
Abstract
Population-based data on COVID-19 are urgently needed. We report on three rounds of probability sample household surveys in the state of Rio Grande do Sul (Brazil), carried out in nine large municipalities using the Wondfo lateral flow point-of-care test for immunoglobulin M and G antibodies against SARS-CoV-2 (https://en.wondfo.com.cn/product/wondfo-sars-cov-2-antibody-test-lateral-flow-method-2/). Before survey use, the assay underwent four validation studies with pooled estimates of sensitivity (84.8%; 95% confidence interval (CI) = 81.4–87.8%) and specificity (99.0%; 95% CI = 97.8–99.7%). We calculated that the seroprevalence was 0.048% (2/4,151; 95% CI = 0.006–0.174) on 11–13 April (round 1), 0.135% (6/4,460; 95% CI = 0.049–0.293%) on 25–27 April (round 2) and 0.222% (10/4,500; 95% CI = 0.107–0.408) on 9–11 May (round 3), with a significant upward trend over the course of the surveys. Of 37 family members of positive individuals, 17 (35%) were also positive. The epidemic is at an early stage in the state, and there is high compliance with social distancing, unlike in other parts of Brazil. Periodic survey rounds will continue to monitor trends until at least the end of September, and our population-based data will inform decisions on preventive policies and health system preparedness at the state level.
Similar content being viewed by others
Main
Despite calls for population-based data on COVID-19 (ref. 1), there have been few household seroprevalence surveys globally, and none in Latin America2. In Rio Grande do Sul, the southernmost state in Brazil (population 11.3 million), the first case of COVID-19 was diagnosed on 29 February 2020. As of 10 June, 12,802 confirmed cases (113 per 1,000,000 inhabitants) and 302 deaths had been reported (http://ti.saude.rs.gov.br/covid19/). In this state, as in the rest of Brazil, only people with moderate to severe symptoms had been tested. The state and most city governments issued strong social distancing policies in mid-March, including closures of schools, shops and services, except for businesses deemed to be essential. Gatherings of more than 100 people were forbidden. Social distancing measures were adopted by most of the population. However, from mid-April onwards, relaxation of social distancing began. While schools and public gatherings remain prohibited, industrial, commercial and services sectors open daily for limited periods of time while staff and customers are required to wear facial masks. Mask use is also compulsory on public transportation and, in some municipalities, for anyone walking or cycling on the streets.
Other than studies based on convenience samples, such as those collected from volunteers, supermarket customers or blood donors, there are few general population surveys available for severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) prevalence. National studies using reverse transcription PCR (RT-PCR) showed prevalences of 0.6% in Iceland3, 0.3% in Austria4 and 0.9% in Sweden5. A national serological survey in Spain found a prevalence of 5.0%, ranging from <2% in some regions to 11.3% in Madrid6. In the Brazilian city of Ribeirão Preto, in the state of São Paulo, the seroprevalence was 1.4% based on the same test used in this paper7.
Smaller studies in hot spots for COVID-19 showed prevalences of 14% in the German city of Gangelt8 and 3% in the Italian village of Vò9. As expected, studies using samples from volunteers found higher prevalence, as was the case for the first study in Iceland (0.9%)3, the population screening in South Korea (2.1%)10 and two studies in California (with prevalences of 1.5% in Santa Clara county11 and 4.1% in Los Angeles County12). The two studies in California and the German survey used point-of-care antibody tests, whereas the other three studies used RT-PCR tests.
Starting on 11–13 April, we began to test the presence of antibodies against SARS-CoV-2 in population-based samples of 500 individuals in each of nine sentinel cities in the state. The same methodology was used in a second round in the same cities on 25–27 April, and again in a third round on 9–11 May. Subsequent rounds are planned to take place every 2 weeks to monitor how the pandemic is evolving.
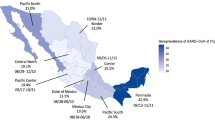
We selected 500 individuals in each of nine cities, including the eight regional hubs in the state, plus the city of Canoas, which is the second most populated city in the metropolitan area after the state capital (Fig. 1). Fifty census tracts were selected in each city, with ten households in each tract. The sample was not intended to be representative of the state’s population, as smaller towns and rural areas were not included. The decision to focus on regional hubs where commerce and services tend to be concentrated was taken to track the progression of the pandemic in the places where the virus was most likely to be introduced in the state.

Inset: location of the state of Rio Grande do Sul in Brazil.
