
Abstract
Land degradation and sediment remobilisation in dryland environments is considered to be a significant global environmental problem. Given the potential for currently stabilised dune systems to reactivate under climate change and increased anthropogenic pressures, identifying the role of external disturbances in driving geomorphic response is vitally important. We developed a novel approach, using artificial neural networks (ANNs) applied to time series of historical reactivation-deposition events from the Nebraska Sandhills, to determine the relationship between historic periods of sand deposition in semi-arid grasslands and external climatic conditions, land use pressures and wildfire occurrence. We show that both vegetation growth and sediment re-deposition episodes can be accurately estimated. Sensitivity testing of individual factors shows that localised forcings (overgrazing and wildfire) have a statistically significant impact when the climate is held at present-day conditions. However, the dominant effect is climate-induced drought. Our approach has great potential for estimating future landscape sensitivity to climate and land use scenarios across a wide range of potentially fragile dryland environments.
Similar content being viewed by others


Introduction
Landscape Reactivation in Dryland Systems
Land degradation and surface sediment remobilisation are major issues in drylands1, which cover 40% of the earth’s land surface2, with their consequences estimated to directly affect up to 2 billion people3. Surface destabilisation induces a variety of problems for local communities2,4,5 including the removal of fertile soils and nutrients6, the burial of small plants, and damage to infrastructure, livestock and crops7. The interactions between climatic stress (i.e. drought)8, land use9,10,11, grazing pressure12,13,14,15,16 and wildfire17,18,19,20,21 bring about damage to surface protective vegetation cover22,23,24 and expose the underlying sediment to erosion by aeolian processes and land degradation4. Disturbance-driven degradation can lead to the reactivation of dryland geomorphological features, such as sand dunes, resulting in the formation of localised blowouts24,25,26,27,28,29 or even large-scale dune remobilisation in some of the world’s most vulnerable regions30,31. In turn, the creation of blowouts acts as an initial source of sediment that can lead to further reactivation and new dune formation25.
With increases in population pressure and land use, and climate models predicting increasing precipitation variability32, there is a greater need to understand the sensitivity of dryland landscapes to future disturbances. In particular, there is a specific concern about how individual forcing factors interact with the environment to induce instability and land degradation22. Current methods of analysis often rely on simple visual comparisons between historic records and the correlation of individual forcing parameters against periods of reactivation in the record27,33, or short-lived individual event analyses in the study of aeolian system surface change34. Univariate analyses focus on individual drivers (see review27) but fail to identify the feedbacks between the range of climatic and anthropogenic forcing factors. At the Quaternary timescale sand dune reactivation studies, for example, have long been used as a proxy for palaeoaridity35,36,37, with luminescence-derived chronologies used to infer periods of historic drought33,38,39,40. Whilst a focus on climatic factors may be suitable on millennial timescales, more recent localised reactivations are driven by a combination of natural and anthropogenic disturbances. Aside from a climatic focus, many studies have commented on the role of wildfire17,18,19,20,21 or grazing pressures12,13,14,15,16, which in themselves demonstrate key biogenic relationships, but might mask the synergies within the wider system. Whilst some studies have suggested the combined role of multiple forcing factors in contributing towards vegetation removal and landscape destabilisation16,22,41,42,43,44,45,46,47,48,49,50, few have quantified the relationship between forcing factor and environmental response using traditional analytical methods.
Quantifying the role of individual parameters and identifying the complex relationship between the forces and geomorphological response is therefore essential to predicting the likelihood of future disturbance-driven reactivations. Ideally, a process-based model would be used to simulate hypothetical geomorphic responses to future climatic and anthropogenic forces. However, these mechanistic models do not yet exist in the form necessary for dryland aeolian environments.
Here, we apply a ‘data-led’ empirical approach, rather than trying to construct a mechanistic model (that comes with the problems of structural and parameter uncertainty). We explore the potential for novel applications of artificial intelligence (AI) techniques to improve our understanding of the relationship between climatic and anthropogenic disturbances and resultant geomorphic response in dryland environments. Artificial neural networks (ANNs) provide a hitherto underutilized method to simultaneously examine multiple forcing factors and uncover their complex relationships51. A supervised learning algorithm takes a known set of paired input-target data and trains a model which can be used to generate reasonable predictions for the response to new unseen data. As such, ANNs have been applied to a range of research problems from predicting stock markets52 to biomedical sciences51 and monitoring water quality53 to name a few. Specifically in environmental research, ANNs have successfully been applied in a range of dendroclimatic54,55,56,57, geomorphological58,59 and aeolian studies60,61,62,63.
Experimental Design
The goal of this study is to identify how changes in drivers of vegetation disturbance induce changes in sediment mobilisation. The main drivers of vegetation disturbance and subsequent sediment reactivation are: climate-induced drought, grazing/land use pressure and wildfire disturbance; both currently and expected in the future. In this study, two ANNs were established to predict the likelihood for identifying episodes of sediment deposition in near-surface sand dune profiles given a set of forcing factors (i.e. climate, grazing pressure and wildfire occurrence). Luminescence-dated sediments from near-surface dune sands provide a historical chronology of deposition events which are used to represent episodes of sediment mobility within the system over the past 400 years (see Methods). Ideally, continuous time series of relevant climate data would be used as an input to train the first ANN (ANN1), and this is indeed possible over more recent time periods. However, such records are not long enough to cover the time period represented by the sediment deposition dates (c. the last 400 yrs). After searching for longer-term records of relevant data, and proxies for climate conditions, we found tree ring growth indices to provide the best available data. Rather than train the ANNs against climate data directly, we therefore trained them against tree ring data as a proxy for climate54,64,65,66. In addition, we used historical records of grazing pressure and wildfire occurrence (see Methods and Supplementary Note 2).
