
Abstract
Imaging technologies are increasingly used to generate high-resolution reference maps of brain structure and function. Comparing experimentally generated maps to these reference maps facilitates cross-disciplinary scientific discovery. Although recent data sharing initiatives increase the accessibility of brain maps, data are often shared in disparate coordinate systems, precluding systematic and accurate comparisons. Here we introduce neuromaps, a toolbox for accessing, transforming and analyzing structural and functional brain annotations. We implement functionalities for generating high-quality transformations between four standard coordinate systems. The toolbox includes curated reference maps and biological ontologies of the human brain, such as molecular, microstructural, electrophysiological, developmental and functional ontologies. Robust quantitative assessment of map-to-map similarity is enabled via a suite of spatial autocorrelation-preserving null models. neuromaps combines open-access data with transparent functionality for standardizing and comparing brain maps, providing a systematic workflow for comprehensive structural and functional annotation enrichment analysis of the human brain.
Similar content being viewed by others

Main
Imaging and recording technologies such as magnetic resonance imaging (MRI), electro- and magnetoencephalography (EEG and MEG), and positron emission tomography (PET) are used to generate high-resolution maps of the human brain. These maps offer insights into the brain’s structural and functional architecture, including gray matter morphometry1,2, myelination3,4,5,6, gene expression7,8, cytoarchitecture9, metabolism10, neurotransmitter receptors and transporters11,12,13,14, laminar differentiation15, intrinsic dynamics16,17,18 and evolutionary expansion19,20,21,22. Such maps are increasingly shared on open-access repositories such as NeuroVault23 or BALSA24, which, collectively, offer a comprehensive multimodal perspective of the central nervous system. However, these data-sharing platforms are restricted to either surface or volumetric data, and do not integrate standardized analytic workflows.
If researchers generate brain maps in their work, such as task functional MRI activations or case–control cortical thickness contrasts, how can they interpret them? Ideally there should be a way to systematically compare and contextualize generated maps with respect to existing structural and functional annotations, using rigorous statistical methods25. In adjacent fields, such as bioinformatics, multiple widely used computational methods for functional profiling and pathway enrichment analysis of gene lists already exist26,27. A comparable structural and functional enrichment tool for neuroimaging would have to support three specific capabilities: a method for generating high-quality transformations across multiple coordinate systems, a curated repository of brain maps in their native space, and a method for estimating map-to-map similarity that accounts for spatial autocorrelation.
In the current report we introduce an open-access Python toolbox, neuromaps, to enable researchers to systematically share, transform, and compare brain maps (Fig. 1). First, we generate a set of group-level transformations between four standard coordinate systems that are widely used in neuroimaging and integrate them via a set of accessible, uniform interfaces. Next, we curate more than 40 reference brain maps from the literature that have been published during the past decade to facilitate contextualization of brain annotations. Finally, we implement spatial autocorrelation-preserving null models for statistical comparison between brain maps that will help researchers to perform standardized, reproducible analyses of brain maps. Collectively, this represents a step towards creating systematized knowledge and rapid algorithmic decoding of the multimodal multiscale architecture of the brain.

The neuromaps software package features a method for generating high-quality transformations across multiple coordinate systems, a curated repository of brain maps in their native systems, and a method for estimating map-to-map similarity that accounts for spatial autocorrelation.
Results
The neuromaps software toolbox is available at https://github.com/netneurolab/neuromaps, on PyPi, Zenodo, it exists as a Docker container, and documentation can be found on GitHub pages (https://netneurolab.github.io/neuromaps). In the following section we highlight features available in neuromaps, demonstrate typical workflows enabled by its functionality, and use neuromaps to examine how choice of coordinate system can affect statistical analyses of brain maps.
The neuromaps data repository
The neuromaps toolbox provides programmatic access to templates for four standard coordinate systems: fsaverage (the default system used by FreeSurfer software, based on 40 normative brains), fsLR (a symmetric version of fsaverage across the left and right hemispheres), CIVET (the default system used by CIVET software) and MNI-152 (developed by the Montreal Neurological Institute using 152 normative MRI scans). For surface-based coordinate systems we distribute template geometry files, sulcal depth maps and average vertex area shape files (computed from Human Connectome Project participants) in standard GIFTI format. For volumetric coordinate systems we distribute T1-, T2-, and proton density-weighted MRI template files, a brain mask, and probabilistic segmentations of gray matter, white matter and cerebrospinal fluid in standard gzipped NIFTI format.
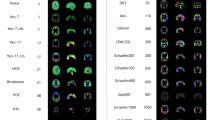
Beyond template files, the neuromaps toolbox offers access to a repository of brain maps obtained from the published literature (Fig. 2 and Supplementary Table 1). These maps were generated using multiple imaging techniques, including MRI, MEG, PET and microarray gene expression. All brain maps except for the genomic gradient are provided in the original coordinate system in which they were defined to avoid errors caused by successive interpolation. The genomic gradient was upsampled to the fsaverage surface with 10,242 vertices (10k surface) using a k-nearest neighbors interpolation. Raw and processed data from the Allen Human Brain Atlas can be accessed at https://abagen.readthedocs.io/en/stable/28. Collectively, these maps represent more than a decade of human brain mapping research and encompass phenotypes including the first principal component of gene expression7, 36 neurotransmitter receptor PET tracer images14, glucose and oxygen metabolism10, cerebral blood flow and volume10, cortical thickness29, T1-weighted/T2-weighted MRI ratio30, six canonical MEG frequency bands29,31, intrinsic timescale29,31, evolutionary expansion19, three maps of developmental expansion19,22, the first 10 gradients of functional connectivity32, intersubject variability33 and the first principal component of NeuroSynth-derived cognitive activation34. This data repository is organized by tags and can be downloaded directly from neuromaps.

Collection of brain maps obtained from the published literature over the past decade that are currently available in the neuromaps distribution. The maps capture the normative multiscale structural and functional organization of the brain, including molecular, cellular, metabolic and neurophysiological features. Refer to Supplementary Table 1 for more information on the coordinate system, resolution and original publication for each brain map. Colormaps were chosen to maximize similarity with how the data were represented in the original publication. Note that two of the maps (second column: evolutionary and developmental expansion) have data only for the right hemisphere; the intrinsic timescale is log-transformed; a selection of four of the 36 neurotransmitter receptor maps are shown here14,61,62,63,64; and the genomic gradient is upsampled to the fsaverage 10k surface (for accessing raw and processed Allen Human Brain Atlas data, see https://abagen.readthedocs.io/en/stable/28). 5-HT1a, 5-hydroxytryptamine receptor 1A; CBF, cerebral blood flow; CBV, cerebral blood volume; CMRGlu, glucose metabolism; CMRO2, oxygen metabolism; M1, muscarinic receptor 1; mGluR5, metabotropic glutamate receptor 5; MOR, μ-opioid receptor; NIH, National Institutes of Health; PC1, first principal component; PNC, Philadelphia Neurodevelopmental Cohort; T1w/T2w, T1-weighted/T2-weighted MRI.
