
Abstract
Grazing intensity, characterized by high spatial heterogeneity, is a vital parameter to accurately depict human disturbance and its effects on grassland ecosystems. Grazing census data provide useful county-scale information; however, they do not accurately delineate spatial heterogeneity within counties, and a high-resolution dataset is urgently needed. Therefore, we built a methodological framework combining the cross-scale feature extraction method and a random forest model to spatialize census data after fully considering four features affecting grazing, and produced a high-resolution gridded grazing dataset on the Qinghai–Tibet Plateau in 1982–2015. The proposed method (R2 = 0.80) exhibited 35.59% higher accuracy than the traditional method. Our dataset were highly consistent with census data (R2 of spatial accuracy = 0.96, NSE of temporal accuracy = 0.96) and field data (R2 of spatial accuracy = 0.77). Compared with public datasets, our dataset featured a higher temporal resolution (1982–2015) and spatial resolution (over two times higher). Thus, it has the potential to elucidate the spatiotemporal variation in human activities and guide the sustainable management of grassland ecosystem.
Similar content being viewed by others

Background & Summary
Grazing is a direct and critical indicator of anthropogenic interference on grasslands1, and the high-spatiotemporal-resolution grazing datasets have been indispensable tools for investigating the influence of grazing on grassland ecosystems2. Detailed geographic grazing information, despite its importance, is not readily available, which is the most pressing challenge limiting grassland ecosystem management. For example, the grassland degradation3,4, caused by the human demand for meat and milk production5 and inappropriate grazing management6,7, is increasingly severe, which is bound to exacerbate human and wildlife conflict because of the aggravated resource competition8. The poor spatial heterogeneity of census grazing data makes it difficult to be combined with remote sensing data for analysis. Therefore, the mechanism of the effect of spatio-temporal changes of grazing on grassland degradation has been rarely documented9,10, which limits the understanding of the influence of grazing on grassland degradation and coordinate the underlying conflicts between livestock production and wild herbivore conservation11. There is an urgent need to obtain reliable high-spatiotemporal-resolution grazing datasets to accurately depict spatially explicit and temporally explicit changes, particularly for fragile grassland ecosystems with a significant contradiction between economic development and sustainable development.
Clarifying the factors influencing the spatial preferences of grazing is vital for obtaining high-spatiotemporal-resolution grazing datasets, considering the inconsistent drivers emerged in producing previous datasets12,13. Grazing, a kind of animal husbandry production activity, is a grassland management and utilization mode14. Climatic and environmental factors, herds’ foraging behavior, herders’ grazing behavior, and ecological protection policies influence the spatial heterogeneity of the distribution of livestock grazing. For example, climatic (i.e., temperature and precipitation) and environmental factors (i.e., terrain slope and soil type) restrict the spatial distribution of livestock15,16,17. The foraging behavior of herds has further influence, for instance, grazing hotspots have also been observed near areas with sufficient water resources and pasture18,19. Moreover, the grazing behaviors of herders are also often closely linked to the travel characteristics of livestock, because the animals move back and forth near herders’ settlements20. Several studies have also reported that ecological protection policies, such as natural reserves, influence resource utilization and human–nature relationship, and have notable restriction for grazing distribution according to the conservation level21. Therefore, it is crucial to further investigate how to fully leverage the spatiotemporal heterogeneity of the influencing factors to more reasonably produce high-resolution gridded grazing datasets.
The method for obtaining high-spatiotemporal-resolution grazing datasets for large-scale areas is also important. The current methods can be broadly classified into two categories: The first category of methods are the simulation methods based on remote sensing data, such as grassland utilization intensity22 and the human appropriation of net primary production23. These methods are substitute indexes of grazing intensity obtained through the simulation of the difference between the potential and real vegetation states, and they are considered to be equivalent to the grazing intensity in grassland ecosystems. Although it is convenient to obtain the spatial heterogeneity of grazing at the pixel level, it may be a challenge for areas with animal husbandry coexisting with abundant herbivorous wildlife, because eliminating the impact of herbivorous wildlife is difficult24. The second category of methods are the spatialization methods based on census grazing data. These methods construct the administrative-level relationship between grazing density and influencing factors using multiple linear regression12 or machine learning algorithms13,25, and then, gridded grazing density is obtained the using the trained model and pixel-level influencing factors. The methods are characterized by grazing data accuracy; however, a scale mismatch exists when the carrier of grazing information is transformed from the administrative level to the pixel level, because the trained model fails to accurately capture the extreme values of the predicted data accurately. Hence, how to integrate the advantages of the two methods to obtain a gridded grazing dataset with both high spatial heterogeneity and high accuracy remains a challenge.
The combination of cross-scale features (CSFs) extraction method and machine learning algorithm can be applied to solves these key issues. The combined approach can integrate the advantages of the two data production methods. The CSFs extraction method can narrow the scale differences in feature representation between administrative-level and pixel-level by replacing the average administrative-level value with a finer-level value, thereby increasing the training sample size and range and ameliorating the scale mismatch problem in the relationship transmission process26. Additionally, the random forest (RF) model, a widely used and well-understood non-parametric machine learning algorithm for regression analysis, is characterized by high computational efficiency and estimation accuracy, and has been used in the spatialization of various census data owing to its simplicity25,27,28. Most important, taking the extracted CSFs as the training data of RF (RF–CSF) model, the advantage of high spatial heterogeneity in the former method and high accuracy of census data in the latter method can be effectively integrated to reduce cross scale differences, and achieve accurate transmission of feature information. In addition to the above advantages, the RF–CSF model has also preponderance in integrating the driving forces of grazing distribution. For example, the RF model can be used to calculate the importance of each independent variable29 and simulate the complex nonlinear relationship between multidimensional independent variables and the dependent variable30, which meets our requirements for integrating the characteristics of multi-source factors.
