
Abstract
Force chains are quasi-linear self-organised structures carrying large stresses and are ubiquitous in jammed amorphous materials like granular materials, foams or even cell assemblies. Predicting where they will form upon deformation is crucial to describe the properties of such materials, but remains an open question. Here we demonstrate that graph neural networks (GNN) can accurately predict the location of force chains in both frictionless and frictional materials from the undeformed structure, without any additional information. The GNN prediction accuracy also proves to be robust to changes in packing fraction, mixture composition, amount of deformation, friction coefficient, system size, and the form of the interaction potential. By analysing the structure of the force chains, we identify the key features that affect prediction accuracy. Our results and methodology will be of interest for granular matter and disordered systems, e.g. in cases where direct force chain visualisation or force measurements are impossible.
Similar content being viewed by others
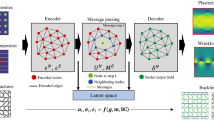


Introduction
Force chains are emergent filament-like structures that carry large stresses when a granular material1,2,3,4,5,6,7,8,9,10, emulsion11,12, foam13, dense active matter14, or assembly of cells15 is deformed. Unlike homogeneous simple solids, the stress in such fragile matter propagates inhomogeneously via these force chains16,17, which therefore act as a crucial component in describing the mechanical and transport properties of such systems18,19,20,21,22,23,24,25. For instance, the knowledge of the force chain network is crucial to understand several key properties of granular materials, such as sound propagation22, non-local mechanisms of momentum transfer26, or the response to external confining stress18. Understanding when force chains will form, how the network that they make up carries the external load and responds to external or internal mechanical deformation 27,28,29, and characterizing the statistical properties of force chains30,31,32,33,34 constitute central challenges in ongoing research in granular matter systems. The study of force chains, initially qualitatively4,6,35 and later quantitatively9,28,36,37,38,39, became popular with the introduction of photoelastic beads in granular matter experiments. For example, the visualization of force chains and subsequent analysis have enabled the validation and verification of theoretical models of granular media6, and have helped to disentangle the distinguishing features of force chains appearing under different boundary conditions such as shear or uniform compression7. A recent study suggests that ants benefit from the force network to remove grains of soil for efficient tunnel excavation40,41.
Predicting where a force chain will arise given a deformation, i.e. predicting which grains will be part of this emergent structure, is a complex problem if the interactions between the grains are unknown—but tackling it is of vital importance in e.g., material design as the force chains will be a key determinant of a material’s properties18,19,20,21,22,23,24,25. While experimental set-ups using the aforementioned photoelastic beads can visualize force chains7, it remains impossible in numerous other experiments on granular matter, emulsions, foams, etc. to say where force chains will form without precise knowledge of the interaction between the particles. In this article, we demonstrate an efficient and accurate solution to this open question, by deploying graph neural networks (GNN) to predict the formation of force chains in both frictionless and frictional granular matter.
Machine learning methods have recently shown great potential in the analysis of physical systems, with applications ranging from quantum chemistry to cosmology42. In the field of granular matter, softness was introduced as a structural predictor of regions susceptible to rearrangement, based on a classification of human-defined structure functions with a support vector machine43,44,45. Neural networks have recently been used to detect local structure in colloidal systems46,47, define a structural order parameter which correlates strongly with dynamical heterogeneities in supercooled liquids48, and have helped in uncovering the critical behavior of a Gardner transition in hard-sphere glasses49. Neural network-based variational methods have also been introduced to study the large deviations of kinetically constrained models, which are lattice-based systems displaying glassy dynamics50,51. Graph neural networks, which operate on the elements of arbitrary graphs and their respective connectivity, have proven successful in predicting quantum-mechanical molecular properties52, describing the dynamics of complex physical materials53, or providing structural predictors for the long-term dynamics of glassy systems without the need for human-defined features54.
In this article, we show how a GNN can be trained in a supervised approach to predict the position of force chains that arise when deforming a granular system, given an undeformed static structure (see Fig. 1 for a schematic). For this, we first deform the system using shear deformation (step strain) and identify the particles that become part of force chains using standard methodology (see Methods section). We optimize the GNN on a set of such configurations, training it to predict where the force chains will appear given the initial configurations. We then demonstrate that the trained GNN can generalize remarkably well, allowing it to predict force chains in new undeformed samples. The method is extremely robust: it works exceptionally well in many different scenarios for which the GNN was not explicitly trained, which involve changes in the system size, composition, step strain amplitude, packing fraction, friction coefficient, and even interaction potential—all without requiring any further training. Overall, our method provides accurate and robust predictions of where force chains will appear, without knowledge of inter-grain forces. This method can be potentially applied to numerous experiments on jammed solids, in order to determine the location of force chains even when it is not possible to visualize them directly.

