
Abstract
To elucidate the genetics of coronary artery disease (CAD) in the Japanese population, we conducted a large-scale genome-wide association study of 168,228 individuals of Japanese ancestry (25,892 cases and 142,336 controls) with genotype imputation using a newly developed reference panel of Japanese haplotypes including 1,781 CAD cases and 2,636 controls. We detected eight new susceptibility loci and Japanese-specific rare variants contributing to disease severity and increased cardiovascular mortality. We then conducted a trans-ancestry meta-analysis and discovered 35 additional new loci. Using the meta-analysis results, we derived a polygenic risk score (PRS) for CAD, which outperformed those derived from either Japanese or European genome-wide association studies. The PRS prioritized risk factors among various clinical parameters and segregated individuals with increased risk of long-term cardiovascular mortality. Our data improve the clinical characterization of CAD genetics and suggest the utility of trans-ancestry meta-analysis for PRS derivation in non-European populations.
This is a preview of subscription content, access via your institution
Access options
Access Nature and 54 other Nature Portfolio journals
Get Nature+, our best-value online-access subscription
$29.99 / 30 days
cancel any time
Subscribe to this journal
Receive 12 print issues and online access
$209.00 per year
only $17.42 per issue
Buy this article
- Purchase on Springer Link
- Instant access to full article PDF
Prices may be subject to local taxes which are calculated during checkout





Similar content being viewed by others


Data availability
The summary statistics of the Japanese GWAS and PRS derived in this study are publicly available from the National Bioscience Database Center (https://biosciencedbc.jp/en) under research ID hum0014.
References
Wang, H. et al. Global, regional, and national life expectancy, all-cause mortality, and cause-specific mortality for 249 causes of death, 1980–2015: a systematic analysis for the Global Burden of Disease Study 2015. Lancet 388, 1459–1544 (2016).
Marenberg, M. E., Risch, N., Berkman, L. F., Floderus, B. & de Faire, U. Genetic susceptibility to death from coronary heart disease in a study of twins. N. Engl. J. Med. 330, 1041–1046 (1994).
Ozaki, K. et al. Functional SNPs in the lymphotoxin-α gene that are associated with susceptibility to myocardial infarction. Nat. Genet. 32, 650–654 (2002).
Samani, N. J. et al. Genomewide association analysis of coronary artery disease. N. Engl. J. Med. 357, 443–453 (2007).
Willer, C. J. et al. Newly identified loci that influence lipid concentrations and risk of coronary artery disease. Nat. Genet. 40, 161–169 (2008).
Erdmann, J. et al. New susceptibility locus for coronary artery disease on chromosome 3q22.3. Nat. Genet. 41, 280–282 (2009).
Nikpay, M. et al. A comprehensive 1,000 Genomes-based genome-wide association meta-analysis of coronary artery disease. Nat. Genet. 47, 1121–1130 (2015).
Nelson, C. P. et al. Association analyses based on false discovery rate implicate new loci for coronary artery disease. Nat. Genet. 49, 1385–1391 (2017).
van der Harst, P. & Verweij, N. Identification of 64 novel genetic loci provides an expanded view on the genetic architecture of coronary artery disease. Circ. Res. 122, 433–443 (2018).
Fuchsberger, C. et al. The genetic architecture of type 2 diabetes. Nature 536, 41–47 (2016).
Luo, Y. et al. Exploring the genetic architecture of inflammatory bowel disease by whole-genome sequencing identifies association at ADCY7. Nat. Genet. 49, 186–192 (2017).
Khera, A. V. et al. Whole-genome sequencing to characterize monogenic and polygenic contributions in patients hospitalized with early-onset myocardial infarction. Circulation 139, 1593–1602 (2019).
Mahajan, A. et al. Fine-mapping type 2 diabetes loci to single-variant resolution using high-density imputation and islet-specific epigenome maps. Nat. Genet. 50, 1505–1513 (2018).
