
Abstract
Rapid and widespread testing of severe acute respiratory coronavirus 2 (SARS-CoV-2) is essential for an effective public health response aimed at containing and mitigating the coronavirus disease 2019 (COVID-19) pandemic. Successful health policy implementation relies on early identification of infected individuals and extensive contact tracing. However, rural communities, where resources for testing are sparse or simply absent, face distinctive challenges to achieving this success. Accordingly, we report the development of an academic, public land grant University laboratory-based detection assay for the identification of SARS-CoV-2 in samples from various clinical specimens that can be readily deployed in areas where access to testing is limited. The test, which is a quantitative reverse transcription polymerase chain reaction (RT-qPCR)-based procedure, was validated on samples provided by the state laboratory and submitted for FDA Emergency Use Authorization. Our test exhibits comparable sensitivity and exceeds specificity and inclusivity values compared to other molecular assays. Additionally, this test can be re-configured to meet supply chain shortages, modified for scale up demands, and is amenable to several clinical specimens. Test development also involved 3D engineering critical supplies and formulating a stable collection media that allowed samples to be transported for hours over a dispersed rural region without the need for a cold-chain. These two elements that were critical when shortages impacted testing and when personnel needed to reach areas that were geographically isolated from the testing center. Overall, using a robust, easy-to-adapt methodology, we show that an academic laboratory can supplement COVID-19 testing needs and help local health departments assess and manage outbreaks. This additional testing capacity is particularly germane for smaller cities and rural regions that would otherwise be unable to meet the testing demand.
Similar content being viewed by others

Introduction
The coronavirus disease 2019 (COVID-19) outbreak caused by the severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) surprised health care systems and diagnostic facilities worldwide. First reported as pneumonia cases of unknown origin in the province of Wuhan, China early in December 20191; SARS-CoV-2 infections rapidly moved to the status of a public health emergency of international concern (PHEIC) by the World Health Organization (WHO) Director-General in late January 2020. On March 11th, 2020, the WHO declared the novel coronavirus outbreak a global pandemic and urged countries to implement large scale testing as a strategy for controlling the spread of SARS-CoV-22.
Three months after public disclosure of the first COVID-19 case, the international community faced a challenging public health scenario: (i) widespread availability of testing was almost nonexistent, (ii) confusion about what would suffice as a reliable read out for diagnostics, and (iii) public health policies were inconsistent, rarely implemented, and enforced. This scenario was particularly challenging in the United States (US), at least in part, due to a lack of coordination among federal and state agencies, inadequate acknowledgement of the crisis and few sufficiently meaningful steps taken to control it. These decisions resulted, as of June 21st, 2021 in 33+ million people being infected and 601,903 deaths in the US alone3.
At the time of the latest US decennial census, approximately 60 million people (roughly 19% of the US population) live in rural communities, an area comprising more than 95% of the total US land mass (United States Census Bureau). Communities in rural areas continue to face unique challenges that stem from social inequities, literacy levels below national standards4, and limited access to quality health care. Consequently, rural Americans are facing the COVID-19 pandemic from a precarious vantage point, which is aggravated by the lack of healthcare infrastructure and the presence of an adult population with disproportionate comorbidities and disabilities compared to their non-rural counterpart5,6,7. A case in point is southwest Virginia (SWVA), the state’s westernmost region including all of Virginia’s seven coal-producing counties. According to the latest US census data, SWVA is poorer, older, less diverse, and has a slower population growth than most regions in the Commonwealth of Virginia8 and yet, it was in this region, where testing capabilities for COVID-19 were scarce or absent when COVID-19 was declared a national emergency.
As a response to the national demand for testing, the US Centers for Disease Control and Prevention (CDC) developed a COVID-19 assay for analyzing patient specimens in laboratories, which was certified under the Clinical Laboratory Improvement Amendments (CLIA) and received Emergency Use Authorization (EUA) permission by the Food and Drug Administration (FDA). However, chemical shortages for reagents placed pressure on laboratories wanting to run COVID-19 tests. Testing laboratories ultimately faced the same roadblock in the reagent supply chain, which affected their diagnostic capabilities. These limitations also increased the wait time for test results, posing stressful uncertainty and constraints on patients and their families. Despite a fragmented national approach within the US, academic laboratories have become an integral element in tracking the spread of COVID-19 across local communities9,10.
With over 300 academic laboratories within the US alone, many of these institutions possess not just the technical capacity but also the expertize required to expand COVID-19 testing. RT-qPCR assays are routinely performed in biomedical research programs and researchers were thus positioned to implement modified versions of these assays to detect SARS-CoV-2. Therefore, the scientific community could serve a specialized function and strengthen its connection to local communities and public health programs by generating its own COVID-19 pipeline operation.
In this work, we report the development of an academic, SARS-CoV-2 RT-qPCR molecular diagnostic test that was validated against samples provided by the state laboratory and submitted for EUA approval (EUA# 200383). Our test has aided multiple local Health Districts of SWVA to track and manage the spread of COVID-19 in the general population, and at potential outbreak sites across the region. Accordingly, our test allows for the in vitro detection of RNA from SARS-CoV-2 in respiratory (nasopharyngeal swabs, oropharyngeal swabs, anterior nasal swabs, mid-turbinate nasal swabs, bronchoalveolar lavage, nasopharyngeal wash/aspirates, and nasal aspirates) and saliva samples obtained from individuals suspected of having COVID-19. Particularly appealing aspects of this molecular test include its flexibility for implementation in various experimental settings, easy incorporation into high-throughput platforms to scale up capacity, and the versatility to maneuver around supply chain deficiencies. As of June 2021, 135,000+ individuals from seven health districts in SWVA, including more than 650 businesses, nursing homes, physician and dentistry offices, construction sites, and all public schools in the New River Valley (NRV) have been tested with this newly developed assay, where specimens were processed and reported within 24 h of sample arrival.
Results
In response to the COVID-19 pandemic, there arose, and continues to be, an urgent need for obtaining timely, accurate test results from large numbers of people throughout the Commonwealth of Virginia. This need is two-fold: (i) to be able to test and provide appropriate medical care and quarantine recommendations for patients who are symptomatic, including those who may currently be hospitalized or may soon need to be hospitalized, and (ii) more wide-scale surveillance testing to identify asymptomatic and pre-symptomatic individuals to facilitate public health mediated contact tracing and associated mitigation strategies. As testing availability was initially unable to meet demands for quick turnaround times and throughput ability were limited, there was considerable need for enhanced testing availability throughout the Commonwealth of Virginia and the country. As a result, our academic institution developed a test and a comprehensive program, in partnership with the Virginia Department of Health and Virginia Department of General Services, to support testing of personnel, students, and the community-at-large in SWVA.
Test principle and optimization
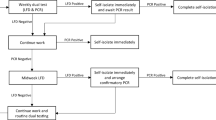
Our assay is a real-time reverse transcription polymerase chain reaction (RT-qPCR)-based test designed to amplify three distinct SARS-CoV-2 genes, i.e., N, E, and S, in the context of the expression of a housekeeping control gene named RPP30. A flow chart of the general procedure is presented in Fig. 1a. Briefly, clinical specimens (e.g., mid-turbinate) were collected using a commercial sterile synthetic rayon/Dacron®/polyester/nylon tipped applicator and transported in a specially formulated transport media. As swabs became a limiting factor during the pandemic, in-house manufacturing of 3D-printed swabs became a stopgap alternative to replace traditional flocked swabs (Fig. 1b, c). Accordingly, nasopharyngeal swabs were fabricated by inverse stereolithography following a design process developed by University of South Florida Health (patent is pending) with materials commonly used for clinical printing that were FDA-approved for biocompatibility11. This design, already evaluated in a clinical trial11, was duplicated in our laboratory as described in the “Methods” section. The mechanical properties of the two printed swabs, an adult and pediatric version, exhibit comparable tensile and torsional strength within the variances observed (Fig. 1d). These results were further compared to the testing values of commercially available swabs previously reported by Formlabs (Copan and Puritan, Swab Verification Summary Report #SR-0010 rev#00). In general, the performance, toughness, and torsional testing results of our 3D-printed swabs fell within those approved to be the standard of care [Copan (highest) and Purtan (lowest)].