Qinghai-Tibet Plateau has a more urgent and realistic need to obtain a high-spatiotemporal-resolution grazing dataset to mitigate grassland degradation and enhance sustainability through grazing intensity adjustment31, because the Qinghai-Tibet Plateau is a typical animal husbandry area with fragile ecosystem and has undergone continuous aggravated grassland degradation over the past few decades32,33. Therefore, the objectives of the present study are (i) to build a methodological framework to improve the traditional methods for developing gridded grazing datasets, (ii) to produce a high-resolution gridded grazing dataset of grassland ecosystems on the Qinghai–Tibet Plateau for 1982–2015, and (iii) to validate the accuracy of the dataset. The dataset can be applied to elucidate the temporal dynamics and spatial variation of human disturbance and their influences on grasslands, and it can also be used in other related studies on the Qinghai–Tibet Plateau.
Methods
Study area
The Qinghai–Tibet Plateau (26°00′-39°47′N, 73°19′-104°47′E), one of the most important pastoral areas in the world, straddles the southwest regions of China, and it includes 244 counties, which belong to six provinces: Tibet, Qinghai, Xinjiang, Gansu, Sichuan, and Yunnan. It is characterized by rich natural grassland resources, including desert steppes, alpine steppes, and alpine meadows (Fig. 1a). The grassland areas account for over 56% of this region34. The grassland plays a vital role in providing regional and national animal husbandry products and fodder35, which enables the local herders to obtain almost all of the resources required for survival36. The grazing density distribution is extremely unbalanced (Fig. 1a) owing to the high spatial heterogeneity of economic development (Fig. 1b-1) and grassland production (Fig. 1b-2), resulting from the differences in resources and environmental factors37. Over the past few decades, there has been a significant change in the number of livestock animals, and the number of sheep exceeded 160 million by 2020. Therefore, it is urgent to obtain a high-resolution gridded grazing dataset for its evaluating spatiotemporal changes and coordinating the relationship between human beings and the grassland ecosystem.

Location of the Qinghai–Tibet Plateau: (a) grassland type and distribution, and grazing density (GD) in 244 counties; (b) spatial heterogeneity of economic development (ED) and grassland production (GP) in 244 counties. GD, ED, and GP are represented by sheep unit per grassland area per county (SU/hm2), human footprint index per pixel (HF/pixel) per county, and net primary production per grassland area per county (gC/m2), respectively.

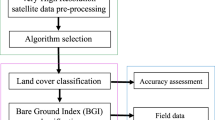
Methodological framework for grazing spatialization.
Methodological framework
We developed a methodological framework for high-resolution gridded grazing dataset mapping. The framework mainly includes four parts: (i) identifying features affecting grazing, (ii) extracting theoretical suitable grazing areas, (iii) building grazing spatialization model, and (iv) correcting the grazing spatialization dataset. Each step is explained in more detail below (Fig. 2).
Step 1: Identifying features affecting grazing
Grazing activities are affected by the spatial heterogeneity of resources and environmental factors, regulated by the grazing behavior of herders and the foraging behavior of herds, and restricted by ecological protection policies. Therefore, the specific implications of the 14 influencing factors from the above four aspects are presented in Table 1. These factors are necessary for spatializing the county-level grazing data.
Step 2: Extracting theoretical suitable grazing areas
The decision tree approach38 was adopted to extract the theoretical suitable grazing areas for further grazing spatialization (step 2 in Fig. 2). First, the potential grazing area was identified according to the boundary of the grassland ecosystem, because grazing behavior only occurs in the grassland. Then, the unsuitable areas for grazing, i.e., extremely-high-altitude areas and areas adjacent to towns, were removed from the potential grazing area stepwise. The areas strictly prohibited for grazing, i.e., the core areas of national nature reserves39 within grassland areas, were also deemed unsuitable for grazing. Finally, the extracted areas were the theoretically suitable grazing areas.
Step 3: Building grazing spatialization model
(i) Extracting cross-scale feature (CSFs)
In the traditional method, the spatial resolution of the training data (i.e., the average value at the administrative level) differs from that of the predicting data (i.e., the value at the pixel level), and the trained model can only capture the characteristics within the training data. However, the extreme value of the predicting data inevitably exceeds the range of the training data, which can result in underestimation in these parts40. To reduce these mismatches, we built an improved method for CSFs extraction (Fig. 2, first part of step 3).
