
Abstract
The Adolescent Brain Cognitive Development (ABCD) Study® has collected data from over 10,000 children across 21 sites, providing insights into adolescent brain development. However, site-specific scanner variability has made it challenging to use diffusion MRI (dMRI) data from this study. To address this, a dataset of harmonized and processed ABCD dMRI data (from release 3) has been created, comprising quality-controlled imaging data from 9,345 subjects, focusing exclusively on the baseline session, i.e., the first time point of the study. This resource required substantial computational time (approx. 50,000 CPU hours) for harmonization, whole-brain tractography, and white matter parcellation. The dataset includes harmonized dMRI data, 800 white matter clusters, 73 anatomically labeled white matter tracts in full and low resolution, and 804 different dMRI-derived measures per subject (72.3 TB total size). Accessible via the NIMH Data Archive, it offers a large-scale dMRI dataset for studying structural connectivity in child and adolescent neurodevelopment. Additionally, several post-harmonization experiments were conducted to demonstrate the success of the harmonization process on the ABCD dataset.
Similar content being viewed by others

Background & Summary
The Adolescent Brain Cognitive Development (ABCD) Study® is a landmark research project focused on child health and brain development1. The ABCD Research Consortium consists of 21 research sites across the US and has collected one of the largest multi-domain datasets, including neuroimaging, behavioral, cognitive, and genetic data, from over 10,000 children from middle childhood into early adulthood2. Using this dataset, the ABCD study aims to provide the opportunity to understand the factors that shape brain and cognitive development during this crucial period of life. To ensure uniformity in scanning protocols, the ABCD study has taken extensive measures to maintain imaging acquisition parameters and protocols consistent across all 21 participating sites3. Despite these efforts, data acquired from different sites and vendors (Siemens, Philips, and GE) introduce significant site effects4, due to scanner-specific MR acquisition sequences and data reconstruction algorithms. In fact, given the vast array of design choices and vendor-specific decisions beyond the users’ control, it is almost always challenging to completely standardize the different scanners in multi-site neuroimaging studies such as the ABCD study, leading to inter-scanner differences in the acquired data.
Diffusion-weighted magnetic resonance imaging (dMRI) is a non-invasive imaging technique that can detect microstructural changes and reveal white matter connectivity in the brain. Studies have shown that even small scanner-related differences in the dMRI data collected from various scanners can result in significant measurement biases in the dMRI measures of white matter connectivity and microstructure5,6,7,8,9,10,11. Even when scanners from the same manufacturer are used across different sites, the measurement biases in the dMRI data can be substantial. For example, Thieleking et al.12 showed that the difference in the fractional anisotropy (FA) from the same healthy participants (N = 121) scanned on two 3 T Siemens Magnetom scanners could be up to 33 times larger than the effect seen in healthy aging. In addition, Schilling et al.13 demonstrated the significant variability in connectivity measures across different scanners (e.g., the density of streamlines in white matter fiber connections/tracts), which also resulted in significant differences in the related microstructural measures. Moreover, multiple studies have highlighted that scanner-related variability is highly non-linear across various tissues and white matter regions/tracts7,10,11,13,14,15. Non-linear effects in scanner-specific imaging can arise from various factors, including magnetic field non-uniformity, B0 shimming order (linear vs higher order shim), gradient non-linearity, RF field inhomogeneity, noise characteristics, variations in acquisition parameters, and differences in reconstruction software. These factors can introduce variations in signal intensity, spatial distribution, geometric distortions, and image quality, necessitating appropriate correction methods for accurate analysis and interpretation of the data11,12. Thus, many studies underscore the significance of eliminating bias due to scanner from dMRI data at the voxel level before running joint analysis in multi-site studies such as the ABCD study4,6,7,16,17,18,19,20,21.
Enabling pooled large-scale analysis of multi-site datasets represents an outstanding opportunity for improving our understanding of the human brain in health and disease. However, such research requires large sample sizes, which can only be obtained by appropriate pooling and removal of scanner-specific effects from dMRI data acquired from multiple scanners. “Harmonization” is a way to mitigate the measurement differences attributed to the scanner-, protocol-, or other site-related effects6,7,16,17,18,19,20,21. The goal of harmonizing dMRI data is to preserve variability that is purely related to biology or disease and remove variability caused by intrinsic or acquisition-related factors of the scanners, which can conceal the desired effect. Various data harmonization methods have been proposed in the literature8,19,22,23,24,25,26. A majority of these approaches are based on adding statistical covariates to remove site effects. These methods are commonly used in multiple fields, from genetics to functional MRI and recently in dMRI19,22,23,24,25,26. They typically involve fitting a dMRI model (such as diffusion tensor imaging) to obtain the desired dMRI measures (e.g., FA) for each subject at each site, followed by regression modeling where the site is added as a linear covariate to minimize inter-site effects. These approaches are limited for several reasons. First, they assume linear site effects in the microstructural measures (such as FA, mean diffusivity, kurtosis, etc.). However, this assumption has been challenged by many studies demonstrating nonlinear site effects7,15,27,28. Second, white matter tractography can be affected by scanner biases13, which raises doubts about the effectiveness of data harmonization after running whole-brain tractography. Tractography plays a crucial role in reconstructing the brain’s white matter connections in vivo and serves as a valuable tool for quantitatively mapping the brain’s structural connectivity using measures of connectivity or tissue microstructure. It is important to note that merely harmonizing the structural connectivity matrices derived from tractography of unharmonized data can be inadequate and ineffective in fully mitigating scanner effects across the diffusion MRI (dMRI) data13.
On the other hand, harmonizing dMRI data obtained directly from the scanner has several advantages. As demonstrated in several of our earlier works6,7, nonlinear and voxel-wise site effects can be removed, allowing robust and unbiased tractography estimation across sites. Further, any dMRI microstructural model (e.g., single or multi-tensor, standard model of diffusion, NODDI, etc.29,30,31) can be used without having to worry about the confounds due to scanner-related biases during the model estimation process. The dMRI community has recognized the value of performing harmonization directly on the scanner data and has organized multiple community challenges to determine the best-performing algorithm as part of the Medical Image Computing and Computer Assisted Intervention (MICCAI) conference10,11. Across all metrics, our harmonization algorithm resulted in the best performance10,11. The effectiveness of our approach has also been demonstrated through several studies in schizophrenia and other disorders7,8,32,33,34,35,36,37,38,39,40,41,42,43,44.
Furthermore, the analysis of very large dMRI data sets represents a significant computational burden for many neuroscience researchers and laboratories. Of particular neuroscientific interest is the quantitative hypothesis-driven study of the brain’s major white matter fiber tracts45. To enable the study of the fiber tracts across very large dMRI datasets, it is critical to define anatomical fiber pathways (e.g., the arcuate fasciculus) consistently across all subjects, irrespective of their age, gender, or disease indications. It is also critical to automate the extraction of these fiber pathways and the measurement of their tissue microstructure. Several approaches have demonstrated the advantages of automated extraction of white matter fiber tracts46,47,48,49,50. In this study, we apply our robust multi-fiber tractography method, which allows the measurement of fiber-specific microstructural properties51,52. We then perform automated tract extraction using a well-established fiber clustering pipeline53,54 together with a neuroanatomically curated white matter atlas46. We have previously demonstrated that this framework consistently parcellates white matter tracts across the lifespan46 with high test-retest reproducibility55.
The aim of this study is to create a dataset of harmonized dMRI data and tract-specific microstructure measures to enable novel scientific investigations across thousands of subjects from the ABCD study, release 3. To produce this novel dataset, which includes data from quality-controlled 9345 subjects of the over 10,000 subjects, we applied our advanced dMRI harmonization, tractography, and white matter parcellation computational pipeline. First, our robust dMRI data harmonization algorithm was applied to remove scanner-specific biases from the multi-site dMRI data. Harmonizing the raw data acquired directly from the scanner in this way enables laboratories to then perform any desired diffusion modeling and analyses on the harmonized dMRI data. Second, robust multi-fiber tractography was computed in the whole brain of all 9345 subjects for highly consistent tracing of white matter connections. Third, 73 subject-specific anatomical white matter tracts were extracted from the tractography of each subject in an automated fashion, and their fiber-specific microstructural properties were quantified. The release of this fiber tract microstructure data will enable laboratories to test neuroscientific hypotheses of interest directly without needing to perform computationally intensive processing. This paper includes several experiments that demonstrate the efficacy of dMRI data harmonization and the success of white matter tract identification on the ABCD dataset. Overall, the release of the proposed dataset represents an unparalleled opportunity for researchers to investigate neurodevelopmental brain changes that were previously challenging to investigate using unharmonized data or smaller sample sizes. The dataset includes harmonized dMRI data, tractography, extracted white matter clusters and tracts, and microstructure measures from the ABCD study, release 3. It is available through the NIMH Data Archive (NDA) repository56, allowing open access to the neuroimaging and neuroscience community.