The neuromaps toolbox enables the contextualization of brain maps to a range of molecular, structural, temporal and functional features. This will facilitate an expansion of research questions and enable researchers to bridge brain topographies across several spatial scales and across disciplines outside of their immediate scope25. Importantly, the included brain maps are only the start of the neuromaps data repository. The contribution pipeline lets researchers add vertex- and voxel-level brain maps to the toolbox, pending approval from the maintainers. The data repository will therefore become an increasingly rich resource of structural and functional brain annotations. As the toolbox expands it will become more comprehensive, giving the neuroscience field the power to identify cross-disciplinary associations. Information on contributing brain maps can be found in the online documentation for the software (https://netneurolab.github.io/neuromaps/).
Transformations between coordinate systems
Despite the multiscale, multimodal collection of brain phenotypes in neuromaps, data cannot be readily compared with one another because they exist in different native coordinate systems. Indeed, a common challenge when relating neuroimaging data to the broader literature is finding a common coordinate space or parcellation in which to conduct the analyses. The neuromaps module provides transformations between four supported coordinates systems as well as a standardized set of functions for their application (Supplementary Table 2). Transformation between volumetric- and surface-based coordinate systems relies on a registration fusion framework (Fig. 3a; ref. 35), whereas transformations between surface-based coordinate systems use a multimodal surface matching (MSM) framework (Fig. 3b; refs. 36,37). We leverage tools from the Connectome Workbench to provide functionality for applying transformations between surface systems; however, users do not need to interact directly with these Workbench commands. In addition to transforming individual annotations, the neuromaps software package includes functionalities that receive two brain maps in different spaces as input and return both brain maps in the same space. By default, neuromaps returns the brain maps in the space of the lower-resolution map, which ensures that neuromaps does not artificially create upsampled data. Collectively, the neuromaps toolbox implements robust transformations between coordinate systems to facilitate the standardization of neuroimaging workflows (Fig. 3c,d).

a, Registration fusion provides a framework for directly projecting group-level volumetric data onto a surface. Here, a probabilistic atlas for the central sulcus35 has been projected independently onto the CIVET (41k), fsLR (32k) and fsaverage (164k) surfaces. b, MSM provides a framework for aligning spherical surface meshes. Here, we show sulcal depth information (originally defined in fsLR space) on spherical meshes that are aligned across the different coordinate systems, where each row represents a different coordinate system and each column represents the space to which that system is aligned. c, Example of a volumetric brain map (the first principal component of cognitive terms from NeuroSynth34) that has been transformed to all surface-based coordinate systems using alignments derived from registration fusion. d, Example of a surface brain map (the first principal component of gene expression from the Allen Human Brain Atlas7) that has been transformed to all other surface-based coordinate systems using alignments derived from MSM. Note that because the original data are represented on the cortical surface, transformation to volumetric space is ill-defined and therefore not shown here.
Spatial null models for comparing brain maps
The primary goal for transforming maps to a common coordinate system is to statistically compare their spatial topographies. The neuromaps software package uses a flexible framework for examining relationships between brain maps, offering researchers the ability to provide their own image similarity metric or function, and handles any missing data. By default, the primary map comparison workflows use the standard Pearson correlation to test the association between provided maps. The neuromaps comparison workflow also integrates multiple methods of performing spatial permutations for significance testing.
Multiple spatial null model frameworks enable statistical comparison between brain maps while accounting for spatial autocorrelation4,38,39,40,41,42,43,44; however, the implementation of these models varies and, to date, there has been limited effort to provide a standardized interface for their use. We have incorporated nine null models into the neuromaps toolbox and offer a common user interface for each model that can be integrated with other aspects of the toolbox. Given the computational overhead of these models, our implementations offer mechanisms for caching intermediate results to enable faster re-use across multiple analyses. Spatial null models are enabled by default in the primary map comparison workflows to encourage their broader adoption. Based on prior work that benchmarks the accuracy and computational efficiency of these models45, we set the non-parametric method as the default for use with surface data38 and the parameterized generative method as the default for use with volumetric data43.
Demonstrating the neuromaps toolbox
To demonstrate the utility of neuromaps we applied three separate analytic workflows that offer neuroscientific insights. First, we applied the neuromaps toolbox to a volumetric map of cortical thinning derived from comparing T1-weighted MRI scans from n = 133 patients with chronic schizophrenia to the T1-weighted MRI scans from n = 113 controls from the Northwestern University Schizophrenia Data and Software Tool (NUSDAST) dataset46 (Fig. 4a). We estimate cortical thinning by applying deformation-based morphometry to T1-weighted MRI scans to calculate the extent of gray matter expansion or contraction in patients relative to controls47. We used the neuromaps transformation functions to convert the MNI-152 volumetric schizophrenia brain map (‘source map’) to the surface space of each of 13 selected brain maps from neuromaps (‘target maps’). Next, we correlate the transformed schizophrenia map with each of these 13 target maps (Pearson’s r) and test the significance using a spatial autocorrelation-preserving null model (‘spin test’)38 and false discovery rate correction48. We find that schizophrenia-related cortical thinning is enriched in areas with the greatest neurodevelopmental expansion (rNIH = 0.26, Pspin = 0.001; rPNC = 0.29, Pspin = 0.001), consistent with the notion that schizophrenia is a neurodevelopmental disease that affects adolescent development49,50. By contrast, we find no evidence to support recent claims that schizophrenia targets specific parts of the unimodal–transmodal processing hierarchy (rfunctional gradient = −0.08, Pspin = 0.35; refs. 51,52).

To demonstrate the utility of neuromaps we use the toolbox to transform, profile and quantitatively assess structural and functional enrichment for two example brain maps (that is, source maps). a, A volumetric map of cortical thinning in patients diagnosed with chronic schizophrenia from the NUSDAST repository (n = 133 patients versus n = 113 controls46) was estimated by applying deformation-based morphometry to T1-weighted MRI scans to calculate the extent of gray matter expansion or contraction in patients relative to controls47. Warm colors represent regions with greater thinning. The map was transformed to the native space of each brain map to which it was correlated (that is, the target maps). b, A surface-based brain map of structural evolutionary expansion represents the ratio of the surface area in humans to that of macaques, as computed using interspecies surface-based registration19. Warm colors indicate regions with greater evolutionary expansion. This map (the source map) was transformed to the native space of each brain map to which it was correlated. Spatial Pearson’s correlations were assessed against a two-sided spatial autocorrelation-preserving null model (‘spin test’)38. Points represent the empirical Pearson’s correlation between source and target maps (with significance defined as Pspin < 0.05). In the boxplots the ends of the boxes represent the first (25%) and third (75%) quartiles, the center line (median) represents the second quartile of the null distribution (n = 1,000 rotations), the whiskers represent the non-outlier end-points of the distribution, and open circles represent outliers. All correlations were corrected for multiple comparisons48.
Next, we applied the same analytic workflow to a surface-based brain map of evolutionary expansion (already included in neuromaps), which represents cortical surface area expansion from macaque to human19 (Fig. 4b). Contextualizing this source map with respect to the other 12 selected target maps from the toolbox, we find that areas with the greatest evolutionary expansion have the greatest interindividual variability of regional functional connectivity profiles (r = 0.58, Pspin = 0.005; ref. 33). This is consistent with the notion that the greatest interindividual differences in brain structure and function are in phylogenetically more recent transmodal cortex53. Moreover, we find significant negative correlations with the first principal component of gene expression (r = −0.51, Pspin = 0.027) and intracortical myelin (r = −0.46, Pspin = 0.005), consistent with the idea that phylogenetically newer cortex is characterized by divergence from genomic gradients and canonical stimulus–response circuit configurations54. We also find that the map is negatively correlated with cerebral blood volume, which suggests that phylogenetic adaptation is concomitant with greater metabolic efficiency (r = −0.37, Pspin = 0.003). Collectively, these two examples show how the neuromaps toolbox can be used to rigorously generate comprehensive structural and functional annotation enrichment profiles.
