
Abstract
The absence of nationwide distribution data regarding heavy metal emissions into the atmosphere poses a significant constraint in environmental research and public health assessment. In response to the critical data deficiency, we have established a dataset covering Cr, Cd, As, and Pb emissions into the atmosphere (HMEAs, unit: ton) across 367 municipalities in China. Initially, we collected HMEAs data and covariates such as industrial emissions, vehicle emissions, meteorological variables, among other ten indicators. Following this, nine machine learning models, including Linear Regression (LR), Ridge, Bayesian Ridge (Bayesian), K-Neighbors Regressor (KNN), MLP Regressor (MLP), Random Forest Regressor (RF), LGBM Regressor (LGBM), Lasso, and ElasticNet, were assessed using coefficient of determination (R2), root-mean-square error (RMSE) and Mean Absolute Error (MAE) on the testing dataset. RF and LGBM models were chosen, due to their favorable predictive performance (R2: 0.58–0.84, lower RMSE/MAE), confirming their robustness in modelling. This dataset serves as a valuable resource for informing environmental policies, monitoring air quality, conducting environmental assessments, and facilitating academic research.
Similar content being viewed by others

Background & Summary
Currently, heavy metal pollution poses a significant threat to both ecological systems and human health. The main sources of heavy metals encompass industrial activities, mining operations, wastewater discharge, and the use of agrochemicals1,2,3. According to Ni et al.4, 86% of Cr, 77% of Cd, 80% of As, and 94% of Pb in farmland are derived from atmospheric deposition in China, specifically PM10 and PM2.5, characterized by their small size and higher bioavailability5. These particles have an increased capacity for dispersion and long-range transport6,7, making them prone to transfer to other carriers such as soil, water, and even plant leaves, subsequently leading to the indirect contamination of crops and water bodies. Moreover, PM2.5 and PM10 particles carrying heavy metals, with high toxicity, concealment, persistence, and biological accumulation8,9, can penetrate deep into the respiratory system of humans, giving rise to a spectrum of deleterious health effects10,11.
However, despite the daily tracking of PM2.5 and PM10 concentration in most of major cities in China since 2013 and various efforts made to generate HMEAs data12,13,14,15,16,17, an assessment of heavy metal emissions into the atmosphere (HMEAs) across the entire country is still infant.
Creating a nationwide dataset for HMEAs is vital for several reasons. First of all, such dataset ensures the assessment on if air quality meets standards and understand its impact on human health, encouraging the implementation of appropriate preventive measures. Secondly, such dataset can be applied to identify pollution sources, therefore benefiting the formulation of effective pollution management strategies14,18. For instance, high levels of Pb in the atmosphere normally indicate highly-possibility of the presence of nearby industrial facilities causing Pb pollution19,20. This identification can be discerned by investigating the distribution and emissions of these nearby industrial facilities. Crucially, the HMEAs dataset can also be used for scientific research in areas like atmospheric chemistry, meteorology, and environmental science, aiding in the prediction of future air quality and environmental pollution trends18.
Nonetheless, the development of such a dataset poses formidable challenges, primarily due to the significant methodological complexities involved in interpolating limited and sparse point data to produce comprehensive large-scale regional datasets21. Machine learning (ML), as a powerful tool for uncovering underlying patterns from both voluminous data and limited sample sizes22,23,24, has been increasingly applied to solve such problems because of its cost-efficiency, predictive accuracy, and robustness22,25. For example, Lyu et al. employed an enhanced Land-Use Regression model to predict the concentration of PM2.5-bound heavy metals in the eastern region of China21.
Therefore, this paper aims to complete the city-level national HMEAs dataset from 2015 to 2020 using a non-interpolation-based, machine learning approach. The decision to focus solely on these six years is due to the limited availability of input variable data. To the best of our knowledge, this is the first dataset of its kind at the city-level for China, covering data from 367 cities.
This city-level national HMEAs dataset can be valuable to a wide audience, including researchers, policymakers, and those interested in the subject. It can help evaluate the health risks associated with exposure to toxic metals, establish reference values for regulations, and track changes in pollution levels over time, which is vital for assessing the effectiveness of pollution control efforts and changes in air quality management practices.
Methods
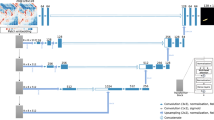
An overview of our methods is shown in Fig. 1.

