
Abstract
Efficiently estimating fermionic Hamiltonian expectation values is vital for simulating various physical systems. Classical shadow (CS) algorithms offer a solution by reducing the number of quantum state copies needed, but noise in quantum devices poses challenges. We propose an error-mitigated CS algorithm assuming gate-independent, time-stationary, and Markovian (GTM) noise. For n-qubit systems, our algorithm, which employs the easily prepared initial state \(\left\vert {0}^{n}\right\rangle \,\left\langle {0}^{n}\right\vert\) assumed to be noiseless, efficiently estimates k-RDMs with \(\widetilde{{{{\mathcal{O}}}}}(k{n}^{k})\) state copies and \(\widetilde{{{{\mathcal{O}}}}}(\sqrt{n})\) calibration measurements for GTM noise with constant fidelities. We show that our algorithm is robust against noise types like depolarizing, damping, and X-rotation noise with constant strengths, showing scalings akin to prior CS algorithms for fermions but with better noise resilience. Numerical simulations confirm our algorithm’s efficacy in noisy settings, suggesting its viability for near-term quantum devices.
Similar content being viewed by others
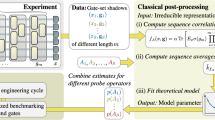
Introduction
Assessing the properties of interacting fermionic systems constitutes one of the core tasks of modern physics, a task that has a wealth of applications in quantum chemistry1, condensed matter physics2, and materials science3. Notions of quantum simulation offer an alternative route to studying this important class of systems. In analog simulation, one prepares the system of interest under highly controlled conditions. However, any such effort makes sense only if one has sufficiently powerful readout techniques available that allow one to estimate properties. In fact, the read-out step constitutes a core bottleneck in many schemes for quantum simulation.
Fortunately, for natural fermionic systems, one often does not need to learn the full unknown quantum state; trying to do so regardless would be highly impractical, as the resources required for a full tomographic recovery would scale exponentially with the size of the system. Instead, what is commonly needed are the so-called k-particle reduced density matrices, abbreviated as k-RDMs. These are expectation values of polynomials of fermionic operators of the 2k-th degree. Naturally, the expectation value of any interaction fermionic Hamiltonian can be estimated using 2-RDMs only4,5. Indeed, the adaptive variational quantum algorithm (VQE)6 also utilizes up to 4-RDMs to simulate many-body interactions in the ground and excited state7,8. That is to say, meaningful methods of read-out often focus on estimating such fermionic reduced density matrices.
On the highest level, several approaches can be pursued when dealing with fermionic operators. One of those—and the one followed here—is to treat the fermionic system basically as a collection of spins. Then given spin Hamiltonians \({\left\{{H}_{i}\right\}}_{i = 1}^{m}\) and an unknown quantum state ρ, where \(m={{{\mathcal{O}}}}\left({{{\rm{poly}}}}(n)\right)\), the classical shadow (CS) algorithm or its variants9,10,11,12,13,14,15,16,17,18,19,20,21 in qubit systems are among the most promising ways to calculate the expectations \({{{\rm{Tr}}}}\left(\rho {H}_{i}\right)\), with the representation of the Hamiltonians \({\left\{{H}_{i}\right\}}_{i = 1}^{m}\) in the Pauli basis, which invokes a fermion-to-spin mapping such as the Jordan-Wigner22,23 or Bravyi-Kitaev encodings24,25. We define the classical shadow channel as \({{{\mathcal{M}}}}\), which involves operating the unitary channel \({{{\mathcal{U}}}}\) uniformly randomly sampled from the Clifford group before measurements in the Z-basis and classical postprocessing operations on the measurement outcomes. By performing the inverse of the classical shadow channel \({{{{\mathcal{M}}}}}^{-1}\) on the resulting state after performing \({{{\mathcal{M}}}}\) on the initial state ρ, we obtain the classical shadow representation \(\hat{\rho }\) of the quantum state ρ, allowing for the calculation of the expected values of observables \({\left\{{H}_{i}\right\}}_{i = 1}^{m}\) with respect to ρ using classical methods.
While the classical shadow algorithm requires exponentially many copies even for some local interacting fermions due to the inefficient representation in the qubit system, recently, several classical shadow algorithms for fermionic systems without encoding of the Hamiltonians have been proposed26,27,28. Zhao, Rubin, and Miyake26 utilize the generalized CS method9 for fermionic systems, and proposed an algorithm that requires \({{{\mathcal{O}}}}((\begin{array}{l}n\\ k\end{array}){k}^{3/2}(\log n)/{\varepsilon }^{2})\) copies for the unknown quantum states to output all the elements of a k-RDM. Low27 proves that all elements of the k-RDM can be estimated with \(\left(\begin{array}{l}\eta \\ k\end{array}\right){(1-\frac{\eta -k}{n})}^{k}\frac{1+n}{1+n-k}/{\varepsilon }^{2}\) number of copies of the quantum state, where η is the number of particles and n is the number of modes. These fermionic shadow estimation methods (along with the generic classical shadow formalism) do not account for noise in the system, which is an inevitability in real physical systems.
Since we are still in the noisy intermediate-scale quantum (NISQ) era, current quantum simulators are heavily affected by noise; hence, any characterization technique needs to be robust for these simulators to be useful. For qubit systems, robust shadow estimation was developed29,30 where Chen et al.29 use techniques from randomized benchmarking to mitigate the effect of gate-independent time-stationary Markovian (GTM) noise channels on the procedure. Jnane et al.31 proposed error-mitigated classical shadow with probabilistic error cancellation.
Utilizing the robust shadow estimation scheme and taking inspiration from the fermionic shadow estimation of Zhao et al.26,28, we present an error-mitigated shadow estimation scheme for fermionic systems and demonstrate its feasibility for realistic noise channels. Note that akin to the fermionic CS approaches proposed in refs. 26,28, our error-mitigated CS method circumvents the need to encode the Hamiltonian using the qubit representation.
We sample our unitaries \({{{{\mathcal{U}}}}}_{Q}\) from the matchgate group32, a natural choice for our protocol as there is a one-to-one correspondence between two-qubit matchgates and free-fermionic evolution33,34. We therefore design the classical postprocessing operations by leveraging the irreducible representation of the matchgate group. We successfully introduce an unbiased estimator \(\widehat{{{{\mathcal{M}}}}}\) for the noisy classical shadow channel \(\widetilde{{{{\mathcal{M}}}}}\), where we require an additional calibration protocol to generate the estimator \(\widehat{{{{\mathcal{M}}}}}\) with the assumption that the computational basis state \(\left\vert {{{\boldsymbol{0}}}}\right\rangle \,\left\langle {{{\boldsymbol{0}}}}\right\vert\) can be prepared noiselessly. Additionally, we demonstrate the efficacy of our protocol under conditions of constant noise strength by evaluating its performance across various common noise channels: depolarizing noise, generalized amplitude damping, X-rotation, and Gaussian unitary noise. The number of samples required for the estimation process of our protocol is in the same order as the noise-free matchgate classical shadow scheme26,28.
We determine the effectiveness of our protocol with the above noise models by calculating the expectations of all elements of the k-particle reduced density matrix (k-RDM) when the noise strength is constant. The number of samples required for estimation, in this case, is \({{{\mathcal{O}}}}\left(k{n}^{k}\ln (n/{\delta }_{e})/{\varepsilon }_{e}^{2}\right)\) and for calibration is \({{{\mathcal{O}}}}\left(\sqrt{n}\ln n\ln (1/{\delta }_{c})/{\varepsilon }_{c}^{2}\right)\) with error εe + εc and success probability (1 − δe)(1 − δc).
We have extended the analysis of our error-mitigated fermionic shadow channel estimation to more general physical quantities inspired by the fermionic shadow analysis of Wan et al.28, with more details in Supplementary Notes 5, 9. We list distinct classical shadow approaches in both noiseless and noisy qubit and fermionic systems in Table 1. Our error-mitigated fermionic classical shadow technique constitutes an extension of the work by Chen et al.29, accommodating scenarios where the gate-set lacks (1) 3-design properties35 and (2) the applicability of the randomized benchmarking scheme developed by Helsen et al.36.
