
Abstract
High-resolution income projections under different Shared Socioeconomic Pathways (SSPs) are essential for the climate change research communities to devise climate change adaptation and mitigation strategies. To generate income projections for Washington state, we obtain state-level GDP per capita projections and convert them into projected annual household income. The resulting state-level income projections are subsequently downscaled to the census block-level based on the Longitudinal Origin-Destination Employment Statistics (LODES) dataset. For accuracy assessment, we downscale historical income data from state- level to block- and block group-level and compare the downscaled results against the actual income data from LODES. County-level accuracy assessment is also conducted based on American Community Survey. The results demonstrate a good agreement (Average R2 of 0.67, 0.8, and 0.99 for block-, block group-, and county-level, respectively) between the downscaled income data and the reference data, thereby validating the methodology employed. Our approach is applicable to other states for income projections, which can be utilized by a broader audience, including those involved in demographic analysis, economic research, and urban planning.
Similar content being viewed by others


Background & Summary
Income is an important data input and is increasingly used in many research fields, such as demographic analysis, economic research, urban planning, market research, and housing studies1,2,3,4,5. In the United States, income data are regularly collected by American Community Survey (ACS), the largest survey in the United States that collects detailed social, economic, housing, and demographic information by sampling about 3 million addresses every year6. ACS provides income data across different census geographic levels (e.g., block group, census tract, county, state) and different temporal resolutions (e.g., annual data, 5-year average data) in various forms, including aggregate income, median household income, number of households by 16 income categories, etc7. However, the ACS estimated income data for small areas (e.g., block groups, census tracts) is subject to significant uncertainty caused by sampling error, which often renders the data too imprecise to be utilized8. On the other side, the US Census Longitudinal Employer-Household Dynamics (LEHD) Origin-Destination Employment Statistics (LODES) dataset9 provides block-level job-related information, including income data (employee compensation), directly compiled from administrative records, which eliminates the issues of sampling errors10. LODES provides three different data types, including Work Area Characteristics (WAC), Residence Area Characteristics (RAC), and Origin-Destination (OD). WAC and RAC respectively provide job information by work census block and residence census block, while OD provides job information associated with both a residence census block and a work census block. The income data in the LODES dataset are shown as the number of jobs by three different wage categories ( ≤ $1,250/month, $1,251 ~ $3,333/month, and > $3,333/month)11. One major difference between the ACS income data and the LODES income data is that LODES focuses on employed individuals, while ACS covers the entire population, including employed individuals, self-employed persons, retirees, and others7,12. Therefore, some income categories, such as self-employment income, pensions, interests and dividends, and rental income, are included in ACS but not in LODES.
The availability of historical and current income data at high spatial and temporal resolution has provided valuable information for research, however, one notable gap in current research and analysis is the limited estimation of future income projections at a similar high resolution. As climate change is projected to accelerate in the future, extreme weather events (e.g., heat wave, flood, drought, etc.) will become more frequent and severe, making humans more vulnerable to them13. Quantifying future demographics in high resolution under different Shared Socioeconomic Pathways (SSPs) scenarios can help to assess climate change vulnerabilities, making it useful for designing climate change adaptation and mitigation strategies on a more detailed and granular scale14. Numerous research has been done to facilitate this, for example, Jones and O’Neill produced global one-eighth degree population grids for every decade from 2000 to 2100 under different SSPs15. As an important indicator for social vulnerability, income projections play a crucial role in depicting future income trajectories and identifying possible disadvantaged communities that may be vulnerable in future climate change scenarios, which is vital for devising climate change adaptation and mitigation strategies16,17. Nevertheless, it’s important to recognize that future incomes in certain spaces may be endogenous to future economic conditions, including economic growth and inequality, as individuals and households can relocate in response to changing circumstances.
