
Abstract
The Global Parkinson’s Genetics Program (GP2) will genotype over 150,000 participants from around the world, and integrate genetic and clinical data for use in large-scale analyses to dramatically expand our understanding of the genetic architecture of PD. This report details the workflow for cohort integration into the complex arm of GP2, and together with our outline of the monogenic hub in a companion paper, provides a generalizable blueprint for establishing large scale collaborative research consortia.
Similar content being viewed by others
Introduction
Parkinson’s disease (PD) is a multifactorial disorder with complex etiology. The largest genome-wide association study (GWAS) to-date included 37,688 cases, 18,618 proxy cases (unaffected first-degree relatives), and 1.4 million controls from European ancestry, and identified 90 independent risk signals across 78 genomic regions; 38 of which were novel signals1. Despite these advances, PD GWAS are currently limited by scale, a focus on European populations, and limited integration with clinical phenotype data.
A power calculation based on the 2019 GWAS data indicates that inclusion of an additional ~99,000 cases would enable variants of smaller effect size that contribute to polygenic risk (p-value cut off: 1.35 × 10−3) to reach genome-wide significance. Therefore, expanding PD GWAS to at least this size will result in identification of additional risk loci and improve genetic prediction of PD occurrence1. The heritability of PD can be estimated using twin studies or statistical genetic methods and is thought to lie between 22% and 40% in European populations. Known genome wide significant loci currently explain ~16% of the heritability of PD1. The use of polygenic risk score analysis (including loci that do not reach genome wide significance) indicates that there are likely to be a substantial number of loci contributing to PD risk that have not yet been defined. Our power analysis indicates that 99,000 PD cases will be needed to define loci with 80% power, a minor allele frequency of 0.21 and similar effects to the current state-of-the-art analysis. The variability of phenotypes observed in PD are likely to have a genetic basis2,3,4. Knowledge of associations between genotype and clinical outcomes will enable clinicians to provide patients with a more accurate prognosis. Understanding the gene-to-phenotype pathways responsible for specific PD features would provide an opportunity to develop treatments targeting phenotype-specific disease pathways, resulting in more efficient and personalized treatment with fewer side effects. We aim to capture the diversity of PD outcomes, including Parkinson’s itself but also related conditions such as prodromal Parkinson’s, dementia with Lewy bodies and other Parkinson’s plus syndromes, and to perform large-scale analyses of clinical-genetic data with sufficient power for gene discovery. This will comprise regression and time-to-event analysis for the phenotype of interest (e.g., dementia, dyskinesias, motor progression). It is likely that this will be limited to around 25% of samples included in this study with in depth longitudinal data, and further large scale longitudinal cohorts will be needed to explore the biology of progression and diverse phenotypes. The focus of PD GWAS on individuals of European ancestry has left gaps in our knowledge of PD-associated genetic variants in underrepresented populations and limited our ability to resolve GWAS loci5. To advance understanding of the genetic determinants of Parkinsonism on a global scale, we need to ensure representation of diverse ancestries with sample sizes sufficient to detect ancestry-specific signals. We aim to include at least 15,000 participants of African, South Asian, and East Asian ancestry, respectively.
The Global Parkinson’s Genetics Program (GP2, http://gp2.org/), funded by the Aligning Science Across Parkinson’s initiative (ASAP, https://parkinsonsroadmap.org/) will recruit PD, Prodromal Parkinson’s and Parkinson’s Plus (including Dementia with Lewy bodies, Progressive Supranuclear Palsy, Multiple System Atrophy and Cortico-basal syndrome) cohorts from across the world6. We will genotype >150,000 participants and integrate genetic data with harmonized clinical data for use in case-control and genotype-phenotype association studies. This figure will include a minimum of 50,000 individuals from ancestries currently underrepresented in Parkinson’s research: including Black American, African, Middle Eastern, Central/ East/South Asian, Indian, Caribbean and Central/South American. The remaining participants are expected to be of European ancestry6. Cleaned genetic and clinical data will be harmonized across cohorts and made available to Parkinson’s, Prodromal and Parkinson’s Plus researchers via a controlled-access online repository with a unified user agreement. Contributing investigators are encouraged to play an active role in the project by proposing and leading analyses, and will receive authorship on GP2 publications as well as support for their analyses. GP2 also provides comprehensive training opportunities for researchers from contributing institutions via an online learning management system. The outcome of GP2 will be an open access resource which will integrate clinical and genetic data from a very large, diverse sample of cases, and facilitate discovery of new genetic determinants of Parkinson’s, Prodromal and Parkinson’s Plus occurrence and phenotypic variation in multiple ancestries. A global network of PD researchers will be established, facilitating future collaboration and advancement of PD research. The project began in January 2020 and current funding extends to 2029.