Mega, J. L. et al. Genetic risk, coronary heart disease events, and the clinical benefit of statin therapy: an analysis of primary and secondary prevention trials. Lancet 385, 2264–2271 (2015).
Khera, A. V. et al. Genetic risk, adherence to a healthy lifestyle, and coronary disease. N. Engl. J. Med. 375, 2349–2358 (2016).
Khera, A. V. et al. Genome-wide polygenic scores for common diseases identify individuals with risk equivalent to monogenic mutations. Nat. Genet. 50, 1219–1224 (2018).
Inouye, M. et al. Genomic risk prediction of coronary artery disease in 480,000 adults: implications for primary prevention. J. Am. Coll. Cardiol. 72, 1883–1893 (2018).
Mahajan, A. et al. Genome-wide trans-ancestry meta-analysis provides insight into the genetic architecture of type 2 diabetes susceptibility. Nat. Genet. 46, 234–244 (2014).
Okada, Y. et al. Genetics of rheumatoid arthritis contributes to biology and drug discovery. Nature 506, 376–381 (2014).
Akiyama, M. et al. Genome-wide association study identifies 112 new loci for body mass index in the Japanese population. Nat. Genet. 49, 1458–1467 (2017).
Auton, A. et al. A global reference for human genetic variation. Nature 526, 68–74 (2015).
Landrum, M. J. et al. ClinVar: public archive of relationships among sequence variation and human phenotype. Nucleic Acids Res. 42, D980–D985 (2014).
Maruyama, T. et al. Common mutations in the low-density-lipoprotein-receptor gene causing familial hypercholesterolemia in the Japanese population. Arterioscler. Thromb. Vasc. Biol. 15, 1713–1718 (1995).
Bodzioch, M. et al. The gene encoding ATP-binding cassette transporter 1 is mutated in Tangier disease. Nat. Genet. 22, 347–351 (1999).
Lu, X. et al. Exome chip meta-analysis identifies novel loci and East Asian-specific coding variants that contribute to lipid levels and coronary artery disease. Nat. Genet. 49, 1722–1730 (2017).
Kamada, F. et al. A genome-wide association study identifies RNF213 as the first Moyamoya disease gene. J. Hum. Genet. 56, 34–40 (2011).
Wang, F. et al. Genome-wide association identifies a susceptibility locus for coronary artery disease in the Chinese Han population. Nat. Genet. 43, 345–349 (2011).
Deloukas, P. et al. Large-scale association analysis identifies new risk loci for coronary artery disease. Nat. Genet. 45, 25–33 (2013).
Tang, C. S. et al. Exome-wide association analysis reveals novel coding sequence variants associated with lipid traits in Chinese. Nat. Commun. 6, 10206 (2015).
Gustafsen, C. et al. Heparan sulfate proteoglycans present PCSK9 to the LDL receptor. Nat. Commun. 8, 503 (2017).
Zhao, Z. et al. UK Biobank whole-exome sequence binary phenome analysis with robust region-based rare-variant test. Am. J. Hum. Genet. 106, 3–12 (2020).
Cali, J. J., Hsieh, C. L., Francke, U. & Russell, D. W. Mutations in the bile acid biosynthetic enzyme sterol 27-hydroxylase underlie cerebrotendinous xanthomatosis. J. Biol. Chem. 266, 7779–7783 (1991).
Hori, M., Miyauchi, E., Son, C. & Harada-Shiba, M. Detection of the benign c.2579C>T (p.A860V) variant of the LDLR gene in a pedigree-based genetic analysis of familial hypercholesterolemia. J. Clin. Lipidol. 13, 335–339 (2019).
Karczewski, K. J. et al. The mutational constraint spectrum quantified from variation in 141,456 humans. Nature 581, 434–443 (2020).
Nanchen, D. et al. Prognosis of patients with familial hypercholesterolemia after acute coronary syndromes. Circulation 134, 698–709 (2016).