We tested the accuracy and efficacy of our protocol by performing numerical experiments to estimate \({{{\rm{Tr}}}}\left(\rho {\widetilde{\gamma }}_{S}\right)\) (where \({\widetilde{\gamma }}_{S}={U}_{Q}^{{\dagger} }{\gamma }_{S}{U}_{Q}\), where γS is the product of \(\left\vert S\right\vert\) Majorana operators and plays a crucial role in computing k-RDMs) on a noisy quantum device subjected to various types of gate noise such as depolarizing, generalized amplitude damping, X-rotation, and Gaussian unitaries. Our numerical investigations confirm the potential of our methods in real-world experimental scenarios.
Results
Basic notations and concepts
Here we give the basic notations and concepts that will be used throughout this work.
Basic notations
The symbols X, Y, and Z denote the Pauli X, Y, and Z operators respectively. The operator \({R}_{X}(\theta )=\exp \left(-i\frac{\theta }{2}X\right)\) denotes the rotation operator around the x-axis. A Z-basis measurement is performed with respect to the basis of eigenstates of the Pauli-Z operator. We utilize \({\mathbb{I}}\) to represent the identity operator on the full system. The set of linear operators on a vector space \({{{\mathcal{H}}}}\) is denoted as \({{{\mathcal{L}}}}({{{\mathcal{H}}}})\). We utilize the symbol \(\widetilde{{{{\mathcal{O}}}}}\) to omit the logarithmic terms.
Superoperator
We denote the superoperator representation of a linear operator \(O\in {{{\mathcal{L}}}}({{{\mathcal{H}}}})\) as \(\left.\left\vert O\right\rangle \!\right\rangle := O/\sqrt{{{{\rm{Tr}}}}\left(O{O}^{{\dagger} }\right)}\) and the scaled Hilbert-Schmidt inner product between linear operators as \(\left\langle \!\langle O| R\rangle \!\right\rangle ={{{\rm{Tr}}}}\left({O}^{{\dagger} }R\right)/\sqrt{{{{\rm{Tr}}}}\left(O{O}^{{\dagger} }\right){{{\rm{Tr}}}}\left(R{R}^{{\dagger} }\right)}\). The action of a channel \({{{\mathcal{E}}}}\in {{{\mathcal{L}}}}({{{\mathcal{L}}}}({{{\mathcal{H}}}}))\) operating on a linear operator \(O\in {{{\mathcal{L}}}}({{{\mathcal{H}}}})\) can hence be written as \({{{\mathcal{E}}}}\left.\left\vert O\right\rangle \,\right\rangle ={{{\mathcal{E}}}}(O)/\sqrt{{{{\rm{Tr}}}}\left(O{O}^{{\dagger} }\right)}\). The channel representation of a measurement with respect to the computational basis can be represented as \({{{\mathcal{X}}}}={\sum }_{x\in {\left\{0,1\right\}}^{n}}\left.\left\vert x\right\rangle \!\right\rangle \,\left\langle \!\left\langle x\right\vert \right.\). We denote the unitary channel corresponding to the unitary operator U as \({{{\mathcal{U}}}}(\cdot )=U(\cdot ){U}^{{\dagger} }\).
Majorana operator
The Majorana operators γj for 1≤j≤2n describes the fermionic system with \({\gamma }_{j}={b}_{(j+1)/2}+{b}_{(j+1)/2}^{{\dagger} }\) for odd j and \({\gamma }_{j}=-i({b}_{j/2}-{b}_{j/2}^{{\dagger} })\) for even j, where bj and \({b}_{j}^{{\dagger} }\) are the annihilation and creation operators, respectively, associated with the j-th mode. Let γS be the product of the Majorana operators indexed by the subset S, denoted as \({\gamma }_{S}={\gamma }_{{l}_{1}}\cdots {\gamma }_{{l}_{| S| }}\) for \(\left\vert S\right\vert > 0\) and \({\gamma }_{{{\emptyset}}}={\mathbb{I}}\), where \(S=\left\{{l}_{1},\ldots ,{l}_{| S| }\right\}\) and l1 < l2 < … < l∣S∣. It can be shown that γS forms the complete orthogonal basis for \({{{\mathcal{L}}}}({{{\mathcal{H}}}})\) for S ⊆ [2n]. Let \({{{\Gamma }}}_{k}:= \left\{{\gamma }_{S}| \left\vert S\right\vert =k\right\}\) be the subspace of γS with cardinality k. We denote the even subspace as \({{{\Gamma }}{}_{{{{\rm{even}}}}}:= \bigoplus }_{l}{{{\Gamma }}}_{2l}\). Also, we denote \({{{{\mathcal{P}}}}}_{k}\) as the projector onto the subspace Γk, i.e.
where we have used the notation that for a set A and an integer k, \((\begin{array}{l}A\\ k\end{array})=\{T\subseteq A:| T| =k\}\) denotes the set of subsets of A with cardinality k.
Gaussian unitaries
Matchgates are in a one-to-one correspondence with the fermionic Gaussian unitaries and can serve as a qubit representation for these unitaries. We denote \({{\mathbb{M}}}_{n}\) as the matchgate group, and write its elements \({U}_{Q}\in {{\mathbb{M}}}_{n}\) in terms of rotation matrices Q belonging to the orthogonal group Orth(2n) (see Supplementary Note 1 for details)33,37. Following Wan et al.’s study28, which demonstrated that the continuous matchgate group \({{\mathbb{M}}}_{n}\) and the discrete subgroup \({{\mathbb{M}}}_{n}\cap {{{{\rm{Cl}}}}}_{n}\) (where Cln represents the Clifford group) deliver equivalent performances for fermionic classical shadows, our findings remain applicable to both continuous and discrete matchgate circuits. Since \({U}_{Q}^{{\dagger} }{\gamma }_{j}{U}_{Q}={\sum }_{k}{Q}_{jk}{\gamma }_{k}\), the matchgate UQ transforms the product of Majorana operators γS in the Γ∣S∣ subspace as \({U}_{Q}^{{\dagger} }{\gamma }_{S}{U}_{Q}={\sum }_{{S}^{{\prime} }\in {\tiny\left(\begin{array}{l}[2n]\atop | S| \end{array}\right)}}\det (Q{| }_{S{S}^{{\prime} }}){\gamma }_{{S}^{{\prime} }}\).
k-particle reduced density matrices (k-RDM)
We denote a k-RDM as kD, which can be obtained by tracing out all but k particles. Here we denote it as a tensor with 2k indices,
where ji and li are in [n] for i ∈ [k]. The fermionic system can be equivalently described in the Majorana basis, in which case a tensor can be rewritten as the linear combinations of \({{{\rm{Tr}}}}\left(\rho {\gamma }_{S}\right)\), and \(\left\vert S\right\vert \le 2k\). Hence all n2k elements of the k-RDM can be obtained by calculating \({{{\rm{Tr}}}}\left(\rho {\gamma }_{S}\right)\), for the scaling of \({{{\mathcal{O}}}}\left({n}^{k}\right)\) different S with \(\left\vert S\right\vert \le 2k\)38.
Pfaffian function
The Pfaffian of a matrix \(Q\in {{\mathbb{R}}}^{2n\times 2n}\) is defined as
which can be calculated in \(O\left({n}^{3}\right)\) time39.