a SARS-CoV-2 testing flow chart. Briefly, tubes containing MDL-TM and swab were checked in the system, a matrix created to follow the sample throughout the whole process, and RNA was extracted as described in the “Methods” section. Plates containing RNA from all 40 samples were either stored at −80 °C until needed or, an aliquot of each sample was diluted and subjected to RT-qPCR amplification. Each sample was tested in duplicate for the expression of four genes (N, E, and S from SARS-CoV-2 and RPP30) in a 384-well format plate. In addition, each plate included positive and negative controls and standard curves for the N and RPP30 genes as specified in the “Methods” section. b Completed print of 324 adult swabs using Formlabs Form2 with Surgical Guide resin. c PurFlock (Puritan Medical Products, LLC) test swab (a) compared to 3D-printed pediatric (b) and adult (c) swabs. d Summary of average tensile (top) and torsional (bottom) testing results of 3D-printed adult and pediatric swabs (n = 10 samples of each type, data are presented as mean ± SD), respectively. e Left panel, RNA integrity analysis (RIN) of clinical samples collected using various transport media (lanes 1–8) or the transport media developed by our laboratory (lanes 9–10, MDL-TM). Duplicate RNA samples were purified the day of delivery or 10 days after collection, respectively (lanes 9 and 10). C+: total RNA sample purified from human cells. Right panel, a suspension of negative nasopharyngeal swabs collected in various formulations of transport media were spiked with inactive SARS-CoV-2 virus (~300 copies, ATCC) (samples 1–14). Samples were extracted and RNA amplified as described in “Methods” section. Matching samples (9 and 10) were processed immediately or maintained at 4 °C for 10 days before being analyzed. Sample 14 was total RNA purified from cultured mammalian cells. N/A not amplification observed. N/S/E gene cutoff: 37.079, 95% CI [35.75, 36.67]; RPP30 gene cutoff: 38.119, 95% CI [36.02, 36.46]. Data was originated from a single experiment that was repeated there times with similar results.
Nasopharyngeal swabs were placed in a specific formulated transport media (MDL-TM) that (i) inactivates infectious agents, (ii) stabilizes RNA molecules, and (iii) does not require uninterrupted cold-chain logistics. We initially demonstrated the efficacy of the MDL transport media in stabilizing nucleic acids by performing RNA integrity analyses (Fig. 1e). Accordingly, inactive SARS-CoV-2 virus was spiked into various formulations of TM consisting of a suspension of a negative nasopharyngeal (NP) swab. Viral particles were released from the swab into the MDL media using mechanical stirring. An aliquot of the eluate was then subjected to a TRIzol/EtOH-based nucleic acid extraction protocol in a 96-well column format system following various washing/elution procedures as described in the “Methods” section. The integrity of purified RNA was evaluated by microcapillary electrophoretic RNA separation and assigned an RNA integrity number (RIN) ranging from 1 (worst) to 10 (best) (Fig. 1e, left panel). The RIN results validated our transport media as an effective diluent as it was the one formulation that best preserved the quality of the RNA even 10 days after collection (Fig. 1e, left panel). Next, we evaluated whether components of the TM might inhibit the amplification reaction. Consequently, total RNA was purified from each transport media sample and used for reverse transcription and amplification in a formulation that contains RNase inhibitor, and additives to reduce formation of the primer’s secondary structure. Primers for the amplification of SARS-CoV-2 (N, E, and S) and human housekeeping (RPP30) genes were included in four independent reaction mixtures. Under these conditions, maximum sensitivity and reliability was ensured as false positives resulting from primer dimers were less likely to occur. Reactions were, then, assembled in a 384-well plate format and amplified as described in the “Methods” section. Results show that the composition of the MDL-TM did not inhibit gene amplification and preserves the quality of the sample, seen by the comparable Ct values obtained for the viral genes, even 10 days after collection (Fig. 1e, right panel).
Clinical specimens were expected to exhibit fluorescence amplification curves when using the Hs_RPP30 primers with Ct values that cross the threshold line below a cutoff determined by a standard curve, thus, confirming the presence of human material via the RPP30 gene. Samples from presumptive positive COVID-19 patients were expected to amplify at least two out of the three genes from SARS-CoV-2, (i.e., N, E, and S), a criterion that allows for higher specificity and reduces the likelihood of false negative results (see Supplementary Table 2 for complete criteria). Standard curves for RPP30 were included in each run and for each plate. Failure to detect RPP30 in any clinical specimen may indicate: (i) improper extraction of RNA from the clinical sample, (ii) absence of sufficient human cellular material due to poor collection or loss of specimen integrity, (iii) improper set-up and execution, or (iv) equipment malfunction. Interpretation of results when a negative RPP30 was reported was as follows: (i) if at least two of the viral genes (N, E, S) were positive even in the absence of a positive RPP30, the result was considered valid. A negative RPP30 signal did not preclude the detection of viral RNA in a clinical specimen, and (ii) if viral genes and RPP30 were negative for the specimen, the result was considered invalid. In this last scenario, if a residual clinical sample was available, it was recommended to repeat the extraction procedure as well as the test. However, if all markers remained negative after a re-test, the result was reported as “invalid” and a new specimen needed to be collected (Supplementary Table 2).
The analytical sensitivity of the assay was determined by limiting dilution studies (limit of detection, LOD). Accordingly, assays were designed for the detection of SARS-CoV-2 using stocks of inactive virus (ATCC) spiked into a diluent consisting of a suspension of a previously characterized negative nasopharyngeal swab maintained in viral transport media. Ten-fold serial dilutions of characterized stocks of viral SARS-CoV-2 were tested in triplicate with each primer set. Of note, the number of copies of SARS-CoV-2 virus was batch-specific and was provided by ATCC on its Certificate of Analysis. Samples were manually extracted and RT-qPCR assays performed following the procedure described in the “Methods” section.
To determine the preliminary LOD, we used a batch of virus with a copy number of 1.2 × 103 copies/µl as determined by droplet digital PCR (ddPCR). Per FDA guidelines, the number of viral copies spiked in the original sample for LOD determination varied from 104 to 10−5. For each dilution, and after sample processing and amplification, the number of viral copies detected using each set of primers in the assay were reported per reaction volume (Table 1). Validation of the LOD was carried out by testing the system’s sensitivity for detection in 20 samples, each spiked with a concentration of inactive virus such that the final number of copies in the reaction was 300, 20, or 1.3 (i.e., thirty-times and two-times above and seven-times below the LOD determined in Table 1, respectively, Supplementary Tables 3, 4, 5). As a result, the LOD (10 copies per reaction) was determined as the lowest concentration, where ≧95% of the replicates were positive.
Inclusivity analysis (Analytical Sensitivity)
In silico analysis using published sequences was performed to determine the predicted inclusivity of our SARS-CoV-2 assay. Thirty-two thousand nine hundred and eleven SARS-CoV-2 sequences were downloaded from NCBI (Supplementary Data 1). The exclusion criteria removed 536 sequences from further analysis as they were incomplete (535 sequences) or of poor quality (1 sequence). Of the remaining 32,375 sequences, 27 sequences contained mismatches near the 3′ end of the primer binding site, that might affect amplification by one of the primers and 60 sequences contained multiple mismatches over the length of a primer binding region that might affect amplification. None of the 32,375 SARS-CoV-2 sequences obtained from NBCI contained mismatches that could affect amplification in more than one primer set. Therefore, our SARS-CoV-2 assay was predicted to have 100% inclusivity by in silico analysis of all SARS-CoV-2 sequences published in NCBI as of January 13th, 2021. A note of caution should be considered when performing in-silico inclusivity analysis as the GISAID and GenBank databases of SARS-CoV-2 sequences largely contain information deposited by countries with resources to perform the analyses, and might not be representative of the population of genomes in circulation globally or locally.
