
Abstract
The concurrent rise of artificial intelligence and quantum information poses an opportunity for creating interdisciplinary technologies like quantum neural networks. Quantum reservoir processing, introduced here, is a platform for quantum information processing developed on the principle of reservoir computing that is a form of an artificial neural network. A quantum reservoir processor can perform qualitative tasks like recognizing quantum states that are entangled as well as quantitative tasks like estimating a nonlinear function of an input quantum state (e.g., entropy, purity, or logarithmic negativity). In this way, experimental schemes that require measurements of multiple observables can be simplified to measurement of one observable on a trained quantum reservoir processor.
Similar content being viewed by others

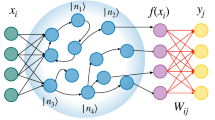
Introduction
Quantum neural networks are emerging technologies that combine the features of artificial neural networks and quantum information technologies.1,2,3 While neural networks are biologically inspired computing systems that learn from example to perform complex tasks in the area of “big data” and machine learning,4,5,6,7 quantum information technologies exploit quantum effects for practical applications like quantum computation, quantum cryptography, and long-distance quantum communications. The interaction between these two promising fields led to many advances. For instance, quantum effects in neural networks8,9 enhance learning efficiency10,11 and speed up solving many classical tasks.12,13,14 Conversely, neural networks are used for solving complex quantum problems,15,16 the control, and design of quantum experiments,17,18,19 and considered as architectures, given a universal quantum computer20,21 or quantum annealer.22
Among the forms of neural networks, recurrent neural networks emerged as particularly suited for solving complex temporal machine-learning tasks. They achieve this by using feedback connections not present in more traditional feedforward neural networks to generate an internal temporal dynamic behavior. However, the training of recurrent neural networks is typically inefficient and computationally expensive.
In reservoir computing, a randomly connected network, called the reservoir, is used as a dynamical processing unit into which an input signal is fed. The training in reservoir computing takes place only at the readout weights that linearly map the readout of the reservoir state to the desired output. The training is conceptually simple and computationally inexpensive.23 Furthermore, they are very suitable for hardware implementation in a wide variety of systems.24,25,26,27,28,29,30 Despite these advantages, reservoir computing is mostly used for tasks in the classical domain, like time-series prediction and speech recognition,26,27,30,31 predicting the evolution of nonlinear dynamics32 and features of chaotic systems,33 while quantum speedup of many of these classical tasks was also considered.34
The idea of reservoir computing is based on the empirical observation that when the nonlinear expansion of the input data is performed randomly, but into a space with a very high dimensionality, one can find good linear cuts for virtually any classification problem. Here, we present a quantum reservoir processing platform designed on the same intuition, but operating on quantum information in a quantum Hilbert space. Our architecture does not require the pre-existence of a quantum computer and is nevertheless capable of performing quantum tasks on a quantum input. Specifically, we consider a 2D fermionic lattice with random intersite coupling excited by an incident quantum state in the form of an optical field, as illustrated in Fig. 1. The architecture is versatile and can perform both qualitative and quantitative tasks. Recognition of quantum entanglement of the input state is an example of a qualitative task. We find that the quantum reservoir processor (QRP) not only recognizes the entanglement of the same class of states as the training set, but is also able to make predictions on states beyond the training class, including bipartite bound entangled states. Our examples of quantitative tasks include estimation of logarithmic negativity, von Neumann entropy, purity, and the trace of any power of an input quantum state. Here, quantum coherence between reservoir nodes and nonlinearity are essential resources behind successful operation of QRP. We discuss the consequences of these findings to simplification of generic quantum experiments. In particular, we argue that measurements of multiple quantum observables can be replaced with a single measurement using QRP that has been suitably trained.

