
Abstract
Large language models (LLMs) such as GPT-4 have recently demonstrated impressive results across a wide range of tasks. LLMs are still limited, however, in that they frequently fail at complex reasoning, their reasoning processes are opaque, they are prone to ‘hallucinate’ facts, and there are concerns about their underlying biases. Letting models verbalize reasoning steps as natural language, a technique known as chain-of-thought prompting, has recently been proposed as a way to address some of these issues. Here we present ThoughtSource, a meta-dataset and software library for chain-of-thought (CoT) reasoning. The goal of ThoughtSource is to improve future artificial intelligence systems by facilitating qualitative understanding of CoTs, enabling empirical evaluations, and providing training data. This first release of ThoughtSource integrates seven scientific/medical, three general-domain and five math word question answering datasets.
Similar content being viewed by others


Background & Summary
The most recent generation of large language models (LLMs) has produced impressive results across a wide range of tasks. Examples of such models include T01, GPT-32, InstructGPT3 and GPT-44. These models demonstrated remarkable ability to generate text that is both realistic and coherent, as well as good performance on a broad spectrum of tasks, despite not explicitly being trained on them3.
However, despite this ability, LLMs are also limited in several ways. They often fail to produce accurate predictions due to their inability to accomplish complex reasoning, such as solving mathematical problems or question answering tasks requiring multi-hop reasoning. Furthermore, they tend to be black boxes, making it difficult to understand how and why predictions are generated. These limitations severely limit the application domains of LLMs and have the potential to cause harm, as lack of explainability and robustness can lead to critical failures and biases when these models are deployed in practice.
One recently proposed method for enabling complex reasoning and generating explanations with LLMs is to force models to explicitly verbalize reasoning steps as natural language, a technique known as chain-of-thought prompting5,6. This method improved performance on a variety of tasks and sparked the active development of further refinements7, such as decomposing problems and structuring reasoning (e.g., least-to-most prompting8, ReAct9, self-ask10, maieutic prompting11, successive prompting12) and/or extending LLM capabilities by leveraging external services for tasks like information retrieval (e.g., self-ask10, IRCoT13, DSP14). The terminology surrounding these rapidly evolving techniques is not settled, hence in this document, we refer to all approaches that result in a linear sequence of reasoning steps as ‘chain-of-thought’ (CoT).
Meta-datasets (datasets of datasets) that are easily accessible and standardized have proven useful for training and evaluating versatile LLMs. Examples include SuperGLUE15 for general-domain language model tasks, BigBIO16 and BLURB17 for biomedical tasks, or Pile18 and ROOTS19 as text corpora for LLM pre-training. Datasets can be complemented by tools such as PromptSource, which was used to convert a large number of datasets into prompts fit for training and interrogating LLMs. PromptSource facilitated training the highly performant T0 model1.
Here we present ThoughtSource, a meta-dataset and software library for chain-of-thought reasoning in LLMs (https://github.com/OpenBioLink/ThoughtSource). The goals of ThoughtSource are to:
-
Facilitate qualitative understanding of CoTs generated by LLMs under various conditions (e.g., across tasks, models and prompts).
-
Enable empirical and quantitative evaluation.
-
Provide a library of diverse CoT training data for improving performance, robustness, explainability and value-alignment of future LLM-based AI systems.
Methods
We selected NLP benchmarks for question answering and natural language inference for which pre-existing data for constructing CoTs was available. For some of the datasets, one or multiple additional datasets were used as sources for additional CoTs, allowing for the comparison of different CoT generation methodologies. We created data loader scripts compatible with the Hugging Face datasets library20 for all datasets. Additionally, we collected metadata of attributes such as descriptions, websites and licenses. We contacted dataset providers and encouraged them to choose an open source/open data license if licensing information was unavailable or unclear.
We implemented two kinds of schemas: (1) source dataset schemas, which are unique to each dataset and provide data close to their original format; and (2) a standardized ThoughtSource schema, which maps all datasets into a common format. The ThoughtSource schema was created by extending the question answering schema of the BigBIO project16.
We implemented tailored algorithms for converting each dataset because the collected datasets provide explanations in different ways, such as math expressions or structured graph-based explanations. Furthermore, we performed preprocessing such as capitalization and punctuation correction. To recover standard formatted text from pre-tokenized datasets, we reversed the tokenization. This preprocessing was performed only on data in the ThoughtSource schema, while data in the Source schemas was left in their original formatting. All code for running these conversions is available in our Github repository.
