
Abstract
The fundamental goal of artificial intelligence (AI) is to mimic the core cognitive activities of human. Despite tremendous success in the AI research, most of existing methods have only single-cognitive ability. To overcome this limitation and take a solid step towards artificial general intelligence (AGI), we develop a foundation model pre-trained with huge multimodal data, which can be quickly adapted for various downstream cognitive tasks. To achieve this goal, we propose to pre-train our foundation model by self-supervised learning with weak semantic correlation data crawled from the Internet and show that promising results can be obtained on a wide range of downstream tasks. Particularly, with the developed model-interpretability tools, we demonstrate that strong imagination ability is now possessed by our foundation model. We believe that our work makes a transformative stride towards AGI, from our common practice of “weak or narrow AI” to that of “strong or generalized AI”.
Similar content being viewed by others

Introduction
Science fictions and sci-fi films, that describe highly intelligent computer minds, robots, or even human-shaped ones, can be said to understand or have primitive cognitive abilities analogous to human intelligence. Since this form of human-level artificial intelligence (AI) is too far from reality hitherto, researchers change to set a less ambitious goal of achieving artificial general intelligence (AGI). Despite not being precisely defined, AGI is broadly agreed to have several key features1 including: (1) matching or exceeding human performance across a broad class of cognitive tasks (e.g., perception, reading comprehension, and reasoning) in a variety of contexts and environments; (2) possessing the ability to handle problems quite different from those anticipated by its creators; and (3) being able to generalize/transfer the learned knowledge from one context to others. As we can imagine, devising and obtaining an AGI system would not only accelerate the AI research itself, but also benefit a wide range of AI+ fields including neuroscience, healthcare, and biomedicine.
In recent years, deep learning2 has achieved tremendous successes in various AI research areas such as computer vision (CV) and natural language processing (NLP). For example, deep residual networks (ResNets)3 have already surpassed human performance on image classification. The language model RoBERTa4 has also outperformed human on several natural language understanding tasks of the GLUE benchmark5. Relation networks6 devised by DeepMind have achieved super-human performance on a relational reasoning dataset. However, most of existing AI advances only focus on approaching or exceeding human intelligence on single cognitive ability (e.g., image classification, language understanding, or relational reasoning). To overcome such a limitation and take a solid step to AGI, we develop a foundation model pre-trained with huge multimodal (visual and textual) data such that it can be quickly adapted for a broad class of downstream cognitive tasks.
Our motivations are two-fold: (1) Foundation models7 (also well-known as pre-trained models) are established because they are exactly designed to be adapted (e.g., finetuned) to various downstream cognitive tasks by pre-training on broad data at scale. Importantly, foundation models are closely related to two breakthroughs of MIT Technology Review’s “10 Breakthrough Technologies 2021”8: GPT-39 (a pre-trained language model) and multi-skilled AI. (2) Our choice of learning from huge multimodal data is inspired by the fact that most human intelligent behaviors are exhibited in a multimodal context using visual-textual content as the primary carrier of knowledge and means of communication (see Fig. 1a). Indeed, researchers have reported that a subset of neurons in the human medial temporal lobe can be selectively activated by representations of a specific object/scene across different sensory modalities (e.g., pictures, written names, and spoken names)10,11. Although the mechanism of cross-modal alignment in our brain is unknown, this still suggests that human brain neurons are able to process multimodal information and encode concepts into invariant representations. Overall, we believe that pre-training a large-scale multimodal foundation model is indeed a potential approach to achieving AGI.

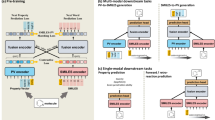
a Comparison between the human brain and our multimodal foundation model BriVL (Bridging-Vision-and-Language) for coping with both vision and language information. b Comparison between modeling weak semantic correlation data and modeling strong semantic correlation data.
Multimodal (visual and textual) foundation models12,13 typically take image-text pairs as input and model the correlation between two different modalities in their pre-training data. Although existing multimodal foundation models have shown promising results on fast learning/transfer and cross-modal understanding tasks, the majority of them12,14,15,16,17,18 make the assumption of strong semantic correlation over the input image-text pairs (e.g., image-caption pairs) and expect exact matches between the objects/regions in an image and the words in a piece of text (see Fig. 1b). This seriously limits these models’ generalization abilities because the strong semantic correlation assumption is often invalid in the real world and multimodal data following this assumption is limited (e.g., only millions of image-caption pairs are collected by years of human annotation). This situation becomes worse when latest multimodal foundation models12,17,19,20,21 often employ object detectors to obtain meaningful image regions and adopt a single-tower network architecture for better modeling the fine-grained region-word matching (i.e., taking the concatenation of image regions and text words as input). These two common practices (i.e., object detectors and the single-tower architecture) are both computationally costly and thus unsuited for real-world applications. Particularly, as for the latter, given a query in cross-modal retrieval (text-to-image or image-to-text), all possible query-candidate pairs need to be fed into the model to compute matching scores, resulting in large latency in retrieval.
To address the above issues, we develop a large-scale multimodal foundation model dubbed Bridging-Vision-and-Language (BriVL) by self-supervised learning22,23,24,25 from huge multimodal data. Firstly, to build our pre-training data collection, we choose to exploit weak semantic correlation data (see Fig. 1b) available on the Internet without any need of human annotation (i.e., we crawl a total of 650 million image-text pairs from the web). Importantly, such huge weak semantic correlation data contains complicated/abstract human emotions and thoughts. Therefore, comparing to modeling strong semantic correlation data by direct image-to-text “translation” in previous works12,17,19,20,21, modeling weak semantic correlation data by image-text matching would help us obtain a more cognitive model. Secondly, to design our network architecture, since there do not necessarily exist fine-grained region-word matches between image and text modalities, we drop the time-consuming object detectors and adopt a simple two-tower architecture (instead of the single-tower one), which encodes image and text inputs using two separate encoders (see Fig. 1a). Note that the two-tower architecture has a clear advantage in efficiency during inference, as the embeddings of candidates can be computed and indexed before querying, meeting the latency requirement of real-world applications. Thirdly, with the advancement of large-scale distributed training techniques26,27 and self-supervised learning22,23,24,25, learning from huge unannotated multimodal data becomes possible. Specifically, to model the weak image-text correlation and learn a unified semantic space where global-level image/text embeddings are aligned, we devise a cross-modal contrastive learning (CL) algorithm, where CL is a special form of self-supervised learning that is initially developed in single-modality (i.e., images)28,29,30,31 with the learning objective of keeping the positive samples close and pushing away the negative ones. The proposed network and algorithm designs are detailed in Methods.
Although OpenAI CLIP13 and Google ALIGN32 are most closely related to our BriVL, there exist two main differences between BriVL and these two latest models: (1) We follow the weak semantic correlation assumption and construct a huge dataset crawled from the Internet, and only pornographic/sensitive data are filtered out in our collected dataset. In contrast, CLIP only keeps image-text pairs with high word frequency (i.e., the long-tail concepts are discarded), while ALIGN also filters its pre-training dataset by some rules (e.g., excluding texts shared by more than 10 images, excluding texts with extremely low word frequency, and excluding texts that are too long or too short). Our dataset thus preserves a data distribution closer to that of the real world. (2) Inspired by the single-modal contrastive learning (CL) algorithm MoCo29, our BriVL model adopts a momentum mechanism to dynamically maintain queues of negative samples across different training batches. In this way, we have a large negative sample size (crucial for CL) while using a relatively small batch size (to reduce GPU memory footprint). On the contrary, both CLIP and ALIGN use negative samples within each training batch, requiring a large batch size (i.e., a great demand for GPU memories/resources). More technical differences can be found in Methods.
