
Abstract
Metre-scale plasma wakefield accelerators have imparted energy gain approaching 10 gigaelectronvolts to single nano-Coulomb electron bunches. To reach useful average currents, however, the enormous energy density that the driver deposits into the wake must be removed efficiently between shots. Yet mechanisms by which wakes dissipate their energy into surrounding plasma remain poorly understood. Here, we report picosecond-time-resolved, grazing-angle optical shadowgraphic measurements and large-scale particle-in-cell simulations of ion channels emerging from broken wakes that electron bunches from the SLAC linac generate in tenuous lithium plasma. Measurements show the channel boundary expands radially at 1 million metres-per-second for over a nanosecond. Simulations show that ions and electrons that the original wake propels outward, carrying 90 percent of its energy, drive this expansion by impact-ionizing surrounding neutral lithium. The results provide a basis for understanding global thermodynamics of multi-GeV plasma accelerators, which underlie their viability for applications demanding high average beam current.
Similar content being viewed by others

Introduction
Localized deposition of concentrated energy into plasmas by particle bunches or laser pulses underlies fast ignition of laser fusion1, formation of plasma waveguides2, and wakefield acceleration of electrons and positrons3. Subrelativistic particles or laser pulses deposit energy into dense uniform plasmas primarily via collisions2, analogous to ohmically heating a resistor, but collisions become inefficient for tenuous plasma and/or relativistic excitation. Relativistic particle bunches (or laser pulses), on the other hand, excite tenuous plasma by creating electron density structures, such as channels4 or Langmuir waves3, via Coulomb (or ponderomotive) forces, analogous to charging a capacitor. Previous experiments in plasmas of millimeter (mm) length and atmospheric electron density (ne ~ 1019 cm−3) have documented the initial (first few ps) stage of transferring energy stored initially in such structures into long-term ion motion4,5.
The emergence of quasi-monoenergetic multi-GeV plasma-wakefield accelerators, in which relativistic particle bunches6,7 (or laser pulses8) deposit energy into strongly nonlinear wakes in plasma of density ne ~ 1017 cm−3, however, raises the question of energy dissipation with renewed urgency. Multi-GeV plasma accelerators require such low ne in order to avoid depleting the driver’s energy before it propagates ~1 m, the length of plasma wake needed to accelerate electrons or positrons to multi-GeV energy3. Heat removal by flowing the medium supersonically transversely to the driver propagation direction, which is routine for mm-long, 10 μm wide, high ne, gas-jet-based MeV plasma accelerators3,5, is not feasible for meter long, 100 μm wide, low ne, multi-GeV accelerators, which require stationary vessels to confine their long, tenuous plasmas6,7,8. Such accelerators will therefore require new strategies for managing deposited heat, based on quantitative understanding of energy dissipation. Such understanding is fundamental to achieving luminosities large enough to observe rare processes at the energy frontier. Accelerators achieve high luminosity by delivering focused high-charge, high-energy beams at high repetition rate. Planned conventional machines such as the International Linear Collider9 or the Compact Linear Collider10, for example, are designed to deliver ~10 megawatt (MW) to the interaction point. Current conceptual designs for plasma-based accelerators aim to achieve comparable luminosity by accelerating ~nC bunches at ~10 kHz repetition rate (i.e. ~100 μs interbunch spacing)11,12. This need has spurred world-wide efforts to develop petawatt-peak-power drive lasers that can operate at multi-kHz repetition rates13. However, the problem of dissipating, or otherwise managing, deposited power of order tens of kW per meter over ~100 m of plasma has received comparatively little attention. The present study aims to understand the fundamental processes by which plasma accelerator structures at ne ~ 1017 cm−3 dissipate their energy into surrounding plasma, and to evaluate their global energy budget over a nanosecond (ns) time scale. It thus builds a thermodynamic foundation on which future engineering solutions of the heat management problem can be based.
