
Abstract
Data storage in DNA is a rapidly evolving technology that could be a transformative solution for the rising energy, materials, and space needs of modern information storage. Given that the information medium is DNA itself, its stability under different storage and processing conditions will fundamentally impact and constrain design considerations and data system capabilities. Here we analyze the storage conditions, molecular mechanisms, and stabilization strategies influencing DNA stability and pose specific design configurations and scenarios for future systems that best leverage the considerable advantages of DNA storage.
Similar content being viewed by others


Introduction
“My hunch is—and I’m not alone in this—that the next decade or so will see this used technically. The machine could be much smaller; it could carry a much larger set of data.” In 1964, just 7 years after the discovery of the structure of DNA1, Wiener and Neiman discussed the potential density advantage of using nucleic acids as a form of memory storage2. Over half a century later, advancements in our understanding of the properties of DNA have confirmed its high theoretical information density of nearly 455 billion GB of data per gram3, ~6 orders of magnitude greater than even the most advanced magnetic tape storage systems4. DNA also provides a host of other unique potential advantages including highly parallelized computation within the storage system itself5,6, low energy requirements7,8,9, rapid high capacity transportation of data10, potentially longer lifetimes, and stabilities of decades or centuries compared to conventional media which are replaced every 3–5 years, as well as ease of replication11 by molecular biology approaches to ward off degradation. While it has taken more than just the decade Wiener predicted, a large body of knowledge in molecular biology12,13 and computer and information systems14,15 has been developed in the intervening period that has set the foundation for the recent interest and investment in DNA-based information storage technologies.
The nature of Wiener’s ‘machine’ will remain in constant flux and development. Indeed, multiple types of systems may arise to address different applications, from long-term ‘write-once-read-never’ archival storage to highly dynamic and frequently accessed data storage, potentially with in-storage computational capabilities. It is important to imagine these possible types of DNA information storage systems and the different unit processes that will comprise these systems, and identify how the chemical, physical, and encoding properties of DNA will influence their design. As DNA or an analog will be the substrate of this class of polymeric systems, its stability under different environmental and process conditions will be a central design consideration, informing the nature of both physical unit processes and encoding algorithms.
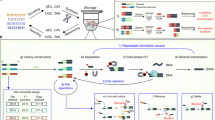
An end-to-end DNA storage system is depicted in Fig. 1 with generic unit processes. As applications range from cold archival storage to frequently accessed or even dynamically manipulated data, the DNA is exposed to more manipulation such as phase changes or physical shearing through liquid handling, and to more distinct types of environmental conditions such as buffers with different salt concentrations and pHs. These present more opportunities for degradation as well as specific degradation mechanisms that may influence encoding strategies and sources for data and decoding errors (Fig. 1). Here we review what is known about the stability of DNA under each of these conditions, organized by their relevance to systems with different operating timescales. We then provide a quantitative analysis of the relative tradeoffs in density, physical redundancy, and encoding strategies that must be sacrificed to achieve increasingly sophisticated system capabilities such as increased access frequency and in-storage computation.

(Top) A generic DNA-based system showing distinct types of storage modes. (Middle) Functional and physical characteristics of each storage mode. (Bottom) Molecular mechanisms of damage most relevant to each storage mode.
It will be useful to also describe the molecular architectures common to almost all DNA storage systems proposed to date. DNA storage systems are comprised of many files, and each file consists of many distinct DNA strands that typically are ~150–200 nt long as that is the current limit of phosphoramidite synthesis chemistries, but could be longer with advances in technology. All strands comprising one file share a common address sequence located on one or both ends of the strands. These addresses can be read and retrieved using PCR or transcription. Mutations within strands, or loss of strands due to breakage or degradation would lead to potential decoding errors or even complete loss of information. Therefore, error correction codes are usually applied to help compensate for errors and lost strands with the trade-off of decreasing information density.
Write-once-read-never archival storage (access frequency once every ~10+ years)
One of the most likely first applications for DNA-based information storage will be long-term ‘cold’ storage intended for the preservation of historical or other records across decades or centuries. This is because the current high cost of DNA synthesis and sequencing can be justified when they are infrequent and amortized over many years16. What is crucial for these applications is a strong understanding of the long-term stability of DNA.
The successful recovery of DNA from fossils or microbes preserved in permafrost, some millions of years old, is commonly used as motivating evidence for the long-term stability of DNA17,18. However, there are several caveats to consider. First, there are substantial concerns that some of these results were misinterpreted due to potential contamination from contemporary bacteria or human DNA19. Therefore, the current best estimate for the recovery of DNA from natural samples based upon a rough agreement between theoretical calculations19 and physical measurements20 is roughly 400,000 years, with the major degradation mechanism in these samples thought to be cross-linking between strands that inhibit PCR-based amplification and detection of the DNA.
Second, estimations of DNA stability from natural samples may be overly optimistic for DNA storage applications. In the context of recovering DNA from fossils, ribosomal and mitochondrial DNA are often used to identify different species of organisms but can be present at hundreds of copies per cell. Yet, these are the sequences used when claiming successful isolation of DNA when in fact genomic DNA sequences are much more difficult to recover than multi-copy mitochondrial DNA. Thus, while some DNA can be recovered from fossilized or permafrost samples, often only the most abundant sequences are detectable due to substantial degradation. This is further reflected by the estimated half-life of fossilized DNA being only ~500 years, corresponding to a per nucleotide fragmentation rate of 5.50E−6 per year assuming an average 242-nt long mitochondrial DNA sequence in the relatively cold temperatures of permafrost (5.5E−6/nt/yr ∗ 242 nt ∗ 500 yrs ~ 50%)17. This is substantially lower than the estimated 400,000 years estimated to recover any DNA signal. Thus, in the context of DNA storage applications where a substantial fraction of the data should be recoverable depending on the encoding strategy and amount of physical redundancy, the ‘useful’ stability of storage systems, based upon data from fossilized DNA, suggests stabilities of a few hundred years or less.
