
Abstract
Word learning constitutes a human faculty which is dependent upon two anatomically distinct processing streams projecting from posterior superior temporal (pST) and inferior parietal (IP) brain regions toward the prefrontal cortex (dorsal stream) and the temporal pole (ventral stream). The ventral stream is involved in mapping sensory and phonological information onto lexical-semantic representations, whereas the dorsal stream contributes to sound-to-motor mapping, articulation, complex sequencing in the verbal domain, and to how verbal information is encoded, stored, and rehearsed from memory. In the present source-based EEG study, we evaluated functional connectivity between the IP lobe and Broca’s area while musicians and non-musicians learned pseudowords presented in the form of concatenated auditory streams. Behavioral results demonstrated that musicians outperformed non-musicians, as reflected by a higher sensitivity index (d’). This behavioral superiority was paralleled by increased left-hemispheric theta coherence in the dorsal stream, whereas non-musicians showed stronger functional connectivity in the right hemisphere. Since no between-group differences were observed in a passive listening control condition nor during rest, results point to a task-specific intertwining between musical expertise, functional connectivity, and word learning.
Similar content being viewed by others
Introduction
In the last two decades, professional musicians have repeatedly been shown to serve as a reliable and powerful model for studying functional and structural plasticity in brain regions supporting auditory perception1,2,3,4,5, motor control6,7,8, and recently also higher cognitive functions9,10. However, such brain changes should not be considered as spatially isolated phenomena but rather as being part of intimately connected and mutually interacting neural networks11,12. This network perspective is supported, for example, by previous diffusion tensor imaging (DTI) studies demonstrating white matter differences (i.e., fractional anisotropy, radial diffusivity, or volume) between musicians and non-musicians in a substantial number of fiber tracts, including the arcuate fasciculus (AF)13,14, different subdivisions of the corpus callosum15,16,17, the corticospinal tract18,19 as well as the extreme capsule20.
Currently, there is striking evidence showing that both plastic changes in the auditory-related cortex (ARC) as well as altered neural network characteristics15,21 lead to remarkable behavioral advantages of musicians in processing a variety of speech cues manipulated in terms of voice-onset time22,23,24, pitch25,26,27,28, duration22,23, timbre4,29, rhythm30, and prosody26,31. However, these behavioral advantages do not seem to be restricted to auditory tasks but can likewise be observed in several cognitive domains, including attention32, short-term memory33, working memory34, and inhibition10. Although the specific origin of these advantages is not yet fully understood, it is supposed that shared neural networks, perceptual functions, and cognitive operations between the domains of speech and music may be one of the key features underlying cognitive facilitation27,35,36.
Music training has not only been shown to facilitate basic processing of speech sounds but also speech segmentation in adults and children37,38,39, one of the first steps of language learning that requires the ability to extract words from continuous speech. Furthermore, recently, Dittinger and colleagues40 took advantage of the multifaceted influence of music training, and investigated the neural signatures underlying word learning mechanisms in musically trained and untrained subjects40,41 and children undergoing music training42 while the participants learned the meaning of new words through word-picture associations of increased mnemonic complexity. Results from these studies showed a behavioral advantage of musicians and musically trained children in word learning, however, only when participants had to access semantic memory in order to judge whether new pictures were related to previously learned words. Accordingly, this behavioral superiority was accompanied by a shift of the N400 component from anterior to posterior scalp sites, possibly indicating a training-related facilitation in incorporating the newly-learned word-meaning associations into established lexical-semantic representations43,44.
Learning words of a new language requires the interplay between auditory perception, memory functions, and articulation40,45. Contemporary biological and linguistic46,47,48,49,50 models of speech processing conjointly postulate important computational differences between the ventral and dorsal processing streams. The ventral stream is bilaterally organized, stretches from pST and IP brain regions toward the temporal pole, and mediates the integration of phonetic entities into lexical and semantic representations51. By contrast, a left-lateralized dorsal stream projecting from pST and IP areas toward the frontal lobe contributes to the translation of the speech signal into articulatory representations49. However, it is noteworthy to mention that the dorsal stream does not exclusively support sensory-motor functions but is likewise recruited across different modalities during higher-level memory tasks52,53,54. In fact, previous MEG source-imaging studies reported that during both verbal55 and non-verbal34,52,56 tasks, brain activity in pST and IP regions as well as in Broca’s area was modulated as a function of working memory load. This perspective is also in line with clinical observations showing that patients with lesions encompassing the left AF often demonstrate impaired working memory functions57,58,59,60 and that intraoperative stimulation in awake brain tumor patients in the vicinity of the AF disrupts non-word repetition61. Furthermore, the dorsal stream has previously been shown to contribute to complex sequencing in the verbal domain62.
Nowadays, there is functional63,64,65 and anatomical66,67 evidence showing that the dorsal and ventral streams differentially contribute to word learning depending, among other factors, on the demands placed on sound-to-meaning and sound-to-articulation mapping mechanisms. By using a multimodal imaging approach, Lopez-Barroso and colleagues67 reconstructed the posterior, the anterior, and the long segment of the AF68,69, and revealed a positive correlation between functional and structural connectivity among Wernicke’s area and Broca’s territory (i.e., long segment of the AF) and the ability of the participants to remember pseudowords presented in the form of auditory streams. These results suggest that the learning of pseudowords leads to an increased recruitment the left dorsal stream, and that sensory-to-motor coupling mechanisms may contribute to generate the motor codes of new phonological sequences for facilitating verbal memory functions49,70. Otherwise, Catani and co-workers66 focused on the relationship between the degree of asymmetry of the long segment of the AF and verbal memory performance in a group of participants who learned word lists by using semantic strategies. In contrast to Lopez-Barroso and colleagues67, results revealed that individuals characterized by a more symmetric distribution of this fiber bundle were better at remembering the previously learned lexical items compared to those with a strong left-hemispheric asymmetry66. Finally, previous fMRI studies investigating the neural underpinnings underlying word learning mechanisms by using picture-word associations64,71 or visually presented sentences72, generally revealed increased brain activity in distributed neocortical areas situated along the two processing streams and accommodating lexical-semantic processes47,51, including the IP lobe, Broca’s area, and the middle-posterior part of the middle temporal gyrus (MTG).
In the present EEG study, we evaluated word learning mechanisms in musicians and non-musicians by relying on a similar paradigm that has previously been shown to recruit the left dorsal stream67. However, the novelty of our approach was that we evaluated dynamic electrophysiological coupling mechanisms between specific brain regions of the dorsal and ventral streams during word learning instead of focusing on white matter architecture, hemodynamic responses as an indirect marker of brain activity, or event-related potentials. Specifically, we collected scalp-EEG data while a group of musicians and non-musicians learned pseudowords auditorily presented in the form of concatenated speech streams (Fig. 1). Afterwards, the EEG signal was segmented in single epochs of 1 second, Fourier transformed, and subjected to functional connectivity (i.e., coherences) analyses in the source-space by using the eLORETA toolbox. Thereby, we used a hierarchical approach consisting of (1) collecting scalp EEG data, (2) validating the inverse-space solution, (3) selecting the frequency band and the regions of interest most reliably representing spectral-density distribution in the dorsal stream, (3) and assessing theta (θ) coherences (i.e., see the discussion section for a detailed description of θ) within the three-dimensional brain space. According to previous studies showing a positive relationship between functional connectivity in the left dorsal stream and word learning in musicians and non-musicians41,67 as well as on anatomical data indicating an optimization of the left dorsal stream as a function of music training13,14, we evaluated functional connectivity between the IP lobe and ventral part of the prefrontal cortex, and predicted that the behavioral advantage of musicians in word learning would be reflected by an increased left-hemispheric asymmetry.

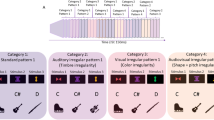
The upper part of the figure (A) provides an overview of the word learning paradigm consisting of different pseudoword lists (LA-LD) pseudorandomly presented in a serial order (L1-L3) during the “learning phase” (l). After the learning phase, participants performed the recognition test (i.e., t, “test phase”) consisting of judging whether the pseudowords have previously been presented in the “learning phase” (i.e., target) or not (i.e., non-target). The bottom part of the figure (B) indicates the spatial position of the ROIs in a canonical MNI template. The red spots indicate the voxels that constitute the BAs 44/45, 39/40, and 21, whereas the black circles show the approximate position of the centroid voxels used for connectivity analyses. x, y, and z = MNI coordinates of the centroid voxel.
Results
Autobiographical data, musical aptitudes, and cognitive capabilities
Separate t-test for independent samples did not reveal between-group differences in age, number of foreign languages spoken, or cumulative number of hours of foreign languages spoken. Furthermore, the two groups did not differ in terms of years of education or years of education of the parents (i.e., t-tests). As expected, the evaluation of musical aptitudes by means of a 2 × 2 ANOVA (i.e., 2 groups x 2 subtests) revealed main effects of group (F(1, 28) = 63.054, p < 0.001) and subtest (F(1, 28) = 23.89, p < 0.001) as well as a significant group x subtest interaction effect (F(1, 28) = 5.465, p = 0.027). The main effect of group was related to an overall better performance of musicians compared to non-musicians (t(28) = −8.731, p < 0.001), whereas the main effect of subtest as well as the group x subtest interaction were driven by a generally better performance in the rhythmical compared to the tonal condition (t(28) = −4.55, p < 0.001), with a more pronounced discrepancy between the two subtests in non-musicians (i.e., t-test performed with difference values, t(28) = 2.338, p = 0.027). Finally, none of the t-tests for independent samples targeting at screening for group differences in cognitive abilities (i.e., WIE, “cognitive speed”, and VLMT) reached significance.