240,791 SARS-CoV-2 sequences were downloaded from GISAID (gisaid.org) (Supplementary Data 2). The exclusion criteria removed 11,453 sequences from further analysis as they were of poor quality. All sequences completely covered the six primer binding regions. Of the remaining 229,338 sequences, 919 sequences contained mismatches near the 3′ end of the primer binding site that might affect amplification by one of the primers, and 378 sequences contained multiple mismatches over the length of a primer binding region that might affect amplification. Two of the 229,338 SARS-CoV-2 sequences contained mismatches that could affect amplification by two different primer sets. Thus, our SARS-CoV-2 assay was predicted to have 99.9991% inclusivity by in silico analysis of all SARS-CoV-2 sequences published in GISAID as of January 7th, 2021.
Cross-reactivity analysis (Analytical Specificity)
To validate our RT-qPCR assay for specificity towards SARS-CoV-2 versus other common respiratory flora and viral pathogens, we performed in silico cross-reactivity analyses. Per FDA guidelines, in silico cross-reactivity is defined when greater than 80% homology between one of the primers/probes and any sequence is present in the targeted microorganism. Respiratory pathogens were separated into two main categories including those that belong to the same family as SARS-CoV-2 (e.g., human coronavirus 229E, OC43, HKU1, NL63, and SARS-CoV and MERS-coronavirus) and others pathogens considered high priority and likely circulating in our area (e.g., influenza A and B, rhinoviruses, Streptococcus pneumoniae, and Pseudomonas aeruginosa). The criteria for potentially affecting specificity of our assay included having greater than 80% homology to at least two of the three primer sets.
BLAST analysis queries of our SARS-CoV-2 qRT-PCR assay primers were performed against the public domain nucleotide sequences listed in Table 2. Among all in silico tested organisms, the N and E primers showed >80% homology for the bat SARS-like coronavirus genome (Supplementary Data 3). Our findings also indicated that N, but not E or S, forward and reverse primers could amplify bat coronavirus CoVZXC21 and CoVZC45 as these sequences perfectly match our N primers, thus may generate a positive result for the N gene in our test. However, the S primers showed no significant homology with any non-target sequence, including bat coronaviruses. For the E primer sets, there is predicted to be no significant amplification for SARS-CoV viruses as only one of the E primers had homology to these viruses. Lastly, sequences of the N, E, S primers did not show significant homology with other pathogens that most commonly cause respiratory infections (Table 2).
Test validation and clinical evaluation
Initial experiments were devoted to validating our test using 66 contrived specimen samples (33 positive and 33 negative) in a pilot study. Samples were contrived by spiking a known concentration of inactive SARS-CoV-2 virus, or a genetically related virus with similar tropism towards the respiratory and gastrointestinal track as SARS-CoV-2 but that was undetectable by our primers (Bovine coronavirus, BCoVs) as the negative control. In either case, samples were loaded with viral particles (analyte) equal to two-times the LOD as established in Table 1. Different amounts of analyte (samples 1–27 and 28–33) was added into matrices previously determined to be negative by the Power SYBRTM Green RNA-to-CTTM 1-Step Kit. Results from positive samples are summarized in Supplementary Table 6. A single plate-specific cutoff value of 36.25, 95% CI [35.60, 36.90] was used for all viral primer sets. Our analyses indicated that the Ct value corresponding to the inferior point of the 95% interval of confidence for the LOD for the E and S genes were smaller (i.e., larger number of viral copies) than that observed for the N gene. To be conservative, a threshold approach was utilized and all sample Ct values for the E, N, and S genes were compared to the Ct value of the inferior point of the 95% interval of confidence calculated for gene N.
Next, to establish the clinical assay performance, 81 participant samples, each consisting of a NP swab, were collected in MDL-TM and tested for the presence of SARS-CoV-2 using our RT-qPCR test. Comparable aliquots of all clinical specimens were submitted to the Virginia Division of Consolidated Laboratory Services (DCLS) for validation. The comparator assay performed by DCLS followed the CDC EUA IFU (CDC DOC 006-0099 rev. 03) “CDC 2019-Novel Coronavirus (2019-nCoV) Real-Time RT-PCR Diagnostic Panel” and used probes, and a primer kit previously approved “IDT-2019-nCoV CDC EUA Kit (primers) cat # 10006606.” Results from our test were reported in accordance with the criteria summarized in Supplementary Table 2 in which amplification of, at least two viral genes (N, E, or S) below the lowest 95% IC value threshold were required to report a positive result. In agreement with CDC guidelines, reports from DCLS were based on the detection of only one viral gene, N, with two different primer sets named N1 and N2. Ct values for all genes and corresponding cut-offs for each clinical sample are summarized in Supplementary Table 7. Results show 100% agreement among samples compared from both laboratories with 45 positive and 33 negative NP swab specimens evaluated in both locations (Positive Percent Agreement: 100%, 95% CI [92.1, 100]; Negative Percent Agreement: 100%, 95% CI [90.3–100]). Overall, our results show the robustness, specificity, and sensitivity of our test for timely identification of the SARS-CoV-2 virus in clinical specimens.
Increasing testing capacity by sample pooling
As infection rates in the population and shortages in the supply chain increased, it was necessary to reallocate resources towards those individuals in need of immediate testing (e.g., health professionals, patients, individuals in nursing homes) versus others for which screening would be advantageous (e.g., family groups, athletic teams, group workers, and students). Therefore, it was determined that a pooling of samples strategy would be useful, for example, in areas with low prevalence of SARS-CoV-2 as was the case for SWVA at specific windows of time during the pandemic.
Initial experiments were devoted to determining the sensitivity of the pooling method and in defining the optimal number of samples per pool. Accordingly, we used our protocol to pool test archived individual samples with n-sample pools each consisting of one positive sample and n−1 negative samples. In all cases, samples were from NP swabs taken from patients and tested in accordance with the protocol described in the “Methods” section. A sample’s status (i.e., positive or negative) was determined based on cut-off values and the 95% CI for the N and RPP30 genes as explained earlier. Once tested, samples were separated into two groups: positives and negatives. To generate the negative pools for testing, four samples from the negative group were used in each of the pooled samples. No negative sample was used in more than one negative pooled sample. Some, but not all, of the negative samples had enough volume to be included in the positive pool. To generate the positive pools for testing, three negative samples were used in combination with one positive sample. All positive pooled samples contained a different set of negative samples; no two positive pooled samples contained the same three negative samples.
First, we validated pooling studies using positive samples with at least 25% of them being within 2–3 Cts of the cut-off, and no more than within 2–4 Cts overall. Validation was performed in pools of 2, 3, and 4 samples (Supplementary Data 4, 5, and 6). For pools containing n = 2 samples [one positive and one negative (P1 + N1) or two negative samples (N1 + N2)], we analyzed 20 negative and positive pools containing two samples in each pool. Supplementary Data 4 summarizes the results of the Cts for the N, E, S, and RPP30 genes and cut-offs for N and RPP30 for each of the two samples in the pool (columns F-L and P-V) and for the pool itself (columns Z-AF). Note that the assay cut-off for each sample varied since thresholds were determined on a plate-by-plate basis. When Ct values for each gene of the positive sample were compared with the corresponding n = 2 pool, we found that Ct differences were less than two in 22 samples analyzed (Supplementary Data 4). Regression analysis of individual versus pooled Cts showed an R2 of 0.94, 0.92, and 0.91 for the N, E, S, genes, respectively [LOD individual N: 38.54, 95% CI (38.12, 38.97); LOD pool N: 37.29, 95% CI (36.91, 37.67)] (Supplementary Data 4). These results indicated that, following this pooling procedure, samples with Cts for the N gene between 38.12 and 36.91 would have been detected using individual testing but not when pooling.
We next evaluated the result of 20 negative and 22 positive pooled samples containing three individual specimens (P2 + N3 + N4 and N3 + N4 + N5, Supplementary Data 5). As was the case when pooling two samples, deviation of Ct values was within two units when comparing individual versus three pooled samples. Regression analysis for individual versus pooled Cts showed that the R2 values for the N, E, and S genes were 0.96, 0.95, and 0.96, respectively [LOD individual N: 36.17, 95% CI (35.79, 36.56); LOD pool N: 37.29, 95% CI (36.91, 37.67)] (Supplementary Data 5). Thus, samples with Cts between 35.79 and 36.91 would have been detected when testing individual samples but would have been missed when pooled. In a set of 20 negative (N6 + N7 + N8 + N9) and 21 positive pooled samples of n = 4 (P3 + N6 + N7 + N8), 4 (19%) patient samples were within 4 Ct values of the threshold. We used the inferior limit from the individual test on the regression analysis tab of Supplementary Data 6. With that value, we identified how many samples had N/E/S within a 4Ct range. Three samples had all three genes within the 4Ct value and one sample had two genes within the 4Ct value. Therefore, four samples were in the “weak” category and were likely missed when pooling. Based on the validation test (20 negative and 21 positive pooled samples), we observed 100% positive percent agreement (PPA) and 100% negative percent agreement (NPA). Per FDA recommendation, results were reported in a two-by-two table (Supplementary Table 8a). There was no difference in processing for pooled and single samples.