Ideal fermionic shadow (Wan et al.28)
Given an unknown quantum state ρ, the classical shadow method applies a unitary UQ uniformly randomly sampled from matchgate group \({{\mathbb{M}}}_{n}\), followed by measuring the generated state in the computational basis. With the measurement result \(\left.\left\vert x\right\rangle \!\right\rangle\), we can generate the classical representation \(\hat{\rho }={{{{\mathcal{M}}}}}^{-1}{{{{\mathcal{U}}}}}_{Q}^{{\dagger} }\left.\left\vert x\right\rangle \!\right\rangle\) for the unknown quantum state ρ, where the channel \({{{\mathcal{M}}}}\) describing the overall process is defined as
Noise assumptions
In this work, we assume that the noise is gate-independent, time-independent, and Markovian (a common assumption in randomized benchmarking (RB) abbreviated as the GTM noise assumption40) and that the preparation noise for the easily prepared state \(\left\vert {{{\boldsymbol{0}}}}\right\rangle \,\left\langle {{{\boldsymbol{0}}}}\right\vert\) is negligible. For the convenience of calculation, we utilize the left-hand side noisy representation for a noisy fermionic unitary \({\widetilde{{{{\mathcal{U}}}}}}_{Q}:= {{\Lambda }}{{{{\mathcal{U}}}}}_{Q}\). Here we define the average fidelity in Γ2k subspace for noise channel Λ as
where \(D(S)=\left\{2j-1,2j| j\in S\right\},0\le k\le n,{x}_{S}={\sum }_{j\in S}{x}_{j}\). It is easy to check that \({{{{\mathcal{B}}}}}_{k}=1\) if k = 0. With some calculations, we have \({{{{\mathcal{B}}}}}_{k}=1\) for the noise-free model where noise channel Λ equals the identity. In the following, we give the analysis of the simplified result for \({{{{\mathcal{B}}}}}_{k}\) for several common noise models in the qubit system and fermionic system when k > 1. See more details for the analysis in Supplementary Note 3.
(1) The depolarizing noise with channel representation \({{{\Lambda }}}_{{{{\rm{d}}}}}(A)=(1-p)A+p{{{\rm{Tr}}}}\left(A\right)\frac{{\mathbb{I}}}{{2}^{n}}\) for any n-qubit linear operator A, where the noise strength p ∈ [0, 1], and \({{{{\mathcal{B}}}}}_{k}=1-p\).
(2) The generalized amplitude-damping noise with the Kraus representation
where \({E}_{uv}=\sqrt{\bar{{p}_{u}}}\left\vert v\right\rangle \,\left\langle u\right\vert\) for u ≠ v ∈ {0, 1}n and \({E}_{0}=\sqrt{{\mathbb{I}}-{\sum }_{\begin{array}{c}u,v\in {\left\{0,1\right\}}^{n}\\ u\ne v\end{array}}{E}_{uv}^{{\dagger} }{E}_{uv}}\), where the probabilities \({\bar{p}}_{u}\) satisfy \(({2}^{n}-1){\bar{p}}_{u}\le 1\) for any \(u\in {\left\{0,1\right\}}^{n}\). The average fidelity \({{{{\mathcal{B}}}}}_{k}=1-{\sum }_{u\in {\left\{0,1\right\}}^{n}}{\bar{p}}_{u}\) if k ≠ 0. We let \({\sum }_{u\in {\left\{0,1\right\}}^{n}}{\bar{p}}_{u}\) denote the noise strength.
(3) The X-rotation noise with the channel representation
where \({R}_{X}({{{\boldsymbol{\theta }}}})=\exp (-i\mathop{\sum }\nolimits_{l = 1}^{n}{\theta }_{l}{X}_{l}/2)\), where the noise strengths θl are some real numbers. By some calculations, we have \({{{{\mathcal{B}}}}}_{k}={(\begin{array}{l}n\\ k\end{array})}^{-1}{\sum }_{S\in (\begin{array}{l}[n]\\ k\end{array})}{\prod }_{l\in S}\cos {\theta }_{l}\). Hence \(\mathop{\min }\limits_{l}{\cos }^{k}{\theta }_{l}\le {{{{\mathcal{B}}}}}_{k}\le \mathop{\max }\limits_{l}{\cos }^{k}{\theta }_{l}\).
(4) Noise that is a Gaussian unitary41,42, where we assume that the noise has no coherence with the environment. This noise channel is denoted as
where UQ is a Gaussian unitary. By selecting the noise model to be Λg, we get \({{{{\mathcal{B}}}}}_{k}={(\begin{array}{l}n\\ k\end{array})}^{-1}{\sum }_{S,{S}^{{\prime} }\in (\begin{array}{l}[n]\\ k\end{array})}\det (Q{| }_{D(S),D({S}^{{\prime} })})\).
Note that for the noise models defined in (1–3), the average fidelity \({{{{\mathcal{B}}}}}_{k}\in [0,1]\) is close to one when the noise strengths are close to zero.
For comparison, it is worth noting that the standard average noise fidelity43\({F}_{{{{\rm{avg}}}}}={\int}_{\psi }d\psi \left\langle \psi | {{\Lambda }}(\left\vert \psi \right\rangle \left\langle \psi \right\vert )| \psi \right\rangle\) where ψ is drawn from the Haar measure, and the Z-basis average noise fidelity defined in Chen et al.29, \({F}_{Z}=\frac{1}{{2}^{n}}{\sum }_{b}\left\langle \!\langle b| {{\Lambda }}| b\rangle \!\right\rangle\) are not equivalent to \({{{{\mathcal{B}}}}}_{k}\) under the same noise model. We present a comparison of these three quantities for Λd, Λa, Λr for a single qubit, as depicted in Table 2. They are closely aligned, with \({{{{\mathcal{B}}}}}_{1}\) slightly smaller than Favg and FZ. We give a more detailed analysis in Supplementary material X.
Mitigation algorithm and error analysis
Let \(\widehat{{{{\mathcal{M}}}}}:= \mathop{\sum }\nolimits_{k = 0}^{n}{\hat{f}}_{2k}{{{{\mathcal{P}}}}}_{2k}\) be the estimator for the noisy shadow channel \(\widetilde{{{{\mathcal{M}}}}}=\mathop{\sum }\nolimits_{k = 0}^{n}{f}_{2k}{{{{\mathcal{P}}}}}_{2k}\). In the Methods Section, we provide an explicit expression and efficiency for the calculation of \({\hat{f}}_{2k}\). Using the estimated noisy channel \(\widehat{{{{\mathcal{M}}}}}\), we can now obtain an estimate for \({\{{{{\rm{Tr}}}}(\rho {H}_{j})\}}_{j = 1}^{m}\), where ρ represents certain quantum states and Hj denotes certain observables. If f2k = 0, the channel \(\widetilde{{{{\mathcal{M}}}}}\) becomes non-invertible. Consequently, the effectiveness of the fermionic CS method diminishes, and we cannot retrieve \({{{\rm{tr}}}}(\rho H)\) using it. In this study, we operate under the assumption that the noise is permissible and the fermionic CS channel is consistently invertible. Additionally, we provide a scenario in Supplementary Note 3 where the extreme noise channel occurs, i.e., fk = 0. However, it is anticipated that such an extreme case will rarely occur. Algorithm 1 demonstrates the method for mitigated estimation.
Algorithm 1
Error-mitigated estimation for noisy fermionic classical shadows
1: Input Quantum state ρ, observables H1, …, Hm, integers Nc, Kc, Ne, Ke.
2: Output\({\hat{v}}_{i}\) for i ∈ [m].
