
Abstract
The identification of transitions in pattern-forming processes are critical to understand and fabricate microstructurally precise materials in many application domains. While supervised methods can be useful to identify transition regimes, they need labels, which require prior knowledge of order parameters or relevant microstructures describing these transitions. Instead, we develop a self-supervised, neural-network-based approach that does not require predefined labels about microstructure classes to predict process parameters from observed microstructures. We show that assessing the difficulty of solving this inverse problem can be used to uncover microstructural transitions. We demonstrate our approach by automatically discovering microstructural transitions in two distinct pattern-forming processes: the spinodal decomposition of a two-phase mixture and the formation of binary-alloy microstructures during physical vapor deposition of thin films. This approach opens a path forward for discovering unseen or hard-to-discern transitions and ultimately controlling complex pattern-forming processes.
Similar content being viewed by others


Introduction
Identifying and characterizing transitions in pattern-forming processes are key to our understanding and control of many systems in physical, chemical, material, and biological sciences. These tasks can be particularly challenging when the transition from one type of microstructural pattern to another is continuous or ambiguous as may be the case in dynamic and second-order phase transition processes. The reason is the state of the material system may exhibit subtle, hard-to-discern changes in the microstructure when the process parameters controlling the formation of patterns vary. For example, in cellular dynamics, cytoskeletal protein actin filaments undergo a continuous isotropic to nematic liquid crystalline phase transition when polymerized1. In chemical systems undergoing a precipitation reaction (Liesegang systems), one can control the transition from one precipitation pattern to another by regulating solid hydrogel and reactant concentrations2,3,4,5. When heated up, block copolymers thin films experience a smooth, thermally induced morphology transition from cylindrical to lamellar microdomains6,7. Similarly, the co-sputter deposition of immiscible elements results in a variety of self-organized microstructural patterns depending on processing conditions8,9,10,11.
The theory describing these types of transitions was first proposed by Landau12 and later improved using renormalization group theory13. In such models, the determination of a pattern transition relies on (i) the identification of a local order parameter that sharply changes from one value to another (i.e., the order parameter changes discontinuously as in first-order transitions) and (ii) straightforward symmetry-breaking considerations of that order parameter. However, in many cases, topological (structural) transitions14,15,16,17 are gradual and elusive, making it more difficult to identify the appropriate indicators of microstructural topology transitions. Supervised learning techniques18,19,20,21,22, that use predetermined labelling of distinct types of patterns for given process parameters, are commonly used to classify and predict transitions. However, generating these labels requires prior knowledge of the regimes in the process parameter space where the transition may occur, limiting the scope of this class of methods primarily to already known and at least partially and previously explored transition cases. In contrast, unsupervised learning techniques23,24,25,26,27,28,29,30 do not require hand labelling or other time-consuming manual and potentially subjective interventions. Many of these unsupervised approaches use dimensionality reduction and clustering to classify topological phases in latent space and detect the topological transitions.
Like unsupervised methods, self-supervised learning does not require predefined labels for the target task of classification. Instead of directly solving a clustering problem, self-supervised learning focuses on solving an auxiliary prediction problem which is easy to measure and closely related and ‘semantically’ connected to the target task. Often the auxiliary problem requires predicting structure of the training data instead of some external labels, hence the “self-supervised” name. The promise of this method is that, while learning to solve the auxiliary task, for which labels can be easy to generate and do not require human supervision, we can learn the structure of the original problem for which the true labels are unknown. In the present case, we aim at learning the structure of the data in pattern-forming processes and use this knowledge to identify the transitions between different classes of patterns for which we do not have labels. Self-learning approaches can lead to models achieving comparable performance as when trained in a traditional supervised fashion, while reducing reliance on predefined labeled data31,32. In computer vision for instance, learning to predict whether two images are modified versions of the same original image, allows to construct a high-quality latent representation of the data, that can subsequently be used for solving an object recognition task33.
With all its advantages, it can be challenging to define an appropriate task to use for the self-supervised training. In the context of the present work, our target task is the identification and characterization of microstructure transitions when the process parameters controlling the pattern formation vary. We propose that a relevant auxiliary task is to solve the inverse problem of predicting input process parameters from observed microstructures. The theoretical motivation behind this inverse problem stems from the fact that in material systems that experience a topological transition (or critical point), the sensitivity of forming specific patterns varies depending on the input process parameter. This sensitivity can sometimes increase, as it would be the case if a given process parameter acts as an order parameter, uniquely characterizing a regime for which a specific pattern exists. Or the sensitivity can decrease, as it would be the case for systems that exhibit universality (i.e., the closer the parameter is to its critical value, the less sensitively the order parameter depends on the dynamical details of the system). Through our study, we found the inverse problem to be strongly related to our target task of identifying microstructure transitions. Interestingly, the most relevant signature for identifying microstructure transition regimes emerged from looking at changes in the neural network’s uncertainty in solving the inverse problem. Our approach is akin to, but distinct from, confusion-based techniques25,34 which attempt to learn a model that directly predicts phase transitions but side-steps the requirement for ground truth labels by training with pseudo-labels.
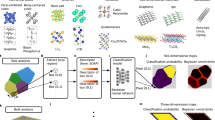
Figure 1 illustrates the steps of our approach. In the first step (Fig. 1a top left panel), we performed high-fidelity phase-field simulations of pattern-forming processes in binary microstructures. The intent of this first step is to generate a large and diverse set of microstructural patterns as a function of the process parameters (e.g., phase fraction, phase mobility, deposition rate) and therefore generate a database of transition regimes where the microstructural patterns switch from one class of patterns to another when the process parameters change. As prototypical examples, we chose two pattern-forming processes, namely the spinodal decomposition of a two-phase mixture and the formation of various self-organized microstructural patterns of binary alloys during the physical vapor deposition of thin films. The first problem is chosen due to its simplicity in identifying different pattern-formation regimes as a function of the concentration and mobility of the two phases. The second problem is used to test the generalizability of our approach, as it displays hard-to-discern transitions from one class of patterns to another when the deposition process parameters change. The difficulty in this second problem lies in the identification of clear transitions in microstructural patterns which appear to have seemingly continuous and non-trivial changes of classes of patterns when the input process parameters vary. In the second step of our approach, we represent these microstructural patterns in a latent space using a pre-trained convolutional neural network (CNN), namely ResNet-50 v235. The goal of this step is to obtain a low-dimensional representation of these patterns (Fig. 1a right panel) in order to learn the structure of the data. While the ResNet model was trained on image data not similar to our simulations, it is still able to discern complex shapes and motifs, which allows different microstructural patterns to be distinguishable. Such performance shows the robustness of this step. As described in the Supplementary Information (Supplementary Notes 1 and 2), we can obtain similar results using different pre-trained models. In this work, we settled for ResNet-50 v2 as a prototypical CNN model due to its wide accessibility and popularity. The latent dimensions obtained from the ResNet model are subsequently regressed with a dense, feedforward, deep neural network to predict the original input process parameters that led to specific microstructural patterns. This last step (Fig. 1a bottom left panel) can be seen as solving our inverse problem (i.e., predicting the initial input process parameters from the output microstructural pattern). The error between the prediction and ground truth process parameter is then compared on a validation set. Transitions between specific classes of microstructural patterns are identified by evaluating the sensitivity of the model prediction error (Fig. 1b) as a function of the input process parameters.