We first generate data on the formation of force chains via a traditional method, i.e., by shearing a model athermal solid in a simulation setup. We then train a graph neural network to predict the location of force chains in the deformed samples from the initial (undeformed) static structures. The trained graph neural network can then be used to predict the formation of force chains for other initial structures—even when e.g., the system size or particle mixture composition are very different from those used during training.
Results
We first demonstrate that an optimized GNN can predict very accurately where force chains will form for the canonical case of a jammed solid consisting of a binary mixture of harmonic particles. We use N particles interacting through a harmonic potential at packing fraction ϕ = 1.0, of which nA particles have radius RA, and nB particles have radius RB (as described in Methods).
In Fig. 2, we compare the force chains obtained through a numerical shear simulation (Fig. 2a) to those predicted by our trained GNN (Fig. 2b), which receives an undeformed configuration as input. Only a few particles (highlighted in red) are misidentified by the GNN, indicating its very high prediction accuracy, as described in Fig. 3. In the following sections, we describe the most useful aspects of the GNN predictor for the prediction of force chains, namely scalability and robustness.

a Force chains (blue) in an athermal solid with nA = nB = 200, obtained through a shear simulation with magnitude of the step strain γ = 0.1 at packing fraction ϕ = 1.0. b Force chains predicted by a graph neural network taking as input the configuration of (a) before the deformation was applied. Particles misidentified by the GNN are highlighted in red.

A graph neural network trained on a data set with a harmonic potential and number of particles (top) can also accurately predict force chains for configurations with different system size (number of particles), different ratio of mixture components or with a different interaction potential. All results shown here are obtained at packing fraction ϕ = 1.0.
Scalability
As each graph-convolutional operation in our GNN only depends on a particle’s local neighborhood (Eq. (4) from Methods), the GNN is not explicitly dependent on the number of nodes in the graph. This allows us to apply the GNN on systems containing a much larger number of particles than it was initially trained on, as long as the relevant physical length-scales stay of the same order when increasing system size. Doing so allows for massive numerical acceleration in the study of large-scale systems, as the largest computational cost for training the GNN lies in the generation of a large enough training data set and in the optimization of the network’s hyperparameters—both of which are much more expensive when training on large systems. We demonstrate the success of this strategy in Fig. 3, where we train a GNN on data acquired for small system size (N = 400) and then apply it to much larger systems (shown up to N = 4000) without a decrease in force chain prediction accuracy. This is important in the context of predicting force chains in experiments: once trained, evaluating our prediction method only demands a cost that increases linearly with system size so that one can easily make predictions on the much larger systems one has to deal with in a typical experiment. More results on scalability near jamming are provided in the SI.
Robustness
We first observe that a GNN can predict force chains very accurately when either trained on a data set generated at high (ϕ = 1.0) or low packing fractions (ϕ = 0.845, close to jamming); Fig. 4a, e show sample configurations. Two separate GNNs were trained on data obtained at the two packing fractions. Fig. 4d, h show their predictions (on previously unseen, undeformed configurations) of force chains, which match remarkably well with the direct simulations at both high and low packing fraction. This consistent accuracy is achieved even though the force networks at the different packing fractions have a very distinct structure, as can be seen from Fig. 4b, f, c, g showing the configurations before and after deformation, respectively.

a Example configuration before deformation with nA = nB = 200 particles interacting through a harmonic potential (as given in Eq. (1)) at packing fraction ϕ = 1.0. b Corresponding force network. c Force network after deformation with step strain of amplitude γ = 0.1. d Force chains of the configuration in (c). Differences between simulation and GNN prediction on the basis of (a) are highlighted in red. e–h Same as in (a–d) but now for a configuration at a packing fraction (ϕ = 0.845) close to jamming.