Our study generates 3-binned block- and block group- level income projections for every five years between 2020 and 2100 under different SSPs for Washington state. These income projections are estimated as number of households by three different income bins consistent with the LODES income categories. Our study provides granular income data for climate research projections, which are vital for devising climate change adaptation and mitigation strategies. For instance, these income projections for Washington state are utilized in the Grid Operations, Decarbonization, Environmental and Energy Equity Platform (GODEEEP), which intends to model the US energy system interactions across scales under decarbonization and assess its impact on environmental and energy equity. Specifically, block-level income projection is employed to predict disadvantaged communities (also referred as DAC)18. The US Council on Environmental Quality’s Justice40 initiatives have recently defined DAC at the census tract-level, enabling an understanding of which areas are currently experiencing the benefits or lack thereof from climate and energy investments. By incorporating block- and block group-level income projections into our spatial disaggregation analysis, we can estimate DAC at finer spatial resolution.
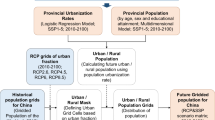
Figure 1 shows the workflow of income reconciliation. More detailed data generation steps are described in the method section. Our approach could also be applied to other states to generate income projections using similar data.

Workflow for income reconciliation.
Methods
We obtain the ACS 2013–2017 state-level population, number of households, aggregate income, and 16-binned income data from the Integrated Public Use Microdata Series (IPUMS)19. ACS 2013–2017 contains 5-year estimates from data collected during 2013–2017 period, which represents the socioeconomic conditions for our baseline year of 2015. To derive the state-level mean household size and average household income, we respectively divide the aggregated state-level income and population by the state-level number of households. The resulting state-level mean household size is used for the calculation of the projected decile income per household while the derived state-level mean household income is used to estimate the state-level income probability density function (PDF) in the baseline year of 2015. Hippel et al. introduced a method of fitting nonparametric continuous distribution based on binned income data by interpolating the corresponding cumulative distribution function20. The resulted PDF can reproduce the bin counts accurately, and the estimation accuracy improves when the interpolation method is constrained to match a known mean. We utilize the “binsmooth” package20 in R and implement the interpolation method using splines to estimate the baseline state-level income PDF based on the state-level 16-binned income data, with the calculated state-level mean household income serving as the mean constraint. Subsequently, we estimate the future projected income PDFs using the derived baseline state-level income PDF to reflect corresponding changes. Furthermore, based on the estimated baseline state-level income PDF, we calculate the baseline state-level decile household income in 2015.
We obtain projected decile real GDP per capita for future years (Gi) under different SSPs21 (Only SSP2, SSP3, and SSP5 are available in this product). We convert projected decile GDP per capita to projected decile income per household (Mi) using the formula:
Where Mi is the projected i-ith decile income per household, Gi is the projected i-th decile GDP per capita, H is the mean household size, and R is the GDP-to-income ratio. This conversion formula assumes that the GDP-to-income ratio and the mean household size remain constant over time, which aligns with the historic observations (Please refer to Supplementary Information for the validation details regarding the constant mean household size and GDP-to-income ratio assumptions).
The derived projected decile income per household is compared with the baseline decile income per household in 2015 (Bi) to calculate decile-specific expanding ratios (ERi) based on the formula:
These decile-specific expanding ratios reflect income changes for each decile, and they are further used to update the income PDF in the baseline year of 2015.
To update the income PDF from the baseline year of 2015 to the projected years, we first discretize the continuous income PDF of 2015 into bins with an equal width of $100. We calculate an updated point for each bin by multiplying the midpoint of its x-axis by the corresponding decile-specific expanding ratio. For instance, the $10,000 - $10,100 bin belongs to the first income decile, with a corresponding expanding ratio of 1.2. Its midpoint at $10,050 is used as its representation and is then multiplied by the expanding ratio, resulting in an updated point with an x-axis value of $12,060, while the y-axis value (probability) remains unchanged. Based on all the updated points, we fit a spline function. We subsequently normalize this fitted spline function to ensure that the cumulative y values sum up to 1 (Sum of probability equals to 1). This normalized spline function serves as the income PDF projection.
