
Abstract
Visual memory for faces has been extensively researched, especially regarding the main factors that influence face memorability. However, what we remember exactly about a face, namely, the pictorial content of visual memory, remains largely unclear. The current work aims to elucidate this issue by reconstructing face images from both perceptual and memory-based behavioural data. Specifically, our work builds upon and further validates the hypothesis that visual memory and perception share a common representational basis underlying facial identity recognition. To this end, we derived facial features directly from perceptual data and then used such features for image reconstruction separately from perception and memory data. Successful levels of reconstruction were achieved in both cases for newly-learned faces as well as for familiar faces retrieved from long-term memory. Theoretically, this work provides insights into the content of memory-based representations while, practically, it may open the path to novel applications, such as computer-based ‘sketch artists’.
Similar content being viewed by others

Introduction
Remembering the visual appearance of a known face is a crucial part of everyday life. To date, extensive research has established the impact of specific contextual and intrinsic facial properties on face memorability (e.g., distinctiveness, familiarity, inter-group similarity, race, emotional expression, and trustworthiness, to name a few)1,2,3,4,5,6,7,8. Yet, much less is currently known about the concrete pictorial information associated with retrieving a face from memory. Arguably, elucidating this issue can provide valuable insights into the nature of the representations subserving face memory and also, into their relationship with face perception.
Accordingly, the current work seeks to elucidate the representational content of visual face memory through the novel use of image reconstruction. Previously, reconstruction approaches have been mainly directed at estimating the perceptual representations of an observer from patterns of neural activation9,10,11,12,13. Importantly though, reconstruction has not targeted long-term memory and its pictorial content as derived from behavioural data (but see recent work on neural-based image reconstruction from working memory14). To handle this challenge, here, we appeal to a robust reconstruction approach11 that capitalises on the structure of internal representations as reflected by empirical data irrespective of their modality (e.g., neural or behavioural). Further, this approach has a twofold goal of deriving facial features directly from empirical data and then using them in the process of image reconstruction.
Theoretically, at the core of our work lies the concept of face space15, a multidimensional construct comprising a population of faces with the property that the distance between any pair of faces reflects their psychological similarity16,17,18,19. Critical for our purposes, perceptual face space and its memory-based counterpart may be closely related20 allowing, in theory, the use of the former to inform the latter. Accordingly, here we rely on behavioral estimates of face similarity, whether between pairs of stimuli or between a stimulus and a face recalled from memory, to construct an integrated perception-memory face space. This construct allows the derivation of perceptual features, namely global pixel image intensities rather than local face parts (e.g., an eye), that exploits its organisation through an analogue of reverse correlation21,22,23. Such features are then combined to deliver image reconstructions for a novel set of faces projected in this space. Naturally, this approach allows perceptual and memory-based reconstructions alike depending on whether the target faces are perceived or remembered – image reconstruction from memory is applied here both to novel faces, learned over the course of the experiment, and to famous faces retrieved from long-term memory. Of particular note, successful memory-based reconstruction from an integrated perception-memory face space would provide strong evidence for shared representations underlying face perception and face memory.
Finally, since subjective personal experience is likely to shape substantially an individual’s memory for faces24, the present work seeks proof of principle that reconstruction can be performed individually, rather than at the group level, provided that sufficient data is collected to allow a robust approximation of face representations in single participants. To handle this challenge, data subserving reconstruction purposes were collected, across multiple experimental sessions, for each of three participants (Experiment 1); then, the accuracy of individual-based reconstructions was assessed objectively with respect to image pixel intensities (Experiment 1) as well as experimentally by a larger group of participants (Experiment 2). From a translational standpoint, the current strategy carries significance in that practical applications of such methodology are likely to target single individual data (e.g., independent estimation and visualisation of face memory in single eyewitnesses). At the same time, reconstructed faces should be recognisable by most individuals sufficiently familiar with the intended targets – such individuals would include, by necessity, but not be limited to the individuals who provided reconstruction data.
In sum, the current work aims to provide a theoretical framework for integrating the study of perceptual and memory representations as well as new methodology for estimating the pictorial content of visual memory in single individuals.
