning step by shortening the time required to obtain optimal fluence maps and will be helpful to maintain the quality of treatment plans by generating fluence maps directly from organ contours and dose distributions.
Data availability
The datasets generated during and/or analysed during the current study are available from the corresponding author on reasonable request.
References
Barton, M. B. et al. Estimating the demand for radiotherapy from the evidence: A review of changes from 2003 to 2012. Radiotherapy and Oncology 112, 140–144, https://doi.org/10.1016/j.radonc.2014.03.024 (2014).
Thomas, B. IMRT: a review and preview. Physics in Medicine & Biology 51, R363 (2006).
Nelms, B. E. et al. Variation in external beam treatment plan quality: An inter-institutional study of planners and planning systems. Practical Radiation Oncology 2, 296–305, https://doi.org/10.1016/j.prro.2011.11.012 (2012).
Appenzoller, L. M., Michalski, J. M., Thorstad, W. L., Mutic, S. & Moore, K. L. Predicting dose-volume histograms for organs-at-risk in IMRT planning. Medical Physics 39, 7446–7461, https://doi.org/10.1118/1.4761864 (2012).
Shiraishi, S., Tan, J., Olsen, L. A. & Moore, K. L. Knowledge-based prediction of plan quality metrics in intracranial stereotactic radiosurgery. Medical Physics 42, 908–917, https://doi.org/10.1118/1.4906183 (2015).
Wu, B. et al. Patient geometry-driven information retrieval for IMRT treatment plan quality control. Medical Physics 36, 5497–5505, https://doi.org/10.1118/1.3253464 (2009).
McIntosh, C. & Purdie, T. G. Contextual Atlas Regression Forests: Multiple-Atlas-Based Automated Dose Prediction in Radiation Therapy. IEEE Transactions on Medical Imaging 35, 1000–1012, https://doi.org/10.1109/TMI.2015.2505188 (2016).
Chris, M. & Thomas, G. P. Voxel-based dose prediction with multi-patient atlas selection for automated radiotherapy treatment planning. Physics in Medicine & Biology 62, 415 (2017).
Shiraishi, S. & Moore, K. L. Knowledge-based prediction of three-dimensional dose distributions for external beam radiotherapy. Medical Physics 43, 378–387, https://doi.org/10.1118/1.4938583 (2016).
Xin, Z. et al. Deep convolutional neural network with transfer learning for rectum toxicity prediction in cervical cancer radiotherapy: a feasibility study. Physics in Medicine & Biology 62, 8246 (2017).
Wolterink, J. M. et al. In International Workshop on Simulation and Synthesis in Medical Imaging. 14–23 (Springer).
Han, X. MR-based synthetic CT generation using a deep convolutional neural network method. Medical Physics 44, 1408–1419, https://doi.org/10.1002/mp.12155 (2017).
Nguyen, D. et al. Dose Prediction with U-net: A Feasibility Study for Predicting Dose Distributions from Contours using Deep Learning on Prostate IMRT Patients. arXiv preprint arXiv:1709.09233 (2017).
Nguyen, D. et al. Three-Dimensional Radiotherapy Dose Prediction on Head and Neck Cancer Patients with a Hierarchically Densely Connected U-net Deep Learning Architecture. arXiv preprint arXiv:1805.10397 (2018).
McIntosh, C., Welch, M., McNiven, A., Jaffray, D. A. & Purdie, T. G. Fully automated treatment planning for head and neck radiotherapy using a voxel-based dose prediction and dose mimicking method. Physics in Medicine & Biology 62, 5926 (2017).
Fan, J. et al. Automatic treatment planning based on three-dimensional dose distribution predicted from deep learning technique. Medical Physics 0, https://doi.org/10.1002/mp.13271.
Choi, H. J. et al. Inter- and intra-observer variability in contouring of the prostate gland on planning computed tomography and cone beam computed tomography. Acta Oncologica 50, 539–546, https://doi.org/10.3109/0284186X.2011.562916 (2011).
Joo, J. H. et al. Analysis of prostate bed motion using an endorectal balloon and cone beam computed tomography during postprostatectomy radiotherapy. OncoTargets and therapy 9, 3095–3100, https://doi.org/10.2147/OTT.S98112 (2016).
Han, Y. & Ye, J. C. Framing U-Net via Deep Convolutional Framelets: Application to Sparse-View CT. IEEE Transactions on Medical Imaging 37, 1418–1429, https://doi.org/10.1109/TMI.2018.2823768 (2018).
Zhou, W., Bovik, A. C., Sheikh, H. R. & Simoncelli, E. P. Image quality assessment: from error visibility to structural similarity. IEEE Transactions on Image Processing 13, 600–612, https://doi.org/10.1109/TIP.2003.819861 (2004).
Zhao, H., Gallo, O., Frosio, I. & Kautz, J. Loss Functions for Image Restoration With Neural Networks. IEEE Transactions on Computational Imaging 3, 47–57, https://doi.org/10.1109/TCI.2016.2644865 (2017).
Pascanu, R., Mikolov, T. & Bengio, Y. In International Conference on Machine Learning 1310–1318 (2013).
Kingma, D. P. & Ba, J. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014).
Byun, S. J., Kim, Y. S., Ahn, H. & Kim, C.-S. Image-guided, whole-pelvic, intensity-modulated radiotherapy for biochemical recurrence following radical prostatectomy in high-risk prostate cancer patients. PLOS ONE 13, e0190479, https://doi.org/10.1371/journal.pone.0190479 (2018).
Kataria, T., Sharma, K., Subramani, V., Karrthick, K. P. & Bisht, S. S. Homogeneity Index: An objective tool for assessment of conformal radiation treatments. Journal of medical physics 37, 207–213, https://doi.org/10.4103/0971-6203.103606 (2012).
Feuvret, L., Noël, G., Mazeron, J.-J. & Bey, P. Conformity index: A review. International Journal of Radiation Oncology*Biology*Physics 64, 333–342, https://doi.org/10.1016/j.ijrobp.2005.09.028 (2006).
Adams, E. et al. EP-1641: Clinical experiences with RapidPlan knowledge-based treatment planning. Radiotherapy and Oncology 119, S766–S767, https://doi.org/10.1016/S0167-8140(16)32892-4 (2016).
Acknowledgements
This research was supported by the Radiation Technology R&D program (2013M2A2A7043506) through the National Research Foundation of Korea funded by the Ministry of Science, ICT & Future Planning, South Korea.
Author information
Authors and Affiliations
Contributions
Hoyeon Lee, Hojin Kim, Young Seok Kim, Sang Wook Lee and Byungchul Cho collected patients’ data. Hoyeon Lee and Hojin Kim designed the study and the experiments. Jungwon Kwak, Seungryong Cho and Byungchul Cho reviewed and guided study design and experimental design. Hoyeon Lee constructed and trained the neural network, analysed the results and wrote the manuscript. Seungryong Cho and Byungchul Cho edited the manuscript. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Lee, H., Kim, H., Kwak, J. et al. Fluence-map generation for prostate intensity-modulated radiotherapy planning using a deep-neural-network. Sci Rep 9, 15671 (2019). https://doi.org/10.1038/s41598-019-52262-x
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-019-52262-x
This article is cited by
-
Automatic IMRT treatment planning through fluence prediction and plan fine-tuning for nasopharyngeal carcinoma
Radiation Oncology (2024)
-
Simultaneous dose distribution and fluence prediction for nasopharyngeal carcinoma IMRT
Radiation Oncology (2023)
-
Dosimetric benefits of daily treatment plan adaptation for prostate cancer stereotactic body radiotherapy
Radiation Oncology (2021)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
