
Abstract
Industrial Kitchens are very energy-intensive businesses, consuming between five and seven times more energy per square meter than other commercial spaces like office spaces and retail stores. Still, very little research has been carried out on improving the energy efficiency of this industry. This paper presents the FIKElectricity dataset, a collection of electricity data from three Portuguese restaurant kitchens during their daily operation. The duration of the datasets spans three to four weeks in each industrial kitchen and comprises aggregated and individual appliance consumption, collected at 1 Hz and \(\frac{1}{5}\) Hz, respectively. The public release of FIKElectricity is expected to draw more attention from the research community to this overlooked industrial sector. The data collection and post-processing methods are thoroughly described in this paper, as well as the dataset organization. Examples showing the dataset’s quality and instructions for its reuse are also provided.
Similar content being viewed by others

Background & Summary
In an era where the energy sector is responsible for the majority of Green House Gases (GHG) emissions1, and the effects of climate change are becoming widely visible2, improving the sustainability of high-consuming businesses has become critical3,4. Industrial Kitchens (IKs) stand out as one of the most energy-intensive sectors, consuming approximately five to seven times more per square meter than other commercial establishments such as office buildings and retail stores5. More importantly, the energy demand of such spaces is poised to surge in the foreseeable future as a consequence of the expansion in the food and beverage services market that is projected to reach $4,651.03 billion by 2027, with a Compound Annual Growth Rate (CAGR) of 5.4%6.
Still, despite the size of the catering industry, very little research exists towards improving the energy efficiency of its underlying processes7. A few noticeable exceptions are a couple of works that either attempted to develop standardized energy efficiency benchmarks8,9,10,11, or aimed at devising strategies to reduce and shape energy demand12,13. Finally, some authors have also looked at the possibility of including Renewable Energy Sources (RESs) in the operation of IKs14,15,16,17.
The Future Industrial Kitchen (FIK) and the Exploring the Human-Water-Energy Nexus in Industrial Kitchens (nexIK) research projects were placed in the Portuguese restaurant kitchen sector. The main goal of these two projects was to understand the interactions between electricity and water consumption and waste generation in such spaces. To this end, in the FIK project, electricity, water, and waste monitoring technology were deployed in three restaurants from Funchal, Portugal, for consecutive periods between three and four weeks18. The same electricity monitoring platform was later deployed in another restaurant in Lisbon in the scope of the nexIK project, which is still ongoing19.
This data descriptor presents the data collected through the real-time monitoring of electricity consumption in the three IKs where the deployment was initialy conducted. More precisely, aggregated (i.e., total) and disaggregated (i.e., per appliance) measurements from the three IKs in Funchal. The aggregated consumption data is available in one-second intervals, whereas the individual appliance data is available at roughly one sample every five seconds. The water consumption and waste generation measurements are publicly available in previously published data descriptors20,21.
To the best of our knowledge, FIKElectricity is the only publicly available dataset with electricity demand from industrial kitchens. In fact, a search on data.world (see https://data.world/search) and openei.org (see https://openei.org/) for the keywords “kitchen electricity” and “restaurant electricity” did not reveal any relevant results that suggested the existence of such datasets. This greatly contrasts the residential and office sectors, where several datasets can be found. For example, the AMPds22 from Canada, the REFIT23 from the U.K., SustDataED224 from Portugal, the BLOND in Germany25, and the MOB dataset from the USA26.
Ultimately, it is expected that the public release of this dataset can draw more attention from the research community to this overlooked industrial sector. For example, this dataset can be used to validate and improve existing energy efficiency benchmarking methodologies, where despite the research efforts, it is still impossible to find a widely accepted normalization factor for energy consumption11. Furthermore, it can also be used to develop and evaluate methodologies to understand how appliances are used in IKs, and with that, help identify opportunities to promote a more efficient use of such devices13,27.
Surprisingly, despite being considered in the literature as one of the pillars for energy efficiency in IKs28, research in integrating Distributed Energy Resources (DERs) is also very scarce. In this context, the FIKElectricity dataset offers an opportunity to explore not only the benefits of the direct integration of DERs like Solar Photovoltaic (PV) and Battery Energy Storage Systems (BESSs) but also develop and assess new methods to enable the participation of IKs in Demand Response (DR) programs19,29. Moreover, a critical aspect of RES integration is the ability to predict electricity demand with different forecasting horizons. As such, this dataset provides a unique opportunity to develop and evaluate forecasting algorithms in the context of IKs, e.g.30.
From a monitoring perspective, it is not expected that every IK will have the resources (physical and monetary) to install circuit-level meters. In this regard, this dataset can also be used to explore if and how Non-Intrusive Load Monitoring (NILM)31,32, which identifies the electricity consumption of individual appliances taking only aggregated demand measurements, can be applied in IKs. Furthermore, if combined with the FIKWater dataset, there is also an exciting opportunity to explore how water and electricity consumption data can be combined to disaggregate wet appliances (e.g., dish washer and glasswasher).
This paper thoroughly describes how the FIKElectricity was collected, including detailed information on post-processing and organizing the data to form the dataset. This paper also analyzes the data quality and provides instructions for its reuse.
Methods
Data collection setup: aggregated consumption
The aggregated consumption data was collected using the Fluke 438-II Power Quality Analyzer & Motor Analyzer (see https://www.fluke.com/en-us/product/electrical-testing/power-quality/438-ii). This device enables the monitoring of several power-related variables, including current, voltage, active power, reactive power, power factor, voltage, and current imbalance, among others.
The collected data is stored locally on an SD Card in csv format, creating one file daily. For this particular project, the sampling rate was set to 1 Hz. At the end of each deployment, the files were downloaded and uploaded to a shared folder in the cloud.
Data collection setup: appliances consumption
The appliance-level data was performed using the eGauge Pro circuit-level smart-meter (see https://www.egauge.net/commercial-energy-monitor/). The eGauge Pro can measure the power of up to 30 individual circuits using sensors called Current Transformers (CTs). The JD-SCT-010-0075 (75 A/0.39”) model, which has a 1% accuracy, was used in this case. The eGauge Pro enables the monitoring of current, voltage, active power, reactive power, apparent power, and power factor, among others. The data was retrieved from the eGauge Pro using the Modbus RTU protocol (see https://www.rtautomation.com/technologies/modbus-rtu/) at the rate of approximately \(\frac{1}{5}\) Hz (i.e., new samples every five seconds).
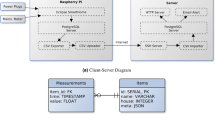
Figure 1 illustrates the main components of the individual appliances’ data collection setup. The CTs are installed in the main breaker box (one per single-phase appliance and three per three-phase appliance). The Raspberry Pi3 gateway is connected to the eGauge Pro via USB using an RS485 (Modbus RTU) to USB converter (see https://store.egauge.net/USB_485). The gateway sequentially requests the last measurement for each circuit, taking around two seconds to scan all 30 circuits. A new scan is requested every five seconds, and the timestamp observed at the request time is shared among all the collected records. This ensures that all the records from a single scan have the same timestamp. Since the meter has a limited number of registers (60), measuring all the quantities from the meter was impossible. Instead, the following measurements were requested from the meter, in RMS values: current (I) in each phase, voltage (V) in each phase, and active power (P) in each phase. From there, the remaining quantities, i.e., apparent power (S), reactive power (Q), and power factor (PF), were calculated using Eqs. (1–3), respectively, for each monitored appliance (a) at timestep t.