3: Rc ≔ NcKc;
4: for j ← 1 to Rc do
5: Prepare state \({\rho }_{0}=\left\vert {0}^{n}\right\rangle\), uniformly sample Q ∈ Orth(2n) or Perm(2n), implement the associated noisy Gaussian unitary \({\widehat{U}}_{Q}\) on ρ0, and measure in the Z-basis with outcomes x;
6: Let \({\hat{f}}_{2k}^{(j)}:= {2}^{n}{(-1)}^{k}{\left(\begin{array}{l}n\\ k\end{array}\right)}^{-1}\langle \!\langle {{{\bf{0}}}}| {{{{\mathcal{P}}}}}_{2k}{{{{\mathcal{U}}}}}_{Q}^{{\dagger} }| x\rangle \!\rangle ,\forall k\in [n]\);
7: end for
8: \({\hat{f}}_{2k}:= \,{{{\bf{MedianOfMeans}}}}\,\left({\left\{{f}_{2k}^{(j)}\right\}}_{j = 1}^{{R}_{c}},{N}_{c},{K}_{c}\right)\forall k\in [n]\);
9: \(\widehat{{{{\mathcal{M}}}}}:= \mathop{\sum }\nolimits_{k = 1}^{n}{\hat{f}}_{2k}{{{{\mathcal{P}}}}}_{2k}\);
10: Re ≔ NeKe;
11: for i ← 1 to m do
12: for j ← 1 to Re do
13: Prepare ρ, uniformly sample Q ∈ O(2n) or Perm(2n), implement the associated noisy Gaussian unitary \({\hat{U}}_{Q}\) on ρ, and measure in the Z-basis with outcomes x;
14: Generate estimation \({\hat{v}}_{i}^{(j)}:= {{{\rm{Tr}}}}\left({H}_{i}{\widehat{{{{\mathcal{M}}}}}}^{-1}{{{{\mathcal{U}}}}}_{Q}^{{\dagger} }(x)\right)\);
15: end for
16: \({\hat{v}}_{i}:= {{{\bf{MedianOfMeans}}}}\,\left({\left\{{\hat{v}}_{i}^{(j)}\right\}}_{j = 1}^{{R}_{e}},{N}_{e},{K}_{e}\right)\);
17: end for
18: return \({\left\{{\hat{v}}_{i}\right\}}_{i = 1}^{m}\)
Incorporating the MedianOfMeans sub-procedure, as explained in Ref. 9, guarantees that the number of quantum state copies needed relies on the logarithm of the number of observables. We included the MedianOfMeans sub-procedure in Supplementary Note 6 to ensure the completeness and consistency of this paper. Our error analysis will involve selecting appropriate values for the number of calibrations and estimation samplings Nc, Ne, Kc, and Ke to estimate the coefficients \({\hat{f}}_{2k}\) associated with the noisy channel.
Let \(\hat{v}:= {{{\rm{Tr}}}}({\widehat{{{{\mathcal{M}}}}}}^{-1}{{{{\mathcal{U}}}}}^{{\dagger} }(\left\vert x\right\rangle \,\left\langle x\right\vert )H)\) be an estimation of \({{{\rm{Tr}}}}\left(\rho H\right)\) for some observables H in the even subspace Γeven and quantum states ρ, where x follows the distribution \({{{\rm{Tr}}}}\left(\left\vert x\right\rangle \,\left\langle x\right\vert \widehat{{{{\mathcal{U}}}}}(\rho )\right)\) for \(x\in {\left\{0,1\right\}}^{n}\), then we have
where \({\varepsilon }_{e}:= \left\vert \hat{v}-{{{\rm{Tr}}}}\left({\widehat{{{{\mathcal{M}}}}}}^{-1}\widetilde{{{{\mathcal{M}}}}}(\rho )\right)\right\vert\) is the estimation error and \({\varepsilon }_{c}:= \left\vert {{{\rm{Tr}}}}\left({\widehat{{{{\mathcal{M}}}}}}^{-1}\widetilde{{{{\mathcal{M}}}}}\left(\rho \right)H\right)-{{{\rm{Tr}}}}\left(\rho H\right)\right\vert\) is the calibration error. Therefore, by determining the necessary number of samples Ne and Ke to achieve the desired level of estimation error εe (as well as Nc and Kc to account for the calibration error εc), we can obtain an estimation \(\hat{v}\) with an overall error of ε = εe + εc, using NeKe copies of the input state ρ.
Theorem 1
Let ρ be an unknown quantum state and \({\left\{{H}_{i}\right\}}_{i = 1}^{m}\) be a set of observables in the even subspace Γeven. Consider Algorithm 1 with the number of estimation samplings
where \(g({l}_{1},{l}_{2},{l}_{3})=\frac{{(-1)}^{{l}_{1}+{l}_{2}+{l}_{3}}{\left(\begin{array}{l}n\\ {l}_{1},{l}_{2},{l}_{3}\end{array}\right)}_{p}\left(\begin{array}{l}2n\\ 2{l}_{1}+2{l}_{2}\end{array}\right)\left(\begin{array}{l}2n\\ 2{l}_{2}+2{l}_{3}\end{array}\right){{{{\mathcal{B}}}}}_{{l}_{1}+{l}_{3}}}{{\left(\begin{array}{l}2n\\ 2{l}_{1},2{l}_{2},2{l}_{3}\end{array}\right)}_{p}\left(\begin{array}{l}n\\ {l}_{1}+{l}_{2}\end{array}\right)\left(\begin{array}{l}n\\ {l}_{2}+{l}_{3}\end{array}\right){{{{\mathcal{B}}}}}_{{l}_{1}+{l}_{2}}{{{{\mathcal{B}}}}}_{{l}_{2}+{l}_{3}}}\), and \({H}_{0}=\mathop{\max }\limits_{i}({H}_{i}-{{{\rm{Tr}}}}\left({H}_{i}\right)\frac{{\mathbb{I}}}{{2}^{n}})\), and the number of calibration samplings
where \({{{{\mathcal{B}}}}}_{\max }=\mathop{\max }\limits_{k}\left\vert {{{{\mathcal{B}}}}}_{k}\right\vert\) and \({{{{\mathcal{B}}}}}_{\min }=\mathop{\min }\limits_{k}\left\vert {{{{\mathcal{B}}}}}_{k}\right\vert\). Then, the outputs \({\left\{{v}_{i}\right\}}_{i = 1}^{m}\) of the algorithm approximate \({\left\{{{{\rm{Tr}}}}\left(\rho {H}_{i}\right)\right\}}_{i = 1}^{m}\) with error εe + εc and success probability 1 − δe − δc, under the assumption that \({\left\Vert {H}_{i}\right\Vert }_{\infty }={{{\mathcal{O}}}}\left(1\right)\), where \({\left\Vert {H}_{i}\right\Vert }_{\infty }\) is the spectral norm of Hi.
We observe that the sampling for estimation we obtained is consistent with Wan et al.28 in the absence of noise. In the following, we will provide an analysis of the necessary number of measurements to compute \({\left\langle \right.}^{{{{\boldsymbol{k}}}}}\left.{{{\bf{D}}}}\right\rangle\) using Algorithm 1. To calculate the representation of each element \({{\left\langle \right.}^{{{{\boldsymbol{k}}}}}\left.{{{\bf{D}}}}\right\rangle }_{{j}_{1},\ldots ,{j}_{k};{l}_{1},\ldots ,{l}_{k}}\), where ji, li are in the range [n] for i ∈ [k], we need to calculate \(m={{{\mathcal{O}}}}\left({n}^{k}\right)\) expectations for different \({\widetilde{\gamma }}_{S}\), where \(\left\vert S\right\vert =2k\). By choosing the observable \({H}_{j}={\widetilde{\gamma }}_{S}\) where \(\left\vert S\right\vert =2k\) and \(m={{{\mathcal{O}}}}\left({n}^{k}\right)\) in Theorem 1, with the number of estimation samplings
and the number of calibration samplings
the estimation error can be bounded to εe + εc. The equations for Re and Rc can be simplified to \({R}_{e}={{{\mathcal{O}}}}(\frac{k{n}^{k}\ln (n/{\delta }_{e})}{{\varepsilon }_{e}^{2}})\) and \({R}_{c}={{{\mathcal{O}}}}(\frac{\sqrt{n}\ln n\ln (1/{\delta }_{c})}{{\varepsilon }_{c}^{2}})\) for the general noises with constant average fidelity \({{{{\mathcal{B}}}}}_{k}\) in subspace Γ2k for any \(k\in \left\{0,\ldots ,n\right\}\). We give more details for the calculations in Supplementary Note 8. However, some types of noise channels, such as certain Gaussian unitary channels present in the related 2n × 2n matrix Q, cannot be mitigated with our mitigation algorithm. In particular, there exists a signed permutation matrix Q for which f2k = 0, resulting in complete loss of projection for the observable onto the subspace Γ2k. As a result, it is impossible to calculate \({{{\rm{Tr}}}}\left(\rho {\widetilde{\gamma }}_{S}\right)\) for any set S containing 2k elements. We anticipate that the noise in the quantum device will differ significantly from the UQ which belongs to the intersection of the matchgate and Clifford groups.
Numerical results
Here we give the numerical results for the mitigated shadow estimation in the fermionic systems. Since the elements of a k-RDM can be expressed in the form \({{{\rm{Tr}}}}\left(\rho {\gamma }_{S}\right)\), we give the numerical results of the errors of the estimators for the expectation value of local fermionic observables \({{{\rm{Tr}}}}\left(\rho {\widetilde{\gamma }}_{S}\right)\).
