
Abstract
Quantum reservoir computing is a promising approach for quantum neural networks, capable of solving hard learning tasks on both classical and quantum input data. However, current approaches with qubits suffer from limited connectivity. We propose an implementation for quantum reservoir that obtains a large number of densely connected neurons by using parametrically coupled quantum oscillators instead of physically coupled qubits. We analyze a specific hardware implementation based on superconducting circuits: with just two coupled quantum oscillators, we create a quantum reservoir comprising up to 81 neurons. We obtain state-of-the-art accuracy of 99% on benchmark tasks that otherwise require at least 24 classical oscillators to be solved. Our results give the coupling and dissipation requirements in the system and show how they affect the performance of the quantum reservoir. Beyond quantum reservoir computing, the use of parametrically coupled bosonic modes holds promise for realizing large quantum neural network architectures, with billions of neurons implemented with only 10 coupled quantum oscillators.
Similar content being viewed by others

Introduction
Quantum neural networks are the subject of intensive research today. They emulate a large number of neurons with only a small number of physical components, which facilitates scaling up compared to classical approaches. Indeed, by encoding the responses of the neurons in the populations of basis states, a system of N qubits provides up to 2N neurons. Moreover, such quantum neural networks could automatically transform complex quantum data into simple outputs representing the class of the input, that could then be measured with just a few samples compared to the millions needed today. The first experimentally realized quantum neural networks are made of 71 to 40 qubits2, each connected to two or four nearest neighbors.
The major challenge of the field is now to experimentally realize neural networks capable of real-world classification tasks, and thus containing millions of neurons each connected by thousands of connections. The use of qubits poses a conceptual and technical problem for this purpose. Indeed, when connectivity is obtained with pairwise couplers between qubits, distant qubits cannot be interconnected without very cumbersome classical circuitry in existing 2D architectures.
Here we develop an alternative approach to quantum neural networks that is both scalable and compatible with experimental implementations. We propose to leverage the complex dynamics of coherently coupled quantum oscillators, combined with their infinite number of basis states, to populate a large number of neurons much more efficiently than with qubits3. We then show through simulations with experimentally-validated models that this system classifies and predicts time-series data with high efficiency through the approach of reservoir computing4.
With just two quantum oscillators, up to 9 states can be populated in each oscillator with significant probability amplitudes, which yields a quantum reservoir with up to 81 neurons.
We evaluate its performance on two benchmark tasks in the field of reservoir computing, sine-square waveform classification and Mackey-Glass chaotic time-series prediction, that test the ability of the reservoir to memorize input data and transform it in a nonlinear way. We obtain a state-of-the-art accuracy of 99% with our system of two coherently coupled oscillators, which otherwise requires 24 classical oscillators to achieve. With 10 oscillators we could have 3 billions of neurons, comparable to the most impressive neural networks capable of hard tasks such as natural language processing or generating images from text descriptions5. Furthermore, these neurons can be populated in a much more efficient way compared to those implemented on qubit systems, by resonantly driving each of the oscillators and coupling them strongly pairwise.
The results show that two coupled quantum oscillators implement a high quality reservoir computer capable of complex tasks, and open the path to experimental implementations of quantum reservoirs based on a large number of basis state neurons, thus providing a quantum neural network platform compatible with numerous algorithms exploiting physics and dynamics for computing6,7,8,9.
Results
Quantum reservoir computing
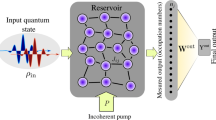
In this paper, we consider reservoir computing, a machine learning paradigm that uses nonlinear dynamical systems for temporal information processing4. Its principle is illustrated in Fig. 1. The reservoir (blue area) is a dynamical system with arbitrary but fixed recurrent connections. It takes as input data that is not easily separable in different classes. The role of the reservoir is to project these inputs into a highly dimensional state space in which the data becomes linearly separable. The reservoir outputs are then classified by a linear, fully connected layer (shown in red arrows) that can be trained by a simple linear regression. Physical implementations of reservoir computing commonly perform this projection of input data to a high dimensional space through complex nonlinear dynamics and the outputs are obtained by measuring specific variables on that system10,11,12,13.