Overview of the data collection setup for individual appliance consumption. Monitoring hardware (left), and main components of the data collection setup (right).
At this point, it’s important to note that because the eGauge meter has a restricted number of registers, obtaining power factor values for every phase was not feasible. Consequently, the reactive power and power factor had to be derived by using the apparent and active power, which inherently returns only positive values. In other words, all the Q vectors are assumed to be inductive and share the same direction. As a result, the total absolute value of Q (as defined in Eq. 5) will be the sum of the absolute values of Q in each individual phase (as described in Eq. 2).
The collected and calculated samples are then stored in the gateway in a relational database. The stored measurements are uploaded to an online database server every minute to provide real-time access to the consumption data33. Finally, every day at 12 AM, a csv file with the daily readings for each appliance is uploaded to a shared folder. Once all the records are uploaded, the local database is cleaned to keep its footprint as small as possible.
Data post-processing
Since both monitoring setups generated one csv file per day, the first step was to merge all the daily files into single csv files.
The aggregated consumption data is made available as it was collected from the devices, i.e., no post-processing was applied. Regarding the individual appliance consumption data, three post-processing steps were required: (1) cleaning, (2) calibration, and (3) total calculation.
In the data cleaning step, all the records that contained negative values in the monitored quantities (current, voltage, and active power) were dropped. Negative values occur due to technical limitations of the monitoring hardware that are out of our control. Still, these represent only a tiny fraction of the collected data (0.041% IK 1, 0.271% IK 2, and 0.0029% IK 3).
The second step was calibrating the current measurements due to the reported accuracy of the used CTs. More precisely, since the used CTs have a reported accuracy of ±1% (corresponding to 0.75 A), all the current measurements below that value and the corresponding active power were set to zero.
Finally, the third step was to calculate the total values for each of the quantities, which was done using Eqs. (4–7).
Deployments
The monitoring platform was deployed in three restaurant kitchens for consecutive periods between three (IK 2) and four weeks (IK 1 and IK 3). Figure 2 depicts the monitoring systems installed in the main breaker box of each of the three IKs. Table 1 summarizes the details of each IK.