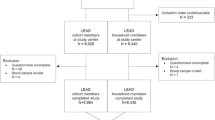
Of the 4,500 individuals we intended to test in each round, it was possible to test 4,151 individuals in the first round, 4,460 in the second and 4,500 in the third. The number of participants in each of the nine cities is provided in Supplementary Table 4. The sample fell short of the planned number in the first and second rounds due to logistical difficulties resulting from the need to complete the survey in a 3-d period. When there was a refusal at a household, it was replaced with the next household in the census tract listing. Refusals were relatively rare: 8.9% in the first round and 7.1% in the third round. The number of households where residents were away increased from 11.0 to 30.3% in the same period.
Self-reported information on sociodemographic variables and social isolation was collected using a questionnaire (available at http://www.rs.epicovid19brasil.org/banco-de-dados/). Table 1 shows the characteristics of individuals who provided blood samples. Participants across the three rounds were similar in terms of sex, age, skin color and schooling. The nine sentinel cities are not representative of the state, and a comparison with state demographics shows that there were higher proportions of women and of older adults among our survey participants. Young children were particularly under-represented.
In the first round, 20.6% of respondents reported leaving home daily, compared with 28.3% in the second round and 30.4% in the third round. Although leaving home did not necessarily mean that they interacted with other people, it may be assumed to have increased the risk of exposure. Those reporting staying at home all of the time comprised 21.1, 18.3 and 16.5% in each of the rounds, respectively. These differences were statistically significant (P = 2.3 × 10−21).
We determined positivity for antibodies to SARS-CoV-2 by using a point-of-care lateral flow test from Wondfo using finger-prick blood samples. This test assays for antibodies of both immunoglobulin M (IgM) and IgG isotypes, without distinction, reactive towards SARS-CoV-2 antigens not specified by the manufacturer or in the literature. According to the manufacturer, the Wondfo antibody test has 86.4% (95% confidence interval (CI) = 82.4–89.6%) sensitivity and 99.6% (95% CI = 97.6–99.9%) specificity. It was one of the two best-performing lateral flow assays of the ten evaluated in a recent pre-print13 and is currently approved for point-of-care testing in China (http://english.nmpa.gov.cn/2020-04/03/c_468570.htm)
As an additional check on how the rapid test performed under fieldwork conditions, we conducted two separate assessments. The first was during the validation study in Porto Alegre, where 83 RT-PCR-positive individuals were tested in the field using the rapid test. As described in the Methods, 64 of these individuals had positive results with the rapid test14. Second, we tested four individuals in the sample who reported having tested positive with RT-PCR in a health facility, three of whom had positive results with the rapid test.
Table 2 shows the seroprevalence estimates. The numbers of positive results were two, six and ten in the three rounds, respectively. There were significant upward time trends in both the absolute and relative analyses. Prevalence in the third round was 0.17 percent points higher than in the first round, or 4.6 times higher. There were 11 individuals with non-conclusive results in the three phases, of whom nine were retested and found to be negative, and the results of two individuals remained non-conclusive.
Given the small numbers of participants who tested positive, we focused the presentation of data on the unadjusted results (additional analyses are described in the Methods and summarized in Supplementary Table 1). Supplementary Tables 2 and 3 provide additional results using other analytical strategies—namely, adjusting for the clustered nature of the sample (which affects the confidence limits, but not the point estimates) and for estimates of sensitivity and specificity of the test (details on these additional analytical approaches and justifications for not using them as the primary analytical methods are provided in the Methods). Adjustment for the clustered nature of the sample made little change to the confidence limits, and the time trends remained statistically significant. Analyses accounting for the sensitivity and specificity of the test resulted in a scenario in which the prevalence would be 0% and there would be no cases in the state. This is because the estimated false positive rate based on validation studies was higher than the prevalence measured in the survey rounds. In the Methods, we discuss these findings in more detail.
The numbers of individuals tested and those who were positive in each city are provided in Supplementary Table 4. Two of the 18 positive individuals lived alone, and the remaining 16 had 39 family members in their households. Of these, 37 were tested and 13 (35.1%) were positive. Six positive individuals had at least one positive family member (see Supplementary Table 5).
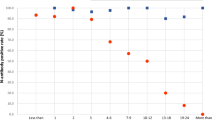
Figure 2 shows the officially reported numbers of cases and deaths in the state, the estimated numbers of cases from our analyses and the seroprevalence in the three rounds. The ratios of estimated to reported cases were 8.4 (95% CI = 1.0–30.3), 13.1 (95% CI = 4.8–28.5) and 9.9 (95% CI = 4.8–18.3) in rounds 1, 2 and 3, respectively, and infection fatality rates were equal to 0.29% (95% CI = 0.08–2.41), 0.23% (95% CI = 0.11–0.62) and 0.38% (95% CI = 0.21–0.80).