To produce high-quality bunches, plasma accelerators of any ne usually operate in a strongly nonlinear regime in which the driver blows out a “bubble”-like cavity devoid of plasma electrons in its immediate wake3. In such structures the energy density ∣E∣2/(2ϵ0) of internal wake fields E approaches the rest energy density nemc2 of plasma electrons14. Simulations predict that such electron wakes can spawn ion wakes of unique structure and dynamics14,15,16, early stages of which were observed5 at high ne. However, no experiments at any ne have yet explored how the enormous energy density stored in a nonlinear wake redistributes over nanoseconds among accelerated electrons, undirected hot electrons, freely streaming ions, radiation, electrostatic fields, and ionization of surrounding gas, as well as collective ion motion. Understanding this complex process at ne ~ 1017 cm−3 demands experiments with precisely characterized multi-GeV drive bunches (or petawatt laser pulses), probes that track particle and energy flow over millimeters, and simulation of multifarious plasma processes over nanoseconds. The scale and complexity of the problem rival those of other energy transport problems involving tenuous plasma, such as heating of the solar corona17 and acceleration of energetic cosmic rays18.
Here we present ps-time-resolved optical shadowgraphic measurements of meter-length plasma columns that emerge from broken, highly nonlinear plasma wakes that energetic electron bunches generate in self-ionized, initially neutral lithium vapor. As a drive bunch propagates ~0.3 m into the vapor, its center and trailing edge self-focus to high density, enabling them to field-ionize a wide plasma column and to drive a strongly nonlinear plasma wake well within its boundaries. The drive bunch then reaches steady state, and continues generating this nonlinear wake over the next meter. A diagnostic optical pulse probes the expanding plasma column at a fixed longitudinal location z within this steady-state region at time delays 0 < Δt < 1.5 ns in 0.1 ns intervals, and coarsely out to 10 μs. These observations serves as a calorimeter that determines the fraction of the initial wake energy that the plasma column retains after the wake breaks. Simulations reveal that the initial wake transfers energy into the surrounding medium via the following sequence of events: the initial wake breaks, expelling fast electrons from the plasma; radial electric fields arise that propel ions outward at tens of keV while escorting electrons; outwardly streaming electrons and ions ionize and excite surrounding neutral lithium, expanding plasma volume several hundred-fold. Benchmarking simulated plasma expansion against measurements quantifies energy retention in the plasma column and elucidates mechanisms that drive its expansion.
Results
Generation of nonlinear wakes
Experiments were carried out at the SLAC Facility for Advanced aCcelerator Experimental Tests (FACET)19. The first 2 km of the SLAC linac delivered drive electron bunches (e-bunches) of energy 20 GeV, charge 2.0 nC, rms radius σr = 30 μm, length σz = 55 μm to the entrance of the interaction region. Unlike small-scale plasma wakefield accelerator experiments, in which parameters of drive e-bunches delivered from a tabletop laser wakefield accelerator could only be estimated5, here e-bunches from SLAC were characterized with high precision (see “Methods”). This is important for simulating subsequent plasma dynamics accurately over an ns time scale. Drive bunches entered a 150-cm-long column of Li vapor, in which a 120-cm-long region of uniform atomic density na = 8 × 1016 cm−3 was centered between 15-cm-long entrance and exit density ramps. This vapor was generated and contained within a cylindrical heat-pipe oven6,20 of 1.6 cm radius (see “Methods”), and provided the medium for plasma formation and wake excitation.
Particle-in-cell (PIC) simulations discussed below showed that the SLAC e-bunches singly field-ionized the Li vapor over its entire length out to initial radius r(0) ≈ 40 μm and electron density ne = na, and drove a strongly nonlinear electron density wake consisting of a train of nearly fully blown-out cavities of radius ƛp = 20 μm, propagating at ~c along the axis of the resulting plasma. Thus the initial plasma column was wide enough to fully support the generated wake. Under these conditions, this wake closely resembles the corresponding wake that a similar e-bunch would form in a pre-ionized plasma of similar density21. The main differences are that, in the self-ionized case, the wake forms further back in the drive bunch profile21 and decays more rapidly along z due to head erosion22,23. For our conditions, ~5% of the drive bunch erodes over 1 m of propagation (see Supplementary Eq. (1)). Neither difference has any bearing on fixed z, ns-scale, transverse plasma expansion dynamics of interest here. These dynamics are determined by the amplitude, structure, and stored energy of the initial wake at the longitudinal location z at which we measure and simulate them, regardless of whether that wake formed in self- or finite-radius pre-ionized plasma.