The reservoir neurons (blue circles) are basis states of a coupled quantum system. The reservoir outputs (purple circles) are the measured occupation probabilities of these states. The black connections in the physical reservoir (blue area) are fixed and the red connections are trained.
The fully connected layer is usually realized in software, and multiplies the measurement outputs F(X) by a weight matrix W, such that
The weight matrix is trained to make the neural network output Y match the target vector \(\tilde{\bf{Y}}\). The particularity of reservoir computing compared to deep neural networks is that training can be performed in a single step by matrix inversion
where Xtrain is the training data, \({\tilde{\bf{Y}}_{\rm{train}}}\) is the training target, and F† is the Moore-Penrose pseudo-inverse of the matrix F containing the outputs f(xi) of the reservoir neurons for all the training examples11,14. The matrix inversion method works well for small matrix dimensions. For larger matrix dimensions other methods can be used, such as linear regression used in reference15 for a 50,000 node classical reservoir. The learned weight matrix is applied on the test data contained in the vector Xtest, in order to find the neural network prediction
Comparing the prediction to the test target \({\tilde{\bf{Y}}_{\rm{test}}}\) allows to evaluate the prediction accuracy, i.e., the fraction of times the data point is correctly classified, as well as the normalized root mean square error
We will use these measures to evaluate the performance of the reservoir, and thus the capacity of the chosen dynamical system to efficiently implement reservoir computing. It should be noted that there are neural networks capable of achieving higher accuracies than reservoir computing for the learning tasks investigated in this study16. Our objective is not to contrast various algorithms, but rather, for a specific task, employing a straightforward network architecture and a designated training method, to assess the benefits conferred by distinct physical properties associated with diverse physical platforms, including quantum aspects, in enhancing the system’s computing capabilities.
Reservoir computing was implemented on different classical physical systems, ranging from silicon photonics12 and optoelectronics10,11, to spintronic nano-oscillators13. Quantum reservoir computing was first proposed in 2017, with a reservoir whose neurons correspond to the basis states of a set of qubits, and computational capabilities are identical to 100–500 classical neurons with only 5–7 qubits17. Experimentally, quantum reservoir was implemented with 4 static spins and 8 neurons18, and a dissipative reservoir was implemented with up to 10 qubits19. We have recently highlighted that dynamical systems of coherently coupled quantum oscillators possess all the required features for quantum reservoir computing3.
Coupled quantum oscillators
We consider the implementation of quantum reservoir computing with two coupled quantum oscillators a and b (Fig. 2). In this case, the reservoir neurons are given by the basis states \(\left\vert {n}_{a},{n}_{b}\right\rangle\), and the reservoir outputs by their occupation probabilities. Such a system can be experimentally implemented using superconducting circuits featuring resonators whose fundamental modes are coupled using three- or four-wave mixing elements such as Josephson mixers20,21,22, SNAIL23, or even a single transmon23,24. The Hamiltonian describing such system writes25
where g = χp is the parametric conversion coupling rate that can typically be controlled by the amplitude of a pump tone. Such tunable coupling allows us to study the performance of the quantum reservoir as a function of the coupling strength.

The oscillators are resonantly driven at frequencies ωa and ωb with amplitudes ϵa and ϵb, with dissipation rates κa and κb. The coherent coupling at a rate g results in the exchange of excitations between oscillators.
We drive each oscillator at resonance with an amplitude that encodes the input data, such that the population of the basis states depends on this input value, the duration for which the drive signal is applied, and the previous input values, as long as each input is sent for a time shorter than the lifetime of the oscillators. The dynamics of the system is driven by three main processes: resonant drives, dissipation and conversion of photons between the oscillators at a rate g. We use typical experimental parameters for superconducting circuits with resonators frequencies ωa = 2π × 10 GHz and ωb = 2π × 9 GHz and dissipation rates κa = 2π × 17 MHz, κb = 2π × 21 MHz.