Flowchart diagram of methods to create HMEAs.
HMEAs data
To further curb the escalating emissions of heavy metals from fuel combustion and industrial processes, the State Council of the Chinese government officially approved a specific comprehensive prevention plan targeting the five most heavily polluted and toxic HMs (Hg, As, Pb, Cd, and Cr) for the 12th Five-Year Plan (2011–2015). Despite the considerable research on mercury emissions into the atmosphere26,27,28, our study focuses on the other atmospheric heavy metals mentioned above due to the highly volatile and unstable nature of mercury. A comprehensive literature search addressing chromium (Cr), cadmium (Cd), arsenic (As) and lead (Pb) emissions into the atmosphere (abbreviated as CrEA, CdEA, AsEA, and PbEA) from 2000 to 2021 was conducted using Web of science and China National Knowledge Infrastructure (Website: https://www.cnki.net/) to obtain data using the following search terms, where “TS” represents the article theme:
TS = [(PM2.5 OR atmosphere) AND (metal OR metals OR heavy metals OR heavy metal OR Cr OR Cd OR As OR Pb OR chromium OR cadmium OR arsenic OR lead) AND (address: China)] AND (From 2000 to 2021)].
A total of 118175 publications were initially identified. These publications were ranked based on their relevance, with the top 1753 most relevant publications retained. Subsequently, a screening process was implemented by examining the sections of materials and methods to determine the suitability, in total, 208 publications of studies were selected based on the following criteria: (1) clear specification of the sampled particulate matter type, (2) explicit documentation of the sampling site locations, and (3) proper labelling of units for HMEAs data. Because some regions had multiple studies available, spanning different years, we selected those studies that provided comprehensive data for all four target heavy metals. This selection process resulted in a final set of 74 studies. Subsequently, we extracted data from tables and figures using the Web GetData Software (https://getdata.com/). This process yielded a dataset comprising 103 data points for Cr, 98 data points for Cd, 92 data points for As, and 108 data points for Pb.
To calculate the HMEAs (Cr, Cd, As and Pb), the following heuristic formula was employed:
Where the parameter “Industrial Particulate Emissions” is obtained from the National Statistical Yearbook, and the parameter k represents the unit conversion factor, ensuring that the resulting HMEAs is reported in ton (t). This formula is based on the following rationale: The majority of the HMEAs data found in literatures represent the concentration of heavy metals within particulate matter. Dividing these values by the particulate matter concentration yields the concentration of heavy metals in the atmosphere. Considering that particulate matter is the primary carrier of heavy metals in the atmosphere, and industrial sources contribute approximately 75.4% of the total atmospheric particulate matter emissions (based on the Second National Pollution Source Census Bulletin), we approximately consider industrial particulate matter emissions as atmospheric content. Multiplying this by the concentration of heavy metals in the air results in the heavy metals emissions into the atmosphere.
Particularly noteworthy is that the HMEAs concentration data collected covers the years 2000 to 2021, spanning 22 years. However, the HMEAs dataset constructed in this study is limited to the six years from 2015 to 2020. On one hand, the original HMEAs concentration data is obtained from literature, and its limited volume for the years 2015–2020 raises concerns about the adequacy for subsequent modeling, making it challenging to ensure the generalization capability of the models. On the other hand, the input variables for prediction, such as industrial pollutant emissions and vehicular emissions, are primarily sourced from national statistical yearbooks, with data available for only a few provinces before 2015, and most cities lack data. For these reasons, we utilized data from 2000 to 2021 for modeling and testing model performance, and employed the established model to predict HMEAs data for the years 2015 to 2020.
Environmental covariates
In this study, environmental covariates, such as industrial emission and Meteorological factors, were chosen based on existing literatures21,29, these covariates play crucial roles in shaping air quality cand, consequently, the presence of heavy metals in particulate matter. Considering data integrity concerns, the covariate data utilized for modeling are all based on the data from the year 2015. Here, the detailed rationale for selecting these covariates and their data source are presented as follows:
Industrial Pollutants
Industrial emissions, including sulfur dioxide (indSO2) and nitrogen oxides (indNOx), are significant contributors to HMEAs9,30. These emissions can serve as oxidizing agents in the atmosphere, reacting with heavy metal compounds and likely transforming them into more mobile and readily dispersible forms31, which remarkably influence HMEAs. The data representing industrial pollutants emissions, were acquired from the National Statistical Yearbook.