Using empirical data, we first identify the relationship between driving forces and sediment deposition events from the historical record before varying the disturbance factors under a set of future scenarios (alternate climatic, grazing and fire frequency futures) to deduce the environmental response and sensitivity to individual parameters. As the ANN was trained using historical tree ring data, future climate scenarios must then also be expressed in this way. A second ANN predicted hypothetical tree ring growth under two different future climatic regimes (ANN2; see Methods). We used two hypothetical climate futures combined with varying wildfire regimes and grazing pressures to sensitivity test the likelihood of deposition events when forcing factors were modelled under a range of conditions. All details are provided in Methods and in the online Supplementary Material.
Nebraska Sandhills: a test case
With the experimental design defined, this approach was applied to empirical data collected from the Niobrara Valley Preserve in northern Nebraska, US. Empirical data from a detailed analysis of historical (101–103 years) land degradation in the Nebraska Sandhills (Buckland et al. submitted 16/08/18), a region synonymous with the 20th century US Dust Bowl and with the potential to experience serious disturbance in future decades67, provides input to this analysis. For our modelling experiments, we chose chronologies of depositional events from six different geomorphological features in the northern Nebraska Sandhills to provide a measure of environmental response to disturbance events over the last 400 years (see Supplementary Note 1). Six separate profiles, from a range of geomorphological features within the local area, are used for inter-site comparison (see Methods and Supplementary Note 3). Input datasets taken from a tree ring growth index (a proxy for climate), a simplified measure of historical grazing/land use pressure, and tree scar records (a proxy for wildfire history) provide the inputs for the model, representing natural and human disturbance forces (see Supplementary Note 2).
ANN1 defines the relationship between climatic and human disturbance forces and the resultant episodes of near-surface sediment deposition. Luminescence-dated periods of deposition are presented as a continuous estimate of probability based on multiple discrete dates spanning the period of interest. ANN2 identifies the historical relationship between climatic inputs (annual growing season precipitation, average max and min temperatures) and tree ring growth65 which is used for the second stage of sensitivity testing.
Model validation and testing were achieved through two methods: (i) partitioning of the original dataset, and (ii) cross-validation between the dune sites. Datasets were randomly partitioned for training, validating and testing purposes during the training of the network. ANN1 consists of an input layer, four hidden layers (comprising 3:30:30:3 fully connected neurons) and an output layer, whilst ANN2 has an input layer, one hidden layer (9 neurons) and an output layer. ANN1 is a time-delay network, incorporating a delay line of up to 8 years between datasets for input (forcings) and output (sediment age probability) (see Methods).
Results
Model training
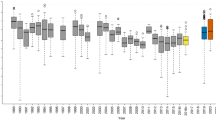
For each of the six study sites, when all sites were included in the training dataset (Fig. 1: upper, ‘in-sample’ prediction), the timings of predicted deposition events (red) align well with the known dataset reconstructed from historical sediments (blue). Additional simulated peaks in the record (centred on 1730 and 1870 AD) suggest episodes of sediment deposition that we would expect to find if deeper sediment samples were extracted at sites A, C and E.

Results from both in-sample (upper) and out-of-sample (lower) testing across the six sites in ANN1. Blue lines refer to the known target datasets taken from empirical measurements of periods of deposition, and red lines are the predicted model outputs for each respective site. Due to the incomplete nature of sedimentary profiles75, periods with no evidence of depositional events have been removed from the training dataset to prevent the model identifying these conditions as conducive to stability (i.e. sites A, C and E).
Cross-validation results (‘out-of-sample’ prediction) demonstrate the capacity to accurately predict the six known depositional profiles when the respective site has been excluded from the network training stage (Fig. 1: lower). All sites, except B, show good correlation between the peak positions of the known target dataset and predicted model output.
Scenario testing
Having effectively trained the model, in this section we assess how example combinations of the key drivers (climate, grazing pressure and wildfire) are expected to induce changes in sediment mobility, given the relationships learnt from historical data. First, using ANN2, after successfully predicting historical tree ring growth from historical growing season precipitation totals and average max and min daily temperatures (Fig. 2) (see Supplementary Note 4), two new tree ring growth futures were simulated based on two hypothetical climates (climate 1 & 2) (see Methods and Supplementary Note 4) (Fig. 3). Climate 1 growing season precipitation totals and max/min temperatures follow the trend set by long-term averages (1908–2015 AD). For comparison, climate 2 growing season temperatures increase by 4.5 °F by the end of the century based on future regional projections across a suite of climate models under a low emission scenario68.

Results from training network ANN2 simulating the relationship between growing season precipitation and temperature conditions with tree ring growth over the period 1908–1997 AD. Black line represents known historical tree ring growth index65 (smoothed 0.1 RLOESS), grey line is simulated tree ring growth based on the trained network.

Simulated tree ring growth indices based on two different climate scenarios: (a) Climate 1 (long-term averages), (b) Climate 2 (low emission conditions with gradually increasing temperatures (see Methods). Mean (black) and standard errors (grey dashed) were calculated using 102 repeats. Multiple repeats ensured that the simulated dataset was not driven by random extreme values.
Tree ring growth outputs across both climatic profiles produced results in line with theoretical expectations. After 8,000 model repeats, datasets which produced multiple extreme values outside of the bounds of the training set were excluded (see Methods); the mean and standard error were calculated with the remaining repeat datasets (Fig. 3). Climate 1 shows a noisy signal with low-level sensitivity to precipitation and temperature changes (Fig. 3a) while the greater climatic stresses of climate 2 force a reduction in tree ring growth with time (Fig. 3b).
Second, using the trained ANN1 and three levels of grazing pressure, simulated tree ring growth indices produced six future likelihoods for identifying deposition events in the near-surface sediments. Across both climate futures, an antiphase relationship between tree ring growth and the likelihood for sediment deposition (deposition event score) suggests sediment movement is largely driven by climatic conditions (Fig. 4, see Supplementary Note 6). Under historical average climatic conditions (climate 1) a noisy signal is seen across all three combinations of grazing conditions with the output profile in general mirroring the signal found in the tree ring growth index (Fig. 4a,c,e). Increased aridity (in climate 2), reduced the tree ring growth index with time, and similarly increased the likelihood of identifying a period of deposition in the sediment (i.e. higher deposition event score) (Fig. 4b,d,f). This relationship is particularly visible under low grazing conditions but is less well-defined with noisy shallow peaks under higher levels of grazing pressure.

