
Abstract
The aim of this study is to develop a prediction model for ESRD in patients with type 2 diabetes. A retrospective cohort study was conducted, consisting of 24,104 Chinese patients with type 2 diabetes. We adopted the procedures proposed by the Framingham Heart Study to develop a prediction model for ESRD. Participants were randomly assigned to the derivation and validation sets at a 2:1 ratio. The Cox proportional hazard regression model was used for model development. A total of 813 and 402 subjects (5.06% and 5.00%, respectively) developed ESRD in the derivation and validation sets over a mean follow-up period of 8.3 years. The risk-scoring systems included age, gender, age of diabetes onset, combined statuses of blood pressure and anti-hypertensive medication use, creatinine, variation in HbA1c, variation in systolic blood pressure, diabetes retinopathy, albuminuria, anti-diabetes medications, and combined statuses of hyperlipidemia and anti-hyperlipidemia medication use. The area under curves of 3-year, 5-year, and 8-year ESRD risks were 0.90, 0.86, and 0.81 in the derivation set, respectively. This risk score model can be used as screening for early prevention. The risk prediction for 3-year, 5-year, and 8-year period demonstrated good predictive accuracy and discriminatory ability.
Similar content being viewed by others


Introduction
Based on WHO report, the standardized mortality rate of diabetes increased from 23.6/105 in 1985 to 39.4/105 in 2006. This increase made diabetes the most rapidly increasing ailment compared with other chronic diseases. Diabetes and its complications are the leading causes of premature mortality and impose a heavy burden on the individual and societal levels1,2,3. Diabetes is also a leading cause of end-stage renal disease (ESRD) in many developed and developing countries4; about 44.6%, 44.5%, and 43.7% ESRD incidence in patients in Japan, Taiwan, and the United States, respectively, are caused by diabetes5. Given the alarming rise in the number of diabetes cases worldwide6, the ESRD population is increasing. In Taiwan, the prevalence and incidence of ESRD is increasing rapidly7. The total number of regular dialysis patients increased by 26.5% from 52 081 in 2006, to 65 883 in 20108. The rising number of ESRD patients who require dialysis therapy or transplantation is a major public health problem; such problem places a substantial burden on affected individuals and health care system5.
Predicting ESRD risks in patients with type 2 diabetes can help guide individualized interventions for secondary prevention and future health care needs. The prediction models or point systems quantify the impact of measurable and modifiable risk factors. The advantage of these point systems incorporated complex statistical models that allowed health professionals and practitioners to use in clinic settings. Patients can easily estimate their own disease risk and monitor their risk over time. These point systems can also be used as a tool for clinicians to guide their decision making regarding treatment and for patients to promote motivation on modifying their behavior. Previous studies established prediction models for various kidney diseases, including CKD or ESRD in general population9, in patients with CKD10,11,12, and in patients with type 2 diabetes and CKD13,14,15. Among those studies targeting at patients with type 2 diabetes, two of them specified their population as those with diabetic nephropathy. One study targeting participants with type 2 diabetes without diabetic nephropathy focused on the composite outcome of major kidney-related event, including doubling of serum creatinine to 2.26 mg/dl, renal replacement therapy, or renal death15. Composite measure has the advantage of being more powerful due to low incidence rates of events, but it has the disadvantage of being less specific. Because the prevention strategy for kidney disease, ESRD, or renal death was different, there is a need to develop prediction model for ESRD. No prior model has been developed for patients with type 2 diabetes on ESRD outcome or in the Chinese population. In addition, prior studies reported that visit-to-visit variation in plasma glucose and blood pressure were associated with ESRD and these two factors haven’t been considered in prediction models of ESRD16, 17. This deficiency results in a need to construct a prediction model of ESRD risk in Chinese patients with type 2 diabetes. With a large cohort of 24,104 participants enrolled from clinical centers in the entire country, the Taiwan Diabetes Study (TDS) cohort represents a significant opportunity to examine whether the characteristics of patients at baseline were associated with ESRD incidence. This prediction model considered risk factors that are generally available in clinical practice and are precisely measured to ensure that this score system is acceptable in clinical practice. In the present study, we develop a point-based risk prediction model for incident ESRD using TDS data.
Results
Taiwan Diabetes study included 24,104 type 2 diabetic patients aged 30–84 years old. These patients were free of ESRD at baseline and had been followed-up for 8.3 years. We randomly assigned 16,070 patients into the derivation set and 8,034 patients into the validation set. A total of 813 (5.06%) and 402 (5.00%) ESRD incident cases were found in the derivation and validation sets, respectively. Table 1 shows the baseline characteristics of participants according to derivation and validation sets. The mean age of participants in the derivation and validation sets was both about 61 years; 47% of the samples were male. All baseline socio-demographic, clinical, and laboratory variables had standardized effect size values less than 0.1, demonstrating that variables in the two sets were distributed similarly.