We developed a suite of Python libraries and tools for generating novel CoTs and answers by calling LLM APIs, as well as tools for evaluating, comparing and annotating datasets. We built upon the LangChain library (https://github.com/hwchase17/langchain/) for interfacing with a wide variety of external LLM APIs.
This first release of ThoughtSource integrates seven scientific/medical, three general-domain and five math word question answering datasets (Table 1). For every dataset except for PubmedQA and MedQA we provide ‘reference CoTs’. We created these reference CoTs by converting rationales provided by original datasets into reasoning chains. These rationales, depending on the dataset, were created by human experts or obtained from crowdsourcing. Furthermore, we added CoTs generated by state-of-the-art LLMs by importing them from previous work, as well as generating them de-novo for this work (details below).
Scientific/medical question answering datasets
WorldTree V221 is one of the most detailed multi-hop science question answering datasets available. Finding the right multiple-choice answers requires a multi-hop inference combining between 1 and 16 facts (average: 6). It contains explanations created by experts in the form of multiple facts. We concatenated these facts and applied a set of rules to improve style and grammaticality to yield reference CoTs that are close to natural language.
EntailmentBank22 contains open-domain science exam questions and answers, along with systematic explanations that show how the correct answer is reached through a series of steps. These steps are organized into a tree structure, known as an entailment tree, which starts with known facts and progresses through intermediate conclusions until the final answer is reached. These entailment trees are also serialized into text-based proofs by traversing the trees. We applied a set of rules to improve style and grammaticality in these proofs to yield reference CoTs that are close to natural language.
OpenBookQA23 contains questions modeled after open-book exams of elementary-level science. They require multi-step reasoning, commonsense knowledge, and a diverse application of core science facts to find the correct answer. The dataset provides over 1,300 core science facts and a mapping to all of the questions. By design, questions in OpenBookQA are answered incorrectly by both retrieval-based and word co-occurrence algorithms. The dataset contains a single-fact explanation of the correct answer for each question, which we adopted to create reference CoTs.
MedQA24 is a free-form multiple-choice OpenQA dataset containing questions from medical board exams in the US (USMLE), Mainland China and Taiwan. We imported the English-language USMLE subset. We have also introduced a version of the dataset wherein the multiple-choice questions have been converted into open-ended questions25. Reference CoTs are not provided.
MedMCQA26 is a multiple-choice question answering dataset containing real-world medical entrance exam questions from the All India Institute of Medical Sciences (AIIMS PG) and National Eligibility cum Entrance Test (NEET PG). Answer rationales authored by human experts were integrated as reference CoTs.
PubmedQA27 is a question answering dataset containing biomedical questions extracted from PubMed abstracts that can be answered with yes/no/maybe answers. In addition to the short answer, each question comes with a longer answer, which can be used as reference CoT.
MMLU28 (Massive Multitask Language Understanding) is a compendium of 57 distinct question-and-answer tasks encompassing a wide range of topics. We have selected six subjects particularly related to medical science: anatomy, clinical knowledge, college biology, college medicine, medical genetics, and professional medicine. Reference CoTs are not provided.
General-domain question answering datasets
CommonsenseQA29 is a collection of multiple-choice questions that test a wide range of general knowledge. We created reference CoTs for the train and validation set derived from the crowd-sourced ECQA dataset³. We also added AI-generated reasoning chains generated with few-shot5 and zero-shot6 prompting, which are available for the validation split.
StrategyQA30 is a question answering dataset that tests the ability to reason through open-domain questions and provide Yes/No answers. Each example includes a question, a decomposition of the question into reasoning steps, and evidence paragraphs from Wikipedia. The dataset was created through a crowdsourcing process to gather creative and diverse questions. Human-generated freetext reasoning chains are part of the train split of the original dataset and were used as CoTs. The dataset also includes relevant paragraphs from Wikipedia, but these were not included in our CoTs. We extended the StrategyQA dataset with AI-generated CoTs created through few-shot5 and zero-shot6 prompting, which are available for the train split.
QED31 is a collection of expert-annotated structured explanations for answers to questions, built upon a subset of the Google Natural Questions dataset. Given a question and a passage from Wikipedia, QED uses linguistic information to represent explanations as a series of interpretable steps, such as referential equality, sentencehood, and entailment. Structured reasoning chains by experts are provided for all examples. To create reference CoTs, we extracted the sentence that entails the answer; statements about referential equality in QED were converted to natural language and added as additional steps in the CoTs (e.g. “The noun phrase […] in the sentence and the noun phrase […] in the question refer to the same thing.”).