Behavioral data
The 2 × 3 repeated-measures ANOVA (i.e., two groups and three “test blocks”) computed on d’ scores yielded significant main effects of “test block” (F(2, 27) = 49.767, p < 0.001) and group (F(1, 28) = 6.433, p = 0.017). The main effect of “test block” originated from significantly higher d prime values in block 1 compared to block 2 and 3 (block 1 vs. block 2: t(29) = 9.962, p < 0.001; block 1 vs. block 3: t(29) = 7.664, p < 0.001), whereas the main effect of group was mediated by an overall better performance of musicians compared to non-musicians (Fig. 2A). All other effects did not reach significance (all ps > 0.05).

(A) shows d’ values, separately for the two groups (blue = non-musicians, red = musicians) and the three test blocks. The left part of (B) depicts between-group comparisons of the AI related to the dorsal and ventral streams during word learning. The right part of (B) shows between-group comparisons (i.e., red = musicians, blue = non-musicians) of the AI in the dorsal stream during the two control conditions, namely the Simon task (ST) and resting-state (RS). * = p < 0.05. n.s. = non-significant. The bars indicate standard error of mean.
Current-density reconstruction: localizer
For validating the three-dimensional eLORETA source reconstruction, the single segments of 1 second were averaged across the three serial language positions and the two groups, and current density values were estimated for each voxel. This procedure clearly demonstrated an intuitive inverse-space solution, with maximal activity originating from the ARC (i.e., BA 42 and 22, see Fig. 3C).

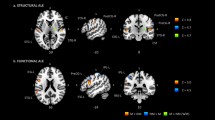
(A) average EEG activity across all electrodes, participants, and serial language positions. The scalp map indicates negative voltage values ranging from high (red color) to low (green color) negativity. (B) Power spectral density (PSD) across all electrodes, participants, and serial language positions. (C) Mean current-density distribution maps of the 1 second EEG segments averaged across participants and serial language positions in the range of 0–2 prop. µA/mm2 × 10−5. a = left lateral hemisphere, b = left medial hemisphere, c = right lateral hemisphere, d = right medial hemisphere. (D,E,F) SnPM results reflecting θ (green box), α (blue box), and low-β (red box) spectral-density distributions for all pseudoword lists (i.e., 1 second segments) averaged across the participants. The bottom bar (i.e., scaled in t units x 101) depicts t-values (threshold for significance at p < 0.01, t = 3.35; one-tailed, corrected for multiple comparisons). a = left lateral hemisphere, b = left medial hemisphere, c = right lateral hemisphere, d = right medial hemisphere.
Spectral-density analyses
Statistical non-parametric mapping (SnPM) analyses computed in the θ, α, and low-β frequency-ranges brought to light three bilaterally distributed but spatially segregated spectral density maps. In particular, θ spectral-density was highest in frontal-parietal brain regions (i.e., including the IP lobe as well as the inferior frontal gyrus) and in the temporal lobe, whereas α was most pronounced at anterior brain sites with maximal spectral-density distribution in the proximity of the temporal pole and the middle and inferior frontal gyri. Otherwise, low-β spectral-density was highest in IP parietal- and posterior frontal regions, however, with lowest t-values around the sylvian fissure. Consequently, based on the fact that θ most reliably reflected spectral-density in the dorsal stream, connectivity analyses were computed in the θ frequency-band between the IP lobe and Broca’s area (see methods section and Fig. 1B). This approach is consistent with a previous MEG study focusing on functional connectivity in the dorsal stream during an auditory working memory task52.
Functional connectivity analyses
Putative group differences in the degree of asymmetry of functional connectivity in the dorsal and ventral streams during the “learning phase” were evaluated by comparing the asymmetry indices (AI) between the two groups (Mann-Whitney U tests). Otherwise, for the two control conditions we only evaluated the AI in the dorsal stream (Mann-Whitney U tests).
“Learning phase”
The Mann-Whitney U tests performed on the AI data revealed a significant group difference in the dorsal (U = 162, p = 0.041) but not in the ventral stream (U = 123, p = 0.683). As visible from Fig. 2B, musicians were characterized by a left-hemispheric asymmetry, whereas in non-musicians functional connectivity was higher in the right hemisphere.
Control conditions
In order to exclude that the group difference we observed in the dorsal stream during the “learning phase” was possibly confounded by resting-state activity or induced by acoustic stimulation per se (i.e., Simon task), we performed two additional Mann-Whitney U tests with the AI data related to the dorsal stream. However, these analyses did not reach significance (Simon task: U = 149, p = 0.137; resting state: U = 101, p = 0.653; Fig. 2B, right side).
Brain-training and brain-behavior relationships
Relationships between brain data, music training, and behavior were inspected by means of within-group correlative analyses (according to Spearman’s rho, one-tailed). In the musicians group we did not reveal a significant relationship between the AI in the dorsal stream during the “learning phase” and age of training commencement (p = 0.423). The same was the case for the correlation between the former variable and the cumulative number of training hours across lifespan (p = 0.093). Furthermore, within both groups, the AI of the “learning phase” did not correlate with d’ (musicians: p = 0.39; non-musicians: p = 0.113).
Discussion
Behavioral data
In the present study, we specifically evaluated a homogeneous group of musicians consisting of pianists. In fact, this specific genre of musicians has previously been shown to be more prone to plastic changes in the left hemisphere, whereas musicians playing instruments producing less sharp and impulsive tones (e.g., bassoon, saxophone, French horn, violoncello, or organ) are more likely characterized by neural adaptations in the right counterpart5. According to the signal detection theory73 which allows to measure individual discrimination sensitivity (d’), musicians showed higher d’ values compared to non-musicians. This result clearly demonstrated a superiority of musicians in learning new words from concatenated speech streams. The behavioral results also uncovered a main effect of test block that originated from a decay of performance from test block 1 to block 2 and 3. Since this effect was not influenced by musical expertise, the data are interpreted as indicating a general interference effect originating from repeated filler stimuli (i.e., non-target stimuli).
Our behavioral results are compatible with a previous EEG study that investigated speech segmentation abilities in children undergoing music training37. Thereby, François and colleagues37 revealed that during the “test phase” musically trained children showed higher familiarity accuracy than children undergoing painting training for pseudowords that have previously been presented in the form of concatenated streams with high transitional probabilities (i.e., pseudowords vs. partial pseudowords). However, improved speech segmentation skills as a function of music training might not be the sole effect contributing to the present results. In fact, Dittinger and colleagues evaluated word learning mechanisms through picture-word associations in children undergoing music training42 and professional musicians40,41 compared to untrained participants, and revealed that musically trained individuals were better able to learn the meaning of new words differing in pitch, duration, voice-onset time, and aspiration. Accordingly, the authors proposed that at least two mechanisms can lead to a behavioral advantage of musicians in word learning, namely enhanced phonetic perception23,31 and a general improvement of cognitive functioning10,74. Here, musicians and non-musicians did not differ in terms of general cognitive functioning (i.e., IQ, short-term memory, and working memory). Consequently, the behavioral advantage we revealed in musicians during word learning might rather be explained by superior phonetic perception abilities and segmentation skills than in terms of a general optimization of cognitive functions. In particular, as previously suggested by Dittinger and colleagues40, it is conceivable that enhanced phonetic perception in musicians may facilitate the building of new phonological representations (i.e., through the recruitment of the left dorsal stream) that are necessary for word segmentation, leading to more stable mnemonic representations.
Frequency-band selection and ROIs
Statistical spectral-density analyses showed that θ oscillations best reflected consistent spatial distribution patterns in the dorsal stream. In fact, α and low-β generators were spatially dissociated from θ current-densities, and were most prominently distributed in anterior-temporal- and frontal areas (α) as well as in the IP lobe and superior frontal brain regions (low-β). Furthermore, low-β activity was generally decreased in perisylvian territories and in the ventral frontal cortex. Interestingly, the spatial distribution of θ spectral-density (see Fig. 3D) showed a strong similarity with the dorsal network recently extracted by Albouy and colleagues by means of MEG during a pitch memory task52 and corroborates also previous findings relating theta oscillatory activity with word learning75. However, this spatial convergence may not be surprising since theta oscillations have repeatedly been linked to a variety of verbal76,77 and non-verbal78 memory functions, including short-term memory79, working memory52 as well as episodic memory80. From a physical perspective, low-frequency oscillations are characterized by high amplitudes and long wavelengths making them particularly suitable for integrating information between spatially dislocated brain areas81 as well as for coordinating neuronal communication over long-range circuits81,82. Furthermore, theta oscillations have previously been shown to play to an important role in “packing” the multi-time speech signal into units of the appropriate temporal granularity83 as well as to contribute to the temporal alignment of neural activity between the speech perception and production systems84. Increased coherence in the θ band (4–8 Hz) has also been observed in participants who learned new words in the context of a speech segmentation task75. This result also fits well with other studies showing a gradual increase in θ power and coherence during the progressive building up of working memory traces of linguistic information during sentence comprehension85,86,87. Finally, increased long-range fronto-parietal θ coherence has been reported in human studies involving periods of information retention and has been attributed to a common mechanism of neural interactions that sustains working memory functions88.