Results
Reconstruction approach
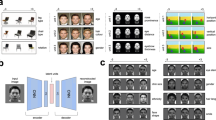
Facial images, including three newly-learned faces, three famous faces retrieved from long-term memory, as well as the 57 unfamiliar faces perceived by participants, were reconstructed separately for each of three participants in Experiment 1 (NC, CB and SA). This endeavour was pursued through a sequence of steps that capitalised on the structure of face space for the purpose of feature derivation and image reconstruction. In short, this sequence included: (i) constructing a multidimensional face space (Fig. 1c) from experimental estimates of pairwise face similarity (Fig. 1a,b) using multidimensional scaling (MDS); (ii) deriving classification images (CIM) for each dimension and assessing their significance regarding the inclusion of relevant visual information (Fig. 1d); (iii) projecting the target face into face space (i.e., approximating its coordinates in that space); and (iv) reconstructing the target by combining significant CIMs proportionally with the target’s coordinates in face space (see Methods and Fig. 1 for further details).

Reconstruction procedure and result evaluation: (a) participants rate the face similarity of two stimuli or of a single stimulus against a facial identity retrieved from memory; (b) pairwise face similarities are converted into a confusability matrix of n distinct facial identities, where face n is the target face for reconstruction purposes; (c) face space is estimated from the similarity of n-1 different faces and the coordinates of the target face are approximated within that space (only 2 dimensions are displayed for convenience; PVE – percent variance explained); (d) visual features corresponding to each dimension are derived through image classification from n-1 faces and analysed, separately for each colour channel in CIEL*a*b*, with a pixelwise permutation test (FDR-corrected across pixels; q < 0.10); (e) visual features are linearly combined to estimate the visual appearance of the target face (CIM k – classification images corresponding to dimension k); (f) face reconstructions are evaluated in a two-alternative forced choice task with face pairs, for novel faces, or with name pairs, for famous faces. As an illustration, (c) and (d) show intermediary reconstruction results for participant NC. (Due to copyright restrictions all images of original face stimuli have been replaced with face images artificially generated in Matlab R2015b).
Representative examples of reconstructed images are shown in Fig. 2 for all three categories of faces: unfamiliar, learned, or famous. Overall, face reconstructions appear to capture the visual characteristics necessary for face identification in all conditions.

Examples of face reconstructions for participant NC. Results are shown separately for: (a) perceptual reconstructions; (b) memory-based reconstructions of learned faces and (c) memory-based reconstructions of famous faces (top to bottom: Jonah Hill, Chris Hemsworth, Jim Parsons) that participants were familiar with from their individual experience. Reconstruction accuracy (%) was estimated objectively through pixelwise image similarity (top left, a–b); additionally, accuracy was assessed experimentally by the same participant (top right) or by an independent group of naïve participants (bottom right) for all types of reconstruction. (Corresponding stimulus images for (a) and (b) could not be reproduced due to copyright restrictions; all image reconstructions were generated using Matlab R2015b).
Evaluation of reconstruction results
To assess reconstruction accuracy, an image-based evaluation procedure computed the pixelwise similarity between reconstructions and face images (e.g., actual stimuli). Then, the percentage of instances for which the reconstruction was more similar to its target than to any other image provided an estimate of image-based accuracy. An analogous, experimentally-based estimate, was further derived in Experiment 2 – a larger group of participants, including NC, CB and SA, were asked to judge the similarity between each reconstruction and two potential targets in a two-alternative forced-choice test.
Image-based estimates (Fig. 3a) as well as experimentally-based estimates collected from the three participants above (Fig. 3b) as well as from other naïve participants (Fig. 3c) all confirmed that the reconstructions were successful. Of note, the average magnitude of reconstruction accuracy was above chance for every type of estimate, for every condition (i.e., perception, memory for learned faces and memory for famous faces), and for every set of reconstructions by participant (NC, CB and SA). Further statistical tests of perceptual reconstructions found that image-based and experimentally-based accuracies computed for the three main participants were significant in all cases (comparisons against chance via two-tailed one-sample t-tests across stimuli, ps < 0.001) (see Table 1 and Fig. 3a,b).

Average reconstruction accuracy for three participants (NC, CB and SA). Accuracy was estimated via (a) objective pixelwise similarity; (b) experimental data from the same participants, tested on their own reconstructions, and (c) experimental data from an independent group of participants (error bars show 1SE; **p < 0.01 ***p < 0.001).