ANN1 and ANN2 simulated output results based on two future climate scenarios and three different grazing pressures. Blue output refers to simulated tree ring growth index based on climate 1 and 2 hypothetical scenarios. Grey output demonstrates ANN1 likelihood of identifying a depositional event (ANN1 output is plotted as ‘deposition event score’ where relative high points correspond with an increased likelihood of identifying an episode of deposition in the sediment). Dotted lines depict mean values calculated after repeat runs were screened for optimum model performance, shaded area corresponds with standard error. Repeat runs were screened according to ability to predict the correct location of deposition events in the training dataset (see Methods).
Third, to explore the added impact of increased grazing pressure (above background levels) and wildfire frequency, additional grazing pressure was added to low and moderate grazing regimes for a 10-year period (Fig. 5 brown bars) and wildfires were added when average max temperatures >80 °F (Fig. 5 red bars). Temperature is considered a strong determinant of fire frequency in the Great Plains69. Under low grazing conditions, an increase in pressure results in a lagged-system response with a notable increase in the likelihood to identify episodes of sediment deposition (Fig. 5a). By contrast, when background grazing conditions are already at moderate levels, or when climates are tending towards more arid conditions, an increase in grazing pressure does not alter the model projections (Fig. 5c,e,g); the signal is driven by climatic disturbances as demonstrated in the tree ring growth index. Additional grazing pressure was not added to the already heavily grazed scenarios (Fig. 5i–l).

Output results when new scenarios of climatic conditions, grazing pressure and wildfire occurrence are combined over a 100-year period. Deposition event scores are presented as mean ± standard error following 5,000 repeats. Repeat runs were screened according to ability to predict the correct location of deposition events in the training dataset (see Methods). Six different disturbance scenarios (see Methods) are plotted across the 4 columns for each of the 3 different grazing pressure levels (Low grazing: a–d, Moderate grazing: e–h, Heavy grazing: i–l). Column 1: compares scenarios 1 and 2. Column 2: compares scenarios 1 and 3. Column 3: compares scenarios 4 and 5. Column 4: compares scenarios 4 and 6. Blue output: simulated tree ring growth index based on either climate 1or 2. Grey output: ANN1 OSL output based on climate-only scenarios. Green output: includes added grazing pressure scenarios. Brown bar depicts period of increased grazing pressure. Red output: includes wildfire. Red bars represent years with wildfire occurrence.
A complex relationship with wildfire occurrence shows a marginal increase in the deposition event score following a wildfire event. Typically, wildfire occurrence results in an amplified likelihood of sediment deposition 1–2 years after the event and tends to follow the general trend of the output profile defined by the climatic conditions. An increased amplification of the sediment deposition likelihood associated with wildfire is particularly apparent under low grazing conditions with consecutive wildfires (Fig. 5b,d). Under heavily grazed conditions, wildfire events do not cause a statistical increase in the likelihood of identifying sediment mobility in the record, except for following a series of three wildfire events (Fig. 5j: 2021–2024 AD) under average climatic conditions (climate 1).
Discussion
Drivers of future deposition events
Results highlight the dominance of climatic disturbance in driving vegetation growth (as shown in the tree ring growth index) which in turn explains the majority of the variability found in the deposition event score (ANN1 output profile). When additional grazing (or land use pressure) is added to a previously low pressure grazed environment, a significant increase in identifying periods of sediment deposition is found. Yet, in environments under already stressed conditions (i.e. moderate/heavy grazing or drier climates), an increase in pressure bares no additional impact on the likelihood of identifying sediment movement in the geomorphic system. These results agree with previous studies70,71 that have commented on the non-linear nature of dryland geomorphic systems, whereby a threshold of disturbance is required to initiate sediment reactivation. Our results show that the force exerted by external disturbances is not linearly related to the likelihood for periods of sediment deposition to be identified in the record; the geomorphic response is binary not continuous. Additional grazing pressure does not increase the likelihood for reactivation in a system that is already experiencing sediment mobilisation, but it might contribute to pockets of localised heterogeneity in the record and, in particular, the formation of blowouts29,72.
Whilst some studies have suggested that fire may not contribute to the likelihood of sediment reactivation in semi-arid grassland environments17, our findings support existing research18,20,21 that has suggested that wildfires may damage surface vegetation and increase the likelihood for sediment remobilisation (e.g. Fig. 5d: 2083–88 AD period) and during periods of low climatic stress (Fig. 5b). Under low and moderate grazing regimes, model outputs predict a marginal increase in the deposition event score following the 2012 wildfire. In 2012, a large wildfire (76,000 acres) stripped the study region of trees, shrubs and grass species. Yet, despite the extensive nature of the fire, anecdotally ranchers and preserve managers commented on the lack of evidence for sediment remobilisation following this event – likely caused by extensive root networks17, sediment crusting73, and wildfire management practices74. Changes in grazing strategy and landscape management following wildfires have been instrumental in determining the subsequent likelihood for sediment remobilisation. The model used in this example has been trained on the land management practices during the 20th-century and is unable to predict how future human decision-making will change. As such, whilst the model predicted a sediment response post-2012 fire, the lack of physical evidence to support this simulation is likely caused by non-analogous behaviour to the training dataset.
Limitations of the approach
Whilst our results have demonstrated the potential application of ANNs for estimating future landscape sensitivity, it is essential to equally understand the limitations of the method used. Out-of-sample predicting is the main limitation for the approach outlined here; this is the likely inability to provide accurate forecasts when models are trained on a limited or non-analogous dataset. The unique set of input conditions found at site B is not replicated at any of the other 5 sites, and without another set of comparable data to train from, the predicted output is beyond the limited conditions represented in the training dataset (e.g. Fig. 1 site B). In this study, we have attempted to reduce such errors in expanding the dataset by training across multiple study sites. As in all inferential methods, a larger dataset that encompasses more drought cycles would improve the training (and therefore the predictable capabilities) further. An inherent weakness of data-informed models in this context is that under future climate change, if forcing conditions (or combinations of conditions) stray significantly far from past experience (significantly ‘non-analogous’), supervised models may no longer be able to accurately predict future landscape responses.