Coordinating cohorts around the world to include 150,000 participants is a considerable logistical challenge. As of May 2022, we have established a workflow for cohort integration, a standardized set of clinical data elements, a recommended consent template, a protocol for evaluating cohorts joining the study, and a process for integrating and harmonizing the incoming clinical data. More broadly, we have established the complex hub framework, which created a code of conduct and publication policy, created a DNA quality and shipping protocol, and created the NeuroBooster Array (NBA) genotyping workflow.
The size and depth of the dataset which is being generated by GP2 will provide a major opportunity to discover new genotype-phenotype associations. Core analyses, analyses that will be continuously updated by the analysis teams at GP2 with the inclusion of new samples, will include case-control, age at onset, and progression GWAS, as well as within-ancestry analyses of previously underrepresented populations. Beyond this, GP2 is supporting additional analytical projects proposed by contributing collaborators. The GP2 network will also facilitate collaboration on auxiliary studies between investigators sharing the same area of interest (e.g., biomarkers of different modalities) to address outstanding questions in PD research.
GP2 is conducted according to overarching principles of democratization of data, collaboration and cooperation, safe and responsible data sharing, commitment to diversity in research, transparency and reproducibility, and production of an actionable resource in accordance with the Findable, Accessible, Interoperable and Reusable (FAIR) scientific data management principles7. It is GP2 policy that local researchers are included in publications that use their data/samples. Here, we report the specific steps undertaken by the Cohort Integration Working Group (CIWG) to identify, recruit, and harmonize clinical cohorts within the complex disease arm of GP2. GP2 also has a monogenic arm (https://gp2.org/working-groups/) which focuses on cases with potential monogenic causes of PD, i.e., those with early age at onset or a family history of PD (Reference: PMID:37369645).
Methods
PD and Parkinson’s Plus investigators and cohorts are identified through relevant publications, or through existing consortia. We welcome contact from interested investigators around the world (Email: cohort@gp2.org). Prospective collaborators complete a Site Interest Form (SIF) (Supplementary Material) to provide a brief overview of their cohort [Supplementary material]. Data availability, type of cohort (e.g., brain bank, drug study etc.), ethnic diversity and sample/data sharing restrictions are all considered by the CIWG when reviewing SIF submissions. Cohorts’ consent documents are reviewed by the Operations and Compliance Working Group (OCWG) to ensure consent for sample/data sharing was obtained, and compliance with regional and cohort-specific data sharing restrictions. The OCWG assists the investigator if revisions are needed, and template consent language is provided online (https://gp2.org/resources/consent-guidelines/ [Supplementary Material]). We have an inclusive approach; to-date >95% of cohorts evaluated have been accepted. Following cohort approval, a concise Collaboration Agreement is signed by the collaborating PI and the Michael J. Fox Foundation (MJFF), and the necessary material and data transfer agreements are completed. The cohort’s samples are then transferred to one of GP2’s genotyping centers, and data are transferred through secure upload to a cloud server.
Once the cohort’s clinical data have been transferred, harmonization and quality control (QC) are performed by the CIWG, following a standard framework8. Core clinical data were decided on the basis of clinical scales available in existing PD cohorts (primarily the Tracking Parkinson’s9, PPMI10, PDBP11, NET PD-LS112, and GEoPD13 cohorts) as well as on the basis of recent proposals for a modular set of assessment criteria to characterize longitudinal PD cohorts14,15. The core clinical data elements are the clinical data categories of interest which will be harmonized across cohorts and used for analysis (Table 1). We have generated a common dataset for brain banks, and have added data elements for time-to-event analysis (Supplementary Table 1). We are also collecting information on availability of other data and samples, including, plasma, serum, RNA, fibroblasts, CSF, skin biopsy, PBL, iPS to expand awareness of the resources that are available at contributing sites (Supplementary Material). The common dataset is defined in a common data dictionary (Supplementary Table 2). The harmonization of raw data uses a set of coding rules for re-coding and handling of missing data, using a modified custom script for each cohort.