We conduct extensive experiments on various downstream cognitive tasks (e.g., news classification in single-modal and visual question answering in cross-modal) and show that our foundation model BriVL achieves promising results, demonstrating its cross-modal understanding ability and cross-domain learning/transfer ability. Although our BriVL is only pre-trained with an image-text matching learning objective, its strong generalization ability has already satisfied some of the key features that an AGI system should have. Importantly, with a couple of model-interpretability tools developed in this work, we manage to visually reveal how a multimodal foundation model reasonably and logically imagines when words or sentences are told, showing that our BriVL exhibits strong imagination ability. A closer examination reveals that the possession of strong imagination is mainly due to the fact that our BriVL leverages weak semantic correlation data in large-scale multimodal pre-training. Overall, these findings indicate that pre-training a multimodal (visual and textual) foundation model can make a giant stride towards AGI. With more sensory modalities exploited for multimodal pre-training and further exploration on more advancing foundation models, we believe that we are approaching AGI and our work will have a broad impact on a variety of AI+ fields including neuroscience, healthcare, and biomedicine.
Results
Our BriVL model has been pre-trained based on a huge weak semantic correlation dataset collected from public web sources. The resulting model possesses excellent imagination ability, evidenced by Neural Network Visualization, Text-to-Image Generation and multiple downstream tasks (i.e., remote sensing scene classification, news classification, cross-modal retrieval, and visual question answering), which are discussed in detail in this section.
Pre-training data collection
We construct a huge web-crawled multi-source image-text dataset called weak semantic correlation dataset (WSCD) as our pre-training data collection. WSCD collects Chinese image-text pairs from multiple sources on the web, including news, encyclopedia, and social media. Concretely, images from these data sources, together with their corresponding/surrounding text descriptions, are used to form image-text pairs. Since the obtained image-text pairs are crawled from the web, the image and the text of each pair are expected to be weakly correlated. For example, an image from social media that contains people having a good time with friends tends to have a simple title of “What a nice day!”, without any finer-grained description of the image content. Note that we only filter out the pornographic/sensitive data from WSCD, without any form of editing/modification to the raw data to preserve the natural data distribution. Totally, WSCD has around 650 million image-text pairs covering a wide range of topics such as sports, lifestyle, and movie posters. Since WSCD is based on Chinese, English texts of all experiments in this section are translated into Chinese for our BriVL. Furthermore, we pre-train our BriVL on an English dataset and show results on English tasks in Supplementary Note Fig. S3, indicating that our foundation model also provides a feasible solution closer to AGI beyond specific languages.
Neural network visualization
Humans have the ability (or even instinct) that scenes, e.g., in the context of images, come into our minds when we hear words or descriptive sentences. As for our BriVL, once pre-trained on such a vast amount of loosely aligned image-text pairs (see Methods), we are fascinated by what exactly it would imagine when texts are given. Instead of examining it indirectly through downstream tasks, we extend Feature Visualization (FeaVis)33 to see the visual responses (i.e., imagination) of BriVL to semantic inputs directly. FeaVis is an algorithm designed only to visualize the features of convolutional neural networks (CNNs). However, given a large-scale cross-modal foundation model like our BriVL, we can visualize any text input by using the joint image-text embedding space as the bridge. Concretely, we first input a piece of text and obtain its text embedding through the text encoder of BriVL. Next, we randomly initialize a noisy image and also get an image embedding through the image encoder. Since the input image is randomly initialized, its embedding does not match that of the input text. We thus define the objective of matching the two embeddings and back-propagate the resultant gradients to update the input image. Note that we do not use any additional module or data for visualization, while the pre-trained BriVL is frozen during the whole process. The finally obtained image thus depicts a clear picture of what BriVL imagines about the input text. The visualizations of different semantic inputs are shown in Fig. 2. Note that the input texts are originally in Chinese and translated into English for illustration purpose.

a Visualizations of the final embedding layer of BriVL w.r.t. high-level concepts. b Visualizations of the final embedding layer of BriVL w.r.t. free-form text inputs. c Visualizations of the final embedding layer of BriVL with semantic restrictions related to “mountains with”. d Visualizations for different neurons of BriVL with semantic restrictions “forest” and “mountains”.
We first present the imagination ability of BriVL to high-level concepts in Fig. 2a. It can be seen that, even though these concepts are rather abstract, the visualizations are able to show concrete embodiment of these concepts (e.g., “nature”: plants like grass; “time”: a clock; “science”: a face with glasses and a conical flask; “dream”: cloud, a bridge leading to a door, and the dream-like atmosphere). This ability to generalize an abstract concept to a series of more concrete objects is a sign of learned common sense and an indication of the effectiveness of our multimodal pre-training using only weak semantic correlation data (which expose the model with abstract concepts).
In Fig. 2b, we show the imagination of sentences. The visualization of “Every cloud has a silver lining.” not only embodies the sunlight behind dark clouds literally, but also seems to show a dangerous situation on the sea (the ship-like object and the waves on the left), expressing the implicit meaning of this sentence. In the visualization of “Let life be beautiful like summer flowers.”, we can see a flower shrub. The next two text inputs describing more complicated scenes are both from ancient Chinese poems written with completely different grammar from most other texts in the dataset. It seems that BriVL also understands them well: for “A few peach flowers start to blossom outside the bamboo grove.”, there are bamboos and pink flowers; for “The sun goes down below the mountains, and the Yellow River flows into the sea.”, we can see mountains with trees hiding the sunset, and a small boat on the river. Overall, we find that BriVL possesses strong capability of imagination given a complicated sentence as prompt.
In Fig. 2c, a few similar text inputs containing a shared prompt are used for network visualization. For “mountains with forests”, there is more green area in the image; for “mountains with stones”, the image is more rocky; for “mountains with snow”, the ground turns into white/blue around the trees in the center; for “mountains with waterfall”, we can see blue water falling down with even vapor visible. These imagination results indicate that our model is capable of linking specific objects with more general visual context.
We also present the neuron visualization results with semantic constraints in Fig. 2d. Concretely, in addition to the image-text matching loss described above, we select neurons (i.e., channels) in the feature map of the last layer before the pooling layer (LLP, short for “Last Layer before Pooling”) in our image encoder and maximize the value of each neuron. Since each text input may contain many semantic contents, we can see what it is equivalent to activating one neuron under certain semantic constraint. Three neurons LLP-108, LLP-456, and LLP-678 (the number means the position of each channel in the feature map) are selected for neuron visualization. The two columns in Fig. 2d show the visualizations with text inputs “forest” and “mountains”, respectively. We can clearly see that even with the same semantic constraint, activating different neurons leads to different imagination results, indicating that each text input has rich semantics with different aspects being captured by different neurons.
Text-to-image generation
Network/neuron visualizations of the imagination are straightforward but sometimes can be hard to interpret. Here, another visualization/interpretability method is developed to make the imagined visual contents of our BriVL better understood by us human. Specifically, we utilize VQGAN34 to generate images under the guidance of our BriVL and contrast them with those generated with CLIP13. A VQGAN pre-trained on the ILSVRC-201235 dataset is excellent in generating photorealistic images given a sequence of tokens. Each of such token is a vector from the pre-trained token set (i.e., codebook) of VQGAN. We first randomly sample a sequence of tokens, and obtain a generated image from the pre-trained VQGAN. Next, we input the generated image into the image encoder of CLIP/BriVL and also input a piece of text into the text encoder. Finally, we define the objective of matching the image and text embeddings, and back-propagate the resultant gradients to update the initial token sequence. Like network/neuron visualization, both VQGAN and CLIP/BriVL are frozen during the generation process. The generated examples are presented in Fig. 3.

a Generation examples of VQGAN inversion with CLIP (w/ ResNet-50x4). b Generation examples of VQGAN inversion with our BriVL. c A series of generation examples by VQGAN inversion with our BriVL. d More generation examples by VQGAN inversion with our BriVL, where concepts/scenes are rarely seen by us humans (e.g., “blazing sea” and “glowing forest”) or even do not exist in real life (e.g., “cyberpunk-styled city” and “castle in the clouds”). Note that VQGAN is pre-trained on ILSVRC-2012. BriVL, CLIP and VQGAN are all frozen during text-to-image generation.