According to the θ spectral-density maxima distributed along the dorsal stream, the ROIs used for connectivity analyses were centered in the IP lobe and in Broca’s area (i.e., see methods section). The IP lobe has repeatedly been associated with higher-level phonetic processing, especially during tasks requiring the integration of acoustic information into short-term memory for later comparisons89,90,91. In addition, the IP lobe is known to usually be more strongly activated while processing pseudowords compared to real words92, and gray and white matter volume in this brain region has been shown to be predictive of speech sounds learning93. Although it is apparent that the spatial location of our posterior ROI diverged from the one used by Lopez-Barroso et al.67, the two approaches are thoroughly reconcilable from an anatomical perspective. In fact, it is well documented that the AG/SMG constitute a “plie de passage” of the long segment of the AF which runs through the temporal-parietal boundary for reaching Broca’s regions68,69. By contrast, the ROI centered in Broca’s area is fully comparable with this previous work67. Currently, it is generally recognized that domain-general and language-selective functions lay side-by-side within Broca’s area94, a territory that has repeatedly been associated with the planning and execution of speech articulation95, syntactic-, lexical-, semantic-, and phonological processes47,96, as well as with a variety of verbal working memory functions94. In addition, Broca’s area seems to be particularly responsive to pseudowords presented in isolation92 or in the context of concatenated speech67.
Functional connectivity during the “learning phase”
In line with our hypothesis, connectivity analyses yielded a group difference in the dorsal but not in the ventral stream that originated from increased left-hemispheric asymmetry in musicians compared to non-musicians, whereas non-musicians showed a shift toward the right hemisphere. These results are not only consistent with previous functional11 and anatomical13,14 studies pointing to an optimization of this left-sided neural circuit in musicians, but also with recent data attributing a fundamental role to the AF in mediating audio-motor learning97. In this context, it results self-explanatory that such sensory-to-motor coupling mechanisms are a fortiori triggered in musicians8,98 due to the continuous adjustment of motor output as a function of auditory feedback. The neural basis of this phenomenon has previously been described in professional musicians by evaluating directional EEG-based intracranial functional connectivity between the ARC and the premotor cortex99. Thereby, unidirectional impulse propagation from the ARC toward the premotor cortex was considerably stronger during piano playing compared to rest. Accordingly, the increased left-hemispheric asymmetry we revealed in musicians suggests that the participants performed the word learning tasks by more strongly reverting to this highly-trained and automated neural mechanism, probably contributing to facilitate keeping phonetic information in verbal memory through sensory-to-motor coupling mechanisms. This perspective is also anchored on a recent study of Tian and colleagues100 showing that articulation-based- (ABS) and hearing-based memory (HBS) strategies dissociate within the dorsal stream. In particular, ABS induced increased activity in frontal-parietal sensorimotor systems, whereas HBS was dependent on brain regions known to be implicated in memory retrieval, including the middle frontal gyrus, the IP lobe as well as the intraparietal sulcus100,101. Consequently, our results are interpreted as pointing to an optimized neural synchronization between brain regions involved in merging syllabic- and articulatory representations, and contributing to facilitate the building-up of more robust multidimensional memory traces102.
Interestingly, in non-musicians we did not reveal a comparable left-hemispheric neural preference. Although this might be seen somewhat in contrast to the previous work of Lopez-Barroso and colleagues67, it is noteworthy to mention that the authors principally found a correlation between left-hemispheric functional and structural connectivity and behavioral performance. Therefore, by taking into account such a linear relationship, our results are thoroughly comparable with these previous data in that the participants who were characterized by a stronger left-hemispheric asymmetry (i.e., the musicians) performed better on the word form learning tasks. However, we are more likely prone to interpret the observed between-group differences by taking into account differential learning strategies103. Based on the fact that sensory-to-motor coupling mechanisms have exclusively been attributed to the left hemisphere, the stronger right-sided engagement of the dorsal stream in non-musicians may rather reflect stronger demands placed on working-104 and episodic105,106 memory functions. This argumentation can be deduced from previous meta-analyses conducted with large samples and pointing to the involvement of widespread bilateral frontal-parietal networks during a variety of working memory task107,108 as well as while encoding auditory events in episodic memory105,106. In addition, working- and episodic memory have been shown to spatially overlap in frontal and parietal brain regions109,110, leading to suggest a mutual interdependence between these two memory systems during word learning45. Alternatively, we cannot neglect that the stronger right-sided engagement of the dorsal stream we revealed in non-musicians may possibly also have been induced by a specific task strategy consisting of anchoring pseudowords onto already established lexical-semantic representations. This view is, at least in parts, supported by a previous anatomical study showing a relationship between the degree of symmetry of the AF and lexical-semantic memory functions66 as well as by numerous studies clearly demonstrating that the IP lobe and Broca’s area are involved in mediating lexical-semantic access at both the word- and sentence level47,48,111.
Brain-behavior relationships
In contrast to Lopez-Barroso and co-workers67, we did not reveal significant correlations between the degree of functional asymmetry in the dorsal stream (i.e., AI during the “learning phase”) and behavior (i.e., d’). Therefore, we presume that possibly a third latent variable that has not been evaluated in the present study may have mediated the brain effects to behavior. Such a latent variable could, for example, be detected by using more sophisticated data-driven procedures, like small-world network analyses or machine learning algorithms, instead of focusing on a-priori defined hypotheses. The second unexpected finding was that within the musicians group we did not reveal significant relationships between brain data (i.e., AI) and training parameters (i.e., age of commencement and cumulative number of training hours), letting open the possibility that the differential recruitment of the dorsal stream we observed between the two groups possibly reflected the influence of domain-specific predispositions rather than experience-dependent brain changes. Such a perspective is thoroughly conceivable in that previous MRI studies have shown that genetic factors have a significant influence on grey matter parameters in Broca’s area and in the IP lobe112, and that functional connectivity between these two brain regions can be inherited113. Finally, one other possible reason for not having found a correlation between the AI and training parameters is that the task we used was not sensitive enough to capture such a relationship. Certainly, for definitively answering this question future studies should make use of longitudinal designs enabling to capture the causal relationship between music training and functional connectivity.
Conclusions
By using a previously tested experimental procedure67,114, we were able to uncover a task-specific relationship between the stronger left-asymmetric recruitment of the dorsal stream in the θ frequency range in musicians and word learning. Results are interpreted as suggesting that an optimization of sensory-to-motor coupling mechanisms and phonological working memory functions enabled the building-up of more robust multimodal memory traces. However, since we did not reveal significant correlations between brain data and training parameters, results may rather indicate the influence of predisposition on brain maturation rather than experience-determined brain changes. Our results may be considered as a first step toward a better understanding of the functional role of θ oscillations in the left dorsal stream as well as of its association with word learning, and open novel insights into the neural dynamics underlying foreign (but phonologically similar) word learning. Nevertheless, it is important to mention that EEG-based functional connectivity only enables an approximation of the neural sources contributing to word learning with a low spatial resolution. Therefore, the ROIs used for connectivity analyses should not be interpreted in an anatomical manner and the data should rather be interpreted as reflecting a coupling between anterior and posterior brain areas with a certain degree of dispersion.
Materials and Methods
Participants
Fifteen professional musicians and 15 non-musicians in the age range of 20–40 years and with no past or current neurological, psychiatric, or neuropsychological disorders participated in the study. All participants were consistently right-handed115 native German speakers, and none of them was bilingual. The musicians group consisted of 15 pianists (7 female; mean age = 26.53 years, SD = 5.23; mean age of training commencement = 7.27, SD = 2.25, mean cumulative number of training hours across lifespan = 18799.47, SD = 10776.5) with a conservatory degree or who were advanced students at the same institution. By contrast, the control group was composed of 15 volunteers without formal musical education (8 female; mean age 24.6 years, SD = 4.85). Furthermore, the non-musicians did not learn to play a musical instrument and did not play or sing in bands. In order to exclude between-group differences in terms of demographic variables and social economic status musicians and non-musicians were also matched in terms of years of education as well as years of education of the parents. The participants were paid for participation, the local ethics committee (i.e., Kantonale Ethikkommission Zurich) approved the study (in accordance with the Helsinki declaration), and written informed consent was obtained from all participants.
Pure tone audiometry
All participants were tested with pure-tone audiometry (MAICO Diagnostic GmBh, Berlin) in the frequency-range of 250–8000 Hz (MAICO Diagnostic GmBh, Berlin). According to this procedure, all participants demonstrated an unremarkable audiological status (i.e., all tested frequencies could be heard below a threshold of 30 dB).