In the absence of city-level data for indNOx in 2015 and 2016, available only at the provincial level, we employed an estimation method based on the data from 2017 to 2020. The estimation procedure is as follows: To complete the data for the years 2017–2020, we applied linear temporal interpolation to fill in missing values for cities with incomplete data for specific years. At this point, it’s worth mentioning that the missing value filling method used here involves linear interpolation, but the subsequent prediction processes utilize non-linear machine learning methods. We observed that the proportion of indNOx emissions from each city to the corresponding provincial emissions in different years was relatively consistent, with most fluctuations hovering around 10%. Therefore, we calculated the indNOx emission data for the years 2015–2016 based on the provincial emissions and the average city-to-province ratio of emissions from 2017 to 2020.
The emission sources of heavy metals vary significantly across different regions. The uniform adoption of industrial sulfur dioxide and industrial nitrogen oxides as emission sources in this study is justified for the following reasons: First, the study covers a broad scope, spanning the national and municipal levels. Unlike smaller regions where pollution sources and emissions are well-defined, the industrial categories for each municipality are highly complex, making it challenging to ascertain emission quantities for the industrial sources across all 367 municipalities in China. Second, currently available data from Chinese government departments such as the Ministry of Ecology and Environment and the Ministry of Energy only provide total emissions of industrial sulfur dioxide and nitrogen oxides without industry-specific breakdowns.
Vehicle Emissions
Vehicle emissions are a major source of nitrogen oxides (carNOx) and particulate matter (carSmoke). These emissions can interact with heavy metals in the atmosphere, potentially increasing the overall load of heavy metals32. For example, during the operation of vehicles, brake and tire wear can cause the release of heavy metals like Cr and Pb19, which can contribute to HMEAs, especially in urban areas with high vehicular traffic. Additionally, the combustion of fuel in vehicles can release emissions containing heavy metals such as As and Pb33,34, which may subsequently be absorbed by airborne particulate matter. Data on vehicle emissions, including nitrogen oxides (NOx) and particulate matter, was obtained from both the National Statistical Yearbook and the National City Statistical Yearbook, but only provincial data on vehicle emissions was available. Considering the city-level vehicle emissions were strongly correlated with the number of motor vehicles, the following formula Considering the city-level vehicle emissions were strongly correlated with the number of motor vehicles, the following formula was utilized:
Since the period from 2015 to 2020 marked the initial stages of the development of new energy vehicles, accounting for a relatively small proportion, ranging from 1.3% to 1.75% of the total number of motor vehicles (data derived from Ministry of Public Security), this study did not take into account the emissions of heavy metals from new energy vehicles.
Population
Human activities, including industrial processes and transportation, exhibit a connection with the heavy metals emissions into the atmosphere35. The size and density of the population in a given area can affect the local concentration of heavy metals in the atmosphere, consequently affecting the HMEAs, as regions such as Henan, Shandong, and Anhui, with more extensive human activity often experience higher emissions21. Population data were retrieved from the National Statistical Yearbook.
Meteorological covariates
Meteorological factors can influence the dispersion, transport, and deposition of particulate matter36,37, have a strong effect of HMEAs. For instance, due to the scavenging effects on particulate matter by wet deposition, precipitation was negatively correlated with particulate matter concentration, evidently impacting HMEAs38. This is attributed to the varying characteristics of heavy metals in the atmosphere, including size distributions, temporal variations, and their relationships with meteorological parameters, these variations contribute to their complex health risks39. Meteorological data, including temperature, humidity, sunlight duration, wind speed, and precipitation, were obtained from the China National Environmental Monitoring Center (http://www.cnemc.cn/).
Data preprocessing
The existing dataset encountered certain challenges characterized by a limited sample size, substantial differences in magnitude between various parameters, and the presence of outliers—extremely large and small values that can significantly contribute to high errors. To address these challenges, data preprocessing was conducted, involving the utilization of the Synthetic Minority Over-sampling Technique (SMOTE) method, which has proven effective in balancing and augmenting data when dealing with limited samples Table 1.