In crude Cox’s proportional hazard analysis, significant factors were observed for age groups of 60–64 years (4.05, 1.01–16.29), 75–79 (4.61, 1.14–18.66) years, and 80–84 years (4.50, 1.07–18.93); age of diabetes onset ≥45 years (0.66, 0.58–0.75), creatinine levels of 2.0–4.0 mg/dL (24.54, 21.25–28.34) and ≥4.0 mg/dL (19.01, 13.85–26.09), the second tertile of HbA1c-CV (1.45, 1.26–1.68), the third tertile of HbA1c-CV (1.70, 1.47–1.96), the third tertile of SBP-CV (1.48, 1.29–1.69), diabetes retinopathy (4.55, 3.51–5.88), albuminuria (1.91, 1.66–2.20), anti-diabetes medication of insulin monotherapy (5.16, 3.63–7.35) and insulin plus OAD (3.02, 2.13–4.28), combined statuses for blood pressure and anti-hypertensive medication: no anti-hypertensive medication and SBP 140–159 mmHg or DBP 90–99 mmHg (1.76, 1.30, 2.38), no anti-hypertensive medication and SBP ≥160 mmHg or DBP ≥ 100 mmHg (2.39, 1.57–3.65), anti-hypertensive medication use and SBP < 130 mmHg and DBP < 85 mmHg (3.39, 2.59–4.43), anti-hypertensive medication use and SBP 130–139 mmHg or DBP 85–89 mmHg (3.91, 3.03–5.04), anti-hypertensive medication use and SBP 140–159 mmHg or DBP 90–99 mmHg (4.77, 3.76, 6.06), anti-hypertensive medication use and SBP ≥160 mmHg or DBP ≥ 100 mmHg (6.86, 5.34, 8.83), and combined statuses of hyperlipidemia and anti-hyperlipidemia medication: no hyperlipidemia and total cholesterol 200–239 mg/dl (1.41, 1.16–1.70), no hyperlipidemia and total cholesterol ≥240 mg/dl (2.40, 1.85–3.10), anti-hyperlipidemia medication use and total cholesterol <200 mg/dl (1.93, 1.63–2.29), anti-hyperlipidemia medication use and total cholesterol 200–239 mg/dl (1.91, 1.60–2.28), and anti-hyperlipidemia medication use and total cholesterol ≥240 mg/dl (3.62, 3.05–4.29) (all p-value < 0.05) (Table 2).
Table 3 shows the adjusted regression coefficients, and means or proportions of significant risk factors that remained in the final multivariate Cox’s proportional hazards model. ESRD risk score of each factor was defined as 5 times the regression coefficient of age. The total risk score ranged from −16 to 97. The 3-, 5-, and 8-year risks of ESRD were estimated for total scores followed by the algorithm developed in the Framingham heart study (Table 4).
The areas under receiver operating curves (AUCs) of the final prediction model for 3-, 5-, and 8-year ESRD risks were 0.91, 0.86, and 0.81, respectively in the derivation set and were 0.92, 0.87, and 0.80, respectively in the validation set (Fig. 1). Our prediction model demonstrated excellent discrimination ability (i.e., AUCs ≥ 0.80) both in the derivation and validation sets.

Receiver-operating characteristic curve (ROC) for (a) 3-year (b) 5-year (c) 8-year ESRD risk in derivation set and for (d) 3-year (e) 5-year (f) 8-year ESRD risk in validation set.
Figure 2 shows the calibration plots, showing the actual and predicted ESRD events according to deciles of 3-, 5-, and 8-year risks in the validation set. The ESRD events increased steadily from the sixth to 9th deciles and then increased sharply at 10th decile. The results of Hosmer–Lemeshow x 2 tests for 3-, 5-, and 8-year risk revealed no significant differences between the observed and predicted ESRD events in the validation set (all p > 0.05). The internal validation of the present model performance was assessed based on 1000 samples from bootstrap resampling. The optimism corrected calibration intercept was 0.009 with a mean absolute error of 0.00008 and the corresponding slope was 0.92 with a mean absolute error of 0.00191. These statistics indicate pretty good calibration for the present model and there is no need for shrinkage of regression coefficients in the prediction model.

Predicted versus observed ESRD numbers according to deciles of (a) 3-year (b) 5-year and (c) 8-year risk in the validation set.
We use multiple imputation method to handle missing data in HbA1c-CV and SBP-CV based on information on age, age of diabetes onset, and duration of type 2 diabetes in the sensitivity analysis. A total of 52,528 patients were included for this sensitivity analysis. The adjusted regression coefficients estimated from dataset with multiple imputation were similar to those from dataset with complete dataset (Supplementary Table 2). We used our risk score to predict ESRD risk for this imputed dataset. We found that the AUC values were 0.90 (95% CI: 0.88−0.91), 0.84 (0.83–0.85), and 0.79 (0.78–0.80) for 3-, 5-, and 8-year periods, respectively. These results were similar to those in our original risk model. Our risk prediction model was robust and not sensitive to missing data.
Discussion
Our study established an ESRD risk prediction model in a nationwide cohort of patients with type 2 diabetes. We identified independent factors, including age, age of diabetes onset, combined statuses of blood pressure and anti-hypertensive medication, creatinine, HbA1c-CV, SBP-CV, diabetes retinopathy, albuminuria, anti-diabetes medication, and combined statuses of hyperlipidemia and antihyperlipidemia medications. The dominance of creatinine, diabetic retinopathy, combined statuses of blood pressure and antihypertensive medication, combined statuses of hyperlipidemia and anti-hyperlipidemia medication, and age in predicting risk is evident. The subsequent factors in terms of dominance were age at diabetes onset, albuminuria, and the clinical management of diabetes (such as HbA1c-CV) and blood pressure (such as SBP-CV). These predictors reflect both the intensity and duration of pathology associated with diabetes and its vascular complications. Utilizing a nationwide cohort from all clinical settings and backgrounds enabled us to confirm the importance of eGFR, albuminuria, other glucose and blood pressure variation indicator and complications in predicting the risk of ESRD events.
