
Abstract
The Santa Barbara Basin is an extraordinary archive of environmental and ecological change, where varved sediments preserve microfossils that provide an annual to decadal record of the dynamics of surrounding ecosystems. Of the microfossils preserved in these sediments, benthic foraminifera are the most abundant seafloor-dwelling organisms. While they have been extensively utilized for geochemical and paleoceanographic work, studies of their morphology are lacking. Here we use a high-throughput imaging method (AutoMorph) designed to extract 2D data from photographic images of fossils to produce a large image and 2D shape dataset of recent benthic foraminifera from two core records sampled from the center of the Santa Barbara Basin that span an ~800-year-long interval during the Common Era (1249–2008 CE). Information on more than 36,000 objects is included, of which more than 22,000 are complete or partially-damaged benthic foraminifera. The dataset also includes other biogenic microfossils including ostracods, pteropods, diatoms, radiolarians, fish teeth, and shark dermal denticles. We describe our sample preparation, imaging, and identification techniques, and outline potential data uses.
Similar content being viewed by others

Background & Summary
Morphological data are the primary phenotypic data preserved in the fossil record. Yet until recently, information on morphological variation within fossil assemblages was limited by the laborious nature of manual morphological data collection. Recent advancements in data collection and processing techniques, such as the adoption of rapid two- and three-dimensional imaging techniques, have greatly accelerated the pace with which researchers can gather large morphological datasets1. However, even with the aid of technological advancements, the collection of morphological information from individual specimens at the population, community, or assemblage scale remains relatively rare, as assessment of trends at these levels requires large amounts of data that remains time-intensive to collect. To address this gap, paleontologists have developed high-throughput approaches for extracting 2D and 3D shape information from photographic images of entire populations or assemblages. One of these approaches, AutoMorph2, which is used primarily for the creation of large microfossil datasets, has led to an explosion of big data in micropaleontology, as datasets generated with this method contain thousands to tens of thousands of individuals3,4. These data have subsequently driven major scientific discoveries, including the identification of a previously unknown potential extinction event in sharks5 and a morphological diversification event in fishes6,7.
While big datasets have been generated for a number of marine microfossil groups, benthic foraminifera have largely been left out of the paleo big data revolution. No major morphological datasets have been generated for benthic foraminifera, and the vast majority of studies employ manual counting or description of morphotypes8,9, labor-intensive morphometry techniques10,11,12, or rely on species- or genus-level exemplar specimens to describe trends within benthic foraminifer assemblages through time13. These manual techniques are not only time-consuming, but are also difficult to replicate without specialized knowledge and access to the physical samples used in a given study.
Benthic foraminifera are a useful focus group for the development of large, individual-level morphological datasets, as these unicellular protists have calcium carbonate tests (i.e., shells) that are distributed throughout the benthos of the modern global ocean, and are cosmopolitan within marine sediments, living anywhere from littoral to deep-water environments14. The abundant fossil record of benthic foraminifera spans back to the early Cambrian15,16, and as a result has been extensively utilized to examine eco-environmental trends through time. These include past environmental conditions, assessed using species distribution data and shell chemistry, among other proxies14,17,18,19, as well as and ecological and evolutionary trends, assessed using genus- and species-level diversity data, classification of ecophenotypes, and quantitative assessments of lineage diversification and extinction20,21,22.
In some highly resolved systems, benthic foraminifera are preserved at seasonal to decadal resolution. One such extraordinary site is the Santa Barbara Basin (SBB), where persistent hypoxia within the center of the basin preserves seasonal varve couplets. The dysoxic bottom waters of the SBB result in part from its bathymetry, where its relatively high eastern (230 m) and western (475 m) sill depths (Fig. 1) restrict intermediate water movement. This hypoxia is further intensified by overlying surface productivity in the Santa Barbara Channel23, which typically serves to exclude large bioturbators from the center of the basin24,25,26. Basin-enhanced hypoxia27, coupled with high seasonal sedimentation rates into the basin (on the order of 140 cm ky−1), aid in the preservation of millimeter-scale couplet pairs for which the basin is famous28. To date, these varved sediments have been extensively used to generate long-term records of climate variability, making the SBB one of the most well-studied marine systems in the world. However, considerably less focus has been paid to developing high-resolution morphological records from the basin’s fossiliferous material, leaving a considerable data gap that stands to be addressed with automated approaches.

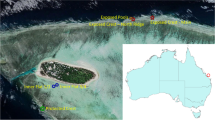
Regional setting and core materials. (Left) The sampling location for kasten and box cores, site MV1012-ST46.9, (34°17.228′ N, 120°02.135′ W), is denoted by a white triangle. The sampling location was chosen as a reoccupation of Ocean Drilling Program site 893 (34°17.25′ N, 120° 2.16′ W, 577 m water depth), denoted by a black circle. Contour lines indicate seafloor depth (m). (Right) Core chronology for box core MV1012-BC-1 and kasten core MV1012-KC1. Core images modified from Jones 2016 and Brandon et al.34.