In Fig. 3a, b, we select four text inputs and show the results obtained by CLIP and our BriVL, respectively. CLIP and BriVL both understand the texts well; however, we also observe two major differences. Firstly, cartoon-styled elements tend to appear in the generated images of CLIP, while images generated by our BriVL are more real and natural. Secondly, CLIP tends to simply put elements together while BriVL-generated images are more coherent globally. The first difference may be due to the differences in the training data used by CLIP and BriVL. The images in our training data are crawled from the Internet (most are real photos), while there may be a fair amount of cartoon images in the training data of CLIP. The second difference lies in the fact that CLIP uses image-text pairs with strong semantic correlation (by word filtering) while we use weakly correlated data. This means that during multimodal pre-training, CLIP is more likely to learn the correspondence between objects (in images) and words (in texts) while BriVL is trying to understand each image with the given text as a whole.
In Fig. 3c, we consider a significantly more challenging task where a series of images should be generated according to multiple coherent sentences. Although each image in Fig. 3c is generated independently, we can observe that all four generated images are visually coherent and of the same style. This finding demonstrates another advantage of our BriVL model: although the environment and background in an image are hard to explicitly mention in the associated text, they are not neglected in our large-scale multimodal pre-training.
We present more text-to-image generation examples obtained by VQGAN inversion with our BriVL in Fig. 3d. Specifically, we choose concepts/scenes rarely seen by us humans (e.g., “blazing sea” and “glowing forest”) or even those not existing in real life (e.g., “cyberpunk-styled city” and “castle in the clouds”). We find that our proposed model can generate images quite consistent with our imagination about the input concepts/scenes, indicating its strong generalization/imagination ability. This also provides evidence that the superior performance of BriVL is not due to overfitting the pre-training data since the text inputs here correspond to concepts/scenes that even do not exist in real life. In addition, these generation examples again demonstrate the advantage of pre-training BriVL on weak semantic correlation data (otherwise the fine-grained region-word matching would harm the imagination ability of BriVL).
Remote sensing scene classification
To show the cross-domain knowledge transfer ability and the out-of-domain imagination ability of our pre-trained BriVL, we conduct zero-shot experiments on two remote sensing scene classification benchmarks. The first dataset is UC Merced Land-Use (UCM)36, which has 21 classes and 100 images for each class. The size of each image in UCM is 256 × 256. The second dataset is AID37, which has 30 classes and 10,000 images in total. The size of each image in AID is 600 × 600. AID is a multi-source dataset, which makes it more challenging for scene classification than the single-source UCM. Concretely, images of each class in AID are extracted from different countries and regions around the world, and also at different times and seasons of the year under different imaging conditions. This leads to larger intra-class data diversity in AID. For each dataset, we first obtain class embeddings by inputting class names into the text encoder of CLIP/BriVL. Then for each test image, we obtain its image embedding via the image encoder of CLIP/BriVL, and compute its cosine similarity with each class embedding to predict the class that it belongs to. Note that since the class names of these two datasets are all English, we need to translate them into Chinese to fit our BriVL (but the original class names are directly used for CLIP).
In the field of zero-shot learning (ZSL)38, datasets typically follow the split of unseen and seen classes. Conventional ZSL models are thus trained with seen class data and evaluated on unseen class data. Although we do not need to train on seen classes, we still follow the common practice and split each dataset with different unseen/seen class ratios (the seen classes are simply not used). Under the split settings where the number of seen classes are not zero, we randomly sample 25 splits and report the standard deviations in brackets along with average accuracy.
The zero-shot classification results on UCM are shown in the table of Fig. 4a. Our BriVL is compared to a strong baseline ZSSC39 specially designed for zero-shot remote sensing scene classification, and also CLIP with different CNN backbones. We can see that large-scale cross-modal foundation models achieve far higher rates compared with ZSSC, indicating their strong cross-domain knowledge transfer abilities. Moreover, our classification rates are also higher than those of all CLIP models with different CNNs, which is impressive considering the loss in English-to-Chinese translation and also cultural differences (CLIP is trained on English data while we use data crawled from Chinese Internet). Results on another dataset AID are shown in the table of Fig. 4b. Since we did not find methods conducting ZSL experiments on AID, we only make comparisons with CLIP variations. As we have mentioned, AID is more challenging than UCM, which is also reflected by the much worse performance of CLIP variations on AID than on UCM. However, our BriVL achieves similar performance on the two datasets when evaluated over all data, and the gap between BriVL and CLIP is larger on AID than that on UCM. This means that BriVL has stronger generalization ability and can cope with more complicated situations.

a Zero-shot accuracies (%) on UCM with different unseen/seen class ratios. b Zero-shot accuracies (%) on AID with different unseen/seen class ratios. c Visualizations of “baseball field”. For (a) and (b), we report standard deviations in brackets over 25 random splits. Highest results in (a) and (b) are highlighted in bold.
Furthermore, we deploy the aforementioned network visualization technique to clarify the visual responses of our BriVL to remote sensing related concepts. Concretely, we select one class “baseball field”, and add the prompt “viewed from above” to the class name as the text input. The imagined visual content of our BriVL is shown in Fig. 4c along with one example of this class. We can see that remote sensing scenes are very different from traditional photos, mainly in the perspective of cameras. Despite this, we can observe from BriVL’s imagination that there is a small sector-shaped area (marked with red lines) in “baseball field viewed from above”. This provides direct explanation to the impressive performance of our BriVL on remote sensing scene classification. In addition, we search the keyword “baseball field” in our pre-training dataset WSCD and find that most of the related images are taken in a normal camera perspective. Given that there is hardly any remote sensing data in our WSCD, this finding suggests that BriVL has somehow learned to generalize transformation of perspectives to unseen domains during pre-training. This again shows the strong imagination ability and even hints of common sense reasoning ability of our BriVL.
News classification
To demonstrate how large-scale multimodal learning can benefit single-modal skills and also improve the imagination ability on single-modal tasks, we conduct zero-shot experiments on two Chinese news classification datasets. The first dataset is Toutiao News40, which has 15 classes and a total of around 380K samples. The second dataset is THUCNews41, which has 14 classes and around 840K samples in total. Since the contents in these two datasets are all texts, we only need the text encoder of our BriVL. Concretely, we first obtain class embeddings by inputting class names into the text encoder. Further, for each piece of news, we only use its title to obtain its embedding via the text encoder. Finally, we compute the cosine similarities between each title embedding and class embeddings to make predictions.
The following methods are chosen for comparison: (1) RoBERTa-base:42 it is an off-the-shelf Chinese language model pre-trained by the original authors on a large Chinese dataset with a total of 5.4B words. (2) RoBERTa-base (finetune): we finetune the pre-trained RoBERTa-base on a subset of our WSCD dataset (i.e., only the text data of 22M image-text pairs is used). (3) BriVL w/ RoBERTa-base: it is a small version of our standard BriVL as we reduce the CNN from EfficientNet-B743 to EfficientNet-B5 and also the text backbone from RoBERTa-large to RoBERTa-base. We pre-train this small version with the aforementioned 22M image-text pairs. (4) RoBERTa-large: it is the larger version of RoBERTa-base and is also pre-trained by the original authors. Its pre-training data is the same as that of RoBERTa-base. (5) BriVL w/ RoBERTa-large: our standard BriVL pre-trained on the whole WSCD.
The zero-shot classification results on Toutiao News and THUCNews are shown in Fig. 5a. It can be seen that: (1) The results of RoBERTa-base are lower than those of RoBERTa-large, which is expected since the latter has more parameters and a larger model capacity. (2) On both datasets, RoBERTa-base (finetune) has limited performance gains over RoBERTa-base, while BriVL w/ RoBERTa-base outperforms RoBERTa-base by large margins. This clearly indicates the advantage of cross-modal learning over single-modal learning, given that the finetuning data of RoBERTa-base (finetune) and BriVL w/ RoBERTa-base is both from the 22M subset of WSCD. (3) When it comes to RoBERTa-large, our BriVL w/ RoBERTa-large also leads to much better results than RoBERTa-large.

a Zero-shot news classification results (%) on two Chinese news datasets. b Zero-shot accuracy gain/loss (%) of BriVL w/ RoBERTa-large comparing to RoBERTa-large on each category of Toutiao News. c Top-30 phrase retrieval results of “sports” (top) and “automobile” (bottom) using RoBERTa-large and BriVL w/ RoBERTa-large, respectively. The candidate phrase list is obtained from Jieba, which consists of 347,728 Chinese phrases. We translate the results into English for presentation clarity. Highest results in (a) are highlighted in bold.
