
We call upon the research community to standardize efforts to use daily self-reported data about COVID-19 symptoms in the response to the pandemic and to form a collaborative consortium to maximize global gain while protecting participant privacy.
The rapid and global spread of COVID-19 led the World Health Organization to declare it a pandemic on 11 March 2020. One factor contributing to the spread of the pandemic is the lack of information about who is infected, in large part because of the lack of testing. This facilitated the silent spread of the causative coronavirus (SARS-CoV-2), which led to delays in public-health and government responses and an explosion in cases. In countries that have tested more aggressively and that had the capacity to transparently share this data, such as South Korea and Singapore, the spread of disease has been greatly slowed1.
Although efforts are underway around the world to substantially ramp up testing capacity, technology-driven approaches to collecting self-reported information can fill an immediate need and complement official diagnostic results. This type of approach has been used for tracking other diseases, notably influenza2. The information collected may include health status that is self-reported through surveys, including those from mobile apps; results of diagnostic laboratory tests; and other static and real-time geospatial data. The collection of privacy-protected information from volunteers about health status over time may enable researchers to leverage these data to predict, respond to and learn about the spread of COVID-19. Given the global nature of the disease, we aim to form an international consortium, tentatively named the ‘Coronavirus Census Collective’, to serve as a hub for amassing this type of data and to create a unified platform for global epidemiological data collection and analysis.
The mission of the Coronavirus Census Collective
The Coronavirus Census Collective (CCC) will be committed to a mission of saving lives through the open sharing of information covering all aspects of the COVID-19 pandemic, to the greatest extent possible, while simultaneously ensuring privacy. This infrastructure could immediately help in the current COVID-19 pandemic, and its consolidation will also facilitate the global response to other communicable diseases that may emerge in the future, as well as those that are currently present. Although it is our hope that the capacity for diagnostic testing will rapidly increase, testing will probably never provide global population-wide coverage, and there is thus a critical and immediate need for collecting additional data on self-reported symptoms and health status at a population level. Moreover, our plan is to integrate the growing official diagnostic testing data from reverse-transcriptase PCR results and serology results with real-time informative data, such as information on self-reported symptoms, to better estimate the incidence of symptoms experienced by patients diagnosed with COVID-19 and to improve the epidemiological and predictive models that we will develop.
The CCC will integrate these data streams and thereby increase the statistical power of analyses carried out on these data, and provide a framework for data collection and a single, central data bank that researchers from around the world can query securely. In addition to ensuring comparability in the data, the CCC will serve as a resource for entities in other countries that are developing surveys for self-reporting, with the goal of facilitating their rapid deployment around the world. The CCC will seek individual grants in the respective countries as well as international funding for its central activities. As many countries are now struggling to find the best strategy to handle the pandemic, we believe that a global collaborative effort to obtain data that can be used to predict outbreaks of COVID-19 is urgently needed. In the long term, this will serve as a rich source of information for understanding disease outbreaks that could facilitate policy decision-making and ensure that society is better positioned to respond to and prepare for future pandemics.
In carrying out this global endeavor, it is very important to engage low- and middle-income countries and to make efforts to include populations that are under-represented or of lower socioeconomic status, such as by distributing the survey in several languages, engaging leaders in local communities and promoting the survey through several diverse channels to increase compliance across all sectors of the population.
Current status of data collection
Early epidemiological studies of the COVID-19 outbreak in China, where COVID-19 was first documented, demonstrated the overwhelming importance of slowing the rate of transmission to reduce the spread of COVID-193,4,5. Slowing the rate of transmission requires information about who is infected and where they are located. The Chinese government achieved this goal in part through testing large numbers of people thought to be infected and moving people who had positive test results into isolation3,4,5. In South Korea, government officials took an approach of combining large-scale testing with transparent data sharing on the whereabouts of affected people to contain the outbreak. Although the success of these approaches is clear, there are two major limitations that prevent their application in the vast majority of other countries: diagnostic testing capacity, and personal and health privacy laws. For example, in the USA, currently the world epicenter of the pandemic, large-scale testing for SARS-CoV-2 infection is still not available in the vast majority of states. For several weeks after community spreading had been documented in multiple US states, testing was still limited to people with severe symptoms and with international travel history to places with early outbreaks (such as China)6. With limited capacity for testing, the numbers reported as ‘confirmed cases’ in these countries (e.g., https://coronavirus.jhu.edu/) probably do not reflect the true numbers or the actual rate of COVID-19 spread, as screening tests reveal a substantial number of asymptomatic people infected with SARS-CoV-27,8,9.
Technology-driven approaches, such as designated apps or online surveys for collecting voluntarily self-reported data on health status, can overcome these limitations. These data can be further integrated with other relevant real-time data resources, including meteorological data and population density at a given time and place, as well as other dynamic data sources. Together, these can provide crucial information that can be immediately leveraged for early identification of disease clusters, with the goal of slowing the spread of disease.