While there are likely substantial stability limitations of natural permafrost or fossilized samples, and frozen aqueous samples in general, fortunately DNA storage systems can be engineered with highly controlled materials and environmental conditions that could substantially augment its stability. Several approaches have been tested, most involving dehydrated forms of DNA to reduce hydrolysis of its phosphate backbone. For example, DNA has been adsorbed onto Flinders Technology Associate (FTA) filter cards, stored in biopolymeric storage matrices such as the commercial product DNA Stable, embedded into silk matrices, or simply stored as lyophilized powder20,21. In many cases, the adsorption of the DNA onto a matrix stabilized the DNA. For example, over 40 days at 25, 37, and 45 °C, 80% of the DNA embedded in silk was recoverable compared to 20% when unprotected22. Silk also offered protection against UV radiation. Salts have also been shown to offer stabilizing effects for dried DNA particularly against high ambient humidity and can maintain high loading of DNA (>20 wt%) while keeping the DNA relatively accessible23.
Of the many different methods tested, the current leading approach that consistently exhibits the best stability has been encapsulation of DNA within an inorganic matrix comprised of silica, iron oxide, or a combination of both. Multiple groups have shown that encapsulation can substantially enhance DNA stability24,25,26,27. For example, Puddu and colleagues directly compared the stability of encapsulated DNA with unprotected DNA at 100 °C for 30 min. Eighty percent of the encapsulated DNA was recovered while only 0.05% of the unprotected dried DNA survived. Grass and colleagues estimated that encapsulation in silica particles could maintain DNA for 20–90 years at room temperature25, 2000 years at 9.4 °C24, to over 2 million years at −18 °C. These estimates were derived from accelerated aging models applied to data obtained from DNA exposed to elevated temperatures of 60–70 °C. In a few studies, diverse populations of DNA strands encoding actual data were decoded after accelerated aging, providing estimates not only of half-lives, but also evidence that complete files could be retrieved24,25. In several cases, data could be retrieved and re-embedded multiple times, although degradation was observed. ‘Break points’ in these systems would depend on the physical redundancy as well as density overhead sacrificed to enable degradation-tolerant encodings.
This work provides substantial evidence for the long-term stability of DNA, especially encapsulated in silica. However, there are several potential limitations to consider. First, the physical processes of encapsulation and retrieval take some time, suggesting this approach is best suited for cold storage applications. Second, the encapsulation of the DNA inherently reduces the information density of the storage system. A layer by layer design with alternating DNA and cationic polyethylenimine with a silica final encapsulation has achieved the best storage density to date in such systems, ~3.4 wt% DNA25. This is a sacrifice of 1–2 orders of magnitude in information density; yet, while not as dense as pure DNA, given the 5–6 orders of magnitude advantage of DNA storage over conventional storage media, sacrificing 1–2 orders of magnitude of density would still yield a very space-efficient system.
The size of DNA strands is also an important design consideration. One hope in the DNA storage field is to develop synthesis technologies that are able to create longer DNA strands. The benefit of longer strands would be to reduce the percentage of overhead per strand devoted to file addresses and indices, thereby increasing the information density of the system. However, prior work has already suggested diminishing returns with regards to density with increasing strand length3. Further supporting the use of shorter DNA strands, empirical evidence suggests that shorter strands are more resilient to environmental insults. For example, exposure to 830 W/m2 of sunlight irradiation led to nearly 2 orders of magnitude greater degradation for a 113 nt compared to a 53 nt DNA strand. While constant exposure to UV is unlikely for a DNA storage system, it may reflect a general principle of length-dependent degradation sensitivities. Indeed, other environmental insults exhibit similar length dependencies, with exposure to 90 °C thermal treatment leading to nearly 3 orders of magnitude greater degradation for longer strands28, while shorter strands were more resilient to freeze-thaw cycles.29 As these are accelerated degradation studies, it is likely that longer strands will be sufficiently stable for practical use; however, shorter strand lengths would likely provide improved stability profiles.
Finally, it is important to note that while seemingly simple, accurately determining long-term DNA stability is not trivial nor a solved problem. There are two primary challenges. First, the accelerated aging models used in many studies that can lead to stability predictions of hundreds or even millions of years are inherently extrapolations and could therefore deviate from actual stabilities over long periods of time. This is especially true if there are unknown degradation mechanisms that are important over long timescales but that do not exhibit the exponential dependency on temperature specifically as commonly assumed by many models. Given that the accuracy of data retrieval is paramount for cold storage systems, additional studies assessing accelerated degradation due to other parameters other than temperature would provide increased confidence in extrapolated stabilities. For example, a broader variety of storage conditions should be tested to develop a more comprehensive mechanistic model of DNA stability, including models that not only artificially accelerate aging through elevated temperature but through elevated exposure to electromagnetic radiation and/or subatomic particles, high or low pH, hydrolysis and humidity, and mechanical rearrangements (e.g., freeze thaws, liquid handling) at the molecular level. In addition, DNA concentration and encapsulation conditions could have inherent effects on stability as there could be degradation mechanisms arising from chemical interactions between DNA molecules or between DNA and the encapsulating materials.
A second challenge of accelerated aging studies is that methods to measure degradation often are not sensitive enough, so rely on large degradation effects or require amplification steps (e.g., through PCR) that could skew or bias results. These issues motivate new future gold standards to assess long-term stability. New approaches could include a combination of deep next-generation sequencing of short-term samples to detect very rare degradation events. In addition, it may be advisable for the field to collaboratively initiate real time, non-accelerated, long-term studies of DNA stability over the course of a human generation or more, and compare these results to deeply sequenced short-term studies as well as those using different modes of accelerated degradation. These could be performed on actual commercially active storage systems as both a way to monitor stability and to provide insights into long-term stability. This work could be paired with studies of different environmental insults to identify dominant degradation modes and their relative contributions to aging. Overall, this data could be used to update and benchmark the stabilities of any DNA storage systems that were created in the past, and to continually inform and adjust models predicting their stability.
