
Abstract
CRISPR-associated transposons (CAST) are programmable mobile genetic elements that insert large DNA cargos using an RNA-guided mechanism1,2,3. CAST elements contain multiple conserved proteins: a CRISPR effector (Cas12k or Cascade), a AAA+ regulator (TnsC), a transposase (TnsA–TnsB) and a target-site-associated factor (TniQ). These components are thought to cooperatively integrate DNA via formation of a multisubunit transposition integration complex (transpososome). Here we reconstituted the approximately 1 MDa type V-K CAST transpososome from Scytonema hofmannii (ShCAST) and determined its structure using single-particle cryo-electon microscopy. The architecture of this transpososome reveals modular association between the components. Cas12k forms a complex with ribosomal subunit S15 and TniQ, stabilizing formation of a full R-loop. TnsC has dedicated interaction interfaces with TniQ and TnsB. Of note, we observe TnsC–TnsB interactions at the C-terminal face of TnsC, which contribute to the stimulation of ATPase activity. Although the TnsC oligomeric assembly deviates slightly from the helical configuration found in isolation, the TnsC-bound target DNA conformation differs markedly in the transpososome. As a consequence, TnsC makes new protein–DNA interactions throughout the transpososome that are important for transposition activity. Finally, we identify two distinct transpososome populations that differ in their DNA contacts near TniQ. This suggests that associations with the CRISPR effector can be flexible. This ShCAST transpososome structure enhances our understanding of CAST transposition systems and suggests ways to improve CAST transposition for precision genome-editing applications.
Similar content being viewed by others
Main
CAST are Tn7-like transposons1 that programmably integrate large DNA cargos at genomic locations dictated by a guide RNA sequence2,3. Multiple independent acquisition events1,4 created the distinct CAST subfamilies characterized to date: I-F33,5, I-B6 and V-K CAST2. One of the most remarkable aspects of CAST function is the precision of the programmable insertions: DNA cargo is inserted in a single orientation, with defined spacing from the protospacer adjacent motif (PAM) and within a narrow window (5–10 bp). These features appear to be generally conserved across CAST families3,5,6,7, and are probably a consequence of the transpososome architecture (that is, the nucleoprotein integration complex containing all CAST components).
Across all CAST elements4, four or more proteins make up the CAST transposition machinery: the CRISPR effector (Cas12k or Cascade), TniQ, TnsC and the transposase (TnsB or TnsA–TnsB). In all Tn7-like transposition systems, a specialized CRISPR effector or DNA-binding protein (TnsD in the case of the prototypic Tn7)8 is hypothesized to recruit core transposition proteins to the target site9. In CAST elements, the TniQ protein (which is related to TnsD) associates with the target site via interactions with the CRISPR effector10. The AAA+ regulator TnsC serves as a molecular matchmaker by interacting with both target-site-binding proteins and the transposase11,12. Very little structural information exists to explain how TnsC bridges the components in the hypothesized transpososome assembly. Furthermore, how the core transposition machinery evolved to adopt different targeting strategies6,13,14 remains an open question.
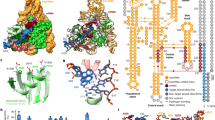
Owing to its simplicity and robust in vitro activity2, ShCAST is an attractive system for understanding the general mechanisms used by CAST elements. Although the structure of each ShCAST component has been individually characterized15,16,17,18, the spatial associations across the entire transposition recruitment process remain unknown. We reconstituted the ShCAST transpososome by mimicking the natural configuration found in programmed integration (Fig. 1a). Using single-particle cryo-electron microscopy (cryo-EM), we obtained a high-resolution structure (3.5 Å resolution) that was sufficient to accurately resolve the interactions between all components within the 961 kDa nucleoprotein complex.

a, Mechanistic model of ShCAST recruitment (left) and integration (right). TnsC (green semicircle) associates with target-site proteins: Cas12k (pink), TniQ (orange) and S15 (tan). The PAM (black) defines the beginning of the protospacer, where Cas12k and single guide RNA (sgRNA) (grey) bind. TnsB (purple) is recruited to the target site through TnsC (red arrow). ATP hydrolysis (yellow lightning bolt) is stimulated by TnsB, resulting in the release of phosphate (Pi) and disassembly of TnsC (green arrows). Upon integration, a nucleoprotein complex containing all CAST components forms at the target site (right). b, Schematic of transpososome sample preparation. Left, the target pot and the donor pot were prepared independently to mimic the process of the RNA-guided transposition. DNA substrates for both the target pot and donor pot have target DNA (light blue) and transposon-end (dark blue) regions that are connected by 5 bp of single-stranded DNA, designed to form a strand-transfer complex (STC) (Methods). The target pot and donor pot include target-site-associated proteins (Cas12k, S15, TniQ and TnsC) and TnsB, respectively, in addition to the corresponding DNA substrate. The transpososome (right) is reconstituted by combining the target and donor pots (Methods). c, The 3.5 Å-resolution cryo-EM reconstruction of the ShCAST transpososome, filtered according to local resolution. Each component in the complex is coloured as in a. Different shades (light or dark green and light or dark purple) indicate different subunits of the protein of the same colour. Target DNA is shown in light blue and transposon DNA is in dark blue. d, The atomic model of the ShCAST transpososome. TniQ N terminus comprises residues 1–10. Right and left refer to the ends of the transposon DNA.
We found that the transpososome architecture promotes modular association across CAST components, and TnsC has dedicated faces of interaction with TniQ and TnsB, consistent with models of Tn7 transposition12,19. Cas12k, TniQ and S15 stabilize R-loop formation, but TniQ and TnsC form the primary connection between the CRISPR effector and transposase. We also observed TnsB–TnsC interactions that are important for TnsB-promoted ATP hydrolysis. Notably, in the context of the transpososome, TnsC protomers make functionally important interactions with the target DNA that are distinct from interactions found in helical TnsC18. Finally, we found that the transpososomes assemble with a slightly different number of TnsC protomers (±1 protomer), hinting at the molecular basis of the intrinsic variability of ShCAST insertions. The structural insight gained from this transpososome structure contributes to the understanding of CAST transposition and serves to identify avenues for protein engineering.
DNA design and transpososome reconstitution
ShCAST insertions occur within a 61- to 66-base pair (bp) window downstream from the PAM in a single orientation2,18. Because transposition is driven primarily via protein–DNA interactions, the transpososome is the most stable structure in the transposition pathway. This principle has been applied successfully in the past to stabilize STC structures of other integrases and transposases, such as PFV20,21. Thus, we designed a strand-transfer substrate (Extended Data Fig. 1a) that contains binding sites for all ShCAST components2. Our designed DNA substrate contains transposon DNA up to the first two internal TnsB binding sites from the right and left ends (Extended Data Fig. 1b), identical to previous studies17,22. The first 30 base pairs have identical TnsB binding sites on either end17, in contrast to the subsequent internal TnsB binding sites that are irregularly spaced in the right transposon end compared with the left transposon end. Therefore, the transposon sequences that we included in our designed substrate most probably do not contribute to the remarkable ability of ShCAST to discriminate the insertion orientation2. The ‘target pot’ from the transpososome reconstitution procedure (Fig. 1b) is similar to the procedure used to reconstitute a ShCAST subcomplex referred to as the ‘recruitment complex’23, which contains all the components except TnsB. We also based our reconstitution procedure on established methods for monitoring transposition in vitro18,24 and reasoned that this procedure would mimic the recruitment and integration process (Fig. 1b). Incubation of target DNA with target-site-binding proteins (Cas12k, TniQ, S15 and TnsC) and ATP resulted in a heterogeneous assembly, comprising different TnsC filament lengths (as assessed by negative-stain electron microscopy; Extended Data Fig. 1c). Subsequent incubation with transposon-DNA-bound TnsB, followed by enrichment for DNA-bound complexes resulted in the successful reconstitution of complete transpososome particles (Fig. 1b and Extended Data Fig. 1d), which we analysed by high-resolution cryo-EM imaging and image analysis (Methods and Extended Data Fig. 2).
Overall transpososome architecture
A 3.5 Å cryo-EM reconstruction (Extended Data Table 1) of the reconstituted ShCAST transpososome reveals an assembly composed of one Cas12k subunit, one TniQ subunit, one ribosomal S15 subunit, four subunits of TnsB, and two full turns of TnsC with six subunits per turn (Fig. 1c). The defined oligomeric assembly of TnsC is important, because the ShCAST recruitment complex (containing all components except TnsB) consists of heterogeneous assemblies of TnsC, distinguished by the direction of TnsC filaments bound to DNA23 and the number of turns of TnsC. In contrast to the heterogeneity of the recruitment complex (captured in the target pot reconstitution, Extended Data Fig. 1c), transpososome particles reveal uniform TnsC directionality (Fig. 1c,d), in which the N-terminal face of TnsC interacts with TniQ at the target site and the C-terminal face of TnsC interacts with TnsB (Extended Data Fig. 3). In addition, TnsC filaments in transpososome particles are of uniform stoichiometry, consisting of two turns of TnsC. TnsC is disassembled by TnsB during recruitment18 (Fig. 1a). Therefore, the homogeneity of the TnsC oligomeric assembly that we observe in our transpososome particles suggests that (1) TnsC protomers lacking productive interactions with target-site proteins are presumably disassembled by TnsB, and (2) TnsB disassembles TnsC filaments until a certain point, reflected in the uniform stoichiometry of TnsC oligomers observed in our transpososome reconstitution. Therefore, the interactions between TnsC and target-site-associated proteins (Cas12k, TniQ and S15) are stabilized against further disassembly by TnsB, probably owing to interactions at the target site (Fig. 1a, right).