Finally, we analyzed a sample of 20 brain maps from the published literature over the past decade (2011–2021), including two microstructural, four metabolic, three functional, four expansion, six band-specific electrophysiological signal power, and one genomic map. We then used neuromaps to transform these maps from their original representation to the space defined by each of four standard coordinate systems, for a total of seven different representations (Fig. 2). Finally, we computed the pairwise correlations between all maps in each of the systems and assessed the statistical significance of these relationships using spatial null models. The goal of this analysis was twofold. First, we sought to assess the extent to which coordinate transforms could influence map-to-map comparisons. Second, given the growing interest in how these system-level maps or ‘gradients’ are related to one another, we sought to assess patterns of relationships among them53,55.
For most map-to-map comparisons the choice of coordinate system has a minimal effect: correlation coefficients on average change only by ∣r∣ = 0.018 (variance of absolute difference, 0.0002; range, −0.10 to 0.079). This is demonstrated by map-to-map correlation matrices (Fig. 5a) and the distribution of correlation changes (Δr) between pairs of brain annotations in different coordinate spaces (Fig. 5b). Specifically, for a given pair of brain annotations we compute their correlation in the six available surface spaces and resolutions. Next, we plot the distribution of correlation differences between each space and a constant space. Each histogram represents the distribution when a different coordinate space and resolution is defined as the constant space. Although the changes are minimal, there are instances in which associations between maps are statistically significant in one coordinate system and not significant in another. For example, the correlation between the functional gradient and National Institutes of Health (NIH) allometric scaling are significantly correlated in CIVET 41k space (r = 0.223, two-sided Pspin = 0.049) but non-significantly correlated in fsLR 32k space (r = 0.217, two-sided Pspin = 0.097) (Fig. 5c). However, in most cases the P value for these relationships was close to the statistical alpha (that is, P ≤ 0.05) such that the actual effect size changed only by r ≤ 0.10. These results are encouraging and suggest that transforming brain annotations between different systems generally preserves their relationships.

a, Correlation matrices for 20 brain maps in the neuromaps toolbox for each of the surface-based coordinate systems. Because transformations from surface-based to volumetric systems are ill-defined for continuous data we omit those associations. The 20 brain maps are shown in panel d. b, For each coordinate space and resolution, we show the distribution of correlation changes (Δr) when two brain maps (across all pairs of brain maps) are correlated in the given coordinate space versus all other spaces. c, An example of two brain maps (the principal functional gradient from ref. 32 and allometric scaling from ref. 22), the association between which is significant in one system (CIVET 41k; Pearson’s r = 0.223, two-sided Pspin = 0.049) and not in another (fsLR 32k; Pearson’s r = 0.217, two-sided Pspin = 0.097). d, A spring-embedded representation of the correlation matrix for the 20 brain maps, shown here for the fsLR 32k system.
Across all examined systems we find that the brain maps tend to form two distinct clusters (Fig. 5d) that largely recapitulate previously established relationships involving anterior–posterior and unimodal–transmodal axes of variation17,32,56. One cluster contains maps including the T1-weighted/T2-weighted MRI ratio57, the principal component of gene expression4,28, cerebral blood flow and metabolic glucose uptake10, whereas the other is composed of maps such as the principal functional gradient32, intersubject functional variability33 and developmental and evolutionary expansion19. This suggests that these brain phenotypes reflect a fundamental organizational principle of the human brain.
Discussion
Technological and data sharing advances have increasingly moved neuroscience research towards integrative questions rooted in data science. Imaging, recording, tracing and sequencing technology offer an ability to quantify multiple features of neuroanatomy and function with unprecedented detail and depth. Easing the standardization and computation of such comparisons is necessary to ensure that new datasets can be integrated into our broader understanding of the human brain25. As the neuromaps toolbox is adopted by the community, annotations from emerging technologies and datasets can be added by users. This will enable maps to be systematically contextualized with respect to multiple canonical annotations from diverse data types and disciplines, resulting in standardized reporting of results, and inspiration for mechanistic follow-up. Ultimately, neuromaps is a step towards integrative analytics for multimodal, multiscale neuroscience.
Given the proliferation of such datasets in recent years, a large body of work has arisen focused on investigating similarities across brain maps17,18,39,41,56,58,59. Indeed, researchers have observed substantial concordance in the spatial topology of brain maps derived from a wide variety of phenotypes, suggesting that these maps may reflect a fundamental organizational principle of the human brain. The unimodal–transmodal, or sensory–association, axis is increasingly recognized as a low-dimensional representation of brain organization6,53,60. However, large-scale analyses will facilitate comprehensive comparisons across multiple brain systems. The question of how gradients representing multiple scales of structural and functional organization interact is an exciting new area of research that can now be addressed using neuromaps.
One consideration that researchers must be aware of when using the neuromaps toolbox is that the provided transformations between coordinate systems are meant to be applied to group-level data; however, in general, when subject-level data are available it is better to reprocess them in the desired coordinate system rather than transforming group-level aggregate data. Unfortunately, in practice, subject-level data for many commonly used brain maps are not available to researchers, and therefore having high-quality transformations between systems is critical to ensuring that analyses are performed in the most accurate manner possible. We have based the provided transformations on state-of-the-art frameworks (that is, registration fusion and multimodal surface matching), which have been rigorously assessed and validated on other datasets35,36,37. Nonetheless, subject-level data that have been registered to a template space can benefit from the functionalities of neuromaps. For example, subject-level data can be contextualized against the neuromaps library to produce a subject-specific ‘fingerprint’ of how the individual expresses different structural and functional brain phenotypes. As new frameworks arise for mapping between coordinate systems we will endeavor to provide updated transformations when possible.
Altogether, the current report introduces an open-source Python package, neuromaps, for use in human brain mapping research. As the rate at which new brain maps are generated in the field continues to grow, we hope that neuromaps will provide researchers with a set of standardized workflows to better understand what these data can tell us about the human brain.
Methods
Human Connectome Project
Generating transformations between coordinate systems requires high-quality data from a large cohort of individuals; for the transformations in the neuromaps toolbox we use data from the Human Connectome Project (HCP29). Raw T1- and T2-weighted structural MRI data were downloaded for n = 1,113 subjects (507 male, age 22–35 years) from the HCP S1200 release, for which informed consent was obtained. After data processing and omission of subjects whose data were not successfully processed using the CIVET pipeline, n = 1,045 subjects remained.
Human Connectome Project processing pipeline
All structural data were preprocessed using the HCP minimal preprocessing pipelines29,65. In brief, T1- and T2-weighted MRI scans were corrected for gradient non-linearity and, when available, images were co-registered and averaged across repeated scans for each individual. Corrected T1-weighted and T2-weighted images were co-registered and cortical surfaces were extracted using FreeSurfer 5.3.0-HCP2,66. Subject-level surfaces were aligned to one another using an MSM procedure (MSMAll)30.