Another difficulty using this method is associated with identifying what the relative peaks and troughs in the simulated outputs represent. As mentioned earlier, the network has been trained on a luminescence-dated target dataset which provides a continuous estimate of the probability of identifying a luminescence age (i.e. episode of deposition) in the sedimentary record. However, ascertaining what peaks in the simulation output correspond with a deposition ‘event’ in the profile is dependent on where the relative baseline associated with stability is positioned (i.e. are all periods with scores >0 indicative of sediment mobilisation episodes?). In this study, the network has been trained on definitively identified episodes of sediment deposition, not periods of known stability (see Methods). A series of erosional filters gradually remove evidence of historic reactivation events from the sedimentary system75. As such, our target dataset does not provide evidence for all deposition events, but more importantly, it does not provide definitive evidence of periods of stability. There is a distinct difference between an absence of evidence and an evidence of absence, but this is not resolved in the depositional record. A baseline at zero therefore, to represent no likelihood of identifying a deposition event in the forecasted plots, is incorrect and thus events are inferred as the most prominent relative peaks in the deposition event profile as opposed to those that are identified above a set threshold, or those that are representative of extreme model runs (see Supplementary Note 5).
The relatively large error margins associated with dated episodes of deposition (see Supplementary Note 3) further compound the difficulty in identifying specific deposition events and associated conditions. This is problematic for the network training as input conditions over large windows are considered to be inducing a short-lived sediment reactivation event that is characterised by large uncertainties (Fig. 6). Conditions that are therefore reflective of landscape stability may falsely be associated with identified periods of deposition. Since the model has trained against a dataset that has already undergone a series of natural filters75, the simulated outcome does not necessarily depict every deposition event. Additional known point-in-time observations taken from historical aerial imagery, oral records, agricultural reports would improve the resolution of the training.

Schematic figure demonstrating how the wide training window of activity as defined by the target dataset (solid line) forces the model to train the equivalent period of input datasets (dashed line) to that target – even if the true ‘disturbance’ was only a short-lived event.
Wider significance
We have shown the capacity to use ANN models coupled with empirical datasets to improve our understanding of aeolian geomorphological systems and future sensitivity to climatic and human disturbance. Our results demonstrate how ANNs can identify relationships between paired historical input-target datasets, as well as the potential for trained models to make predictions about the likelihood of future reactivations. When known forcings are included in the simulations, we can identify peaks in reactivation driven largely by perturbations in climatic conditions, but also grazing pressure and fire frequency when aridity stresses are low. Results from this study suggest that fire can increase the capacity for near-surface reactivation and could be used to explain heterogeneity in local sediment profiles under low-stress climatic conditions. Likewise, the resilience of grasslands to grazing pressures is largely related to the ambient climate71. As expected, the dynamic nature of dryland environments means that the likelihood for sediment reactivation is not linearly related to individual forcings. Through ANN simulations, we demonstrate the dynamic relationships between disturbances and response, exploring the idea of thresholds and a lagged-response to external perturbations.
The black box nature of ANNs prevent a defined weighting of each disturbance parameter being produced, but sensitivity testing has demonstrated the non-linear response of the system to different combinations of disturbance conditions. These findings corroborate with existing research that synergies between forcing parameters are the key to near-surface reactivations in semi-arid grasslands43,45.
Using cross-validation tests, we have demonstrated the bounds within which these models most optimally perform. Without all potential outcomes represented in the original training dataset, the ability to predict accurate outcomes is limited. If future models are to accurately predict future sediment reactivation events, non-linear multivariate tools are needed to fully-integrate the variety of parameters influencing near-surface activation. ANNs represent an opportunity within drylands, and wider landscape dynamics, to define environmental relationships and thresholds in systems where process-based mechanistic models are absent. The potential for future models, however, to accurately simulate hypothetical futures is constrained by the capacity to identify suitable training datasets that capture analogues for forthcoming conditions.
Methods
All neural networks have been developed in Matlab R2017b using the Neural Network toolbox and code written by the authors (CEB & RMB).
ANN1
ANN1 is an artificial neural network used to identify the relationship between climatic and anthropogenic disturbances and the likelihood of a luminescence age, indicating sediment deposition, to be found in the sedimentary record. ANN1 was trained with input-target data from 1590–1997 AD and used to stimulate the likelihood of identifying future deposition events in the sediment in the following 100 years under a series of alternative climatic and grazing pressure scenarios (see Future scenario forecasting).
Pre-processing input datasets
Three primary contributors to vegetation cover, and thus surface stability, were selected for inclusion in the model: grazing pressure, wildfire occurrence, and climatic conditions. Instrumental measurements (capturing the last 100 years of climatic data) were not used due to the relatively short time series measured. A longer dendrochronological record of tree ring growth from the Niobrara Valley Preserve (NVP)65 provided an integrated record of precipitation and temperature change over the past 400 years. Annual tree ring growth data was extracted and smoothed by a factor of 0.2 RLOESS function, to allow a signal to be identified by the model amongst the environmental noise. Grazing pressure for the six dune sites was based on the levels identified in the index defined in Buckland et al. (submitted – 16/08/2018) and smoothed by a moving average factor of 0.1 to represent progressive changes in management strategy. Wildfire occurrence was included as a binary input (i.e. ‘1’ – fire, ‘0’ – no fire) based on the fire scar records from NVP76.
