
Abstract
Contemporary methods for benchmarking noisy quantum processors typically measure average error rates or process infidelities. However, thresholds for fault-tolerant quantum error correction are given in terms of worst-case error rates—defined via the diamond norm—which can differ from average error rates by orders of magnitude. One method for resolving this discrepancy is to randomize the physical implementation of quantum gates, using techniques like randomized compiling (RC). In this work, we use gate set tomography to perform precision characterization of a set of two-qubit logic gates to study RC on a superconducting quantum processor. We find that, under RC, gate errors are accurately described by a stochastic Pauli noise model without coherent errors, and that spatially correlated coherent errors and non-Markovian errors are strongly suppressed. We further show that the average and worst-case error rates are equal for randomly compiled gates, and measure a maximum worst-case error of 0.0197(3) for our gate set. Our results show that randomized benchmarks are a viable route to both verifying that a quantum processor’s error rates are below a fault-tolerance threshold, and to bounding the failure rates of near-term algorithms, if—and only if—gates are implemented via randomization methods which tailor noise.
Similar content being viewed by others

Introduction
Quantum bits (qubits) in the noisy intermediate-scale quantum (NISQ)1 era are short-lived and susceptible to a variety of errors and noise due to imperfect control signals and imperfect isolation from the surrounding environment. Therefore, utilizing quantum computers to solve classically intractable problems (e.g., integer factoring2) will likely require quantum error correction (QEC)3,4,5,6,7. QEC can protect logical qubits from errors, but it is only guaranteed to work if the error rate of each physical qubit is below some fault tolerance (FT) threshold8,9,10,11,12,13. Analytic lower bounds on FT thresholds for various QEC codes have been derived, ranging from ~ 10−6 for generic local noise13 to ~ 10−5–10−3 for stochastic and depolarizing noise14,15,16,17,18. More optimistic estimates obtained via numerical simulation are orders of magnitude larger than the lower bounds, ranging from ~10−3–10−119,20,21,22,23,24,25,26,27, but often assume stochastic (e.g., Pauli, dephasing, or depolarizing) noise models. While recent claims of quantum gates approaching or surpassing FT thresholds boast impressive gate fidelities28,29,30, there is a discrepancy between these claims and the formulation of FT thresholds, which are specified in terms of worst-case error rates.
Various error metrics and measures exist for quantifying the “error rate” of a quantum gate. Randomized benchmarks31,32,33,34,35 typically define error rates in terms of the average gate fidelity, or, equivalently, the process fidelity
where \(\rho =\left\vert \psi \right\rangle \left\langle \psi \right\vert\) is a maximally entangled state, \({{{\mathcal{E}}}}\) is the error channel associated with some quantum gate, and \({\mathbb{I}}\) the identity operation. A gate’s process infidelity \({e}_{F}({{{\mathcal{E}}}})=1-F\) (or average error rate) quantifies the probability that the gate induces an error on a random input state, or, equivalently, the average failure rate of random circuits that contain one instance of this gate but that are otherwise perfect. However, FT thresholds are typically defined via each gate’s worst-case error rate (also called the diamond norm)36,
where the supremum is taken over all pure states and \({\left\Vert X\right\Vert }_{1}={{{\rm{Tr}}}}\sqrt{{X}^{{\dagger} }X}\) is the trace norm. Operationally, \({\epsilon }_{\diamond}{({{{\mathcal{E}}}})}\) represents the worst-case performance of a quantum gate in any circuit, whereas \({e}_{F}({{{\mathcal{E}}}})\) represents the average-case performance for a single instance of the gate. While the diamond norm is a pessimistic estimate of the error rate of a quantum gate, it provides much more rigorous performance guarantees in the context of QEC. This is because the diamond norm upper bounds the accumulation of error in any quantum circuit, since the distance between the ideal and actual output probability distributions (measured via total variation distance) for any circuit is bounded above by the sum of the worst-case error rates of all its gates36.
While \({e}_{F}({{{\mathcal{E}}}})\) can be measured directly via randomized benchmarks, there exists no known scalable method for measuring \({\epsilon }_{\diamond}{({{{\mathcal{E}}}})}\). Tomographic methods, such as gate set tomography (GST)37,38,39,40,41, can be used to estimate \({\epsilon }_{\diamond}{({{{\mathcal{E}}}})}\)40, but they are exponentially expensive in the number of qubits. If only \({e}_{F}{({{{\mathcal{E}}}})}\) is known, \({\epsilon }_{\diamond}{({{{\mathcal{E}}}})}\) can be bounded using42,43,44,45
where d = 2n (for n qubits). The lower bound of \({\epsilon }_{\diamond}{({{{\mathcal{E}}}})}\) is saturated when \({{{\mathcal{E}}}}\) is a stochastic Pauli channel, and the upper bound, which is quadratically larger in eF and scales with the dimension d, is saturated by a unitary channel. While modern experimental platforms routinely report single- and two-qubit infidelities on the order of eF,1Q ≲ 10−4 and eF,2Q ≲ 10−230,46,47,48,49,50,51, respectively, even if coherent errors account for a tiny fraction of the infidelity, they can dominate the diamond norm, in which case worst-case error rates can be as large as \({\epsilon }_{\diamond,1Q} \sim \sqrt{{e}_{F,1Q}}\,\lesssim\, 1{0}^{-2}\) and \({\epsilon }_{\diamond,2Q} \sim \sqrt{{e}_{F,2Q}}\,\lesssim\, 1{0}^{-1}\)43,44,52. Therefore, \({e}_{F}({{{\mathcal{E}}}})\) and \({\epsilon }_{\diamond}{({{{\mathcal{E}}}})}\) can differ by orders of magnitude in the presence of coherent errors. This means that randomized benchmarks are generally inadequate for testing whether gate error rates are below FT thresholds43,45. Refs. 28,29,30 report single- and two-qubit error rates below the FT threshold for the surface code, but base their claims on average error rates from randomized benchmarking (RB) or GST, not diamond norms. Refs. 53,54 make similar claims about state-preparation and measurement (SPAM) errors, but only report average preparation and assignment fidelities, not their worst-case infidelities. Notably, Ref. 30 includes estimates of the diamond norm that are an order of magnitude larger than their reported process infidelities.
While it is not generally possible to directly compare \({e}_{F}({{{\mathcal{E}}}})\) to a FT threshold for QEC, if it can be guaranteed that \({e}_{F}({{{\mathcal{E}}}})\approx {\epsilon }_{\diamond}{({{{\mathcal{E}}}})}\) then randomized benchmarks can be used to efficiently verify that gate error rates are below a FT threshold. One method for ensuring that an error budget is dominated by stochastic noise is randomized compiling (RC)52,55, which converts all gate errors into stochastic Pauli channels via Pauli twirling. This ensures that the direct measurement of \({e}_{F}({{{\mathcal{E}}}})\) (e.g., via cycle benchmarking56) accurately captures the worst-case error rate, which enables the comparison to FT thresholds as well as bounding the overall failure rate of any quantum circuit or application.
In this work, we use GST to study RC performed on two qubits (labeled Q5 and Q6; see Methods) on a superconducting transmon processor (AQT@LBNL Trailblazer8-v5.c2). GST enables measurements of both the process infidelity and diamond norm for all gates in our gate set, allowing us to study the impact of RC on gate errors. We find that RC eliminates signatures of coherent errors, enabling one to accurately describe the gates’ errors by stochastic Pauli noise. We further show that RC suppresses spatially correlated coherent errors and non-Markovian errors. Finally, we show that the diamond norm converges to the process infidelity under RC, saturating the lower bound of Eq. (3), providing strong experimental evidence that our quantum logic operations are approaching or below a threshold for fault tolerance. By combining RC with GST, our results provide a novel framework for verifying that FT-required assumptions are satisfied, demonstrating that FT thresholds can be accurately measured using randomized benchmarks as long as quantum circuits are implemented using RC or related randomization methods57,58,59,60,61.
Results
Gate set tomography
Gate set tomography is a robust method for tomographically reconstructing the errors and noise impacting all gate operations within a gate set41. Like traditional quantum process tomography (QPT)62, GST fully characterizes the process matrix of a quantum gate; however, unlike QPT, it does so in a self-consistent manner that simultaneously characterizes the errors in all the gates and in the state-preparation and measurement (SPAM). Using the open-source Python library pyGSTi63,64, one can obtain a best-fit model for the gate set, consisting of a process matrix for each gate, using maximum-likelihood estimation40,41. In this work, our gate set consists of all possible combinations of I, Xπ/2, and Yπ/2 single-qubit gates applied simultaneously to both qubits, as well as the controlled-Z (CZ) gate: \({\mathbb{G}}=\{{G}_{1}\otimes {G}_{2}:{G}_{1},{G}_{2}\in \{I,{X}_{\pi /2},{Y}_{\pi /2}\}\}\cup \{CZ\}\). We utilized GST up to depth L = 128 layers to benchmark the performance of all gates in the gate set.