Several such efforts have been started independently. For example, in Israel, a daily one-minute online survey, called Predict-Corona (https://coronaisrael.org/) (Fig. 1a), has been developed, in which respondents are asked to report their daily body temperature and whether they are experiencing any of the symptoms found to be common in patients with COVID-19, according to the existing literature. Within approximately 2 months of its launch, there have been over 2.5 million responses, and initial analyses demonstrate the potential of this approach for detecting future outbreak regions10. In the USA, the app HowWeFeel (http://www.howwefeel.org), which administers a 30-second survey of the person’s well-being to collect epidemiological data, has been developed (Fig. 1b). Similarly, CovidNearYou (https://covidnearyou.org/) and covid19 Risk Survey, a web app with open-access visualization tools collecting the same information in a fully anonymous way (https://covid19.eipm-research.org), were launched. In the USA and the UK, the Coronovirus Pandemic Consortium was established (https://www.monganinstitute.org/cope-consortium) to use the Covid Symptom Tracker (https://covid.joinzoe.com) and join the efforts of international prospective observational cohorts (e.g., population based, clinical data) and clinical trials11. This has led to a model that predicted COVID-19 incidence in over 2.7 million users12.

a, The English-language version of the daily questionnaire used in Israel (at https://coronaisrael.org/en/), showing a map of Israel with colors corresponding to a weighted average of COVID-19-associated symptoms, which is updated daily. The color of each region indicates a category defined by the average symptoms ratio, calculated by averaging of the reported symptoms rate by the responders in that city or neighborhood (color scale ranges from bright yellow (low symptoms ratio) to pink (high symptoms ratio)). Publ. note: Springer Nature is neutral about jurisdictional claims in maps. b, HowWeFeel: a 30-second survey of the person’s well-being to collect epidemiological data.
This work parallels efforts in other countries to develop similar surveys, such as the COVID-19:CH Survey Project, which was developed in Switzerland (https://covidtracker.ch), and COVID-19 self-reporting in Slovenia (https://covid-19-stats.si/) and Estonia (koroona.ut.ee). These apps are currently managed and distributed by researchers in their respective research institutions.
A framework for collecting and sharing data
Survey responses containing symptom information relevant to COVID-19, along with geospatial location, time, and demographic information on age and pre-existing and comorbid medical conditions, will be collected. Once the data have been collected, they will be de-identified and made further differentially private13 before researchers obtain access. Indeed, where feasible, we are implementing differential privacy at the data-collection source — the cellphone, website or app — so that any information that leaves the control of the research subjects cannot be used to learn about any person or whether a person is part of our dataset. We thus plan to provide specific mathematical assurances for the privacy of research subjects while still enabling scholars to make statistically valid inferences from these data. Because the privacy of our participants is essential to our mission, we commit to remaining at the cutting edge of privacy-protective technologies, developing novel methods where needed and implementing improvements over time wherever possible. Given differences in privacy regulations from region to region, individual-level data from the surveys from some countries may not be accessible, but we will aim to make the results of differentially private statistical analyses available to all researchers. The mechanism of data sharing has not been determined yet and may be provided by an independent third party.
One of the main goals of the CCC is to create a federated common data model to facilitate data sharing while ensuring data security and privacy across different countries. To achieve this goal, we will define guidelines to ensure that the underlying data model collected from all contributors can be easily amalgamated and harmonized, and a consortium data-sharing policy will be developed. We will also apply different methods, such as differential privacy13, that will enable researchers to share and analyze the data while preserving the confidentiality of the participants. To maximize the impact of the data collected, we will provide an app programming interface to allow accredited researchers to access the data to perform additional statistical analyses (Fig. 2).
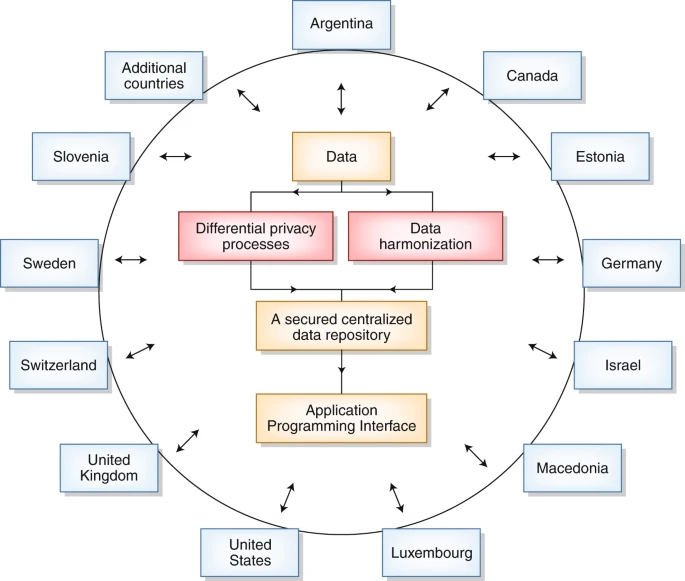
A flowchart of the data coordination process of the Coronavirus Census Collective (CCC).