Musical aptitudes, history of music training, and foreign language competence
Musical aptitudes were estimated by means of the “Advanced Measure of Music Audition” (AMMA) test116. This test consisted of 30 successive trials in which subjects had to compare pairs of piano melodies, and to decide whether the melodies were equivalent, rhythmically different, or tonally different. Autobiographical data on the history of music training as well as on the usage of foreign languages were collected by using an in-house questionnaire2.
Cognitive capabilities
A set of standardized psychometric tests was used to compare a wide spectrum of basic cognitive functions between the two groups. Intelligence was assessed by means of four subtests117 of the WIE test battery118, including (1) “number-symbol associations”, (2) “commonalities finding”, (3) “mosaic test”, and (4) “digit span forward and backward”. Shortly, the “number-symbol association” test enables to estimate non-verbal associative memory functions, and consists of associating geometric patterns with numbers as fast as possible. During the “commonalities finding” procedure targeting at testing semantic memory functions, participants had to mention the generic term that coalesced the meaning of two words (e.g., musical instrument for the words piano and drum). The “mosaic test” was used to assess visual-spatial abilities and consisted of assembling cubes according to a predetermined visual template. Finally, during the “digit span forward” (i.e., short-term memory) and “backward” (i.e., working memory) tests the participants had to overtly reproduce sequences of digits of increased length. The raw values of these four subtests were transformed to a standardized composite T-value previously shown to adequately capture general intellectual abilities117. In addition, all participants performed a verbal memory (VLMT) test119 consisting of remembering as many auditory-presented words as possible from a pool of fifteen items as well as a “cognitive speed” test120 requiring to link serial numbers as fast as possible.
Auditory stimuli
The pseudowords used in the present study consisted of disyllabic and low-associative items that were assembled according to German phonotactic constraints121. These auditory stimuli (i.e., totally 80, 40 presented in the “learning phase” and 40 presented as distractors during the “test phase”) were recorded by a native female speaker with a sample rate of 44.1 KHz and by using a two-channel record device (Teac Professional, DR-05). For each item, fundamental frequency (f0) was assessed by using the Praat software (http://www.fon.hum.uva.nl/praat/), and set to a timely-constant value of 200 Hz in order to eliminate pitch fluctuations over time (i.e., flattened speech). Furthermore, 20 ms logarithmic fade-in and fade-out were applied for avoiding an abrupt onset and decay, and amplitudes were normalized to a mean value of −23 dB by using the Adobe Audition software (Version 3.0, http://www.adobe.com/ch_de/products/audition.html). Afterwards, for each of the four pseudoword lists, 10 disyllabic pseudowords were concatenated as auditory streams (i.e., four different pseudo-randomized versions were presented in the four blocks of the “learning phase”) with a brief pauses of 25 ms inserted between the single words (Praat, http://www.fon.hum.uva.nl/praat/) for marking words boundaries67,114. This procedure resulted in three naturally spoken pseudoword lists (i.e., single word duration ~ 500–600 ms).
Experimental procedure
During the “learning phases” (i.e., each of them consisting of four learning blocks, total duration of about 3 minutes), the pseudoword lists were successively presented in the form of auditory streams, and participants had to memorize as many pseudowords as possible (see Fig. 1A). During each of the four learning blocks, the same 10 disyllabic items were presented 5 times, however, in a pseudo-randomized order (i.e., same order for all participants, the same word was never repeated in succession). Furthermore, in order to minimize interferences between the four pseudoword lists, each syllable was uniquely presented within but not across languages. For example, if the word “benter” was part of the first language, than neither the syllables /ben/ nor /ter/ was part of the other languages. After the “learning phase”, participants started the “test phase” (i.e., duration of about 1 minute), consisting of judging (i.e., via a button press) whether each single auditorily presented item has previously been presented in the “learning phase” or not. For each pseudoword list, the “test phase” consisted of 3 blocks in which all learned items as well as non-learned items (i.e., 50%, distractors) were presented 3 times (i.e., once in each block). The distractors consisted of the same syllables as the learned items but were arranged in a scrambled manner. For example, if the words “benter” and “halzen” were learned items, then the word “zenben” was a possible distractor. Two minutes after the “test phase”, the next pseudoword list (i.e., “learning phase”) was presented. The serial order (i.e., L1-L3) of the four pseudoword lists (i.e., LA-LD) was pseudo-randomized within the two groups according to the following sequences: (1) LA-LB-LC, (2) LB-LA-LD, (3) LC-LD-LA, (4) LD-LC-LB. The auditory stimuli were delivered by using in-ear headphones (Sennheiser, CX 350) at an intensity of 70 dB, and stimulus presentation was controlled by the “Presentation” software (Neurobehavioral Systems, https://www.neurobs.com).
Experimental control conditions
At the beginning and at the end of the word learning paradigm, the participants were additionally tested on two control conditions used for corroborating the specificity of the EEG effects observed during word learning. The first control condition consisted of a resting-state measurement of 3 minutes (i.e., eyes closed), and targeted at excluding between-group differences in intrinsic functional connectivity11 that might have interacted with brain oscillations during word form learning. By contrast, the second control condition was used for excluding that between-group differences during pseudoword learning were spuriously driven by acoustic stimulation per se. With this purpose in mind, at the end of the experiment, all participants were additionally exposed to the four pseudoword lists (i.e., pseudo-randomized within the two groups) while performing a Simon task122. This specific task relies on conflict monitoring functions122, and is known to dissociate from activity in the dorsal stream by principally recruiting anterior cingulate areas123. During the Simon task, participants sat in front of a computer monitor, and blue and red boxes were presented on the left or right side of the screen. Participants were instructed to press the button on the right when they see the red box appear on the screen and the button on the left when they see the blue one while at the same time ignoring acoustic stimulation. In such an experimental condition, reaction times are usually faster when the spatial position of the boxes (i.e., left or right) is congruent with the location of the response button (i.e., congruent spatial stimulus-response compatibility). Due to a technical problem with the response box, the behavioral data of one subject of the control group could not be collected.
EEG data acquisition and pre-processing
Continuous EEG (32 electrodes, provided by Easy Cap) was recorded with a sampling rate of 1000 Hz and a high-pass filter of 0.1 Hz by using an EEG amplifier (Brain Products). The electrodes (sintered silver/silver chloride) were located at frontal, temporal, parietal, and occipital scalp sites according to the international 10–10 system (Fp1, Fp2, F7, F3, Fz, F4, F8, FT7, FC3, FCz, FC4, FT8, T7, C3, Cz, C4, T8, TP9, TP7, CP3, CPz, CP4, TP8, TP10, P7, P3, Pz, P4, P8, O1, Oz, and O2). The reference electrode was placed on the tip of the nose, and impedances were reduced to 10 kΩ by using electro-gel. For all pre-processing steps, we used the Brain Vision Analyzer software package (version 2.01; Brain Products). Data were filtered off-line with a low-pass filter of 30 Hz (i.e., including a Notch filter of 50 Hz), and artifacts (i.e., eye movements and blinks) were corrected by using an independent component analysis124 in association with a semi-automatic raw data inspection. After data pre-processing, the “resting-state” period, the “learning phase”, as well as the “Simon task” were segmented into single sweeps of 1000 ms, and subjected to eLORETA toolbox for analyses.
Current-density source estimation: localizer
In a first hierarchical processing step, we validated the eLORETA (eLORETA software package; http://www.uzh.ch/keyinst/loreta.htm) source estimation approach by demonstrating current-density maxima originating from the ARC across pseudoword lists. The single artifact-free EEG segments of all the “learning phases” (i.e., segments of 1 second) were averaged for each participant and across the two groups and subjected to eLORETA source estimation. The eLORETA approach, unlike conventional dipole fitting, does not require a-priori assumptions about the number and the localization of the dipoles. eLORETA calculates the three-dimensional distribution of electrically active neuronal generators in the brain as a current density value (µA/mm2), and provides a solution for the inverse problem by assuming that the smoothest of all possible activity distributions is the most plausible one for explaining the data. The characteristic feature of this particular inverse solution approach is the low spatial resolution, which conserves the location of maximal activity, but with a certain degree of dispersion125.
In the current implementation of eLORETA, computations were made within a realistic head model126 by using the Montreal Neurological Institute (MNI) 152 template127, with a three-dimensional solution restricted to cortical gray matter, as determined by the probabilistic Talairach atlas128. The intracranial volume is partitioned in 6239 voxels at 5 mm spatial resolution. eLORETA images represent the electric activity at each voxel in the neuroanatomic MNI space as the magnitude of the estimated current density. Anatomical labels and Brodmann areas (BA) are reported using MNI space, with correction to Talairach space129.
