
Abstract
Mass media plays an important role in the construction and circulation of risk perception associated with animals. Widely feared groups such as spiders frequently end up in the spotlight of traditional and social media. We compiled an expert-curated global database on the online newspaper coverage of human-spider encounters over the past ten years (2010–2020). This database includes information about the location of each human-spider encounter reported in the news article and a quantitative characterisation of the content—location, presence of photographs of spiders and bites, number and type of errors, consultation of experts, and a subjective assessment of sensationalism. In total, we collected 5348 unique news articles from 81 countries in 40 languages. The database refers to 211 identified and unidentified spider species and 2644 unique human-spider encounters (1121 bites and 147 as deadly bites). To facilitate data reuse, we explain the main caveats that need to be made when analysing this database and discuss research ideas and questions that can be explored with it.
Measurement(s) | Newspaper articles on human-spider encounters |
Technology Type(s) | Manual extraction |
Sample Characteristic - Organism | Spiders (Arachnida: Araneae) |
Sample Characteristic - Environment | Online |
Sample Characteristic - Location | Global |
Similar content being viewed by others


Background & Summary
Spiders have an unfortunate reputation. There are tales about massive infestations of false black widows shutting down entire schools; apocryphal stories of dangerous arachnids lurking under toilet seats of international airports; and urban myths of tiny spiders crawling into your mouth while you are asleep. Of course, these are just anecdotes, but they illustrate how, even today, arachnophobic sentiments permeate our society at all levels1,2,3,4. This is nothing surprising: arachnophobia is likely the most widespread fear related to animals5, with an estimated prevalence between 3.5–11.4% of the world population6,7,8,9. However, such a skewed perception towards the potential harm that spiders can cause humans contrasts with two facts. First, less than 0.5% of spider species can cause severe envenomation in humans10. Second, the habitat of these few potentially dangerous species rarely overlaps with that of humans, making dangerous human-spider encounters unlikely11. Since a limited number of fatalities due to spider bites have occurred in the past few decades12,13,14,15,16, the reasons behind our exaggerated perception of risk associated with spiders remain uncertain.
Despite gigantic leaps forward in cognitive science and neurology, we still do not know the exact reason why arachnophobia is so widespread. What we do know is that arachnophobic sentiments have a significant social and cultural component17,18,19. For example, a recent study suggested that arachnophobic behaviours may be reduced following an exposure to the superhero movie Spider-Man20. Likewise, it was suggested that ongoing urbanization is the key driver of the prevalence of disgust for insects and spiders, because exposure to animals in urban areas is less frequent21. Accordingly, it is reasonable to hypothesize that the public perception of spiders should be affected by how spider-related information is framed and circulated2, given that traditional media are particularly effective in disseminating knowledge by conveying messages quickly and reaching a broad audience22. From the belief in the role of bats as disease spreaders23,24 to the fear of being attacked by large carnivores25,26, the crucial role of traditional media in the construction and circulation of risk perception associated with wild animals is undisputed27. However, media representation of spiders is still a poorly studied subject: as far as we are aware, the only two available studies are focused on a local selection of news in Australia28 and Italy2.
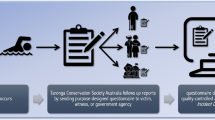
Intending to fill this gap, here we compiled an expert-curated global database on the coverage of human-spider encounters in online newspaper media and their accuracy and reliability over the past ten years (2010–2020) (Fig. 1). This database includes detailed information about the location of each human-spider encounter reported by the media, year of publication, and a quantitative characterisation of the content of each piece of news (presence of photographs of spiders and bites, number and type of errors, whether experts were consulted, and whether the content is sensationalistic or neutral). With this database, we hope to stimulate further research on the human dimension of spiders and their representation in the media.

The potential of news articles as a source of data. This database offers a quantitative baseline to pursue research on the human-dimensions of spiders and their representation in the media. This research may include answering questions related to the cultural component of spider conservation, evaluation of people’s perceptions of spiders via opinion mining techniques, and generation of ecological insights, among others. Original illustration by Jagoba Malumbres-Olarte.