Methods
The ABCD study dataset
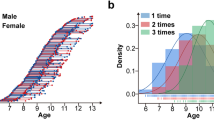
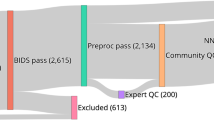
The ABCD study has longitudinally collected an extensive dataset of 11,878 participants across 21 sites with a baseline age of 107–133 months to gain a better understanding of neurodevelopment between childhood and early adulthood (Fig. 1a). In our study, we have exclusively utilized the dMRI scans obtained during the baseline session (i.e., first time point), focusing on the preprocessed version 3.0 of the data release. Refer to Fig. 1a for age, sex, IQ and scanner distribution of the dataset. The details about data recruitment, acquisition, and MRI data preprocessing steps of the ABCD study were previously reported in4,57.

The ABCD study dataset: (a) The original dataset before quality control (QC) procedures were applied to the dMRI data (N=11,878); (b) After QC procedures are applied to the dMRI data by the ABCD study team (N=10,866 for the quality passed dMRI scans); (c) Additional QC steps are applied to the dMRI data in this study, where 3 sites with 12 scanners are removed from the sample (N=9345 for the final dMRI scans used in the subsequent processing steps in this study). We note that our study exclusively incorporated dMRI data from the baseline session of the ABCD study.
The ABCD study provides a longitudinally collected wealth of measured attributes, such as neuroimaging, cognitive, biospecimen, behavioral, youth self-report and parent self-report metrics, and environmental data. The ABCD study dataset can be publicly accessed by researchers through a data use agreement with the NDA2. The study places a strong emphasis on ethical conduct and informed consent, with detailed information given to participants and guardians about potential risks and benefits. In particular, it employs measures to ensure confidentiality and minimize harm, and participants can choose whether to receive feedback on their individual results. Further information is available in Clark et al.58. Notably, the neuroimaging data includes dMRI, structural MRI (both T1- and T2-weighted), and functional MRI data, all of which were collected every two years for almost all participants (48% of whom are female). The participants were scanned using Siemens, Philips, and GE scanners with similar acquisition parameters across 21 sites.
The ABCD study dMRI data acquisition and minimal preprocessing
The dMRI data preprocessing methodologies within the ABCD study were previously documented in the publication dedicated to the ABCD study57. Herein, we provide a concise overview of dMRI data acquisition and the minimal preprocessing steps undertaken in the ABCD study.
DMRI scans were acquired at 1.7 × 1.7 × 1.7 mm3 resolution using multiband EPI with a slice acceleration factor of 33. Siemens and GE scanners collected dMRI data using a single acquisition with 96 diffusion gradient directions, seven b = 0 volumes, and four b-values (6 directions with b = 500 s/mm2, 15 directions with b = 1000 s/mm2, 15 directions with b = 2000 s/mm2, and 60 directions with b = 3000 s/mm2). The Philips scanner used two acquisitions to collect the dMRI data. Philips scan 1 parameters were: 3 directions with b = 0 s/mm2, 4 directions with b = 500 s/mm2, 7 directions with b = 1000 s/mm2, 8 directions with b = 2000 s/mm2 and 29 directions with b = 3000 s/mm2. Philips scan 2 parameters were: 4 directions with b = 0 s/mm2, 2 directions with b = 500 s/mm2, 8 directions with b = 1000 s/mm2, 7 directions with b = 2000 s/mm2 and 30 directions with b = 3000 s/mm2 (Table 1). Minimal preprocessing steps were consistently applied to the dMRI data of each study site by the ABCD study, which included: eddy and motion correction, b0 inhomogeneity correction, gradient unwarp, and resampling to isotropic resolution (1.7 mm3)4,57. While these preprocessing steps are well established and known to improve data quality in release 3 of the ABCD study, they do not correct for biases due to multiple acquisition sites and scanners, which are addressed as part of this study.
Scanner-Software Upgrades in each ABCD Study Site
Several studies have revealed that even slight modification to the scanner software can result in bias in the acquired dMRI data, similar to a site effect, even when the acquisition protocol remains unchanged14,59. However, it is often difficult to predict the bias in the data due to such software updates. Therefore, scanner software (version) updates should ideally be avoided entirely during the course of a study to avoid introducing bias in the dMRI data. However, this is often not feasible in practice. Similar to many large-scale multi-site neuroimaging studies, several scanners within the ABCD study underwent software upgrades during the acquisition of dMRI data. Therefore, we treated each upgrade as an independent scanner. Hence, after counting each software upgrade as a separate “scanner,” the ABCD study included 45 total scanners. Table 2 provides details about the scanners and related upgrades.
DMRI Data Quality Control
The ABCD study applied several automated quality control (QC) procedures, such as head motion statistics and the detection of signal drops to remove low-quality dMRI scans4,57. The trained technicians at the sites of the ABCD study also did manual checks by reviewing the dMRI scans for poor image quality and various imaging artifacts. The scans that did not pass the QC checks were marked as unacceptable data. Refer to Fig. 1b for the distribution of the subjects (per site) that passed the required dMRI data quality.
Additionally, we applied our own automated and manual QC steps to ensure the data was of good quality for harmonization and connectivity analysis (i.e., whole brain tractography and white matter parcellation). This involved using the average whole-brain FA as well as regional FA to screen for outliers, as described in our previous study7. We also conducted manual QC checks on a randomly selected subset of subjects from each scanner. Our findings showed that the dMRI data from most GE and Siemens sites was good quality and suitable for harmonization and tractography analysis. Regarding the minimally processed dMRI data obtained from the Philips scanners, the following observations were made: 1) Artifacts: The data exhibited artifacts, including ringing artifacts, motion artifacts, and excessive smoothing. These artifacts could have originated during the acquisition or pre-processing stages. 2) Multiple Acquisitions: Unlike Siemens and GE data, which were acquired with a single acquisition, Philips data required two separate acquisitions. This difference in acquisition methods may introduce additional variability in the data. Considering these challenges, it was necessary to exclude the data obtained from the Philips scanners from the current study to ensure the reliability and accuracy of the dataset used for analysis.
Due to these factors, data from the Philips scanners that included three sites with 12 scanners used to scan 1518 subjects were excluded from the current study. Our final sample consisted of dMRI data from 9345 participants from Siemens and GE scanners, obtained from 18 sites and 33 scanners. Refer to Fig. 1c for the distribution of subjects and sites used in this work (i.e., for harmonization and tractography analysis). Table 3 details the sites and scanners used in this work.
Convolutional Neural Network (CNN) DMRI Brain Segmentation: A prerequisite for the dMRI data processing pipeline
Before applying the major computational steps as described in Section 2.6, brain masks were generated to isolate only the brain tissue and exclude the skull. This was crucial to focus solely on the brain region, making it an indispensable prerequisite for many processing pipelines in neuroimaging studies, including ours.
The CNN architecture in this method is based on the study of Dey et al.60, which was trained to skull-strip the T1-weighted images. In our case, however, we trained the network on b = 0 s/mm^2 images of the dMRI data to separate the brain from non-brain regions in the image. We modified the CNN architecture to improve the segmentation further by integrating a multi-view aggregation step61. This step combined the results from models trained on 2D slices along three primary axes: coronal, sagittal, and axial. The final brain mask is obtained by combining the probability maps from all three networks.
The brain masking process included a pre-processing step where we registered the b0 images to the standard MNI space along with performing data normalization (scaling the b0 values between 0 and 1) using antsRegistrationSynQuick.sh62 with rigid body transformation to improve the performance of the model in the training step. The deep learning models were trained using manually curated masks of dMRI data from 1500 subjects collected from 10 different datasets, including 200 subjects from the ABCD study. We employed the Adam optimizer with a learning rate of 1e-3 during the training process, and all networks were run for up to 10 epochs. We implemented the deep learning algorithm in Keras-Tensorflow 2.2.4. Finally, as a post-processing step, we transformed the resulting brain mask from the MNI space back to the subject space. These steps are summarized in Fig. 2.

CNN dMRI Brain Segmentation: (1) Pre-processing; (2) Multi-view CompNet; (3) Post-processing. Multi-view CompNet includes three branches: (i) Segmentation Branch - learns the brain region; (ii) Complementary Branch - learns complement of the brain region; (iii) Reconstruction Branch - provides direct feedback to the segmentation and complementary branches and expects reasonable reconstructions. Segmentation and reconstruction branches include a series of encoder and decoder networks with a kernel of size 3 × 3. The number of convolutional filters in the encoder starts from 32, followed by 64, 128, 256, and 512, while the number in the decoder starts from 256, followed by 128, 64, and 32.
To demonstrate the effectiveness of our method with respect to existing tools, we compared our deep learning brain masking method with the most commonly used approach, Brain Extraction Tool (BET)63. We evaluated approximately 400 manually corrected masks from the ABCD study with the output of our deep learning network, resulting in a Dice overlap coefficient of 0.99 and a Jaccard index of 0.987. We note that none of these ~400 subjects were part of the training dataset. In contrast, BET produced lower performance on the same dataset, with a Dice overlap coefficient of 0.957 and a Jaccard index of 0.945.
