
Abstract
We present an experimental illustration on the quantum sensitivity of decision making machinery. In the decision making process, we consider the role of available information, say hint, whether it influences the optimal choices. To the end, we consider a machinery method of decision making in a probabilistic way. Our main result shows that in decision making process our quantum machine is more highly sensitive than its classical counterpart to the hints we categorize into “good” and “poor”. This quantum feature originates from the quantum superposition involved in the decision making process. We also show that the quantum sensitivity persists before the quantum superposition is completely destroyed.
Similar content being viewed by others


Introduction
We live in a chain of decisions everyday. We make a decision whether to take an umbrella as assessing the chance of raining. Decisions are made by accounting for available information, e.g., the dark clouds through a window and/or the 30% chance of raining that the weather forecast announces. Yet we often make wrong decisions due to inadequate or noisy information. The relations of decisions with given information were studied in the theory of decision making (DM)1. However, it is not easy that DM processes are consistently analyzed2,3. This is mainly because each decision maker has the different degree of “sensitivity” to a given available information; ones are more biased with the given information than others1,4. This is an intrinsic trait of decision makers5. In this work we focus on the sensitivity to the available information which we categorize as “good” and “poor” hints, qualitatively.
Our DM study is presented in a framework of game theory6. Game theory deals with the strategies by which players (decision makers in this paper) maximize their own rewards. Nowadays quantum science has extended game theory to the quantum domain, revealing distinctive quantum features and opening a new avenue of applications7,8,9. As in quantum game theory, we are to investigate a quantum trait in decision makers, which originates from quantum properties10,11, i.e. the quantum sensitivity to the available information during a DM process. This is intimate to an issue of quantum game theory, whether any quantum effects are revealed when no quantum strategies are involved. This has been regarded to be negative12,13. To this end, we consider machines which play (or simulate) rational decision makers, equipped with a simple and reasonable DM algorithm. We then compare the two types of decision making machines, classical and quantum. Here, game elements including strategies are assumed to be classical, except the decision processes, in which the quantum machine is allowed to exploit a quantum algorithm14. Our main result shows that the quantum decision maker is more highly sensitive than its classical counterpart to given available information, categorized to good and poor hints. This is attributed to the quantum coherence involved in the quantum DM process. We also show that the quantum sensitivity persists before the quantum coherence is completely destroyed. These results will be applicable to reinforcement learning and preference updating15,16,17,18; they expect a risk-averse machine to learn more slowly.
Results
Secret-bit guessing game
We suggest a simple game, called the “secret-bit guessing game” (see Fig. 1a)19. In this game, one player (say Alice) has a couple of cards Cκ (κ = 0, 1), on each of which her secret-bit number xκ is written. The other player (say Bob) should make a guess yκ (or “strategy” in the language of game theory) at her secret-bit xκ. By a successful guess (i.e., yκ = xκ), Bob receives a positive score of ξ/2; however, by a wrong guess (i.e., \({y}_{\kappa }\ne {x}_{\kappa }\)), Bob receives a penalty, i.e., a negative score of −ξ/2 (see Fig. 1b). After the two guesses, Bob will get a score among {−ξ, 0, ξ}. Then, Bob wins (loses) with a score of ξ (−ξ). The game ends in a draw if Bob has a score of zero. Here, we raise a question whether some (additional) hints can help Bob to increase his winning probability or score. In particular, we explore how Bob’s winning probability depends on a DM algorithm, considering the two types of DM processes which work classically and quantum-mechanically, respectively. Our results suggest that some quantum features play roles in the DM process with no use of quantum strategies.

Schematic picture of a secret-bit guessing game. (a) One player Bob guesses the numbers chosen by the other player, say Alice. Alice selects two numbers \({x}_{\kappa }\in \{0,1\}\) and writes on two cards Cκ. These numbers are unknown for Bob. Bob is to guess Alice’s secret numbers xκ. In doing so, Bob can exploit some available information, which we call “hints.” (b) Table presents the scores which Bob will get in the game. Bob receives a score, positive of ξ/2 on a correct guess and negative of −ξ/2 on a wrong guess.