Working storage (~ accessed multiple times per year)
While there is promise for the ability to store DNA stably over centuries or even millennia, methods capable of this type of stability typically require fully encapsulating and sealing DNA within a matrix, like silica. This is because encapsulation protects the DNA from exposure to humidity, radiation, fluctuations in temperature, and other potential reactants. Furthermore, it may be the most robust and economical storage method, requiring the least amount of specialized storage equipment such as tightly controlled refrigeration and humidity. However, due to substantial DNA loss associated with retrieval from encapsulated media, and the relatively involved encapsulation and retrieval processes, this form of storage is best matched with applications where access is infrequent or never occurs. In a generic DNA storage system, encapsulated DNA could be used to store the ‘master’ or preservation copy of data, while ‘working’ copies are maintained using less stable but more accessible methods.
There are three semi-accessible forms of storage that might be compatible with working storage, all of which are similar to how research labs in the biological sciences currently store DNA samples: refrigerated in aqueous solution, frozen in aqueous solution (typically at −20 or −80 °C), or as a dry solid. While DNA recoveries near 100% have been reported from all of these storage forms after ~2 years30,31,32,33, accelerated aging studies at elevated temperatures suggest storing DNA in these forms would not be sufficient for multi-decade stability21,34 especially when compared to encapsulated storage strategies. For example, at 70 °C, substantial degradation of dried, adsorbed, and aqueous DNA was observed at 15–70% after only 5 days22,23,35,36, while encapsulated DNA showed no appreciable degradation after 7 days22. This may be surprising to many working in the biological sciences where plasmid DNA preparations are stored for entire scientific careers; however, it is important to consider that many such research samples are usually single plasmid constructs stored at very high copy number (1010 copies/μL − 1 μg/μL) so that recovery of the plasmid through bacterial retransformation can occur even with 99% DNA degradation. Regardless, there is strong evidence that storage at 4 °C or below in aqueous or dried form would provide at least a couple of years of stability, appropriate for storing working copies of DNA-based information31,32,33, with lyophilized DNA showing better stability than aqueous DNA solutions37. One additional important caveat for DNA solutions appears to be the starting concentration of DNA, with dilute solutions of ~0.02 ng/mL exhibiting substantial degradation within weeks when stored at −20 °C30. Inclusion of non-specific carrier RNA or DNA was able to abrogate this degradation.
If stored for only a few years, the key concern for working copies of data then becomes the amount of degradation that occurs each time information is accessed, e.g., freeze-thaw of solubilized DNA or rehydration of dried DNA. Likely due to the ability to directly measure the effect of multiple access events within a reasonable experimental time frame rather than needing to simulate or accelerate degradation over time, many more studies have investigated these mechanical effects on DNA stability as opposed to the basal stability of unperturbed samples.
During the freezing and thawing process, ice crystals are formed that generate forces that could lead to breakage of DNA polymers. There is also evidence that freezing makes DNA more susceptible to breakage than non-frozen DNA at similar tensional forces38. Several studies have repeatedly frozen and thawed DNA samples, generally observing exponential degradation. An approximately 10% degradation of lambda DNA in Tris-EDTA buffer was observed after 1 freeze-thaw, and 75% degradation was observed after 20 freeze thaws39. An exponential fit modeled this process relatively closely (% intact DNA = 0.9484*e−0.068*freeze-thaws). A study of DNA stored in water or 50% glycerol found similar degradation rates with more than 75% degradation after 16 freeze thaws, and samples in 50% glycerol performing worse than in water40.
As with archival storage, one important consideration in assessing degradation from freeze thaws is the size of the DNA strands. Empirical evidence suggests smaller DNA strands would be preferable for improved stability against freeze thaws. This effect was observed comparing genomic DNA above and under 100 kb, but also at smaller length scales of 5 kb29. In addition, increased DNA concentrations exhibited a self-protective effect. As freeze thaws cause mechanical stresses on DNA, there is some intuition for why longer DNA strands would be more susceptible to breakage. The effect of concentration of DNA stability may be due to less intuitive mechanisms that should be investigated in more detail, such as altering the phase transition boundaries of the aqueous solution41.
Dehydration is another means of storing DNA at intermediate (~2–10 years) timescales. Vacuum dried DNA, for example, was shown to be stable at 5 °C for at least 22 months36. While detailed studies of repeated rehydrations are lacking and need to be performed, a few studies have assessed the recovery efficiency from dried DNA and the impact of prior exposure to elevated temperatures on this recovery. For example, a library of 2042 unique sequences comprising ~20 kb of data was dehydrated on a microfluidic “PurpleDrop” device42. Rehydration with water was performed at various dwell times ranging from 1 to 120 s. While increasing the dwell time generally increased the amount of DNA recovered, just 1 s was able to recover ~77% of the DNA by mass. The degradation rate was not directly reported but with sufficient physical redundancy (copy number) and sequencing depth, the entire file was recovered and successfully decoded. Of note, the consistency of the retrieval process exhibited substantial variability and suggests further work investigating mechanisms of the dehydration process, potential irreversible denaturation of the DNA into different helical forms (i.e., forms A or B), and molecular degradation chemistries will be important. For example, exposure of dried DNA to elevated temperatures could irreversibly denature the secondary helical structure of DNA35, resulting in samples that are difficult to process or sequence.
Other forms of DNA instability should also be considered for both solution and dried sample storage methods. These include depurination (removal of adenine or guanine bases from the DNA backbone) and oxidation (8-oxo-dG). Both in solution and in dried form, the rate of depurination and oxidation are both higher by 1–2 orders of magnitude compared to strand breakage. Roughly 6% of strands that are 200 nt would develop a depurinated or 8-oxo-dG nucleotide per year at room temperature35, with rapid increases in these rates with temperature, following an Arrehenius dependence. These degradation mechanisms have functional impacts. Depurination would result in missing or incorrect nucleotides during sequencing, while 8-oxo-dG can lead to cross-linking between DNA strands which inhibits both rehydration of dried DNA as well as amplification and sequencing of the DNA. Depending on the encoding method and physical redundancy of the storage system, these could further reduce the estimated longevity of solution, frozen, and dried storage methods.