Wang, X. et al. Comparing methods for performing trans-ethnic meta-analysis of genome-wide association studies. Hum. Mol. Genet. 22, 2303–2311 (2013).
Lu, X. et al. Coding-sequence variants are associated with blood lipid levels in 14,473 Chinese. Hum. Mol. Genet. 25, 4107–4116 (2016).
Pers, T. H. et al. Biological interpretation of genome-wide association studies using predicted gene functions. Nat. Commun. 6, 5890 (2015).
Iyer, D. et al. Coronary artery disease genes SMAD3 and TCF21 promote opposing interactive genetic programs that regulate smooth muscle cell differentiation and disease risk. PLoS Genet. 14, e1007681 (2018).
Wirka, R. C. et al. Atheroprotective roles of smooth muscle cell phenotypic modulation and the TCF21 disease gene as revealed by single-cell analysis. Nat. Med. 25, 1280–1289 (2019).
Brown, B. C. & et al. Transethnic genetic-correlation estimates from summary statistics. Am. J. Hum. Genet. 99, 76–88 (2016).
Martin, A. R. et al. Clinical use of current polygenic risk scores may exacerbate health disparities. Nat. Genet. 51, 584–591 (2019).
Aguet, F. et al. Genetic effects on gene expression across human tissues. Nature 550, 204–213 (2017).
Cai, B. et al. MerTK receptor cleavage promotes plaque necrosis and defective resolution in atherosclerosis. J. Clin. Invest. 127, 564–568 (2017).
Chau, Y.-Y. et al. Visceral and subcutaneous fat have different origins and evidence supports a mesothelial source. Nat. Cell Biol. 16, 367–375 (2014).
Després, J.-P. & Lemieux, I. Abdominal obesity and metabolic syndrome. Nature 444, 881–887 (2006).
Huang, J. et al. Improved imputation of low-frequency and rare variants using the UK10K haplotype reference panel. Nat. Commun. 6, 8111 (2015).
McCarthy, S. et al. A reference panel of 64,976 haplotypes for genotype imputation. Nat. Genet. 48, 1279–1283 (2016).
Natarajan, P. et al. Deep-coverage whole genome sequences and blood lipids among 16,324 individuals. Nat. Commun. 9, 3391 (2018).
Nagai, A. et al. Overview of the BioBank Japan Project: study design and profile. J. Epidemiol. 27, S2–S8 (2017).
Hirata, M. et al. Cross-sectional analysis of BioBank Japan clinical data: a large cohort of 200,000 patients with 47 common diseases. J. Epidemiol. 27, S9–S21 (2017).
Tsugane, S. & Sawada, N. The JPHC study: design and some findings on the typical Japanese diet. Jpn. J. Clin. Oncol. 44, 777–782 (2014).
Loh, P.-R., Palamara, P. F. & Price, A. L. Fast and accurate long-range phasing in a UK Biobank cohort. Nat. Genet. 48, 811–816 (2016).
Das, S. et al. Next-generation genotype imputation service and methods. Nat. Genet. 48, 1284–1287 (2016).
Wang, K., Li, M. & Hakonarson, H. ANNOVAR: functional annotation of genetic variants from high-throughput sequencing data. Nucleic Acids Res. 38, e164 (2010).
Benn, M., Watts, G. F., Tybjærg-Hansen, A. & Nordestgaard, B. G. Mutations causative of familial hypercholesterolaemia: screening of 98 098 individuals from the Copenhagen General Population Study estimated a prevalence of 1 in 217. Eur. Heart J. 37, 1384–1394 (2016).
Khera, A. V. et al. Diagnostic yield and clinical utility of sequencing familial hypercholesterolemia genes in patients with severe hypercholesterolemia. J. Am. Coll. Cardiol. 67, 2578–2589 (2016).
Newton-Cheh, C. et al. Genome-wide association study identifies eight loci associated with blood pressure. Nat. Genet. 41, 666–676 (2009).