CIVET processing pipeline
Images were separately processed with the minc-bpipe-library (https://github.com/CoBrALab/minc-bpipe-library), which performs N4 bias correction, cropping of the neck region, and brain mask generation. Outputs of minc-bpipe-library were then processed through the CIVET pipeline (v2.1.0, ref. 67), which performs non-linear registration to the MNI International Consortium for Brain Mapping (ICBM) 152 volumetric template, cortical surface extraction, and registration of subject surface meshes to the MNI ICBM 152 surface template. Due to CIVET processing failures the data for n = 68 subjects were omitted from further analysis.
Standard coordinate systems
Here, we describe in brief the four standard coordinate systems (one volumetric and three surface) considered in the current report. Although other coordinate systems are used in neuroimaging research, these four arguably represent the most commonly used systems in the published literature.
The MNI-152 system
A significant body of work has been dedicated to explaining what is meant when researchers refer to ‘MNI-152 space’, given that several variations of this space exist depending on the choice of template68. In addition to variations on the MNI-152 template, there exist many other MNI spaces that differ from one another sufficiently to affect downstream analyses69. Here, we use the MNI-152 space as defined by the template from the University of Minnesota–Washington University Human Connectome Project group29, which is a variation of the MNI ICBM 152 non-linear sixth generation symmetric template (identical to the MNI template provided with the FSL distribution70). This template was selected because it is the default template in HCP processing pipelines, of which some were used to generate transformations between coordinate systems. This template was created by averaging the T1-weighted MRI scans of 152 healthy young adults that had been linearly and non-linearly (over six iterations) transformed to a symmetric model in Talairach space.
Note, however, that volumetric data are often available in other MNI-152 templates. neuromaps does not currently host functions for transforming between MNI-152 templates (but see https://figshare.com/articles/dataset/MNI_T1_6thGen_NLIN_to_MNI_2009b_NLIN_ANTs_transform/3502238 for transformations between the MNI-152 sixth generation template and the MNI-152 2009b non-linear template). Nonetheless, the transformation functionalities can be applied to data in other MNI-152 templates. These transformations ignore the differences between MNI-152 templates and should therefore be used only when data cannot be registered to the HCP MNI-152 template and if it suits the specific research aim.
The fsaverage system
The fsaverage system, used by FreeSurfer, represents data on the fsaverage template, a triangular surface mesh created via the spherical registration of 40 individuals using an energy minimization algorithm to align surface-based features (for example, convexity; refs. 66,71). In current distributions of FreeSurfer there are five scales of the fsaverage template (fsaverage and fsaverage3–6), ranging in density from 642 to 163,842 vertices per hemisphere. The fsaverage system is roughly aligned to the space of the MNI-305 volumetric system, which was the precursor of the MNI-152 template72,73.
The fsLR system
The fsLR coordinate system was created to overcome perceived shortcomings of the fsaverage system: namely, hemispheric asymmetry74. That is, the left and right hemispheres of the fsaverage surface are not in geographic correspondence, such that vertex A in the left hemisphere does not correspond to the same brain region as vertex A in the right hemisphere. The fsLR atlas was created by aligning the two hemispheres of the fsaverage surface into a common hybrid surface, using landmark surface-based registration (originally called the ‘fs_LR hybrid atlas’). fsLR templates are available in densities ranging from 32,492 to 163,842 vertices per hemisphere.
The CIVET system
The coordinate system used by the CIVET software is a group-averaged surface reconstruction of the individual-participant volumes comprising the volumetric MNI ICBM 152 non-linear sixth generation template75,76. In its most commonly used format each hemisphere is represented by 41,962 vertices; a high-resolution version with 163,842 vertices per hemisphere is also available. Because this system is derived from the volumetric MNI template, it ensures that aligned surfaces have good correspondence with volumetric images in the MNI-152 system.
Generating transformations between systems
Transformation of individual data to a common coordinate system is often performed to account for anatomical differences between individual subjects prior to group aggregation, and makes derived maps more comparable across datasets72,77. Data collected from MRI are traditionally represented as volumetric images and are therefore commonly transformed to a standard ‘population’ image in volumetric space (for example, the MNI ICBM 152 template; refs. 78,79); however, standardized triangular (that is, ‘surface’) meshes are increasingly used to represent data as well (for example, the fsaverage, fsLR and CIVET surfaces66,71,74,76). Transforming individual, subject-level data between different representations and coordinate systems is non-trivial and has been the focus of substantial research over the past several decades36,80,81,82,83,84,85,86,87.
Although there are numerous methods for transforming data between coordinate systems, high-quality mappings for group-averaged data are limited35,88,89. In creating the neuromaps toolbox, we used two previously validated frameworks to generate transformations between all four standard coordinate systems described above (Fig. 3). All of the transformations were generated using unsmoothed anatomical data and are therefore not biased against data that have been smoothed.
Registration fusion framework
Registration fusion is a framework for projecting data between volumetric and surface coordinate systems35,90. In its most well-known implementation, researchers used data from the Brain Genomics Superstruct Project91 to generate non-linear mappings between MNI-152 space and the 164k fsaverage surface35.
Registration fusion works by generating two sets of mappings for a group of subjects: a mapping between each subject’s native image and MNI-152 space, and a mapping between each subject’s native image and fsaverage space. These mappings are concatenated (MNI-152 to native to fsaverage) and then averaged across subjects, yielding a single, high-fidelity mapping that can be applied to new datasets.
Here, we generated mappings via registration fusion between the MNI-152 volumetric and the fsaverage, fsLR and CIVET surface-based coordinate systems using data from the HCP. All mappings used functionality from the Connectome Workbench92 rather than FreeSurfer to ensure standardization of methodology irrespective of the target coordinate systems.
MNI-152 to CIVET
Unlike for the fsaverage and fsLR surfaces, CIVET surfaces are extracted from subject T1-weighted MRI volumes after the images have been transformed to the standard MNI-152 system. As such, there is no need to generate composite mappings for CIVET surfaces as for the other coordinate systems. Instead, we simply computed the mapping from each subject’s MNI-152-transformed T1-weighted MRI volume to the subject’s native CIVET surface, and then applied the CIVET-generated surface resampling to register the mapping to the CIVET standard template system. These mappings were then averaged across subjects to generate a single, group-level transformation.
fsaverage, fsLR or CIVET to MNI-152
Although every surface vertex has a corresponding voxel representation in volumetric space, not every voxel has a corresponding vertex representation in surface space. As such, generating transformations from the surface coordinate systems to the MNI-152 volumetric system cannot yield a dense output map. When the current registration fusion framework was proposed35, a nearest neighbors, ribbon-filling approach was adopted to handle this shortcoming; however, this is a viable approach only when applied to label data (that is, integer-based parcellation images). We reproduce this approach for completeness but caution against the application of surface-to-volume projections for continuous data and omit such projections from our analyses.
Multimodal surface matching framework
The MSM framework36,37 aims to align surfaces defined on different meshes using information from various descriptors of brain structure and function. This procedure has been previously used to generate mappings between the fsaverage and fsLR coordinate systems.
