
Abstract
Inexpensive and accessible sensors are accelerating data acquisition in animal ecology. These technologies hold great potential for large-scale ecological understanding, but are limited by current processing approaches which inefficiently distill data into relevant information. We argue that animal ecologists can capitalize on large datasets generated by modern sensors by combining machine learning approaches with domain knowledge. Incorporating machine learning into ecological workflows could improve inputs for ecological models and lead to integrated hybrid modeling tools. This approach will require close interdisciplinary collaboration to ensure the quality of novel approaches and train a new generation of data scientists in ecology and conservation.
Similar content being viewed by others


Technology to accelerate ecology and conservation research
Animal diversity is declining at an unprecedented rate1. This loss comprises not only genetic, but also ecological and behavioral diversity, and is currently not well understood: out of more than 120,000 species monitored by the IUCN Red List of Threatened Species, up to 17,000 have a ‘Data deficient’ status2. We urgently need tools for rapid assessment of wildlife diversity and population dynamics at large scale and high spatiotemporal resolution, from individual animals to global densities. In this Perspective, we aim to build bridges across ecology and machine learning to highlight how relevant advances in technology can be leveraged to rise to this urgent challenge in animal conservation.
How are animals currently monitored? Conventionally, management and conservation of animal species are based on data collection carried out by human field workers who count animals, observe their behavior, and/or patrol natural reserves. Such efforts are time-consuming, labor-intensive, and expensive3. They can also result in biased datasets due to challenges in controlling for observer subjectivity and assuring high inter-observer reliability, and often unavoidable responses of animals to observer presence4,5. Human presence in the field also poses risks to wildlife6,7, their habitats8, and humans themselves: as an example, many wildlife and conservation operations are performed from aircraft and plane crashes are the primary cause of mortality for wildlife biologists9. Finally, the physical and cognitive limitations of humans unavoidably constrain the number of individual animals that can be observed simultaneously, the temporal resolution and complexity of data that can be collected, and the extent of physical area that can be effectively monitored10,11.
These limitations considerably hamper our understanding of geographic ranges, population densities, and community diversity globally, as well as our ability to assess the consequences of their decline. For example, humans conducting counts of seabird colonies12 and bats emerging from cave roosts13 tend to significantly underestimate the number of individuals present. Furthermore, population estimates based on extrapolation from a small number of point counts have large uncertainties and can fail to capture the spatiotemporal variation in ecological relationships, resulting in erroneous predictions or extrapolations14. Failure to monitor animal populations impedes rapid and effective management actions3. For example, insufficient monitoring, due in part to the difficulty and cost of collecting the necessary data, has been identified as a major challenge in evaluating the impact of primate conservation actions15 and can lead to the continuation of practices that are harmful to endangered species16. Similarly, poaching prevention requires intensive monitoring of vast protected areas, a major challenge with existing technology. Protected area managers invest heavily in illegal intrusion prevention and the detection of poachers. Despite this, rangers often arrive too late to prevent wildlife crime from occurring17. In short, while a rich tradition of human-based data collection provides the basis for much of our understanding of where species are found, how they live, and why they interact, modern challenges in wildlife ecology and conservation are highlighting the limitations of these methods.
Recent advances in sensor technologies are drastically increasing data collection capacity by reducing costs and expanding coverage relative to conventional methods (see the section “New sensors expand available data types for animal ecology”, below), thereby opening new avenues for ecological studies at scale (Fig. 1)18. Many previously inaccessible areas of conservation interest can now be studied through the use of high-resolution remote sensing19, and large amounts of data are being collected non-invasively by digital devices such as camera traps20, consumer cameras21, and acoustic sensors22. New on-animal bio-loggers, including miniaturized tracking tags23,24 and sensor arrays featuring accelerometers, audiologgers, cameras, and other monitoring devices document the movement and behavior of animals in unprecedented detail25, enabling researchers to track individuals across hemispheres and over their entire lifetimes at high temporal resolution and thereby revolutionizing the study of animal movement (Fig. 1c) and migrations.

a The BirdNET algorithm61 was used to detect Carolina wren vocalizations in more than 35,000 h of passive acoustic monitoring data from Ithaca, New York, allowing researchers to document the gradual recovery of the population following a harsh winter season in 2015. b Machine-learning algorithms were used to analyze movement of savannah herbivores fitted with bio-logging devices in order to identify human threats. The method can localize human intruders to within 500 m, suggesting `sentinel animals' may be a useful tool in the fight against wildlife poaching148. c TRex, a new image-based tracking software, can track the movement and posture of hundreds of individually-recognized animals in real-time. Here the software has been used to visualize the formation of trails in a termite colony149. d, e Pose estimation software, such as DeepPoseKit (d)75 and DeepLabCut (e)74,142 allows researchers to track the body position of individual animals from video imagery, including drone footage, and estimate 3D postures in the wild. Panels b, c, and d are reproduced under CC BY 4.0 licenses. Panels b and d are cropped versions of the originals; the legend for panel b has been rewritten and reorganized. Panel e is reproduced with permission from Joska et al.142.
There is a mismatch between the ever-growing volume of raw measures (videos, images, audio recordings) acquired for ecological studies and our ability to process and analyze this multi-source data to derive conclusive ecological insights rapidly and at scale. Effectively, ecology has entered the age of big data and is increasingly reliant on sensors, advanced methodologies, and computational resources26. Central challenges to efficient data analysis are the sheer volume of data generated by modern collection methods and the heterogeneous nature of many ecological datasets, which preclude the use of simple automated analysis techniques26. Crowdsourcing platforms like eMammal (emammal.si.edu), Agouti (agouti.eu), and Zooniverse (www.zooniverse.org) function as collaborative portals to collect data from different projects and provide tools to volunteers to annotate images, e.g., with species labels of the individuals therein. Such platforms drastically reduce the cost of data processing (e.g., ref. 27 reports a reduction of seventy thousand dollars), but the rapid increase in the volume and velocity of data collection is making such approaches unsustainable. For example, in August 2021 the platform Agouti hosted 31 million images, of which only 1.5 million were annotated. This is mostly due to the manual nature of the current annotation tool, which requires human review of every image. In other words, methods for automatic cataloging, searching, and converting data into relevant information are urgently needed and have the potential to broaden and enhance animal ecology and wildlife conservation in scale and accuracy, address prevalent challenges, and pave the way forward towards new, integrated research directives.
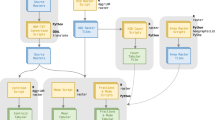
Machine learning (ML, see glossary in Supplementary Table 1) deals with learning patterns from data28. Presented with large quantities of inputs (e.g., images) and corresponding expected outcomes, or labels (e.g., the species depicted in each image), a supervised ML algorithm learns a mathematical function leading to the correct outcome prediction when confronted with new, unseen inputs. When the expected outcomes are absent, the (this time unsupervised) ML algorithm will use solely the inputs to extract groups of data points corresponding to typical patterns in the data. ML has emerged as a promising means of connecting the dots between big data and actionable ecological insights29 and is an increasingly popular approach in ecology30,31. A significant share of this success can be attributed to deep learning (DL32), a family of highly versatile ML models based on artificial neural networks that have shown superior performance across the majority of ML use cases (see Table 1 and Supplementary Table 2). Significant error reduction of ML and DL with respect to traditional generalized regression models has been reported routinely for species richness and diversity estimation33,34. Likewise, detection and counting pipelines moved from rough rule of thumb extrapolations from visual counts in national parks to ML-based methods with high detection rates. Initially, these methods proposed many false positives which required further human review35, but recent methods have been shown to maintain high detection rates with significantly fewer false positives36. As an example, large mammal detection in the Kuzikus reserve in 2014 was improved significantly by improving the detection methodologies, from a recall rate of 20%35 to 80%37 (for a common 75% precision rate). Finally, studies involving human operators demonstrated that ML enabled massive speedups in complex tasks such as individual and species recognition38,39 and large-scale tasks such as animal detection in drone surveys40. Recent advances in ML methodology could accelerate and enhance various stages of the traditional ecological research pipeline (see Fig. 2), from targeted data acquisition to image retrieval and semi-automated population surveys. As an example, the initiative Wildlife Insights41 is now processing millions of camera trap images automatically (17 million in August 2021), providing wildlife conservation scientists and practitioners with the data necessary to study animal abundances, diversity, and behavior. Besides pure acceleration, use of ML also massively reduces analysis costs, with reduction factors estimated between 2 and 1042.

Traditional ecological research pipeline (colored text and boxes) and contributions of ML to the different stages discussed in this paper (black text).