Data augmentation
In this study, we applied SMOTE to expand the dataset, resulting in increased data points for HMEAs, specifically 264 for CrEA, 199 for CdEA, 217 for AsEA, and 285 for PbEA. As demonstrated in Fig. 2, the augmentation process effectively rectified the data distribution, particularly by supplementing the initial dataset with additional data points for the rare, extremely high values, thereby enhancing data balance. A t-test was conducted on the synthetic data generated by SMOTE and the real data (results in Table 2), revealing non-significant differences between the synthetic and real data. This suggests the credibility of the synthetic data.

Distribution charts of original data (left) for CrEA/CdEA/AsEA/PbEA, augmented data (center) by SMOTE, and the combined dataset (right).
Data Transformation
With the purpose of achieving a more favorable approximation to a normal distribution, a natural logarithm transformation was applied to CrEA, CdEA, AsEA, PbEA, indSO2, indNOx, carNOx, carSmoke, sd, wsp, and preci. Subsequently, outliers were removed from each column using a 3-fold standard deviation criterion.
Machine learning modeling
Dataset Splitting
In our data partitioning strategy, we employed 10-fold cross-validation to rigorously assess the performance of the ML models. The dataset comprises both real data and synthetic data generated using SMOTE. For the training set, 50% of the real data was thoughtfully combined with 50% of the synthetically generated data, while the remaining 50% of the real data was reserved for the test set. This process was repeated ten times, with each iteration using a distinct data partition. To emphasize, the test evaluations were conducted exclusively on the entirely real data subset. This approach mitigates the risk of overfitting to the training data, and allows us to evaluate the model based on real data’s characteristics, as the synthetic data was deemed unsuitable for testing.
Model Selection
To identify the most suitable model for predicting HMEAs, we evaluated nine machine learning models. Including a variety of machine learning models serves the purpose of exploring different approaches and capturing the diverse patterns present in the data. Among the chosen models, some are linear, while others are non-linear.
Linear Models: including Linear Regression (LR), Ridge, BayesianRidge (Bayesian), Lasso, ElasticNet, these models assume a linear relationship between input features and the target variable. Despite their simplicity, using multiple linear models allows for capturing different aspects of the linear relationship and accounting for potential collinearity issues.
Non-linear Models: including KNeighborsRegressor (KNN), MLPRegressor (MLP), RandomForestRegressor (RF), LGBMRegressor (LGBM), these models are capable of capturing non-linear relationships in the data. KNN relies on local patterns, MLP is a neural network capable of handling complex non-linearities, and RF and LGBM are ensemble methods effective in capturing intricate relationships and feature importance.
The application of multiple linear models is motivated by the desire to investigate different facets of linear relationships and potential collinearity challenges. Additionally, this approach provides a comparison against non-linear models to assess whether the data exhibits significant non-linearities that the linear models may not capture effectively. Parameter design can be provided upon request. The coefficient of determination (R2), root-mean-square error (RMSE) and Mean Absolute Error (MAE) on the testing dataset were utilized to compare the prediction performance. R2, RMSE and MAE values were calculated using Eqs. 3, 4 and 5, respectively.
Where \({\widehat{{\rm{y}}}}_{{\rm{i}}}\), yi and \(\bar{\mathrm{y}}\) represent the predicted values, observations and average observations, respectively. Models with high R2 values and low RMSE and MAE will be selected.
Model uncertainty
We calculated the probability of coverage for prediction intervals (PICP). This probability represents the percentage of samples falling within the boundaries of a prediction interval, given a specific level of confidence. If the uncertainty estimates are appropriately determined, the PICP values should approximate 0.90.
HMEAs prediction creation
Once the models were trained on the training dataset, we utilized the trained models to predict HMEAs for the test dataset. The predictions, initially provided in logarithmic form, were transformed into their original content values. We then assessed the model’s performance by calculating R2, RMSE, and MAE between the predicted and actual values. Subsequently, this approach provides a more accurate assessment of the model’s performance, helping to prevent overly optimistic results and ensuring that the model’s predictions are in closer agreement with real observations.
Data Records
The dataset of HMEAs is available on figshare with a doi of https://doi.org/10.6084/m9.figshare.24762513.v440.
Specifically, the dataset encompasses HMEAs data spanning the time window from 2000 to 2021 at the city level. The files comprise six distinct datasets: CrEA_predictions, CdEA_predictions, AsEA_predictions, PbEA_predictions, HMEAs_data, and Environmental_covariates_data. Each of the first four tables contains eight columns. The first and second columns denote the province and the city, respectively, while columns 3–8 correspond to data for the years 2000–2021, measured in tons.