Here, we used MSM to generate a mapping between the CIVET and fsLR systems by aligning HCP subject data processed through the CIVET pipeline with the same data processed through the HCP processing pipeline. Given that MSM requires that input data be provided on spherical surface meshes (a representation not produced in the standard CIVET pipeline) we used FreeSurfer functionality to generate spherical mesh representations and sulcal depth information for each subject’s CIVET-derived white matter surfaces. We used these spherical meshes and sulcal depth measurements to drive alignment between the CIVET and fsLR systems via two rounds of the MSM procedure. The first round was used to generate a rotational affine transform to align gross features of the CIVET and fsLR systems; the generated affines were averaged across all subjects and used to seed a second round of finer resolution alignment, similar to the procedure previously described37. The final, aligned subject-level spherical surfaces defined in the CIVET system were averaged to create a single, group-level surface that could be used in future transformations.
The CIVET-to-fsaverage mapping was generated as the composite of the transformations between the CIVET-and-fsLR and fsLR-and-fsaverage systems.
Parcellations
Performing analyses at the voxel or vertex level can be computationally intensive. The neuromaps software package can be extended to parcellated data and also integrates tools for parcellating volumetric and surface-based data. The base parcellating function assumes that the given parcellation indexes each region with a unique value, where values of 0 are considered background and ignored. Helper functions are provided to flexibly handle alternative parcellation formats. For example, surface parcellations are often defined in separate left–right GIFTI files for which the same identification numbers are used across both hemispheres, even though each hemisphere has unique parcels. In this case, the user can relabel the parcellation identification numbers such that they are consecutive across hemispheres. This default format was selected to keep surface and volumetric parcellations consistent, and to avoid confusion when hemispheres are not symmetric.
Published brain maps
We curated a selection of brain maps from the published literature of the past decade (Fig. 2). Maps were obtained in their original coordinate system, with the exception of the genomic gradient derived from the Allen Human Brain Atlas. The Allen Human Brain Atlas samples across the surface were upsampled to the fsaverage 10k surface using a k-nearest neighbors interpolation before applying principal component analysis. A complete list of maps and their coordinate systems is given in Supplementary Table 1. Some of these maps were originally defined in coordinate systems that are no longer used. In brief, we describe the transformations we used to project these maps to one of the current standard coordinate systems.
PALS-TA24 to fsLR
Data obtained from ref. 19 were originally aligned to a study-specific PALS-TA24 template (derived using a similar landmark-based procedure to the PALS-B12 template93), which has been supplanted by the fsLR coordinate system. To project data from the PALS-TA24 template to the fsLR system we applied the deformation map provided by the original researchers for transforming data between these spaces using nearest neighbors interpolation.
CIVET v1 to v2
The maps obtained from ref. 22 were originally created using surface templates from CIVET v1.1.12; however, with the release of CIVET v2.0.0 in 2014 the population surface templates provided with the CIVET distribution were updated, effectively rendering the older templates redundant. To project data from the CIVET v1.1.12 templates to the CIVET v2.0.0 templates we used a nearest neighbors interpolation, matching vertex coordinates in the newer template to coordinates in the older template and assigning the value corresponding to the closest vertex22.
Spatial null frameworks
Recent research has consistently highlighted the importance of spatially constrained null models when statistically comparing brain maps38,43,45. The neuromaps software package integrates nine different spatial null frameworks45. These include six spatial permutation models and three parametrized data models, which, collectively, can be constructed for surface-based, volumetric and parcellated data4,38,39,40,41,42,43,44. Note that four of the null models are adaptations of the original spatial permutation framework38 when applied to parcellated data39,40,41,42. These frameworks differ in how they reassign the medial wall (for which most brain maps contain no data), whether that be by discarding missing data41,42, ignoring the medial wall entirely40 or reassigning missing data to the nearest parcel39. The three parametrized data models circumvent spatial rotations by applying generative frameworks such as a spatial lag model4, spectral randomization44 or variogram matching43.
For analyses in the current report using surface-based coordinate systems, we apply the original spatial permutation framework procedure38; for analyses using volumetric systems we apply the variogram-matching method43. Null distributions were systematically derived from 1,000 null maps generated by each framework. The mechanism for each null framework used for analyses in the present work is described in brief in the following sections.
Spatial permutation null model
The spatial permutation procedure used in the present report generates spatially constrained null distributions by applying random rotations to spherical projections of a cortical surface38. A rotation matrix (R) is applied to the three-dimensional coordinates of the cortex (V) to generate a set of rotated coordinates (Vrot = VR). The permutation is constructed by replacing the original values at each coordinate with those of the closest rotated coordinate. Rotations are generated independently for one hemisphere and then mirrored across the anterior–posterior axis for the other.
Variogram estimation null model
The parametric model used in the present report operates in two main steps: first the values in a given image are randomly permuted, then the permuted values are smoothed and re-scaled to reintroduce spatial autocorrelation characteristic of the original, non-permuted data43. Reintroduction of spatial autocorrelation onto the permuted data is achieved via the transformation \({{{\bf{y}}}}=| \beta {| }^{1/2}{{{\bf{x}}}}^{\prime} +| \alpha {| }^{1/2}{{{\bf{z}}}}\), where \({{{\bf{x}}}}^{\prime}\) is the permuted data, \({{{\bf{z}}}} \sim {{{\mathcal{N}}}}(0,1)\) is a vector of random Gaussian noise, and α and β are estimated via a least-squares optimization between variograms of the original and permuted data.
Assessing the impact of coordinate system
When transforming two datasets (that is, a source and target dataset) defined in distinct coordinate spaces to a common system there are at least three options available: transform the source dataset to the system of the target, transform the target dataset to the system of the source, or transform both source and target datasets to an alternate system. If comparisons are being made across several pairs of datasets a fourth option becomes available: always transform the higher resolution dataset to the system of the lower-resolution dataset.
To examine whether the choice of coordinate system affects statistical relationships estimated between brain maps we performed several analyses. First, we transformed a selection of 20 brain maps into every other coordinate system (for example, fsaverage → fsLR, CIVET and MNI-152, fsLR → fsaverage, CIVET and MNI-152, and so on). We then correlated every pair of these brain maps according to each of the four possible resampling options described above. When transforming both source and target datasets to an alternate system (option 3 above), we comprehensively tested every target coordinate system and data resolution. Spatial null models were used to assess the significance of all of the correlations.
Reporting summary
Further information on research design is available in the Nature Research Reporting Summary linked to this article.
Data availability
Data used in the present analyses are publicly available on GitHub (https://github.com/netneurolab/neuromaps). The schizophrenia deformation-based morphometry map used in Fig. 4 is derived from the Northwestern University Schizophrenia Data and Software Tool dataset available at https://central.xnat.org/. The Human Connectome Project database is available at https://db.humanconnectome.org/data/projects/HCP_1200.
Code availability
All code used for data processing, analysis and figure generation directly relies on the following open-source Python packages: BrainSMASH43, BrainSpace44, IPython94, Jupyter95, Matplotlib96, NiBabel97, Nilearn98, NumPy99,100, Pandas101, PySurfer102, Scikit-learn103, SciPy104, Seaborn105 and SurfPlot (https://github.com/danjgale/surfplot106). Additional software used in the reported analyses includes CIVET (v2.1.1, http://www.bic.mni.mcgill.ca/ServicesSoftware/CIVET63), FreeSurfer (v6.0.0, http://surfer.nmr.mgh.harvard.edu/67) and the Connectome Workbench (v1.5.0, https://www.humanconnectome.org/software/connectome-workbench88). Source code for neuromaps is available on GitHub (https://github.com/netneurolab/neuromaps) and is provided under the Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License (CC-BY-NC-SA; https://creativecommons.org/licenses/by-nc-sa/4.0/). We have integrated neuromaps with Zenodo, which generates unique digital object identifiers (DOIs) for each new release of the toolbox. Researchers can install neuromaps as a Python package via the PyPi repository (https://pypi.org/project/neuromaps) and can access comprehensive online documentation via GitHub Pages (https://netneurolab.github.io/neuromaps). The neuromaps toolbox is also available as a Docker container (https://hub.docker.com/r/netneurolab/neuromaps/tags), which ensures that the toolbox remains functional even as dependencies are updated and changed. Finally, as an open-source toolbox, neuromaps is open to user suggestions and improvements, ensuring that it remains an evolving resource.