Methods
Geographical coverage of the database
We aimed to compile a comprehensive database of global coverage of countries, languages and online newspapers. To this end, we put together a large network of spider experts to mine data in as many languages and countries as possible. We searched for news in 40 unique languages and covered the online press in 81 countries and all six continents where spiders can be found. Due to an uneven availability of experts, however, there is a bias in the database towards temperate regions (Europe and North America). African countries are the least represented.
Temporal coverage of the database
We focused on newspaper articles published online between 2010 and 2020 (partial and uneven temporal coverage for 2020). Thus, the temporal span of our study mostly covered the advent of online journalism and the parallel diffusion of news through social media platforms29.
Data mining protocol
We adapted the methodology of Mammola et al. (ref. 2) for retrieving news articles on human-spider encounters published in online newspapers in the target countries. To ensure that different authors in charge of different countries and languages adhered to an unequivocal data mining strategy, we began by preparing a general protocol for retrieving and extracting information from the news (Appendix S1). This protocol, shared with all authors, included: i) instructions for media report retrieval and data mining (see below); ii) a continuously updated list of Frequently Asked Questions discussing how to handle specific cases; iii) a description of the most common envenomation symptoms, which was used to standardize the assessment of the errors related to spider venom (see next section).
For each country and language, we carried out online searches in different languages with Google News (Appendix S1 – Figure S1), choosing multiple keyword combinations and the years between 2010 and 2020—this can be specified using the ‘Custom range’ tool in Google News (Appendix S1 – Figure S2). Note that for a few countries that were not available in Google News at the time of the search, such as Finland, Denmark, or Botswana, we performed searches directly in Google. We first searched for the words for ‘spider’ in each language, followed by the word ‘bite’ (e.g., “spider bite”). We repeated the search using the word ‘sting’ instead of ‘bite’, which is anatomically incorrect but often used30. We then repeated the search by changing the general word ‘spider’ with scientific and vernacular names of the main species perceived as “dangerous” in each country. These include species that are considered medically important (e.g., Latrodectus spp., Atrax spp., Loxosceles spp., and Phoneutria spp.; list of genera in Appendix S1 – Table S1) and/or widely feared (e.g., Cheiracanthium spp., Lampona spp., and Steatoda spp.; list of genera in Appendix S1 – Table S2). The list of species names used in searches for each country was tailored by each author, based on their expertise and knowledge of the spider fauna and the scientific literature on spider bites in the assigned country. We noted, however, that including additional search terms besides ‘spider bite’ and ‘spider sting’ yielded diminishing returns since these two broad keywords usually covered the vast majority of relevant news articles.
For each unique keyword search combination, we manually inspected all news up to the final available page in Google News, systematically collecting news articles referring to one or more purported encounters between humans and spiders. We included i) all news articles referring to a human-spider encounter (e.g., a family interviewed by a local newspaper about the spider they found in their house; a farmer bitten by a spider while working in the field; a person who was hospitalized following a spider bite); and ii) events that occurred either in the searched country or abroad (e.g., an Indian newspaper talking about a biting event that occurred in England). Note that we included all reports of human-spider interactions regardless of the likelihood of a spider actually being involved (e.g., a person claiming to have a spider bite when they likely had a skin infection instead). We disregarded: i) media items reporting general facts about spiders, venomous spiders, arachnophobia, spider-related research findings, and doctors’ advice about what to do in case of a spider bite; and ii) blog posts.
Extraction of information for each news article
For each news article, we extracted the qualitative and quantitative information detailed in Table 1. We first reported basic information: a) URL; b) title; c) date of publication; d) newspaper name (or news outlet if not a traditional newspaper); e) newspaper type, broken down into “Traditional newspaper” (Official newspaper in a country, with both a printed and an online version), “Online newspaper” (online only newspaper), or “Magazine” (for magazines, tabloids, and similar); and f) newspaper circulation (regional, national, or international).