While there is a history of (semi-) automated approaches being used on benthic foraminifer taxa to extract information such as size29, 2D shape8,30, calcite thickness31, life history variation11,32, and biovolume through ontogeny13,33, these datasets are rarely publicly available in their raw forms. This combined lack of data on individual-level trends and a lack of accessibility for those data that do exist have limited the ability of additional studies to build on previous results and describe trends at population and community scales. As biologists increasingly strive to elucidate the impacts of climate change on marine life at all scales, large, individual-level datasets that span across historic periods of environmental change are critical both for building ecosystem baselines that place modern change into context and for leveraging the predictive power of the fossil record to understand the range of biological responses expected under projected climate scenarios.
Existing workflows can be used to address benthic foraminifer data gaps and begin to build large, open-access datasets that collect information on the individual-level intraspecific morphological trait distributions needed to reconstruct community ecological characteristics. Here we provide an image library of individual benthic foraminifera and high-resolution 2D assemblage images, individual images, coordinate data, and morphometric measurements from Santa Barbara Basin (SBB) sediment core samples. Images of 27,508 complete and damaged benthic foraminifera are provided along with 2D morphometric data. Images and shape data for an additional ~1,000 objects are also provided, encompassing general categories including planktonic foraminifera, ostracods, pteropods, diatoms, radiolarians, fish teeth and skeletal structures, shark dermal denticles, and foraminiferal test fragments (see Methods for further information). Benthic foraminifera are identified to species, and classifications of reproductive mode (i.e, sexually vs. asexually produced offspring) are included for four biserial species with significant and visible dimorphism that allows for examination of life history trends among reproductive morphotypes.
Methods
Core sampling and chronology development
As part of previous studies34,35, a kasten core and a box core from the center of the SBB (Southern California) were collected in 2010 at station MV1012-ST46.9 (34°17.228′N, 120°02.135′W) at approximately 580 m water depth (Fig. 1). This station was chosen as a re-occupation of Ocean Drilling Program Site 89336 and was designated as Station 46.9 following the station naming convention of the California Cooperative Oceanic Fisheries Investigations (CalCOFI)37,38. 2-cm vertical core slices from each subcore were X-radiographed and scanned at 1-mm intervals in a linear, non-rotational scan34,35. Composite X-radiographs were used with color photographs to develop a high-resolution chronology for each core (Fig. S1). The age model for the kasten core MV1012-KC1 was adapted from Hendy et al.39 and Schimmelmann et al.40; dates assigned to each sample were the average of the dates of the upper and lower surfaces of the sample transverse section. Kasten core MV1012-KC1 spans from 107 BC to 1885 CE (Fig. 1); however, we utilized a subset from 1249 CE to 1841 CE to develop the present dataset (Table 1). Box core MV1012-BC1 was sufficiently shallow to use traditional varve chronology for couplet dating; a regression model was used to assign dates to the sediment stratigraphy prior to 1871, thus extending the chronology to 1834 CE34.
Sample preparation
Prior to the present study, subcore cross-sections were cut transversely at every 0.5 cm to create transverse sections of 97.5cm3, and these were stored at −80 °C prior to further processing. Near-instantaneous event layers were combined with chronologically-correlated transverse sections to create larger samples. These sections were dried overnight at 50 °C, washed in distilled water, and wet-sieved over a 104- and 63-μm mesh. Two previous studies, Jones and Checkley35 and Brandon et al.34 picked the >104 μm fractions for fish otoliths and plastic particles, respectively. To generate the present dataset, we picked samples from the 63–104 and >104 μm fractions for benthic foraminifera. These fractions were combined to create a single >63 μm fraction for all cores. Kasten core samples were dry split using a sediment splitter to achieve aliquots of approximately equivalent sample volumes for subsample picking, while box core samples were processed in their entirety. Kasten core samples were picked exclusively for biserial benthic foraminifera, while box core samples were picked for all benthic foraminifer individuals present within a given sample. Split fractions and community data types (biserial only, or representative of the full benthic foraminifer community) are reported in Table 1.
Imaging
We imaged all benthic foraminifera picked from entire samples or representative split fractions. Benthic foraminifera were manually picked from each sample or split under a Leica EZ4 dissecting microscope at 16x magnification, and were arranged for imaging on matte black coated brass plates. Arranging ensured that individual foraminifera and other objects were not touching, a critical step for simplified post-processing using high-throughput imaging techniques2. On the few occasions that all sample material did not fit within the boundaries of a single plate, multiple plates were imaged and named accordingly (e.g., MV1012-BC-40_1, MV1012-BC-40_2, etc.). Arranged samples were imaged in bulk using a Keyence VHX-7000 digital imaging microscope at 150x magnification, and the same lighting settings were used across samples to improve comparability. Each sample took between 30 minutes to 4 hours to image; runtime was dependent on the number of individuals present in each given sample.