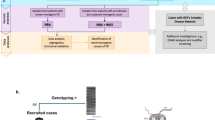
DNA samples from each cohort are genotyped on the Neuro Booster Array (NBA; https://github.com/GP2code/Neuro_Booster_Array), developed in collaboration between Data Tecnica International, NIA, NINDS, Illumina Inc and GP2. The NBA consists of the Illumina Infinium Global Diversity Array (GDA; https://www.illumina.com/products/by-type/microarray-kits/infinium-global-diversity.html), a high-density (1.9 M total variants) global backbone optimized for cross-population imputation coverage of the human genome, and additional custom content (>95,000 variants) which includes known causal variants for various neurodegenerative diseases and imputation boosters for underrepresented populations. QC of genotype data by the Data Analysis Working Group (DAWG) follows a standard pipeline. A custom genotype clustering file is used to ensure representation of the diverse genetic ancestries within the GP2 data. The clustering file used for the latest data release is based on 2793 samples across 6 ancestry groups, and includes 420 Gaucher disease cases to capture variants of interest in the GBA1 risk gene. This file is available for download via the GP2 Github repository (https://github.com/GP2code). Cleaned genetic data are returned to the contributing investigator to use as they wish, and are uploaded to the GP2 repository for use in combined analyses (Fig. 1). GP2 covers the costs of genotyping and sample shipment for all contributing cohorts, and can assist investigators with the analysis of their cohort’s data.

Data are contributed and returned to the local PI (green); new genetic data, data cleaning and harmonization are carried out by GP2 and made available for analysis within the GP2 consortium (blue); and data are released to qualified investigators via AMP-PD (orange). AMP-PD Accelerating Medicines Partnership - Parkinson’s Disease (https://amp-pd.org).
The dataset which we are currently aggregating and harmonizing contains a wide variety of demographic and clinical factors, thanks to the diversity of contributing cohorts. As of March 2023, the CIWG has approved 145 cohorts for inclusion in GP2, of which 128 have been approved by the OCWG, and 74 have completed all necessary agreements and are in the process of transferring samples and clinical data. Samples that have been transferred are currently being genotyped and passed through the data QC pipeline. So far, the approved cohorts span over 50 different countries and territories. A map showing the geographic distribution of these cohorts, as well as current expected and completed sample numbers, can be found on the GP2 website (https://gp2.org/cohort-dashboard/ [Supplementary Material]).
Reporting summary
Further information on research design is available in the Nature Research Reporting Summary linked to this article.
Data availability
GP2 has partnered with the Accelerating Medicines Partnership - Parkinson’s Disease (AMP-PD; https://amp-pd.org) to share data generated by GP2, and in December 2021 the first GP2 genotyping data were released on the AMP-PD platform. As of 2023, the data consist of 14,902 samples (8190 PD cases), representing a broad range of diverse ancestries defined directly from the genotyping data from these cohorts. Genotyping and data QC is ongoing, and there will be regular data releases (2–4 times per year) as the project progresses. All contributing investigators have access to GP2 data, and external researchers can also gain access by following instructions on the GP2 website (https://gp2.org/applying-for-gp2-data-access-on-the-amp-pd-platform/). There are two tiers of data access. Tier 1 consists of summary statistics and any researcher can gain access by completing an online application. Tier 2 access includes deidentified, individual level genetic data, and to gain access researchers must sign a Data Usage Agreement co-signed by their institution.
Code availability
Code used in GP2 core analyses and the custom clustering files are deposited in the GP2 GitHub repository (https://github.com/GP2code). Code created and used by the CIWG can be found on the “GP2-WorkingGroups/CD-Cohort-Integration” subpage of the GP2 GitHub repository (https://github.com/GP2code/GP2-WorkingGroups/tree/main/CD-Cohort-Integration). The Data and Code Dissemination Working Group (DCD-WG) at GP2 is committed to making these data, resources, and training materials accessible to the scientific community. The DCD-WG actively supports efforts to consolidate analysis scripts with the necessary analytical tools and decisions via GitHub (https://github.com/GP2code), consolidate training materials with several translations in collaboration with the Training and Networking Working Group (https://gp2.org/training/), and consolidate additional analytical pipelines on Terra (https://amp-pd.org/tools).
