
Abstract
A new coronavirus was recently discovered and named severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2). Infection with SARS-CoV-2 in humans causes coronavirus disease 2019 (COVID-19) and has been rapidly spreading around the globe1,2. SARS-CoV-2 shows some similarities to other coronaviruses; however, treatment options and an understanding of how SARS-CoV-2 infects cells are lacking. Here we identify the host cell pathways that are modulated by SARS-CoV-2 and show that inhibition of these pathways prevents viral replication in human cells. We established a human cell-culture model for infection with a clinical isolate of SARS-CoV-2. Using this cell-culture system, we determined the infection profile of SARS-CoV-2 by translatome3 and proteome proteomics at different times after infection. These analyses revealed that SARS-CoV-2 reshapes central cellular pathways such as translation, splicing, carbon metabolism, protein homeostasis (proteostasis) and nucleic acid metabolism. Small-molecule inhibitors that target these pathways prevented viral replication in cells. Our results reveal the cellular infection profile of SARS-CoV-2 and have enabled the identification of drugs that inhibit viral replication. We anticipate that our results will guide efforts to understand the molecular mechanisms that underlie the modulation of host cells after infection with SARS-CoV-2. Furthermore, our findings provide insights for the development of therapies for the treatment of COVID-19.
Similar content being viewed by others

Main
At the end of 2019, a cluster of cases of severe pneumonia of unknown cause was described in Wuhan (eastern China), and a SARS-like acute respiratory distress syndrome was noted in many patients. Early in January 2020, next-generation sequencing revealed that a novel coronavirus (named SARS-CoV-2) was the causal factor for the disease1, which was later designated COVID-19. SARS-CoV-2 shows high infectivity, which has resulted in rapid global spreading2.
Currently, there is no established therapy for the treatment of COVID-19. Treatment is based mainly on supportive and symptomatic care4,5. Therefore, the development of therapies that inhibit infection with or replication of SARS-CoV-2 are urgently needed. Molecular examination of infected cells by unbiased proteomics approaches offers a potent strategy for revealing pathways that are relevant for viral pathogenicity to identify potential drug targets. However, this strategy depends on the availability of cell-culture models that are amenable to virus infection and sensitive proteomics approaches that can be used for temporal infection profiling in cells. SARS-CoV-2 was recently successfully isolated using the human colon epithelial carcinoma cell line6 Caco-2. SARS-CoV-2 replicates in gastrointestinal cells in vivo7 and is frequently detected in stool—regardless of the occurrence of diarrhoea8. Caco-2 cells were extensively used to study infection with SARS-CoV and can be used for SARS-CoV-2 infection6,9. For proteome analysis, a method—multiplexed enhanced protein dynamics (mePROD) proteomics—was recently described that enables the determination of translatome and proteome changes at high temporal resolution3. Owing to the quantification of translational changes by naturally occurring heavy isotope labelling using stable isotope labelling by amino acids in cell culture (SILAC), this method does not affect cellular behaviour and therefore enables the perturbation-free and unbiased analysis of the response of cells to viral infection.
In this study, we used quantitative translatome and proteome proteomics to obtain an unbiased profile of the cellular response to SARS-CoV-2 infection in human cells. We monitored different time points after infection and identified key determinants of the host cell response to infection. These findings revealed pathways that are relevant for SARS-CoV-2 infection. We tested several drugs that target these pathways, including translation, proteostasis, glycolysis, splicing and nucleotide synthesis pathways. These drugs inhibited SARS-CoV-2 replication at concentrations that were not toxic to the human cells, potentially providing therapeutic strategies for the treatment of COVID-19.
SARS-CoV-2 rapidly replicates in cells
To investigate potential antiviral compounds that inhibit SARS-CoV-2, we established a highly permissive SARS-CoV-2 cell-culture model in Caco-2 cells. Addition of SARS-CoV-2 at a multiplicity of infection (MOI) of one (to enable the infection of most of the cells while preventing multiple infections) led to a fast progression of viral infection and visible cytopathogenic effects were apparent after 24 h (Fig. 1a). To determine whether productive viral infection takes place in this model, we measured the number of viral RNA copies in the supernatant during a 24-h time period. SARS-CoV-2 RNA molecules increased continuously after infection (Fig. 1b), indicating that the virus underwent full replication cycles. Staining for viral nucleoprotein additionally revealed the production of viral proteins in most cells (Extended Data Fig. 1). Taken together, we established a functional SARS-CoV-2 cell-culture model that enables the investigation of the different steps of the life cycle of SARS-CoV-2 in cells.

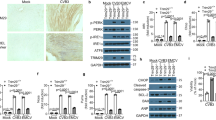
a, Caco-2 cells were either mock-infected or infected with SARS-CoV-2 and cultured for 24 h. Microscopy images show the cytopathogenic effects of SARS-CoV-2 infection. Scale bars, 100 μm. Representative images from three independent biological replicates are shown. b, Quantitative PCR analysis of viral genome copies per ml of cell culture after the indicated infection time (n = 3 independent biological samples). Points indicate the mean of replicate measurements and shades represent the s.d.