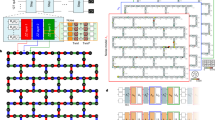
In this work, we represent gate errors using the Pauli transfer matrix (PTM) representation of superoperators (see Fig. 1a and Methods), denoted Λ. We fit our data to the following parameterized error models:
-
1.
General completely positive and trace-preserving (CPTP) model: each gate’s errors are modeled by a general CPTP two-qubit PTM \({\Lambda }_{A,B}^{(1,2)}\), where A (B) denotes the gate acting on qubit 1 (2).
-
2.
General Pauli stochastic (S) model: the errors in the general model are restricted to be diagonal in the Pauli basis \(\left({\Lambda }_{S:A,B}^{(1,2)}\right)\).
-
3.
Context-dependent (CD) model: the errors on each single-qubit gate is described by a single-qubit PTM that can depend on the gate acting on the other qubit \(\left({\Lambda }_{A| B}^{(1)}\otimes {\Lambda }_{B| A}^{(2)}\right)\).
-
4.
Stochastic context-dependent (SCD) model: the errors in the CD model are restricted to be stochastic Pauli errors \(\left({\Lambda }_{S:A| B}^{(1)}\otimes {\Lambda }_{S:B| A}^{(2)}\right)\).
-
5.
Context-free (CF) model: the errors on each single-qubit gate is described by a single-qubit PTM that is unconditional on the gate acting on the other qubit \(\left({\Lambda }_{A}^{(1)}\otimes {\Lambda }_{B}^{(2)}\right)\).
-
6.
Stochastic context-free (SCF) model: the errors in the CF model are restricted to be stochastic Pauli errors \(\left({\Lambda }_{S:A}^{(1)}\otimes {\Lambda }_{S:B}^{(2)}\right)\).

(a) The PTM is divided into four blocks: the top row (red) represents trace-preservation (TP). The lower right-hand block (blue) captures unital processes, such as unitary errors. The leftmost column (cyan) captures non-unital processes, such as T1 decay. And the diagonal of the PTM (orange) represents state preservation (SP); ΛPP = 1 ( < 1) if the Pauli channel P is (not) preserved under an error process such as stochastic Pauli noise. (b) Hierarchy of nested GST models. For single-qubit gates A and B acting on qubits 1 and 2, respectively, the general CPTP model contains all weight-1 and weight-2 error generators. The S model restricts the errors to be stochastic (i.e., the error generator is diagonal in the PTM) [red arrows]. The CD (SCD) model restricts the error generators to be weight-1 (stochastic) errors [blue arrows], but allows contextual dependence. The CF (SCF) model restricts the error generators to be context-independent weight-1 (stochastic) errors [purple arrows].
The hierarchy of all of the nested GST models can be seen in Fig. 1b.
In general, models with greater complexity are able to capture more complex dynamics; however, they also require fitting a larger number of free parameters. The general CPTP model makes no assumption of locality and can completely capture all two-qubit interactions, including quantum crosstalk errors. The CD model assumes that errors on single-qubit gates must be local (weight-1), since the PTMs decompose as a tensor product of operations, but allows the errors to be classically correlated (i.e., the error impacting qubit 1 can be correlated with the gate being applied to qubit 2, but it cannot depend on the state of qubit 2). This can model errors due to classical crosstalk, but not entangling quantum crosstalk. The CF model assumes that the errors on single-qubit gates are local and independent of the gate being applied to the other qubit. The corresponding S-type models make the same assumptions, but restrict the errors to be stochastic Pauli noise. All models make an assumption of Markovianity.
Randomized compiling
Randomized compiling is an efficient method for converting arbitrary Markovian errors into stochastic Pauli noise for each cycle (or layer) in a quantum circuit via Pauli twirling. This can benefit circuit performance in two different regimes (see Methods):
-
1.
Single-randomization limit: a single randomization under RC interrupts the coherent accumulation of unitary errors between cycles of gates, similar to dynamical decoupling sequences65.
-
2.
Many-randomization limit: averaging over many (N) randomizations under RC tailors errors into stochastic Pauli channels, completely eliminating off-diagonal terms in the error process in the limit that N ⟶ ∞.
In this work, we apply RC to GST circuits using N = 1, N = 10, and N = 100 randomizations to study the transition of RC from the single- to many-randomization limit, and compare the results to GST performed without randomization (denoted by N = 0).
To study the types of errors present in a gate’s process matrix G estimated using GST, we write a noisy quantum gate as
where G0 is the ideal quantum gate, Λ the gate error channel, and \({{{\mathcal{L}}}}\) the gate error generator66. \({{{\mathcal{L}}}}\) is analogous to the Linbladian superoperator that generates all gate errors (coherent, stochastic, and non-unital).
Figure 2 shows the error generator \({{{\mathcal{L}}}}\) of the CZ gate for N = 0, 1, 10, 100 randomizations. We find that RC transforms the error generator from dense to sparse as we increase N, twirling \({{{\mathcal{L}}}}\) into a stochastic Pauli channel (these channels correspond to diagonal PTMs). Going from N = 0 (Fig. 2a) to N = 1 (Fig. 2b) randomizations significantly reduces the magnitude of \({{{\mathcal{L}}}}\)’s off-diagonal elements, which signifies the presence of coherent errors, but \({{{\mathcal{L}}}}\) for N = 1 still has significant magnitude in its off-diagonal elements. As N increases from 1 to 10, and from 10 to 100, the magnitude of the off-diagonal terms is greatly reduced. This is referred to as the “noise tailoring” property of RC.

The error generator \({{{\mathcal{L}}}}\) in the PTM representation for the CPTP model of the CZ gate is plotted for (a) N = 0, (b) N = 1, (c) N = 10, and (d) N = 100 randomizations under RC. If an error channel (i.e., PTM cell) in \({{{\mathcal{L}}}}\) is zero, then this component of the estimated gate matches the corresponding component of the ideal target gate. (e) The model violation Nσ for each GST model, plotted as a function of N. The evidence ratio γ is labeled above each nested model, and the number of free parameters Np of each model is listed in the legend. For each N, we choose the model with the least number of parameters that satisfies γ≤1, finding that CPTP is the best fit for N = 0, N = 1, and N = 10, and S for N = 100; blue (red) text indicates that the model is accepted (rejected). The CZ gate error generator \({{{\mathcal{L}}}}\) is plotted for the S model for (f) N = 10 and (g) N = 100, showing that the stochastic models capture the dominant error for both. Even though it is ultimately rejected by the evidence ratio for N = 10, the S model could be reasonably selected for its simplicity. As the S model is selected for N = 100, all off-diagonal elements in (d) are statistically consistent with zero.
Model Selection
GST enables the comparison of nested error models in a self-consistent manner67,68. To compare two nested models, we utilize the evidence ratio γ67,
where λ is the model’s log-likelihood ratio (see Methods), and L (S) denotes the larger (smaller) model defined in terms of the number of free parameters Np describing the model. If γ≤1, then we automatically choose the smaller model, as it describes the data at least as well as the larger model without extra (potentially unused) parameters. If γ > 1, there is evidence for rejecting the smaller model, but even if 1 ≲ γ ≲ 10 the smaller model may still be preferable due to its simplicity51. In this work, we compute the evidence ratio for each pair of nested models down the two separate branches of the hierarchy in Fig. 1b: if γ≤1 we select the smaller model and continue down the hierarchy until γ > 1, at which point we select the larger of the two models and stop. If two independent models satisfy this criteria, we select the model with the fewest free parameters, as this model represents the best fit estimate of our data without over-fitting.
Additionally, we compute the model violation Nσ of each model, which captures the number of standard deviations that λ is from the expected mean (see Methods). If Nσ≤1, then the GST model faithfully captures all of the errors in the device. However, on actual NISQ hardware, typically Nσ > 1 (and sometimes even Nσ ≫ 1) is observed40,60,68, indicating the presence of significant model violation. Because GST can model all Markovian gate errors, large Nσ for the CPTP model indicates that there is strong evidence in the data for non-Markovian errors—which can be true even if these non-Markovian errors are small in magnitude (see the Non-Markovian Errors section for further discussion).
To choose a best-fit model for each dataset, we compute γ and Nσ for each model, shown in Fig. 2e. We find that the general CPTP model fits best for N = 0, N = 1, and N = 10, and that the S model fits as well as the general CPTP model for N = 100. For N = 10, none of the nested models satisfy the evidence ratio criteria, but the S or CD model could also be reasonably selected, as γ = 2.0 and 2.4, respectively (there is therefore only weak evidence for coherent errors). For N = 100, only the S model satisfies the evidence ratio criteria, and we therefore prefer this model over the general CPTP model. For the data presented in the rest of this work, we fix the model for each dataset using the best-fit models outlined above.