Math word problem datasets
Algebra Question Answering with Rationales (AQUA-RAT)32 is a large-scale multiple-choice dataset containing algebraic word problems. Each problem consists of a question with five possible answers and a rationale, a step-by-step natural language explanation of the solution. We used natural language explanations as reference CoTs.
Academia Sinica Diverse (ASDiv) math word problem (MWP) dataset33 aims to provide more diverse language patterns and problem types than previous datasets. It covers most of the math topics taught in elementary school. Each MWP is labeled with its grade level (for indicating difficulty), the needed math operation (e.g. division) and includes a short explanation of the solution. ASDiv contains explanations of answers in the form of nested math expressions using common operators such as addition, subtraction, division and multiplication. We generated reference CoTs by converting these math expressions into natural language explanation chains using a rule-based method.
Grade School Math 8 K (GSM8K)34 contains grade school math word problems. Despite their conceptual simplicity, these problems are more challenging to process than earlier datasets due to their linguistic diversity. The creators of GSM8K instructed crowd workers to write solutions to problems in free text format, which we used as reference CoTs in ThoughtSource, omitting any additional arithmetic specifications.
Math Word Problems (MAWPS)35 is an online platform that provides a collection of math word problems. The problems have simple one- or two-line explanations for their solutions. MAWPS includes datasets from various sources, offers tools for automatically creating datasets with specific characteristics as well as the possibility to tune lexical and template overlap. We converted explanatory math expressions to reference CoTs with an approach similar to the one used for ASDiv.
Simple Variations on Arithmetic Math Word Problems (SVAMP)36 was created by applying carefully chosen variations to examples from existing datasets, such as ASDiv and MAWPS. These variations make it difficult for language models to solve the problems using simple heuristics, and instead require a deeper understanding and reasoning ability. We converted math expressions to reference CoTs with an approach similar to the one used for ASDiv.
AI-generated CoTs
Liévin et al. CoTs were generated for MedQA, MedMCQA and PubmedQA with the AI systems text-davinci-0023 and code-davinci-00237 (described in detail by co-authors Liévin et al. in a separate manuscript38).
Wei et al. and Kojima et al. CoTs for CommonsenseQA and StrategyQA were integrated from previous external studies on few-shot5 and zero-shot6 prompting.
ThoughtSource-33 refers to a collection of 198 items, comprising 33 randomly selected items from each of six datasets: Commonsense QA, MedQA (USMLE), MedMCQA, OpenBookQA, StrategyQA and WorldTree V2. For every item of this collection, we created 60 unique zero-shot CoTs by executing ten different prompting strategies39 with six models: OpenAI text-davinci-0023, OpenAI text-davinci-0033, OpenAI GPT-3.5-turbo, OpenAI GPT-44, Flan-T5-XXL40 and Cohere command-xlarge-nightly (https://docs.cohere.ai/). Since current LLM models are still prone to errors, it should be noted that AI-generated CoTs may contain faulty reasoning.
Data Records
The suggested method for accessing datasets is through programmatic access through our dataloader libraries. A comprehensive guide on how to achieve this is provided on the project’s Github repository (https://github.com/OpenBioLink/ThoughtSource), and a snapshot of the code is available on Zenodo41. Additionally, a snapshot of the data available through an open license is also available on Zenodo42.
Table 2 shows the example counts, CoT counts and answer types of each dataset. The majority of datasets in the current collection are of the multiple choice answer type. The medical dataset MedMCQA is the largest among all datasets.
Dataset schema
Tables 3–6 provide descriptions and datatypes of the various fields in the ThoughtSource schema. Any performed sample task leads to a generated CoT and answer to the question. Annotations can be added programmatically or through an annotator tool.
We analyzed the distribution of question and reference CoT field lengths (Fig. 1). MedQA has the longest median question length, while PubMedQA has the longest median CoT length. Several datasets contain outlier CoT with extremely long text lengths. Context fields were only filled for the PubmedQA and QED datasets, with mean context lengths of 116 and 56 tokens, respectively.

Distribution of question (a) and reference (b) CoT field lengths.
Technical Validation
The datasets were reviewed by three team members and issues were tracked on the issue tracker of the associated GitHub repository.
To characterize potential overlaps and relations between datasets, we calculated mutual n-gram overlap using n = 3. (Fig. 2). To quantify the overlap between two sets of n-grams we use the Szymkiewicz–Simpson coefficient (overlap coefficient), which can be interpreted as the proportion of n-grams of the smaller dataset that are contained in the bigger dataset:

n-gram overlap in questions and reference CoTs. Overlap is measured by mutual n-gram overlap using n = 3, values < 0.01 are omitted.