Finally, we deployed this brain masking tool on the dMRI data of 9345 subjects from the ABCD study using Amazon Web Services (AWS) Elastic Compute Cloud (EC2) g4dn.2xlarge instances (32 GiB CPU memory, NVIDIA T4 GPU with 32 GiB GPU memory, 8 vCPUs), where the entire brain masking process took about 1 min and 30 seconds for each subject. Refer to Fig. 3 for the demonstration of the dMRI data brain masks on five randomly picked brains.

Our deep learning CNN method (https://github.com/pnlbwh/CNN-Diffusion-MRIBrain-Segmentation) was used to perform dMRI Brain Segmentation on the ABCD study’s dMRI data. The results of the segmentation are denoted by the red outlines, which successfully delineate the brains of five randomly selected subjects (Subject A, B, C, D, E) from the ABCD study. We employed fsl’s slicesdir87 for visualization purposes, and each row of the visualization represents a different subject’s brain, while each column displays the various brain slices of that subject.
Overview of the pipeline to process the dMRI Data (N = 9345)
This section describes the major computational steps used to create a dataset of harmonized and processed dMRI data derived from the ABCD study (see Fig. 4). We applied the following computational steps respectively: a) dMRI data harmonization, b) whole-brain tractography, c) subject-specific white matter parcellation, and d) extracting dMRI measures.

DMRI data processing pipeline overview. (a) DMRI datasets are harmonized with the reference scanner (scanner 29) to remove possible site/scanner-specific effects. (b) Whole-brain tractography was computed for each subject using the Unscented Kalman Filter tractography algorithm. (c) White matter parcellation was performed using the WhiteMatterAnalysis package in conjunction with an anatomical white matter atlas, resulting in the parcellation of 73 anatomically well-defined tracts. (d) Multiple dMRI measures were extracted for each parcellated tract.
DMRI Data Harmonization
We applied our retrospective multi-shell dMRI data harmonization algorithm (https://github.com/pnlbwh/multi-shell-dMRIharmonization) to remove the scanner-related differences across 33 scanners (Cetin-Karayumak et al.7). Our harmonization approach employs rotation invariant spherical harmonics (RISH) features and operates at the signal level, effectively mitigating scanner-related biases while accommodating non-linearities inherent in the diffusion magnetic resonance imaging (dMRI) data, which can vary across regions and tissues. To derive the RISH features, we utilize a spherical harmonics basis to represent the dMRI data. The spherical harmonics coefficients are calculated using a small regularization parameter, and the order of the spherical harmonics is determined based on the number of gradient directions. The RISH features are obtained by computing the energy of these spherical harmonics coefficients.
The harmonization algorithm follows a procedure where one scanner is chosen as the reference, and the remaining scanners are harmonized to match the reference scanner. The RISH features of each site are appropriately scaled to adjust the dMRI signal and align the dMRI data from each site with the reference site. The primary objective is to estimate a voxel-wise mapping of the RISH features between the reference and other sites, employing matched healthy controls. This mapping can then be utilized to harmonize the remaining subjects within each respective site, ensuring consistency and comparability across scanners.
In the dMRI data of the ABCD study, scanner 29 from site 16 (a Siemens Prisma scanner) was selected as the reference due to its large sample size (N = 959) and high data quality. The dMRI data from the remaining 32 scanners were harmonized with this reference scanner (for a full list, see Table 3). While scanner 29 was chosen as the reference in this study, we have previously shown that choosing a different scanner as the reference does not affect the performance of harmonization7. In the harmonization process, specific hyperparameters were configured. The selection of spherical harmonics order was based on the number of gradient directions: an order of 2 for b = 500 s/mm^2, an order of 4 for both b = 1000 and b = 2000 s/mm^2, and an order of 8 for b = 3000 s/mm^2. Additionally, a spherical harmonics regularization parameter of 0.00001 was applied to the entire dMRI dataset. These parameters were automatically set within our multi-shell dMRI harmonization pipeline, which can be found at https://github.com/pnlbwh/multi-shell-dMRIharmonization.
The dMRI data harmonization comprises two steps. The first step, template creation, involves aligning around > = 35 subjects per scanner with the reference scanner based on age, sex, IQ, and behavioral information. In a prior study7, we found that approximately 18 subjects can effectively capture scanner-related differences, which is vital for multi-site neuroimaging studies with limited control subjects. While this average number is suitable for resource-constrained clinical studies, the larger sample size in the ABCD study enabled us to match > = 35 subjects per site. This increased number was aimed at minimizing the influence of other data factors and enhancing population mean accuracy.
This matching process is conducted at a group level to eliminate differences between scanners while preserving inter-subject biological variability as much as possible. The following steps below are applied to achieve the matching:
-
1)
Exclusion Criteria: To ensure we capture only scanner-related effects, subjects with a history of cerebral palsy, stroke, tumor, hemorrhage, TBI, aneurysm, hemorrhage, hematoma, epilepsy, seizure, gestational weight <1200 g, birth complications were not included in the template creation step. Moreover, participants diagnosed with psychiatric disorders and those deemed genetically high-risk were also excluded from this step.
-
2)
Quality Controlling: To only include subjects with the highest quality dMRI data in this step, we utilized the “iqc_dmri_1_nbad_frame_slices” metric from the “mriqcrp102” table. This metric signifies the count of censored slices in all frames. The threshold for exclusion (10–20) was determined based on the sample size of each site.
-
3)
Sex Matching: We proceeded to select an equal number of females and males from each site to ensure balance in terms of sex in the analysis.
-
4)
Age Matching: We performed age matching in terms of months to control for potential confounding effects. Subjects with similar ages were paired across sites.
-
5)
IQ Matching: For further control, we utilized the National Institute of Health (NIH) Toolbox - Cognition Total Composite Score Fully-Corrected T-score extracted from the “abcd_tbss01” table for IQ matching. Subjects with similar IQ scores were paired across sites. This fully-corrected score takes into account certain demographic characteristics, such as education and race/ethnicity, which are standardized with a mean of 50 and a standard deviation of 10.
-
6)
Behavioral Data Matching: Finally, we examined the total problem score (cbcl_scr_syn_totprob_t) from the child behavioral checklist (abcd_cbcls01) across the matched subjects.
-
7)
Quality Assessment: To assess the quality of the matching process, we conducted unpaired t-tests to compare the matched groups.
We want to emphasize that these matching steps were only applied in the template creation step, and subjects excluded from the datasets to learn scanner-related measurement differences were later included in the harmonization process.
After the matching is completed as optimally as possible, the matched set of > = 35 subjects is then used to learn a nonlinear mapping between dMRI data from different scanners. This inter-scanner mapping is voxel-specific and uses the fiber-orientation-independent RISH feature representation to learn a specific mapping for each RISH feature. These RISH features capture different microstructural tissue properties that are independent of the orientation64 and provide the ability to reconstruct the harmonized dMRI signal. In the second step, harmonizing dMRI data, the learned mappings (from the template creation step) across RISH features were applied to all the dMRI data of the corresponding scanner to be harmonized with the reference (including the excluded subjects in the template creation step). We note that our harmonization process involves averaging b0 images before the spherical harmonics fitting, and then we calculate RISH features. Using the RISH feature templates, we scale the spherical harmonic coefficients to harmonize the DWI, but we do not scale the b0 images in this process. We note that along both steps of the harmonization, including template creation, nonlinear registration using ANTs62,65 was utilized to create RISH feature templates and apply RISH templates to each dMRI data for harmonization. The other methodological details of these steps can be found in Cetin-Karayumak et al.7.
To harmonize this large-scale dataset (N = 9345), we used the Amazon Web Services (AWS) EC2 platform. Specifically, r5d.4xlarge EC2 instances (128GiB of memory, 16 vCPUs) were used in template generation, where it took ~48 hours to generate each template. We then used r5d.large EC2 instances (16GiB of memory, 2 vCPUs) in the harmonization step, where harmonization of each subject took ~15 mins. The whole pipeline was tailored for parallel execution in 32 instances. In total, it took about 3872 CPU hours (~162 CPU days) to complete the harmonization of all dMRI data (N = 9345) in this step.
Whole Brain Tractography
Tractography was performed using our well-validated multi-tensor unscented Kalman filter (UKF) fiber tracking algorithm51,52,66 on the b = 3000 s/mm2 shell. The two-tensor model adopted in the UKF tractography algorithm is able to depict crossing fibers, which are prevalent in white matter tracts67,68. In this way, the first tensor is associated with the fiber that is being traced and enables quantification of fiber-specific microstructural properties, while the second tensor models the fibers that cross through the fiber. Moreover, the two-tensor model allows UKF tractography to consistently trace fibers across various populations46 as well as disease states such as tumors69,70,71. We successfully applied UKF tractography on 9345 subjects from the harmonized ABCD dataset. For each harmonized dMRI data, ~450k fiber streamlines were generated to create a whole brain tractography dataset.