Then, we read the full article and scored the g) spider species identity based on the description in the news article, even if the attribution was incorrect based on our expert opinion. We reported species identity to the lowest taxonomic level possible based on the information in the article (typically species or genus level, but sometimes only family level). If the species identification was not provided in the article but it was possible to infer (e.g., referring to a species being identifiable from a picture or a report of a “widow spider” identifiable to species based on geography), we reported this identification in the database. To achieve standardization throughout the database, we converted all names to the closest valid scientific name, based on the most updated spider taxonomy31. We next recorded the h) type of event, broken down into “encounter”, “bite”, or “deadly bite”; i) year of the event; and j) location of the event (latitude and longitude in decimal degrees). We used Google Maps to obtain WGS84 coordinates of the approximate centre of the most precise geographic region named in the article (i.e., the country, province/state, or city/town where the encounter occurred). Finally, we recorded the k) presence/absence of any photograph of the spider [whether or not of the actual spider(s) involved in the encounter]; l) presence/absence of photographs of the bite (regardless of whether the bite is being reported); and m) presence/absence of an expert-opinion, broken down into the categories “arachnologist” (e.g., spiders experts, taxonomists, entomologists), “medical professional” (e.g., doctors, veterinarians), and “other expert” (e.g., pest controllers) (see ref. 32 for a discussion).
Since several news articles often covered the same event, we created an identifier for each unique event (ID_Event), by combining location, country, and year of the event (e.g., “London_UK_2018”).
We assessed the quality of each news article by recording the presence/absence of any of four types of errors in the text and figures:
-
i)
errors in photographs/figures, when the photograph(s) of the species in the news article (if any) did not correspond to the species mentioned in the text, or when the attribution was not possible (e.g., blurry photographs);
-
ii)
errors in systematics and taxonomy, like the common mistake of considering spiders insects33 or inaccuracies in terms of species names and in higher Linnaean taxonomic ranks (e.g., referring to tarantulas as a single species or the genus Latrodectus as a family);
-
iii)
errors in the description of venom toxicity, symptoms of envenomation, and other physiological or medical aspects or terminology (e.g., stating only female black widows can be venomous or describing the venom of recluse spiders, which causes tissue necrosis, as “neurotoxic”; see Appendix S1 for more details); and
-
iv)
errors in morphology and anatomy, such as the frequent “spider sting” instead of “spider bite”30, or errors in describing the number of legs or eyes.
Each error type was scored as present or absent, so we did not count cumulative errors of the same type in the same news article.
Finally, we evaluated the title, subheadings, main text, and photographs/video content of each news article and assessed it as overstated (sensationalistic) or not (neutral). Sensationalism in animal-related news articles is often associated with emotional words, expressions, and images2,25,26. Examples of titles of sensationalistic versus non-sensationalistic news articles focusing on the same event are: “Thousands of spiders ‘bleed out of the walls’ and force family from home” vs. “Home Infested With Brown Recluse Spiders in Missouri”. Throughout the database, frequent words associated with sensationalistic content were ‘alarm’, ‘agony’, ‘attack’, ‘boom’, ‘deadly’, ‘creepy crawly’, ‘devil’, ‘fear’, ‘hell’, ‘killer’, ‘murderer’, ‘nasty’, ‘nightmare’, ‘panic’, ‘terrible’, ‘terrifying’, and ‘terror’2, as well as magnifying adjectives that exaggerated any features of the encounter (e.g., body size34,35,36, hairiness35). However, the presence of one of these words did not necessarily result in an article being scored as sensationalistic. For example, articles that referred to spider species whose venom can be fatal without medical intervention (e.g., Latrodectus and Atrax spp.) as ‘deadly’ could be overall non-sensationalistic, whereas articles describing non-medically important spiders as ‘deadly’ were more likely to be scored as sensational.
Data Records
Database availability
The database is freely available in Figshare37. The database is provided both as a tab-delimited file (.csv) and as an excel file (.xslx). Description of columns is in Table 1 but also in the metadata file uploaded alongside the database in Figshare. Code to access the database in R environment38 and derive basic summary statistics and graphs shown in this paper is available in GitHub (see section “Code Availability”).
Description of the database
In total, we collected 5348 unique news articles from 81 countries in 40 languages. The database has an uneven temporal coverage, with most news articles concentrating in recent years (Fig. 2a). There is also a seasonal pattern in the distribution of news articles. In the northern hemisphere, most news articles occur throughout the summer season (Fig. 2b), whereas the pattern is less clear in the south (Fig. 2c). The number of news items by countries varies by at least three orders of magnitude, from hundreds (United Kingdom: 865; United States: 537; Italy: 412; Russia: 395; France: 319) to a handful of news articles, or none (Table 2).

