
Abstract
To better understand the relationship between soil bacterial communities, soil physicochemical properties, land use and geographical distance, we considered for the first time ever a European transect running from Sweden down to Portugal and from France to Slovenia. We investigated 71 sites based on their range of variation in soil properties (pH, texture and organic matter), climatic conditions (Atlantic, alpine, boreal, continental, Mediterranean) and land uses (arable, forest and grassland). 16S rRNA gene amplicon pyrosequencing revealed that bacterial communities highly varied in diversity, richness, and structure according to environmental factors. At the European scale, taxa area relationship (TAR) was significant, supporting spatial structuration of bacterial communities. Spatial variations in community diversity and structure were mainly driven by soil physicochemical parameters. Within soil clusters (k-means approach) corresponding to similar edaphic and climatic properties, but to multiple land uses, land use was a major driver of the bacterial communities. Our analyses identified specific indicators of land use (arable, forest, grasslands) or soil conditions (pH, organic C, texture). These findings provide unprecedented information on soil bacterial communities at the European scale and on the drivers involved; possible applications for sustainable soil management are discussed.
Similar content being viewed by others

Introduction
Monitoring soil microbial communities represents a major challenge to better valorize soil resources and to implement a more sustainable management of soils in agriculture and forestry1,2. A more thorough knowledge of the geographical distribution of microbial communities across different soil types and the identification of potential biotic indicators of changes are critical to better understand the ways soils and land uses impact microbial diversity under different climates. These indicators will help managers devise strategies for monitoring microbial diversity and soil functioning for end users and policy makers3.
A large debate on the relative importance of soil properties and plants on belowground biodiversity has been running over the last decades4,5,6. Local- to continental-scale studies have suggested that soil properties (e.g. the pH) are major drivers of the structure and diversity of soil microbial communities, with plant communities and land use as secondary confounded correlates7,8,9,10,11,12,13,14,15. However, more locally focussed experiments revealed that in certain soils, microbial communities are also strongly affected by plants species, developmental stage and phenology16,17,18. These observations are consistent with the recent proposal by several authors that a core microbiome associated with plant roots is specific to the host genotype and includes populations beneficial for plant growth and health19,20,21,22. However, the rhizosphere effect is known to vary according to the soil type, even for a given plant species16,23,24. Plants indeed recruit their rhizosphere microbiota from the soil reservoir25, whose biodiversity varies among soils as indicated by biogeographical studies12. Moreover, as a given land use can be found in various types of soils, it is essential for sustainable soil management to better understand the effects of land use on microbial communities specific to the soil type. Furthermore, specific indicators of land use vs. soil type are needed. So far, most of the biogeographic surveys have focused on broad-scale patterns and drivers, and few attempts have been made to disentangle the effects of different land use on similar soils, and vice versa. A key issue with broad landscape surveys is that human land management is strongly determined by the prevailing soil and climatic properties of the environment. With the onset of agricultural development, human populations have shaped their environment locally by converting the most fertile and easily manageable soils to agriculture and grassland, leaving infertile and rocky soils to forest, heathland and bog26,27. At a small scale, this phenomenon confounds gradients of soil properties with land management, masking the primary drivers of soil communities. At a larger spatial scale, these parallel events have led to the distribution of given land uses on very different soil types, although certain soil types are preferentially used for arable land, grassland or forest. For example, grassland tends to occur across a broader range of soil conditions than arable land. Forests are usually developed on nutrient-poor soils, which vary from very acidic to neutral pH values.
This study addresses these shortcomings by specifically determining the relative effects of land use and soil properties on bacterial diversity and structure in a large number of soil samples collected and characterised across the first European transect for soil microbes. This transect ran from Sweden down to Portugal and from France to Slovenia. The distribution of different land uses on various soil conditions across this transect allowed us to test the respective effects of these two categories of drivers on soil bacterial communities. The sampled sites represented three major land uses (arable, forest, grassland) across a range of soils chosen for their contrasting pH values, textures, and organic matter contents, and covering a broad range of climatic conditions. We analysed these soil samples for their physicochemical properties, and for their bacterial diversity and community composition by 16S rRNA gene amplicon pyrosequencing. We used a k-mean classification analysis to group the soils on the basis of their physicochemical properties and land use into homogeneous clusters, and then test if a potential land use effect was observable in these clusters. Finally, we performed an indicator species analysis to identify the genera indicative of particular soil conditions and/or land uses.
Results and Discussion
Soil properties
According to physicochemical analyses, the 71 soil samples collected across Europe differed strongly in terms of pH, texture, density, and C or N contents (Table 1). pH ranged from 3.7 to 8.2, textures varied from very fine (70% clay in a French arable soil) to coarse (94% sand in a Danish grassland), and organic C content ranged from 0.4% (arable soil, France) to 33% (forest soil, Sweden). The sites were all distinguishable from one another based on soil properties. Studies on the effect of land use or soil properties on bacterial communities had already been performed at a continental scale7,9,15, but our study characterises bacterial communities at the European scale for the first time28. The sampling design was representative of the variations in soil properties, i.e. organic matter content, pH and texture, across different geographical/climatic zones in Europe, and it covered three land uses (arable, forestry, grassland, Table 1). This extensive sampling strategy was consistent in investigating different environmental characteristics regarding the multivariate analyses (Fig. 1A–F). Such a strategy minimises possible biases related to land use. Highly fertile soils are indeed commonly dedicated to agriculture, while nutrient-poor and rocky soils are usually associated to forest as highlighted in previous studies7,9,12,15. Thus, our sampling strategy was adequate for disentangling the effects of land use from those of soil properties on bacterial diversity across Europe.

Multivariate analyses of the soil physicochemical properties (A–C) and bacterial communities (D–F) for each land use: arable (A,D), forest (B,E), grassland (C,F). The principal component analyses generated from the physicochemical characteristics (A–C) or relative abundance of all the detected taxa (D–F) illustrate the diversity of soil properties and bacterial communities according to the three land uses tested. Each symbol represents a sampling site.