Schematic representation of a quantum reservoir processor. A quantum state in the form of an optical field excites a fermionic lattice with random couplings Jij in an effective Fermi–Hubbard model. The occupation numbers of the fermionic sites are extracted and combined to give a final output. This generic architecture can perform various tasks, such as identifying separability of a quantum state and simultaneously estimating its various properties
Results
The model
Our considered quantum reservoir is a set of fermions (e.g., quantum dots) arranged in a 2D lattice with random nearest-neighbor hopping. The reservoir is defined by the Fermi–Hubbard Hamiltonian:
where \(\hat b_i\) is the fermionic field operator of the site i and Jij are the random hopping amplitudes uniformly distributed in the interval [−1, +1] and normalized, such that the spectral radius (largest modulus of the eigenvalues) of the Hamiltonian is \(\tilde J\). Here, we considered nearest-neighbor coupling in the choice of Jij. A comparison to the case of all-to-all coupling is included in the Supplementary Material (section VIII). Each site in the lattice is driven by an incoherent excitation (e.g., a nonresonant optical field) with the strength P.35 In our scheme, an input bipartite state, in bosonic (e.g., optical) modes \(\hat a_1\) and \(\hat a_2\), is represented by the density matrix ρin. It is incident on the reservoir, interacting for a short time with all fermions. We consider that the two modes of the input state are coupled to the reservoir one at a time. This is to model the physical process, where wave packets are sequentially incident on the reservoir one after the other. The couplings of the input modes to the reservoir are realized via the “cascaded formalism”35,36,37 which eliminates any feedback from the reservoir to the input modes. Due to this coupling, the input state merges to the reservoir. The incident state thus influences the evolution of the reservoir. As readout, we measure the occupation number of each fermionic site of the reservoir. This model can be practically realized in a variety of platforms, including arrays of semiconducting quantum dots or superconducting qubits.38 We note that precise and deterministic quantum dots, which are typically a key challenge,39 are unnecessary for our scheme, where random positioning and coupling are actually useful.
The whole phenomenon can be described by the combined density matrix ρ which includes the quantum reservoir and the incident modes. It follows the quantum master equation:
Here, the Lindblad operator \({\cal{L}}(\hat x) = 2\hat x\rho \hat x^\dagger - \hat x^\dagger \hat x\rho - \rho \hat x^\dagger \hat x\) for a field operator \(\hat x\). On the right side of Eq. (2), the first term represents the coherent Hamiltonian evolution of the reservoir; the second term represents decay of the reservoir modes with a rate γ/ℏ; the third term represents the gain from a nonresonant optical field with strength P and the rest represents the cascade between the input modes \(\hat a_k\) and the reservoir modes \(\hat b_j\).35,36 Here, the second line in Eq. (2) describes quantum excitation of the reservoir (target) by a source \((\hat a_k)\), while the last line in Eq. (2) describes the necessary loss of particles from the source due to the same process. This formalism is appropriate where the source corresponds to incident flying qubits or chiral optics is used to ensure unidirectional coupling.35 Win is an input weight vector with random components uniformly distributed in the interval [0,W] and \(\eta = \mathop {\sum}\nolimits_j {(W_j^{{\mathrm{in}}})^2}\) is set to remove source photons that have excited the reservoir. The functions fk(t) (for k = 1, 2) indicate that the input modes \(\hat a_k\) are sequentially coupled to the reservoir for brief periods of time at different instances. We consider f1(t) = 1 for t1 < t < t1 + τ when the first mode \(\hat a_1\) is connected to the reservoir, whereas f2(t) = 1 for t1 + τ < t < t1 + 2τ, when the second mode is connected to the reservoir; both f1,2(t) = 0 at any other time. We express all energies and times using γ and ℏ/γ, which are natural scales for the respective quantities of our driven–dissipative reservoir. For our numerical simulations, we consider P/γ = 0.1 for the nonresonant optical field, \(\tilde J/\gamma = 1\) for the random hopping amplitudes, W/γ = 1 for the random input weight matrix Win, and τ = 1.5ℏ/γ. While the performance of a QRP weakly depends on P, the appropriate choice of other parameters is important (see Supplementary Material).