The wake cavities enclose accelerating fields of magnitude E ~ mωpc/e ~ 1 GV/cm, where \({\omega }_{{\rm{p}}}={[{n}_{{\rm{e}}}{e}^{2}/({\epsilon }_{0}m)]}^{1/2}\) is the electron plasma frequency. Although we have the capability at FACET to pre-ionize the lithium vapor along the entire drive beam path out to r ~ 500 μm24, here we retained the Li vapor blanket as an in situ medium for recording energy transport out of the directly excited wake. As discussed below, outwardly streaming ions and electrons, which carry away most of the wake’s energy, ionize neutral Li atoms, inducing a large change in the vapor’s refractive index η. This enables us to detect the ionization front with ~15 ps time and <40 μm space resolution (both limited primarily by imaging resolution) using a probe pulse. Ionization of the Li blanket consumes <1% of outwardly streaming particle energy during the first ~1 ns, and thus does not perturb overall energy transport significantly. Consequently the wake dissipation dynamics measured and simulated here in self-ionized plasma also reflect those of an equivalent wake generated in pre-ionized plasma of similar finite radius.
When SLAC delivered 2 nC, 20 GeV (i.e. 40 J total energy) drive bunches to the interaction region at repetition rate 1 Hz or less, no heat-pipe temperature rise, nor other time-dependent behavior, was observed upon turning on the beam. Downstream measurements of spent driver energy (see Supplementary Fig. 2) show that ~60% of electrons in each bunch contribute to forming a plasma wake, each losing 11% of its energy in so doing—i.e. each bunch deposits 7% of its total incident energy, or 2.6 J, into the 1.2 m-long plasma wake (2.2 J/m). Thus at 1 Hz, the plasma acquires energy at 2.6 W, which is only 0.2% of typical oven heater power (1300 W). When, on the other hand, we increased repetition rate to ~10 Hz, oven temperature typically rose tens of degrees within minutes, even though this repetition rate is ~1000× lower than current design projections11. Here we report data acquired at 1 Hz to avoid drifts in oven temperature during extended data acquisition runs. No witness e-bunch was injected with the driver. Moreover, non-intercepting beam charge monitors positioned before and after the plasma detected no change in beam charge (see “Methods”), suggesting that the wake trapped negligible charge from background plasma. Indeed, in view of the near-light speed of the driver and the sub-1017 cm−3 plasma density, trapping and acceleration of background electrons requires an external trigger, such as an optical injection pulse, under these conditions25. Thus plasma wave energy was dissipated entirely within the medium.
Measurement of plasma expansion
To diagnose the evolving radial profile of the plasma column, a collimated probe laser pulse (wavelength λ = 0.8 μm, duration τ = 0.1 ps, transverse width 0.5 cm FWHM) that was electronically synchronized with the drive e-bunch with ~0.1 ps jitter entered one end of the heat pipe 0.8 cm off-center. It then propagated through a 100-cm-long central section of the Li column at angle θ = 8 mrad to the e-bunch propagation direction [see Fig. 1a, b] at time delay −1 ps < Δt < 10 μs after the e-bunch, before exiting the other end on the opposite side of center. By using this grazing θ, the largest that the long narrow heat-pipe oven allowed without clipping the probe pulse, we probed the tenuous plasma profile ~100× more sensitively than with a transverse (θ = π/2 rad) probe, because of the long interaction length, at the mild cost of averaging longitudinal (z) density variations ne(z) over Δz ~ 0.5 cm. Moreover, as discussed below, with this geometry we maximized sensitivity to the region of interest—the expanding profile’s advancing outer edge—at the cost of insensitivity to its internal structures. Use of an e-bunch driver eliminated strong depolarized, forward-directed supercontinuum that a laser-driven nonlinear wake generates26, which is extremely challenging to discriminate from probe light in this near co-propagating pump-probe geometry.