We then obtain state-level population projections from Zoraghein and O’Neil et al.22 and calculate state-level number of households projections based on the following formula:
where N represents the state-level number of households projection, P is the projected state-level population projection, and H is the mean household size. We integrate the income PDF projection with the corresponding state-level number of households projection to derive the projected state-level income data, which is represented as the number of households in three income bins defined by LODES.
However, before integration, we need to first address the mismatch between the income units used in the income PDF projections and the LODES data. The income PDF projections represent income as annual household income, while LODES defines three income bins as monthly wages per person. Therefore, we convert the income unit in LODES to annual household income based on the following formula:
where Income represents annual household income, Wage is monthly wage per person, and E is the average number of employees per household, calculated as a temporal mean based on LODES data from 2002 to 2015. As a result, the three income bins defined by LODES (≤$1,250/month/person, $1,251~$3,333/month/person, and >$3,333/month/person) are transformed to annual household income bins (≤$18,150/year/household, $18,150~$48,396/year/household, and >$48,396/year/household).
Once we obtain income projections at the state-level, we further downscale them to block-level using the following formula:
Here, BKi,j is the downscaled block-level number of households for the i-th income bin and the j-th census block, Si is the state-level number of households in the i-th income bin, and Wi, j is the redistribution weight for the j-th census block in terms of the i-th income bin. Wi, j is a temporal mean weight and can be calculated by the following formula:
where BKi, j,k is the number of households for the i-th income bin for the j-th census block in historical year k, and Si, k is the state total number of households for i-th income bin in historical year k. This downscaling procedure assumes that the block-level weight remains relatively stable over years. Once the block-level income projections are calculated, we aggregate them into block group-level.
Data Records
Income projections for Washington state (under census geographic boundary 2020) for every five years from 2020 to 2100 under different SSPs (SSP2, SSP3, and SSP5) are publicly available at Zenodo repository23 (Version 4). The files “bg_binned_income_proj_rounded.csv” and “bk_binned_income_proj_rounded.csv” contain income projections at the block group- and block-level, respectively. Income projection data are shown as the projected number of households for each of the three different income categories. In the data file, “GISJOIN” is the unique identifier for each block (or block group). Each number of households projection is stored in a column, where the first four characters of the column name represent the projection year (e.g., 2020, 2030), and the remaining characters indicate the income category (Income1 represents annual household income less than $18,150, Income2 represents annual household income between $18,150 and $48,396, and Income3 represents annual household income greater than $48,396). For example, “2020SSP2Income1” indicates the number of households projection for the first income bin in 2020 under SSP2.
Technical Validation
In this study, we assume that the GDP-to-income ratio, the mean household size, and the average number of employees per household are constant over time for generating state-level income projections. To further downscale these projections to the block level, we assume that the proportion of households within each block, categorized by income, remains stable to the state’s total households in the same income category over time. To validate our method, we apply it to downscale historical income data from state-level to block- and block group-level, and then compare the downscaled results against the actual income data.
Specifically, three-binned income data at the state-level for years between 2016 and 2020 are obtained by aggregating block-level LODES income data9. Then, state-level three-binned incomes are downscaled to block-level based on the income-bin-specific block-level population weights based on LODES 2002–2015. To obtain block group-level income data, the downscaled block-level income data are aggregated to block group-level. The downscaled block/block group-level income data are compared with the actual block/block group-level LODES income data. We calculate the R2, median absolute percentage error (MdAPE), Households Placed Incorrectly (HPI), and Percent of Households Placed Incorrectly (PHPI) for each income bin and each validation year between 2016 and 2020. HPI is calculated based on the following equation:
where ri and ai are the downscaled number of households and actual number of households for certain income bin at the ith block/block group, respectively. The division by two corrects for the double counting of the incorrectly placed households in the block/block group where they actually reside and the block/block group where they were mistakenly placed24. PHPI is calculated as the percentage of HPI over the state total number of households.