a We simulate the dynamical evolution of the physical system for a broad range of process parameters. Next, we project the final state of the microstructural pattern into a latent space (using a pre-trained ResNet-50 v235). We regress on these latent dimensions to estimate the original process parameters. b To detect specific classes of microstructural patterns, we evaluate the model error by predicting the corresponding initial process parameters. By measuring the change in sensitivity of forming specific patterns for various input process parameters, we learn where the transition regime(s) might occur.
Results
Ambiguity of identifying microstructural transitions
We first explore the ambiguity of fingerprinting nontrivial transitions in pattern formation when those patterns are represented in latent space. We compare different dimensionality reduction techniques to represent the broad range of pattern configurations. Details on the phase-field models and latent embedding approach are provided in Methods.
Figure 2 illustrates how difficult and equivocal it is to identify transitions between different patterns as a function of the input process parameters. When taking the naive approach of performing principal component analysis36 (PCA) directly on the original microstructure images for both problems (see panels a and b), we note that this projection technique is incapable of identifying or explaining transition regimes via distinct clusters. This assertion is especially true when trying to distinguish the different microstructural patterns forming in the case of the physical vapor deposition model when the principal components are colored as a function of the normalized deposition rate vN (defined as the deposition rate normalized by the average bulk phase mobility of the system, see exact definition in Methods).

Spinodal decomposition of a two-phase mixture representations are displayed in left panels, physical vapor deposition of a binary alloy thin film representations in right panels. a, b These panels show the projection using a linear embedding technique (PCA) directly on the microstructure images (defined as dimensionality reduction on the ambient space). c–f Second and third rows show the projection of the ResNet-50 v2 latent vector using PCA (panels c and d) and UMAP (panels e and f). Latent vectors are colored according to relevant input process parameters for both problems, namely the phase fraction (f) for spinodal decomposition and the normalized deposition rate (vN) for physical vapor deposition. Definition of the normalized deposition rate is provided in Methods. For the microstructure insets across both spinodal and physical vapor deposition problems, yellow denotes the A phase, and purple the B phase.
To further illustrate this point, we present the results for two additional alternative projection techniques for both exemplar problems in Fig. 2c–f. In this case, even though the pre-trained ResNet-50 v235 model accurately learns a compact representation of the microstructural patterns (i.e., from a 256 × 256 pixelated microstructure representation to a 2048 latent vector), the dimension of the latent space is still too large to obtain any visual and interpretable classification of the different types of patterns forming in the two processes investigated in this study. We used linear (PCA) and non-linear (uniform manifold approximation and projection37,38 or UMAP) embedding unsupervised algorithms to further reduce the ResNet latent vectors into lower dimensions. Figure 3 shows the difference in explained variance when PCA is performed (i) directly on the actual high-dimensional microstructure images (denoted as ambient space) or (ii) on the already compact representation of the microstructures obtained from the ResNet model (denoted as latent space). We note that combining PCA and ResNet requires fewer principal components to capture most of the variance in our datasets, making the dimensionality reduction procedure (PCA/UMAP+ResNet) appealing and useful.

a Explained variance for the spinodal decomposition problem. b Explained variance for the physical vapor deposition problem. Ambient space denotes dimensionality reduction when PCA is performed directly on the high-dimensional microstructure images, while latent space denotes the projection when PCA is performed on the already compact representation of the microstructures obtained from the ResNet model.
Unfortunately, even with this improvement in the latent representation of the microstructural patterns, regardless of the embedding technique used in combination with ResNet, we observe that there is no intuitive, distinct clustering of data points about where exactly the transitions are. This statement is apparent even in the simple case of the spinodal decomposition problem (Fig. 2c, e), where the transition is expected to occur for a 50% phase fraction. When colored as a function of the phase fraction, f, the latent representation of the microstructural patterns continuously changes from one structure type to another (i.e., from B-rich spherical-precipitate patterns when f = 0.3 to A-rich spherical-precipitate patterns when f = 0.7). This latent representation does not clearly disentangle the different classes of patterns and cannot provide a priori any information on where the transition occurs when the phase fraction changes. The identification of topological transitions is doubly more difficult in the case of the physical vapor deposition problem (Fig. 2d, f). In this case, neither PCA nor UMAP embedding shows any obvious way to distinguish transitions between vertical-oriented to horizontal-oriented patterns, aside from noticing that nearby points will have similar microstructural patterns (as PCA and UMAP methods are designed to preserve similarities in feature space). Here, in both examples, we used PCA/UMAP and the ResNet model for illustrative purposes only. The results in Fig. 2 demonstrate that identifying dynamic and second-order transitions using classical dimensionality reduction techniques does not enable us to unequivocally separate different pattern-formation regimes in latent space. To further illustrate this point, as described in the Supplementary Information (Supplementary Note 1), we tested other projection methods (simple convolutional neural network, ResNet-34, t-SNE) to show that the results are not specific to the particular choice of a pre-trained model or dimensionality reduction technique. These supplementary results show that we can obtain similar results using different pre-trained models.
Solving the inverse mapping problem to identify transition regimes
Because the seemingly obvious breakdown of automatically clustering and classifying microstructural patterns for the examples shown in Fig. 2, and inspired by the universality principle for dynamical systems (i.e., near a phase transition the properties of a system become nearly independent of some dynamical details of that system), we instead develop a method that aims at measuring the difficulty of solving an inverse problem: mapping the microstructural patterns back to the original input process parameters. If this task is accurate, then the input process parameters uniquely map to a given microstructural pattern. Conversely, if this mapping is difficult or ambiguous, then there is a broad range of possible microstructural patterns that can be obtained with similar input process parameters, possibly indicating a topological transition (similar to the changes in sensitivity to some parameters when reaching the critical universality classes in second-order phase transitions39,40). This inverse-mapping solution is outlined in Fig. 1. Details on the inverse mapping workflow are provided in Methods. Details on the quality of the training of the neural network are also provided in Methods and in the Supplementary Information, Supplementary Note 5.
We first illustrate how intuitively this workflow works for the spinodal decomposition problem, because in this simple case, based on symmetry considerations of the free energy functional, we expect the transition to occur at the 50% phase fraction. Examples of predictions of input process parameters with high and low errors are listed in Table 1. We present results for the full range of parameters in Fig. 4. To obtain those results, we calculated the average mean absolute error (MAE) of our predictions in intervals (f − 0.025, f + 0.025) where f denotes the phase fraction. The sensitivity score per instance “i” is defined as the inverse of the MAE for each value of phase fraction, \({{{{\mathcal{S}}}}}_{i}=1/| {\hat{y}}_{i}-{y}_{i}|\), where \(\hat{y}\) is the prediction and y the true value. The mean sensitivity score of the entire dataset in a given interval is defined as \({{{\mathcal{S}}}}=N/\mathop{\sum }\nolimits_{i}^{N}| {\hat{y}}_{i}-{y}_{i}|\). A high sensitivity score indicates that we are able to predict the input process parameters accurately and this parameter acts as an indicator for a given class microstructural pattern. Conversely, a low sensitivity score indicates that the relation between the initial value of the process parameter and the microstructural pattern is weak, and this process parameter has little influence on the formation of that specific pattern. When the sensitivity score changes from high to low or vice versa, this indicates that we are near a transition with respect to that input process parameter. In other words, the task of evaluating the change in sensitivity score is analogous to a mutual information analysis41 from the field of information theory, which consists of evaluating the information gain to feature selection. In this context, here the underlying assumption is that, for a given set of process parameters, the microstructural pattern formation is a stochastic process, and each microstructure realization is a realization of this stochastic process. Mutual information here is calculated between the microstructural patterns and the process parameters and measures the change in uncertainty for the process parameters given a known observed microstructure.