The large model violation for N = 0 (Nσ ≈ 535) is strong evidence that there are non-Markovian errors, which cannot be modeled by a PTM. N = 10 (Nσ ≈ 180) and N = 100 (Nσ ≈ 25) have significantly less model violation, indicating less statistical evidence of non-Markovian errors. For a single randomization (N = 1) there is even larger model violation (Nσ ≈ 1394) than with no randomization (N = 0). This effect arises because when N = 1, each circuit is replaced with a single randomization of that circuit, and no averaging occurs. Therefore, the implementation of a logical gate (in \({\mathbb{G}}\)) will not correspond to the average action of multiple PTMs (which decoheres errors) corresponding to the different Pauli-equivalent implementations of the gate, but instead the action of a particular PTM corresponding to one randomly selected Pauli-equivalent implementation of the gate. Importantly, the PTM describing the action of a logic gate will change depending on the randomization selected (and therefore it varies between circuits and uses of the logical gate within a circuit). Therefore, even when each physical gate is describable by a PTM (i.e., all errors are Markovian), when N = 1 each logical gate is not generally describable by a single PTM. This violates the assumptions of GST—which finds the best-fit PTM for each gate—and so a GST model fit to the N = 1 data can exhibit significant model violation. (See Methods for further discussion and examples.)
Impact of randomized compiling on error budgets
To explore how effective RC is at converting all errors into stochastic Pauli noise, we calculate the total amount of stochastic and coherent errors for each gate. To do so, we divide each gate’s error generator \({{{\mathcal{L}}}}\) into stochastic and Hamiltonian components, and compute the total error,
where ϵagg = ∑iϵi is the sum of the rates of all stochastic error generators, and \({\theta }_{\rm{agg}}=\sqrt{{\sum }_{i}{\theta }_{i}^{2}}\) is the quadrature sum of all Hamiltonian error generators51. The total error is closely related to the diamond norm. For single qubit error generators \({{{\mathcal{L}}}}\), the total error upper-bounds the diamond norm error, \({\epsilon }_{\diamond}\left({e}^{{{{\mathcal{L}}}}}\right)\le {\epsilon }_{{{{\rm{tot}}}}}\left({e}^{{{{\mathcal{L}}}}}\right)\). For two or more qubits, the bound is much weaker51.
In Fig. 3 we plot the fraction of the total error due to stochastic and coherent (Hamiltonian) errors. We find that the error budget of the simultaneous single-qubit gates is dominated by coherent errors for N = 0, and that coherent errors account for approximately two-thirds of the total error for the CZ gate. For N = 1, coherent errors still dominate the single-qubit gates, but the contribution from coherent errors and stochastic noise are both approaching 50% for the CZ gate. By N = 10, stochastic noise makes up the largest contribution to the total error for the CZ gate, but we observe only a modest change for the single-qubit gates. However, by N = 100 the error budget for all gates is entirely due to stochastic noise. We note that for the N = 100 data, our model selection chose the S model, which enforces the constraint that the error budget is entirely due to stochastic Pauli noise (see the diagram in Fig. 1b). This is because there is no statistically significant evidence in the data for any coherent errors (if more data were taken, evidence for some residual coherent errors might be found). These data demonstrate the effectiveness of RC in eliminating the impact of coherent errors. However, this does not mean that coherent errors are physically not present; rather, each individual randomization under RC is impacted by coherent errors in a different manner, in such a way that the aggregate effect is to randomize the impact of coherent errors.

(a) Fraction of the total error due to coherent errors (blue) and stochastic noise (orange) as a function of the number of randomizations N under RC. As N increases, stochastic noise makes up a larger fraction of the total error, which is dominated by coherent errors for small N. For (a) and (b), triangular markers denote the CZ gate, and circular markers denote the single-qubit gates {G5 ⊗ G6} (small transparent markers depict the individual gates, large markers depict the averages, and violin plots outline the distribution). (b) Saturation of the lower bound of the diamond norm under RC. We plot the GST process infidelity eF (blue) and diamond norm ϵ♢ (purple) as a function of the number of randomizations N. We observe that ϵ♢ > eF for all gates for N = 0, 1, 10, but that the two are equal for N = 100. For visual clarity, we omit the idle cycle for N = 0, as eF,II = 0.0001 and ϵ◇,II = 0.001 fall well below their respective averages. We compare the GST estimates with the process infidelity measured via cycle benchmarking (CB) for the CZ gate (dashed green line) and idle cycle {I5 ⊗ I6} (solid green line). The GST error bars and CB transparent bands indicate the 95% confidence intervals. Additionally, we compare the benchmarked error rates with the 1% FT threshold for the surface code (black line) and find that the single qubit gates are well below the threshold value, whereas the CZ gate is approaching, but does not surpass the threshold.
Alternative methods for quantifying the magnitude of coherent errors include purity RB (PRB)69 and cross-entropy benchmarking (XEB)70. However, methods for measuring coherent errors that use random circuits have two disadvantages. First, these methods measure averages over gates, so they cannot separate out each gate’s error rate into stochastic and coherent contributions (as done herein). Second, although the unitarity (estimated by PRB) and infidelity (estimated by RB) can be used to upper bound the diamond norm error69, this method is inefficient (see Ref. 40 for details).
Process infidelity vs. diamond norm
Error rates measured via randomized benchmarks cannot in general be directly compared to FT thresholds. However, although the diamond norm [Eq. (2)] enables rigorous comparison to FT thresholds, it is difficult to measure in a scalable manner. If the error model of a quantum processor is dominated by stochastic noise, the process infidelity and diamond norm will be equal, in which case randomized benchmarks can be used to efficiently demonstrate that gate errors are below a FT threshold.
In Fig. 3, we plot the process infidelity and the diamond norm as a function of N for all gates in our gate set. We find that \({\epsilon }_{\diamond}({{{\mathcal{E}}}})\) converges to \({e}_{F}({{{\mathcal{E}}}})\) as N increases. This is strong experimental evidence that \({\epsilon }_{\diamond}({{{\mathcal{E}}}})={e}_{F}({{{\mathcal{E}}}})\) in the many-randomization limit for N = 100 [saturating the lower bound of Eq. (3)]. We also compare these results with process infidelities measured independently via CB and find good agreement between the two. These results demonstrate that randomized benchmarks are sufficient for benchmarking FT thresholds if—and only if—a quantum application is impacted only by stochastic noise, which can be guaranteed if implemented using methods which tailor noise. We note that similar results were previously reported using Pauli frame randomization71,72 for single-qubit gates60.
The largest diamond norm error over a gate set is arguably the most relevant quantity to compare to a FT threshold. The surface code73 is a popular QEC code due to its high FT threshold, which is estimated to be between ~0.75−3%22,74,75,76,77,78, with 1% being the threshold that is typically quoted in the literature28,30. In Fig. 3, we find that the diamond norm of simultaneous single-qubit gates is below the surface code threshold for N = 10 and N = 100, and that the error rate of our CZ gate is approaching—but does not surpass—the surface code threshold.
Correlated errors under Pauli twirling
A major requirement for reliable fault-tolerant QEC is the absence of correlated errors, which can occur temporally79 or spatially80. Many-qubit correlated errors cannot be corrected by QEC (each QEC scheme has a maximal weight of error that it can correct), causing logical failures. Therefore, the rate of correlated errors must be low to achieve reliable fault-tolerant quantum computation. To characterize the extent to which spatially correlated errors are present in our system with and without Pauli twirling, we extract the weight-1 and weight-2 errors of each gate in our gate set. Figure 4 shows the weight-1 and weight-2 coherent (stochastic) errors for the idle cycle {I5 ⊗ I6} for the CPTP (S) model for N = 0 (N = 100) randomizations. We focus on coherent (stochastic) errors for N = 0 (N = 100) as they dominate the total the error budget; see Fig. 3a. We observe significant weight-2 coherent errors for N = 0 (Fig. 4a), which corresponds to unintended entanglement (i.e., quantum crosstalk), such as static ZZ coupling81,82,83. In contrast, we observe that weight-1 Pauli errors dominate for N = 100, and that weight-2 errors are largely suppressed in comparison.

Heat maps of the weight-1 and weight-2 errors acting on Q5 and Q6 during the idle cycle {I5 ⊗ I6} reconstructed using (a) the Hamiltonian projection of the GST error generator \({{{\mathcal{L}}}}\) for N = 0, (b) error rates calculated from the stochastic projection of \({{{\mathcal{L}}}}\) for N = 100, and (c) cycle error reconstructing via CB measurements. The x-axis labels the target gate; the y-axis labels the Hamiltonian error for (a), and the Pauli Kraus error for (b) and (c); the cell color denotes the over-rotation angle for (a), and error rate for (b) and (c); the cell gradient defines the 95% confidence interval; the first (second) row of subplots shows marginalized weight-1 (correlated weight-1 and weight-2) errors. While weight-2 errors are dominant for N = 0, (b) and (c) show that Pauli twirling suppresses weight-2 errors to negligible levels.
Additionally, we compare the Pauli error rates for N = 100 (Fig. 4b) to independently estimated Pauli error rates (Fig. 4c) measured using cycle benchmarking (CB)56 and reconstructed using cycle error reconstruction (CER)55,84,85. We find good agreement between the reconstructed Pauli noise in the two error maps, showing similar magnitudes of correlated errors, and demonstrating that the dominant errors in our system are weight-1. These results show that that Pauli twirling can suppress spatially correlated coherent errors due to entangling crosstalk and static ZZ coupling between superconducting qubits. (See Methods for a similar CER analysis of correlated errors in cycles acting on four qubits.)