Finally, to assess the impact of pooling on individually tested samples evaluated in our laboratory, the FDA recommends comparing pooled Cts versus individual Ct values for the corresponding samples using Passing-Bablok regression analysis. The estimates for the slope and 95% confidence intervals of the slopes for the N, E, and S genes are summarized in Supplementary Table 8b. These results suggest that the relationship between pooled and individual samples are similar, as indicated by all confidence intervals, including a slope of 1.
We then evaluated the sensitivity of pooled testing. For this, we considered the most recent 100 positive samples as determined through individual testing. We evaluated their observed Ct values compared to theoretical and estimated Ct shifts for n = 2, n = 3, and n = 4 (Supplementary Data 7). Using the theoretical Ct shift as a result of pooling two samples (log2(2) = 1Ct shift), we observed a sensitivity of 82%. In addition, we estimated the pooled Ct threshold for each individual assay using the estimated observed shift in Ct value as a result of pooling (\({{{N}}}_{{\rm{pooled}}}= \frac{{{{N}}}_{{\rm{individual}}}{{\mbox{-}}}2.6}{.9}; N_{{\rm{pooled}}}\); is the estimated Ct threshold for an individual plate and \({{{N}}}_{{\rm{individual}}}\) is the observed Ct threshold for the respective plate). From this analysis, we observed a sensitivity of 100%. Using the theoretical Ct shift as a result of pooling three samples (log2(3) = 1.58 Ct shift), we observed a sensitivity of 76%. In addition, we estimated the pooled Ct threshold for each individual assay using the estimated observed shift in Ct value as a result of pooling (\({{{N}}}_{{\rm{pooled}}}=\frac{{{\rm{N}}}_{{\rm{individual}}}\,{{\mbox{-}}}1.48}{.99};N_{{\rm{pooled}}}\); is the estimated Ct threshold for an individual plate and \({{{N}}}_{{\rm{individual}}}\) is the observed Ct threshold for the respective plate). From this analysis, we observed a sensitivity of 82%. Using the theoretical Ct shift as a result of pooling four samples (log2(4) = 2Ct shift), we observed a sensitivity of 71%. In addition, we estimated the pooled Ct threshold for each individual assay using the estimated observed shift in Ct value as a result of pooling (\({{{N}}}_{{\rm{pooled}}}=\frac{{{{N}}}_{{\rm{individual}}}\,{{\mbox{-}}\,}4.97}{.895};N_{\rm{pooled}}\); is the estimated Ct threshold for an individual plate and \({{{N}}}_{{\rm{individual}}}\) is the observed Ct threshold for the respective plate). From this analysis, we observed a sensitivity of 82%.
Pooling as screening strategy in rural areas
Next, we implemented pooled testing as strategy for screening individuals suspected of COVID-19 within a region of SWVA. To determine whether pooling versus individual testing was a better choice for COVID-19 screening, we needed to evaluate the prevalence of positive cases within a certain time frame in the area. As a proof-of-concept, we chose to monitor the positivity rate among 3807 individuals tested between July 10th to July 30th, 2020 as follows: (i) July 10th to 16th, 1288 individuals, (ii) July 17th to 23rd, 1136 individuals, and (iii) July 24th to 30th, 1383 individuals living in the New River Valley (Table 3). The highest positivity rate within that time-frame was 4.4%; thus, using this positivity rate, pooling (n = 4) would reduce the number of expected tests by 59% compared to individual sample testing. This was calculated using the Shiny application for pooled testing as described by Abdalhamid et al.12 [https://www.chrisbilder.com/shiny]. Here, we used estimates of 95% sensitivity and 100% specificity for our calculations. These estimates also showed that when the positivity rate in the sample reaches above 25%, individual sample testing would be a more efficient approach than pooling. If the positivity rate exceeds 25%, then we will return to testing samples individually. As positivity rate is an important variable for consideration when deciding to use pooled versus individual sample testing, it became important to monitor its value and the number of weak positives in the region by individual sample testing using a 7-day moving average (i.e., the average positive testing rate of the prior 7 days). Comparison among weekly positivity rates and the 25% positivity threshold were used to adjust our testing strategy.
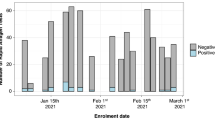
Samples from participants located in two health districts in SWVA were used for initial pooled testing—the New River Valley and the Mt. Rogers Health Districts (NRVHD and MRHD, respectively) (Fig. 2a). These districts are considered “at-risk” regions as defined by the Appalachian Regional Commission based on economic indicators such as unemployment rate, income per capita, and poverty rate. People in rural areas face multiple challenges associated with coverage and access to health care as a result of unemployment, low annual income, limited number of providers, and hospitals in the region, as well as long travel distances to access care4. As a result, individuals in rural areas are less likely to have private health coverage than those in urbanized districts of the same state (Supplementary Table 9). In fact, enrollment in Medicaid and Medicare are higher in the NRVHD (9.08% and 12.20%, respectively) and the MRHD (15.60% and 18%, respectively) than in urban health districts in Virginia [e.g., Fairfax Health District (FHD) (6.03% and 8.36%, respectively), Supplementary Table 9].

a Map of the State of Virginia, U.S. with all 95 counties and 38 independent cities, considered county-equivalents, on display. Our laboratory’s service area is shaded in orange. The limits of the New River Valley Health District (NRVHD) and Mt. Rogers Health Districts (MRHD) are indicated in green and red, respectively. b Graphs indicate the daily number of RT-qPCR tests processed (blue) in NRVDH (left) and MRHD (right) along with the number of positive results (red).
Of these, samples from NRVHD and MRHD were from a cohort of 7,792 and 648 participants, respectively. Positivity rates in NRV and MRHD were <5% at times of collection (July 29th to August 18th, 2020, Fig. 2b). Nasopharyngeal swabs were pooled in groups of 4 and samples were processed as described in “Methods” section. The Cts from pooled samples were compared against the cut-off and deemed positive, negative, inconclusive (and therefore a repeat), or invalid (Fig. 3a, b). Results for NRVDH showed that 96.71% of pool samples were negative (7,536 unique samples) and only 3.29% (256 unique samples) were below the threshold and, therefore, individually retested (Fig. 3a). Of those 256 samples, 64.06% were negative (164 samples), 26.17% were positive (67 samples), 6.64% were inconclusive (17 samples), and 3.13% invalid (eight samples) (Fig. 3a). Interestingly, the analysis of MRDH pooled samples was comparable to that of NRVHD, this is 95.06% were negative (616 samples) and 4.94% were retested (32 samples) (Fig. 3b). Of the retest of the MRHD pooled samples, 70.97% were negative (22 samples) and 29.03% were positive (nine samples) and one invalid (Fig. 3b). These results indicate that pooling is a reliable and effective approach for large screening of participants when positivity rates are below the threshold.

Samples were collected from participants at two locations MRHD (648 participants) and NRVHD (7,792 participants) (a, b, respectively) and used for pooling studies. Briefly, pools of four samples from each district were analyzed by RT-qPCR and deemed negative based on our threshold criteria for Ct values or “retest”, if positive or inconclusive. Samples from “retest pools” were analyzed as singles. Accordingly, the RNA from each of the original samples in the pool was re-extracted before amplification and the results grouped as negative, positive, invalid, and inconclusive. c, d Scatter plot showing the association between the Ct value for the pooled sample compared to the Ct value for the positive sample(s) within the pool from the MRHD (n = 9) (c) and NRVHD (n = 68) (d). Points were colored based on the total number of positive samples in the pool of four samples (gray: one positive sample, white: two positive samples, black: three positive samples). Red lines indicate the theoretical Ct value shift (2 Ct units) expected when pooling together one positive sample with three negative samples.