To estimate more thoroughly reconstruction results, a two-way mixed-design analysis of variance (3 within-participants reconstruction types: unfamiliar, learned, or famous ×3 between-participants face triplets: NC, CB or SA) was applied to naïve participant data from Experiment 2. This analysis found a main effect of reconstruction type (F(1.289, 34.79) = 61.13, p < 0.001, η2 = 0.694, Greenhouse-Geiser correction for sphericity) and an interaction effect (F(2.577, 34.79) = 3.21, p = 0.04, η2 = 0.192, Greenhouse-Geiser correction), but no effect of face triplet. Further pairwise comparisons revealed that the accuracy of learned faces was significantly larger than that of either unfamiliar (t(29) = 12.44, p < 0.001, CI of the difference: [0.20, 0.26], d = 2.27) or famous faces (t(29) = 7.56, p < 0.001, CI: [0.13, 0.26], d = 1.38).
Importantly, comparisons against chance found that reconstructions were significant in all cases (two-tailed one-sample t-tests across participants; famous face reconstructions for NC, CB, and SA: p = 0.005, p = 0.003, p = 0.002, respectively; all other ps < 0.001) (see Fig. 3c and Table 2).
Reconstruction consistency across participants
To assess the consistency of perceptual reconstructions across our three main participants, we correlated image-based accuracies of the 57 unfamiliar faces across pairs of participants in Experiment 1. This analysis found significant Pearson correlations in every case (NC-CB: r(55) = 0.66; NC-SA: r(55) = 0.65; CB-SA: r(55) = 0.61; all ps < 0.001). Similar results were found by correlating experimentally-based estimates based on group-averaged data of naïve participants in Experiment 2 (NC-CB: r(55) = 0.54; NC-SA: r(55) = 0.62; CB-SA: r(55) = 0.62; all ps < 0.001).
Discussion
The current work aims to achieve image reconstruction from both perception and memory on the basis of behavioural data. Notably, this work points to the possibility of extracting and reconstructing the appearance of facial identity from long-term memory. This demonstration evinces a number of theoretical and practical implications, as discussed below.
First, our empirical data were generated by appeal to a simple, intuitive task, requiring participants to judge the similarity between a current stimulus and a face recalled from memory, in order to derive a hybrid perception-memory face space construct. The twofold success of perception and memory-based reconstructions relying on such a construct may speak to the close integration of these two cognitive processes. Specifically, the ability to use perceptual features extracted from face stimuli to reconstruct the appearance of faces recalled from memory is consistent with the hypothesis of visual representations shared across perception, imagery and memory25,26,27. According to this viewpoint it is useful to consider perception and memory as highly interactive cognitive processes as suggested by previous work. For instance, brain regions associated with long-term memory (i.e., medial temporal lobe structures) have been found to play an important role in perception28,29,30,31,32 and, similarly, visual imagery has been linked to neural resources underlying perceptual processing33,34,35. Although the present work focuses on faces as a visual category, it is likely that this integration of multiple cognitive processes extends to other categories such as objects and scenes25,26,27.
Second, regarding the nature of visual representations, the present work provides evidence that perception and memory share pictorial content, as needed for reconstruction purposes. Notably, our results show that face representations contain sufficient pictorial detail to support image reconstruction even of faces retrieved from long-term memory. Interestingly, the level of reconstruction accuracy for newly-learned faces surpassed that corresponding to famous faces and even to viewed unfamiliar faces. This outcome is likely due, as intended, to the extensive familiarisation of our participants with a small set of face images that aimed to facilitate access to relevant facial features in the memory task. Arguably, familiarisation would not only allow a visually richer experience with faces recalled from memory but also could refine the representation of these faces over time by allowing the participants to zero in on features diagnostic for identification and encode such features preferentially36. At the same time though, we note that low-level image properties were controlled in all face stimuli. Further, in the case of famous face reconstruction, representations were not associated with specific images throughout the experiment as participants were required to retrieve the appearance of famous faces from their own personal knowledge. Hence, our results arguably speak to intermediate-level visual representations of facial identity37,38,39.
Third, reconstruction was carried out with the aid of facial features synthesised directly from experimental data rather than predefined ones, such as those extracted from face images via principal component analysis or independent component analysis14, 40. Specifically, we appealed to a technique akin to reverse correlation to derive facial features from perceptual data and then used such features for image separately for perception and memory-based reconstruction. In a broader context, our procedure capitalises on the extensive work with reverse correlation as a strategy for deriving perceptual representations directly from visual stimuli and the responses they elicit. For instance, in the study of face recognition, considerable insights have been gained by its application to face detection22 and discrimination41, 42 as well as to emotional expression43 and attractiveness44. Here, we adapt the strategy of reverse correlation to exploit the structure of face space, dimension by dimension, with the aim of uncovering visual features for face identification. Thus, the current strategy is instrumental in clarifying the featural basis of perceptual/memory representations while, also, providing feature codes for reconstruction purposes and, conversely, using image reconstruction to validate the psychological plausibility of such features.