A network trained on a fixed, single value of the packing fraction ϕ provides inaccurate predictions when applied to configurations obtained at other packing fractions (see Fig. 5a). If, however, we provide the GNN with information about the packing fraction during training, it can correctly predict force chain formation over a wide range of values for the packing fraction, even for values not included in the training data. Likewise, we can provide the neural network with the magnitude of the step strain γ, and apply it to correctly predict force chains when varying the value of γ for a given configuration. Again, this works even for values of γ for which the GNN did not observe any data during optimization: in Fig. 5b we demonstrate that the GNN produces highly accurate predictions both when interpolating between values of γ included in the training set, and when extrapolating towards higher values of γ. The trained GNN is also robust to changes in the composition of the binary mixture. To demonstrate this, we generate samples with a very different composition by changing the ratio of nA:nB, while keeping the packing fraction fixed. This is demonstrated in Fig. 3 for the cases of nA:nB = 3:1, and nA:nB = 1:3, with a GNN that was originally trained on data with nA:nB = 1:1. The predictions are remarkably good for both cases, with only a minimal loss of accuracy when compared to the original mixture composition.

a Force chain prediction accuracy for systems at γ = 0.1 and with different packing fractions, ranging between ϕ = 0.85 and ϕ = 1.0, with a GNN conditioned on ϕ. We show results obtained with a GNN trained on a data set obtained at ϕ = 1.0 (red), and a GNN trained on data of samples obtained at ϕ ≤ 0.88 and ϕ ≥ 0.98 (blue). The latter GNN provides highly accurate predictions in the interpolation regime 0.9 ≤ ϕ ≤ 0.96, even though it was never trained on these values of the packing fraction. b Same as in (a) but now for GNNs conditioned on the step strain amplitude γ. A GNN trained on γ ≤ 0.04 and 0.10 ≤ γ ≤ 0.12 (blue) successfully interpolates between these deformation magnitudes; it also extrapolates reliably to larger values of γ. A GNN trained only on γ ≤ 0.04 (red) fails to do this accurately. c Same as in (a) and (b), but now for a GNN conditioned on the friction coefficient μ. Both the GNN trained only on μ = 0.0 (red) and the GNN trained on μ = {0.0, 0.1, 0.9, 1.0} (blue) provide accurate results across all values of μ. The small systematic difference in testing accuracy can be explained by the latter GNN having access to four times as many training examples overall.
The fact that a GNN can provide predictions without any significant loss in accuracy in these three different generalization scenarios is highly advantageous, as it implies that large amounts of data only need to be obtained (either through experiment or simulation) at a few model parameter combinations, thus greatly reducing the cost for predicting where force chains will form in a generic experiment.
Next, we ask our GNN to predict the force chains in a jammed solid with different pairwise interactions—either through a Hertzian potential or a power-law potential (see Methods). We find that even in these cases, the GNN retains most of its accuracy (Fig. 3), with a larger performance reduction for the power-law potential. This robustness to the nature of the interaction potential is extremely important for the applicability of our method in an experimental context, where the particle interactions might not be straightforward to estimate.
We have further extended our study to frictional jammed granular solids55,56 (see details of the frictional simulation in the Supplementary Information). We first observe that our prediction using the GNN works equally well in the case of frictional particles with friction coefficient μ = 1.0, with a similar prediction accuracy of ~96% (see Fig. 6 in the Supplementary Information). Next, we train a GNN on a data set consisting of configurations obtained for μ = {0.0, 0.1, 0.9, 1.0}, where the GNN is conditioned on the value of μ by including it as a feature for each node in the graph (we hence train on all these values of μ simultaneously). Once training is completed, we use the set of weights that achieved the lowest loss on a validation data set consisting of configurations obtained at the same values of μ = {0.0, 0.1, 0.9, 1.0} as used during training. We then apply the network with these weights to predict the force chains for unseen test configurations with μ = {0.0, 0.1, 0.2, …, 0.8, 0.9, 1.0}. Note that the GNN was not trained on frictional coefficients in the range 0.2 ≤ μ ≤ 0.8, so the GNN has to interpolate between its learned classification at high and low values of μ. We observe that this interpolation can again be achieved with extremely high accuracy of ~96%, as plotted in Fig. 5c. As an additional check of robustness, we also generated strained packings of frictional particles using a finite deformation rate, with particle configurations relaxing as they are strained in contrast to the previous analysis where we implemented only affine strain. Though slightly less accurate than for the case of step strain, the GNN is still able to classify particles as being part of a force chain with an accuracy of approximately 90%.

a Structure factor of force chains predicted by a GNN at ϕ = 0.86; the GNN was conditioned on the packing fraction ϕ, and trained on data for ϕ = {0.86, 0.88, 0.90}. b Same as in (a), but now predictions are made at ϕ = 1.0, for which the GNN was not trained. c Structure factor of force chains predicted at γ = 0.16 by a GNN conditioned on γ and trained on γ = {0.02, 0.03, 0.04}. Inset (in all three cases) shows an absolute error of the structure factor w.r.t. the structure factor of the exact force chains; a distinct pattern can be observed in the inset of (b) and (c).