Monitoring system installed in the three IKs: IK 1 (left), IK 2 (middle), and IK 3 (right). Note that the Fluke system was also installed in IK 2, even though it is not shown in the photo.
A total of 45 appliances were monitored between the three IKs. From these, 27 are single-phase, and 18 are three-phase. A list of the appliances monitored in each IK is provided in Table 2.
Data Records
The FIKElecricity dataset is made available individually for each monitored kitchen, and all the data files are in csv format. The data is available on the Open Science Framework (OSF) data repository at https://doi.org/10.17605/OSF.IO/K3G8N34.
Figure 3 shows an overview of the underlying organization of the FIKElectricity dataset. The following subsections describe the contents of the different files.

Underlying folder and file organization of FIKElectricity Dataset.
Aggregated consumption measurements
The aggregated consumption measurements are available for each kitchen in a single csv file. The files named aggregated.csv are available in the root folder of each kitchen. The columns of the csv files are described in Table 3. The reported values correspond to the average values within each second.
Disaggregated consumption measurements
The files with data for individual appliance consumption are available in the “appliances” folder. For each appliance, there is a csv file, named using the <id>_<name>.csv convention, where <id> refers to the unique identifier of the appliance, and <name> is the appliance name. The underlying fields of the individual appliance consumption files are described in Table 4. The reported current, voltage, and active power values correspond to the meter readings at the given timestamp. The remaining quantities were calculated from the former as per Eqs. (1–7).
Technical Validation
Aggregated consumption
To illustrate the aggregated consumption data, Fig. 4 depicts some of the measurements contained in the aggregated consumption files. More precisely, the current (left) and power values (right).

Graphical representations of part of the aggregated consumption measurements.
First and foremost, it is important to remark that due to a technical issue, the aggregated consumption from IK 1 is only complete until the 15th of February 2019. After that day, only the current, voltage, and frequency measurements were retrieved from the Fluke meter. Regarding IK 2, except for a period between the 2nd and 3rd of March, all the measurements are available (96% of the expected data was collected). As for IK 3, due to technical issues with the installation, there are several periods where the Fluke meter was not collecting data. These periods amount to 24% of the expected data.
Individual appliance consumption
To illustrate the data collected for each appliance, Figs. 5–7 depicts the measurements obtained for the entire duration of the deployment, resampled to \(\frac{1}{5}\) Hz, which was the original rate of acquisition as mentioned in the methods section.

Graphical representation of the measurements obtained for each appliance for the entire deployment duration in IK 1. The data is resampled to \(\frac{1}{5}\) Hz.

Graphical representation of the measurements obtained for each appliance for the entire deployment duration in IK 2. The data is resampled to \(\frac{1}{5}\) Hz.