On a related note, we find that our reconstructions tended to capture primarily low and medium spatial frequency information, typical of classification images21, 22. Specifically, the comparison of a visual template to a stimulus is prone to spatial uncertainty as the observer applies the template over a range of spatial locations in the stimulus, leading to the smearing of the signal over the region of uncertainty and, thus, to blurred CIMs45. Here, CIM features appeared to encode extensive shape and surface information but much less high-frequency textural information. However, this is not necessarily a limitation in the present case: while our face recognition system exhibits considerable flexibility46, we tend to rely on a narrow band of low spatial frequencies for face identification47 optimal for exploiting the statistical properties of facial images48. Thus, since the aim of reconstruction is not to produce a photographic replica of a given stimulus but rather to extract and to visualise the representational content supporting recognition, it appears that the methodology deployed here is largely successful in this respect.
As a caveat to our present findings, we note that in order to maximise our ability to validate the current research paradigm, participation was restricted in Experiment 1 to three individuals with high levels of recognition performance (see Screening, Supplementary Information). While psychophysical studies using reverse correlation often rely on small sample sizes41, 43, 45, further research will clearly be required to confirm the general applicability of our approach to a broader population as well as to clarify the precise nature of the personal experience and the individual characteristics that facilitate successful retrieval of visual information for reconstruction purposes.
Thus, if proven to be effective across the wider population, the present approach may open up new paths for theoretical and applied investigations. For instance, our approach could be directed at testing specific hypotheses regarding face space structure17, 49, the nature of configural processing50, 51 or the developmental trajectory of face recognition and its representational basis52, 53. Further, optimised versions of the method above could serve as a basis for forensic applications. For instance, automated ‘sketch artists’ relying on judgments of facial similarity, instead of verbal descriptions, may provide a complement to current strategies for depicting and visualising the face of a person of interest.
Methods
Experiment 1 – facial image reconstruction
Participants
We sought to assess our approach separately with three participants (NC, Caucasian female, 22 years; CB, Caucasian female, 21 years; SA, Asian male, 26 years) selected based on their performance in several screening tests. On passing our eligibility criteria (see Screening, Supplementary Information), these participants completed four 1-hour experimental sessions on separate days over the course of at most two weeks. All participants had normal or corrected-to-normal vision and no history of neurological or visual disorders. Informed consent was obtained from all participants. All procedures were carried out in accordance with University of Toronto Research Ethics Guidelines and were approved by the University of Toronto Research Ethics Board.
Stimuli
Sixty unfamiliar face images selected from four databases: Radboud54, AR55, FEI56, and FERET57, 58, along with thirty images of famous individuals (i.e., media celebrities) from publicly available sources were selected to display front views of Caucasian males with a neutral expression. All images were cropped, spatially normalised, and colour-normalised for mean values and contrast separately in each CIEL*a*b* colour channel.
Next, from our pool of 60 unfamiliar faces, three were selected to serve as targets for experimentally-controlled face familiarisation and learning (see Novel face learning, Supplementary Information). Also, from our pool of 30 famous individuals, three images were selected for each participant based on their familiarity with the individuals depicted by these images (i.e., at least 5 on a 1–7 familiarity scale for each famous individual) – the remaining famous face images were eliminated from further testing. Of note, while all participants were tested with the same triplet of learned faces for reconstruction purposes, different triplets of famous faces were used for each participant depending on their relative familiarity with different celebrities.
Experimental procedures
Data intended for reconstruction purposes were collected with the aid of several pairwise similarity-rating tasks. Specifically, participants performed a perception-based task with unfamiliar faces, and two memory-based tasks, for learned faces and for famous faces, respectively (Fig. 1a).
In the perception-based task, each trial started with a centrally-presented fixation cross (500 ms), followed by a pair of face images presented side by side for 2000 ms against a dark background. Each face subtended an angle of 2.6° × 4° from 90 cm and was displaced 2.4° from the centre of the screen. Participants were asked to rate the similarity of the two faces on a 7-point scale by pressing a corresponding number key. The left/right location of the images was counterbalanced and each face was paired with every other face exactly once, leading to 1596 trials divided equally over 14 blocks.