Data on cumulative cases and deaths (lines) are from the Rio Grande do Sul State Secretariat of Health. Survey prevalence estimates were based on the following numbers of positive tests/sample sizes: 2/4,149, 6/4,460 and 10/4,500 in phases 1–3, respectively. The estimated numbers of total cases in the state were obtained by multiplying the survey prevalence estimate by the state population (11,377,239 according to the Brazilian Institute of Geography and Statistics). Error bars are 95% confidence intervals.
Four out of the ten cases in the most recent round were in the city of Passo Fundo (population: 203,000 inhabitants) where an outbreak in a meat-processing plant resulted in 455 reported cases per 100,000, whereas the other eight cities in the sample showed incidences ranging from 32 to 105 per 100,000 (https://coronavirus.rs.gov.br/inicial).
This is the first report on repeated population-based surveys for the detection of SARS-CoV-2 antibodies in Brazil. Based on reported death rates by 14 May 2020 (the reference date for the third survey wave), Rio Grande do Sul was one of the states with the lowest mortality (11 per million)—well below Rio de Janeiro (130 per million), Sao Paulo (94 per million) and the national mortality rate (67 per million) (https://covid.saude.gov.br/).
The low prevalence levels reported in our study are compatible with an initial phase of the pandemic. We estimate that nine out of ten cases in the state are not reported, and that the infection fatality rate is well below 1%. Our finding of low prevalence is comparable to the results of other population-based studies in Iceland3, Austria4 and Sweden5, and lower than the 5.0% prevalence detected in Spain6.
Important concerns have been raised about rapid serological tests, but these mostly refer to their use in making clinical decisions15, and in issuing immunity passports16 for individuals who are assumed to have developed immunity. Both circumstances refer to individual-level diagnoses based on rapid tests. The use of rapid tests for population-based estimates, and particularly for monitoring trends over time, may be acceptable.
The results of rapid serological tests in the field may be affected by operator error in use and interpretation, but all test results were photographed and sent to a researcher (M.F.S.) who confirmed all of the positive results, as well as a 20% sample of negative results. Further validation of the Wondfo test will be carried out, using enzyme-linked immunosorbent assay, in the sample evaluated in the validation study.
The limitations of our analyses include the restriction of sampling to sentinel cities that collectively account for 31% of the state’s population, while smaller towns and rural areas were not included. Second, antibody tests result in many false negatives for recent infections, particularly within the first 2 weeks since contagion, and thus prevalence reflects levels of infection 1–2 weeks before the survey. The non-response rates at the household level were relatively low compared with other population-based studies3,4, or with studies using volunteers. Our surveys had fewer children participants than expected, due to their reluctance to undergo a finger prick when randomly selected within the household. In addition, it was not feasible to collect venous blood samples for confirmatory exams.
Lastly, our results were at the lower range of the 95% CI for the false positive rate, which was estimated at 1.0% (95% CI = 0.3–2.2%) in the pooled estimate from four validation studies. In these studies, specificity was measured using frozen samples, and the possibility of non-specific binding leading to false positives has been mentioned by some authors13. Our findings suggest the possibility that existing validation results may have overestimated the false positive rate.
Additional results suggest that the performance of the rapid test was adequate under field conditions. Clustering was observed in six families, and 35% of family members of all positive index cases also tested positive. These cases were probably true positives, accounting for 0.05% (95% CI = 0.02–0.10%) of the combined sample in the three rounds. Further evidence supporting the validity of our results includes documentation of a significant upward time trend, a near-constant tenfold excess of estimated over reported cases in the state, detection of the outbreak in the city of Passo Fundo, and confirmation of three out of four cases that had been previously diagnosed.
These surveys are being partly funded by the state and national governments of Brazil. Survey results were disseminated, 2 d after the completion of data collection, in press briefings, and the state governor is making use of the information to guide stay-at-home measures and other policies. Results from the next rounds of our study will allow us to follow the dynamics of the pandemic in the state as social restriction measures start to be relaxed.
Methods
The state of Rio Grande do Sul is divided by the Brazilian Institute of Geography and Statistics into eight intermediary regions (Fig. 1). The main city in each region was selected for the study. In the main metropolitan region, we selected the state capital, Porto Alegre, as well as Canoas—the second largest city in the metropolitan area. Populations ranged from 78,915 in Ijuí to 1,409,351 in Porto Alegre (https://cidades.ibge.gov.br/brasil/rs/panorama).
Sampling
We used multi-stage sampling to select 50 census tracts with probability proportionate to size in each sentinel city, and ten households at random in each tract based on census listings updated in 2019. All household members were listed at the beginning of the visit, and one individual was randomly selected through an app used for data collection. The survey waves took place on 10–12 and 25–27 April.