Short-term storage for dynamic handling of data
The active development of DNA-based computation preceded the development of DNA storage systems by over a decade5,6,43,44. The idea of now merging these two fields to perform in-storage computation has intriguing implications including potentially providing the ability to directly search45 and edit46 DNA databases. In addition to computation, there is also the hope that DNA storage systems may be capable of dramatically lower latencies of operation than the current multi-hour to multi-day process of reading and writing information. For both of these applications, physical manipulation of DNA will be necessary. An important factor to consider for dynamically accessible storage is the complexity of storage methods. Most likely, DNA for these applications will need to be stored in a soluble aqueous form with buffers compatible with molecular processes including dynamic DNA–DNA hybridizations, transcription or polymerization, and other enzyme-driven reactions. Alternatives may include the use of magnetic particles as long as the adsorption/desorption of DNA is relatively rapid. Understanding and potentially improving the stability of DNA in these contexts will inform the operating lifetime of systems as well as dictate the types of error-tolerant encodings that will be necessary.
Almost all manipulations performed on DNA will involve liquid handling, often through small apertures such as pipette tips, microfluidic channels, or tubing. These manipulations impart shear forces on DNA that can lead to strand breakage. Several studies have investigated the effect of vortexing or the use of other shearing devices on DNA stability and showed substantial degradation, for example nearly 70% fragmentation after 3 min39,47,48,49 on a standard table-top vortexer at maximum speed. While these types of shearing devices are unlikely to be used in DNA storage systems, they may be useful in providing relationships between degradation rates and shear forces or energy inputs if used in controlled settings, like rheometers. More directly relevant to storage systems is the measurement of DNA fragmentation due to actual pipetting. With a relatively rapid single pipetting action through a 1 mL tip, 70% of long lambda phage DNA was fragmented. Slower and gentler pipetting still led to more than 50% of lambda DNA being fragmented39. This is somewhat concerning given liquid handling often uses even smaller 200, 20, and 2 μL tips that would result in higher shear forces. With automation, the pipetting actions could be slowed significantly to be less turbulent; however, this might present a significant trade-off in increasing the time required to perform each physical operation or manipulation. What is clear is whatever form of liquid handling is used, careful assessment of DNA stability will be important and processing parameters tuned to ensure DNA stability. New forms of liquid handling should also be explored but also quantitatively assessed for their impacts on DNA stability. For example, acoustic liquid handling of nanoliter to microliter droplets, may exhibit distinct impacts on DNA stability through additional types of forces such as exposure to surface tensions through high surface area to volume ratios. In addition, as in the case of freeze-thawing where smaller DNA strands were qualitatively shown to be more resistant to fragmentation, comprehensive determinations of thresholds and quantitative relationships between DNA length and resiliency to shear forces are currently lacking but would be useful for designing storage systems with low latency or in-storage computation.
While physical manipulations will likely impart some level of unavoidable damage to DNA, the biochemical environment of the DNA and the properties of the DNA molecules themselves could improve stability and resilience to these processes as well as enhance stability in aqueous and unfrozen states. For example, as was already discussed, DNA stored at 4 °C can remain relatively stable over a few years, and maintaining a high concentration of DNA or including carrier DNA or RNA helps slow down degradation rates. DNA degradation can occur through several mechanisms including oxidation and hydrolysis of the phosphate backbone or the base from the sugar (depurination). In addition to temperature which generally accelerates rates of most degradation reactions, controlling pH is perhaps the next most obvious candidate for improving DNA stability against these mechanisms. Both acidic and basic conditions can enhance the hydrolysis rate of DNA by either increasing the electrophilicity of the DNA or the nucleophilicity of water. For example, it was estimated that a change from pH 6 to 5 could increase the degradation rate of DNA by an order of magnitude50, and even just a 90-min exposure to pH 4.0 at 65 °C led to almost complete degradation of DNA samples51. While these experiments were performed at elevated temperatures that might be argued could be avoided, there are many molecular biology manipulations that require transient exposures to elevated temperatures above at least 37 °C and often above 70 °C where many polymerases function optimally. These include DNA in-storage computation, in-storage editing, or even simply copying information by PCR. Furthermore, for search-type functions that rely on DNA–DNA hybridizations, stable hybridizations for ~20 nt sequences occur at between ~50 and 60 °C. Room temperature operation would not provide adequate energy to first melt any secondary structures that might have formed that would block hybridization, and would also result in non-specific sequences hybridizing with each other. Shorter DNA sequence lengths that hybridize near room temperature would be too short to confer adequate sequence specificity amongst large, highly diverse libraries of DNA strands that will comprise most DNA storage systems. Therefore, tightly controlling pH as well as the time exposure to elevated temperatures will be important design considerations for storage systems. The use of many standard buffers such as PBS and TE could help maintain pH levels at appropriate targets. Other additives may also have protective effects including DNAstableTM 52, salts23, and trehalose21,30.
Tradeoffs between DNA stability and information density
This review has focused on empirical measurements of DNA stability under a range of different conditions. Together with theoretical analyses4,53,54, there is strong evidence for the utility of DNA as a storage medium. Nevertheless, DNA has finite stabilities, and is especially labile in conditions relevant for frequent access and dynamic processing. This does not preclude the use of DNA for storage applications but does affect the information density of systems by requiring higher redundancy in the number of copies of each distinct strand as well as in the encoding methods used to achieve certain reliability. Understanding the effect of DNA stability on these tradeoffs will be important in designing unit processes and systems for specific types of storage applications. Here we discuss these tradeoffs through a series of analyses shown in Fig. 2, and in particular demonstrate how relationships between copy number, strand loss, strand length, information density can be modeled and used to inform system design. The goal here is to show how models can reveal both intuitive and unintuitive relationships between parameters; it is important to note that ranges of parameter values and observed trends shown here may change depending on the specific details of each system.