In memory-based tasks, participants were first instructed to recall and hold in memory one of three learned faces or, alternatively, one of three famous individuals. In each trial, a 600 ms central fixation cross was replaced by one of the 57 unfamiliar faces for 400 ms. Participants rated the similarity between the presented face and the recalled face on a 7-point scale, and a 100 ms white-noise mask appeared at the centre of the screen as soon as a response was recorded. Each learned/familiar face was paired with every other unfamiliar face once (171 trials per memory-based task, spread over 9 blocks). Of note, participants were not exposed to any images of the three famous faces during this testing, nor did they encounter such images outside of the lab via other means (e.g., media), as they confirmed at the end of the experiment. In contrast, the learned faces were presented at the beginning of each memory-based block so as to refresh their memory of these faces.
For all tasks, trial order was randomised and practice trials were provided at the beginning of each session. Data collection relied on Matlab R2015b (Mathworks, Natick, MA) with the aid of Psychtoolbox 3.0.1259, 60.
Reconstruction procedure
Our approach broadly followed that of Nestor et al.11 with the main difference that, first, reconstruction was performed separately for each participant rather than at the group level and second, perception-based reconstruction was accompanied by its memory-based counterparts. Briefly, the method involved: (i) computing a confusability matrix that contained the average pairwise similarity of n-1 unfamiliar faces (Fig. 1b); (ii) estimating a 20-dimension face space by applying metric MDS to the confusability matrix of each participant and normalising each dimension by z-scoring (Fig. 1c); (iii) deriving CIM’s by deploying, separately for each dimension, an analogue of reverse correlation that computes a weighted average of face images proportionally with their coordinates; (iv) assessing CIM significance through a pixelwise permutation test (i.e., by randomising images with respect to their coordinates on each dimension and by recomputing CIM’s for a total of 104 permutations; pixelwise two-tailed t-test; FDR correction across pixels: q < 0.1); (v) projecting a target face (image n in Fig. 1b,c) in the existing face space based on its similarity with the n-1 faces, and (vi) reconstructing the appearance of the target face through a linear combination of significant CIM’s added onto an average face image derived from the linear combination of the original n-1 faces (Fig. 1e).
Importantly, the procedure above enforces non-circularity by excluding the target face from the estimation of the CIM’s that enter its reconstruction. Specifically, memory-based reconstruction used the 57 unfamiliar faces to estimate face space features while the learned/famous faces provided the reconstruction targets. Similarly, perception-based reconstruction utilised a leave-one-out schema by using 56 unfamiliar images at a time to derive facial features while the remaining face was the reconstruction target (see Face space and facial feature derivation, Image reconstruction procedure in Supplementary Information).
Image-based evaluation of reconstruction results
Objective image-based reconstruction accuracy was measured as the pixelwise similarity of reconstructed images relative to the target faces. Specifically, accuracy was estimated as the percentage of instances for which a reconstruction image was closer, via an Euclidean metric, to its target than to any other alternative image. For perception-based reconstruction alternative images were provided by all unfamiliar faces other than the target; similarly, for memory-based reconstruction of learned faces the alternatives to any target were provided by the other two learned images. Such estimates were not computed for famous face reconstruction since no corresponding visual stimuli were presented during the main part of the experiment.
Next, reconstruction accuracies were averaged across all faces, separately for each participant, and tested against chance (50%) using a one-sample t-test. Notably, significance testing was conducted solely for perception-based reconstruction though, and not for memory-based reconstructions, due to the small sample size (and, also, due to the absence of relevant estimates, for famous faces). Hence, to provide a more thorough evaluation of reconstruction results and to complement the image-based assessment above a second experiment was conducted as follows.
Experiment 2 – experimental evaluation of reconstruction results
Participants
In addition to our three participants above, 30 other naïve participants (16 female; age: 18–32 years) were recruited for this experiment – we deemed a sample of this size would suffice for the purpose of capturing effects as robust as those found with the image-based procedure described above. Each session took one hour to complete - for NC, CB and SA, this additional session was conducted within two days of completing Experiment 1. Informed consent was obtained from all participants; all procedures were carried out in accordance with University of Toronto Research Ethics Guidelines and were approved by the University of Toronto Research Ethics Board.