Analysis of structure factors of the force chains predicted by the GNNs reveals that the structure factor is quite different at different packing fractions: at ϕ = 0.86, it is strongly anisotropic, while at ϕ = 1.0 it is nearly isotropic due to the presence of more branched chains; see SI Fig. 7. For two different frictional cases (see SI Fig. 8), on the other hand, very similar structures result. This is consistent with, and rationalizes, the fact that training only on data with μ = 0.0 is highly effective for predicting force chains at larger values of μ, whereas performing an extrapolation toward higher values of ϕ while only training on data for ϕ = 0.86 is not (for more details see Supplementary Information). It also underscores the relevance of the GNN in establishing the fact that at high enough packing fractions, friction does not play a significant role and demonstrates that the GNN prediction in an unknown system is able to provide important information about the force chains under different, physically relevant conditions. To explore this matter further, we show the structure factor of the force chains predicted by GNNs in different scenarios in Fig. 6, along with the absolute prediction errors. This structure factor is highly accurate when the GNN is tasked with predicting force chains for conditions on which it is trained (Fig. 6a), or where it can interpolate. However, when the GNN is asked to extrapolate far from its training regime (Fig. 6b, c) strong systematic bias is present in this structure factor. This reveals structural properties the GNN misses out on when performing its extrapolation, such as branching events. We provide more details on the presence of this systematic bias in the extrapolation regime of GNNs in the Supplementary Information.
Discussion
In this article, we made use of graph neural networks (GNN) to accurately predict where force chains will arise upon the deformation of jammed disordered solids (both frictional and frictionless). Our network is trained on data obtained through direct shear simulations and exhibits a very high generalization ability to unseen configurations. Crucially, the optimized GNN is robust to changes in a variety of model parameters, such as the packing fraction, system size, magnitude of deformation, friction coefficient, and interaction potential: it produces very accurate predictions for such cases, without having ever observed them during its training. Although we have used data obtained through numerical simulations to train our GNN, the methodology would be identical for experimental data, where it is not always possible to measure inter-particle forces. We have also analysed the structure factor of the predicted force chains in different physical scenarios, and discussed the implication on the performance of GNN while doing extrapolation. We have verified (see Supplementary Information for details) that the predictions of our GNN are not correlated with the local \({D}_{\min }^{2}\), an indicator of plastic rearrangements. This can in turn be predicted using softness, which is a machine learning feature that has recently been used extensively43,44,45. Overall, this indicates that our GNN is picking up on novel features in the local structure of such disordered solids.
Our study will open new possibilities in experiments on such disordered solids (granular matter, emulsions, foams, etc.) where direct visualization of force chains is not possible, allowing for more in-depth analysis of structural properties as quantified by force chains. Even though for the demonstration of the success of our method we have used data generated by simulations of two-dimensional grains it is straightforward to extend the method to three-dimensional configurations where visualization of force chains in experiments is a very challenging task11,57,58.
Methods
Model and simulation
We first train our GNN on configurations of a frictionless59,60,61,62,63 athermal soft binary sphere mixture with harmonic interactions64,65,66 as a model athermal solid. The pair-interaction potential between two particles i and j is completely repulsive, and of the form
when particles overlap and zero otherwise. Here Ri and Rj are the radii of the i-th and j-th particle respectively, rij is the distance between them, and R is a characteristic particle radius parameter. All the lengths in the problem are described in units of R and energies in units of GR3. For generating the initial jammed structure we employed overdamped athermal dynamics with friction coefficient ζ. This, along with the choices for R and G, sets the time unit as ζ/(GR). Our initial simulations (for training data generation) are performed using a binary mixture of nA = nB = 200 particles with RA = R, RB = 1.4R in a two-dimensional box of linear size L and with periodic boundary conditions. We have also used a Hertzian potential of the form
and power-law potential
where we choose the energy scale for the Hertzian potential as before, and as ϵ for the power-law potential. For these training data generation runs, the simulations are performed at a fixed packing fraction ϕ, which is defined as \(\phi =({n}_{A}\pi {R}_{A}^{2}+{n}_{B}\pi {R}_{B}^{2})/{L}^{2}\). We always start with a force-free configuration under athermal conditions, and then deform the system by applying a step shear strain of magnitude γ. Lees-Edwards periodic boundary conditions are used to implement the step strain. The simulation methodology for the frictional jammed systems, which are discussed in the section on robustness, is described in the Supplementary Information.