Temporal distribution of unique news articles. (a) Annual distribution of news articles by type of event (partial data for 2020). (b) Monthly distribution of news articles (cumulative of all years) in the northern hemisphere. (c) Monthly distribution of news articles (cumulative of all years) in the southern hemisphere—darker colours highlight months with the highest numbers of news articles.
The database includes 6204 reports of human-spider encounters (corresponding to 2644 unique events) and 211 identified and unidentified spider species—note that a single news article may report about multiple human-spider encounters. Of these unique events, 1121 were reported by the news articles as bites, and 147 as deadly bites (Fig. 3a). The majority of reported encounters is concentrated at northern latitudes in the northern hemisphere (median latitude = 46.9°), whereas the median latitude of reported bites and deadly bites is further south (41.3° and 26.1°, respectively) (Fig. 3b).

Geographical coverage of the human-spider encounters in the database. (a) Global distribution of event localities reported in the media report; due to the proximity of several localities, most points appear superimposed. (b) Latitudinal distribution of events. (c) News coverage by spider families. (d) News coverage by spider genera. Danger symbol marks genera with species of medical importance. In c–d, for the four most abundant families, colours represent families.
The presence of comments from experts consulted for articles about human-spider encounters varies substantially across countries and continents (Fig. 4a). Spider experts were only rarely consulted (Fig. 4b). One or more error types are present in 47% of news articles (Fig. 4c), although the frequency of different types of errors is variable (data not shown). Also, 43% of news articles were assessed by experts as sensationalistic; the frequency of sensationalistic versus non-sensationalistic news varied substantially by continent (Fig. 4d).

Content of news articles by continent. (a) Frequency of expert consultation in news articles (any type of expert). (b) Frequency of spider expert consultation (arachnologists, entomologists and similar) in news articles. (c) Frequency of errors in news articles (any type of error). (d) Frequency of sensationalistic versus non-sensationalistic news articles.
Even zeros matter
For a few countries, we found no online news articles reporting human-spider encounters (Table 2). An informative case is Botswana, where the authors in charge performed an in-depth investigation to explain the lack of relevant results. Since Google News does not work for Botswana, they carried out the initial search in Google, which yielded no relevant results using any combination of keywords. To exclude the possibility this result was an artefact due to the searching tool, they repeated the search directly on the websites of the nine Botswana newspapers; once again, this search yielded no positive results. Finally, they phoned each of these nine newspapers individually. Six newspapers (Sunday Standard, The Midweek Sun, The Patriot, The Weekend Post, Mmegi, and Daily News) explained that their online presence is very recent and that the content placed online remains very selective. Thus, there were no human-spider encounters reported online. Conversely, they could not reach two newspapers by phone (Botswana Gazette and Botswana Guardian) and a third (The Voice Newspaper) declined to provide any information. This suggests that the search strategy is reliable in detecting absence of news articles, and these absences can be considered in analyses as ‘true zeros’39.
Technical validation
Data accuracy and curation
To increase the accuracy and internal consistency of our database, and given subjectivity in the assignment of certain values (e.g., sensationalism, errors), we re-assessed news for most articles in English (N = 1719; 80%) and some of the other most common languages based on the availability of native speakers (French, 53%; Italian, 88%; Spanish, 48%). The column “Quality_check” in the database indicates whether this re-assessment was performed for a given article. We assigned a pair of authors to a subset of these language-based datasets so they could independently re-examine and score articles that were previously mined by the original contributor. The re-assessors scored the articles in the same manner as described previously (see section “Extraction of information for each media report”) and compared their individual datasets with each other. Discrepancies in scores were discussed and compared with the original dataset to reach a consensus on final scores.
We estimated the rate of agreement between two re-assessors via Cohen’s kappa statistic40, calculated for all the scores of variables that may imply a degree of subjectivity in the assessment. We derived the confidence intervals using variance estimate41. We carried out this analysis only on English news (Table 3).
Limitations in using the database
Users of the database must be aware of the following limitations:
-
i)
The data collected here refer to online journalism only. The database does not cover the representation of spiders in the printed versions of traditional newspapers;
-
ii)
Because Google’s search algorithm varies by country and user, the relationship between the number of published news articles and the number of results returned is likely not consistent. For example, the total number of news articles in China is unreliable due to the restrictions imposed by the government on Google. Consequently, we recommend against comparing absolute numbers of news items across countries, but rather always using relative numbers (e.g., proportion of errors, proportion of spider bites versus encounters, relative frequency of a given species in the press); and
-
iii)
Likewise, any temporal trend must be interpreted with caution because news publishers can occasionally remove pieces of news from the Google News index or simply delete old news. The probability of this happening increases with time and thus may be partly responsible for the apparent increase in the volume of news articles over time in this database (Fig. 2a).