Classical & quantum decision making algorithm
To proceed, we adopt a DM algorithm, which is assumed to work in Bob’s brain. The DM algorithm is modeled as a machinery process (see Fig. 2), which runs with two channels: an input channel of a single bit for Alice’s card number \(\kappa \in \{0,1\}\), and the other is an ancillary channel for processing the input with an output which is used for Bob’s guess. The ancillary channel consists of two probabilistic operations uj (j = 0, 1), each supposed to be either the identity \(1\) (doing nothing) or the logical-not X (flipping the signal). Here, applying u1 is conditioned on the input κ: i.e., u1 is applied only if κ = 1. The algorithm commences with receiving an input κ from Alice. The two probabilistic operations uj in the ancillary channel are carried out with respect to the probabilities \(P({u}_{j}\to 1)\) and \(P({u}_{j}\to X)=1-P({u}_{j}\to 1)\). Here, \(P({u}_{j}\to 1)\) and P(uj → X) are the probabilities that uj is to be \(1\) and X, respectively. The ancillary input is prepared to a fiducial bit α in the classical case or state |α〉 in the quantum case. It is flipped or unchanged as successively passing through u0 and u1. The output is measured with an outcome \({m}_{k}\in \{0,1\}\). Then, Bob’s guess yκ at Alice’s secret numbers xκ is made such that \({y}_{\kappa }={m}_{\kappa }\oplus \alpha \) for each input κ. Note that this DM algorithm is universal in the sense that it realizes all possible guesses yκ of Bob (for more details, see Table in Fig. 2 and/or Sec. S1-A of the Supplementary Material).

Bob’s decision making (DM) algorithm. A machinery with an algorithm is assumed to simulate Bob’s decision-making process. We consider and compare the machines of two types, classical and quantum. Equipped with a DM algorithm, machine “Bob” is supposed to guess Alice’s secret-bit number xκ on card Cκ for each input \(\kappa \in \{0,1\}\). The algorithm implements all possible guesses of Bob with two operations u0 and u1 in the ancillary channel. The operation u1 is conditional on input κ: i.e., u1 is applied only if κ = 1. In case of the quantum machine, the operations u0 and u1 are unitary, applied to an initial fiducial state |α〉, where each of them is composed of quantum superpositions with the identity (doing nothing) and the logical-not (flipping). The output state in the ancillary channel is measured with outcome \({m}_{\kappa }\in \{0,1\}\). In case of the classical counterpart, on the other hand, the operations are stochastic and work probabilistically the identity or logical-not, to the initial fiducial bit value α, with outcome mκ. Then, Bob’s guesses at Alice’s secret numbers xκ are given by \({y}_{\kappa }={m}_{\kappa }\oplus \alpha \). Table lists the outcomes mκ generated by the possible set of operations u0 and u1 in the deterministic cases.
Here the probabilities \(P({u}_{j}\to \mathrm{1)}\) and P(uj → X) (j = 0, 1) refer to the DM preferences6. For example, if \(P({u}_{j}\to \mathrm{1)}\) is larger than \(1/2\), Bob (or his brain) prefers setting \({u}_{j}\to 1\) to uj → X. We can represent these probabilities as (for j = 0, 1)
where hint \({h}_{j}\in [\,-\,1/2,1/2]\). Note that the hints are not always informative20; for instance, a decision maker may acquire some hint fabricated with malicious, which we say poor. We thus need to characterize the quality of given hints, which we represent by a hint vector h = (h0, h1)T. We categorize hint vectors into “good” and “poor.” A hint vector h is categorized to good if, by using it, Bob can improve his winning probability. Otherwise, it is to poor.
We consider and compare the machinery DM processes of two types, classical and quantum. The classical DM (cDM) is defined using the classical elements for the ancillary channel: the input α is a classical bit number and uj (j = 0, 1) is applied in a classical probabilistic way, namely, either to be \(1\) or to be X based on Eq. (1). In this case, the probabilistic application of uj is represented by a stochastic evolution matrix,
On the other hand, the quantum DM (qDM) runs with the quantum state |α〉 and the application of uj is represented by a unitary matrix,
Here we note that the additional degree of freedom, i.e., the quantum phase ϕj, is introduced in the unitary operation. The qDM utilizes these phases with the directional condition h = (h0, h1)T in addition to the individual components of h, according to the following rules:
where Δ = |ϕ1 − ϕ0| is defined as the absolute difference of the quantum phases ϕj. These rules were built based on the postulate of “rational” game player (Bob, here) who can find the best algorithm by utilizing all available resources—which is often referred to as the theory of rationality6. Actually, the rules in Eq. (4) optimizes Bob’s DM algorithm and thus maximizes his winning probability (see Sec. S1-B of the Supplementary Material). It is worth noting that we run the DM process quantum-mechanically, even though we keep the game strategies classical, such as Alice’s secret numbers and Bob’s guesses.