Yang, J. et al. FTO genotype is associated with phenotypic variability of body mass index. Nature 490, 267–272 (2012).
Chang, C. C. et al. Second-generation PLINK: rising to the challenge of larger and richer datasets. Gigascience 4, 7 (2015).
So, H.-C., Gui, A. H. S., Cherny, S. S. & Sham, P. C. Evaluating the heritability explained by known susceptibility variants: a survey of ten complex diseases. Genet. Epidemiol. 35, 310–317 (2011).
Roth, G. A. et al. Global, regional, and national burden of cardiovascular diseases for 10 causes, 1990 to 2015. J. Am. Coll. Cardiol. 70, 1–25 (2017).
Bulik-Sullivan, B. et al. LD Score regression distinguishes confounding from polygenicity in genome-wide association studies. Nat. Genet. 47, 291–295 (2015).
Zhou, W. et al. Scalable generalized linear mixed model for region-based association tests in large biobanks and cohorts. Nat. Genet. 52, 634–639 (2020).
Morris, A. P. Transethnic meta-analysis of genomewide association studies. Genet. Epidemiol. 35, 809–822 (2011).
Han, B. & Eskin, E. Random-effects model aimed at discovering associations in meta-analysis of genome-wide association studies. Am. J. Hum. Genet. 88, 586–598 (2011).
Malik, R. et al. Multiancestry genome-wide association study of 520,000 subjects identifies 32 loci associated with stroke and stroke subtypes. Nat. Genet. 50, 524–537 (2018).
Frey, B. J. & Dueck, D. Clustering by passing messages between data points. Science 315, 972–976 (2007).
Marouli, E. et al. Rare and low-frequency coding variants alter human adult height. Nature 542, 186–190 (2017).
Maller, J. B. et al. Bayesian refinement of association signals for 14 loci in 3 common diseases. Nat. Genet. 44, 1294–1301 (2012).
Vilhjálmsson, B. J. et al. Modeling linkage disequilibrium increases accuracy of polygenic risk scores. Am. J. Hum. Genet. 97, 576–592 (2015).
Acknowledgements
We thank the staff of BBJ for their excellent assistance in collecting samples and clinical information. We thank the Nagahama, JPHC, J-MICC and OACIS studies for their invaluable contributions to the study. We are grateful to the CARDIoGRAMplusC4D investigators, P. van der Harst and N. Verweij, for making their data publicly available. We thank A. P. Morris for providing us with the MANTRA software and valuable advice. This research was funded by the Japan Agency for Medical Research and Development (AMED) under grant numbers JP20km0405209 (the GRIFIN project), JP20km0405209 and JP20ek0109487. The BBJ was supported by the Tailor-made Medical Treatment Program of the Ministry of Education, Culture, Sports, Science, and Technology and AMED. The JPHC study has been supported by the National Cancer Center Research and Development Fund since 2011 and was supported by a Grant-in-Aid for Cancer Research from the Ministry of Health, Labour and Welfare of Japan from 1989 to 2010. The J-MICC study was supported by Grants-in-Aid for Scientific Research for Priority Areas of Cancer (no. 17015018) and Innovative Areas (no. 221S0001) and by Japan Society for the Promotion of Science (JSPS) KAKENHI grant nos. JP16H06277 from the Japanese Ministry of Education, Culture, Sports, Science and Technology. The Nagahama study was supported by a JSPS Grant-in-Aid for Scientific Research (C), KAKENHI grant numbers JP17K07255 and JP17KT0125, and the Practical Research Project for Rare/Intractable Diseases from AMED under grant numbers JP16ek0109070, JP18kk0205008, JP18kk0205001, JP19ek0109283 and JP19ek0109348.