The UKF tractography was run on the AWS EC2 platform. Specifically, r5d.large EC2 instances (16GiB of memory, 2 vCPUs) were used, where tractography took ~4.5 hours per subject. A total of ~500 instances were used, with each instance running tractography for about 20 subjects. In total, it took about ~42,052 CPU hours/~1752 CPU days to complete whole brain tractography.
Subject-specific White Matter Parcellation
Tractography parcellation was performed using our WhiteMatterAnalysis (WMA) fiber clustering pipeline53,72 in conjunction with our anatomical white matter atlas46. This pipeline produces a fine-scale whole-brain tractography parcellation into 800 fiber clusters and a coarse-scale anatomical tract parcellation, including 57 major deep WM tracts and 16 categories of superficial fiber clusters organized according to the brain lobes they connect. Expert neuroanatomical knowledge was used during this process to annotate and categorize the fiber clusters as described by Zhang et al.46. The seven corpus callosum subdivisions were categorized in the atlas following the traditional Witelson subdivisions73,74. Refer to Table 4 for a list of all anatomical tracts. Figure 5 gives a visualization of example tracts from 10 randomly selected subjects from 10 different scanners.

Visualization of example anatomical tracts. Ten randomly selected subjects (from 10 different sites) are used. In general, the parcellated anatomical tracts are visually highly similar across the different subjects. Refer to Table 4 for the definition of the acronyms for tract names.
We used the AWS r5d.large EC2 instances (16GiB of memory, 2vCPUs) for the computation, where it took ~1.6 hours per subject. A total of ~500 instances were used, with each instance running white matter parcellation for about 20 subjects. In total, it took about ~14,952 CPU hours/~623 CPU days to complete the white matter parcellation.
Extracting DMRI Measures
Multiple dMRI measures were extracted from each parcellated cluster and anatomical tract using SlicerDMRI75,76 for all subjects. These include the widely used dMRI measures: FA, mean diffusivity (MD), axial diffusivity (AD), radial diffusivity (RD), number of streamlines (NoS), number of streamline points (NoF) and streamline length (LenS). The tensors associated with each streamline location were also saved in the corresponding VTK file. Additional measures of interest can also be computed from the tensors by downloading the appropriate VTK file corresponding to a particular anatomical tract or fiber cluster. The information on how to download the harmonized dMRI data, tracts, clusters, and dMRI-derived measures is provided in Data Records.
Quality Control of the processed dMRI Data (N = 9345)
After the harmonization process, we conducted both manual and automated quality control checks on the data. Specifically, we manually examined the FA maps of the subjects involved in the template creation process. After the tractography analysis, we performed extensive quality control by calculating the identification performance of all clusters and tracts in the entire dataset comprising N = 9345 subjects (refer to Section 4.1.a for detailed information on the identification rate). Furthermore, to provide users with quantitative quality information, we included the number of streamlines and points for all tracts/bundles in the shared data. This allows users to directly access this information and utilize it if they wish to establish a streamline of point detection threshold specific to their tract or bundle of interest, thus enhancing their analysis and assessment of data quality.
Data Records
Our data collection of harmonized dMRI data and measures is available for browsing in the NDA without requiring a data agreement56. However, to download the data, users must have NDA access. This section provides instructions for downloading our data collection from the NDA77. Specifically, Section 3.1 provides an overview of the shared harmonized dMRI data and measures that are available for access through the NDA. To access shared data, a Data Access Request (DAR) is required by the NDA, which is explained in Section 3.2. Section 3.3 outlines the steps required to download the shared data from the platform. We have provided detailed instructions to ensure that researchers can easily access and download our data with minimal difficulties.
Sharing the harmonized dMRI measures and processed dMRI data in NDA
The generated imaging files and corresponding dMRI measures for each tract are shared in NDA through two separate submissions.
First, a total of 804 different derived measures, including FA, MD, NoS, etc., for each of the 73 white matter fiber bundles (bilateral, commissural, superficial, and cerebellar) were uploaded on the NDA for 9345 subjects. Refer to Table 5 for the list of shared dMRI measures.
Second, we shared the harmonized and processed imaging data, including the harmonized dMRI data, brain masks, whole brain tractography, anatomical fiber tracts, and white matter clusters with the NDA community. For the anatomical fiber tracts, we have provided both full-size VTK files for comprehensive visualization and quantitative analysis, as well as downsampled VTK files for quicker download and lower-resolution tract visualization. The full-size VTK files for white matter clusters have also been shared. It should be noted that the shared VTK files contain tensors estimated at each point, allowing for the computation of additional measures if necessary.
Access request in NDA
NDA is a well-established and widely recognized resource for sharing and accessing publicly available neuroimaging datasets and other relevant data. Many researchers in the neuroimaging field have already been accessing numerous projects funded by the NIH through the NDA.
To initiate a DAR for shared data on the NDA, researchers who do not already have access must follow a standard process. This involves selecting the “NIMH Data Archive” permission group, which provides standard access to phenotypic, imaging, and genomic data, as well as supporting documentation for NIH-funded grants for a period of one year. To gain access, researchers must also provide a Research Data Use Statement, contact information for all recipients who will access the data, and the name of a Signing Official (SO) at the lead recipient’s research institution.
Once a request has been submitted, it typically takes between 2–4 weeks for NDA to provide access. During this time, NDA staff reviews the Data Use Certification (DUC) for completeness and sends the request to the Data Access Committee (DAC), which makes decisions based on research subject protection and adherence to data use limitations consented to by the research subjects.
Access to harmonized dMRI data and measures requires only permission from the standard “NIMH Data Archive” permission group. Renewal requests must be submitted at the end of each year to maintain access. Additional details about the DAR process can be found on the NDA’s website (https://nda.nih.gov/nda/access-data-info.html).
Downloading the harmonized dMRI data and measures
Once access to NDA has been granted, users can utilize the NDA website and NDA Query Tool to search our project titled “Harmonizing multi-site diffusion MRI acquisitions for neuroscientific analysis across ages and brain disorders.” Please find below the step-by-step instructions to download the datasets of harmonized ABCD dMRI data and measures from the NDA:
-
1.
Launch a web browser and navigate to the NDA website at https://nda.nih.gov/. Proceed to log in to the system using the provided login credentials.
-
2.
Click on the “Get Data” option on the website’s primary menu or utilize the link https://nda.nih.gov/general-query.html?q=query=collections%20~and~%20orderBy=id%20~and~%20orderDirection=Ascending to access the “Get Data” page directly.
-
3.
Employ the NDA Query Tool and input one of the following search criteria into the “Text Search” box to locate our project:
-
Enter the full project title: “Harmonizing multi-site diffusion MRI acquisitions for neuroscientific analysis across ages and brain disorders.”
-
Alternatively, search using keywords such as “Harmonize AND ABCD.”
-
-
4.
Once our project is located, select it by clicking on the “Add to Workspace” button to add the dataset to your personal workspace.
-
5.
Proceed to your “Workspace” and click on it to submit the dataset to the “Filter Cart.” The cart may take a few moments to update.
-
6.
Within the “Filter Cart,” click on “Create Data Package/Add Data to Study” to access the Data Packaging Page.
-
7.
On the Data Packaging Page, click on “Create Data Package.” Assign a unique name to the package, and ensure that “include associated data files” is selected to download the imaging data. To monitor the status of your package, access “Data Packages” on your user profile and periodically refresh the webpage until the package is ready for download.
-
8.
Finally, install the “NDA Download Manager” from the following link: https://nda.nih.gov/nda/nda-tools.html#download-manager. Use this tool to download your data package once the package is ready to download.
Please note that this interface might be updated by the NDA in the next few years, in which case, we would ask the user to refer to their updated manuals for accessing the data. It is important to mention that the process of accessing and downloading the NDA data is treated with the utmost confidentiality. The NDA is overseen by the National Institute of Mental Health and offers a safe and centralized means for researchers to share and access data.
Technical Validation
Descriptions of the post-harmonization experiments on the ABCD dataset
The baseline dMRI data from 9345 subjects of the ABCD study underwent harmonization, which brought the dMRI data of all 32 scanners from 18 different sites in line with the reference dataset (dataset #29 from site 16). In this section, we describe two experiments to demonstrate the effectiveness of the harmonization algorithm to remove scanner effects from the baseline dMRI data in the ABCD study (Fig. 6).

Overview of the experiments that demonstrate the effectiveness of harmonization. Experiment 1 evaluated the impact of harmonization on dMRI measures, such as FA and tract identification rate, obtained through tractography analysis and white matter parcellation. In contrast, Experiment 2 assessed the impact of harmonization on multi-shell dMRI measures, such as RTOP, RTAP, RTPP, and MSD, using white matter ROIs defined by the Illinois Institute of Technology’s (IIT) probabilistic white matter atlas.