Translation inhibitors block replication
To determine the temporal profile of SARS-CoV-2 infection, we infected Caco-2 cells with SARS-CoV-2, cultured them for a range of 2–24 h and quantified translatome and proteome changes by mePROD proteomics compared with time-matched mock-infected samples (Fig. 2a). Across all replicates, we quantified translation for 2,715 proteins and total protein levels for 6,382 proteins (Supplementary Table 1). Principal component analysis showed that replicates clustered closely and that infected samples showed the first separation from control clusters after 6 h (Extended Data Fig. 2a). Many RNA viruses decrease protein synthesis in cells, as has been suggested for SARS-CoV10. When monitoring global translation rates, only minor changes in translation were observed (Fig. 2b and Extended Data Fig. 2b). We detected translation rates for five viral proteins, all of which exhibited increasing translation rates over time (Fig. 2c). To identify pathways that are potentially important for virus amplification, we determined host proteins that exhibited translation kinetics, which correlated with viral proteins. Averaged profiles of all quantified viral proteins were used as reference profiles; the distance to this profile was calculated for all quantified host proteins and a network analysis was carried out for the top 10% quantile of nearest profiles (244 proteins) (Extended Data Fig. 2c–f). Pathway analyses of the network revealed an extensive increase in the translation machinery of the host (Fig. 2d and Extended Data Fig. 2g). In addition, we detected significant enrichment of components of several other pathways, such as splicing and nucleobase synthesis (Fig. 2d).

a, Experimental scheme for translatome and proteome measurements. Caco-2 cells were infected with SARS-CoV-2 isolated from patients, incubated as indicated and analysed by quantitative translation and whole-cell proteomics. K8, lysine with 8 heavy isotopes; R10, arginine with 10 heavy isotopes; LC–MS/MS, Liquid chromatography–tandem mass spectrometry. b, Global translation rates, showed by distribution plots of mean log2-transformed fold changes of infected replicates to mock control for each time point and protein. The black line indicates the median and the dashed lines indicate 25% and 75% quantiles. Significance was tested by one-way ANOVA and two-sided post hoc Bonferroni test. ***P < 0.001 (10 h compared with 2 h, 4 × 10−26; 10 h compared with 6 h, 2.4 × 10−23; 10 h compared with 24 h, 2.3 × 10−28; n = 2,716 measured proteins averaged from 3 independent biological samples). c, Translation of viral proteins over time. Mean translation in arbitrary units (AU; normalized and corrected summed peptide spectrum matches were averaged) is plotted for control and infected samples. Shading indicates the s.d. (n = 3). d, Reactome pathway analysis of top 10% proteins following viral gene expression. Pathway results are shown with the number of proteins found in the dataset and computed FDRs for pathway enrichment. ER, endoplasmic reticulum. e, f, The antiviral assays show that the inhibition of viral replication is dependent on the concentrations of cycloheximide (e, n = 3) and emetine (f, n = 4). Each data point indicates biological replicates and the red line shows the dose–response curve fit. R2 and half-maximum inhibitory concentration (IC50) values were computed from the curve fit and the s.d. of the IC50 is indicated in parentheses. All n numbers represent independent biological samples if not stated otherwise.
Host translation has previously been targeted to pharmacologically inhibit the replication of diverse coronaviruses, such as SARS-CoV or MERS-CoV11,12 (Extended Data Fig. 2h). As components of the translation machinery were translated at higher rates (Fig. 2d), we hypothesized that SARS-CoV-2 replication might be sensitive to inhibition of translation. We tested two translation inhibitors—cycloheximide (an inhibitor of translation elongation) and emetine (an inhibitor of the 40S ribosomal protein S14)—for their ability to reduce SARS-CoV-2 replication. Both compounds significantly inhibited SARS-CoV-2 replication at concentrations that are not toxic to human Caco-2 cells (Fig. 2e, f and Extended Data Fig. 2i, j). Taken together, translatome analyses of cells infected with SARS-CoV-2 revealed the temporal profile of viral and host protein responses with prominent increases in the translation machinery. Translation inhibitors prevented SARS-CoV-2 replication in cells.
Pathways changed by SARS-CoV-2 infection
To obtain a general understanding of changes in the host proteome after infection, we analysed system-wide differences in protein levels over time (Fig. 3a and Supplementary Table 2). Whereas early time points showed only minor changes in the host proteome, the proteome underwent extensive modulation 24 h after infection (Fig. 3a and Extended Data Fig. 3). Hierarchical clustering identified two main clusters of proteins that were differentially regulated. The first cluster consisted of proteins that were reduced during infection and was enriched in proteins that belonged to cholesterol metabolism (Extended Data Fig. 4a, b and Supplementary Table 3). The second cluster was composed of proteins that were increased by infection and revealed strong increases in RNA-modifying proteins, such as spliceosome components (consistent with translatome measurements in Fig. 2d), and carbon metabolism (Fig. 3b, c, Extended Data Fig. 5a and Supplementary Table 4). Notably, for 14 out of 25 spliceosome components that were increased after infection with SARS-CoV-2, direct binding to viral proteins of SARS-CoV or other coronaviruses had been shown13,14,15,16 (Extended Data Fig. 5b). We therefore tested whether the inhibition of splicing or glycolysis may be able to prevent SARS-CoV-2 replication. Addition of pladienolide B, a spliceosome inhibitor that targets the splicing factor SF3B117, prevented viral replication at concentrations that were not toxic to the human Caco-2 cells (Fig. 3d and Extended Data Fig. 5c), revealing that splicing is an essential pathway for SARS-CoV-2 replication and a potential therapeutic target.

a, Patterns of protein levels across all samples. The proteins that were significantly up- or downregulated (two-sided, unpaired Student’s t-test with equal variance assumed, P < 0.05, n = 3) in at least one infected sample compared with the corresponding control are shown. Data were standardized using Z-scoring before row-wise clustering and plotting. TCA, tricarboxylic acid. b, Reactome pathway analysis of the protein network created from cluster II, which includes host cell proteins that are increased after SARS-CoV-2 infection (a; Supplementary Table 4). Pathway results are shown with the number of proteins found in the dataset and computed FDR for pathway enrichment. c, Functional interaction network of proteins found annotated to carbon metabolism in the Reactome pathway analysis. Lines indicate functional interactions. d, e, The antiviral assays show that the inhibition of viral replication is dependent on the concentrations of pladienolide B (d, n = 3) and 2-deoxy-d-glucose (e, n = 3). Each data point indicates a biological replicate and the red line shows the dose–response curve fit. R2 and IC50 values were computed from the curve fit and the s.d. of IC50 is indicated in parentheses. Cmax, maximum plasma concentration; E7107, the indicated Cmax was obtained for the E7107, a derivative of pladienolide B. All n numbers represent independent biological samples.