The HMEAs_data file specifies the sources and references for all original data in the manuscript, providing a comprehensive list of detailed original HMEAs data.
The Environmental_covariates_data table consists of 15 sheets (Table 3), each dedicated to the raw data used in calculating 10 environmental covariates based on the Methods above. These data were obtained from publicly available statistical yearbooks, meteorological monitoring stations, and other sources on the Chinese government website. The raw data, sourced from these platforms, underwent necessary conversions before being incorporated as input data into the model.
On Github is available the code in Python language to reproduce the HMEAs computation starting from the raw data. In the main folder “Code” there are four sub-folders named “CrEA_code”, “CdEA_code”, “AsEA_code”, and “PbEA_code”, containing the scripts used for the HMEAs computation.
Technical Validation
Model performance
The results, averaged over 10-fold cross-validation on the training and testing dataset for R2, RMSE, and MAE, are presented in Table 4. All models exhibit lower performance metrics on the excluded testing dataset compared to their training counterparts (10-fold CV). This difference is primarily due to the testing data not being involved in model development and the inherent variability introduced by the random assignment of monitoring sites to the testing set. Among these models, both RF and LGBM consistently exhibited significantly higher R2 values and lower RMSE and MAE scores than other models. Specifically, for CrEA, the LGBM model demonstrated superior performance with an R2 value of 0.84 (compared to 0.76 for RF), accompanied by lower RMSE and MAE, showing a reduction of 15%-20%. However, a different trend was observed for CdEA, AsEA, and PbEA, where the RF model exhibited top performance, yielding the highest R2 values: 0.58 for CdEA (0.41, the second-best result from LGBM), 0.73 for AsEA (0.68, the second-best result from LGBM), and 0.70 for PbEA (0.61, the second-best result from LGBM). Furthermore, the RF model achieved lower RMSE and MAE values by 7%-65% for these three HMEAs. Consequently, based on a comprehensive evaluation and superior performance, the LGBM model was chosen for CrEA, while the RF model was selected for CdEA, AsEA, and PbEA.
The scatter plots depicted values predicted by RF and LGBM versus observed values in Fig. 3. It’s noteworthy that the PbEA dataset exhibits an exceptionally wide numerical range, spanning from 0 to 1800, while the data spans for the other three HMEAs reach a maximum of only 90. Additionally, there are very few values in the PbEA dataset exceeding 700t (only 2), and these two values may be outliers. The models perform well on lower numerical values, encompassing both the training and testing sets, with AsEA standing out. Specifically, the fitted R2 for AsEA predictions versus actual values in the testing sets reaches as high as 0.87, with the R2 remaining at 0.8 when AsEA values are below 20t. Additionally, CrEA, CdEA, and PbEA demonstrate satisfactory performance in the testing set within the ranges of 0-10t, 0-10t, and 0-100t, respectively, with R2 values ranging from 0.44 to 0.72. A consistent trend is observed across all models, indicating an inclination to underestimate HMEAs values beyond the specified numerical ranges. This tendency probably partly stems from the scarcity of high values in the training set compared to low values, suggesting a potential limitation in capturing extreme values during model training. Other factors, such as hyperparameter settings or the unique distribution of data within the context of modeling, may also contribute.

Scatter plot of predicted values versus actual values in training (gray) and testing set (blue). Red circles indicate magnified regions.
Predictions assessment
Comparative analysis of point data
After predicting HMEAs data for 367 cities nationwide from 2015 to 2020 using the selected model, we compared these predictions with the actual data found in literatures, as shown in Table 5. In comparison, the fitting R2 is higher for AsEA, CdEA, and PbEA than that for CrEA, particularly for PbEA, with an average R2 value as high as 0.83, and the R2 remains consistently above 0.7 for all years, despite the high RMSE and MAE in 2017 and 2018. In general, according to the RMSE and MAE, the order of errors from smallest to largest is: CdEA, CrEA, AsEA, and PbEA, indicating that CdEA values are likely the most accurate. Due to the larger data volume for the four HMEAs and the model being trained based on covariate data from 2015, the fitting R2 is relatively higher in this year. Some individual years have R2 values exceeding 0.8, such as the 2016 (1.00) and 2020 (0.98) for AsEA, possibly due to the small data size for these two, with only 5 and 3 data points, respectively. Transferring the model trained on 2015 data to other years resulted in a decrease in performance, but overall, it remains acceptable.