Quantum sensitivity to additional hints
In such settings, we investigate quantum sensitivity to the given hints. First, we indicate that qDM allows Bob to enjoy much higher winnings with good hints. More specifically, by analyzing Bob’s average score Ξ (often-called the average payoff function — a term from game theory)6, we arrive at
where the indices C and Q denote classical and quantum, respectively. Bob’s quantum score differentiates from the classical by the amount of Γ. We set α = 0 and ξ = 1 for a sake of simplicity. As in Eq. (S15), the Supplementary Materials, the differential
and clearly this leads to an advantage for qDM since Γ ≥ 0. If the hints are poor, on the other hand, qDM makes it more difficult to make the correct guesses. In the worst case [see Eq. (S16) in the Supplementary Materials],
This implies that the differential Γ becomes disadvantageous with the minus sign. Here, the most surprising fact is that, in qDM, Bob’s score exhibits an abrupt transition near the boundary between good and poor hints. For example, when the amounts of hints are small but non-zero, approximately Bob’s scores \({{\rm{\Xi }}}_{Q}\simeq +\,{\rm{\Gamma }}\) and \({{\rm{\Xi }}}_{Q}\simeq -\,{\rm{\Gamma }}\) for the good and poor hints, respectively, if the hints are symmetric, i.e., |h0| = |h1| = |h|, where the symmetric hints were taken into account as hints are usually dependent and correlated. As the symmetric hint comes to zero, more explicitly, Bob’s quantum score
where we used ΞC → 0 as |h(G,P)| → 0. Here, h(G) and h(P) respectively stand for the good and poor symmetric hints. This abrupt score-transition (which resembles quantum phase transition)21 is a representative of the quanum sensitivity. Without any hints, i.e., |h| = 0, however, there is no gain or loss from the quantum assumption (for detailed calculations and theoretical analyses, see Sec. S1-B of the Supplementary Material).
Experimental demonstration
Now, we design linear-optical settings for the proof-of-principle experiments, as drawn in Fig. 3. To simulate the qDM algorithm, we use single-photon light as the ancillary system input22. Horizontal and vertical polarizations of the photon represent the qubit signal, such that \(|H\rangle \leftrightarrow |0\rangle \) and \(|V\rangle \leftrightarrow |1\rangle \). The unitary operations uj (j = 0, 1) can be realized as combinations of half-wave-plate (HWP) and quarter-wave-plate (QWP). More specifically, u0 is composed of HWP(ϑ0)-QWP(φ0)-QWP(χ), and u1 is realized by one HWP(ϑ1). Here, ϑ0, φ0, and ϑ1 are controllable rotation angles of the wave plates. The angle χ is fixed to be \(\pi /4\). Such a setting for qDM can generate all possible outputs for Bob’s guesses by controlling the wave plate angles, according to the following rules:

Linear-optical setups for simulating two types of DM, classical (cDM) and quantum (qDM). (a) In qDM, heralded single photons are prepared as the input light source by applying the post-selection to orthogonally polarized photon pairs generated by a type-II SPDC process (see Methods for more details). The single-photon polarizations, i.e., horizontal (H) and vertical (V), are employed as a quantum bit (qubit), an information carrier in the ancillary channel. The first operation u0 is composed of HWP(ϑ0)-QWP(φ0)-QWP(π/4) with the controlling angles ϑ0 and φ0, where HWP and QWP are half and quarter wave plates. The second operation u1 is realized by only HWP(ϑ1) with the controlling angle ϑ1. In this setting, u0 and u1 are so adjusted according to the rules in Eq. (9) together with Eq. (1). The quantum interference between the two unitary operations of the single-photon polarization is thus exploited in the qDM. (b) In cDM, the thermal state of light is employed as the ancillary input, which does not possess the quantum coherence. To do so, we do not apply the post-selection contrary to the qDM. The operations u0,1 are implemented by only HWPs with either ϑj = 0 (for uj → identity \(1\)) or \({\vartheta }_{j}=\pi /4\) (for uj → logical-not X), randomly chosen in the probabilities by Eq. (1).