Spectral-density statistics
In a second hierarchical step, we evaluated eLORETA-based spectral-density maps in the theta (θ, 4–7 Hz), alpha (α, 8–12 Hz), and low-beta (β, 13–20 Hz) frequency-range, across all pseudoword lists, by means of voxel-by-voxel t-tests for zero-mean130. The decision to focus on the lower-β band was motivated by previous EEG studies showing an association between this frequency-range and word consolidation131 and word learning41. We used a statistical non-parametric mapping (SnPM) procedure that (1) has previously been shown to generate spatial results overlapping with fMRI results130, (2) enables to estimate the probability distribution by means of randomization statistics (i.e., 5000 permutations), and (3) is corrected for multiple comparisons with a high statistical power132. This procedure was used for selecting the frequency band of interest best reflecting activity in the dorsal stream52. In particular, we used a threshold of p < 0.01 (one-tailed) and only tested for current-density values above average (i.e., one-tailed) because we reasoned that the specificity of brain regions responsive to word learning should be reflected in increased and not decreased EEG activity. For each participant, the single sweeps of 1000 ms related to the “learning phase” were Fourier transformed in the a-priori defined frequency-ranges and averaged. Afterwards, eLORETA images corresponding to the estimated neuronal generators of brain activity within a given frequency band (i.e., for each voxel)133 were computed and subjected to SnPM analyses (i.e., p < 0.01, corrected for multiple comparisons). For SnPM analyses, the estimated spectral-density values for each voxel in the whole sample of participants were subjected to voxel-by-voxel comparisons by using the eLORETA toolbox. By using a t-test for zero-mean, the spectral density values of each voxel were statistically compared to the average spectral density distribution. This procedure enables to calculate t-values for each voxel through permutation statistics according to a critical value of p < 0.01.
Functional connectivity analyses
Functional connectivity (eLORETA software package; http://www.uzh.ch/keyinst/loreta.htm) was evaluated by using lagged coherence values as a measure of the variability of two signals in a specific frequency band134. This nonlinear functional connectivity measure was calculated based on normalized Fourier transforms for each voxel, and is corrected in order to represent the alignment between two signals after the instantaneous zero-lag contribution has been excluded135,136. Such a correction is warranted because zero-lag connectivity in a given frequency band is normally due to non-physiological effects or intrinsic physical artifacts.
In the current implementation of the eLORETA software, computations are made within a realistic head model126 relying on the Montreal Neurological Institute (MNI) 152 template127. Based on the results of the SnPM statistics (Fig. 3D–F), functional connectivity was computed in the θ frequency-range between frontal and parietal brain regions, and the ROIs were centered in BA 39/40 and BA 44/45. Since eLORETA has a low spatial resolution that does not enable to distinguish between anatomically adjacent brain regions, these ROIs were selected based on (1) a previous fMRI study that used a similar word learning paradigm and showed activity in posterior perisylvian and IP (i.e., roughly corresponding to BA 39/40) brain regions as well as in Broca’s area (i.e., roughly corresponding to BA 44/45)67, (2) previous anatomical studies describing a direct white matter projection between the IP lobe and the ventral part of the prefrontal cortex68,69, as well as (3) on a recent EEG study that evaluated word learning in musicians and non-musicians by using a similar inverse-space solution as the one used in the present work41. Furthermore, functional connectivity between the BA 39/40 and BA 21 was used as a control condition. The latter brain region was chosen according to current models of speech processing postulating its contribution to lexical-semantic access at the word level47,49,111. For functional connectivity analyses (see Fig. 1B), a method using a single voxel at the centroid of the ROIs was chosen137. Mathematical details on eLORETA functional connectivity algorithms can be found elsewhere138. Finally, it is important to remark that EEG-based functional connectivity data are always a composite of signal of interest and noise and this method does not preclude that functional connectivity between two regions of interest is indirectly mediated via a non-evaluated connection139.
Statistical analyses
The analyses of autobiographical-, psychometric-, and behavioral data were performed by using t-tests for independent samples (i.e., two-tailed) and omnibus analyses of variance (i.e., ANOVA, repeated measurements). Since coherence measures in small samples deviate from normal distribution140, we tested putative group x hemisphere interactions in the dorsal and ventral streams by using non-parametric Mann-Whitney U tests. In particular, we computed separate Mann-Whitney U tests for the dorsal and ventral streams, and compared functional connectivity differences (i.e., left minus right = asymmetry index = AI) between the two groups. Thereby, we evaluated mean connectivity values across serial language positions. Furthermore, based on specific a-priori hypotheses, brain-behavior relationships were assessed by means of one-tailed correlative analyses according to Spearman’s rho. In particular, we expected to find a positive relationship between the amount of music practice and functional connectivity (i.e., AI) as well as between functional connectivity and behavioral data.
References
Elmer, S., Hänggi, J., Meyer, M. & Jäncke, L. Increased cortical surface area of the left planum temporale in musicians facilitates the categorization of phonetic and temporal speech sounds. Cortex https://doi.org/10.1016/j.cortex.2013.03.007. [Epub ahead of print] (2013).
Elmer, S., Meyer, M. & Jancke, L. Neurofunctional and Behavioral Correlates of Phonetic and Temporal Categorization in Musically Trained and Untrained Subjects. Cerebral Cortex 22, 650–658 (2012).
Marie, C., Magne, C. & Besson, M. Musicians and the Metric Structure of Words. Journal of Cognitive Neuroscience 23, 294–305 (2011).
Pantev, C., Roberts, L. E., Schulz, M., Engelien, A. & Ross, B. Timbre-specific enhancement of auditory cortical representations in musicians. Neuroreport 12, 169–174 (2001).
Schneider, P., Sluming, V., Roberts, N., Bleeck, S. & Rupp, A. Structural, functional, and perceptual differences in Heschl’s gyrus and musical instrument preference. Neurosciences and Music Ii: from Perception to Performance 1060, 387–394 (2005).
Bangert, M. & Schlaug, G. Specialization of the specialized in features of external human brain morphology. European Journal of Neuroscience 24, 1832–1834 (2006).
Hyde, K. L. et al. Musical Training Shapes Structural Brain Development. Journal of Neuroscience 29, 3019–3025 (2009).
Munte, T. F., Altenmuller, E. & Jancke, L. The musician’s brain as a model of neuroplasticity. Nature Reviews Neuroscience 3, 473–478 (2002).
Bermudez, P., Lerch, J. P., Evans, A. C. & Zatorre, R. J. Neuroanatomical Correlates of Musicianship as Revealed by Cortical Thickness and Voxel-Based Morphometry. Cerebral Cortex 19, 1583–1596 (2009).
Zuk, J., Benjamin, C., Kenyon, A. & Gaab, N. Behavioral and Neural Correlates of Executive Functioning in Musicians and Non-Musicians (vol 9, e99868, 2014). Plos One 1 0 (2015).
Klein, C. L., Hänggi, F., Elmer, J. & Jäncke, S. L. The “silent” imprint of musical training. Human Brain Mapping 37, 536–546 (2016).
Li, J. et al. Probabilistic diffusion tractography reveals improvement of structural network in musicians. Plos One 9, e105508, https://doi.org/10.1371/journal.pone.0105508 (2014).
Halwani, G. F., Loui, P., Ruber, T. & Schlaug, G. Effects of practice and experience on the arcuate fasciculus: comparing singers, instrumentalists, and non-musicians. Frontiers in Psychology 2 (2011).
Oechslin, M. S., Imfeld, A., Loenneker, T., Meyer, M. & Jancke, L. The plasticity of the superior longitudinal fasciculus as a function of musical expertise: a diffusion tensor imaging study. Frontiers in Human Neuroscience 4 (2010).
Elmer, S., Hanggi, J. & Jancke, L. Interhemispheric transcallosal connectivity between the left and right planum temporale predicts musicianship, performance in temporal speech processing, and functional specialization. Brain Struct Funct 221, 331–344, https://doi.org/10.1007/s00429-014-0910-x (2016).
Schlaug, G., Jancke, L., Huang, Y., Staiger, J. F. & Steinmetz, H. Increased corpus callosum size in musicians. Neuropsychologia 33, 1047–1055 (1995).
Steele, C. J., Bailey, J. A., Zatorre, R. J. & Penhune, V. B. Early musical training and white-matter plasticity in the corpus callosum: evidence for a sensitive period. J Neurosci 33, 1282–1290, https://doi.org/10.1523/JNEUROSCI.3578-12.2013 (2013).
Bengtsson, S. L. et al. Extensive piano practicing has regionally specific effects on white matter development. Nat Neurosci 8, 1148–1150, https://doi.org/10.1038/nn1516 (2005).
Imfeld, A., Oechslin, M. S., Meyer, M., Loenneker, T. & Jancke, L. White matter plasticity in the corticospinal tract of musicians: a diffusion tensor imaging study. Neuroimage 46, 600–607, https://doi.org/10.1016/j.neuroimage.2009.02.025 (2009).
Oechslin, M. S., Gschwind, M. & James, C. E. Tracking Training-Related Plasticity by Combining fMRI and DTI: The Right Hemisphere Ventral Stream Mediates Musical Syntax Processing. Cereb Cortex, 1–10, https://doi.org/10.1093/cercor/bhx033 (2017).
Kuhnis, J., Elmer, S. & Jancke, L. Auditory Evoked Responses in Musicians during Passive Vowel Listening Are Modulated by Functional Connectivity between Bilateral Auditory-related Brain Regions. Journal of Cognitive Neuroscience 26, 2750–2761 (2014).
Chobert, J., Francois, C., Velay, J. L. & Besson, M. Twelve Months of Active Musical Training in 8-to 10-Year-Old Children Enhances the Preattentive Processing of Syllabic Duration and Voice Onset Time. Cerebral Cortex 24, 956–967 (2014).