Comparative analysis of annual totals
To further validate the data quality, we compared the predicted data with the reported annual emissions of four HMEAs by Cheng et al.41, as shown in Fig. 4. We performed linear regression between the 2010 data and our predicted data for the years 2015–2020, revealing a good fit with R2 values all exceeding 0.8. The R2 values for AsEA and PbEA were exceptionally high, exceeding 0.95. Due to the scale setting, CrEA and AsEA from 2015 to 2020 appear to overlap on the graph. This is because of the close proximity of their emission levels during these years. Detailed data can be found in the table below, with differences ranging between 4.7% and 15.5%, except for the year 2020, where the difference is 27.4%, resulting in the appearance of overlapping data points. However, in 2010, there is a substantial difference between the values of CrEA and AsEA (13715t and 4196t, respectively), leading to significant variations in the fitting R2. Notably, the data for the years 2011–2014 is currently unavailable. However, based on the graph, it is evident that after the implementation of China’s Action Plan for the Prevention and Control of Air Pollution in 2013, and following a year or two of preparation, there was a significant decrease in HMEAs by the year 2015. The policy’s effectiveness in implementation appears to be highly favorable.

HMEAs emissions compared with other literature report. The red dashed vertical line represents the year 2013 when China’s Action Plan for the Prevention and Control of Air Pollution was implemented.
Model uncertainty
Regarding uncertainty, for a 95% confidence interval, the PICP values were 0.93, 0.94, 0.9, and 0.93 for CrEA, CdEA, AsEA, and PbEA, respectively. All four HMEAs’ PICP values are above 0.9, indicating that the data estimates are reasonable.
Usage Notes
The results of this study have certain limitations due to the quality and quantity of data collected from published papers. The data distribution of some input features and output targets was inconsistent due to multiple variations in research objectives, methodologies, and experimental conditions. For instance, the HMEAs values were determined based on a wide range of features, including, but not limited to, emissions of household pollutants, vegetation coverage, municipal solid waste incineration, etc. Additionally, in this study, the dataset for HMEAs covers a 20-year span, while covariate data used for modeling are from 2015. This time difference may introduce errors. Future research should consider a time series approach to better capture the temporal variations in HMEAs.
Another significant concern involves the considerable disparities in the sources of different heavy metals across diverse regions. Employing a uniform contribution ratio for industrial sources could introduce uncertainty in estimation results. While acknowledging the validity of this concern, obtaining pollution source emission data categorized by industry for all 367 municipalities poses a formidable challenge. Addressing this issue is crucial for enhancing the model’s accuracy. In the event that detailed emission data by industry become available in the future, refining the model would be beneficial, presenting a potential focal point for subsequent research.
These constraints may cause uncertainties in some of the prediction results and may not precisely reflect real-world scenarios. Therefore, future research should focus on improving the ML model using a database that includes studies with well-defined scientific objectives and similar methodologies under uniform experimental conditions.
In addition, it is crucial to note that further research on the atmospheric emissions of other heavy metals, including mercury, copper, zinc, nickel, and so on, is essential. This extension of our study aims to contribute to a comprehensive understanding of the broader spectrum of atmospheric heavy metal pollutants and to support ongoing environmental research efforts.
Code availability
Data processing was performed in Python 3.10, and data used for the computation of HMEAs at city level are available can be accessed at Github repository located at https://github.com/Olivia-2012/HMEAs_DataSet. We implemented the procedure described in the Methods section.
References
Jayakumar, M., Surendran, U., Raja, P., Kumar, A. & Senapathi, V. A review of heavy metals accumulation pathways, sources and management in soils. Arab. J. Geosci 14, 2156 (2021).
Liu, F. et al. Impact of different industrial activities on heavy metals in floodplain soil and ecological risk assessment based on bioavailability: A case study from the Middle Yellow River Basin, northern China. Environ. Res. 235, 116695 (2023).
Jing, F., Chen, X., Yang, Z. & Guo, B. Heavy metals status, transport mechanisms, sources, and factors affecting their mobility in Chinese agricultural soils. Environ. Earth Sci. 77, 104 (2018).