Experimental procedures
In three separate conditions (corresponding to perception, memory-learned, and memory-famous face reconstructions), participants systematically evaluated the similarity between a reconstructed image and two potential targets using two-alternative forced-choice testing. For perception-based and for memory-based reconstructions of learned faces, participants were shown a reconstructed image at the top of the screen alongside two images at the bottom (i.e., a target and a randomly selected foil from the remaining 57 unfamiliar faces or the other 2 learned faces). Participants then selected, via a button press, the bottom image that was the most similar to the top one. In contrast, for memory-based reconstructions of famous faces, each reconstructed image was paired with two names (the target plus a randomly selected name for one of the other 2 famous faces) and participants had to judge which of the two named individuals was closest in appearance to the reconstruction (Fig. 1f). Each trial lasted 2 s (perception) or 3 s (memory), and a 100 ms white-noise mask appeared at the location of each stimulus following a response. For the perception-based condition, each reconstructed image was presented 8 times (4 blocks of 114 trials) whereas for the two memory-based conditions, each reconstructed image was presented 36 times (2 blocks of 54 trials).
Of note, NC, CB and CA evaluated their own reconstructions whereas each new participant assessed reconstructions derived from a single participant in Experiment 1, depending on their relative familiarity with different famous face triplets (as used with NC, CB or SA).
Experimentally-based reconstruction accuracy was next computed as the percentage of instances for which a reconstructed image was matched correctly with its target. Accuracies were averaged across reconstructions, separately for each condition, and then compared against chance (one-sample two-tailed t-test across participants against 50% accuracy). Mean accuracies were also analysed using a mixed-design two-way analysis of variance (3 within-participants reconstruction types x 3 between-participants reconstruction source: NC, CB or CA).
Data Availability
The datasets generated during and/or analysed during the current study are available from the corresponding author on reasonable request.
References
Busey, T. A. & Tunnicliff, J. L. Accounts of blending, distinctiveness, and typicality in the false recognition of faces. J. Exp. Psychol. Learn. Mem. Cogn. 25, 1210–1235 (1999).
Bruce, V., Burton, M. A. & Dench, N. What’s distinctive about a distinctive face? Q. J. Exp. Psychol. 47, 119–141 (1994).
Cheung, O. S. & Gauthier, I. Selective interference on the holistic processing of faces in working memory. J. Exp. Psychol. Hum. Percept. Perform. 36, 448–461 (2010).
Meissner, C. A. & Brigham, J. C. Thirty years of investigating the own-race bias in memory for faces: A meta-analytic review. Psychol. Public Policy, Law 7, 3–35 (2001).
Oosterhof, N. N. & Todorov, A. The functional basis of face evaluation. Proc. Natl. Acad. Sci. 105, 11087–92 (2008).
Bainbridge, W. A., Isola, P. & Oliva, A. The intrinsic memorability of face photographs. J. Exp. Psychol. Gen. 142, 1323–1334 (2013).
D’Argembeau, A., V der Linden, M., Etienne, A. M. & Comblain, C. Identity and expression memory for happy and angry faces in social anxiety. Acta Psychol. 114, 1–15 (2003).
Balas, B. & Saville, A. N170 face specificity and face memory depend on hometown size. Neuropsychologia 69, 211–217 (2015).
Naselaris, T., Prenger, R. J., Kay, K. N., Oliver, M. & Gallant, J. L. Bayesian reconstruction of natural images from human brain activity. Neuron 63, 902–915 (2009).
Miyawaki, Y. et al. Visual image reconstruction from human brain activity using a combination of multiscale local image decoders. Neuron 60, 915–929 (2008).
Nestor, A., Plaut, D. C. & Behrmann, M. Feature-based face representations and image reconstruction from behavioral and neural data. Proc. Natl. Acad. Sci. 113, 416–421 (2016).
Nishimoto, S. et al. Reconstructing visual experiences from brain activity evoked by natural movies. Curr. Biol. 21, 1641–1646 (2011).
Cowen, A. S., Chun, M. M. & Kuhl, B. A. Neural portraits of perception: Reconstructing face images from evoked brain activity. Neuroimage 94, 12–22 (2014).
Lee, H. & Kuhl, B. A. Reconstructing perceived and retrieved faces from activity patterns in lateral parietal cortex. J. Neurosci. 36, 6069–6082 (2016).
Valentine, T. A unified account of the effects of distinctiveness, inversion, and race in face recognition. Q. J. Exp. Psychol. 43, 161–204 (1991).
Griffin, H. J., McOwan, P. W. & Johnston, A. Relative faces: Encoding of family resemblance relative to gender means in face space. J. Vis. 11, 1–11 (2011).