a Mean sensitivity score for predicting mobilities as a function of phase fraction. When changing the phase fraction from low to high, the dominant role of the phase mobility switches from B to A. The dashed line indicated the expected transition from a A-rich patterns regime to a B-rich patterns regime. Insets depict example realizations for particular values of the phase fraction order parameter. For the microstructure insets, yellow denotes phase A, and purple phase B. b Variation (derivative) of the sensitivity score as a function of phase fraction. c, d Scatterplots of the variability on the number of phase domains A as a function of the phase A and B mobilities respectively.
We observe from the results listed in Table 1 that for high phase fractions (i.e., when A is the majority phase, f > 0.5) the outcome is highly sensitive to the choice of initial value of the phase A mobility. Conversely, the outcome does not change in any meaningful way if we vary the value of phase B mobility (as indicated by low values of the sensitivity score calculated with respect to the phase B mobility). An interesting observation is that looking at the highest sensitivity scores, we can distinguish three groups of patterns. Instances 1042, 2106, and 4157 display high sensitivity scores for the phase B mobility. Similarly, instances 814, 1543, and 4753 display high sensitivity scores for the phase A mobility. However, instances 2868, 4496, and 4545 show mixed results with sometimes high sensitivity scores for phase A or phase B mobilities. While individual sensitivity scores may already be good predictors of when the topological transition may occur, we observe a large variability in those scores. For example, comparing individual sensitivity scores for similar microstructural patterns in Table 1, the sensitivity score varies from 1 (instance 1042) to 14 (instance 4157). Therefore, to detect the transitions we will look at the averaged value of the sensitivity score, as discussed next.
Comparing individual scores to identify microstructural transitions could be deceiving (\({{{{\mathcal{S}}}}}_{i}\) with respect to phase A mobility for example 4157 is larger than \({{{{\mathcal{S}}}}}_{i}\) with respect to phase B mobility for example 2106). We can mitigate this issue by evaluating the mean sensitivity scores on the predicted mobilities. The mean sensitivity scores \({{{\mathcal{S}}}}\) on the predicted mobilities for phases A and B are presented in Fig. 4a. Variations (i.e., derivative) of the sensitivity scores with respect to the phase fraction are presented in Fig. 4b. To see whether or not we can identify the transition regime at the 50% phase fraction, we can first look at the left part of Fig. 4a. First, we would expect a strong correlation between the value of the phase B mobility and the size or shape of the phase A domains when B is the majority phase. This correlation translates into a high value of the sensitivity score with respect to phase B mobility. Conversely, we would also expect a weak relation between the value of the phase B mobility and the dynamics of the A domain when A is the majority phase, i.e. in this case the sensitivity score will be low. Indeed, if we look at the data and plot the number of phase A domains (i.e., the number of small spherical domains) as a function of mobility (see Fig. 4c, d), we see that the relation to phase B mobility is very strong (especially for low values of phase fraction), while relation to phase A mobility is almost non-existent (it does not matter what the value of phase A mobility is, the number of domains might be very different). As such, we note that when predicting the mobilities for phases A and B respectively in Fig. 4a, the sensitivity of those predictions switches to a relatively low sensitivity score at the 50% phase fraction. This is further evidenced if we look at the variation of the sensitivity score as a function of the phase fraction in Fig. 4b. We observe a transition from (i) a regime with a monomodal microstructure of A-rich spherical precipitates entrapped in a B matrix (denoted as encircled A in Fig. 4b) to (ii) an intermediate microstructural configuration (denoted as encircled B) which consists of interconnected A or B domains to (iii) finally another regime (denoted as encircled C) with a monomodal microstructure of B-rich spherical precipitates entrapped in a A matrix. This intermediate regime corresponds to the gradual transition in pattern formation between the two other distinct regimes.
Generalization to more complex pattern-forming processes: physical vapor deposition of binary alloy thin films
We now turn to the physical vapor deposition problem which presents multiple transition regimes when the deposition rate and bulk mobility change. At low normalized deposition rates (corresponding in the present case to values of \(\log ({{{{\rm{v}}}}}^{{{{\rm{N}}}}}) \sim -4\)), vertical-oriented microstructural patterns form, while higher normalized deposition rates (corresponding in the present case to values of \(\log ({{{{\rm{v}}}}}^{{{{\rm{N}}}}}) \sim -1\)) yield horizontal layer patterns. At very high normalized deposition rates (corresponding in the present case to values of \(\log ({{{{\rm{v}}}}}^{{{{\rm{N}}}}}) \sim -0.5\)) random microstructural patterns can form. Similarly to the spinodal decomposition problem above, we list in Table 2 examples of predictions with high and low sensitivity scores as a function of the deposition rate (∣v∣). Predictions of the deposition rate, ∣v∣, for vertical-oriented patterns are highly sensitive (i.e., \({{{{\mathcal{S}}}}}_{i}\) is high) at low normalized deposition rates (\(\log ({{{{\rm{v}}}}}^{{{{\rm{N}}}}}) \sim -4.0\)), while predictions for the average bulk mobility, MBulk, are relatively insensitive. We observe a different behavior for the normalized deposition rates that result in horizontal layer patterns for which in this case predictions for the deposition rate exhibit a low sensitivity score (see instance 444) and a high sensitivity score for the average bulk mobility.
We show in Fig. 5 how solving the inverse mapping problem for predicting the deposition rate, ∣v∣ (Fig. 5 panels a, c), and average bulk mobility, MBulk (Fig. 5 panels b, d), helps us identify the transition regime(s) between vertical- and horizontal-oriented microstructural patterns as a function of the normalized deposition rate vN. First, we notice in Fig. 5 panels a and b that when the orientation of the microstructural patterns changes from vertically oriented (denoted as regime A) to horizontally oriented (denoted as regime C), the sensitivity score for the deposition rate gradually changes from high to low accordingly and from low to high for the average bulk mobility. We can interpret it as a change in the importance of the input process parameter based on the resulting microstructural pattern considered (horizontal vs. vertical). The piecewise linear fits in Fig. 5 panels a and b provide a visual guide as to when a transition occurs, while the thin blue lines show individual instances and the resulting variability around the averaged sensitivity scores. While the sensitivity scores on the deposition rate and average bulk mobility enable us to detect the major change in the overall orientation of the microstructural patterns, the variations in the level of the sensitivity scores (cf. Fig. 5c) reveal much more subtle changes. Our self-supervised approach detects a second transition and the existence of an intermediate regime (denoted by encircled B) that corresponds to a regime with a class of microstructures that are neither vertical nor horizontal. We also note a third transition at \(\log {{{{\rm{v}}}}}^{{{{\rm{N}}}}} \sim -1.5\) which corresponds to a horizontal-to-multimodal (or horizontal-to-random) transition. When we compare the variation of the sensitivity scores between the two input process parameters in Fig. 5 panels c and d, we confirm the identification of those four regimes. The marginal differences as to when the transitions occur in terms of the normalized deposition rate illustrate the relative importance of the specific predicted input process parameters on those regimes. Second, our results reveal the range of each transition and existence of a specific pattern regime. Indeed, we observe for instance that the horizontal-oriented pattern regime only exists for a specific range of normalized deposition rates, namely for \(\log {{{{\rm{v}}}}}^{{{{\rm{N}}}}}\in [-2.5,-1.5]\).