Next, we asked whether the Ct values of the four-pooled samples that were retested correlate with the Ct value of the positive sample in that pool. Since a high correlation and the theoretical shift in Ct values assume that only one sample in the pool is positive, we chose for comparison pools that had only only positive sample (Fig. 3c, d). We found correlation values of 0.877 (p-value: <0.001), 0.908 (p-value: <0.001), 0.846 (p-value: <0.001) for the N, E, and S genes from NRVHD samples, respectively whereas those from the MRHD showed stronger correlations with values of 0.996 (p-value: <0.001), 0.992 (p-value: <0.001), and 0.994 (p-value: <0.001) for the N, E, and S genes, respectively. Thus, pooling of samples is a relevant public health alternative for large scale screening and for the detection of pre-symptomatic and asymptomatic individuals. Pooling of as low as one positive sample with up to three negatives prior to single sample testing using our assay did not adversely impact the detection of positives. At positivity rates of less than 5 or 10%, this approach could save up to 57 and 42% reagents and kits used for testing, respectively. This is in addition to saving processing time, speeding up the reporting of results, and aiding in the implementation of safe reopening plans.
Expanding specimen collection and clinical evaluation
Next, we focused our efforts on developing a collection strategy for a noninvasive alternative to upper respiratory swabbing for testing. The need for this development rested in three important factors: (i) swab sampling causes the patients to cough, sneeze, or have other uncomfortable reactions that makes collection more challenging, especially in children and the elderly people, while exposing healthcare workers to an increased risk of virus transmission, (ii) swabbing requires a level of technical proficiency that could affect the quality of the sample collected if not properly done, and (iii) continuous disruptions in the production of operational material with testing swabs were the weakest link in the supply chain.
To address these underlying problems, we expanded our test to include saliva as a noninvasive alternative to respiratory swabbing. Saliva is easy to collect, is presumably preferred by the participant, and does not require any particular technical proficiency for collection. Therefore, we proceeded to compare paired self-collected saliva samples with NP swabs collected by a healthcare worker (comparator assay) from 122 suspected COVID-19 patients. Participants provided written informed consent and had COVID-19 symptoms. To minimize the occurrence of discordant results, both clinical specimens were simultaneously collected, transported into MDL-TM, and processed using the protocol for extraction and amplification described in the “Methods” section. Of the 122 participants, 92 were negative and 30 were positive for SARS-CoV-2 as determined by our RT-qPCR test. Per FDA criteria, a minimum of 95% positive and negative agreement with similar Ct values for paired specimen types was considered an acceptable clinical performance. As shown in Supplementary Data 8, Ct values for the N gene in positive swab samples ranged from ~15 to 35 and, thus, covered a range of clinically relevant values for comparison. Our findings showed that matching saliva samples were 100% in agreement with swab reports resulting in 100% PPA and 100% NPA. Thus, the use of saliva specimens in our assay can provide a reliable read-out for those patients for which swabbing is not the preferred option.
Discussion
Widespread diagnostic testing and contact tracing are of utmost importance for slowing and, in some cases, containing the COVID-19 pandemic while vaccines are being developed, distributed, and administered. Implementation of aggressive testing schemes, quick reporting of test results, effective public health interventions, and adequate policymaking have contributed to limiting COVID-related death and SARS-CoV-2 spread in countries such as Germany, South Korea, and Singapore. The US, however, lags behind these countries in testing capability, resources, and organization, particularly in rural areas.
As the number of COVID-19 cases increased in the US, the Health and Human Services Secretary determined, based on the potential risk to national security and US citizens, that circumstances justified the authorization of emergency use (EUA) in vitro diagnostics for the detection/identification of SARS-CoV-2. By the end of February 2020, the Food and Drug Administration (FDA) issued a guidance, which was updated in March and May 2020, with specifics for the development of in vitro tests. Since then, 314 molecular-based and antibody-based tests, with wide differences in analytical performances, have been granted or are under review by the FDA for EUA authorization (https://www.fda.gov/emergency-preparedness-and-response/mcm-legal-regulatory-and-policy-framework/emergency-use-authorization#covidinvitrodev).
Diagnostic tests can be cataloged based on their intended use, (e.g., detection of viral RNA, antigens, or antibodies developed by the host, early-stage diagnostics of COVID-19 disease, screening), detection method (e.g., RT-qPCR, RT-LAMP, RT-RPA, ELISA, ddPCR, and neutralization test), and sensitivity (number of viral copies detected), to mention a few. As is the case for other molecular and immunological tests used for viral diagnostics, factors such as the quality/type of the clinical specimen, the material used for collection, the composition of the transport media, and storage conditions directly impact test performance. On top of these technical hurdles, large scale testing faced logistical, implementation, and turnaround time issues that were critical to the implementation of efficient contact tracing strategies and for containing the spread of the virus. These additional hurdles are particularly exacerbated in rural areas, where access to public health resources, healthcare preparedness, and testing capabilities are limited or scattered under the best scenario, or, in most cases, are simply absent. It is at this juncture, where technical necessity meets rapid implementation, that innovation is required to overcome a broken supply chain and academic laboratories can fill the gap.
Our molecular test is technically designed to be sensitive and specific for the detection of SARS-CoV-2 using various clinical specimens (nasopharyngeal and saliva (in this paper), oropharyngeal, anterior nasal, mid-turbinate, bronchoalveolar, nasal aspirates in our EUA #200883 application) and strategies (single versus pooled samples), and for test results to be reported within hours of receiving a patient’s sample. Our RT-qPCR-based test has an analytical sensitivity of ten copies, a predicted inclusivity of 99.9991% over 240,000+ SARS-CoV-2 sequences analyzed, and a specificity of 100% for the SARS-CoV-2 virus. Combined, these statistics make our test comparable or better than other molecular-based technologies for SARS-CoV-2 detection, including ddPCR [sensitivity: two copies, specificity: 94.9%13], isothermal amplification [RT-LAMP (sensitivity: ~500 copies, specificity: 99%14; RT-NEAR (sensitivity: 15 copies, specificity: 99.9%, Abbott 2020; RT-RPA); and CRISPR-based [DETECTR, (sensitivity: ~1000 copies, specificity: 95%15; STOP, (sensitivity: ~200 copies, specificity: 99.9%16] methods.
A notable difference between our assay and other molecular diagnostic technologies lies in our design strategy for identifying and classifying a clinical sample as either positive or negative. Many molecular diagnostics rely on the detection of a single gene in the SARS-CoV-2 virus, e.g., the N gene (VitaPCRTM platform/VitaPCR™ SARS-CoV-2 assay, Menarini; GenMark ePlex instrument/ePlex® SARS-CoV-2 Test, GenMark; BD MAX™ System/BD SARS-CoV-2 Reagents, Becton Dickinson; Vivalytic analyzer/Vivalytic VRI test, BOSCH; ID Now COVID-19, Abbott). Other commercial kits rely on the detection of two targets on the virus (Xpert® Xpress SARS-CoV-2, Cepheid; ARIES® SARS-CoV-2, Luminex Corporation; Cobas 6800/8800/cobas SARS-CoV-2, Roche; Alinity m System/Alinity m SARS-CoV-2 assay, Abbott; QIAstat-Dx Respiratory SARS-CoV-2 Panel, Qiagen). Very few commercial tests use three or more genes, as they require specialized equipment for extraction and amplification and, therefore, low versatility and considerable investment (Seegene NIMBUS/STARlet/Maelstrom 9600/Allplex™ SARS-CoV-2 Assay, Seegene; KingFisher Flex Purification system/TaqPath™ COVID-19 RT-PCR Kit, Life Technologies Corporation)17. Our assay, however, reports the result of the amplification of three SARS-CoV-2 genes (N, E, and S). The rationale behind this considers genetic variations of SARS-CoV-2 among circulating variants for which the sole amplification of a single gene could result in a false negative result, if the mutation takes place in a region of the genome assessed by the test. Thus, a molecular diagnostics test developed to detect multiple genetic targets of SARS-CoV-2 is less susceptible to genetic variation. The FDA provides regular alerts to health care providers of potential false negative results that might result as a consequence of using commercial kits, where detection could be compromised by a prevalent new variant of the virus. False positive results are equally concerning and arise from different sources, some of which are related to the format of the test and others to the sensitive nature of its amplification. The most notorious, and certainly unfortunate, case of false positive results appeared early in the pandemic and resulted from both contamination of the US. CDC test kits during the production phase18 and cross-reactivity of a primer-probe set19. As such, we developed a multilevel approach to address these issues starting with an efficient laboratory design, where processing stations are physically segregated, included an array of controls in each plate that flags sources of cross-contaminations and carryover-contaminations, monitored for human error using cross-analysis, and developed a criterion for which at least two SARS-CoV-2 genes needed to amplify below a threshold cut-off for a sample to be reported positive.