In general, one can expect RC to provide a quadratic suppression of correlated coherent errors—RC converts a coherent error that contributes \({{{\mathcal{O}}}}(\theta )\) to the diamond norm (and the total error) into a stochastic error that contributes \({{{\mathcal{O}}}}({\theta }^{2})\) to the diamond norm. Therefore, while correlated errors might not be entirely suppressed by Pauli twirling, this reduction in the magnitude of correlated errors may reduce the cost of QEC86. While the current work focuses on spatial correlations, temporal correlations can also be detrimental to worst-case error rates87. However, we expect that a single randomization under RC can similarly suppress temporally correlated errors, although we leave an exploration of this topic to future work.
Non-Markovian errors
In the context of quantum computing, in particular for characterization and benchmarking, an error process is typically considered to be non-Markovian if it cannot be modeled by a process matrix. More precisely, non-Markovian errors are present if each n-qubit cycle (or layer) of gates cannot be modeled by a fixed, context-independent n-qubit process matrix. Various common sources of non-Markovianity in NISQ systems include leakage out of the computation basis states88,89,90,91,92,93, unwanted entangling interactions (e.g., static ZZ coupling) with qubits outside of the studied system, drift in qubit parameters94 (e.g., stochastic fluctuations in transition frequencies), unwanted coupling to environmental systems with memory beyond the timescale of a cycle (e.g., two-level fluctuators and nonequilibrium quasiparticles80,95,96,97), and qubit heating98; see Fig. 5a. Studying and suppressing non-Markovian errors is important for at least two reasons: they interfere with the quantification of Markovian errors, and their impacts on QEC are less well-understood.

(a) Non-Markovian errors in gate-based quantum computing. Markovian errors for a given system of qubits (black) are defined to occur within the timescale of a given cycle of gates (blue rectangle). Sources of non-Markovianity include leakage (seapage) out of (into) the computational basis states (purple), unintended entanglement (green) with external qubits (gray) or two-level fluctuators in the environment, drift in the system properties (e.g., fluctuations in the qubit frequency ω, with \({\omega }^{{\prime} }=\omega +\delta \omega\)), and classical EM signals from outside of the defined system (red) that reach the system qubits within their pseudo light cone (blue). (b) Unmodeled error versus the diamond norm. The per-gate wildcard wG is plotted on top of the diamond norm for each gate in \({\mathbb{G}}\) (plus SPAM) as a function of N. As N increases, wG becomes negligible, indicating that non-Markovian errors are suppressed under RC.
GST is designed to reconstruct all possible Markovian errors on any cycle of quantum gates. So, when GST cannot fit the data, this implies that there are non-Markovian errors. While model violation Nσ is useful for providing evidence of the existence of non-Markovian errors, to quantify the magnitude of such errors, we add a wildcard error model99 to each of our GST models. These wildcard error models assign a wildcard error rate wG ∈ [0, 1] to each gate G, and a wildcard error rate to the SPAM wSPAM ∈ [0, 1], which quantifies how much additional error on each operation is missing from the model (i.e., how much is required to make the model consistent with the data; see Methods for more details). By comparing wG to ϵ♢ for each gate, we are able to quantify whether Markovian or unmodeled non-Markovian errors dominate the error model68,99. If wG ≪ ϵ♢ for all gates, then Markovian errors dominate and non-Markovian errors are negligible. In this case, the model captures the majority of the errors in the gate (or, more precisely, all those errors that were revealed in this experiment), despite the fact that there is evidence that the model is incomplete. On the other hand, if wG≥ϵ♢, the non-Markovian errors dominate the Markovian errors, and the so the GST estimate is unreliable.
Figure 5 b shows the wildcard error and the diamond norm error for all of the gates in our gate set and SPAM, for N = 0, 10, 100 (we omit the N = 1 data due to its systematic inconsistency with a Markovian error model; see Model Selection and Methods). Without RC (N = 0), we observe diamond norm errors as large as ϵ♢ ≈ 0.07, with up to 0.01 additional non-Markovian error. For N = 10 randomizations, the wildcard errors are still significant, but they are much smaller in magnitude than N = 0 and they are a small fraction of the diamond norm error rates. By N = 100 randomizations, the wildcard errors are negligible—in absolute terms and as a fraction of ϵ♢—contributing at most 0.0012 additional error per gate. This indicates that the S model accurately captures almost all of the N = 100 data (note that in this case the wildcard error quantifies the combined contribution of both non-Markovian errors and all non-S Markovian errors). Because \({w}_{G}\ll {\epsilon }_{\diamond}\,\forall \,G\in {\mathbb{G}}\) for all N, we consider all of our models trustworthy, even for N = 0. We additionally note that RC significantly improves both the wildcard error and worst-case error rate for SPAM, which is the sum of the trace distance for the state-preparation and the diamond norm for the positive operator-valued measure. However, even in the N = 100 case, the SPAM error rate remains around ~ 4%, well above the 1% surface code threshold; these errors are equally as important as gate errors in the context of fault-tolerant QEC, and will need to be dramatically improved for achievable QEC in the future.
The N = 100 data was gathered over a period of over 40 hours, and no re-calibration of gates was performed during the experiment. Therefore, the negligible amount of unmodeled error speaks to the robustness of RC to the inevitable drift in gate and qubit parameters during this time period. While RC was not designed to specifically target non-Markovian errors, its apparent robustness to both non-Markovian errors and correlated errors is promising for future large-scale fault-tolerant applications.
Discussion
The field of quantum characterization, verification, and validation (QCVV) was developed in part to benchmark our progress toward fault-tolerant QEC. While full-scale fault-tolerant QEC is still many years away, contemporary quantum gates are rapidly approaching the necessary thresholds for many QEC codes, such as the surface code. Therefore, it is important to be able to accurately benchmark our progress toward this goal. While average error rates measured via randomized benchmarks are useful for tracking progress, they fall short of capturing the information required to determine whether all gate errors fall below a given FT threshold, for which the diamond norm is the relevant metric43,45. In this work, we demonstrate that FT thresholds can in fact be captured by randomized benchmarks, but only if the error-corrected application is performed using a randomization method which tailors noise. In fact, utilizing artificial randomness to suppress coherent dynamics is not new, and has been previously discussed for disorder-assisted error correction methods100,101,102. While our results were measured in the many-shot, many-randomization limit, they are still relevant for error correction, which operates in the single-shot, single-randomization limit, because results measured in latter limit sample from the same distribution that is estimated in the former limit; in other words, results measured in the single-shot, single-randomization limit are indistinguishable from those sampled from a distribution impacted by only stochastic noise.
The current approach also helps resolve a discrepancy regarding logical error rates in the Pauli twirling approximation (PTA). While some have argued that logical noise is well approximated by Pauli errors for large-distance codes103, others have shown that the PTA is a dishonest approximation of the impact of coherent errors104,105,106,107,108 and breaks down for large numbers of qubits109, and that despite the projective nature of QEC, coherent errors at the physical level can lead to coherent errors at the logical level110,111,112,113, which can increase logical error rates114. Our results show that Pauli twirling can efficiently be implemented at the physical level, which may even impact the kinds of errors that manifest at the logical level, potentially negating any need to approximate the accuracy of Pauli twirling at the logical level. Moreover, while coherent errors may continue persist even at the logical level, recent studies suggest that the diamond norm of gates at the logical level is smaller than the diamond norm of gates at the physical level115, which bodes favorably for the future of QEC. An exploration of this topic would be a natural extension of this work, and would provide insight into the necessity and/or potential benefits of using randomization methods for QEC.
While rapid improvements in two-qubit gates on many hardware platforms engender optimism for FT, caution must be taken in the claims inferred from gate fidelities, as results which include estimates of the diamond norm suggest that many contemporary two-qubit gates fall short of FT thresholds30,51,116,117,118. Furthermore, while isolated single- and two-qubit gates may be approaching the necessary requirements for fault-tolerance, any gate(s) performed in parallel with other qubits are likely to be impacted by crosstalk-induced coherent errors, potentially causing the diamond norm to scale with \(\sqrt{{e}_{F}}\). The figure of merit for determining whether low logical error rates can be achieved via QEC is the error rate of a cycle containing all active qubits in a register, not simply the error rate of isolated gates within the cycle86. Thus, whether or not randomization methods such as RC will be effective at the scale of the large number of qubits needed for QEC is an open question. However, in theory the efficiency of noise tailoring via Pauli twirling does not depending on system size119. Therefore, future work could explore the efficacy of RC at saturating the lower bound of the diamond norm for larger cycles of simultaneous gate operations.