Next, we assessed the effects of the inhibition of carbon metabolism (that is, glycolysis) on SARS-CoV-2 replication. 2-deoxy-d-Glucose, an inhibitor of hexokinase (the rate-limiting enzyme in glycolysis), has previously been shown to be effective against other viruses in cell culture and suppressed infection with rhinovirus in mice18. Blocking glycolysis with non-toxic concentrations of 2-deoxy-d-glucose prevented SARS-CoV-2 replication in Caco-2 cells (Fig. 3e and Extended Data Fig. 5d). Notably, we also observed changes in proteins that reside in the endoplasmic reticulum and that are involved in lipid metabolism (Extended Data Fig. 6), consistent with previous reports on other coronaviruses19. Together, our quantitative analyses of proteome changes after infection with SARS-CoV-2 revealed host pathways that change after infection and revealed that spliceosome and glycolysis inhibitors are potential therapeutic agents for the treatment of COVID-19.
Kinetic profiling of the infection proteome
To identify additional potential inhibitors of SARS-CoV-2 replication, we determined proteins with abundance trajectories that were similar to the nine detected viral proteins (Fig. 4a and Extended Data Fig. 7a–d; measurement depth does not allow us to distinguish polyprotein from processed protein). We compared the distance and false-discovery rate (FDR) for each protein to an averaged viral protein profile and performed gene ontology analysis (459 proteins with a FDR-adjusted P < 0.01). We identified a major cluster of metabolic pathways, which consisted of diverse nucleic acid metabolism sub-pathways (Fig. 4b and Supplementary Table 5). Coronavirus replication depends on the availability of cellular nucleotide pools20. Compounds that interfere with nucleic acid metabolism, such as ribavirin, have been used in the past to inhibit viral replication21. We tested the effect of the inhibition of nucleotide synthesis on SARS-CoV-2 replication in cells. Ribavirin, which inhibits inosine monophosphate dehydrogenase (IMPDH), the rate-limiting enzyme in de novo synthesis of guanosine nucleotides, inhibited SARS-CoV-2 replication at low micromolar and clinically achievable concentrations22 (Fig. 4c and Extended Data Fig. 7e), consistent with data in monkey cells23. Inhibition of IMPDH had been shown to prevent replication of coronaviruses HCoV-43, CoV-NL63 and MERS-CoV but not of SARS-CoV24. Considering the clinical use of ribavirin to treat viruses such as hepatitis C and respiratory syncytial virus25,26, it may be regarded as a treatment option for patients with COVID-19.

a, Protein levels of all detected viral proteins are plotted with their log2-transformed changes compared with the corresponding control for different infection times. Mean fold changes are plotted (n = 3). b, Gene ontology network analysis of host proteins that correlated with viral protein expression (FDR-adjusted P < 0.01). Proteins were clustered according to the gene ontology term of the biological process and plotted as a network with FDR colour coding. Annotated pathways represent parent pathways in the network. c, d, The antiviral assays show that the inhibition of viral replication is dependent on the concentrations of ribavirin (c, n = 3) and NMS873 (d, n = 3). Each data point indicates a biological replicate and the red line indicates the dose–response curve fit. R2 and IC50 values were computed from the curve fit and the s.d. of IC50 is indicated in parentheses. All n numbers represent independent biological samples.
Components of the proteostasis machinery also acted in a comparable manner to the viral proteins (Extended Data Fig. 3e), consistent with the perturbation of host cell proteostasis due to the higher folding load, which is the results of the high translation rates of viral proteins. We therefore tested the effects of proteostasis perturbation on SARS-CoV-2 replication using NMS-873, a small-molecule inhibitor of the AAA ATPase p97. p97 is a key component of proteostasis, which affects protein degradation, membrane fusion, vesicular trafficking and disassembly of stress granules27. NMS-873 has previously been shown to inhibit the replication of influenza A and B28. We show that NMS-873 inhibits SARS-CoV-2 replication at low nanomolar concentrations (Fig. 4d and Extended Data Fig. 7f). In summary, analyses of the effects of SARS-CoV-2 infection on the host cell proteome revealed major readjustments in cellular function, particularly of splicing, proteostasis and nucleotide biosynthesis. Compounds that modulate these pathways prevented SARS-CoV-2 replication in human cells.
Discussion
Identifying and testing potential drug candidates for the treatment of COVID-19 is of high priority. So far, only limited data have been obtained that describes the response of the host cell to infection with SARS-CoV-2, preventing a databased assessment of treatment options. We describe a SARS-CoV-2 cell-infection system that can be used to determine the changes in host cell pathways after infection, which result from host cell (antiviral) responses or viral effector proteins, and assess inhibitors. At the MOI used, most of the cells were infected, enabling us to determine global changes across the whole cell population with minimal ratio compression from uninfected cells. We found that the expression of the previously described SARS-CoV-2 entry receptor ACE2 was mildly reduced after infection (Extended Data Fig. 8), consistent with a drop in ACE2 levels due to shedding by ADAM10 that has been described for SARS-CoV29. Temporal proteome and translatome proteomics showed limited translation attenuation and revealed core cellular pathways that were modulated after infection (Fig. 2). For SARS-CoV and other RNA viruses, severe effects on translation have been described30. Our observations suggest that SARS-CoV-2 reshapes host cell translation, probably by increasing the production of translation machinery components to compensate for the inhibition of host cell translation. We tested two translation inhibitors with different modes of action and found that these to efficiently prevented viral replication in cells. These findings encourage further testing of translation inhibitors for the prevention of SARS-CoV-2 replication.