We then also simulate the cDM algorithm for comparison. For cDM, we prepare the thermal state of light as the ancilla input, leaving no room for unexpected quantum effects on the cDM. The signal bits are also represented by the light polarization, i.e., \(H\leftrightarrow 0\) and \(V\leftrightarrow 1\). However, in such a cDM, application of the given hint h is limited without the ability to fully exploit the quantum superposition; i.e., the directional information of h cannot be encoded. The classical operations uj (j = 0, 1) can thus be implemented with only HWPs placed at either ϑj = 0 (for \({u}_{j}\to 1\)) or \({\theta }_{j}=\pi /4\) (for uj → X), probabilistically, based on Eq. (1) (see Fig. 3b).
The experiments are carried out for all of Alice’s possible strategies, i.e., her choices of the secret bits x0 and x1. In the experiments, we evaluate Bob’s average scores ΞC and ΞQ by repeating 104 games for a given h = (h0, h1)T. We perform such evaluations by varying h0 and h1 from −0.5 to 0.5 at 0.01 increments. Thus a given hint h is good or poor for the secret bits xκ, which holds for both in cDM and qDM. We represent the experimental results of ΞC and ΞQ as density-plots in the space of h0 and h1 (see Fig. 4). The average scores ΞC and ΞQ are undifferentiated at each corner point, whereas they differentiate, if far from the corners, maximally near to the origin, i.e., when the hints are very small. At the origin, i.e., h0 = h1 = 0, the average scores are to be zero in both DMs. Here, note that in the qDM, Bob’s average score ΞQ is discontinuous as crossing the axes, while ΞC is continuous everywhere in the cDM. Meanwhile, ΞQ is always higher (lower) than ΞC for good (poor) hints. To see these features conspicuously, we also perform experiments for the symmetric hints, i.e., |hj| = |h|, along the blue and red dashed lines in Fig. 4a,b. These lines, which are toward the best and worst hints from the origin, are represented by h whose sign is positive (negative) when its quality is good (poor). The result clearly shows the abrupt score-change between the quantum advantage Γ and disadvantage −Γ (see Fig. 5). All these results indicate that qDM exhibits higher sensitivity between the boundary for good and poor hints, as described in Eq. (8).

Average scores for Bob in the cDM and the qDM experiments. Bob’s average scores for all pairs of Alice’s secret bits (x0, x1) are presented in the density plots for (a) cDM and (b) qDM experiments as described in Fig. 3. The score values are obtained by repeating 104 games for each hint vector h = (h0, h1)T, on the square mesh lattice in the increments of 0.01 from −\(1/2\) to \(1/2\). A hint vector h is good or poor, depending on the secret bits xκ; for instance, \({h}_{0}={h}_{1}=1/2\) is the best hint in case of x0 = x1 = 0, while it is the worst in case of x0 = x1 = 1. These hold for both of cDM and qDM. Bob’s average scores are undifferentiated in both DMs at each corner point, whereas they differentiate, if far from the corners, maximally near to the origin. At the origin, both DMs have score value of 0. In the cDM, Bob’s average score is continuous on the entire hint space. In the qDM, to the contrary, it is discontinuous as crossing the axes, in particular the origin. The blue and red dashed lines represent the hint vectors with equal degrees |h0| = |h1|, connecting the minimal and the maximal scores.

Average scores with respect to the symmetric hints. The experimentally obtained average scores of Bob are presented along the blue and red dashed lines in Fig. 4a,b. These lines, which are toward the best and worst hints from the origin, correspond to the case of symmetric hints, i.e., |h0| = |h1| = |h|. The red and blue points are Bob’s average scores ΞC and ΞQ, respectively, as a function of h. Both DMs share the best and the worst scores ΞQ,C = ±1 at \(h=\pm \,1/2\), and ΞQ,C = 0 at the origin (no hint). For all other points, ΞQ is higher (lower) than ΞC for good (poor) hints. As a big contrast between cDM and qDM, ΞC is continuous in the whole range of symmetric hint h, whereas its quantum counterpart ΞQ is clearly discontinuous at h = 0. ΞQ abruptly changes near the origin when the hint h passes the origin, resembling critical phenomena of matters.
Analyzing further, we consider the decoherence effects, which cause degradation of the quantum superposition, during the process of qDM. Here, without loss of the generality, the signals transmitted in the ancillary system in qDM are assumed to be decohered (mathematically, a decay of off-diagonal elements of the density matrix of the signal state \(\hat{\rho }\))23 at a rate of 1 − γ ≤ 1. Then, it is predicted that the decoherence effectively results in a smaller hint-sensitivity with
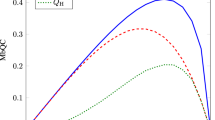
With this prediction, the experiments are carried out for symmetric hints |h| = |h0| = |h1|. Here, the hints are assumed to be good. The experiments are repeated for 104 games to evaluate the average score ΞQ. The experimental results clearly confirm the prediction: the quantum advantages become smaller with increasing decoherence rate γ (see Fig. 6). However, note that even in this case, qDM still has more advantages than cDM, unless the quantum superposition is completely washed out. This result is also quite remarkable, since quantum properties usually disappear rapidly with very small decoherence.