The statewide sample of 4,500 individuals allowed estimation of prevalence levels of 3 and 10% with margins of error of 0.5 and 1.0 percentage points, respectively.
In the first wave, interviewers had listings of 35 households in each tract. Any refusals at household level led to selection of the next household on the list, and so on until ten households were included. In the second wave, field workers went to the house visited in the first wave, then selected the tenth household to its right. In case of refusal, the next household to the right side was selected. In the case of acceptance at the household level but refusal by the index individual to provide a sample, a second member was selected. If this person also refused, the field workers moved on to the next household on the list.
Laboratory methods
The prevalence of antibodies was assessed with a rapid point-of-care test—the Wondfo SARS-CoV-2 Antibody Test (Wondfo Biotech)—using finger-prick blood samples. This test detects immunoglobulins of both IgG and IgM isotypes specific to SARS-CoV-2 antigens in a lateral flow assay. Two drops of blood from a pinprick are sufficient to detect the presence of antibody. The assay reagent consists of colloidal gold particles coated with recombinant SARS-CoV-2 antigens. Following introduction of the blood sample, reactive antibody–antigen–colloidal gold complexes, if present, are captured by antibodies against human IgM and IgG present on the test (T) line in the kit’s window, leading to the appearance of a dark-colored line. Samples without SARS-CoV-2-reactive antibodies will not result in the appearance of this line. Valid tests are identified by a positive control line (C) in the same window. If this control line is not visible, the test is deemed inconclusive, which is uncommon.
Four independent validation studies are available for the rapid test. Its sensitivity and specificity are 86.4 and 99.6%, respectively, according to the manufacturer, using samples collected from 361 confirmed cases and 235 negative controls (https://en.wondfo.com.cn/product/wondfo-sars-cov-2-antibody-test-lateral-flow-method-2/). The tests were purchased in bulk by the Brazilian government, being earmarked for use in population surveys and surveillance programs. An initial validation study was carried out by the National Institute for Quality Control in Health (Oswaldo Cruz Foundation) using 18 positive serum samples and 77 negative serum samples based on quantitative RT-PCR. The reported sensitivity was 100.0% (95% CI = 81.5–100.0%), while the specificity was 98.7% (95% CI = 93.0–100.0%). Recently, Whitman and colleagues13 evaluated ten different lateral flow assays using as specimens plasma or serum samples from symptomatic SARS-CoV-2 RT-PCR-positive individuals and 108 pre-COVID-19 negative controls. The sensitivity of the Wondfo test was 81.5% (95% CI = 70.0–90.1%) among 65 patients with a positive RT-PCR 11 d or more before the test, and the specificity was 99.1% (95% CI = 94.9–100.0%). Of the ten tests studied, the Wondfo test was one of the two lateral flow tests with the best performance. Lastly, we carried out our own validation study, based on 83 volunteers with a positive quantitative RT-PCR result 10 d or more before the rapid test. This analysis showed a sensitivity of 77.1% (95% CI = 66.6–85.6%). We also analyzed 100 serum samples collected in 2012 from participants of the 1982 Pelotas (Brazil) Birth Cohort Study19 and found 98 negative results, yielding a specificity estimate of 98.0% (95% CI = 93.0–99.8%). By pooling the results from the four separate validations studies, weighted by sample sizes, the sensitivity was estimated at 84.8% (95% CI = 81.4–87.8%) and the specificity was estimated at 99.0% (95% CI = 97.8–99.7%). Data collection in 2012 received ethical approval by the Ethics Committee of the Faculty of Medicine of the Federal University of Pelotas (review number 16/2012); participants signed informed consent forms to allow the drawing and storage of serum samples for analysis. In early 2020, the National Research Ethics Committee of the Brazilian Ministry of Health approved the use of these samples for the validation study (review number 4.059.173).
Details of the validation study are available from ref. 14.
Data collection
Participants answered short questionnaires, including sociodemographic information (sex, age, schooling and skin color), COVID-19-related symptoms, use of health services, compliance with social distancing measures and use of masks. Field workers used tablets or smartphones to record the full interviews, register all answers and photograph the test results. All positive or inconclusive tests were read by a second observer, as well as 20% of the negative tests. If the index participant in a household had a positive result, all other family members were invited to be tested.
Ethical approval
Interviewers were tested and found to be negative for the virus, and were provided with individual protection equipment that was discarded after visiting each home. Ethical approval was obtained from the Brazilian National Ethics Committee (process number 30415520.2.0000.5313), with written informed consent from all participants. A separate informed consent form was used to obtain permission from parents or legally authorized representatives for minors who were part of the study. Positive cases were reported to the statewide COVID-19 surveillance system. The study protocol was published before the first wave of data collection20.
