
Abstract
Regioindustry trade flow data are useful inputs for economists and policy makers for a range of planning and disaster-response applications. Within the European Union (EU) whose members enjoy free trade, small variations in these granular trade flows can often propagate to other member-countries far beyond the original trade-shock. In spite of their importance, this information is either outdated or non-existent in the EU as the official databases only provide data at the national-sectoral or regional-only (non-industry specific) level. To fill this gap, we construct Multi-Regional Input-Output (MRIO) tables for 272 European NUTS-2 regions for the period 2008–2018, building on freight transport data as their main trade route across them. The database covers 10 sectors for industry, services and agriculture. We successfully validate our estimates through a direct comparison with a previous MRIO dataset for European regions (REGIO), a sub-sample of countries reporting regional trade flow data as the “ground truth” and a sensitivity analysis reporting relative standard errors well below the MRIO literature average.
Similar content being viewed by others

Background & Summary
The classic approach for estimating trade flows in the literature starts from the largest spatial scale - the global trade networks - studied through Multi-Regional Input-Output (MRIO) tables and global trade-flow databases. However, this coarse level of analysis does not provide direct insights about the domestic and cross-border trade flows at the sub-national level1,2. This situation creates a gap between the information that describes the structure of the sub-national economy, and the top-down information of Inter-Country Input-Output (ICIO) tables used to understand these regional economic characteristics. Constructing a finer-grade representation for the scale and channels through which each regional industry interacts with the others is one way to address this issue. This information can provide a detailed description of the linkages between regions and sectors, along with their implications for a broad range of societal, economic and ecological repercussions. For example, an understanding of the criticality of a region for domestic and global supply chains can help us prevent or mitigate the impact of future disruptions, predict regional demand with labor or demographic mobility and trace its trade-flow environmental footprint.
Despite these benefits, the existing global input-output databases like WIOD3, OECD-ICIO, EXIOBASE4 ESA FIGARO5 and Eora6 rarely provide information for trade flows at the sub-national level. To address this, researchers have attempted to construct datasets that provide estimates of the trade flows for each region. For example, there is a comprehensive database for an EU MRIO at the NUTS-2 level (Nomenclature of Territorial Units for Statistics, level 2) covering the period 2000–20107, and a further dataset with estimated EU regional trade flows for 2013 only8. While these are both credible efforts, these datasets have not been updated, and the changes in regional classifications over time (due to mergers across NUTS-2 regions and redefinitions) have made some of the findings less relevant for policy-makers9.
A regional MRIO table would need to include data on intermediate goods used by firms in different sectors or the goods consumed by households, however such data are not readily available at that level. Moreover, regional information about exports and imports is also missing in most cases, as national statistical authorities neglect them and regional producers can not easily build a comprehensive dataset themselves. Statistical agencies and policy-makers often turn to surveys to fill the existing secondary data gaps which are often unrepresentative and expensive10,11. Therefore regional table construction activities have shifted away from survey-based tables to datasets based on the so-called non-survey or hybrid (partial survey) methods12. The most adopted non-survey methods are Location Quotient methods (LQ)13,14,15, in which regional input-output tables are measured by the sectoral employment distribution, and adjusted national input-output tables by means of regional location coefficients. Other established methods include the commodity balance method (CB)16,17, GRAS18, the cross-entropy method (CE)8 and the cross-hauling adjusted regionalization method (CHARM)19. Methods that include the use of regional information collected from surveys (hybrid methods or partial-survey methods), follow a procedure very similar to the ones described above. In particular, they only substitute the modification of national coefficients on LQ measurements with estimates based on information collected through the survey.
In the MRIO we provide in this paper, there are 272 regions and 10 sectors. The regions are classified at NUTS-2 level, and the sectors are classified at the statistical classification of economic activities in the European Community (NACE) level 1. For each year, we estimate inter-region and inter-sector trade data. Using existing data we are able to provide these estimates for the period 2008–2018.
Methods
In this study, we combine survey and non-survey methods to construct the database. There are 3 steps involved in constructing MRIO tables: (1) Estimating marginal accounts for each NUTS2 region; (2) Estimating regional IO values based on marginal accounts and the IO coefficients; (3) Estimating the inter-regional trade matrix. Table 1 lists the inputs used in each of these steps.
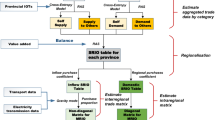
The MRIO tables at NUTS-2 level could be regarded as linking region SRIO tables (colored in yellow) together with trade matrices (colored in green) in Fig. 1. The MRIO tables at NUTS-2 level were constructed by a hybrid method, which combines the micro transport survey data and the modelled outcomes. SRIO tables are produced using National IO tables and Eurostat regional accounts. Trade flows between regions are estimated from road freight flows20 that are anchored to the 20138 trade data. In this study, the cross-entropy approach is employed to ensure maximum similarity between the target and the prior distribution.