Transposition requires TniQ–TnsC contacts
Owing to slight flexibility in the DNA substrate, the distal ends of the transpososome exhibit lower local resolution in our structure (5–7 Å; Extended Data Fig. 2e). As expected, local refinement focused on the Cas12k-proximal region improved the quality of the reconstruction (Supplementary Fig. 1a,b). Consistent with the functional importance of TniQ in ShCAST transposition16, TniQ is located at the PAM-distal end of the R-loop close to Cas12k and S15 (Extended Data Fig. 4a). TniQ primarily interacts with TnsC and RNA, consistent with the productive recruitment complex23. S15 is nestled between the REC2 domain of Cas12k and the PAM-distal sgRNA–DNA heteroduplex (Extended Data Fig. 4d). The rooftop loop of the sgRNA is flanked on either side by S15 and TniQ, respectively. TniQ bridges the two TnsC protomers closest to Cas12k (Fig. 2a and Supplementary Fig. 2), however the TniQ–TnsC12 interface is much smaller than the TniQ–TnsC11 interface (325 Å2 versus 915 Å2; Methods). More specifically, the N-terminal tail of TniQ forms structured interactions with the finger loop of TnsC11 and is generally hydrophobic in nature (Fig. 2b). From the structure, we identified hydrophobic residues W10 and F12, which are buried into a hydrophobic cleft in TnsC11 formed by the finger loop (Fig. 2b), as important residues. H34 forms hydrogen-bonding interactions with the acidic residue E131 on the N-terminal face of TnsC11 (Fig. 2c). Truncation of the first ten residues or mutation of the hydrophobic residues W10, F12 and H34 results in a near-complete loss of transposition activity (Fig. 2d), consistent with the essential role suggested by our structural observations. Consistent with the importance of S15 for formation of the productive recruitment complex23, we find that S15 generally improves transposition activity (Fig. 2d). However, the addition of S15 does not change our conclusions regarding the importance of the TniQ residues (Fig. 2d). Cas12k–TnsC interactions are completely absent (Extended Data Fig. 4c), and 3D variability analysis suggests that Cas12k enables flexible linkage to the other ShCAST components (Supplementary Video 1). Together, these observations collectively suggest that the TniQ–TnsC interactions that we observe are the primary connections required to direct insertions to a guide RNA-directed target site. This supports the idea that engineering new associations with target-site recognition modules (that is, novel non-CAST CRISPR effectors) can be achieved by focusing on TniQ.

a, The composite cryo-EM map was created using two separate reconstructions from the local refinements (Methods). The composite map is coloured as in Fig.1. TnsC protomers are labelled according to their position in the transpososome (TnsC1 is the closest TnsC protomer to TnsB). The outline indicates the TniQ–TnsC interface. b,c, The atomic model of interactions at the TniQ–TnsC interface rotated 120° around the vertical axis (b) and 30° around the horizontal (c) with respect to the outlined region in a. b, The N-terminal tail of TniQ is shown—as sticks—interacting with a hydrophobic cleft created by the finger loop of TnsC. c, Hydrogen-bonding interactions are shown as dashed black lines; distance between the donor and acceptor atoms is indicated. d, TniQ mutations eliminate in vitro transposition activity, consistent with the interactions observed in our transpososome structure. WT, wild type. In vitro transposition activity was monitored by transforming the reaction product into competent cells, and counting the number of transformants after plating on an antibiotic-containing plate (Methods). Data are mean ± s.d. (n = 3 biological triplicates). Raw data points are shown in red.
TnsB forms structured interactions with TnsC
We next focused on the interactions between TnsB and TnsC in the transpososome structure (Fig. 3a). TnsB belongs to the DDE/D transposase family, and bears significant similarities to MuA from bacteriophage Mu17,22,25,26. TnsB contains multiple functionally distinct domains dedicated to DNA-binding, catalytic activity and interactions with TnsC17 (Supplementary Fig. 3). The previously determined tetrameric TnsB STC structure17 (PDB: 7SVW) docks well into the transpososome cryo-EM map, requiring only minimal modifications throughout (1.54 Å Cα root mean squared deviation (r.m.s.d.), Supplementary Fig. 4). Full-length TnsB has a 52-residue-long flexible linker (residues 518–569), that connects the STC to the C-terminal ‘hook’ (TnsBhook, residues 570–584) (Supplementary Fig. 3). TnsBhook serves as the point of contact with the TnsC filament body and is critically important for CAST transposition17. We identified well-defined density corresponding to the TnsBhook at 4 of the 6 TnsC protomers closest to TnsB (TnsC protomers 2–5) (Fig. 3b and Extended Data Fig. 5). After docking in TnsB STC structure17, we found additional unassigned density corresponding to TnsB residues 475–542. These residues, which were previously missing in STC and predicted to be disordered by DISOPRED327 (Supplementary Fig. 3), form a helix–turn–helix motif (Fig. 3c). Therefore, although TnsB–TnsC associations may be flexible in principle, we see very well-defined TnsB–TnsC interactions in the transpososome, with all four TnsB protomers engaged at precise locations on the TnsB-proximal TnsC hexamer.

a, An overview of TnsB–TnsC interactions in the transpososome. b, The N-terminal face of the TnsC hexamer closest to TnsB, as indicated in a. TnsC protomers are labelled according to their position (1 indicates the TnsC protomer closest to TnsB). The dashed line indicates where the hexamer ends. TnsBhook peptides bind at TnsC protomers 2–5 and are coloured according to nearest TnsB protomer. The red asterisk indicates where domain IIβ (residues 410–474) associates across 2 TnsC protomers on the C-terminal face of TnsC. c, Side view of TnsB–TnsC interactions, as indicated in a. Residues 475–542 correspond to the additional structured TnsB domain (highlighted with black lines) that is observed to interact between the two TnsC protomers shown in b. The red asterisk indicates the beginning of helix α4. Dotted lines indicate the flexible linker (not observed in our structure). d, TnsB–TnsC interactions near the ATP-binding pocket. Interacting residues are shown and dashed lines represent hydrogen bonds. e, Alterations to TnsB domain IIβ decrease ATP hydrolysis activity. The hydrolysis rate (vo) is shown for each variant. Data are mean ± s.d. (n = 3 biological triplicates). f, In vitro transposition assay testing TnsB mutants in the presence (dark grey) or absence (light grey) of S15. The number of transformants is plotted for each condition tested as a proxy for the transposition activity. Data are mean ± s.d. (n = 3 biological triplicates). Raw data points are shown in red. The on-target percentage of transposition was estimated from Illumina sequencing and indicated on the corresponding bar plot. g, The ATP-binding pocket of TnsC with cryo-EM density (grey with transparent surface), magnesium ion (green sphere) and hydrogen bonds (dashed lines) shown.
TnsB domain IIβ stimulates ATPase activity
In the ShCAST system, TnsB is recruited to the target site via TnsC17 (Fig. 1a, left). This is intrinsically tied to ATP hydrolysis, because substitution with a non-hydrolyzable ATP analogue (AMP-PNP) inhibits TnsB-mediated filament disassembly and results in non-targeted transposition18. Therefore, a crucial role of TnsB is also to stimulate the ATPase activity of TnsC in the process of target-site selection. In prototypic Tn7, C-terminal fragments are sufficient to stimulate TnsC ATPase activity28. In ShCAST, two TnsB–TnsC interactions have been biochemically demonstrated to be required for this process, one of which corresponds to TnsBhook and the other is located elsewhere in full-length TnsB17. Notably, within the transpososome structure, we observe a second TnsB–TnsC interaction at the C-terminal face of TnsC (Fig. 3c,d). In particular, TnsB residues 410–542 (including part of a flexible linker) are positioned to bridge two TnsC protomers (Fig. 3c). Notably, domain IIβ (residues 410–474) localizes close to the ATP-binding pocket of TnsC, abutting against helix α4 in TnsC (Fig. 3d). This helix contains functionally important, conserved residues Q185 and R189 (Fig. 3d), which recognize the nucleotide-bound state18.
To test whether the TnsB–TnsC interactions that we observe in the transpososome structure are required for the ability of TnsB to stimulate the ATPase activity of TnsC (and trimming of the TnsC filament), we tested various mutations using a malachite green ATP hydrolysis assay (Fig. 3e and Methods). Consistent with expectations, TnsC has low basal levels of ATPase activity on its own, and wild-type TnsB substantially stimulates ATPase activity (Fig. 3e). Introduction of the Y439A mutation in TnsB reduced the ability of TnsB to stimulate ATP hydrolysis, but other mutations (such as R432A; Fig. 3d,e) had no effect. To test whether domain IIβ is generally required, we next tested various TnsB fragments for their ability to stimulate ATP hydrolysis. The C-terminal domain (CTD, residues 476–584) of TnsB or a C-terminal truncation (ΔCTD, residues 1–475) of TnsB did not stimulate ATP hydrolysis, consistent with previous work17. By contrast, the C-terminal domain with the domain IIβ (IIβ+CTD, residues 410–584) increased ATP hydrolysis above basal levels of TnsC ATPase activity (that is, without TnsB) or CTD (Fig. 3e). Despite these effects on ATP hydrolysis, TnsB mutations at this interface only slightly reduced transposition activity compared with the wild type (Fig. 3f). However, consistent with the idea that these TnsB mutants have a reduced capacity to stimulate ATP hydrolysis, targeted transposition (as assessed by Illumina sequencing (Methods)) was significantly reduced in the absence of S15 (69% for the wild type versus less than 6% for the mutants) (Fig. 3f and Extended Data Fig. 6). The addition of S15, which has been shown to boost overall transposition activity23, resulted in a less marked effect on on-site targeting (99% for the wild type versus 76–93% for the mutants) (Fig. 3f and Extended Data Fig. 6), consistent with the idea that S15 can generally promote targeted transposition by stabilizing CRISPR effector binding. It is particularly noteworthy that, in the absence of S15, wild-type TnsB retains high levels of on-site targeting (69%), whereas TnsB mutants have no targeting ability (Extended Data Fig. 6). These marked effects suggest that the ability of TnsB to promote TnsC filament disassembly is compromised, similar to the effects observed with AMP-PNP18.
In this context, the defined assembly of TnsC that we observe in the transpososome may correspond to either an ATP hydrolysis-resistant state or a stable post-hydrolysis state. To distinguish between these two possibilities, we used local refinement (focusing on TnsC) to generate a 3.2 Å map (Supplementary Fig. 1c,d), that is sufficient to unambiguously distinguish between ATP and ADP. This improved map demonstrates that ATP is bound to all protomers (Fig. 3g and Supplementary Fig. 5). Our observations are consistent with the idea that although TnsB stimulates ATP hydrolysis and TnsC filament disassembly, aspects of the transpososome structure probably prevent hydrolysis, allowing the stable configurations observed here.
