
Abstract
Although continental urban areas are relatively small, they are major drivers of environmental change at local, regional and global scales. Moreover, they are especially vulnerable to these changes owing to the concentration of population and their exposure to a range of hydro-meteorological hazards, emphasizing the need for spatially detailed information on urbanized landscapes. These data need to be consistent in content and scale and provide a holistic description of urban layouts to address different user needs. Here, we map the continental United States into Local Climate Zone (LCZ) types at a 100 m spatial resolution using expert and crowd-sourced information. There are 10 urban LCZ types, each associated with a set of relevant variables such that the map represents a valuable database of urban properties. These data are benchmarked against continental-wide existing and novel geographic databases on urban form. We anticipate the dataset provided here will be useful for researchers and practitioners to assess how the configuration, size, and shape of cities impact the important human and environmental outcomes.
Measurement(s) | local climate zones |
Technology Type(s) | digital curation |
Factor Type(s) | building footprint • building height • impervious surface area • Sky view factor • anthropogenic heat flux • population |
Sample Characteristic - Environment | anthropogenic environment • city |
Sample Characteristic - Location | contiguous United States of America |
Machine-accessible metadata file describing the reported data: https://doi.org/10.6084/m9.figshare.12599966
Similar content being viewed by others

Background & Summary
There is a scientific consensus on the need for spatially detailed information on urban landscapes at a global scale to support a range of environmental services1. The consensus has emerged as the simulation and forecasting capabilities of models have improved radically over the last decade and the demand for reliable urban-scale information that can inform policies has increased2. The latter is an acknowledgment of cities as places of: intense resource consumption and waste generation and; foci of population and infrastructure that are exposed to multiple hazards of natural and anthropogenic origin. A number of projects have mapped the global urban extent at finer and finer detail3,4,5,6 but most do not account for the spatial variation within cities, that is, the urban layout as a consequence of historic urbanization patterns that reflect local terrain, culture, economy, etc. These data are needed as part of a basic infrastructure to support a host of studies on historical urbanization processes7,8,9, transportation behavior10,11, exposure to environmental hazards12,13,14,15,16,17, energy demand18, climate mitigation solutions19 and human health20, as examples. Moreover, the data are needed to support planning decisions that can address aspects of urban form (e.g. green fraction) and function (e.g. transportation networks) to mitigate the urban impact1,21,22,23. While these data can be assembled for data-rich cities, the challenge is to acquire sufficient information at very large scales using a consistent methodology. While there are established geographical databases on natural land-cover that have been derived using consistent methodologies, until recently there has been no equivalent for urban land-cover types. Since 2000 there have been a number of initiatives at mapping population and building land-covers at global scales using earth observation data, census and building footprint information24,25,26. However, these need to be complemented by a landscape approach that can distinguish urban surfaces on a holistic basis, which accounts for the typical combination of micro-scale land-covers and associated physical properties.
The Local Climate Zone (LCZ) typology is a good candidate for such classification scheme27. Each of the 10 urban types are linked to a series of relevant variables that describe the physical characteristics of that type. In an urban environment, each LCZ refers to a neighborhood (sized about 1 km2) that is relatively homogeneous in terms of urban layout, that is the spatial coherence of the attributes (the types of buildings, green space, impermeable fraction, etc.) that distinguish one area from another. The product is distinguished from other urban typologies (e.g.26,28,29) which focus on individual aspects of urban cover (e.g. residential, commercial and industrial) without providing ancillary information. Critically, the LCZ scheme can be employed to examine the nature of urbanization and its likely environmental impact30. The World Urban Database Access Portal Tools (WUDAPT) project has adopted the LCZ scheme as a basic description of urban land-cover and has developed a process for automatically classifying urban areas globally into types using satellite imagery and training areas31. Moreover, experiments have shown that training areas derived for one city can be used to classify other urban areas with certain caveats. Demuzere et al.32 demonstrated that this insight could be harnessed within the computation environment of Google’s Earth Engine33 to access a suite of remote sensing data and effectively map LCZ types at the scale of Europe34.
In this paper, expert derived training data (the original approach developed by WUDAPT) are combined with crowd-sourced training data from Amazon Mechanical Turk (MTurk, https://www.mturk.com/https://www.mturk.com/) to create a gridded, high-resolution, Local Climate Zone map for the continental United States (CONUS). This resulting map is evaluated using a variety of available geographical databases that provide information on individual aspects of the urban landscape, such as impermeability, building footprints and heights. These data will be of value to a variety of users because of the consistency of methodology and scale. For example, continental-scale studies of environmental hazards are often limited by inconsistent data of varying quality to describe land use and urban form35,36,37,38. Similarly, research that assesses how the built environment impacts travel behavior (e.g., alternative transportation)39,40,41, physical activity42,43, and mental health44 is often limited to a single urban area or suffers from crude or inconsistent measures across large geographies. We anticipate the dataset provided here will be useful for researchers and practitioners to assess how the configuration, size, and shape of cities impact these important human and environmental outcomes. More generally, our approach demonstrates the potential for integrating crowd-sourced data into LCZ model-building for the purpose of developing global LCZ maps.
Methods
Concept of local climate zones
LCZ typology has been adopted as a baseline description of global urban areas into recognisable types that are formally defined as ‘regions of uniform surface cover, structure, material, and human activity that span hundreds of meters to several kilometres in horizontal scale’, exclude ‘class names and definitions that are culture or region specific’, and are characterized by ‘a characteristic screen-height temperature regime that is most apparent over dry surfaces, on calm, clear nights, and in areas of simple relief’27. Seventeen LCZ types exist, 10 of which are considered ‘urban’ (Fig. 1), and all are associated with characteristic urban canopy parameters (UCP, Table 1). In the current study, two ‘urban’ LCZ classes are not considered: LCZ 7 (lightweight lowrise) referring to informal settlements hardly present in CONUS, and LCZ 9 (sparsely built) characterised by a high abundance of natural land-cover which thus behaves thermally as a natural land-cover.

An automated (offline) LCZ mapping procedure was suggested by Bechtel et al.31, and adopted by the WUDAPT project to create consistent LCZ maps of global cities. To facilitate the expansion of the coverage of LCZ maps, Demuzere et al.32,34 introduced the transferability concept of labeled Training Areas (TAs)32 and the use of Google’s Earth Engine cloud computing environment33, which allows for up-scaling the default WUDAPT approach to the continental scale (e.g. Europe34). In this approach, the three key operations from the original WUDAPT protocol remain unchanged: (1) the preprocessing of earth observation data as input features for the random classifier, (2) the digitization and preprocessing of appropriate training areas, and (3) the application of the classification algorithm and the accuracy assessment45. These steps are described in more detail below.
Input data
Earth observation data
The default WUDAPT workflow typically uses a number of single Landsat 8 (L8) tiles as input to the random forest classifier31. Here we adopt the approach of Demuzere et al.34, by using 41 input features from a variety of sensors and time periods. L8 mean composites (2016–2018) are made for the full year and the summer/winter half-year, and include the blue (B2), green (B3), red (B4), near-infrared (B5), shortwave infrared (B6 and B7) and thermal infrared (B10 and B11) bands. In addition, a number of spectral indices are derived (as composites covering the period 2016–2018): the minimum and maximum Normalized Difference Vegetation Index (NDVI), the Biophysical Composition Index (BCI46) using the Tasseled Cap transformation coefficients from DeVries et al.47, the mean Normalized Difference BAreness Index (NDBAI48), the mean Enhanced Built-up and Bare land Index (EBBI49), the mean Normalized Difference Water Index (NDWI50), the mean Normalized Difference Built Index (NDBI51) and the Normalized Difference Urban Index (NDUI52). Synthetic aperture radar (SAR) imagery (2016–2018) is included as well, as this feature was previously found to be key32,34,53. In line with Demuzere et al.32,34, this study uses the Sentinel-1 VV single co-polarization backscatter filtered by the Interferometric Wide swath acquisition mode and both ascending and descending orbits, composited into a single image (hereafter referred to S1). From the S1 backscatter composite, an entropy and Geary’s C (a local measure of spatial association54) image is calculated, using a squared kernel of 5x5 pixels and a 9x9 spatial neighborhood kernel respectively. Finally, some other datasets are included such as the Global Forest Canopy Height product (GFCH55), the GTOPO30 digital terrain model (DTM) and derived slope and aspect from the U.S. Geological Survey’s Earth Resources Observation and Science (EROS) Center, the ALOS World 3D global digital surface model (DSM) dataset56,57 and a digital elevation model (DEM) by subtracting the DTM from the DSM. Note that the full set of features is processed on a resolution of 100 meters, following the default mapping resolution suggested by Bechtel et al.31. The reader is referred to Demuzere et al.34 for more details.