a Sensitivity score for predicting the deposition rate (∣v∣) as a function of the normalized deposition rate. b Sensitivity score for predicting the bulk mobility (MBulk) as a function of the normalized deposition rate. c Variation (derivative) of the sensitivity score for the deposition rate as a function of the normalized deposition rate. d Variation (derivative) of the sensitivity score for predicting the bulk mobility as a function of the normalized deposition rate. e Number of horizontal and vertical phase domains as a function of the normalized deposition rate. f Topology connectivity (defined as the number of irregular elements of morphologies e.g., kinks, terminated subdomains, etc.) as a function of the normalized deposition rate. Thin blue lines in (a) and (b) illustrates particular runs of our procedure and indicate the variability around the averaged sensitivity score.
When plotting the number of horizontal- and vertical-oriented microstructural domains as a function of the normalized deposition rate in Fig. 5c, we confirm that indeed the microstructure topology switches from one type of pattern to another for the detected transitions via our self-supervised approach. When plotting these regimes as a function of the connectivity of the pattern in Fig. 5d, we note that the first transition (from A to B) can be associated with a transition from ordered vertical-oriented patterns to more complex, disjointed vertical patterns. The second transition (from B to C) then corresponds to a clear change from disjointed vertical patterns to horizontal layer patterns. The last transition (from C to D) corresponds to a transition from monomodal horizontal microstructure to a multimodal patterned structure. These results contrast with those obtained via a human-annotated method to map two-phase patterned morphologies8 for a similar problem, although it is unclear if this previous work fully captures the nuanced morphology classes.
Discussion
We have demonstrated above that solving the inverse problem of mapping microstructural patterns back to the corresponding input process parameters is a powerful approach to infer and characterize transitions in pattern-forming processes, without any a priori knowledge of where these transitions occur in the input space. This approach therefore allows microstructures to be objectively determined rather than relying on human perception and predefined labelling. In contrast to using clustering as a mean to identify transitions, this approach relies on the ability to relate transitions in microstructural patterns to changes in the error of predicting the inverse problem of mapping microstructure to input process parameters. This self-supervised approach relaxes the assumption in confusion-based techniques25 which requires two distinctive phases to exist in the considered transition regime. Instead, if there are multiple, intermediate, or hard-to-discern transitions present in the data (including transitions not characterized as first- or second-order transitions, cf. Fig. 5), we can still detect and identify where these transitions occur and establish a hierarchy of transitions via our approach. As seen in the physical vapor deposition example, transitions can happen at different levels of complexity (i.e., monomodal vs. multimodal patterns as seen in panels c and d of Fig. 5). Therefore, we can use this approach to provide a hierarchy of transitions from the most pronounced (such as pattern orientation) to more subtle (such as complexity). The CNN model used in this work can detect both simple geometric shapes (such as the orientation and width of the domains, size of the subdomains, etc.) as well as more complex patterns (bifurcation of different subdomains). This ability is possible due to the way information is organized in large CNN models, such as the ResNet model used in the present work. Even if the model is initially trained on images from different scientific domains (animals, plants, and various natural objects such as cars and buildings), the neural network learns to recognize basic patterns such as the orientation of lines, curvatures of edges, etc. Those simple patterns are encoded in the lower part of the network and are easily transferable between domains. This remarkable property of CNNs to generalize42 from one visual domain to another allowed us to efficiently apply a model that was pre-trained on the ImageNet database to our pattern-forming process datasets. One possible improvement to provide even more granularity and generality in detecting and categorizing transition sub-regimes within these pattern-forming processes would be to look at cross-correlations between sensitivity scores or consider the sensitivity scores directly as a multi-dimensional surface response of the input process parameter space. Local and global minima within this surface response could be identified as the different transitions.
In this study, we passed microstructure images to an existing, pre-trained ResNet model. We did not have to fine-tune the ResNet model. We kept this model as is to show how well the framework generalizes from one domain to another (in other words, how robust the framework is to the choice of the raw data embedding method). To further support this claim, we trained several dedicated models tasked to extract important features from the raw input data as detailed in the Supplementary Information, Supplementary Notes 1 and 2. We show that all those different embedding methods produce very similar results (see Supplementary Figs. 1 and 2). This means that the methodology presented here is robust to the particular choice of the embedding method to predict topological transitions. While we used ResNet-50 v2 to demonstrate that an out-of-the-shelf method works well here, other models could have been used instead as discussed in the Supplementary Information. Indeed, there is a variety of other models (such as ResNet-15235, VGG-1643, AlexNet44, and EfficientNetV245 to name a few) that have been trained on the same ImageNet dataset46 as the ResNet model used in this study. These models may prove to increase the sensitivity and accuracy of our results by enabling further clustering and disentangling of complex datasets in latent space. As an alternative to neural network models, statistical and spectral-density functions47,48,49,50 could be used for example as cost-effective, representative approaches to characterize microstructural patterns via a finite set of characteristic functions and/or features. As pointed out by Aggarwal et al.51, besides the improvements on these latent embedding approaches, the choice of a particular distance metric may significantly improve the results of these standard algorithms. If the (microstructure) data lies on some smooth manifold and we are interested in preserving the local geometry of the microstructure data on that manifold, then using different distance metrics (i.e., non Euclidean) when applying ResNet + PCA/UMAP to our data can shed alternative light on the same data and potentially further improve our classification of hierarchy of transition regimes.
In addition to the self-taught labelling of topological transitions, compared to other methods that focus solely on detecting transitions, our self-supervised approach can also provide additional insights into the role of the different input process parameters on the process-microstructure linkage. By interpreting changes in sensitivity scores, we reveal the role of different input process parameters in controlling different pattern-formation regimes. This includes which process parameters are responsible for the largest portion of the variation in microstructural patterns, and therefore which parameter(s) triggers specific classes of microstructural patterns. For instance, our results reveal that the bulk mobility plays a role in controlling the complexity of the pattern seen in the physical vapor deposition problem. Such linkage is important in the context of unraveling the mechanisms needed to fabricate multi-scale, microstructurally precise materials.
In the results presented above, we show that predicting error is not only useful to determine pattern class transitions, but also for sensitivity analysis. Namely, when the microstructure morphology changes slowly as a function of a given input process parameter, there will be a high error when mapping the final microstructural pattern back to that process parameter. In contrast, when the morphology changes significantly, there is a narrow range where a process parameter produces a particular microstructural pattern, and therefore error will be low. This observation provides insight into the process parameters that need low or high tolerance. In addition, some input process parameters may yield a class of microstructural consistently, while others may be affected by stochasticity in their initial values (see variability in sensitivity scores in Fig. 5a for instance). This consistency metric will be inferred by the error when mapping control parameters to the microstructure morphology; in other words, much like a typical surrogate model, one can find the final microstructural pattern from initial conditions; error in this task will give insight into input process parameters that consistently, or inconsistently, yield a given microstructure of interest.
Going forward, we note that our framework could be extended to other, more complex pattern-forming processes. In the current work, we assessed topological transition in binary phase systems, but the same methods could also be applied to, for example, complex multi-component ternary or quaternary phase-separating processes52,53. Further, our self-supervised-learning model did not have to be built exclusively on simulation-based data. We chose to illustrate our concept via simulation to establish comprehensive datasets to serve as ground truths for model evaluation. However, experimental microscopy data could have been used and combined with our simulation data to explore nuanced effects54,55 on actual synthesis processes. Another direction would be to increase the efficiency of our approach. As discussed above, interpreting individual sensitivity score can be misleading. Instead, one must average the individual scores on a previously prepared validation set. However, it might be possible to directly measure the uncertainty of the network in solving the inverse problem. This could be done using e.g., the concrete dropout56. Consequently, it would allow us to measure the score on the individual sample-label, eliminating the need of averaging over a large number of samples. Although the approach used in this study could be improved both to enhance sensitivity and accuracy, this work is a step towards automatically detecting critical transitions during evolutionary systems and opens new ways for discovering and understanding unseen or hard-to-discern transition regimes in these systems.