The evolving nature of SARS-CoV-2 brings an additional consideration for test development and implementation that is of particular concern to commercial enterprises, as they struggle to add alternative laboratory tests into routine use for the detection of new variants of the virus. Unlike large clinical laboratories, the operational flow for testing in laboratories within academic institutions facilitates just-in-time adaptations to the evolving nature of the SARS-CoV-2 virus. A case-in-point is the variant B.1.1.7 (VUI202012/01) of SARS-CoV-2, which was first identified in the United Kingdom in September 2020, and has spread to over 30 countries by the end of January 202120 (https://assets.publishing.service.gov.uk/government/uploads/system/uploads/attachment_data/file/948152/Technical_Briefing_VOC202012-2_Briefing_2_FINAL.pdf). Implementation of procedures for the detection of new genomic variants of SARS-CoV-2 would need to rely on de novo production of specific supply kits and scale up operations. Thus, high-throughput academic laboratories with customized procedures can easily substitute individual components and be rapidly operational. A resilient test system like ours would prompt rapid public health responses and assess SARS-CoV-2 variant transmissibility and severity in the population. For instance, the D614G variant of SARS-CoV-2, which emerged in late January 2020, replaced the original SARS-CoV-2 variant identified in Wuhan, China in a period of several months to become the dominant variant globally21, could not be specifically identified by any single commercially available kit22. Under this circumstance, the only tool for public health officials to rely on for decision-making in response to an outbreak from a new variant virus was real-time whole-genome sequencing (WGS). Although a cutting-edge technology, WGS presents some logistical and technical challenges that make it difficult to broadly implement. This includes the need for streamlined sample preparation and a bioinformatics pipeline that ensures access to highly accurate and complete sequence platforms, access to metadata for interpretation, and automated tools for data analysis. A customized in-house screening test for a new variant can easily be developed by generating mutations of interest within an oligonucleotide sequence; thus, an alternative screening test can be developed and implemented in a matter of hours.
In addition to this technical nimbleness, an academic institution such as ours (Virginia Tech) that is a public land-grant university with a motto of Ut Prosim (that I may serve), has demonstrated that is able to nimbly pivot its daily operations and support for its academic research community from standard activities to a service-oriented model that in cooperation with public agencies can rapidly deploy leading edge science in the provision of service for the immediate public good.
Therefore, the ability of academic institutions to establish reliable SARS-CoV-2 detection assays is paramount to mitigating the devastating health and economic toll triggered by the COVID-19 pandemic. This is particularly important in rural communities, where the burden associated with a lack of testing capacity adds to the stigma of being diagnosed with a positive result causing a dangerous downward spiral, where people might choose not to be tested even when showing symptoms of the disease23. If there has been one thing this pandemic has taught us, it is that academic institutions have the desire, expertize, and resources to step up when the diagnostic system is overwhelmed.
Methods
Specimen collection
The testing protocol was submitted for Emergency Use Authorization from the Federal Drug Administration (EUA# 200383) and approved by the Virginia Tech Institutional Review Board (IRB# 20-852). Informed written consent was obtained from the participants for both sample collection and its use for the research. Clinical specimens were collected from individuals suspected of having COVID-19 using nasopharyngeal swabbing (NP) by trained health professionals24. When indicated, paired saliva (~1 ml) and NP samples were collected from the same patient and analyzed simultaneously for comparison. Swabbing was performed using an ultrafine, flocked, polyester/rayon/DacronTM bicomponent fiber tipped swab (Puritan) and placed into 100 mm round-bottom, polystyrene collection tubes (Corning) containing 1.5 ml of transport media. Transport media (named MDL, Molecular Diagnostics Laboratory, media) was formulated to inactivate the virus shortly after collection while preserving the integrity of the sample at room temperature during transport. Thus, the media consisted of 1:1 volume of Dulbecco’s Modified Eagle’s Medium (DMEM) containing low glucose (1 g/l), sodium pyruvate and l-glutamine (Corning) media and 2× DNA/RNA ShieldTM (Zymo Research).
Analytical laboratory layout for in-house SARS-CoV-2 testing
Our academic laboratory assembles the sample collection kits for distribution, receives and neutralizes clinical specimens, purifies the nucleic acid, amplifies the SARS-CoV-2 virus and human genes, and performs data analysis and reporting. As a result, there was a need to design a specific laboratory layout that would allow for manipulation of a large number of samples (i.e., ~1600 samples/day) and high-throughput processing without risking contamination in 8,780 sq.ft. (~816 m2) of space. Accordingly, sample processing and analysis were physically separated in “stations”, each of which was color-coded and represented the following processes: sample neutralization (red), sample check in (black), RNA extraction (yellow), kit assembly (orange), RT-qPCR master mix assembly (green), and RNA dilution/standard curve preparation (blue). An additional station, data analysis and reporting, takes place remotely. Importantly, red/yellow/black/orange stations are physically separated from the blue/green stations by a buffer area of 300 sq.ft. (~28 m2) to reduce any potential aerosol contamination. In addition, personnel entry to the red/yellow/black/orange stations is segregated from that of the blue/green entry to avoid cross-circulation. Supplementary Fig. 1 shows a blueprint of our current facility and a description of major instrumentation in place for sample analysis.
Fabrication and quality control testing of 3D-printed nasopharyngeal swabs
Two types of nasopharyngeal swabs for COVID-19 testing were fabricated by inverse stereolithography desktop 3D printing. The two swab designs, one adult and one pediatric, were developed and released by University of South Florida (USF) and Northwell Health in collaboration with Formlabs, Inc. (Boston, MA). Both swab designs have an overall length of 155 mm and a breakpoint approximately 70 mm from the swab tip. The cylindrical swab tip of the adult type is 20 mm in length and 3.8 mm in diameter. In comparison, the pediatric type swab tip is slightly longer (21.5 mm) and narrower (2.6 mm). Both designs are textured for sample collection and have a rounded end for comfort. 3D printable swab files can be obtained from USF Health (https://health.usf.edu/medicine/radiology/3d/3dprinting). Swabs were printed in batches of 324 per build using a Formlabs Form 2 printer with Surgical Guide (v1) resin. The build platform with swabs still attached were washed for 20 min in molecular biology grade isopropanol (Fisher Bioreagents) using a Form Wash (Formlabs). The swabs were allowed to dry in air for 30 min and then removed using a scraper. An initial inspection was performed to look for uncured resin and remove defective parts. The swabs were then mounted in groups of 80 onto a custom fixture design (Formlabs). The fixture with swabs was loaded in a Form Cure (Formlabs) and cured for 30 min at 60 °C. After cooling in air to room temperature, the swabs were removed from the rack and again inspected for defects, ragging (loosely attached bits of cured resin, especially around the handle tab), and excessive bending (>10°). Several swabs from each batch were randomly selected for destructive mechanical testing. The remaining swabs were inserted tip-first and in groups of 20 or 25 along with an additional sterilization indicator into 5¼″ × 10″ strip self-sealing autoclavable pouches (FisherbrandTM). Sterilization was done according to the CDC recommended cycle of 30 min at 121 °C/250 °F in a gravity displacement autoclave. Labels showing the manufacturer, swab type (adult or pediatric), reference and lot number, and contact and other information were applied subsequent to autoclaving to avoid damage to the label.