Transpososome TnsC–DNA interactions
In the absence of additional factors, ATP-bound TnsC forms continuous helical filaments (referred to throughout as helical TnsC) with DNA, and has no preference for filament length15,18. However, the precise insertion profiles of ShCAST suggest that TnsB trims back TnsC filaments to a specific length before transposon DNA integration2. Thus, we explored whether structural differences distinguish helical TnsC from the structure observed here. Although TnsC in the transpososome is globally similar to helical TnsC (Protein Data Bank (PDB) ID: 7M99; overall Cα r.m.s.d. = 1.6 Å), it is not helically symmetric (Supplementary Video 2 and Supplementary Fig. 6), because imposing helical symmetry resulted in a lower resolution reconstruction with aberrant features (Supplementary Fig. 7). The largest structural changes in the assembly correspond to the TnsB-proximal (TnsC1) and Cas12k-proximal (TnsC12) (Fig. 4a) TnsC protomers. These protomers are collapsed towards the centre of the TnsC assembly with Cα r.m.s.d. between 2.1 and 2.5 Å (Fig. 4a). This suggests that the slight conformational changes observed here are due to interactions with other CAST components within the transpososome, namely TniQ and TnsB.

a, TnsC protomers are coloured by changes in Cα r.m.s.d. between the helical TnsC (PDB: 7M99) and TnsC in the transpososome. The arrows represent the inward movement of TnsC, starting from the helical filament. b, TnsC–DNA interactions throughout the transpososome. TnsC residues forming hydrogen-bonding interactions with DNA, at least 4 Å away, are represented by red (K103, T121 and K150, previously identified interacting residues) or blue (R182 and K119; newly identified interacting residues) spheres. TnsC residues that are close to, but do not form specific interactions with the DNA backbone, more than 4 Å away, are represented by grey spheres. The target strand DNA (tsDNA) (light blue) and non-target strand DNA (ntDNA) (dark blue) are represented in ribbon. c, TnsB-proximal TnsC protomers interact with the sugar-phosphate backbone of tsDNA. d, TnsB-proximal TnsC protomers are shown to interact with the ntDNA backbone. e, TnsC protomers adjacent to Cas12k interact with both tsDNA and ntDNA immediately downstream of the R-loop. In c–e, hydrogen-bonding interactions between protein residues and the sugar-phosphate backbone of DNA are represented with dashed lines. Rotations relative to b are indicated. f, In vitro transposition assay of TnsC residues observed to interact with DNA. Data are mean ± s.d. (n = 3 biological triplicates). Raw data points are shown in red.
Given the lack of structural rearrangements of TnsC within the transpososome, it was notable that TnsC–DNA interactions appeared markedly different in the context of the transpososome compared with previous TnsC structures obtained in the absence of other transposition factors. In previous work, the helical symmetry of TnsC tracked with that of the bound DNA duplex15,18. In doing so, helical TnsC imposes its own helical symmetry, which distorts the bound DNA through underwinding15,18. In contrast to previous TnsC structures, within the transpososome, TnsC does not track specifically with either strand of the DNA duplex (Fig. 4b). Comparing the structure of transpososome target DNA to B-form DNA, we find that target DNA is only slightly underwound compared with B-form DNA (11 bp versus 10 bp per turn) and does not match the layer line spacing of TnsC in the transpososome (~40 Å; Extended Data Fig. 7).
Owing to the mismatch in TnsC (40 Å) and DNA (36 Å) repeat lengths, the specific TnsC–DNA interactions made in each of the two TnsC turns in the transpososome are distinct (Fig. 4b). In helical TnsC structures, residues K103 and T121 are consistently found to track with one particular strand of duplex DNA18 (5′ to 3′ in the direction of the C-terminal to the N-terminal face, Supplementary Fig. 8), which we confirmed in improved, high-resolution (3.5 Å) cryo-EM reconstructions of TniQ–TnsC (Supplementary Fig. 9 and 10). In the context of the transpososome, we observed a network of interactions, some of which correspond to new interactions by previously identified DNA-binding residues15,18 (T121, K103 and K150, red) (Fig. 4b) or new interactions made by residues not previously associating with DNA (K119 and R182, blue) (Fig. 4b). The remaining interactions throughout the two turns of TnsC correspond to general electrostatic interactions, as these residues are too distant to form specific hydrogen-bonding interactions with the DNA backbone (grey residues) (Fig. 4b and Extended Data Table 2). Notably, we find that the two different sets of residues forming specific interactions with the DNA backbone are generally segregated spatially, either towards the Cas12k-proximal end (red residues) (Fig. 4b) or towards the TnsB-proximal end (blue residues) (Fig. 4b). In particular, the new interactions with the DNA backbone, involving R182 (Fig. 4c) and K119 (Fig. 4d) are supported by cryo-EM density (Supplementary Fig. 11). Residues previously shown to interact with DNA (T121 and K103) in previous structures of TnsC are now shown to associate with both target and non-target strands of the DNA duplex (Fig. 4e).
We thus hypothesized that TnsC residue R182 is critical for ShCAST transposition. Consistently, both single (R182A) and triple mutants (K103A/T121A/R182A) significantly decreased the overall transposition activity (Fig. 4f), whereas the double mutant K103/T121 showed an overall increase in transposition activity (Fig. 4f), consistent with our previous results18. Mutant phenotypes were consistent regardless of whether S15 is added (Fig. 4f), further emphasizing the importance of R182. We hypothesize that this network of interactions corresponds to the distinct roles of TnsC residues in transpososome formation and stabilization. Furthermore, because these interactions are not observed in the TniQ–TnsC structure (Supplementary Fig. 10), this is not solely owing to the binding of TniQ, but must be related to R-loop formation, consistent with other reports23.
The basis of insertion spacing variability
We were able to distinguish two different transpososome populations containing either 12 or 13 TnsC protomers (the former is shown in Fig. 1). Because particles containing 12 TnsC protomers were most frequently observed (73% of particles used in final refinement) and yielded a slightly higher resolution cryo-EM map (3.5 Å versus 3.7 Å; Extended Data Table 1), we refer to this configuration as the major configuration. Comparing the two configurations, the specific TnsC–DNA interactions in protomers adjacent to TnsB are virtually identical, since the same interactions are made at the same positions on the target DNA substrate (Extended Data Fig. 8). Aligning both transpososome reconstructions (major and minor configurations) on the basis of TnsB reveals an additional TnsC protomer (TnsC13) next to Cas12k in the minor configuration, which contains an additional TnsC protomer compared with the major configuration (12 TnsC protomers) (Fig. 5a). Correspondingly, Cas12k is rotated by approximately 60° in the minor configuration (solid surface, Fig. 5a) compared with the major configuration (transparent surface, Fig. 5a). At first glance, the TnsC–DNA contacts adjacent to Cas12k also appear similar. However, these contacts are shifted over by one nucleotide in the minor configuration compared with the major configuration (Fig. 5b). That is, the last two TnsC protomers in both configurations interact in the same way with TniQ, resulting in a translational shift of TnsC–DNA interactions (Fig. 5b,c). This leads to slight variability in the number of base pairs contacted by TniQ (5 bp (major configuration) versus 4 bp (minor configuration)) (Fig. 5c) and TnsC (30 bp versus 31 bp, respectively) (Fig. 5c). The structural variations described here suggest that more than one transpososome complex is stable, leading to an elegant mechanism to explain the slight variability (around 5 bp) in ShCAST insertion profiles2.

a, The cryo-EM reconstructions (low pass filtered to 10Å) of major and minor configurations of transpososome. The reconstructions were aligned with respect to TnsB, where protein–DNA interactions are identical in the two configurations. The map corresponding to the minor configuration is coloured and opaque, and the major configuration is transparent. The outline indicates TnsC–DNA interactions at the Cas12k face. b, Expanded view of the outlined region in a, showing that major and minor configurations interact with both target-strand DNA (tsDNA) and non-target strand DNA (ntDNA). Residues from TniQ and TnsC in the minor configuration interact with the phosphate backbone that are shifter by 1 bp towards the R-loop compared with the major configuration. Hydrogen-bonding interactions between protein residues and the DNA backbone are represented with dashed lines. Base pairs interacting with the final two protomers of TnsC are represented in stick. Positions three bases downstream of the R-loop (−3 on tsDNA and +3 on ntDNA) are coloured magenta as a landmark, facilitating comparison of the two configurations. c, Schematic of DNA-binding contacts of each component (Cas12k, TniQ and TnsC) in major (top) and minor (bottom) configurations. The number of base pairs contacted by each component is shown and the length is indicated with bar-ended lines. Positions interacting with two protein components (Cas12k and TniQ or TnsC and TnsB) are indicated as overlapping bars. The minor configuration includes and additional TnsC protomer (TnsC13, dashed outline) proximal to Cas12k, which makes the DNA-binding contribution of TniQ and TnsC different in the two configurations (highlighted in red). The third base pair downstream of the R-loop is coloured magenta, as in b.
Discussion
Our structural observations enable us to fill in crucial mechanistic details of the recruitment and insertion of transposon DNA at a CRISPR-defined target site (Fig. 6). Once a productive complex is formed consisting of target-site proteins Cas12k, S15, TniQ and TnsC (Fig. 6a,b), TnsB–TnsC interactions stimulate ATP hydrolysis and TnsC filament disassembly. Our structure also suggests that the TnsB–TnsC contacts required for filament disassembly involve two TnsB domains, TnsBhook and domain IIβ (Fig. 6c). ATP hydrolysis (and TnsC filament disassembly) continues until TnsB encounters the two TnsC turns closest to Cas12k. We hypothesize that two turns of TnsC are required for transpososome formation with the ShCAST element (Fig. 6d), a state resistant to TnsB-mediated ATP hydrolysis (Fig. 6e) and stabilized by new TnsC–DNA contacts, among them K103, T121, K119 and R182. These contacts appear to stabilize a TnsC configuration that is not fully engaged with DNA compared to the helical TnsC formed outside the transpososome. We speculate that the two turns of TnsC that resist TnsB-promoted disassembly might be a basis for the specific activation of TnsB at the target site. However, the detailed mechanism whereby TnsC activates ATPase activity, resists filament disassembly and stimulates integration requires further investigation.