Methods
Experiment
All experimental gate set tomography (GST) results were measured in a manner which normalizes shot statistics between circuits implemented with and without randomized compiling (RC). Bare GST sequences were measured K = 1000 times. For GST sequences implemented with N randomizations under RC, we fix K = 1000 and measure each randomization K/N times. By computing the union over the N different logically equivalent randomizations of each GST sequence, one obtains an equivalent statistical distribution for a single GST circuit measured K times.
Qubit parameters
Table 1 lists the relevant qubit parameters for the two transmon qubits used in this work. Qubit frequencies and anharmonicities are measured using Ramsey spectroscopy. Relaxation (T1) and coherence (\({T}_{2}^{* }\) and \({T}_{2}^{{{{\rm{echo}}}}}\)) times are extracted by fitting exponential decay curves to the excited state lifetime and Ramsey spectroscopy measurements (without and with an echo pulse), respectively. The reader is referred to Ref. 55 for details of the sample AQT@LBNL Trailblazer8-v5.c2 and the experimental setup of the device, as well as Refs. 50,61,68,120 for the previous characterization of the qubits used in this experiment.
Representations of quantum processes
Various representations of quantum processes exist39. A common representation is the operator-sum, or Kraus, representation which maps any density matrix ρ into
where the set {Ki} is a general class of operators known as Kraus operators. For a Pauli channel,
where the Kraus operators are \(K=\sqrt{{c}_{P}}P\), with cP the probability that P is applied (which is an error, except in the case of the identity Pauli), and \({{\mathbb{P}}}^{\otimes n}={\{I,X,Y,Z\}}^{\otimes n}\) is the set of 4n generalized Pauli operators.
Another useful representation of a quantum operator is the Pauli transfer matrix (PTM) representation, which is used throughout this work. The PTM representation can be defined by expanding any density matrix ρ in the Pauli basis,
where αP are the expansion coefficients. By vectorizing the expansion coefficients, we obtain a vectorized density matrix \(\left.\left\vert \rho \right\rangle \right\rangle ={\left(\begin{array}{ccc}{\alpha }_{{I}^{\otimes n}}&\ldots &{\alpha }_{{Z}^{\otimes n}}\end{array}\right)}^{T}\). A linear completely positive and trace-preserving (CPTP) quantum map \(\rho \mapsto {\rho }^{{\prime} }=\Lambda (\rho )\) in the PTM representation is completely defined by a 4n × 4n matrix Λ, with values \({\Lambda }_{ij}={{{\rm{Tr}}}}[{P}_{i}{{{\mathcal{E}}}}({P}_{j})]/d\) that can derived directly from the Kraus representation [Eq. (8)] for a Hilbert space of dimension d = 2n. All entries in the PTM are real and are bounded by Λij ∈ [ − 1, 1]. PTMs have the useful property that the composite map (i.e. the PTM of a quantum circuit) can be constructed by taking the matrix products of the individual maps (i.e. the PTMs of the individual gates).
For a single qubit,
The quantum map \({\rho }^{{\prime} }=\Lambda (\rho )\) can be expressed in vector form, \(\left.\left\vert {\rho }^{{\prime} }\right\rangle \right\rangle =\Lambda \left.\left\vert \rho \right\rangle \right\rangle\), or more explicitly,
As shown in Fig. 1a, some important properties of a process can be easily extracted from the components of its PTM. The PTM can be divided into four blocks: the upper left-hand corner represents trace-preservation, with ΛII = 1 if a process is trace-preserving (TP). This constraint can be succinctly summarized by stating that a process is TP if Λ0j = δ0j (i.e. the first row of the PTM is [1, 0, …, 0]). The lower right-hand block is the unital block, which captures processes such as stochastic Pauli noise and unitary errors. A unital process is one that maps the identity operation to the identity operation \(\Lambda ({\mathbb{I}})={\mathbb{I}}\) (it cannot purify a mixed state). The row above the unital block captures state-dependent leakage, represented by ΛIP ≠ 0 for P ∈ {X, Y, Z}; leakage is therefore not TP. The column to the left of the unital block is the non-unital block, which captures processes such as spontaneous emission (i.e., T1 decay) or amplitude damping. This constraint can be summarized by stating that a process is unital if Λi0 = δi0 (i.e. the first column of the PTM is [1, 0, …, 0]T). Finally, the diagonal of Λ represents state-preservation, with ΛPP = 1 ( < 1) for processes which (do not) preserve the Pauli channel P ∀ {I, X, Y, Z}.
The process fidelity of a map in the PTM representation is the weighted average of the diagonal components,
Therefore, the process infidelity is given by eF = 1 − FΛ.
Gate set tomography
In GST, the quality of the model is quantified by computing the log-likelihood ratio λ of the likelihood \({{{\mathcal{L}}}}\) of the GST model with the likelihood \({{{{\mathcal{L}}}}}_{\max }\) of the “maximal model”,
The maximal model is the one in which each independent measurement outcome in the data set is assigned a distinct probability equal to the observed frequencies. Wilks’ theorem121 states that if \({{{\mathcal{L}}}}\) and \({{{{\mathcal{L}}}}}_{\max }\) are both valid models, then the log-likelihood ratio is a \({\chi }_{k}^{2}\) random variable, where \(k={N}_{\max }-{N}_{p}\) is the difference in the number of free parameters between the maximal and GST models. If λ is not consistent with \({\chi }_{k}^{2}\) distribution (i.e. it does not lie within the interval \([k-\sqrt{2k},k+\sqrt{2k}]\), with mean k and standard deviation \(\sqrt{k}\)), then this indicates that the GST data are inconsistent with the GST model.
We quantify the model violation, or “goodness of fit,” by the number of standard deviations that λ is from the expected mean k,
If Nσ ≤ 1, then the GST model can be considered trustworthy and faithfully captures the behavior of the device. GST makes an assumption of Markovianity (i.e. any Markovian process can—by definition—be captured in a generalized model based on process matrices), therefore large Nσ indicates the presence of non-Markovian errors. However, Nσ does not quantify the magnitude of these non-Markovian errors. Because Nσ will grow linearly with the number of shots (and will typically increase with the depth of the GST circuits), a large Nσ can be observed even if the underlying non-Markovian errors are small in magnitude. Therefore, large Nσ simply indicates that some non-Markovianity is present with high statistical certainty.
While Nσ provides statistical evidence of non-Markovianity, a wildcard error model99 can capture the magnitude of these errors. The wildcard error rate wG ∈ [0, 1] quantifies the unmodeled error per logic gate operation. A wildcard error can also be assigned for a circuit C containing gates by summing over the wildcard error rates for all gates G ∈ C: wC = ∑G∈CwG. The wildcard model is chosen to be minimal, such that assigning wG to a gate G is just sufficient to make the model’s predictions consistent with the observed data. This is enforced by requiring that the total variation distance (TVD)
between the observed probability distribution pC and the wildcard-augmented probability distribution qC be bounded by the total wildcard error for circuit C,
The wildcard-augmented model is therefore not unique, as qC can be chosen from any distribution that satisfies Eq. (16). Because the wildcard error quantifies the magnitude of unmodeled error per gate, and because unmodeled errors are often attributed to non-Markovianity in the system, the per-gate wildcard error budget is a good estimate of the magnitude of non-Markovian errors impacting the gate. The TVD is a useful metric for quantifying the magnitude of unmodeled errors because it captures the rate at which measurement outcomes are incorrectly predicted by a model. Because the TVD is upper-bounded by the diamond norm36, one can compare the wildcard error wG to the diamond error ϵ♢ for any gate G to inform whether unmodeled errors in the GST estimate are dominant or negligible, and thus whether the GST model can be trusted. By extension, comparing wG to ϵ♢ quantifies whether Markovian or non-Markovian errors dominate the total error.
Randomization compiling: single-randomization limit
To understand how RC suppresses the coherent accumulation of unitary errors between cycles of gates, consider the simple example of applying many Rx(2π) rotations to a qubit in the ground state, but each time the qubit over-rotates by a small angle θ. The resulting state of the qubit after M rotations is
The fidelity of this state with respect to \(\left\vert 0\right\rangle\) is \({{{\mathcal{F}}}}=| \langle 0| \psi \rangle {| }^{2}={\cos }^{2}(M\theta )\approx 1-{(M\theta )}^{2}\), thus the infidelity \(r=1-{{{\mathcal{F}}}}\approx {(M\theta )}^{2}\). Therefore, the infidelity scales quadratically in both the over-rotation angle θ and the number of rotations M. Under RC, the trajectory from the initial state to the final state is randomized, thus ensuring that coherent errors will not grow quadratically between gates. While exact quadratic growth is highly unlikely for longer-depth multi-qubit circuits due to the complex dynamics of crosstalk, and because coherent errors can act in any direction (not just along the axis of rotation), coherent errors can still accumulate in an adversarial fashion and grow faster than average error rates, especially in structured quantum circuits122.