Statistical analyses
We estimated the seroprevalence in each survey using three different analytical strategies, as summarized in Supplementary Table 1. For each analytical strategy, we calculated absolute (in percentage points) and relative differences between the surveys regarding the prevalence of infection. P values were calculated using Cochran’s Q heterogeneity test assuming a linear (in the absolute or relative scales, respectively) trend over time (and thus with 1 d.f.), implemented as fixed-effects meta-regression. For strategy 3, differences were not calculated because all point estimates were zero. We also compared the distribution of social distancing behavior between the three surveys using a chi-squared test with Rao and Scott second-order correction20, which accounts for the sampling design and yields a statistic that follows an F-distribution with d.f.1–d.f.2 degrees of freedom. In our analysis, d.f.1 = 3.9664 and d.f.2 = 1,749.1659. All analyses were performed using R version 3.6.1 (ref. 21). The survey package22,23 was used to incorporate the sampling design and to compare the distribution of social distancing behavior between surveys. The metafor package24 was used to compare the prevalence between surveys.
Analytical strategies
Results from the different analytical strategies are shown in Supplementary Tables 2 and 3.
In strategy 1, we analyzed the surveys as though these were simple random samples from the population25. This allowed us to calculate the confidence intervals of the prevalence using the exact binomial method, which were wider than confidence intervals obtained after accounting for the sampling design, which must be calculated using conventional approximations (for example, the normal approximation method).
In strategy 2, we analyzed the surveys accounting for the sampling design. As mentioned above, standard methods for confidence interval estimation were not valid in our study (probably due to the very small number of positive tests). To overcome this limitation, we implemented the following strategy to calculate confidence intervals:
- 1.
Inform the sampling design to the statistical software.
- 2.
Calculate the standard error of the logit of the prevalence by fitting a logistic regression where the test result (0 = negative; 1 = positive) is the dependent variable, with no predictor (just the intercept). Let \(\hat \delta\) denote the estimated prevalence and \(\sigma _{{\mathrm{logit}}\left( {\hat \delta } \right)}\) denote the standard error of \(\log {\mathrm{it}}\left( {\hat \delta } \right)\).
- 3.
Generate the empirical sampling distribution of the logit of the prevalence by sampling R times (where R = 5 × 106 is the number of re-samples) from the normal distribution with mean = \({\mathrm{logit}}\left( {\hat \delta } \right)\) and variance = \(\sigma _{{\mathrm{logit}}\left( {\hat \delta } \right)}^2\), such that \({\mathrm{logit}}\left( {\hat \delta _r} \right)\sim N\left( {{\mathrm{logit}}\left( {\hat \delta } \right),\sigma _{{\mathrm{logit}}\left( {\hat \delta } \right)}^2} \right)\), where \(r \in \left\{ {1, \ldots ,R} \right\}\).
- 4.
Convert the empirical sampling distribution to the natural prevalence scale by applying the sigmoid function.
- 5.
Use the standard deviation of the converted empirical sampling distribution as an estimate of the standard error of the prevalence (that is, \(\sigma _{\hat \delta }\)).
- 6.
Calculate the effective sample size \(\left({N^\prime}\right)\) (that is, the sample size that a study using simple random sampling would be expected to have so that the standard error of \(\hat \delta\) equals \(\sigma _{\hat \delta }\)). This was calculated as \({N^\prime} = {\mathrm{min}}\left[ {N,\frac{{\hat \delta \left( {1 - \hat \delta } \right)}}{{\sigma _{\hat \delta }^2}}} \right]\), where N is the actual sample size. N′ was rounded to the nearest integer.
- 7.
Calculate the effective number of positive tests as \(n_{\rm{p}}^\prime = \hat \delta N^\prime\).
- 8.
Use \(n_{\rm{p}}^\prime\) and N to calculate the exact binomial confidence interval. When \(n_{\rm{p}}^\prime\) was not an integer, we opted to not round it because, due to the small number of tests, any rounding would correspond to a substantial relative change in the prevalence. To overcome this issue, we calculated two confidence intervals: one for the nearest smaller integer (that is, \(\left[n_{\rm{p}}^\prime\right]\)) and another for the nearest larger integer (that is, \(\left[n_{\rm{p}}^\prime\right]\)). Let a1 and b1, respectively, denote the lower and upper limits of the confidence interval using \(\left[n_{\rm{p}}^\prime\right]\), and a2 and b2 denote the same for \(\left[n_{\rm{p}}^\prime\right]\). The confidence interval for \(n_{\rm{p}}^\prime\) was then calculated as follows: \(a = \mathop {\sum }\limits_{k = 1}^2 a_kw_k\) and \(b = \mathop {\sum }\limits_{k = 1}^2 b_kw_k\), where wk is the weight that each confidence interval receives, calculated as follows: \(w_1 = 1 - \left( {n_{\rm{p}}^\prime - \left[ n_{\rm{p}}^\prime \right]} \right)\) and \(w_2 = \left( {n_{\rm{p}}^\prime - \left[ n_{\rm{p}}^\prime \right]} \right)\).