Experiment 1: Tractography analysis
We first assessed the effects of dMRI harmonization on white matter parcellation (Section 2.4.c) and the extracted dMRI measures (Section 2.4.d) at the tract level. Specifically, for each tract per scanner, we measured the identification rate46,48 to quantify the quality of the tracts detected before and after harmonization. Here, a tract is considered to be successfully identified if there are at least 50 streamlines inside the tract46,48,78, and its identification rate is defined as the percentage of successfully identified tracts across all analyzed subjects. In three randomly selected sites, we repeated this experiment on the original dMRI data to be able to compare the identification rate before and after harmonization. In addition, for each tract, we also computed the mean FA (from tensor 1) across all subjects for each dataset before and after harmonization and compared it to the reference data (to which all datasets were harmonized). We repeated the entire analysis at the cluster level as well to demonstrate the effects of dMRI harmonization on the clusters. However, as the number of streamlines in the clusters are smaller than the tracts, we used 10 streamlines inside the cluster to calculate its identification rate. We note that, for this experiment, we reconstructed spherical harmonics fitted data with a very small regularization parameter (0.00001) at the reference site.
In addition, to evaluate the spatial overlap of fiber tracts obtained before and after harmonization, we compared the tract maps of both original and harmonized datasets using both the standard Dice (sDice) and weighted Dice (wDice) coefficients for 210 subjects. First, sDice coefficient is utilized to emphasize the overall overlap between two binary maps generated by projecting tract locations into voxels, with these voxels being assigned a value of one/true for locations within the tract and zero/false for locations outside of the tract. As discussed in79, sDice might not always adequately represent the mathematical metric properties of the structures. Therefore, wDice, adapted to specifically measure tract spatial overlap48,80, is also utilized to compare the tract maps of original and harmonized dMRi data. This metric extends the sDice coefficient to non-binary maps and assigns greater weights to voxels with higher values, offering a more refined assessment of tract overlap.
Experiment 2: Regions-of-interest (ROI) analysis
We further evaluated the performance of the harmonization on multi-shell dMRI measures. To this end, we computed several multi-shell dMRI measures such as Return-To-Origin Probability (RTOP), Return to Axis Probability (RTAP), Return to the Plane Probability (RTPP), and Mean Squared Displacement (MSD)29,81,82 in the original, harmonized and reference dMRI datasets using all b-value shells in the dMRI data. We note that for computational efficiency, we compared these measures across the 35 matched subjects that were used in the template creation step. Averages of the multi-shell dMRI measures were calculated over the whole brain white matter skeleton and 42 white matter regions using the Illinois Institute of Technology’s (IIT) brain ROI atlas in the standard MNI space83,84. To evaluate the performance of the harmonization, we compared the original and harmonized datasets to the reference dataset using unpaired t-tests. We note that, for this experiment, we utilized raw data from the reference site without spherical harmonics fitting for comparison.
To further verify the effectiveness of harmonization, we conducted a test using a set of 35 subjects that were not included in the process of creating the template for harmonization. These subjects were selected from the dataset that was being harmonized to the reference data and were chosen based on their similarity in age, sex, and IQ to the reference data, in order to minimize any biological differences that could affect the results. This test on the unseen dataset was carried out to replicate the ROI analysis results in an independent dataset that was not used during the template creation (i.e., the learning process).
Results of the post-harmonization experiments on the ABCD study
The harmonization demonstrated consistent results across all dMRI measures in two separate experiments. The outcomes of each of these experiments are detailed in the following sections.
Experiment 1: Tractography analysis
The impact of harmonization on dMRI measures obtained through tractography analysis was evaluated using three randomly selected sites that used different scanners (Siemens Prisma, Siemens Prisma-fit, GE) to investigate the effect of harmonization on white matter parcellation and extracted dMRI measures. The analysis included both cluster- and tract-level evaluations. Figure 7 illustrates the effect of harmonization on white matter parcellation. Harmonization was found to improve the identification rates in both cluster- and tract-level parcellations (see Fig. 7a,c) for all three scanners). Furthermore, the mean cluster and tract FA values (Fig. 7b,d) were found to be closer to the reference data after harmonization. Across all 9345 harmonized dMRI data from 21 sites in the ABCD study, high identification rates were observed in both tract- and cluster-level parcellations, at 99% and 97.5%, respectively. Figure 8 demonstrates the average FA comparisons for each tract individually. Any significant differences that were observed between the reference and original datasets (p < 0.01) were eliminated after harmonization (p > 0.1). Figure 9 illustrates the spatial overlap of fiber tracts between the original (before harmonization) and harmonized (after harmonization) dMRI data for each tract. The average sDice, measuring overall overlap, was high (0.98 ± 0.05) across 210 subjects, indicating that harmonization did not significantly alter the overall structure of the tract maps. Furthermore, the average wDice computed using original and harmonized dMRI data was also relatively high (0.85 ± 0.06). This suggests that harmonization preserved not only the overall structure but also the fine-grained spatial details of the tract maps. Notably, the wDice values obtained in this study well exceed the 0.72 threshold established by Cousineau et al.80 for good overlap. These high sDice and wDice coefficients underscore the effectiveness of the harmonization process in maintaining the tractography representations within diffusion MRI data.

Experiment 1, Section 4.1.a and 4.2.a investigated the effects of dMRI harmonization on white matter parcellation in three randomly selected scanners. For this analysis, thirty-five (35) subjects from each scanner, who were part of the learning process of harmonization, were selected for comparison. These subjects were matched in terms of age, sex, and IQ to the reference scanner (scanner 29). The cluster-level analysis is presented in (a) and (b), while the tract-level analysis is shown in (c) and (d). In (a) and (c), a paired t-test was conducted for each scanner to determine whether there was a significant improvement in the identification rate after harmonization. In (b) and (d), two unpaired t-tests were performed for each scanner to compare the average FA between (i) the original and reference scanners and (ii) the harmonized and reference scanners. The resulting p-values were presented on the plots.

Experiment 1, section 4.1.a and 4.2.a, demonstrated the effects of dMRI harmonization on 73 white matter tracts by comparing the average FA of reference, original, and harmonized datasets. Table 4 defines the acronyms for the tract names. For this analysis, 35 subjects from scanner 10 (Siemens Prisma fit) were selected for comparison. These subjects were used as part of the learning process of harmonization and were matched in terms of age, sex, IQ, and total behavioral problem to the reference scanner (scanner 29). Any significant differences observed prior to harmonization (p < 0.01) were eliminated after harmonization (p > 0.1).

Spatial overlap of fiber tracts between the original (before harmonization) and harmonized dMRI data (after harmonization). Mean standard Dice (sDice) and weighted Dice (wDice) coefficients are reported for each tract, averaged across 210 subjects (approximately 2.25% of participants per site). (a) shows sDice, while (b) presents wDice. Overall, the average sDice and wDice were 0.98 ± 0.05 and 0.85 ± 0.06, respectively. For wDice, a value of 0.72 is considered indicative of good overlap.
Experiment 2: Regions-of-interest (ROI) analysis
The impact of harmonization on the multi-shell dMRI measures (RTOP, RTAP, RTPP, and MSD) was evaluated. The outcome of this experiment is presented in Fig. 10, which demonstrates a comparison of the average multi-shell dMRI measures for different white matter ROIs across eight distinct scanners. The comparison was made between the original data (before harmonization), harmonized data, and reference data. The results indicated significant differences (p < 0.01) in the multi-shell dMRI measures between the original and reference datasets. However, after harmonization, these differences were reduced and statistically diminished (p > 0.1).

Experiment 2, Section 4.1.b and 4.2.b, demonstrated the effects of dMRI harmonization on ROI analysis and multi-shell dMRI measures, namely RTOP, RTPP, MSD, and RTAP, in eight randomly selected scanners and white matter ROIs. Thirty-five (35) subjects from each scanner were chosen to create a template for harmonization, and they were matched to the reference scanner in terms of age, sex, and IQ (scanner 29). Using these subjects from each scanner, two unpaired t-tests were conducted to compare each multi-shell dMRI measure between (i) the original and reference scanners (orig. vs. ref.) and (ii) the harmonized and reference scanners (harmo. vs. ref.). The resulting p-values were presented on the plots. To demonstrate the effectiveness of the harmonization process, we present representative plots for each dMRI measure. It is important to note that any significant differences observed prior to harmonization (p < 0.01) were statistically eliminated after the harmonization procedure (p > 0.1) in all measures derived from the 73 white matter tracts and 33 scanners. The resulting p-values, which confirm the successful harmonization, are displayed on the plots for a few randomly selected scanners and white matter tracts.
To further validate the performance of harmonization, we repeated experiment 2 on the dMRI data of new and unseen subjects (i.e., these were not included in the learning process of harmonization/template creation). These subjects were selected from eight scanners and matched with the reference dataset in terms of age, sex, and IQ. The results of the experiment are demonstrated in Fig. 11, which compares the average RTOP, RTAP, RTPP, and MSD measures of the several white matter ROIs between the reference, original, and harmonized datasets. Once again, harmonization eliminated any existing scanner-related differences between the original and reference datasets.