Mechanical testing of ten pediatric and ten adult swabs was conducted by a third party, SGS Polymer Solutions Incorporated (SGS PSI, Christiansburg, VA). As reported by the company, the samples were conditioned in accordance with ASTM D618-33 for >40 h at 23 ± 1 °C and 50 ± 10% relative humidity. Tensile testing was performed using a custom method which is congruent with ASTM D638-14+. Tensile tests used an MTS Insight 30 test frame with a 250N load cell and TestWorks 4 software. Torsion testing was also performed using a custom method. In brief, a torque wrench was fitted with an adapter holding a chuck into which the swab (with end tab removed) could be inserted and held. The full length of the swab was used except for the tab at the end. The swab was rotated until failure. The rotations were counted manually every 90° and the max torque was recorded at failure.
Molecular diagnostic testing for SARS-CoV-2
The tube containing the transport media and flocked swab was vigorously vortexed for 30 s (~1,300 rpm) and 300 µl of the solution was transferred to a 5 ml RNase-free tube (Eppendorf) containing 900 µl TRIzolTM reagent (Thermo Fisher Scientific). Isolation of total RNA was carried out using a 96-well spin column plate using a protocol readily adaptable to any acid-guanidinium-phenol based reagent. All steps of the purification protocol were carried out at room temperature and the initial transfer of the transport media to the TRIzol-containing tube was the sole step carried out inside a Biosafety Type A2 Cabinet. A volume of 1.2 ml of ethanol (95–100%) was added to the specimen/TRIzol mixture, vortexed for 10 s, and transferred (600 µl) into a well of a 96-well spin plate (Zymo Research). Plates were centrifuged at 3,600 × g for 6 min and the procedure was repeated, as needed, until the specimen/TRIzol/EtOH (~2.4 ml) volume was centrifuged through the column and the flow-through was discarded. Washes were carried out following manufacturer’s instructions (Zymo Research). A final spin was included in the protocol in which unloaded plates were centrifuged at 3,600 × g for 2 min to ensure complete removal of residual volume before eluting the RNA. Elution of total RNA from spin plates was carried out using 20 µl of DNase/RNase-free water and quantification was carried out using a Nanodrop 2000TM system. Based on our experience of processing more than 64,000 samples, total RNA concentrations varied from as low as 5 to 280 ng/μl. Plates were stored at −80 °C until RT-qPCR reactions were ready for assembly.
Total RNA samples were diluted 1:20 in nuclease-free water and a master mix for each primer set was prepared using the Power SYBRTM Green RNA-to-CTTM 1-Step Kit (Applied Biosystems). The RT-qPCR assay was developed to amplify three distinct viral genes encoding the nucleocapsid (N), envelope (E), and spike (S) proteins, as well as a human ribonuclease (RNAseP) control gene (RPP30) using 2 µl of the diluted RNA sample as a template (Supplementary Table 1). Reagents were distributed into a 384-well format using an epMotion 5073 m automated liquid handling system and RT-qPCR amplification was performed in a Bio-Rad CFX384 Touch Real-Time PCR Detection System. Detailed experimental conditions are summarized in Supplementary Table 1a.
Cross-contamination and reaction set up controls
A number of controls, both positive and negative, were routinely included in each plate and aimed at monitoring the RT-qPCR reaction set-up, reagent integrity, cross-contamination during RNA extraction, and to detect the presence of a potential positive, yet asymptomatic, operator. As a result, controls were as follows: (i) no template RT-qPCR reaction with each set of primers tested, (ii) detection of RPP30 gene in all samples using the Hs_RPP30 primers, (iii) source of plasmid for RNAse P and N genes (standard curves), (iv) purified RNA from inactive virus (ATCC® VR-1986HKTM) as an amplification control for the E and S primers, and (v) purified RNA from a previously confirmed negative patient.
Primer design
Primers targeting the SARS-CoV-2 nucleocapsid and envelope were previously validated and published25. A set of S primers was designed against the publicly available NCBI reference sequence NC_045512.2 “Severe acute respiratory syndrome coronavirus 2 isolate Wuhan-Hu-1, complete genome”, with the gene encoding for the spike protein being located between positions 21,563–25,384 nt. Housekeeping primers against human ribonuclease P gene (RPP30) were from the CDC 2019-nCoV Real-Time RT-PCR Diagnostic Panel (Division of Viral Diseases, National Center for Immunization and Respiratory Diseases, Centers for Disease Control and Prevention, Atlanta, GA, USA). A summary of the primers used in our studies is presented in Supplementary Table 1b.
Assay results and interpretation
Cut-off threshold cycle (Ct) and 95% interval of confidence values were experimentally determined in each plate for the N and RPP30 genes using a standard dilution curve with the 2019-nCoV_N_Positive (Integrated DNA Technologies) and Hs_RPP30 Positive (Integrated DNA Technologies) control DNA. Specifically, a linear model is fit to determine the relationship between the Ct values for standard dilution concentrations of each control as a function of the concentration of virus in the log scale (see Supplementary Fig. 2). The intercept of the linear model (i.e., log10 (viral copy) = 0) estimates the expected Ct value when only one copy of the N gene is present in the sample, or the limit of detection (LOD) for the assay. To account for uncertainty, the 95% interval of confidence for this LOD was calculated as:
-
(1)
LOD ± t(n−2975) * s.e.,
where
-
(2)
\({\rm{s.e.}}={s}_{{{\rm{yx}}}}\sqrt{\frac{1}{n}+\frac{{(x-\bar{x})}^{2}}{{{{\rm{ss}}}}_{{\rm{x}}}}}\)
-
(3)
\({s}_{{{\rm{yx}}}}=\sqrt{\frac{\sum {({y}_{{\rm{i}}}-\bar{y})}^{2}}{n-2}}\)
-
(4)
\({{ss}}_{{\rm{x}}}=\sum {({x}_{{\rm{i}}}-\bar{x})}^{2}\)
The final Ct threshold used to determine positivity corresponds to the inferior point of the 95% interval of confidence (i.e., \({{\rm{LOD}}}-{t}_{\left(n-2,.975\right)}\ast {\rm{s.e.}}\)). That is, if the Ct value reported for a sample is less than the inferior point for gene N, then the sample is determined to be positive for gene N; otherwise, the sample is determined to be negative for gene N. Preliminary analyses indicated that the Ct value corresponding to the inferior point of the 95% interval of confidence for the E and S genes were smaller (i.e., larger number of viral copies) than that observed for the N gene. To be conservative and to reduce the false positive rate, a one threshold approach was utilized and all sample Ct values for the E, N, and S genes were compared to the Ct value of the inferior point of the 95% interval of confidence calculated for gene N. A similar procedure was completed for the RPP30 gene. The inferior point of the 95% interval of confidence for the LOD was computed, and if the observed Ct value for RPP30 was less than the inferior point of the 95% interval of confidence value for a sample, the RPP30 gene was determined to be positive for the sample; otherwise, the gene was determined to be negative. A sample was determined to be positive if at least two genes were determined positive. Supplementary Table 2 summarizes the criteria used to report results.
Sequence analysis
All available complete SARS-CoV-2 sequences (taxid: 2697049) were downloaded on January 13, 2021 from NCBI (https://www.ncbi.nlm.nih.gov/labs/virus/vssi/#/virus?SeqType_s=Nucleotide&VirusLineage_ss=SARS-CoV-2,%20taxid:2697049&Completeness_s=complete). In addition, all SARS-CoV-2 sequences that were identified as being complete and having high coverage were downloaded from GISAID (gisaid.org) to include sequences available up to January 7th, 2021. GISAID sequences were downloaded from https://www.gisaid.org/ in batches of less than 10,000 sequences. The two sets of SARS-CoV-2 sequences were aligned separately using the DECIPHER software toolset26 in R studio (rstudio.com). To mitigate limitations due to computing power, sequence alignments were performed using subsets of 1,000 sequences at a time. Each of these aligned subsets were merged to include up to 10,000 sequences. These merged alignments were merged with three other alignment sets of up to 10,000 sequences to generate alignments of up to 40,000 sequences total. This resulted in seven alignment groups for the downloaded GISAID sequences and one for the downloaded NCBI sequences. These sequence alignment groups were used to analyze each of the primer binding regions.