Creatinine is a clinical measurement of renal function and albuminuria is a measure of kidney damage. They are also major factors in our prediction model. Several studies have reported that serum albumin, serum creatinine, and eGFR are strongly associated with ESRD10,11,12,13,14, 18,19,20,21,22,23,24,25,26,27,28. Most of the prediction models for ESRD included these important factors; these factors were considered essential in predicting ESRD10,11,12,13,14, 24, 28. In addition to the assessment of markers of renal function, our model examined the contribution of socio-demographic factors, laboratory variables, diabetes-related factors, and medication use to increase prediction ability.
HbA1c and BP measurements were performed routinely for diabetes care. HbA1c reflects the average of blood glucose levels, but not glucose fluctuations. Visit-to-visit variation in HbA1c measured by HbA1c-CV could provide long-term fluctuation of blood glucose. Monitoring HbA1c during follow-up visits facilitated the availability of this glucose variation measure. Prior studies demonstrated that glucose variation is an independent predictor of ESRD16, 29. High BP may increase pressure on the kidney, which may cause kidney damage. Existing literature reports that poor blood pressure control is associated with increased ESRD risk30, 31. Similar results are observed in our study. We found that variation in HbA1c and SBP, and baseline BP are strong predictors of ESRD risk. Both variation in HbA1c and SBP were the novel predictors that were first considered in the risk score prediction model.
Most studies that developed a prediction model for renal diseases examined general population9, 18, 32 or individuals with CKD10,11,12, 14, 18, 22, 23, 26, 28, 31,32,33,34. Only three prediction models were developed for patients with diabetes. The ADVANCE study enrolled 11,140 type 2 diabetes patients aged 55 years or older in 20 counties for 5 years. This study predicted two kidney-related outcomes, namely, doubling of serum creatinine to >= 2.26 mg/dL, renal replacement therapy, or renal death and new-onset albuminuria15. The TREAT study was a prospective cohort study nested within a randomized clinical trial to establish ESRD risk and composite of death or ESRD risk models using serum levels of the cardiac biomarkers TnT and NT-pro-BNP in 4038 patients with type 2 diabetes, anemia, and CKD14. The RENAAL study was also a prospective cohort study nested within a multinational randomized control trial to develop ESRD risk scores in 1,513 patients with type 2 diabetes and nephropathy13. The former two prediction models demonstrated good discrimination ability (C statistic of 0.84–0.85)14, 15, whereas the RENAAL study did not report statistics for discriminatory ability. The predictors identified in these three studies, such as age, creatinine, blood pressure, albuminuria, diabetic retinopathy, and insulin use, were similar to those in our model. In addition to these factors, our prediction model also considers HbA1c variation, one of key indicator for diabetes care. Besides blood pressure level, our prediction model integrates information of anti-hypertensive medication and variation in SBP. Our prediction model showed excellent discrimination ability (AUCs of 0.90). The frequency of 3-, 5- and 8-year observed and predicted events were similar in the derivation and validation sets and in the Hosmer–Lemeshow x 2 test. Our prediction models fit the data with good prediction ability.
Risk prediction models can provide individual estimates of risks to specific diseases and serve as guidance for the clinical management of high risk patients. The use of the risk scores for risk stratification can be helpful to clinicians or health policy providers to provide interventions such as diets to modify behaviors to reduce ESRD risk and health cost. It has been reported that dietary intervention improved renal function measured by eGFR in moderately obese persons with moderate impaired renal function35. Several disease risk models have been developed and validated in Taiwan; these models are targeted for diseases including stroke in general population36, type 2 diabetes37, cirrhosis and hepatocellular carcinoma38,39,40, gastric cancer41, and periodontal disease42. There was no risk prediction model being established to determine ESRD in patients with type 2 diabetes in Taiwan. The present study developed a risk score to predict the 3-, 5-, and 8-year ESRD risk in patients with type 2 diabetes in Taiwan.
Strengths and limitations
Our study has the advantages of a relatively large group of patients with type 2 diabetes and a long-term follow-up period of 8.3 years. Our study took into account a wide range of potential risk factors. Baseline macro- and microvascular diseases were evaluated and chosen in our prediction model. Medical management for the control of diabetes, hypertension, and hyperlipidemia were also considered in our model. Baseline renal function, albuminuria, and visit-to-visit variation in HbA1c and SBP play principal roles in our prediction model. The present study showed excellent discrimination ability (AUCs of 0.90) for ESRD risk score in Chinese patients with type 2 diabetes.