Graphical representation of the measurements obtained for each appliance for the entire deployment duration in IK 3. The data is resampled to \(\frac{1}{5}\) Hz.
Overall, there are very few gaps in the data. In IK 1, the average percentage of collected samples is 90.74% (standard deviation: 3.5%, minimum: 79%, maximum: 93.45%). For IK 2, the average percentage of complete data is 94.83% (standard deviation: 1.5%, minimum: 89.97%, maximum: 95.68%). Finally, in IK 3, the average percentage is 96.97% (standard deviation: 4.22%, minimum: 82.6%, maximum: 98.63%).
To further illustrate the collected ground-truth data, Figs. 8–10, depicts one day of aggregated consumption vs. consumption of the individual appliances resampled to 1/60 Hz in each of the three industrial kitchens. In all three graphs, the operation patterns are visible, with IK 1 and IK 2 operating mostly during the afternoon and evening (dinner services), whereas IK 3 operates in the morning and afternoon periods (breakfast and dinner services).

Graphical representation of 24 hours of aggregated and individual appliances consumption from IK 1. The data is resampled to 1/60 Hz.

Graphical representation of 24 hours of aggregated and individual appliances consumption from IK 2. The data is resampled to 1/60 Hz.

Graphical representation of 24 hours of aggregated and individual appliances consumption from IK 3. The data is resampled to 1/60 Hz.
Through these graphs, it is also possible to see that the amount of explained aggregated energy (i.e., the ratio between the consumption of the individual appliances and the aggregated) is considerably low in all the IKs. In this regard, IK 3 has the highest percentage of explained energy (38% on average), despite having fewer individual appliances monitored. There are a few possible explanations for that, including the fact that this was the only IK where the Air Conditioning was monitored. Another reason for the lower explanation percentage of the other IKs is that the aggregated consumption does not include only the kitchen appliances. For example, in IK 1, the aggregated date also includes the demand for a support bar and the dining area. The total demand (in kWh) and percentages of explained energy in the three IKs are summarized in Table 5.
Usage Notes
The FIKElectricity dataset is made available in csv format, which is usable in most scientific computing packages, e.g., Python (pandas/numpy), MATLAB (readmatrix), and R(read.csv). Multiple examples of data handling using Python3 can be found in the provided source code.
Concerning the missing data, we deliberately did not clean or strip any of the data. This allows us to retain the data as closely as possible from its raw form. Furthermore, this leaves room for the dataset users to apply their preferred data-cleaning and filling methods. For example, in the case of aggregated demand, the missing data points can be replaced with the sum of all the individual appliances complemented with data generated from a probabilistic distribution of the unexplained demand (i.e., the difference between the aggregated demand and the sum of appliances) estimated from the samples in the vicinity of the missing data points. As for the appliance demand, several methods can be applied depending on the type of appliance and the amount of missing points. Such strategies can vary from quick fixes such as forward-fill or interpolation (linear or weighted) to more advanced techniques using forecasting algorithms, such as the Auto-Regressive Integrated Moving Average (ARIMA)27.
This dataset was collected in Madeira Island in Portugal, and during the data collection, two different timezones were observed: WET time until March 31st 2019, and WEST from April 1st 2019. However, to simplify the dataset handling, it was decided to ignore the timezone by representing the timestamps in UTC.
Code availability
The code used to collect and store the individual consumption data is available at https://github.com/feelab-info/eGaugeDataAcquisition. The code was developed using Python3.6 and deployed on a Linux machine (Raspbian see http://www.raspbian.org/)). The Python3 code to reproduce the examples presented in this paper is available on the dataset repository at https://doi.org/10.17605/OSF.IO/K3G8N34.