A growing body of literature promotes the use of ML in various ecological subfields by educating domain experts about ML approaches29,43,44, their utility in capitalizing on big data26,45, and, more recently, their potential for ecological inference (e.g., understanding the processes underlying ecological patterns, rather than only predicting the patterns themselves)46,47. Clearly, there is a growing interest in applying ML approaches to problems in animal ecology and conservation. We believe that the challenging nature of ecological data, compounded by the size of the datasets generated by novel sensors and the ever-increasing complexity of state-of-the-art ML methods, favor a collaborative approach that harnesses the expertise of both the ML and animal ecology communities, rather than an application of off-the-shelf ML methodologies to ecological challenges. Hence, the relation between ecology and ML should not be unidirectional: integrating ecological domain knowledge into ML methods is essential to designing models that are accurate in the way they describe animal life. As demonstrated by the rising field of hybrid environmental algorithms (leveraging both DL and bio-physical models48,49) and, more broadly, by theory-guided data science50, such hybrid models tend to be less data-intensive, avoid incoherent predictions, and are generally more interpretable than purely data-driven models. To reach this goal of an integrated science of ecology and ML, both communities need to work together to develop specialized datasets, tools, and knowledge. With this objective in mind, we review recent efforts at the interface of the two disciplines, present success stories of such symbiosis in animal ecology and wildlife conservation, and sketch an agenda for the future of the field.
New sensors expand available data types for animal ecology
Sensor data provide a variety of perspectives to observe wildlife, monitor populations, and understand behavior. They allow the field to scale studies in space, time, and across the taxonomic tree and, thanks to open science projects (Table 2), to share data across parks, geographies, and the globe51. Sensors generate diverse data types, including imagery, soundscapes, and positional data (Fig. 3). They can be mobile or static, and can be deployed to collect information on individuals or species of interest (e.g., bio-loggers, drones), monitor activity in a particular location (e.g., camera traps and acoustic sensors), or document changes in habitats or landscapes over time (satellites, drones). Finally, they can also be opportunistic, as in the case of community science. Below, we discuss the different categories of sensors and the opportunities they open for ML-based wildlife research.

Studies frequently combine data from multiple sensors at the same geographic location, or data from multiple locations to achieve deeper ecological insights. Sentinel-2 (ESA) satellite image courtesy of the U.S. Geological Survey.
Stationary sensors
Stationary sensors provide close-range continuous monitoring over long time scales. Sensors can be image-based (e.g., camera traps) or signal-based (e.g., sound recorders). Their high level of temporal resolution allows for detailed analysis, including presence/absence, individual identification, behavior analysis, and predator-prey interaction. However, because of their stationary nature, their data is highly spatiotemporally correlated. Based on where and when in the world the sensor is placed, there is a limited number of species that can be captured. Furthermore, many animals are highly habitual and territorial, leading to very strong correlations between data taken days or even weeks apart from a single sensor52.
-
Camera traps are among the most used sensors in recent ML-based animal ecology papers, with more than a million cameras already used to monitor biodiversity worldwide20. Camera traps are inexpensive, easy to install, and provide high-resolution image sequences of the animals that trigger them, sufficient to specify the species, sex, age, health, behavior, and predator-prey interactions. Coupled with population models, camera-trap data has also been used to estimate species occurrence, richness, distribution, and density20. But the popularity of camera traps also creates challenges relative to the quantity of images and the need for manual annotation of the collections: software tools easing the annotation process are appearing (see, e.g., AIDE in Table 1) and many ecologists have already incorporated open-source ML approaches for filtering out blank images (such as the Microsoft AI4Earth MegaDetector36, see Table 1) into their camera trap workflows52,53,54. However, problems related to lack of generality across geographies, day/night acquisition, or sensors are still major obstacles to production-ready accurate systems55. The increased scale of available data due to de-siloing efforts from organizations like Wildlife Insights (www.wildlifeinsights.org) and LILA.science (www.lila.science) will help increase ML accuracy and robustness across regions and taxa.
-
Bioacoustic sensors are an alternative to image-based systems, using microphones and hydrophones to study vocal animals and their habitats56. Networks of static bioacoustic sensors, used for passive acoustic monitoring (PAM), are increasingly applied to address conservation issues in terrestrial57, aquatic58, and marine59 ecosystems. Compared to camera traps, PAM is mostly unaffected by light and weather conditions (some factors like wind still play a role), senses the environment omnidirectionally, and tends to be cost-effective when data needs to be collected at large spatiotemporal scales with high resolution60. While ML has been extensively applied to camera trap images, its application to long-term PAM datasets is still in its infancy and the first DL-based studies are only starting to appear (see Fig. 1a, ref. 61). Significant challenges remain when utilizing PAM. First and foremost among these challenges is the size of data acquired. Given the often continuous and high-frequency acquisition rates, datasets often exceed the terabyte scale. Handling and analyzing these datasets efficiently requires access to advanced computing infrastructure and solutions. Second, the inherent complexity of soundscapes requires noise-robust algorithms that generalize well and can separate and identify many animal sounds of interest from confounding natural and anthropogenic signals in a wide variety of acoustic environments62. The third challenge is the lack of large and diverse labeled datasets. As for camera trap images, species- or region-specific characteristics (e.g., regional dialects63) affect algorithm performance. Robust, large-scale datasets have begun to be curated for some animal groups (e.g., www.macaulaylibrary.org and www.xeno-canto.org for birds), but for many animal groups as well as relevant biological and non-biological confounding signals, such data is still nonexistent.
Remote sensing
Collecting data on free-ranging wildlife has been restricted traditionally by the limits of manual data collection (e.g., extrapolating transect counts), but have increased greatly through the automation of remote sensing35. Using remote sensing, i.e., sensors mounted on moving platforms such as drones, aircraft, or satellites—or attached to the animals themselves—allows us to monitor large areas and track animal movement over time.
-
On-animal sensors are the most common remote sensing devices deployed in animal ecology10. They are primarily used to acquire movement trajectories (i.e., GPS data) of animals, which can then be classified into activity types that relate to the behavior of individuals or social groups10,64. Secondary sensors, such as microphones, video cameras, heart rate monitors, and accelerometers, allow researchers to capture environmental, physiological, and behavioral data concurrently with movement data65. However, power supply and data storage and transmission limitations of bio-logging devices are driving efforts to optimize sampling protocols or pre-process data in order to conserve these resources and prolong the life of the devices. For example, on-board processing solutions can use data from low-cost sensors to identify behaviors of interest and engage resource-intensive sensors only when these behaviors are being performed66. Other on-board algorithms classify raw data into behavioral states to reduce the volume of data to be transmitted67. Various supervised ML methods have shown their potential in automating behavior analysis from accelerometer data68,69, identifying behavioral state from trajectories70, and predicting animal movement71.
-
Unmanned aerial vehicles (UAVs) or drones for low-altitude image-based approaches, have been highlighted as a promising technology for animal conservation72,73. Recent studies have shown the promise of UAVs and deep learning for posture tracking74,75,76, semi-automatic detection of large mammals42,77, birds78, and, in low-altitude flight, even identification of individuals79. Drones are agile platforms that can be deployed rapidly—theoretically on demand—and with limited cost. Thus, they are ideal for local population monitoring. Lower altitude flights in particular can provide oblique view points that partially mitigate occlusion by vegetation. The reduced costs and operation risks of UAVs further make them an increasingly viable alternative to low-flying manned aircraft.
Common multi-rotor UAV models are built using inexpensive hardware and consumer-level cameras, and only require a trained pilot with flight permissions to perform the survey. To remove the need for a trained pilot, fully autonomous UAV platforms are also being investigated79. However, multi-rotor drone-based surveys remain limited in the spatial footprint that can be covered, mostly because of battery limitations (which become even more stringent in cold climates like Antarctica) and local legislation. Combustion-driven fixed wing UAVs flying at high altitudes and airplane-based acquisitions can overcome some of these limitations, but are significantly more costly and preclude close approaches for visual measurements of animals. Finally, using drones also has a risk of modifying the behavior of the animals. A recent study80 showed that flying at lower altitudes (e.g., lower than 150 m) can have a significant impact on group and individual behavior of mammals, although the severity of wildlife disturbance from drone deployments will depend heavily on the focal species, the equipment used, and characteristics of the drone flight (such as approach speed and altitude)81—this is a rapidly changing field and advances that will limit noise are likely to come. More research to quantify and qualify such impacts in different ecosystems is timely and urgent, to avoid both biased conclusions and increased levels of animal stress.