Overall, our proteomics analyses highlight cellular pathways for therapeutic interventions, including a marked increase in components of the spliceosome, proteostasis and nucleotide biosynthesis pathways. This enabled us to assess new drug targets, which were based on the behaviour of SARS-CoV-2 in human cells and which had not previously been tested with other coronaviruses. Some of the inhibitors, for which we observed inhibition of SARS-CoV-2, are approved drugs, such as ribavirin, or are undergoing clinical trials (that is, 2-deoxy-d-glucose). A clinical trial for ribavirin was recently initiated (ClinicalTrials.gov; NCT04356677).
Analysis of pathways that are important for viral infection in cells by combinatorial profiling using proteomics and translatomics represents a useful tool to propose likely pathways that inhibit viral replication. Determining possible compounds based on the specific cellular infection profile of the virus enables an unbiased determination of potential drug targets. Here, using such an experimental-data-driven approach, we identified several drugs that prevent SARS-CoV-2 replication in cells for further testing in clinical settings for the treatment of COVID-19.
Methods
Cell culture
Human Caco-2 cells, derived from colon carcinoma, were obtained from the Deutsche Sammlung von Mikroorganismen und Zellkulturen (DSMZ; AC169). The cell-authentification certificate from DSMZ is available and cells have been tested negative for mycoplasma infection.
Cells were grown at 37 °C in minimal essential medium (MEM) supplemented with 10% fetal bovine serum (FBS) and containing 100 IU/ml penicillin and 100 μg/ml streptomycin. All culture reagents were purchased from Sigma.
Virus preparation
SARS-CoV-2 was isolated from samples of travellers returning from Wuhan (China) to Frankfurt (Germany) using the human colon carcinoma cell line Caco-2 as described previously6. SARS-CoV-2 stocks used in the experiments had undergone one passage on Caco-2 cells and were stored at −80 °C. Virus titres were determined as TCID50/ml in confluent cells in 96-well microtitre plates.
Quantification of viral RNA
SARS-CoV-2 RNA from cell-culture supernatant samples was isolated using AVL buffer and the QIAamp Viral RNA Kit (Qiagen) according to the manufacturer’s instructions. Absorbance-based quantification of the RNA yield was performed using the Genesys 10S UV-Vis Spectrophotometer (Thermo Scientific). RNA was subjected to OneStep qRT–PCR analysis using the Luna Universal One-Step RT-qPCR Kit (New England Biolabs) and a CFX96 Real-Time System, C1000 Touch Thermal Cycler. Primers were adapted from the WHO protocol31 targeting the open-reading frame for RNA-dependent RNA polymerase (RdRp): RdRP_SARSr-F2 (GTGARATGGTCATGTGTGGCGG) and RdRP_SARSr-R1 (CARATGTTAAASACACTATTAGCATA) using 0.4 μM per reaction. Standard curves were created using plasmid DNA (pEX-A128-RdRP) that contained the corresponding amplicon regions of the RdRP target sequence according to GenBank accession number NC_045512. For each condition three biological replicates were used. Mean ± s.d. were calculated for each group.
Antiviral and cell viability assays
Confluent layers of Caco-2 cells in 96-well plates were infected with SARS-CoV-2 at a MOI of 0.01. Virus was added together with drugs and incubated in MEM supplemented with 2% FBS with different drug dilutions. Cytopathogenic effects were assessed visually 48 h after infection. To assess the effects of drugs on Caco-2 cell viability, confluent cell layers were treated with different drug concentration in 96-well plates. The viability was measured using the Rotitest Vital (Roth) according to the manufacturer’s instructions. Data for each condition were collected for at least three biological replicates. For dose–response curves, data were fitted with all replicates using OriginPro 2020 with the following equation:
IC50 values were generated by Origin together with metrics for curve fits.
Detection of the nucleoprotein of SARS-CoV-2
Viral infection was assessed by staining of SARS-CoV-2 nucleoprotein. In brief, cells were fixed with acetone:methanol (40:60) solution and immunostaining was performed using a monoclonal antibody directed against the nucleoprotein of SARS-CoV-2 (1:500, Sinobiological, 40143-R019-100ul), which was detected with a peroxidase-conjugated anti-rabbit secondary antibody (1:1,000, Dianova), followed by addition of AEC substrate.
Isotope labelling and cell lysis
In brief, 2 h before collection, cells were washed twice with warm PBS to remove interfering medium and cultured for an additional 2 h with DMEM medium containing 84 mg/l l-arginine (13C615N4 (R10); Cambridge Isotope Laboratories, CNLM-539-H) and 146 mg/l l-lysine (13C615N2 (K8), Cambridge Isotope Laboratories, CNLM-291-H) to label nascent proteins. After labelling culture, the cells were washed three times with warm PBS and lysed with 95 °C hot lysis buffer (100 mM EPPS pH 8.2, 2% sodium deoxycholate, 1 mM TCEP, 4 mM 2-chloracetamide, protease inhibitor tablet mini EDTA-free (Roche)). Samples were then incubated for an additional 5min at 95 °C, followed by sonication for 30 s and a further 10-min incubation at 95 °C.