Aligned SARS-CoV-2 sequences were included for further analysis if sequence information was available for all six primer binding regions, and if the sequences contained less than four mixed bases in any one primer binding region. For the remaining sequences, the alignments for each primer binding region were analyzed for mismatches that could affect amplification. The criteria for mismatches that could affect amplification included having any mismatch within three nucleotides of the 3′ end of a primer binding region or having three or more mismatches over the length of the primer binding region. The criteria for potentially affecting inclusivity of the assay included having mismatches that could affect amplification for at least two different primer sets.
Reporting summary
Further information on research design is available in the Nature Research Reporting Summary linked to this article.
Data availability
All of the data supporting the findings presented in this article can be found within the body of the text and the accompanying Supplementary Information files. The raw data are included in all files. Custom code is provided as supplementary data file. SARS-CoV-2 sequences were downloaded from GISAID (gisaid.org) and GenBank (https://www.ncbi.nlm.gov/nucleotide/). Sequence accession numbers are listed in Supplementary Data 1 and 2.
References
Zhu, N. et al. A novel coronavirus from patients with pneumonia in China, 2019. N. Engl. J. Med. 382, 727–733 (2020).
WHO, https://www.who.int/emergencies/diseases/novel-coronavirus-2019.
Johns Hopkins University & Medicine – Coronavirus Resource Center, https://coronavirus.jhu.edu/map.html.
United States Census Bureau, https://data.census.gov/cedsci/?q=rural%20america
Henning-Smith, C. The unique impact of COVID-19 on older adults in rural areas. J. Aging Soc. Policy 32, 396–402 (2020).
Peters, D. J. Community susceptibility and resiliency to COVID-19 across the rural-urban continuum in the United States. J. Rural Health 36, 446–456 (2020).
Ranscombe, P. Rural areas at risk during COVID-19 pandemic. Lancet Infect. Dis. 20, 545 (2020).
United States Census Bureau, https://data.census.gov/cedsci/all?q=virginia.
Maxmen, A. Thousands of coronavirus tests are going unused in US labs. Nature 580, 312–313 (2020).
Steel, J. J. et al. Empowering academic labs and scientists to test for COVID-19. Biotechniques 69, 245–248 (2020).
Ford, J. et al. A 3D-printed nasopharyngeal swab for COVID-19 diagnostic testing. 3D Print. Med. 6, 21 (2020).
Abdalhamid, B. et al. Assessment of specimen pooling to conserve SARS CoV-2 testing resources. Am. J. Clin. Pathol. 153, 715–718 (2020).
Suo, T. et al. ddPCR: a more accurate tool for SARS-CoV-2 detection in low viral load specimens. Emerg. Microbes Infect. 9, 1259–1268 (2020).
Zhang, Y. et al. Enhancing colorimetric loop-mediated isothermal amplification speed and sensitivity with guanidine chloride. Biotechniques 69, 178–185 (2020).
Broughton, J. P. et al. CRISPR-Cas12-based detection of SARS-CoV-2. Nat. Biotechnol. 38, 870–874 (2020).
Joung, J. et al. Point-of-care testing for COVID-19 using SHERLOCK diagnostics. Preprint at medRxiv (2020).
Arena, F., Pollini, S., Rossolini, G.M. & Margaglione, M. Summary of the available molecular methods for detection of SARS-CoV-2 during the ongoing pandemic. Int. J. Mol. Sci. 22, 1298 (2021).
Willman, D. Contamination at CDC lab delayed rollout of coronavirus tests. https://www.washingtonpost.com/investigations/contamination-at-cdc-lab-delayed-rollout-of-coronavirus-tests/2020/04/18/fd7d3824-7139-11ea-aa80-c2470c6b2034_story.html.(2020).
Vogels, C. B. F. et al. Analytical sensitivity and efficiency comparisons of SARS-COV-2 qRT-PCR assays. https://www.medrxiv.org/content/10.1101/2020.03.30.20048108v2.full.pdf+html (2020).
Kirby, T. New variant of SARS-CoV-2 in UK causes surge of COVID-19. Lancet Respir. Med. 9, e20–e21 (2021).
Korber, B. et al. Tracking changes in SARS-CoV-2 spike: evidence that D614G increases infectivity of the COVID-19 virus. Cell 182, 812–827 (2020).
Kilic, T., Weissleder, R. & Lee, H. Molecular and immunological diagnostic tests of COVID-19: current status and challenges. iScience 23, 101406 (2020).
Bagcchi, S. Stigma during the COVID-19 pandemic. Lancet Infect. Dis. 20, 782 (2020).
Daley, P., Castriciano, S., Chernesky, M. & Smieja, M. Comparison of flocked and rayon swabs for collection of respiratory epithelial cells from uninfected volunteers and symptomatic patients. J. Clin. Microbiol. 44, 2265–2267 (2006).
Won, J. et al. Development of a laboratory-safe and low-cost detection protocol for SARS-CoV-2 of the coronavirus disease 2019 (COVID-19). Exp. Neurobiol. 29, 107–119 (2020).
Wright, E. S. RNAconTest: comparing tools for noncoding RNA multiple sequence alignment based on structural consistency. RNA 26, 531–540 (2020).
Acknowledgements
We gratefully acknowledge the originating and submitting laboratories of the SARS-CoV-2 sequences from GISAID’s database on which our predicted inclusivity analysis is based. Implementation of this program included important contributions from not only the researchers listed in this article, but also from the leadership at our University (Virginia Tech). Establishment of the testing laboratory was through a highly collaborative approach under the auspices of the university’s student health center, local health districts and state health department epidemiologists and information technology teams. This project was supported by a Go Virginia Economic Resilience and Recovery Grant (20-GOVA-ERR-02A and 20-GOVA-ERR-02D), the Department of General Services of the Commonwealth of Virginia (DGS-201020-UVT), and funds from Virginia Tech, the Fralin Biomedical Research Institute at VTC, and the Fralin Life Sciences Institute. F.M.M. acknowledges support from NSF through CAREER-1652237 and the Virginia Tech Center for Earth and Environmental Nanotechnology “NanoEarth” (NNCI-1542100).
Author information
Authors and Affiliations
Contributions
A.C. analyzed the data summarized in Figs. 2b, 3a, and 3b, Tables 1 and 3, Supplementary Tables 4, 6, 7, and Supplementary Data 4, 5, 6, 7, and 8. C.M.B contributed to Fig. 2b, Table 1, Supplementary Tables 1, 3, 5, and 9, and developed the statistical framework used for data analyses throughout the paper. A.N.T. contributed to Fig. 3c and 3d, Table 3, Supplementary Fig. 2, Supplementary Tables 7 and 8, and Supplementary Data 4, 5, 6, 7, and 8. K.L.B. contributed to Supplementary Data 1, 2, and 3. R.A.U. contributed to Table 1 and Supplementary Tables 1, 3, and F.M.M. contributed to Fig. 1b–d. D.M.M. contributed to Table 2. T.M. contributed to Supplementary Table I. C.V.F. contributed to Fig. 1e and Table 3. P.B. and N.B. contributed to sample collection. C.M.B., R.A.U., D.P., B.T., J.M., O.A., D.M.M., and T.M. worked out the technical details to optimize the experimental protocols used for sample analysis. T.M. and C.V.F. aided in interpreting results. M.J.F. contributed to the implementation of the research and the coordination and validations of the testing program with regulatory agencies at the state and national level. C.V.F. designed all figures and wrote the paper with input from all authors. C.V.F. and H.S. were involved in planning and co-supervising the project. All authors are indebted to R.F.C.M.
Corresponding author
Ethics declarations
Ethics declarations
We confirm we have complied with all relevant ethical regulations for human studies and research, as detailed in methods. The Institutional Review Board approved the sample collection and its used for research.
Competing interests
The authors declare no competing interests.
Additional information
Peer review information Nature Communications thanks the anonymous reviewer(s) for their contribution to the peer review of this work.
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ceci, A., Muñoz-Ballester, C., Tegge, A.N. et al. Development and implementation of a scalable and versatile test for COVID-19 diagnostics in rural communities. Nat Commun 12, 4400 (2021). https://doi.org/10.1038/s41467-021-24552-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41467-021-24552-4
This article is cited by
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