In our scheme, we start with an empty reservoir at time t = 0 and turn on the nonresonant optical field P. With P turned on, the reservoir reaches a steady state at time t = t1. Then the input modes \(\hat a_k\) are coupled in a temporal sequence into the reservoir, driving it out of its steady state. In this transient at time t = t1 + 2τ, the occupation numbers \(n_j = \langle \hat b_j^\dagger \hat b_j\rangle\) of the reservoir fermionic sites provide a readout. Our desired output can then be defined as \(Y_i^{{\mathrm{out}}} = \mathop {\sum}\limits_j {W_{ij}^{{\mathrm{out}}}} n_j\), that is, a linear combination of the readout occupation numbers. Due to the fermionic nature of our considered reservoir, the occupation numbers nj are nonlinear functions of the input state. We thus expect to recognize and estimate the nonlinear properties of the input state by linearly processing the readout nj. The output weight matrix Wout is optimized using a training dataset, such that the Yout is best fitted with known training data, corresponding to a particular task. We will now describe exemplary nonclassical tasks.
Recognition of quantum entanglement
We first train the QRP with a set of bipartite squeezed–thermal states that are randomly distributed between separable and entangled states. The two-mode squeezing operator \(\hat {\cal{S}}(\alpha ) = {\mathrm{exp}}(\alpha \hat a_1^\dagger \hat a_2^\dagger - \alpha ^ \ast \hat a_1\hat a_2)\) is applied on bipartite thermal states ρth, with an average occupation number per mode \(\bar n\), to obtain the squeezed–thermal input:
where the squeezing parameter α = |α|eiθ, and |α| and θ are chosen randomly, such that on average, 50% of states are entangled while others are separable (see Supplementary Material). The task is to find the states that are entangled.
For the considered supervised training, the input states must be unambiguously classified into entangled and separable. The squeezed–thermal states are bipartite Gaussian states, and can thus be unambiguously characterized by the logarithmic negativity.40 We train the processor using a set of these states by assigning Yout = (1, 0) if a state is entangled and Yout = (0, 1) otherwise. The training determines the optimum output weights Wout by minimizing the prediction error using ridge regression.
For a performance test, we again prepare a set of random input states ρin which are then fed to the quantum reservoir processor. For each input ρin, the processor then provides an output Yout, which is a 2D vector. If the first element of the vector is larger than the other element, then we assign the input state as entangled and otherwise as separable. In order to test the prediction efficiency, we calculate the logarithmic negativity N(ρin) (retaining the negative values, see Supplementary Material) to independently verify whether ρin is entangled. In an ideal situation, the processor predicts ρin as entangled whenever N(ρin) > 0. In Fig. 2, we represent the input states in a polar plot, where the radius gives the minimum symplectic eigenvalue \(\tilde \nu _{{\mathrm{min}}}\) related to the log-negativity of the state \(N(\rho _{{\mathrm{in}}}) = - {\mathrm{log}}(2\tilde \nu _{{\mathrm{min}}})\) and the angle gives the squeezing angle θ. The prediction of the reservoir processor is presented by the color of each point. The predicted entangled states are the magenta points and the predicted separable states are the blue points. We can see that the entangled states are clustered inside the circle \(\tilde \nu _{{\mathrm{min}}}\, < \,0.5\) indicating that the predicted entangled states are of positive log-negativity.