References
Nalls, M. A. et al. Identification of novel risk loci, causal insights, and heritable risk for Parkinson’s disease: a meta-analysis of genome-wide association studies. Lancet Neurol. 18, 1091–1102 (2019).
Iwaki, H. et al. Genetic risk of Parkinson disease and progression: an analysis of 13 longitudinal cohorts. Neurol. Genet. 5, 1–14 (2019).
Latourelle, J. C. et al. Large-scale identification of clinical and genetic predictors of Parkinson’s disease motor progression in newly-diagnosed patients: a longitudinal cohort study and validation. Lancet Neurol. 16, 908–916 (2017).
Tan, M. M. X. et al. Genome-wide association studies of cognitive and motor progression in Parkinson’s disease. Mov. Disord. 36, 424–433 (2021).
Heinzel, S., Lerche, S., Maetzler, W. & Berg, D. Global, yet incomplete overview of cohort studies in Parkinson’s disease. J. Parkinsons. Dis. 7, 423–432 (2017).
The Global Parkinson’s Genetics Program (GP2). GP2: the global parkinson’s genetics program. Mov. Disord. 36, 842–851 (2021).
Wilkinson, M. D. et al. The FAIR Guiding Principles for scientific data management and stewardship. Sci. Data 3, 160018 (2016).
Bennett, S. N. et al. Phenotype harmonization and cross-study collaboration in GWAS consortia: the GENEVA experience. Genet. Epidemiol. 35, 159–173 (2011).
Malek, N. et al. Tracking Parkinson’s: study design and baseline patient data. J. Parkinsons. Dis. 5, 947–959 (2015).
Parkinson Progression Marker Initiative. The Parkinson Progression Marker Initiative (PPMI). Prog. Neurobiol. 95, 629–635 (2011).
Rosenthal, L. S. et al. The NINDS Parkinson’s disease biomarkers program. Mov. Disord. 31, 915–923 (2016).
Kieburtz, K. et al. Effect of creatine monohydrate on clinical progression in patients with Parkinson disease. JAMA 313, 584–593 (2015).
Bardien, S., Mellick, G. D., Hattori, N., Ross, O. A. & Lesage, S. Celebrating the Diversity of Genetic Research to Dissect the Pathogenesis of Parkinson’s Disease (Frontiers Media SA, Lausanne, 2021).
Lerche, S. et al. Aiming for study comparability in Parkinson’s disease: proposal for a modular set of biomarker assessments to be used in longitudinal studies. Front. Aging Neurosci. 8, 1–4 (2016).
Lerche, S. et al. Methods in neuroepidemiology characterization of European longitudinal cohort studies in Parkinson’s disease-report of the JPND working group BioLoC-PD. Neuroepidemiology 45, 282–297 (2015).
Grinnon, S. T. et al. National institute of neurological disorders and stroke common data element project - approach and methods. Clin. Trials 9, 322–329 (2012).
Postuma, R. B. et al. MDS clinical diagnostic criteria for Parkinson’s disease. Mov. Disord. 30, 1591–1601 (2015).
Gibb, W. R. G. & Lees, A. J. The relevance of the Lewy body to the pathogenesis of idiopathic Parkinson’s disease. J. Neurol. Neurosurg. Psychiatry 51, 745–752 (1988).
Martínez-Martín, P. et al. Global versus factor-related impression of severity in Parkinson’s disease: a new clinimetric index (CISI-PD). Mov. Disord. 21, 208–214 (2006).
Goetz, C. G. et al. Movement disorder society-sponsored revision of the unified Parkinson’s disease rating scale (MDS-UPDRS): process, format, and clinimetric testing plan. Mov. Disord. 22, 41–47 (2007).