Moreover, in Fig. 5b, we present the performance gain/loss of our BriVL w/ RoBERTa-large comparing to RoBERTa-large on each category of Toutiao News. We can observe that the performance of BriVL decreases only on 5 categories but increases on the other 10, validating that the single-modal imagination/association ability can be improved by multimodal learning. Further, in Fig. 5c, we show top-30 phrase retrieval results of the category names “sports” and “automobile” using these two models to take a closer look. Concretely, we use a Chinese phrase list from Jieba44 as the candidate list, which contains 347,728 phrases. Then we obtain the text embeddings of all candidates using RoBERTa-large and BriVL w/ RoBERTa-large, respectively. For each model and each category name, we compute the category name embedding and retrieve top-30 phrases by comparing it with all candidate embeddings using the cosine similarity. Finally, we visualize the results with the UMAP algorithm45. For “sports”, we can see that our BriVL relates it to phrases with a higher variety than RoBERTa-large does. However, for “automobile”, the retrieved top-30 phrases of our BriVL are more monotonous.
Cross-modal retrieval
Here we conduct experiments on the cross-modal retrieval downstream task, which is exactly what we train our BriVL to do. Since our BriVL is pre-trained with Chinese data, we choose the only available multimodal Chinese dataset AIC-ICC46 for performance evaluation. AIC-ICC is originally designed for image captioning, which was first released in AI Challenger 2017, a competition organized by Sinovation Ventures, Sogou, and Toutiao (ByteDance). The training set of AIC-ICC has 300K images and the validation set has 30K images. Each image has 5 Chinese captions. Since the test set is not released, we take the first 10K images along with their corresponding 50K pieces of texts from the validation set for testing.
The cross-modal retrieval results on AIC-ICC are shown in the table of Fig. 6a. The method “BriVL (direct training)” means that we directly train a randomly-initialized BriVL model on the training set of AIC-ICC rather than using the pre-trained BriVL. Moreover, the results of three “BriVL (pre-train & finetune)” variations are all obtained by finetuning our pre-trained BriVL on the training set of AIC-ICC with different finetuning strategies. We only consider two finetuning factors: whether to fix all the batch normalization (BN) layers in the CNN (i.e., EfficientNet-B7), and how many blocks should be unfixed in the CNN. We perform both image-to-text and text-to-image retrieval for evaluation, and report the results with Recall@k (k = 1, 5, 10) as well as Recall@SUM (i.e., the summation of six Recall@k metrics).

a Cross-modal retrieval results (%) on the Chinese dataset AIC-ICC. b VQA results on Visual7W. Overall accuracies (%) along with results on each question type are reported. The dataset is translated into Chinese. c VQA examples of our BriVL model regarding whether it is pre-trained to validate the strong imagination ability of our pre-trained BriVL. Highest results in (a) and (b) are highlighted in bold.
We can observe from the table of Fig. 6a that image-to-text retrieval results are generally higher than text-to-image ones, which is expected because like us humans, describing a given image is easier than imagining a picture from a sentence. We can also see that three “BriVL (pre-train & finetune)” variations achieve far better results than “BriVL (direct training)” for all evaluation metrics, indicating the usefulness of large-scale multimodal pre-training. In addition, using pre-trained models like our BriVL is more beneficial to image-to-text retrieval than to text-to-image retrieval, which may be due to the fact that image-to-text retrieval is an easier task. From the performance of three “BriVL (pre-train & finetune)” variations, we find that different finetuning strategies do affect the final results, which should be kept in mind when we finetune pre-trained models for different downstream tasks.
Visual question answering
We consider another multimodal downstream task called visual question answering (VQA)47 to further validate the strong imagination ability of our pre-trained BriVL on the Visual7W dataset48. Visual7W has 47.3K images from MSCOCO49 and each image comes with a question and four answer candidates, where only one is the correct answer. The whole dataset can be divided into “Telling” questions and “Pointing” ones. Since “Pointing” questions rely on the bounding boxes of objects in images, we only conduct experiments on the “Telling” part, which can be further divided into six question types: “What”, “Where”, “When”, “Who”, “Why”, and “How”. We randomly make the training and test splits with 70% and 30%, respectively. Since Visual7W is an English dataset, we translate all of the questions and answer candidates into Chinese.
In the table of Fig. 6b, we report the overall accuracies on the test set, as well as the results on each question type. Similar to the situation on the cross-modal retrieval task, three “BriVL (pre-train & finetune)” variations achieve much better results than “BriVL (direct training)” for all question types, again indicating the usefulness of large-scale pre-training on downstream tasks. We also notice that the best finetuning strategy for cross-modal retrieval (i.e., fixing BN and keeping 4 blocks of the CNN unfixed) is no longer the best for VQA. In addition, although the strategy of not fixing BN and keeping 2 blocks unfixed obtains the best overall result, it does not achieve the best for all question types. This is expected as different tasks require different finetuning strategies.
Furthermore, we present four VQA examples in Fig. 6c. From these examples, we see our pre-trained BriVL clearly showing the strong imagination ability and even hints of common sense as it knows that the train in the picture looks blurry because it is moving fast, the picture of horses was taken in a field rather than in a zoo, the boats being tied to the dock are simply not moving instead of floating, and the traffic is stopped because of the red light instead of traffic jam. We believe that this is achieved by pre-training with our weak semantic correlation data: the texts are not detailed descriptions of their corresponding images, and thus our BriVL has to figure out the complicated connections hidden among this weak correlation during pre-training. With large pre-training data as much as 650 million, our BriVL finally succeeds in acquiring the ability of reasonably and logically imagining/associating, and also manages to learn some common sense.
Discussion
We have developed a large-scale multimodal foundation model called BriVL, which is efficiently trained on weak semantic correlation dataset (WSCD) consisting of 650 million image-text pairs. We have identified the direct evidence of the aligned image-text embedding space by neural network visualizations and text-to-image generation. In addition, we have visually revealed how a multimodal foundation model understands language and how it makes imagination or association about words and sentences. Moreover, extensive experiments on other downstream tasks show the cross-domain learning/transfer ability of our BriVL and the advantage of multimodal learning over single-modal learning. Particularly, our BriVL appears to acquire abilities in imagination and reasoning. Last but not least, we believe that all of these advantages are mainly due to the weak semantic correlation assumption followed by our BriVL. That is, by effectively fusing the complex human emotions and thoughts from those weakly correlated image-text pairs, our BriVL is made more cognitive and general (i.e., much closer to AGI).
We believe that the solid step we take towards AGI would have a broad impact not only on the AI development community but also on a wide range of AI+ fields. For the AI research field itself, based on our GPU-resource-saving multimodal pre-training framework, researchers could easily extend our BriVL to a larger capacity with more modalities, leading to more general foundation models. Moreover, with the help of large-scale multimodal foundation models, it would also be much easier for researchers to explore novel tasks (especially those without abundant human-annotated samples). For AI+ fields, such foundation models could be quickly adapted to specific working context or environment, thanks to their strong generalization abilities. For example, in healthcare, multimodal foundation models could make full use of case data in multi-modality (e.g., computed tomography data, and blood routine examination data) to improve the diagnosing accuracy. Moreover, in neuroscience, multimodal foundation models could even help find out the mechanism of how multimodal data connect and fuse since artificial neural networks are much simpler to examine than real neural systems in human brains.
Nevertheless, multimodal foundation models still face potential risks and challenges. Since the performance of foundation models is based on the data that they are pre-trained on, it is likely that the models learn prejudices and stereotypes about certain issues, which should be carefully handled before model training and monitored/addressed in downstream applications. Moreover, as foundation models master more and more skills, creators of these models should be aware of model misuse by ill-intentioned people (e.g., manipulating or generating fake contents), which would have a negative influence on the society. In addition, on the evolution challenges of foundation models academically, it is of grand challenge for (1) developing model-interpretability tools deeper into the foundation models, (2) constructing huge pre-training datasets with more modalities, as well as (3) applying foundation models to various downstream tasks with more effective adaptation/finetuning techniques.