Usage Notes
This database allows users to investigate questions related to the social dimension of spiders and the psychology of arachnophobia, but also contemporary problems in ecology42,43 and conservation biology44. To stimulate the use of the database, we discuss what we believe are some important avenues of research—while being aware that many other questions and patterns await to be explored45. Note that some of these research questions have already been briefly introduced in Mammola et al. (ref. 2), but here are expanded on and contextualized within the framework of a global-scale database.
Comparison among countries and through time
Some of the first questions that come to mind are about the reasons underlying the disparity in the quality of news across regions and countries2, namely what are the main ecological, cultural, and/or social factors that explain the observed patterns? This dataset could be used to test the hypothesis that socio-economic factors, demographic features, level of education or literacy and/or cultural values affect the quality and taxonomic bias of spider-related news in a given country. For example, the relative number of reports of (presumed) bites in relation to encounters and quality of news articles may be greater in those countries/regions with either a high number of medically important species that can seriously harm humans (e.g., South America, Australia) or with a high species diversity (e.g., Brazil). Alternatively, an opposite pattern could emerge due to the paradoxically high prevalence of arachnophobia in areas with few or no dangerous spider species (e.g., the UK46). All these questions can be directly answered, among other ways, by summarizing relative values by country (e.g., proportion of errors, proportion of spider bites versus encounters) and by relating these variables with country-level indicators47.
Comparison with other animal groups
The protocol for data mining discussed here is effective and inexpensive, and thus can be adapted to other cases. This would allow for comparisons of the types of errors and the levels of sensationalism across multiple taxa, including other venomous animals (e.g., bees, scorpions, wasps, snakes, and jellyfish) and answering questions such as:
-
i)
Is there a relationship between taxon-specific features (distribution, diversity, adaptations, dangerousness, interactions with humans) and the content and quality of the media articles referring to them?
-
ii)
Does a negative representation by the traditional media translate to a lower prioritization and fewer measures for conservation48? Conversely, does such sensationalism heighten public interest in nature, biodiversity monitoring, and invasive species?
Link between traditional and social media
Social media have changed the way news information is framed and circulated49, including biodiversity-related content. In a recent study set in Italy, we found that the volume of newspaper articles shared on Facebook has increased substantially in recent years and that sensationalistic and overstated news stories about human-spider encounters are more likely to be shared2. Using the URL associated with each news article, one could directly analyse the shares on different social media platforms to answer questions about the factors that drive the popularity of news online22,50. To better understand the opinions, sentiments, and subjectivity of people sharing these news reports, one could even use text mining algorithms to perform quantitative analyses (e.g., sentiment analysis) on the public comments posted in response to the news (see next section).
Linguistic analysis
The title of each news article and other bodies of texts that can be automatically extracted using the URL of each news item (e.g., comments on the online article, comments in response to the shares of the article on social media) offer a large source of data in the domain of Sentiment Analysis or Opinion Mining—defined as the computational study of people’s emotions and attitudes toward a given topic51. A very simple example is provided in Fig. 5, where we used R text mining tools52 to compare the usage of words in sensationalistic versus non-sensationalistic titles of articles written in English. Inevitably, these kinds of analyses are more easily performed on news published in English because of the larger sample size.

Usage of words in sensationalistic (a) versus non-sensationalistic (b) news articles titles. Word Clouds illustrating the most frequently used 50 words in the titles of English news articles. Common words (stop_words sensu ref. 52) and the terms used for online searching (e.g., ‘spider’, ‘bite’, ‘sting’, species names) are excluded from the analysis. Text size is proportional to the frequency of each word. Warm colours highlight words that appeal to emotions and are often associated with sensationalistic content. Original silhouettes by Irene Frigo, reproduced from ref. 2.