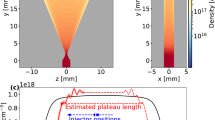
a Overview of experimental setup, showing path of laser probe pulse (orange solid line) through plasma column (dashed blue line) at grazing angle 8 mrad with variable time delay Δt after e-bunch excitation. The resulting diffraction pattern is imaged from vacuum object plane (O) onto a CCD. b Schematic depiction of evolving probe intensity profile as it passes obliquely through plasma column and imaging lens. An obstruction blocked the gray area on the lens. c Experimental probe images for Δt = 100, 300, 600, 900, and 1200 ps, normalized to unperturbed probe intensity I0 (see color scale, lower right), averaged over 30 shots. See Supplementary Fig. 1 for comparative single-shot images. Dashed vertical white lines: intersection of plane O with plasma column. Each probe image is 4 mm high ×7.5 mm wide; horizontal dimension corresponds to projected distance 1.0 m along plasma column axis. d–f Simulated probe images for three plasma expansion models: d including dynamics of ions within initial plasma column only; e including impact ionization of ground state neutral lithium surrounding initial plasma column; f including impact excitation of neutral lithium to 2P, 3S, and 3P states and impact ionization. g Experimental probe image at Δt = 10 μs, for which plasma column expanded well beyond field of view. Horizontal and vertical scales in g also apply to each image in panels c–f.
A lens imaged the portion of the transmitted probe pulse that it collected within its f/40 cone from a vacuum object plane at longitudinal position z = 75 cm near the center of the heat pipe (labeled O in Fig. 1a) to a charge-coupled device (CCD) camera. Here z = 0 refers to the foot of the entrance density ramp. Images had ~1 cm depth of field and unity magnification. Unavoidable obstructions blocked ~1/4 of the circular lens aperture [see gray area, Fig. 1b], which influenced some nonessential details of images, as discussed below. When the probe arrived before the e-bunch (Δt < 0), only the incident probe pulse profile was observed. At Δt > 0, an approximately parabola-shaped shadow outlined with alternating bright and dark fringes, resulting from probe refraction and diffraction from the e-bunch-excited plasma column, was observed. Figure 1b shows schematically how the shadow/fringe pattern evolves for fixed Δt as the probe propagates through the near field of the plasma column. Figure 1c shows how it evolves in the far field as Δt varies from 100 to 1200 ps. The parabolic shadow expands at ~106 m/s, eventually exceeding the camera’s field of view for Δt > 1200 ps. Figure 1d–f shows calculated images for three simulations of plasma evolution, discussed below and in “Methods”. One horizontal position in these patterns (highlighted by vertical white dashed line in Fig. 1c–f) corresponds to plane O. Fringed regions straddling this plane are out-of-focus images of upstream (z < 75 cm) and downstream (z > 75 cm) slices of the column. They represent images of near-field diffraction patterns of this obliquely illuminated column at each z27. At small Δt, the vertex of the parabola appears to be located at z = 75 cm [see 100 ps images in Fig. 1c–f], i.e. the position in the images where the object plane intersects the plasma column. In fact, the vertex is shifted slightly to z = 75 cm + Δz. As the plasma column widens, Δz increases [see 100 to 1200 ps images in Fig. 1c, f]. This is the result of increasing refraction in the cylindrical plasma column.
Figure 1g shows an image at the longest accessible delay Δt = 10 μs. The uniformly dark image shows that the plasma column continues to refract probe light out of the imaging lens collection cone long after the column expands beyond the field of view. Here, we focus on the first 1.3 ns of plasma expansion, a range accessible to PIC simulations.