Methods
Spinodal decomposition of a two-phase mixture
Spinodal decomposition of a two-phase mixture is one of the oldest and simplest phase-field problems57. This model looks into the diffusion of solutes within a matrix and serves as the basis for a large number of phase-field models. In this model, a single compositional order parameter c(x, t) is used to describe the atomic fraction of solute in space (x) and time (t).
The evolution of c is described via the Cahn-Hilliard equation57 such that,
where ωc is the energy-barrier height between the equilibrium phases and κc is the archetypal curvature-energy penalty term. The concentration-dependent Cahn-Hilliard mobility is taken to be Mc = s(c)MA + (1 − s(c))MB, where Mi denotes the mobility of each phase. The switching function \(s(c)=\frac{1}{4}(2-c){(1+c)}^{2}\) is a smooth interpolation function between the mobilities. The values of the energy barrier height between the equilibrium phases and the gradient energy coefficients were assumed to be constant with ωc = κc = 1. The choice of the initial concentrations of phase A and B (cA and cB) as well as the choice of mobilities for each phase (MA and MB) constitute the input process parameter space and dictate the resulting microstructures.
Physical vapor deposition of binary-alloy thin films
The phase-field model used to simulate physical vapor deposition (PVD) is described in detail elsewhere17. This model uses conserved order-parameters, ϕ and c to describe the structural and compositional ordering of the system as the thin film grows. The field variable ϕ is meant to distinguishes between the vapor and solid phases and is used to track the growing thin film. The compositional field variable c distinguishes between the two phases of the growing binary alloy thin film. The composition evolution is described via the Cahn-Hilliard equation such that,
where Mc is the structurally and compositionally dependent mobility function and \({{{\mathcal{F}}}}\) is the total free energy of the system. The mobility functional Mc is constructed to describe both bulk and surface mobilities for each phase, \({{{{\rm{M}}}}}_{{{{\rm{i}}}}}^{{{{\rm{Bulk}}}}}\) and \({{{{\rm{M}}}}}_{{{{\rm{i}}}}}^{{{{\rm{Surf}}}}}\) respectively. The complete expression for \({{{\mathcal{F}}}}\) is the same as in Stewart and Dingreville17 without the elasticity contributions. The expression for Mc is provided in Eqs. (8) and (9) in Stewart and Dingreville17. To describe thin-film growth, a source term is incorporated in the Cahn-Hilliard equation, such that the evolution of the vapor-solid field variable, ϕ, is given by,
where Mϕ is the Cahn-Hilliard mobility. The second term couples the thin-film evolution to the incident vapor flux (via a vapor density field ρ and deposition rate v) and acts as the source term for interfacial growth and surface roughening. We defined a normalized deposition rate8 \({{{{\rm{v}}}}}^{{{{\rm{N}}}}}=2\sin \left(\alpha \right)| {{{\bf{v}}}}| /({{{{\rm{M}}}}}_{{{{\rm{A}}}}}^{{{{\rm{Bulk}}}}}+{{{{\rm{M}}}}}_{{{{\rm{B}}}}}^{{{{\rm{Bulk}}}}})\) (where α is the deposition angle) which is meant to account for the competition between film growth and phase separation in the growing film. In this problem, the choice of the initial concentrations of phase A and B (cA and cB), the choice of bulk and surface mobilities for each phases (\({{{{\rm{M}}}}}_{{{{\rm{A}}}}}^{{{{\rm{i}}}}}\) and \({{{{\rm{M}}}}}_{{{{\rm{B}}}}}^{{{{\rm{i}}}}}\), with i being either Bulk or Surf), and the deposition rate v constitute the input process parameter space and dictate the resulting microstructures.
Data preparation
These two phase-field models have been implemented in Sandia’s in-house multiphysics phase-field modeling code: Mesoscale Multiphysics Phase-Field Simulator17,58 (MEMPHIS). Examples of simulation results for these two models are provided as supplementary information in Supplementary Note 3. The two-dimensional (2D), spatio-temporal evolution of the microstructural patterns (as captured through the c compositional field variable in both models) were numerically solved using a finite-difference scheme with second-order central difference stencils for all spatial derivatives. Numerical temporal integration of the equations was performed using the explicit Euler method. All 2D simulations were performed on a uniform numerical grid of 512 × 512 for the spinodal decomposition model and 256 × 256 for the PVD model, a spatial discretization of Δx = Δy = 1, and a temporal discretization of Δt = 10−4 for the spinodal decomposition model and a variable Δt ∈ [10−3, 10−2] for the PVD model. The composition field within the simulation domain was initially randomly populated by sampling a truncated Gaussian distribution between − 1 and 1 with a standard deviation of 0.35. Each spinodal decomposition simulation was run for 50,000,000 time steps with periodic boundary conditions applied to all sides of the domain. The run time for the PVD simulations varied depending on the deposition rate to achieve a given film height.
We used a Latin Hypercube Sampling (LHS) approach to generate our training and testing datasets. For the spinodal decomposition model, we varied the phase concentrations and phase mobilities parameters. For the phase concentration parameter, we varied the concentration of phase A, cA ∈ [0.15, 0.85]. Note that the phase concentration of B is simply cB = 1 − cA. For the mobility parameters, we independently varied the mobility values over four orders of magnitude such that Mi ∈ [0.01, 100], i = A or B. For the PVD model, we keep the phase fraction at 50% and sampled the bulk and surface mobilities \({{{{\rm{M}}}}}_{{{{\rm{i}}}}}^{{{{\rm{Bulk}}}}}\in [0.1,10]\), \({{{{\rm{M}}}}}_{{{{\rm{i}}}}}^{{{{\rm{Surf}}}}}\in [0.1,100]\), as well as the deposition rate conditions ∣v∣ ∈ [0.1, 1]. For the spinodal decomposition model, this resulted in total in 4998 simulations, 80% of which was used to train the model (3998 instances) and the remaining 20% of data (1000 instances) was used for testing. For the PVD model, we selected the final microstructure pattern at the time step that corresponded to a film height of 224 pixels, resulting in a 224 × 224 image. For this model, our dataset had 11775 simulations. We used 60% of the data instances for training and 40% for testing purposes.
Selection of neural network architecture
The outcome of detecting transitions is determined by both the initial condition (e.g., value of a random seed) and values of the process parameters (phase mobility, deposition rate in case of PVD, etc.). While the local details of microstructural patterns depend on the specific initial conditions, the overall characteristics of those patterns are determined mostly by the values of the input process parameters. When solving the inverse problem, we wish to measure and gauge the role of the process parameters, not the random initialization of the simulations. We achieved this by first transforming the input using a CNN. This type of network is equivariant to translations of the input and therefore insensitive to relative shifts of the overall characteristics of the microstructural patterns that could be incurred by random initialization values of the simulations. We can use CNNs to extract features from the raw data, that are related to the overall shape of the patterns, not the specific position of those. See an extended discussion of that topic in Supplementary Information, Supplementary Note 3.