First, the census grazing data are simply distributed from county level to pixel level using the weight of the absolute disturbance (AD) index as Eq. (1). The AD index is measured by Mahalanobis distance using Eq. (2), which is calculated according to the deviation between the potential and observed normalized difference vegetation index (NDVI) values22. Second, the distributed grazing data are graded via the hierarchical clustering method, and the optimal number of the group can be determined using the Davies–Bouldin index (DBI)41 as Eq. (3), an index for evaluating the quality of clustering algorithm. The smaller the DBI, the smaller the distance within each group. Therefore, the DBI can be used to select the best similar values to minimize the deviation within each group. Finally, we can obtain the scope of the groups within each county using the above two steps and obtain the average value of all independent variables and the dependent variable accordingly. As expected, we can decompose the average value at the county level (traditional features in Fig. 2) into the average value at the group level (improved features in Fig. 2).
where SUi and \(S{U}_{j}^{C}\) are the grazing value for pixel i and the census grazing value for county j; \({w}_{A{D}_{i}}\) is the weight of the AD index for pixel i and \({w}_{A{D}_{j}}\) represents the summed weight of the AD index values for all pixels in county j.
where ADi is the AD index for pixel i; the vector composed of its observed NDVI \(\left(NDV{I}_{i}^{T}\right)\) and potential NDVI \(\left(NDV{I}_{i}^{P}\right)\) time-series data could be considered as two points in the feature space for pixel i, and Di and u are the difference and the mean value of the vector, respectively; cov is the covariance matrix.
where DBIk is the DBI coefficient when the cluster number is k; \(\overline{{a}_{x}}\) and \(\overline{{a}_{y}}\) are the average distances of the group xth and the group yth, respectively; δx and δy are the center distance of the group xth and the group yth, respectively.
Different from the traditional method, our method can decompose features into multiple features using the grading AD index. The differences among counties will not be easily averaged out. Moreover, our method is less affected by scale mismatch and can be transferred to cross-scale modeling26.
(ii) Building RF model with partitioning
A single model cannot accurately obtain the variation information of the Qinghai–Tibet Plateau with high spatial heterogeneity. The partition model, a widely used method for estimating population distribution and others42,43, can be incorporated into the proposed model to improve its performance. The thresholds (0.43, 0.35 and 0.21 SU/hm2), determined according to the theoretical livestock carrying capacity (equation S1), were calculated and used to separate independent variables and dependent variable for each grassland types: alpine meadow, alpine steppe and alpine desert steppe (see Section 6.1 for details). Then, the RF models were established, and the training and testing samples were randomly divided in the proportion of 3:1. It is notable that transforming the response variable using natural log prior to RF model fitting is necessary to achieve higher prediction accuracies44. Finally, the independent variables at the pixel level were inputted into the two trained RF models, and the corresponding grid grazing dataset was output by combining the two results (Fig. 2, second part of step 3).
(iii) Validating the accuracy of the methods
The performance of the grazing spatialization model was evaluated through a comparison of the predicted value with census value26. Accuracy validation indexes, including coefficients of determination (R2), root mean square error (RMSE), and mean absolute error (MAE), were used to evaluate the performances of the proposed RF-based models (Table 2), as presented in Eq. (4).
where \(S{U}_{j}^{C}\) and \(S{U}_{j}^{P}\) are the census grazing value and the predicted grazing value for county j, respectively; \(\overline{S{U}^{C}}\) is the average census data for all counties; and N is the number of all counties.
Step 4: Correcting grazing spatialization dataset
(i) Correcting residuals of dataset
Correcting residuals is necessary to obtain datasets with higher accuracy45,46, because propagating the cross-scale relationship in the RF models will inevitably generate errors47. The residuals, calculated by the difference between the average census grazing and predicted grazing values at the administrative level, were used to calibrate the errors related to all pixels within this county. The revised dataset after residual correction is the final product provided in this study. The residual correction method is expressed by Eq. (5), and the process is shown in the fourth step in Fig. 2.
where \(S{U}_{i}^{RP}\) denotes the predicted grazing value revised by the residuals for pixel i, \(S{U}_{i}^{P}\) denotes the predicted grazing for pixel i, and Rj denotes the residuals calculated from the difference between census grazing and predicted grazing data for county j.
(ii) Validating the accuracy of dataset
Two goodness-of-fit indexes were used to validate the consistency of spatial distribution and the temporal trend between predicted grazing data and census grazing data. Generally, the coefficient of determination (R2), defined in Eq. (4), is used to verify the consistency of spatial distribution, and the Nash–Sutcliffe efficiency (NSE, Eq. (6)) is used to verify the consistency of temporal trend. An index value closer to 1 corresponds to a more accurate dataset. Meanwhile, we also collected field grazing data from 56 sites to further validate the spatial accuracy of the dataset, and it measured using the R2 in Eq. (4).
where \(S{U}_{t}^{RP}\) and \(S{U}_{t}^{C}\) are the predicted grazing value revised by residuals and the census grazing value of all counties in year t, respectively; \(\overline{S{U}^{{C}^{{\prime} }}}\) is the average census grazing value of all years; and T is the number of time steps.
(iii) Identifying uncertainties associated with dataset
The uncertainties associated with the dataset originate from the following two aspects: First, the unreasonableness of our method, owing to the errors related to cross-scale modeling or the inappropriate selection of influencing factors, is an important source of uncertainties. Second, the incompleteness of auxiliary variables also introduces uncertainties. In this instance, grassland-free areas are not accurately identified in some counties, but livestock animals are raised in these counties. These counties have no effective value for livestock density prediction. Overall, the uncertainties can be identified in terms of the mean relative error (MRE) in Eq. (7).
where \(S{U}_{j}^{C}\) is the census grazing value for county j, \(S{U}_{j}^{RP}\) is the predicted grazing value revised by residuals for county j, and N is the number of counties.