AutoMorph (automated morphometric post-processing)
Bulk images were processed with the AutoMorph software package (v. 2017-06)2, an open-access bioinformatics pipeline designed to segment individual objects from light microscope and camera images and extract 2D and 3D shape information. The AutoMorph protocol contains four modules for 2D and 3D image processing: segment, focus, run2Dmorph, and run3Dmorph. For this study, the segment module was used to identify all unique objects in a 2D extended-depth-of-focus (EDF) bulk image, extract these objects and label them with sample metadata, and save these slices in unique directories. Because the bulk images used for this study were already compiled into EDF images, the focus module, which is designed to compile z-slices into EDF images, was not needed. Once images were segmented, we used the run2dmorph module to extract shape coordinates and basic measurements in 2D and create images of 2D shape extraction for visual quality control (Fig. 2). The AutoMorph software package and documentation is freely available on GitHub and can be accessed at https://github.com/HullLab/AutoMorph. The software suite and resultant datasets are described in detail in several publications2,3,4,41. AutoMorph is adapted to run on local computers and supercomputer clusters; for this study, a laptop computer with a 2.6 GHz Quad-Core Intel i7 processor was sufficient to process all samples. AutoMorph processing is relatively quick; runtime was on the order of minutes for each sample processed with both segment (per bulk image) and run2dmorph (per thousand individual images).
Image identification
Individual images produced by the segment module were used to identify all unique objects (Table 2) using a custom-made application for image viewing and the assignment of general object information to images, including the certainty of object classification. This application, called classifier, is a modified version of classify-specify (https://github.com/HullLab/Classify-Specify) designed for use on unix systems. The classifier application and documentation can be accessed at https://github.com/GregDMeyer/classifier. For samples with multiple bulk images, object numbers for each image following the first were modified, typically by adding an additional number to the beginning (e.g., obj. 00001 of the second bulk image becomes obj. 10001; for the third, obj. 20001, etc.) to avoid overlapping numbers. These allowed for smooth classification using the classifier application.
Preparation for machine learning workflows
A subset of 10,827 images was formatted for use with Tensorflow workflows, a commonly-used open-source platform for machine learning42. We used Tensorflow v. 2.12.0 (2022) to develop the models reported on in this analysis. Images were stripped of AutoMorph-generated metadata labels and resized to 224 × 224 pixels for standardization. This machine learning image dataset includes two label types: one label for species identity (originally encoded numerically, from 0–54, with the encoding 0 denoting objects other than benthic foraminifera) and a second boolean label for the fragmentation state of the shell (1 denoting broken, 0 denoting intact). This dataset has been split into subsets for training (80%), validation (10%), and testing (10%), and data augmentation has been omitted in the presentation of the dataset. The Tensorflow dataset is also provided as a zip file containing the image dataset and its corresponding Tensorflow dataset descriptor (see Data Records).
We applied a resnet-50 transfer learning classifier to simultaneously classify species identity and specimen fragmentation state. We found that this classification approach has a validation accuracy of 80.6% for species and 85.6% for genera (Fig. 3). This demonstrates that even standard, unoptimized transfer learning model architectures can be successful for automated identification of benthic foraminifera, particularly for usage applications where common species are considered (see Usage Notes).
Data Records
We provide metadata, image, and shape data for all 36,275 objects in the dataset, of which 27,508 are complete and damaged benthic foraminifera from ~60 unique species (Fig. 4), and 26,399 for which shape information was successfully extracted using AutoMorph. The tables within this data report provide relevant metadata, summary statistics, and technical validation information. The coring location and an overview of core chronology are shown in Fig. 1, and sample ages and split fractions (i.e., aliquot sizes) are reported in Table 1. The workflow employed for sample preparation, imaging, and processing with AutoMorph is shown in Fig. 2. Supplementary Table 1 provides references for taxonomic identifications and common synonyms, and reference images can be found in Figs. 5, 6. All data products of this study are available on Zenodo43; this repository contains 8 distinct data types uploaded as distinct files, and includes the following:
-
(I)
bulk_images.zip: Bulk images with objects identified by segment boxed in red
-
(II)
individual_images.zip: EDF images of individual objects within the dataset
-
(III)
identification_files.zip: Classifications for individual objects, including both general categories and species-specific classifications (when possible) for benthic foraminifera
-
(IV)
cleaning_scripts.zip: Directory containing R scripts used to clean object category misspellings or inconsistencies
-
(V)
outline_images.zip: EDF images of objects successfully extracted for 2D outlines and measurements; included for quality control. This includes one text file (unextracted_objects_2D.txt) listing objects with failed extractions
-
(VI)
2d_coordinates.zip: CSV files containing all extracted outline coordinates for each of the samples imaged, a text file of failed 2D extractions (unextracted_objects_2D.txt), and a summary CSV file including coordinates for all extracted objects (all_coordinates.csv)
-
(VII)
2d_properties.zip: 2D measurements for all objects
-
(VIII)
metadata_tables.zip: Tables 1–3 and Supplementary Table 1 from this publication, describing sample metadata, including site coordinates, sample names, object information, and summary statistics
Table 3 Technical validation measurements. -
(IX)
forams.zip: Images formatted for use with Tensorflow workflows and associated image labels for object and species identity and fragmentation state (fragment_labels.csv), along with a Tensorflow dataset descriptor (forams.py) and an instructional vignette (README.txt)

High-throughput imaging and AutoMorph image processing protocols. AutoMorph is an open-source software suite used for high-throughput image processing and automated morphometric measurements. For this study, two AutoMorph modules were used: segment (top panel) and run2dmorph (bottom panel). Segment takes as an input a full slide image and a settings file with metadata (sample name, age, location of collection, catalog number, etc.), size information (typically expressed as pixel size, e.g. microns per pixel), and settings flags. Segment outputs include a full-slide image with boxed and numbered individual objects, which correspond to individual images of objects, which are labeled with metadata as well as a scale bar. Run2dmorph takes as input the individual images created with segment (for this study, EDF images) as well as a settings file with measurement and filtering flags. Run2morph processes individual images through filters to create outlines, and uses outlines to generate outline-based measurements of area, perimeter, major and minor axis length, eccentricity, aspect ratio, and rugosity. Outlines and aspect ratios are output as images for visual checks, and measurements and outline coordinates are output as CSV files.