Sample preparation for LC–MS/MS
Samples were prepared as previously described3. In brief, proteins were precipitated using methanol:chloroform precipitation and resuspended in 8 M urea and 10 mM EPPS pH 8.2. Isolated proteins were digested with 1:50 w/w LysC (Wako Chemicals) and 1:100 w/w trypsin (Promega, Sequencing-grade) overnight at 37 °C after dilution to a final urea concentration of 1 M. Digests were then acidified (pH 2–3) using TFA. Peptides were purified using C18 (50 mg) SepPak columns (Waters) as previously described. Desalted peptides were dried and 25 μg of peptides were resuspended in TMT-labelling buffer (200 mM EPPS pH 8.2, 10% acetonitrile). Peptides were subjected to TMT labelling with 1:2 peptide TMT ratio (w/w) for1 h at room temperature. The labelling reaction was quenched by addition of hydroxylamine to a final concentration of 0.5% and incubation at room temperature for an additional 15 min. Labelled peptides were pooled and subjected to high pH reverse Phase fractionation with the HpH RP Fractionation kit (ThermoFisher Scientific) following the manufacturer’s instructions. All multiplex reactions were mixed with a bridge channel, which consists of a control sample labelled in one reaction and split to all multiplexed reactions in equimolar amounts.
LC–MS/MS
Peptides were resuspended in 0.1% formic acid and separated on an Easy nLC 1200 (ThermoFisher Scientific) and a 22-cm-long, 75-μm-inner-diameter fused-silica column, which had been packed in house with 1.9-μm C18 particles (ReproSil-Pur, Dr. Maisch), and kept at 45 °C using an integrated column oven (Sonation). Peptides were eluted by a nonlinear gradient from 5–38% acetonitrile over 120 min and directly sprayed into a QExactive HF mass spectrometer equipped with a nanoFlex ion source (ThermoFisher Scientific) at a spray voltage of 2.3 kV. Full-scan MS spectra (350–1,400 m/z) were acquired at a resolution of 120,000 at m/z 200, a maximum injection time of 100 ms and an AGC target value of 3 × 106. Up to 20 most intense peptides per full scan were isolated using a 1 Th window and fragmented using higher-energy collisional dissociation (normalized collision energy of 35). MS/MS spectra were acquired with a resolution of 45,000 at m/z 200, a maximum injection time of 80 ms and an AGC target value of 1 × 105. Ions with charge states of 1 and >6 as well as ions with unassigned charge states were not considered for fragmentation. Dynamic exclusion was set to 20 s to minimize repeated sequencing of already acquired precursors.
LC–MS/MS data analysis
Raw files were analysed using Proteome Discoverer 2.4 software (ThermoFisher Scientific). Spectra were selected using default settings and database searches performed using SequestHT node in Proteome Discoverer. Database searches were performed against a trypsin-digested Homo sapiens SwissProt database, the SARS-CoV-2 database (Uniprot pre-release) and FASTA files of common contaminants (‘contaminants.fasta’ provided with MaxQuant) for quality control. Fixed modifications were set as TMT6 at the N terminus and carbamidomethyl at cysteine residues. One search node was set up to search with TMT6 (K) and methionine oxidation as static modifications to search for light peptides and one search node was set up with TMT6+K8 (K, +237.177), Arg10 (R, +10.008) and methionine oxidation as static modifications to identify heavy peptides. Searches were performed using Sequest HT. After each search, posterior error probabilities were calculated and peptide spectrum matches (PSMs) filtered using Percolator using default settings. Consensus Workflow for reporter ion quantification was performed with default settings, except the minimal signal-to-noise ratio was set to 5. Results were then exported to Excel files for further processing. For proteome quantification all PSMs were summed intensity normalized, followed by IRS32 and TMM33 normalization and peptides corresponding to a given UniProt accession were summed, including all modification states.
For translatome measurements, Excel files were processed in Python, as previously described3. Python 3.6 was used together with the following packages: pandas 0.23.434, numpy 1.15.435 and scipy 1.3.0. Excel files with normalized PSM data were read in and each channel was normalized to the lowest channel based on total intensity. For each peptide sequence, all possible modification states containing a heavy label were extracted and the intensities for each channel were averaged between all modified peptides. Baseline subtraction was performed by subtracting the measured intensities for the non-SILAC-labelled sample from all other values. Negative intensities were treated as zero. The heavy label incorporation at the protein level was calculated by summing the intensities of all peptide sequences belonging to one unique protein accession. These values were combined with the standard protein output of Proteome Discoverer 2.4 to add annotation data to the master protein accessions.
Hierarchical clustering and profile comparison
Hierarchical cluster analysis and comparison with viral protein profiles for all samples was performed using Perseus36 software package (version 1.6.5.0) after centring and scaling of data (Z-scores). K-means pre-processing was performed with a cluster number of 12 and a maximum of 10 iterations. For the comparison of profiles, the viral profiles were Z-scored and averaged to generate reference profile. Profiles of all proteins were compared to the reference (Pearson), distances and FDRs were computed.
Network analysis
For network analysis, Cytoscape 3.7.137 software was used with the BiNGO 3.0.338 plugin for gene ontology analysis, EnrichmentMap 3.1.039 and ReactomeFI 6.1.040. For gene ontology analyses, gene sets were extracted from data as indicated using fold change and significance cut-offs.
Statistical analysis
No statistical methods were used to predetermine sample size. Significance was, unless stated otherwise, tested using unpaired two-sided Student’s t-tests with equal variance assumed. Statistical analysis was performed using OriginPro 2020 analysis software. For network and gene ontology analysis all statistical computations were performed by the corresponding packages.
Reporting summary
Further information on research design is available in the Nature Research Reporting Summary linked to this paper.
Data availability
The LC–MS/MS proteomics data have been deposited in the ProteomeXchange Consortium via the PRIDE41 partner repository with the dataset identifier PXD017710. We furthermore created a webpage (http://corona.papers.biochem2.com/), in which the presented data is visualized for easy access of the published data.
References
Zhu, N. et al. A novel coronavirus from patients with pneumonia in China, 2019. N. Engl. J. Med. 382, 727–733 (2020).
Zhao, S. et al. Preliminary estimation of the basic reproduction number of novel coronavirus (2019-nCoV) in China, from 2019 to 2020: a data-driven analysis in the early phase of the outbreak. Int. J. Infect. Dis. 92, 214–217 (2020).