There is an overlap of 1.0 between the set of questions in WorldTree v2 and EntailmentBank. The QA pairs in EntailmentBank were taken from the WorldTree v2 dataset22, so all the questions in EntailmentBank are a subset of WorldTree v2.
Furthermore, there is significant overlap between the questions contained in ASDiv and SVAMP and those in ASDiv and MAWPS. ASDiv and SVAMP have overlapped questions because a subset of examples from ASDiv was used as seed examples for the creation of SVAMP. For MAWPS and ASDiv, questions were crawled from web resources. The overlap could be due to examples being crawled from the same web resources.
Besides overlaps in questions, we also identified overlaps in reference CoTs. WorldTree v2 provided an initial pool of atomic facts that the annotators could use to construct an explanation tree in EntailmentBank (in addition to creating their own facts). This explains the high overlap of n-grams of CoTs in WorldTree v2 and EntailmentBank. Similarly, a subset of WorldTree v2 facts was used for the creation of explanations in OpenBookQA.
Usage Notes
Python libraries for accessing and working with data can be downloaded from the Github repository and installed with the pip tool. Figure 3 demonstrates how to load a dataset, randomly sample from the pre-populated data in the dataset, call an external LLM API to generate novel CoTs and answers, automatically evaluate the accuracy of generated answers, and finally save all generated data to a JSON file. Figure 4 depicts an excerpt of the resulting JSON file.

Demonstration of the ThoughtSource API. Basic functionalities of the data loader, generator and evaluator modules are demonstrated.

An excerpt of data generated by running the example code. Data for a single question from Worldtree V2 are shown, including human-authored reference CoT, gold-standard answer, an AI-generated CoT and extracted answer, as well as evaluation results. Some fields were omitted for legibility.
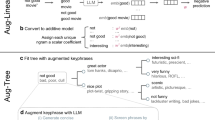
In a zero-shot setup, specific text fragments can be used to prompt question answering and CoT reasoning in LLMs. ThoughtSource includes a curated list of text fragments that can be used to generate novel CoTs (Fig. 5). Where possible, we also mapped individual CoTs in pre-existing CoT datasets to the text fragments that were used in their creation.

An excerpt of the collection of prompt fragments. These fragments can be used to build prompts for interacting with LLMs, allowing for empirical testing of how different prompts affect model performance.
We provide two web-based interfaces for exploring and annotating ThoughtSource data, the Dataset Viewer and the Annotator. The Dataset Viewer is a simple interface for exploring dataset contents. The Annotator (Fig. 6) allows you to upload specific subsets of a dataset, provides convenience functions for highlighting similarities between different generated CoTs and the correctness of generated answers, and allows you to annotate individual CoTs interactively. The annotator facilitates identifying strengths and weaknesses of different CoTs. Annotations can be used for downstream model evaluation and further improving the capabilities of AI models through fine-tuning/reinforcement learning.

The ThoughtSource Annotator. The web-based interface allows for convenient inspection and annotation of reasoning chains and answers. Text that is similar between CoTs can be automatically highlighted based on an easily adjustable similarity threshold, facilitating a better understanding of similarities and differences of different reasoning chains.
All tools and libraries, as well as more detailed demonstration notebooks, can be found on the project Github page.
We plan to add more datasets and generated CoTs to the ThoughtSource repository, and we welcome outside contributions. Novel CoTs for existing core datasets can be generated and shared through the ThoughtSource APIs and JSON files. Completely new datasets can also be added, as described in the Github repository’s contribution guide.
Code availability
All code, data and tools are openly available at https://github.com/OpenBioLink/ThoughtSource, a snapshot of the GitHub repository is archived at https://doi.org/10.5281/zenodo.819939041, and a snapshot of dataset contents is archived at https://doi.org/10.5281/zenodo.819953842. Our code and data are licensed under an MIT license, while data adapted from existing datasets are available under the licenses of their respective sources.
References
Sanh, V. et al. Multitask Prompted Training Enables Zero-Shot Task Generalization. Preprint at https://doi.org/10.48550/arXiv.2110.08207 (2021).
Brown, T. B. et al. Language Models are Few-Shot Learners. Preprint at https://doi.org/10.48550/arXiv.2005.14165 (2020).
Ouyang, L. et al. Training language models to follow instructions with human feedback. Preprint at https://doi.org/10.48550/arxiv.2203.02155 (2022).