Learning tasks with the quantum reservoir
In order to evaluate the capacity of the quantum reservoir with oscillators, we address two standard benchmark tasks of reservoir computing, i.e., a classification task that requires a lot of nonlinearity and short-term memory, and a prediction task that requires both short- and long-term memory. In order to assess the advantage brought by the quantum nature of the reservoir, we compare its performance with that of classical reservoirs on the same tasks. We differentiate between the contributions of dynamic features and distinctively quantum properties, by conducting comparisons with both static and dynamic classical reservoirs. For the static reservoir we perform software simulations of reservoirs with neurons that apply a nonlinear ReLu function (typically used in machine learning). For the dynamical reservoir we simulate spin-torque nano-oscillators as neurons, such as they were used in refs. 13,26, and also compare the different simulation results with the experimental performance obtained in ref. 26. The methodology and parameters used for simulations are described in “Methods”.
The first learning task that we address is the classification of points belonging to sine and square waveforms. The input data is sent as a time-series, consisting of 100 randomly arranged sine and square waveforms, each discretized in 8 points, as shown in Fig. 3a. The neural network gives a binary output, equal to 0 if it estimates that the input point belongs to a square, and to 1 if it estimates that it belongs to a sine. This task was specifically conceived to test the nonlinearity and the memory of a neural network as the input data points cannot be linearly separated and the extremal points require memory to be distinguished (input points equal to ±1 can both belong to a sine and to a square). At least 24 classical neurons are needed to solve this task with an accuracy > 99%26.

a The input data is a time series of points belonging to a sine or a square discretized in 8 points. b Performance on the sine and square waveform classification task with 16 measured basis state occupations as neural outputs (up to \(\left\vert 33\right\rangle\)) and c with 9 measured basis state occupations (up to \(\left\vert 22\right\rangle\)). The target is shown in full orange line and the reservoir prediction in dashed green line. For simulations methodology see “Methods”.
We send the input drives to the oscillators for 100 ns, one immediately after the other, and we measure the occupation probabilities at the end of each drive. Half of the data is used for training, and another half for testing the performance. We investigate the performance of the quantum reservoir as a function of the number of measured basis states. We first measure the states \(\left\vert 00\right\rangle\) to \(\left\vert 33\right\rangle\), yielding 16 output neurons. The reservoir prediction, obtained with Eq. (3) is shown in Fig. 3b. The prediction matches the target with 99.7% accuracy. This is a very good performance—indeed, it requires at least 40 static classical neurons and 24 dynamical classical neurons (see Fig. 4 for simulations and ref. 26 for experiments) to achieve it. The fact that it is obtained with only 16 measured quantum neurons points to the first aspect of quantum advantage: all the 81 basis states that are populated participate to data processing and transformation even though they are not measured. We push this even further and perform learning while only measuring states up to \(\left\vert 22\right\rangle\), which yields 9 neurons. Strikingly, we still obtain an accuracy of 99% (Fig. 3c). Therefore, this task that requires at least 24 classical dynamical neurons, is perfectly solved by measuring only 9 quantum neurons.

Accuracy on the sine-square waveform classification task as a function of the number of measured neurons, for classical reservoir (both static and dynamic) and for quantum reservoir with quantum oscillators (including the classical limit obtained at large dephasing). For more details on simulations see “Methods”.
To better understand where does this advantage come from, we also performed learning with our quantum system in the classical limit of large dephasing. In this limit, the oscillators exist in a statistical mixture of states instead of the quantum superposition, and quantum coherences vanish. Our observation shows that for 4 and 9 neurons, quantum oscillators perform better than in the classical limit (see Fig. 4), indicating that quantum coherences play a crucial role. Moreover, the classical limit outperforms classical spintronic oscillators, which can be attributed to the fact that even unmeasured basis states still participate in the transformation of input data. This aspect is interesting from an experimental perspective because, even though quantum measurements need to be repeated multiple times to reconstruct the probability amplitudes to find a system in a specific state, it implies that a much smaller number of states need to be measured in comparison to the classical case. Furthermore, all the measurements are performed on the same device, which simplifies the experimental setup, and enables simultaneous measurement using frequency multiplexing27.