Klann, K., Tascher, G. & Münch, C. Functional translatome proteomics reveal converging and dose-dependent regulation by mTORC1 and eIF2α. Mol. Cell 77, 913–925 (2020).
Jin, Y.-H. et al. A rapid advice guideline for the diagnosis and treatment of 2019 novel coronavirus (2019-nCoV) infected pneumonia (standard version). Mil. Med. Res. 7, 4 (2020).
She, J. et al. 2019 novel coronavirus of pneumonia in Wuhan, China: emerging attack and management strategies. Clin. Transl. Med. 9, 19 (2020).
Hoehl, S. et al. Evidence of SARS-CoV-2 infection in returning travelers from Wuhan, China. N. Engl. J. Med. 382, 1278–1280 (2020).
Xiao, F. et al. Evidence for gastrointestinal infection of SARS-CoV-2. Gastroenterology 158, 1831–1833 (2020).
Young, B. E. et al. Epidemiologic features and clinical course of patients infected with SARS-CoV-2 in Singapore. J. Am. Med. Assoc. 323, 1488–1494 (2020).
Cinatl, J. et al. Treatment of SARS with human interferons. Lancet 362, 293–294 (2003).
Kamitani, W., Huang, C., Narayanan, K., Lokugamage, K. G. & Makino, S. A two-pronged strategy to suppress host protein synthesis by SARS coronavirus Nsp1 protein. Nat. Struct. Mol. Biol. 16, 1134–1140 (2009).
Shen, L. et al. High-throughput screening and identification of potent broad-spectrum inhibitors of coronaviruses. J. Virol. 93, e00023-19 (2019).
Pillaiyar, T., Meenakshisundaram, S. & Manickam, M. Recent discovery and development of inhibitors targeting coronaviruses. Drug Discov. Today 25, 668–688 (2020).
Neuman, B. W. et al. Proteomics analysis unravels the functional repertoire of coronavirus nonstructural protein 3. J. Virol. 82, 5279–5294 (2008).
Jourdan, S. S., Osorio, F. & Hiscox, J. A. An interactome map of the nucleocapsid protein from a highly pathogenic North American porcine reproductive and respiratory syndrome virus strain generated using SILAC-based quantitative proteomics. Proteomics 12, 1015–1023 (2012).
Song, T. et al. Quantitative interactome reveals that porcine reproductive and respiratory syndrome virus nonstructural protein 2 forms a complex with viral nucleocapsid protein and cellular vimentin. J. Proteomics 142, 70–81 (2016).
Emmott, E. et al. The cellular interactome of the coronavirus infectious bronchitis virus nucleocapsid protein and functional implications for virus biology. J. Virol. 87, 9486–9500 (2013).
Cretu, C. et al. Structural basis of splicing modulation by antitumor macrolide compounds. Mol. Cell 70, 265–273 (2018).
Gualdoni, G. A. et al. Rhinovirus induces an anabolic reprogramming in host cell metabolism essential for viral replication. Proc. Natl. Acad. Sci. USA 115, E7158–E7165 (2018).
Yan, B. et al. Characterization of the lipidomic profile of human coronavirus-infected cells: implications for lipid metabolism remodeling upon coronavirus replication. Viruses 11, 73 (2019).
Pruijssers, A. J. & Denison, M. R. Nucleoside analogues for the treatment of coronavirus infections. Curr. Opin. Virol. 35, 57–62 (2019).
Saijo, M. et al. Inhibitory effect of mizoribine and ribavirin on the replication of severe acute respiratory syndrome (SARS)-associated coronavirus. Antiviral Res. 66, 159–163 (2005).
Wu, L. S. et al. Population pharmacokinetic modeling of plasma and intracellular ribavirin concentrations in patients with chronic hepatitis c virus infection. Antimicrob. Agents Chemother. 59, 2179–2188 (2015).
Wang, M. et al. Remdesivir and chloroquine effectively inhibit the recently emerged novel coronavirus (2019-nCoV) in vitro. Cell Res. 30, 269–271 (2020).
Cinatl, J. et al. Glycyrrhizin, an active component of liquorice roots, and replication of SARS-associated coronavirus. Lancet 361, 2045–2046 (2003).
Martin, P. & Jensen, D. M. Ribavirin in the treatment of chronic hepatitis C. J. Gastroenterol. Hepatol. 23, 844–855 (2008).
Marcelin, J. R., Wilson, J. W. & Razonable, R. R. Oral ribavirin therapy for respiratory syncytial virus infections in moderately to severely immunocompromised patients. Transpl. Infect. Dis. 16, 242–250 (2014).
Ye, Y., Tang, W. K., Zhang, T. & Xia, D. A mighty “protein extractor” of the cell: structure and function of the p97/CDC48 ATPase. Front. Mol. Biosci. 4, 39 (2017).
Zhang, J. et al. Identification of NMS-873, an allosteric and specific p97 inhibitor, as a broad antiviral against both influenza A and B viruses. Eur. J. Pharm. Sci. 133, 86–94 (2019).
Jia, H. P. et al. Ectodomain shedding of angiotensin converting enzyme 2 in human airway epithelia. Am. J. Physiol. Lung Cell. Mol. Physiol. 297, L84–L96 (2009).
Narayanan, K. et al. Severe acute respiratory syndrome coronavirus nsp1 suppresses host gene expression, including that of type I interferon, in infected cells. J. Virol. 82, 4471–4479 (2008).
Corman, V. M. et al. Detection of 2019 novel coronavirus (2019-nCoV) by real-time RT-PCR. Euro Surveill. 25, 2000045 (2020).