Decoherence effect on the qDM algorithm. (a) We consider the decoherence effect that arises between the operations u0 and u1 on the ancilla qubit channel for the qDM algorithm. (b) Experimental simulations are carried out for different values of the decoherence rate γ (0 to 1, 0.25 step). The symmetric hint h is assumed to be positive, h > 0. Bob’s average scores ΞQ are presented for the experimental data (dots) and for the theoretical predictions of qDM (dashed lines) in Eq. (10) together with the experimental data of cDM (blue solid line). The results clearly show that the quantum advantage, i.e., the positive differential from the cDM score decreases as increasing the decoherence rate γ, and the quantum score eventually becomes equal to the classical if completely decohered with γ = 1.
Discussion
We performed the study of quantum decision making, adopting a two-player game where one player (Bob) tries to guess the secret bit numbers chosen by the other player (Alice). In this game, we focused on Bob’s decision process in terms of his guesses. Primarily, we attempted to investigate novel quantum features, assuming that Bob (i.e., the decision maker) uses a pre-programmed algorithm by which favorable quantum properties can be exploited. As the main result, we demonstrated both theoretically and experimentally that the quantum aspects make the choosing tendency stronger in the quantum, establishing the high sensitivity at the boundary of opposite hint quality. This quantum feature originates from the fact that quantum DM is able to find additional way of using the quality (i.e., the directional condition) of the given hint h, while the classical DM uses only the amount (i.e., the size). Through the further experiments and analyses, we also demonstrated that the high hint-sensitivity persists before the quantum coherence is completely destroyed. Our study is expected to provide the insight to understand some DM processes at the quantum level.
This work is also intimate to the issue whether novel quantum features exist in a classical game. The issue has been regarded to be negative, while quantum features in quantum games have been discussed mostly by considering quantum strategies12,13. To attack the issue, on the other hand, we proposed to employ the machinery that plays (or simulates) the decision processes made by the rational players. We hope that the present work would accelerate the studies on potential applications, including quantum cryptography24,25 and quantum machine learning26.
Methods
Preparation of the ancillary input
In the qDM experiments, we prepared a heralded single-photon state (H-polarized) as the ancillary input. Photon pairs are produced in type-II spontaneous parametric down conversion (SPDC) using a periodically poled KTiOPO4 crystal (length, 10 mm) and a continuous wave pump laser (wavelength, 401.5 nm). The vertically polarized photons reflected by a PBS are used as trigger photons, and the transmitted horizontally polarized photons are used as signal photons. Signal photons were counted only when the trigger photons were detected. Here, if this post-selection is not applied, the signals toward the gate operations are the thermal state with supper-Poissonian photon statistics. In the cDM experiments, the thermal state of light was employed as the ancillary input, which does not possess the quantum coherence (see Fig. 3).
Experimental simulation of decoherence
Effectively, the decoherence can be simulated in the experiments by setting the relative phases of the states either as 0 or as π (a phase flip) randomly with a ratio of 1 − γ/2 to γ/2. Then, statistically, the state ρ can be described as23
References
Zsambok, C. E. & Klein, G. (Eds) Naturalistic decision making. (Psychology Press, 2014).
Tversky, A. & Kahneman, D. Judgment under uncertainty: Heuristics and biases. Science 185, 1124–1131 (1974).
Tversky, A. & Shafir, E. The disjunction effect in choice under uncertainty. Psychol. Sci. 3, 305–310 (1992).
Blackhart, G. C. & Kline, J. P. Individual differences in anterior EEG asymmetry between high and low defensive individuals during a rumination/distraction task. Pers. Individ. Dif. 39, 427–437 (2005).
Resulaj, A., Kiani, R., Wolpert, D. M. & Shadlen, M. N. Changes of mind in decision-making. Nature 461, 263 (2009).
González-Díaz, J., García-Jurado, I. & Fiestras-Janeiro, M. G. An Introductory Course on Mathematical Game Theory, vol. 115 of Graduate Studies in Mathematics (American Mathematical Society, 2010).