Identification of force chains
To quantitatively detect force chains we follow the approach detailed in67,68, where force chains are defined as quasi-linear structures formed of particles that carry above-average load, i.e., compressive stress. To identify the particles within the force chains, we first calculate the stress tensor \({\hat{\sigma }}_{\alpha \beta }=\mathop{\sum }\nolimits_{i = 1}^{{N}_{nb}}{f}_{\alpha }^{i}{r}_{\beta }^{i}\) for each particle in the instantaneously sheared configuration, where Nnb is the number of neighboring particles exerting a force on the central particle, and \({f}_{\alpha }^{i}\) and \({r}_{\beta }^{i}\) are the components of the force and the radius vector connecting the centers of the two interacting particles, respectively. The largest eigenvalue of \({\hat{\sigma }}_{\alpha \beta }\) is the magnitude of the particle load vector, while its orientation is given by the corresponding eigenvector. Neighboring particles whose load vectors align within an angle of 45∘ (in Fig. 4 of the SI and the associated discussion we show that the GNN’s accuracy does not depend on the choice of this angle.) and have above-average (arithmetic mean) magnitude are assigned as part of a force chain67,68. In a completely analogous fashion, one could train neural networks on force chains identified using other approaches, e.g. based on community detection69,70 or topological properties of the force network71. Note that these detection techniques67,68,69,70,71 allow for the analysis of the force network, but do not provide any predictive power on how it will change upon deforming a system.
Training of GNN and prediction of force chains
To predict the location of force chains after a deformation with graph neural networks, we first transform a given initial configuration into a graph by drawing edges between particles that are within a fixed cutoff distance (here set to 2RB). Each node of this graph has the corresponding particle radius as feature n0. When conditioning our graph neural network on a global property such as the magnitude of the deformation γ or packing fraction ϕ, we include this property as an additional (uniform) node feature. The features assigned to each edge of the graph eij consist of the distance between the two particles connected by the edge and the unit vector in the direction of their relative distance. Importantly, we do not need to include any knowledge of the contact forces between the particles, which are typically difficult to measure37,72.
In order to predict which particles will become part of force chains after deforming the initial configuration, we apply a graph neural network to this graph. Such a GNN consists of Nl layers, where in every layer l the node features corresponding to each particle i are updated according to the features of the particles in their neighborhood \({{{{{{{\mathcal{N}}}}}}}}(i)\) and the features of the edges that connect them (see schematic in Fig. 1). Specifically,
where \({f}_{{{{{{{{\mathcal{W}}}}}}}}}^{l}\) is a parameterized nonlinear function (neural network) that calculates new node features for each particle. Importantly, we use the same function \({f}_{{{{{{{{\mathcal{W}}}}}}}}}^{l}\) for each particle, which allows us to apply the GNN to systems with an arbitrary number of particles.
For our force chain prediction, we pass the features \({n}_{{N}_{l}}\) of each node in the final layer through a fully-connected neural network with one output feature and a sigmoid activation function. This final result is, for each particle, the probability \(\hat{p}\) of being part of a force chain after deformation, as assigned by the neural network.
During training we optimize the weights of the GNN such as to minimize the cross-entropy73
where M is the number of configurations in the training set and N is the number of particles in each configuration, p = 1 if a particle is part of a force chain in a particular training configuration, and p = 0 otherwise. We use the Adam optimizer74 to minimize this loss function on a training set, and choose the model hyperparameters as those that perform best on a validation set consisting of configurations not included in the training set. We then evaluate our network on an independent test set. The optimized hyperparameter values and more details on the neural network architecture and training can be found in the SI.
Data availability
A representative data set generated for the results in the main text and in the supplementary information has been deposited in the Göttingen Research Online database under accession code https://doi.org/10.25625/TCFCVI. The complete data are available from the authors upon reasonable request.
Code availability
A representative code used to do the ML analysis has been deposited in the Göttingen Research Online database under accession code https://doi.org/10.25625/TCFCVI. The complete code is available from the authors upon reasonable request.
References
Travers, T. et al. Uniaxial compression of 2d packings of cylinders. effects of weak disorder. Europhys. Lett. 4, 329 (1987).
Oda, M., Konishi, J. & Nemat-Nasser, S. Experimental micromechanical evaluation of strength of granular materials: effects of particle rolling. Mech. Mater. 1, 269–283 (1982).
Oda, M., Nemat-Nasser, S. & Konishi, J. Stress-induced anisotropy in granular masses. Soils Found. 25, 85–97 (1985).