A Reed-Solomon inner-outer encoding scheme. B Relationship between log decoder error probability during RS decoding and DNA strand length, including the effects of symbol error rate (mutations, insertions, and deletion, Perror) and copy number. C Relationship between information density of a DNA storage system and the probability of symbol erasure (strand loss due to breakage) as a function of strand length. D Relationship between information density and strand length as a function of the probability of strand breakage. C and D assume a copy number of 1.
Most DNA data storage systems use short sequences or ‘addresses’ written into strands of each file for retrieval. These addresses typically are complementary to short DNA oligomers used to amplify the files through PCR3 or to extract them through affinity-based methods55. To function at reasonable temperature ranges (<100 °C) the addresses are generally limited to <25 nt as longer sequences would require higher temperatures to ‘melt’ during PCR cycling. However, addresses cannot be much shorter without sacrificing diversity in addresses46. The addresses take up space on each strand and do not encode data (e.g., overhead). Index sequences are also overhead and are necessary to include to know how the different strands comprising a file should be ordered.
In addition to the address and index, error correction codes may use additional overhead. Electronic storage systems adopt and employ many error correction mechanisms to ensure the reliability of stored data. Similarly, to cope with frequent errors, DNA storage systems can leverage error correction codes that are capable of detecting and correcting errors that occur as a result of strand breakage or loss and due to substitutions, insertions, and deletions within strands. Error correction codes work by adding enough redundancy to recompute the original data even in the presence of errors or missing strands. Hence, to maintain the same reliability of information transfer or recovery, error correction forces a trade-off between density of information and tolerance to errors. The higher the likelihood of strand error or loss due to reduced DNA stability, the more overhead must be spent on error correction.
While a variety of codes have been proposed for DNA storage, Reed-Solomon (RS) codes are particularly popular given their configurability and tolerance to errors24,56,57,58. The error correction properties of RS codes are well known, and we use them here to explore the combined effects of strand errors, breakage, and length on the information density and reliability of DNA storage systems. We will not focus on the details of different codes but rather use RS codes to illustrate some general trends to consider when designing DNA storage systems. Additional details of popular error correction approaches can be found in a few recent references14,15, while details about our implementation of RS codes and parameters used (shown in brackets) can be found in the Supplemental Information. In brief, the key features of the implementation used here are (1) that the RS code is capable of detecting and differentiating two kinds of errors, symbol errors such as insertions, deletions, and mutations, collectively having a probability of perror, and symbol erasures such as the breakage or loss of a DNA strand with probability pstrand erasure; (2) inner and outer RS codes are interleaved where the inner code protects against errors within a strand and the outer code corrects for missing or erroneous strands (Fig. 2A); (3) an error probability can be calculated to estimate the probability the code will not be able to account for and correct errors given certain error and strand loss rates; (4) the amount of redundancy in the code is tunable in order to achieve a certain error probability or system reliability; (5) the code accounts for multiple copies of each distinct DNA strand, with strand loss or ‘erasure’ only occurring when all copies of a distinct DNA strand are lost; and (6) the length of the DNA strands can be tuned with effects on density due to the ‘overhead’ of addresses and indices.
Decoding error analysis
To provide a non-exhaustive example of the potential importance of trade-off analyses, here we focus on a major mode of DNA degradation, strand loss through hydrolysis or mechanical breakage. First, to better understand the impact of strand loss on the probability of a decoding error, we analytically model its effect on the decoding error probability of an outer RS[255,223,33] code. Based upon experimental observations, we conservatively model the probability of strand breakage as linearly dependent on strand length, and we assume that strand loss due to breakage is equivalent to an erasure in the outer code. We further assume that multiple copies of a strand exponentially reduce the likelihood of loss because all copies of the strand must be lost to cause an erasure. An exact analytical formula for this probability is unknown so we estimate the relationship as pstrand erasure(length L, copies c) = (L ∗ 5E−3)c. This equation is chosen so that strands of length 1000 nt have a probability of 50% or less of erasure, a value that can be tuned depending on the stability measured for any particular DNA storage system. We fix the perror to 1e−2 and 1e−3 per nt to cover the range of typical synthesis and sequencing errors59,60.
Figure 2B shows the impact of longer strands on the decoder error probability for several system configurations with different copy numbers of each strand and different error rates. The y-axis shows the log decoding error probability and the x-axis is the strand length. We have chosen for comparison a system with similar read error rates to hard drives (on the order of 10−14 per bit, log error probability of −1.5E + 01)61. For this system that has a linearly dependent probability of strand breakage on strand length, the trend is that longer strands increase the likelihood of strand loss, and substantially increase the decoder’s probability of error. Other parameters matter, too. Lower perror significantly reduces the residual likelihood of error. Also, higher numbers of copies per strand also have a large effect since it becomes exponentially less likely that all copies of a strand are lost. Current experimental systems tend to operate in a regime with large numbers of copies; however, even if future systems may wish to be more lean, this analysis suggests copy number requirements may not need to be as high as intuition may suggest particularly if strand length designs remain in the 200–500 nt range.
Information density
To demonstrate how the relationship between strand loss and information density can be studied, we vary the probability of strand breakage per nt from 10−3 to 10−8 and analyze the information density for many different strand lengths. For a given strand length, there are many different possible designs for a RS inner-outer code. We use an algorithm to find a design with a residual error probability <10−14 and maximum information density while keeping the outer block size at 255, and the index to 4. In Fig. 2C, we report the density on the y-axis vs. the probability of strand loss on the x-axis for each strand length (L) considered. We assume a single copy of each strand to maximize information density and fully exploit the error-correcting capability of RS codes.
In this system, shorter strands achieve superior density at high strand breakage rates. This is a result of shorter strands being overall less likely to break, and therefore the outer code needs fewer error correction symbols. Longer strands have a higher overall likelihood to break and need more error correction in the outer code to compensate. However, as the overall probability of breakage per nt decreases (to the left), all strands are less likely to break, and this gives longer strands an advantage since they can hold a larger fraction of information per strand and the outer code can work effectively even with a relatively small number of error correction symbols. A deeper analysis further shows that the magnitude of the strand breakage rate can fundamentally alter the relationship between information density and optimal strand length (Fig. 2D). In fact, it is not simply that shorter strands are better for high strand loss rates but that there can be optimal lengths that balance the overhead needed for file addresses and indices with the encoding overhead required to account for strand loss.