Training data
TA data are generally created by urban experts31, a time-demanding procedure, both because of the intrinsic nature of the task (i.e., the extent and heterogeneity of urban areas) and the ability of the urban expert to identify and digitize TAs consistently58,59. Here, expert TAs are used from nine U.S. cities: Phoenix and Las Vegas60, Salt Lake City61, Chicago and New York62,63, Houston, Washington D.C., Philadelphia and Los Angeles. The expert TAs from these cities are supplemented with polygons covering LCZ classes E (bare rock or paved) and F (bare soil or sand) to fully capture the spectral signature of the hot desert regions in the southwestern parts of CONUS.
A limitation of the expert TA procedure is that data are collected from only 9 cities (due to the time-demanding procedure described above). To address this limitation, additional training data are created based on a crowd-sourcing platform: MTurk (https://www.mturk.com). MTurk is highly scalable and allows for collecting a large number of urban and natural TAs across CONUS. The following process was used to collect MTurk TAs. First, MTurk participation is limited to workers with a Masters Qualification (i.e., users who have demonstrated high performance on MTurk in previous tasks) from English speaking countries (to avoid confusion from the instructions). The MTurk workers are shown a tutorial and asked to classify a satellite image (500 by 500 m) of an urban or natural area. For each satellite image (https://www.google.com/earth), users are also shown the corresponding Google Street View images (https://www.google.com/streetview/) within the 500 by 500 m area. Based on the satellite and Street View images, MTurk workers are asked to classify the area as a single LCZ. Locations are selected based on: (1) U.S. Environmental Protection Agency Air Quality Monitoring Sites (which are located in all major metropolitan areas) and (2) a supplement of manually chosen locations for LCZs that were under-sampled (from the 60 largest Urban Areas), to ensure that a wide range of built and natural environments are included. For each location, responses are obtained from at least ten unique MTurk workers; only when at least 70% of MTurk workers agreed on the classification (defined as the same LCZ or a near-neighbor LCZ), the MTurk TAs are included in the final training dataset.
Three different approaches (using TAs in the nine ‘expert’ cities) are used to compare the consistency between EX and MTurk TAs based on the degree of spatial overlap of the TA polygons: (1) full match where the MTurk TA falls completely within the EX TA, (2) match by centroid where the centroid of the MTurk TA is within the EX TA, and (3) match by intersection where the MTurk TA and EX TA intersect at some point in space. Using each approach we assessed to what degree the EX and MTurk TAs represent the same LCZ. The match percentage was 100% (n [number of matched polygons] = 8) for the full match approach, 87% (n = 69) for the match by centroid, and 65% (n = 141) for the match by intersection (Supplementary Table S1). While differences occur, the degree of consistency is actually higher compared to the results of HUMINEX (HUMan INfluence EXperiment58,59), that indicated large discrepancies between training area sets from multiple ‘experts’, nevertheless leading to strong improvements in overall accuracy when used all together. Combining expert and crowd-sourced data are therefore a reasonable approach to diversify training data for developing LCZ classification models.
As a final TA preprocessing step, the surface area of large polygons is reduced to a radius of approximately 300 m, following Demuzere et al.32,34. These large polygons typically represent homogeneous areas such as water bodies and forests58,59, a characteristic that is neither needed nor wanted, as this leads to more imbalanced training data and computational inefficiency of the classifier. In addition, because of the imbalance of the MTurk TA sample (Fig. 2), the amount of all non-LCZ 6 MTurk classes (open lowrise) is increased five-fold, by randomly sampling five small polygons (100 x 100 m) from each original MTurk polygon (black boxes in Fig. 2), excluding LCZ 6 polygons. This results in a more balanced training set consisting of 13,216 polygons (10,323 MTurk and 2,893 EX TAs, Fig. 2).

Number of expert (EX) and Amazon Mechanical Turk (MTurk) training areas used in the CONUS LCZ classification. Black boxes refer to the amount of original imbalanced MTurk TAs.
Classification procedure, quality assessment, and post-processing
As a final step in WUDAPT’s LCZ classification protocol, the random forest algorithm64 is applied, using the earth observation data and the labeled TAs30,31 as inputs. The accuracy of the resulting maps is then assessed in two ways, via (1) a pixel-based ‘random-sampling’ and (2) a polygon-based ‘city hold out’ procedure.
The random-sampling procedure is based on the default automated WUDAPT cross-validation procedure outlined in Bechtel et al.45 and is performed as described in Demuzere et al.34. Ten pixels are randomly sampled from each TA (resulting in a total of 132,160 pixels). From the resulting TA pixel pool, 50% is selected as the training set and the other 50% as test set based on a stratified (LCZ type) random sampling. This exercise is then repeated 25 times allowing us to provide confidence intervals around the accuracy metrics described in more detail below.
This strategy might lead to a biased accuracy assessment because of the potential spatial correlation in the train and test samples. Therefore, a second approach is applied in line with the methodology used in Demuzere et al.32. In this polygon-based city hold out procedure, TAs from all-but-one cities are used to train the classifier, while the remaining TAs from the held out city are used for the accuracy assessment. This is then repeated for all nine expert TA cities. As the information for training is independent of that used for testing, no bootstrapping is performed. The variability around the accuracy is, in this case, provided by the variable mapping quality for the different target cities. This city hold out approach is equivalent to cross-learning or model-transferability experiments in other recent studies62,65,66,67.
For both quality assessment approaches, the following accuracy measures are used: overall accuracy (OA), overall accuracy for the urban LCZ classes only (OAu), overall accuracy of the built versus natural LCZ classes only (OAbu), a weighted accuracy (OAw), and the class-wise metric F132,34,58,68,69,70. The overall accuracy denotes the percentage of correctly classified pixels. OAu reflects the percentage of classified pixels from the urban LCZ classes only, and OAbu is the overall accuracy of the built versus natural LCZ classes only, ignoring their internal differentiation. The weighted accuracy (OAw) is obtained by applying weights to the confusion matrix and accounts for the (dis)similarity between LCZ types58,70. For example, LCZ 1 is most similar to the other compact urban types (LCZs 2 and 3), leaving these pairs with higher weights compared to e.g., an urban and natural LCZ class pair. This results in penalizing confusion between dissimilar types more than confusion between similar classes. Finally, the class-wise accuracy is evaluated using the F1 metric, which is a harmonic mean of the user’s and producer’s accuracy68,69.