Diversity and composition of the bacterial communities
We obtained more than 3*106 16S rRNA sequences from the 71 samples we collected, and a total of 8,085 sequences per soil sample after bioinformatics processing. The rarefaction curves of bacterial OTUs followed a logarithmic model (data not shown) without reaching a plateau. We detected a total of 34,190 OTUs among all the soil samples. At the European scale, the number of OTUs per soil sample ranged from 653 to 1,860 (mean: 1,307 OTUs; Standard Deviation (sd): 244; Fig. 2A). The Shannon index ranged from 4.1 to 6.2 (mean: 5.5; sd: 0.4; Fig. 2B), and evenness from 0.62 to 0.82 (mean: 0.76; sd: 0.04; Fig. 2C). The number of detected OTUs ranged from 1,022 to 1,860, 653 to 1,437, and 987 to 1,722 in soils dedicated to arable, forest, and grassland uses, respectively. The Shannon index varied from 4.1 to 5.6, 4.9 to 6.0, and 5.3 to 6.2, in forests, grasslands, and arable lands, and evenness from 0.63 to 0.78, 0.71 to 0.81, and 0.76 to 0.82. Altogether, the variations of richness, evenness, and of the Shannon index were in the range of those observed in the literature for a similar sequencing effort29,30,31,32. Nevertheless, these indices revealed a non-significant trend of lower bacterial richness and diversity from arable to forest soils. This is not in agreement with the literature since other studies demonstrated that microbial indices were affected by land-use at the plot scale33, the landscape scale34, and at more global scales29,31,35. The much greater variability of soil physicochemical properties relatively to land use in our study may account for this discrepancy since soil physicochemical characteristics are known to frequently be the most influencing factor of soil microbial indices, followed by land use29,31,34,36.

Relative distribution of bacterial richness (A), Shannon index (B) and evenness (C). Bacterial richness was determined from the number of clusters derived from the bioinformatics analysis.
We detected a total of 27 phyla after taxonomic assignment (Supplementary Table 1). For each sample representing a specific environmental condition (i.e. a combination of a given soil property and a land use), the most represented bacterial phyla were Proteobacteria (average relative abundance 56.4%), Actinobacteria (15.7%), and Acidobacteria (7.1%) (Supplementary Table 1). The dominance of these phyla is in agreement with Lauber et al.10 and Delgado-Baquirezo et al.30. Other phyla, i.e. Bacteroidetes, Firmicutes, Planctomycetes, Chloroflexi, and Nitrospirae, were also represented (above 1% on average) but their relative abundance greatly varied according to the environmental conditions. We detected a total of 1,033 bacterial genera (data not shown), whose abundance varied according to environmental conditions from 157 genera in a Swedish forest soil, up to 397 in a Dutch arable soil. A total of 7.23% of the sequences remained unclassified at the genus level. The number of detected genera ranged from 310 to 397 in arable land (mean: 355; sd: 25), 157 to 313 in forest (mean: 260; sd: 48), and 264 to 386 in grassland (mean: 327; sd: 33), without any significant difference between land uses. These results are in the range of those reported in the literature30,32,36. The absence of a relationship between the number of genera and land use type may be related to the high number of genera represented at very low relative abundances, which we did not take in account. Similarly, Karimi et al.36 identified a total of 1,355 genera out of which only 47 had a relative abundance higher than 0.5%. Similar trends have also been observed at a global scale30,32.
Spatial distance, soil properties and land use as drivers of bacterial communities
We performed further analyses to better evaluate the spatial structuration of soil bacterial communities and better specify the environmental and spatial drivers of the variations of bacterial communities across Europe. First, we evaluated TAR for soil bacterial communities at the European scale (Fig. 3). This relationship was significant since the similarity of bacterial community composition across sites significantly decreased with increasing geographical distance, as shown by a significant community composition turnover (z = 0.0532, b = −0.0034; r² = 0.07; P < 0.001). Although the turnover intensity was low, its level was in the range (0.1 to 0.23) of those reported in several studies applying the same methodology at different spatial scales and in different environmental matrices37,38,39,40,41,42. Furthermore, even lower turnover intensity values, ranging from 0.006 to 0.05, have recently been reported at the scale of France12,13,43. Altogether, the significant TAR observed at the scale of Europe in our study supports that soil bacterial community composition is non-randomly distributed and spatially structured. This result is in agreement with other studies focusing on soil microbial biogeography12,44,45. This spatial structuration of soil bacterial communities may be related to environmental filters (i.e. environmental selection) and to limited dispersal.

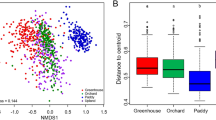
Taxa area relationship of soil bacterial community. Dots represent paired-comparison of sites for each distance class and line represents the weighted linear regression model used for the estimation of soil bacterial community turnover following the equation: \({\mathrm{log}}_{10}\,({{\rm{\chi }}}_{{\rm{d}}})=(\,\,-\,\,2\ast {\rm{z}})\ast {\mathrm{log}}_{10}\,({\rm{d}})+{\rm{b}}\). Estimated z: 0.0532; estimated b: −0.0034.
We applied two complementary approaches to better understand the factors involved in the spatial structuration of soil bacterial communities and supporting environmental selection and dispersal limitation. A descriptive approach based on NMDS applied on Unifrac distance (Supplementary Fig. 1) showed that pH (R = 0.87, P < 0.001, ANOSIM, 1,000 permutations), texture (R = 0.64, P < 0.001, ANOSIM, 1,000 permutations) and organic carbon content (R = 0.58, P < 0.001, ANOSIM) were major drivers of bacterial community structure. Other drivers such as the nitrogen content and CEC were strongly correlated to the organic carbon content; moreover, assimilable phosphorous was non significantly correlated to soil bacterial community variation (P > 0.24). Similarly, we recorded significant differences in the community structures of the three types of land use (grassland, arable, forest) (ANOSIM-land use: R = 0.32, P < 0.001). Even if soil properties and land use both had discriminating effects on soil bacterial communities, cross-effects must be considered together with the effect of distance between sites.