A MRIO at NUTS-2 level.
Estimating marginal accounts for each region
There is a Single Region Input Output (SRIO) table in Fig. 1, whose regional accounts including taxes less subsides, value added, imports and final demand need to be disaggregated from the national level using the commodity balance approach. The reference relationship is shown in Table 2. Regional gross value added was used to disaggregate taxes less subsides, value added and output for each region by sector. Regional income statistics were used to distribute the demand categories (household demand and government demand) over regions, which includes Household Final Consumption Expenditure (HFCE), Non-Profit Institutions Serving Households (NPISH) and General government Final Consumption (GGFC). Gross capital formation is divided into three items: gross fixed capital formation (GFCF), changes in inventories and changes in valuables (INVNT)7. The formula used for estimating regional accounts is the following:
where Xr is the element of the SRIO for region r, Xn is the corresponding element of the national IO table of country n, Ir is the used indicator, Sn is the set of NUTS-2 regions of country n.
Estimating regional input-output table based on marginal accounts and input-output coefficients
Once the regional accounts are confirmed, intermediate demands are derived from Eq. 2.
The Location Quotient (LQ) approach is used to add heterogeneity when estimating SRIO. According to the literature, the LQ approach is based on the assumption that regional and national technologies are identical and that regional trade coefficients differ from the national input coefficients based on their respective labor inputs. The LQ is defined by the following equation:
with empri indicating regional employment of region r in industry i. LQri describes the relative significance of regional employment in industry i compared to the national employment level in the same industry. If LQri≥1, it is assumed that the region is specialized in industry i. This implies that the regional industry can meet the regional demand requirements for its goods or services and therefore the regional coefficient is assumed to be equal to the national coefficient. However, if LQ < 1, it is assumed that the regional specialization is lower than the national average14:
where \({\widehat{Z}}^{n}\) is the preliminary intermediate transaction matrix from sector i to sector j of region n. The hat accent indicates a preliminary variable; \({a}_{ij}^{nation}\) is the national technical coefficient from sector i to sector j.
By means of these modifications to national technical coefficients, new coefficients should represent intermediate demands produced locally within the region.
Once intermediate demands and regional accounts are established through the above steps, we balance the SRIO with the commodity balance method. That is, when a region has a surplus supply, it is expected to export to other regions or countries, and when a region’s demand cannot be met by itself, it is expected to import from other regions or countries. This could be described as the following equations:
After this step, we derive 272 balanced SRIOs.
Estimating inter-regional trade matrix
The essence of estimating trade pattern is to transfer the probability between regions and sectors. We apply regional road freight flow data and trade data within EU regions in 2013 to build a prior distribution, and use the cross-entropy method to minimise the difference between them. We apply regional freight transportation data with sector information to estimate the share of freight flows between regions8,19.
where qij is the prior distribution gained from previous MRIO works, and pij are the estimates we are after and v is the total trade volume within regions available from the OECD-ICIOs.
We want to minimise the cross entropy distance between two distributions, while three constraints need to be satisfied: (1) The sum for whole elements should equal to 1; (2)/(3) The regional imports/exports have to satisfy the marginal trade derived from SRIO tables.
Data Records
All input data and the output dataset are available on Zenodo21.
The data set of the European Multi Regional Input Output Data for 2008–2018 contains 11 data files for each year in XLSX format. Each file contains transactions between sectors within regions, as green and yellow segments show in Fig. 1. Figure 1 presents the structure of the environmental data for each year by region and sector. Each matrix includes 272 regions (deposited in Zenodo) and 10 sectors (Table 3). In total, 10 matrices are included in the database. The measured units for all environmental data are million dollars($). The metadata information for the datasets including abbreviations of regions, countries, sectors, acronyms of variables can be found in “Metadata” deposited at Zenodo Tables 4,5.
For some of the input data included in Zenodo, we have made adaptations to match their classification on regions or sectors with the final results. Specifically, there is no regional gross value added data for the UK in Eurostat statistics because of Brexit. We use statistics from the UK Office for National Statistics as an alternative, and add their mapping on our NACE-1 sectors. This information is stored as “UK rgva.xlsx” in the “Regional account” folder. For the NUTS2 regional trade flows, which are not publicly accessible, we place them as “Trade Data EU 2013 ref.xlsx” under “REGIO” folder.