Drescher, A. & de Josselin de Jong, G. Photoelastic verification of a mechanical model for the flow of a granular material. J. Mech. Phys. Solids 20, 337–340 (1972).
Oda, M., Konishi, J. & Nemat-Nasser, S. Experimental micromechanical evaluation of strength of granular materials: effects of particle rolling. Mech. Mater. 1, 269–283 (1982).
Liu, C. H. et al. Force fluctuations in bead packs. Science 269, 513–515 (1995).
Majmudar, T. S. & Behringer, R. P. Contact force measurements and stress-induced anisotropy in granular materials. Nature 435, 1079–1082 (2005).
Brodu, N., Dijksman, J. A. & Behringer, R. P. Spanning the scales of granular materials through microscopic force imaging. Nat. Commun. 6, 6361 (2015).
Behringer, R. P. & Chakraborty, B. The physics of jamming for granular materials: a review. Rep. Prog. Phys. 82, 012601 (2018).
Krishnaraj, K. P. & Nott, P. R. Coherent force chains in disordered granular materials emerge from a percolation of quasilinear clusters. Phys. Rev. Lett. 124, 198002 (2020).
Brujić, J. et al. 3d bulk measurements of the force distribution in a compressed emulsion system. Faraday Discuss. 123, 207–220 (2003).
Desmond, K. W., Young, P. J., Chen, D. & Weeks, E. R. Experimental study of forces between quasi-two-dimensional emulsion droplets near jamming. Soft Matter 9, 3424–3436 (2013).
Katgert, G. & van Hecke, M. Jamming and geometry of two-dimensional foams. Europhys. Lett. 92, 34002 (2010).
Mandal, R., Bhuyan, P. J., Chaudhuri, P., Dasgupta, C. & Rao, M. Extreme active matter at high densities. Nat. Commun. 11, 1–8 (2020).
Delarue, M. et al. Self-driven jamming in growing microbial populations. Nat. Phys. 12, 762–766 (2016).
Cates, M. E., Wittmer, J. P., Bouchaud, J.-P. & Claudin, P. Jamming, force chains, and fragile matter. Phys. Rev. Lett. 81, 1841–1844 (1998).
Ostojic, S., Somfai, E. & Nienhuis, B. Scale invariance and universality of force networks in static granular matter. Nature 439, 828–830 (2006).
Makse, H. A., Johnson, D. L. & Schwartz, L. M. Packing of compressible granular materials. Phys. Rev. Lett. 84, 4160–4163 (2000).
Hidalgo, R. C., Grosse, C. U., Kun, F., Reinhardt, H. W. & Herrmann, H. J. Evolution of percolating force chains in compressed granular media. Phys. Rev. Lett. 89, 205501 (2002).
Radjai, F., Wolf, D. E., Jean, M. & Moreau, J.-J. Bimodal character of stress transmission in granular packings. Phys. Rev. Lett. 80, 61–64 (1998).
Vandewalle, N., Lenaerts, C. & Dorbolo, S. Non-gaussian electrical fluctuations in a quasi-2d packing of metallic beads. Europhys. Lett. 53, 197–201 (2001).
Owens, E. T. & Daniels, K. E. Sound propagation and force chains in granular materials.Europhys. Lett. 94, 54005 (2011).
Smart, A., Umbanhowar, P. & Ottino, J. Effects of self-organization on transport in granular matter: a network-based approach. Europhys. Lett. 79, 24002 (2007).
Royer, J. R., Blair, D. L. & Hudson, S. D. Rheological signature of frictional interactions in shear thickening suspensions. Phys. Rev. Lett. 116, 188301 (2016).
Ness, C. & Sun, J. Shear thickening regimes of dense non-brownian suspensions. Soft Matter 12, 914–924 (2016).
Khalilitehrani, M., Sasic, S. & Rasmuson, A. Characterization of force networks in a dense high-shear system. Particuology 38, 215–221 (2018).
Geng, J. et al. Footprints in sand: the response of a granular material to local perturbations. Phys. Rev. Lett. 87, 035506 (2001).
Geng, J. & Behringer, R. P. Slow drag in two-dimensional granular media. Phys. Rev. E 71, 011302 (2005).
Krishnaraj, K. P. Emergence of preferred subnetwork for correlated transport in spatial networks: on the ubiquity of force chains in dense disordered granular materials. Preprint at arXiv:2102.07130 (2021).