Our research has five limitations. First, we obtained data on renal function, HbA1c-CV, SBP-CV, medication data, and risk factors from 2001 to 2003, but we did not had data after 2003. Exposure status may have changed during the follow-up period. In addition, the ESRD risk score was not able to predict ESRD risk longer than 8 years because of unavailability of data for ESRD. Second, the NDCMP database did not contain any physical activity, diet, genetic risks, and cardiac biomarkers that may be associated with ESRD risk. Third, although these patients were prospectively followed up by care managers, we had no control over the nature and the quality of the measurements that were made because the study design was retrospective. In addition, the diagnosis of comorbidity is based on ICD codes, which were dependent on the diagnostic accuracy of our database. The accuracy of diagnoses in the database had been improved by the routine check on samples of medical charts conducted by the bureau of NHI in Taiwan43. The punishment on every false diagnostic report was severe. Further, to ensure accurate diagnosis of comorbidity, we included only those cases with at least three outpatient visits or at least one hospitalization. Therefore, the prevalence of comorbidity could be somewhat underestimated. This kind of underestimation might be random. Because there is no evidence indicates that undiagnosed comorbidity is associated with ESRD. Thus, this error results in the effect may be toward the null, a lesser threat to validity. Fourth, our study had NDCMP participants as study subjects, which may result in selection bias. In order to assess the possibility of selection bias, we assessed age and gender distributions between NDCMP participants and population with type 2 diabetes in Taiwan. We found similar distributions and non-differential distributions in age and sex demonstrated this kind of selection error might be random, resulting in the effect toward the null, a lesser threat to results’ validity. Last, the primary outcome measure, ESRD, was ascertained by ICD-9-CM code in catastrophic illness certification from the Registry for Catastrophic Illness database of NHI program. Because each individual registered in the catastrophic illnesses database is exempted from any co-payment for treatment, the process for evaluating applicants’ eligibility for this registry is strict and comprehensive. For the case of ESRD, the catastrophic illness certification was issued by a nephrologist and confirmed by another nephrologist. Under this condition, the possibility of ESRD cases identified in this study being true positive are high and there is a likelihood of underestimation of ESRD incidence. If a true association exists between each factor and ESRD incidence, then this type of underestimation would result in reduction in the power of the study for detecting such an association. Even though the power of the present study may be lessened, the prediction model has very good predictive and discriminatory ability.
In conclusion, our study developed 3-, 5-, and 8-year ESRD risk scores with good prediction accuracy and discriminatory ability. Our study need additional sample for further external validation. Our results demonstrate the risk prediction model is a useful screening tool for preventing ESRD in Chinese patients with type 2 diabetes. This tool can guide clinicians in planning intervention and providing information for policy makers to set up public health strategies to prevent ESRD and reduce healthcare costs.
Methods
Data source
The National Diabetes Care Management Program (NDCMP), which was established by National Health Insurance (NHI) program in 2001, enrolled patients with type 1 and type 2 diabetes. NDCMP emphasized coordinated physician-led multidisciplinary team care. It enhanced high quality health care through increased monitor frequency, self-care education and annual diabetes-specific physical examinations and laboratory tests by provision of additional financial incentives. NDCMP required health professionals in fields of endocrinology, nephrology, internal medicine, cardiology, family medicine, and others to have clinical education and training programs to become certificated and eligible to be care providers of NDCMP, who voluntarily enroll patients into this program. Standardization of clinical practice, including care and treatment, assessment and diagnosis of diabetic complications were enhanced by these clinical continuing education and training programs. A retrospective cohort study was conducted in patients with type 2 diabetes who enrolled in the NDCMP from 2001–2004. Date of entry was defined as the index date. We used the NDCMP and National Health Insurance Research Database (NHIRD) to construct a cohort of patients with type 2 diabetes. We combined the datasets of NDCMP and NHIRD, including the details of ambulatory care orders of NHIRD from 2002–2004. Such approach enabled us to acquire information on baseline characteristics, including socio-demographic factors, duration of type 2 diabetes, age of onset, diabetes-related factor and biomarkers, comorbidity, types of anti-diabetes medications, hypertension medications, cardiovascular medications, and hyperlipidemia medications. We then used inpatient and outpatient databases of Taiwan NHIRD from 2001 to 2011 to obtain subsequent ESRD events 1 year after the index date to 2011. Each patient was followed up from the date of entry until 31 December 2011. Patients were also monitored for withdrawal from NHI program, death, or development of ESRD. We used baseline characteristics to build a point-based prediction model for ESRD risk in patients with type 2 diabetes.
Study subjects
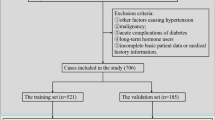
A total of 63,084 enrolled diabetic patients were diagnosed with type 2 diabetes based on the criteria of American Diabetes Association in the NDCMP from 2002 to 2004. We included patients who had at least 1 year of follow-up for calculation of visit-to-visit variation in glycated hemoglobin (HbA1c) and blood pressure, and without ESRD at baseline or missing information regarding baseline characteristics of comorbidities and laboratory blood test results. Figure 3 shows the flowchart of the recruitment procedure in the study. Baseline factors were com_pared between patients included and those excluded using standardized mean differences. We observed most of standardized mean differences were less than 0.1 standard deviations (SD), indicating a negligible difference in proportions or means between included and excluded patients. Although the standardized mean differences of fasting plasma glucose, eGFR, and variation in HbA1c were greater than 0.1 (0.11, 0.11, and 0.11, respectively), the mean values between excluded and included patients were acceptable (179.15 ± 11.471.6 vs. 171.67 ± 64.83 for fasting plasma glucose; 75.86 ± 23.12 vs. 73.38 ± 21.78 for eGFR; and 18.14 ± 16.88 vs. 16.47 ± 14.64 for variation in HbA1c). A total of 24,104 participants were randomly assigned to a derivation set (n = 16, 070) and a validation set (n = 8,034) at a 2:1 ratio. This study was approved by the Human Research Committee of China Medical University Hospital and all methods were performed in accordance with the relevant guidelines and regulations. Informed consent of the study participants was not required because the dataset used in this study consists of de-identified secondary data released for research purposes.

Flowchart for recruitment procedures of the predictive model for ESRD.