Confusion matrices of a resnet-50 transfer learning classifier. Note that this model is simultaneously classifying species and specimen fragmentation state. Panels a and b show species classification confusion matrices while panels c and d show genera classification confusion matrices, where a and c are unnormalized and b and d are normalized. Normalization scales values across each ground-truth label (i.e., row) such that they sum to 1; thus, the color saturation represents the fraction of that true label that was classified for each predicted label (where greater saturation indicates more images in the category). Confusion matrices for species classification shows that only extremely rare species are heavily misclassified (typically as a non-foram object). Panels e and f show unnormalized and normalized confusion matrices for fragmentation state, respectively. In this use case, the classifier tends to misclassify the fragmentation state for fragmented shells, but not for complete shells. This standard, unoptimized transfer learning classification approach has validation accuracies of 80.6% (species), 85.6% (genus), and 76.1% (fragmentation state).

Histogram of species abundances within the dataset. Counts are shown for species with more than 10 occurrences within the entire data record (28 of the 77 total unique species represented in the data). Six common species (Suggrunda eckisi, Bolivina argentea, Nonionella stella, Bolivina seminuda, Bolivina seminuda var. humilis, and Bulimina exilis) make up the majority of the dataset.

Common biserial benthic foraminifera from site MV1012. (a) Bolivina alata; (b) B. argentea; (c) B. pacifica; (d) B. seminuda; (e) B. spissa; (f) Bulimina exilis. Megalospheric and microspheric morphotypes within each species are denoted; all individuals are arranged with the proloculus (first chamber) facing downwards. Scale bars denote 100 μm.

Common benthic foraminifera from site MV1012. (a) Cassidulina crassa, with individuals show variation in shell coloration; (b) Chilostomella ovoidea, with individuals showing variation in coloration and porosity; (c) Fursenkoina cornuta, with individuals rotated ~180° opposite one another; (d) Globocassidulina subglobosa; (e) Nonionella stella; and (f) Suggrunda eckisi. Scale bars denote 100 μm.
Technical Validation
Technical validation occurred at several steps in the image processing pipeline to ensure that measurements were consistent across samples, and that all measurements were extracted from outlines that were true to the original sample shape. The major validation steps occurred at the object selection, shape extraction and size measurement, and object classification phases.
Object selection
The AutoMorph segment module produces a bulk image overview that provides an object number for each individual segmented object, which is boxed in red for ease of identification (Fig. 2; full sample set of boxed images available in data citation). Full-sample images taken on the Keyence VHX-7000 digital imaging microscope were output as extended-depth-of-focus (EDF) images, and these EDF images were passed to the segment module in ‘sample’ mode to produce a series of boxed images, which denoted the object numbers for each segmented individual, for visual validation prior to finalizing the segmentation output. Each boxed image was visually checked to verify that most, if not all, microfossils were identified and segmented from each image. If this visual check failed—i.e., some or many microfossils were excluded from the segmentation—image selection parameters were adjusted in segment to optimize segmentation. Once an optimal parameter was identified, the segment module was run in ‘final’ mode to create individual images of each of the objects identified from the full-sample image. These individual images provide the basis for the run2dmorph module, which produces 2D measurements, and for taxonomic identification.
Shape extraction
2D shape extraction occurred via the AutoMorph run2dmorph module, which takes as input individual 2D EDF images and produces outline coordinates, measurements, and validation images with outlines overlain atop the input image. The quality of 2D shape extraction was checked visually for the first 100 objects in a slide using these outline-object overlays. run2dmorph also outputs a list of objects with failed outline extractions for each sample processed; these are provided alongside 2D shape data in the Data Citation. When a majority of complete benthic foraminifera failed to extract, the run2dmoprh routine was re-run with adjusted image extraction parameters to attain the best possible extraction.
Successful shape extractions can sometimes produce outlines that do not reflect the true outline of the specimen. To account for these errors, outline-based measurements can be filtered by using a rugosity threshold. Because the threshold of filtering needed may vary based on the data application, we provide all outline-based measurements in the Data Citation. See Usage Notes for suggested filtering thresholds.