Mueth, D. M., Jaeger, H. M. & Nagel, S. R. Force distribution in a granular medium. Phys. Rev. E 57, 3164–3169 (1998).
Kondic, L. et al. Topology of force networks in compressed granular media. Europhys. Lett. 97, 54001 (2012).
Tighe, B. P., Snoeijer, J. H., Vlugt, T. J. H. & van Hecke, M. The force network ensemble for granular packings. Soft Matter 6, 2908–2917 (2010).
Tighe, B. P., van Eerd, A. R. T. & Vlugt, T. J. H. Entropy maximization in the force network ensemble for granular solids. Phys. Rev. Lett. 100, 238001 (2008).
Snoeijer, J. H., Vlugt, T. J. H., van Hecke, M. & van Saarloos, W. Force network ensemble: a new approach to static granular matter. Phys. Rev. Lett. 92, 054302 (2004).
Wakabayashi, T. Photo-elastic method for determination of stress in powdered mass. J. Phys. Soc. Jpn. 5, 383–385 (1950).
Howell, D., Behringer, R. P. & Veje, C. Stress fluctuations in a 2d granular couette experiment: a continuous transition. Phys. Rev. Lett. 82, 5241–5244 (1999).
Gendelman, O., Pollack, Y. G., Procaccia, I., Sengupta, S. & Zylberg, J. What determines the static force chains in stressed granular media? Phys. Rev. Lett. 116, 078001 (2016).
Wang, D., Ren, J., Dijksman, J. A., Zheng, H. & Behringer, R. P. Microscopic origins of shear jamming for 2d frictional grains. Phys. Rev. Lett. 120, 208004 (2018).
Fischer, D., Stannarius, R., Tell, K., Yu, P. & Sperl, M. Force chains in crystalline and frustrated packing visualized by stress-birefringent spheres. Soft Matter 17, 4317–4327 (2021).
Buarque de Macedo, R. et al. Unearthing real-time 3d ant tunneling mechanics. Proc. Natl Acad. Sci. USA 118, e2102267118 (2021).
Middleton, C. Ants make efficient excavators. https://physicstoday.scitation.org/do/10.1063/PT.6.1.20210908a/full/ (2021).
Carleo, G. et al. Machine learning and the physical sciences. Rev. Mod. Phys. 91, 045002 (2019).
Cubuk, E. D. et al. Identifying structural flow defects in disordered solids using machine-learning methods. Phys. Rev. Lett. 114, 108001 (2015).
Schoenholz, S. S., Cubuk, E. D., Sussman, D. M., Kaxiras, E. & Liu, A. J. A structural approach to relaxation in glassy liquids. Nat. Phys. 12, 469–471 (2016).
Rocks, J. W., Ridout, S. A. & Liu, A. J. Learning-based approach to plasticity in athermal sheared amorphous packings: Improving softness. APL Mater. 9, 021107 (2021).
Boattini, E., Ram, M., Smallenburg, F. & Filion, L. Neural-network-based order parameters for classification of binary hard-sphere crystal structures. Mol. Phys. 116, 3066–3075 (2018).
Boattini, E., Dijkstra, M. & Filion, L. Unsupervised learning for local structure detection in colloidal systems. J. Chem. Phys. 151, 154901 (2019).
Boattini, E. et al. Autonomously revealing hidden local structures in supercooled liquids. Nat. Commun. 11, 5479 (2020).
Li, H., Jin, Y., Jiang, Y. & Chen, J. Z. Y. Determining the nonequilibrium criticality of a gardner transition via a hybrid study of molecular simulations and machine learning. Proc. Natl Acad. Sci. USA 118, e2017392118 (2021).
Whitelam, S., Jacobson, D. & Tamblyn, I. Evolutionary reinforcement learning of dynamical large deviations. J. Chem. Phys. 153, 044113 (2020).
Casert, C., Vieijra, T., Whitelam, S. & Tamblyn, I. Dynamical large deviations of two-dimensional kinetically constrained models using a neural-network state ansatz. Phys. Rev. Lett. 127, 120602 (2021).
Gilmer, J., Schoenholz, S. S., Riley, P. F., Vinyals, O. & Dahl, G. E. Neural message passing for quantum chemistry. In International Conference on Machine Learning 1263–1272 (PMLR, 2017).
Sanchez-Gonzalez, A. et al. Learning to simulate complex physics with graph networks. In International Conference on Machine Learning 8459–8468 (PMLR, 2020).
Bapst, V. et al. Unveiling the predictive power of static structure in glassy systems. Nat. Phys. 16, 448–454 (2020).