Experimentally, the states would be measured by coupling a qubit to each resonator and using the dispersive readout. We study the number of measurements that are needed to obtain sufficiently precise basis state occupations in order to perform learning with the same accuracy as with the exact probability amplitude values28. The variance of the probability amplitude of the occupation of the states is given by the multinomial law
where Nshots is the number of measurements. For three different values of Nshots, we add to the probability amplitude of the occupation of the states an error drawn from a Gaussian distribution of variance 〈p〉. Accuracy on the sine and square waveform classification task is shown in Fig. 5. For the small drives that we apply in our simulations, lower energy levels in each oscillator have higher probabilities to be occupied, which means that their measurement induces smaller errors. We find that for the first two levels in each oscillator (4 neurons in Fig. 5), we obtain with \((\rm{N}_{\dim }+1)^{5}\) shots sufficiently precise values to obtain the same accuracy as with the exact values. For 2 photon states (9 neurons in Fig. 5) with need \((\rm{N}_{\dim }+1)^{9}\) shots and for 3 and 4 photon states (16 and 25 neurons in Fig. 5) we need \((\rm{N}_{\dim }+1)^{11}\) shots.

Accuracy on the sine and square waveform task as a function of the number of measured neurons with a finite number of measurement samples a Nshots= (Ndim + 1)5, b Nshots= (Ndim + 1)9 and c Nshots= (Ndim + 1)11, compared to the ideal measurement of the quantum system (quantum exact) and classical dynamic.
Each measurement in a quantum system disrupts the coherence, making it necessary to remember prior inputs for time-dependent tasks. As a result, portions of the input sequence must be replayed before every measurement. However, recent studies have demonstrated that a quantum reservoir can effectively learn using weak measurements29. This approach eliminates the need for constant replays and subsequently reduces the overall duration of the experiment.
The second benchmark task that we address is the prediction of Mackey-Glass chaotic time-series. Compared to classification, time-series prediction requires the reservoir to have an enhanced memory. It also allows us to investigate the impact of the reservoir temporal dynamics on its prediction capacity; in particular we study how the coupling between the oscillators and their dissipation rates impacts the reservoir performance. Figure 6 shows that the dynamics of a quantum reservoir exhibits greater complexity than that of its classical limit. To make full use of this richness, we can sample the system occupations at several distinct times for a single input.

Mean photon populations in oscillators Namean and Nbmean for a sample input in the sine and square waveform classification task a for the quantum reservoir, and b in the classical limit featuring strong dephasing.
The input data is obtained from the equation
It is chaotic for parameters β = 0.2, γ = 0.1, and τM = 1730. A subset of the input data is shown in Fig. 7a. The time here takes discrete values (point index). The task consists in predicting a point with a certain delay in the future. We have trained the reservoir for different delays varying from 1 to 100 (delay = 20 is shown in Fig. 7a). Each point is sent for 100 ns, such that delay = 20 corresponds to 2 μs. In all the simulations we measure 16 basis state neurons, from \(\left\vert 00\right\rangle\) to \(\left\vert 33\right\rangle\), and we sample the reservoir 10 times for each input, corresponding to a measurement every 10 ns.

a Mackey-Glass chaotic time-series data. b For each input point, the target is the point with a certain delay in the future, here illustrated for delay = 20. c Logarithmic error of the reservoir for the Mackey-Glass task as a function of the number of points in future that the reservoir attempts to predict for two different dissipation rates and for fixed coupling g = 700 MHz, and d for two different oscillator coupling values g and fixed dissipation rates κa = 17 MHz and κb = 21 MHz.