While there are many different possible convolutional architectures, one natural choice is to use a CNN from the ResNet family59. ResNet networks are built with what are known as residual blocks. CNNs are those with convolution layers, in which a small batch of an image is scanned, and features, such as colors and shades, of that small image are fed through a node. There are multiple ways to weigh features in a batch, which are known as filters. Residual blocks take features from earlier convolution layers and feed them wholesale into a layer that could be many levels away from the initial layer. This allows for features to not get “lost in translation” when moving from one layer to the next. This network can therefore achieve respectable predictive accuracy with comparatively more layers, thus capturing long-range and non-linear correlations between far-away parts of an image, or in this case, a microstructure evolution simulation. In effect, ResNet models can take advantage of deeper architectures reducing the impact of the infamous vanishing gradient problem60. We further elaborated on this topic in Supplementary Information, Supplementary Note 4.
Latent embedding
We embedded microstructural pattern images using ResNet-50 v235, a popular model that has been used to automatically classify a variety of images. ResNet-50 v2 is a fifty-layer-deep CNN. In particular, the ResNet-50 v2 model used in this work was trained on images from the ImageNet46 database but not on the phase-field data. Training of the ResNet-50 v2 model was first done by He et al.35. The model trained on ImageNet learns to extract a hierarchy of features, from simple geometric shapes (vertical, horizontal, or skew lines, shapes of different sizes, lines of different curvatures, etc.) to more complex, composed patterns. Images present in the ImageNet database depict 1000 classes such as different types of animals, everyday objects, and various building structures. While most of the training examples represent colorful (3-channel) images, there is also a small proportion (about ~2%) of monochromatic images. To make the phase-field simulation data input compatible with our model, we copied each image three times (created 3 identical pseudo-color channels). While it creates some redundancy (the network might detect “red”, “green” and “blue” edges of the same orientation), it did not affect the ability to produce a consistent embedding for the collection of our data. Examples and details of the data used for training the ResNet-50 v2 model are presented in the Supplementary Information, Supplementary Note 4. We took all but the classification layer of this pre-trained model to embed simulation images into several hundred dimensional latent feature space. The size of this feature space is small enough to reduce the feature dimension from 65536 (256 × 256 pixels where we treat each pixel as a feature) to something that is far more manageable, 2048 latent dimensions (i.e., 1% of this), but this space is large enough to capture nuances in microstructural patterns from subtle variations in control parameters or initial conditions. Parameter predictions are then made by applying a few dense all-to-all connection neural network layers to this set of latent features.
Inverse mapping workflow
Spinodal decomposition
The original simulations were saved as 4998 × 101 × 512 × 512 (simulation number, time frame, X position, Y position) dimensional numpy arrays, with float16 numbers that range from around −1 to +1. We reduced the dimensions of each frame from 512 × 512 to 256 × 256 (replacing every block of 2 × 2 pixels by the mean value). From the 4998 original simulations, we randomly selected 1000 of them (20%) to form a validation set. We used the remaining 3998 simulations to construct the training set. The input images are expected to have color values in the range [0, 1] and the expected size of the input images is 224 × 224 pixels by default, but other input sizes are possible. Because the ResNet-50 v2 model requires a 3-channel input, we just tripled our output (each channel has the same pictures). The inverse problem was solved by training a neural network, a simple feedforward neural network with two hidden layers (with 512 and 1024 neurons, respectively). The output of the network was a dense layer with two neurons with linear activation – one neuron to predict mobility of the phase A, and another to predict mobility of the phase B. We used dropout layers and ReLU activation functions. Schematically, the network architecture was \({{\mathtt{Dense}}}_{512}^{{{{\rm{ReLU}}}}}\times {{\mathtt{Dropout}}}_{0.25}\times {{\mathtt{Dense}}}_{1024}^{{{{\rm{ReLU}}}}}\times {{\mathtt{Dropout}}}_{0.25}\times {{\mathtt{Dense}}}_{2}^{{{{\rm{linear}}}}}\). We trained the model to predict the correct values of mobility, with the mean squared error (MSE) loss function. We applied early stopping with the patience 4 and tolerance of 0.0001.
Physical vapor deposition
The original simulations were saved as 11775 × 51 × 256 × 256 (simulation number, time frame, X position, Y position) dimensional numpy arrays. For each simulation, we selected the time step that corresponds to a thin film height of 224 pixels to avoid capturing any surface roughness effects. We rejected simulations that had heights smaller than 224 (this simulation corresponded to extremely slow deposition rates; only 5 simulations were rejected in the process). We cut four 224 × 224 squares from each original frame, translating the cut origin by 64 pixels each time (we apply horizontal periodic boundary conditions). This gave us 11770 × 4 = 47080 individual data points. We truncated values larger than 1, and smaller than −1, and then we scaled everything from 0 to 1 (we applied transformation x → (x + 1)/2). To speed-up the next step, we reduced the dimension of each square by two, from 224 × 224 to 112 × 112 pixels. We used the pre-trained ResNet-50 v2 model to produce 2048-dimension latent embeddings of each square (to do this, we had to emulate the 3 channel colors by copied the one-channel input three times, just as we did for spinodal decomposition). Since original simulations were repeated 5 times for each unique set of parameters, the 47080 data points correspond to 2354 unique sets of initial parameters. We reserved 40% of the data for the validation set (18840 input examples, corresponding to 942 unique sets of initial parameters). The remaining 60% was used for training (28240 input examples, corresponding to 1412 unique sets of initial parameters). The inverse problem was solved by training a neural network, a simple feed-forward neural network with two hidden layer (similar to the architecture used for spinodal decomposition), namely \({{\mathtt{Dense}}}_{512}^{{{{\rm{ReLU}}}}}\times {{\mathtt{Dropout}}}_{0.25}\times {{\mathtt{Dense}}}_{1024}^{{{{\rm{ReLU}}}}}\times {{\mathtt{Dropout}}}_{0.25}\times {{\mathtt{Dense}}}_{1}^{{{{\rm{linear}}}}}\). The only modification with respect to the previous setup was, that we used here only a single output neuron. The motivation for this was that was that the predicted parameters had different physical units. When predicting multiple values at once, the MSE loss function would be sensitive to the particular choice of the units for each parameter. To address this issue, we decided to train separate network for each control parameter – thus, the single output unit in the architecture above. We trained the network with early stopping with the patience 4 and tolerance of 0.001.
Model training setup for the inverse problem
What matters when solving the inverse problem is the relative performance. This situation is similar to that described in the “Learning phase transitions by confusion” paper by van Nieuwenburg et al.25. In that work, the proposition was to use a small feedforward neural network, with one hidden layer and 80 neurons. There are two possible regimes where neural networks generalize well. One is when the number of training examples is larger than the number of trainable parameters. Second, when the number of trainable parameters is much larger than the number of training examples (an overparameterized region)61. Keeping in mind that in practical applications the number of training examples can be limited, we decided to explore the second regime. As discussed in the next section, to solve the inverse problem we used a network with two hidden layers, having 512 and 1024 neurons, respectively. We further elaborated on this topic in Supplementary Information, Supplementary Note 5.