Author information
Authors and Affiliations
Contributions
S.K., K.I., C.T., M.K. and Y.K. conceived and designed the study. C.K., J.S., K.H. and F.M. collected, managed and genotyped the Nagahama cohort. K.M., Y. Murakami and M.K. collected and managed the BBJ sample. M.I., T.Y., N.S. and S.T. collected and managed the JPHC study. T.K., H. Ikezaki, N.T., K.T., K.A., K.K., M.N. and K.W. collected and managed the J-MICC study. S.S., Yasuhiko Sakata, H.S., M. Hori, I.K. and Yasushi Sakata collected and managed the OACIS study. C.T., Y. Momozawa, A.T., M.K. and Y.K. performed the genotyping. S.K., K.I., C.T. and Y.K. performed the statistical analysis. S.K., K.I., C.T., M.A., M. Horikoshi, H. Matsunaga, H. Ieki, K.O. and Y.O. contributed to data processing, analysis, and interpretation. S.N., H. Morita, H. Akazawa, H. Aburatani and I.K. supervised the study. S.K. and K.I. wrote the manuscript and several authors provided valuable edits.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Extended data
Extended Data Fig. 1 Improved imputation accuracy of BBJ CAD panel.
a, The mean-observed R2 for each MAF bin is plotted. Observed R2 indicates Fisher’s correlation coefficient between imputed dosage and genotypes determined by the genotyping array. b, Imputation quality of down-sampled (n = 500) reference panels. For 1KGAll and BBJCAD, the analyses were repeated four times. c, The distributions of all imputed variants stratified by MAF and R2. z-axis indicates the number of variants d, The distributions of variants with imputation quality ≥ 0.3. Note that the z-axes in c have different scales. e, The number of testable (R2 ≥ 0.3 and MAF ≥ 0.0002) variants in various functional classes. The x-axis indicates the reference population, and y-axis indicates the number of variants in each class. The color indicates the proportion of the variants in minor allele frequency bins. f, The number of testable exonic variants. g, The number of testable variants registered in the ClinVar database. Numbers of variants in each class are found in Supplementary Table 2. MAF; minor allele frequency; 1KG, 1000 Genomes Project; EAS, East Asian; BBJ, Biobank Japan; CAD, coronary artery disease; ncRNA, non-coding RNA; UTR, untranslated region; SNV, single nucleotide variant.
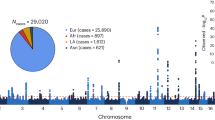
Extended Data Fig. 2 Manhattan plots for the Japanese GWAS.
The results of the Japanese GWAS (25,892 CAD-cases, 142,336 controls) are shown. The negative log10 P-values on the y-axes are shown against the genomic positions (hg19) on the x-axes. Variants in 8 novel and 40 previously reported loci are presented in orange and blue, respectively. Dashed lines indicate genome-wide significant thresholds (P = 5 × 10−8). Two-sided P-values were calculated using a logistic regression model.
Extended Data Fig. 3 Contributions of rare coding variants to the CAD and its clinical presentation.
a, Quantile-quantile plot for the gene-based test in the Japanese population. A total of 16,582 genes were tested and the genome-wide significance was set at P = 3.0 × 10−6 (0.05/16,582). b, Negative log10 P-value for each gene on the y-axis was plotted against the genomic position on the x-axis. c, Lollipop plots of the genes with genome-wide significance or FDR < 0.05. Z-value for CAD by the single variant test on the y-axis was plotted against the exonic coordinate on the x-axis. The color of the point indicates the variant class. d, Allele frequencies stratified by the disease status. Data are presented as median and 95% CI estimated by 105 times bootstrapping (14,062 ACS cases, 11,830 SAP cases, and 142,336 controls). e, Effect of rare coding variants in FH genes on long term survival. Data are presented as estimated hazard ratio and its 95% CI. (6,223 deaths among 121,450 cases and controls, 1,968 deaths among 23,138 CAD cases). Hazard ratios, confidence intervals, and two-sided P-values were calculated using a Cox proportional hazard model. FDR, false discovery rate; SNV, single nucleotide variant; SAP, stable angina pectoris; ACS, acute coronary syndrome; FH, familial hypercholesterolemia.