Source of iEcological knowledge
This database has the potential to generate ecological insights. Similar applications broadly fall within the domain of iEcology, an emerging research field that “[…] seeks to quantify patterns and processes in the natural world using data accumulated in digital sources collected for other purposes”42. The database of spider news provides data on > 200 spider species (Fig. 3d); for most of these species, we have recorded the coordinates of the locality where the human-spider encounter supposedly took place. Some of these records are clearly wrong (i.e., the species reported is not correct), but the presence of the supposedly encountered species could be verified by experts. In other words, the news reports could be used by experts (spider experts, in this case) to inspect areas where a given species may be present. Once a reliable database for a given species is cleaned, one could explore different ecological patterns.
In Italy, for example, the seasonal distribution of news articles on the Mediterranean black widow [Latrodectus tredecimguttatus (Rossi, 1790)] overlaps almost perfectly with the known phenology of the species2. Similar phenological insights may be checked for other species. Also, recent niche modelling studies have shown that internet-derived distribution data can be useful for mapping the predicted distribution of spiders (reviewed in ref. 53), especially species that are easily identified in the field or by photos54,55,56,57. For some of the most abundant species in our database (e.g., Loxosceles spp. and Latrodectus spp.), it is possible to compare whether the known distribution of a species overlaps with the predicted distribution based on the news. This way, one could quantify if the geographic and temporal distribution of human-spider encounters and bites reported in the news is related to the real distribution of a spider species, how and why this relationship varies among species, and what conservation-related or biosecurity measures may be necessary. Discoveries of spiders outside of their historical ranges may provide clues to pathways and new populations resulting from human-mediated dispersal events, such as western black widows (Latrodectus hesperus Chamberlin & Ivie, 1935) found in packages of grapes transported from California to Eastern North America and the UK, and reports of brown recluse spiders (Loxosceles reclusa Gertsch & Mulaik, 1940) in Michigan (USA).
Code availability
The R code to generate analyses and figures is available in GitHub (https://github.com/StefanoMammola/Analysis_Global-Spider-News-Database).
References
Gerdes, A. B. M., Uhl, G. & Alpers, G. W. Spiders are special: fear and disgust evoked by pictures of arthropods. Evol. Hum. Behav. 30, 66–73 (2009).
Mammola, S., Nanni, V., Pantini, P. & Isaia, M. Media framing of spiders may exacerbate arachnophobic sentiments. People Nat. 2, 1145–1157 (2020).
Vetter, R. S. & Visscher, P. K. Oh, what a Tangled web we weave: The anatomy of an internet spider hoax. Am. Entomol. 46, 221–224 (2000).
Vetter, R. S. Arachnophobic entomologists: When two more legs makes a big difference. Am. Entomol. 59, 169–175 (2013).
Mammola, S., Michalik, P., Hebets, E. A. & Isaia, M. Record breaking achievements by spiders and the scientists who study them. PeerJ 5, e3972 (2017).
Jacobi, F. et al. Prevalence, co-morbidity and correlates of mental disorders in the general population: Results from the German Health Interview and Examination Survey (GHS). Psychol. Med. 34, 597–611 (2004).
Schmitt, W. J. & Müri, R. M. Neurobiology of spider phobia | Neurobiologie der spinnenphobie. Schweizer Arch. fur Neurol. und Psychiatr. 160, 352–355 (2009).
Zsido, A. N., Arato, N., Inhof, O., Janszky, J. & Darnai, G. Short versions of two specific phobia measures: The snake and the spider questionnaires. J. Anxiety Disord. 54, 11–16 (2018).
Oosterink, F. M. D., de Jongh, A. & Hoogstraten, J. Prevalence of dental fear and phobia relative to other fear and phobia subtypes. Eur. J. Oral Sci. 117, 135–143 (2009).
Hauke, T. J. & Herzig, V. Dangerous arachnids—Fake news or reality? Toxicon 138, 173–183 (2017).
Diaz, J. H. & Leblanc, K. E. Common spider bites. Am. Fam. Physician 75, 869–873 (2007).
Nentwig, W. & Kuhn-Nentwig, L. Spider venoms potentially lethal to humans. In Spider Ecophysiology (ed. Nentwig, W.) https://doi.org/10.1007/978-3-642-33989-9_19 (Springer, 2013).
Stuber, M. & Nentwig, W. How informative are case studies of spider bites in the medical literature? Toxicon 114, 40–44 (2016).