Pre-processing target dataset
The target dataset for each of the six dune sites was represented by a probability density function (PDF) of stacked luminescence (optically stimulated luminescence – OSL) ages that depict episodes of sediment deposition in the dune profile. The target dataset represents a likelihood of identifying an OSL age, it does not necessarily capture every sediment reactivation event that has occurred for two reasons. First, historical events may have been eroded from the sedimentary record, and whilst a multicore strategy has been used to increase the overall representation of reactivation events, due to the fragmented nature of aeolian sedimentary profiles some events may be eroded from the record. Second, the event may not have been captured in the OSL dating due to sampling strategy. Considering these caveats, whilst a peak in the PDF dataset represents a depositional event, a trough does not equally represent a period of stability. A positive peak is a true result, but a negative absence only suggests that we did not find evidence of an event. As such, it is essential to pre-process the target dataset to avoid falsely training the ANN to interpret certain conditions as conducive to stability. Where long gaps between peaks (regions of contiguous values at zero) were found in the luminescence record, target values were removed, preventing the model from associating periods which might be due to erosional loss of sediment to specific environmental conditions, thereby learning a false relationship (for the present purposes).
Model structure and architecture
Final model structure used ‘timedelaynet’ function to allow for an adjustable lag to be incorporated into the network architecture. A lag of up to 8 years for the input variables was selected following a series of trials of different time lags. Given the complex nature of the relationship between the input variables and the resultant likelihood of sediment movement, four hidden layers were used with a structure of [3 30 30 3] neurons in the layers (Fig. 7). The Levenberg-Marquadt algorithm was used to train the network (minimizing distance between model outputs and target data) and the mean square error (MSE) of each model run was used as the performance indicator for each iteration. Training datasets were randomly partitioned for training (90%), validation (5%) and testing (5%) purposes during cross-validation experiments, but to reduce over-fitting in the future scenario simulations this split was altered to increase the test portion of the datasets (50% training, 5% validation, 45% testing) and improve the robustness of the model outputs.

Schematic diagram demonstrating the model architecture of the final models used in ANN1. Training model was based on input-target dataset from 1590–1997 AD, with scenario datasets based on measured climatic data from 1998–2014 and simulated tree ring growth indices from 2015–2098.
ANN2
ANN2 is an artificial neural network used to identify the relationship between individual climatic parameters (growing season precipitation, average max and min daily temperatures) and tree ring growth index65 from 1908–1997 AD. ANN2 was used to produce simulated tree ring growth indices under a range of hypothetical new climatic scenarios.
Pre-processing datasets
Precipitation and temperatures measurements (sourced from Ainsworth Met Station (42.58°N, −100.05°W)) were used as input datasets and smoothed by a factor of 0.2. A tree ring growth index produced using ponderosa pine tree rings within the NVP was used as the target dataset65.
Model structure and architecture
Final model structure used ‘fitnet’ function, a single hidden layer with 9 neurons (Fig. 8) and the Levenberg-Marquadt algorithm. Known time series data was randomly partitioned for training (70%), validation (10%) and testing (20%) purposes.

Schematic diagram demonstrating the model architecture of the final models used in ANN2. Training model was based on input-target dataset from 1908–1997 AD, with scenario datasets based on measured data from 1998–2014 and simulated data from 2015–2098.
Future scenario forecasting
Future scenario data refers to the 100 years post-1998 with the period from 1998–2014 using measured instrumental data, followed by 84 years of future ‘scenario’ data based on a range of climatic conditions, grazing pressure and wildfire frequency.
Scenario Forecasting (part 1): Tree Ring Growth Index
Trained ANN2 was used to model the predicted tree ring growth indices associated with two hypothetical climate scenarios and used as the new inputs alongside combinations of grazing pressure and wildfire occurrence in ANN1. Future climate data (2015–2100 AD) was produced using an autoregressive model to identify the normal levels of ‘noise’ identified in the measured historical precipitation and temperature datasets, before being added to two different future trends (Table 1) (see Supplementary Note 4).
Using the training dataset (1908–1997 AD) to define ANN2, the model was ran for 8,000 repeats with the simulated outputs associated with each network repeat stored by the model. Multiple cycles of the network ensured that the simulated target dataset was not driven by random extreme values. Repeats that produced more than seven tree ring indices >5,000 (i.e. extreme values) were excluded from the final dataset. The mean and standard error for each year was calculated for the two climatic scenarios and used as the new tree ring growth index for simulating future sediment deposition events in ANN1.
Scenario Forecasting (part 2): Future likelihood of sediment deposition events
Simulated tree ring indices were modelled against three levels of grazing pressure: low, moderate and heavy. Further analysis to sensitivity test the role of wildfires and additional periods of grazing pressure when applied against a background level were completed to produce six different combinations of future disturbance conditions (Table 2).
Using the known datasets (1590–1997 AD) to define ANN1, 5,000 repeats were completed using the six training sites. The training dataset was partitioned with a relatively low training portion (50%) and high validation and testing partition (5% + 45%) (based on a short time series) to prevent over-fitting and improve the robustness of the future scenario outputs. With each repeat, the model simulated the predicted future likelihood of identifying depositional episodes in the sediment, classified as a deposition event score, according to the six future disturbance scenarios.
Model validation and selection
Repeats were assessed according to the model’s ability to correctly reproduce the peaks found in the known historical deposition dataset (ANN1 training target). ANN1 training target is characterised by a continuous curve with peaks of varying magnitude, but the nature of the response is binary (i.e. sediment moves, or it does not). The size and magnitude of the model-derived peaks are therefore not significant, with the location of the peaks relative to the known dataset (Fig. 9) a good indication of overall model performance and ‘fit’. Given this, the mean squared error (MSE) of the model is not an appropriate method for determining overall model performance. In this study, we assessed the performance of the model based on the variation in location between the known and modelled peaks, with the best model identified as having the closest alignment of peaks across the six study sites. To identify the optimum models, we sum the differences between training and predicted peak positions for each model repeat across the six sites and select the models of best fit. The model identified a predicted peak which fell within a defined time window of the target peak and calculated the difference in location between the two peaks. If a target peak was not reproduced in the predicted dataset (i.e. a predicted peak does not occur within the peak window), a model penalty value (e.g. 1e6 used in this study) was assigned. Total peak location differences and penalties were summed across the identified peaks in each site, and across the six sites for each neural network repeat run. A moderate number of iterations (300) per repeat was used to prevent the model from attempting to improve the network to the optimum MSE, which is not necessarily the best peak-location-performing model. Maximum peak window size was defined as half the distance between the two closest known peaks in the target dataset (i.e. 13 in this study).