OpenAI. GPT-4 Technical Report. Preprint at https://doi.org/10.48550/arXiv.2303.08774 (2023).
Wei, J. et al. Chain of Thought Prompting Elicits Reasoning in Large Language Models. Preprint at https://doi.org/10.48550/arxiv.2201.11903 (2022).
Kojima, T., Gu, S. S., Reid, M., Matsuo, Y. & Iwasawa, Y. Large Language Models are Zero-Shot Reasoners. Preprint at https://doi.org/10.48550/arxiv.2205.11916 (2022).
Huang, J. & Chang, K. C.-C. Towards Reasoning in Large Language Models: A Survey. Preprint at https://doi.org/10.48550/arXiv.2212.10403 (2022).
Zhou, D. et al. Least-to-Most Prompting Enables Complex Reasoning in Large Language Models. Preprint at https://doi.org/10.48550/arxiv.2205.10625 (2022).
Yao, S. et al. ReAct: Synergizing Reasoning and Acting in Language Models. Preprint at https://doi.org/10.48550/arxiv.2210.03629 (2022).
Press, O. et al. Measuring and Narrowing the Compositionality Gap in Language Models. Preprint at https://doi.org/10.48550/arxiv.2210.03350 (2022).
Jung, J. et al. Maieutic Prompting: Logically Consistent Reasoning with Recursive Explanations. Preprint at https://doi.org/10.48550/arxiv.2205.11822 (2022).
Dua, D., Gupta, S., Singh, S. & Gardner, M. Successive Prompting for Decomposing Complex Questions. Preprint at https://doi.org/10.48550/arXiv.2212.04092 (2022).
Trivedi, H., Balasubramanian, N., Khot, T. & Sabharwal, A. Interleaving Retrieval with Chain-of-Thought Reasoning for Knowledge-Intensive Multi-Step Questions. Preprint at https://doi.org/10.48550/arXiv.2212.10509 (2022).
Khattab, O. et al. Demonstrate-Search-Predict: Composing retrieval and language models for knowledge-intensive NLP. Preprint at https://doi.org/10.48550/arXiv.2212.14024 (2023).
Wang, A. et al. SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems. in Advances in Neural Information Processing Systems (eds. Wallach, H. et al.) vol. 32, 3266–3280 (Curran Associates, Inc., 2019).
Fries, J. A. et al. BigBIO: A Framework for Data-Centric Biomedical Natural Language Processing. in. Advances in Neural Information Processing Systems. https://doi.org/10.48550/arXiv.2206.15076 (2022).
Gu, Y. et al. Domain-Specific Language Model Pretraining for Biomedical Natural Language Processing. ACM Trans. Comput. Healthc. 3, 2:1–2:23 (2021).
Gao, L. et al. The Pile: An 800GB Dataset of Diverse Text for Language Modeling. Preprint at https://doi.org/10.48550/arXiv.2101.00027 (2020).
Laurençon, H. et al. The BigScience ROOTS Corpus: A 1.6TB Composite Multilingual Dataset. in Advances in Neural Information Processing Systems (2022).
Lhoest, Q. et al. Datasets: A Community Library for Natural Language Processing. in Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing: System Demonstrations 175–184, https://doi.org/10.18653/v1/2021.emnlp-demo.21 (Association for Computational Linguistics, 2021).
Xie, Z. et al. WorldTree V2: A Corpus of Science-Domain Structured Explanations and Inference Patterns supporting Multi-Hop Inference. in Proceedings of the Twelfth Language Resources and Evaluation Conference 5456–5473 (European Language Resources Association, 2020).
Dalvi, B. et al. Explaining Answers with Entailment Trees. Preprint at https://doi.org/10.48550/arXiv.2104.08661 (2022).
Mihaylov, T., Clark, P., Khot, T. & Sabharwal, A. Can a Suit of Armor Conduct Electricity? A New Dataset for Open Book Question Answering. in Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing 2381–2391, https://doi.org/10.18653/v1/D18-1260 (Association for Computational Linguistics, 2018).
Jin, D. et al. What Disease Does This Patient Have? A Large-Scale Open Domain Question Answering Dataset from Medical Exams. Appl. Sci. 11, 6421 (2021).
Nair, V., Schumacher, E., Tso, G. & Kannan, A. DERA: Enhancing Large Language Model Completions with Dialog-Enabled Resolving Agents. Preprint at https://doi.org/10.48550/arxiv.2303.17071 (2023).