Quantum reservoir processor trained to recognize entangled squeezed–thermal states. A quantum reservoir processor of four fermions was trained with 200 squeezed–thermal states and tested with another set of squeezed–thermal states with squeezing parameters |α|eiθ. Each point in the radial plot shows an input state ρin with radius being the minimum symplectic eigenvalue \(\tilde \nu _{{\mathrm{min}}}\) related to the logarithmic negativity \(N(\rho _{{\mathrm{in}}}) = - {\mathrm{log}}(2\tilde \nu _{{\mathrm{min}}})\) and angle being the squeezing angle θ. The solid black line represents the circle \(\tilde \nu _{{\mathrm{min}}} = 0.5\). Clearly, the predicted entangled states are largely concentrated inside the circle \(\left( {\tilde \nu _{{\mathrm{min}}} \,<\, 0.5} \right)\) and the separable states are largely on and outside the circle \(\left( {\tilde \nu _{{\mathrm{min}}} \ge 0.5} \right)\). The overall prediction error is (3.7 ± 0.7)%
It turns out that the separability criterion recognized by the QRP is applicable to a wider class of input states beyond the training states. We consider frequently used non-Gaussian states (see the Methods section for detailed expressions): two-mode squeezed states with a photon added or subtracted (the mean photon number comparable to that in the training set), state c0|00〉 + c1|11〉, and bound entangled states introduced in ref. 41. We emphasize that QRP is trained only with the squeezed–thermal states. Surprisingly, it recognizes the non-Gaussian entangled states very efficiently. This suggests that the processor has truly identified the entanglement pattern from the considered Gaussian input states and has used that pattern to recognize the non-Gaussian entangled states, see Fig. 3.

Quantum reservoir processor recognizes other classes of entangled states. In this simulation, the QRP consists of four fermions. The heights of the bars give the percentage of sampled states with correctly identified separability properties. The processor is trained with 200 examples of only squeezed–thermal states. The data are averaged over 10 different configurations of the random couplings Jij between the fermions and input weights Win, and the error bars are indicating the corresponding standard deviations
We show in the Supplementary Material that successful entanglement classification requires quantum coherence between reservoir nodes, confirming that QRP processed quantum rather than classical information.
Quantitative estimations and multiprocessing
QRP can also perform accurate quantitative estimations of nontrivial physical quantities. Furthermore, the method allows simultaneous estimation of many parameters and observables. Suppose we want to estimate M quantities of interest given an input state ρin. For this, we take Yout as an M-dimensional vector. In the training phase, each element of the output vector, \(Y_i^{{\mathrm{out}}}\), is taken as an estimate of the ith parameter. Once the optimum output weight matrix Wout is obtained from the training states, the QRP can predict the values of all M parameters at once. Notice that estimating one parameter at a time requires to repeat M times the same process of sending ρin to the reservoir and measuring nj.
As an example, consider the following set of six parameters: log-negativity M0 = N(ρin), von Neumann entropy M1 = S(ρin), and \(M_n = {\mathrm{Tr}}(\rho _{{\mathrm{in}}}^n)\) for n = 2…5. Clearly, any parameter with series expansion \(\left\langle {\mathop {\sum}\nolimits_n {c_n} \rho ^n} \right\rangle\) can be estimated similarly. We again used the squeezed–thermal states as a training set in order to obtain the weight matrix Wout. Figure 4 shows the excellent capability of the QRP for predicting accurate and precise values of all parameters in one go. We find that increasing the size of the quantum reservoir improves estimation up to a limited amount (see Supplementary Material).