Training and validation of the inverse problem network
To minimize any potential overfitting, we followed best practices during the training. Namely, we used a validation set to track the generalization error, we used dropout to combat the overfitting, we used data augmentation (we used the advantage of the periodic boundaries conditions and we prepared several cropped versions of the input from each sample), and when training we used an early stop. We visualize the training and validation error in case of spinodal decomposition data in Fig. 6. In case of the spinodal decomposition, we can easily determine the theoretical minimum for the mean squared error. The outcome of the process is determined by the value of mobility of the majority phase. Thus, assuming uniform distribution of samples and normalization of the target values to [0, 1], the best we can hope is to have zero error, ΔB, when predicting mobility of the majority phase and an error of \({\Delta }_{{{{\rm{A}}}}}=\int\nolimits_{0}^{1}{(x-0.5)}^{2}\,dx=1/12\) when predicting the mobility value of the minority phase. Consequently, the lower bound for the cumulative mean square error is \(\bar{\Delta }=({\Delta }_{{{{\rm{A}}}}}+{\Delta }_{{{{\rm{B}}}}})/2=\left(1/12+0\right)/2\approx 0.0416(6)\). Looking at Fig. 6, we see that the validation set approaches the theoretical limit of the irreducible/intrinsic error, indicating a relatively good generalization capability and good quality of training. Additional details on the training performance of the ResNet-50 model and comparison with other pre-trained models are provided in the Supplementary Information in Supplementary Note 5.

The mean value baseline corresponds to ΔA and the theoretical minimum to \(\bar{\Delta }\). Here, we used a network with two hidden layers, having 1024 and 512 neurons, respectively, \({{\mathtt{Dense}}}_{512}^{{{{\rm{ReLU}}}}}\times {{\mathtt{Dropout}}}_{0.25}\times {{\mathtt{Dense}}}_{1024}^{{{{\rm{ReLU}}}}}\times {{\mathtt{Dropout}}}_{0.25}\times {{\mathtt{Dense}}}_{2}^{{{{\rm{linear}}}}}\).
Data availability
Samples of our datasets are available at https://github.com/marcinabram/topological_transitions/tree/main/data_sample. The full training datasets as well as all validation and test cases are available from the corresponding author upon reasonable request.
Code availability
Source code for training and evaluating the machine learning models is available at https://github.com/marcinabram/topological_transitions.
References
Viamontes, J., Oakes, P. W. & Tang, J. X. Isotropic to nematic liquid crystalline phase transition of f-actin varies from continuous to first order. Phys. Rev. Lett. 97, 118103 (2006).
Antal, T., Droz, M., Magnin, J. & Rácz, Z. Formation of Liesegang patterns: a spinodal decomposition scenario. Phys. Rev. Lett. 83, 2880 (1999).
Toramaru, A., Harada, T. & Okamura, T. Experimental pattern transitions in a Liesegang system. Phys. D: Nonlinear Phenom. 183, 133–140 (2003).
Shimizu, Y., Matsui, J., Unoura, K. & Nabika, H. Liesegang mechanism with a gradual phase transition. J. Phys. Chem. B 121, 2495–2501 (2017).
Nabika, H., Itatani, M. & Lagzi, I. Pattern formation in precipitation reactions: the Liesegang phenomenon. Langmuir 36, 481–497 (2019).
Sakurai, S. et al. Morphology transition from cylindrical to lamellar microdomains of block copolymers. Macromolecules 26, 485–491 (1993).
Castelletto, V. & Hamley, I. W. Morphologies of block copolymer melts. Curr. Opin. Solid State Mater. Sci. 8, 426–438 (2004).
Lu, Y. et al. Microstructure map for self-organized phase separation during film deposition. Phys. Rev. Lett. 109, 086101 (2012).
Herman, E., Stewart, J. A. & Dingreville, R. A data-driven surrogate model to rapidly predict microstructure morphology during physical vapor deposition. Appl. Math. Model. 88, 589–603 (2020).
Powers, M., Derby, B., Shaw, A., Raeker, E. & Misra, A. Microstructural characterization of phase-separated co-deposited Cu–Ta immiscible alloy thin films. J. Mater. Res. 35, 1531–1542 (2020).
Powers, M., Stewart, J. A., Dingreville, R., Derby, B. K. & Misra, A. Compositionally-driven formation mechanism of hierarchical morphologies in co-deposited immiscible alloy thin films. Nanomaterials 11, 2635 (2021).
Landau, L. D. Zur Theorie der phasenumwandlungen II. Phys. Z. Sowjetunion 11, 26–35 (1937).
Müller, S. Variational models for microstructure and phase transitions. In Calculus of Variations and Geometric Evolution Problems: Lectures given at the 2nd Session of the Centro Internazionale Matematico Estivo (C.I.M.E.), 85–210 (Springer, Berlin Heidelberg, 1999).
Kosterlitz, J. M. & Thouless, D. J. Ordering, metastability and phase transitions in two-dimensional systems. J. Phys. C. Solid State Phys. 6, 1181 (1973).
Bagchi, K., Andersen, H. C. & Swope, W. Computer simulation study of the melting transition in two dimensions. Phys. Rev. Lett. 76, 255 (1996).
Bel-Hadj-Aissa, G., Gori, M., Franzosi, R. & Pettini, M. Geometrical and topological study of the Kosterlitz–Thouless phase transition in the XY model in two dimensions. J. Stat. Mech. Theory Exp. 2021, 023206 (2021).
Stewart, J. A. & Dingreville, R. Microstructure morphology and concentration modulation of nanocomposite thin-films during simulated physical vapor deposition. Acta Mater. 188, 181–191 (2020).
Carrasquilla, J. & Melko, R. G. Machine learning phases of matter. Nat. Phys. 13, 431–434 (2017).
Wei, Q., Melko, R. G. & Chen, J. Z. Y. Identifying polymer states by machine learning. Phys. Rev. E 95, 032504 (2017).
Li, C.-D., Tan, D.-R. & Jiang, F.-J. Applications of neural networks to the studies of phase transitions of two-dimensional Potts models. Ann. Phys. 391, 312–331 (2018).
Casert, C., Vieijra, T., Nys, J. & Ryckebusch, J. Interpretable machine learning for inferring the phase boundaries in a nonequilibrium system. Phys. Rev. E 99, 023304 (2019).
Zhang, W., Liu, J. & Wei, T.-C. Machine learning of phase transitions in the percolation and XY models. Phys. Rev. E 99, 032142 (2019).
Wang, L. Discovering phase transitions with unsupervised learning. Phys. Rev. B 94, 195105 (2016).
Hu, W., Singh, R. R. P. & Scalettar, R. T. Discovering phases, phase transitions, and crossovers through unsupervised machine learning: A critical examination. Phys. Rev. E 95, 062122 (2017).
van Nieuwenburg, E. P. L., Liu, Y.-H. & Huber, S. D. Learning phase transitions by confusion. Nat. Phys. 13, 435–439 (2017).
Wetzel, S. J. Unsupervised learning of phase transitions: From principal component analysis to variational autoencoders. Phys. Rev. E 96, 022140 (2017).
Liu, Y.-H. & Van Nieuwenburg, E. P. L. Discriminative cooperative networks for detecting phase transitions. Phys. Rev. Lett. 120, 176401 (2018).
Yoshioka, N., Akagi, Y. & Katsura, H. Learning disordered topological phases by statistical recovery of symmetry. Phys. Rev. B 97, 205110 (2018).
Rodriguez-Nieva, J. F. & Scheurer, M. S. Identifying topological order through unsupervised machine learning. Nat. Phys. 15, 790–795 (2019).
Lee, K., Ayyasamy, M., Delsa, P., Hartness, T. & Balachandran, P. Phase classification of multi-principal element alloys via interpretable machine learning. npj Comput. Mater. 8, 1–12 (2022).