Randomization compiling: many-randomization limit
Regardless of the rate at which coherent errors accumulate between cycles of gates, they can still impact each computational gate G in a circuit. We can model this process as an ideal gate G0 followed by an unwanted unitary operator \(G=U(\hat{{{{\bf{n}}}}},\theta ){G}_{0}\), where \(U(\hat{{{{\bf{n}}}}},\theta )={e}^{-i\theta \hat{{{{\bf{n}}}}}\cdot {{{\boldsymbol{\sigma }}}}/2}\), \(\hat{{{{\bf{n}}}}}\) is the axis of rotation, σ the Pauli vector, and θ is the rotation angle relative to the intended target state. For simplicity, consider a unitary error about the x-axis for a single qubit,
In the PTM representation (see Fig. 1a), this coherent error takes the following form,
For small θ, the diagonal components of Λ scale as \(\cos (\theta )\approx 1-\frac{1}{2}{\theta }^{2}\), and the off-diagonal terms scale as \(\sin (\theta )\approx \theta\). While the infidelity of the diagonal terms is eF ≈ θ2, we see that the off-diagonal terms are quadratically larger, with \(\sqrt{{e}_{F}}\approx \theta\). While not all error metrics are sensitive to the off-diagonal terms in an error process (e.g. fidelity-based measures), norm-based error metrics such as the diamond norm generally are sensitive to such terms, setting the \(\sim \sqrt{{e}_{F}}\) upper bound of Eq. (3).
Under RC in the many-randomization limit, all off-diagonal terms in the error process are completely suppressed in the limit that N ⟶ ∞. To understand how this occurs, consider Pauli twirling Λ, i.e. PΛP† for any P ∈ {I, X, Y, Z}, where P represents the Pauli superoperator. Under Pauli conjugation, the signs of the off-diagonal terms remain the same (are reversed) if P commutes (does not commute) with Λ. Thus, the off-diagonal terms change sign with a 50% probability upon conjugation with a randomly selected Pauli. When averaging over N randomizations, the magnitude of the off-diagonal terms scale as \(\theta /\sqrt{N}\), reminiscent of a random walk, and thus vanish as N ⟶ ∞ or if by luck the correct Paulis were sampled which average to zero. While the “noise tailoring” property of RC rests on assumption that the noise impacting the easy gates is gate-independent, Wallman et al.52 prove that RC is robust to small gate-dependent errors, which are inevitable in modern-day experiments.
Method for performing randomized compiling on GST sequences
In order to preserve the circuit depth of GST sequences under RC, randomly sampled single-qubit Paulis and their correction gates are inserted between every layer. For circuits only containing single-qubit gates, the random Paulis are compiled into the previous layer and the correction gates are compiled into the subsequent layer. For circuits containing two-qubit gates, the correction gates are commuted through the two-qubit gate before being compiled into the subsequent layer.
To highlight this method, consider a circuit \({{{\mathcal{C}}}}\) containing N layers L of single-qubit gates:
Under RC, a single randomized circuit takes the following form
where \({P}_{N}^{{\dagger} }\) is omitted in the circuit but taken into account in the final ideal measurement results. The compiled circuit is
where the kth layer \({\tilde{L}}_{k}={P}_{k}{L}_{k}{P}_{k-1}^{{\dagger} }\) (except for the first layer, which does not contain a correction gate). For circuits containing two-qubit gates in layer k − 1, the kth layer becomes \({\tilde{L}}_{k}={P}_{k}{L}_{k}{P}_{k-2}^{c}\), where \({P}_{k-2}^{c}={L}_{k-1}{P}_{k-2}^{{\dagger} }{L}_{k-1}^{{\dagger} }\). This method therefore randomizes all layers of single-qubit gates, while also maintaining the original circuit depth, and was developed within the pyGSTi framework specifically for the purpose of randomizing GST and related benchmarking circuits.
As highlighted in the main text, we observe larger model violation for a single-randomization under RC than for no randomizations. This is expected behavior for N = 1 even when the physical gates are Markovian, which we illustrate with the following example: consider two single-qubit circuits, \({{{{\mathcal{C}}}}}_{1}={G}_{I}{G}_{I}\) and \({{{{\mathcal{C}}}}}_{2}={G}_{I}{G}_{I}{G}_{I}{G}_{I}\), and consider a physical gate set {GI, GX, GY, GZ}, with GX = Xπ, etc. Consider a simple error model where each gate is followed by a small coherent Xθ rotation error. When we implement \({{{{\mathcal{C}}}}}_{1}\) with a single randomization under RC, we actually implement a circuit that should perform the identity rotation, but the gates have been randomized according to the method outlined above. Let’s assume our randomized circuit \({\tilde{{{{\mathcal{C}}}}}}_{1}\) is the same as the original circuit, \({\tilde{{{{\mathcal{C}}}}}}_{1}={{{{\mathcal{C}}}}}_{1}={G}_{I}{G}_{I}\). If we initialize our qubit in the ground state, we will observe a small coherent over-rotation error by 2θ, which will result in some θ-dependent probability of not measuring 0. Similarly, when we run \({{{{\mathcal{C}}}}}_{2}\) we will actually actually implement one of the many length-4 combinations of Pauli gates that produces the identity rotation. For example, suppose we sampled \({\tilde{{{{\mathcal{C}}}}}}_{2}={G}_{Z}{G}_{Z}{G}_{Z}{G}_{Z}\); this combination of gates would echo away the X rotation error, and we would measure 0 with probability 1. Therefore, altogether we observe \(\Pr (0| {{{{\mathcal{C}}}}}_{1})\,<\, 1\) and \(\Pr (0| {{{{\mathcal{C}}}}}_{2})=1\). This is inconsistent with every possible process matrix for GI (or at least every process matrix that is close to the target identity matrix), because repeating an identity gate amplifies all of its error parameters, but does not echo away errors. Finally, note that this argument is predicated on the assumption that we measure each circuit many times; if we measure each circuit only once, the results will not be inconsistent, but also will not be very informative.
Cycle error reconstruction
In Fig. 6, we plot the results of CER applied to the identity cycle {I4 ⊗ I5 ⊗ I6 ⊗ I7} across all four qubits on the quantum processor. We measure all 44 = 256 Pauli channels, but omit values which fall below 12% of the maximum value for visual clarity. We observe no significant contribution from weight-k≥2 in the plot, demonstrating that Pauli twirling can break larger-scale correlations across an entire quantum processor. Furthermore, Refs. 55,120 present similar results for multi-qubit cycles containing two-qubit gates, and the conclusions were the same: the most dominant errors under Pauli twirling are single-body errors (i.e. weight-1 errors for single-qubit gates, weight-1 or weight-2 errors for two-qubit gates, etc.). Moreover, because two-body errors are the sum of all errors that act non-trivially on the corresponding two bodies, irrespective of their action on other qubits, the fact that two-body errors are negligible indicates that higher-body errors are also negligible.

Weight-1 errors dominate the error map; all weight-k≥2 errors are negligible in comparison. Rows in which all errors fall below 12% of the maximum value have been omitted for visual clarity.
Data availability
All data are available from the corresponding author upon reasonable request.
References
Preskill, J. Quantum computing in the nisq era and beyond. Quantum 2, 79 (2018).
Shor, P. W. Polynomial-time algorithms for prime factorization and discrete logarithms on a quantum computer. SIAM Rev. 41, 303–332 (1999).
Shor, P. W. Scheme for reducing decoherence in quantum computer memory. Phys. Rev. A 52, R2493 (1995).
Gottesman, D. Class of quantum error-correcting codes saturating the quantum hamming bound. Phys. Rev. A 54, 1862 (1996).
Steane, A. Multiple-particle interference and quantum error correction. Proc. Roy. Soc. A 452, 2551–2577 (1996).
Steane, A. Introduction to quantum error correction. Philos. Trans. Royal Soc. A 356, 1739–1758 (1998).
Calderbank, A. R., Rains, E. M., Shor, P. & Sloane, N. J. Quantum error correction via codes over gf (4). IEEE Trans. Inf. Theory 44, 1369–1387 (1998).
Shor, P. W. Fault-tolerant quantum computation. In: Proceedings of 37th Conference on Foundations of Computer Science 56–65 (IEEE, 1996).
Knill, E. & Laflamme, R. Concatenated quantum codes. Preprint at https://arxiv.org/abs/quant-ph/9608012 (1996).
Knill, E., Laflamme, R. & Zurek, W. H. Resilient quantum computation. Science 279, 342–345 (1998).
Preskill, J. in Introduction to Quantum Computation and Information 213–269 (World Scientific, 1998).
Kitaev, A. Y. Fault-tolerant quantum computation by anyons. Ann. Phys. 303, 2–30 (2003).
Aharonov, D. & Ben-Or, M. Fault-tolerant quantum computation with constant error rate. SIAM J. Sci. Comput. 38 (2008).
Aliferis, P., Gottesman, D. & Preskill, J. Quantum Accuracy Threshold for Concatenated Distance-3 Codes. Quantum Info. Comput. 6, 97–165 (2006).
Aliferis, P. & Cross, A. W. Subsystem fault tolerance with the bacon-shor code. Phys. Rev. Lett. 98, 220502 (2007).