Quantitative predictions for nonlinear functions of an input quantum state. Here, we demonstrate simultaneous estimation of six parameters. In each panel, we plot the true values versus the predicted values with reservoirs of two fermions (blue) and four fermions (orange). The solid black line corresponds to the ideal predictions. The predicted values became more precise and accurate when the number of fermionic sites in the reservoir is increased from 2 to 4. Panel a is for logarithmic negativity (where we retain negative values), panel b for von Neumann entropy, and the remaining panels for trace of higher powers of the input state. The processor is trained with 200 examples of squeezed–thermal states and the test states are also from this class
In this way, QRP provides a platform for simplification of quantum experiments. In a typical experiment, a good estimation of a nonlinear function of ρin requires measurements of multiple quantum observables. In the worst case, one has to perform full quantum state tomography. This is a consequence of the fact that the probability of the measurement result r is a linear function of ρin, i.e., pr = Tr(ρinΠr), where Πr is the corresponding POVM element. The advantage of QRP is that only one measurement is conducted (on the reservoir) and then different parameters are obtained by post-processing of the results. This comes at the expense of additional resources needed to train the processor. As seen in our example, the quality of prediction depends on the number of fermionic sites in the reservoir. If the required precision is obtained with a QRP small enough to be simulated on a classical computer, the training can be done by supplying density matrices likely to be produced in an experiment (or random mixed states in the case of no prior knowledge of the experiment). For a large QRP, the training requires supplying well-characterized physical input states, for which the parameters of interest can be calculated/measured independently and efficiently. Note that this needs to be done only once.
Discussion
We have presented a quantum reservoir processing platform for recognition of quantum entanglement and estimation of nonlinear functions of the input state. This architecture can be used both as a programmable quantum hardware device that can be programmed by training according to the need, or as a software architecture for quantum machine learning that can work for quantum tasks which are otherwise hard. For instance, a software implementation could be to use a quantum reservoir processing platform for identifying bound entangled states.
For hardware implementation, our considered reservoir, that is a 2D fermionic lattice, can be realized in a variety of systems, such as semiconductor quantum dots, NV centers in diamond, and trapped atoms. While here our considered quantum reservoir is a fermionic system, we have found that strongly interacting bosonic systems can also be used for quantum reservoir processing (see Supplementary Material). For instance, the model of our reservoir could be equivalently realized with an array of photonic crystal cavities42 or exciton–polaritons in semiconductor microcavities, which are now approaching the polariton blockade regime43,44,45,46 and were shown to receive the entanglement of external optical fields.47
Although we considered systems in which the source is cascade coupled into the reservoir without feedback, quantum reservoir processing should not be seen as model specific. Considering a system where the source and reservoir are coherently coupled (with feedback) we obtain similar results (see Supplementary Material). Also, our presented quantum-processing tasks are performed by a QRP of four fermions. While considering larger QRPs (if required) for processing quantum information, the sparsity of the reservoir parameters can be important (see Supplementary Material).
Methods
Squeezed–thermal states
A bipartite thermal state can be represented by the density matrix: \(\rho _{{\mathrm{th}}} = \mathop {\sum}\nolimits_{n_1,n_2} {\rho _{n_1n_2}} |n_1,n_2\rangle \langle n_1,n_2|\) with the Fock space elements:
and \(\bar n\) being the average occupation number per mode. The squeezed–thermal states are then obtained as \(\rho _{{\mathrm{sq}}-{\mathrm{th}}} = \hat {\cal{S}}(\alpha )\rho _{{\mathrm{th}}}\hat {\cal{S}}^\dagger (\alpha )\) where the squeezing operator \(\hat {\cal{S}}(\alpha ) = {\mathrm{exp}}(\alpha \hat a_1^\dagger \hat a_2^\dagger - \alpha ^ \ast \hat a_1\hat a_2)\). We write the squeezing parameter as α = |α|eiθ and further |α| = s sinϕ and the average thermal occupation number \(\bar n = s^2{\mathrm{cos}}^2\phi\). Thus, the parameters θ, s, and ϕ are the parameters characterizing the states ρsq-th. We take θ, s, and ϕ as random numbers uniformly distributed in the intervals [0, 2π], [0.8, 0.95], and 0.5 ± π/10, respectively. We have chosen the intervals for all the parameters such that 50% of the states are Gaussian entangled.