According to Bechtel et al.31, the ideal scale for classification differs from the scale defined by the LCZ concept. More specifically, the optimal resolution for a pixel-based classification should be systematically higher than the preferred LCZ scale (hundreds of meters to kilometres)27, to account for non-regular and rectangular shapes of the patches. Consequently, single pixels do not constitute an LCZ and have to be removed. In the classical WUDAPT workflow, the granularity is reduced by a majority post-classification filter with a default radius of 300 m. This however has several shortcomings. Firstly, it does not account for distance, i.e. the center pixel is weighted as important as a pixel at the border of the filter mask. Secondly, it does not account for differences in the typical patch size between classes and consequently, linear features like rivers tend to be removed. Finally, it produces some artifacts. Therefore, a different filtering approach was chosen here. For each class the likelihood was defined by convolution of the binary membership mask derived from the initial map (1 if pixel is assigned to class i, 0 otherwise) with a Gaussian kernel with standard deviation σi and kernel size > = 2 σi, resulting in a likelihood map per class. Subsequently the class with the highest likelihood was chosen for each pixel. Since the typical patches differ in size between LCZs, σi values of 100 m for LCZ 1, 250 m for LCZ 8 and 10 and 150 m for all remaining urban classes were chosen. For the natural classes, 25 m was chosen for water and 75 m for all other classes. Since these numbers were derived by experts, they introduce a priori knowledge to the procedure and deserve further investigation and adjustment in future. In particular, optimal σi are assumed to differ between cities and continents.
Urban canopy parameter and population data
The LCZ scheme is considered to be a universal classification, that not only provides a common platform for knowledge exchange and a pathway to model applications in cities with little data infrastructure, but also provides a numerical description of urban canopy parameters (UCPs) that are key in urban ecosystem processes71. These UCPs, among others, include the building footprints (BF), average building height (BH), impervious surface area (ISA), the sky view factor (SVF), and the anthropogenic heat flux (AHF). Class-specific, globally generic, UCP ranges are provided in Table 1, and are especially useful in areas where such information is not available/incomplete and/or available at poor spatial/temporal resolutions30,34. CONUS does have such datasets available, which allows us to 1) evaluate the LCZ map with these independent datasets and 2) potentially fine-tune the existing generic UCP ranges provided by Stewart and Oke27. As outlined above, the LCZ typology is chiefly a description of land-cover but some of the types can be linked to land use and population. For example, compact highrise (LCZ 1) and midrise (LCZ 2) are generally associated with downtown commercial districts in most US cities, although it also includes tall residential apartment blocks. Compact lowrise (LCZ 3) are typically associated with densely occupied neighborhoods close to city centers, many of which were built in the early-twentieth century. Open types of all heights (LCZ 4–6) can be linked to the suburban residential areas. Finally, the large lowrise (LCZ 8) and heavy industry(LCZ 10) types are associated with storage units and large emitting facilities, respectively. In other words, one can expect each type to be associated with different populations. To evaluate the LCZs on the basis of this proposition, LCZ types are benchmarked against resident population counts as well.
Building footprints
The Bing Maps team at Microsoft released a nation-wide vector building dataset in 201872. This dataset is generated from aerial images available to Bing Maps using deep learning methods for object classification. This dataset includes over 125 million building footprint polygons in all 50 U.S. States in GeoJSON vector format. The dataset is distributed separately for each state and has a 99.3% precision and 93.5% pixel recall accuracy. Since vector layers are highly challenging for large-scale analysis, Heris et al.73,74 converted the dataset to a raster format with 30 m spatial resolution in line with the National Land-Cover Dataset (NLCD) grid29, providing six building footprint summary variables for each cell. Our study uses the total footprint coverage per grid cell, with values ranging from 0 m2 (0%, no buildings) to 900 m2 (100%, completely built).
Building height
To our knowledge, there is currently no publicly-available, recent and high-quality building height (BH, m) dataset that spans the continental United States. Therefor, building height is taken from Falcone75, who provides a categorical mapping of estimated mean building heights, by census block group for the continental United States. The data were derived from the NASA Shuttle Radar Topography Mission, which collected ‘first return’ (top of canopy and buildings) radar data at 30-m resolution in February 2000. Non-urban features were filtered out, so that height values refer to object heights where urban development is present, e.g., buildings and other man-made structures (stadiums, towers, monuments). Due to difficulties in mapping exact building heights, information was aggregated on 216,291 census block groups across CONUS. In turn, block height values were categorized into six groups according to their statistical distribution and were categorized as ‘Low’, ‘Low-Medium’, ‘Medium’, ‘Medium-High’, ‘High’, and ‘Very High’. Using the building heights and footprints for 85,166 buildings in San Francisco (representative for 2010), the data quality was assessed (correlation of 0.8), and the mean and standard deviation (SD) of actual heights were calculated for block groups where actual building height data were available. This procedure resulted in the following mean (SD) height values: ‘Low’: too few observations to be meaningful, ‘Low-Medium’: 11.5 m (3.2 m), ‘Medium’: 13.1 m (3.1 m), ‘Medium-High’: 16.3 m (4.4 m), ‘High’: 21.7 m (8.2 m), and ‘Very High’: 35.3 m (14.2 m).
The procedure described above makes it clear that this dataset serves as a first-order proxy for actual building height data. Data were taken in the year 2000, which does not correspond to the year 2017 representative for this CONUS LCZ map. As such, benchmarking the LCZ map against this building height dataset neglects a net 6.7% increase in developed urban land, derived as the difference between the NLCD 2016 and 2001 developed land-cover classes76. Also, Falcone’s75 building heights are categorical and reflect the observed variability in San Francisco, which is not necessarily representative for all other CONUS urban areas. The spatial footprint is defined by census block groups, which vary in shape and scale as their original goal is to sample the population. The impact of these limitations is assessed using more recent, high-resolution and freely available datasets from the metropolitan areas of Austin, Boston, Des Moines, Los Angeles and New York, covering over 5 million buildings (Supplementary Table S2).
Impervious surface area
Impervious surface is taken from the National Land-Cover Database (NLCD) 2016 product29,77, which provides the percent of each 30 m pixel covered by developed impervious surface (range 0 to 100%). These authors created the dataset in four steps: (1) training data development using nighttime light products, (2) impervious surface modeling using regression tree models and Landsat imagery, (3) comparison of initial model outputs to remove false estimates due to high reflectance from non-urban areas and to retain 2011 impervious values unchanged from 2011 to 2016, and (4) final editing and product generation (see Section 6.1 in Yang et al.29 for more details).
Sky view factor
Information on sky view factor (SVF) is available for 22 U.S. cities (Atlanta, Baltimore, Boston, Buffalo, Cleveland, Denver, El Paso, Fresno, Las Vegas, Miami, Orlando, Philadelphia, Portland, Richmond, Salt Lake City, San Diego, San Francisco, San Jose, Seattle, Tampa, Tuscon, and Washington D.C.) and are obtained from Google Street View (GSV) images that are examined using a deep learning approach78,79. A complete sample of GSV locations in each city is retrieved through the Google Maps API; for all locations, an image cube is downloaded in the form of six 90-degree field-of-view images that face upwards, downwards, north, east, south, and west. The images are segmented by a convolutional neural network that was fine-tuned with GSV 90-degree images from cities around the world to yield six classes: sky, trees, buildings, impervious and pervious surfaces, and non-permanent objects79. Here, only the SVF is used, which is obtained by projecting the segmented upper half of the image cube into a hemispherical fish-eye to calculate the SVF using sky and non-sky pixels80. GSV images are inherently biased towards street locations, and thus greatly under-sample open spaces, including parks, golf courses, backyards, and natural areas in general78. Benchmarking with SVF data (ranges between 0–100%) is, therefore, only done for the urban LCZ classes within the CONUS domain.
Anthropogenic heat flux
Annual mean anthropogenic heat flux (AHF, Wm−2) data are provided by Dong et al.81, which are available globally at a spatial resolution of 30 arc-seconds. This product includes four heating components: energy loss, heating from the commercial, residential, and transportation sectors, heating from the industrial and agricultural sectors, and heating from human metabolism.