a, The CRISPR effector Cas12k (pink) bound to sgRNA (grey) defines the target site by forming an R-loop and associating with S15 (tan) and TniQ (orange). b, TnsC (green) may polymerize on DNA (blue) in two directions: towards or away from the target site (indicated by the black arrows and the question mark). TnsC interacts with target-site-associated proteins (Cas12k–sgRNA, S15 and TniQ) to form the recruitment complex. c, Two interactions between TnsB (purple) and TnsC: TnsB is recruited to TnsC filaments by TnsBhook (purple, indicated with a red asterisk) and domain IIβ (indicated approximately by a yellow star) from TnsB can interact with TnsC (indicated by a red double arrow), lead to disassembly of TnsC and promote ATP hydrolysis (yellow lightning bolt), resulting in the release of phosphate (green arrows). Dashed lines (purple) represent flexible linkers between TnsBhook and the rest of TnsB. d, TnsB is recruited to the target site and forms the STC upon integration. Four TnsBhook are bound to four TnsC protomers proximal to TnsB through the flexible linker (dashed purple line). Two turns of TnsC (12 protomers) are stably formed against disassembly. Together with target-site-associated proteins and TnsB STC, all CAST components form the transpososome at the integration site. e, A magnified view of TnsC (boxed) in the transpososome shown in d. All TnsC protomers are in the ATP-bound state (ATP is shown as a red circle). TnsC in the transpososome does not specifically track with DNA helical symmetry, unlike previous helical structures of TnsC.
This structure also reveals how ShCAST transpososome architecture conserves TnsC function across Tn7-like elements. ShCAST TnsC forms continuous helical filaments on DNA15,18, which are distinct from TnsC configurations found in the prototypic Tn719 and I-F3 CAST subfamily11. TnsC from prototypic Tn7 forms heptameric oligomers19 and led to the original hypothesis that the ring would allow segregated interaction interfaces: the TnsD interface maps to the N-terminal face, and the TnsA–TnsB interface maps to the C-terminal face19. Although the I-F3a CAST TnsC adopts a heptameric structure11, it remains unknown whether TnsC in this system has similarly segregated interaction interfaces. However, chromatin immunoprecipitation–sequencing experiments suggest that TnsC has a key role in associating with the Cascade complex, serving as a selectivity factor in subsequent recruitment of TnsA–TnsB11. Therefore, despite the structural differences in ShCAST TnsC, we hypothesize that the segregated interactions that we observe in the ShCAST transpososome are conserved across Tn7-like transposition systems.
The segregation of interactions that we observe in the transpososome also suggests a mechanism for how the core transposition machinery can co-opt different CRISPR effectors via TniQ. This is particularly interesting, considering the I-B CAST elements, which contain features of both prototypic Tn7 and CAST elements6. TnsC and the cognate transposase in I-B CAST elements can associate with two different TniQ domain proteins: TnsD (sequence-specific DNA-binding protein) or TniQ (associated with a CRISPR effector) to direct insertions6. Competition between these two targeting modalities suggests that a single interface on TnsC can interact with either TniQ or TnsD6. Our structure provides an elegant explanation for how this is achieved: by separating targeting machinery (TniQ or TnsD) from the core transposition machinery (TnsA–TnsB) via segregated interfaces on TnsC. This ensures that co-option of target-site-binding proteins (that is, with different CRISPR effectors or different DNA-binding proteins) does not interfere with the function of core transposition machinery.
Although the transpososome structure is remarkably uniform and well-resolved (Extended Data Fig. 2) compared with the heterogeneity of other reconstitutions23, we observe a slight variability in the oligomeric composition of TnsC within transpososome populations. This is not altogether unexpected, since CAST insertion profiles also contain a slight variability (around 5 bp) in their insertion profiles2. Notably, the protein–protein associations that we observe in either configuration are essentially identical, except that TnsC and TniQ are shifted one nucleotide closer to Cas12k (Fig. 5c). Therefore, transpososome associations are constructed to allow minor flexibility. Taking this a step further, it is possible that the basis of CAST insertion variability lies in the stable configurations of TnsC that preserve CAST component interactions. This suggests that more precise CAST elements can be engineered by reinforcing (that is, stabilizing) specific spatial associations between CAST components within the transpososome.
Methods
Protein cloning of ShCAST mutants and S15
TnsC (K103A, T121A, and R182A), TnsB (ΔCTD; residues 1–475, CTD; residues 476–584, IIβ+CTD; residues 410–584, R432A, and Y439A), and TniQ (Δ1–10; residues 11–167, W10A, F12A, and H34A) mutants were cloned from pXT130-TwinStrep-SUMO-ShTnsC (Addgene #135526), pXT129-TwinStrep-SUMO-ShTnsB (Addgene #135525) and pXT131-TwinStrep-SUMO-ShTniQ (Addgene #135527), respectively, using the Q5 site-directed mutagenesis kit (NEB) and two corresponding primers (forward and reverse primer pair are listed in Supplementary Table 1). Double or triple mutants were generated by introducing mutation on top of the mutant plasmid vectors. For S15, the DNA sequence for Escherichia coli S15 was amplified by PCR from E. coli K-12 MG1655 chromosomal DNA using the following primers: RPS15_Ext_Hifi_F and RPS15_Ext_Hifi_R (Supplementary Table 1). This gene fragment was cloned into a linearized vector backbone (original ShTniQ vector from Addgene #135527) containing TwinStrep-SUMO at the N terminus of S15 using the NEBuilder HiFi assembly protocol (NEB). TnsC clones were transformed into E. coli BL21(DE3) competent cells (NEB), while TnsB and S15 clones were transformed into homemade T1 phage-resistant pRIPL BL21(DE3), derived from transforming pRIPL into BL21(DE3) Competent E. coli (NEB).
Protein expression and purification of ShCAST components and S15
All clones except S15 were purified using previously described protocols2,18. For purification of S15, single colonies were inoculated in 10 ml LB medium containing 34 μg ml−1 chloramphenicol and 100 μg ml−1 ampicillin, and grown overnight at 37 °C as starter cultures. The overnight starter culture was added to 1.5 L of TB medium containing the same ratio of antibiotics and grown until an absorbance of 0.4 at 37 °C. The temperature was lowered to 20 °C and the culture was induced at an absorbance of 0.6 with 0.4 mM isopropyl-β-d-thiogalactopyranoside and continued to grow overnight (16–18 h). Cells were collected by centrifugation at 5,000 rpm for 10 min and resuspended in lysis buffer (50 mM Tris pH 7.4, 500 mM NaCl, 5% glycerol, 1 mM DTT, 1 mM PMSF, 0.1% NP-40 and protease inhibitors (Pierce, ThermoScientific). The cell lysate was sonicated for 15 min with a pulse on for 2 s with 10 s rest in between. The sonicated lysate was centrifuged for 30 min at 10,000 rpm at 4 °C. The supernatant was loaded onto a Strep-Tactin Superflow resin column (Qiagen) equilibrated with loading buffer (50 mM Tris pH 7.4, 500 mM NaCl, 1 mM DTT, and 5% glycerol). The column was washed with 5 column volumes (~15 ml) of wash buffer (50 mM Tris pH 7.4, 500 mM NaCl, 5% glycerol) before eluting with elution buffer (50 mM Tris pH 7.4, 500 mM NaCl, 5% glycerol and 4 mM desthiobiotin (SigmaAldrich)). The consolidated eluate was then incubated overnight at 4 °C with SUMO protease (1/100 mass ratio of SUMO protease to S15 protein).
S15 was next purified using a heparin purification step. Protein from the Strep-Tactin elution (in 500mM NaCl) was diluted to a final salt concentration of 200 mM NaCl before loading onto a 1 ml heparin column (GE Healthcare) equilibrated in low-salt buffer (50 mM Tris pH 7.4, 200 mM NaCl, 1 mM DTT and 5% glycerol). The heparin column was washed with 20 column volumes of low-salt buffer, followed by a gradient elution from 200mM NaCl to 1 M NaCl using high-salt buffer (50 mM Tris pH 7.4, 1.2M NaCl, 1 mM DTT, and 5% glycerol). Fractions containing S15 were concentrated, and buffer exchanged before size-exclusion chromatography was performed using a Superdex 200 increase 10/300 (Cytiva) equilibrated in the following buffer: 20 mM HEPES pH 7.5, 250 mM KCl, 1 mM DTT, and 5% glycerol. Fractions containing S15 were consolidated and concentrated to ~2 mg ml−1 using a 6 ml 3K molecular weight cut-off centrifugal concentrator (ThermoFisher), before being aliquoted and flash-frozen in liquid nitrogen for long-term storage at −80 °C.
Preparation of DNA substrate
The general idea of the substrate design for the STC was described previously17. However, instead of a symmetric strand-transfer DNA, we designed an asymmetric DNA that mimics the Cas12k-guided transposition product (Supplementary Table 1). This design includes two DNA substrates: (1) target-pot DNA containing left-end (LE) sequence and protospacer and (2) donor pot DNA containing right-end (RE) sequence. Each DNA substrate was prepared independently. First, target-pot DNA substrate was prepared by annealing four synthetic oligonucleotides (IDT) of the following: target-LE_F, non-target_R, LE_R, and 5′ dethiobiotinylated LUEGO29 (Supplementary Table 1). These four oligonucleotides were mixed in a molar ratio of 10:11:11:10. Second, donor pot DNA is composed of three synthetic oligonucleotides including: RE_F, RE_R1 and RE_R2 (Supplementary Table 1). These oligonucleotides were mixed in a 10:11:11 molar ratio. The mixture of oligonucleotides was supplemented with a 10× concentrated annealing buffer to make the final buffer composition the following: 10 mM Tris pH 7.5, 50 mM NaCl, and 1 mM EDTA. The mixture was then heated up to 95 °C for 5 min and cooled down to 30 °C at the rate of 1 °C per minute using a thermal cycler (BioRad).