We train the reservoir on 1000 points and test it on another set of previously unseen 1000 points. The results are shown in Fig. 7b, c. We plot the average logarithmic error on 1000 test points as a function of the delay for different reservoir parameters such as dissipation rates and oscillator couplings. In all the cases, we observe an overall logarithmic increase of the error as a function of the delay, which corresponds to the memory of the reservoir—points further in future are harder to predict because the memory is lost. Still, the error saturates for large delays. This saturation is due to the fact that the reservoir learns the range in which the points are situated, and in particular the region where the minima and the maxima of the time-series, that contain a lot of points, are concentrated. Another common feature that can be noticed in all the figures are the oscillations in the error signal that reflect the periodicity in the input data.
We first study the impact of the oscillator dissipation rates κa and κb on the reservoir performance (Fig. 7b). We observe that for high dissipation, the error is globally larger, and most importantly, increases faster—meaning that the memory of the neural network is shorter. It is thus important to have high-quality-factor oscillators to solve tasks that require a lot of memory. Second, we study the impact of the oscillator coupling rate g on the reservoir performance (Fig. 7c). For larger couplings the error decreases; indeed, strong coupling gives rise to multiple data transformations between different basis states which is essential for learning. It also leads to a significant population of a larger number of basis state neurons that contribute to computing.
In previous works, this task was solved in simulations with similar performance using 50 classical dynamical neurons such as skyrmions30 and experimentally with a classical RC oscillator that was time-multiplexed 400 times to obtain 400 virtual neurons14. In comparison, here we solve it with just two physical devices and 16 measured basis state neurons.
Discussion
We have shown that a simple superconducting circuit, composed of two coherently coupled quantum oscillators, can successfully implement quantum reservoir computing. This circuit has been exploited for quantum computing for years, and can be readily used to realize experimentally larger scale quantum reservoir computing.
Compared to classical reservoir, quantum reservoir allows to encode neurons as basis states and to obtain a number of neurons exponential in the number of physical devices. Furthermore, even though it was not the focus of this paper, where we processed classical data, numerical simulations of different quantum reservoirs have shown that quantum reservoirs can process input quantum states31,32 and simultaneously estimate their different properties, as well as perform quantum tomography33. This is particularly interesting in the age where quantum computing encodes information in quantum states and begins to produce more and more quantum data that will need to be automatically classified.
Quantum reservoirs can be implemented on different quantum systems17,31,32,34,35. First works have naturally focused on qubits, as the most common quantum hardware17,31. Nevertheless, quantum oscillators compared to qubits have a net advantage for scaling—they have an infinite number of basis states, compared to qubits that only have two—and they can be much more efficiently populated using resonant drives and coherent coupling. With just two quantum oscillators, we can populate up to 9 states in each oscillator with significant probability amplitudes, which yields a quantum reservoir with up to 81 neurons. By measuring only 16 basis states, we obtain a performance equivalent to 24 classical oscillators. Compared to classical neuromorphic networks, there is an advantage in the number of physical devices, which simplifies experimental implementation, and also in the number of neurons that need to be measured, which simplifies the measurement procedure. Of course, this does not mean that for classical learning tasks it is more efficient to use a quantum neural network, as the whole processing with the measurement will take longer than on a classical computer. Instead, it proves that measuring basis states of quantum oscillators induces sufficient nonlinearity to transform information, as well as that quantum coherences participate to information processing. The tasks that will certainly be more promising for actual quantum speedup are learning on quantum states provided by another coupled quantum system or a quantum computer.
Reservoir computing was already simulated on a single nonlinear quantum oscillator36 and on a system of coupled nonlinear parametric oscillators32. Our work significantly differs from these approaches. In these works, quantum oscillators were operating in the semi-classical regime, where a strong input signal with a large number of photons induces Kerr nonlinearity. In that regime, each oscillator yields two output neurons, i.e., the two field quadratures, that can be sampled in time in order to increase the number of effective neurons. Our approach fully exploits the quantum nature of the system by using the basis states as neurons, which allows to increase the memory of the system as there is no need for sampling, and reduce both the number of physical devices in the system and the number of necessary measurements. Measuring basis states compared to field quadratures has the advantage for the quantum tasks that it avoids the need for an amplifier between the quantum system and the quantum reservoir, but the disadvantage of taking longer to measure the outputs. It will remain an open question to decide depending on the task which observables it makes more sense to measure.