Extended Data Fig. 4 Manhattan plots for the trans-ancestry meta-analysis.
The results of the trans-ancestry meta-analysis (121,234 CAD-cases, 527,824 controls) are shown. The log10 BFs on the y-axes are plotted against the genomic positions (hg19) on the x-axes. Variants in 40 novel and 135 previously reported loci are presented in orange and blue, respectively. Dashed lines indicate genome-wide significant thresholds (log10 BF = 6). BF, Bayes Factor.
Extended Data Fig. 5 Tissue and gene-set enrichment analysis.
a, The result of tissue enrichment analysis (log10BF > 5, 19,348 variants, 660 loci). y-axis indicates -log10 P-value. Forty-eight exemplar tissues (Methods) were tested, and the significance level was set at P = 1 × 10−3 (0.05/48). b, The comparison of tissue enrichment P-values between the European meta-analysis (C4D + UKBB) and the trans-ancestry meta-analysis (BBJ + C4D + UKBB). The x-axis indicates -log10 P-values in the European analysis and y-axis indicates -log10 P-values in the trans-ancestry meta-analysis. c-e, The results of gene-set enrichment analysis for mouse phenotype (c), gene ontology (d), and KEGG, reactome, and PPI subnetwork (e). A total of 1,157 exemplar gene-sets were tested and the significance level was set at P = 4.3 × 10−5 (0.05/1,157). The pathways significantly associated only in the trans-ancestry analysis are annotated in orange, only in the European analysis in green, and in both analyses in blue. KEGG, Kyoto Encyclopedia of Genes and Genomes; PPI, protein-protein interaction; BBJ, Biobank Japan; C4D, CARDIoGRAMplusC4D; UKBB, UK Biobank.
Extended Data Fig. 6 Trans-ancestry credible-set analysis.
a, Pairwise comparisons of the number of variants included in 99% credible sets for previously established CAD associated loci (n = 61). Two-sided P-values were calculated by paired-Wilcoxon rank sum test. b, Local association for the loci, which includes only one variant in its 99% credible set in the trans-ancestry meta-analysis (BBJ and C4D). The x-axis indicates chromosomal coordinates, and y-axis indicates the log10 Bayes factor. The color of the point indicates r2 to the lead variant of the locus. r2 was calculated from 1KGEAS (BBJ/C4D, BBJ/C4D/UKBB) or 1KGEUR (C4D/UKBB). CAD, coronary artery disease; BBJ, Biobank Japan; C4D, CARDIoGRAMplusC4D; UKBB, UK Biobank; 1KG, 1000 genomes project; EUR, European; EAS, East Asian.
Extended Data Fig. 7 Trans-ancestry comparison of allele frequencies and allelic effects.
a, Comparisons of alternate allele frequencies of the 175 lead variants identified in the current trans-ancestry meta-analysis. b, Comparisons of estimated effect sizes of the 175 lead variants. Data are presented as estimated β (log odds ratio) and 95% confidence interval in each study (n = 168,228 in BBJ; n = 184,305 in C4D; n = 296,525 in UKBB). Effect sizes, confidence intervals, and two-sided P-values were calculated using a logistic regression model. Alleles were aligned to the reference genome (hg19). Grey points indicate previously reported loci and orange points indicate newly identified loci in this study. ρ indicates Spearman’s correlation coefficient. c, Trans-ancestry genetic correlation analysis. Values indicate the genetic correlations between studies found in x-axis and y-axis. The genetic correlations between BBJ and C4D or UKBB were determined by the Popcorn algorithm, and the genetic correlation between C4D and UKBB was determined by LD score regression. d, Comparisons of estimated effect sizes of all the tested variants. Variants were pruned using the summary statistics of the C4D with indicated threshold (n = 853,795 in r2 < 0.8; n = 105,227 in P < 0.1, r2 < 0.8; n = 56,230 in P < 0.05, r2 < 0.8). Then, the variants were separated into 50 bins based on the rank in the BBJ. Each point indicates each bin, the x-axis indicates averaged effect size in the BBJ (x-axis) and the y-axis indicates averaged effect size in the UKBB. Data are presented as mean and standard error. AAF, alternate allele frequency; BBJ, Biobank Japan; C4D, CARDIoGRAMplusC4D; UKBB, UK Biobank.