Size measurements
The accuracy of 2D size extraction was confirmed by measuring individuals with successful shape extraction on a Keyence VHX-7000 imaging microscope. Table 3 contains 10 benthic foraminifera from 7 species used to check 2D size extraction. Individuals were measured along their major and minor axes and outline-based area measurements were collected using ImageJ measurement software. We find that automated and “human” measurements are comparable, such that AutoMorph measurements range, on average, from 97% to 104% of hand measurements. Average differences between major and minor axes was ~5 μm. Extended technical evaluations of AutoMorph measurements can be found in publications associated with the software suite2,3,4.
Object classification
6 individual researchers worked simultaneously to classify objects from images. These researchers were undergraduate students without prior knowledge of foraminiferal morphology or taxonomy. In order to ensure inter-identifier consistency, all were trained to identify objects using a set of samples pre-identified by the first author (SSK), building on object categories outlined in Elder et al.4. Each sample was not considered completely identified until at least two unique identifiers provided classifications for all objects within the sample. These object classifications were then compared, and disagreements between identifiers were checked by SSK, who provided the final classification. Additionally, all identifiers provided a confidence (scale of 1–3, from least to most confident) for each object classification, which allowed for identifications with low confidence to be checked and updated. In cases where objects remained difficult to identify with certainty, the object classification was changed to ‘unknown’ to prevent misidentification. Errors are described briefly here, with each classification category described in more detail in Usage Notes. Most misidentifications were for species-level taxonomic classifications of benthic foraminifera (see below). For general object classification, classification errors included misidentification of non-benthic objects, including radiolaria, planktonic foraminifera, diatoms, and pteropods, which, when classified in error, were typically identified as ‘benthic foraminifer fragments’ or ‘junk.’ Images that contained multiple objects (e.g., had not been properly arranged during the sample preparation step and as a result were touching, or had overlapping outlines) were also misclassified when individual classifiers chose to identify one or more objects rather than classify them as ‘touching’. Chunks of consolidated sediment were typically poorly classified, and as a result, were assigned to the ‘unknown’ category. In cases where individual images were of large individuals, the segmented image boundary occasionally contained other, smaller individuals (which typically were captured within their own segmented images), some of which were erroneously classified alongside the larger individual. To remedy inconsistent object classifications, visual checks (as described above) were used to reassign object categories. Following visual checks, automated cleaning scripts were employed to remedy misspellings or inconsistent spellings among object categories. These scripts are included within Data Citation 1.
Taxonomic classification
Taxonomic classification of benthic foraminifera occurred during the same classification step as general object classification (see Table S1.1 for taxonomic references). Benthic foraminifera were identified to species whenever possible, and identifiers were trained to make species-level identifications using a set of reference images classified by SSK. Reference images for twelve of the most common species can be found in Figs. 5, 6. During object classification, identifiers classified benthic foraminifera to species and provided a confidence level for their classification. While the majority of confident classifications were for benthic foraminifera with complete or partially-damaged shells, on occasion classifications could be made from fragmentary pieces of shell (see Usage Notes for suggestions on how to filter out these specimens when using morphometrics data). In total, ~60 unique species were identifiable from all samples, and are listed in Supplementary Table 1.
Usage Notes
Following their collection and preparation, many of the samples used in this study were picked for fish otoliths and plastic particles prior to the present study. However, the remainder of objects, including the benthic foraminifera on which we focus, were, to our knowledge, unbiased by previous research efforts undertaken on this material. It is worth noting that the benthic foraminifera that we observe for this study represent death assemblages, and as such may not be fully representative of the composition of living communities at the time of sediment layer deposition.
Time averaging
In studies of nearby sites in the Southern California Borderlands, death assemblages of benthic foraminifera are shown to differ in species composition, proportion, and distribution when compared to living assemblages44. However, these studies have lower temporal resolution than the present contribution, and may be observing time-averaged differences in assemblages that result from changes to shelf, slope, and basin environments that have taken place over the last several hundred years45. Yet even within the well-resolved sediments of the Santa Barbara Basin, there may be migration of benthic foraminifera between sediment layers. Some species undertake daily to seasonal migrations between the sediment-water interface and the uppermost centimeters of sediment46,47, and as a result, sediment layers of a given age may contain individuals from younger populations. Because vertical migration may be less pronounced during periods of anoxia46, the dysoxic waters of the Santa Barbara Basin may serve to limit this effect. Although the effects of time-averaging and differential vertical migratory behavior are likely small for the Santa Barbara Basin, mere differences in population dynamics between taxa can also produce live and death assemblage discrepancies. Populations with shorter longevity will contribute tests to the death assemblage at a higher rate than long-lived ones, and will thus be relatively overrepresented in the fossil record. We caution that any analyses that utilize these data take benthic foraminifer ecology, population dynamics and the broader environmental and temporal setting of these samples into account.