Figure 2a–d illustrates via probe propagation simulations (see “Methods”) how details of the images in Fig. 1c–f arise. Figure 2a shows a half cross-section of the plasma column’s refractive index profile η(r) at a representative Δt, with contours (black circles) in Δη = 10−5 increments superposed. Figure 2b shows the corresponding intensity half-profile of the probe pulse at the same z-plane. In this picture, the probe emerges along the page normal, while the plasma column axis is tilted 8 mrad from left (behind page) to right (in front of page). A parabolic shadow (left) develops as probe light refracts away from columns axis, after penetrating to the η − 1 = 10−5 contour in the plane of incidence. Fringes (right) approximately parallel to the shadow boundary develop as refracted probe light interferes with un-deflected incident probe light. This probe profile is, however, not directly observed. Rather, a lens relays it to a CCD. For an ideal unobstructed lens and cylindrically symmetric plasma column, the detector would record the profile shown in Fig. 2c. Because the probe passes through the remainder of the plasma column, the image is distorted in two ways from the probe’s in situ shape. First, a nephroid-shaped cusp singularity forms in the image of the parabola’s vertex, similar to bright optical caustics that form within the shadow of an obliquely illuminated drinking glass28. Second, a second set of interference fringes approximately orthogonal to the shadow boundary develops outside the shadow.

a–d Electromagnetic simulations showing how probe intensity profile evolves through plasma column to detector: a Typical refractive index cross-section η(r) of plasma column at object plane O, with column axis tilted at 8 mrad to page normal from left (back) to right (front); black circles: index contours in Δη = 10−5 increments; b radial intensity profile of probe, propagating normally out of page, at O, showing light penetration to η − 1 = 10−5 contour, parabolic shadow and surrounding interference fringes; c corresponding probe profile after ideal imaging to detector, showing axial caustic and orthogonal interference fringes acquired in passing through remainder of plasma column. d Corresponding probe profile after non-ideal imaging to detector, showing re-shaping of vertex region due to partial blockage of imaging lens shown in Fig. 1b. e–g Plots of e rO(Δt), f rB(Δt), and g Δz(Δt) from measured probe images (orange-filled circle data points), showing 1σ (dark gray) and 2σ (light gray band) variations over 30 shots, and from the three theoretical models corresponding to Fig. 1d–f: no impact ionization (open gray squares), ground state impact ionization (filled black squares), impact excitation+impact ionization (filled blue circles). h–k Lineouts of measured single shot (black curves) and 30-shot averaged (orange curves) normalized probe intensity at positions O (h, j) and B (i, k) for Δt = 100 ps (h, i) and 1200 ps (j, k), compared to Simulation 3 calculations (blue dashed curves).
The first of these features proved sensitive to the above-mentioned partial blockage of the lens aperture. Figure 2d shows the reshaped shadow vertex that results when probe propagation calculations take this blockage into account. The second of these features proved sensitive to slight deviations of the simulated column from cylindrical symmetry, and to small longitudinal non-uniformities. Thus these two features were seldom observed in actual images (see Fig. 1c). Nevertheless, the vertex shift Δz, along with shadow radii rO at O and rB at another selected longitudinal location B, as marked in Fig. 1c, were consistently observed. Orange data points and gray uncertainty ranges in Fig. 2e–g show evolving values rO(Δt), rB(Δt), and Δz(Δt), respectively, for 0 < Δt < 1200 ps, where B here corresponds to z = 55 cm. Black and orange curves in Fig. 2h–k show single-shot and 30-shot averaged lineouts, respectively, of shadows at O (Fig. 2h, j) and B (Fig. 2i, k) for Δt = 100 ps (Fig. 2h, i) and 1200 ps (Fig. 2j, k). Fringes outside of, and parallel to, the shadow boundary were observed frequently in both single-shot (Fig. 2i, black curve) and multi-shot averaged (Fig. 1c) data. Probe propagation simulations showed that fringe spacing was sensitive to θ, but agreed well with observed fringe spacing for θ = 8.0 ± 0.1 mrad, thus corroborating the independently measured probe angle. However, observed fringe contrast is invariably lower than calculated, due to imperfect symmetry of the plasma column. In addition, fringes sometimes wash out upon multi-shot averaging, because of shot-to-shot fluctuations in θ and in drive bunch intensity. Thus, rO(Δt), rB(Δt), and Δz(Δt) constituted the most robust observables for quantitative comparison with simulations.