Population
Resident population counts representative for 2015 are provided by the Global Human Settlement global population grid (GHS-POP)82,83. These data are disaggregated from CIESIN’s GPWv484 census or administrative units to grid cells with a resolution of 250 m, a manipulation that is informed by the distribution and density of built-up as mapped in the Global Human Settlement Layer dataset3,5,83. For other global and continental population datasets, and their fitness-for-use, the reader is referred to Leyk et al.85.
Technical Validation
Accuracy assessment
Accuracy assessment for the random sampling procedure using 132,160 pixels and all 41 earth observation input features result in scores of ≥80% for all OA metrics (Fig. 3a) (full confusion matrices are available in Supplementary Tables S3 and S4). The class-wise F1 metric shows larger variability with values for the urban classes between 55% (LCZ 5 - Open midrise) and 85% (LCZ 6 - Open lowrise), and >80% for all natural classes. The lowest accuracy is obtained for LCZs 4 (Open highrise) and 5, similar to previous studies34, and in line with the results of the 2017 IEEE GRSS Data Fusion Contest62,86 or Qiu et al.67 who found that LCZs 4 and 5 were difficult to distinguish. These LCZ types are characterised by the same building footprint and impervious surface areas, yet differ mainly due to the height of their roughness elements (≥25 m and 10–25 m respectively (see urban canopy parameter ranges in Table 1). This points to a current limitation of the input feature space87, i.e., apart from the S1 backscatter information, which responds to vertical elements in the landscape88 and the DEM information (which is subject to errors56,57), there is currently no publicly-available high-quality building height dataset spanning CONUS providing the much needed building height information to improve model performance (see also the ‘Urban canopy parameter data’ section).

Overall and class-wise accuracies for the (a) random sampling and (b) city hold out approach. Colored boxes and grey whiskers span the 25–75 and 5–95 percentiles respectively. The means and medians are indicated by the white dots and black lines respectively. Note that the underlying confusion matrices are available in Supplementary Tables S3 and S4.
Figure 3b shows that model accuracy is lower for the more stringent city hold out assessment, with average overall accuracy values ranging between 48% (OA) and 87% (OAbu). The average urban F1 metric ranges from 15% for LCZ 5 to 55% for LCZ 6, while average F1 values for natural classes range from 20% for LCZ C (bush, scrub) to 82% for LCZ G (water). These accuracies are only low to moderate. However, they can be considered as lower estimates of the real accuracy of the product, since most large urban agglomerations have specific training data and thus presumably higher accuracies. In addition, one has to keep in mind that much confusion occurs between similar classes, show-cased by the high weighted accuracy (OAw), ranging between 75 and 88%. Finally, our accuracies are within the range of accuracies reported from other transferability experiments using random forest classifiers32,65, acknowledging the somewhat higher accuracies using (residual) convolutional neural networks65,66,67. While the latter method is considered to constitute a feasible approach for automated large-scale LCZ mapping66, this feasibility to date has not yet been demonstrated.
LCZ map and its relevance
The resulting final CONUS LCZ classification, based on all TAs (13,216), all input features (41), and the random forest classifier in Google’s Earth Engine is shown in Fig. 4. The map is filtered using the morphological Gaussian filter described under ‘Classification procedure and quality assessment’, has a 100 m resolution, and is projected using the Albers Conical Equal Area NAD83 (North American Datum 1983) projection and NLCD grid. This map is used to benchmark the UCP data described in the following section and shown in Figs. 5 and 6.

CONUS Local Climate Zone Map.

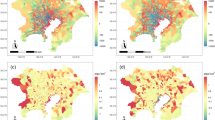
LCZ and urban canopy parameter maps for two selected urban areas: New York (top row) and San Francisco (bottom row). Examples of SVF maps for selected U.S. cities are provided in Middel et al.78,79. GHS-POP and other global population grids can be explored interactively via the POPGRID mapping tool 85.

CONUS-wide urban canopy parameter ranges provided by Stewart and Oke27 (black lines, see also Table 1) and as a result from the spatial intersection between the final CONUS LCZ map (Fig. 4) and the urban canopy parameter and population datasets (colored bars) (Fig. 5). The colored dots present the mean, the extent of the bars ±1σ. Results from the metropolitan (five cities) building heights datasets (urban LCZ classes only) are depicted with triangles (mean) and dash-dotted bars (±1σ). SVF values are only benchmarked over the 22 cities for which such data are available, and are omitted for the natural LCZ classes. No reference population ranges are provided by Stewart and Oke27.
Urbanization is an intrinsic part of the Anthropocene epoch (the human-influenced geologic time period89) in which urban areas represent a critical spatial nexus where climate drivers are concentrated, climate hazards are accentuated, and population exposure is greatest90. The effect of urbanization on the environment is an outcome of its physical form (i.e., the land-cover, the materials, and the geometry of buildings) and its functions (the transportation, energy usage, and generation of waste products) that sustain human activities. As these features and functions vary in space and time - and adversely affect local climate, hydrology, biodiversity, and air quality - it is crucial to characterize these urban properties to allow the assessment of their impact on human and environmental systems1,30,91. This CONUS-wide LCZ map contributes to this effort, and should be considered as a complementary source of information to existing and commonly-used land-cover maps such as the National land-cover Database29, which provides a limited number of urban classes (open space and developed low-, medium- and high-intensity areas). The latter classes typically reflect a degree of imperviousness, yet lack additional information on other types of urban characteristics that are key for various climate, weather, environment, and urban planning purposes30,34,92.
To this end, the CONUS LCZ map is benchmarked against the auxiliary urban form and population data described in section ‘Urban canopy parameter and population data’. As an illustration, Fig. 5 shows the LCZ map for parts of the New York and San Francisco urban areas, in conjunction with their benchmark data for impervious surface area, building height from Falcone75, building footprint, and anthropogenic heat flux.
Figure 6 provides a more in-depth analysis of the UCPs, comparing the theoretical ranges provided by Stewart and Oke27 with the CONUS-wide ranges estimated from the LCZ map presented here. For the SVF and lidar-based building height data (dash-dotted bars and triangles), this analysis is limited to the respectively 22 and 5 U.S. cities where these datasets are available. As LCZs are mainly related to structural and land-cover characteristics, no reference population ranges are provided by Stewart and Oke27.
Overall, UCP ranges match very well, yet differences occur which might be related to the confusion between LCZs 3, 4 and 5, and the characteristics and parameter representation of the underlying UCP data sources. LCZ-derived building heights are lower for LCZs 1, 4 and 5, and higher for LCZ 3. The benchmark against the more recent high-resolution lidar-based building height data (dash-dotted bars and triangles) is more in line with the ranges provided by Stewart and Oke27. This is most clear for LCZ 1, yet in general this behavior can be explained by the fact that 1) the metropolitan building height datasets are more representative in both time (more recent) and space (providing the actual building height for individual buildings, without categorizing and spatial averaging) and 2) NLCD classes 23 (developed - medium intensity) and 24 (developed - high intensity) show the greatest increase among the developed categories76. Also, the Stewart and Oke27 height ranges for LCZ A (dense trees) and B (scattered trees) are not visible in the benchmark against the Falcone75 nor the metropolitan products, as the former includes the height of all roughness elements (including trees), while the latter two are only representative for man-made structures. For the SVF, LCZ-derived values for LCZ classes 4, 5, 6, 8 (large lowrise) and 10 (heavy industry) are systematically lower than the range provided by Stewart and Oke27. These differences can be attributed partly to the difference in how SVF is obtained as part of the LCZ scheme versus that obtained by Google street view imagery. As the latter methodology is based on a perspective from the road surface, the derived SVF values generally do not account for urban spaces that are inaccessible to cars, such as backyards, parks, etc.78,79. This is also the motivation for omitting the natural classes from this analysis (Fig. 6). Finally, notwithstanding the various assumptions that have been made in the creation of both the LCZ map and the GHS-POP grid, the results are generally in line with expectations: the mean population counts in urban areas (LCZs 1–10) differ by type, and although there is considerable overlap, the compact types associated with higher built fractions have higher population densities than the open types. Concurrently, natural classes are characterised by very low population counts. As a first-order evaluation of the LCZ types, the population data are in agreement with the landscape categorization.