-
Satellite data is used to widen the spatial footprint and reduce invasive impact on behavior. Public programs such as Landsat and Sentinel provide free and open imagery at medium resolution (between 10 and 30 m per pixel), which, though usually not sufficient for direct wildlife observations, can be useful for studying their habitats34,82. Meanwhile, commercial very high resolution (less than one meter per pixel) imagery is narrowing the gap between UAV acquisitions and large-scale footprinting with satellites. Remote sensing has a long tradition of application of ML algorithms. Thanks to the raster nature of the data, remote sensing has fully adopted the new DL methods83, which are nowadays entering most fields of application that exploit satellite data49. In animal ecology, studies focused on large animals such as whales84 or elephants85 attempt direct detection of the animals on very high-resolution images, increasingly with DL. When focusing on smaller-bodied species, studies resort to aerial surveys to increase resolution in order to directly visualize the animals or focus on the detection of proxies instead of the detection of the animal itself (e.g., the detection of penguin droppings to locate colonies86). More research is currently required to really harness the power of remote sensing data, which lies, besides the large footprint and image resolution, in the availability of image bands beyond the visible spectrum. These extra bands are highly appreciated in plant ecology87 and multi- and hyperspectral DL approaches88 are yet to be deployed in animal ecology, where they could help advancing the characterization of habitats.
Community science for crowd-sourcing data
An alternative to traditional sensor networks (static or remote) is to engage community members as wildlife data collectors and processors89,90. In this case, community participants (often volunteers) work to collect the data and/or create the labels necessary to train ML models. Models trained this way can then be used to bring image recognition tasks to larger scale and complexity, from filtering out images without animals in camera trap sequences to identifying species or even individuals. Several annotation projects based on community science have appeared recently (Table 2). For simple tasks like animal detection, community science effort can be open to the public, while for more complex ones such as identifying bird species with subtle appearance differences (“fine-grained classification”, also see the glossary), communities of experts are needed to provide accurate labels. A particularly interesting case is Wildbook (see Box 1 and Table 1), which routinely screens videos from social media platforms with computer vision models to identify individuals; community members (in this case video posters) are then queried in case of missing or uncertain information. Recent research shows that ML models trained on community data can perform as well as annotators91. However, it is prudent to note that the viability of community science services may be limited depending on the task and that oftentimes substantial efforts are required to verify volunteer-annotated data. This is due to annotator errors, including misdetected or mislabeled animals due to annotator fatigue or insufficient knowledge about the annotation task, as well as systematic errors from adversarial annotators. Another form of community science is the use of images acquired by volunteers: in this case, volunteers replace camera traps or UAVs and provide the raw data used to train the ML model. Although this approach sacrifices control over image acquisitions and is likewise prone to inducing significant noise to datasets, for example through low-quality imagery, it provides a substantial increase in the number of images and the chances of photographing species or single individuals in different regions, poses, and viewing angles. Community science efforts also increase public engagement in science and conservation. The Great Grevy’s Rally, a community science-based wildlife census effort occurring every 2 years in Kenya92, is a successful demonstration of the power of community science-based wildlife monitoring.

Machine learning to scale-up and automate animal ecology and conservation research
The sensor data described in the previous section has the potential to unlock ecological understanding on a scale difficult to imagine in the recent past. But to do so, it must be interpreted and converted to usable information for ecological research. For example, such conversion can take the form of abundance mapping, individual animal re-identification, herd tracking, or digital reconstruction (three-dimensional, phenotypical) of the environment the animals live in. The measures yielded by this conversion, reviewed in this section, are also sometimes referred to as animal biometrics93. Interestingly, the tasks involved in the different approaches show similarities with traditional tasks in ML and computer vision (e.g., detection, localization, identification, pose estimation), for which we provide a matching example in animal ecology in Fig. 5.

Imagery can be used to capture a range of behavioral and ecological data, which can be processed into usable information with ML tools. Aerial imagery (from drones, or satellites for large species) can be used to localize animals and track their movements over time and model the 3D structure of landscapes using photogrammetry. Posture estimation tools allow researchers to estimate animal postures, which can then be used to infer behaviors using clustering algorithms. Finally, computer vision techniques allow for the identification and re-identification of known individuals across encounters.
Wildlife detection and species-level classification
Conservation efforts of endangered species require knowledge on how many individuals of the species in question are present in a study area. Such estimations are conventionally realized with statistical occurrence models that are informed by sample-based species observations. It is these observations where imaging sensors (camera traps, UAVs, etc.), paired with ML models that detect and count individuals in the imagery, can provide the most significant input. Early works used classical supervised ML algorithms (algorithms needing a set of human-labeled annotations to learn, see Supplementary Table 2): these algorithms were used to make the connection between a set of characteristics of interest extracted from the image (visual descriptors, e.g., color histograms, spectral indices, etc., also see the glossary) and the annotation itself (presence of an animal, species, etc.)35,94. Particularly in camera trap imagery, foreground (animal) segmentation is occasionally performed as a pre-processing step to discard image parts that are potentially confusing for a classifier. These approaches, albeit good in performance, suffer from two limitations: first, the visual descriptors need to be specifically tailored to the problem and dataset at hand. This not only requires significant engineering efforts, but also bears the risk of the model becoming too specific to the particular dataset and external conditions (e.g., camera type, background foliage amount, and movement type) at hand. Second, computational restrictions in these models limit the number of training examples, which is likely to have detrimental effects on variations in data (temporal, seasonal, etc.), thus reducing the generalization capabilities to new sensor deployments or regions. For these reasons, detecting and classifying animal species with DL for the purpose of population estimates is becoming increasingly popular for images52,53, acoustic spectrograms95, and videos96. Models performing accurately and robustly on specific classes (e.g., the MegaDetector - see Box 2 - or AIDE; see Table 1) are now being used routinely and integrated within open systems supporting ecologists performing both labeling and detection, respectively counting of their image databases. Issues related to dependence of the models performance to specific training locations are still at the core of current developments52, an issue known in ML as “domain adaptation” or “generalization”.

Individual re-identification
Another important biometric is animal identity. The standard for identification of animal species and identity is DNA profiling97, which can be difficult to scale to large, distributed populations54,93. As an alternative to gene-based identification, manual tagging can be used to keep track of individual animals10,93. Similar to counting and reconstruction (see next section), computer vision recently emerged as a powerful alternative for automatic individual identification54,98,99,100. The aim is to learn identity-bearing features from the appearance of animals. Identifying individuals from images is even more challenging than species recognition, since the distinctive body patterns of individuals might be subtle or not be sufficiently visible due to occlusion, motion blur, or overhead viewpoint in the case of aerial imagery. Yet, conventional101 and more recently DL-based38,54,102 methods have reached strong performance for specific taxa, especially across small populations. Some species have individually-unique coat or skin markings that assist with re-identification: for example, accuracy exceeded 90% in a study of 92 tigers across 8000 video clips103. However, effective re-identification is also possible in the absence of patterned markings: a study of a small group of 23 chimpanzees in Guinea applied facial recognition techniques to a multi-year dataset comprising 1 million images and achieved >90% accuracy38. This study compared the DL model to manual re-identification by humans: where humans achieved identification accuracy between 20% (novices) and 42% (experts) with an annotation time between 1 and 2 h, the DL model achieved an identification accuracy of 84% in a matter of seconds. The particular challenges for animal (re-)identification in wild populations are related to the difficulty of manual curation, larger populations, changes in appearance (e.g., due to scars, growth), few sightings per individual, and the frequent addition of new individuals that may enter the system due to birth or immigration, therefore creating an “open-set” problem104 wherein the model must deal with “classes” (individuals) unseen during training. The methods must have the ability to identify not only animals that have been seen just once or twice but also recognize new, previously unseen animals, as well as adjust decisions that have been made in the past, reconciling different views and biological stages of an animal.
Animal synthesis and reconstruction
3D shape recovery and pose estimation of animals can provide valuable, non-invasive insights on wild species in their natural environment. The 3D shape of an individual can be related to its health, age, or reproductive status; the 3D pose of the body can provide finer information with respect to posture attributes and allows, for instance, kinematic as well as behavioral analyses. For pose estimation, marker-less methods based on DL have tremendously improved over the last years and already impacted biology105. Various user-friendly toolboxes are available to extract the 2D posture of animals from videos (Fig. 1d, e), while the user can define which body parts should be estimated (reviewed in ref. 76). Extracting a dense set of body surface points is also possible, as elegantly shown in ref. 106, where the DensePose technique originally developed for humans was extended to chimpanzees. The reconstruction of the 3D shape and pose of animals from images often follows a model-based paradigm, where a 3D model of the animal is fit to visual data. Recent work defines the SMAL (Skinned Multi-Animal Linear) model, a 3D articulated shape model for a set of quadruped families107. Biggs et al. built on this work for 3D shape and motion of dogs from video108 and for recovery of dog shape and pose across many different breeds109. In ref. 110, the SMAL model has been used in a DL approach to predict 3D shape and pose of the Grevy’s zebra from images. 3D shape models have been recently defined also for birds111. Image-based 3D pose and shape estimation methods provide rich information about individuals but require, in addition to accurate shape models, prior knowledge about the animal’s 3D motion.