Sample preparation and classification
While the 63 μm size limit we apply here can be considered a general lower bound for the size of objects within our samples, some smaller particles may have been retained during processing stage. These smaller objects should not be considered representative of the <63 μm fraction and should be excluded from the majority of data applications. In addition, while objects other than benthic foraminifera are included within these data, the majority were not intentionally picked out of the larger sample and should not be considered representative. However, a few classes were picked within intentionality and can be considered a representative fraction, where the entirety of the sample has been picked for a given class. These include fish teeth, shark dermal denticles, pteropods, and other small (including larval) bivalve and gastropod shells. These, alongside the benthic foraminifera, are the only objects that should be considered for future systematic and ecological studies that employ these data. Each object was classified by a human observer (i.e., identifier) and placed into one of 15 categories along with an indication of confidence in the classification (1: not confident, 2: somewhat confident, 3: very confident).
Broad classification categories are defined following Elder et al.4. ‘Junk’ denotes any fibers, inorganic crystalline structures, sand, rocks, captured images of light reflecting off of the background imaging plate, and other unidentifiable, non-biological forms. ‘Planktic’ indicates any planktonic foraminifer, and includes shells that are complete, damaged, and fragmented. ‘Fragment’ includes any fragment of a benthic foraminifer that is not easily identifiable to species. ‘Gastropod’ denotes any gastropod shell, other than pteropods. ‘Pteropod’ denotes any pteropod shell, and includes shells that are complete, damaged, and fragmented. ‘Bivalve’ denotes small (potentially larval) bivalve shells. ‘Fish tooth’ denotes any fish dental structure, but does not include shark dermal denticles. ‘Dermal Denticle’ denotes any shark dermal denticle of any species. The ‘Radiolaria’ category contains radiolarians, ‘Diatom’ contains diatom frustules, ‘Echinoid’ contains echinoid fragments (including spines), ‘Spicule’ contains sponge spicules, and ‘Ostracod’ contains ostracods. In each of these categories, complete or larger individuals in clear, well-focused images were typically identified with greater confidence than broken or smaller objects, or those in out-of-focus images. Finally, ‘Touching’ denotes any images of multiple objects, which cannot be given a single identification. Objects in direct or very near contact are unable to be used for accurate 2D size and shape extraction, and should be excluded from any morphometric analyses.
Morphometrics and machine learning
Morphometric data should be checked prior to analyses according to the given use case. For example, data used for a study of body size may be filtered to remove poorly-extracted outlines by applying a rugosity filter, where objects with a rugosity greater than a given threshold are excluded from analyses. Other morphometric outputs that can aid in automated cleaning include aspect ratio and the outline coordinates.
Objects for which 2D size and shape extraction failed are listed in each relevant measurement file. Metadata including pixel sizes used for automated measurement can be found in the labels attached to each bulk and individual image provided in the data file individual_images.zip of Data Citation 1. These pixel sizes can be used for future measurement via AutoMorph or other morphometric software. Additional metadata provided via image labels includes the sample name, object number, age, locality name, where images were processed, and the identity of the individual who processed the images. This metadata is permanently associated with images to ensure that no information is lost should these images be separated from other data files.
Select samples were run with an incorrect size factor. As a result, the morphometric measurements for these samples were corrected in post-processing using a set of conversion factors. Table 4 reports these samples and the conversion factors for linear and 2D measurements. Note that while measurements for these samples have been corrected, the scale bars will not provide an accurate measurement of pixel size (i.e., μm/pixel); corrected pixel sizes are reported in Table 4.
Images in the Tensorflow dataset have been pre-processed for machine learning workflows and can be readily loaded into python with two lines of code (Data Records for readme document). Machine learning models and outputs should be used with caution in studies where quantification of the abundance of rare species is a central goal, as the models we show here will require further tuning and optimization to accurately report rare species identity. Fragmentation state labels should not be considered representative without information on species identity, as all debris and other non-microfossil objects are labeled as ‘unbroken’ by default Fig. 3.
Code availability
Images were processed using AutoMorph software, which is described in Hsiang et al.2 and freely available on GitHub at www.github.com/HullLab/AutoMorph. The classifier software used to tag images with taxonomic identifications can be found on GitHub at https://github.com/GregDMeyer/classifier.
References
Nelson, G. & Ellis, S. The history and impact of digitization and digital data mobilization on biodiversity research. Philos. Trans. R. Soc. B 374, 20170391 (2019).
Hsiang, A. Y. et al. AutoMorph: Accelerating morphometrics with automated 2D and 3D image processing and shape extraction. Methods Ecol. Evol. 9, 605–612 (2017).
Kahanamoku, S. S. et al. Twelve thousand recent patellogastropods from a northeastern Pacific latitudinal gradient. Sci. Data 5, 170197–170197 (2018).
Elder, L. E. et al. Sixty-one thousand recent planktonic foraminifera from the Atlantic Ocean. Sci. Data 5, 180109–180112 (2018).
Sibert, E. C. & Rubin, L. D. An early Miocene extinction in pelagic sharks. Science 372, 1105–1107 (2021).
Sibert, E. C. & Norris, R. D. New Age of Fishes initiated by the Cretaceous−Paleogene mass extinction. Proc. Natl. Acad. Sci. 112, 8537–8542 (2015).
Sibert, E., Friedman, M., Hull, P., Hunt, G. & Norris, R. Two pulses of morphological diversification in Pacific pelagic fishes following the Cretaceous–Palaeogene mass extinction. Proc. R. Soc. B Biol. Sci. 285, 20181194–20181197 (2018).