Experiment 2, Section 4.1.b and 4.2.b, investigated the effects of dMRI harmonization on ROI analysis and multi-shell dMRI measures, namely RTOP, RTPP, MSD, and RTAP, in eight randomly selected scanners and white matter ROIs. For this analysis, an unseen set of thirty-five (35) subjects who were not involved in creating the template, but were still matched in terms of age, sex, and IQ to the reference scanner (scanner 29), were selected. Using these subjects from each scanner, two unpaired t-tests were conducted to compare each multi-shell dMRI measure between (i) the original and reference scanners (orig. vs. ref.) and (ii) the harmonized and reference scanners (harmo. vs. ref.). To demonstrate the effectiveness of the harmonization process, we present representative plots for each dMRI measure. It is important to note that any significant differences observed prior to harmonization (p < 0.01) were statistically eliminated after the harmonization procedure (p > 0.1) in all measures derived from the 73 white matter tracts and 32 scanners. The resulting p-values, which confirm the successful harmonization, are displayed on the plots for a few randomly selected scanners and white matter tracts.
Usage Notes
The purpose of this study was to create a harmonized and processed dMRI dataset for the ABCD study, which would enable researchers to analyze all the dMRI data together. The study involved a significant computational undertaking, which required approximately 50,000 CPU hours to successfully harmonize the dMRI data and perform tractography on the entire brain, along with white matter parcellation into 800 clusters per subject. The results of this effort have been made available to the scientific community via the NDA. Researchers can query the project titled “Harmonizing multi-site diffusion MRI acquisitions for neuroscientific analysis across ages and brain disorders” on the NDA website using the NDA access (see section Data Records for details on how to download the shared data).
This dataset includes the output of the harmonization algorithm, brain masking, and whole brain tractography, as well as white matter tracts, white matter clusters, and derived dMRI-related measures. The measures of the white matter anatomical tracts extracted from the harmonized and processed dMRI data are accessible through the NDA. This includes a total of 808 different derived measures, including FA, MD, NoF, etc., for each of the white matter fiber bundles (73 bilateral, commissural, superficial, and cerebellar) per each subject. Leveraging the harmonized and processed dMRI data will allow for pooled large-scale data analysis as if the data came from the same scanner, which would significantly increase the statistical power of all neuroimaging studies using this comprehensive dataset, the ABCD study.
We note that the number of streamlines per subject (~450 K) was determined based on a careful balance between tract identification performance and computational costs. Our study utilized the multi-fiber UKF algorithm that is demonstrated to be robust across the lifespan46. The results revealed that the computed tractography data was highly effective in successfully identifying all fiber tracts defined in the ORG atlas, as evidenced by a tract identification rate exceeding 99%. While increasing the number of streamlines could potentially enhance tract identification performance further, this would come at a substantial cost in terms of data storage (already totaling 72.3 TB) and data transfer expenses.
In addition, we have observed minor variations between the harmonized FA values and the target sites in a few instances (e.g., Sup-P-right in Figure 6). Although these deviations do not hold statistical significance (p > 0.05), they might arise due to the refined tracing and identification of fiber tracts facilitated by the harmonized data. This improved capability to detect clusters and potentially increased streamline counts can influence the final FA estimation after the harmonization process. Moreover, the cluster and tract identification rate improved through the harmonization process. This enhancement can be attributed to the denoising effect of the spherical harmonic fitting procedure, particularly noticeable at higher b-values (e.g., b = 3000) where noise is more pronounced. In the original dataset, clusters with fewer streamlines could have been classified as undetected due to our imposed threshold. However, the reduction in noise following harmonization allows for the successful tracing of more streamlines, leading to cluster sizes that surpass the identification threshold for both tracts and clusters. Consequently, harmonization consistently improves the detection rate of clusters and anatomical fiber bundles. The effects of the harmonization algorithm on the microstructural measurements of the underlying tracts, including changes in the FA of these tracts, likely play a role in improving the accuracy of tract tracing. This enhancement can also directly influence the overall identification rate. Finally, high sDice and wDice scores (Fig. 9) demonstrate the successful harmonization of dMRI data in the ABCD study without altering the underlying tract maps. This is crucial because it signifies that while harmonization improved the dMRI data’s overall quality, including signal-to-noise ratio and tractography performance, it still preserved the crucial spatial overlap of tracts before and after the process. This finding is particularly significant for enabling accurate comparisons and analyses across different sites and scanners in the ABCD study. By maintaining the intrinsic structure of tract maps, harmonization ensures that observed differences in subsequent analyses will likely reflect true neurodevelopmental variations rather than technical artifacts arising from scanner discrepancies.
It is important to note that the study has limitations. One primary limitation is that the dMRI scans acquired on the Philips scanner had to be excluded as they did not pass quality checks. Although the excluded scans make up a small portion of the overall dMRI data (less than 13% of all dMRI scans), these subjects can still be distinct enough to affect the statistical significance of studies investigating specific biology- or disease-related characteristics. Additionally, all dMRI data included in this sample comes from only baseline sessions. The ABCD study has been collecting dMRI data for each subject every two years, and future work will focus on harmonizing the dMRI data from the following years to provide the ability to analyze the longitudinal dMRI data (e.g., characterize long-term white matter changes). Finally, in addition to the quality control measures implemented for the white matter tracts, we recognize the potential benefit of conducting visual quality control on a larger set of subjects using a standardized tool, such as the one available at https://github.com/scilus/dmriqcpy85. However, it is important to note that we have included the number of streamlines and points for all tracts in the shared data. This quantitative quality information allows users to access and utilize the tract data directly, enabling them to establish a threshold specific to their data of interest.
In conclusion, the harmonized dMRI dataset of the ABCD study, which pools together data from multiple sites and scanners without significant scanner bias, will significantly enhance the statistical power of research in the ABCD study. This will provide the ability to run more advanced statistical and machine learning analyses aimed at uncovering the neurodevelopmental changes in the white matter of adolescents86.
Code availability
The open-access dMRI data processing software used in this study can be accessed on GitHub. The repositories contain the processing pipeline and scripts used for harmonizing and processing the dMRI data, as well as for performing whole brain tractography and white matter parcellation. Researchers and clinicians interested in utilizing these tools for their own research or clinical applications can easily download and customize the software to fit their specific needs.
Additionally, the GitHub repositories include detailed documentation on how to use the software, as well as examples of how to run the scripts on sample data. The repositories also provide information on the dependencies required to run the software, ensuring that researchers have access to all the necessary tools to use the software effectively.
By making the dMRI data processing software openly accessible on GitHub, we hope to encourage further research and clinical applications of the software and facilitate collaboration across the scientific community. Please refer to the following GitHub links for each of the specific dMRI data processing software:
a) Convolutional neural network dMRI brain segmentation
b) https://github.com/pnlbwh/CNN-Diffusion-MRIBrain-Segmentation
c) DMRI data harmonization: https://github.com/pnlbwh/dMRIharmonization, in this study we used the multi-shell version of this script: https://github.com/pnlbwh/multi-shell-dMRIharmonization
d) UKF two tensor whole brain tractography: https://github.com/pnlbwh/ukftractography
e) White Matter Analysis: https://github.com/SlicerDMRI/whitematteranalysis
f) SlicerDMRI: http://dmri.slicer.org
References
Jernigan, T. L., Brown, S. A. & Dowling, G. J. The Adolescent Brain Cognitive Development Study. J. Res. Adolesc. 28, 154–156 (2018).
ABCD Study Database. https://nda.nih.gov/abcd/
Casey, B. J. et al. The Adolescent Brain Cognitive Development (ABCD) study: Imaging acquisition across 21 sites. Dev. Cogn. Neurosci. 32, 43–54 (2018).
Hagler, D. J. Jr et al. Image processing and analysis methods for the Adolescent Brain Cognitive Development Study. Neuroimage 202, 116091 (2019).
Vollmar, C. et al. Identical, but not the same: Intra-site and inter-site reproducibility of fractional anisotropy measures on two 3.0T scanners. Neuroimage 51(4), 1384-94, https://doi.org/10.1016/j.neuroimage.2010.03.046 (2010).
Mirzaalian, H. et al. Inter-site and inter-scanner diffusion MRI data harmonization. Neuroimage 135, 311–323 (2016).
Cetin Karayumak, S. et al. Retrospective harmonization of multi-site diffusion MRI data acquired with different acquisition parameters. Neuroimage 184, 180–200 (2019).
Cetin-Karayumak, S., Kubicki, M. & Rathi, Y. Harmonizing diffusion MRI data across magnetic field strengths. Med. Image Comput. Comput. Assist. Interv. (2018).