Tables 1 and 2 show the accuracy assessment results for block-level and block group-level income data, respectively. The downscaled block group-level income data outperforms the downscaled block-level income data across all validation years. In addition, these two tables demonstrate the stability of the accuracy for each income bin across different validation years, except for year 2020 where both block- and block group-level income data showed deteriorated accuracy. The observed deteriorated accuracy for 2020 can be attributed to various factors. One significant contributor is the population migrations induced by COVID-19 in 2020, which led to considerable variations in population distributions in 2020 compared with past years25. Additionally, the way the LODES data were compiled could also contribute to this deteriorated accuracy in 2020. Specifically, LODES data for 2016–2019 used the census block boundary from 2010, whereas LODES 2020 was compiled based on the census block boundary from 2020. To align the original LODES data from 2016–2019 with the 2020 census geographic boundary, the US Census Bureau employed areal interpolation11. However, this areal interpolation step could introduce additional uncertainty for those years, resulting a larger divergence from LODES 2020, which directly utilized the census block boundary of 2020.
Besides accuracy assessment for historical years between 2016 and 2019 based on LODES dataset, we extend the evaluation to our income projection product in 2020 under SSP2 (Business-as-usual scenario) based on the ACS dataset. Unlike the LODES-based evaluations, the ACS-based accuracy assessment is conducted at a coarser resolution of county-level due to the high sampling errors associated with the ACS income data at finer spatial resolutions8. As ACS 1-year estimate of income for 2020 is not available due to covid26, we download ACS 2019 and ACS 2021 and then calculate their mean to represent ACS income data in 2020. Then, we aggregate our income projection in 2020 under SSP2 to the county-level, followed by the comparison with county-level ACS income data in 2020. Table 3 shows the accuracy assessment result. The result reveals that the county-level accuracy assessment exhibits superior performance, characterized by higher R2 values and lower error values.
Code availability
Code for generating block/block group-level 3-binned income for the projected years under different SSPs can be found at GitHub (https://github.com/crystalandwan/Income-Reconciliation.git).
Change history
29 January 2024
A Correction to this paper has been published: https://doi.org/10.1038/s41597-024-02992-z
References
Becker, G. S., Murphy, K. M. & Werning, I. The equilibrium distribution of income and the market for status. Journal of Political Economy 113, 282–310 (2005).
Bischoff, O. Explaining regional variation in equilibrium real estate prices and income. Journal of Housing Economics 21, 1–15 (2012).
Fransham, M. Income and population dynamics in deprived neighbourhoods: measuring the poverty turnover rate using administrative data. Applied Spatial Analysis and Policy 12, 275–300 (2019).
Zhou, X. Economic transformation and income inequality in urban China: evidence from panel data. American Journal of Sociology 105, 1135–1174 (2000).
Zhou, Q. & Shi, W. How does town planning affect urban-rural income inequality: evidence from China with simultaneous equation analysis. Landscape and Urban Planning 221, 104380 (2022).
Bishaw, A., & Semega, J. Income, Earnings, and Poverty Data From the 2007 American Community Survey. Report No. ACS-09 (US Government Printing Office, Washington, DC, 2008).
US Census Bureau. Understanding and Using American Community Survey Data: What All Data Users Need to Know. (US Government Publishing Office, Washington, DC, 2020).
Spielman, S. E., Folch, D. & Nagle, N. Patterns and causes of uncertainty in the American Community Survey. Applied geography 46, 147–157 (2014).
US Census Longitudinal Employer-Household Dynamics Origin-Destination Employment Statistics https://lehd.ces.census.gov/data/ (2023)
Manduca, R. The US census longitudinal employer-household dynamics datasets. Region: the journal of ERSA 5, R5–R12 (2018).
US Census Bureau. LEHD Origin-Destination Employment Statistics (LODES) Dataset Structure Format Version 8.0. https://lehd.ces.census.gov/data/lodes/LODES8/LODESTechDoc8.0.pdf (2023).