To summarize, this work represents the first CONUS-wide LCZ map - a data product that integrates building morphology and natural elements into existing datasets that describe land-cover. This result builds on previous city-based and continental-scale LCZ mapping efforts34, and adds to the growing globally consistent description of urban form and functions relevant to climate, weather, and the environment - the key mission of the WUDAPT project30.
The primary value of the LCZ scheme is that it can generate the urban data needed by climate models to simulate the impact of landscape change on the overlying atmosphere. As such, it is an integrative description of the urbanized landscape that accounts for the variety of urban characteristics that have climatic impacts. The continental scale map of LCZ types generated here can be used to evaluate the exposure of the urbanized landscape and population to hazards associated with current and future climate changes. These include for example the impacts of heat stress in the different types of LCZ and on those that reside and/or work there93. While cities are known to generate localized warming (urban heat islands), the impact of global climate change is expected to increase the frequency and magnitude of heatwaves, enhancing existing heat stress and risk in cities93,94,95. Finally, this work also demonstrates the possibility of integrating expert-derived and crowd-sourced training data in the LCZ mapping process. We expect that this data product will be useful to other researchers and practitioners who need descriptions of urban form and functions at the national scale to assess the impact of cities and urban planning on human and environmental systems.
Data Records
The CONUS LCZ map provides a CONUS-wide LCZ classification for 2017 and is provided on a 100 m spatial resolution in the Albers Conic Equal Area projection (matching the projection of the NLCD maps29). All original training areas are combined in one shapefile, on the same NLCD projection. Both datasets are available via figshare96. The various urban canopy parameter datasets are freely available and can be obtained via their corresponding authors. All earth observation input features derived from Landsat 8, Sentinel-1 and some other data sources are freely available, and are computed on and stored as assets in Google Earth Engine.
Usage Notes
Local Climate Zones were originally designed as a new framework for urban heat island studies, and therefore contain ‘natural’ land-cover classes that can be used as ‘control’ or ‘natural reference’ areas27. Yet the very few natural classes in the LCZ scheme can not capture the world’s existing natural variability, and can thus - with respect to the natural land-cover classes - not compete with other products such as the 16 natural land-cover classes from NLCD29 or the 20 and 36 layers that describe the Earth’s terrestrial surface in the Copernicus Global Land-Cover Layers97 and the European Space Agency Climate Change Initiative land-cover98 products respectively. In contrast, the strongest added value of the LCZ framework (and map) is the high number of urban classes, that are easily interpretable, globally consistent, and shown to exhibit class-specific thermal characteristics87,93,99,100,101,102,103,104,105,106,107. As this provides strong added value to other, often binary, global urban products (e.g. the Global Human Settlement Layer (GHSL3,5), the Global Urban Footprint (GUF4), the global annual urban database (GAUD108) and the Global Artificial Impervious Areas (GAIA6)), we advise users to combine the urban LCZ classes with any other land-cover product that provides a wider range of natural land-cover classes.
Code availability
All Google Earth Engine codes to pre-process the earth observation input features and perform the actual LCZ classification are available upon request. The pixel-based random-sampling assessment was done using the randomForest v4.16-14 package available in R-project109. The CONUS LCZ map figure is produced with QGIS v3.4. All other data processing and visualizations are done in Python v3.6.9.
References
Creutzig, F. et al. Upscaling urban data science for global climate solutions. Glob. Sustain. 2, e2, https://doi.org/10.1017/sus.2018.16 (2019).
van den Hurk, B. et al. The match between climate services demands and Earth System Models supplies. Clim. Serv. 12, 59–63, https://doi.org/10.1016/j.cliser.2018.11.002 (2018).
Pesaresi, M. et al. A global human settlement layer from optical HR/VHR RS data: Concept and first results. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 6, 2102–2131, https://doi.org/10.1109/JSTARS.2013.2271445 (2013).
Esch, T. et al. Breaking new ground in mapping human settlements from space -The Global Urban Footprint-. ISPRS J. Photogramm. Remote. Sens. 134, 30–42, https://doi.org/10.1016/j.isprsjprs.2017.10.012 (2017). 1706.04862.
Corbane, C. et al. Big earth data analytics on Sentinel-1 and Landsat imagery in support to global human settlements mapping. Big Earth Data, https://doi.org/10.1080/20964471.2017.1397899 (2017).
Gong, P. et al. Annual maps of global artificial impervious area (GAIA) between 1985 and 2018. Remote. Sens. Environ. 236, 111510, https://doi.org/10.1016/j.rse.2019.111510 (2020).
Fang, Y. & Jawitz, J. W. Data Descriptor: High-resolution reconstruction of the United States human population distribution, 1790 to 20 10. Sci. Data 5, 1–15, https://doi.org/10.1038/sdata.2018.67 (2018).
Leyk, S. & Uhl, J. H. HISDAC-US, historical settlement data compilation for the conterminous United States over 200 years. Sci. Data 5, 180175, https://doi.org/10.1038/sdata.2018.175 (2018).
Leyk, S., Uhl, J. H., Balk, D. & Jones, B. Assessing the accuracy of multi-temporal built-up land layers across rural-urban trajectories in the United States. Remote. Sens. Environ. 204, 898–917, https://doi.org/10.1016/j.rse.2017.08.035 (2018).
Ewing, R. & Cervero, R. Travel and the built environment. J. Am. Plan. Assoc. 76, 265–294, https://doi.org/10.1080/01944361003766766 (2010).
Ewing, R., Pendall, R. & Chen, D. Measuring sprawl and its transportation impacts. Transp. Res Rec 1831, 175–183, https://doi.org/10.3141/1831-20 (2003).
Foley, J. et al. Global consequences of land use. Science 309, 570–574, https://doi.org/10.1126/science.1111772 (2005).
McDonald, R. I. et al. Research gaps in knowledge of the impact of urban growth on biodiversity. Nat. Sustain., https://doi.org/10.1038/s41893-019-0436-6 (2019).
Hankey, S. & Marshall, J. D. Impacts of urban form on future US passenger-vehicle greenhouse gas emissions. Energy Policy 38, 4880–4887, https://doi.org/10.1016/j.enpol.2009.07.005 (2010).
Hankey, S. & Marshall, J. D. Urban Form, Air Pollution, and Health. Curr. Environ. Heal. Reports 4, 491–503, https://doi.org/10.1007/s40572-017-0167-7 (2017).
Hoek, G. et al. A review of land-use regression models to assess spatial variation of outdoor air pollution. Atmospheric Environ. 42, 7561–7578, https://doi.org/10.1016/j.atmosenv.2008.05.057 (2008).
Stone, B. J. Urban sprawl and air quality in large US cities. J Environ Manag. 86, 688–698, https://doi.org/10.1016/j.jenvman.2006.12.034 (2008).
Perera, A. T. D., Coccolo, S. & Scartezzini, J.-L. The influence of urban form on the grid integration of renewable energy technologies and distributed energy systems. Sci. Reports 9, 17756, https://doi.org/10.1038/s41598-019-53653-w (2019).
Lamb, W. F., Creutzig, F., Callaghan, M. W. & Minx, J. C. Learning about urban climate solutions from case studies. Nat. Clim. Chang. 9, 279–287, https://doi.org/10.1038/s41558-019-0440-x (2019).
Jackson, R., Dannenberg, A. L. & Frumkin, H. Health and the built environment: 10 years after. Am J Public Heal. 103, 1542–1544, https://doi.org/10.2105/AJPH.2013.301482 (2013).