Plubell, D. L. et al. Extended multiplexing of tandem mass tags (TMT) labeling reveals age and high fat diet specific proteome changes in mouse epididymal adipose tissue. Mol. Cell. Proteomics 16, 873–890 (2017).
Robinson, M. D. & Oshlack, A. A scaling normalization method for differential expression analysis of RNA-seq data. Genome Biol. 11, R25 (2010).
McKinney, W. Data structures for statistical computing in Python. In Proc. 9th Python in Science Conference 56–61 (SCIPY, 2010).
van der Walt, S., Colbert, S. C. & Varoquaux, G. The NumPy Array: a structure for efficient numerical computation. Comput. Sci. Eng. 13, 22–30 (2011).
Tyanova, S. et al. The Perseus computational platform for comprehensive analysis of (prote)omics data. Nat. Methods 13, 731–740 (2016).
Shannon, P. et al. Cytoscape: a software environment for integrated models of biomolecular interaction networks. Genome Res. 13, 2498–2504 (2003).
Maere, S., Heymans, K. & Kuiper, M. BiNGO: a Cytoscape plugin to assess overrepresentation of gene ontology categories in biological networks. Bioinformatics 21, 3448–3449 (2005).
Merico, D., Isserlin, R., Stueker, O., Emili, A. & Bader, G. D. Enrichment map: a network-based method for gene-set enrichment visualization and interpretation. PLoS ONE 5, e13984 (2010).
Wu, G. & Haw, R. Functional interaction network construction and analysis for disease discovery. Methods Mol. Biol. 1558, 235–253 (2017).
Perez-Riverol, Y. et al. The PRIDE database and related tools and resources in 2019: improving support for quantification data. Nucleic Acids Res. 47, D442–D450 (2019).
Chen, J.-Y. et al. Interaction between SARS-CoV helicase and a multifunctional cellular protein (Ddx5) revealed by yeast and mammalian cell two-hybrid systems. Arch. Virol. 154, 507–512 (2009).
Wong, H.-H. et al. Genome-wide screen reveals valosin-containing protein requirement for coronavirus exit from endosomes. J. Virol. 89, 11116–11128 (2015).
Acknowledgements
We thank C. Pallas and L. Stegmann for experimental support and G. Tascher and M. Adrian-Allgood for proteomics support. J.C. acknowledges funding by the Hilfe für krebskranke Kinder Frankfurt and the Frankfurter Stiftung für krebskranke Kinder. C.M. was supported by the European Research Council under the European Union’s Seventh Framework Programme (ERC StG 803565), CRC 1177 and the Emmy Noether Programme of the Deutsche Forschungsgemeinschaft (DFG, MU 4216/1-1), the Johanna Quandt Young Academy at Goethe and an Aventis Foundation Bridge Award.
Author information
Authors and Affiliations
Contributions
B.K., J.C. and C.M. conceived the study. D.B. carried out tissue-culture work, virus experiments and cytotoxicity assays. K.K. performed proteomic analyses of viral infection kinetics and bioinformatics analyses. M.W. carried out quantitative PCRs. B.K. analysed literature for established inhibitors in viral therapy. D.K. developed the online tool for data visualization. S.C., J.C. and C.M. supervised the work. K.K., J.C. and C.M. wrote the initial manuscript, with contributions from all authors. All authors read and approved the final manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Peer review information Nature thanks Ileana M. Cristea, Michael P. Weekes and the other, anonymous, reviewer(s) for their contribution to the peer review of this work.
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Extended data figures and tables
Extended Data Fig. 1 Viral protein accumulation in Caco-2 cells after SARS-CoV-2 infection.
Cells were infected with SARS-CoV-2 at a MOI of 1 and incubated for 10 or 24 h. Cells were fixed and stained with an antibody against the nucleoprotein of SARS-CoV-2, followed by staining with a peroxidase-conjugated secondary antibody and the addition of substrate. Three independent biological samples are shown. n = 3 independent biological samples.
Extended Data Fig. 2 Translatome analysis of cells infected with SARS-CoV-2.
a, Principal component analysis of all replicate translatome measurements. Blue dots and red dots (both shaded according to time after infection) represent different mock controls and SARS-CoV-2 infected samples, respectively. b, Volcano plots showing differentially translated genes between infected cells and the mock control group for each time point. log2-transformed fold changes (FC) are plotted against P values (two-sided unpaired Student’s t-test with equal variance assumed; n = 3 independent biological samples). Blue dots indicate significant decrease in translation (FC < −0.5, P < 0.05), red dots indicate significant increase in translation (FC > 0.5, P < 0.05). c, Histogram of distances from host protein expression profile to viral proteins. Viral protein translation profiles were Z-scored, averaged (5 viral proteins) and used as a reference profile to compare to each host protein in dataset. The blue curve shows a distribution curve fitted to data, the red line indicates the top 10% quantile of distances used for pathway analysis (in Fig. 2). d, Averaged viral protein-translation Z-score profile over all replicate samples (5 viral proteins). Grey shade indicates s.d. of averaged profiles, coloured profiles in the background represent individual viral proteins. e, Translation Z-score profiles for four example proteins (ENO1, FLNA, CEBPZ and COTL1) following the viral profile from c. f, Translation Z-score profiles for four example proteins (SH3BGRL, SNRPB, PPA1 and SEPT11) that do not follow the viral reference profile. g, Network of functional interactions between proteins annotated with function in host translation. Arrows indicate functional interactions. h, Drugs targeting host translation that have been used in vitro for treatment of other (that is, non-SARS-CoV-2) coronavirus infections. i, j, Cytotoxicity assays for different concentrations of cycloheximide (i) and emetine (j) relative to control. Mean values ± s.d. are plotted (n = 3 independent biological samples). Line represents 100% viable cells.
Extended Data Fig. 3 Volcano plots of the change in total protein levels over time.