Kuhnis, J., Elmer, S., Meyer, M. & Jancke, L. The encoding of vowels and temporal speech cues in the auditory cortex of professional musicians: An EEG study. Neuropsychologia 51, 1608–1618 (2013).
Marie, C., Kujala, T. & Besson, M. Musical and linguistic expertise influence pre-attentive and attentive processing of non-speech sounds. Cortex 48, 447–457 (2012).
Magne, C., Schon, D. & Besson, M. Musician children detect pitch violations in both music and language better than nonmusician children: behavioral and electrophysiological approaches. J Cogn Neurosci 18, 199–211, https://doi.org/10.1162/089892906775783660 (2006).
Marques, C., Moreno, S., Castro, S. L. & Besson, M. Musicians detect pitch violation in a foreign language better than nonmusicians: behavioral and electrophysiological evidence. J Cogn Neurosci 19, 1453–1463, https://doi.org/10.1162/jocn.2007.19.9.1453 (2007).
Schon, D. et al. Similar cerebral networks in language, music and song perception. Neuroimage 51, 450–461 (2010).
Wong, P. C., Skoe, E., Russo, N. M., Dees, T. & Kraus, N. Musical experience shapes human brainstem encoding of linguistic pitch patterns. Nat Neurosci 10, 420–422, https://doi.org/10.1038/nn1872 (2007).
Tervaniemi, M., Janhunen, L., Kruck, S., Putkinen, V. & Huotilainen, M. Auditory Profiles of Classical, Jazz, and Rock Musicians: Genre-Specific Sensitivity to Musical Sound Features. Front Psychol 6, 1900, https://doi.org/10.3389/fpsyg.2015.01900 (2015).
Tervaniemi, M., Huotilainen, M. & Brattico, E. Melodic multi-feature paradigm reveals auditory profiles in music-sound encoding. Front Hum Neurosci 8, 496, https://doi.org/10.3389/fnhum.2014.00496 (2014).
Marie, C., Delogu, F., Lampis, G., Belardinelli, M. O. & Besson, M. Influence of Musical Expertise on Segmental and Tonal Processing in Mandarin Chinese. Journal of Cognitive Neuroscience 23, 2701–2715 (2011).
Kraus, N. & Chandrasekaran, B. Music training for the development of auditory skills. Nature Reviews Neuroscience 11, 599–605 (2010).
George, E. M. & Coch, D. Music training and working memory: an ERP study. Neuropsychologia 49, 1083–1094, https://doi.org/10.1016/j.neuropsychologia.2011.02.001 (2011).
Schulze, K. & Koelsch, S. Working memory for speech and music. Neurosciences and Music Iv: Learning and Memory 1252, 229–236 (2012).
Anderson, S. & Kraus, N. Sensory-cognitive interaction in the neural encoding of speech in noise: a review. J Am Acad Audiol 21, 575–585, https://doi.org/10.3766/jaaa.21.9.3 (2010).
Besson, M., Chobert, J. & Marie, C. Transfer of training between music and speech: common processing, attention, and memory. Frontiers in Psychology 2 (2011).
Francois, C., Chobert, J., Besson, M. & Schon, D. Music Training for the Development of Speech Segmentation. Cerebral Cortex 23, 2038–2043 (2013).
Francois, C., Jaillet, F., Takerkart, S. & Schon, D. Faster sound stream segmentation in musicians than in nonmusicians. Plos One 9, e101340, https://doi.org/10.1371/journal.pone.0101340 (2014).
Francois, C. & Schon, D. Musical expertise boosts implicit learning of both musical and linguistic structures. Cereb Cortex 21, 2357–2365, https://doi.org/10.1093/cercor/bhr022 (2011).
Dittinger, E. et al. Profesional music training and novel word learning: from faster semantic encoding to longer-lasting word representations. Journal of Cognitive Neuroscience (2016).
Dittinger, E., Valizadeh, S. A., Jancke, L., Besson, M. & Elmer, S. Increased functional connectivity in the ventral and dorsal streams during retrieval of novel words in professional musicians. Hum Brain Mapp, https://doi.org/10.1002/hbm.23877 (2017).
Dittinger, E., Chobert, J., Ziegler, J. C. & Besson, M. Fast Brain Plasticity during Word Learning in Musically-Trained Children. Frontiers in Human Neuroscience 11, ARTN 233 https://doi.org/10.3389/fnhum.2017.00233 (2017).
Koelsch, S. et al. Music, language and meaning: brain signatures of semantic processing. Nat Neurosci 7, 302–307, https://doi.org/10.1038/nn1197 (2004).
Kutas, M. & Federmeier, K. D. Thirty Years and Counting: Finding Meaning in the N400 Component of the Event-Related Brain Potential (ERP). Annual Review of Psychology, Vol 62 62, 621–647 (2011).
Rodriguez-Fornells, A., Cunillera, T., Mestres-Misse, A. & de Diego-Balaguer, R. Neurophysiological mechanisms involved in language learning in adults. Philos Trans R Soc Lond B Biol Sci 364, 3711–3735, https://doi.org/10.1098/rstb.2009.0130 (2009).
Bornkessel-Schlesewsky, I. & Schlesewsky, M. Reconciling time, space and function: A new dorsal-ventral stream model of sentence comprehension. Brain Lang 125, 60–76 (2013).
Friederici, A. D. The cortical language circuit: from auditory perception to sentence comprehension. Trends in Cognitive Sciences 16, 262–268 (2012).
Hagoort, P. Nodes and networks in the neural architecture for language: Broca’s region and beyond. Current Opinion in Neurobiology 28, 136–141 (2014).
Hickok, G. & Poeppel, D. Opinion - The cortical organization of speech processing. Nature Reviews Neuroscience 8, 393–402 (2007).
Rauschecker, J. P. & Scott, S. K. Maps and streams in the auditory cortex: nonhuman primates illuminate human speech processing. Nature Neuroscience 12, 718–724 (2009).
Friederici, A. D. Pathways to language: fiber tracts in the human brain. Trends in Cognitive Sciences 13, 175–181 (2009).
Albouy, P., Weiss, A., Baillet, S. & Zatorre, R. J. Selective Entrainment of Theta Oscillations in the Dorsal Stream Causally Enhances Auditory Working Memory Performance. Neuron 94, 193–206 e195, https://doi.org/10.1016/j.neuron.2017.03.015 (2017).
Foster, N. E., Halpern, A. R. & Zatorre, R. J. Common parietal activation in musical mental transformations across pitch and time. Neuroimage 75, 27–35, https://doi.org/10.1016/j.neuroimage.2013.02.044 (2013).
Foster, N. E. & Zatorre, R. J. A role for the intraparietal sulcus in transforming musical pitch information. Cereb Cortex 20, 1350–1359, https://doi.org/10.1093/cercor/bhp199 (2010).
Herman, A. B., Houde, J. F., Vinogradov, S. & Nagarajan, S. S. Parsing the phonological loop: activation timing in the dorsal speech stream determines accuracy in speech reproduction. J Neurosci 33, 5439–5453, https://doi.org/10.1523/JNEUROSCI.1472-12.2013 (2013).
Schulze, K., Vargha-Khadem, F. & Mishkin, M. Test of a motor theory of long-term auditory memory. Proceedings of the National Academy of Sciences of the United States of America 109, 7121–7125 (2012).
Baldo, J. V., Klostermann, E. C. & Dronkers, N. F. It’s either a cook or a baker: Patients with conduction aphasia get the gist but lose the trace. Brain Lang 105, 134–140, https://doi.org/10.1016/j.bandl.2007.12.007 (2008).
Buchsbaum, B. R. et al. Conduction aphasia, sensory-motor integration, and phonological short-term memory - An aggregate analysis of lesion and fMRI data. Brain Lang 119, 119–128, https://doi.org/10.1016/j.bandl.2010.12.001 (2011).
Damasio, H. & Damasio, A. R. The anatomical basis of conduction aphasia. Brain 103, 337–350 (1980).
Meyer, L., Cunitz, K., Obleser, J. & Friederici, A. D. Sentence processing and verbal working memory in a white-matter-disconnection patient. Neuropsychologia 61, 190–196, https://doi.org/10.1016/j.neuropsychologia.2014.06.014 (2014).
Sierpowska, J. et al. Words are not enough: nonword repetition as an indicator of arcuate fasciculus integrity during brain tumor resection. J. Neurosurg. 126, 435–445, https://doi.org/10.3171/2016.2.JNS151592 (2017).
Meyer, L., Obleser, J., Anwander, A. & Friederici, A. D. Linking ordering in Broca’s area to storage in left temporo-parietal regions: The case of sentence processing. Neuroimage 62, 1987–1998, https://doi.org/10.1016/j.neuroimage.2012.05.052 (2012).
Mestres-Misse, A., Camara, E., Rodriguez-Fornells, A., Rotte, M. & Munte, T. F. Functional neuroanatomy of meaning acquisition from context. J Cogn Neurosci 20, 2153–2166, https://doi.org/10.1162/jocn.2008.20150 (2008).
Takashima, A., Bakker, I., van Hell, J. G., Janzen, G. & McQueen, J. M. Richness of information about novel words influences how episodic and semantic memory networks interact during lexicalization. Neuroimage 84, 265–278, https://doi.org/10.1016/j.neuroimage.2013.08.023 (2014).