In strategy 3, we analyzed the surveys accounting for the sampling design and the test validity (that is, sensitivity and specificity). By pooling multiple validation studies6, the sensitivity was estimated to be \(\hat s = \frac{{446}}{{526}}\) and the specificity was estimated to be \(\hat e = \frac{{513}}{{518}}\). Diggle20 proposed the following equation to obtain a corrected prevalence estimate: \(\hat \theta = \frac{{\hat \delta - \left( {1 - \hat e} \right)}}{{\left( {\hat s + \hat e - 1} \right)}}\), where \(\hat \theta\) is the corrected prevalence. Of note, if \(\hat \theta < 0\) or \(\hat \theta > 1\), it is truncated at 0 or 1, respectively. The same applies for confidence intervals. We also performed additional analyses using two other sets of sensitivity and specificity estimates: (1) the manufacturer’s estimates, which were \(\hat s = \frac{{312}}{{361}}\) and \(\hat e = \frac{{234}}{{235}}\); and (2) local estimates, which were \(\hat s = \frac{{64}}{{83}}\) and \(\hat e = \frac{{98}}{{100}}\).
To incorporate the uncertainty of \(\hat s\) and \(\hat e\) in the confidence interval for \(\hat \theta\), we used parametric bootstrapping, as follows:
- 1.
Assuming that \(\hat s\sim \frac{{B\left( {N_s,s} \right)}}{{N_s}}\) and \(\hat e\sim \frac{{B\left( {N_e,e} \right)}}{{N_e}}\) (where Ns = 526 and Ne = 518 denote the sample sizes used to estimate sensitivity and specificity, respectively), the empirical sampling distribution of these parameters can be obtained as \(\hat s_r\sim \frac{{B\left( {N_s,\hat s} \right)}}{{N_s}}\) and \(\hat e_r\sim \frac{{B\left( {N_e,\hat e} \right)}}{{N_e}}\), where \(r \in \left\{ {1, \ldots ,R} \right\}\).
- 2.
Generate the empirical sampling distribution of δ as \(\hat \delta _r\sim \frac{{B\left( {N^\prime ,\hat \delta } \right)}}{{N^\prime }}\).
- 3.
Generate the empirical sampling distribution of θ as \(\hat \theta _r = \frac{{\hat \delta _r - \left( {1 - \hat e_r} \right)}}{{\left( {\hat s_r + \hat e_r - 1} \right)}}\).
- 4.
Calculate the confidence interval of \(\hat \theta\) using the percentile method (that is, using percentiles \(\left( {\frac{\alpha }{2}} \right)100\%\) and \(\left( {1 - \frac{\alpha }{2}} \right)100\%\) of the empirical sampling distribution as the lower and upper limits of a (1 − α)100% confidence interval (truncating the intervals if necessary)).
Given multiple possible analytical strategies, it is important to define which is the primary strategy and which are secondary strategies. In this study, strategy 1 was chosen as the primary analytical strategy and was used to perform the analyses reported in the body of this article, even though it does not account for the sampling design and estimates of validity. Below, we justify this decision.
Not accounting for sampling design
Given the multi-stage sampling design used in the survey, it is necessary to account for the sampling design for proper estimation of confidence intervals. However, it should be noted that, in the case of proportions, such design-adjusted confidence intervals can only be calculated using approximations of the binomial distribution (typically, the normal approximation), while design-unadjusted confidence intervals can be calculated using the exact binomial method. In our study, the design-unadjusted confidence intervals were narrower than the design-adjusted confidence intervals, probably due to the very low prevalence of positive tests (which violates the assumptions required by the approximated method).
As shown in Supplementary Table 2, the confidence intervals estimated in strategy 2 are wider than in strategy 1, because the first were estimated using an alternative strategy that attempted to mitigate the limitation of conventional design-adjusted confidence interval estimation. However, since the interpretation of the results does not change between strategies 1 and 2, we preferred strategy 1 over strategy 2 because the second is not an established method in the literature.