This analysis is just one example of many that can be performed interrogating the effects of diverse parameters of DNA storage systems. It underscores the need to tailor error correction and system parameters like strand length and copy number to different settings including error rates that vary according to environmental conditions and data storage applications. For example, long-term archival storage will likely encapsulate the data in silica helping keep the probability of strand loss or breakage low, allowing longer DNA strands to be used and achieving higher information densities. In contrast, working storage or short-term dynamic storage would benefit from shorter strand lengths to compensate for higher strand loss rates.
Future prospects
The robustness and failure rates of information storage systems are of utmost importance as the reliability of data retrieval must be concretely reported, verifiable, and trustworthy62,63,64,65. While we have some rough estimates and measurements of DNA stability in a variety of conditions, often measurements exhibit considerable noise and variability between experimentalists and research groups in addition to substantial noise between samples in an individual experiment. There are likely experimental details affecting the accurate interpretation of measurements including the manipulation of DNA itself in setting up experiments, or confounding parameters like DNA solubility. Experiments exploring a more comprehensive set of parameters and that assess sources of variability in results could provide more confidence in the design and utility of DNA storage technologies. Fine-tuning exact buffer conditions, assessing changes in its composition, and maintaining strict control and provenance records over the environmental exposures of the DNA throughout its complete lifetime starting with DNA synthesis will be important for commercial DNA storage products.
In addition, while many studies have quantified DNA degradation through some form of quantitative PCR, mass measurements, or even next-generation sequencing, the definition of DNA degradation remains unprecise and too limited despite its considerable impact on the physical design and encoding of reliable storage systems. For example, there are many ways a DNA storage system can be degraded. (1) The loss of DNA strands could be biased toward strands with certain properties such as length, base content, or presence of specific sequences. (2) DNA strands may be fragmented in different patterns and frequencies depending on base content, length, and physical processing conditions. (3) Depurination or chemical alterations of bases may occur and not be directly assessed by sequencing or QPCR based approaches. How each of these types of degradation mechanisms are affected by environmental conditions is important for system design and should be carefully assessed.
There is also the intriguing possibility that the physical stability of storage systems could be enhanced by the use of another polymer that is chemically more stable than DNA, although substantial work would likely be needed to replicate the synthesis, processing, and sequencing technologies and infrastructure available for DNA66. For example, ‘locked’ nucleic acid monomers possess a methylene bridge between a 2′ oxygen and the 4′ carbon of the pentose ring and offer substantial resistance to nuclease enzymes present abundantly in the ambient environment. There are many other potential chemistries of nucleic acid polymer backbones that may offer differing stabilities tuned for specific environmental conditions or applications, including bicyclo-DNA or glycerol-DNA that have altered sugar backbone chemistries67 or nuclease resistant nucleic acids66. In addition to altering the biopolymer substrate itself, protective additives or even active repair systems similar to those in natural biological systems may improve storage system reliability.
There are clearly many opportunities and an important need to better understand, characterize, and improve DNA stability. While seemingly a straightforward concept, assessing the stability of DNA and making appropriate choices of storage methods is not trivial. DNA stability has been experimentally measured and reported in many diverse ways, including mutational rate, breakage rate per base, and loss of intact DNA strands. Degradation rates have also been reported in a mix of many different environmental, temperature, buffer, and temporal conditions. Furthermore, the functional impact of different types of degradation will depend on the nature of the storage system. For example, mechanical degradation may affect systems that use longer DNA strands compared to shorter strands, degradation rate may be complicated to predict depending on the density of storage systems due to its potential nonlinear dependency on DNA concentration, and some encoding algorithms may sacrifice information density but be more resistant to the loss of strands. However, it is clear that even with our current nascent knowledge of DNA stability, reliable DNA storage systems can already be created with existing technologies. In addition to developing a better understanding of DNA stability, what will be important is the recognition that the appropriate tradeoffs and limitations in system properties and capabilities should be made and can be supported through models. With improving measurements, a better understanding of degradation mechanisms, new technologies, models, and enhanced encoding algorithms, the efficiency of these systems will continue to improve the commercial viability of DNA-based information storage.
Reporting summary
Further information on research design is available in the Nature Research Reporting Summary linked to this article.
Code availability
Plots in Fig. 2 were developed using Excel and custom code is available at https://github.com/jamesmtuck/DNA_stability under a permissive open source license with instructions for installation.
References
Watson, J. & Crick, F. Molecular structure of nucleic acids: a structure for deoxyribose nucleic acid. Nature 171, 737–738 (1953).
Wiener, N. Interview: Machines Smarter Than Men? 84–86 (U.S. News & World Report, Inc., 1964).
Bornholt, J. et al. A DNA-based archival storage system, ASPLOS ’16. https://doi.org/10.1145/2872362.2872397 (2016).
Ceze, L., Nivala, J. & Strauss, K. Molecular digital data storage using DNA. Nat. Rev. Genet. 20, 456–466 (2019).
Adleman, L. M. Molecular computation of solutions to combinatorial problems. Science 266, 1021–1024 (1994).
Cox, J. C., Cohen, D. S. & Ellington, A. D. The complexities of DNA computation. Trends Biotechnol. 171, 151–154 (1999).
Shehabi, A. et al. United States Data Center Energy Usage Report (Lawrence Berkeley National Laboratory, 2016).
Masanet, E., Shehabi, A., Lei, N., Smith, S. & Koomey, J. Recalibrating global data center energy-use estimates. Science 367, 984–986 (2020).
Jones, N. How to stop data centres from gobbling up the world’s electricity. Nature 561, 163–166 (2018).