To disentangle potential cross-effects and take the effect of distance between sites into account, we applied a parsimonious variance partitioning approach on the three diversity indexes (richness, Shannon index, and evenness) and on soil bacterial community structure to determine the relative importance of soil properties and/or land use and/or climate conditions and/or distance between sites on bacterial communities. This analysis notably showed that soil properties explained a large part of the variance of bacterial richness (48.4% of variance, P < 0.001); that effect was mostly related to pH, texture class and total carbon content, which accounted for 13.8%, 10.8%, and 6.9% of the variance of soil bacterial richness, respectively (Fig. 4). Other environmental parameters (land use, climate, and spatial autocorrelation) did not explain significant amounts of variance during model building, suggesting that they did not affect soil bacterial richness. We observed similar trends for the Shannon index and for evenness (63.2% and 61.7% of variance; respectively; P < 0.01) except that the texture was very slightly significant. The percentage of variance explained by the soil pH ranged from 17.7% for the Shannon index to 19.0% for evenness, while the total carbon content explained 8.6% for the Shannon index and 20.2% for evenness. Soil texture did not explain any variation of bacterial evenness and was slightly significant for bacterial Shannon index (6.4%, P < 0.1). For each diversity index, interactions between environmental factors represented a large portion of the explained variance (16.8% for richness, 30.4% for Shannon index, 22.5% for evenness). A large portion of the variance still remains unexplained, suggesting that other environmental factors may contribute to structure bacterial communities, and confirming previous findings15,31,43. Conversely to diversity indices, soil bacterial community structure based on Unifrac distance was only slightly explained by environmental factors (17.3% of variance, P < 0.001). Among all the environmental factors we identified, the soil pH (3.8%) ranked first, followed by land use (3.3%) and the total carbon content (1.7%). This is in agreement with other studies of soil microbial biogeography7,11,14,31,43,46,47 and is fairly related to the soil reactional conditions and trophic level and to biological interactions, e.g. between plants and soil bacteria. This study also identifies the climatic zone as a driving factor of soil bacterial community structure. Nevertheless, even if its marginal effect appeared to be substantial as compared to other variables, it was only very slightly significant (5.7%, P < 0.1). Its selection may be related to particular sites belonging to boreal and Mediterranean climatic zones located far from the rest of the transect. Surprisingly, longitude, latitude, or PCNMs (representing the neighbouring relationships between sites) were not selected when we built the model. This suggests that bacterial communities are not dispersal-limited at the scale of Europe. Nevertheless, other studies demonstrated that bacterial communities may be dispersal-limited at smaller spatial scales (France, Scotland)12,13,44. This discrepancy may be explained by differences in terms of sampling efforts.

Variance partitioning of bacterial richness, diversity and evenness parameters within the European transect sampling.
Soil clustering and indicator species analysis
Each sampling site exhibited different soil properties and land uses, so we further explored the relative contribution of these two types of parameters to bacterial diversity. For this purpose, we clustered sites according to the homogeneity of their soil physicochemical characteristics, land use and climate, as assessed by the k-mean method. The k-mean approach allowed us to the delineate four clusters with contrasting soil properties and covering different land uses: the first cluster (cluster 1, n = 27 sampling sites) included the three land uses (arable, grass, and forestry) and encompassed soils with a low carbon and nitrogen content, an average pH of ca. 6 and a coarse texture; the second cluster (cluster 2, n = 24) also encompassed representative soils from the three land uses but they displayed distinct properties, with medium carbon and nitrogen contents, an average pH of ca. 6 and a medium to fine texture; the third cluster (cluster 3, n = 5) included mainly forest soils but also one grassland, and the soils exhibited high carbon and nitrogen contents, an acidic pH and an organic texture; finally the fourth cluster (cluster 4, n = 18) included all three land uses but only one forest site and encompassed soils with a medium to fine texture, a neutral pH, and a low carbon content (Table 2). As suggested by Hermans et al.48 and Banerjee et al.49 specific soil bacterial genera may be identified as bioindicators of the different clusters. To test this hypothesis, we performed an indicator species analysis on the four clusters to determine whether specific genera were specifically associated with a single cluster, making them bioindicators. For each bacterial genus identified in this analysis, the relative abundance and the relative coverage of a cluster condition are presented in Table 2. For example, the Blastochloris genus, whose maximum abundance reached 18.6%, is represented in 76% of the samples of cluster 3, while the Pseudolabrys genus, whose maximum abundance reached 4.2%, is represented in 50% of the samples of cluster 4. Previous reports have shown that this approach can be successfully applied to identify microbial groups (i.e. fungi or bacteria), phyla, or even genera as environmental indicators50,51. We recorded a total of 118 genera with an average relative abundance above 0.1% (Table 2). Cluster 1 was characterised by 17 indicator genera, mainly related to the Proteobacteria (11) or Firmicutes (3) phyla; the most abundant indicator genera were assigned to Pseudolabrys (max. relative abundance 4.23%) and Azospira (4.11%). Cluster 2 harboured only three indicator genera, belonging to the Elusimicrobia and Proteobacteria phyla and assigned to the Elusimicrobium (2.61%), Pelobacter (0.41%) and Xanthomonas (0.27%) genera. Cluster 3 was characterised by 59 indicator genera mainly related to Proteobacteria, Actinobacteria, and Bacteroidetes; the most abundant indicator genera were assigned to Blastochloris (max. relative abundance 18.65%), Halophaga (13.2%), and Steroidobacter (8.51%). Nevertheless, this result remains to be confirmed by other studies because of it was obtained from a small number of sites (n = 5). Cluster 4 encompassed 39 indicator genera mostly related to Proteobacteria and Actinobacteria; the most abundant indicator genera were assigned to Gaiella (max. relative abundance 9.65%) and Bacillus (5.22%). Overall, we found higher numbers of indicator genera in the clusters with the lowest variety of land uses (clusters 3 and 4), and conversely lower numbers of indicator genera in the clusters encompassing more different land uses (clusters 1 and 2), suggesting that land use is a major driver of soil biodiversity52.