Variables
Independent variables included sociodemographic factors, lifestyle behaviors such as smoking and alcohol drinking, diabetes-related factors and biomarkers, comorbidity, and medication use. Three types of personal information (sociodemographic factors, lifestyle behaviors, and diabetes related factors and biomarkers) were obtained at baseline from NDCMP database by case managers who did not know the objectives of the present study objective. The coefficient of variation (CV) for HbA1c and SBP measurements from outpatient visits within the first year of index date for each patient were calculated for those with more than two HbA1c and SBP measurements in the first year. To adjust for the possibility that the number of visits might affect variation, the CV of HbA1c and SBP was divided by square root of the ratio of total visits divided by total visits minus 1. Comorbidity and medication use of individual patients were retrieved from NHIRD database for 1-year period after index date. Comorbidity was determined by at least three service claims for outpatient care, or one service claim for inpatient care. The comorbidities of hypertension (ICD-9-CM codes 404–405), stroke (ICD-9-CM codes 431–438), cardiovascular disease (ICD-9 code 410 to 413, 414.01 to 414.05, 414.8 and 414.9), peripheral neuropathy (ICD-9-CM codes 356), diabetes retinopathy (ICD-9-CM codes 362.0), hypoglycemia (ICD-9-CM codes 250.3, 250.8, 251.0, 251.1, 251.2, 270.3, 775.0, 775.6, and 962.3), chronic kidney disease (ICD-9 codes 585), ketoacidosis (ICD-9-CM codes 250.1), postural hypotension (ICD-9-CM codes 458), arterial embolism and thrombosis (ICD-9-CM codes 444), hyperlipidemia (ICD-9-CM codes 272), and albuminuria (ICD-9-CM code 719.0 or urinary albumin-to-creatinine ratio ≥30 mg g−1 creatinine) from NDCMP were identified. History of medication included anti-diabetes medications (no medication, oral anti-diabetes drug (OAD), insulin monotherapy, and insulin plus OAD), hypertension medications (ACE inhibitors, ARBs, β-blockers, calcium channel blockers, and diuretics), cardiovascular medication (antiarrhythmic, anticoagulants, antiplatelet, digoxin, and nitrates) and hyperlipidemia medications (statins and fibrates).
The primary outcome was ESRD incidence, which was ascertained from catastrophic illness certification (ICD-9-CM code 585 with V45.1) database. In Taiwan, the diagnosis of ESRD is based on tests and exams including a discussion of health history, physical exam, blood and urine tests, and imaging test for assessment of kidney’s structure and size to look for abnormalities. The classification of chronic kidney disease adopts the National Kidney Foundation’s (NKF) Kidney Disease Outcomes Quality Initiative (KDOQI) staging criteria according to estimated glomerular filtration rate (eGFR) and the presence of kidney damage44, 45. The Modified Diet in Renal Disease (MDRD) formula is used as the equation for estimating GFR44. An individual is defined as ESRD case if his/her level of eGFR is less than 15 mL/min/1.73 m2, accompanying by signs and symptoms of uremia, or he/she needs for initiation of kidney replacement therapy (dialysis or transplantation) for treatment for complications of decreased GFR. We identified individuals who experienced ESRD from 1 year after their enrollment in NDCMP to 31 December 2011. This approach enabled the elimination of potential inverse causality. To enable patients with ESRD to obtain certificates from NHI and to be registered in the catastrophic illness certification database, they had to be diagnosed by at least two nephrologists who will assert their ESRD status. Given this requirement, patients who have been diagnosed with ESRD were less likely to be false positives. In addition, the validity of administrative claim data was assessed by the expert reviews performed by NHI Bureau on random samples of every 50 to 100 outpatient and inpatient claims in each hospital and clinic. Because the outcome ascertainment had been done in clinical setting, health professionals assessing the outcome status were not aware of the objective of the study, i.e., outcome assessment being blind.
Statistical analysis
Proportions were presented for categorical variables. Means and standard deviations (SDs) were presented for continuous variables. The effect sizes were calculated to describe baseline characteristics of derivation and validation sets. The hazards ratios of predictor variables were estimated using Cox’s proportional hazards models to develop a prediction model of ESRD in the derivation set and to assess the model’s predictive accuracy in the validation set. We have four steps to select independent variables that result in a “best” model46. First, we conducted a careful univariable analysis of each variable. Second, we selected variables with univariable test of a p-value < 0.2547, 48 as a candidate for our multivariable model. Third, we constructed a multivariable model with candidate variables without collinearity. In addition, only variables with p-value < 0.05 were retained. Lastly, after refining a main effects model, we checked assumption of Cox’s proportional hazard model for all variables in our multivariate model. We verified the proportional hazards assumption by the graph of the log (−log(survival)) versus the log of the survival time graph and by comparing the regression coefficients from models censored at 3, 5, and 8 years.