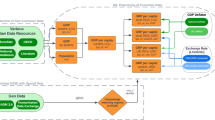
For the technical validation, we use regional input-output table estimations provided by local governments. For Austria, we requested the data from the authors of estimation12 and placed them in the “Austria” folder. For Finland, we relabelled the region names in NUTS-2 codes for each sheet in “io reg 2014.xlsx” and placed them in the “Finland” folder. For Scotland, we relabelled the sector names at NACE-1 level as “Scotland 2008.xlsx” and placed them in the “Scotland” folder Fig. 2.

Regionalisation and commodity balance.
Technical Validation
To validate the MRIO we derive, we use data from the most adopted MRIO tables (PBL-MRIO, hereafter)7,8 at NUTS2 level. Following previous work in the MRIO literature, three indicators are used in this process including mean absolute deviation (MAD), the Isard-Romanoff similarity index (DSIM), and Pearson correlation. MAD measures the absolute distance between each element in the two matrices and DSIM measures the relative distance16.
where r, s indicates regions, and i, j indicates sectors.
Table 6 provides the comparison across 10 sectors. It turns out the MADa and DSIM are relatively small and highly significant (p = 0.000) with a linear correlation approximately 0.8.
Given that the existing REGIO tables overlap with our data only for the period 2008–2010, we compare our trade flow results (MRIO) with REGIO for these three years by using their SRIO tables in Table 7 by Eqs. 8, 9 and Pearson’s Correlation. Since the sectors do not directly match across the two datasets, we reclassify sectors in both datasets into 7 sectors. Overall, DISM is less than 0.5 and the correlation for Finland, Latvia, Netherlands, Malta, Slovakia and UK are around 0.4 and statistically significant.
Further, we use Regional IO tables for specific countries based on surveys conducted locally as the ground truth with which we compare our data and the REGIO ones. The actual trade-flow data cover SRIOs for regions in Austria12, Finland (https://github.com/pttry/alta) and Scotland (https://www.gov.scot/publications/input-output-latest/) as we could not find readily available trade-flows for more countries. For MAD, both MRIO and REGIO have large differences with the ground truth. For DISM, both MRIO and REGIO capture around 30% similarity of the actual data. For Pearson’s correlation, MRIO has 0.36 for regions in Austria, and over 0.9 for regions in Finland and Scotland (Table 8).
Following the best practices in the MRIO literature22, we further provide our estimates for the relative standard error (RSE) for our MRIO data and the ground truth (i.e. the original survey data from local governments). To compute these, we employ a Monte Carlo sensitivity analysis on the MRIOs and the ground truth under three standard deviation (σ) scenarios. Specifically, we generate a vector of emissions intensities randomly from these datasets as we found no empirical data to compare them with. Then we introduce the stressor F = Xs. X, Y, Z, A are known from the datasets. Then at each round, we add a perturbation EZ~N(0, σz), EF~N(0, σF), EY~N(0, σY) on Z, F, Y, and get the outcome C = s(I–A)−1Y. After 1000 simulations for each case, we collect the population of C results. From these we obtain the relative standard error (RSE) in Table 9. Here MRIO refers to results from our estimated datasets, while “Ground truth” refers to results from the local surveys. The mean average of RSE is in most cases much smaller than 10% in the table.
Code availability
The code to run the model is available on Zenodo21.
References
Verschuur, J., Koks, E. & Hall, J. Ports’ criticality in international trade and global supply-chains. Nat. Commun. 13, 4351 (2021).
Bolea, L., Duarte, R., Hewings, G. J., Jiménez, S. & Sánchez-Chóliz, J. The role of regions in global value chains: an analysis for the european union. Pap. Reg. Sci. 101(4), 771-794 (2022).
Dietzenbacher, E., Los, B., Stehrer, R., Timmer, M. & De Vries, G. The construction of world input-output tables in the WIOD project. Econ. Syst. Res. 25, 71–98 (2013).
Tukker, A. et al. Exiopol-development and illustrative analyses of a detailed global MR EE SUT/IOT. Econ. Syst. Res. 25, 50–70 (2013).
Eurostat. Figaro database-EU inter-country supply, use and input-output tables. https://ec.europa.eu/eurostat/web/esa-supply-use-input-tables/data/database (2022).
Lenzen, M., Moran, D., Kanemoto, K. & Geschke, A. Building Eora: A global multi-region input-output database at high country and sector resolution. Econ. Syst. Res. 25, 20–49 (2013).
Thissen, M., Lankhuizen, M., van Oort, F., Los, B. & Diodato, D. Euregio: The construction of a global io database with regional detail for europe for 2000–2010. JRC Working Papers on Territorial Modelling and Analysis (2018).