Leopold, D. A., O’Toole, A. J., Vetter, T. & Blanz, V. Prototype-referenced shape encoding revealed by high-level aftereffects. Nat. Neurosci. 4, 89–94 (2001).
Tanaka, J. W., Kantner, J. & Bartlett, M. How category structure influences the perception of object similarity: The atypicality bias. Front. Psychol. 3, 1–11 (2012).
Rhodes, G. et al. How distinct is the coding of face identity and expression? Evidence for some common dimensions in face space. Cognition 142, 123–137 (2015).
Yotsumoto, Y., Kahana, M. J., Wilson, H. R. & Sekuler, R. Recognition memory for realistic synthetic faces. Mem. Cognit. 35, 1233–1244 (2007).
Murray, R. F. Classification images: A review. J. Vis. 11, 1–25 (2011).
Smith, M. L., Gosselin, F. & Schyns, P. G. Measuring internal representations from behavioral and brain data. Curr. Biol. 22, 191–196 (2012).
Neri, P. & Levi, D. M. Receptive versus perceptive fields from the reverse-correlation viewpoint. Vision Res. 46, 2465–2474 (2006).
Chiroro, P. & Valentine, T. An investigation of the contact hypothesis of the own-race bias in face recognition. Q. J. Exp. Psychol. 48, 879–894 (1995).
Graham, K. S., Barense, M. D. & Lee, A. C. H. Going beyond LTM in the MTL: A synthesis of neuropsychological and neuroimaging findings on the role of the medial temporal lobe in memory and perception. Neuropsychologia 48, 831–853 (2010).
Lee, A. C. H., Yeung, L.-K. & Barense, M. D. The hippocampus and visual perception. Front. Hum. Neurosci. 6, 1–17 (2012).
Saksida, L. M. & Bussey, T. J. The representational–hierarchical view of amnesia: Translation from animal to human. Neuropsychologia 48, 2370–2384 (2010).
Lee, A. C. H. et al. Perceptual deficits in amnesia: challenging the medial temporal lobe ‘mnemonic’ view. Neuropsychologia 43, 1–11 (2005).
O’Neil, E. B., Cate, A. D. & Köhler, S. Perirhinal cortex contributes to accuracy in recognition memory and perceptual discriminations. J. Neurosci. 29, 8329–8334 (2009).
Lee, A. C. H. & Rudebeck, S. R. Human medial temporal lobe damage can disrupt the perception of single objects. J. Neurosci. 30, 6588–6594 (2010).
Lee, A. C. H., Brodersen, K. H. & Rudebeck, S. R. Disentangling spatial perception and spatial memory in the hippocampus: A univariate and multivariate pattern analysis fMRI study. J. Cogn. Neurosci. 25, 534–546 (2013).
Lech, R. K. & Suchan, B. Involvement of the human medial temporal lobe in a visual discrimination task. Behav. Brain Res. 268, 22–30 (2014).
Ganis, G., Thompson, W. L. & Kosslyn, S. M. Brain areas underlying visual mental imagery and visual perception: An fMRI study. Cogn. Brain Res. 20, 226–241 (2004).
Lee, S. H., Kravitz, D. J. & Baker, C. I. Disentangling visual imagery and perception of real-world objects. Neuroimage 59, 4064–4073 (2012).
O’Craven, K. M. & Kanwisher, N. Mental imagery of faces and places activates corresponding stimulus-specific brain regions. J. Cogn. Neurosci. 12, 1013–1023 (2000).
O’Donnell, C. & Bruce, V. Familiarisation with faces selectively enhances sensitivity to changes made to the eyes. Perception 30, 755–764 (2001).
Harel, A., Ullman, S., Epshtein, B. & Bentin, S. Mutual information of image fragments predicts categorization in humans: Electrophysiological and behavioral evidence. Vision Res. 47, 2010–2020 (2007).
Nestor, A., Vettel, J. M. & Tarr, M. J. Task-specific codes for face recognition: How they shape the neural representation of features for detection and individuation. PLoS One 3, (2008).
Ullman, S., Vidal-Naquet, M. & Sali, E. Visual features of intermediate complexity and their use in classification. Nat. Neurosci. 5, 682–687 (2002).
Nestor, A., Plaut, D. C. & Behrmann, M. Face-space architectures: Evidence for the use of independent color-based features. Psychol. Sci. 24, 1294–300 (2013).