References
Bethlehem, R. A. et al. Brain charts for the human lifespan. Nature 604, 525–533 (2022).
Dale, A. M., Fischl, B. & Sereno, M. I. Cortical surface-based analysis: I. Segmentation and surface reconstruction. Neuroimage 9, 179–194 (1999).
Glasser, M. F. & Van Essen, D. C. Mapping human cortical areas in vivo based on myelin content as revealed by T1- and T2-weighted MRI. J. Neurosci. 31, 11597–11616 (2011).
Burt, J. B. et al. Hierarchy of transcriptomic specialization across human cortex captured by structural neuroimaging topography. Nat. Neurosci. 21, 1251–1259 (2018).
Whitaker, K. J. et al. Adolescence is associated with genomically patterned consolidation of the hubs of the human brain connectome. Proc. Natl Acad. Sci. USA 113, 9105–9110 (2016).
Huntenburg, J. M. et al. A systematic relationship between functional connectivity and intracortical myelin in the human cerebral cortex. Cereb. Cortex 27, 981–997 (2017).
Hawrylycz, M. et al. An anatomically comprehensive atlas of the adult human brain transcriptome. Nature 489, 391–399 (2012).
Akbarian, S. et al. The PsychENCODE project. Nat. Neurosci. 18, 1707–1712 (2015).
Scholtens, L. H., de Reus, M. A., de Lange, S. C., Schmidt, R. & van den Heuvel, M. P. An MRI Von Economo–Koskinas atlas. Neuroimage 170, 249–256 (2018).
Vaishnavi, S. N. et al. Regional aerobic glycolysis in the human brain. Proc. Natl Acad. Sci. USA 107, 17757–17762 (2010).
Zilles, K. & Palomero-Gallagher, N. Multiple transmitter receptors in regions and layers of the human cerebral cortex. Front. Neuroanat. 11, 78 (2017).
Beliveau, V. et al. A high-resolution in vivo atlas of the human brain’s serotonin system. J. Neurosci. 37, 120–128 (2017).
Nørgaard, M. et al. A high-resolution in vivo atlas of the human brain’s benzodiazepine binding site of GABAA receptors. Neuroimage 232, 117878 (2021).
Hansen, J. Y. et al. Mapping neurotransmitter systems to the structural and functional organization of the human neocortex. Preprint at https://doi.org/10.1101/2021.10.28.466336 (2021).
Wagstyl, K. et al. Bigbrain 3D atlas of cortical layers: cortical and laminar thickness gradients diverge in sensory and motor cortices. PLoS Biol. 18, e3000678 (2020).
Murray, J. D. et al. A hierarchy of intrinsic timescales across primate cortex. Nat. Neurosci. 17, 1661–1663 (2014).
Shafiei, G. et al. Topographic gradients of intrinsic dynamics across neocortex. Elife 9, e62116 (2020).
Gao, R., van den Brink, R. L., Pfeffer, T. & Voytek, B. Neuronal timescales are functionally dynamic and shaped by cortical microarchitecture. Elife 9, e61277 (2020).
Hill, J. et al. Similar patterns of cortical expansion during human development and evolution. Proc. Natl Acad. Sci. USA 107, 13135–13140 (2010).
Wei, Y. et al. Genetic mapping and evolutionary analysis of human-expanded cognitive networks. Nat. Commun. 10, 4839 (2019).
Xu, T. et al. Cross-species functional alignment reveals evolutionary hierarchy within the connectome. Neuroimage 223, 117346 (2020).
Reardon, P. et al. Normative brain size variation and brain shape diversity in humans. Science 360, 1222–1227 (2018).
Gorgolewski, K. J. et al. NeuroVault.org: a repository for sharing unthresholded statistical maps, parcellations, and atlases of the human brain. Neuroimage 124, 1242–1244 (2016).
Van Essen, D. C. et al. The Brain Analysis Library of Spatial maps and Atlases (BALSA) database. Neuroimage 144, 270–274 (2017).
Voytek, J. B. & Voytek, B. Automated cognome construction and semi-automated hypothesis generation. J. Neurosci. Methods 208, 92–100 (2012).
Reimand, J. et al. Pathway enrichment analysis and visualization of omics data using g:Profiler, GSEA, Cytoscape and EnrichmentMap. Nat. Protoc. 14, 482–517 (2019).
Baryshnikova, A. Systematic functional annotation and visualization of biological networks. Cell Syst. 2, 412–421 (2016).
Markello, R. D. et al. Standardizing workflows in imaging transcriptomics with the abagen toolbox. Elife 10, e72129 (2021).
Van Essen, D. C. et al. The WU-Minn Human Connectome Project: an overview. Neuroimage 80, 62–79 (2013).
Glasser, M. F. et al. A multi-modal parcellation of human cerebral cortex. Nature 536, 171–178 (2016).
Tadel, F., Baillet, S., Mosher, J. C., Pantazis, D. & Leahy, R. M. Brainstorm: a user-friendly application for MEG/EEG analysis. Comput. Intell. Neurosci. 2011, 879716 (2011).
Margulies, D. S. et al. Situating the default-mode network along a principal gradient of macroscale cortical organization. Proc. Natl Acad. Sci. USA 113, 12574–12579 (2016).
Mueller, S. et al. Individual variability in functional connectivity architecture of the human brain. Neuron 77, 586–595 (2013).
Yarkoni, T., Poldrack, R. A., Nichols, T. E., Van Essen, D. C. & Wager, T. D. Large-scale automated synthesis of human functional neuroimaging data. Nat. Methods 8, 665–670 (2011).
Wu, J. et al. Accurate nonlinear mapping between MNI volumetric and FreeSurfer surface coordinate systems. Hum. Brain Mapp. 39, 3793–3808 (2018).
Robinson, E. C. et al. MSM: a new flexible framework for multimodal surface matching. Neuroimage 100, 414–426 (2014).
Robinson, E. C. et al. Multimodal surface matching with higher-order smoothness constraints. Neuroimage 167, 453–465 (2018).
Alexander-Bloch, A. F. et al. On testing for spatial correspondence between maps of human brain structure and function. Neuroimage 178, 540–551 (2018).
Vázquez-Rodríguez, B. et al. Gradients of structure–function tethering across neocortex. Proc. Natl Acad. Sci. USA 116, 21219–21227 (2019).
Váša, F. et al. Adolescent tuning of association cortex in human structural brain networks. Cereb. Cortex 28, 281–294 (2018).
Baum, G. L. et al. Development of structure–function coupling in human brain networks during youth. Proc. Natl Acad. Sci. USA 117, 771–778 (2020).
Cornblath, E. J. et al. Temporal sequences of brain activity at rest are constrained by white matter structure and modulated by cognitive demands. Commun. Biol. 3, 261 (2020).