Our technologies and the code for our app will be open source so that others can adapt them for their particular situations, find bugs and help us improve it. We envision that all members will use surveys with a common set of ‘core’ questions, but additional region-specific questions may be added, in accordance with local regulations, researcher interest and community need. This set of core questions may grow over time as more is learned about COVID-19.
These data will allow researchers to perform several immediately useful analyses. These include the following: monitoring of the health status of the respondent population, using statistics on self-reported symptoms and/or official COVID-19 test results within particular geographic regions at any given time; analysis of the epidemiological factors associated with symptoms and testing results; and identification of the areas likely to have COVID-19 outbreaks on the basis of the co-occurrence of many people’s reporting similar patterns of symptoms at the same time. This will be potentially useful for identifying areas to which additional testing or medical resources should be allocated.
Additional applications include using methods of quantification, distinct from those of classification, to produce accurate estimates of the population prevalence of COVID-19, based on participants who have positive or negative test results, even when people cannot be reliably classified from their symptoms alone14, and evaluating the effectiveness of the various social-distancing measures taken and their contribution to reducing the number of symptomatic people.
Data coordination by a consortium
We envision that the CCC will be coordinated by a board of directors that will be agreed upon by all consortium members and who will vet new members, maintain a secured centralized data repository or federated multisite data repositories and develop mechanisms to enable researchers from around the world to query the data. The selection of the board of directors will take into account issues of expertise in organizing consortia, data privacy, epidemiology and technology. Individual members will be responsible for ensuring adherence to local regulations.
Conclusions
In summary, we call for participation in an international consortium, the CCC, that will serve as a hub for the integration of COVID-19-related information. This collective effort to track and share information will be invaluable in predicting hotspots of disease outbreak; identifying which factors control the rate of spreading; informing immediate policy decisions; evaluating the effectiveness of measures taken by health organizations on pandemic control; and providing critical insights on the etiology of COVID-19. It will also help people stay informed on this rapidly evolving situation and contribute to other global efforts to slow the spread of disease.
Change history
26 June 2020
A Correction to this paper has been published: https://doi.org/10.1038/s41591-020-0983-4
References
Tariq, A. et al. medRxiv https://doi.org/10.1101/2020.02.21.20026435 (2020).
Smolinski, M. S. et al. Am. J. Public Health 105, 2124–2130 (2015).
Tian, H. et al. Science 368, 638–642 (2020).
Guan, W.-J. et al. N. Engl. J. Med. 382, 1708–1720 (2020).
Wu, Z. & McGoogan, J. M. JAMA 323, 1239–1242 (2020).
Adalja, A. A., Toner, E. & Inglesby, T. V. JAMA 323, 1343–1344 (2020).
Gudbjartsson, D. F. et al. N. Engl. J. Med. https://doi.org/10.1056/NEJMoa2006100 (2020).
Mizumoto, K., Kagaya, K., Zarebski, A. & Chowell, G. Eurosurveillance https://doi.org/10.2807/1560-7917.ES.2020.25.10.2000180 (2020).
Sutton, D., Fuchs, K., D’Alton, M. & Goffman, D. N. Engl. J. Med. https://doi.org/10.1056/NEJMc2009316 (2020).
Rossman, H. et al. Nat. Med. 26, 634–638 (2020).
Drew, D. A. et al. Science https://doi.org/10.1126/science.abc0473 (2020).
Menni, C. et al. Nat. Med. https://doi.org/10.1038/s41591-020-0916-2 (2020).
Dankar, F. K. & El Emam, K. Trans. Data Priv. 6, 35–67 (2013).
King, G. & Lu, Y. Stat. Sci. 23, 78–91 (2008).
Acknowledgements
The CCC is a nonprofit consortium open to anyone who shares the vision of making data available to help the public good and fight COVID-19; as of May 2020 participating countries are Argentina, Canada, Estonia, Germany, Israel, Luxembourg, Macedonia, Slovenia, Sweden, Switzerland, UK and USA. There are no membership fees. Please contact us at info@coronaviruscensuscollective.org if you are interested in joining.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Rights and permissions
About this article

Cite this article
Segal, E., Zhang, F., Lin, X. et al. Building an international consortium for tracking coronavirus health status. Nat Med 26, 1161–1165 (2020). https://doi.org/10.1038/s41591-020-0929-x
Published:
Issue Date:
DOI: https://doi.org/10.1038/s41591-020-0929-x
This article is cited by
-
COVID-19 and its sequelae: a platform for optimal patient care, discovery and training
Journal of Thrombosis and Thrombolysis (2021)
-
Population-scale longitudinal mapping of COVID-19 symptoms, behaviour and testing
Nature Human Behaviour (2020)