Batty, M. The size, scale, and shape of cities. Science 319, 769–771, https://doi.org/10.1126/science.1151419 (2008).
Stone, B., Mednick, A. C., Holloway, T. & Spak, S. N. Is compact growth good for air quality? J Am Plann Assoc 73, 404–418, https://doi.org/10.1080/01944360708978521 (2007).
Seto, K. C., Güneralp, B. & Hutyra, L. R. Global forecasts of urban expansion to 2030 and direct impacts on biodiversity and carbon pools. Proc. Natl. Acad. Sci. United States Am. 109, 16083–8, https://doi.org/10.1073/pnas.1211658109 (2012).
Azar, D., Engstrom, R., Graesser, J. & Comenetz, J. Generation of fine-scale population layers using multi-resolution satellite imagery and geospatial data. Remote. Sens. Environ. 130, 219–232, https://doi.org/10.1016/j.rse.2012.11.022 (2013).
Frye, C., Nordstrand, E., Wright, D. J., Terborgh, C. & Foust, J. Using Classified and Unclassified Land Cover Data to Estimate the Footprint of Human Settlement. Data Sci. J. 17, 1–12, https://doi.org/10.5334/dsj-2018-020 (2018).
Leyk, S., Balk, D., Jones, B., Montgomery, M. R. & Engin, H. The heterogeneity and change in the urban structure of metropolitan areas in the United States, 1990–2010. Sci. Data 6, 321, https://doi.org/10.1038/s41597-019-0329-6 (2019).
Stewart, I. D. & Oke, T. R. Local Climate Zones for Urban Temperature Studies. Bull. Am. Meteorol. Soc. 93, 1879–1900, https://doi.org/10.1175/BAMS-D-11-00019.1 (2012).
Homer, C. et al. Completion of the 2011 national land cover database for the conterminous United States – Representing a decade of land cover change information. Photogramm. Eng. Remote. Sens., https://doi.org/10.1016/S0099-1112(15)30100-2 (2015).
Yang, L. et al. A new generation of the United States National Land Cover Database: Requirements, research priorities, design, and implementation strategies. ISPRS J. Photogramm. Remote. Sens. 146, 108–123, https://doi.org/10.1016/j.isprsjprs.2018.09.006 (2018).
Ching, J. et al. WUDAPT: An Urban Weather, Climate, and Environmental Modeling Infrastructure for the Anthropocene. Bull. Am. Meteorol. Soc. 99, 1907–1924, https://doi.org/10.1175/BAMS-D-16-0236.1 (2018).
Bechtel, B. et al. Mapping Local Climate Zones for a Worldwide Database of the Form and Function of Cities. ISPRS Int. J. Geo-Information 4, 199–219, https://doi.org/10.3390/ijgi4010199 (2015).
Demuzere, M., Bechtel, B. & Mills, G. Global transferability of local climate zone models. Urban Clim. 27, 46–63, https://doi.org/10.1016/j.uclim.2018.11.001 (2019).
Gorelick, N. et al. Google Earth Engine: Planetary-scale geospatial analysis for everyone. Remote. Sens. Environ. 202, 18–27, https://doi.org/10.1016/j.rse.2017.06.031 (2017).
Demuzere, M., Bechtel, B., Middel, A. & Mills, G. Mapping Europe into local climate zones. Plos One 14, e0214474, https://doi.org/10.1371/journal.pone.0214474 (2019).
Bechle, M. J., Millet, D. B. & Marshall, J. D. National Spatiotemporal Exposure Surface for NO2: Monthly Scaling of a Satellite-Derived Land-Use Regression, 2000–2010. Environ. Sci. & Technol. 49, 12297–12305, https://doi.org/10.1021/acs.est.5b02882 (2015).
Knibbs, L. D., Hewson, M. G., Bechle, M. J., Marshall, J. D. & Barnett, A. G. A national satellite-based land-use regression model for air pollution exposure assessment in Australia. Environ. Res. 135, 204–211, https://doi.org/10.1016/j.envres.2014.09.011 (2014).
Hystad, P. et al. Creating National Air Pollution Models for Population Exposure Assessment in Canada. Environ. Heal. Perspectives 119, 1123–1129, https://doi.org/10.1289/ehp.1002976 (2011).
de Hoogh, K. et al. Development of Land Use Regression Models for Particle Composition in Twenty Study Areas in Europe. Environ. Sci. & Technol. 47, 5778–5786, https://doi.org/10.1021/es400156t (2013).
Le, H. T., Buehler, R. & Hankey, S. Correlates of the Built Environment and Active Travel: Evidence from 20 US Metropolitan Areas. Environ. Heal. Perspectives 126, 077011, https://doi.org/10.1289/EHP3389 (2018).
de Nazelle, A. et al. Improving health through policies that promote active travel: A review of evidence to support integrated health impact assessment. Environ. Int. 37, 766–777, https://doi.org/10.1016/j.envint.2011.02.003 (2011).
Nieuwenhuijsen, M. J. & Khreis, H. Car free cities: Pathway to healthy urban living. Environ. Int. 94, 251–262, https://doi.org/10.1016/j.envint.2016.05.032 (2016).
Ferdinand, A. O., Sen, B., Rahurkar, S., Engler, S. & Menachemi, N. The Relationship Between Built Environments and Physical Activity: A Systematic Review. Am. J. Public Heal. 102, e7–e13, https://doi.org/10.2105/AJPH.2012.300740 (2012).
Handy, S., Boarnet, M. G., Ewing, R. & Killingsworth, R. E. How the built environment affects physical activity: views from urban planning. Am. J. Prev. Medicine 23, 64–73 (2002).
Evans, G. W. The Built Environment and Mental Health. J. Urban Heal. Bull. New York Acad. Medicine 80, 536–555, https://doi.org/10.1093/jurban/jtg063 (2003).
Bechtel, B. et al. Generating WUDAPT Level 0 data – Current status of production and evaluation. Urban Clim. 27, 24–45, https://doi.org/10.1016/j.uclim.2018.10.001 (2019).
Deng, C. & Wu, C. BCI: A biophysical composition index for remote sensing of urban environments. Remote. Sens. Environ. 127, 247–259, https://doi.org/10.1016/j.rse.2012.09.009 (2012).
Devries, B., Pratihast, A. K., Verbesselt, J., Kooistra, L. & Herold, M. Characterizing forest change using communitybased monitoring data and landsat time series. Plos One 11, 1–25, https://doi.org/10.1371/journal.pone.0147121 (2016).
Li, H. et al. Mapping urban bare land automatically from Landsat imagery with a simple index. Remote. Sens. 9, https://doi.org/10.3390/rs9030249 (2017).
As-syakur, A. R., Adnyana, I. W. S., Arthana, I. W. & Nuarsa, I. W. Enhanced built-UP and bareness index (EBBI) for mapping built-UP and bare land in an urban area. Remote. Sens. 4, 2957–2970, https://doi.org/10.3390/rs4102957 (2012).
Ko, B. C., Kim, H. H. & Nam, J. Y. Classification of potential water bodies using landsat 8 OLI and a combination of two boosted random forest classifiers. Sensors (Switzerland) 15, 13763–13777, https://doi.org/10.3390/s150613763 (2015).
Bhatti, S. S. & Tripathi, N. K. Built-up area extraction using Landsat 8 OLI imagery. GIScience Remote. Sens. 51, 445–467, https://doi.org/10.1080/15481603.2014.939539 (2014).
Zhang, Q., Li, B., Thau, D. & Moore, R. Building a better urban picture: Combining day and night remote sensing imagery. Remote. Sens. 7, 11887–11913 (2015).
Ren, C. et al. Assessment of Local Climate Zone Classification Maps of Cities in China and Feasible Refinements. Sci. Reports 9, 18848, https://doi.org/10.1038/s41598-019-55444-9 (2019).