Takashima, A., Bakker, I., van Hell, J. G., Janzen, G. & McQueen, J. M. Interaction between episodic and semantic memory networks in the acquisition and consolidation of novel spoken words. Brain Lang 167, 44–60, https://doi.org/10.1016/j.bandl.2016.05.009 (2017).
Catani, M. et al. Symmetries in human brain language pathways correlate with verbal recall. Proc Natl Acad Sci USA 104, 17163–17168, https://doi.org/10.1073/pnas.0702116104 (2007).
Lopez-Barroso, D. et al. Word learning is mediated by the left arcuate fasciculus. Proceedings of the National Academy of Sciences of the United States of America 110, 13168–13173 (2013).
Catani, M., Howard, R. J., Pajevic, S. & Jones, D. K. Virtual in vivo interactive dissection of white matter fasciculi in the human brain. Neuroimage 17, 77–94 (2002).
Catani, M., Jones, D. K. & ffytche, D. H. Perisylvian language networks of the human brain. Ann Neurol 57, 8–16, https://doi.org/10.1002/ana.20319 (2005).
Liberman, A. M. & Mattingly, I. G. The Motor Theory of Speech-Perception Revised. Cognition 21, 1–36 (1985).
Takashima A, B. I., van Hell J. G., Janzen G, McQueen J. M. Interaction between episodic and semantic memory networks in the acquisition and consolidation of novel spoken words. Brain and Language https://doi.org/10.1016/j.bandl.2016.05.009. [Epub ahead of print] (2016).
Mestres-Misse, A., Camara, E., Rodriguez-Fornells, A., Rotte, M. & Munte, T. F. Functional Neuroanatomy of Meaning Acquisition from Context. Journal of Cognitive Neuroscience 20, 2153–2166, https://doi.org/10.1162/jocn.2008.20150 (2008).
Stanislaw, H. & Todorov, N. Calculation of signal detection theory measures. Behav Res Methods Instrum Comput 31, 137–149 (1999).
Elmer, S., Greber, M., Pushparaj, A., Kuhnis, J. & Jancke, L. Faster native vowel discrimination learning in musicians is mediated by an optimization of mnemonic functions. Neuropsychologia 104, 64–75, https://doi.org/10.1016/j.neuropsychologia.2017.08.001 (2017).
de Diego-Balaguer, R., Fuentemilla, L. & Rodriguez-Fornells, A. Brain Dynamics Sustaining Rapid Rule Extraction from Speech. Journal of Cognitive Neuroscience 23, 3105–3120, https://doi.org/10.1162/jocn.2011.21636 (2011).
Chen, Y. Y. & Caplan, J. B. Rhythmic Activity and Individual Variability in Recognition Memory: Theta Oscillations Correlate with Performance whereas Alpha Oscillations Correlate with ERPs. J Cogn Neurosci 29, 183–202, https://doi.org/10.1162/jocn_a_01033 (2017).
Scholz, S., Schneider, S. L. & Rose, M. Differential effects of ongoing EEG beta and theta power on memory formation. Plos One 12, e0171913, https://doi.org/10.1371/journal.pone.0171913 (2017).
Inostroza, M., Brotons-Mas, J. R., Laurent, F., Cid, E. & de la Prida, L. M. Specific impairment of “what-where-when” episodic-like memory in experimental models of temporal lobe epilepsy. J Neurosci 33, 17749–17762, https://doi.org/10.1523/JNEUROSCI.0957-13.2013 (2013).
Garrido, M. I., Kilner, J. M., Kiebel, S. J. & Friston, K. J. Evoked brain responses are generated by feedback loops. Proc Natl Acad Sci USA 104, 20961–20966, https://doi.org/10.1073/pnas.0706274105 (2007).
Nilakantan, A. S., Bridge, D. J., Gagnon, E. P., VanHaerents, S. A. & Voss, J. L. Stimulation of the Posterior Cortical-Hippocampal Network Enhances Precision of Memory Recollection. Curr Biol 27, 465–470, https://doi.org/10.1016/j.cub.2016.12.042 (2017).
Ward, L. M. Synchronous neural oscillations and cognitive processes. Trends Cogn Sci 7, 553–559 (2003).
Polania, R., Nitsche, M. A., Korman, C., Batsikadze, G. & Paulus, W. The importance of timing in segregated theta phase-coupling for cognitive performance. Curr Biol 22, 1314–1318, https://doi.org/10.1016/j.cub.2012.05.021 (2012).
Giraud, A. L. & Poeppel, D. Cortical oscillations and speech processing: emerging computational principles and operations. Nat Neurosci 15, 511–517, https://doi.org/10.1038/nn.3063 (2012).
Giraud, A. L. et al. Endogenous cortical rhythms determine cerebral specialization for speech perception and production. Neuron 56, 1127–1134, https://doi.org/10.1016/j.neuron.2007.09.038 (2007).
Bastiaansen, M. C. M., van Berkum, J. J. A. & Hagoort, P. Event-related theta power increases in the human EEG during online sentence processing. Neuroscience Letters 323, 13–16, https://doi.org/10.1016/S0304-3940(01)02535-6 (2002).
Meyer, L., Grigutsch, M., Schmuck, N., Gaston, P. & Friederici, A. D. Frontal-posterior theta oscillations reflect memory retrieval during sentence comprehension. Cortex 71, 205–218, https://doi.org/10.1016/j.cortex.2015.06.027 (2015).
Weiss, S. et al. Increased neuronal communication accompanying sentence comprehension. International Journal of Psychophysiology 57, 129–141, https://doi.org/10.1016/j.ijpsycho.2005.03.013 (2005).
Sarnthein, J., Petsche, H., Rappelsberger, P., Shaw, G. L. & von Stein, A. Synchronization between prefrontal and posterior association cortex during human working memory. Proceedings of the National Academy of Sciences of the United States of America 95, 7092–7096, https://doi.org/10.1073/pnas.95.12.7092 (1998).
Deschamps, I., Baum, S. R. & Gracco, V. L. On the role of the supramarginal gyrus in phonological processing and verbal working memory: evidence from rTMS studies. Neuropsychologia 53, 39–46, https://doi.org/10.1016/j.neuropsychologia.2013.10.015 (2014).
Macher, K., Bohringer, A., Villringer, A. & Pleger, B. Cerebellar-parietal connections underpin phonological storage. J Neurosci 34, 5029–5037, https://doi.org/10.1523/JNEUROSCI.0106-14.2014 (2014).
Paulesu, E. et al. Supercalifragilisticexpialidocious: how the brain learns words never heard before. Neuroimage 45, 1368–1377, https://doi.org/10.1016/j.neuroimage.2008.12.043 (2009).
Newman, S. D. & Twieg, D. Differences in auditory processing of words and pseudowords: an fMRI study. Hum Brain Mapp 14, 39–47 (2001).
Golestani, N., Paus, T. & Zatorre, R. J. Anatomical correlates of learning novel speech sounds. Neuron 35, 997–1010 (2002).
Fedorenko, E., Duncan, J. & Kanwisher, N. Language-Selective and Domain-General Regions Lie Side by Side within Broca’s Area. Current Biology 22, 2059–2062 (2012).
Eickhoff, S. B., Heim, S., Zilles, K. & Amunts, K. A systems perspective on the effective connectivity of overt speech production. Philosophical Transactions of the Royal Society A-Mathematical Physical and Engineering Sciences 367, 2399–2421 (2009).
Rilling, J. K. et al. The evolution of the arcuate fasciculus revealed with comparative DTI. Nature Neuroscience 11, 426–428 (2008).
Engel, A. et al. Inter-individual differences in audio-motor learning of piano melodies and white matter fiber tract architecture. Hum Brain Mapp 35, 2483–2497, https://doi.org/10.1002/hbm.22343 (2014).
Jancke, L. The plastic human brain. Restorative Neurology and Neuroscience 27, 521–538 (2009).
Jancke, L. The dynamic audio-motor system in pianists. Ann N Y Acad Sci 1252, 246–252, https://doi.org/10.1111/j.1749-6632.2011.06416.x (2012).
Tian, X., Zarate, J. M. & Poeppel, D. Mental imagery of speech implicates two mechanisms of perceptual reactivation. Cortex 77, 1–12, https://doi.org/10.1016/j.cortex.2016.01.002 (2016).
Klingberg, T., O’Sullivan, B. T. & Roland, P. E. Bilateral activation of fronto-parietal networks by incrementing demand in a working memory task. Cereb Cortex 7, 465–471 (1997).
Berti, S., Munzer, S., Schroger, E. & Pechmann, T. Different interference effects in musicians and a control group. Exp Psychol 53, 111–116, https://doi.org/10.1027/1618-3169.53.2.111 (2006).
Wong, P. C. M., Vuong, L. C. & Liu, K. Personalized learning: From neurogenetics of behaviors to designing optimal language training. Neuropsychologia 98, 192–200, https://doi.org/10.1016/j.neuropsychologia.2016.10.002 (2017).
Holler-Wallscheid, M. S., Thier, P., Pomper, J. K. & Lindner, A. Bilateral recruitment of prefrontal cortex in working memory is associated with task demand but not with age. Proc Natl Acad Sci USA 114, E830–E839, https://doi.org/10.1073/pnas.1601983114 (2017).