The estimator \(\hat{v}\) for \({{{\rm{Tr}}}}\left(\rho {\widetilde{\gamma }}_{S}\right)\) can be represented as in Eq. (17). Here we choose the number of qubits n = 4 and \(S=\left\{1,2\right\}\), and \({\widetilde{\gamma }}_{S}={U}_{Q}^{{\dagger} }{\gamma }_{S}{U}_{Q}\) and Q is uniformly randomly chosen from Perm(2n). The quantum state ρ is a uniformly randomly generated 4-qubit pure state. As shown in Fig. 1, we depict the estimations of classical shadow estimators28 and our mitigated Algorithm 1, with the changes of noise strength (Fig. 1a–d) and the changes of the number of samples (Fig. 1e–h). Here we numerically test the estimations with respect to depolarizing, amplitude damping, X-rotation, and Gaussian unitaries.

The estimations with the changes of (a–d) the noise strength and (e–h) the number of samples for fixed noise parameters, where (a, e) are associated with depolarizing noise, (b, f) are associated with generalized amplitude damping noise, (c, g) are associated with X-rotation noise, (d, h) are associated with Gaussian unitary noise. The error bar is the estimation of the standard deviation by repeating the procedure for R = 10 rounds, and it is estimated to be \(\sqrt{\mathop{\sum }\nolimits_{i = 1}^{R}{({\hat{v}}_{i}-\bar{v})}^{2}/R}\), where \(\bar{v}\) is the expectation of the corresponding estimations. Specially, \(\bar{v}=\frac{{f}_{| S| }}{g}{{{\rm{Tr}}}}\left(\rho {\gamma }_{S}\right)\), \(g={\hat{f}}_{\left\vert S\right\vert }\) for Mitigated estimation, and \(g=\frac{{{n}\choose{k/2}}}{{{2n}\choose{k}}}\) for CS estimation. In (a–d), the x-axis represents the labels for different noise parameters. The dotted horizontal line indicates the value \({{{\rm{Tr}}}}\left(\rho {\widetilde{\gamma }}_{S}\right)\).
The calibration samples in Algorithm 1 for the numerics are Nc = 4, 000 and Kc = 20 for all noise models. The number of samples for the classical shadow method is set as Ne = 4, 000, Ke = 10, and for Algorithm 1 are set as Ne = 4, 000/(1 − pnoise) and Ke = 10, where pnoise is the noise strength varying for different noise settings:
-
(1)
Depolarizing noise \({{{\Lambda }}}_{{{{\rm{d}}}}}(\rho )=(1-p)\rho +p\frac{{\mathbb{I}}}{{2}^{n}}\), where ρ is any quantum state and p is the depolarizing noise strength. In Fig. 1a, p varies from 0.05 to 0.3 (p = 0.05j for x-axis equals j where j ∈ [6]), and in Fig. 1 (b), p = 0.2.
-
(2)
Generalized amplitude damping noise Λa with representation
$${{{\Lambda }}}_{{{{\rm{a}}}}}(\rho )=\mathop{\sum}\limits_{\displaystyle{u,v\in {\left\{0,1\right\}}^{n}\atop u\ne v}}{E}_{uv}\rho {E}_{uv}^{{\dagger} }+{E}_{0}\rho {E}_{0}^{{\dagger} },$$(12)where \({E}_{uv}=\sqrt{{p}_{uv}}\left\vert v\right\rangle \,\left\langle u\right\vert\) for u ≠ v ∈ {0, 1}n and \({E}_{0}=\sqrt{{\mathbb{I}}-{\sum }_{\begin{array}{c}u,v\in {\left\{0,1\right\}}^{n}\\ u\ne v\end{array}}{E}_{uv}^{{\dagger} }{E}_{uv}}\). Note that Eq. (12) is a generalization of Eq. (6), which connects to Eq. (6) by setting \({p}_{uv}={\bar{p}}_{u}\) for any u, v ∈ [n]. Here we uniformly randomly choose puv in \(\frac{[0,1]+j-1}{6\times {2}^{n+1}}\), and labeled it as j in the x-axis of Fig. 1 where j ∈ [6], and choose the generated damping errors for j = 5 case in Fig. 1 (b) as the damping errors for Fig. 1f.
-
(3)
X-rotation noise Λr defined in Eq. (7) with noise parameters \({\theta }_{j}=\frac{\pi }{2\left(8-j\right)}\) for j ∈ [6], and the noise strength is chosen as \(1-\cos \theta\) in Fig. 1c, and Fig. 1g depicts the errors in the X-rotation noise with noise parameter θ6. The x-axis of the mitigation results of X-rotation noise in Fig. 1c denotes the label for noise parameters \(\cos {\theta }_{j}\) for j range from 1 to 6.
-
(4)
The Gaussian unitary noise channel \({{{{\mathcal{U}}}}}_{Q}\) is chosen such that Q is sampled from the signed permutation group, ensuring that the coefficient f1 for the noise channel is non-zero. The associated numerical results are shown in Fig. 1d, h. The number of estimation samplings Ne = 8000, Ke = 10 for Fig. 1d. Fig. 1h choose the same noise parameter with the fifth noise parameter in Fig. 10d. From the figure, we see that without mitigation, the error is enormous with the CS algorithm.
In Fig. 1e–h the number of samples ranges from \(\left\lfloor 900+100\exp (j)\right\rfloor\) for \(j\in \left\{0,\ldots ,5\right\}\). From Fig. 1, we see that with the increase of the noise strength, the classical shadow method with depolarizing, amplitude damping, and X-rotation noise all gradually diverge to the expected value \({{{\rm{Tr}}}}\left(\rho {\widetilde{\gamma }}_{S}\right)\), while our error-mitigated estimation protocol in Alg. 1 gives an expected value that is close to the noiseless value. Based on the numerical results depicted in Fig. 1e–h, it is evident that as the number of samples increases, the estimation outcomes generated by Algorithm 1 approaches the expected value \({{{\rm{Tr}}}}\left(\rho {\widetilde{\gamma }}_{S}\right)\), while the convergent value for the classical shadow method is far from the expected value with depolarizing, amplitude damping, and X-rotation noises. Conversely, the error bar associated with CS estimations is observed to be smaller compared to mitigated estimations, using the same number of samplings, as illustrated in Fig. 1e–h. This is due to the variance of the mitigated estimations associated with the average noise fidelities in Γ2k subspace \({{{{\mathcal{B}}}}}_{k}\).
Discussion
We present an error-mitigated classical shadow algorithm for noisy fermionic systems, thereby extending matchgate classical shadows for noiseless systems26,28. With our method, the calibration process requires a number of copies of the classical state \(\left\vert {{{\boldsymbol{0}}}}\right\rangle \,\left\langle {{{\boldsymbol{0}}}}\right\vert\) that scales logarithmically with the number of qubits. Assuming a constant average noise fidelity for the noise channel, our algorithm requires the same order of estimation copies as the matchgate classical shadow without error mitigation28. Our algorithm is applicable for efficiently calculating all the elements of a given k-RDM.
To provide a clearer demonstration of the average fidelity of common noises, we consider depolarizing, amplitude damping, and X-rotation noises. The average fidelity of depolarizing and amplitude damping noises are given by (1 − p) and \((1-{\sum }_{u}{\bar{p}}_{u})\) respectively, where \(p,{\bar{p}}_{u}\) are the noise parameters. For X-rotation noise, the average fidelity lies between \([\mathop{\min}\nolimits_{\theta }{\cos }^{k}\theta ,\mathop{\max }\nolimits_{\theta }{\cos }^{k}\theta ]\) where θ is the rotated angles. To evaluate the effectiveness of our algorithm in mitigating these noises, we compare its performance with the matchgate CS algorithm to calculate the expectations of \({\widetilde{\gamma }}_{S}\), where \(\left\vert S\right\vert =2k\), which is crucial for calculating k-RDMs. Our numerical results show good agreement with the theory, validating the effectiveness of our algorithm.