The steps for predictive model development were based on Framingham Heart study in the determination of the ESRD risk score49. The seven steps were as follows: (1) estimating the parameters of the multivariable Cox’s proportional hazards model with backward elimination approach for model building strategy; (2) grouping the risk factors into categories and determine their reference values W ij ; (3) assigning a score for each category to determine the referent risk factor profile; a base category for each risk factor has a 0 score; (4) determining the distance from the base category to each category in regression units; (5) setting the constant B, which is the number of regression units that reflect 1 point in the final points system; (6) calculating the number of points for each category of each risk factor, where Pointij = (W ij − W iREF )/B; and (7) determining the prediction risks for all possible total scores. The risk of ESRD was calculated by the following equation: \(\hat{p}=1-{S}_{0}{(t)}^{\exp ({\rm{\Sigma }}{\beta }_{i}\times {X}_{i}-{\beta }_{i}\times {\bar{X}}_{i})}\), where \(\hat{p}\). is the baseline disease-free probability, β i is the regression coefficient for X i , and the \({\bar{X}}_{i}\) is the mean level of X i . The calculation of constant B depends on age considered in multivariate model. If we consider eGFR as a risk factor in the prediction model, it will result in collinearity issue due to overlapped information of age and eGFR. Thus, serum creatinine is considered in our study instead of eGFR. There were six continuous variables being categorized in step 2. Age was classified into categories by 5 years for an interval, the same as Framingham study; variations in HbA1c and systolic blood pressure were based on their tertiles; total cholesterol was based on NCEP ATP III criteria; systolic and diastolic blood pressure were based on classification of blood pressure for WHO/ISH reports50; serum creatinine was according to proposed classification/staging system for acute kidney injury based on modification of RIFLE criteria51. The receiver operating characteristic (ROC) curve analysis was applied to assess the predictive accuracy, and area under curve (AUC) was used to assess the discriminatory ability of the predictive model. Goodness-of-fit was performed by comparing the observed and predicted events of ESRD based on risk groups of deciles using the Hosmer–Lemeshow x 2 test. Internal validation was carried out to correct the potential for overfitting or “optimism” by using 1000 times bootstrap resampling52. Model calibration was conducted to evaluate the agreement between model-predicted probabilities and observed probabilities. We used calibration-in-large approach to calculate the intercept for evaluation of the extent whether predictions are systematically too low or too high. When the value of intercept is close to zero, it indicates that there is no systematic deviation of estimation of predicted probabilities. In addition, we calculate the calibration slope, an estimate of extremeness of predicted probabilities to test whether its value deviates from the ideal of 1.0. If the value of slope is close to one, it would reflect there is no overfitting of a model, i.e., there is no condition that the probability of an ESRD event tends to be underestimated in low risk patients and overestimated in high risk patients. Furthermore, the mean absolute error in calibration for slope and intercept were reported for assessing calibration, with error referring to the difference between the observed values and the bias-corrected calibrated values. We used a multiple imputation method to impute missing data for sensitivity analysis. A total of 28,424 subjects were imputed for missing data of variation in HbA1c and systolic blood pressure because of too short duration to calculate these two measurements. The method we used is multiple imputation method with a fully conditional specification (FCS) method, assuming the existence of a joint distribution for baseline variables of age, age of diabetes onset, duration of type 2 diabetes, and variation in HbA1c and systolic blood pressure, and regression analysis as imputation method. We performed statistical analysis using SAS version 9.4 (SAS Institute Inc., Cary, NC). Two-tailed p < 0.05 denotes statistical significance.
References
IDF. IDF diabetes atlas - 7th edition, http://www.diabetesatlas.org/ (2015).
CDC. 2014 National Diabetes Statistics Report, https://www.cdc.gov/diabetes/data/statistics/2014statisticsreport.html (2014).
WHO. Diabetes Programme http://www.who.int/diabetes/en/ (2015).
USRDS. USRDS 2013 Annual Data Report: Atlas of chronic kidney disease and end-stage renal disease in the United States, https://www.usrds.org/atlas13.aspx (2013).
Collins, A. J. et al. 'United States Renal Data System 2011 Annual Data Report: Atlas of chronic kidney disease & end-stage renal disease in the United States. American journal of kidney diseases: the official journal of the National Kidney Foundation 59, A7, e1–420, doi:10.1053/j.ajkd.2011.11.015 (2012).
The global dominance of diabetes. Lancet (London, England) 382, 1680, doi:10.1016/s0140-6736(13)62390-9 (2013).
Yang, W. C. & Hwang, S. J. Incidence, prevalence and mortality trends of dialysis end-stage renal disease in Taiwan from 1990 to 2001: the impact of national health insurance. Nephrology, dialysis, transplantation: official publication of the European Dialysis and Transplant Association - European Renal Association 23, 3977–3982, doi:10.1093/ndt/gfn406 (2008).
NHI. The Report of National Health Insurance, http://www.nhi.gov.tw/webdata/webdata.aspx?menu=17&menu_id=661&WD_ID=685&webdata_id=3627 (2011).
Hippisley-Cox, J. & Coupland, C. Predicting the risk of chronic Kidney Disease in men and women in England and Wales: prospective derivation and external validation of the QKidney Scores. BMC family practice 11, 49, doi:10.1186/1471-2296-11-49 (2010).
Johnson, E. S., Thorp, M. L., Platt, R. W. & Smith, D. H. Predicting the risk of dialysis and transplant among patients with CKD: a retrospective cohort study. American journal of kidney diseases: the official journal of the National Kidney Foundation 52, 653–660, doi:10.1053/j.ajkd.2008.04.026 (2008).
Landray, M. J. et al. Prediction of ESRD and death among people with CKD: the Chronic Renal Impairment in Birmingham (CRIB) prospective cohort study. American journal of kidney diseases: the official journal of the National Kidney Foundation 56, 1082–1094, doi:10.1053/j.ajkd.2010.07.016 (2010).
Tangri, N. et al. A predictive model for progression of chronic kidney disease to kidney failure. Jama 305, 1553–1559, doi:10.1001/jama.2011.451 (2011).
Keane, W. F. et al. Risk scores for predicting outcomes in patients with type 2 diabetes and nephropathy: the RENAAL study. Clinical journal of the American Society of Nephrology: CJASN 1, 761–767, doi:10.2215/cjn.01381005 (2006).