Schematic diagram demonstrating that MSE caused by variation in magnitude of peaks between training and predicted datasets (left) is not useful because the event occurred at the same point in time. The difference in the location of the peak (right) in time is a more appropriate measure of model performance.
Following 5,000 repeats, the mean and standard error associated with the repeats from the top 10% of models was calculated (model repeats for each timepoint were normally distributed). Increasing the percentage of models used to calculate the mean and standard error confidence intervals would reduce the overall uncertainty on the profile, but potentially includes the output from models that are poorly trained against the known datasets and are therefore more precise but less accurate (see Supplementary Note 5).
Code Availability
The model is implemented in MatLab® (version R2017b) using code written by the authors. A full version of the neural network code is freely available on GitHub (https://github.com/CatherineBuckland/ANN).
Data Availability
The authors declare that most of the data supporting the findings of this research are within the paper and corresponding Supplementary Information. Any other additional data supporting the results presented are available from the corresponding author upon request.
References
United Nations. Desertification. Available at, www.un.org/esa/sustdev/publications/trends2008/desertification.pdf. (Accessed: 27th August 2018) (2008).
Wang, L. et al. Dryland ecohydrology and climate change: critical issues and technical advances. Hydrol. Earth Syst. Sci. 16, 2585–2603 (2012).
Middleton, N., Stringer, L., Goudie, A. & Thomas, D. S. G. The Forgotten Billion: MDG achievement in the drylands (2011).
Reynolds, J. F. et al. Global desertification: building a science for dryland development. Science 316, 847–851 (2007).
Middleton, N. J. & Sternberg, T. Climate hazards in drylands: A review. Earth-Science Rev. 126, 48–57 (2013).
Wasson, R. J. & Nanninga, P. M. Estimating wind transport of sand on vegetated surfaces. Earth Surf. Process. Landforms 11, 505–514 (1986).
Wiggs, G. F. S. Geomorphological hazards in drylands. In Arid Zone Geomorphology: Process, Form and Change in Drylands (ed. Thomas, D. S. G.) 583–598 (Wiley, 2011).
Swain, S., Wardlow, B. D., Narumalani, S., Tadesse, T. & Callahan, K. Assessment of vegetation response to drought in Nebraska using Terra-MODIS land surface temperature and normalized difference vegetation index. GIScience Remote Sens. 48, 432–455 (2011).
Middleton, N. The human impact. In Arid Zone Geomorphology (ed. Thomas, D. S. G.) 571–579 (Wiley-Blackwell, 2011).
Viglizzo, E. F. & Frank, F. C. Ecological interactions, feedbacks, thresholds and collapses in the Argentine Pampas in response to climate and farming during the last century. Quat. Int. 158, 122–126 (2006).
Worster, D. Dust Bowl. (Oxford University Press, NY, 1979).
Ash, J. E. & Wasson, R. J. Vegetation and sand mobility in the Australian desert dunefield. Zeitschrift fur Geomorphol. Suppl. 45, 7–25 (1983).
Milchunas, D. G., Lauenroth, W. K., Chapman, P. L. & Mohammad, K. K. Effects of grazing, topography, and precipitation on the structure of a semiarid grassland. Vegetatio 80, 11–23 (1989).
Thomas, D. S. G. The geomorphological role of vegetation in the dune systems of the Kalahari. In Geomorphological Studies in Southern Africa (eds Dardis, G. & Moon, B. P.) 145–158 (Balkema, 1988).
Yan, L., Zhou, G. & Zhang, F. Effects of different grazing intensities on grassland production in China: A meta-analysis. Plos One 8, e81466 (2013).
Biondini, M. E., Patton, B. D. & Nyren, P. E. Grazing intensity and ecosystem processes in northern-mixed grass prarie, USA. Ecol. Appl. 8, 469–479 (1998).
Arterburn, J. R., Twidwell, D., Schacht, W. H., Wonkka, C. L. & Wedin, D. A. Resilience of Sandhills Grassland to Wildfire During Drought. Rangel. Ecol. Manag. 71, 53–57 (2018).
Esteves, T. C. J. et al. Mitigating land degradation caused by wildfire: Application of the PESERA model to fire-affected sites in central Portugal. Geoderma 191, 40–50 (2012).
Levin, N., Levental, S. & Morag, H. The effect of wildfires on vegetation cover and dune activity in Australia’s desert dunes: A multisensor analysis. Int. J. Wildl. Fire 21, 459–475 (2012).
Santín, C. & Doerr, S. H. Fire effects on soils: The human dimension. Philos. Trans. R. Soc. B Biol. Sci. 371, 28–34 (2016).
Wiggs, G. F. S., Livingstone, I., Thomas, D. S. G. & Bullard, J. E. Effect of vegetation removal on airflow patterns and dune dynamics in the southwest Kalahari desert. L. Degrad. Dev. 5, 13–24 (1994).
Barchyn, T. E. & Hugenholtz, C. H. Reactivation of supply-limited dune fields from blowouts: A conceptual framework for state characterization. Geomorphology 201, 172–182 (2013).
Wolfe, S. A. & Nickling, W. G. The protective role of sparse vegetation in wind erosion. Prog. Phys. Geogr. 17, 50–68 (1993).
Wolfe, S. A. & Nickling, W. G. Sensitivity of eolian process to climate change in Canada. Geol. Surv. Canada Bull. 421 (1997).
Barchyn, T. E. & Hugenholtz, C. H. Dune field reactivation from blowouts: Sevier Desert, UT, USA. Aeolian Res. 11, 75–84 (2013).
Hugenholtz, C. H., Bender, D. & Wolfe, S. A. Declining sand dune activity in the southern Canadian prairies: Historical context, controls and ecosystem implications. Aeolian Res. 2, 71–82 (2010).
Provoost, S., Jones, M. L. M. & Edmondson, S. E. Changes in landscape and vegetation of coastal dunes in northwestEurope: A review. J. Coast. Conserv. 15, 207–226 (2011).