Burt, J. B., Helmer, M., Shinn, M., Anticevic, A. & Murray, J. D. Generative modeling of brain maps with spatial autocorrelation. Neuroimage 220, 117038 (2020).
Vos de Wael, R. et al. BrainSpace: a toolbox for the analysis of macroscale gradients in neuroimaging and connectomics datasets. Commun. Biol. 3, 103 (2020).
Markello, R. D. & Misic, B. Comparing spatial null models for brain maps. Neuroimage 236, 118052 (2021).
Kogan, A., Alpert, K., Ambite, J. L., Marcus, D. S. & Wang, L. Northwestern University schizophrenia data sharing for SchizConnect: a longitudinal dataset for large-scale integration. Neuroimage 124, 1196–1201 (2016).
Shafiei, G. et al. Spatial patterning of tissue volume loss in schizophrenia reflects brain network architecture. Biol. Psychiatry 87, 727–735 (2020).
Benjamini, Y. & Hochberg, Y. Controlling the false discovery rate: a practical and powerful approach to multiple testing. J. R. Stat. Soc. B 57, 289–300 (1995).
Murray, R. M. & Lewis, S. W. Is schizophrenia a neurodevelopmental disorder?. Br. Med. J. (Clin. Res. Ed.) 295, 681–682 (1987).
Rapoport, J., Giedd, J. & Gogtay, N. Neurodevelopmental model of schizophrenia: update 2012. Mol. Psychiatry 17, 1228–1238 (2012).
Dong, D. et al. Compressed sensorimotor-to-transmodal hierarchical organization in schizophrenia. Psychol. Med., https://doi.org/10.1017/S0033291721002129 (2021).
Dong, D. et al. Compression of cerebellar functional gradients in schizophrenia. Schizophr. Bull. 46, 1282–1295 (2020).
Sydnor, V. J. et al. Neurodevelopment of the association cortices: patterns, mechanisms, and implications for psychopathology. Neuron 109, 2820–2846 (2021).
Buckner, R. L. & Krienen, F. M. The evolution of distributed association networks in the human brain. Trends Cogn. Sci. 17, 648–665 (2013).
Huntenburg, J. M., Bazin, P.-L. & Margulies, D. S. Large-scale gradients in human cortical organization. Trends Cogn. Sci. 22, 21–31 (2018).
Hansen, J. Y. et al. Mapping gene transcription and neurocognition across human neocortex. Nat. Hum. Behav. 5, 1240–1250 (2021).
Glasser, M. F., Goyal, M. S., Preuss, T. M., Raichle, M. E. & Van Essen, D. C. Trends and properties of human cerebral cortex: correlations with cortical myelin content. Neuroimage 93, 165–175 (2014).
Wang, P. et al. Inversion of a large-scale circuit model reveals a cortical hierarchy in the dynamic resting human brain. Sci. Adv. 5, eaat7854 (2019).
Demirtaş, M. et al. Hierarchical heterogeneity across human cortex shapes large-scale neural dynamics. Neuron 101, 1181–1194 (2019).
Hilgetag, C. C., Goulas, A. & Changeux, J.-P. A natural cortical axis connecting the outside and inside of the human brain. Network Neuroscience https://doi.org/10.1162/netn_a_00256 (2022).
Kantonen, T. et al. Interindividual variability and lateralization of μ-opioid receptors in the human brain. Neuroimage 217, 116922 (2020).
Naganawa, M. et al. First-in-human assessment of 11C-LSN3172176, an M1 muscarinic acetylcholine receptor PET radiotracer. J. Nucl. Med. 62, 553–560 (2021).
Savli, M. et al. Normative database of the serotonergic system in healthy subjects using multi-tracer PET. Neuroimage 63, 447–459 (2012).
Smart, K. et al. Sex differences in [11C] ABP688 binding: a positron emission tomography study of mGlu5 receptors. Eur. J. Nucl. Med. Mol. Imaging 46, 1179–1183 (2019).
Glasser, M. F. et al. The minimal preprocessing pipelines for the Human Connectome Project. Neuroimage 80, 105–124 (2013).
Fischl, B., Sereno, M. I. & Dale, A. M. Cortical surface-based analysis: II: inflation, flattening, and a surface-based coordinate system. Neuroimage 9, 195–207 (1999).
Ad-Dab’bagh, Y. et al. The CIVET image-processing environment: a fully automated comprehensive pipeline for anatomical neuroimaging research. In Proceedings of the 12th Annual Meeting of the Organization for Human Brain Mapping, Vol. 2266 (2006).
Brett, M., Johnsrude, I. S. & Owen, A. M. The problem of functional localization in the human brain. Nat. Rev. Neurosci. 3, 243–249 (2002).
Li, X. et al. Moving beyond processing and analysis-related variation in neuroscience. Preprint at https://doi.org/10.1101/2021.12.01.470790 (2021).
Jenkinson, M., Beckmann, C. F., Behrens, T. E., Woolrich, M. W. & Smith, S. M. FSL. Neuroimage 62, 782–790 (2012).
Fischl, B., Sereno, M. I., Tootell, R. B. & Dale, A. M. High-resolution intersubject averaging and a coordinate system for the cortical surface. Hum. Brain Mapp. 8, 272–284 (1999).
Evans, A. C. et al. 3D statistical neuroanatomical models from 305 MRI volumes. In 1993 IEEE Conference Record Nuclear Science Symposium and Medical Imaging Conference 1813–1817 (IEEE, 1993).
Evans, A. C., Janke, A. L., Collins, D. L. & Baillet, S. Brain templates and atlases. Neuroimage 62, 911–922 (2012).
Van Essen, D. C., Glasser, M. F., Dierker, D. L., Harwell, J. & Coalson, T. Parcellations and hemispheric asymmetries of human cerebral cortex analyzed on surface-based atlases. Cereb. Cortex 22, 2241–2262 (2012).
Lyttelton, O., Boucher, M., Robbins, S. & Evans, A. An unbiased iterative group registration template for cortical surface analysis. Neuroimage 34, 1535–1544 (2007).
Fonov, V. S., Evans, A. C., McKinstry, R. C., Almli, C. & Collins, D. Unbiased nonlinear average age-appropriate brain templates from birth to adulthood. Neuroimage 47, S102 (2009).
Van Essen, D. C. Windows on the brain: the emerging role of atlases and databases in neuroscience. Curr. Opin. Neurobiol. 12, 574–579 (2002).
Fonov, V. et al. Unbiased average age-appropriate atlases for pediatric studies. Neuroimage 54, 313–327 (2011).
Mazziotta, J. et al. A probabilistic atlas and reference system for the human brain: International Consortium for Brain Mapping (ICBM). Philos. Trans. R. Soc. Lond. B Biol. Sci. 356, 1293–1322 (2001).
Ashburner, J. & Friston, K. J. Nonlinear spatial normalization using basis functions. Hum. Brain Mapp. 7, 254–266 (1999).
Collins, D. L., Neelin, P., Peters, T. M. & Evans, A. C. Automatic 3D intersubject registration of MR volumetric data in standardized Talairach space. J. Comput. Assist. Tomogr. 18, 192–205 (1994).
Hamm, J., Ye, D. H., Verma, R. & Davatzikos, C. GRAM: a framework for geodesic registration on anatomical manifolds. Med. Image Anal. 14, 633–642 (2010).