While our algorithm demonstrates good performance in the presence of common types of noise in near-term quantum devices, further investigations are required to explore its potential limitations and improvements. Some of the open questions that can be addressed in future research include:
-
(1)
Is it possible to extend our algorithm to handle other types of noise, such as time-dependent, non-Markovian and environmental noise44, or more generally, noise that does not satisfy the GTM assumption? If so, how would these different types of noise impact the performance of our algorithm?
-
(2)
We provide numerical results under the assumption of Gaussian unitary noise, a common noise model in the fermionic platform. An intriguing unanswered question pertains to the performance of our algorithm in the presence of more typical noise channels inherent to fermionic platform.
-
(3)
The number of gates required by the matchgate circuit is \({{{\mathcal{O}}}}({n}^{2})\)45. As a result, the accumulation of noise significantly increases the error mitigation threshold46,47, which raises the intriguing question of whether it is feasible to provide an error-mitigated classical shadow using a shallower circuit. This may be compared with Bertoni et al.48, who propose a shallower classical shadow approach for qubit systems.
-
(4)
In addition, we have included in the Supplementary materials the analysis and numerical results regarding the overlap between a Gaussian state and any quantum states, as well as the inner product between a Slater determinant and any pure state. This prompts the question of whether our algorithm can be utilized to calculate other physical, chemical, or material properties beyond the scope of this paper.
Exploring these questions would enhance our comprehension of the potential and limitations of our algorithm, and could potentially pave the way for advancements in the estimation of fermionic Hamiltonian expectation values with near-term quantum devices.
Note added
Following the completion of our manuscript, we became aware of recent independent work by Zhao and Miyake49, who also study ways to counteract noise in the fermionic shadows protocol.
Methods
Noisy fermionic channel representation
Here we present an unbiased estimation approach for the noisy representation of the fermionic shadow channel, which utilizes a protocol similar to the matchgate benchmarking protocol50. According to representation theory51 (see details in Supplementary Note 1), the noisy fermionic shadow channel can be represented as \(\widetilde{{{{\mathcal{M}}}}}=\mathop{\sum }\nolimits_{k = 0}^{n}{f}_{2k}{{{{\mathcal{P}}}}}_{2k}\). Since \({{{\rm{Tr}}}}(H\widetilde{{{{\mathcal{M}}}}}(\rho ))={{{\rm{Tr}}}}(\rho \widetilde{{{{\mathcal{M}}}}}(H))\), with the pre-knowledge of f2k we can calculate \({{{\rm{Tr}}}}(H\widetilde{{{{\mathcal{M}}}}}(\rho ))\) for any observable H in the even subspace. To learn the 2(n + 1) coefficients, we begin with the easily prepared state \({\rho }_{0}=\left\vert {{{\boldsymbol{0}}}}\right\rangle \,\left\langle {{{\boldsymbol{0}}}}\right\vert\) and apply a noisy unitary channel \(\widehat{{{{\mathcal{U}}}}}\) with \({{{\mathcal{U}}}}\) sampled from the matchgate group. We then perform a Z-basis measurement \({{{\mathcal{X}}}}\) with measurement outcomes \(x\in {\left\{0,1\right\}}^{n}\), followed by classically operating the unitary channel \({{{{\mathcal{U}}}}}^{{\dagger} }\) on \(\left\vert x\right\rangle \,\left\langle x\right\vert\). The generated state has expected value \(\mathop{\sum }\nolimits_{k = 0}^{n}{f}_{2k}{{{{\mathcal{P}}}}}_{2k}({\rho }_{0})\), and f2k is obtained by projecting the final state to the \({{{{\mathcal{P}}}}}_{2k}\) subspace with some classical post-processing. We illustrate the learning process of the noisy channel in Fig. 2a. The following theorem provides an unbiased estimation of the noisy fermionic classical shadow.

a Protocol to learn the noisy classical shadow channel, where \(\widetilde{{{{\mathcal{M}}}}}={{{{\mathcal{U}}}}}_{Q}^{{\dagger} }\circ {{{\mathcal{X}}}}\circ {{\Lambda }}\circ {{{{\mathcal{U}}}}}_{Q}(\cdot )=\mathop{\sum }\nolimits_{k = 0}^{n}{f}_{2k}{{{{\mathcal{P}}}}}_{2k}(\cdot )\), where \({{{{\mathcal{U}}}}}_{Q}\) is uniformly randomly sampled from the matchgate group. The estimation \({\hat{f}}_{2k}\) for f2k is obtained by projecting \(\widetilde{{{{\mathcal{M}}}}}\) to \({{{{\mathcal{P}}}}}_{2k}\) subspace with input state \({\rho }_{0}=\left\vert {{{\boldsymbol{0}}}}\right\rangle \,\left\langle {{{\boldsymbol{0}}}}\right\vert\). b The shadow estimation \(\hat{\rho }\) for input state ρ with the noisy quantum circuit and classical post-processing with the approximated noisy classical shadow channel in (a), where \({{{{\mathcal{U}}}}}_{{Q}^{{\prime} }}\) is uniformly randomly sampled from the matchgate group.
Theorem 2
The noisy fermionic shadow channel can be represented as \(\widetilde{{{{\mathcal{M}}}}}={\sum }_{k}{f}_{2k}{{{{\mathcal{P}}}}}_{2k}\), where \({{{{\mathcal{P}}}}}_{2k}\) is defined in Eq. (1), and \({\hat{f}}_{2k}={2}^{n}\langle \!\langle {{{\bf{0}}}}| {{{{\mathcal{P}}}}}_{2k}{{{{\mathcal{U}}}}}_{Q}^{{\dagger} }| x\rangle \!\rangle /\left(\begin{array}{l}n\\ k\end{array}\right)\) is an unbiased estimator of \({f}_{2k}\in {\mathbb{R}}\), where \(\left.\left\vert x\right\rangle \!\right\rangle\) is the measurement outcome from the noisy shadow protocol obtained by starting from the input state \(\left.\left\vert {{{\boldsymbol{0}}}}\right\rangle \!\right\rangle\) and applying a noisy quantum circuit \({\widetilde{{{{\mathcal{U}}}}}}_{Q}\) followed by a Z-basis measurement, where \({{{{\mathcal{U}}}}}_{Q}\) is uniformly randomly picked from the matchgate group.
The representation of the noisy fermionic channel, denoted by \(\widetilde{{{{\mathcal{M}}}}}={\sum }_{k}{f}_{2k}{{{{\mathcal{P}}}}}_{2k}\), where \({f}_{2k}\in {\mathbb{C}}\), can be obtained by the irreducible representation of the Gaussian unitary. A detailed proof of this theorem is provided in Supplementary Note 4. We claim that the coefficients \({\hat{f}}_{2k}\) can be efficiently calculated with the following lemma.
Lemma 1
\({\hat{f}}_{2k}\) is the coefficient of xk in the polynomial pQ(x), where
where \({C}_{\left\vert x\right\rangle }{ = \bigoplus }_{i = 1}^{n}\left(\begin{array}{rc}0&{(-1)}^{{x}_{j}}\\ {(-1)}^{{x}_{j}+1}&0\end{array}\right)\) is the covariance matrix of \(\left\vert x\right\rangle\).
This lemma can be obtained by Proposition 1 in Ref. 28. For the completeness of this paper, we also give the proof of this lemma in Supplementary Note 4. The coefficients can be calculated with the polynomial interpolation method in polynomial time. With Theorem 2, we can give an unbiased estimation \(\widehat{{{{\mathcal{M}}}}}\) for \(\widetilde{{{{\mathcal{M}}}}}\).
By the definition of \({\hat{f}}_{2k}\), and the twirling properties of \({\int}_{Q}d\mu (Q){{{{\mathcal{U}}}}}_{Q}^{\otimes 2}\), the expectation value for the estimation \({\hat{f}}_{2k}\) can be formulated as
We postpone the details of this proof to Supplementary Note 4. It implies that in the noiseless scenario, \(\widetilde{M}\) degenerates into \({{{\mathcal{M}}}}\) as defined in Equation (4). Combined with the definition of \({{{{\mathcal{B}}}}}_{k}\) in Eq. (5), f2k is close to \({\left(\begin{array}{l}2n\\ 2k\end{array}\right)}^{-1}\left(\begin{array}{l}n\\ k\end{array}\right)\) if the average noise fidelity in Γ2k subspace is close to one. Recall that \({{{{\mathcal{B}}}}}_{k}\) is a constant in the depolarizing, amplitude-damping, and X-rotation noises with a constant noise strength, which implies that these noises can be efficiently mitigated with our algorithm.