The bioindicator analysis also revealed that such an analysis must be conducted at a fine taxonomic level (i.e., the genus level). We indeed demonstrated that different indicator genera belonging to a same phylum could be indicators of different soil conditions (i.e. cluster type). For example, within the Actinobacteria phylum, the Actinospica genus was an indicator of cluster 3 and the Geodermatophilus genus an indicator of cluster 4 (Table 2). Another important feature is related to the relative abundance of these indicator genera. Indicators were represented at high or low relative abundance levels (maximum relative abundance above 10% and below 0.5%, respectively) e.g. the Blastochloris, Holophaga or Steroidobacter genera, and Myxococcus or Collimonas, respectively. The latter would be good candidates as indicators of specific environmental conditions. The Collimonas genus was indeed more specifically found in cluster 3 (forest) confirming previous works done on this genus18,25. The Myxococcus genus was more specifically found in cluster 4 (arable land: 11, grassland: 4). Then we constructed models to refine and predict the contribution of the three environmental parameters - soil properties, land use, and climate - associated with these clusters for each indicator genus (Table 2). For example, the indicator genus Acidothermus in cluster 3 was mostly explained by soil pH (41.08%) and land use (5.79%), while the indicator genus Gaiella in cluster 4 was explained by the total carbon (29.09%) and nitrogen (16.7%) contents. Globally, a broad range of the bioindicators (40 out of 118) identified in this study were determined by the soil pH, confirming the importance of this parameter for soil biodiversity as reported in previous studies7,9,11,14, while C content50, climate zone, land use15 and texture13 explained the relative distribution of 30, 27, 25 and 12 other bioindicators, respectively. Only 12 bioindicator genera were explained specifically by land use exclusive of any other parameter (Table 2): in cluster 1, Nitrospira (Betaproteobacteria); in cluster 2, Elusimicrobium (Elusimicrobia); in cluster 3, Skermanella (Alphaproteobacteria), Steroidobacter (Gammaproteobacteria), Novispirillum (Alphaproteobacteria), Herminiimonas (Betaproteobacteria), Holophaga (Acidobacteria), and Aquicella (Gammaproteobacteria); in cluster 4, Methylobacterium (Alphaproteobacteria), Thermoacetogenium (Firmicutes), Dehalococcoides (Chloroflexi), and Thermincola (Firmicutes). Nevertheless, 37 of the bacterial genera identified as indicators of clusters remained unexplained by any of the parameters tested (soil properties, land use, climate), e.g. Blastochloris (max. relative abundance of 18.65%) or Mycobacterium (max. relative abundance of 2.61%), Myxococcus (0.1%), or Collimonas (0.32%).
Land use effects within soil clusters
We further tested the relative impacts of land use on the bacterial communities under similar soil conditions using the land use distribution found in each cluster as generated by the k-mean classification. In contrast with the very small cluster 3 including only five sites (4 forests and 1 grassland) and cluster 4 that included only one forest site out of 18, clusters 1 and 2 encompassed the three land uses (i.e. forestry, arable land, and grassland). We therefore analysed clusters 1 and 2 to test whether variations of bacterial communities were mostly explained by land use or soil properties. We performed multivariate analyses independently, on the soil physicochemical properties and then on the distribution of the bacterial genera characterising the sites encompassed in clusters 1 and 2. The results showed that the soils were mostly grouped in terms of soil properties according to the land use, with a clear separation between forests and other land uses as confirmed by ANOSIM analysis (in cluster 1: Rsoil data = 0.60, P < 0.001; in cluster 2: Rsoil data = 0.68, P < 0.001) (Fig. 5). Furthermore, bacterial genera appeared to be distributed differentially in cluster 1 according to the land use, not to the soil properties (ANOSIM analysis Rgenus data = 0.524, P < 0.001); the major driving effect of the land use in this cluster was also supported by the absence of a significant correlation (P > 0.05) between soil parameters and the distribution of bacterial genera (Fig. 5). This was not the case in cluster 2 (ANOSIM analysis Rgenus data = 0.251, p = 0.055) that encompassed forest sites differing by their constitutive soil properties. Taken together, our data show that, under similar soil properties, land use is a major driver of bacterial community structure. Compared with previous reports6,8,53,54, this conclusion is strongly supported by the large variety of soil properties for each land use in contrast with previous studies that addressed the land use effect only on a given soil type54,55,56.

Multivariate analysis of soil physicochemical properties (A) and bacterial communities (B) according to the land use within soil cluster 1. The correspondence factor analyses generated from the physicochemical characteristics (A) or relative abundance of all the detected taxa (B) in the soils belonging to cluster 1 illustrate the impact of land use on bacterial communities. Colored ellipses corresponding to the different land uses have been manually added.
Conclusions
We analysed the effect of soil properties and land use on the soil bacterial communities using an unprecedented extensive European transect allowing us to sample soils representative of a range of soil properties (organic matter content, pH, texture) from different geographical and climatic zones across Europe. Our analysis generated a broad overview of the soil bacterial diversity, richness and composition across Europe, which is strongly complementary to other intensive approaches dedicated to specific countries in Europe (the United Kingdom11, France31,36 and the Netherlands). Combining soil analyses with 16S rRNA gene amplicon pyrosequencing revealed that the soil bacterial communities are non-randomly distributed across Europe but determined by environmental factors. More specifically, soil properties, notably the pH and texture, appeared to be the main drivers of soil bacterial community composition and distribution at the European scale. However, under given soil properties corresponding to delineated clusters, the influence of land use was apparent. We identified bacterial genus indicators of soil physicochemical properties through a cluster analysis; some genera were land use specific within these clusters.
Taken together our data provide an overview of the soil bacterial diversity across Europe and identify potential bacterial indicators of different soils and land uses. We confirmed at a large spatial (continental) scale the strong impact of soil properties on soil bacterial communities, but we also showed that under similar soil conditions, land use also contributed to their structure. These findings and the identification of indicators open up onto stimulating new prospects in terms of land management for monitoring soil biodiversity and ultimately expected services from soils.
Methods
Site description, soil properties and sampling strategy
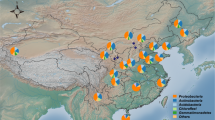
Soil samples were collected across 71 European sites (Fig. 6) in 11 countries (5 in Denmark, 19 in France, 9 in Germany, 6 in Ireland, 4 in Italy, 2 in The Netherlands, 2 in Portugal, 4 in Slovenia, 4 in Sweden, 5 in Switzerland, and 11 in the United Kingdom), as described in Stone et al.28. The sampling sites were identified on the basis of EFSA spatial legacy data (Version 1.0) provided by the Joint Research Centre, of the European Commission57. We chose four parameter maps among the 52 spatial layers available: topsoil organic matter; topsoil pH in water; topsoil texture class; and EFSA Corine land cover data. The sites encompassed three types of land uses (arable, forest, grassland) (see Table 1 for details). Soil sampling was performed from early September to mid-November 2012 to avoid the influence of seasonal variation using the same standardized optimised procedure (SOP)28. For each site, a composite sample was made from twelve cores (5 cm in diameter and 5 cm depth) randomly taken within a 1 × 1 m surface. All soil samples were sieved to <2 mm and prepared for soil analyses by Teagasc and DNA extraction was performed in Dijon by the GenoSol platform, UMR Agroécologie, https://www2.dijon.inra.fr/plateforme_genosol/plateforme-genosol. Soil properties were measured as described in Creamer et al.58. Briefly, soil texture was characterised following the particle pipette size method59. Total C and N were measured according to the ISO 10694 standard60; organic carbon (OC) was determined by LECO elemental analysis, conducted on 0.25 mm dry milled soil sub-samples61. The cation exchange capacity (CEC) was analysed using the BaCl2 extraction method62. The pH was measured in a 1:2.5 soil in water suspension using a glass electrode63. N mineralisation was analysed using the Illinois soil nitrogen test for amino sugar-N64. Available phosphorus content was measured using the Mehlich 3 methodology65. The sites were grouped based on their pH values (<5, between 5 and 7, >7), organic C content (less than 2%, between 2 and 15%, over 15%) and texture (fine, medium or coarse). The distribution and characteristics of the samples are presented in Table 1 and Fig. 1.