Nenning, K.-H. et al. Diffeomorphic functional brain surface alignment: functional demons. Neuroimage 156, 456–465 (2017).
Rueckert, D. et al. Nonrigid registration using free-form deformations: application to breast MR images. IEEE Trans. Med. Imaging 18, 712–721 (1999).
Tong, T., Aganj, I., Ge, T., Polimeni, J. R. & Fischl, B. Functional density and edge maps: characterizing functional architecture in individuals and improving cross-subject registration. Neuroimage 158, 346–355 (2017).
Woods, R. P., Grafton, S. T., Holmes, C. J., Cherry, S. R. & Mazziotta, J. C. Automated image registration: I. General methods and intrasubject, intramodality validation. J. Comput. Assist. Tomogr. 22, 139–152 (1998).
Yushkevich, P. A., Wang, H., Pluta, J. & Avants, B. B. From label fusion to correspondence fusion: a new approach to unbiased groupwise registration. In 2012 IEEE Conference on Computer Vision and Pattern Recognition 956–963 (IEEE, 2012).
Lancaster, J. L. et al. Bias between MNI and Talairach coordinates analyzed using the ICBM-152 brain template. Hum. Brain Mapp. 28, 1194–1205 (2007).
Laird, A. R. et al. Comparison of the disparity between Talairach and MNI coordinates in functional neuroimaging data: validation of the Lancaster transform. Neuroimage 51, 677–683 (2010).
Buckner, R. L., Krienen, F. M., Castellanos, A., Diaz, J. C. & Yeo, B. T. The organization of the human cerebellum estimated by intrinsic functional connectivity. J. Neurophysiol. 106, 2322–2345 (2011).
Holmes, A. J. et al. Brain Genomics Superstruct Project initial data release with structural, functional, and behavioral measures. Sci. Data 2, 150031 (2015).
Marcus, D. et al. Informatics and data mining tools and strategies for the human connectome project. Front. Neuroinform. 5, 4 (2011).
Van Essen, D. C. A Population-Average, Landmark- and Surface-based (PALS) atlas of human cerebral cortex. Neuroimage 28, 635–662 (2005).
Pérez, F. & Granger, B. E. IPython: a system for interactive scientific computing. Computing in Science and Engineering 9, 21–29 (2007).
Kluyver, T. et al. Jupyter Notebooks: A publishing format for reproducible computational workflows. In Positioning and Power in Academic Publishing: Players, Agents and Agendas (eds Loizides, F. & Schmidt, B.) 87–90 (IOS Press, 2016).
Hunter, J. D. Matplotlib: a 2D graphics environment. Computing in Science and Engineering 9, 90–95 (2007).
Brett, M. et al. nipy/nibabel. Zenodo https://doi.org/10.5281/zenodo.591597 (2019).
Abraham, A. et al. Machine learning for neuroimaging with scikit-learn. Front. Neuroinform. 8, 14 (2014).
Oliphant, T. E. A Guide to NumPy Vol. 1 (Trelgol Publishing USA, 2006).
Van Der Walt, S., Colbert, S. C. & Varoquaux, G. The NumPy array: a structure for efficient numerical computation. Computing in Science and Engineering 13, 22–30 (2011).
McKinney, W. et al. Data structures for statistical computing in Python. In Proceedings of the 9th Python in Science Conference (eds van der Walt, S. & Millman, J.) Vol. 445, 56–61 (2010).
Waskom, M. et al. nipy/pysurfer. Zenodo https://doi.org/10.5281/zenodo.592515 (2020).
Pedregosa, F. et al. Scikit-learn: machine learning in Python. Journal of Machine Learning Research 12, 2825–2830 (2011).
Virtanen, F. et al. Scipy 1.0: fundamental algorithms for scientific computing in Python. Nat. Methods 17, 261–272 (2020).
Waskom, M. et al. mwaskom/seaborn. Zenodo https://doi.org/10.5281/zenodo.592845 (2020).
Gale, D. J., Vos de Wael, R., Benkarim, O. & Bernhardt, B. Surfplot: publication-ready brain surface figures (v0.1.0). Zenodo https://doi.org/10.5281/zenodo.5567926 (2021).
Acknowledgements
R.D.M. acknowledges support from the Fonds de Recherche du Québec – Nature et Technologies and the Canadian Open Neuroscience Platform. J.Y.H. acknowledges support from the Helmholtz International BigBrain Analytics and Learning Laboratory, the Natural Sciences and Engineering Research Council of Canada and the Fonds de Reserche du Québec – Nature et Technologies. S.B. acknowledges support from the National Institutes of Health (NIH) (R01 EB026299), a Discovery Grant from the Natural Science and Engineering Research Council of Canada (436355-13) and the Canadian Institutes of Health Research (CIHR) Canada Research Chair in Neural Dynamics of Brain Systems. T.D.S. acknowledges support from the NIH (R01 MH112847 and R01 MH120482). M.M.C. acknowledges support from the Natural Sciences and Engineering Research Council of Canada, the Canada Research Chairs Program, Healthy Brains for Healthy Lives, and the Fonds du Recherche Québec – Nature et Technologies. B.M. acknowledges support from the Natural Sciences and Engineering Research Council of Canada (NSERC Discovery Grant RGPIN 017-04265), CIHR, the Canada Research Chairs Program, the Healthy Brains for Healthy Lives initiative (HBHL), the Brain Canada Future Leaders Fund and the Michael J. Fox Foundation.
Author information
Authors and Affiliations
Contributions
R.D.M., J.Y.H. and B.M. conceived the study and wrote the manuscript, with valuable revision from all of the authors. R.D.M. developed the software toolbox with help from J.Y.H., Z.-Q.L., V.B., G.S. and L.E.S. J.Y.H. performed the analyses. J.Y.H., G.S., N.B., J.S., S.B., T.D.S., M.M.C. and A.R. contributed data. B.M. was the project administrator.
Corresponding author
Ethics declarations
Competing interests
R.D.M. is currently employed by Octave Bioscience. The work in this study was performed as part of his graduate studies at McGill University and is in no way related to his employment at Octave Bioscience. All other authors have no competing interests.
Peer review
Peer review information
Nature Methods thanks Camille Maumet, Tehila Nugiel and Bradley Voytek for their contribution to the peer review of this work. Peer reviewer reports are available. are available. Primary Handling Editor: Nina Vogt, in collaboration with the Nature Methods team.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Markello, R.D., Hansen, J.Y., Liu, ZQ. et al. neuromaps: structural and functional interpretation of brain maps. Nat Methods 19, 1472–1479 (2022). https://doi.org/10.1038/s41592-022-01625-w
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1038/s41592-022-01625-w
This article is cited by
-
Biophysical models applied to dementia patients reveal links between geographical origin, gender, disease duration, and loss of neural inhibition
Alzheimer's Research & Therapy (2024)
-
Cortical gene expression architecture links healthy neurodevelopment to the imaging, transcriptomics and genetics of autism and schizophrenia
Nature Neuroscience (2024)
-
Temporal dissociation between local and global functional adaptations of the maternal brain to childbirth: a longitudinal assessment
Neuropsychopharmacology (2024)
-
BrainTACO: an explorable multi-scale multi-modal brain transcriptomic and connectivity data resource
Communications Biology (2024)
-
Connectome-based reservoir computing with the conn2res toolbox
Nature Communications (2024)