Reconstructing the environment
Wildlife behavior and conservation cannot be dissociated from the environment animals evolve and live in. Studies have shown that animal observations like trajectories highly benefit from additional cues included in the environmental context112. Satellite remote sensing has become an integral part to study animal habitats, biological diversity, and spatiotemporal changes of abiotic conditions113, since it allows to map quantities like land cover, soil moisture, or temperature at scale. Reconstructing the 3D shape of the environment has also become central in behavior studies: for example, 3D reconstructions of kill sites for lions in South Africa revealed novel insights into the predator-prey relationships and their connection to ecosystem stability and functioning114, while 3D spatial reconstructions shed light on the impact of forest structures on bat behavior115. Such spatial reconstructions of the environment can either be extracted by using dedicated sensors such as LiDAR116 or can be reconstructed from multiple images, either by stitching the images into a unified two-dimensional panorama (e.g., mosaicking117) or by computing the three-dimensional environment from partially overlapping images (e.g., structure from motion118 or simultaneous localization and mapping119). All these approaches have strongly benefited from recent ML advancements120, but have seldom been applied for wildlife conservation purposes, where they could greatly help when dealing with images acquired by moving or swarms of sensors121. However, applying these techniques to natural wildlife imagery is not trivial. For example, unconstrained continuous video recordings at potentially high frame-rates will result in large image sets which require efficient image processing117. Moreover, ambiguous environmental appearances and structural errors such as drift accumulate over time and therefore decrease the reconstruction quality118. Last but not least, a variety of inappropriate camera motions or environmental geometries can result in so-called critical configurations which cannot be resolved by the existing optimization schemes122. As a consequence, cues from additional external sensors are usually integrated to achieve satisfactory environmental reconstructions from video data123.
Modeling species diversity, richness, and interactions
Analyses of biodiversity, represented by such measures as species abundance and richness, are foundational to much ecological research and many conservation initiatives. Spatially explicit linear regression models have been conventionally used to predict species and community distribution based on explanatory variables such as climate and topography124,125. Non-parametric ML techniques like Random Forest126 have been successfully used to predict species richness and have shown significant error reduction with respect to the traditional counterparts used in ecology, for example in the estimation of richness distributions of fishes127,128, spiders 129, and small mammals130. Tree-based techniques have also been used to predict species interactions: for example, regression trees significantly outperformed classical generalized linear models in predicting plant-pollinator interactions33. Tree-based methods are well-suited to these tasks because they perform explicit feature ranking (and thus feature selection) and are able to model nonlinear relationships between covariates and species distribution. More recently, graph regression techniques were deployed to reconstruct species interaction networks in a community of European birds with promising results, including better causality estimates of the relations in the graph131.
Attention points and opportunities
Machine and deep learning are becoming necessary accelerators for wildlife research and conservation actions in natural reserves. We have discussed success stories of the application of approaches from ML into ecology and highlighted the major technical challenges ahead. In this section, we want to present a series of “attention points" that highlight new opportunities between the two disciplines.
What can we focus on now?
State-of-the-art ML models are now being applied to many tasks in animal ecology and wildlife conservation. However, while an out-of-the-box application of existing open tools is tempting, there are a number of points and potential pitfalls that must be carefully considered to ensure responsible use of these approaches.
-
Inherent model biases and generalization. Most ecological datasets suffer from some degree of geographic bias. For example, many open imagery repositories such as Artportalen.se, Naturgucker.de, and Waarneming.nl collect images from specific regions, and most contributions on iNaturalist132 (see Table 2) come from the Northern hemisphere. Such biases need to be understood, acknowledged, and communicated to avoid incorrect usage of methods or models that by design may only be accurate in a specific geographic region. Biases are not limited to the geographical provenance of images: the type of sensors used (RGB vs. infrared or thermal), the species they depict, and the imbalance in the number of individuals observed per species55,132 must also be considered when training or using models to avoid potentially catastrophic drop-offs in accuracy, and transparency around the training data and the intended model usage is a necessity133.
-
Curating and publishing well-annotated benchmark datasets without doing harm. The long-term advancement of the field will ultimately require the curation of large, diverse, accurately labeled, and publicly available datasets for ecological tasks with defined evaluation metrics and maintained code repositories. However, opening up existing datasets (and especially when using private-owned images acquired by non-professionals as in ref. 92) is both a necessary and difficult challenge for the near future. Fostering a culture of individual and cross-institutional data sharing in ecology will allow ML approaches to improve in robustness and accuracy. Furthermore, proper credit has to be given to the data collectors, for example through appropriate data attribution and digital object identifiers (DOIs) for datasets133.
-
Understanding the ethical risks involved. Computer scientists must also be aware of the ethical and environmental risks of publishing certain types of datasets. It is important to understand the limits of open data sharing in animal conservation in nature parks. In some cases, it is imperative that the privacy of the data be preserved, for instance to avoid giving poachers access to locations of animals in near-real-time134. Security of rangers themselves is also at stake; for example, the flight path of drones might be backtracked to reveal their location.
-
Standards of quality control are urgently needed. Accountability for open models needs to be better understood. The estimations of models remain approximations and need to be treated as such: population counts without uncertainty estimation can lead to erroneous and potentially devastating conclusions. Increased quality control on the adequacy of a model to a new scientific question or study area is important and can be achieved by close cooperation between model developers (who have the ability to design, calibrate, and run the models at their best) and practitioners (who have the domain and local knowledge). Without such quality control measures, relying on model-based results is risky and could have difficult-to-evaluate impacts on research in animal ecology, as incorrect results hidden in a suboptimally trained model will become more and more difficult to detect. Computer scientists must be aware that errors by their models can lead to erroneous decisions on site that can be catastrophic for the population they are trying to preserve or for the populations that live at the border of human/wildlife conflicts.
-
Environmental and financial costs of machine learning. ML is not free. Training and running models with millions of parameters on large volumes of data requires powerful, somewhat specialized hardware. Purchasing prices of such machines alone are often prohibitively high especially for budget-constrained conservation organizations; programming, running, and maintenance costs further add to the bill. Although cloud computing services exist that forgo the need of hardware management, they likewise pose per-resource costs that quickly scale to several thousands of dollars per month for a single virtual machine. Besides monetary costs, ML also uses significant amounts of energy: recently, it has been estimated that large, state-of-the-art models for understanding natural language emit as much carbon as several cars in their entire lifetime135. Even though the models currently used in animal ecology are far from such a carbon footprint, environmental costs of AI are often disregarded, as energy consumption of large calculations is still considered an endless resource (assuming that the money to pay for it is available). We believe this is a mistake, since disregarding environmental costs of ML models equals exchanging one source environmental harm (loss and biodiversity) for another (increase of emissions and energy consumption). Particular care needs to be paid to designing models that are not oversized and that can be trained efficiently. Smaller models are not only less expensive to train and use, their lighter computational costs allow them to be run on smaller devices, opening opportunities for real-time ML “on the edge”—i.e., within the sensors themselves.
What’s new: vast scientific opportunities lie ahead
In the previous sections, we describe the advances in research at the interface of ML, animal ecology, and wildlife conservation. The maturity of the various detection, identification, and recognition tools opens a series of interesting perspectives for genuinely novel approaches that could push the boundaries towards true integration of the disciplines involved.
-
Involving domain knowledge from the start. The ML and DL fields have focused mainly on black box models that learn correlations from data directly, and domain knowledge has been repeatedly ignored in favor of generic approaches that could fit to any kind of dataset. Such universality of ML is now strongly questioned and the inductive bias of traditional DL models is challenged by new approaches that bridge domain knowledge, fundamental laws, and data science. This “hybrid models” paradigm48,50 is one of the most exciting avenues in modern ML and promises real collaboration between domains of application and ML, especially when coupled with algorithmic designs that allow interpretation and understanding of the visual cues that are being used136. This line of interdisciplinary research is small but growing, with several studies published in recent years. A representative one is Context R-CNN52 for animal detection and species classification, which leverages the prior knowledge that backgrounds in camera trap imagery exhibit little variation over time and that camera traps acquire data with low sampling frequency and occasional dropouts. By integrating image features over long time spans (up to a month), the model is able to increase mean species identification precision in the Snapshot Serengeti dataset137 by 17.9%. In another example138, the hierarchical structure of taxonomies, as well as locational priors, are leveraged to constrain plant species classification from iNaturalist in Switzerland, leading to improvements of state-of-the-art models of about 5%. Similarly ref. 139, incorporate knowledge about the distribution of species as well as photographer biases into a DL model for species classification in images and report accuracy improvements of up to 12% in iNaturalist over a baseline without such priors. Finally ref. 140, used expert knowledge of park rangers to augment sparse and noisy records of poaching activity, thereby improving predictions of poaching occurrence and enabling more efficient use of limited patrol resources in a Chinese nature reserve. These approaches challenge the dogma of ML models learning exclusively from data and achieve more efficient model learning (since base knowledge is available from the start and does not have to be re-learnt) and enhanced plausibility of the solutions (because the solution space can be constrained to a range of ecologically plausible outcomes).