Anselin, L. Local indicators of spatial association—LISA. Geogr. analysis 27, 93–115 (1995).
Simard, M., Pinto, N., Fisher, J. B. & Baccini, A. Mapping forest canopy height globally with spaceborne lidar. J. Geophys. Res. Biogeosciences 116 (2011).
Tadono, T. et al. Precise Global DEM Generation by ALOS PRISM. ISPRS Annals Photogramm. Remote. Sens. Spatial Inf. Sci., https://doi.org/10.5194/isprsannals-II-4-71-2014 (2014).
Tadono, T. et al. Generation of the 30 M-MESH global digital surface model by alos prism. In International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences - ISPRS Archives, 157–162, https://doi.org/10.5194/isprsarchives-XLI-B4-157-2016 (2016).
Bechtel, B. et al. Quality of Crowdsourced Data on Urban Morphology—The Human Influence Experiment (HUMINEX). Urban Sci. 1, 15, https://doi.org/10.3390/urbansci1020015 (2017).
Verdonck, M.-l et al. The Human Influence Experiment (Part 2): Guidelines for Improved Mapping of Local Climate Zones Using a Supervised Classification. Urban Sci. 3, 27, https://doi.org/10.3390/urbansci3010027 (2019).
Wang, C. et al. Assessing local climate zones in arid cities: The case of Phoenix, Arizona and Las Vegas, Nevada. ISPRS J. Photogramm. Remote. Sens. 141, 59–71, https://doi.org/10.1016/j.isprsjprs.2018.04.009 (2018).
Collins, J. & Dronova, I. Urban Landscape Change Analysis Using Local Climate Zones and Object-Based Classification in the Salt Lake Metro Region, Utah, USA. Remote. Sens. 11, 1615, https://doi.org/10.3390/rs11131615 (2019).
Yokoya, N. et al. Open Data for Global Multimodal Land Use Classification: Outcome of the 2017 IEEE GRSS Data Fusion Contest. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 11, 1363–1377, https://doi.org/10.1109/JSTARS.2018.2799698 (2018).
Zhang, G., Ghamisi, P. & Zhu, X. X. Fusion of Heterogeneous Earth Observation Data for the Classification of Local Climate Zones. IEEE Transactions on Geosci. Remote. Sens. 57, 7623–7642, https://doi.org/10.1109/TGRS.2019.2914967 (2019). 1905.12305.
Breiman, L. Random Forests. Mach. Learn. 45, 5–32 (2001).
Yoo, C., Han, D., Im, J. & Bechtel, B. Comparison between convolutional neural networks and random forest for local climate zone classification in mega urban areas using {Landsat} images. ISPRS J. Photogramm. Remote. Sens. 157, 155–170, https://doi.org/10.1016/j.isprsjprs.2019.09.009 (2019).
Rosentreter, J., Hagensieker, R. & Waske, B. Towards large-scale mapping of local climate zones using multitemporal Sentinel 2 data and convolutional neural networks. Remote. Sens. Environ. 237, 111472, https://doi.org/10.1016/j.rse.2019.111472 (2020).
Qiu, C., Mou, L., Schmitt, M. & Zhu, X. X. Local climate zone-based urban land cover classification from multiseasonal Sentinel-2 images with a recurrent residual network. ISPRS J. Photogramm. Remote. Sens. 154, 151–162, https://doi.org/10.1016/j.isprsjprs.2019.05.004 (2019).
Chinchor, N. MUC-4 evaluation metrics. In Proceedings of the 4th conference on Message understanding - MUC4’92, 22, https://doi.org/10.3115/1072064.1072067 (Association for Computational Linguistics, Morristown, NJ, USA, 1992).
Verdonck, M.-l et al. Influence of neighbourhood information on ‘Local Climate Zone’ mapping in heterogeneous cities. Int. J. Appl. Earth Obs. Geoinformation 62, 102–113, https://doi.org/10.1016/j.jag.2017.05.017 (2017).
Bechtel, B., Demuzere, M. & Stewart, I. D. A Weighted Accuracy Measure for Land Cover Mapping: Comment on Johnson et al. Local Climate Zone (LCZ) Map Accuracy Assessments Should Account for Land Cover Physical Characteristics that Affect the Local Thermal Environment. Remote Sens. 2019, 11, 2420. Remote. Sens. 12, 1769, https://doi.org/10.3390/rs12111769 (2020).
Oke, T. R., Mills, G., Christen, A. & Voogt, J. A. Urban Climates (Cambridge University Press, Cambridge, 2017).
Bing Maps Team, M. Computer Generated Building Footprints for the United States (2018).
Heris, M. P., Foks, N. L., Bagstad, K. J., Troy, A. & Ancona, Z. H. A rasterized building footprint dataset for the United States. Sci. Data 7, 207, https://doi.org/10.1038/s41597-020-0542-3 (2020).
Heris, M., Foks, N., Bagstad, K. & Troy, A. A national dataset of rasterized building footprints for the U.S. U.S. Geological Survey https://doi.org/10.5066/P9J2Y1WG (2020).
Falcone, J. A. U.S. national categorical mapping of building heights by block group from Shuttle Radar Topography Mission data. U.S. Geological Survey https://doi.org/10.5066/F7W09416 (2016).
Homer, C. et al. Conterminous United States land cover change patterns 2001–2016 from the 2016 National Land Cover Database. ISPRS J. Photogramm. Remote. Sens. 162, 184–199, https://doi.org/10.1016/j.isprsjprs.2020.02.019 (2020).
Xian, G. & Homer, C. Updating the 2001 National Land Cover Database Impervious Surface Products to 2006 using Landsat Imagery Change Detection Methods. Remote. Sens. Environ. 114, 1676–1686, https://doi.org/10.1016/j.rse.2010.02.018 (2010).
Middel, A., Lukasczyk, J., Maciejewski, R., Demuzere, M. & Roth, M. Sky View Factor footprints for urban climate modeling. Urban Clim. 25, 120–134, https://doi.org/10.1016/j.uclim.2018.05.004 (2018).
Middel, A., Lukasczyk, J., Zakrzewski, S., Arnold, M. & Maciejewski, R. Urban form and composition of street canyons: A human-centric big data and deep learning approach. Landsc. Urban Plan. 183, 122–132, https://doi.org/10.1016/j.landurbplan.2018.12.001 (2019).
Middel, A., Lukasczyk, J. & Maciejewski, R. Sky View Factors from Synthetic Fisheye Photos for Thermal Comfort Routing—A Case Study in Phoenix, Arizona. Urban Plan. 2, 19–30, https://doi.org/10.17645/up.v2i1.855 (2017).
Dong, Y., Varquez, A. C. G. & Kanda, M. Global anthropogenic heat flux database with high spatial resolution. Atmospheric Environ. 150, 276–294, https://doi.org/10.1016/j.atmosenv.2016.11.040 (2017).
Joint Research Centre (JRC), E. C. & Center for International Earth Science Information Network-CIESIN, C. U. GHS Population Grid, Derived from GPW4, Multitemporal (1975, 1990, 2000, 2015) (2015).
Freire, S. et al. Enhanced data and methods for improving open and free global population grids: putting ‘leaving no one behind’ into practice. Int. J. Digit. Earth 8947, https://doi.org/10.1080/17538947.2018.1548656 (2018).
Doxsey-Whitfield, E. et al. Taking Advantage of the Improved Availability of Census Data: A First Look at the Gridded Population of the World, Version 4. Pap. Appl. Geogr. 1, 226–234, https://doi.org/10.1080/23754931.2015.1014272 (2015).
Leyk, S. et al. The spatial allocation of population: a review of large-scale gridded population data products and their fitness for use. Earth Syst. Sci. Data 11, 1385–1409, https://doi.org/10.5194/essd-11-1385-2019 (2019).