Alternatively, we have a counterexample in Supplementary Note 3 that illustrates the limitations of our mitigation algorithm. Specifically, if the noise follows a Gaussian unitary channel \({{{{\mathcal{U}}}}}_{Q}\) where Q is a signed permutation matrix (associated with a discrete Gaussian unitary), then \({{{{\mathcal{B}}}}}_{k}\) may become zero. Hence, f2k = 0, rendering our estimation approach unsuitable.
Recall that our goal is to estimate \({\left\{{{{\rm{Tr}}}}\left(\rho {H}_{i}\right)\right\}}_{i = 1}^{m}\) using a noisy quantum device and polynomial classical cost, where ρ is an n-qubit quantum state and Hi is an observable in the even subspace Γeven. Here we visualize the estimation process with the guarantee in Theorem 2. We uniformly randomly sample a matchgate UQ from the matchgate group and apply it to the quantum state ρ, and then measure in the Z-basis to get outcomes x. We define the estimator
It is easy to show that \({{{\rm{tr}}}}(H{\widehat{{{{\mathcal{M}}}}}}^{-1}\widetilde{{{{\mathcal{M}}}}}(\rho ))\) is an unbiased estimation of \({{{\rm{tr}}}}(\rho H)\) when \(\widetilde{{{{\mathcal{M}}}}}\) is invertible, specifically when f2k ≠ 0 for any k, and H belongs to the even subspace Γeven. Given that \({\mathbb{E}}[\widehat{{{{\mathcal{M}}}}}]=\widetilde{{{{\mathcal{M}}}}}\) and \(\hat{v}\) serves as an unbiased estimator of \({{{\rm{tr}}}}(H{\widehat{{{{\mathcal{M}}}}}}^{-1}\widetilde{{{{\mathcal{M}}}}}(\rho ))\), it implies that the estimation error \(\varepsilon := | \hat{v}-{{{\rm{tr}}}}(\rho H)|\) is bounded by \(| \hat{v}-{{{\rm{tr}}}}(H{\widehat{{{{\mathcal{M}}}}}}^{-1}\widetilde{{{{\mathcal{M}}}}}(\rho ))| +| {{{\rm{tr}}}}(H{\widehat{{{{\mathcal{M}}}}}}^{-1}\widetilde{{{{\mathcal{M}}}}}(\rho ))-{{{\rm{tr}}}}(\rho H)|\), which can be minimized with the increasing of the number of samplings for the estimations \(\hat{v}\) and \({{{\rm{tr}}}}(H{\widehat{{{{\mathcal{M}}}}}}^{-1}\widetilde{{{{\mathcal{M}}}}}(\rho ))\), as shown in Eq. (9). Note that the estimator defined in Eq. (16) is not always efficient for all states ρ and observables H. Here we claim that with this estimator, we can efficiently calculate substantial physical quantities such as the expectation value of k-RDM, which not only serves the variational quantum algorithm (VQE) of a fermionic system with up to k particle interactions52,53, but also provide supports to the calculations of derivatives of the energy54,55 and multipole moments56. It is also an indispensable resource for the error mitigation technique8,57. It also serves to calculate the overlap between a Gaussian state and any quantum state, and the inner product between a Slater determinant and any pure state inspired by the fermionic shadow analysis of Wan et al.28. We postpone the details to Supplementary Note 5.
Note that all elements of k-RDMs can be derived through \({{{\rm{Tr}}}}\left(\rho {\gamma }_{S}\right)\) for a total of \({{{\mathcal{O}}}}\left({n}^{k}\right)\) sets S with ∣S∣ = 2k. In an expansion of this concept, we now focus on evaluating \({{{\rm{Tr}}}}\left(\rho {\widetilde{\gamma }}_{S}\right)\) for \({{{\mathcal{O}}}}\left({n}^{k}\right)\) different S with ∣S∣ = 2k. To calculate the expectation value \({{{\rm{Tr}}}}\left(\rho {\widetilde{\gamma }}_{S}\right)\), we set the input quantum state to be ρ and the observable to be \(H={\widetilde{\gamma }}_{S}\) in the estimation formula of Eq. (16), which can then be simplified to
where \({\widetilde{\gamma }}_{j}={\sum }_{l\in [2n]}{Q}_{1}(j,l){\gamma }_{l}\), Q1(j, l) is the (j, l)-th element of Q1, and \({C}_{\left\vert x\right\rangle }{ = \bigoplus }_{i = 1}^{n}(\begin{array}{rc}0&{(-1)}^{{x}_{j}}\\ {(-1)}^{{x}_{j}+1}&0\end{array})\) is the covariance matrix of \(\left\vert x\right\rangle \,\left\langle x\right\vert\). Here, A∣S refers to the submatrix obtained by taking the columns and rows of the matrix A that are indexed by S. The simplified quantity can be calculated in polynomial time since \({\hat{f}}_{c}\) and the Pfaffian function can be calculated efficiently. We give a detailed proof of the simplification process in Supplementary Note 5.
Data availability
The datasets produced during the current study are available at https://github.com/GillianOoO/Error-mitigated-fermionic-classical-shadow.git.
References
Cramer, C. J. Essentials of computational chemistry: Theories and models (John Wiley and Sons, Chichester, 2002).
Sachdev, S. Quantum Phase Transitions (Cambridge University Press, Cambridge, 2011).
Kaxiras, E. & Joannopoulos, J. D. Quantum Theory of Materials (Cambridge University Press, 2019).
Schwerdtfeger, C. A., DePrince III, A. E. & Mazziotti, D. A. Testing the parametric two-electron reduced-density-matrix method with improved functionals: Application to the conversion of hydrogen peroxide to oxywater. J.Chem. Phys. 134, 174102 (2011).
Peterson, M. R. & Nayak, C. More realistic Hamiltonians for the fractional quantum hall regime in GaAs and graphene. Phys. Rev. B 87, 245129 (2013).
Cerezo, M. et al. Variational quantum algorithms. Nat. Rev. Phys. 3, 625–644 (2021).
Parrish, R. M., Hohenstein, E. G., McMahon, P. L. & Martínez, T. J. Quantum computation of electronic transitions using a variational quantum eigensolver. Phys. Rev. Lett. 122, 230401 (2019).
Takeshita, T. et al. Increasing the representation accuracy of quantum simulations of chemistry without extra quantum resources. Phys. Rev. X 10, 011004 (2020).
Huang, H.-Y., Kueng, R. & Preskill, J. Predicting many properties of a quantum system from very few measurements. Nat. Phys. 16, 1050–1057 (2020).
Hadfield, C., Bravyi, S., Raymond, R. & Mezzacapo, A. Measurements of quantum Hamiltonians with locally-biased classical shadows. Commun. Math. Phys. 391, 951–967 (2022).
Huang, H.-Y., Kueng, R. & Preskill, J. Efficient estimation of Pauli observables by derandomization. Phys. Rev. Lett. 127, 030503 (2021).
Wu, B., Sun, J., Huang, Q. & Yuan, X. Overlapped grouping measurement: A unified framework for measuring quantum states. Quantum 7, 896 (2023).
Hadfield, C. Adaptive Pauli shadows for energy estimation arXiv preprint arXiv:2105.12207 (2021).
Hu, H.-Y., Choi, S. & You, Y.-Z. Classical shadow tomography with locally scrambled quantum dynamics. Phys. Rev. Res. 5, 023027 (2023).
Acharya, A., Saha, S. & Sengupta, A. M. Shadow tomography based on informationally complete positive operator-valued measure. Phys. Rev. A 104, 052418 (2021).
Bu, K., Koh, D. E., Garcia, R. J. & Jaffe, A. Classical shadows with Pauli-invariant unitary ensembles. npj Quantum Inf. 10, 6 (2024).