-
Laboratories as development spaces. In recent years, modern ML has rapidly changed laboratory-based non-invasive observation of animals76,105. Neuroscience studies in particular have embraced novel tools for motion tracking, pose estimation (Fig. 1d, e), and behavioral classification (e.g., ref. 141). The high level of control (e.g., of lighting conditions, sensor calibration, and environment) afforded by laboratory settings facilitated the rapid development of such tools, many of which are now being adopted for use in field studies of free-moving animals in complex natural environments75,142. In addition, algorithmic insights gained in the lab can be transferred back into the wild—studies on short videos or camera traps can leverage lab-generated data that is arguably less diverse, but easier to control. This opens interesting research opportunities for the adaptation of lab-generated simulation to real-world conditions, similar to what has been observed in the field of image synthesis for self driving143 and robotics144 in the last decade. Thus, laboratories rightly serve as the ultimate development space for such in-the-wild applications.
-
Towards a new generation of biodiversity models. Statistical models for species richness and diversity are routinely used to estimate abundances and study species co-occurrence and interactions. Recently, DL methods have also started to be employed to model species’ ecological niches82,145, facilitated by the development of machine-learning-ready datasets such as GeoLifeCLEF. GeoLifeCLEF curated a dataset of 1.9 million iNaturalist observations from North America and France depicting over 31,000 species, together with environmental predictors (land cover, altitude, climatic data, etc.), and asked users to predict a ranked list of likely species per geospatial grid cell. The task is complex: only positive counts are provided, no absence data are available, and predictions are counted as correct if the ground truth species is among the 30 predicted with highest confidence. This challenging task remains an open challenge—the winners of the 2021 edition achieved only an approximate 26% top-30 accuracy.
A recent review of species distribution modeling aimed at ML practitioners146 provides an accessible entry point for those interested in tackling the challenges in this complex, exciting field. Open challenges include increasing the scale of joint models geospatially, temporally, and taxonomically, building methods that can leverage multiple data types despite bias from non-uniform sampling strategies, incorporating ecological knowledge such as species dispersal and community composition, and expanding methods for the evaluation of these models.
Finally, we wish to re-emphasize that the vision described here cannot be achieved without interdisciplinary thinking: for all these exciting opportunities, processing big ecological data is necessitating analytical techniques of such complexity that no single ecologist can be expected to have all the technical expertise (plus domain knowledge) required to carry out groundbreaking studies65. Cross-disciplinary collaborations are undeniably a critical component of ecological and conservation research in the modern era. Mutual understanding of the field-specific vocabularies, of the fields’ expectations, and of the implications and consequences of research ethics are within reach, but require open dialogs between communities, as well as cross-domain training of new generations.
Conclusions
Animal ecology and wildlife conservation need to make sense of large and ever-increasing streams of data to provide accurate estimations of populations, understand animal behavior and fight against poaching and loss of biodiversity. Machine and deep learning (ML; DL) bring the promise of being the right tools to scale local studies to a global understanding of the animal world.
In this Perspective, we presented a series of success stories at the interface of ML and animal ecology. We highlighted a number of performance improvements that were observed when adopting solutions based on ML and new generation sensors. Although often spectacular, such improvements require ever-closer cooperation between ecologists and ML specialists, since recent approaches are more complex than ever and require strict quality control and detailed design knowledge. We observe that skillful applications of state-of-the-art ML concepts for animal ecology now exist, thanks to corporate (e.g., Wildlife Insights) and research (AIDE, MegaDetector, DeepLabCut) efforts, but that there is still much room (and need) for genuinely new concepts pushed by interdisciplinary research, in particular towards hybrid models and new habitat distribution models at scale.
Inspired by these observations, we provided our perspective on the missing links between animal ecology and ML via a series of attention points, recommendations, and vision on future exciting research avenues. We strongly incite the two communities to work hand-in-hand to find digital, scalable solutions that will elucidate the loss of biodiversity and its drivers and lead to global actions to preserve nature. Computer scientists have yet to integrate ecological knowledge such as underlying biological processes into ML models, and the lack of transparency of current DL models has so far been a major obstacle to incorporating ML into ecological research. However, an interdisciplinary community of computer scientists and ecologists is emerging, which we hope will tackle this technological and societal challenge together.
Data availability
Data sharing is not applicable to this article as no datasets were generated or analyzed during the current study.
References
Ceballos, G., Ehrlich, P. R. & Raven, P. H. Vertebrates on the brink as indicators of biological annihilation and the sixth mass extinction. Proc. Natl Acad. Sci. USA 117, 13596–13602 (2020).
Committee, T. I. R. L. The IUCN Red List of Threatened Species - Strategic Plan 2017-2020. Tech. Rep., IUCN (2017).
Witmer, G. W. Wildlife population monitoring: some practical considerations. Wild. Res. 32, 259–263 (2005).
McEvoy, J. F., Hall, G. P. & McDonald, P. G. Evaluation of unmanned aerial vehicle shape, flight path and camera type for waterfowl surveys: disturbance effects and species recognition. PeerJ 4, e1831 (2016).
Burghardt, G. M. et al. Perspectives–minimizing observer bias in behavioral studies: a review and recommendations. Ethology 118, 511–517 (2012).
Giese, M. Effects of human activity on Adelie penguin Pygoscelis adeliae breeding success. Biol. Conserv. 75, 157–164 (1996).
Köndgen, S. et al. Pandemic human viruses cause decline of endangered great apes. Curr. Biol. 18, 260–264 (2008).
Weissensteiner, M. H., Poelstra, J. W. & Wolf, J. B. W. Low-budget ready-to-fly unmanned aerial vehicles: an effective tool for evaluating the nesting status of canopy-breeding bird species. J. Avian Biol. 46, 425–430 (2015).
Sasse, D. B. Job-related mortality of wildlife workers in the united states, 1937–2000. Wildl. Soc. Bull. 31, 1015–1020 (2003).
Kays, R., Crofoot, M. C., Jetz, W. & Wikelski, M. Terrestrial animal tracking as an eye on life and planet. Science 348, aaa2478 (2015).
Altmann, J. Observational study of behavior: sampling methods. Behaviour 49, 227–266 (1974).
Hodgson, J. C. et al. Drones count wildlife more accurately and precisely than humans. Methods Ecol. Evolution 9, 1160–1167 (2018).
Betke, M. et al. Thermal imaging reveals significantly smaller Brazilian free-tailed bat colonies than previously estimated. J. Mammal. 89, 18–24 (2008).
Rollinson, C. R. et al. Working across space and time: nonstationarity in ecological research and application. Front. Ecol. Environ. 19, 66–72 (2021).
Junker, J. et al. A severe lack of evidence limits effective conservation of the world’s primates. BioScience 70, 794–803 (2020).
Sherman, J., Ancrenaz, M. & Meijaard, E. Shifting apes: Conservation and welfare outcomes of Bornean orangutan rescue and release in Kalimantan, Indonesia. J. Nat. Conserv. 55, 125807 (2020).
O’Donoghue, P. & Rutz, C. Real-time anti-poaching tags could help prevent imminent species extinctions. J. Appl. Ecol. 53, 5–10 (2016).
Lahoz-Monfort, J. J. & Magrath, M. J. L. A comprehensive overview of technologies for species and habitat monitoring and conservation. BioScience biab073. https://academic.oup.com/bioscience/advance-article/doi/10.1093/biosci/biab073/6322306 (2021).
Gottschalk, T., Huettmann, F. & Ehlers, M. Thirty years of analysing and modelling avian habitat relationships using satellite imagery data: a review. Int. J. Remote Sens. 26, 2631–2656 (2005).
Steenweg, R. et al. Scaling-up camera traps: monitoring the planet’s biodiversity with networks of remote sensors. Front. Ecol. Environ. 15, 26–34 (2017).
Hausmann, A. et al. Social media data can be used to understand tourists’ preferences for nature-based experiences in protected areas. Conserv. Lett. 11, e12343 (2018).
Sugai, L. S. M., Silva, T. S. F., Ribeiro, J. W. & Llusia, D. Terrestrial passive acoustic monitoring: review and perspectives. BioScience 69, 15–25 (2018).
Wikelski, M. et al. Going wild: what a global small-animal tracking system could do for experimental biologists. J. Exp. Biol. 210, 181–186 (2007).
Belyaev, M. Y. et al. Development of technology for monitoring animal migration on Earth using scientific equipment on the ISS RS. in 2020 27th Saint Petersburg International Conference on Integrated Navigation Systems (ICINS), 1–7 (IEEE, 2020).