Bednarz, A. Amazon, Google, IBM, Microsoft: how their data-migration appliances stack up. https://www.networkworld.com/article/3295937/migrate-data-to-the-cloud-how-appliances-from-amazon-google-microsoft-and-ibm-stack-up.html (2018).
Mullis, K. B. The unusual origin of the polymerase chain reaction. Sci. Am. 262, 56–65 (1990).
Hughes, R. A. & Ellington, A. D. Synthetic DNA synthesis and assembly: putting the synthetic in synthetic biology. Cold Spring Harb. Perspect. Biol. 9, a023812 (2017).
Burel, A., Carapito, C., Lutz, J.-F. & Charles, L. Macromolecules 50, 8290–8296 (2017).
De Silva, P. Y. & Ganegoda, G. U. New trends of digital data storage in DNA. BioMed Res. Int. https://doi.org/10.1155/2016/8072463 (2016).
Erlich, Y. & Zielinski, D. DNA Fountain enables a robust and efficient storage architecture. Science 355, 950–954 (2017).
Byron, J., Long, D. D. E. & Miller, E. L. Measuring the cost of reliability in archival systems. Proceeding of the Conference on Mass Storage Systems and Technologies (MSST '20) (2020).
Allentoft, M. E. et al. The half-life of DNA in bone: measuring decay kinetics in 158 dated fossils. Proc. R. Soc. B Biol. Sci. 279, 4724–4733 (2012).
Bada, J. L., Wang, X. S., Poinar, H. N., Pääbo, S. & Poinar, G. O. Amino acid racemization in amber-entombed insects: implications for DNA preservation. Geochim. Cosmochim. Acta 58, 3131–3135 (1994).
Hofreiter, M., Serre, D., Poinar, H. N., Kuch, M. & Pääbo, S. Hofreiter_Ancient DNA_NatRevGen_2001_1556040. Nat. Com. 2, 3–9, https://doi.org/10.1038/35072071 (2001).
Willerslev, E. et al. Long-term persistence of bacterial DNA. Curr. Biol. 14, 13–14 (2004).
Organick, L. et al. An Empirical Comparison of Preservation Methods for Synthetic DNA Data Storage. Small Methods. e2001094 (2021).
Liu, Y. et al. DNA preservation in silk. Biomat. Sci. 1279–1292, https://doi.org/10.1039/c6bm00741d (2017).
Kohll, A. X. et al. Stabilizing synthetic DNA for long-term data storage with earth alkaline salts. Chem. Commun. 56, 3613–3616 (2020).
Grass, R. N., Heckel, R., Puddu, M., Paunescu, D. & Stark, W. J. Robust chemical preservation of digital information on DNA in silica with error-correcting codes. Angew. Chem. - Int. Ed. 54, 2552–2555 (2015).
Chen, W. D. et al. Combining data longevity with high storage capacity—layer-by-layer DNA encapsulated in magnetic nanoparticles. Adv. Funct. Mater. 29, 1–8 (2019). This study compares a novel method of layer-by-layer DNA encapsulation in magnetic nanoparticles to previous DNA storage techonologies and demonstrates four orders of magnitude higher data loading capacity and stability.
Koch, J. et al. A DNA-of-things storage architecture to create materials with embedded memory. Nat. Biotechnol. 38, 39–43 (2020).
Clermont, D. et al. Assessment of DNA encapsulation, a new room-temperature DNA storage method. Biopreserv. Biobank. 12, 176–183 (2014).
Mikutis, G., Schmid, L., Stark, W. J. & Grass, R. N. Length-dependent DNA degradation kinetic model: decay compensation in DNA tracer concentration measurements. 65 https://doi.org/10.1002/aic.16433 (2019).
Shao, W., Khin, S. & Kopp, W. C. Characterization of effect of repeated freeze and thaw cycles on stability of genomic DNA using pulsed field gel electrophoresis. Biopreserv. Biobank. 10, 4–11 (2012).
Baoutina, A., Bhat, S., Partis, L. & Emslie, K. R. Storage stability of solutions of DNA standards. Anal. Chem. 91, 12268–12274 (2019).
Ivanova, N. V. & Kuzmina, M. L. Protocols for dry DNA storage and shipment at room temperature. Mol. Ecol. Resour. 13, 890–898 (2013).
Madisen, L. The effects of storage of blood and isolated DNA on the integrity of DNA. Am. J. Med. Genet. 27, 379–390 (1987).
Smith, S. & Morin, P. A. Optimal storage conditions for highly dilute DNA samples: a role for trehalose as a preserving agent. J. Forensic Sci. 50, 1–8 (2005).
Dhanasekaran, S., Doherty, T. M. & Kenneth, J. Comparison of different standards for real-time PCR-based absolute quantification. J. Immunol. Methods 354, 34–39 (2010).
Bonnet, J. et al. Chain and conformation stability of solid-state DNA: implications for room temperature storage. Nucleic Acids Res. 38, 1531–1546 (2009).
Trapmann, S. et al. Development of a novel approach for the production of dried genomic DNA for use as standards for qualitative PCR testing of food-borne pathogens. Accredit. Qual. Assur. 9, 695–699 (2004).
Podivinsky, E., Love, J. L., van der Colff, L. & Samuel, L. Effect of storage regime on the stability of DNA used as a calibration standard for real-time polymerase chain reaction. Anal. Biochem. 394, 132–134 (2009). This work compared the stability of potential calibration standards stored in both aqueous and lyophilized samples at 3 different temperatures.
Chung, W. J. et al. Freezing shortens the lifetime of DNA molecules under tension. J. Biol. Phys. 43, 511–524 (2017).
Yoo, H.-B. Flow cytometric investigation on degradation of macro-DNA by common laboratory manipulations. J. Biophys. Chem. 02, 102–111 (2011).
Schaudien, D., Baumgärtner, W. & Herden, C. High preservation of DNA standards diluted in 50% glycerol. Diagnostic Mol. Pathol. 16, https://doi.org/10.1097/PDM.0b013e31803c558a (2007).