Mapping of sampling sites across the European transect. Individual sampling sites are shown in black. Geographical coordinates were degraded at the 1 km2 scale for privacy reasons.
Molecular characterisation of soil bacterial communities
DNA was extracted and purified from all soil samples using the improved ISO 11063 soil DNA extraction procedure as described by Plassart et al.66. Briefly, 1 g of soil of each soil sample was added to a 15 ml Falcon tube containing 2.5 g of 1.4 mm diameter ceramic beads, 2 g of 100 μm diameter silica beads and 4 mm diameter glass beads. The samples were then mixed with a solution of 100 mM Tris-HCl (pH 8), 100 mM EDTA (pH 8), 100 mM NaCl, 2% (w/v) of polyvinylpyrrolidone (40 g mol−1) and 2% (w/v) sodium dodecyl sulphate. The tubes were shaken for 3 × 30 s at 4 m.s−1 in a FastPrep®−24 (MP-Biomedicals, NY, USA), before incubation for 10 min at 70 °C and centrifugation at 14,000 x g for 1 min. The supernatant was removed and then proteins were precipitated with 1/10 volume of 3 M sodium acetate prior to centrifugation (14,000 g for 5 min at 4 °C). Nucleic acids were precipitated by adding 1 volume of ice-cold isopropanol. The DNA pellets obtained after centrifugation (14,000 g for 5 min at 4 °C) were washed with 70% ethanol. Crude DNA extracts were then purified using a MinElute gel extraction kit (Qiagen, France) and quantified using a QuantiFluor staining kit (Promega, USA), prior to further investigations.
The diversity, composition and structure of the bacterial communities were determined on the 71 soil DNA samples by 16S rRNA gene amplicon pyrosequencing. A 450 bp fragment of the 16S rRNA gene was amplified using the primers F479 (5′- AGCMGCYGCNGTAANAC-3′) and R888 (5′-CCGYCAATTCMTTTRAGT-3′)43. Five ng of DNA were used in 25 μL of PCR mixture. The PCR was conducted under the following conditions: 94 °C for 2 min, 35 cycles of 30 s at 94 °C, 30 s at 52 °C, and 1 min at 72 °C, followed by 7 min at 72 °C. The PCR products were purified using a MinElute gel extraction kit (Qiagen, Courtaboeuf, France) and quantified using the PicoGreen staining Kit (Molecular Probes, Paris, France) on an Infinite 200 Pro fluorimeter (Tecan, Lyon, France). A second PCR of nine cycles was then conducted for each sample under similar PCR conditions using purified PCR products as DNA template and modified F479 and R888 primers containing 10 bp multiplex identifiers added at 5′ position to specifically identify each DNA sample. Two 25 µL reactions were performed for each DNA sample and pooled, before purification and quantification as previously described. Pyrosequencing was then carried out on a GS FLX Titanium (Roche 454 Sequencing System) by Genoscreen (Lille, France).
We performed the 16S rRNA gene sequence analysis according to Terrat et al.43, using the GnS-PIPE67. Briefly, all the raw reads were sorted according to the multiplex identifier sequences. The raw reads were then quality filtered and trimmed based on (i) their length (370 b), (ii) their number of ambiguities (Ns = 0) and (iii) their primer(s) sequence(s). The reads were dereplicated (i.e. clustering of strictly identical sequences) and aligned using INFERNAL alignment tool66, then clustered into OTUs using a PERL program that groups rare reads to abundant ones, and does not count differences in homopolymer lengths67. A filtering step was then carried out to check all singletons based on the quality of their taxonomic assignments to keep or discard them from the data sets. Finally, the retained reads were homogenised by random selection to 8,085 sequences per sample (the minimum number of reads per sample after GnS-PIPE processing) to compare the datasets and avoid biaised community comparisons. These sequences were then clustered into OTUs (97% similarity threshold) prior to determining diversity and richness indices. OTUs were further identified taxonomically using the Silva database. The raw data sets are available on the European Bioinformatics Institute database system under BioProject id. 254033, accession numbers from SAMN04384084 to SAMN04384190.
Statistical analyses
All the statistical analyses were performed using R free software version 3.0.268, using the packages Ade-469, Vegan70 and Indicspecies71. The physical and chemical heterogeneity of soils was assessed by Hill & Smith Principal Component Analysis for mixed data using the dudi.hillsmith function in ade4 package. This analysis involved the following set of variables: Soil texture according to the FAO classification (qualitative variable), soil organic carbon, total nitrogen content, available phosphorous, soil pH, and cation exchange capacity. Land use was used as a categorical variable, and differences among land uses were tested by permutation (Monte-Carlo test, 1,000 permutations).
The turnover rates (z) for bacterial community composition were derived from the slope of the Taxa-Area Relationship (TAR) as described in Ranjard et al.12 following the method described in Harte et al.72 and by applying the equation:
where χd is the observed Sørensen’s similarity between two soil samples that are d meters apart from each other. χd and d are determined based on community structure data and geographical coordinates of sampling sites; respectively. b is the intercept of the linear relationship and z the turnover rate of the community composition. The z estimate and its 95% confidence interval were derived from the slope (−2*z) of the relationship between similarity and distance by weighted linear regression. Only distances greater than 1 km were considered.
Differences in soil microbial community structure were characterized using UniFrac distances73. Non metric multidimensional scaling (NMDS) was then used to graphically depict differences between soil microbial communities using the MetaMDS function of the vegan package. The significance of the observed clustering of samples on the ordination plot was assessed by an analysis of similarity (ANOSIM, 1000 permutations).