P values have been calculated using a two-sided, unpaired Student’s t-test with equal variance assumed and were plotted against the log2-transformed ratio between SARS-CoV-2-infected and mock cells for each time point (n = 3 independent biological samples).
Extended Data Fig. 4 Network of proteins that are decreased during SARS-CoV-2 infection.
a, Proteins belonging to cluster I in Fig. 3a were used for the creation of a functional interaction network. Lines indicate functional interactions. The network was created using the ReactomeFI plugin in Cytoscape, protein names were added in the plugin and the network adjusted by the yFiles Layout algorithm. b, ReactomeFI network analysis of proteins downregulated in total protein levels. Circle size represents number of proteins found in the pathway, colour shows the FDR for enrichment.
Extended Data Fig. 5 Networks of proteins that are increased during SARS-CoV-2 infection.
a, Network of proteins increased during SARS-CoV-2 infection with spliceosome annotation in reactome pathway analysis. Lines indicate functional interactions. b, Table summarizing viral proteins (from different coronaviruses) interacting with various spliceosome components13,14,15,16,42,43. c, d, Cytotoxicity assays for different concentrations of pladienolide B (c) and 2-deoxy-d-glucose (d) relative to control. Mean values ± s.d. (n = 3 independent biological samples). Line represents 100% viable cells. e, Protein network showing increased proteins during infection with annotation to the molecular function of ‘unfolded protein binding’. Lines indicate functional interactions.
Extended Data Fig. 6 Compartment analysis of proteins that were significantly regulated.
The STRING network was created with proteins filtered for significant changes in protein levels (log2-transformed fold change; FC > |0.35|, P < 0.05) and filtered for each compartment (cut-off maximum of [5]). Circle heat maps represent the log2-transformed ratios between infected and mock cells at different time points of infection starting from the innermost circle (2 h) to the outer circle (24 h).
Extended Data Fig. 7 Viral protein profiles and cytotoxicity assay for nucleic acid and p97 inhibitors.
a, Total protein profiles for each viral protein with individual replicate measurements to indicate variation. log2-transformed ratios of infected versus mock cells are plotted against time of infection. Line indicates averaged curve (n = 3 independent biological samples) and dots represent individual measurements. b, Averaged reference profile of total protein levels for all viral proteins from a (9 viral proteins). Shade indicates s.d. c, Example profiles of three proteins (NPM1, HSPA5 and HSPA9) that significantly follow the viral reference profile (Fig. 4). d, Example profiles of proteins (RAPH1 and MGME1) that do not follow the viral reference profile. e, f, Cytotoxicity assays for different concentrations of ribavirin (e) and NSM-873 (f) relative to control. Mean values ± s.d. are plotted (n = 3 independent biological samples). Line represents 100% viable cells.
Extended Data Fig. 8 ACE2 total protein levels after 24 h of infection.
Total ACE2 protein levels 24 h after infection compared to mock samples (n = 3 independent biological samples). Significance was assessed by an unpaired, two-sided Student’s t-test. *P < 0.05.
Supplementary information
Supplementary Table 1
| Data of translatome measurements by MS Contains Uniprot Accession, Species annotation, Gene Symbol and normalized translation data for each replicate (Data was normalized using summed intensity normalisation for sample loading, followed by internal reference scaling and Trimmed mean of M normalisation). Log2 ratios and P values were computed for each group comparison (two-sided, unpaired t-test with equal variance assumed, n = 3 independent biological samples). See Fig. 2.
Supplementary Table 2
| Data of proteome measurements by MS Contains UniProt Accession, Gene Symbol and normalized protein abundances for each sample. (Data was normalized using summed intensity normalisation for sample loading, followed by internal reference scaling and Trimmed mean of M normalisation). Log2 ratios and P values were computed for each group comparison (two-sided, unpaired t-test with equal variance assumed, n = 3 independent biological samples). See Fig. 3, 4.
Supplementary Table 3
| Results of Reactome pathway analysis of genes decreased in protein level during infection (Fig. 3a, S3) Pathway names, size of pathway, proteins found in dataset, P values and FDR are given (P values by binomial test and FDR by binomial test and Benjamini-Hochberg correction).
Supplementary Table 4
| Results of Reactome pathway analysis of genes increased in protein level during infection (Fig. 3a, b) Pathway names, size of pathway, proteins found in dataset, P values and FDR are given (P values by binomial test and FDR by binomial test and Benjamini-Hochberg correction).
Supplementary Table 5
| Results of gene ontology (biological process) analysis of genes following viral gene expression (Fig. 4) GO term, proteins found in dataset, GO size, P value and FDR are given (P values by binomial test and FDR by binomial test and Benjamini-Hochberg correction).
Rights and permissions
About this article

Cite this article
Bojkova, D., Klann, K., Koch, B. et al. Proteomics of SARS-CoV-2-infected host cells reveals therapy targets. Nature 583, 469–472 (2020). https://doi.org/10.1038/s41586-020-2332-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1038/s41586-020-2332-7
This article is cited by
-
COVID-19 drug discovery and treatment options
Nature Reviews Microbiology (2024)
-
Proteomic analysis of SARS-CoV-2 particles unveils a key role of G3BP proteins in viral assembly
Nature Communications (2024)
-
Airway epithelial CD47 plays a critical role in inducing influenza virus-mediated bacterial super-infection
Nature Communications (2024)
-
Alterations in Circadian Rhythms, Sleep, and Physical Activity in COVID-19: Mechanisms, Interventions, and Lessons for the Future
Molecular Neurobiology (2024)
-
Deciphering the similarities and disparities of molecular mechanisms behind respiratory epithelium response to HCoV-229E and SARS-CoV-2 and drug repurposing, a systems biology approach
DARU Journal of Pharmaceutical Sciences (2024)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