Ni, R. & Ma, Y. Current inventory and changes of the input/output balance of trace elements in farmland across China. PLoS ONE 13, e0199460 (2018).
Liu, P., Zhang, Y., Wu, T., Shen, Z. & Xu, H. Acid-extractable heavy metals in PM2.5 over Xi’an, China: seasonal distribution and meteorological influence. Environ. Sci. Pollut. Res. 26, 34357–34367 (2019).
Kim, E., Kim, B.-U., Kang, Y.-H., Kim, H. C. & Kim, S. Role of vertical advection and diffusion in long-range PM2. 5 transport in Northeast Asia. Environ. Pollut. 320, 120997 (2023).
He, B. et al. Contributions of Regional Transport Versus Local Emissions and Their Retention Effects During PM2. 5 Pollution Under Various Stable Weather in Shanghai. Front. Environ. Sci. 10, 219 (2022).
Ahmad, H. R. et al. Integrated risk assessment of potentially toxic elements and particle pollution in urban road dust of megacity of Pakistan. Human Ecological Risk Assessment: An International Journal (2019).
Li, F. et al. PM2.5-bound heavy metals from the major cities in China: Spatiotemporal distribution, fuzzy exposure assessment and health risk management. J. Clean. Prod. 286, 124967 (2021).
Moreno, T. et al. Variations in time and space of trace metal aerosol concentrations in urban areas and their surroundings. Atmos. Chem. Phys. 11, 9415–9430 (2011).
Yan, J. et al. Industrial PM2. 5 cause pulmonary adverse effect through RhoA/ROCK pathway. Sci. Total Environ. 599, 1658–1666 (2017).
Zhu, W. K., Yang, Y. K., Li, P. Y. & Liu, J. Distribution characteristics of PM2.5/PM10 and heavy metals in autumn and winter in Haikou. Environ Sci Manage 43, 49–52 (2018). in Chinese.
Shan, H. et al. Heavy metals in PM2.5 in four metropolitan cities in Northwest China: pollution characteristics and health risk assessment. Chin J Public Health 38, 476–480 (2022). in Chinese.
Chen, R., J, L. Y. & Lliu, X. Y. Analysis on health risks of ten elements in ambient PM 2.5 in Lanzhou during 2015-2017. J. Environ. Health 36, 419–422 (2019). in Chinese.
Chen, J. et al. Characteristics of trace elements and lead isotope ratios in PM(2.5) from four sites in Shanghai. J. Hazard. Mater. 156, 36–43 (2008).
Ma, Y. et al. Comparison of inorganic chemical compositions of atmospheric TSP, PM(10) and PM(2.5) in northern and southern Chinese coastal cities. J. Environ. Sci. (China) 55, 339–353 (2017).
Liu, Y., Zhu, P. & Geng, Y. C. Lead pollution in air particles in Zhenjiang city. Environmental Protection and Technology 24, 31–33 (2018). in Chinese.
Liu, S. et al. Significant but Spatiotemporal-Heterogeneous Health Risks Caused by Airborne Exposure to Multiple Toxic Trace Elements in China. Environ. Sci. Technol. 55, 12818–12830 (2021).
Luo, H. et al. Heavy metal pollution levels, source apportionment and risk assessment in dust storms in key cities in Northwest China. J. Hazard. Mater. 422, 126878 (2022).
Wang, F. et al. A hybrid framework for delineating the migration route of soil heavy metal pollution by heavy metal similarity calculation and machine learning method. Sci. Total Environ. 858, 160065 (2023).
Lyu, T. et al. Estimating the geographical patterns and health risks associated with PM2.5-bound heavy metals to guide PM2.5 control targets in China based on machine-learning algorithms. Environ. Pollut. 337, 122558 (2023).
Zhong, S. et al. Machine Learning: New Ideas and Tools in Environmental Science and Engineering. Environ. Sci. Technol. 55, 12741–12754 (2021).
Costa-Climent, R., Haftor, D. M. & Staniewski, M. W. Using machine learning to create and capture value in the business models of small and medium-sized enterprises. Int. J. Inf. Manage. 73, 102637 (2023).
Mohammadiun, S. et al. Evaluation of machine learning techniques to select marine oil spill response methods under small-sized dataset conditions. J. Hazard. Mater. 436, 129282 (2022).