Photon-added squeezed states
The photon-added squeezed states are written as \(\rho _{{\mathrm{sq}} - {\mathrm{add}}} = A_{{\mathrm{add}}}{\kern 1pt} \hat a_1^\dagger \hat a_2^\dagger \hat {\cal{S}}(\alpha )|00\rangle \langle 00|{\kern 1pt} \hat {\cal{S}}^\dagger (\alpha )\hat a_2\hat a_1\) where we have considered α = |α|eiθ with |α| and θ uniformly distributed in [0.1, 0.25] and [0, 2π], respectively, and Aadd is the normalization constant. The separability of these states is not always easy to recognize. For example, the Simon criterion does not detect the entanglement of these states for |α| < 0.378.48,49 We have chosen the parameter α in such a way that the prepared states have an average occupation number close to that of the training squeezed–thermal states.
Photon-subtracted squeezed states
The photon-subtracted squeezed states are experimentally relevant.50 These states are expressed as \(\rho _{{\mathrm{sq}} - {\mathrm{sub}}} = A_{{\mathrm{sub}}}{\kern 1pt} \hat a_1\hat a_2\hat {\cal{S}}(\alpha )|00\rangle \langle 00|{\kern 1pt} \hat {\cal{S}}^\dagger (\alpha )\hat a_2^\dagger \hat a_1^\dagger\) where we have considered α = |α|eiθ with |α| and θ uniformly distributed in [0.8, 0.95] and [0, 2π], respectively, and Asub is the normalization constant. We have chosen the parameter α in such a way that the prepared states have an average occupation number close to that of the training states (squeezed–thermal).
The states c 0|00〉 + c 1|11〉
For these states, we have considered the parameterization c0 = sinθ and c1 = cosθeiϕ, and we have sampled these states uniformly on a Bloch sphere.
Bound entangled states
We considered a family of bound entangled states defined by41
where Ab is the normalization constant, \(|\Psi \rangle = \mathop {\sum}\nolimits_{n = 1}^\infty {a^n} |n,n\rangle\), and |Ψmn〉 = cman|n, m〉 + amc−m|m, n〉. The two parameters a and c satisfy the condition 0 < a < c < 1 to impose finite Ab. c and a/c are chosen randomly in ranges [0.3, 0.6] and [0+, 0.1], respectively. These states are bound entangled in the infinite dimensional continuous variable limit as well as in finite dimensions.41 We achieve the continuous variable limit with a small a/c < 0.1 in a truncated Fock space.
Data availability
Data are available from the authors on reasonable request.
Code availability
Computer code used to solve the quantum master equation in this study is available from the authors on reasonable request.
References
Biamonte, J. et al. Quantum machine learning. Nature 549, 195–202 (2017).
Dunjko, V. & Briegel, H. J. Machine learning & artificial intelligence in the quantum domain: a review of recent progress. Rep. Prog. Phys. 81, 7 (2018).
Altaisky, M. V. et al. Towards a feasible implementation of quantum neural networks using quantum dots. Appl. Phys. Lett. 108, 103108 (2016).
Stajic, J., Stone, R., Chin, G. & Wible, B. Rise of the machines. Science 349, 248–249 (2015).
Chouard, T. & Venema, L. Machine intelligence. Nature 521, 435 (2015).
LeCun, Y., Bengio, Y. & Hinton, G. Deep learning. Nature 521, 436–444 (2015).
Butler, K. T., Davies, D. W., Cartwright, H., Isayev, O. & Walsh, A. Machine learning for molecular and materials science. Nature 559, 547–555 (2018).
Lewenstein, M. Quantum perceptrons. J. Mod. Opt. 41, 2491–2501 (1994).
Kak, S. On quantum neural computing. Inf. Sci. 83, 143–160 (1995).
Dunjko, V., Taylor, J. M. & Briegel, H. J. Quantum-enhanced machine learning. Phys. Rev. Lett. 117, 130501 (2016).
Paparo, G. D., Dunjko, V., Makmal, A., Martin-Delgado, M. A. & Briegel, H. J. Quantum speedup for active learning agents. Phys. Rev. X 4, 031002 (2014).