A variance partitioning approach was used to investigate the relative influences of soil physicochemical characteristics (FAO classification for soil texture, total C content, assimilable P, soil pH, and CEC), land use, climatic zone, and geographical location (represented by geographical coordinates and spatial descriptors derived from geographical coordinates by means of a principal coordinates neighbour matrices approach, PCNMs, representing neighbourhood relationships between sites69) on diversity indices (richness, evenness, and Shannon-Weaver index) and on soil bacterial community structure. Total nitrogen was not considered as an explanatory variable because it was highly correlated to the total soil carbon content (r2 = 0.96). This approach consisted of two successive steps. First, we investigated the effect of environmental variables. Then, we tested the effect of geographical location and neighbourhood relationships on the residuals derived from the first step using the same methodology. For diversity indices, each step first consisted in evaluating each combination of explanatory variables relatively to its adjusted R2 (to maximize) and its Bayesian Indication Criterion (to minimize) using the regsubsets function in the leaps package. This led to a reduced set of explanatory variables which was submitted to an iterative selection by means of Canonical Redundancy Analysis using the rda and ordiR2Step functions in the vegan package (forward selection) to identify the most parsimonious model. For bacterial community structure, each step was based on a distance-based redundancy analysis on the Unifrac distance matrix and consisted of a forward selection of the most parsimonious model by the capscale and ordiR2step functions in the vegan package. Finally, in each case, the total explained variance and the marginal effect of the selected explanatory variables were determined through an ANOVA-like approach using the anova.cca function in the vegan package.
In order to evaluate if microbial groups could represent indicators of soil conditions, land use and/or climate conditions, we clustered the sites into different environment types using the k-means method74. The k-means method is one of the most widely used techniques to establish clusters from environmental observations. First, initial groups were formed, and centroids were calculated as barycenters of the clusters. Then, the algorithm assigned each observation for the group to the closest centroid, and new centroids were calculated. These steps were repeated until the centroids no longer moved. The data used for this classification were soil physicochemical properties (pH, texture, organic C, total N) and land use (arable, forest, grassland). This classification method identified four clusters (cluster 1: nutrient poor soils, cluster 2: moderately rich soils, cluster 3: nutrient-rich and acidic soils, and cluster 4: nutrient-poor soils with an alkaline pH). To identify the indicator genera of each cluster obtained by the k-mean method, the multipatt function of the indicspecies package was used71. Based on the microbial groups identified as environmental indicators, a variance partitioning approach was used to model the influence of soil physicochemical properties, land use, climate and geographic location on the relative abundance of each bacterial genus. The land use effect within the clusters was tested by multivariate analysis and analysis of similarity (ANOSIM).
References
Lemanceau, P. et al. Understanding and managing soil biodiversity: a major challenge in agroecology. Agron. Sustain. Dev. 35, 67–81 (2015).
Bender, S. F. et al. An underground revolution: biodiversity and soil ecological engineering for agricultural sustainability. Trends Ecol. Evolut. 31, 440–452 (2016).
Ranjard, L. et al. Biogeography of soil microbial communities: a review and a description of the ongoing French national initiative. Agron. Sustain. Dev. 30, 359–365 (2010).
Latour, X. et al. The composition of fluorescent pseudomonad populations associated with roots is influenced by plant and soil type. Appl. Environ. Microbiol. 62, 2449–2456 (1996).
Berg, G. & Smalla, K. Plant species and soil type cooperatively shape the structure and function of microbial communities in the rhizosphere. FEMS Microbiol. Ecol. 68, 1–13 (2009).
Kuramae, E. et al. Soil and plant factors driving the community of soil-borne microorganisms across chronosequences of secondary succession of chalk grasslands with a neutral pH. FEMS Microbiol. Ecol. 77, 285–294 (2011).
Fierer, N. & Jackson, R. B. The diversity and biogeography of soil bacterial communities. Proc. Natl. Acad. Sci. USA 103, 626–631 (2006).
Lauber, C. L. et al. The influence of soil properties on the structure of bacterial and fungal communities across land-use types. Soil. Biol. Biochem. 40, 2407–2415 (2008).
Lauber, C. L. et al. Pyrosequencing-based assessment of soil pH as a predictor of soil bacterial community structure at the continental scale. Appl. Environ. Microbiol. 75, 5111–5120 (2009).
Lauber, C. L. et al. Temporal variability in soil microbial communities across land-use types. ISME J. 7, 1641–1650 (2013).
Griffiths, R. I. et al. The bacterial biogeography of British soils. Environ. Microbiol. 13, 1642–1654 (2011).
Ranjard, L. et al. Turnover of soil bacterial diversity driven by wide-scale environmental heterogeneity. Nat. Commun. 4, 1434, https://doi.org/10.1038/ncomms2431 (2013).
Chemidlin Prévost-Bouré, N. et al. Similar processes but different environmental filters for soil bacterial and fungal community composition turnover on a broad spatial scale. Plos One 9, e111667, https://doi.org/10.1371/journal.pone.0111667 (2014).
Jeanbille, M. et al. Soil parameters drive the structure, diversity and metabolic potentials of the bacterial communities across temperate beech forest soil sequences. Microb. Ecol. 71, 482–493 (2015).
Thomson, B. C. et al. Soil conditions and land use intensification effects on soil microbial communities across a range of European field sites. Soil. Biol. Biochem. 88, 403–413 (2015).
Marschner, P. et al. Soil and plant specific effects on bacterial community composition in the rhizosphere. Soil Biol. Biochem. 33, 1437–1445 (2001).
Mougel, C. et al. Dynamic of the genetic structure of bacterial and fungal communities at different developmental stages of Medicago truncatula Gaertn. cv. Jemalong line J5. New Phytol. 170, 165–175 (2006).
Uroz, S. et al. Specific impacts of beech and Norway spruce on the structure and diversity of the rhizosphere and soil microbial communities. Sci. Rep. 6, https://doi.org/10.1038/srep27756 (2016).
Lundberg, D. S. et al. Defining the core Arabidopsis thaliana root microbiome. Nature 488, 86–90 (2012).
Mendes, R., Garbeva, P. & Raaijmakers, J. M. The rhizosphere microbiome: significance of plant beneficial, plant pathogenic, and human pathogenic microorganisms. FEMS Microbiol. Rev. 37, 634–663 (2013).
Vandenkoornhuyse, P. et al. The importance of the microbiome of the plant holobiont. New Phytol. 206, 1196–1206 (2015).