Hesp, P. A. Foredunes and blowouts: initiation, gemorphology and dynamics. Geomorphology 48, 245–268 (2002).
Hugenholtz, C. H. & Wolfe, S. A. Morphodynamics and climate controls of two aeolian blowouts on the northern Great Plains, Canada. Earth Surf. Process. Landforms 31, 1540–1557 (2006).
Thomas, D. S. G., Knight, M. & Wiggs, G. F. S. Remobilization of southern African desert dune systems by twenty-first century global warming. Nature 435, 1218–1221 (2005).
Wang, X., Yang, Y., Dong, Z. & Zhang, C. Responses of dune activity and desertification in China to global warming in the twenty-first century. Glob. Planet. Change 67, 167–185 (2009).
Christensen, J. H., et al. Regional Climate Projections. In The Physical Science Basis. Contribution of Working Group I to the Fourth Assessment Report of the Intergovernmental Panel on Climate Change (eds Solomon, S. et al.)847–940, https://doi.org/10.1080/07341510601092191 (Cambridge University, Cambridge, UK, 2007).
Burrough, S. L. & Thomas, D. S. G. Central southern Africa at the time of the African Humid Period: A new analysis of Holocene palaeoenvironmental and palaeoclimate data. Quat. Sci. Rev. 80, 29–46 (2013).
Bogle, R., Redsteer, M. H. & Vogel, J. Field measurement and analysis of climatic factors affecting dune mobility near Grand Falls on the NavajoNation, southwestern United States. Geomorphology. 228, 41–51 (2015).
Shaw, P. A. & Thomas, D. S. G. Late Quaternary environmental change in central southern Africa: new data, synthesis, issues and prospects. Quat. Sci. Rev. 21, 783–797 (2002).
Stokes, S., Thomas, D. S. G. & Washington, R. Multiple episodes of aridity in southern Africa since the last interglacial period. Nature 388, 154–158 (1997).
Stokes, S., Thomas, D. S. G. & Shaw, P. A. New chronological evidence for the nature and timing of linear dune development in the southwest Kalahari Desert. Geomorphology 20, 81–93 (1997).
Halfen, A. F. & Johnson, W. C. A review of Great Plains dune field chronologies. Aeolian Res. 10, 135–160 (2013).
Hesse, P. P., Magee, J. W. & Van Der Kaars, S. Late Quaternary climates of the Australian arid zone: a review. Quat. Int. 118–119, 87–102 (2004).
Thomas, D. S. G. & Leason, H. C. Dunefield activity response to climate variability in the southwest Kalahari. Geomorphology 64, 117–132 (2005).
Propastin, P. A. & Kappas, M. Reducing Uncertainty in Modeling the NDVI-Precipitation Relationship: A Comparative Study Using Global and Local Regression Techniques. GIScience Remote Sens. 45, 47–67 (2008).
Paudel, K. P. & Andersen, P. Assessing rangeland degradation using multi temporal satellite images and grazing pressure surface model in Upper Mustang, Trans Himalaya, Nepal. Remote Sens. Environ. 114, 1845–1855 (2010).
Mangan, J. M., Overpeck, J. T., Webb, R. S., Wessman, C. & Goetz, A. F. H. Response of Nebraska Sand Hills natural vegetation to drought, fire, grazing, and plant functional type shifts as simulated by the Century model. Clim. Change 63, 49–90 (2004).
Cook, B. I., Miller, R. L. & Seager, R. Amplification of the North American ‘Dust Bowl’ drought through human-induced land degradation. Proc. Natl. Acad. Sci. USA 106, 4997–5001 (2009).
Stubbendieck, J. Seventy-eight years of vegetation dynamics in a sandhills grassland. Nat. Areas J. 28, 58–65 (2008).
Wolfe, S. A., Hugenholtz, C. H., Evans, C. P., Huntley, D. J. & Ollerhead, J. Potential Aboriginal-Occupation-Induced Dune Activity, Elbow Sand Hills, Northern Great Plains, Canada (2007).
Lee, J. A. & Gill, T. E. Multiple causes of wind erosion in the Dust Bowl. Aeolian Res. 19, 15–36 (2015).
Herrmann, S. M., Anyamba, A. & Tucker, C. J. Recent trends in vegetation dynamics in the African Sahel and their relationship to climate. Glob. Environ. Chang. 15, 394–404 (2005).
Evans, J. & Geerken, R. Discrimination between climate and human-induced dryland degradation. J. Arid Environ. 57, 535–554 (2004).
Wessels, K. J. et al. Can human-induced land degradation be distinguished from the effects of rainfall variability? A case study in South Africa. J. Arid Environ. 68, 271–297 (2007).
Zhang, W., Li, J., Li, Z.-B. & Li, Z. Predicting postoperative facial swelling following impacted mandibular third molars extraction by using artificial neural networks evaluation. Sci. Rep. 8, 12281 (2018).
Ahangar, R. G., Yahyazadehfar, M. & Pournaghshband, H. The Comparison of Methods Artificial Neural Network with Linear Regression Using Specific Variables for Prediction Stock Price in Tehran Stock Exchange. Int. J. Comput. Sci. Inf. Secur. 7, 038–046 (2010).
Zhang, Y., Liang, X., Wang, Z. & Xu, L. A novel approach combining self-organizing map and parallel factor analysis for monitoring water quality of watersheds under non-point source pollution. Sci. Rep. 5, 1–12 (2015).
Woodhouse, C. A. Artificial neural networks and dendroclimatic reconstructions: An example from the Front Range, Colorado, USA. Holocene 9, 521–529 (1999).
Fang, K. Y. et al. Comparisons of drought variability between central High Asia and monsoonal Asia: Inferred from tree rings. Front. Earth Sci. 4, 277–288 (2000).
Zhang, Q. B., Hebda, R. J., Zhang, Q. J. & Alfaro, R. I. Modeling tree-ring growth responses to climatic variables using artificial neural networks. For. Sci. 46, 229–239 (2000).
Tiwari, R. K. & Maiti, S. Bayesian neural network modeling of tree-ring temperature variability record from the Western Himalayas. Nonlinear Process. Geophys. 18, 515–528 (2011).