Neigovzen, R., Neves, J. L., Sollacher, R. & Glaser, S. J. Quantum pattern recognition with liquid-state nuclear magnetic resonance. Phys. Rev. A 79, 042321 (2009).
Benedetti, M., Realpe-Gómez, J., Biswas, R. & Perdomo-Ortiz, A. Estimation of effective temperatures in quantum annealers for sampling applications: a case study with possible applications in deep learning. Phys. Rev. A 94, 022308 (2016).
Alvarez-Rodriguez, U., Lamata, L., Escandell-Montero, P., Martn-Guerrero, J. & Solano, E. Supervised quantum learning without measurements. Sci. Rep. 7, 13645 (2017).
Behler, J. & Parrinello, M. Generalized neural-network representation of high-dimensional potential-energy surfaces. Phys. Rev. Lett. 98, 146401 (2007).
Carleo, G. & Troyer, M. Solving the quantum many-body problem with artificial neural networks. Science 355, 602–606 (2017).
Krenn, M., Malik, M., Fickler, R., Lapkiewicz, R. & Zeilinger, A. Automated search for new quantum experiments. Phys. Rev. Lett. 116, 090405 (2016).
Melnikov, A. A. et al. Active learning machine learns to create new quantum experiments. Proc. Natl Acad. Sci. USA 115, 1221–1226 (2018).
Bukov, M. et al. Reinforcement learning in different phases of quantum control. Phys. Rev. X 8, 031086 (2018).
Farhi, E. & Neven, H. Classification with quantum neural networks on near term processors. Preprint at https://arxiv.org/abs/1802.06002 (2018).
Grant, E. et al. Hierarchical quantum classifiers. npj Quantum Inf. 4, 65 (2018).
Amin, M. H., Andriyash, E., Rolfe, J., Kulchytskyy, B. & Melko, R. Quantum Boltzmann machine. Phys. Rev. X. 8, 021050 (2018).
Lukoševičius, M. A Practical Guide to Applying Echo State Networks. (Springer Berlin Heidelberg, Berlin, Heidelberg, 2012).
Paquot, Y. et al. Optoelectronic reservoir computing. Sci. Rep. 2, 287 (2012).
Duport, F., Schneider, B., Smerieri, A., Haelterman, M. & Massar, S. All-optical reservoir computing. Opt. Express 20, 22783–22795 (2012).
Brunner, D., Soriano, M. C., Mirasso, C. R. & Fischer, I. Parallel photonic information processing at gigabyte per second data rates using transient states. Nat. Commun. 4, 1364 (2013).
Vandoorne, K. et al. Experimental demonstration of reservoir computing on a silicon photonics chip. Nat. Commun. 5, 3541 (2014).
Du, C. et al. Reservoir computing using dynamic memristors for temporal information processing. Nat. Commun. 8, 2204 (2017).
Kudithipudi, D., Saleh, Q., Merkel, C., Thesing, J. & Wysocki, B. Design and analysis of a neuromemristive reservoir computing architecture for biosignal processing. Front. Neurosci. 9, 502 (2016).
Larger, L. et al. High-speed photonic reservoir computing using a time-delay-based architecture: million words per second classification. Phys. Rev. X 7, 011015 (2017).
Maass, W., Natschläger, T. & Markram, H. Real-time computing without stable states: a new framework for neural computation based on perturbations. Neural Comput. 14, 2531–2560 (2002).
Jaeger, H. & Haas, H. Harnessing nonlinearity: predicting chaotic systems and saving energy in wireless communication. Science 304, 78–80 (2004).
Pathak, J., Hunt, B., Girvan, M., Lu, Z. & Ott, E. Model-free prediction of large spatiotemporally chaotic systems from data: a reservoir computing approach. Phys. Rev. Lett. 120, 024102 (2018).
Fujii, K. & Nakajima, K. Harnessing disordered-ensemble quantum dynamics for machine learning. Phys. Rev. Appl. 8, 024030 (2017).