Data source
Census grazing data at county level
Eight types of livestock, namely cattle, yaks, horses, donkeys, mules, camels, goats, and sheep, were considered according to the regional characteristics, and livestock stocking quantity at the end of year for each county can be determined from statistical yearbooks. However, the numbers of livestock at the county level for some years between 1982 and 2015 were not recorded. The missing data were indirectly approximated from city- or provincial-level data (e.g., interpolation using their temporal trends). Each type of livestock stocking quantity was converted into standard sheep unit (SU) according to the national standards using Eq. (8)48, namely the calculation of rangeland carrying capacity (NY/T 635-2015). Of the 244 counties of the Qinghai–Tibet Plateau, only 242 counties were considered, as the census grazing data for the other 2 counties were unavailable. The unit of grazing statistics data at the county level is defined as SU per county per year (SU·county−1·year−1).
where Nsheep, Ngoats, Ncattle, Nyaks, Nhorses, Ndonkeys, Nmules, Ncamels are the number of sheep, goats, cattle, yaks, horses, donkeys, mules, and camels at the year-end, respectively. SU denotes the standard sheep unit (SU·county−1·year−1).
Data of grazing influencing factors at pixel level
The types of features affecting grazing were obtained from the first step described in Methods, and the detailed information, such as original spatiotemporal resolution, format, and source, is shown in Table 3. The format (i.e., GeoTIFF), spatial resolution (i.e., 0.083°), and the number of rows and columns of the gridded features were leveraged to further produce a high-resolution grazing dataset.
Data Records
The gridded grazing dataset of the grassland ecosystem on the Qinghai–Tibet Plateau for 1982–201549 is available at https://doi.org/10.6084/m9.figshare.21501390. The dataset was named according to the year corresponding to the grazing data and stored in GeoTIFF format in SU per pixel per year. The spatial resolution was 0.083°, with an annual temporal resolution. The geographic coordinate system of the dataset was GCS_WGS_1984. To reduce the file size, the data of 34 years were compressed and stored in zip format. They can be downloaded, uncompressed, and then viewed using various GIS software programs.
Technical Validation
Performance of grazing spatialization method
Compared with the traditional RF model (M1), the proposed RF model with a partition and CSFs (M4) exhibited 35.59% higher overall accuracy. The proposed method considerably contributes to the accuracy of the traditional RF model (M1). Each step, including the RF model with partition (M2), RF model with CSFs (M3), and RF model with partition and CSFs (M4), improved the accuracy of the model (Fig. 3a). Compared with M1 (R2 = 0.59), M2 and M3 exhibited 0.10 and 0.15 higher R2, respectively, and reduced errors. Moreover, the overall R2 of M4 reached 0.80. Figure 3b shows the scatter plot and the fitting results between the census grazing data and the M1- and M4-predicted data for each county in 1982–2015. The M4 data exhibited a comparable scatter point distribution pattern to M1, but the scatter points were more convergent to the 1:1 diagonal line. The comparison of the R2 values of M1 and M4 reveals that M4 remarkably improved prediction accuracy; thus, M4 can alleviate scale mismatch in grazing spatialization.

Performance of the proposed method on the sum of SUs for each county from 1982 to 2015: (a) Performances of the proposed methods. M1, M2, M3, and M4 denote the traditional RF model, RF model with a partition, RF model with CSFs, and RF model with a partition and CSFs, respectively. (b) Scatterplots of M1- and M4-predicted census grazing and predicted grazing. The blue solid line and the black dotted line are the fitting line and the 1:1 diagonal line, respectively.
Validation of the grazing spatialization dataset at the county level
Our dataset was highly consistent with the county-level census grazing dataset, and the spatial accuracy (R2) was 0.96 and the temporal trend (NSE) was 0.96, demonstrating its accuracy. The census grazing data in 2015 was calculated according to the average sheep unit per pixel for each county, which poorly expressed the spatial heterogeneity within the counties (Fig. 4b, left figure). In contrast, the grazing spatialization dataset (Fig. 4b, right figure) considerably increased the within-county spatial heterogeneity while maintaining the original spatial distribution (R2 = 0.96, N = 242) (Fig. 4a). In addition, the grazing spatialization dataset exhibited consistent temporal trends with census grazing data at the regional level: the grazing intensity significantly increased from 1982 to 2015 (NSE = 0.96, N = 34) (Fig. 4c). Moreover, our dataset also can capture the spatial distribution of the temporal trends of census grazing data, that is, grazing intensity decreased and fluctuated in the central areas, but increased in others (Fig. 4d).

Validation of the grazing spatialization dataset using census grazing data: (a) violin plot of census grazing and gridded grazing in 2015; (b) spatial distribution in SU per pixel in 2015; (c) temporal change in 108 SU per year from 1982 to 2015; (d) temporal trend in SU per pixel from 1982 to 2015, and the gray areas indicate significant threds (p < 0.05).