Cundall, P. A. & Strack, O. D. L. A discrete numerical model for granular assemblies. Géotechnique 29, 47–65 (1979).
Silbert, L. E. Jamming of frictional spheres and random loose packing. Soft Matter 6, 2918–2924 (2010).
Brujić, J., F. Edwards, S., Hopkinson, I. & Makse, H. A. Measuring the distribution of interdroplet forces in a compressed emulsion system. Phys. A Stat. Mech. Appl. 327, 201–212 (2003).
Zhou, J., Long, S., Wang, Q. & Dinsmore, A. D. Measurement of forces inside a three-dimensional pile of frictionless droplets. Science 312, 1631–1633 (2006).
Tkachenko, A. V. & Witten, T. A. Stress in frictionless granular material: adaptive network simulations. Phys. Rev. E 62, 2510–2516 (2000).
Tkachenko, A. V. & Witten, T. A. Stress propagation through frictionless granular material. Phys. Rev. E 60, 687–696 (1999).
Head, D. A., Tkachenko, A. V. & Witten, T. A. Robust propagation direction of stresses in a minimal granular packing. Eur. Phys. J. E 6, 99–105 (2001).
Ellenbroek, W. G., Somfai, E., van Hecke, M. & van Saarloos, W. Critical scaling in linear response of frictionless granular packings near jamming. Phys. Rev. Lett. 97, 258001 (2006).
Pathak, S. N., Esposito, V., Coniglio, A. & Ciamarra, M. P. Force percolation transition of jammed granular systems. Phys. Rev. E 96, 042901 (2017).
Durian, D. J. Foam mechanics at the bubble scale. Phys. Rev. Lett. 75, 4780–4783 (1995).
Durian, D. J. Bubble-scale model of foam mechanics:mmelting, nonlinear behavior, and avalanches. Phys. Rev. E 55, 1739–1751 (1997).
Chacko, R. N., Sollich, P. & Fielding, S. M. Slow coarsening in jammed athermal soft particle suspensions. Phys. Rev. Lett. 123, 108001 (2019).
Peters, J. F., Muthuswamy, M., Wibowo, J. & Tordesillas, A. Characterization of force chains in granular material. Phys. Rev. E 72, 041307 (2005).
Tordesillas, A., Walker, D. M. & Lin, Q. Force cycles and force chains. Phys. Rev. E 81, 011302 (2010).
Bassett, D. S., Owens, E. T., Porter, M. A., Manning, M. L. & Daniels, K. E. Extraction of force-chain network architecture in granular materials using community detection. Soft Matter 11, 2731–2744 (2015).
Huang, Y. & Daniels, K. E. Friction and pressure-dependence of force chain communities in granular materials. Granul. Matter 18, 85 (2016).
Kramar, M., Goullet, A., Kondic, L. & Mischaikow, K. Persistence of force networks in compressed granular media. Phys. Rev. E 87, 042207 (2013).
DeGiuli, E. & McElwaine, J. N. Comment on “what determines the static force chains in stressed granular media?”. Phys. Rev. Lett. 117, 159801 (2016).
Murphy, K. P. Machine Learning: A Probabilistic Perspective (MIT Press, 2012).
Kingma, D. P. & Ba, J. Adam: a method for stochastic optimization. Preprint at arXiv:1412.6980 (2014).
Acknowledgements
We are grateful to Bulbul Chakraborty for her valuable comments on the manuscript. R.M. and C.C. would like to thank Mehdi Bouzid and Pritam Kumar Jana for their help in setting up the LAMMPS simulation for frictional particles. R.M. acknowledges funding from the European Union’s Horizon 2020 research and innovation program under the Marie Skłodowska-Curie grant agreement No 893128. Computational resources (Stevin Supercomputer Infrastructure) and services used in this work were provided by the VSC (Flemish Supercomputer Center), and the Flemish Government—department EWI We acknowledge support by the Open Access Publication Funds of the Göttingen University.
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Contributions
R.M. and C.C. conceived the idea, performed the simulation, numerical calculations, implemented the machine learning algorithms, and contributed equally to this work. R.M., C.C., and P.S. designed the research and wrote the paper.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Nature Communications thanks Joshua Dijksman, and the other, anonymous, reviewer(s) for their contribution to the peer review of this work.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Mandal, R., Casert, C. & Sollich, P. Robust prediction of force chains in jammed solids using graph neural networks. Nat Commun 13, 4424 (2022). https://doi.org/10.1038/s41467-022-31732-3
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41467-022-31732-3
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