Chen, K. et al. Comparative analysis of surface water quality prediction performance and identification of key water parameters using different machine learning models based on big data. Water Res. 171, 115454 (2020).
Wu, Q. et al. Temporal Trend and Spatial Distribution of Speciated Atmospheric Mercury Emissions in China During 1978–2014. Environ. Sci. Technol. 50, 13428–13435 (2016).
Liu, K. et al. Measure-Specific Effectiveness of Air Pollution Control on China’s Atmospheric Mercury Concentration and Deposition during 2013–2017. Environ. Sci. Technol. 53, 8938–8946 (2019).
Zhang, Y. et al. Improved Anthropogenic Mercury Emission Inventories for China from 1980 to 2020: Toward More Accurate Effectiveness Evaluation for the Minamata Convention. Environ. Sci. Technol. 57, 8660–8670 (2023).
Reid, C. E., Considine, E. M., Maestas, M. M. & Li, G. Daily PM2.5 concentration estimates by county, ZIP code, and census tract in 11 western states 2008–2018. Scientific Data 8, 112 (2021).
Cheng, K. et al. Atmospheric Emission Characteristics and Control Policies of Five Precedent-Controlled Toxic Heavy Metals from Anthropogenic Sources in China. Environ. Sci. Technol. 49, 1206–1214 (2015).
Xie, J.-J. et al. Speciation and bioaccessibility of heavy metals in PM2.5 in Baoding city, China. Environ. Pollut. 252, 336–343 (2019).
Bi, C. et al. Characteristics, sources and health risks of toxic species (PCDD/Fs, PAHs and heavy metals) in PM2.5 during fall and winter in an industrial area. Chemosphere 238, 124620 (2020).
Bonfiglio, R., Scimeca, M. & Mauriello, A. The impact of environmental pollution on cancer: Risk mitigation strategies to consider. Sci. Total Environ. 902, 166219 (2023).
Nachana’a Timothy, E. T. W. Environmental pollution by heavy metal: an overview. Chemistry 3, 72–82 (2019).
Vareda, J. P., Valente, A. J. & Durães, L. Assessment of heavy metal pollution from anthropogenic activities and remediation strategies: A review. J. Environ. Manag. 246, 101–118 (2019).
Sharma, P. et al. Seasonal dynamics of particulate matter pollution and its dispersion in the city of Delhi, India. Meteorology Atmospheric Physics 134, 28 (2022).
Li, X. et al. Particulate matter pollution in Chinese cities: Areal-temporal variations and their relationships with meteorological conditions (2015–2017). Environ. Pollut. 246, 11–18 (2019).
Lai, S. et al. Characterization of PM2.5 and the major chemical components during a 1-year campaign in rural Guangzhou, Southern China. Atmos. Res. 167, 208–215 (2016).
Tian, Y. et al. Size distribution, meteorological influence and uncertainty for source-specific risks: PM2.5 and PM10-bound PAHs and heavy metals in a Chinese megacity during 2011–2021. Environ. Pollut. 312, 120004 (2022).
Dong, Q. et al. A city-level dataset of heavy metal emissions into the atmosphere across China from 2015-2020. figshare https://doi.org/10.6084/m9.figshare.24762513.v4 (2024).
Cheng, K. et al. Atmospheric emission characteristics and control policies of five precedent-controlled toxic heavy metals from anthropogenic sources in China. Environ. Sci. Technol. 49, 1206–1214 (2015).
Acknowledgements
Financial supports in this study were from the Science and Technology Innovation Project of Chinese Academy of Agricultural Sciences, and The Central Public-interest Scientific Institution Basal Research Fund (1102021500170022301).
Author information
Authors and Affiliations
Contributions
All authors contributed to the study. Qi Dong and Yue Li contributed equally to this paper. Qi Dong and Yue Li—investigation and data collection; methodology; modelling; validation; visualization; writing—original draft; Xinhua Wei, Le Jiao, Lina Wu, Zexin Dong—data collection; methodology; proofreading; Yi An—conceptualization; formal analysis; methodology; supervision; visualization; writing—review & editing. The authors have read and approved the final draft of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Dong, Q., Li, Y., Wei, X. et al. A city-level dataset of heavy metal emissions into the atmosphere across China from 2015–2020. Sci Data 11, 258 (2024). https://doi.org/10.1038/s41597-024-03089-3
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41597-024-03089-3