Lutze, G. F. Statistical investigations on the variability of Bolivina argentea Cushman. Contrib. Cushman Found. Foraminifer. Res. 15, 105–116 (1964).
Boltovskoy, E., Scott, D. B. & Medioli, F. S. Morphological variations of benthic foraminiferal tests in response to changes in ecological parameters: a review. J. Paleontol. 65, 175–185 (1991).
Foster, L. C., Schmidt, D. N., Thomas, E., Arndt, S. & Ridgwell, A. Surviving rapid climate change in the deep sea during the Paleogene hyperthermals. Proc. Natl. Acad. Sci. 110, 9273–9276 (2013).
Schmidt, D. N., Thomas, E., Authier, E., Saunders, D. & Ridgwell, A. Strategies in times of crisis—insights into the benthic foraminiferal record of the Palaeocene–Eocene Thermal Maximum. Philos. Trans. R. Soc. Math. Phys. Eng. Sci. 376, 20170328 (2018).
Tetard, M., Licari, L., Tachikawa, K., Ovsepyan, E. & Beaufort, L. Toward a global calibration for quantifying past oxygenation in oxygen minimum zones using benthic Foraminifera. Biogeosciences Discuss. 1–17 https://doi.org/10.5194/bg-2020-482 (2021).
Keating-Bitonti, C. R. & Payne, J. L. Environmental influence on growth history in marine benthic foraminifera. Paleobiology 44, 736–757 (2018).
Kucera, M. Chapter Six Planktonic Foraminifera as Tracers of Past Oceanic Environments BT - Proxies in Late Cenozoic Paleoceanography. in Proxies in Late Cenozoic Paleoceanography vol. 1 213–262 (Elsevier, 2007).
Culver, S. J. Early Cambrian foraminifera from west Africa. Science 254, 689–691 (1991).
Pawlowski, J. et al. The evolution of early Foraminifera. Proc. Natl. Acad. Sci. 100, 11494–11498 (2003).
Zachos, J., Pagani, M., Sloan, L., Thomas, E. & Billups, K. Trends, rhythms, and aberrations in global climate 65 Ma to present. science 292, 686–693 (2001).
Zachos, J. C., Dickens, G. R. & Zeebe, R. E. An early Cenozoic perspective on greenhouse warming and carbon-cycle dynamics. Nature 451, 279–283 (2008).
Hönisch, B. et al. The geological record of ocean acidification. Science 335, 1058–1063 (2012).
Ezard, T. H. G., Aze, T., Pearson, P. N. & Purvis, A. Interplay between changing climate and species’ ecology drives macroevolutionary dynamics. Science 332, 349–351 (2011).
Norris, R. D., Turner, S. K., Hull, P. M. & Ridgwell, A. Marine Ecosystem Responses to Cenozoic Global Change. Science 341, 492–498 (2013).
Hull, P. M. Emergence of modern marine ecosystems. Curr. Biol. 27, R466–R469 (2017).
Bray, N. A., Keyes, A. & Morawitz, W. M. L. The California Current system in the Southern California Bight and the Santa Barbara Channel. J. Geophys. Res. Oceans 104, 7695–7714 (1999).
Emery, K. O. & Hülsemann, J. The relationships of sediments, life and water in a marine basin. Deep Sea Res. 1953 8, 165–IN2 (1961).
Soutar, A. & Crill, P. A. Sedimentation and climatic patterns in the Santa Barbara Basin during the 19th and 20th centuries. Geol. Soc. Am. Bull. 88, 1161–1161 (1977).
Thunell, R. C., Tappa, E. & Anderson, D. M. Sediment fluxes and varve formation in Santa Barbara Basin, offshore California. Geology 23, 1083–1083 (1995).
Moffitt, S. E., Hill, T. M., Ohkushi, K., Kennett, J. P. & Behl, R. J. Vertical oxygen minimum zone oscillations since 20 ka in Santa Barbara Basin: A benthic foraminiferal community perspective. Paleoceanography 29, 44–57 (2014).
Kennett, J. P. & Ingram, B. L. A 20,000-year record of ocean circulation and climate change from the Santa Barbara basin. Nature 377, 510–514 (1995).
Santana, B. F., de, B. B., Freitas, T. R., Leonel, J. & Bonetti, C. Biometric and biomass analysis of Quaternary Uvigerinidae (Foraminifera) from the Southern Brazilian continental slope. Mar. Micropaleontol. 169, 102041 (2021).
Keating-Bitonti, C. R. & Payne, J. L. Ecophenotypic responses of benthic foraminifera to oxygen availability along an oxygen gradient in the California Borderland. Mar. Ecol. 38, e12430–16 (2017).
Kuroyanagi, A. et al. Decrease in volume and density of foraminiferal shells with progressing ocean acidification. Sci. Rep. 11, 19988 (2021).
Saraswat, R., Deopujari, A., Nigam, R. & Heniriques, P. J. Relationship between abundance and morphology of benthic foraminifera Epistominella exigua: Paleoclimatic. implications. J. Geol. Soc. India 77, 190–196 (2011).