Extended Data Fig. 8 PRS performance.
The performance of PRS in the test cohort are shown (1,827 cases and 9,172 controls). a, Distribution of PRS in the case and controls samples. b, Prevalence of CAD based on the CAD-PRS deciles. Data are presented as median and 95% CI. c, Pairwise comparison of the performance. The distributions of ΔPseudo R2 are shown. ΔPseudo R2 was obtained by Pseudo R2Score Y – Pseudo R2Score X. Score X indicates scores found in the top of the panel, and Score Y indicates scores found in the right of the panel. The distributions of ΔPseudo R2 were obtained by 105 times bootstrapping. Two-sided bootstrap P-values were presented. The significance was set at P = 2.4 × 10−3 (0.05/21). CAD, coronary artery disease; PRS, polygenic risk score; BBJ, Biobank Japan; C4D, CARDIoGRAMplusC4D; UKBB, UK Biobank.
Extended Data Fig. 9 Significant associations between clinical traits and CAD-PRS.
a, Negative log10 P-values of Spearman’s correlation coefficient or that of the beta coefficient estimated by logistic regression (for cigarette smoking and alcohol drinking behavior) are presented. Orange points indicate traits with Bonferroni adjusted significance (P = 0.05/34). b, Each point represents the mean value of standardized phenotypes corresponding to CAD-PRS decile. Regression lines and 95% confidence intervals are shown in dashed lines and grey areas, respectively. CAD, coronary artery disease; PRS, polygenic risk score. Number of individuals included each analysis are found in Supplementary Table 15. Abbreviations for the phenotypes are defined in Supplementary Table 19.
Extended Data Fig. 10 Functional clustering and causal gene prioritization of 175 genome-wide significant loci.
One hundred seventy-five genome-wide significant loci were clustered into six clusters by k-means clustering of Z-score. Heatmaps show the normalized Z-score of each lead variant for CAD-PRS associated phenotypes. Red color indicates positive, and blue color indicates negative normalized Z-score. Z-scores are aligned to CAD risk-increasing alleles. The bar charts on the top of the heatmaps indicate the cluster-mean effect on the phenotypes. Each locus was annotated with the prioritized genes based on the functional evidence that are shown on the right side of each heatmap. The rightmost bar-charts indicate the total scores for annotated genes. Abbreviations for the clinical phenotypes are defined in Supplementary Table 19. MGI, Mouse Genome Informatics; BP, blood pressure; BMI, body mass index; WBC, white blood cell.
Supplementary information
Supplementary Information
Supplementary Figs. 1–6, Supplementary Note and Supplementary Datasets 1–4
Supplementary Tables
Supplementary Tables 1–22
Rights and permissions
About this article

Cite this article
Koyama, S., Ito, K., Terao, C. et al. Population-specific and trans-ancestry genome-wide analyses identify distinct and shared genetic risk loci for coronary artery disease. Nat Genet 52, 1169–1177 (2020). https://doi.org/10.1038/s41588-020-0705-3
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1038/s41588-020-0705-3
This article is cited by
-
Emerging applications of single-cell profiling in precision medicine of atherosclerosis
Journal of Translational Medicine (2024)
-
Sex-specific genetic architecture of blood pressure
Nature Medicine (2024)
-
Integrative common and rare variant analyses provide insights into the genetic architecture of liver cirrhosis
Nature Genetics (2024)
-
Genetic drivers of heterogeneity in type 2 diabetes pathophysiology
Nature (2024)
-
Evaluating significance of European-associated index SNPs in the East Asian population for 31 complex phenotypes
BMC Genomics (2023)