Aliferis, P., Gottesman, D. & Preskill, J. Accuracy Threshold for Postselected Quantum Computation. Quantum Info. Comput. 8, 181–244 (2008).
Aliferis, P. & Preskill, J. Fibonacci scheme for fault-tolerant quantum computation. Phys. Rev. A 79, 012332 (2009).
Chamberland, C., Jochym-O’Connor, T. & Laflamme, R. Thresholds for universal concatenated quantum codes. Phys. Rev. Lett. 117, 010501 (2016).
Knill, E. Quantum computing with realistically noisy devices. Nature 434, 39–44 (2005).
Aliferis, P. et al. Fault-tolerant computing with biased-noise superconducting qubits: a case study. New J. Phys. 11, 013061 (2009).
Duclos-Cianci, G. & Poulin, D. Fast decoders for topological quantum codes. Phys. Rev. Lett. 104, 050504 (2010).
Wang, D. S., Fowler, A. G. & Hollenberg, L. C. Surface code quantum computing with error rates over 1%. Phys. Rev. A 83, 020302 (2011).
Bombin, H., Andrist, R. S., Ohzeki, M., Katzgraber, H. G. & Martin-Delgado, M. A. Strong resilience of topological codes to depolarization. Phys. Rev. X 2, 021004 (2012).
Wootton, J. R. & Loss, D. High threshold error correction for the surface code. Phys. Rev. Lett. 109, 160503 (2012).
Stephens, A. M. Fault-tolerant thresholds for quantum error correction with the surface code. Phys. Rev. A 89, 022321 (2014).
Auger, J. M., Anwar, H., Gimeno-Segovia, M., Stace, T. M. & Browne, D. E. Fault-tolerance thresholds for the surface code with fabrication errors. Phys. Rev. A 96, 042316 (2017).
Tuckett, D. K., Bartlett, S. D., Flammia, S. T. & Brown, B. J. Fault-tolerant thresholds for the surface code in excess of 5% under biased noise. Phys. Rev. Lett. 124, 130501 (2020).
Barends, R. et al. Superconducting quantum circuits at the surface code threshold for fault tolerance. Nature 508, 500–503 (2014).
Rong, X. et al. Experimental fault-tolerant universal quantum gates with solid-state spins under ambient conditions. Nat. Commun. 6, 1–7 (2015).
Xue, X. et al. Quantum logic with spin qubits crossing the surface code threshold. Nature 601, 343–347 (2022).
Emerson, J., Alicki, R. & Życzkowski, K. Scalable noise estimation with random unitary operators. J. opt., B Quantum semiclass. opt. 7, S347 (2005).
Knill, E. et al. Randomized benchmarking of quantum gates. Phys. Rev. A 77, 012307 (2008).
Dankert, C., Cleve, R., Emerson, J. & Livine, E. Exact and approximate unitary 2-designs and their application to fidelity estimation. Phys. Rev. A 80, 012304 (2009).
Magesan, E., Gambetta, J. M. & Emerson, J. Scalable and robust randomized benchmarking of quantum processes. Phys. Rev. Lett. 106, 180504 (2011).
Magesan, E. et al. Efficient measurement of quantum gate error by interleaved randomized benchmarking. Phys. Rev. Lett. 109, 080505 (2012).
Kitaev, A. Y. Quantum computations: algorithms and error correction. Usp. Mat. Nauk 52, 53–112 (1997).
Merkel, S. T. et al. Self-consistent quantum process tomography. Phys. Rev. A 87, 062119 (2013).
Blume-Kohout, R. et al. Robust, self-consistent, closed-form tomography of quantum logic gates on a trapped ion qubit. Preprint at https://arxiv.org/abs/1310.4492 (2013).
Greenbaum, D. Introduction to quantum gate set tomography.Preprint at https://arxiv.org/abs/1509.02921 (2015).
Blume-Kohout, R. et al. Demonstration of qubit operations below a rigorous fault tolerance threshold with gate set tomography. Nat. Commun. 8, 1–13 (2017).
Nielsen, E. et al. Gate set tomography. Quantum 5, 557 (2021).
Wallman, J. J. & Flammia, S. T. Randomized benchmarking with confidence. New J. Phys. 16, 103032 (2014).
Sanders, Y. R., Wallman, J. J. & Sanders, B. C. Bounding quantum gate error rate based on reported average fidelity. New J. Phys. 18, 012002 (2015).
Wallman, J. J. Bounding experimental quantum error rates relative to fault-tolerant thresholds. Preprint at https://arxiv.org/abs/1511.00727 (2015).
Kueng, R., Long, D. M., Doherty, A. C. & Flammia, S. T. Comparing experiments to the fault-tolerance threshold. Phys. Rev. Lett. 117, 170502 (2016).
Sheldon, S. et al. Characterizing errors on qubit operations via iterative randomized benchmarking. Phys. Rev. A 93, 012301 (2016).
Arute, F. et al. Quantum supremacy using a programmable superconducting processor. Nature 574, 505–510 (2019).
Wang, Y. et al. High-fidelity two-qubit gates using a microelectromechanical-system-based beam steering system for individual qubit addressing. Phys. Rev. Lett. 125, 150505 (2020).
Pino, J. M. et al. Demonstration of the trapped-ion quantum ccd computer architecture. Nature 592, 209–213 (2021).
Mitchell, B. K. et al. Hardware-efficient microwave-activated tunable coupling between superconducting qubits. Phys. Rev. Lett. 127, 200502 (2021).
Mądzik, M. T. et al. Precision tomography of a three-qubit electron-nuclear quantum processor in silicon. Nature 601, 348–353 (2022).
Wallman, J. J. & Emerson, J. Noise tailoring for scalable quantum computation via randomized compiling. Phys. Rev. A 94, 052325 (2016).
Ryan-Anderson, C. et al. Realization of real-time fault-tolerant quantum error correction. Phys. Rev. X 11, 041058 (2021).
Chen, L. et al. Transmon qubit readout fidelity at the threshold for quantum error correction without a quantum-limited amplifier. npj Quantum Inf. 9, 26 (2023).
Hashim, A. et al. Randomized compiling for scalable quantum computing on a noisy superconducting quantum processor. Phys. Rev. X 11, 041039 (2021).
Erhard, A. et al. Characterizing large-scale quantum computers via cycle benchmarking. Nat. Commun. 10, 1–7 (2019).
Hastings, M. B. Turning gate synthesis errors into incoherent errors. Preprint at https://arxiv.org/abs/1612.01011 (2016).
Campbell, E. Shorter gate sequences for quantum computing by mixing unitaries. Phys. Rev. A 95, 042306 (2017).
Cai, Z., Xu, X. & Benjamin, S. C. Mitigating coherent noise using pauli conjugation. npj Quantum Inf. 6, 1–9 (2020).
Ware, M. et al. Experimental pauli-frame randomization on a superconducting qubit. Phys. Rev. A 103, 042604 (2021).
Hashim, A. et al. Optimized swap networks with equivalent circuit averaging for qaoa. Phys. Rev. Res. 4, 033028 (2022).
Chuang, I. L. & Nielsen, M. A. Prescription for experimental determination of the dynamics of a quantum black box. Journal of Modern Optics 44, 2455–2467 (1997).
Nielsen, E. et al. Python gst Implementation (pygsti) v. 0.9. Tech. Rep., Sandia National Lab.(SNL-NM), Albuquerque, NM (United States) (2019).
Nielsen, E. et al. Probing quantum processor performance with pygsti. Quantum Sci. Technol. 5, 044002 (2020).
Viola, L., Knill, E. & Lloyd, S. Dynamical decoupling of open quantum systems. Phys. Rev. Lett. 82, 2417 (1999).
Blume-Kohout, R. et al. A taxonomy of small markovian errors. PRX Quantum 3, 020335 (2022).
Nielsen, E., Rudinger, K., Proctor, T., Young, K. & Blume-Kohout, R. Efficient flexible characterization of quantum processors with nested error models. New J. Phys. 23, 093020 (2021).
Rudinger, K. et al. Experimental characterization of crosstalk errors with simultaneous gate set tomography. PRX Quantum 2, 040338 (2021).
Wallman, J., Granade, C., Harper, R. & Flammia, S. T. Estimating the coherence of noise. New J. Phys. 17, 113020 (2015).
Boixo, S. et al. Characterizing quantum supremacy in near-term devices. Nat. Phys. 14, 595–600 (2018).
Knill, E. Fault-tolerant postselected quantum computation: threshold analysis. Preprint at https://arxiv.org/abs/quant-ph/0404104 (2004).
Kern, O., Alber, G. & Shepelyansky, D. L. Quantum error correction of coherent errors by randomization. Eur. Phys. J. D 32, 153–156 (2005).
Fowler, A. G., Mariantoni, M., Martinis, J. M. & Cleland, A. N. Surface codes: Towards practical large-scale quantum computation. Phys. Rev. A 86, 032324 (2012).
Wang, C., Harrington, J. & Preskill, J. Confinement-higgs transition in a disordered gauge theory and the accuracy threshold for quantum memory. Ann. Phys. 303, 31–58 (2003).