Lemanceau, P., Blouin, M., Muller, D. & Moenne-Loccoz, Y. Let the core microbiota be functional. Trends Plant Sci. 22, 583–595 (2017).
Latour, X. et al. The establishment of an introduced community of fluorescent pseudomonads is affected both by the soil-type and the rhizosphere. FEMS Microbiol. Ecol. 30, 163–170 (1999).
Schreiter, S. et al. Effect of the soil type on the microbiome in the rhizosphere of field-grown lettuce. Front. Microbiol. 5, 144, https://doi.org/10.3389/fmicb.2014.00144 (2014).
Colin, Y. et al. Taxonomic and functional shifts in the beech rhizosphere microbiome across a natural soil toposequence. Sci. Rep. 7, 9604, https://doi.org/10.1038/s41598-017-07639-1 (2017).
Kareiva, P., Watts, S., McDonald, R. & Boucher, T. Domesticated nature: shaping landscapes and ecosystems for human welfare. Science 316, 1866–1869 (2007).
Ellis, E. C. et al. Used planet: A global history. Proc. Natl. Acad. Sci. USA 110, 7978–7985 (2013).
Stone, D. et al. A method of establishing a transect for biodiversity and ecosystem function monitoring across Europe. Appl. Soil. Ecol. 97, 3–11 (2016).
Delgado‐Baquerizo, M. et al. It is elemental: soil nutrient stoichiometry drives bacterial diversity. Environ. Microbiol. 19, 1176–1188 (2017).
Delgado-Baquerizo, M. et al. A global atlas of the dominant bacteria found in soil. Science 359, 320–325 (2018).
Terrat, S. et al. Mapping and predictive variations of soil bacterial richness across France. PLoS One 12, e0190128, https://doi.org/10.1371/journal.pone.0186766 (2017).
Thompson, L. R. et al. A communal catalogue reveals Earth’s multiscale microbial diversity. Nature 551, 457–463 (2017).
Lienhard, P. et al. Pyrosequencing evidences the impact of cropping on soil bacterial and fungal diversity in Laos tropical grassland. Agron. Sustain. Dev. 34, 525–533 (2014).
Constancias, F. et al. Mapping and determinism of soil microbial community distribution across an agricultural landscape. Microbiologyopen 4, 505–517 (2015).
Kuramae, E. E. et al. Soil characteristics more strongly influence soil bacterial communities than land‐use type. FEMS Microbiol. Ecol. 79, 12–24 (2012).
Karimi, B. et al. Biogeography of soil bacteria and archaea across France. Sci Adv (in press).
Fierer, N., Bradford, M. A. & Jackson, R. B. Toward an ecological classification of soil bacteria. Ecology 88, 1354–1364 (2008).
Green, J. L. et al. Spatial scaling of microbial eukaryote diversity. Nature 432, 747–750 (2004).
Horner-Devine, M. C., Lage, M., Hughes, J. B. & Bohannan, B. J. M. A taxa-area relationship for bacteria. Nature 432, 750–753 (2004).
Barreto, D. P., Conrad, R., Klose, M., Claus, P. & Enrich-Prast, A. Distance-decay and taxa-area relationships for bacteria, archaea and methanogenic archaea in a tropical lake sediment. Plos One 9, e110128, https://doi.org/10.1371/journal.pone.0110128 (2014).
Tu, Q. et al. Biogeographic patterns of soil diazotrophic communities across six forests in the North America. Mol. Ecol . 25, 2937–2948 (2016).
Zinger, L., Boetius, A. & Ramette, A. Bacterial taxa-area and distance-decay relationships in marine environments. Mol. Ecol. 23, 954–964 (2014).
Terrat, S. et al. Improving soil bacterial taxa–area relationships assessment using DNA meta-barcoding. Heredity 114, 468–475 (2015).
Powell, J. R. et al. Deterministic processes vary during community assembly for ecologically dissimilar taxa. Nat. Commun. 6, 8444, https://doi.org/10.1038/ncomms9444 (2015).
Van Der Gast, C. Microbial biogeography: the end of the ubiquitous dispersal hypothesis? Environ. Microbiol. 17, 544–546 (2014).
Griffiths, R. I. et al. Mapping and validating predictions of bacterial biodiversity using European and national scale datasets. Appl. Soil Ecol. 97, 61–68 (2016).
Hanson, C., Fuhrman, J., Horner-Devine, M. C. & Martiny, J. B. H. Beyond biogeographic patterns: processes shaping the microbial landscape. Nat. Rev. Microbiol. 10, 497–506 (2012).
Hermans, S. M. et al. Bacteria as emerging indicators of soil condition. Appl. Environ. Microbiol. 83, 1–13 (2016).
Banerjee, S., Schlaeppi, K. & van der Heijden, M.G.A. Keystone taxa as drivers of microbiome structure and functioning. Nat. Rev. Microbiol. 16, https://doi.org/10.1038/s41579-018-0024-1 (2018).
Keith, A. M. et al. Cross-taxa congruence, indicators and environmental gradients in soils under agricultural and extensive land management. Eur. J. Soil Biol. 49, 55–62 (2012).
Van Horn, D. J. et al. Factors controlling soil microbial biomass and bacterial diversity and community composition in a cold desert ecosystem: role of geographic scale. PLoS One 8, e66103, https://doi.org/10.1371/journal.pone.0066103 (2013).
Constancias, F. et al. Contrasting spatial patterns and ecological attributes of soil bacterial and archaeal taxa across a landscape. Microbiologyopen 4, 518–531 (2015).
Bergmann, G. T. et al. The under-recognized dominance of Verrucomicrobia in soil bacterial communities. Soil. Biol. Biochem. 43, 1450–1455 (2011).
Kuramae, E. E. et al. Soil characteristics more strongly influence soil bacterial communities than land-use type. FEMS Microbiol. Ecol. 79, 12–24 (2012).
Acosta-Martinez, V., Dowd, S., Sun, Y. & Allen, V. Tag-encoded pyrosequencing analysis of bacterial diversity in a single soil type as affected by management and land use. Soil Biol. Biochem. 40, 2762–2770 (2008).
da C Jesus, E. et al. Changes in land use alter the structure of bacterial communities in Western Amazon soils. ISME J. 3, 1004–1011 (2009).