Preparation of sgRNA
Using two primers, sgRNA_For and sgRNA_PSP1_Rev (Supplementary Table 1), the DNA sequence encoding the T7 RNA polymerase promoter and sgRNA was amplified by PCR from pHelper_ShCAST_sgRNA vector (Addgene, #127921). The DNA template was then subjected to GeneJet PCR purification (ThermoScientific). sgRNA was produced by in vitro transcription using the HiScribe T7 High Yield RNA synthesis kit (NEB) with the PCR amplified DNA sequence as the template. Purified sgRNA was aliquoted and stored at −20 °C.
Reconstitution of transpososome complex and recruitment complex
The transpososome complex and recruitment complex were generated by stepwise assembly using a pull-down assay on streptavidin beads (Fig. 1b). For the target pot, annealed target-pot DNA was first bound to Streptavidin Mag Sepharose magnetic beads (Cytiva) equilibrated with reaction buffer (20 mM HEPES pH 7.5, 250 mM KCl, 15 mM MgCl2, and 1 mM DTT) and incubated at room temperature with shaking for 30 min. Cas12k and sgRNA were reconstituted in a 1:2 molar ratio and incubated for 30 min at 37 °C in the following buffer: 20 mM HEPES pH 7.5, 160 mM NaCl, 15 mM MgCl2, and 1 mM DTT. The Cas12k–sgRNA complex was added to the target-pot DNA-bound beads and incubated for 30 min at 37 °C in the presence of a fivefold molar excess of S15 to DNA. The beads were washed three times with 500 μl wash buffer (20 mM HEPES pH 7.5, 250 mM KCl, 15 mM MgCl2, 0.05% Tween20, and 1 mM DTT) to remove excess protein and nucleic acids. Twentyfold molar excess of TniQ and tenfold molar excess of S15 to DNA were added to the beads and incubated at 37 °C for 30 min. Tenfold molar excess of TnsC was diluted to a final salt concentration of 250 mM NaCl and added to the TniQ–S15 beads solution containing a final concentration of 1 mM ATP. The sample was incubated for 30 min at 37 °C before the beads were washed three times with 500 μl wash buffer containing 1 mM ATP. The recruitment complex was prepared by eluting the target-pot DNA at this point using 50 μl of elution buffer (20 mM HEPES, 250 mM KCl, 15 mM MgCl2, 0.05% Tween20, 10 mM biotin, 1 mM ATP, and 1 mM DTT). For transpososome assembly, donor pot containing TnsB and donor pot DNA was prepared independently in 6:1 molar ratio with the following final buffer composition: 25 mM HEPES pH 7.5, 100 mM NaCl, 15 mM MgCl2, and 1 mM DTT; and incubated at 37 °C for 30 min. The reconstituted donor pot was added to the beads and incubated for 40 min at 37 °C. Three washes of 500 μl wash buffer containing 1 mM ATP were performed before eluting the transpososome complex from the beads with 50 μl elution buffer. The eluate was diluted with the wash buffer containing 1 mM ATP for cryo-EM or negative-staining EM sample preparation by 6–10 fold or 15 fold respectively.
In vitro transposition assay and high-throughput mapping of transposition events
All purified proteins (except Cas12k) were diluted to 2.5 µM using stock buffer (500 mM NaCl, 50 mM Tris pH 7.4, 10% glycerol, 0.5 mM EDTA, 1 mM DTT). Cas12k was assembled with sgRNA before incubation with other components in the following manner: sgRNA was added to Cas12k to make 2.5 µM Cas12k and 30 µM sgRNA. Separate reactions were prepared for the target pot and donor pot. The target pot contains 2.24 nM pTarget_pBC_KS+_PSP1 (a gift from the J. E. Peters laboratory), 104 nM of Cas12k, 104 nM TnsC, 104 nM TniQ and 1.25 µM sgRNA in transposition buffer (26 mM HEPES, 50 mM KCl, 0.2 mM MgCl2) supplemented with 2 mM DTT, 50 µg ml−1 BSA and 2 mM ATP. The donor pot contains 1.08 nM pDonor_ShCAST_kanR (Addgene #127924), 104 nM TnsB, 2 mM DTT, 50 µg ml−1 BSA and 2 mM ATP in transposition buffer. Both pots were incubated at 37 °C for 30 min before combining and adding MgOAc2 to a final concentration of 15 mM. The combined reaction was further incubated at 37 °C for 2 h. After the final incubation step, 20 μl of the reaction mixture was digested by 1 μl of Proteinase K (Ambion) and incubated at 37 °C for 1 h. 10 μl of the reaction was then transformed into 100 μl of Stellar competent cells (Takara Bio) and plated on kanamycin plates. All the experiments were done in biological triplicates.
From the plates of each condition, the colonies were washed up and diluted to absorbance of 0.5 using LB. The liquid culture was then grown for 3 h at 37 °C before the plasmid extraction using a miniprep kit (QIAGEN). Prepared DNA was sequenced by the Microbial Genome Sequencing Center (https://www.seqcenter.com/) using the Illumina DNA sequencing service on the NextSeq 2000 platform. Paired-end reads (2 × 151 bp) were analysed using BBtools v38.98 (http://sourceforge.net/projects/bbmap/). First, the reads were processed by BBDuk (BBtools v38.98) to collect adjacent target DNA sequences from all the reads containing 30bp of the ShCAST left-end sequence. Then these sequences were mapped onto the pTarget_pBC_KS+_PSP1 using BBMap (BBtools v38.98) with a 90% sequence identity cut–off. Number of base pairs between the end of the PAM and the beginning of the ShCAST left-end sequence was used to define the position of the transposition. Based on the mapping, the transpositions at 55–70 bp downstream of the PAM were considered to be on-target transposition. The number of on-target transposition reads was divided by the total number of transposition reads to estimate the on-target ratio.
Malachite green ATP hydrolysis assay
One-hundred millilitres of malachite green reagent was prepared by the following protocol. First, 34 mg of malachite green carbinol base (ChemCruz) was dissolved into 40 ml of 1N HCl. 1 g of Ammonium Molybdate (MacronChemicals) was dissolved in a separate 14 ml of 1N HCl. These two solutions were mixed and diluted up to 100 ml using ddH2O. The reagent was then filtered using 0.45 μm syringe filter (VWR), and covered with an aluminum foil to avoid light. ATPase assay was completed using purified protein stocks of TnsC, and constructs of TnsB (wild type, ΔCTD, CTD, IIβ+CTD, R432A and Y439A). To minimize the processing time, 2× protein pot and 2× ATP pot were prepared independently. Buffer composition for both pots was the same as follows: 25 mM HEPES pH 7.5, 150 mM NaCl, 1 mM DTT. In addition to the described buffer, 2× protein pot contains 10 μM TnsC, 2 μM TnsB, and 2.5 μM 60 bp DNA (annealed using 60bp_top and 60bp_bot, Supplementary Table 1), and 2× ATP pot contains 1 mM ATP and 2 mM MgCl2. One-hundred microlitres of each pot was mixed to initiate the ATP hydrolysis reaction. For each time point (10, 20, 30, 40, 50, 60, 90 and 120 min), 20 μl of the reaction mix was transferred to the 96-well plate (Corning) that contains 5 μl of 0.5 M EDTA to quench further hydrolysis. After taking all the time points, 150 μl of the room-temperature Malachite Green reagent was added to each well, and the plate was shaken for ~5 min to develop the colour for imaging. Absorbance at 650 nm was read from each well using the i-control v1.101.4 software on an Infinite 200 plate reader (TECAN). For calibration, KH2PO4 solutions of the following concentrations were used to generate a calibration curve: 0 μM, 4 μM, 8 μM, 12 μM, 16 μM, 24 μM, 40 μM and 60 μM. The data was plotted with time as the x-axis and the concentration of released inorganic phosphate as the y-axis. The slope was obtained from the linear regression to get the reported vo values (in moleculas of ATP per min). Three independent experiments were done for each condition, to generate the reported bar plot.
Cryo-EM sample preparation and freezing of transpososome complex
The transpososome complex sample was prepared by diluting the elution from the pull-down by 6-, 8- and 10-fold using wash buffer (described above) containing 1 mM ATP. Graphene oxide-coated grids were prepared following the protocol described previously17,30,31. Four microlitres of transpososome complex sample was loaded on the carbon side of a graphene oxide-coated grid and incubated for 20 s in the Mark IV vitrobot chamber (ThermoFisher), which was set to 4 °C and 100% humidity. Each grid was blotted for 6 s with a blot force of 5, and then plunged into liquid ethane cooled with liquid nitrogen.
Cryo-EM imaging and image processing of transpososome complex
Vitrified samples of transpososome complex were first screened using Talos Arctica (ThermoFisher) operated at 200 kV prior to large-scale data collection. Screened grids were imaged using a Titan Krios (300 kV, ThermoFisher) equipped with a BioQuantum energy filter (Gatan) and K3 direct electron detector (Gatan). A total of 15,740 micrographs were collected using Leginon v3.532 at 81,000× magnification (1.067 Å per pixel) using image shift, with the nominal defocus from −0.8 μm to −2.5 μm. Each movie was collected with 2 s of exposure with a total dose of 49.91 electrons per Å2, fractionated into 50 frames. Frames were aligned using MotionCor233 through Appion v3.434, which was then imported to cryoSPARC v3.3.135 for contrast transfer function (CTF) estimation and downstream image analysis. The workflow described below is shown in Extended Data Fig. 2. Using a template picker from cryoSPARC v3.3.1, initial particle stack was subjected to 2D classification in cryoSPARC v3.3.1. Two-dimensional classification resulted in 536,450 particles from selected 2D averages, which was subjected to ab initio reconstruction in cryoSPARC v3.3.1. Ab initio reconstruction separated particles into two classes, one containing 53% (285,090 particles) and another containing 47% (250,842 particles). The two classes were then subjected to homogenous refinement in cryoSPARC respectively. The particle stacks from both classes were subjected to 3D classification in RELION v436,37, which removed junk particles with weak densities of Cas12k or TnsB. Each classification resulted in a particle stack that had well-defined configurations of ShCAST transpososome. The final particle stacks (188,055 particles for major configuration of transpososome and 67,096 particles for minor configuration of transpososome) were subjected to iterative CTF refinements38 and Bayesian polishing39 to improve resolution. The final maps of both major and minor configurations were then subjected to local refinement in cryoSPARC v3.3.1. Volume maps of Cas12k–S15-TniQ only, TnsC only, and TnsB only were generated in UCSF Chimera v1.1440 using the volume eraser tool to remove the map. A mask for Cas12k–S15–TniQ, TnsC and TnsB, respectively, was then generated in RELION v436 using the volume produced by Chimera as the input. Local refinement was then done in cryoSPARC v3.3.135 with the mask generated by RELION v4 and the full map without particle subtraction. Local refinement of the major configuration of the transpososome resulted in 3.1 Å for the Cas12k–S15–TniQ region, 3.2 Å for both the TnsC and TnsB region. Local refinement of the minor configuration of the transpososome resulted in 3.6 Å for the Cas12k–S15–TniQ region, 3.6 Å for TnsC, and 3.8 Å for the TnsB region.