Cetin Karayumak, S.*, Billah, T.*, Bouix, S. & Rathi, Y. Multi-site Diffusion MRI Harmonization, https://doi.org/10.5281/zenodo.2584275 (2019).
Ning, L. et al. Cross-scanner and cross-protocol multi-shell diffusion MRI data harmonization: Algorithms and results. Neuroimage 221, 117128 (2020).
Tax, C. M. et al. Cross-scanner and cross-protocol diffusion MRI data harmonisation: A benchmark database and evaluation of algorithms. Neuroimage 195, 285–299 (2019).
Thieleking, R. et al. Same Brain, Different Look?—The Impact of Scanner, Sequence and Preprocessing on Diffusion Imaging Outcome Parameters. J. Clin. Med. 10(21), 4987, https://doi.org/10.3390/jcm10214987 (2021).
Schilling, K. G. et al. Fiber tractography bundle segmentation depends on scanner effects, vendor effects, acquisition resolution, diffusion sampling scheme, diffusion sensitization, and bundle segmentation workflow. Neuroimage 242, 118451 (2021).
Bayer, J. M. M. et al. Site effects how-to and when: An overview of retrospective techniques to accommodate site effects in multi-site neuroimaging analyses. Front. Neurol. 13, 923988 (2022).
Botvinik-Nezer, R. et al. Variability in the analysis of a single neuroimaging dataset by many teams. Nature 582, 84–88 (2020).
Mirzaalian, H. et al. Multi-site harmonization of diffusion MRI data in a registration framework. Brain Imaging Behav. 12, 284–295 (2018).
Pinto, M. S. et al. Harmonization of Brain Diffusion MRI: Concepts and Methods. Front. Neurosci. 14, (2020).
Mirzaalian, H. et al. Harmonizing Diffusion MRI Data Across Multiple Sites and Scanners. in Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015 (eds. Navab, N., Hornegger, J., Wells, W. M. & Frangi, A.) vol. 9349 12–19 (Springer International Publishing, 2015).
Fortin, J.-P. et al. Harmonization of multi-site diffusion tensor imaging data. Neuroimage 161, 149–170 (2017).
Huynh, K. M., Chen, G., Wu, Y., Shen, D. & Yap, P.-T. Multi-Site Harmonization of Diffusion MRI Data via Method of Moments. IEEE Trans. Med. Imaging 38, 1599–1609 (2019).
Moyer, D., Ver Steeg, G., Tax, C. M. W. & Thompson, P. M. Scanner invariant representations for diffusion MRI harmonization. Magn. Reson. Med. 84, 2174–2189 (2020).
Kochunov, P. et al. Multi-site study of additive genetic effects on fractional anisotropy of cerebral white matter: Comparing meta and megaanalytical approaches for data pooling. Neuroimage 95, 136–150 (2014).
Thompson, P. M. et al. The ENIGMA Consortium: large-scale collaborative analyses of neuroimaging and genetic data. Brain Imaging Behav. 8, 153–182 (2014).
Thompson, P. M. et al. ENIGMA and global neuroscience: A decade of large-scale studies of the brain in health and disease across more than 40 countries. Transl. Psychiatry 10, 100 (2020).
Zhang, G. et al. ENIGMA-Viewer: interactive visualization strategies for conveying effect sizes in meta-analysis. BMC Bioinformatics 18, 253 (2017).
Johnson, W. E., Li, C. & Rabinovic, A. Adjusting batch effects in microarray expression data using empirical Bayes methods. Biostatistics 8, 118–127 (2007).
Cetin-Karayumak, S. et al. Exploring the limits of ComBat method for multi-site diffusion MRI harmonization. Cold Spring Harbor Laboratory 2020.11.20.390120, https://doi.org/10.1101/2020.11.20.390120 (2020).
De Luca, A. et al. Harmonization of diffusion kurtosis imaging metrics with rotational invariant spherical harmonics (RISH) to remove cross-site biases.
Özarslan, E. et al. Mean apparent propagator (MAP) MRI: a novel diffusion imaging method for mapping tissue microstructure. Neuroimage 78, 16–32 (2013).
Zhang, H., Schneider, T., Wheeler-Kingshott, C. A. & Alexander, D. C. NODDI: practical in vivo neurite orientation dispersion and density imaging of the human brain. Neuroimage 61, 1000–1016 (2012).
Jelescu, I. O., Veraart, J., Fieremans, E. & Novikov, D. S. Degeneracy in model parameter estimation for multi-compartmental diffusion in neuronal tissue. NMR Biomed. 29, 33–47 (2016).
Cetin-Karayumak, S. et al. White matter abnormalities across the lifespan of schizophrenia: a harmonized multi-site diffusion MRI study. Mol. Psychiatry 25, 3208–3219 (2020).
Seitz-Holland, J. et al. Elucidating the relationship between white matter structure, demographic, and clinical variables in schizophrenia-a multicenter harmonized diffusion tensor imaging study. Mol. Psychiatry, https://doi.org/10.1038/s41380-021-01018-z (2021).
Seitz, J. et al. Investigating Sexual Dimorphism of Human White Matter in a Harmonized, Multisite Diffusion Magnetic Resonance Imaging Study. Cereb. Cortex 31, 201–212 (2021).
Di Biase, M. A. et al. Large-Scale Evidence for an Association Between Peripheral Inflammation and White Matter Free Water in Schizophrenia and Healthy Individuals. Schizophr. Bull. 47(2), 542–551, https://doi.org/10.1093/schbul/sbaa134 (2021).
De Luca, A. et al. Cross-site harmonization of multi-shell diffusion MRI measures based on rotational invariant spherical harmonics (RISH). Neuroimage 259, 119439 (2022).
Seitz-Holland, J. et al. Cognitive deficits, clinical variables, and white matter microstructure in schizophrenia: a multisite harmonization study. Mol. Psychiatry 27, 3719–3730 (2022).
Cetin-Karayumak, S. et al. Characterization of the extracellular free water signal in schizophrenia using multi-site diffusion MRI harmonization. Mol. Psychiatry. 28(5), 2030–2038, https://doi.org/10.1038/s41380-023-02068-1 (2023).
Elad, D. et al. Improving the predictive potential of diffusion MRI in schizophrenia using normative models—Towards subject‐level classification. Hum. Brain. Mapp. 42(14), 4658–4670, https://doi.org/10.1002/hbm.25574 (2021).
Ye, H. et al. Network Analysis of Symptom Comorbidity in Schizophrenia: Relationship to Illness Course and Brain White Matter Microstructure. Schizophr. Bull, https://doi.org/10.1093/schbul/sbab015 (2021).
Lv, J. et al. Individual deviations from normative models of brain structure in a large cross-sectional schizophrenia cohort. Mol. Psychiatry, https://doi.org/10.1038/s41380-020-00882-5 (2020).
Hegde, R. et al. Cognitive Enhancement Therapy Might Halt Progressive White Matter Microstructural Changes in Early Course Schizophrenia. Biological Psychiatry 89, S211, https://doi.org/10.1016/j.biopsych.2021.02.534 (2021).
Kelly, S., Guimond, S., Pasternak, O. & Lutz, O. White matter microstructure across brain-based biotypes for psychosis–findings from the bipolar-schizophrenia network for intermediate phenotypes. Psychiatry Res. (2021).
Levitt, J. et al. The Organization of Frontostriatal Brain Wiring in Non-Affective Early Psychosis Compared with Healthy Subjects Using a Novel Diffusion Imaging Fiber Cluster Analysis. Mol Psychiatry 28, 2301–2311, https://doi.org/10.1038/s41380-023-02031-0 (2023).
Zhang, F. et al. Quantitative mapping of the brain’s structural connectivity using diffusion MRI tractography: A review. Neuroimage 249, 118870 (2022).
Zhang, F. et al. An anatomically curated fiber clustering white matter atlas for consistent white matter tract parcellation across the lifespan. Neuroimage 179, 429–447 (2018).
Wasserthal, J., Neher, P. & Maier-Hein, K. H. TractSeg - Fast and accurate white matter tract segmentation. Neuroimage 183, 239–253 (2018).
Zhang, F. et al. Deep white matter analysis (DeepWMA): Fast and consistent tractography segmentation. Med. Image Anal. 65, 101761 (2020).
Schilling, K. G. et al. Tractography dissection variability: what happens when 42 groups dissect 14 white matter bundles on the same dataset? Cold Spring Harbor Laboratory 2020.10.07.321083, https://doi.org/10.1101/2020.10.07.321083 (2020).
Yendiki, A. et al. Automated probabilistic reconstruction of white-matter pathways in health and disease using an atlas of the underlying anatomy. Front. Neuroinform. 5, 23 (2011).
Malcolm, J. G., Shenton, M. E. & Rathi, Y. Filtered multitensor tractography. IEEE Trans. Med. Imaging 29, 1664–1675 (2010).
Reddy, C. P. & Rathi, Y. Joint Multi-Fiber NODDI Parameter Estimation and Tractography Using the Unscented Information Filter. Front. Neurosci. 10, 166 (2016).