Doersch, C. & Zisserman, A. Multi-task self-supervised visual learning. In Proceedings of the IEEE International Conference on Computer Vision, 2070–2079 (IEEE Computer Society, 2017).
Zbontar, J., Jing, L., Misra, I., LeCun, Y. & Deny, S. Barlow Twins: Self-supervised learning via redundancy reduction. In Proceedings of the 38th International Conference on Machine Learning, vol. 139, 12310–12320 (PMLR, 2021).
Chen, T., Kornblith, S., Norouzi, M. & Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the 37th International Conference on Machine Learning, vol. 119, 1597–1607 (PMLR, 2020).
Lee, S. S. & Kim, B. J. Confusion scheme in machine learning detects double phase transitions and quasi-long-range order. Phys. Rev. E 99, 043308 (2019).
He, K., Zhang, X., Ren, S. & Sun, J. Identity mappings in deep residual networks. In European Conference on Computer Vision, 630-645 (Springer International Publishing, 2016).
Abdi, H. & Williams, L. J. Principal component analysis. Wiley Interdiscip. Rev. Comput. Stat. 2, 433–459 (2010).
McInnes, L., Healy, J. & Melville, J. Umap: Uniform manifold approximation and projection for dimension reduction. Preprint at https://doi.org/10.48550/arXiv.1802.03426 (2018).
McInnes, L., Healy, J., Saul, N. & Grossberger, L. UMAP: uniform manifold approximation and projection. J. Open Source Softw. 3, 861 (2018).
Stauffer, D., Ferer, M. & Wortis, M. Universality of second-order phase transitions: the scale factor for the correlation length. Phys. Rev. Lett. 29, 345 (1972).
Nikoghosyan, G., Nigmatullin, R. & Plenio, M. B. Universality in the dynamics of second-order phase transitions. Phys. Rev. Lett. 116, 080601 (2016).
Gierlichs, B., Batina, L., Tuyls, P. & Preneel, B. Mutual information analysis. In International Workshop on Cryptographic Hardware and Embedded Systems, 426-442 (Springer Berlin Heidelberg, 2008).
Bau, D. et al. Understanding the role of individual units in a deep neural network. Proc. Natl Acad. Sci. U.S.A. 117, 30071–30078 (2020).
Simonyan, K. & Zisserman, A. Very deep convolutional networks for large-scale image recognition. Preprint at https://doi.org/10.48550/arXiv.1409.1556 (2014).
Krizhevsky, A. One weird trick for parallelizing convolutional neural networks. Preprint at https://doi.org/10.48550/arXiv.1404.5997 (2014).
Tan, M. & Le, Q. EfficientNetV2: Smaller models and faster training. In Proceedings of the 38th International Conference on Machine Learning, vol. 139, 10096–10106 (PMLR, 2021).
Deng, J. et al. ImageNet: A large-scale hierarchical image database. In 2009 IEEE Conference on Computer Vision and Pattern Recognition, 248–255 (IEEE, 2009).
Torquato, S. Statistical description of microstructures. Ann. Rev. Mater. Res. 32, 77–111 (2002).
Niezgoda, S. R., Kanjarla, A. K. & Kalidindi, S. R. Novel microstructure quantification framework for databasing, visualization, and analysis of microstructure data. Integr. Mater. Manuf. Innov. 2, 54–80 (2013).
Bostanabad, R. et al. Computational microstructure characterization and reconstruction: review of the state-of-the-art techniques. Prog. Mater. Sci. 95, 1–41 (2018).
Montes de Oca Zapiain, D., Stewart, J. A. & Dingreville, R. Accelerating phase-field-based microstructure evolution predictions via surrogate models trained by machine learning methods. npj Comput. Mater. 7, 1–11 (2021).
Aggarwal, C. C., Hinneburg, A. & Keim, D. A. On the surprising behavior of distance metrics in high dimensional space. In Database Theory – International Conference on Database Theory 2001, 420-434 (Springer Berlin Heidelberg, 2001).
Cogswell, D. A. & Carter, W. C. Thermodynamic phase-field model for microstructure with multiple components and phases: The possibility of metastable phases. Phys. Rev. E 83, 061602 (2011).
Kim, J. Phase-field models for multi-component fluid flows. Commun. Comput. Phys. 12, 613–661 (2012).
Weis, C. et al. Morphological and rheological detection of the phase inversion of PMMA/PS polymer blends. Polym. Bull. 40, 235–241 (1998).
Hedström, P., Baghsheikhi, S., Liu, P. & Odqvist, J. A phase-field and electron microscopy study of phase separation in Fe–Cr alloys. Mater. Sci. Eng. A 534, 552–556 (2012).
Gal, Y., Hron, J. & Kendall, A. Concrete dropout. In Advances in Neural Information Processing Systems, (NIPS 2017), vol. 30 (Curran Associates, Inc., 2017).
Chen, L.-Q. Phase-field models for microstructure evolution. Ann. Rev. Mater. Res. 32, 113–140 (2002).
Dingreville, R., Stewart, J. A., Chen, E. Y. & Monti, J. M. Benchmark problems for the mesoscale multiphysics phase field simulator (MEMPHIS). Tech. Rep. SAND2020-12852, Sandia National Laboratories (SNL-NM), Albuquerque, NM, USA (2020). https://doi.org/10.2172/1615889.
He, K., Zhang, X., Ren, S. & Sun, J. Deep residual learning for image recognition. In 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, 770-778 (IEEE, 2016).
Bengio, Y., Simard, P. & Frasconi, P. Learning long-term dependencies with gradient descent is difficult. IEEE Trans. Neural Netw. 5, 157–166 (1994).
d’Ascoli, S., Sagun, L. & Biroli, G. Triple descent and the two kinds of overfitting: Where & why do they appear? In Advances in Neural Information Processing Systems 33 (NeurIPS 2020), vol. 33, 3058–3069 (Curran Associates, Inc., 2020).
Acknowledgements
The authors would like to thank M D’Elia from Sandia National Laboratories for comments and review of this work. MA acknowledges funding from USC-ISI and Sandia National Laboratories. KB also acknowledges funding from Sandia National Laboratories. RD acknowledges funding under the BeyondFingerprinting Sandia Grand Challenge Laboratory Directed Research and Development (GC LDRD) program. The phase-field framework is supported by the Center for Integrated Nanotechnologies (CINT), an Office of Science user facility operated for the U.S. Department of Energy. Sandia National Laboratories is a multi-mission laboratory managed and operated by National Technology and Engineering Solutions of Sandia, LLC., a wholly owned subsidiary of Honeywell International, Inc., for the U.S. Department of Energy National Nuclear Security Administration under contract DE-NA0003525. This paper describes objective technical results and analysis. Any subjective views or opinions that might be expressed in the paper do not necessarily represent the views of the U.S. Department of Energy or the United States Government.
Author information
Authors and Affiliations
Contributions
M.A., K.B., R.D., J.S., G.V.S., and A.G. conceived the research, contributed to the investigation, and wrote the manuscript. M.A. and K.B. developed the methodology and visualization. Phase-field simulations were performed at CINT. R.D., G.V.S., and A.G. acquired funding, administered the project, and supervised the research.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Abram, M., Burghardt, K., Ver Steeg, G. et al. Inferring topological transitions in pattern-forming processes with self-supervised learning. npj Comput Mater 8, 205 (2022). https://doi.org/10.1038/s41524-022-00889-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41524-022-00889-2