Carreño, J. C. L. & Laussy, F. P. Excitation with quantum light. I. Exciting a harmonic oscillator. Phys. Rev. A 94, 063825 (2016).
Gardiner, C. W. Driving a quantum system with the output field from another driven quantum system. Phys. Rev. Lett. 70, 2269–2272 (1993).
Carmichael, H. J. Quantum trajectory theory for cascaded open systems. Phys. Rev. Lett. 70, 2273–2276 (1993).
Georgescu, I. M., Ashhab, S. & Nori, F. Quantum simulation. Rev. Mod. Phys. 86, 153–185 (2014).
Schmidt, O. G. Lateral Alignment of Epitaxial Quantum Dots. (Springer-Verlag Berlin Heidelberg, 2007).
Werner, R. F. & Wolf, M. M. Bound entangled gaussian states. Phys. Rev. Lett. 86, 3658–3661 (2001).
Horodecki, P. & Lewenstein, M. Bound entanglement and continuous variables. Phys. Rev. Lett. 85, 2657–2660 (2000).
Gerace, D., Türeci, H. E., Imamoglu, A., Giovannetti, V. & Fazio, R. The quantum-optical Josephson interferometer. Nat. Phys. 5, 281–284 (2009).
Verger, A., Ciuti, C. & Carusotto, I. Polariton quantum blockade in a photonic dot. Phys. Rev. B 73, 193306 (2006).
Muñoz-Matutano, G. et al. Emergence of quantum correlations from interacting fibre-cavity polaritons. Nat. Mater. 18, 213–218 (2019).
Jia, N. et al. A strongly interacting polaritonic quantum dot. Nat. Phys. 14, 550–554 (2018).
Delteil, A. et al. Towards polariton blockade of confined exciton-polaritons. Nat. Mater. 18, 219–222 (2019).
Cuevas, Á. et al. First observation of the quantized exciton-polariton field and effect of interactions on a single polariton. Sci. Adv. 4, eaao6814 (2018).
Simon, R. Peres-Horodecki separability criterion for continuous variable systems. Phys. Rev. Lett. 84, 2726–2729 (2000).
Nha, H., Lee, S.-Y., Ji, S.-W. & Kim, M. S. Efficient entanglement criteria beyond gaussian limits using gaussian measurements. Phys. Rev. Lett. 108, 030503 (2012).
Ourjoumtsev, A., Ferreyrol, F., Tualle-Brouri, R. & Grangier, P. Preparation of non-local superpositions of quasi-classical light states. Nat. Phys. 5, 189–192 (2009).
Acknowledgements
This work is supported by the Singapore Ministry of Education Academic Research Fund Tier 2, Project No. MOE2015-T2-2-034 and MOE2017-T2-1-001. MM and AO acknowledge support from the National Science Center, Poland grant No. 2016/22/E/ST3/00045.
Author information
Authors and Affiliations
Contributions
S.G. and T.C.H.L. conceived the project through discussion with A.O., M.M., and T.P. S.G. performed the calculations. S.G., T.P., and T.C.H.L. wrote the paper. All authors analyzed the data, discussed the results, and agreed with the conclusions. T.C.H.L. supervised the project.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ghosh, S., Opala, A., Matuszewski, M. et al. Quantum reservoir processing. npj Quantum Inf 5, 35 (2019). https://doi.org/10.1038/s41534-019-0149-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41534-019-0149-8
This article is cited by
-
Emerging opportunities and challenges for the future of reservoir computing
Nature Communications (2024)
-
Binding affinity predictions with hybrid quantum-classical convolutional neural networks
Scientific Reports (2023)
-
Online quantum time series processing with random oscillator networks
Scientific Reports (2023)
-
Taking advantage of noise in quantum reservoir computing
Scientific Reports (2023)
-
Quantum reservoir computing implementation on coherently coupled quantum oscillators
npj Quantum Information (2023)