Our understanding of what BriVL (or any large-scale multimodal foundation model) has learned and what it is capable of has only just started. There is still much room for further study to better understand the foundation model and develop more novel use cases. For instance, since the image can be regarded as a universally-understood “language”, soliciting an even larger dataset containing multiple languages could result in a language translation model obtained as a by-product of multimodal pre-training. Moreover, additional modalities (e.g., videos and audios) can be also explored to pre-train a more intelligent model, taking us even closer to AGI.
Methods
Architecture overview
The notion of pre-training a large-scale machine learning model and then using it for downstream tasks first appeared in natural language processing (NLP). As shown in Supplementary Note Fig. S1c, large-scale NLP models like GPT50, BERT51, and their variants, take Transformers52 as text encoders to encode input texts into text embeddings, and then design pre-training objectives on top of these embeddings (e.g., generative loss and masked language modeling loss). In computer vision (CV), large-scale pre-training also becomes popular. Models like BiT53 and ViT54 use convolutional neural networks (CNNs) or Transformers as image encoders to obtain embeddings of input images. Similarly, pre-training losses are computed using the image embeddings (e.g., image classification loss and masked image patch prediction loss). However, these models are single-modal and thus only benefit downstream tasks in one modality. For multimodal (e.g., image, text, and audio) pre-training12,13,14,15,16,17,18,32, existing works can be divided into two groups according to their network architectures: single-tower models (e.g., UNITER17, OSCAR12, and M618) and two-tower ones (e.g., CLIP13 and ALIGN32). Our BriVL can also be categorized into the two-tower models since we use separate image and text encoders. But note that we actually adopt two additional momentum encoders to help with the pre-training process (i.e., to dynamically maintain negative sample queues across training batches), resulting in a four-tower pre-training architecture.
The pre-training goal of our BriVL is to learn two encoders that can embed image and text inputs into the same semantic space for effective image-text retrieval. To enforce the image and text encoders to learn better representations in the same embedding space, we introduce cross-modal contrastive learning with the InfoNCE loss23 into our BriVL. Specifically, our learning objective is to find the corresponding image embedding from a batch of them for a given text embedding and vice versa. By maximizing the cosine similarity of the image and text embeddings for each ground-truth pair while minimizing the cosine similarities of the embeddings from negative pairs, we jointly train the image and text encoders to learn an aligned cross-modal embedding space.
Formally, for the image-text retrieval task, we denote the training set as \({{{{{{{\mathcal{D}}}}}}}}=\{({x}_{i}^{(i)},{x}_{i}^{(t)})| i=1,\cdots \,,N\}\), where \(({x}_{i}^{(i)},{x}_{i}^{(t)})\) is a matched image-text pair, and N is the size of \({{{{{{{\mathcal{D}}}}}}}}\). Our BriVL leverages contrastive learning by applying MoCo29 into the cross-modal scenario, as illustrated in Supplementary Note Fig. S1a. Each image \({x}_{i}^{(i)}\) (or each text \({x}_{i}^{(t)}\)) is encoded by the image encoder f(i) (or the text encoder f(t)) to obtain its d-dimensional embedding \({{{{{{{{\bf{z}}}}}}}}}_{i}^{(i)}\) (or \({{{{{{{{\bf{z}}}}}}}}}_{i}^{(t)}\)). The image encoder (see Supplementary Note Fig. S1b) contains a CNN backbone, a successive self-attention (SA) block, and a multi-layer perceptron (MLP). A sequence of patch embeddings are first obtained by applying multi-scale patch pooling (MSPP) to the feature map from CNN. They are then fused/encoded by the SA block. The text encoder, on the other hand, is stacked by several SA blocks such as BERT51 and RoBERTa4. A two-layer MLP block with a ReLU55 activation layer is used for mapping each encoder’s representation into the joint cross-modal embedding space. The parameters of f(i) and f(t) are denoted as θ(i) and θ(t), respectively.
Image encoder
To obtain better performance in the image-text retrieval task, most previous methods19,20,21,56 utilize a bottom-up attention mechanism57 with object features extracted by the Faster R-CNN detector58. However, extracting region/object features with a heavy detector is computationally expensive, e.g., a Faster R-CNN detector typically costs 0.064s (15.6 fps) to extract fine-grained region information from an image of moderate size. Meanwhile, the image-text retrieval would be inevitably limited by the detector’s performance, which is not adaptable to real-world applications. In this paper, we thus introduce a simple yet effective module named Multi-Scale Patch Pooling (MSPP) to address this problem.
For each input image x(i), we first split it into multiple patches at different scales and record the patch coordinates. In all experiments, we take two scales as 1 × 1 and 6 × 6, resulting in a total of 37 patches. Next, we project each set of patch coordinates onto the feature map that is obtained by the CNN backbone (e.g., EfficientNet43) and generate a sequence of 37 region feature maps. Finally, we apply average pooling to each region feature map and obtain a sequence of patch features \({{{{{{{\bf{S}}}}}}}}\in {{\mathbb{R}}}^{c\times {N}_{p}}\), where each column corresponds to a patch, Np is the number of patches (i.e., Np = 37 in this paper), and c is the number of channels in the feature map.
To better capture the relationship of image patch features, we deploy a self-attention (SA) block containing multiple Transformer52 encoder layers. Each Transformer encoder layer consists of a multi-head attention (MultiHeadAttn) layer and a feed forward network (FFN) layer:
We then fuse the extracted patch features by applying an average pooling layer:
where Sj is the j-th column of S. A two-layer MLP block with a ReLU activation layer is adopted to project r(i) to the joint cross-modal embedding space, resulting in the final d-dimensional image embedding \({{{{{{{{\bf{z}}}}}}}}}^{(i)}\in {{\mathbb{R}}}^{d}\).
Text encoder
Given a sentence x(t), we first tokenize it to obtain a sequence of tokens \({{{{{{{\mathcal{T}}}}}}}}=\{{{{{{{{{\bf{t}}}}}}}}}_{j}| j=1,...,l\}\), where l denotes the length of the sentence (e.g., the number of words) and tj denotes the j-th token of \({{{{{{{\mathcal{T}}}}}}}}\). A pre-trained Transformer encoder (e.g., RoBERTa42) is then used to map text tokens to a sequence of feature vectors (each feature vector corresponds to a word). Similarly, to better capture the relationship between words, we use the same self-attention mechanism as in the image encoder to extract the text representation r(t). A two-layer MLP block with a ReLU activation layer is also used for mapping the text representation r(t) to the joint cross-modal embedding space, resulting in the final d-dimensional text embedding \({{{{{{{{\bf{z}}}}}}}}}^{(t)}\in {{\mathbb{R}}}^{d}\).
Contrastive loss
The cross-modal contrastive loss in our BriVL is defined based on MoCo29, which provides a mechanism of building dynamic sample queues for contrastive learning. Since the two negative queues used in our BriVL decouple the queue size from the mini-batch size, we can have a much larger negative sample size than the mini-batch size (thus GPU-resource-saving).