For Fig. 2, the composite map was generated using UCSF Chimera v1.1440 command ‘vop maximum’ with the aligned reconstructions from local refinements of Cas12k and TnsC. 3D Variability in cryoSPARC v3.3.141 was performed on the major configuration of the transpososome using the mask and particles from the final refinement. The filter resolution was set to 6 Å and the number of modes to solve was set to 3. After the job was completed, the 3D variability display job using the particles and volumes from the 3D Variability job was completed with the output mode set to simple with 20 frames. The first series was then visualized in UCSF Chimera v1.1440 using the “vop morph” command with all 20 frames. The results are presented in Supplementary Video 1.
To impose helical symmetry on the two turns of TnsC in the transpososome, a mask was first created using a map of TnsC only (generated by the same protocol described above) as input in cryoSPARC v3.3.135. Helical refinement was then done in cryoSPARC v3.3.135 with the mask and the full map (major configuration) without particle subtraction. Initial helical parameters of the ATPγS-bound TnsC filaments (PDB: 7M99, rise = 6.82 Å and twist = 60º)18 were used. Helical parameters were refined with the following range: 6.14 Å to 7.50 Å for the helical rise, and from 57º to 63º for the twist.
Model building of transpososome complex
Initial models from previous studies, including TnsC (PDB: 7M99)18, TnsB (PDB: 7SVW)17 and sgRNA (PDB: 7PLA)15, were first docked into the cryo-EM density and manually rebuilt using Coot v0.9.8.242. Additional models were created using AlphaFold243 for the following components: Cas12k, TniQ and S15, and rigid-body docked into the density. Coot v0.9.8.2 was used to manually remodel or rebuild sections of the model. Real space refinement of the DNA substrate was completed in Phenixv1.19.1-412244 with both base-pair and secondary structure restraints enforced. For measuring the interface area between TniQ and TnsC protomers, UCSF ChimeraXv1.2.545 command ‘measure buriedarea’ was used with the desired two chains as inputs.
Model validation of transpososome complex
Map-model Fourier shell correlation (FSC) was computed using Mtriage in Phenixv1.19.1-412244. Map-model FSC resolution of each dataset was estimated from Mtriage FSC curve, using 0.5 cut-off. The masked cross-correlation (CCmask) from Mtriage was reported as representative model-map cross-correlation. Model geometry was validated using MolProbity v4.5.146. All the deposited models were submitted to MolProbity v4.5.1 server to check the clashes between atoms, Ramachandran plot, bond angles, bond lengths, side-chain rotamers, CaBLAM and C-beta outliers. All the model validation stats are summarized in Extended Data Table 1.
Helical parameter estimation using Rosetta
Helical parameters are estimated between the adjacent TnsC protomers within the complexes of the following: ATPγS-bound TnsC helical filament (PDB: 7M99), major configuration, and minor configuration of the transpososome. For example, from the major configuration of transpososome, helical parameters were estimated in between TnsC1 and TnsC2, between TnsC2 and TnsC3, between TnsC3 and TnsC4, and so on. Rosetta tool ‘make_symmdef_file.pl’ was used for each pair of the TnsC protomers, with an example command presented at the bottom of this section. Obtained helical rises and turns were averaged to plot a bar-graph presented in Supplementary Fig. 6.
The Rosetta command that we used for helical parameter is Rosetta/main/source/src/apps/public/symmetry/make_symmdef_file.pl -m HELIX-p input.pdb-a A-b B.
Reconstitution of TnsBCTD–TnsC–TniQ complex and imaging for cryo-EM
The C-terminal 109 residues from wild-type TnsB (termed hereafter as TnsBCTD) was cloned from pXT129_TwinStrep-SUMO-ShTnsB vector (Addgene, #135525) using Q5 site-directed mutagenesis kit (NEB) and two primers of following: TnsB_CTD_For and Ndel_primer_Rev (Supplementary Table 1). Cloned TnsBCTD was transformed to E. coli BL21-RIPL competent cells (Agilent) and purified following the protocol for TniQ purification. DNA substrate was prepared by annealing two synthetic oligonucleotides of BCQ_top and BCQ_bot (Supplementary Table 1). TniQ and TnsC were buffer exchanged into 25 mM HEPES pH 7.5, 200 mM NaCl, 2% glycerol, and 1 mM DTT (reaction buffer) prior to reconstitution of the complex. TnsC filament was first reconstituted by supplementing the reaction buffer with the following components: 128 μM TnsC, 8 μM DNA, 2 mM ATP, and 2 mM MgCl2. After 5 min of incubation on ice, sixfold molar excess of TniQ was added to TnsC filaments and incubated at 37 °C for 1 h. TnsBCTD was then added to the TniQ–TnsC mixture (4:1 molar ratio of TnsBCTD to TnsC), followed by incubation at 37 °C for 40 min. Four microlitres of the TnsBCTD–TnsC–TniQ sample was loaded on UltrAuFoil R1.2/1.3 gold grids (Quantifoil) and vitrified using the Mark IV Vitrobot (ThermoFisher) set to 100% humidity and 4 °C. Samples were blotted for 7 s with blot force 5, and then plunged into liquid ethane cooled with liquid nitrogen. Vitrified grids were imaged using Talos Arctica (ThermoFisher, 200 kV) with K3 direct detector (Gatan) and BioQuantum energy filter (Gatan), at 63,000× nominal magnification (1.33Å per pixel). SerialEM v4.047 was used for data acquisition with 3 × 3 image shift, and nominal defocus range from −1 μm to −2.5 μm. Total dose was set to 50 e− Å−2, which was fractionated into 50 frames.
Image processing and model building for TnsBCTD–TnsC–TniQ complex
Beam-induced motion correction, CTF estimation, and initial particle picking were done using Warp v1.0.948 for the collected 1,271 movies. Initial particle stack from Warp was subjected to 2D classification cryoSPARC v3.3.135, to get subset of TniQ-bound particles to train topaz neural network49, which resulted in the 795,631 particles. 2D classification resulted in 624,597 particles from selected 2D averages with high-resolution features, which were subjected to heterogeneous refinement in cryoSPARC v3.3.135. One class with better resolved TniQ (34%, 214,291 particles) was selected for downstream non-uniform refinement in cryoSPARC v3.3.135. The particle stack was subjected to 3D classification in RELION v436,37 resulting in the intermediate particle stack with a stronger density of TniQ (70%, 150,358 particles). To improve the resolution of TniQ, this particle stack was subjected to two rounds of focused 3D classification (skipping alignments, tau fudge factor of 16), iterative CTF refinements38 and bayesian polishing39. This resulted in the final dataset of 61,515 particles, with the gold standard FSC resolution of 3.5 Å. Due to the local variation of the map quality, LocSpiral50 was used to post-process the map through COSMIC2 51. For model building of TnsC and TniQ, previously published structure of TnsC (PDB: 7M99)18, and AlphaFold243 generated TniQ were manually docked into the density, followed by manual editing using Coot v0.9.8.242 and relaxation using Rosetta relax52.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Data availability
The atomic models are available through the PDB with accession codes: 8EA3 (major configuration), 8EA4 (minor configuration) and 7SVU (TnsBCTD–TnsC–TniQ complex). All cryo-EM reconstructions are available through the EMDB with accession codes: EMD-27971 (major configuration), EMD-27972 (minor configuration) and EMD-25453 (TnsBCTD–TnsC–TniQ complex).
References
Peters, J. E., Makarova, K. S., Shmakov, S. & Koonin, E. V. Recruitment of CRISPR–Cas systems by Tn7-like transposons. Proc. Natl Acad. Sci. USA 114, E7358–E7366 (2017).
Strecker, J. et al. RNA-guided DNA insertion with CRISPR-associated transposases. Science 365, 48–53 (2019).
Klompe, S. E., Vo, P. L. H., Halpin-Healy, T. S. & Sternberg, S. H. Transposon-encoded CRISPR–Cas systems direct RNA-guided DNA integration. Nature 571, 219–225 (2019).
Faure, G. et al. CRISPR–Cas in mobile genetic elements: counter-defence and beyond. Nat. Rev. Microbiol. 17, 513–525 (2019).
Petassi, M. T., Hsieh, S. C. & Peters, J. E. Guide RNA categorization enables target site choice in Tn7–CRISPR–Cas transposons. Cell 183, 1757–1771 e1718 (2020).
Saito, M. et al. Dual modes of CRISPR-associated transposon homing. Cell 184, 2441–2453.e18 (2021).
Benler, S. et al. Cargo genes of Tn7-Like transposons comprise an enormous diversity of defense systems, mobile genetic elements, and antibiotic resistance genes. mBio 12, e0293821 (2021).
Bainton, R. J., Kubo, K. M., Feng, J. N. & Craig, N. L. Tn7 transposition: target DNA recognition is mediated by multiple Tn7-encoded proteins in a purified in vitro system. Cell 72, 931–943 (1993).
Peters, J. E. Targeted transposition with Tn7 elements: safe sites, mobile plasmids, CRISPR/Cas and beyond. Mol. Microbiol. 112, 1635–1644 (2019).
Halpin-Healy, T. S., Klompe, S. E., Sternberg, S. H. & Fernández, I. S. Structural basis of DNA targeting by a transposon-encoded CRISPR–Cas system. Nature 577, 271–274 (2020).
Hoffmann, F. T. et al. Selective TnsC recruitment enhances the fidelity of RNA-guided transposition. Nature 609, 384–393 (2022).