We believe that this solution is very promising for the implementation of quantum neural networks as it is scalable. Indeed, it has recently been shown that multiple oscillators can be parametrically coupled all-to-all through a common waveguide37. The paradigm that we propose would thus allow to realize larger scale quantum neural networks with readily available devices.
Methods
Quantum simulations
We simulate the dynamics of the coupled quantum oscillators using the library QuantumOptics.jl for simulating open quantum systems in Julia38. The dynamics can be captured by the quantum master equation
where ρ is the density matrix of the system. \(\hat{H}_{\rm{drive}}\) is the resonant drive Hamiltonian39,40,41
and
are the drive amplitudes that encode the input data xi. For sine-square waveform classification task we use \({\epsilon }_{0}^{a}={\epsilon }_{0}^{b}=1.2\times 1{0}^{6}\sqrt{{{{\rm{Hz}}}}}\) in order to populate with a significant probability the first 5 levels in each oscillator, and to have negligible probability to populate states above 8 (we truncate the Hilbert space at 8 photons in each oscillator). The Mackey-Glass data takes, on average, larger values compared to sine and square waveform classification—we thus use a smaller value for the drives amplitudes, \({\epsilon }_{0}^{a}={\epsilon }_{0}^{b}=5\times 1{0}^{5}\sqrt{{{{\rm{Hz}}}}}\).
We consider that oscillators couplings to transmission lines κa and κb are dominant terms in the oscillators dissipation, such that we can neglect the internal losses. The collapse operator associated with the decay in the modes a and b can thus be written as
Finally, reservoir outputs are obtained as the expectation values of the basis states occupations
Classical limit of the quantum system
We simulate the classical limit of our quantum reservoir by adding a large dephasing term to the collapse operator in the matrix equation
with κϕ = 100 MHz. With dephasing, the mean values of the photon numbers in oscillators are higher than without dephasing, and we would need to increase the size of the simulated Hilbert space to \({\rm{N}}_{\dim }\) = 12, which would make the simulations too computationally demanding. This is why in the simulations with dephasing we decrease the input drive amplitudes to \({\epsilon }_{a}^{0}={\epsilon }_{b}^{0}=5.5\times 1{0}^{5}\sqrt{{{{\rm{Hz}}}}}\), which gives the same mean number of photons as for simulations without dephasing.
Classical static reservoir simulations
The simulations of the classical reservoirs, both static and dynamic, were performed in the library pytorch for training neural networks in Python.
The state of the reservoir at time t is
where f is the ReLu function, Win is the vector that has the length of the size of the reservoir, and maps the input data on the reservoir, \({{{{\bf{W}}}}}_{{{{\rm{res}}}}}\) is a square matrix that has the dimension of the size of the reservoir and which gives the memory to the reservoir. Here the reservoir has the memory of a single step in the time, which is sufficient for the sine and square waveform classification task. In the simulations of the static reservoir, the size of the reservoir is equal to the number of measured neurons, shown in Fig. 4.
Classical dynamic reservoir simulations
The simulations of dynamical classical reservoir were realized considering a spin-torque nano-oscillator as a neuron, as in ref. 13. The dynamics of the nano-oscillator can be modeled as that of a nonlinear auto-oscillator42
where p is the power of the oscillator, Γ is the damping rate, Q is the nonlinearity, I is the current that drives the oscillator and σ is a factor related to the geometry of the oscillator. The current I encodes the input data and randomly generated Win maps it on the reservoir. Reservoir outputs are obtained from the oscillator power p by numerically integrating Eq. (15).
Data availability
The data that support this study are available in Zenodo with the identifier https://doi.org/10.5281/zenodo.7817435.
Code availability
The code that supports this study is available in Zenodo with the identifier https://doi.org/10.5281/zenodo.7817435.
References
Herrmann, J. et al. Realizing quantum convolutional neural networks on a superconducting quantum processor to recognize quantum phases. Nat. Commun. 13, 4144 (2022).