Harel, R., Loftus, J. C. & Crofoot, M. C. Locomotor compromises maintain group cohesion in baboon troops on the move. Proc. R. Soc. B 288, 20210839 (2021).
Farley, S. S., Dawson, A., Goring, S. J. & Williams, J. W. Situating ecology as a big-data science: current advances, challenges, and solutions. BioScience 68, 563–576 (2018).
Lasky, M. et al. Candid critters: Challenges and solutions in a large-scale citizen science camera trap project. Citizen Science: Theory and Practice 6, https://doi.org/10.5334/cstp.343 (2021).
Hastie, T., Tibshirani, R. & Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction (Springer, 2001).
Christin, S., Hervet, É. & Lecomte, N. Applications for deep learning in ecology. Methods Ecol. Evolution 10, 1632–1644 (2019).
Kwok, R. Ai empowers conservation biology. Nature 567, 133–135 (2019).
Kwok, R. Deep learning powers a motion-tracking revolution. Nature 574, 137–139 (2019).
LeCun, Y., Bengio, Y. & Hinton, G. Deep learning. Nature 521, 436–444 (2015).
Pichler, M., Boreux, V., Klein, A.-M., Schleuning, M. & Hartig, F. Machine learning algorithms to infer trait-matching and predict species interactions in ecological networks. Methods Ecol. Evolution 11, 281–293 (2020).
Knudby, A., LeDrew, E. & Brenning, A. Predictive mapping of reef fish species richness, diversity and biomass in Zanzibar using IKONOS imagery and machine-learning techniques. Remote Sens. Environ. 114, 1230–1241 (2010).
Rey, N., Volpi, M., Joost, S. & Tuia, D. Detecting animals in African savanna with UAVs and the crowds. Remote Sens. Environ. 200, 341–351 (2017).
Beery, S., Morris, D. & Yang, S. Efficient pipeline for camera trap image review. in Proceedings of the Workshop Data Mining and AI for Conservation, Conference for Knowledge Discovery and Data Mining (2019).
Kellenberger, B., Marcos, D. & Tuia, D. When a few clicks make all the difference: improving weakly-supervised wildlife detection in UAV images. in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (2019).
Schofield, D. et al. Chimpanzee face recognition from videos in the wild using deep learning. Sci. Adv. 5, eaaw0736 (2019).
Ditria, E. M. et al. Automating the analysis of fish abundance using object detection: optimizing animal ecology with deep learning. Front. Mar. Sci. 7, 429 (2020).
Kellenberger, B., Veen, T., Folmer, E. & Tuia, D. 21 000 birds in 4.5 h: efficient large-scale seabird detection with machine learning. Remote Sens. Ecol. Conserv. 7, 445–460 (2021).
Ahumada, J. A. et al. Wildlife insights: a platform to maximize the potential of camera trap and other passive sensor wildlife data for the planet. Environ. Conserv. 47, 1–6 (2020).
Eikelboom, J. A. J. et al. Improving the precision and accuracy of animal population estimates with aerial image object detection. Methods Ecol. Evolution 10, 1875–1887 (2019).
Weinstein, B. G. A computer vision for animal ecology. J. Anim. Ecol. 87, 533–545 (2018).
Valletta, J. J., Torney, C., Kings, M., Thornton, A. & Madden, J. Applications of machine learning in animal behaviour studies. Anim. Behav. 124, 203–220 (2017).
Peters, D. P. C. et al. Harnessing the power of big data: infusing the scientific method with machine learning to transform ecology. Ecosphere 5, art67 (2014).
Yu, Q. et al. Study becomes insight: ecological learning from machine learning. Methods Ecol. Evol. 12, 2117–2128 (2021).
Lucas, T. C. D. A translucent box: interpretable machine learning in ecology. Ecol. Monogr. 90, https://doi.org/10.1002/ecm.1422 (2020).
Reichstein, M. et al. Deep learning and process understanding for data-driven Earth system science. Nature 566, 195–204 (2019).
Camps-Valls, G., Tuia, D., Zhu, X. X. & Reichstein, M. Deep Learning for the Earth Sciences: A Comprehensive Approach to Remote Sensing, Climate Science and Geosciences (Wiley & Sons, 2021).
Karpatne, A. et al. Theory-guided data science: A new paradigm for scientific discovery from data. IEEE Trans. Knowl. Data Eng. 29, 2318–2331 (2017).
Oliver, R. Y., Meyer, C., Ranipeta, A., Winner, K. & Jetz, W. Global and national trends, gaps, and opportunities in documenting and monitoring species distributions. PLoS Biol 19, e3001336 https://doi.org/10.1371/journal.pbio.3001336 (2021).
Beery, S., Wu, G., Rathod, V., Votel, R. & Huang, J. Context R-CNN: long term temporal context for per-camera object detection. in 2020 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 13075–13085 (2020).
Norouzzadeh, M. S. et al. Automatically identifying, counting, and describing wild animals in camera-trap images with deep learning. Proc. Natl Acad. Sci. USA 115, E5716–E5725 (2018).
Schneider, S., Taylor, G. W., Linquist, S. & Kremer, S. C. Past, present and future approaches using computer vision for animal re-identification from camera trap data. Methods Ecol. Evolution 10, 461–470 (2019).
Beery, S., Van Horn, G. & Perona, P. Recognition in terra incognita. in 2018 European Conference on Computer Vision (ECCV), 456–473 (2018).
Sugai, L. S. M., Silva, T. S. F., Ribeiro Jr, J. W. & Llusia, D. Terrestrial passive acoustic monitoring: review and perspectives. BioScience 69, 15–25 (2019).
Wrege, P. H., Rowland, E. D., Keen, S. & Shiu, Y. Acoustic monitoring for conservation in tropical forests: examples from forest elephants. Methods Ecol. Evolution 8, 1292–1301 (2017).
Desjonquères, C., Gifford, T. & Linke, S. Passive acoustic monitoring as a potential tool to survey animal and ecosystem processes in freshwater environments. Freshw. Biol. 65, 7–19 (2020).
Davis, G. E. et al. Long-term passive acoustic recordings track the changing distribution of North Atlantic right whales (eubalaena glacialis) from 2004 to 2014. Sci. Rep. 7, 1–12 (2017).
Wood, C. M. et al. Detecting small changes in populations at landscape scales: a bioacoustic site-occupancy framework. Ecol. Indic. 98, 492–507 (2019).
Kahl, S., Wood, C. M., Eibl, M. & Klinck, H. Birdnet: a deep learning solution for avian diversity monitoring. Ecol. Inform. 61, 101236 (2021).
Stowell, D., Wood, M. D., Pamuła, H., Stylianou, Y. & Glotin, H. Automatic acoustic detection of birds through deep learning: the first bird audio detection challenge. Methods Ecol. Evolution 10, 368–380 (2019).
Ford, J. K. B. in Encyclopedia of Marine Mammals 253–254 (Elsevier, 2018).
Hughey, L. F., Hein, A. M., Strandburg-Peshkin, A. & Jensen, F. H. Challenges and solutions for studying collective animal behaviour in the wild. Philos. Trans. R. Soc. B: Biol. Sci. 373, 20170005 (2018).
Williams, H. J. et al. Optimizing the use of biologgers for movement ecology research. J. Anim. Ecol. 89, 186–206 (2020).
Korpela, J. et al. Machine learning enables improved runtime and precision for bio-loggers on seabirds. Commun. Biol. 3, 1–9 (2020).
Yu, H. An evaluation of machine learning classifiers for next-generation, continuous-ethogram smart trackers. Mov. Ecol. 9, 14 (2021).
Browning, E. et al. Predicting animal behaviour using deep learning: GPS data alone accurately predict diving in seabirds. Methods Ecol. Evolution 9, 681–692 (2018).
Liu, Z. Y.-C. et al. Deep learning accurately predicts white shark locomotor activity from depth data. Anim. Biotelemetry 7, 1–13 (2019).
Wang, G. Machine learning for inferring animal behavior from location and movement data. Ecol. Inform. 49, 69–76 (2019).
Wijeyakulasuriya, D. A., Eisenhauer, E. W., Shaby, B. A. & Hanks, E. M. Machine learning for modeling animal movement. PLoS ONE 30, e0235750 (2020).
Linchant, J., Lisein, J., Semeki, J., Lejeune, P. & Vermeulen, C. Are unmanned aircraft systems (UASs) the future of wildlife monitoring? A review of accomplishments and challenges. Mammal. Rev. 45, 239–252 (2015).
Hodgson, J. C., Baylis, S. M., Mott, R., Herrod, A. & Clarke, R. H. Precision wildlife monitoring using unmanned aerial vehicles. Sci. Rep. 6, 1–7 (2016).
Mathis, A. et al. DeepLabCut: markerless pose estimation of user-defined body parts with deep learning. Nat. Neurosci. 21, 1281–1289 (2018).