Validation of the grazing spatialization dataset at the pixel level
To further validate the accuracy of our dataset, we collected field grazing data from 56 sites, and our dataset was highly consistent with the 56 field grazing data (R2 = 0.77). The data of the 56 sites were collected from the four aspects: data on 15 sites (red points) were obtained from 13 literatures on free grazing or conventional grazing (Table 4), data on 11 sites (blue points) and 17 sites (green points) were obtained from questionnaires and the field survey in August 2021 (no grazing), respectively, and data on other 13 sites (purple points) were obtained from fenced sites (no grazing)50.The unit of grazing intensity was transformed into standard sheep unit/ hm2 (SU/hm2) according to the Eq. (8). The grazing intensity of the 56 sites were ranged from 0 to 8.50 sheep unit per hectare (SU/hm2), and their distribution covered three grassland types: the alpine meadow (N = 29), alpine steppe (N = 23), and alpine desert steppe (N = 4). The spatial accuracy (R2) of the two datasets from different sources reached to 0.77 (N = 56, Fig. 5b), and it can make up for the uncertainty verified by census grazing data to a certain extent.

Validation of the grazing spatialization dataset using field grazing data: (a) validation by field grazing points; (b) Spatial distribution of the field grazing points.
Comparison with other grazing spatialization datasets
The temporal and spatial resolutions of our dataset are advantageous over the actual livestock carrying capacity (ALCC) dataset, Gridded Livestock of the World 2.01 (GLW2), and Gridded Livestock of the World 3 (GLW3) (Table 5) in the following aspects: The temporal resolution of our dataset (1982–2015) is higher than those of the three public datasets. Our dataset is more suitable for long-term scale research than ALCC (2000–2019), while the other two global livestock datasets (GLW2 and GLW3) have been proved unsuitable for long-term series studies47. In addition, our dataset can improve the accuracy of spatial resolution (Fig. 6). Considering that the census data of GLW2 and GLW3 are for 2001, the accuracies of the four datasets were compared for the corresponding year. The four datasets exhibited relatively consistent spatial patterns, showing high and low spatial patterns in the southeast and northwest, respectively. However, the datasets significantly differed in accuracy. Our dataset exhibited the highest accuracy (R2 = 0.98), which was at least twice those of the others, followed by ALCC (R2 = 0.44), and the global livestock datasets GLW2 and GLW3 exhibited poor accuracy, with R2 of 0.07 and 0.14, respectively.

Comparisons of grazing spatial patterns for 2001: (a) this study result; (b) ALCC result; (c) GLW2 result; (d) GLW3 result. ALCC, GLW2, and GLW3 denote the actual livestock-carrying capacity, Gridded Livestock of the World 2.01, and Gridded Livestock of the World 3, respectively.
Uncertainties and limitations of grazing spatialization dataset
(i) Overall, the relative error associated with the dataset from 1982 to 2015 was 8.77%, calculated from the average errors of the 242 counties, which fluctuated with temporal trends (Fig. 7a, blue solid line). Among these counties, 225 counties exhibited a mean error of only 1.47% (Fig. 7a, orange solid line), attributable to the unreasonableness of our method, which is worth further improving in future studies. The error related to the other 17 counties originated from the incompleteness of auxiliary variables (Fig. 7b, bright blue areas); nonetheless, their influence on the Qinghai–Tibet Plateau is almost negligible because the 17 counties accounted for a mean SU of only 0.15% (Fig. 7b). (ii) In addition, our dataset might have some limitations. Estimating the dataset using the livestock stocking quantity at the end of year may result in the underestimation of grazing intensity, because the rates of livestock off-take were not considered owing to the data unavailability. Moreover, it’s should be clarified that proportion of forage-dependent livestock51, the distribution of nomadic herding52 and others, such as the regional differences in grazing time (equation S1), were not considered here.

Uncertainties associated with grazing spatialization dataset: (a) Temporal trends of mean relative error (MRE); the orange and blue solid lines indicate the average errors for 252 and 242 counties in the corresponding year, respectively, and the difference between the data for the 252 and 242 counties was due to the lack of grassland boundary in the other 17 counties. (b) The spatial distribution of MRE for the 252 counties. The 17 counties are displayed in the light blue areas, and the proportion of SU in the 17 counties is summarized in b-1.
Code availability
The code is fully operational under Python 3.6, and the Python scripts used to implement the gridded grazing dataset can be obtained from https://github.com/nanmeng123456/Grazing-spatilization.git. Further questions can be directed to Nan Meng (nanmeng_st@rcees.ac.cn).
References
Sun, Y. X. et al. Grazing intensity and human activity intensity data sets on the Qinghai- Tibetan Plateau during 1990–2015. Geosci. Data J. 9, 140–153, https://doi.org/10.1002/gdj3.127 (2021).
Sun, J. et al. Toward a sustainable grassland ecosystem worldwide. Innovation-Amsterdam. 3, 100265, https://doi.org/10.1016/j.xinn.2022.100265 (2022).
Bardgett, R. D. et al. Combatting global grassland degradation. Nat. Rev. Earth Environ. 2, 720–735, https://doi.org/10.1038/s43017-021-00207-2 (2021).
Dai, L. C. et al. Effect of grazing management strategies on alpine grassland on the northeastern Qinghai-Tibet Plateau. Ecol. Eng. 173, 106418, https://doi.org/10.1016/j.ecoleng.2021.106418 (2021).
O’Mara, F. P. The role of grasslands in food security and climate change. Ann. Bot. 110, 1263–1270, https://doi.org/10.1093/aob/mcs209 (2012).
Yu, L. F. et al. Effects of grazing exclusion on soil carbon dynamics in alpine grasslands of the Tibetan Plateau. Geoderma. 353, 133–143, https://doi.org/10.1016/j.geoderma.2019.06.036 (2019).