Qualitative plasma expansion mechanisms
Results in Fig. 2e, f show that empirical radii rO(Δt) and rB(Δt) grow on average at 1.4 × 106 m/s over 1.3 ns, and even accelerate slightly during this interval. Probe propagation simulations show that these radii are approximately twice the plasma column radius rp, here defined as the radius at which ne(rp) ≈ 0.2na, implying that rp expands at near-constant velocity vp ≈ 0.7 × 106 m/s. Such kinetics rule out expansion driven by electron heat or radiative transport29, since heat front velocity would decrease rapidly with time4. They also cannot be explained by a radial shock wave at the ion acoustic velocity, which is initially only ~104 m/s for our conditions, and would also decrease within ~1 ns as electron temperature cools2. Rather, the observed near-constant vp must be attributed to an ionization front driven by charged particles, particularly high-momentum Li ions, streaming freely into surrounding Li vapor4. Li ions propagating at the observed vp, for example, would have energy Ei ~ 20 keV. These could be produced if average outward radial electrostatic fields of order \(0.01\, < \, \langle{E}_{r}\rangle \, < \, 0.05\) GV/cm acted on the ions over radial distance of order 200 > r > 40 μm (or time interval 50 > τ > 10 ps) in the collapsed electron wake following its excitation. Such ions have mean free paths of several mm in Li vapor of na = 0.8 × 1017 cm−3, experience only small angle elastic scattering, and lose energy to neutral atoms primarily via impact excitation and ionization, which entails loss per impact only up to the first ionization energy (~5.4 eV) of Li. These characteristics are consistent with near-constant-velocity expansion over a ns time scale. In addition, the ions escort electrons, which maintain charge quasi-neutrality and assist in exciting and ionizing Li atoms.
Simulations of plasma expansion
To understand plasma expansion quantitatively, we carried out PIC simulations of Li plasma dynamics out to Δt ~ 1.3 ns using two complementary PIC codes OSIRIS and LCODE. We modeled ionization, self-focusing of the drive bunch, electron wake excitation, and early (Δt ≤ 40 ps) electron wake and ion dynamics in a fully self-consistent manner using OSIRIS30 in cylindrical geometry (see “Methods” for details). These simulations modeled radial acceleration of ions and electrons by electrostatic fields of the collapsing electron wake with high space and time resolution, before these particles began to interact significantly with surrounding Li gas. OSIRIS simulations tracked self-consistent driver and plasma evolution for 15 cm of propagation through the gas density up-ramp and an additional 16.9 cm into the 120-cm-long density plateau (i.e. up to z = 31.9 cm). No particle trapping was observed at z ≤ 31.9 cm up to Δt = 40 ps of wake evolution. Trapping can thus be assumed negligible at larger Δt, when wake amplitude and electron energy are lower.
To simulate long-term plasma evolution, we input the compressed e-bunch and plasma profiles from the OSIRIS simulation output at z = 31.9 cm into the quasistatic, axisymmetric LCODE31 as initial conditions. LCODE then simulated plasma dynamics at this fixed z, which do not depend on continuing evolution of the drive bunch in the downstream plasma (i.e. at z > 31.9 cm). Consequently, the bunch evolution no longer needed to be tracked, enabling time-efficient simulation of long-term plasma dynamics out to Δt ≈ 1.3 ns. Moreover, impact ionization of neutral gas by outwardly streaming electrons and ions comes into play on this time scale, and in fact dominates plasma expansion for Δt > 100 ps. Accordingly, we introduced well-established collisional/ionization schemes into LCODE that have been extensively implemented and tested in other codes32,33. Specifically, we included the most important elementary collisional processes—elastic binary collisions32,34 and impact ionization of neutral lithium atoms by electrons35 and fast lithium ions36. For electron-impact ionization, we included single-step ionization from the neutral lithium ground state and two-step ionization37,38 via 2P, 3S, and 3P excited states. Conditions simulated here do not involve highly relativistic collisions, high density, or other extreme parameters, and thus fall well within previously tested precision limits of these collision/ionization schemes. Nevertheless, because of the special importance of collisional fast electron deceleration in determining the expansion rate of the plasma column, we carried out a new test to ensure that the collision scheme implemented in LCODE reproduced the deceleration rate of 1–4 keV electrons predicted by analytical theory39 with high accuracy (see “Methods”).