Thissen, M., Ivanova, O., Mandras, G. & Husby, T. European NUTS 2 regions: construction of interregional trade-linked Supply and Use tables with consistent transport flows. JRC Working Papers on Territorial Modelling and Analysis (2019).
Eurostat. History of NUTS. https://ec.europa.eu/eurostat/web/nuts/history. Accessed: 2022-10-04.
Flegg, A. T., Lamonica, G. R., Chelli, F. M., Recchioni, M. C. & Tohmo, T. A new approach to modelling the input-output structure of regional economies using non-survey methods. J. Econ. Struct. 10, 1–31 (2021).
Boero, R., Edwards, B. K. & Rivera, M. K. Regional input-output tables and trade flows: an integrated and interregional non-survey approach. Reg. Stud. 52, 225–238 (2018).
Rokicki, B., Fritz, O., Horridge, J. M. & Hewings, G. J. D. Survey-based versus algorithm-based multi-regional input–output tables within the CGE framework – the case of Austria. Econ. Syst. Res. 33, 470–491 (2021).
Bonfiglio, A. & Chelli, F. Assessing the behaviour of non-survey methods for constructing regional input-output tables through a Monte Carlo simulation. Econ. Syst. Res. 20, 243–258 (2008).
Kowalewksi, J. Regionalization of national input-output tables: Empirical evidence on the use of the FLQ formula. Reg. Stud. 49, 240–250 (2015).
Jahn, M. Extending the FLQ formula: a location quotient-based interregional input-output framework. Reg. Stud. 51, 1518–1529 (2017).
Zheng, H. et al. Chinese provincial multi-regional input-output database for 2012, 2015, and 2017. Sci. Data 8, 244 (2021).
Zheng, H. et al. Entropy-based Chinese city-level MRIO table framework. Econ. Syst. Res. 34, 1–26 (2021).
Valderas-Jaramillo, J. M. & Rueda-Cantuche, J. M. The multidimensional nD-GRAS method: Applications for the projection of multiregional input–output frameworks and valuation matrices. Pap. Reg. Sci. 100, 1599–1624 (2021).
Többen, J. & Kronenberg, T. H. Construction of multi-regional input-output tables using the CHARM method. Econ. Syst. Res. 27, 487–507 (2015).
Speth, D., Sauter, V., Plötz, P. & Signer, T. Synthetic European road freight transport flow data. Data Bri. 40, 107786 (2022).
Huang, S. & Koutroumpis, P. European Multi Regional Input Output Data for 2008–2018, Zenodo, https://doi.org/10.5281/zenodo.7765776 (2023).
Moran, D. & Wood, R. Convergence between the Eora, WIOD, EXIOBASE, and OpenEU’s consumption-based carbon accounts. Econ. Syst. Res. 26, 245–261 (2014).
OECD. Organisation for Economic Co-operation and Development. OECD inter-country input-output database Data retrieved in Jun, 2022, http://oe.cd/icio (2021).
Eurostat. Gross value added at basic prices by NUTS 3 regions. Data retrieved in Apr, 2022 https://ec.europa.eu/eurostat/databrowser/view/nama_10r_3gva/default/table?lang=en (2022).
Fenton, T. Office for National Statistics. Regional gross value added (balanced), UK: 1998 to 2016 Data retrieved in Jun, 2022 https://www.ons.gov.uk/economy/grossvalueaddedgva/bulletins/regionalgrossvalueaddedbalanceduk/1998to2016 (2022).
Eurostat. Gross fixed capital formation by NUTS 2 regions. Data retrieved in Apr, 2022 https://ec.europa.eu/eurostat/databrowser/view/nama_10r_2gfcf/default/table?lang=en (2022).
Eurostat. Income of households by NUTS 2 regions. Data retrieved in Apr, 2022 https://ec.europa.eu/eurostat/databrowser/view/nama_10r_2hhinc/default/table?lang=en (2022).
Eurostat. SBS data by NUTS 2 regions and NACE Rev. 2 (from 2008 onwards). Data retrieved in Apr, 2022 https://ec.europa.eu/eurostat/databrowser/view/sbs_r_nuts06_r2/default/table?lang=en (2022).
Acknowledgements
The authors are grateful to the anonymous reviewers and Oxford Martin Programme of Technological and Economic Change. This study was supported by a PhD scholarship (No.202106040105) from the China Scholarship Council (CSC). This research has also been supported by Citi.
Author information
Authors and Affiliations
Contributions
P.K. conceived the concepts, S.H. collected the data and built the model. All authors analysed the results and reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Huang, S., Koutroumpis, P. European multi regional input output data for 2008–2018. Sci Data 10, 218 (2023). https://doi.org/10.1038/s41597-023-02117-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41597-023-02117-y