Nentwig, W., Gnädinger, M., Fuchs, J. & Ceschi, A. A two year study of verified spider bites in Switzerland and a review of the European spider bite literature. Toxicon 73, 104–110 (2013).
Hauke, T. J. & Herzig, V. Love bites – Do venomous arachnids make safe pets? Toxicon 190, 65–72 (2021).
Chippaux, J.-P. Epidemiology of envenomations by terrestrial venomous animals in Brazil based on case reporting: from obvious facts to contingencies. J. Venom. Anim. Toxins Incl. Trop. Dis. 21, 13 (2015).
Davey, G. C. L. The ‘disgusting’ spider: The role of disease and illness in the perpetuation of fear of spiders. Soc. Anim. 2, 17–25 (1994).
Davey, G. C. L. et al. A cross-cultural study of animal fears. Behav. Res. Ther. 36, 735–750 (1998).
Merckelbach, H., Muris, P. & Schouten, E. Pathways to fear in spider phobic children. Behav. Res. Ther. 34, 935–938 (1996).
Hoffman, Y. S. G., Pitcho-Prelorentzos, S., Ring, L. & Ben-Ezra, M. “Spidey Can”: Preliminary evidence showing arachnophobia symptom reduction due to superhero movie exposure. Front. Psychiatry 10, 354 (2019).
Fukano, Y. & Soga, M. Why do so many modern people hate insects? The urbanization–disgust hypothesis. Sci. Total Environ. 777, 146229 (2021).
Vosoughi, S., Roy, D. & Aral, S. The spread of true and false news online. Science 359, 1146–1151 (2018).
López-Baucells, A., Rocha, R. & Fernández-Llamazares, Á. When bats go viral: negative framings in virological research imperil bat conservation. Mamm. Rev. 48, 62–66 (2018).
MacFarlane, D. & Rocha, R. Guidelines for communicating about bats to prevent persecution in the time of COVID-19. Biol. Conserv. 248, 108650 (2020).
Nanni, V. et al. Social media and large carnivores: Sharing biased news on attacks on humans. Front. Ecol. Evol. 8, 71 (2020).
Bombieri, G. et al. Content analysis of media reports on predator attacks on humans: Toward an understanding of human risk perception and predator acceptance. Bioscience 68, 577–584 (2018).
Gerber, D. L. J., Burton-Jeangros, C. & Dubied, A. Animals in the media: New boundaries of risk? Heal. Risk Soc. 13, 17–30 (2011).
Cushing, N. & Markwell, K. ‘Watch out for these KILLERS!’: Newspaper coverage of the Sydney funnel web spider and its impact on antivenom research. Health History 12, 79–96 (2010).
Ju, A., Jeong, S. H. & Chyi, H. I. Will social media save newspapers?: Examining the effectiveness of Facebook and Twitter as news platforms. Journal. Pract. 8, 1–17 (2014).
Afshari, R. Bite like a spider, sting like a scorpion. Nature 537, 167 (2016).
World Spider Catalog. Version 23.0. Natural History Museum Bern 10.24436/2 (2022).
Vetter, R. S. Arachnids misidentified as brown recluse spiders by medical personnel and other authorities in North America. Toxicon 54, 545–547 (2009).
Jambrina, C. U., Vacas, J. M. & Sánchez-Barbudo, M. Preservice teachers’ conceptions about animals and particularly about spiders. Electron. J. Res. Educ. Psychol. 8, 787–814 (2010).
Leibovich, T., Cohen, N. & Henik, A. Itsy bitsy spider?: Valence and self-relevance predict size estimation. Biol. Psychol. 121, 138–145 (2016).
Zvaríková, M. et al. What makes spiders frightening and disgusting to people? Frontiers in Ecology and Evolution 9, 424 (2021).
Frynta, D. et al. Emotions triggered by live arthropods shed light on spider phobia. Sci. Rep. 11, 22268 (2021).
Mammola, S. et al. Global Spider News. Database. Figshare https://doi.org/10.6084/m9.figshare.14822301 (2021).
R Core Team. R: A Language and Environment for Statistical Computing. (2021).
Blasco-Moreno, A., Pérez-Casany, M., Puig, P., Morante, M. & Castells, E. What does a zero mean? Understanding false, random and structural zeros in ecology. Methods Ecol. Evol. 10, 949–959 (2019).