References
IEA. World Energy Outlook 2022. Tech. Rep., International Energy Agency, Paris (2022).
Tollefson, J. Climate change is hitting the planet faster than scientists originally thought. Nature https://doi.org/10.1038/d41586-022-00585-7 (2022).
Li, M.-J. & Tao, W.-Q. Review of methodologies and polices for evaluation of energy efficiency in high energy-consuming industry. Applied Energy 187, 203–215, https://doi.org/10.1016/j.apenergy.2016.11.039 (2017).
IRENA. World Energy Transitions Outlook 2022: 1.5 C Pathway. Tech. Rep., International Renewable Energy Agency, Abu Dhabi (2022).
EnergyStar. ENERGY STAR for Small Business: Restaurants (2017).
Food And Beverage Services Global Market Report 2023. Tech. Rep. 6193681, The Business Research Company (2023).
Higgins-Desbiolles, F., Moskwa, E. & Wijesinghe, G. How sustainable is sustainable hospitality research? A review of sustainable restaurant literature from 1991 to 2015. Current Issues in Tourism 22, 1551–1580, https://doi.org/10.1080/13683500.2017.1383368 (2019).
Hedrick, R., Smith, V. & Field, K. Restaurant Energy Use Benchmarking Guideline. Tech. Rep. NREL/SR-5500-50547, 1019165, NERL http://www.osti.gov/servlets/purl/1019165-J8VWR3/ (2011).
Etienne Paillat. Energy Efficiency In Food-Service Facilities: The Case Of Långbro Värdshus. Master’s thesis, KTH Royal Institute of Technology, Stockholm, Sweden (2011).
Hearnshaw, S. A., Essah, E. A., Grandison, A. & Felgate, R. Energy Reduction and Benchmarking in Commercial Kitchens. In Technologies for Sustainable Built Environments, 8 (Reading, UK, 2012).
Mudie, S. Energy benchmarking in UK commercial kitchens. Building Services Engineering Research and Technology 37, 205–219, https://doi.org/10.1177/0143624415623067 (2016).
Nonaka, T., Shimmura, T., Fujii, N. & Mizuyama, H. Energy Consumption in the Food Service Industry: A Conceptual Model of Energy Management Considering Service Properties. In Advances in Production Management Systems: Innovative Production Management Towards Sustainable Growth, IFIP Advances in Information and Communication Technology, 605–611, 10/ggjf9x (Springer International Publishing, Cham, 2015).
Mudie, S. & Vadhati, M. Low energy catering strategy: Insights from a novel carbon-energy calculator. Energy Procedia 123, 212–219, https://doi.org/10.1016/j.egypro.2017.07.244 (2017).
Young, W. Applying Solar Energy to Food Trucks. In Proceedings of the SOLAR 2017 Conference, 1–8, https://doi.org/10.18086/solar.2017.05.01 (International Solar Energy Society, Denver, 2017).
Aldaouab, I. & Daniels, M. Renewable energy dispatch control algorithms for a mixed-use building. In 2017 IEEE Green Energy and Smart Systems Conference (IGESSC), 1–5, https://doi.org/10.1109/IGESC.2017.8283446 (2017).
Hashmi, M. U., Cavaleiro, J., Pereira, L. & Bušić, A. Sizing and Profitability of Energy Storage for Prosumers in Madeira, Portugal. In 2020 IEEE Power & Energy Society Innovative Smart Grid Technologies Conference (ISGT 2020) (IEEE, Washington, DC, USA, 2020).
Pereira, L., Cavaleiro, J. & Morais, H. Understanding the Role of Solar PV and Battery Energy Storage in a Snack Bar: A Case Study in Madeira Island. In 2022 IEEE 20th International Conference on Industrial Informatics (INDIN) (IEEE, Lemgo, Germany, 2023).
Pereira, L., Aguiar, V. & Vasconcelos, F. Future Industrial Kitchen: Challenges and Opportunities. In Proceedings of the 6th ACM International Conference on Systems for Energy-Efficient Buildings, Cities, and Transportation, BuildSys ‘19, 163–164, https://doi.org/10.1145/3360322.3360872 (ACM, New York, NY, USA, 2019).
Ana Oliveira et al. On The Role Of Industrial Kitchens In Sustainable Energy Systems: The nexIK Vision. In CIRED 2023 - The 27th International Conference and Exhibition on Electricity Distribution (Rome, Italy, 2023).
Pereira, L., Aguiar, V. & Vasconcelos, F. FIKWater: A Water Consumption Dataset from Three Restaurant Kitchens in Portugal. Data 6, 26, https://doi.org/10.3390/data6030026 (2021).