Not adjusting for validity estimates of the test
The test is an imperfect way of measuring the true prevalence of infection. Given that the main interest is to measure the true prevalence of infection, it is conceptually better to consider prevalence estimates corrected for sensitivity and specificity as the primary result instead of uncorrected estimates (that is, to use strategy 3 as the primary analytical strategy). Although this is conceptually correct, some aspects of the present study led to the decision of using strategy 1 as the primary one.
First, the test result is itself a valid and interpretable result (that is, it shows the prevalence of positive tests rather than the prevalence of infection). Second, pooled estimates of sensitivity and specificity of the test (estimated in >500 individuals each) were 85 and 99%, respectively. This indicates that the test validity is quite high, especially for surveys aimed at estimating the prevalence in the population rather than individual-level diagnosis. Third, the number of positives in both surveys was substantially smaller than the expected number based on the specificity estimated in previous validation studies. This suggests that the specificity of the test may be even higher (very close to 100%); therefore, using estimates from the existing validation studies would result in overcorrections (some possible reasons for this are discussed in the main text). Indeed, Supplementary Table 2 shows that corrections based on sensitivity and specificity estimates from validation studies (strategies 4 and 5) yield prevalence estimates of 0%. Indeed, the untruncated estimates were negative, which is an impossible result.
Not weighting according to population size
Although none of the analytical strategies incorporates weighting according to population size, it is important to recognize that there are substantial differences in population size between the nine cities included in the survey and that the number of interviews per city was fixed. Therefore, one could argue that the primary results should be weighted according to population size. Although this is a reasonable argument, the very small number of positive cases in our survey renders the results very sensitive to the specific choice of weights. In the case of weighting according to population size, the overall results become drastically influenced by the results in Porto Alegre (which is the capital and by far the largest city of the state), which is not a desirable property.
The strong influence of weighting by population size can be seen in the following results. In survey 1, out of the two positive tests, neither of them was in Porto Alegre, which caused the weighting to reduce the prevalence from 0.048 to 0.027%. However, in survey 2, three out of six positive tests were in Porto Alegre, causing the weighting to increase the prevalence from 0.133 to 0.309%. Moreover, weighted estimates indicate that the prevalence reduced from survey 2 to survey 3 (for survey 3, the weighted prevalence estimate was 0.196%), which is not only known to not be the case, but is also conceptually impossible (because repeated surveys using serological tests measure the cumulative prevalence (that is, the proportion of individuals who have been infected at some point in the past). Although these are small absolute differences, they are large relative differences, and produce time trends that are implausible.
Reporting Summary
Further information on research design is available in the Nature Research Reporting Summary linked to this article.
Data availability
The dataset used to produce the analyses presented in this article is freely available at http://www.rs.epicovid19brasil.org/banco-de-dados/ and from the corresponding author upon request. Source data are provided with this paper.
References
Pearce, N., Vandenbroucke, J. P., VanderWeele, T. J. & Greenland, S. Accurate statistics on COVID-19 are essential for policy guidance and decisions. Am. J. Public Health 110, 949–951 (2020).
Barreto, M. L. et al. What is urgent and necessary to inform policies to deal with the COVID-19 pandemic in Brazil? Rev. Bras. Epidemiol. 23, e200032 (2020).
Gudbjartsson, D. F. et al. Spread of SARS-CoV-2 in the Icelandic population. N. Engl. J. Med. 382, 2302–2315 (2020).
Ogris, G. & Hofinger, C. COVID-19 Prevalence (SORA Institute for Social Research and Consulting, 2020).
Nya Resultat från Undersökning av Förekomsten av COVID-19 i Sverige (Public Health Agency of Sweden, 2020).
Estudio ENE-COVID19: Primera Ronda Estudio Nacional de Sero-Epidemiologia de la Infección por SARS-CoV-2 en España. Informe Preliminar 13 Mayo de 2020 (Ministerio de Ciencia e Innovacion and Ministerio de Salud, 2020).
Comitê Técnico do Inquérito Epidemiológico SARS-CoV-2 Avaliação da Prevalência de Marcadores Virológicos e Sorológicos do SARS-CoV-2 na População de Ribeirão Preto: um Inquérito Epidemiológico. Resultados Preliminares (Universidade de São Paulo, Ribeirão Preto, 2020).
Regalado, A. Blood tests show 14% of people are now immune to COVID-19 in one town in Germany. MIT Technology Review (9 April 2020).
Day, M. COVID-19: identifying and isolating asymptomatic people helped eliminate virus in Italian village. Br. Med. J. 368, m1165 (2020).
Coronavirus Disease 19, Republic of South Korea (Ministry of Health and Welfare (South Korea), 2020).
Bendavid, E. et al. COVID-19 antibody seroprevalence in Santa Clara County, California. Preprint at medRxiv https://doi.org/10.1101/2020.04.14.20062463 (2020).