Fahn S., Elton R. Members of the UPDRS Development Committee. in Recent Developments in Parkinson’s Disease, Vol 2, (eds. Fahn S., Marsden C. D., Calne D. B., & Goldstein M.) 153-163, 293-304 (Macmillan Health Care Information, 1987).
Folstein, M. F., Folstein, S. E. & McHugh, P. R. Mini-mental state’. A practical method for grading the cognitive state of patients for the clinician. J. Psychiatr. Res. 12, 189–198 (1975).
Nasreddine, Z. S. et al. The Montreal Cognitive Assessment, MoCA: A brief screening tool for mild cognitive impairment. J. Am. Geriatr. Soc. 53, 695–699 (2005).
Hoehn, M. M. & Yahr, M. D. Parkinsonism: onset, progression and mortality. Neurology 17, 427–442 (1967).
Visser, M., Marinus, J., Stiggelbout, A. M. & van Hilten, J. J. Assessment of autonomic dysfunction in Parkinson’s disease: the SCOPA-AUT. Mov. Disord. 19, 1306–1312 (2004).
Stiasny-Kolster, K. et al. The REM sleep behavior disorder screening questionnaire - a new diagnostic instrument. Mov. Disord. 22, 2386–2393 (2007).
Johns, M. W. A new method for measuring daytime sleepiness: the Epworth sleepiness scale. Sleep 14, 540–545 (1991).
Yesavage, J. A. & Sheikh, J. I. Geriatric Depression Scale (GDS) recent evidence and development of a shorter version. Clin. Gerontol. 5, 165–173 (1986).
Doty, R. L., Shaman, P. & Dann, M. Development of the University of Pennsylvania Smell Identification Test: a standardized microencapsulated test of olfactory function. Physiol. Behav. 32, 489–502 (1984).
Wolfensberger, M. Sniffin’sticks: a new olfactory test battery. Acta Otolaryngol. 120, 303–306 (2000).
Doty, R. L., Marcus, A. & Lee, W. W. Development of the 12-item Cross-Cultural Smell Identification Test (CC-SIT). Laryngoscope 106, 353–356 (1996).
Schwab, R. S. & England, A. C. Projection technique for evaluating surgery in Parkinson’s disease. in Third Symposium on Parkinson’s Disease (eds Billingham, F. H. & Donaldson, M. C.) p. 152–157 (Churchill Livingstone, 1969).
Jenkinson, C., Fitzpatrick, R., Peto, V., Greenhall, R. & Hyman, N. The PDQ-8: development and validation of a short-form Parkinson’s disease questionnaire. Psychol. Health 12, 805–814 (1997).
Chaudhuri, K. R. et al. King’s Parkinson’s disease pain scale, the first scale for pain in PD: an international validation. Mov. Disord. 30, 1623–1631 (2015).
Acknowledgements
This research is supported by the Aligning Science Across Parkinson’s Initiative, the Intramural Research Program, National Institute on Aging, National Institutes of Health, Department of Health and Human Services, project ZO1 AG000949, and the Michael J. Fox Foundation for Parkinson’s Research. Data used in the preparation of this article were obtained from Global Parkinson’s Genetics Program (GP2). GP2 is funded by the Aligning Science Across Parkinson’s (ASAP) initiative and implemented by The Michael J. Fox Foundation for Parkinson’s Research (https://gp2.org). For a complete list of GP2 members see https://gp2.org.
Author information
Authors and Affiliations
Consortia
Contributions
C.T., M.R., S.J., E.J.S., J.J., T.A., A.C.M., M.M.X.T., H.I., and H.R.M. are members of the GP2 Cohort Integration Working Group (CIWG), of which H.R.M. is the lead, and M.M.X.T. and H.I. are co-leads. C.T. was the primary contributor in the drafting of this manuscript, assisted by M.R. and J.J. The draft was reviewed by all CIWG members prior to circulation to other contributing authors for review. M.B.M. is the co-lead of the GP2 Data and Code Dissemination Working Group and drafted the data availability section of this manuscript, together with B.C. who is senior associate director at the Michael J. Fox Foundation’s research division. D.V., K.L., H.L., and M.A.N. are members of the GP2 Complex Disease Data Analysis Working Group (DAWG), of which M.A.N. is the lead and H.L. is a co-lead. DAWG are responsible for the data cleaning and analysis described in this manuscript. DGH directs the Genomic Technologies Group within the Laboratory of Neurogenetics at NIH, which conducts the majority of sample genotyping for the Complex Network. C.E.W. and J.S. are members of the GP2 Operations and Compliance Working Group of which J.S. is a co-lead. C.B.P. and L.A.S. are scientific program managers for the GP2 Complex Disease Network. A.B.S. is the lead of the GP2 Complex Disease Network and C.B. is the co-lead. All listed authors reviewed the manuscript and provided comments and revisions prior to submission.