To maintain large queues of samples coming from different mini-batches and address the problem that sample features are extracted by encoders with very different parameters, we need two more smoothly updated encoders, that is, momentum encoders. The parameters \({\theta }_{m}^{(i)}\) (or \({\theta }_{m}^{(t)}\)) of the momentum image encoder \({f}_{m}^{(i)}\) (or the momentum text encoder \({f}_{m}^{(t)}\)) are updated in each training iteration with a momentum hyper-parameter m:
Further, we maintain two negative sample queues \({{{{{{{{\mathcal{Q}}}}}}}}}^{(i)}\) and \({{{{{{{{\mathcal{Q}}}}}}}}}^{(t)}\), which contain Nq image negatives and Nq text negatives for contrastive learning, respectively. In each pre-training iteration with the batch size Nb, all Nb image negatives and Nb text negatives are separately pushed into these two queues. Meanwhile, there are Nb earliest samples being popped out of each queue. Concretely, at iteration t, the image and text negatives from the current data batch \(({{{{{{{{\mathcal{B}}}}}}}}}_{t}^{(i)},{{{{{{{{\mathcal{B}}}}}}}}}_{t}^{(t)})\) are computed by respectively forwarding the momentum encoders \({f}_{m}^{(i)}\) and \({f}_{m}^{(t)}\):
where \(| {{{{{{{{\mathcal{B}}}}}}}}}_{t}^{(i)}| =| {{{{{{{{\mathcal{B}}}}}}}}}_{t}^{(t)}| ={N}_{b}\). The obtained \({{{{{{{{\mathcal{N}}}}}}}}}_{t}^{(i)}\) and \({{{{{{{{\mathcal{N}}}}}}}}}_{t}^{(t)}\) are then pushed into \({{{{{{{{\mathcal{Q}}}}}}}}}^{(i)}\) and \({{{{{{{{\mathcal{Q}}}}}}}}}^{(t)}\), respectively. Note that although we generally call \({{{{{{{{\mathcal{N}}}}}}}}}_{t}^{(i)}\) (or \({{{{{{{{\mathcal{N}}}}}}}}}_{t}^{(t)}\)) image negatives (or text negatives), there is still one sample being positive to each text (or image). Here, we denote the positive image sample (or text sample) for the j-th input text \({x}_{j}^{(t)}\) (or the j-th input image \({x}_{j}^{(i)}\)) of the current mini-batch as:
With the two negative queues, the loss function in each training iteration is thus computed as follows. For each input image \({x}_{i}^{(i)}\), we define the contrastive loss between its image embedding \({{{{{{{{\bf{z}}}}}}}}}_{i}^{(i)}\) and all positive/negative texts in the queue \({{{{{{{{\mathcal{Q}}}}}}}}}^{(t)}\) as an InfoNCE loss23:
where \({{{{{{{{\bf{n}}}}}}}}}^{(t)}\in {{{{{{{{\mathcal{Q}}}}}}}}}^{(t)}\setminus \{{{{{{{{{\bf{p}}}}}}}}}_{i}^{(t)}\}\) denotes a text negative for each image, τ is the temperature hyper-parameter, and the vector similarity is measured by dot product (⋅). Similarly, for each input text \({x}_{i}^{(t)}\), the InfoNCE loss is given by:
where \({{{{{{{{\bf{n}}}}}}}}}^{(i)}\in {{{{{{{{\mathcal{Q}}}}}}}}}^{(i)}\setminus \{{{{{{{{{\bf{p}}}}}}}}}_{i}^{(i)}\}\) denotes an image negative for each text.
The total loss function for pre-training our BriVL is then defined as:
In the test/evaluation stage, given each query image (or text), the cross-modal retrieval results are obtained simply by the dot product defined over the outputs of the text (or image) encoder.
Implementation details
Over the input images, we adopt random graying and random color jittering for data augmentation. All images are resized to 600 × 600 pixels. We adopt EfficientNet-B743 as the CNN backbone in the image encoder and RoBERTa-Large42 as the basis Transformer in the text encoder. For both image and text encoders, the self-attention block consists of 4 Transformer encoder layers and the MLP block has two fully-connected layers with a ReLU activation layer. The final embedding size of the joint cross-modal space is 2,560. We select the hyper-parameters heuristically for pre-training our BriVL model due to the computational constraint: the temperature hyper-parameter τ = 0.07, momentum m = 0.99, and the queue size Nq = 13, 440. We adopt the Adam optimizer59, with the weight decay 1e-5 and the learning rate 1e-4. We use a mini-batch size of 192 for each of the 14 machines (each machine has 8 NVIDIA A100 GPUs), resulting in a total batch size of 2688 (far smaller than Nq). The resource-saving advantages of such batch setting are shown by the ablation study results in Supplementary Note Fig. S2. We also deploy the latest distributed-training framework DeepSpeed26 to accelerate the pre-training process and save the GPU memories. With 112 NVIDIA A100 GPUs in total, it takes about 10 days to pre-train our BriVL model over our WSCD of 650 million image-text pairs.
Differences from CLIP/ALIGN
We have stated two main differences between our BriVL and CLIP/ALIGN in the Introduction section. Below we give more detailed differences technically. (1) We adopt a four-tower network architecture (see Supplementary Note Fig. S1a) for pre-training. By extending the original single-modal contrastive learning (CL) algorithm MoCo29, we introduce momentum encoders and negative sample queues for multimodal pre-training in a more GPU-resource-saving way. In contrast, both CLIP and ALIGN employ the standard two-tower architecture, which requires large batch size (thus enough negative samples) to be effective, taking up a mass of GPU memories. (2) We additionally devise a multi-scale patch pooling (MSPP) module (see Supplementary Note Fig. S1b) to capture fine-grained image region representations without using object detectors. While CLIP and ALIGN only consider global-level image embeddings, which impedes their ability to learn fine-grained/local image features.
Formalization of neural network visualization
Neural network visualization is developed to directly show the visual response/imagination of BriVL w.r.t. the semantic input. Formally, given the pre-trained image and text encoders f(i) and f(t) of BriVL, we first input a piece of text x(t) and obtain its text embedding \({{{{{{{{\bf{z}}}}}}}}}^{(t)}={f}^{(t)}({x}^{(t)})\in {{\mathbb{R}}}^{d}\). In the mean time, we randomly initialize a noisy image \({x}^{(i)}\in {{\mathbb{R}}}^{600\times 600\times 3}\), which contains all the learnable parameters throughout the entire visualization process. Further, we obtain the image embedding \({{{{{{{{\bf{z}}}}}}}}}^{(i)}={f}^{(i)}({x}^{(i)})\in {{\mathbb{R}}}^{d}\) and define the learning objective by matching the two embeddings:
where \(\cos (\cdot ,\cdot )\) computes the cosine similarity between two vectors. With the resultant gradients, we are able to update the input image x(i) by back-propagation. After repeating the above updating step with multiple iterations, we finally obtain an image x(i), which can be regarded as BriVL’s response/imagination about the input text. The algorithm for neural network visualization is summarized in Algorithm 1.
Algorithm 1
Neural Network Visualization
Input: The pre-trained image and text encoder f(i) and f(t) of our BriVL
A piece of text x(t)
A randomly initialized image x(i)
A learning rate parameter λ
Output: The updated input image
1: Obtain the text embedding z(t) = f(t)(x(t));
2: for all iteration = 1, 2, ⋯ , MaxIteration do
3: Obtain the image embedding z(i) = f(i)(x(i));
4: Compute \({{{{{{{{\mathcal{L}}}}}}}}}_{vis}\) with Eq. (13);
5: Compute the gradients \({\nabla }_{{x}^{(i)}}{{{{{{{{\mathcal{L}}}}}}}}}_{vis}\);
6: Update x(i) using gradient descent with λ;
7: end for
8: return the updated input image.