Graving, J. M. et al. DeepPoseKit, a software toolkit for fast and robust animal pose estimation using deep learning. Elife 8, e47994 (2019).
Mathis, A., Schneider, S., Lauer, J. & Mathis, M. W. A primer on motion capture with deep learning: principles, pitfalls, and perspectives. Neuron 108, 44–65 (2020).
Kellenberger, B., Marcos, D. & Tuia, D. Detecting mammals in UAV images: best practices to address a substantially imbalanced dataset with deep learning. Remote Sens. Environ. 216, 139–153 (2018).
Kellenberger, B., Veen., T., Folmer, E. & Tuia, D. 21,000 birds in 4.5 hours: efficient large-scale seabird detection with machine learning. Remote Sens. Ecol. Conserv. https://doi.org/10.1002/rse2.200 (2021).
Andrew, W., Greatwood, C. & Burghardt, T. Aerial animal biometrics: individual Friesian cattle recovery and visual identification via an autonomous UAV with onboard deep inference. in International Conference on Intelligent Robots and Systems (IROS) (2019).
Schroeder, N. M., Panebianco, A., Gonzalez Musso, R. & Carmanchahi, P. An experimental approach to evaluate the potential of drones in terrestrial mammal research: a gregarious ungulate as a study model. R. Soc. open Sci. 7, 191482 (2020).
Bennitt, E., Bartlam-Brooks, H. L. A., Hubel, T. Y. & Wilson, A. M. Terrestrial mammalian wildlife responses to Unmanned Aerial Systems approaches. Sci. Rep. 9, 1–10 (2019).
Deneu, B., Servajean, M., Botella, C. & Joly, A. Evaluation of deep species distribution models using environment and co-occurrences. in International Conference of the Cross-Language Evaluation Forum for European Languages, 213–225 (Springer, 2019).
Zhu, X. et al. Deep learning in remote sensing: A comprehensive review and list of resources. IEEE Geosci. Remote Sens. Mag. 5, 8–36 (2017).
Guirado, E., Tabik, S., Rivas, M. L., Alcaraz-Segura, D. & Herrera, F. Whale counting in satellite and aerial images with deep learning. Sci. Rep. 9, 1–12 (2019).
Duporge, I., Isupova, O., Reece, S., Macdonald, D. W. & Wang, T. Using very-high-resolution satellite imagery and deep learning to detect and count African elephants in heterogeneous landscapes. Remote Sens. Ecol. Conserv. https://doi.org/10.1002/rse2.195 (2020).
Fretwell, P. T. & Trathan, P. N. Discovery of new colonies by Sentinel2 reveals good and bad news for emperor penguins. Remote Sens. Ecol. Conserv. https://doi.org/10.1002/rse2.176 (2020).
Brodrick, P. G., Davies, A. B. & Asner, G. P. Uncovering ecological patterns with convolutional neural networks. Trends Ecol. Evolution 34, 734–745 (2019).
Audebert, N., Le Saux, B. & Lefèvre, S. Deep learning for classification of hyperspectral data: a comparative review. IEEE Geosci. Remote Sens. Mag. 7, 159–173 (2019).
McKinley, D. C. et al. Citizen science can improve conservation science, natural resource management, and environmental protection. Biol. Conserv. 208, 15–28 (2017).
Wäldchen, J. & Mäder, P. Machine learning for image based species identification. Methods Ecol. Evolution 9, 2216–2225 (2018).
Torney, C. J. et al. A comparison of deep learning and citizen science techniques for counting wildlife in aerial survey images. Methods Ecol. Evolution 10, 779–787 (2019).
Parham, J., Crall, J., Stewart, C., Berger-Wolf, T. & Rubenstein, D. I. Animal population censusing at scale with citizen science and photographic identification. in AAAI Spring Symposium-Technical Report (2017).
Kühl, H. S. & Burghardt, T. Animal biometrics: quantifying and detecting phenotypic appearance. Trends Ecol. Evolution 28, 432–441 (2013).
Yu, X. et al. Automated identification of animal species in camera trap images. EURASIP J. Image Video Process. 2013, 1–10 (2013).
Mac Aodha, O. et al. Bat detective–deep learning tools for bat acoustic signal detection. PLoS Computat. Biol. 14, e1005995 (2018).
Schindler, F. & Steinhage, V. Identification of animals and recognition of their actions in wildlife videos using deep learning techniques. Ecol. Inform. 61, 101215 (2021).
Avise, J. C. Molecular Markers, Natural History and Evolution (Springer Science & Business Media, 2012).
Vidal, M., Wolf, N., Rosenberg, B., Harris, B. P. & Mathis, A. Perspectives on Individual Animal Identification from Biology and Computer Vision. Integr. Comp. Biol. 61, 900–916 https://doi.org/10.1093/icb/icab107 (2021).
Berger-Wolf, T. Y. et al. Wildbook: crowdsourcing, computer vision, and data science for conservation. Preprint at https://arxiv.org/abs/1710.08880 (2017).
Parham, J. et al. An animal detection pipeline for identification. in IEEE Winter Conference on Applications of Computer Vision (WACV), 1075–1083 (IEEE, 2018).
Weideman, H. et al. Extracting identifying contours for African elephants and humpback whales using a learned appearance model. in Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) (2020).
Brust, C.-A. et al. Towards automated visual monitoring of individual gorillas in the wild. in 2017 IEEE International Conference on Computer Vision Workshops (ICCVW), 2820–2830 (2017).
Li, S., Li, J., Tang, H., Qian, R. & Lin, W. ATRW: a benchmark for Amur tiger re-identification in the wild. in 2020 ACM International Conference on Multimedia, 2590–2598 (2020).
Bendale, A. & Boult, T. E. Towards open set deep networks. in 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 1563–1572 (2016).
Mathis, M. W. & Mathis, A. Deep learning tools for the measurement of animal behavior in neuroscience. Curr. Opin. Neurobiol. 60, 1–11 (2020).
Sanakoyeu, A., Khalidov, V., McCarthy, M. S., Vedaldi, A. & Neverova, N. Transferring dense pose to proximal animal classes. in 2020 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 5233–5242 (2020).
Zuffi, S., Kanazawa, A., Jacobs, D. W. & Black, M. J. 3D menagerie: modeling the 3D shape and pose of animals. in 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 6365–6373 (2017).
Biggs, B., Roddick, T., Fitzgibbon, A. & Cipolla, R. Creatures great and smal: recovering the shape and motion of animals from video. in 2018 Asian Conference on Computer Vision (ACCV), 3–19 (Springer, 2018).
Biggs, B., Boyne, O., Charles, J., Fitzgibbon, A. & Cipolla, R. Who left the dogs out? 3D animal reconstruction with expectation maximization in the loop. in 2020 European Conference on Computer Vision (ECCV), 195–211 (Springer, 2020).
Zuffi, S., Kanazawa, A., Berger-Wolf, T. & Black, M. J. Three-D safari: learning to estimate zebra pose, shape, and texture from images" in the wild". in 2019 IEEE International Conference on Computer Vision (ICCV), 5359–5368 (2019).
Wang, Y., Kolotouros, N., Daniilidis, K. & Badger, M. Birds of a feather: capturing avian shape models from images. in 2021 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 14739–14749 (2021).
Haalck, L., Mangan, M., Webb, B. & Risse, B. Towards image-based animal tracking in natural environments using a freely moving camera. J. Neurosci. methods 330, 108455 (2020).
Pettorelli, N. et al. Satellite remote sensing for applied ecologists: opportunities and challenges. J. Appl. Ecol. 51, 839–848 (2014).
Davies, A. B., Tambling, C. J., Kerley, G. I. H. & Asner, G. P. Effects of vegetation structure on the location of lion kill sites in African thicket. PLoS ONE 11, e0149098 (2016).
Froidevaux, J. S. P., Zellweger, F., Bollmann, K., Jones, G. & Obrist, M. K. From field surveys to LiDAR: shining a light on how bats respond to forest structure. Remote Sens. Environ. 175, 242–250 (2016).
Risse, B., Mangan, M., Stürzl, W. & Webb, B. Software to convert terrestrial LiDAR scans of natural environments into photorealistic meshes. Environ. Model. Softw. 99, 88–100 (2018).
Haalck, L. & Risse, B. Embedded dense camera trajectories in multi-video image mosaics by geodesic interpolation-based reintegration. in 2021 IEEE Winter Conference on Applications of Computer Vision (WACV), 1849–1858 (2021).
Schonberger, J. L. & Frahm, J.-M. Structure-from-motion revisited. in 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 4104–4113 (2016).
Mur-Artal, R. & Tardós, J. D. ORB-SLAM2: an open-source SLAM system for monocular, stereo, and RGB-D cameras. IEEE Trans. Robot. 33, 1255–1262 (2017).