Corresponding author
Ethics declarations
Competing interests
A.B.S. and C.B. are supported by the Intramural Research Program of the National Institute on Aging and have received grant support from the Michael J. Fox Foundation for Parkinson’s Research and the Aligning Science Across Parkinson’s Initiative. A.B.S. has received royalty payments related to a diagnostic for stroke. A.B.S. is an editor for npj Parkinson’s Disease. A.B.S. was not involved in the journal’s review of, or decisions related to, this manuscript. H.L., H.I., D.V., K.L., and M.A.N. are consultants employed by Data Tecnica International. Data Tecnica is engaged in a consulting agreement with the US National Institutes of Health. H.R.M. is employed by UCL. In the last 24 months, he reports paid consultancy from Biogen, Biohaven, Lundbeck; lecture fees/honoraria from Wellcome Trust, Movement Disorders Society; Research Grants from Parkinson’s UK, Cure Parkinson’s Trust, PSP Association, CBD Solutions, Drake Foundation, Medical Research Council, Michael J. Fox Foundation. H.R.M. is also a co-applicant on a patent application related to C9ORF72—Method for diagnosing a neurodegenerative disease (PCT/GB2012/052140). BC and JS are employed by the Michael J. Fox Foundation for Parkinson’s Research. All other authors declare no financial or non-financial competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
41531_2023_533_MOESM1_ESM.pdf
Global Parkinson’s Genetics Program: Emilia M Gatto, Marcelo Kauffman, Samson Khachatryan, Zaruhi Tavadyan, Claire E Shepherd, Julie Hunter, Kishore Kumar, Melina Ellis, Miguel E. Rentería, Sulev Koks, Alexander Zimprich, Artur F. Schumacher-Schuh, Carlos Rieder, Paula Saffie Awad, Vitor Tumas, Sarah Camargos, Edward A. Fon, Oury Monchi, Ted Fon, Benjamin Pizarro Galleguillos, Marcelo Miranda, Maria Leonor Bustamante, Patricio Olguin, Pedro Chana, Beisha Tang, Huifang Shang, Jifeng Guo, Piu Chan, Wei Luo, Gonzalo Arboleda, Jorge Orozco, Marlene Jimenez del Rio, Alvaro Hernandez, Mohamed Salama, Walaa A. Kamel, Yared Z. Zewde, Alexis Brice, Jean-Christophe Corvol, Ana Westenberger, Anastasia Illarionova, Brit Mollenhauer, Christine Klein, Eva-Juliane Vollstedt, Franziska Hopfner, Günter Höglinger, Harutyun Madoev, Joanne Trinh, Johanna Junker, Katja Lohmann, Lara M. Lange, Manu Sharma, Sergio Groppa, Thomas Gasser, Zih-Hua Fang, Albert Akpalu, Georgia Xiromerisiou, Georgios Hadjigorgiou, Ioannis Dagklis, Ioannis Tarnanas, Leonidas Stefanis, Maria Stamelou, Efthymios Dadiotis, Alex Medina, Germaine Hiu-Fai Chan, Nancy Ip, Nelson Yuk-Fai Cheung, Phillip Chan, Xiaopu Zhou, Asha Kishore, Divya KP, Pramod Pal, Prashanth Lingappa Kukkle, Roopa Rajan, Rupam Borgohain, Mehri Salari, Andrea Quattrone, Enza Maria Valente, Lucilla Parnetti, Micol Avenali, Tommaso Schirinzi, Manabu Funayama, Nobutaka Hattori, Tomotaka Shiraishi, Altynay Karimova, Gulnaz Kaishibayeva, Cholpon