Desai, A. S. et al. Association between cardiac biomarkers and the development of ESRD in patients with type 2 diabetes mellitus, anemia, and CKD. American journal of kidney diseases: the official journal of the National Kidney Foundation 58, 717–728, doi:10.1053/j.ajkd.2011.05.020 (2011).
Jardine, M. J. et al. Prediction of kidney-related outcomes in patients with type 2 diabetes. American journal of kidney diseases: the official journal of the National Kidney Foundation 60, 770–778, doi:10.1053/j.ajkd.2012.04.025 (2012).
Yang, Y. F. et al. Visit-to-Visit Glucose Variability Predicts the Development of End-Stage Renal Disease in Type 2 Diabetes: 10-Year Follow-Up of Taiwan Diabetes Study. Medicine 94, e1804, doi:10.1097/md.0000000000001804 (2015).
Chang, T. I., Tabada, G. H., Yang, J., Tan, T. C. & Go, A. S. Visit-to-visit variability of blood pressure and death, end-stage renal disease, and cardiovascular events in patients with chronic kidney disease. Journal of hypertension 34, 244–252, doi:10.1097/hjh.0000000000000779 (2016).
Echouffo-Tcheugui, J. B. & Kengne, A. P. Risk models to predict chronic kidney disease and its progression: a systematic review. PLoS medicine 9, e1001344, doi:10.1371/journal.pmed.1001344 (2012).
Van Pottelbergh, G., Bartholomeeusen, S., Buntinx, F. & Degryse, J. The evolution of renal function and the incidence of end-stage renal disease in patients aged >/=50 years. Nephrology, dialysis, transplantation: official publication of the European Dialysis and Transplant Association - European Renal Association 27, 2297–2303, doi:10.1093/ndt/gfr659 (2012).
Astor, B. C. et al. Lower estimated glomerular filtration rate and higher albuminuria are associated with mortality and end-stage renal disease. A collaborative meta-analysis of kidney disease population cohorts. Kidney international 79, 1331–1340, doi:10.1038/ki.2010.550 (2011).
Gansevoort, R. T. et al. Lower estimated GFR and higher albuminuria are associated with adverse kidney outcomes. A collaborative meta-analysis of general and high-risk population cohorts. Kidney international 80, 93–104, doi:10.1038/ki.2010.531 (2011).
Cerqueira, D. C. et al. A predictive model of progression of CKD to ESRD in a predialysis pediatric interdisciplinary program. Clinical journal of the American Society of Nephrology: CJASN 9, 728–735, doi:10.2215/cjn.06630613 (2014).
Drawz, P. E., Goswami, P., Azem, R., Babineau, D. C. & Rahman, M. A simple tool to predict end-stage renal disease within 1 year in elderly adults with advanced chronic kidney disease. Journal of the American Geriatrics Society 61, 762–768, doi:10.1111/jgs.12223 (2013).
Goto, M. et al. A scoring system to predict renal outcome in IgA nephropathy: a nationwide 10-year prospective cohort study. Nephrology, dialysis, transplantation: official publication of the European Dialysis and Transplant Association - European Renal Association 24, 3068–3074, doi:10.1093/ndt/gfp273 (2009).
Wakai, K. et al. A scoring system to predict renal outcome in IgA nephropathy: from a nationwide prospective study. Nephrology, dialysis, transplantation: official publication of the European Dialysis and Transplant Association - European Renal Association 21, 2800–2808, doi:10.1093/ndt/gfl342 (2006).
Bansal, N. et al. Development and validation of a model to predict 5-year risk of death without ESRD among older adults with CKD. Clinical journal of the American Society of Nephrology: CJASN 10, 363–371, doi:10.2215/cjn.04650514 (2015).
Keane, W. F. et al. The risk of developing end-stage renal disease in patients with type 2 diabetes and nephropathy: the RENAAL study. Kidney international 63, 1499–1507, doi:10.1046/j.1523-1755.2003.00885.x (2003).
Hallan, S. I. et al. Combining GFR and albuminuria to classify CKD improves prediction of ESRD. Journal of the American Society of Nephrology: JASN 20, 1069–1077, doi:10.1681/asn.2008070730 (2009).
Luk, A. O. et al. Risk association of HbA1c variability with chronic kidney disease and cardiovascular disease in type 2 diabetes: prospective analysis of the Hong Kong Diabetes Registry. Diabetes/metabolism research and reviews 29, 384–390, doi:10.1002/dmrr.2404 (2013).
Klag, M. J. et al. Blood pressure and end-stage renal disease in men. The New England journal of medicine 334, 13–18, doi:10.1056/nejm199601043340103 (1996).
Agarwal, R. Blood pressure components and the risk for end-stage renal disease and death in chronic kidney disease. Clinical journal of the American Society of Nephrology: CJASN 4, 830–837, doi:10.2215/cjn.06201208 (2009).
Collins, G. S., Omar, O., Shanyinde, M. & Yu, L. M. A systematic review finds prediction models for chronic kidney disease were poorly reported and often developed using inappropriate methods. Journal of clinical epidemiology 66, 268–277, doi:10.1016/j.jclinepi.2012.06.020 (2013).
Taal, M. W. & Brenner, B. M. Predicting initiation and progression of chronic kidney disease: Developing renal risk scores. Kidney international 70, 1694–1705, doi:10.1038/sj.ki.5001794 (2006).
Tangri, N. et al. Risk prediction models for patients with chronic kidney disease: a systematic review. Annals of internal medicine 158, 596–603, doi:10.7326/0003-4819-158-8-201304160-00004 (2013).