Woutersen, S., Ensing, B., Hilbers, M., Zhao, Z. & Austen Angell, C. A liquid-liquid transition in supercooled aqueous solution related to the HDA-LDA transition. Science 359, 1127–1131 (2018).
Newman, S. et al. Dehydration with digital micro fluidic retrieval. Nat. Commun. https://doi.org/10.1038/s41467-019-09517-y (2019).
Boneh, D., Dunworth, C. & Lipton, R. J. in DNA Based Computers (American Mathematical Society, 1996).
Winfree, E. Simulations of Computing by Self-Assembly. Technical Report CaltechCSTR:1998.22 (1998).
Bee, C. et al. Content-based similarity search in large-scale DNA data storage systems. Preprint at bioRxiv https://doi.org/10.1101/2020.05.25.115477 (2020).
Lin, K. N., Volkel, K., Tuck, J. M. & Keung, A. J. Dynamic and scalable DNA-based information storage. Nat. Commun. 11, 1–12 (2020).
Lengsfeld, C. S. & Anchordoquy, T. J. Shear-induced degradation of plasmid DNA. J. Pharm. Sci. 91, 1581–1589 (2002).
Freitas, S., Monteiro, G. A., Prazeres, D. M. F., Wu, M. L. & Santos, A. L. Stabilization of naked and condensed plasmid DNA against degradation induced by ultrasounds and high-shear vortices. Biotech. Appl. Biochem. 246, 237–246 (2009).
Levy, M. S. et al. Effect of Shear on Plasmid DNA in Solution. Bioprocess Eng. 20, 7–13 (1999).
Lindahl, T. & Nyberg, B. Rate of depurination of native deoxyribonucleic acid. Biochemistry 11, 3610–3618 (1972).
Bauer, T., Weller, P., Hammes, W. P. & Hertel, C. The effect of processing parameters on DNA degradation in food. Eur. Food Res. Technol. 217, 338–343 (2003).
Howlett, S. E., Castillo, H. S., Gioeni, L. J., Robertson, J. M. & Donfack, J. Evaluation of DNAstableTM for DNA storage at ambient temperature. Forensic Sci. Int. Genet. 8, 170–178 (2014).
Zhirnov, V., Zadegan, R. M., Sandhu, G. S., Church, G. M. & Hughes, W. L. Nucleic acid memory. Nat. Mater. 15, 366–370 (2016). This work presented the specific advantages of nucleic acid memory over electronic memory in relation to storage capacity, scalability, and ultralow energy requirements and also modeled DNA degradation as a function of energy inputs.
Anchordoquy, T. J. & Molina, M. C. Preservation of DNA. Cell Preserv. Technol. 5, https://doi.org/10.1089/cpt.2007.0511 (2007).
Tomek, K. J. et al. Driving the scalability of DNA-based information storage systems. ACS Synth. Biol. 8, 1241–1248 (2019).
Lin, S. & Costello, D. Error Control Coding (Prentice Hall, 2004).
Blawat, M. et al. Forward error correction for DNA data storage. Procedia Comput. Sci. 80, 1011–1022 (2016).
Organick, L. et al. Random access in large-scale DNA data storage. Nat. Biotechnol. 36, 242–248 (2018).
Ma, S., Saaem, I. & Tian, J. Error correction in gene synthesis technology. Trends Biotechnol. 30, 147–154 (2012).
Pfeiffer, F. et al. Systematic evaluation of error rates and causes in short samples in next-generation sequencing. Sci. Rep. 8, 1–14 (2018).
Gray, J. & Van Ingen, C. Empirical measurements of disk failure rates and error rates. Microsoft Research Technical Report MSR-TR-2005-166 (2005).
Ghemawat, S., Gobioff, H. & Leung, S. T. The Google file system. in Proceedings of the Nineteenth ACM Symposium on Operating Systems Principles 29–43 (2003).
Patterson, D. A., Gibson, G. & Katz, R. H. A case for redundant arrays of inexpensive disks (RAID). in Proceedings of the 1988 ACM SIGMOD International Conference on Management of Data 109–116 (1988).
Heckel, R., Shomorony, I., Ramchandran, K. & David, N. C. Fundamental limits of DNA storage systems. in IEEE International Symposium on Information Theory (ISIT) 3130–3134 (2017).
Shomorony, I. & Heckel, R. Capacity results for the noisy shuffling channel. in IEEE International Symposium on Information Theory (ISIT) (2019).
Yang, K., McCloskey, C. M. & Chaput, J. C. Reading and writing digital information in TNA. ACS Synth. Biol. https://doi.org/10.1021/acssynbio.0c00361 (2020).
Epple, C. & Leumann, C. Bicyclo(3.2.1]-DNA, a new DNA analog with a rigid backbone and flexibly linked bases: pairing properties with complementary DNA. Chem. Biol. 5, 209–216 (1998).
Acknowledgements
This work was supported by the National Science Foundation (ECCS-2027655 & CNS-1901324) to A.J.K. and J.M.T.
Author information
Authors and Affiliations
Contributions
K.M., J.M.T. and A.J.K. conceived the manuscript and wrote the paper. J.M.T. developed the model and simulations.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Peer review information Nature Communications thanks the anonymous reviewer(s) for their contribution to the peer review of this work.
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Matange, K., Tuck, J.M. & Keung, A.J. DNA stability: a central design consideration for DNA data storage systems. Nat Commun 12, 1358 (2021). https://doi.org/10.1038/s41467-021-21587-5
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41467-021-21587-5
This article is cited by
-
Recent Progress in High-Throughput Enzymatic DNA Synthesis for Data Storage
BioChip Journal (2024)
-
Modelling for Efficient Scientific Data Storage Using Simple Graphs in DNA
SN Computer Science (2024)
-
Management practices and technologies for efficient biological sample collection from domestic animals with special reference to Indian field conditions
Animal Diseases (2023)
-
Digital data storage on DNA tape using CRISPR base editors
Nature Communications (2023)
-
Navigating bottlenecks and trade-offs in genomic data analysis
Nature Reviews Genetics (2023)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