Cohen, J. A coefficient of agreement for nominal scales. Educ. Psychol. Meas. 20, 37–46 (1960).
Fleiss, J. L., Cohen, J. & Everitt, B. S. Large sample standard errors of kappa and weighted kappa. Psychol. Bull. 72, 323–327 (1969).
Jarić, I. et al. iEcology: Harnessing large online resources to generate ecological insights. Trends Ecol. Evol. 35, 630–639 (2020).
Jarić, I. et al. Expanding conservation culturomics and iEcology from terrestrial to aquatic realms. PLOS Biol. 18, e3000935 (2020).
Ladle, R. J. et al. Conservation culturomics. Front. Ecol. Environ. 14, 269–275 (2016).
Yanai, I. & Lercher, M. A hypothesis is a liability. Genome Biol. 21, 231 (2020).
Cavell, M. Arachnophobia and early english literature. In New Medieval Literature (eds. Ashe, L., Knox, P., Lawton, D. & Scase, W.) 1–44 (D.S. Brewer, 2018).
Mammola, S. et al. The global spread of (mis)information on spiders. Research Square, https://doi.org/10.21203/rs.3.rs-1383492/v1.
Knight, A. J. ‘Bats, snakes and spiders, Oh my!’ How aesthetic and negativistic attitudes, and other concepts predict support for species protection. J. Environ. Psychol. 28, 94–103 (2008).
Jones-Jang, S. M., Hart, P. S., Feldman, L. & Moon, W.-K. Diversifying or reinforcing science communication? Examining the flow of frame contagion across media platforms. Journal. Mass Commun. Q. 97, 98–117 (2019).
Palazzi, M. J. et al. Resilience and elasticity of co-evolving information ecosystems. arXiv 2005.07005 (2020).
Medhat, W., Hassan, A. & Korashy, H. Sentiment analysis algorithms and applications: A survey. Ain Shams Eng. J. 5, 1093–1113 (2014).
Silge, J. & Robinson, D. tidytext: Text mining and analysis using tidy data principles in R. J. Open Source Softw. 1, 37 (2016).
Mammola, S. et al. Challenges and opportunities of species distribution modelling of terrestrial arthropod predators. Divers. Distrib. 27, 2596–2614 (2021).
Wang, Y., Casajus, N., Buddle, C., Berteaux, D. & Larrivee, M. Predicting the distribution of poorly-documented species, Northern black widow (Latrodectus variolus) and Black purse-web spider (Sphodros niger), using museum specimens and citizen science data. PLoS One 13 (2018).
Jimenez-Valverde, A., Pena-Aguilera, P., Barve, V. & Burguillo-Madrid, L. Photo-sharing platforms key for characterising niche and distribution in poorly studied taxa. Insect Conserv. Divers. 12, 389–403 (2019).
Hart, A. G., Nesbit, R. & Goodenough, A. E. Spatiotemporal variation in house spider phenology at a national scale using citizen science. Arachnology 17, 331–334 (2018).
Sadir, M. & Marske, K. A. Urban environments aid invasion of Brown Widows (Theridiidae: Latrodectus geometricus) in North America, constraining regions of overlap and mitigating potential impact on native widows. Front. Ecol. Evol. 9, 757902 (2021).
Acknowledgements
We are grateful to Dr. Ingi Agnarsson for checking the presence of spider-related news in Icelandic newspapers. Thanks to Dr. Aino K. Juslen and the Finnish Museum of Natural History (LUOMUS; University of Helsinki, Helsinki, Finland) for financially supporting the publication of this work.
Author information
Authors and Affiliations
Contributions
Conceptualization: SM, JM-O, CS, AC; Data collection & validation: all authors; Data management: SM, VN, AC; Data analysis & visualization (Figs. 2–5): SM; Summary illustration (Fig. 1): JM-O; Writing (first draft): SM; Writing, contributions: JM-O, CS, AC; All authors read the text, provided comments, suggestions, and corrections, and approved the final version.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Mammola, S., Malumbres-Olarte, J., Arabesky, V. et al. An expert-curated global database of online newspaper articles on spiders and spider bites. Sci Data 9, 109 (2022). https://doi.org/10.1038/s41597-022-01197-6
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41597-022-01197-6