USC-LA County Study: Early Results of Antibody Testing Suggest Number of COVID-19 Infections Far Exceeds Number of Confirmed Cases in Los Angeles County (County of Los Angeles Public Health, 2020).
Whitman, J. D. et al. Test performance evaluation of SARS-CoV-2 serological assays. Preprint at medRxiv https://doi.org/10.1101/2020.04.25.20074856 (2020).
Pellanda, L. C. et al. Sensitivity and specificity of a rapid test for assessment of exposure to SARS-CoV-2 in a community-based setting in Brazil. Preprint at medRxiv https://doi.org/10.1101/2020.05.06.20093476 (2020).
Advice on the Use of Point-of-Care Immunodiagnostic Tests for COVID-19 Scientific Brief (WHO, 2020).
“Immunity passports” in the Context of COVID-19 Scientific Brief (WHO, 2020).
Pesquisa Nacional por Amostra de Domicílios: Síntese de Indicadores 2015 (Instituto Brasileiro de Geografia e Estatística, 2016).
Projeções da População (Instituto Brasileiro de Geografia e Estatística, 2019).
Horta, B. L. et al. Cohort profile update: the 1982 Pelotas (Brazil) Birth Cohort Study. Int J. Epidemiol. 44, 441 (2015).
Hallal, P. C. et al. Evolução da prevalência de infecção por COVID-19 no Rio Grande do Sul: inquéritos sorológicos seriados. Cien Saude Colet. 25, 2395–2401 (2020).
Diggle, P. J. Estimating prevalence using an imperfect test. Epidemiol. Res. Int. 2011, e608719 (2011).
R Core Development Team R: A Language and Environment for Statistical Computing (R Foundation for Statistical Computing, 2018); https://www.R-project.org/
Lumley, T. Analysis of complex survey samples. J. Stat. Softw. 9, 1–19 (2004).
Lumley, T. survey: Analysis of complex survey samples. R package version 3.35-1 https://CRAN.R-project.org/package=survey (2019).
Viechtbauer, W. Conducting meta‐analyses in R with the metafor package. J. Stat. Softw. 36, 1–48 (2010).
Acknowledgements
This work was started through the Data Committee created by the State of Rio Grande do Sul government to fight the COVID-19 pandemics. The tests used in the study have been provided by the Brazilian Ministry of Health. Funding for data collection was provided by UNIMED Porto Alegre, Instituto Cultural Floresta and Instituto Serrapilheira.
Author information
Authors and Affiliations
Contributions
M.F.S., A.J.D.B., B.L.H., L.C.P., O.A.D., F.P.H., A.M.B.M., F.C.B., P.C.H. and C.G.V. contributed to conception and design of the work, acquisition, analysis and interpretation of the data, and writing of the draft of the manuscript. G.D.V., C.J.S. and M.N.B. contributed to analysis and interpretation of the data. A.R.M.V., E.M.B., J.M.M., M.L.R.I., M.A.M., M.M., M.M.D. and R.A.B. contributed to acquisition of the data. All authors approved the submitted version of the manuscript. All authors have also agreed to be personally accountable for their own contributions and to ensure that questions related to the accuracy or integrity of any part of the work—including parts they were not personally involved with—are appropriately investigated and resolved, and the resolution documented in the literature.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Peer review information Saheli Sadanand was the primary editor on this article and managed its editorial process and peer review in collaboration with the rest of the editorial team.
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Supplementary Information
Supplementary results, Tables 1–5 and questionnaire.
Source data
Source Data Fig. 2
Statistical source data.
Rights and permissions
About this article

Cite this article
Silveira, M.F., Barros, A.J.D., Horta, B.L. et al. Population-based surveys of antibodies against SARS-CoV-2 in Southern Brazil. Nat Med 26, 1196–1199 (2020). https://doi.org/10.1038/s41591-020-0992-3
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1038/s41591-020-0992-3
This article is cited by
-
Safety of International Professional Sports Competitions During the COVID-19 Pandemic: The Association Football Experience
Sports Medicine (2023)
-
SARS-CoV-2 seroprevalence around the world: an updated systematic review and meta-analysis
European Journal of Medical Research (2022)
-
A COVID-19 model incorporating variants, vaccination, waning immunity, and population behavior
Scientific Reports (2022)
-
Current Advances in Paper-Based Biosensor Technologies for Rapid COVID-19 Diagnosis
BioChip Journal (2022)
-
Prevalence and associated characteristics of anti-SARS-CoV-2 antibodies in Mexico 5 months after pandemic arrival
BMC Infectious Diseases (2021)