Raussendorf, R., Harrington, J. & Goyal, K. A fault-tolerant one-way quantum computer. Ann. Phys. 321, 2242–2270 (2006).
Raussendorf, R., Harrington, J. & Goyal, K. Topological fault-tolerance in cluster state quantum computation. New J. Phys. 9, 199 (2007).
Raussendorf, R. & Harrington, J. Fault-tolerant quantum computation with high threshold in two dimensions. Phys. Rev. Lett. 98, 190504 (2007).
Fowler, A. G., Whiteside, A. C. & Hollenberg, L. C. Towards practical classical processing for the surface code. Phys. Rev. Lett. 108, 180501 (2012).
Lu, F. & Marinescu, D. C. Quantum error correction of time-correlated errors. Quantum Inf. Process. 6, 273–293 (2007).
Wilen, C. D. et al. Correlated charge noise and relaxation errors in superconducting qubits. Nature 594, 369–373 (2021).
Mundada, P., Zhang, G., Hazard, T. & Houck, A. Suppression of qubit crosstalk in a tunable coupling superconducting circuit. Phys. Rev. App. 12, 054023 (2019).
Zhao, P. et al. High-contrast zz interaction using superconducting qubits with opposite-sign anharmonicity. Phys. Rev. Lett. 125, 200503 (2020).
Ni, Z. et al. Scalable method for eliminating residual zz interaction between superconducting qubits. Phys. Rev. Lett. 129, 040502 (2022).
Flammia, S. T. & Wallman, J. J. Efficient estimation of pauli channels. ACM Trans. Quantum Comput. 1, 1–32 (2020).
Beale, S. J. et al. True-q (2020). https://doi.org/10.5281/zenodo.3945250.
Fowler, A. G. & Martinis, J. M. Quantifying the effects of local many-qubit errors and nonlocal two-qubit errors on the surface code. Phys. Rev. A 89, 032316 (2014).
Ball, H., Stace, T. M., Flammia, S. T. & Biercuk, M. J. Effect of noise correlations on randomized benchmarking. Phys. Rev. A 93, 022303 (2016).
Ghosh, J., Fowler, A. G., Martinis, J. M. & Geller, M. R. Understanding the effects of leakage in superconducting quantum-error-detection circuits. Phys. Rev. A 88, 062329 (2013).
Wallman, J. J., Barnhill, M. & Emerson, J. Robust characterization of leakage errors. New J. Phys. 18, 043021 (2016).
Chen, Z. et al. Measuring and suppressing quantum state leakage in a superconducting qubit. Phys. Rev. Lett. 116, 020501 (2016).
Wood, C. J. & Gambetta, J. M. Quantification and characterization of leakage errors. Phys. Rev. A 97, 032306 (2018).
Hayes, D. et al. Eliminating leakage errors in hyperfine qubits. Phys. Rev. Lett. 124, 170501 (2020).
Babu, A. P., Tuorila, J. & Ala-Nissila, T. State leakage during fast decay and control of a superconducting transmon qubit. npj Quantum Inf. 7, 1–8 (2021).
Proctor, T. et al. Detecting and tracking drift in quantum information processors. Nat. Commun. 11, 1–9 (2020).
Serniak, K. et al. Hot nonequilibrium quasiparticles in transmon qubits. Phys. Rev. Lett. 121, 157701 (2018).
de Graaf, S. et al. Two-level systems in superconducting quantum devices due to trapped quasiparticles. Sci. Adv. 6, eabc5055 (2020).
Berlin-Udi, M. et al. Changes in electric field noise due to thermal transformation of a surface ion trap. Phys. Rev. B 106, 035409 (2022).
Webb, A. E. et al. Resilient entangling gates for trapped ions. Phys. Rev. Lett. 121, 180501 (2018).
Blume-Kohout, R., Rudinger, K., Nielsen, E., Proctor, T. & Young, K. Wildcard error: Quantifying unmodeled errors in quantum processors. Preprint at https://arxiv.org/abs/2012.12231 (2020).
Wootton, J. R. & Pachos, J. K. Bringing order through disorder: Localization of errors in topological quantum memories. Phys. Rev. Lett. 107, 030503 (2011).
Stark, C., Pollet, L., Imamoğlu, A. & Renner, R. Localization of toric code defects. Phys. Rev. Lett. 107, 030504 (2011).
Bravyi, S. & König, R. Disorder-assisted error correction in majorana chains. Commun. Math. Phys. 316, 641–692 (2012).
Bravyi, S., Englbrecht, M., König, R. & Peard, N. Correcting coherent errors with surface codes. npj Quantum Inf. 4, 1–6 (2018).
Geller, M. R. & Zhou, Z. Efficient error models for fault-tolerant architectures and the Pauli twirling approximation. Phys. Rev. A 88, 012314 (2013).
Tomita, Y. & Svore, K. M. Low-distance surface codes under realistic quantum noise. Phys. Rev. A 90, 062320 (2014).
Katabarwa, A. & Geller, M. R. Logical error rate in the Pauli twirling approximation. Sci. Rep. 5, 1–6 (2015).
Puzzuoli, D. et al. Tractable simulation of error correction with honest approximations to realistic fault models. Phys. Rev. A 89, 022306 (2014).
Gutiérrez, M. & Brown, K. R. Comparison of a quantum error-correction threshold for exact and approximate errors. Phys. Rev. A 91, 022335 (2015).
Katabarwa, A. A dynamical interpretation of the pauli twirling approximation and quantum error correction. Preprint at https://arxiv.org/abs/1701.03708 (2017).
Fern, J., Kempe, J., Simic, S. N. & Sastry, S. Generalized performance of concatenated quantum codes—a dynamical systems approach. IEEE Trans. Autom. Control 51, 448–459 (2006).
Gutiérrez, M., Smith, C., Lulushi, L., Janardan, S. & Brown, K. R. Errors and pseudothresholds for incoherent and coherent noise. Phys. Rev. A 94, 042338 (2016).
Darmawan, A. S. & Poulin, D. Tensor-network simulations of the surface code under realistic noise. Phys. Rev. Lett. 119, 040502 (2017).
Greenbaum, D. & Dutton, Z. Modeling coherent errors in quantum error correction. Quantum Science and Technology 3, 015007 (2017).
Hakkaku, S., Mitarai, K. & Fujii, K. Sampling-based quasiprobability simulation for fault-tolerant quantum error correction on the surface codes under coherent noise. Phys. Rev. Res. 3, 043130 (2021).
Huang, E., Doherty, A. C. & Flammia, S. Performance of quantum error correction with coherent errors. Phys. Rev. A 99, 022313 (2019).
Dehollain, J. P. et al. Optimization of a solid-state electron spin qubit using gate set tomography. New J. Phys. 18, 103018 (2016).
Hughes, A. et al. Benchmarking a high-fidelity mixed-species entangling gate. Phys. Rev. Lett. 125, 080504 (2020).
White, G. A., Hill, C. D. & Hollenberg, L. C. Performance optimization for drift-robust fidelity improvement of two-qubit gates. Phys. Rev. App. 15, 014023 (2021).
Goss, N. et al. Extending the computational reach of a superconducting qutrit processor. Preprint at https://arxiv.org/abs/2305.16507 (2023).
Ferracin, S. et al. Efficiently improving the performance of noisy quantum computers. Preprint at https://arxiv.org/abs/2201.10672 (2022).
Wilks, S. S. The large-sample distribution of the likelihood ratio for testing composite hypotheses. Ann. Math. Stat. 9, 60–62 (1938).
Proctor, T., Rudinger, K., Young, K., Nielsen, E. & Blume-Kohout, R. Measuring the capabilities of quantum computers. Nat. Phys. 18, 75–79 (2021).
Acknowledgements
This work was supported by the U.S. Department of Energy, Office of Science, Office of Advanced Scientific Computing Research Quantum Testbed Program under Contract No. DE-AC02-05CH11231 and the Quantum Testbed Pathfinder Program.
Author information
Authors and Affiliations
Contributions
A.H. conceptualized and performed the experiments. K.R., S.S., T.P., and N.G. assisted in the design of the experiments. A.H. analyzed the data with the help of K.R., S.S., and T.P. J.M.K. fabricated the sample. R.K.N., D.I.S., and I.S. supervised all experimental work. A.H. and T.P. wrote the manuscript with input from all coauthors. A.H. acknowledges fruitful discussions with Joel Wallman, Joseph Emerson, Robin Blume-Kohout, Samuele Ferracin, and Long Nguyen. T.P. acknowledges helpful discussions with Kevin Young and Robin Blume-Kohout.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Hashim, A., Seritan, S., Proctor, T. et al. Benchmarking quantum logic operations relative to thresholds for fault tolerance. npj Quantum Inf 9, 109 (2023). https://doi.org/10.1038/s41534-023-00764-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41534-023-00764-y
This article is cited by
-
Quantum error mitigation in the regime of high noise using deep neural network: Trotterized dynamics
Quantum Information Processing (2024)