O’Donnell, L. J. & Westin, C.-F. Automatic tractography segmentation using a high-dimensional white matter atlas. IEEE Trans. Med. Imaging 26, 1562–1575 (2007).
O’Donnell, L. J., Wells, W. M. 3rd, Golby, A. J. & Westin, C.-F. Unbiased groupwise registration of white matter tractography. Med. Image Comput. Comput. Assist. Interv. 15, 123–130 (2012).
Zhang, F. et al. Test-retest reproducibility of white matter parcellation using diffusion MRI tractography fiber clustering. Hum. Brain Mapp. 40, 3041–3057 (2019).
Harmonizing multi-site diffusion MRI acquisitions for neuroscientific analysis across ages and brain disorders. https://nda.nih.gov/edit_collection.html?id=3371.
Hatton, S. Preview of the Adolescent Brain Cognitive Development (ABCD) Study Release 3.0. Biological Psychiatry vol. 87 S110–S111 Preprint at https://doi.org/10.1016/j.biopsych.2020.02.303 (2020).
Clark, D. B. et al. Biomedical ethics and clinical oversight in multisite observational neuroimaging studies with children and adolescents: The ABCD experience. Dev. Cogn. Neurosci. 32, 143–154 (2018).
Medawar, E. et al. Estimating the effect of a scanner upgrade on measures of grey matter structure for longitudinal designs. PLoS One 16, e0239021 (2021).
Dey, R. & Hong, Y. CompNet: Complementary Segmentation Network for Brain MRI Extraction. In Frangi, A., Schnabel, J., Davatzikos, C., Alberola-López, C. & Fichtinger, G. (eds) Medical Image Computing and Computer Assisted Intervention – MICCAI 2018. Lecture Notes in Computer Science(), vol 11072, 628–636. Springer Cham, https://doi.org/10.1007/978-3-030-00931-1_72 (2018).
Guha Roy, A., Conjeti, S., Navab, N. & Wachinger, C. QuickNAT: A fully convolutional network for quick and accurate segmentation of neuroanatomy. Neuroimage 186, 713–727 (2019).
Avants, B. B. et al. A reproducible evaluation of ANTs similarity metric performance in brain image registration. Neuroimage 54, 2033–2044 (2011).
Smith, S. M. Fast robust automated brain extraction. Hum. Brain Mapp. 17, 143–155 (2002).
Reisert, M., Kellner, E., Dhital, B., Hennig, J. & Kiselev, V. G. Disentangling micro from mesostructure by diffusion MRI: A Bayesian approach. Neuroimage 147, 964–975 (2017).
Avants, B. B. et al. The optimal template effect in hippocampus studies of diseased populations. Neuroimage 49, 2457–2466 (2010).
Fillard, P. et al. Quantitative evaluation of 10 tractography algorithms on a realistic diffusion MR phantom. Neuroimage 56, 220–234 (2011).
Farquharson, S. et al. White matter fiber tractography: why we need to move beyond DTI. J. Neurosurg. 118, 1367–1377 (2013).
Vos, S. B., Viergever, M. A. & Leemans, A. Multi-fiber tractography visualizations for diffusion MRI data. PLoS One 8, e81453 (2013).
Olszewski, A. K. et al. The social brain network in 22q11.2 deletion syndrome: a diffusion tensor imaging study. Behav. Brain Funct. 13, 4 (2017).
Zhang, F. et al. Whole brain white matter connectivity analysis using machine learning: An application to autism. Neuroimage 172, 826–837 (2018).
Hamoda, H. M. et al. Abnormalities in thalamo-cortical connections in patients with first-episode schizophrenia: a two-tensor tractography study. Brain Imaging Behav. 13, 472–481 (2019).
O’Donnell, L. J., Wells, W. M. III, Golby, A. J. & Westin, C.-F. Unbiased Groupwise Registration of White Matter Tractography. in Medical Image Computing and Computer-Assisted Intervention – MICCAI 2012 (eds. Ayache, N., Delingette, H., Golland, P. & Mori, K.) 123–130 (Springer Berlin Heidelberg, 2012).
Witelson, S. F. Hand and sex differences in the isthmus and genu of the human corpus callosum. A postmortem morphological study. Brain 112(Pt 3), 799–835 (1989).
Makris, N. et al. MRI-Based topographic parcellation of human cerebral white matter and nuclei II. Rationale and applications with systematics of cerebral connectivity. Neuroimage 9, 18–45 (1999).
Norton, I. et al. SlicerDMRI: Open Source Diffusion MRI Software for Brain Cancer Research. Cancer Res. 77, e101–e103 (2017).
Zhang, F. et al. SlicerDMRI: Diffusion MRI and Tractography Research Software for Brain Cancer Surgery Planning and Visualization. JCO Clin Cancer Inform (2020).
NIMH Data Archive (NDA). https://nda.nih.gov/
Zhang, F. et al. Creation of a novel trigeminal tractography atlas for automated trigeminal nerve identification. Neuroimage 220, 117063 (2020).
Cousineau, M. et al. A test-retest study on Parkinson’s PPMI dataset yields statistically significant white matter fascicles. Neuroimage Clin 16, 222–233 (2017).
Ning, L., Westin, C.-F. & Rathi, Y. Estimating diffusion propagator and its moments using directional radial basis functions. IEEE Trans. Med. Imaging 34, 2058–2078 (2015).
Garyfallidis, E. et al. Dipy, a library for the analysis of diffusion MRI data. Front. Neuroinform. 8, 8 (2014).
Varentsova, A., Zhang, S. & Arfanakis, K. Development of a high angular resolution diffusion imaging human brain template. Neuroimage 91, 177–186 (2014).
Qi, X. & Arfanakis, K. Regionconnect: Rapidly extracting standardized brain connectivity information in voxel-wise neuroimaging studies. Neuroimage 225, 117462 (2021).
Theaud, G. & Descoteaux, M. dMRIQCpy: a python-based toolbox for diffusion MRI quality control and beyond. in.
Volkow, N. D. et al. The conception of the ABCD study: From substance use to a broad NIH collaboration. Dev. Cogn. Neurosci. 32, 4–7 (2018).
Jenkinson, M., Beckmann, C. F., Behrens, T. E. J., Woolrich, M. W. & Smith, S. M. FSL. Neuroimage 62, 782–790 (2012).
Acknowledgements
We gratefully acknowledge funding provided by the following National Institutes of Health (NIH) grant: R01 MH119222 (PIs: Dr. Yogesh Rathi, Dr. Lauren J. O’Donnell). We also acknowledge funding provided by the Brigham and Women’s Hospital Program for Interdisciplinary Neurosciences through a gift from Lawrence and Tina Rand and the Brain and Behavior Research Foundation NARSAD Young Investigator Award (PI: Dr. Suheyla Cetin-Karayumak). Data used in the preparation of this article were obtained from the Adolescent Brain Cognitive DevelopmentSM (ABCD) Study (https://abcdstudy.org), held in the NIMH Data Archive (NDA). This is a multisite, longitudinal study designed to recruit more than 10,000 children age 9–10 and follow them over 10 years into early adulthood. The ABCD Study® is supported by the National Institutes of Health and additional federal partners under award numbers U01DA041048, U01DA050989, U01DA051016, U01DA041022, U01DA051018, U01DA051037, U01DA050987, U01DA041174, U01DA041106, U01DA041117, U01DA041028, U01DA041134, U01DA050988, U01DA051039, U01DA041156, U01DA041025, U01DA041120, U01DA051038, U01DA041148, U01DA041093, U01DA041089, U24DA041123, U24DA041147. A full list of supporters is available at https://abcdstudy.org/federal-partners.html. A listing of participating sites and a complete listing of the study investigators can be found at https://abcdstudy.org/consortium_members/. ABCD consortium investigators designed and implemented the study and/or provided data but did not necessarily participate in the analysis or writing of this report. This manuscript reflects the views of the authors and may not reflect the opinions or views of the NIH or ABCD consortium investigators.
Author information
Authors and Affiliations
Contributions
The study involved multiple authors with distinct roles and responsibilities. S.C.K. was responsible for the data preparation, setting up AWS platforms, running brain masking and harmonization, and drafting the manuscript. F.Z. was responsible for running the whole brain tractography and white matter analysis pipelines. T.B. played a role in developing the harmonization software, while L.Z. contributed to preparing the white matter atlas figures. N.M. was involved in identifying the white matter tracts, and S.P. created the low-resolution white matter tracts for visualization. The study was conceived by L.J.O. and Y.R., who participated in its design and coordination and contributed to drafting the manuscript. All authors carefully reviewed and approved the final manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Cetin-Karayumak, S., Zhang, F., Zurrin, R. et al. Harmonized diffusion MRI data and white matter measures from the Adolescent Brain Cognitive Development Study. Sci Data 11, 249 (2024). https://doi.org/10.1038/s41597-024-03058-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41597-024-03058-w