Yang, X. et al. Global negative effects of livestock grazing on arbuscular mycorrhizas: A meta-analysis. Sci. Total Environ. 708, 134553, https://doi.org/10.1016/j.scitotenv.2019.134553 (2020).
Odadi, W. O. et al. African wild ungulates compete with or facilitate cattle depending on season. Science. 333, 1753–1755, https://doi.org/10.1126/science.1208468 (2011).
Li, G. Y. et al. Grazing alters the phenology of alpine steppe by changing the surface physical environment on the northeast Qinghai-Tibet Plateau, China. J. Environ. Manage. 248, 109257, https://doi.org/10.1016/j.jenvman.2019.07.028 (2019).
Wei, Y. Q. et al. Dual influence of climate change and anthropogenic activities on the spatiotemporal vegetation dynamics over the Qinghai-Tibetan Plateau from 1981 to 2015. Earth’s Future. 10, e2021EF002566, https://doi.org/10.1029/2021EF002566 (2022).
Pozo, R. A. et al. Reconciling livestock production and wild herbivore conservation: challenges and opportunities. Trends Ecol. Evol. 36, 750–761, https://doi.org/10.1016/j.tree.2021.05.002 (2021).
Robinson, T. P. et al. Mapping the global distribution of livestock. Plos One. 9, e96084, https://doi.org/10.1371/journal.pone.0096084 (2014).
Nicolas, G. et al. Using random forest to improve the downscaling of global livestock census data. Plos One. 11, e0150424, https://doi.org/10.1371/journal.pone.0150424 (2016).
Ren, J. Z. Grazing, the basic form of grassland ecosystem and its transformation. Journal of Natural Resources. 27, 1259–1275, https://doi.org/10.11849/zrzyxb.2012.08.001 (In Chinese) (2012).
Homburger, H. et al. Patterns of livestock activity on heterogeneous subalpine pastures reveal distinct responses to spatial autocorrelation, environment and management. Mov. Ecol. 3, 35, https://doi.org/10.1186/s40462-015-0053-6 (2015).
Rivero, M. J. et al. Factors affecting site use preference of grazing cattle studied from 2000 to 2020 through GPS tracking: a review. Sensors. 21, 2696, https://doi.org/10.3390/s21082696 (2021).
Halasz, A. et al. Weather regulated cattle behaviour on rangeland. Appl. Ecol. Environ. Res. 14, 149–158, https://doi.org/10.15666/aeer/1404_149158 (2016).
Tomkins, N. & O’Reagain, P. Global positioning systems indicate landscape preferences of cattle in the subtropical savannas. Rangeland J. 29, 217–222, https://doi.org/10.1071/RJ07024 (2007).
Ganskopp, D. Manipulating cattle distribution with salt and water in large arid-land pastures: a GPS/GIS assessment. Appl. Anim. Behav. Sci. 73, 251–262, https://doi.org/10.1016/S0168-1591(01)00148-4 (2001).
Hu, X. Y. et al. Spatialization method of grazing intensity and its application in Tibetan Plateau. Acta Geographica Sinica. 77, 547–558, https://doi.org/10.11821/dlxb202203004 (In Chinese) (2022).
Wu, R. D. et al. Optimized spatial priorities for biodiversity conservation in China: a systematic conservation planning perspective. Plos One. 9, e103783, https://doi.org/10.1371/journal.pone.0103783 (2014).
Ma, C. H. et al. Spatial quantification method of grassland utilization intensity on the Qinghai-Tibetan Plateau: A case study on the Selinco basin. J. Environ. Manage. 302, 114073, https://doi.org/10.1016/j.jenvman.2021.114073 (2022).
Kastner, T. et al. Land use intensification increasingly drives the spatiotemporal patterns of the global human appropriation of net primary production in the last century. Glob. Change Biol. 28, 307–322, https://doi.org/10.1111/gcb.15932 (2021).
Ren, Y. H. et al. Optimizing livestock carrying capacity for wild ungulate-livestock coexistence in a Qinghai-Tibet Plateau grassland. Sci Rep. 11, 3635, https://doi.org/10.1038/s41598-021-83207-y (2021).
Gilbert, M. et al. Global distribution data for cattle, buffaloes, horses, sheep, goats, pigs, chickens and ducks in 2010. Sci. Data. 5, 180227, https://doi.org/10.1038/sdata.2018.227 (2018).
Mei, Y. et al. Population spatialization with pixel-level attribute grading by considering scale mismatch issue in regression modeling. Geo-Spat. Inf. Sci. https://doi.org/10.1080/10095020.2021.2021785 (2022).
Gaughan, A. E. et al. Spatiotemporal patterns of population in mainland China,1990 to 2010. Sci. Data. 3, 160005, https://doi.org/10.1038/sdata.2016.5 (2016).
Liang, H. D. et al. GDP spatialization in Ningbo city based on NPP/VIIRS night-time light and auxiliary data using random forest regression. Advance in Space Research. 65, 481–493, https://doi.org/10.1016/j.asr.2019.09.035 (2020).
Fararoda, R. et al. Improving forest above ground biomass estimates over Indian forests using multi source data sets with machine learning algorithm. Ecol. Inform. 65, 101392, https://doi.org/10.1016/j.ecoinf.2021.101392 (2021).