Choi, K. Y., Spencer, J. M. & Craig, N. L. The Tn7 transposition regulator TnsC interacts with the transposase subunit TnsB and target selector TnsD. Proc. Natl Acad. Sci. USA 111, E2858–E2865 (2014).
Waddell, C. S. & Craig, N. L. Tn7 transposition: two transposition pathways directed by five Tn7-encoded genes. Genes Dev. 2, 137–149 (1988).
Klompe, S. E. et al. Evolutionary and mechanistic diversity of Type I-F CRISPR-associated transposons. Mol. Cell 82, 616–628.e615 (2022).
Querques, I., Schmitz, M., Oberli, S., Chanez, C. & Jinek, M. Target site selection and remodelling by type V CRISPR–transposon systems. Nature 599, 497–502 (2021).
Xiao, R. et al. Structural basis of target DNA recognition by CRISPR-Cas12k for RNA-guided DNA transposition. Mol. Cell 81, 4457–4466.e5 (2021).
Park, J. U., Tsai, A. W., Chen, T. H., Peters, J. E. & Kellogg, E. H. Mechanistic details of CRISPR-associated transposon recruitment and integration revealed by cryo-EM. Proc. Natl Acad. Sci. USA 119, e2202590119 (2022).
Park, J. U. et al. Structural basis for target site selection in RNA-guided DNA transposition systems. Science 373, 768–774 (2021).
Shen, Y. et al. Structural basis for DNA targeting by the Tn7 transposon. Nat. Struct. Mol. Biol. 29, 143–151 (2022).
Yin, Z., Lapkouski, M., Yang, W. & Craigie, R. Assembly of prototype foamy virus strand transfer complexes on product DNA bypassing catalysis of integration. Protein Sci. 21, 1849–1857 (2012).
Maertens, G. N., Hare, S. & Cherepanov, P. The mechanism of retroviral integration from X-ray structures of its key intermediates. Nature 468, 326–329 (2010).
Tenjo-Castano, F. et al. Structure of the TnsB transposase–DNA complex of type V-K CRISPR-associated transposon. Nat. Commun. 13, 5792 (2022).
Schmitz, M., Querques, I., Oberli, S., Chanez, C. & Jinek, M. Structural basis for the assembly of the type V CRISPR-associated transposon complex. Cell https://doi.org/10.1016/j.cell.2022.11.009 (2022).
Gary, P. A., Biery, M. C., Bainton, R. J. & Craig, N. L. Multiple DNA processing reactions underlie Tn7 transposition. J. Mol. Biol. 257, 301–316 (1996).
Montano, S. P., Pigli, Y. Z. & Rice, P. A. The mu transpososome structure sheds light on DDE recombinase evolution. Nature 491, 413–417 (2012).
Kaczmarska, Z. et al. Structural basis of transposon end recognition explains central features of Tn7 transposition systems. Mol. Cell 82, 2618–2632.e7 (2022).
Jones, D. T. & Cozzetto, D. DISOPRED3: precise disordered region predictions with annotated protein-binding activity. Bioinformatics 31, 857–863 (2015).
Skelding, Z., Queen-Baker, J. & Craig, N. L. Alternative interactions between the Tn7 transposase and the Tn7 target DNA binding protein regulate target immunity and transposition. EMBO J. 22, 5904–5917 (2003).
Jullien, N. & Herman, J. P. LUEGO: a cost and time saving gel shift procedure. Biotechniques 51, 267–269 (2011).
Wang, F. et al. General and robust covalently linked graphene oxide affinity grids for high-resolution cryo-EM. Proc. Natl Acad. Sci. USA 117, 24269–24273 (2020).
Patel, A., Toso, D., Litvak, A. & Nogales, E. Efficient graphene oxide coating improves cryo-EM sample preparation and data collection from tilted grids. Preprint at bioRxiv https://doi.org/10.1101/2021.03.08.434344 (2021).
Suloway, C. et al. Automated molecular microscopy: the new Leginon system. J. Struct. Biol. 151, 41–60 (2005).
Zheng, S. Q. et al. MotionCor2: anisotropic correction of beam-induced motion for improved cryo-electron microscopy. Nat. Methods 14, 331–332 (2017).
Lander, G. C. et al. Appion: an integrated, database-driven pipeline to facilitate EM image processing. J. Struct. Biol. 166, 95–102 (2009).
Punjani, A., Rubinstein, J. L., Fleet, D. J. & Brubaker, M. A. cryoSPARC: algorithms for rapid unsupervised cryo-EM structure determination. Nat. Methods 14, 290–296 (2017).
Scheres, S. H. RELION: implementation of a Bayesian approach to cryo-EM structure determination. J. Struct. Biol. 180, 519–530 (2012).
Scheres, S. H. Processing of structurally heterogeneous cryo-EM data in RELION. Methods Enzymol. 579, 125–157 (2016).
Zivanov, J. et al. New tools for automated high-resolution cryo-EM structure determination in RELION-3. eLife 7, e42166 (2018).
Zivanov, J., Nakane, T. & Scheres, S. H. W. A Bayesian approach to beam-induced motion correction in cryo-EM single-particle analysis. IUCrJ 6, 5–17 (2019).
Pettersen, E. F. et al. UCSF Chimera-a visualization system for exploratory research and analysis. J. Comput. Chem. 25, 1605–1612 (2004).
Punjani, A. & Fleet, D. J. 3D variability analysis: resolving continuous flexibility and discrete heterogeneity from single particle cryo-EM. J. Struct. Biol. 213, 107702 (2021).
Emsley, P., Lohkamp, B., Scott, W. G. & Cowtan, K. Features and development of Coot. Acta Crystallogr. D 66, 486–501 (2010).
Jumper, J. et al. Highly accurate protein structure prediction with AlphaFold. Nature 596, 583–589 (2021).
Afonine, P. V. et al. New tools for the analysis and validation of cryo-EM maps and atomic models. Acta Crystallogr. D 74, 814–840 (2018).
Goddard, T. D. et al. UCSF ChimeraX: meeting modern challenges in visualization and analysis. Protein Sci. 27, 14–25 (2018).
Williams, C. J. et al. MolProbity: more and better reference data for improved all-atom structure validation. Protein Sci. 27, 293–315 (2018).
Mastronarde, D. N. Automated electron microscope tomography using robust prediction of specimen movements. J. Struct. Biol. 152, 36–51 (2005).
Tegunov, D. & Cramer, P. Real-time cryo-electron microscopy data preprocessing with Warp. Nat. Methods 16, 1146–1152 (2019).
Bepler, T. et al. Positive-unlabeled convolutional neural networks for particle picking in cryo-electron micrographs. Nat. Methods 16, 1153–1160 (2019).
Kaur, S. et al. Local computational methods to improve the interpretability and analysis of cryo-EM maps. Nat. Commun. 12, 1240 (2021).
Cianfrocco MA, W. M., Youn, C., Wagner, R. & Leschziner, A. E. COSMIC²: a science gateway for cryo-electron microscopy structure determination. Pract. Exp. Adv. Res. Comput. http://doi.acm.org/10.1145/3093338.3093390 (2017).
Leaver-Fay, A. et al. ROSETTA3: an object-oriented software suite for the simulation and design of macromolecules. Methods Enzymol. 487, 545–574 (2011).
Acknowledgements
This work was performed at the National Center for Cryo-EM Access and Training (NCCAT) and the Simons Electron Microscopy Center located at the New York Structural Biology Center, supported by the NIH Common Fund Transformative High Resolution Cryo-Electron Microscopy Program (U24 GM129539,) and by grants from the Simons Foundation (SF349247) and NY State Assembly. This work also relied on data collected using an instrument supported by the NIH through award S10OD030470-01. We additionally acknowledge XSEDE for computational resources used for image processing (MCB200090 to E.H.K.). We thank S.-C. Hsieh for sharing the protocol to analyse Illumina sequencing results; J. E. Peters, S. H. Sternberg and A. Guarné along with the A. Guarné, J. E. Peters and E. H. Kellogg laboratories for feedback and stimulating discussion. This research is supported by the NIH: R01GM144566 (E.H.K.) and Pew Biomedical Foundation (E.H.K.). This work relied on data collected using an instrument supported by the NIH through award S10OD030470-01.
Author information
Authors and Affiliations
Contributions
E.H.K. designed and supervised the project. J.-U.P., A.W.-L.T. and T.X.W. carried out protein expression and purification. R.D.S. cloned S15. J.-U.P., A.W.-L.T. and V.H.T prepared sample components and completed DNA-based pulldowns. J.-U.P., A.W.-L.T., V.H.T., A.N.R. and T.X.W. prepared GO grids and optimized the sample for cryo-EM imaging. J.-U.P., A.W.-L.T. and A.N.R. collected, processed, analysed, and refined cryo-EM data. J.-U.P. and A.N.R. built and refined atomic models. J.-U.P. and A.W.-L.T. carried out all in vitro assays (ATP hydrolysis and in vitro transposition assays). J.-U.P., A.W.-L.T., A.N.R. and E.H.K. contributed to figures and manuscript writing. All authors contributed to manuscript writing and editing.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Nature thanks the anonymous reviewer(s) for their contribution to the peer review of this work. Peer review reports are available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Extended data figures and tables
Extended Data Fig. 1 Designed DNA substrate schematic and negative staining microscopy of target pot and transpososome.
a. DNA substrate design for the transpososome assembly includes two DNA substrates: target pot DNA containing a Cas12k-binding site and the first two TnsB binding sites of left-end (LE), and donor pot DNA with the first two TnsB binding sites of right-end (RE). DNA substrates were designed to form a strand-transfer complex by having 5 base pairs (bp) single-stranded DNA (ssDNA) connecting the target DNA region and the transposon DNA region. The design for target-pot DNA is composed of four single-stranded DNA (ssDNA) of the following: Target-LE_F (light blue), non-target_R (red), desthiobiotinylated LUEGO (green), and LE_R (dark blue). Cas12k-binding region contains PAM and a 10 bp mismatch to facilitate R-loop formation as indicated as a displaced strand. 5′ end labeled desthiobiotin (green circle) on the LUEGO was used to conjugate target-pot DNA on magnetic beads for the pulldown. Second, donor-pot DNA consists of three ssDNA: RE_F (grey), RE_R1 (purple), and RE_R2 (orange). LE_R region and RE_R1 region of each DNA substrate corresponds to the first two TnsB binding sites of LE and RE, respectively. Two DNA substrates have 5 bp of complementary sequences to each other, which are annealed upon transpososome assembly. Locations of PAM, and R-loop are annotated in black. Sequences for all DNA substrates are included in Supplementary Table 1. b. Features of the designed DNA substrate. Each left-end and right-end transposon region of the DNA includes 8 bp terminal sequences and the two TnsB binding sites (L1 and L2 for the left end, R1 and R2 for the right end). The beginning of the left-end sequence (red triangle) is 61 bp distant from the PAM as indicated with a black arrow. PAM and the 5 bp of complementary sequences (target site duplication) were represented in red.c. Negative stain image of the target pot (i.e. recruitment complex containing Cas12k, S15, TniQ, and TnsC) shows a heterogenous assembly with variable length TnsC filaments (indicated by black arrows). d. Negative stain image of the transpososome complex shows the addition of donor pot disassembled TnsC filaments and resulted in a homogeneous sample. Scale bar (white) represents 100 nm. The micrographs shown are examples images from negative-stain screening datasets consisting of 20 and 100 micrographs, respectively.