Huang, H.-Y. et al. Quantum advantage in learning from experiments. Science 376, 6598 (2022).
Dudas, J., Grollier, J. & Marković, D. Coherently coupled quantum oscillators for quantum reservoir computing. in 2022 IEEE 22nd International Conference on Nanotechnology (NANO) 397–400 (2022).
Haas, H. & Jaeger, H. Harnessing nonlinearity: predicting chaotic systems and saving energy in wireless communication. Science 304, 78–80 (2004).
Ramesh, A., Dhariwal, P., Nichol, A., Chu, C. & Chen, M. Hierarchical text-conditional image generation with CLIP latents. Preprint at https://arxiv.org/abs/2204.06125 (2022).
Amin, M. H., Andriyash, E., Rolfe, J., Kulchytskyy, B. & Melko, R. Quantum Boltzmann machine. Phys. Rev. X 8, 21050 (2018).
Scellier, B. & Bengio, Y. Equilibrium propagation: bridging the gap between energy-based models and backpropagation. Front. Comp. Neurosci. 11, 24 (2017).
Chen, R. T. Q., Rubanova, Y., Bettencourt, J. & Duvenaud, D. Neural ordinary differential equations. NeurIPS 6572–6583 (2018).
Onodera, T., Ng, E. & McMahon, P. L. A quantum annealer with fully programmable all-to-all coupling via Floquet engineering. npj Quantum Inf. 6, 48 (2020).
Paquot, Y. et al. Optoelectronic reservoir computing. Sci. Rep. 2, 287 (2012).
Brunner, D., Soriano, M. C., Mirasso, C. R. & Fischer, I. Parallel photonic information processing at gigabyte per second data rates using transient states. Nat. Commun. 4, 1364 (2013).
Vandoorne, K. et al. Experimental demonstration of reservoir computing on a silicon photonics chip. Nat. Commun. 5, 3541 (2014).
Torrejon, J. et al. Neuromorphic computing with nanoscale spintronic oscillators. Nature 547, 428–431 (2017).
Appeltant, L. et al. Information processing using a single dynamical node as complex system. Nat. Commun. 2, 468 (2011).
Rafayelyan, M., Dong, J., Tan, Y., Krzakala, F. & Gigan, S. Large-scale optical reservoir computing for spatiotemporal chaotic systems prediction. Phys. Rev. X 10, 41037 (2020).
Prater, A. A. Comparison of echo state network output layer classification methods on noisy data. in 2017 International Joint Conference on Neural Networks (IJCNN) 2644–2651 (2017).
Fujii, K. & Nakajima, K. Harnessing disordered-ensemble quantum dynamics for machine learning. Phys. Rev. Appl. 8, 024030 (2017).
Negoro, M., Mitarai, K., Fujii, K., Nakajima, K. & Kitagawa, M. Machine learning with controllable quantum dynamics of a nuclear spin ensemble in a solid. Preprint at https://arxiv.org/abs/1806.10910 (2018).
Chen, J., Nurdin, H. I. & Yamamoto, N. Temporal information processing on noisy quantum computers. Phys. Rev. Applied 14, 024065 (2020).
Bergeal, N. et al. Phase-preserving amplification near the quantum limit with a Josephson ring modulator. Nature 465, 64–68 (2010).
Abdo, B. et al. Full coherent frequency conversion between two propagating microwave modes. Phys. Rev. Lett. 110, 173902 (2013).
Abdo, B. et al. Josephson directional amplifier for quantum measurement of superconducting circuits. Phys. Rev. Lett. 112, 167701 (2014).
Frattini, N. et al. 3-wave mixing Josephson dipole element. App. Phys. Lett. 110, 222603 (2017).
Gao, Y. Y. et al. Programmable interference between two microwave quantum memories. Phys. Rev. X 8, 21073 (2018).
Abdo, B., Kamal, A. & Devoret, M. Nondegenerate three-wave mixing with the Josephson ring modulator. Phys. Rev. B 87, 014508 (2013).