Breiman, L. Random forests. Mach. Learn. 45, 5–32, https://doi.org/10.1023/A:1010933404324 (2001).
Dong, S. K. et al. Enhancing sustainability of grassland ecosystems through ecological restoration and grazing management in an era of climate change on Qinghai-Tibetan Plateau. Agriculture, Ecosystems and Environment. 287, 106684, https://doi.org/10.1016/j.agee.2019.106684 (2020).
Li, T. et al. Characteristics and trends of grassland degradation research. J. Soils Sediments. 22, 1901–1912, https://doi.org/10.1007/s11368-022-03209-9 (2022).
Gang, C. C. et al. Quantitative assessment of the contributions of climate change and human activities on global grassland degradation. Environ. Earth Sci. 72, 4273–7282, https://doi.org/10.1007/s12665-014-3322-6 (2014).
Meng, N. et al. Climate change indirectly enhances sandstorm prevention services by altering ecosystem patterns on the Qinghai-Tibet Plateau. Journal of Monuntain Science. 18, 1711–1724, https://doi.org/10.1007/s11629-020-6526-0 (2021).
Fassnacht, F. E. et al. A Landsat-based vegetation trend product of the tibetan Plateau for the time-period 1990–2018. Sci. Data. 6, 78, https://doi.org/10.1038/s41597-019-0075-9 (2019).
Yang, M. Y. et al. Trade-offs in ecological, productivity and livelihood dimensions inform sustainable grassland management: Case study from the Qinghai-Tibetan Plateau. Agriculture, Ecosystems and Environment. 313, 107377, https://doi.org/10.1016/j.agee.2021.107377 (2021).
Huang, W., Bruemmer, B. & Huntsinger, L. Incorporating measures of grassland productivity into efficiency estimates for livestock grazing on the Qinghai-Tibetan Plateau in China. Ecol. Econ. 122, 1–11, https://doi.org/10.1016/j.ecolecon.2015.11.025 (2016).
Jung, M. et al. A global map of terrestrial habitat types. Sci. Data. 7, 256, https://doi.org/10.1038/s41597-020-00599-8 (2020).
Wang, C. H. The construction and management of China’s nature reserves in the past forty years of reformand opening-up: achievements, challenges and prospects. Chinese Rural Economy. 10, 93–106 (In Chinese) (2018).
Sinha, P. et al. Assessing the spatial sensitivity of a random forest model: application in gridded population modeling. Computers, Environment and Urban Systems. 75, 132–145, https://doi.org/10.1016/j.compenvurbsys.2019.01.006 (2019).
Wu, J. H. et al. Population Spatialization by Considering Pixel-level Attribute Grading and Spatial Association. Geomatics and Information Science of Wuhan University. 1–14, https://doi.org/10.13203/j.whugis20200379 (2021).
Briggs, D. J. et al. Dasymetric modelling of small-area population distribution using land cover and light emissions data. Remote Sens. Environ. 108, 451–466, https://doi.org/10.1016/j.rse.2006.11.020 (2007).
Su, M. D. et al. Multi-layer multi-class dasymetric mapping to estimate population distribution. Sci. Total Environ. 408, 4807–4816, https://doi.org/10.1016/j.scitotenv.2010.06.032 (2010).
Stevens, F. R. et al. Disaggregating census data for population mapping using random forests with remotely-sensed and ancillary data. Plos One. 10, e0107042, https://doi.org/10.1371/journal.pone.0107042 (2015).
Chen, Y. Y. et al. A new downscaling-integration framework for high-resolution monthly precipitation estimates: Combining rain gauge observations, satellite-derived precipitation data and geographical ancillary data. Remote Sens. Environ. 214, 154–172, https://doi.org/10.1016/j.rse.2018.05.021 (2018).
Chen, S. D. et al. Spatial downscaling methods of soil moisture based on multisource remote sensing data and its application. Water. 11, 1401, https://doi.org/10.3390/w11071401 (2019).
Li, X. H., Hou, J. L. & Huang, C. L. High-resolution gridded livestock projection for western China based on machine learning. Remote Sens. 13, 5038, https://doi.org/10.3390/rs13245038 (2022).
Wang, L. J. Ecological carrying capacity and changes in the Qinghai-Tibet Plateau. Beijing: University of Chinese Academy of Sciences. (In Chinese) (2022).
Meng, N. A high-resolution gridded grazing dataset on the Qinghai–Tibet Plateau V2. figshare. https://doi.org/10.6084/m9.figshare.21501390 (2022).
Zhang, X., Niu, B. The vegetation biomass data of the North Tibet transect (2017). National Tibetan Plateau Data Center. https://doi.org/10.11888/Ecolo.tpdc.270982 (2019).
Li, G. et al. Balance between actual number of livestock and livestock carrying capacity of grassland after added forage of straw based on remote sensing in Tibetan Plateau. Transactions of the Chinese Society of Agricultural Engineering. 30, 200–211 (In Chinese) (2014).
Zhuang, M. H. et al. Community-based seasonal movement grazing maintains lower greenhouse gas emission intensity on Qinghai-Tibet Plateau of China. Land Use Pol. 85, 155–160 (2019).
He, K. D., Sun, J. & Chen, Q. J. Response of climate and soil texture to net primary productivity and precipitation-use efficiency in the Tibetan Plateau. Pratacultural Science. 36, 1053–1065, https://doi.org/10.11829/j.issn.1001-0629.2019-0036 (2019).