Extended Data Fig. 2 Cryo-EM imaging and image processing pipeline of the transpososome complex.
a. Representative cryo-EM micrograph from the reconstituted transpososome sample. Scale bar (white, bottom right) represents 100 nm. The micrograph shown is an example image from a full dataset consisting of 17,554 micrographs. b. Image processing workflow used to analyze the cryo-EM data. 2D classification in cryoSPARC v3.3.1 on template picked particles (from 14,017 micrographs) resulted in 535,932 particles. Ab-initio reconstruction on the initial particle stack resulted in two classes, one with 53% of the particles (pink) and the other with 47% of the particles (gray). The two classes were separated for subsequent classification and refinement steps. Before performing 3D classification in RELION v4, each class underwent homogenous refinement in cryoSPARCv3.3.135. RELION v4 3D classification (without alignments, skip_align)36,37 was applied to both populations from the ab-initio reconstruction resulting in the colored volumes shown (blue, pink, and yellow). On the left, the two classes (pink and yellow) that have the best resolved Cas12k density were combined for downstream refinement to produce the final 3D reconstruction (boxed), which is the major configuration of the transpososome complex with 12 TnsC protomers. Local refinement was performed on three different segments of the map, focusing on: Cas12k (3.1 Å), TnsC (3.2 Å) and TnsB (3.2 Å). On the right, the class that has the best resolved Cas12k and TnsB density (27% of particles, shown in pink) was selected for downstream refinement to produce the final 3D reconstruction (boxed), which is the minor configuration of the transpososome complex with 13 TnsC protomers. Similar local refinement was performed on three different segments of the minor TnsC complex to result in high resolution reconstructions of the target site proteins (Cas12k+TniQ+S15), TnsC, and TnsB. c-d. Fourier shell correlation (FSC) curve of the major (c) and minor (d) configuration of the transpososome complex, respectively. Masked (dashed) or unmasked (solid) gold standard half-map FSC (blue) and model-map FSC (red) curves are shown for the refined reconstruction and atomic model. Model-map cutoff (0.5) and gold-standard FSC cutoffs (0.143) are indicated with dashed lines. Estimated resolution based on these cutoffs are indicated. e-f. Local resolution filtered reconstruction for the major (e) and minor (f) configuration of the transpososome complex, respectively, are shown with estimated local resolution indicated using colored surface. Local resolution ranges from 3.0 Å (blue) to 7.0 Å (red). Legend at the bottom indicates local resolution range and values in Angstrom. g-h. Angular distribution plot for particle projections of the major (g) and minor (h) configuration of the transpososome complex, respectively. The plot was calculated in cryoSPARC v3.3.1 and shows the number of particles for each viewing angle. Colors indicate counts; red corresponds to high particle counts for that particular viewing angle, blue to low particle counts.
Extended Data Fig. 3 TnsC has dedicated faces for TniQ and TnsB within the transpososome.
A simulated map is colored by different regions of TnsC (opaque surface) to represent the N- and C-terminal face of TnsC. The regions are colored as follows: N-terminal face (residues 19–140 on TnsC7-TnsC12, rose-brown), and C-terminal face (residues 141–275 on TnsC1-TnsC6, light blue). Region not included in either N- or C-terminal face is colored green. TniQ (orange ribbon) and TnsB (purple ribbon) associates with the N-terminal face and C-terminal face respectively.
Extended Data Fig. 4 Interactions between transpososome components near R-loop.
a. DNA (blue ribbon) forms 17 base pair heteroduplex with RNA (gray) in Cas12k (pink). Cas12k, S15 (tan), and TniQ (orange) are shown in surface representation. Close-up view on the right shows the model docked into the cryo-EM density of the R-loop. The PAM distal end of the R-loop is indicated with an asterisk (*). b. Atomic model of the ShCAST transpososome, focusing on Cas12k. The TnsC protomer closest to Cas12k (TnsC10) is labeled. TnsC protomers are numbered as previously defined (see Main Text, Fig. 2). ShCAST protein and nucleic acid components are labeled and colored according to previously defined colors (see Main Text, Fig. 1). Black box indicates the TnsC finger loop that is close to Cas12k shown as inset in panel B. c. The closet distance between TnsC protomer TnsC10 and Cas12k is shown with dashed line and labeled (in Å). d. S15 (beige) is positioned between the REC2 domain of Cas12k (pink(and the sgRNA-DNA heteroduplex (blue/grey). The rooftop loop of sgRNA (grey) is stabilized by S15 (beige) and TniQ (orange). Rotation with respect to panel a is indicated in top left corner.
Extended Data Fig. 5 TnsBHook density occupies select TnsC protomers in the TnsC hexamer closest to TnsB.
a. Local resolution filtered cryo-EM reconstruction (same as that shown in Fig. 1) colored by assignment reveals that TnsBHook (light and dark purple) occupies binding sites on TnsC (green). b. Rotation of the cryo-EM reconstruction by 30° shows the adjacent TnsBHook binding pocket on TnsC (white dashed lines) is empty.
Extended Data Fig. 6 High throughput mapping of the in vitro transposition events reveals that the identified interaction between TnsC and TnsB IIβ domain is crucial for target-site selection.
Insertion positions were determined by Illumina sequencing of the plasmids extracted from colonies from in vitro transpositions under the following conditions (same with Fig. 3f, see Methods): a. TnsB wild-type (WT) with S15, b. TnsB WT without S15, c. TnsB R432A with S15, d. TnsB R432A without S15, e. TnsB Y439A with S15, and f. TnsB Y439A without S15. Determined insertion positions were plotted as a histogram indicating the percentage of the reads at the 10 base-pair (bp) windows within the target plasmid. Position numbers (x-axis) correspond to the number of base pairs between the PAM and the beginning of the transposon-end sequence after the transposition. Red and blue bars represent the transposition products with the left end-right end (L-R, correct) or the right end-left end (R-L, wrong) orientation respectively. For the conditions with high on-target percentage (> 60%, panels a, b, c, and e), insets are presented for the positions around the PSP1 protospacer (from 0 bp to 70 bp), which is indicated with black brackets on the x-axis. Grey bar in the inset indicates the 17 bp PSP1 protospacer. For panel e, a red bar on the y-axis represents the region for zoom-in on the lower panel to visualize signals from the off-target transposition events. Two origins of replications within the target plasmids (f1 ori and ori) are annotated as black bars on the x-axis, which explains the reason for the cold spots for the transpositions.
Extended Data Fig. 7 TnsC in ShCAST transpososome does not match helical parameters of the bound DNA.
The repeat length of TnsC turn (~6 protomers per turn) is approximately 40 Å, while the repeat length of the TnsC-bound DNA (~11 base pairs per turn) is approximately 36 Å. DNA model is represented in a solid ribbon. Protein components and sgRNA in the transpososome are represented as transparent surfaces. Color scheme is identical to the established colors in Fig. 1.
Extended Data Fig. 8 TnsC-DNA interaction proximal to TnsB is identical in the major and minor configurations.
a. Low pass filtered (10 Å) cryo-EM reconstructions of both major (transparent grey) and minor (solid, colored) configurations are aligned with respect to TnsB. The dashed box indicates the TnsC-DNA interactions at the TnsB proximal region shown as inset in panel B. b. Three TnsB-proximal TnsC protomers (From TnsC1 to TnsC3) in both major and minor configurations interact with target strand DNA (tsDNA) in an identical manner through residue R182. Hydrogen bonding interactions (distance cut off <4 Å) between protein residues and the sugar-phosphate backbone of DNA are represented with dashed lines. Base pairs that are interacting with TnsC are represented as filled nucleotides and stick phosphate-backbone.
Supplementary information
Supplementary Information
Supplementary Figs. 1–11; Table 1, which includes all the oligonucleotides used in this study; and references.
Supplementary Video 1
3D variability analysis visualizes a flexible association of Cas12k with respect to the rest of the transpososome. Components in the transpososome were coloured following the convention established in Fig. 1. See Methods for details.
Supplementary Video 2
Conformational change between TnsC filaments in the major configuration of transpososome and helical TnsC. The movie shows the morphing between twelve protomers of TnsC from the major configuration of transpososome and helical TnsC structure (PDB: 7M99).
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Park, JU., Tsai, A.WL., Rizo, A.N. et al. Structures of the holo CRISPR RNA-guided transposon integration complex. Nature 613, 775–782 (2023). https://doi.org/10.1038/s41586-022-05573-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1038/s41586-022-05573-5
This article is cited by
-
Automated model building and protein identification in cryo-EM maps
Nature (2024)
-
Genomic language model predicts protein co-regulation and function
Nature Communications (2024)
-
CRISPR technologies for genome, epigenome and transcriptome editing
Nature Reviews Molecular Cell Biology (2024)
-
Molecular basis for transposase activation by a dedicated AAA+ ATPase
Nature (2024)
-
Distinct horizontal transfer mechanisms for type I and type V CRISPR-associated transposons
Nature Communications (2024)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