Kuppala, K., Banda, S. & Barige, T. R. An overview of deep learning methods for image registration with focus on feature-based approaches. Int. J. Image Data Fusion 11, 113–135 (2020).
Lisein, J., Linchant, J., Lejeune, P., Bouché, P. & Vermeulen, C. Aerial surveys using an unmanned aerial system (UAS): comparison of different methods for estimating the surface area of sampling strips. Tropical Conserv. Sci. 6, 506–520 (2013).
Wu, C. Critical configurations for radial distortion self-calibration. in 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 25–32 (2014).
Ferrer, J., Elibol, A., Delaunoy, O., Gracias, N. & Garcia, R. Large-area photo-mosaics using global alignment and navigation data. in Mts/IEEE Oceans Conference, 1–9 (2007).
Guisan, A. & Zimmermann, N. E. Predictive habitat distribution models in ecology. Ecol. Model. 135, 147–186 (2000).
Lehmann, A., Overton, J. M. & Austin, M. P. Regression models for spatial prediction: their role for biodiversity and conservation. Biodivers. Conserv. 11, 2085–2092 (2002).
Breiman, L. Random forests. Mach. Learn. 45, 5–32 (2001).
Parravicini, V. et al. Global patterns and predictors of tropical reef fish species richness. Ecography 36, 1254–1262 (2013).
Smoliński, S. & Radtke, K. Spatial prediction of demersal fish diversity in the baltic sea: comparison of machine learning and regression-based techniques. ICES J. Mar. Sci. 74, 102–111 (2017).
Čandek, K., Čandek, U. P. & Kuntner, M. Machine learning approaches identify male body size as the most accurate predictor of species richness. BMC Biol. 18, 1–16 (2020).
Baltensperger, A. P. & Huettmann, F. Predictive spatial niche and biodiversity hotspot models for small mammal communities in Alaska: applying machine-learning to conservation planning. Landscape Ecol. 30, 681–697 (2015).
Faisal, A., Dondelinger, F., Husmeier, D. & Beale, C. M. Inferring species interaction networks from species abundance data: a comparative evaluation of various statistical and machine learning methods. Ecol. Inform. 5, 451–464 (2010).
Van Horn, G. et al. The inaturalist species classification and detection dataset. in 2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 8769–8778 (2018).
Copas, K. et al. Training machines to improve species identification using GBIF-mediated datasets. in AGU Fall Meeting Abstracts, Vol. 2019, IN53C–0758 (2019).
Lennox, R. J. et al. A novel framework to protect animal data in a world of ecosurveillance. BioScience 70, 468–476 (2020).
Strubell, E., Ganesh, A. & McCallum, A. Energy and policy considerations for deep learning in NLP. in Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 3645–3650 (2019).
Samek, W., Montavon, G., Vedaldi, A., Hansen, L. K. & Müller, K.-R. Explainable AI: Interpreting, Explaining and Visualizing Deep Learning, Vol. 11700 (Springer Nature, 2019).
Swanson, A. et al. Snapshot Serengeti, high-frequency annotated camera trap images of 40 mammalian species in an African savanna. Sci. data 2, 1–14 (2015).
de Lutio, R. et al. Digital taxonomist: identifying plant species in community scientists’ photographs. ISPRS J. Photogramm. Remote Sens. 182, 112–121 (2021).
Mac Aodha, O., Cole, E. & Perona, P. Presence-only geographical priors for fine-grained image classification. in Proceedings of the IEEE/CVF International Conference on Computer Vision, 9596–9606 (2019).
Gurumurthy, S. et al. Exploiting Data and Human Knowledge for Predicting Wildlife Poaching. in Proceedings of the 1st ACM SIGCAS Conference on Computing and Sustainable Societies, 1–8, https://doi.org/10.1145/3209811.3209879 (ACM, 2018).
Datta, S., Anderson, D., Branson, K., Perona, P. & Leifer, A. Computational neuroethology: a call to action. Neuron 104, 11–24 (2019).
Joska, D. et al. AcinoSet: a 3D pose estimation dataset and baseline models for Cheetahs in the wild. 2021 IEEE International Conference on Robotics and Automation (ICRA) Preprint at https://arxiv.org/abs/2103.13282 (IEEE, Xi’an, China, 2021).
Chen, Q. & Koltun, V. Photographic image synthesis with cascaded refinement networks. in 2019 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 1511–1520 (2017).
Lee, J., Hwangbo, J., Wellhausen, L., Koltun, V. & Hutter, M. Learning quadrupedal locomotion over challenging terrain. Sci. Robot. 5, eabc5986 (2020).
Botella, C., Joly, A., Bonnet, P., Munoz, F. & Monestiez, P. Jointly estimating spatial sampling effort and habitat suitability for multiple species from opportunistic presence-only data. Methods Ecol. Evolution 12, 933–945 (2021).
Beery, S., Cole, E., Parker, J., Perona, P. & Winner, K. Species distribution modeling for machine learning practitioners: a review. in Proceedings of the 4th ACM SIGCAS Conference on Computing and Sustainable Societies (2021).
Arzoumanian, Z., Holmberg, J. & Norman, B. An astronomical pattern-matching algorithm for computer-aided identification of whale sharks Rhincodon typus. J. Appl. Ecol. 42, 999–1011 (2005).
de Knegt, H. J., Eikelboom, J. A. J., van Langevelde, F., Spruyt, W. F. & Prins, H. H. T. Timely poacher detection and localization using sentinel animal movement. Sci. Rep. 11, 1–11 (2021).
Walter, T. & Couzin, I. D. TRex, a fast multi-animal tracking system with markerless identification, and 2D estimation of posture and visual fields. eLife 10, e64000 (2021).
Kellenberger, B., Tuia, D. & Morris, D. AIDE: accelerating image-based ecological surveys with interactive machine learning. Methods Ecol. Evolution 11, 1716–1727 (2020).
Settles, B. Active learning. Synth. lectures Artif. Intell. Mach. Learn. 6, 1–114 (2012).
Ofli, F. et al. Combining human computing and machine learning to make sense of big (aerial) data for disaster response. Big Data 4, 47–59 (2016).
Simpson, R., Page, K. R. & De Roure, D. Zooniverse: observing the world’s largest citizen science platform. in Proceedings of the 23rd International Conference on World Wide Web 1049–1054 (2014).
Pocock, M. J. O., Roy, H. E., Preston, C. D. & Roy, D. B. The biological records centre: a pioneer of citizen science. Biol. J. Linn. Soc. 115, 475–493 (2015).
Acknowledgements
We thank Mike Costelloe for assistance with figure design and execution. S.B. would like to thank the Microsoft AI for Earth initiative, the Idaho Department of Fish and Game, and Wildlife Protection Solutions for insightful discussions and providing data for figures. M.C.C. and T.B.W. were supported by the National Science Foundation (IIS 1514174 & IOS 1250895). M.C.C. received additional support from a Packard Foundation Fellowship (2016-65130), and the Alexander von Humboldt Foundation in the framework of the Alexander von Humboldt Professorship endowed by the Federal Ministry of Education and Research. C.V.S. and T.B.W. were supported by the US National Science Foundation (Awards 1453555 and 1550853). S.B. was supported by the National Science Foundation Grant No. 1745301 and the Caltech Resnick Sustainability Institute. I.D.C. acknowledges support from the ONR (N00014-19-1-2556), and I.D.C., B.R.C., M.W., and M.C.C. from, the Deutsche Forschungsgemeinschaft (German Research Foundation) under Germany’s Excellence Strategy-EXC 2117-422037984. M.W.M. is the Bertarelli Foundation Chair of Integrative Neuroscience. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the funding agencies.
Author information
Authors and Affiliations
Contributions
D.T. coordinated the writing team; D.T., B.K., S.B., and B.C. structured and organized the paper with equal contributions; all authors wrote the text; B.C. created the figures.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Nature Communications thanks Aileen Nielsen and the other, anonymous, reviewer(s) for their contribution to the peer review of this work.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Tuia, D., Kellenberger, B., Beery, S. et al. Perspectives in machine learning for wildlife conservation. Nat Commun 13, 792 (2022). https://doi.org/10.1038/s41467-022-27980-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41467-022-27980-y
This article is cited by
-
Embracing firefly flash pattern variability with data-driven species classification
Scientific Reports (2024)
-
The limits of acoustic indices
Nature Ecology & Evolution (2024)
-
The conservation value of forests can be predicted at the scale of 1 hectare
Communications Earth & Environment (2024)
-
Forestry Ecosystem Protection from the Perspective of Eco-civilization Based on Self-Attention Using Hierarchical Dilated Convolutional Neural Network
International Journal of Computational Intelligence Systems (2024)
-
Applying XGBoost and SHAP to Open Source Data to Identify Key Drivers and Predict Likelihood of Wolf Pair Presence
Environmental Management (2024)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