Belanger, C. L. Volumetric analysis of benthic foraminifera: Intraspecific test size and growth patterns related to embryonic size and food resources. Mar. Micropaleontol. 176, 102170 (2022).
Brandon, J. A., Jones, W. & Ohman, M. D. Multidecadal increase in plastic particles in coastal ocean sediments. Sci. Adv. 5, eaax0587–eaax0587 (2019).
Jones, W. A. & Checkley, D. M. Mesopelagic fishes dominate otolith record of past two millennia in the Santa Barbara Basin. Nat. Commun. 10, 4564 (2019).
Baldauf, J. & Lyle, M. Proceedings of the Ocean Drilling Program, Scientific Results. Vol. 146, Part 2. Santa Barbara Basin: covering Leg 146 of the cruises of the Drilling Vessel” Joides Resolution”, Santa Barbara Channel, California, Site 893, 20 September-22. (Texas A & M University, Ocean Drilling Program, 1995).
Bograd, S. J., Checkley, D. A. Jr & Wooster, W. S. CalCOFI: a half century of physical, chemical, and biological research in the California Current System. Deep Sea Res. Part II Top. Stud. Oceanogr. 50, 2349–2353 (2003).
CalCOFI. CalCOFI – California Cooperative Oceanic Fisheries Investigations. https://calcofi.org/ (2022).
Hendy, I. L., Dunn, L., Schimmelmann, A. & Pak, D. K. Resolving varve and radiocarbon chronology differences during the last 2000 years in the Santa Barbara Basin sedimentary record, California. Quat. Int. 310, 155–168 (2013).
Schimmelmann, A., Hendy, I. L., Dunn, L., Pak, D. K. & Lange, C. B. Revised ∼2000-year chronostratigraphy of partially varved marine sediment in Santa Barbara Basin, California. GFF 135, 258–264 (2013).
Hsiang, A. Y. et al. Endless Forams: >34,000 Modern Planktonic Foraminiferal Images for Taxonomic Training and Automated Species Recognition Using Convolutional Neural Networks. Paleoceanogr. Paleoclimatology 34, 1157–1177 (2019).
Abadi, M. et al. Tensorflow: Large-scale machine learning on heterogeneous distributed systems. ArXiv Prepr. ArXiv160304467 (2016).
Kahanamoku, S. et al. Twenty-two thousand Common Era benthic foraminifera from the Santa Barbara Basin., Zenodo, https://doi.org/10.5281/zenodo.7274658 (2022).
Douglas, R. G., Liestman, J., Walch, C., Blake, G. & Cotton, M. L. The Transition from Live to Sediment Assemblage in Benthic Foraminifera from the Southern California Borderland. 257–280 (1980).
Douglas, R. G. & Heitman, H. L. Slope and basin benthic foraminifera of the California borderland (1979).
Duijnstee, I., Ernst, S. & Van der Zwaan, G. Effect of anoxia on the vertical migration of benthic foraminifera. Mar. Ecol. Prog. Ser. 246, 85–94 (2003).
Koho, K. A., Piña-Ochoa, E., Geslin, E. & Risgaard-Petersen, N. Vertical migration, nitrate uptake and denitrification: survival mechanisms of foraminifers (Globobulimina turgida) under low oxygen conditions. FEMS Microbiol. Ecol. 75, 273–283 (2011).
Acknowledgements
This work was partially supported by NSF/GSA Graduate Student Geoscience Grant No. 12739-20, which is funded by NSF Award No. 1949901 to SSK. SSK was also supported by an NSF Graduate Research Fellowship under Grant No. DGE 2146752 and a UC Berkeley Chancellor’s fellowship. It was partially supported by National Science Foundation awards NSF EAR-1740214 to SF. The authors thank Jenni Brandon, William Jones, and Richard Norris for providing washed core samples and their corresponding age models. We also thank Pincelli Hull, Alison Hsiang, Leanne Elder, and Kaylea Nelson for their development of and assistance with the AutoMorph software suite, and Gregory Kahanamoku-Meyer for writing the classify software used for identification.
Author information
Authors and Affiliations
Contributions
S.S.K. and S.F. conceived and coordinated the study, selected samples for analysis, drafted the manuscript, and created figures. S.S.K., M.S.F., S.M.K., D.S., L.K., M.T., Y.A.M., J.T.E., G.G.M., C.L. and H.F. picked samples for benthic foraminifera. S.S.K. and M.S.F. performed all imaging, image processing, and morphometric analyses, and were aided by S.F. and I.A.P.D. in dataset compilation and technical validations. S.S.K., M.S.F., S.M.K., Y.S.L., C.S. and R.C.B. classified objects, and SSK performed taxonomic verifications to ensure that classifications were consistent among identifiers. B.Z.W. processed images for machine learning workflows and implemented a classification model. All authors contributed to the final writing of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Kahanamoku-Meyer, S.S., Samuels-Fair, M., Kamel, S.M. et al. An 800-year record of benthic foraminifer images and 2D morphometrics from the Santa Barbara Basin. Sci Data 11, 144 (2024). https://doi.org/10.1038/s41597-024-02934-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41597-024-02934-9