Grier, D., Pashayan, H. & Schaeffer, L. Sample-optimal classical shadows for pure states. arXiv preprint arXiv:2211.11810 (2022).
Ippoliti, M. Classical shadows based on locally-entangled measurements. Quantum 8, 1293 (2024).
Zhou, Y. & Liu, Q. Performance analysis of multi-shot shadow estimation. Quantum 7, 1044 (2023).
Garcia, R. J., Zhou, Y. & Jaffe, A. Quantum scrambling with classical shadows. Phys. Rev. Res. 3, 033155 (2021).
Zhou, Y. & Liu, Z. A hybrid framework for estimating nonlinear functions of quantum states. arXiv preprint arXiv:2208.08416 (2023).
Jordan, P. & Wigner, E. P.Über das paulische äquivalenzverbot (Springer, 1993).
Nielsen, M. A. The fermionic canonical commutation relations and the Jordan-Wigner transform. School Phys. Sci. Univ. Queensland 59, 75 (2005).
Bravyi, S. B. & Kitaev, A. Y. Fermionic quantum computation. Ann. Phys. 298, 210–226 (2002).
Tranter, A. et al. The Bravyi–Kitaev transformation: Properties and applications. Int. J. Quantum Chem. 115, 1431–1441 (2015).
Zhao, A., Rubin, N. C. & Miyake, A. Fermionic partial tomography via classical shadows. Phys. Rev. Lett. 127, 110504 (2021).
Low, G. H. Classical shadows of fermions with particle number symmetry arXiv preprint arXiv:2208.08964 (2022).
Wan, K., Huggins, W. J., Lee, J. & Babbush, R. Matchgate shadows for fermionic quantum simulation. Commun. Math. Phys. 404, 629–700 (2023).
Chen, S., Yu, W., Zeng, P. & Flammia, S. T. Robust shadow estimation. PRX Quantum 2, 030348 (2021).
Koh, D. E. & Grewal, S. Classical shadows with noise. Quantum 6, 776 (2022).
Jnane, H., Steinberg, J., Cai, Z., Nguyen, H. C. & Koczor, B. Quantum error mitigated classical shadows. PRX Quantum 5, 010324 (2023).
Valiant, L. G. Expressiveness of matchgates. Theoretical Computer Sci. 289, 457–471 (2002).
Knill, E. Fermionic linear optics and matchgates. arXiv preprint quant-ph/0108033 (2001).
Terhal, B. M. & DiVincenzo, D. P. Classical simulation of noninteracting-fermion quantum circuits. Phys. Rev. A 65, 032325 (2002).
Zhu, H., Kueng, R., Grassl, M. & Gross, D. The clifford group fails gracefully to be a unitary 4-design. arXiv preprint arXiv:1609.08172 (2016).
Helsen, J., Xue, X., Vandersypen, L. M. & Wehner, S. A new class of efficient randomized benchmarking protocols. npj Quant. Inf. 5, 1–9 (2019).
DiVincenzo, D. P. & Terhal, B. M. Fermionic linear optics revisited. Foundations Phys. 35, 1967–1984 (2005).
Bonet-Monroig, X., Babbush, R. & O’Brien, T. E. Nearly optimal measurement scheduling for partial tomography of quantum states. Phys. Rev. X 10, 031064 (2020).
Wimmer, M. Algorithm 923: Efficient numerical computation of the pfaffian for dense and banded skew-symmetric matrices. ACM Trans. Math Softw. (TOMS) 38, 1–17 (2012).
Flammia, S. T. & Wallman, J. J. Efficient Estimation of Pauli Channels. ACM Transac. Quantum Comput. 1, 1–32 (2020).
Campbell, E. T. Decoherence in Open Majorana Systems. In Beigi, S. & Koenig, R. (eds.) 10th Conference on the Theory of Quantum Computation, Communication and Cryptography (TQC 2015), vol. 44 of Leibniz International Proceedings in Informatics (LIPIcs), 111–126 (Schloss Dagstuhl–Leibniz-Zentrum fuer Informatik, Dagstuhl, Germany, 2015).
Onuma-Kalu, M., Grimmer, D., Mann, R. B. & Martín-Martínez, E. A classification of markovian fermionic gaussian master equations. J. Phys. A: Math. Theoretical 52, 435302 (2019).
Magesan, E., Gambetta, J. M. & Emerson, J. Scalable and robust randomized benchmarking of quantum processes. Phys. Rev. Lett. 106, 180504 (2011).
Van Etten, W. C.Introduction to random signals and noise (John Wiley & Sons, New York, NY, USA, 2006).
Jiang, Z., Sung, K. J., Kechedzhi, K., Smelyanskiy, V. N. & Boixo, S. Quantum algorithms to simulate many-body physics of correlated fermions. Phys. Rev. Appl. 9, 044036 (2018).
Deshpande, A. et al. Tight bounds on the convergence of noisy random circuits to the uniform distribution. PRX Quant. 3, 040329 (2022).
Quek, Y., França, D. S., Khatri, S., Meyer, J. J. & Eisert, J. Exponentially tighter bounds on limitations of quantum error mitigation. arXiv preprint arXiv:2210.11505 (2022).
Bertoni, C. et al. Shallow shadows: Expectation estimation using low-depth random clifford circuits. arXiv preprint arXiv:2209.12924 (2022).
Zhao, A. & Miyake, A. Group-theoretic error mitigation enabled by classical shadows and symmetries. arXiv preprint arXiv:2310.03071 (2023).
Helsen, J., Nezami, S., Reagor, M. & Walter, M. Matchgate benchmarking: Scalable benchmarking of a continuous family of many-qubit gates. Quantum 6, 657 (2022).
Fulton, W. & Harris, J. Representation theory: a first course, vol. 129 (Springer Science & Business Media, New York, NY, USA, 2013).
Malone, F. D. et al. Towards the simulation of large scale protein–ligand interactions on nisq-era quantum computers. Chem. Sci. 13, 3094–3108 (2022).
Liu, J., Li, Z. & Yang, J. An efficient adaptive variational quantum solver of the schrödinger equation based on reduced density matrices. J. Chem. Phys. 154, 244112 (2021).
Overy, C. et al. Unbiased reduced density matrices and electronic properties from full configuration interaction quantum monte carlo. J. Chem. Phys. 141, 244117 (2014).
O’Brien, T. E. et al. Calculating energy derivatives for quantum chemistry on a quantum computer. npj Quantum Inf. 5, 113 (2019).
Rubin, N. C., Babbush, R. & McClean, J. Application of fermionic marginal constraints to hybrid quantum algorithms. New J. Phys. 20, 053020 (2018).
McClean, J. R., Kimchi-Schwartz, M. E., Carter, J. & de Jong, W. A. Hybrid quantum-classical hierarchy for mitigation of decoherence and determination of excited states. Phys. Rev. A 95, 042308 (2017).
Acknowledgements
We express our appreciation for the valuable input and feedback given by Jens Eisert, Janek Denzler, and Ellen Derbyshire. We are also thankful for the enlightening conversations held with Xiao Yuan and Yukun Zhang. Furthermore, we extend our gratitude to Janek Denzler and Ellen Derbyshire for their assistance with certain numerical aspects. We also thank Guang Hao Low for their comments on an earlier version of this manuscript. BW acknowledges funding support from the Bundesministerium für Bildung und Forschung (FermiQP, DAQC), Bundesministerium für Wirtschaft und Klimaschutz (EniQmA), and the Munich Quantum Valley (K-8). DEK acknowledges funding support from the Agency for Science, Technology and Research (A*STAR) Central Research Fund (CRF) Award, A*STAR C230917003, and the National Research Foundation, Singapore and A*STAR under its Quantum Engineering Programme (NRF2021-QEP2-02-P03).
Author information
Authors and Affiliations
Contributions
Bujiao Wu and Dax Enshan Koh conducted, discussed, and wrote the paper together. Bujiao Wu performed the numerical simulation.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Wu, B., Koh, D.E. Error-mitigated fermionic classical shadows on noisy quantum devices. npj Quantum Inf 10, 39 (2024). https://doi.org/10.1038/s41534-024-00836-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41534-024-00836-7