Pereira, L., Aguiar, V. & Vasconcelos, F. FIKWaste: A Waste Generation Dataset from Three Restaurant Kitchens in Portugal. Data 6, 25, https://doi.org/10.3390/data6030025 (2021).
Makonin, S., Ellert, B., Bajić, I. V. & Popowich, F. Electricity, water, and natural gas consumption of a residential house in Canada from 2012 to 2014. Scientific Data 3, 160037, https://doi.org/10.1038/sdata.2016.37 (2016).
Murray, D., Stankovic, L. & Stankovic, V. An electrical load measurements dataset of United Kingdom households from a two-year longitudinal study. Scientific Data 4, 160122, 10/f9k7k9 (2017).
Pereira, L., Costa, D. & Ribeiro, M. A residential labeled dataset for smart meter data analytics. Scientific Data 9, 134, https://doi.org/10.1038/s41597-022-01252-2 (2022).
Kriechbaumer, T. & Jacobsen, H.-A. BLOND, a building-level office environment dataset of typical electrical appliances. Scientific Data 5, 180048, https://doi.org/10.1038/sdata.2018.48 (2018).
Yoon, Y., Jung, S., Im, P. & Gehl, A. Datasets of a Multizone Office Building under Different HVAC System Operation Scenarios. Scientific Data 9, 775, https://doi.org/10.1038/s41597-022-01858-6 (2022).
Martins, R. Data-driven Modeling of Energy Consumption in Industrial Kitchens - Detection of Activations and Unsupervised Classification. MSc, Técnico Lisboa, University of Lisbon, Lisbon, Portugal (2022).
Legrand, W., Sloan, P., Simons-Kaufmann, C. & Fleischer, S. A review of restaurant sustainable indicators. In S. Chen, J. (ed.) Advances in Hospitality and Leisure, vol. 6 of Advances in Hospitality and Leisure, 167–183, https://doi.org/10.1108/S1745-3542(2010)0000006013 (Emerald Group Publishing Limited, 2010).
Krutnik, M., Pedro, A., Yadack, V. M., Morais, H. & Pereira, L. On the Potential of Tertiary Espresso Machines to Provide Frequency Containment Reserves Services. IEEE Transactions on Consumer Electronics (2023).
Amantegui, J., Morais, H. & Pereira, L. Benchmark of Electricity Consumption Forecasting Methodologies Applied to Industrial Kitchens. Buildings 12, 2231, https://doi.org/10.3390/buildings12122231 (2022).
Kalinke, F., Bielski, P., Singh, S., Fouché, E. & Böhm, K. An Evaluation of NILM Approaches on Industrial Energy-Consumption Data. In Proceedings of the Twelfth ACM International Conference on Future Energy Systems, E-Energy ‘21, 239–243, https://doi.org/10.1145/3447555.3464863 (Association for Computing Machinery, New York, NY, USA, 2021).
Faustine, A. & Pereira, L. Applying Symmetrical Component Transform for Industrial Appliance Classification in Non-Intrusive Load Monitoring. In ICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 1–5, https://doi.org/10.1109/ICASSP49357.2023.10096324 (2023).
Quintal, F. et al. Energy Monitoring in the Wild: Platform Development and Lessons Learned from a Real-World Demonstrator. Energies 14, 5786, https://doi.org/10.3390/en14185786 (2021).
Pereira, L. FIKElectricity: A Electricity Consumption Dataset from Three Restaurant Kitchens in Portugal. OSF https://doi.org/10.17605/OSF.IO/K3G8N (2021).
Acknowledgements
LP received funding from the Portuguese Foundation for Science and Technology (FCT) under grants. CEECIND/01179/2017 and UIDB/50009/2020. HM received funding from FCT under grant UIDB/50021/2020. This research was funded by the projects M1420-01-0247-FEDER-000018 (Madeira 14-20) and EXPL/CCI-COM/1234/2021 (FCT).
Author information
Authors and Affiliations
Contributions
Conceptualization: L.P.; methodology: L.P.; software development: L.P., V.A. and T.G.; deployment and data collection: L.P., and V.A.; data preparation: L.P., V.A., R.M. and T.G.; dataset curation: L.P., and R.M.; writing original draft: L.P. review and editing: L.P., V.A., F.V., T.G. and H.M.; visualizations: L.P. and T.G.; formal analysis: L.P.; supervision: L.P. and H.M.; All authors have reviewed and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Pereira, L., Aguiar, V., Vasconcelos, F. et al. FIKElectricity: A Electricity Consumption Dataset from Three Restaurant Kitchens in Portugal. Sci Data 10, 779 (2023). https://doi.org/10.1038/s41597-023-02698-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41597-023-02698-8