Dai, Y. J. et al. Development of a China Dataset of Soil Hydraulic Parameters Using Pedotransfer Functions for Land Surface Modeling. J. Hydrometeorol. https://doi.org/10.1175/JHM-D-12-0149.1 (2013).
Shangguan. W., Dai. YJ. A China Dataset of soil hydraulic parameters pedotransfer functions for land surface modeling (1980). National Tibetan Plateau/Third Pole Environment Data Center. https://doi.org/10.11888/Soil.tpdc.270606 (2013).
Dai, L. C. et al. Long-term grazing exclusion greatly improve carbon and nitrogen store in an alpine meadow on the northern Qinghai-Tibet Plateau. Catena. 197, 104955, https://doi.org/10.1016/j.catena.2020.104955 (2021).
Chen, J. et al. Divergent responses of ecosystem respiration components to livestock exclusion on the Qinghai Tibetan Plateau. Land Degrad. Dev. 29, 1726–1737, https://doi.org/10.1002/ldr.2981 (2018).
Zou, J. R. et al. Relationship of plant diversity with litter and soil available nitrogen in an alpine meadow under a 9-year grazing exclusion. Ecol. Res. 31, 841–851, https://doi.org/10.1007/s11284-016-1394-3 (2016).
Li, W. et al. Analysis of soil respiration under different grazing management patterns in the alpine meadow-steppe of the Qinghai - Tibet Plateau. Acta Prataculturae Sinica. 24, 22–32 (In Chinese) (2015).
Lu, X. et al. Short-term grazing exclusion has no impact on soil properties and nutrients of degraded alpine grassland in Tibet, China. Solid Earth. 6, 1195–1205, https://doi.org/10.5194/se-6-1195-2015 (2015).
Shi, X. M. et al. Grazing exclusion decreases soil organic C storage at an alpine grassland of the Qinghai–Tibetan Plateau. Ecol. Eng. 57, 183–187, https://doi.org/10.1016/j.ecoleng.2013.04.032 (2013).
Wang, X. et al. Grazing induces direct and indirect shrub effects on soil nematode communities. Soil Biology and Biochemistry. 121, 193–201, https://doi.org/10.1016/j.soilbio.2018.03.007 (2018).
Zhang, M. H. et al. Community-based seasonal movement grazing maintains lower greenhouse gas emission intensity on Qinghai-Tibet Plateau of China. Land Use Pol. 85, 155–160, https://doi.org/10.1016/j.landusepol.2019.03.032 (2019).
Wang, J. L. et al. Effects of grazing exclusion on soil respiration components in an alpine meadow on the north-eastern Qinghai-Tibet Plateau. Catena. 194, 104750, https://doi.org/10.1016/j.catena.2020.104750 (2020).
Ma, L. et al. Grazing rest versus no grazing stimulates soil inorganic N turnover in the alpine grasslands of the Qinghai-Tibet plateau. Catena. 204, 105382, https://doi.org/10.1016/j.catena.2021.105382 (2021).
Guo, X. W. et al. Restoration of Degraded Grassland Significantly Improves Water Storage in Alpine Grasslands in the Qinghai-Tibet Plateau. Front. Plant Sci. 12, 778656, https://doi.org/10.3389/fpls.2021.778656 (2021).
Shao, Q. Q. et al. Using UAV remote sensing to analyze the population and distribution of large wild herbivores. Journal of Remote Sensing. 22, 497–507 (In Chinese) (2018).
Lin, L. et al. Response and adaptation of plant community in alpine kobresia meadow to different grazing intensities. Chinese Journal of Grassland. 44, 19–30 (In Chinese) (2022).
Liu, B. T. Actual livestock carrying capacity estimation product in Qinghai-Tibet Plateau (2000-2019). National Tibetan Plateau Data Center. https://doi.org/10.11888/Ecolo.tpdc.271513 (2021).
Acknowledgements
This article was supported by the Second Tibetan Plateau Scientific Expedition and Research Program (Grant No. 2019QZKK0307). Special thanks to Prof. Shikui Dong from the School of Grassland Science of Beijing Forestry University for his valuable suggestion on the revised version of this manuscript. The authors thank all of the editors and anonymous reviewers for their beneficial suggestions to improve the quality of this article.
Author information
Authors and Affiliations
Contributions
N.M., Y.Y., and H.Z. conceived the main concept of the study and constructed the methodology. L.W. provided the census grazing data. N.M. and W.Q. developed and implemented the code. N.M. developed the dataset and wrote the manuscript. Y.Y. and H.Z. revised the manuscript. X.D., Z.L., R.L., and J.M. provided recommendations. All authors contributed to the final paper.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests. All authors have read and agreed to the published version of the manuscript.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
41597_2023_1970_MOESM1_ESM.xlsx
Supplementary Table S1. The comparison of average theoretical livestock carrying capacity (LCCT) among our result and others on the Qinghai–Tibet Plateau
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Meng, N., Wang, L., Qi, W. et al. A high-resolution gridded grazing dataset of grassland ecosystem on the Qinghai–Tibet Plateau in 1982–2015. Sci Data 10, 68 (2023). https://doi.org/10.1038/s41597-023-01970-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41597-023-01970-1