Otten, L. J., Henson, R. N. & Rugg, M. D. State-related and item-related neural correlates of successful memory encoding. Nat Neurosci 5, 1339–1344, https://doi.org/10.1038/nn967 (2002).
Rugg, M. D., Otten, L. J. & Henson, R. N. The neural basis of episodic memory: evidence from functional neuroimaging. Philos Trans R Soc Lond B Biol Sci 357, 1097–1110, https://doi.org/10.1098/rstb.2002.1102 (2002).
Owen, A. M., McMillan, K. M., Laird, A. R. & Bullmore, E. N-back working memory paradigm: a meta-analysis of normative functional neuroimaging studies. Hum Brain Mapp 25, 46–59, https://doi.org/10.1002/hbm.20131 (2005).
Rottschy, C. et al. Modelling neural correlates of working memory: a coordinate-based meta-analysis. Neuroimage 60, 830–846, https://doi.org/10.1016/j.neuroimage.2011.11.050 (2012).
Cabeza, R., Dolcos, F., Graham, R. & Nyberg, L. Similarities and differences in the neural correlates of episodic memory retrieval and working memory. Neuroimage 16, 317–330, https://doi.org/10.1006/nimg.2002.1063 (2002).
Rugg, M. D., Johnson, J. D., Park, H. & Uncapher, M. R. Encoding-retrieval overlap in human episodic memory: a functional neuroimaging perspective. Prog Brain Res 169, 339–352, https://doi.org/10.1016/S0079-6123(07)00021-0 (2008).
Price, C. J. The anatomy of language: contributions from functional neuroimaging. J Anat 197(Pt 3), 335–359 (2000).
Thompson, P. M. et al. Genetic influences on brain structure. Nat Neurosci 4, 1253–1258, https://doi.org/10.1038/nn758 (2001).
Sinclair, B. et al. Heritability of the network architecture of intrinsic brain functional connectivity. Neuroimage 121, 243–252, https://doi.org/10.1016/j.neuroimage.2015.07.048 (2015).
D D Balaguer, R., Toro, J. M., Rodriguez-Fornells, A. & Bachoud-Levi, A. C. Different neurophysiological mechanisms underlying word and rule extraction from speech. Plos One 2, e1175, https://doi.org/10.1371/journal.pone.0001175 (2007).
Annett, M. A Classification of Hand Preference by Association Analysis. British Journal of Psychology 61, 303–321 (1970).
Gordon, E. E. (G.I.A. Publications, Inc., Chicago, 1989).
Waldmann, H. C. Kurzformen des HAWIK-IV: Statistische bewertung in verschiedenen anwendungsszenarien. Diagnostica 54, 202–210 (2008).
Wechsler, D. In San Antonio, TX: The Psychological Corporation (WISC-IV) (2003).
Helmstädter, C., Michael, L., & Lux, S. Verbaler Lern- und Merkfähigkeitstest (VLMT). Göttingen: Beltz Test (2001).
Oswald, W. D., & Roth, E. Der Zahlen-Verbindungs-Test (ZVT). Ein sprachfreier Intelligenz-Test zur Messung der “kognitiven Leistungsgeschwindigkeit”. Handanweisung (2nd ed.). Göttingen: Hogrefe (1987).
Kuhnis, J., Elmer, S., Meyer, M. & Jancke, L. Musicianship boosts perceptual learning of pseudoword-chimeras: an electrophysiological approach. Brain Topogr 26, 110–125, https://doi.org/10.1007/s10548-012-0237-y (2013).
Simon, J. R. Reactions toward the source of stimulation. J Exp Psychol 81, 174–176 (1969).
Kerns, J. G. Anterior cingulate and prefrontal cortex activity in an FMRI study of trial-to-trial adjustments on the Simon task. Neuroimage 33, 399–405, https://doi.org/10.1016/j.neuroimage.2006.06.012 (2006).
Jung, T. P. et al. Removing electroencephalographic artifacts by blind source separation. Psychophysiology 37, 163–178 (2000).
Mulert, C. et al. Integration of fMRI and simultaneous EEG: towards a comprehensive understanding of localization and time-course of brain activity in target detection. Neuroimage 22, 83–94, https://doi.org/10.1016/j.neuroimage.2003.10.051 (2004).
Fuchs, M., Kastner, J., Wagner, M., Hawes, S. & Ebersole, J. S. A standardized boundary element method volume conductor model. Clin Neurophysiol 113, 702–712 (2002).
Mazziotta, J. et al. A probabilistic atlas and reference system for the human brain: International Consortium for Brain Mapping (ICBM). Philos Trans R Soc Lond B Biol Sci 356, 1293–1322, https://doi.org/10.1098/rstb.2001.0915 (2001).
Lancaster, J. L. et al. Automated Talairach atlas labels for functional brain mapping. Hum Brain Mapp 10, 120–131 (2000).
Brett, M., Johnsrude, I. S. & Owen, A. M. The problem of functional localization in the human brain. Nat Rev Neurosci 3, 243–249, https://doi.org/10.1038/nrn756 (2002).
Pascual-Marqui, R. D., Esslen, M., Kochi, K. & Lehmann, D. Functional imaging with low-resolution brain electromagnetic tomography (LORETA): a review. Methods Find Exp Clin Pharmacol 24(Suppl C), 91–95 (2002).
Bakker, I., Takashima, A., van Hell, J. G., Janzen, G. & McQueen, J. M. Changes in Theta and Beta Oscillations as Signatures of Novel Word Consolidation. J Cognitive Neurosci 27, 1286–1297, https://doi.org/10.1162/jocn_a_00801 (2015).
Nichols, T. E. & Holmes, A. P. Nonparametric permutation tests for functional neuroimaging: a primer with examples. Hum Brain Mapp 15, 1–25 (2002).
Frei, E. et al. Localization of MDMA-induced brain activity in healthy volunteers using low resolution brain electromagnetic tomography (LORETA). Hum Brain Mapp 14, 152–165, https://doi.org/10.1002/hbm.1049 (2001).
Lehmann, D., Faber, P. L., Gianotti, L. R., Kochi, K. & Pascual-Marqui, R. D. Coherence and phase locking in the scalp EEG and between LORETA model sources, and microstates as putative mechanisms of brain temporo-spatial functional organization. J Physiol Paris 99, 29–36, https://doi.org/10.1016/j.jphysparis.2005.06.005 (2006).
Nolte, G. et al. Identifying true brain interaction from EEG data using the imaginary part of coherency. Clin Neurophysiol 115, 2292–2307, https://doi.org/10.1016/j.clinph.2004.04.029 (2004).
Stam, C. J. & van Straaten, E. C. Go with the flow: use of a directed phase lag index (dPLI) to characterize patterns of phase relations in a large-scale model of brain dynamics. Neuroimage 62, 1415–1428, https://doi.org/10.1016/j.neuroimage.2012.05.050 (2012).
Elmer, S., Rogenmoser, L., Kuhnis, J. & Jancke, L. Bridging the gap between perceptual and cognitive perspectives on absolute pitch. J Neurosci 35, 366–371, https://doi.org/10.1523/JNEUROSCI.3009-14.2015 (2015).
Pascual-Marqui, R. D. et al. Assessing interactions in the brain with exact low-resolution electromagnetic tomography. Philos Trans A Math Phys Eng Sci 369, 3768–3784, https://doi.org/10.1098/rsta.2011.0081 (2011).
Bastos, A. M. & Schoffelen, J. M. A Tutorial Review of Functional Connectivity Analysis Methods and Their Interpretational Pitfalls. Front Syst Neurosci 9, doi:ARTN 17510.3389/fnsys.2015.00175 (2016).
Ben-Soussan, T. D., Glicksohn, J., Goldstein, A., Berkovich-Ohana, A. & Donchin, O. Into the Square and out of the Box: The effects of Quadrato Motor Training on Creativity and Alpha Coherence. Plos One 8, doi:ARTN e5502310.1371/journal.pone.0055023 (2013).
Acknowledgements
This research was supported by the Swiss National Science Foundation (SNF, grant nr. 320030_163149 to Lutz Jäncke). CF was supported by a Spanish MINECO project (PSI2015-69132P) and by the Catalan Government (Generalitat de Catalunya, PERIS2017). We would like to thank Lutz Jäncke for having provided the necessary infrastructure and technology for the study as well as for his financial support. No conflicts of interest are declared.
Author information
Authors and Affiliations
Contributions
S.E. and A.R.F. planned the study, J.A. performed the EEG. measurements, and S.A.V. contributed to the functional connectivity analyses. S.E. evaluated the data and drafted the manuscript together with C.F. and A.R.F. C.F., A.R.F., and S.E. contributed to the interpretation of the data.
Corresponding author
Ethics declarations
Competing Interests
The authors declare no competing interests.
Additional information
Publisher's note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Elmer, S., Albrecht, J., Valizadeh, S.A. et al. Theta Coherence Asymmetry in the Dorsal Stream of Musicians Facilitates Word Learning. Sci Rep 8, 4565 (2018). https://doi.org/10.1038/s41598-018-22942-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-018-22942-1
This article is cited by
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