Rahmati, O., Tahmasebipour, N., Haghizadeh, A., Pourghasemi, H. R. & Feizizadeh, B. Evaluation of different machine learning models for predicting and mapping the susceptibility of gully erosion. Geomorphology 298, 118–137 (2017).
Pham, B. T., Prakash, I. & Tien Bui, D. Spatial prediction of landslides using a hybrid machine learning approach based on Random Subspace and Classification and Regression Trees. Geomorphology 303, 256–270 (2018).
Houser, C., Bishop, M. P. & Barrineau, P. Characterizing instability of aeolian environments using analytical reasoning. Earth Surf. Process. Landforms 40, 696–705 (2015).
Vaz, D. A. & Silvestro, S. Mapping and characterization of small-scale aeolian structures on Mars: An example from the MSL landing site in Gale Crater. Icarus 230, 151–161 (2014).
Jamali, A. A., Zarekia, S. & Randhir, T. O. Risk assessment of sand dune disaster in relation to geomorphic properties and vulnerability in the Saduq-Yazd Erg. Appl. Ecol. Environ. Res. 16, 579–590 (2018).
Shanmugam, S., Lucas, N., Phipps, P., Richards, A. & Barnsley, M. Assessment of Remote Sensing Techniques for Habitat Mapping in Coastal Dune Ecosystems. J. Coast. Res. 19, 64–75 (2016).
Woodhouse, C. A. & Brown, P. M. Tree-ring evidence for Great Plains drought. Tree-ring Res. 57, 89–103 (2001).
Brown, P. M., Woodhouse, C. A. & Bragg, T. Niobrara Valley Preserve - PIPO - Tree Ring Index - ITRDB NE004. Available at, https://www.ncdc.noaa.gov/paleo/study/2873. (Accessed: 27th February 2018).
Cook, E. R., Woodhouse, C. A., Eakin, C. M., Meko, D. M. & Stahle, D. W. Long-term aridity changes in the western United States. Science 306, 1015–1018 (2004).
Schmeisser McKean, R. L., Goble, R. J., Mason, J. B., Swinehart, J. B. & Loope, D. B. Temporal and spatial variability in dune reactivation across the Nebraska Sand Hills, USA. The Holocene 25, 523–535 (2014).
Bathke, D. J., Oglesby, R. J., Rowe, C. M. & Wilhite, D. A. Understanding and Assessing Climate Change: Implications for Nebraska (2014).
Stambaugh, M. C., Guyette, R. P., McMurry, E. R., Marschall, J. M. & Willson, G. Six centuries of fire history at Devils Tower National Monument with comments on regionwide temperature influence. Gt. Plains Res. 18, 177–187 (2008).
Gillson, L. & Hoffman, M. T. Rangeland Ecology in a Changing World. Science (80-.). 315, 53–54 (2007).
Lohmann, D., Tietjen, B., Blaum, N., Joubert, D. F. & Jeltsch, F. Shifting thresholds and changing degradation patterns: Climate change effects on the simulated long-term response of a semi-arid savanna to grazing. J. Appl. Ecol. 49, 814–823 (2012).
Mason, J. A., Swinehart, J. B., Goble, R. J. & Loope, D. B. Late-Holocene dune activity linked to hydrological drought, Nebraska Sand Hills, USA. The Holocene 14, 209–217 (2004).
Viles, H. A. Understanding Dryland LandscapeDynamics: Do Biological Crusts Hold the Key? Geogr. Compass. 23, 899–919 (2008).
Forman, S. L., Oglesby, R. & Webb, R. S. Temporal and spatial patterns of Holocene dune activity on the Great Plains of North America: Megadroughts and climate links. Glob. Planet. Change 29, 1–29 (2001).
Bailey, R. M. & Thomas, D. S. G. A quantitative approach to understanding dated dune stratigraphies. Earth Surf. Process. Landforms 39, 614–631 (2014).
Guyette, R. P., Stambaugh, M. C. & Marschall, J. M. A quantitative analysis of fire history at national parks in the Great Plains. A report prepared for the Great Plains Cooperative Ecosystem Studies Unit and National Park Service. 78 pp. (2011).
Acknowledgements
This research was funded by the UK Natural Environmental Research Council (grant: NE/L002612/1), Jesus College Graduate Research Allowance funding, and Elsevier Travel Grant (October 2015). We thank Drs Paul Hanson and Dave Wedin (University of Nebraska-Lincoln), The Nature Conservancy and the staff at Niobrara Valley Preserve, Al and Lois Steuter and Larry O’Kief for field site access and support.
Author information
Authors and Affiliations
Contributions
C.E.B. and R.M.B. co-wrote the scripts for the two neural network models. C.E.B. carried out all data pre-processing, numerical simulations, data analysis and wrote the manuscript. R.M.B. developed the autoregressive model and helped to design the study. D.S.G.T. helped to design the study and assisted in the field. All authors discussed the results and commented on drafts of the manuscript.
Corresponding author
Ethics declarations
Competing Interests
The authors declare no competing interests.
Additional information
Publisher’s note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Buckland, C.E., Bailey, R.M. & Thomas, D.S.G. Using artificial neural networks to predict future dryland responses to human and climate disturbances. Sci Rep 9, 3855 (2019). https://doi.org/10.1038/s41598-019-40429-5
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-019-40429-5
This article is cited by
-
Prediction and monitoring of LULC shift using cellular automata-artificial neural network in Jumar watershed of Ranchi District, Jharkhand
Environmental Monitoring and Assessment (2023)
-
Building wildland–urban interface zone resilience through performance-based wildfire engineering. A holistic theoretical framework
Euro-Mediterranean Journal for Environmental Integration (2023)
-
Accuracy, uncertainty, and interpretability assessments of ANFIS models to predict dust concentration in semi-arid regions
Environmental Science and Pollution Research (2021)
-
An Amazon stingless bee foraging activity predicted using recurrent artificial neural networks and attribute selection
Scientific Reports (2020)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