Formalization of text-to-image generation
To make BriVL’s response/imagination on input texts better understood, we further adopt VQGAN34 to help generate more photo-realistic images. The reason of utilizing VQGAN instead of other GANs60 is as follows. Although classic GANs are able to generate high quality images under specific domains (e.g., natural sceneries or human faces), they tend to fail when complex scenarios are involved. In contrast, VQGAN alleviates this problem and performs better under complex scenarios by combining VQVAE61 and GAN. For our text-to-image generation, we only need a codebook \({{{{{{{\mathcal{C}}}}}}}}\) and a CNN generator g of the VQGAN pre-trained on ILSVRC-201235. The pre-trained codebook \({{{{{{{\mathcal{C}}}}}}}}=\{{{{{{{{{\bf{c}}}}}}}}}_{k}\in {{\mathbb{R}}}^{{d}_{c}}| k=1,2,\cdots ,{N}_{c}\}\) is a collection of tokens/codes, where dc is the dimension of each code and Nc is the number of codes in the codebook (dc = 256 and Nc = 1, 024 in our case). The pre-trained CNN generator g takes a spatial collection of codebook entries \({{{{{{{\bf{U}}}}}}}}\in {{\mathbb{R}}}^{h\times w\times {d}_{c}}\) as input to generate an image (U can also be regarded as a sequence of hw codes, h = w = 16 in our case), where each element \({{{{{{{{\bf{u}}}}}}}}}_{ij}\in {{\mathbb{R}}}^{{d}_{c}}\) (i = 1, 2, \(\cdots,\) h and j = 1, 2, \(\cdots,\) w) must come from the codebook \({{{{{{{\mathcal{C}}}}}}}}\) (i.e., \({{{{{{{{\bf{u}}}}}}}}}_{ij}\in {{{{{{{\mathcal{C}}}}}}}}\)). With the pre-trained image and text encoders f(i) and f(t) of BriVL, we first input a piece of text x(t) and obtain its text embedding \({{{{{{{{\bf{z}}}}}}}}}^{(t)}={f}^{(t)}({x}^{(t)})\in {{\mathbb{R}}}^{d}\). Meanwhile, we randomly initialize an input code collection U, which is the only parameter matrix to be learned. Afterwards, we generate an image from the generator x(i) = g(U) and further obtain its image embedding \({{{{{{{{\bf{z}}}}}}}}}^{(i)}={f}^{(i)}({x}^{(i)})\in {{\mathbb{R}}}^{d}\). The learning objective is to maximize the similarity between two embeddings:
After updating the input U and obtaining \({{{{{{{\bf{U}}}}}}}}^{\prime}\) by back-propagation, we need to perform an element-wise quantization of each spatial code \({{{{{{{{\bf{u}}}}}}}}}_{ij}^{\prime}\in {{\mathbb{R}}}^{{d}_{c}}\) in \({{{{{{{\bf{U}}}}}}}}^{\prime}\) onto its closest codebook entry ck:
By repeating the above updating step with multiple iterations, we finally obtain an image x(i) generated with the updated U. The algorithm for text-to-image generation is summarized in Algorithm 2.
Algorithm 2
Text-to-Image Generation
Input: The pre-trained image and text encoder f(i) and f(t) of our BriVL
The codebook \({{{{{{{\mathcal{C}}}}}}}}\) and the CNN generator g of the pre-trained VQGAN
A piece of text x(t)
A randomly initialized collection of codebook entries U
A learning rate parameter λ
Output: The image generated with the updated U
1: Obtain the text embedding z(t) = f(t)(x(t));
2: for all iteration = 1, 2, ⋯ , MaxIteration do
3: Generate an image x(i) = g(U);
4: Obtain the image embedding z(i) = f(i)(x(i));
5: Compute \({{{{{{{{\mathcal{L}}}}}}}}}_{t2i}\) with Eq. (14);
6: Compute the gradients \({\nabla }_{{{{{{{{\bf{U}}}}}}}}}{{{{{{{{\mathcal{L}}}}}}}}}_{t2i}\);
7: Obtain \({{{{{{{\bf{U}}}}}}}}^{\prime}\) by updating U using gradient descent with λ;
8: Obtain U by performing element-wise quantization on \({{{{{{{\bf{U}}}}}}}}^{\prime}\) with Eq. (15);
9: end for
10: return the image generated with the updated U.
Neural network visualization vs. text-to-image generation
The intrinsic difference between neural network visualization and text-to-image generation lies in that they produce images following different data distributions. Not utilizing extra modules or data, neural network visualization exhibits BriVL’s primitive visual understanding of a given piece of text. However, the VQGAN34 used for text-to-image generation is pre-trained on ILSVRC-201235 (i.e., the classic ImageNet dataset), which generates images following the data distribution of ImageNet and thus being more photo-realistic. Due to such an intrinsic difference, we present the visualization results of these two tasks for different purposes in this paper. Specifically, neural network visualization allows us to see what exactly a pre-trained multi-modal foundation model imagines about semantic concepts and sentences, while text-to-image generation is used to generate images matched with given texts in a more human-friendly way.
Data availability
The availability of datasets used in this study is detailed as follows: (1). Two remote sensing scene classification datasets: UC Merced Land-Use (UCM, http://weegee.vision.ucmerced.edu/datasets/landuse.html) and AID (https://captain-whu.github.io/AID/). (2). Two news classification datasets: THUCNews (http://thuctc.thunlp.org/) and Toutiao News (https://github.com/aceimnorstuvwxz/toutiao-text-classfication-dataset). (3). The Chinese cross-modal retrieval dataset AIC-ICC is available at https://github.com/neilfei/brivl-nmi. (4). The VQA dataset Visual7W is available at http://ai.stanford.edu/yukez/visual7w/. (5). The dataset used for pre-training our model is available at https://resource.wudaoai.cn/home. Please note that the available datasets (1) – (4) are sufficient for finetuning our pre-trained BriVL model in order to interpret, verify and extend our research.
Code availability
The pre-trained BriVL and its inference code are available at https://github.com/neilfei/brivl-nmi under Creative Commons Attribution-Non Commercial-No Derivatives 4.0 International Licence (CC BY-NC-ND).
References
Goertzel, B. Artificial general intelligence: Concept, state of the art, and future prospects. J. Artif. Gen. Intell. 5, 1–48 (2014).
LeCun, Y., Bengio, Y. & Hinton, G. Deep learning. Nature 521, 436–444 (2015).
He, K., Zhang, X., Ren, S. & Sun, J. Deep residual learning for image recognition. In IEEE Conference on Computer Vision and Pattern Recognition, 770–778 (2016).
Liu, Y. et al. RoBERTa: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692 (2019).
Wang, A. et al. GLUE: A multi-task benchmark and analysis platform for natural language understanding. In International Conference on Learning Representations (2019).
Santoro, A. et al. A simple neural network module for relational reasoning. In Advances in Neural Information Processing Systems, 4967–4976 (2017).
Bommasani, R. et al. On the opportunities and risks of foundation models. arXiv preprint arXiv:2108.07258 (2021).
Editors of MIT Technology Review. 10 breakthrough technologies 2021. (2021).
Brown, T. B. et al. Language models are few-shot learners. In Advances in Neural Information Processing Systems, 1877–1901 (2020).
Quiroga, R. Q., Reddy, L., Kreiman, G., Koch, C. & Fried, I. Invariant visual representation by single neurons in the human brain. Nature 435, 1102–1107 (2005).
Quian Quiroga, R., Kraskov, A., Koch, C. & Fried, I. Explicit encoding of multimodal percepts by single neurons in the human brain. Current Biology 19, 1308–1313 (2009).
Li, X. et al. Oscar: Object-semantics aligned pre-training for vision-language tasks. In European Conference on Computer Vision, 121–137 (2020).
Radford, A. et al. Learning transferable visual models from natural language supervision. In International Conference on Machine Learning, 8748–8763 (2021).
Li, L. H., Yatskar, M., Yin, D., Hsieh, C. & Chang, K. VisualBERT: A simple and performant baseline for vision and language. arXiv preprint arXiv:1908.03557 (2019).
Li, G., Duan, N., Fang, Y., Gong, M. & Jiang, D. Unicoder-VL: A universal encoder for vision and language by cross-modal pre-training. In AAAI Conference on Artificial Intelligence, 11336–11344 (2020).
Su, W. et al. VL-BERT: Pre-training of generic visual-linguistic representations. In International Conference on Learning Representations (2020).
Chen, Y.-C. et al. UNITER: Universal image-text representation learning. In European Conference on Computer Vision, 104–120 (2020).
Lin, J. et al. M6: A chinese multimodal pretrainer. arXiv preprint arXiv:2103.00823 (2021).
Wu, Y., Wang, S., Song, G. & Huang, Q. Learning fragment self-attention embeddings for image-text matching. In ACM International Conference on Multimedia, 2088–2096 (2019).
Chen, H. et al. Imram: Iterative matching with recurrent attention memory for cross-modal image-text retrieval. In IEEE Conference on Computer Vision and Pattern Recognition, 12655–12663 (2020).
Diao, H., Zhang, Y., Ma, L. & Lu, H. Similarity reasoning and filtration for image-text matching. In AAAI Conference on Artificial Intelligence, 1218–1226 (2021).
Wu, Z., Xiong, Y., Yu, S. X. & Lin, D. Unsupervised feature learning via non-parametric instance discrimination. In IEEE Conference on Computer Vision and Pattern Recognition, 3733–3742 (2018).