Pal, A., Umapathi, L. K. & Sankarasubbu, M. MedMCQA: A Large-scale Multi-Subject Multi-Choice Dataset for Medical domain Question Answering. in Proceedings of the Conference on Health, Inference, and Learning 248–260 (PMLR, 2022).
Jin, Q., Dhingra, B., Liu, Z., Cohen, W. & Lu, X. PubMedQA: A Dataset for Biomedical Research Question Answering. in Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP) 2567–2577, https://doi.org/10.18653/v1/D19-1259 (Association for Computational Linguistics, 2019).
Hendrycks, D. et al. Measuring Massive Multitask Language Understanding. Preprint at https://doi.org/10.48550/arXiv.2009.03300 (2020).
Talmor, A., Herzig, J., Lourie, N. & Berant, J. CommonsenseQA: A Question Answering Challenge Targeting Commonsense Knowledge. in Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) 4149–4158, https://doi.org/10.18653/v1/N19-1421 (Association for Computational Linguistics, 2019).
Geva, M. et al. Did Aristotle Use a Laptop? A Question Answering Benchmark with Implicit Reasoning Strategies. Trans. Assoc. Comput. Linguist. 9, 346–361 (2021).
Lamm, M. et al. QED: A Framework and Dataset for Explanations in Question Answering. Trans. Assoc. Comput. Linguist. 9, 790–806 (2021).
Ling, W., Yogatama, D., Dyer, C. & Blunsom, P. Program Induction by Rationale Generation: Learning to Solve and Explain Algebraic Word Problems. in Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) 158–167, https://doi.org/10.18653/v1/P17-1015 (Association for Computational Linguistics, 2017).
Miao, S., Liang, C.-C. & Su, K.-Y. A Diverse Corpus for Evaluating and Developing English Math Word Problem Solvers. in Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics 975–984, https://doi.org/10.18653/v1/2020.acl-main.92 (Association for Computational Linguistics, 2020).
Cobbe, K. et al. Training Verifiers to Solve Math Word Problems. Preprint at https://doi.org/10.48550/arXiv.2110.14168 (2021).
Koncel-Kedziorski, R., Roy, S., Amini, A., Kushman, N. & Hajishirzi, H. MAWPS: A Math Word Problem Repository. in Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies 1152–1157, https://doi.org/10.18653/v1/N16-1136 (Association for Computational Linguistics, 2016).
Patel, A., Bhattamishra, S. & Goyal, N. Are NLP Models really able to Solve Simple Math Word Problems? in Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies 2080–2094,https://doi.org/10.18653/v1/2021.naacl-main.168 (Association for Computational Linguistics, 2021).
Chen, M. et al. Evaluating Large Language Models Trained on Code. Preprint at https://doi.org/10.48550/arXiv.2107.03374 (2021).
Liévin, V., Hother, C. E. & Winther, O. Can large language models reason about medical questions? Preprint at https://doi.org/10.48550/arxiv.2207.08143 (2022).
Hebenstreit, K., Praas, R., Kiesewetter, L. P. & Samwald, M. An automatically discovered chain-of-thought prompt generalizes to novel models and datasets. Preprint at https://doi.org/10.48550/arxiv.2305.02897 (2023).
Chung, H. W. et al. Scaling Instruction-Finetuned Language Models. Preprint at https://doi.org/10.48550/arxiv.2210.11416 (2022).
Ott, S. et al. ThoughtSource: A central hub for large language model reasoning data (code snapshot). Zenodo https://doi.org/10.5281/zenodo.8199390 (2023).
Ott, S. et al. ThoughtSource: A central hub for large language model reasoning data (dataset snapshot). Zenodo https://doi.org/10.5281/zenodo.8199538 (2023).
Acknowledgements
We thank primary dataset contributors who assisted with assembling the ThoughtSource meta-dataset.
Author information
Authors and Affiliations
Contributions
S.O. and K.H. wrote the code for accessing, converting, generating and analyzing datasets, and wrote parts of the manuscript and documentation. V.L., C.E. and O.W. generated and analyzed CoT data for medical datasets. M.Ma. wrote the code of the annotator software. M.Mo. wrote a first prototype of code for accessing and converting datasets. R.P. contributed to improving code and documentation quality. M.S. conceived and supervised the project and wrote parts of the manuscript and documentation. All authors have read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ott, S., Hebenstreit, K., Liévin, V. et al. ThoughtSource: A central hub for large language model reasoning data. Sci Data 10, 528 (2023). https://doi.org/10.1038/s41597-023-02433-3
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41597-023-02433-3