Blumenberg, E. & Siddiq, F. Commute distance and jobs-housing fit. Transportation 50, 869–891 (2023).
Perera, A. T. D., Nik, V. M., Chen, D., Scartezzini, J.-L. & Hong, T. Quantifying the impacts of climate change and extreme climate events on energy systems. Nat. Energy 5, 150–159 (2020).
Frantzeskaki, N. et al. Nature-based solutions for urban climate change adaptation: linking science, policy, and practice communities for evidence-based decision-making. BioScience 69, 455–466 (2019).
Jones, B., & O’Neill, B. C. Global one-eighth degree population base year and projection grids based on the Shared Socioeconomic Pathways, revision 01. Palisades, New York: NASA Socioeconomic Data and Applications Center (SEDAC) https://doi.org/10.7927/m30p-j498 (2020).
Cuaresma, J. C. Income projections for climate change research: A framework based on human capital dynamics. Global Environmental Change 42, 226–236 (2017).
Chu, E. K. & Cannon, C. E. Equity, inclusion, and justice as criteria for decision-making on climate adaptation in cities. Current Opinion in Environmental Sustainability 51, 85–94 (2021).
Jain, M. et al. Training machine learning models to characterize temporal evolution of disadvantaged communities. Preprint at https://arxiv.org/abs/2303.03677 (2023).
Manson, S., Schroeder, J., Riper, D.V., Kugler, T. & Ruggles, S. IPUMS national historical geographic information system: version 17.0. Minneapolis, MN: IPUMS. https://doi.org/10.18128/D050.V17.0 (2022).
Von Hippel, P. T., Hunter, D. J. & Drown, M. Better estimates from binned income data: interpolated CDFs and mean-matching. Sociological Science 4, 641–655 (2017).
Casper, K., Narayan, K. B., O’Neil, B. C. & Waldhoff, S. State level income distributions for net income deciles for the US for historical years (2011-2014) and projections for different SSP scenarios (2015-2100). Zenodo https://doi.org/10.5281/zenodo.7227128 (2022).
Zoraghein, H. & O’Neil, B. Data supplement: U.S. state-level projections of the spatial distribution of population consistent with Shared Socioeconomic. Pathways. Zenodo https://doi.org/10.5281/zenodo.3756179 (2020).
Wan, H. et al. Block-level & block group-level income projections for Washington state under different SSPs from 2020 to 2100. Zenodo https://doi.org/10.5281/zenodo.10108728 (2023).
Wan, H., Yoon, J., Srikrishnan, V., Daniel, B. & Judi, D. Landscape metrics regularly outperform other traditionally-used ancillary datasets in dasymetric mapping of population. Computers, Environment and Urban Systems 99, 101899 (2023).
Nelson, P. B. & Frost, W. Migration responses to the covid-19 pandemic: a case study of New England showing movements down the urban hierarchy and ensuing impacts on real estate markets. The Professional Geographer 75, 415–429 (2023).
U.S. Census Bureau. Census Bureau Announces Changes for 2020 American Community Survey 1-Year Estimates. https://www.census.gov/newsroom/press-releases/2021/changes-2020-acs-1-year.html (2021).
Acknowledgements
This work was internally supported by the Laboratory Directed Research and Development (LDRD) program of the Pacific Northwest National Laboratory,
Author information
Authors and Affiliations
Contributions
H.W., S.G., M.J., D.A., N.M.M, and K.W. designed the study. H.W. implemented data collection and data processing. H.W. drafted the manuscript. All authors edited the manuscript, read, and approved the final version of it.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Wan, H., Ganguli, S., Mohankumar, N.M. et al. Projected income data under different shared socioeconomic pathways for Washington state. Sci Data 11, 85 (2024). https://doi.org/10.1038/s41597-023-02906-5
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41597-023-02906-5