Meyer, D. A. Quantum Strategies. Phys. Rev. Lett. 82, 1052–1055 (1999).
Eisert, J., Wilkens, M. & Lewenstein, M. Quantum Games and Quantum Strategies. Phys. Rev. Lett. 83, 3077–3080 (1999).
Lee, C. F. & Johnson, N. F. Efficiency and formalism of quantum games. Phys. Rev. A 67, 022311 (2003).
Deutsch, D. Quantum theory of probability and decisions. Proc. R. Soc. A 455, 3129 (1999).
Pothos, E. M. & Busemeyer, J. R. A quantum probability explanation for violations of ‘rational’ decision making. Proc. R. Soc. B 276, 2171 (2009).
van Enk, S. J. & Pike, R. Classical rules in quantum games. Phys. Rev. A 66, 024306 (2002).
Aharon, N. & Vaidman, L. Quantum advantages in classically defined tasks. Phys. Rev. A 77, 052310 (2008).
Bang, J., Ryu, J., Pawłowski, M., Ham, B. S. & Lee, J. Quantum-mechanical machinery for rational decision-making in classical guessing game. Sci. Rep. 6, 21424 (2016).
Mihatsch, O. & Neuneier, R. Risk-sensitive reinforcement learning. Mach. Learn. 49, 267–290 (2002).
Lee, D. Game theory and neural basis of social decision making. Nat. Neurosci. 11, 404 (2008).
Molleman, L., Van den Berg, P. & Weissing, F. J. Consistent individual differences in human social learning strategies. Nat. Commun. 5, 3570 (2014).
Ghahramani, Z. Probabilistic machine learning and artificial intelligence. Nature 521, 452 (2015).
Lungo, A. D., Louchard, G., Marini, C. & Montagna, F. The Guessing Secrets problem: a probabilistic approach. J. Algorithm. 55, 142–176 (2005).
Lehner, P. E., Mullin, T. M. & Cohen, M. S. When Should a Decision Maker Ignore the Advice of a Decision Aid? arXiv preprint arXiv:1304.1515 (2013).
Park, C. Y. et al. Quantum macroscopicity measure for arbitrary spin systems and its application to quantum phase transitions. Phy. Rev. A 94, 052105 (2016).
Naruse, M. et al. Single-photon decision maker. Sci. Rep. 5, 13253 (2015).
Audretsch, J. Entangled Systems: New Directions in Quantum Physics. (John Wiley & Sons, 2008).
Werner, A. H., Franz, T. & Werner, R. F. Quantum cryptography as a retrodiction problem. Phys. Rev. Lett. 103, 220504 (2009).
Kaniewski, J. & Wehner, S. Device-independent two-party cryptography secure against sequential attacks. New J. Phys. 18, 055004 (2016).
Clausen, J. & Briegel, H. J. Quantum machine learning with glow for episodic tasks and decision games. Phys. Rev. A 97, 022303 (2018).
Acknowledgements
The authors thank Jaewan Kim and Byoung Seung Ham for valuable discussions. J.B. thanks Marcin Wieśniak, Wiesław Laskowski, Marcin Pawłowski. This research was supported through the National Research Foundation of Korea (NRF) grant (No. 2014R1A2A1A10050117 and No. 2016R1A2B4014370) and the Institute for Information and communications Technology Promotion (IITP-2018-2015-0-00385), funded by the Korea government(MSIT), Korea. This research was also implemented as a research project on quantum machine learning (No. 2018-104) by the ETRI affiliated research institute. J.B. acknowledge the support of the R&D Convergence program of NST (National Research Council of Science and Technology) of Republic of Korea (No. CAP-18-08-KRISS).
Author information
Authors and Affiliations
Contributions
J.B., J.L. and K.G.L. developed the theoretical idea. J.S.L. and K.G.L. performed the experiments, and J.B. and J.L. provided theoretical support. J.B. and J.S.L. wrote the manuscript. All the authors contributed to analysis of the results. The first two authors (J.S.L. and J.B.) contributed equally to this work and can be regarded as the main authors.
Corresponding authors
Ethics declarations
Competing Interests
The authors declare no competing interests.
Additional information
Publisher’s note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Lee, JS., Bang, J., Lee, J. et al. Experimental Demonstration on Quantum Sensitivity to Available Information in Decision Making. Sci Rep 9, 681 (2019). https://doi.org/10.1038/s41598-018-36945-5
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-018-36945-5
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