Riou, M. et al. Neuromorphic computing through time-multiplexing with a spin-torque nano-oscillator. in 2017 IEEE International Electron Devices Meeting (IEDM) (2017).
Essig, A. et al. Multiplexed photon number measurement. Phys. Rev. X 11, 031045 (2021).
Khan, S. A., Hu, F., Angelatos, G. & Türeci, H. E. Physical reservoir computing using finitely-sampled quantum systems. Preprint at https://arxiv.org/abs/2110.13849 (2021).
Mujal, P. et al. Time-series quantum reservoir computing with weak and projective measurements. npj Quantum Inf. 9, 16 (2023).
Chen, X. et al. Forecasting the outcome of spintronic experiments with Neural Ordinary Differential Equations. Nat. Commun. 13, 1016 (2022).
Ghosh, S., Opala, A., Matuszewski, M., Paterek, T. & Liew, T. C. H. Quantum reservoir processing. npj Quantum Inf. 5, 35 (2019).
Angelatos, G., Khan, S. & Türeci, H. E. Reservoir computing approach to quantum state measurement. Phys. Rev. X 11, 041062 (2021).
Ghosh, S., Opala, A., Matuszewski, M., Paterek, T. & Liew, T. C. Reconstructing quantum states with quantum reservoir networks. IEEE Trans. Neural Netw. Learn. Syst. 32, 3148–3155 (2020).
Nokkala, J. et al. Gaussian states of continuous-variable quantum systems provide universal and versatile reservoir computing. Commun. Phys. 4, 53 (2021).
Govia, L. C., Ribeill, G. J., Rowlands, G. E., Krovi, H. K. & Ohki, T. A. Quantum reservoir computing with a single nonlinear oscillator. Phys. Rev. Res. 3, 013077 (2021).
Kalfus, W. D. et al. Hilbert space as a computational resource in reservoir computing. Phys. Rev. Res. 4, 33007 (2022).
Zhou, C. et al. A modular quantum computer based on a quantum state router. Preprint at https://arxiv.org/abs/2109.06848 (2021).
Krämer, S., Plankensteiner, D., Ostermann, L. & Ritsch, H. QuantumOptics. jl: A Julia framework for simulating open quantum systems. Comput. Phys. Commun. 227, 109–116 (2018).
Gardiner, C. W. Driving a quantum system with the output field from another driven quantum system. Phys. Rev. Lett. 70, 2269–2272 (1993).
Carmichael, H. J. Quantum trajectory theory for cascaded open systems. Phys. Rev. Lett. 70, 2273–2276 (1993).
Kiilerich, A. H. & Mølmer, K. Input-output theory with quantum pulses. Phys. Rev. Lett. 123, 123604 (2019).
Slavin, A. & Tiberkevich, V. Nonlinear auto-oscillator theory of microwave generation by spin-polarized current. IEEE Trans. Magn. 45, 1875–1918 (2009).
Acknowledgements
This research was supported by the Quantum Materials for Energy Efficient Neuromorphic Computing (Q-MEEN-C), an Energy Frontier Research Center funded by the U.S. Department of Energy (DOE), Office of Science, Basic Energy Sciences (BES), under Award DE-SC0019273, by the Paris Ȋle-de-France Region in the framework of DIM SIRTEQ and by European Union (ERC, qDynnet, 101076898). Views and opinions expressed are however those of the author(s) only and do not necessarily reflect those of the European Union or the European Research Council. Neither the European Union nor the granting authority can be held responsible for them.
Author information
Authors and Affiliations
Contributions
D.M. and J.G. conceived the project. D.M. performed the calculations. J.D. performed the quantum simulations. B.C. participated to analytical calculations and quantum simulations. E.P. and F.A.M. performed the classical dynamical simulations. D.M. performed the classical static simulations. D.M. and J.G. wrote the paper.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Dudas, J., Carles, B., Plouet, E. et al. Quantum reservoir computing implementation on coherently coupled quantum oscillators. npj Quantum Inf 9, 64 (2023). https://doi.org/10.1038/s41534-023-00734-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41534-023-00734-4