Sekuler, A. B., Gaspar, C. M., Gold, J. M. & Bennett, P. J. Inversion leads to quantitative, not qualitative, changes in face processing. Curr. Biol. 14, 391–396 (2004).
Martin-Malivel, J., Mangini, M. C. & Biederman, I. Do humans and baboons sse the same information when categorizing human and baboon faces? Psychol. Sci. 17, 599–607 (2006).
Gosselin, F. & Schyns, P. G. Superstitious perceptions reveal properties of internal representations. Psychol. Sci. 14, 505–509 (2003).
Karremans, J. C., Dotsch, R. & Corneille, O. Romantic relationship status biases memory of faces of attractive opposite-sex others: Evidence from a reverse-correlation paradigm. Cognition 121, 422–426 (2011).
Tjan, B. S. & Nandy, A. S. Classification images with uncertainty. J. Vis. 6, 387–413 (2006).
Pilz, K. S., Bülthoff, H. H. & Vuong, Q. C. Learning influences the encoding of static and dynamic faces and their recognition across different spatial frequencies. Vis. Cogn. 17, 716–735 (2009).
Näsänen, R. Spatial frequency bandwidth used in the recognition of facial images. Vision Res. 39, 3824–3833 (1999).
Keil, M. S. Does face image statistics predict a preferred spatial frequency for human face processing? Proc. R. Soc. London B Biol. Sci. 275, 2095–2100 (2008).
Ross, D. A., Deroche, M. & Palmeri, T. J. Not just the norm: Exemplar-based models also predict face aftereffects. Psychon. Bull. Rev. 21, 47–70 (2014).
Maurer, D., Le Grand, R. & Mondloch, C. J. The many faces of configural processing. Trends Cogn. Sci. 6, 255–260 (2002).
Tanaka, J. W. et al. The effects of information type (features vs. configuration) and location (eyes vs. mouth) on the development of face perception. J. Exp. Child Psychol. 124, 36–49 (2014).
Scherf, K. S. & Scott, L. S. Connecting developmental trajectories: Biases in face processing from infancy to adulthood. Dev. Psychobiol. 54, 643–663 (2012).
Mondloch, C. J., Geldart, S., Maurer, D. & Le Grand, R. Developmental changes in face processing skills. J. Exp. Child Psychol. 86, 67–84 (2003).
Langner, O. et al. Presentation and validation of the Radboud Faces Database. Cogn. Emot. 24, 1377–1388 (2010).
Martinez, A. R. & Benavente, R. The AR Face Database, CVC Technical Report #24. (1998).
Thomaz, C. E. & Giraldi, G. A. A new ranking method for principal components analysis and its application to face image analysis. Image Vis. Comput. 28, 902–913 (2010).
Phillips, P. J., Wechsler, H., Huang, J. & Rauss, P. J. The FERET database and evaluation procedure for face-recognition algorithms. Image Vis. Comput. 16, 295–306 (1998).
Phillips, P. J., Moon, H., Rizvi, S. A. & Rauss, P. J. The FERET evaluation methodology for face-recognition algorithms. IEEE Trans. Pattern Anal. Mach. Intell. 22, 1090–1104 (2000).
Brainard, D. H. The Psychophysics Toolbox. Spat. Vis. 10, 433–436 (1997).
Pelli, D. G. The VideoToolbox software for visual psychophysics: Transforming numbers into movies. Spat. Vis. 10, 437–442 (1997).
Acknowledgements
This work was supported by the Natural Sciences and Engineering Research Council of Canada (AL, AN) and a Connaught New Investigator Award (AN). Portions of the research in this paper use the FERET database57, 58 of facial images collected under the FERET program, sponsored by the DOD Counterdrug Technology Development Program Office.
Author information
Authors and Affiliations
Contributions
C.-H. Chang, A. C. H. Lee, and A. Nestor developed the study concept, designed the experiments and wrote the manuscript; C.-H. Chang performed data collection; C.-H. Chang and D. Nemrodov performed data analysis.
Corresponding author
Ethics declarations
Competing Interests
The authors declare that they have no competing interests.
Additional information
Publisher's note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Chang, CH., Nemrodov, D., Lee, A.C.H. et al. Memory and Perception-based Facial Image Reconstruction. Sci Rep 7, 6499 (2017). https://doi.org/10.1038/s41598-017-06585-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-017-06585-2
This article is cited by
-
Modelling face memory reveals task-generalizable representations
Nature Human Behaviour (2019)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