Sukhanov, S. et al. Multilevel ensembling for local climate zones classification. Int. Geosci. Remote. Sens. Symp. (IGARSS) 2017-July, 1201–1204, https://doi.org/10.1109/IGARSS.2017.8127173 (2017).
Vandamme, S., Demuzere, M., Verdonck, M.-L., Zhang, Z. & Coillie, F. V. Revealing Kunming’s (China) Historical Urban Planning Policies Through Local Climate Zones. Remote. Sens. 11, 1731, https://doi.org/10.3390/rs11141731 (2019).
Koppel, K., Zalite, K., Voormansik, K. & Jagdhuber, T. Sensitivity of Sentinel-1 backscatter to characteristics of buildings. Int. J. Remote. Sens. 38, 6298–6318 (2017).
Crutzen, P. J. & Stoermer, E. F. Global change newsletter. The “Anthropocene” (2000).
Grimm, N. B. et al. Global Change and the Ecology of Cities. Sci. 319, 756–760, https://doi.org/10.1126/science.1150195 (2008).
Baklanov, A. et al. From urban meteorology, climate and environment research to integrated city services. Urban Clim., https://doi.org/10.1016/j.uclim.2017.05.004 (2017).
Masson, V. et al. City-descriptive input data for urban climate models: Model requirements, data sources and challenges. Urban Clim. 31, 100536, https://doi.org/10.1016/j.uclim.2019.100536 (2020).
Verdonck, M.-L., Demuzere, M., Hooyberghs, H., Priem, F. & Van Coillie, F. Heat risk assessment for the Brussels capital region under different urban planning and greenhouse gas emission scenarios. J. Environ. Manag. 249, 109210, https://doi.org/10.1016/j.jenvman.2019.06.111 (2019).
Li, D. & Bou-Zeid, E. Synergistic Interactions between Urban Heat Islands and Heat Waves: The Impact in Cities Is Larger than the Sum of Its Parts*. J. Appl. Meteorol. Climatol. 52, 2051–2064, https://doi.org/10.1175/JAMC-D-13-02.1 (2013).
Wouters, H. et al. Heat stress increase under climate change twice as large in cities as in rural areas: A study for a densely populated midlatitude maritime region. Geophys. Res. Lett. 44, 8997–9007, https://doi.org/10.1002/2017GL074889 (2017).
Demuzere, M. et al. CONUS-WIDE LCZ map and Training Areas. figshare https://doi.org/10.6084/m9.figshare.11416950 (2020).
Buchhorn, M. et al. Copernicus global land cover layers-collection 2. Remote. Sens. 12, 1–14, https://doi.org/10.3390/rs12061044 (2020).
ESA. Land Cover CCI Product User Guide Version 2.0. Tech. Rep., European Space Agency (2017).
Alexander, P. & Mills, G. Local Climate Classification and Dublin’s Urban Heat Island. Atmosphere 5, 755–774, https://doi.org/10.3390/atmos5040755 (2014).
Stewart, I. D., Oke, T. R. & Krayenhoff, E. S. Evaluation of the ‘local climate zone’ scheme using temperature observations and model simulations. Int. J. Climatol. 34, 1062–1080, https://doi.org/10.1002/joc.3746 (2014).
Skarbit, N., Stewart, I. D., Unger, J. & Gál, T. Employing an urban meteorological network to monitor air temperature conditions in the ‘local climate zones’ of Szeged, Hungary. Int. J. Climatol. 37, 582–596, https://doi.org/10.1002/joc.5023 (2017).
Verdonck, M.-l et al. The potential of local climate zones maps as a heat stress assessment tool, supported by simulated air temperature data. Landsc. Urban Plan. 178, 183–197, https://doi.org/10.1016/j.landurbplan.2018.06.004 (2018).
Yang, X. et al. Assessing the thermal behavior of different local climate zones in the Nanjing metropolis, China. Build. Environ. 137, 171–184, https://doi.org/10.1016/j.buildenv.2018.04.009 (2018).
Kotharkar, R. & Bagade, A. Evaluating urban heat island in the critical local climate zones of an Indian city. Landsc. Urban Plan. 169, 92–104, https://doi.org/10.1016/j.landurbplan.2017.08.009 (2018).
Bechtel, B. et al. SUHI analysis using Local Climate Zones—A comparison of 50 cities. Urban Clim. 28, 100451, https://doi.org/10.1016/j.uclim.2019.01.005 (2019).
Mushore, T. D. et al. Remotely sensed retrieval of Local Climate Zones and their linkages to land surface temperature in Harare metropolitan city, Zimbabwe. Urban Clim. 27, 259–271, https://doi.org/10.1016/j.uclim.2018.12.006 (2019).
Martilli, A., Krayenhoff, E. S. & Nazarian, N. Is the Urban Heat Island intensity relevant for heat mitigation studies? Urban Clim. 31, 1–4, https://doi.org/10.1016/j.uclim.2019.100541 (2020).
Liu, X. et al. High-spatiotemporal-resolution mapping of global urban change from 1985 to 2015. Nat. Sustain. x https://doi.org/10.1038/s41893-020-0521- (2020).
Liaw, A. & Wiener, M. Breiman and Cutler’s Random Forests for Classification and Regression. Tech. Rep., R Package randomForest 4, 6–14 (2018).
Acknowledgements
This work was conducted in the context of project ENLIGHT, funded by the German Research Foundation (DFG) under grant No. 437467569. We acknowledge all WUDAPT contributors for providing the training areas of the USA cities used in this study. We thank USGS and NASA for the free Landsat data, the Copernicus programme of ESA for the Sentinel data and the National Centers for Environmental Information at the National Oceanic and Atmospheric Administration (NOAA) for the DMSP-OLS data, all acquired via Google Earth Engine. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the authors and do not necessarily reflect the views of the sponsoring organizations. This publication was developed as part of the Center for Air, Climate and Energy Solutions (CACES), which was supported under Assistance Agreement No. R835873 awarded by the U.S. Environmental Protection Agency. It has not been formally reviewed by EPA. The views expressed in this document are solely those of authors and do not necessarily reflect those of the Agency. EPA does not endorse any products or commercial services mentioned in this publication. Moreover, we thank Jonas Kittner for help with Fig. 1. Open access funding provided by Projekt DEAL.
Author information
Authors and Affiliations
Contributions
M.D. and S.H. devised the project. T.L., W.Z. and S.H. created the Amazon Mechanical Turk training dataset. B.B. designed the Gaussian filter procedure and supported other methodological aspects. M.D. performed all other data collection, pre-processing, classification and analysis to produce the Local Climate Zone map and benchmark the urban canopy parameter data. All authors contributed to the writing and revision of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
The Creative Commons Public Domain Dedication waiver http://creativecommons.org/publicdomain/zero/1.0/ applies to the metadata files associated with this article.
About this article

Cite this article
Demuzere, M., Hankey, S., Mills, G. et al. Combining expert and crowd-sourced training data to map urban form and functions for the continental US. Sci Data 7, 264 (2020). https://doi.org/10.1038/s41597-020-00605-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41597-020-00605-z
This article is cited by
-
Mapping urban form into local climate zones for the continental US from 1986–2020
Scientific Data (2024)
-
An assessment of WRF-urban schemes in simulating local meteorology for heat stress analysis in a tropical sub-Saharan African city, Lagos, Nigeria
International Journal of Biometeorology (2024)
-
Gridded land use data for the conterminous United States 1940–2015
Scientific Data (2022)
-
Urbanization Impact on Regional Climate and Extreme Weather: Current Understanding, Uncertainties, and Future Research Directions
Advances in Atmospheric Sciences (2022)
-
Development of a Web GIS for small-scale detection and analysis of COVID-19 (SARS-CoV-2) cases based on volunteered geographic information for the city of Cologne, Germany, in July/August 2020
International Journal of Health Geographics (2021)