Shambetova, Rejko Krüger, Ai Huey Tan, Azlina Ahmad-Annuar, Mohamed Ibrahim Norlinah, Nor Azian Abdul Murad, Norlinah Mohamed Ibrahim, Shahrul Azmin, Shen-Yang Lim, Wael Mohamed, Yi Wen Tay, Daniel Martinez-Ramirez, Mayela Rodriguez-Violante, Paula Reyes-Pérez, Bayasgalan Tserensodnom, Rajeev Ojha, Tim J. Anderson, Toni L. Pitcher, Arinola Sanyaolu, Njideka Okubadejo, Oluwadamilola Ojo, Jan O. Aasly, Lasse Pihlstrøm, Manuela Tan, Shoaib Ur-Rehman, Mario Cornejo-Olivas, Maria Leila Doquenia, Raymond Rosales, Angel Vinuela, Elena Iakovenko, Bashayer Al Mubarak, Muhammad Umair, Eng-King Tan, Jia Nee Foo, Ferzana Amod, Jonathan Carr, Soraya Bardien, Beomseok Jeon, Yun Joong Kim, Esther Cubo, Ignacio Alvarez, Janet Hoenicka, Katrin Beyer, Maria Teresa Periñan, Pau Pastor, Sarah El-Sadig, Christiane Zweier, Krack Paul, Chin-Hsien Lin, Hsiu-Chuan Wu, Pin-Jui Kung, Ruey-Meei Wu, Serena Wu, Yihru Wu, Rim Amouri, Samia Ben Sassi, A. Nazlı Başak, Gencer Genc, Özgür Öztop Çakmak, Sibel Ertan, Alastair Noyce, Alejandro Martínez-Carrasco, Anette Schrag, Anthony Schapira, Camille Carroll, Claire Bale, Donald Grosset, Eleanor J. Stafford, Henry Houlden, Huw R Morris, John Hardy, Kin Ying Mok, Mie Rizig, Nicholas Wood, Nigel Williams, Olaitan Okunoye, Patrick Alfryn Lewis, Rauan Kaiyrzhanov, Rimona Weil, Seth Love, Simon Stott, Simona Jasaitye, Sumit Dey, Vida Obese, Alberto Espay, Alyssa O'Grady, Andrew B Singleton, Andrew K. Sobering, Bernadette Siddiqi, Bradford Casey, Brian Fiske, Cabell Jonas, Carlos Cruchaga, Caroline B. Pantazis, Charisse Comart, Claire Wegel, Cornelis Blauwendraat, Dan Vitale, Deborah Hall, Dena Hernandez, Ejaz Shiamim, Ekemini Riley, Faraz Faghri, Geidy E. Serrano, Hampton Leonard, Hirotaka Iwaki, Honglei Chen, Ignacio F. Mata, Ignacio Juan Keller Sarmiento, Jared Williamson, Jonggeol Jeff Kim, Joseph Jankovic, Joshua Shulman, Justin C. Solle, Kaileigh Murphy, Karen Nuytemans, Karl Kieburtz, Katerina Markopoulou, Kenneth Marek, Kristin S. Levine, Lana M. Chahine, Laurel Screven, Lauren Ruffrage, Lisa Shulman, Luca Marsili, Maggie Kuhl, Marissa Dean, Mary B Makarious, Mathew Koretsky, Miguel Inca-Martinez, Mike A. Nalls, Naomi Louie, Niccolò Emanuele Mencacci, Roger Albin, Roy Alcalay, Ruth Walker, Sara Bandres-Ciga, Sohini Chowdhury, Sonya Dumanis, Steven Lubbe, Tao Xie, Tatiana Foroud, Thomas Beach, Todd Sherer, Yeajin Song, Duan Nguyen, Toan Nguyen, Masharip Atadzhanov Supplementary Material
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Towns, C., Richer, M., Jasaityte, S. et al. Defining the causes of sporadic Parkinson’s disease in the global Parkinson’s genetics program (GP2). npj Parkinsons Dis. 9, 131 (2023). https://doi.org/10.1038/s41531-023-00533-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41531-023-00533-w
This article is cited by
-
Genotype–phenotype correlation in PRKN-associated Parkinson’s disease
npj Parkinson's Disease (2024)