Oord, A. v. d., Li, Y. & Vinyals, O. Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748 (2018).
Hjelm, R. D. et al. Learning deep representations by mutual information estimation and maximization. In International Conference on Learning Representations (2019).
Zhuang, C., Zhai, A. L. & Yamins, D. Local aggregation for unsupervised learning of visual embeddings. In International Conference on Computer Vision, 6002–6012 (2019).
Rajbhandari, S., Ruwase, O., Rasley, J., Smith, S. & He, Y. Zero-infinity: Breaking the GPU memory wall for extreme scale deep learning. In International Conference for High Performance Computing, Networking, Storage and Analysis (2021).
Riquelme, C. et al. Scaling vision with sparse mixture of experts. In Advances in Neural Information Processing Systems, 8583–8595 (2021).
Chen, T., Kornblith, S., Norouzi, M. & Hinton, G. A simple framework for contrastive learning of visual representations. In International Conference on Machine Learning, 1597–1607 (2020).
He, K., Fan, H., Wu, Y., Xie, S. & Girshick, R. Momentum contrast for unsupervised visual representation learning. In IEEE Conference on Computer Vision and Pattern Recognition, 9729–9738 (2020).
Grill, J.-B. et al. Bootstrap your own latent—a new approach to self-supervised learning. In Advances in Neural Information Processing Systems, 21271–21284 (2020).
Chen, X. & He, K. Exploring simple siamese representation learning. In IEEE Conference on Computer Vision and Pattern Recognition, 15750–15758 (2021).
Jia, C. et al. Scaling up visual and vision-language representation learning with noisy text supervision. In International Conference on Machine Learning, 4904–4916 (2021).
Olah, C., Mordvintsev, A. & Schubert, L. Feature visualization. Distill, https://doi.org/10.23915/distill.00007 (2017).
Esser, P., Rombach, R. & Ommer, B. Taming transformers for high-resolution image synthesis. In IEEE Conference on Computer Vision and Pattern Recognition, 12873–12883 (2021).
Russakovsky, O. et al. ImageNet large scale visual recognition challenge. Int. J. Comput. Vision 115, 211–252 (2015).
Yang, Y. & Newsam, S. D. Bag-of-visual-words and spatial extensions for land-use classification. In International Symposium on Advances in Geographic Information Systems, 270–279 (2010).
Xia, G.-S. et al. AID: A benchmark data set for performance evaluation of aerial scene classification. IEEE Transactions on Geoscience and Remote Sensing 55, 3965–3981 (2017).
Guan, J. et al. Zero and few shot learning with semantic feature synthesis and competitive learning. IEEE Transactions on Pattern Analysis and Machine Intelligence 43, 2510–2523 (2021).
Li, A., Lu, Z., Wang, L., Xiang, T. & Wen, J. Zero-shot scene classification for high spatial resolution remote sensing images. IEEE Transactions on Geoscience and Remote Sensing 55, 4157–4167 (2017).
Contributors of Toutiao News. Toutiao text classification dataset. (2021).
Li, J., Sun, M. & Zhang, X. A comparison and semi-quantitative analysis of words and character-bigrams as features in chinese text categorization. In Proc. 21st International Conference on Computational Linguistics and 44th Annual Meeting of the Association for Computational Linguistics, 545–552 (2006).
Cui, Y. et al. Revisiting pre-trained models for chinese natural language processing. In Conference on Empirical Methods in Natural Language Processing: Findings, 657–668 (2020).
Tan, M. & Le, Q. EfficientNet: Rethinking model scaling for convolutional neural networks. In International Conference on Machine Learning, 6105–6114 (2019).
Sun, J. “Jieba” Chinese text segmentation. https://github.com/fxsjy/jieba (2020).
McInnes, L., Healy, J., Saul, N. & Großberger, L. UMAP: Uniform manifold approximation and projection. J. Open Source Softw. 3, 861 (2018).
Wu, J. et al. AI challenger: A large-scale dataset for going deeper in image understanding. arXiv preprint arXiv:1711.06475 (2017).
Niu, Y. et al. Counterfactual VQA: A cause-effect look at language bias. In IEEE Conference on Computer Vision and Pattern Recognition, 12700–12710 (2021).
Zhu, Y., Groth, O., Bernstein, M. S. & Fei-Fei, L. Visual7W: Grounded question answering in images. In IEEE Conference on Computer Vision and Pattern Recognition, 4995–5004 (2016).
Lin, T.-Y. et al. Microsoft coco: Common objects in context. In European Conference on Computer Vision, 740–755 (2014).
Radford, A., Narasimhan, K., Salimans, T. & Sutskever, I. Improving language understanding by generative pre-training. OpenAI Blog (2018).
Devlin, J., Chang, M.-W., Lee, K. & Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. In Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 4171–4186 (2019).
Vaswani, A. et al. Attention is all you need. In Advances in Neural Information Processing Systems, 5998–6008 (2017).
Kolesnikov, A. et al. Big Transfer (BiT): General visual representation learning. In European Conference on Computer Vision, 491–507 (2020).
Dosovitskiy, A. et al. An image is worth 16x16 words: Transformers for image recognition at scale. In International Conference on Learning Representations (2021).
Nair, V. & Hinton, G. E. Rectified linear units improve restricted boltzmann machines. In International Conference on Machine Learning, 807–814 (2010).
Wei, X., Zhang, T., Li, Y., Zhang, Y. & Wu, F. Multi-modality cross attention network for image and sentence matching. In IEEE Conference on Computer Vision and Pattern Recognition, 10941–10950 (2020).
Anderson, P. et al. Bottom-up and top-down attention for image captioning and visual question answering. In IEEE Conference on Computer Vision and Pattern Recognition, 6077–6086 (2018).
Ren, S., He, K., Girshick, R. B. & Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Advances in Neural Information Processing Systems, 91–99 (2015).
Kingma, D. P. & Ba, J. Adam: A method for stochastic optimization. In International Conference on Learning Representations (2015).
Goodfellow, I. J. et al. Generative adversarial nets. In Advances in Neural Information Processing Systems, 2672–2680 (2014).
van den Oord, A., Vinyals, O. & Kavukcuoglu, K. Neural discrete representation learning. In Advances in Neural Information Processing Systems, 6306–6315 (2017).
Acknowledgements
Z.L. acknowledges National Natural Science Foundation of China (61976220). J.R.W. acknowledges National Natural Science Foundation of China (61832017), Beijing Outstanding Young Scientist Program (BJJWZYJH012019100020098), and Large-Scale Pre-Training Program 468 of Beijing Academy of Artificial Intelligence (BAAI). N.F. acknowledges the Outstanding Innovative Talents Cultivation Funded Programs 2021 of Renmin Univertity of China. We acknowledge the WenLan Data Group for helping us collect the pre-training dataset.
Author information
Authors and Affiliations
Contributions
Z.L. contributed the original idea, model design, and experimental analysis. Z.L. and N.F. wrote the majority of the manuscript. N.F., Y.G. and Y.H. contributed the source code. The experiments were conducted by N.F., G.Y., J.W., H.L. and Y.G. The review and editing of the manuscript were carried out by H.S., T.X., X.G., R.S. and J.R.W. The entire project was supervised by J.R.W.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Nature Communications thanks Qingming Huang, and the other, anonymous, reviewer(s) for their contribution to the peer review of this work. Peer reviewer reports are available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Fei, N., Lu, Z., Gao, Y. et al. Towards artificial general intelligence via a multimodal foundation model. Nat Commun 13, 3094 (2022). https://doi.org/10.1038/s41467-022-30761-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41467-022-30761-2
This article is cited by
-
Pretraining a foundation model for generalizable fluorescence microscopy-based image restoration
Nature Methods (2024)
-
The shaky foundations of large language models and foundation models for electronic health records
npj Digital Medicine (2023)
-
Equity, autonomy, and the ethical risks and opportunities of generalist medical AI
AI and Ethics (2023)
-
An Alternative to Cognitivism: Computational Phenomenology for Deep Learning
Minds and Machines (2023)
-
Application of animation products via multimodal information and semantic analogy
Multimedia Tools and Applications (2023)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