Tirosh, A. et al. Renal function following three distinct weight loss dietary strategies during 2 years of a randomized controlled trial. Diabetes care 36, 2225–2232, doi:10.2337/dc12-1846 (2013).
Chien, K. L. et al. Constructing the prediction model for the risk of stroke in a Chinese population: report from a cohort study in Taiwan. Stroke; a journal of cerebral circulation 41, 1858–1864, doi:10.1161/strokeaha.110.586222 (2010).
Sun, F., Tao, Q. & Zhan, S. An accurate risk score for estimation 5-year risk of type 2 diabetes based on a health screening population in Taiwan. Diabetes research and clinical practice 85, 228–234, doi:10.1016/j.diabres.2009.05.005 (2009).
Wen, C. P. et al. Hepatocellular carcinoma risk prediction model for the general population: the predictive power of transaminases. Journal of the National Cancer Institute 104, 1599–1611, doi:10.1093/jnci/djs372 (2012).
Farinati, F. et al. Development and Validation of a New Prognostic System for Patients with Hepatocellular Carcinoma. 13, e1002006, doi:10.1371/journal.pmed.1002006 (2016).
Lee, M. H. et al. Prediction models of long-term cirrhosis and hepatocellular carcinoma risk in chronic hepatitis B patients: risk scores integrating host and virus profiles. Hepatology (Baltimore, Md.) 58, 546–554, doi:10.1002/hep.26385 (2013).
Lee, T. Y. et al. A tool to predict risk for gastric cancer in patients with peptic ulcer disease on the basis of a nationwide cohort. Clinical gastroenterology and hepatology: the official clinical practice journal of the American Gastroenterological Association 13, 287–293.e281, doi:10.1016/j.cgh.2014.07.043 (2015).
Lai, H. et al. A prediction model for periodontal disease: modelling and validation from a National Survey of 4061 Taiwanese adults. Journal of clinical periodontology 42, 413–421, doi:10.1111/jcpe.12389 (2015).
Wen, C. P., Tsai, S. P. & Chung, W. S. A 10-year experience with universal health insurance in Taiwan: measuring changes in health and health disparity. Annals of internal medicine 148, 258–267 (2008).
Levey, A. S. et al. A more accurate method to estimate glomerular filtration rate from serum creatinine: a new prediction equation. Modification of Diet in Renal Disease Study Group. Annals of internal medicine 130, 461–470 (1999).
Levey, A. S. et al. National Kidney Foundation practice guidelines for chronic kidney disease: evaluation, classification, and stratification. Annals of internal medicine 139, 137–147 (2003).
Hosmer, D. W. & Lemeshow, S. Applied Logistic Regression. (Wiley-Interscience Publication, 2000).
Bendel, R. B. & Afifi, A. A. Comparison of stopping rules in forward regression. Journal of the American Statistical Association 72 (1977).
Mickey, R. M. & Greenland, S. The impact of confounder selection criteria on effect estimation. American journal of epidemiology 129, 125–137 (1989).
Sullivan, L. M., Massaro, J. M. & D'Agostino, R. B. Sr. Presentation of multivariate data for clinical use: The Framingham Study risk score functions. Statistics in medicine 23, 1631–1660, doi:10.1002/sim.1742 (2004).
1999 World Health Organization-International Society of Hypertension Guidelines for the Management of Hypertension. Guidelines Subcommittee. Journal of hypertension 17, 151–183 (1999).
Molitoris, B. A. et al. Improving outcomes of acute kidney injury: report of an initiative. Nature clinical practice. Nephrology 3, 439–442, doi:10.1038/ncpneph0551 (2007).
Steyerberg, E. Clinical Prediction Models - A Practical Approach to Development, Validation, and Updating. 1 edn, (Springer-Verlag New York, 2009).
Acknowledgements
This study was supported primarily by the Bureau of National Health Insurance (DOH94-NH-1007), the Ministry of Science and Technology of Taiwan (NSC 101-2314-B-039 -017-MY3 & NSC 102-2314-B-039-005-MY2 & MOST 104-2314-B-039-016) and Taiwan Ministry of Health and Welfare Clinical Trial and Research Center of Excellence (MOHW106-TDU-B-212-113004) and China Medical University Hospital (DMR-105-071).
Author information
Authors and Affiliations
Contributions
C.C. Lin and T.C. Li designed the research. C.S. Liu, W.Y. Lin and C.H. Lin performed the experiments. C.I. Li and S.Y. Yang analyzed data and wrote the paper. All authors contributed to interpretation, revised the manuscript and gave final approval for publication.
Corresponding author
Ethics declarations
Competing Interests
The authors declare that they have no competing interests.
Additional information
Publisher's note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Lin, CC., Li, CI., Liu, CS. et al. Development and validation of a risk prediction model for end-stage renal disease in patients with type 2 diabetes. Sci Rep 7, 10177 (2017). https://doi.org/10.1038/s41598-017-09243-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-017-09243-9
This article is cited by
-
A simplified prediction model for end-stage kidney disease in patients with diabetes
Scientific Reports (2022)
-
Machine learning to predict end stage kidney disease in chronic kidney disease
Scientific Reports (2022)
-
External validation of prognostic models for chronic kidney disease among type 2 diabetes
Journal of Nephrology (2022)
-
Scoring model to predict risk of chronic kidney disease in Chinese health screening examinees with type 2 diabetes
International Urology and Nephrology (2022)
-
Prognostic models of diabetic microvascular complications: a systematic review and meta-analysis
Systematic Reviews (2021)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