Gardi, C. et al. Soil biodiversity monitoring in Europe: ongoing activities and challenges. Eur. J Soil. Sci. 60, 807–819 (2009).
Creamer, R. E. et al. Ecological network analysis reveals the inter-connection between soil biodiversity and ecosystem function as affected by land use across Europe. Appl. Soil Ecol. 97, 112–124 (2016).
ISO (International Organization for Standardization). Soil Quality - Determination of particle size distribution in mineral soil – Method by sieving and sedimentation. ISO 11277, Geneva, Switzerland (1998).
ISO (International Organization for Standardization). Soil quality - Determination of organic and total Carbon after dry combustion (elementary analysis). ISO 10694, Geneva, Switzerland (1995).
Massey, P. et al. Irish Soil Information System: Laboratory Standard Operating Procedures. Technical Report (2007-S-CD-1-S1), published online by Environmental Protection Agency, Ireland. Preprint at https://erc.epa.ie/safer/iso19115/ displayISO19115jsp?isoID=3062 (2014).
ISO (International Organization for Standardization). Soil quality - Determination of effective cation exchange capacity and base saturation level using barium chloride solution. ISO 11260, Geneva, Switzerland (1994).
van Reeuwijk, L. P. Procedures for soil analysis, 6th Ed. Technical Paper 9, International Soil Reference and Information Centre, FAO (2002).
McDonald, N. T. et al. Evaluation of soil tests for predicting nitrogen mineralization in temperate grassland soils. Soil Sci. Soc. Am. J. 78, 1051–1064 (2014).
Mehlich, A. Mehlich-3 soil test extractant: a modification of Mehlich- 2 extractant. Commun. Soil. Sci. Plant Anal. 15, 1409–1416 (1984).
Plassart, P. et al. Evaluation of the ISO standard 11063 DNA extraction procedure for assessing soil microbial abundance and community structure. PLoS One 7, e44279, https://doi.org/10.1371/journal.pone.0044279 (2012).
Terrat, S. et al. Molecular biomass and MetaTaxogenomic assessment of soil microbial communities as influenced by soil DNA extraction procedure. Microb. Biotechnol. 5, 135–141 (2012).
R Core Team. R: A language and environment for statistical computing. R Foundation for Statistical Computing, Vienna, Austria. http://www.R-project.org (2013).
Dray, S. & Dufour, A. B. The ade4 package: implementing the duality diagram for ecologists. J. Stat. Softw. 22, 1–20 (2007).
Oksanen J. et al. Vegan: Community ecology. Preprint at http://ftp.uni-bayreuth.de/math/statlib/R/CRAN/doc/packages/vegan.pdf (2015).
De Cáceres, M. & Legendre, P. Associations between species and groups of sites: indices and statistical inference. Ecology 90, 3566–3574 (2009).
Harte, J., Kinzig, A. & Green, J. Self-similarity in the distribution and abundance of species. Science 284, 334–336 (1999).
Lozupone, C. & Knight, R. UniFrac: a new phylogenetic method for comparing microbial communities. Appl. Environ. Microbiol. 71, 8228–8235 (2005).
Hartigan, J. A. & Wong, M. A. A K-means clustering algorithm. J. R. Stat. Soc. Ser. C Appl. Stat. 28, 100–108 (1979).
Acknowledgements
This work was supported by the European Commission project EcoFINDERS (FP7-264465) and INRA Méta-omiques & écosystèmes microbiens (MEM) metaprogram. The UMR1136 is supported by the French Agency through the Laboratory of Excellence Arbre (ANR-11-LABX-0002-01). For soil sampling, we thank: M. Bonkowski & S. Geisen (Institute of Zoology, University of Cologne, Germany), H. Bracht Jørgensen (Department of Biology, Lund University, Sweden), F. Carvalho & S. Mendes (Department of Life Sciences, University of Coimbra, Portugal), M.B. Dunbar, C. Gardi & A. Orgiazzi (European Commission - DG JRC, Ispra, Italy), R. Griffiths (Centre for Ecology & Hydrology, Wallingford, the United Kingdom), A.S. Hug (Agroscope Institute for Sustainability Sciences, Zürich, Switzerland), J. Jensen (Department of Bioscience, Aarhus University Silkeborg, Denmark), H. Laudon (Dept. of Forest Ecology and Management, Umeå, Sweden), J. Römbke (ECT Oekotoxikologie GmbH, Flörsheim am Main, Germany), M. Rutgers & E. Steenbergen (National Institute for Public Health and the Environment, Bilthoven, The Netherlands), M. Suhadolc & M. Zupan (University of Ljubljana, Center for Soil and Env. Science, Ljubljana, Slovenia). GenoSol platform is a partner of ANAEE France, and received a grant from the French state through the National Agency for Research under the program “Investments for the Future” (reference ANR-11-INBS-0001). Many thanks to Tiffanie Régnier for assistance in the lab. We are grateful to Annie Buchwalter for editing English language.
Author information
Authors and Affiliations
Contributions
The present study was part of the EU project EcoFINDERS coordinated by P.L. with M.B. and L.R. being workpackage leaders. D.S. and R.C. defined the sampling strategy. P.P. carried the samplings with the help of D.S. and R.C. he performed the molecular analyses together with N.C.P.B., S.D., R.I.G., S.U. and L.R., and the data processing together with N.C.P.B., R.I.G., L.R. and S.U. The manuscript was written by P.P., P.L., S.U. and N.C.B.B. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing Interests
The authors declare no competing interests.
Additional information
Publisher’s note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Plassart, P., Prévost-Bouré, N.C., Uroz, S. et al. Soil parameters, land use, and geographical distance drive soil bacterial communities along a European transect. Sci Rep 9, 605 (2019). https://doi.org/10.1038/s41598-018-36867-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-018-36867-2
This article is cited by
-
Dynamic Changes in Rhizosphere Microbial Communities of Watermelon During Continuous Monocropping with Gravel Mulch
Journal of Soil Science and Plant Nutrition (2024)
-
Patterns in soil microbial diversity across Europe
Nature Communications (2023)
-
Evolution of soil texture in mid-subtropical forests in the past 32 years: taking Fanjing mountain in Southwest China as an example
Tropical Ecology (2023)
-
Soil Conditioner Affects Tobacco Rhizosphere Soil Microecology
Microbial Ecology (2023)
-
Soil bacterial depth distribution controlled by soil orders and soil forms
Soil Ecology Letters (2022)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