Figure 3 shows OSIRIS simulation results. The electron bunch, initially of bi-Gaussian r, z profile (see Fig. 3a), ionized Li according to the Ammosov–Delone–Krainov (ADK) model40. Figure 3b shows the driver (blue) and plasma (orange) after the former propagated to z = 31.9 cm. The bunch’s leading edge was not dense enough to ionize Li, and thus propagated as in vacuum. Ionization started in the denser center of the bunch, which then drove a nonlinear plasma wake, which in turn compressed the beam waist radially. In Fig. 3b, the bunch’s trailing edge has compressed to ~100 times its initial density. This enabled it to singly-ionize Li gas completely out to r ≈ 40 μm, and partially out to r ≈ 65 μm, and to drive fully blown-out plasma bubbles of radius ƛp = 20 μm.

Drive bunch profile at a z < 0 (blue), before entering Li vapor at z = 0, and at b z ≈ 32 cm, after entering the Li density plateau, focusing, and creating trailing beam-ionized plasma and electron wake (orange). c Fixed-window simulation of longitudinally averaged and d full radial electric field Er(r, z) profiles at Δt ~ 1 ps after the driver passes. The non-zero averaged field [red curve in c] attracts (repels) ions at r ≤ 30 μm (r > 30 μm) to (from) the axis. e Longitudinally-averaged and f full ion density at Δt ~ 40 ps after driver passage. Dashed line indicates the maximum r ≈ 65 μm to which drive bunch directly ionized Li. g Calculated probe diffraction pattern from density profile in e, cf. measured pattern for Δt ~ 100 ps in Fig. 1c.
Figure 3d shows the radial electric field Er(r, z) remaining at Δt = 1 ps. Typical of the aftermath of a nonlinear wake, this field is still non-zero15. Because of their large mass, plasma ions initially respond to \(\langle{E}_{r}(r)\rangle\), i.e. Er(r, z) averaged longitudinally over ~6λp, shown in Fig. 3c. Since \(\langle{E}_{r}(r)\rangle\) switches sign at r ≈ 30 μm, it attracts ions initially (i.e. before wave-breaking occurs) at r < 30 μm toward the axis, while pushing ions initially at r > 30 μm outward. The driver also expels a fraction of plasma electrons into surrounding neutral gas, leaving net positive charge in the plasma that further propels outward ion motion. The resulting ion density structure \({n}_{{{\rm{Li}}}^{+}}(r,z)\), seen in Fig. 3e, f at Δt = 40 ps before (Fig. 3f) and after (Fig. 3e) longitudinal averaging, has a peak on axis. In addition, the outermost ions diffuse outward, moving from ~65 μm (dashed lines in Fig. 3e, f) to ~100 μm. Figure 3g shows the calculated probe diffraction pattern from a longitudinally uniform plasma column of the shape of Fig. 3e for our experimental geometry. It is very close to Δt = 100 ps data (Fig. 1c) and simulation (Fig. 1d). Indeed, our simulations predict negligible change in this pattern during the interval 40 < Δt < 100 ps, since radially accelerated ions and electrons have not yet begun to impact-ionize surrounding Li neutrals substantially.
Figure 4 presents LCODE simulation results for Δt > 100 ps. Figure 4a shows how the plasma density profile ne(r, Δt) evolves over the interval 100 < Δt < 1200 ps in the absence of impact ionization processes (Simulation 1). At Δt = 100 ps, the dominant feature is a sharp axial electron density maximum ne(r < 0.01 mm). This is the electron counterpart of the ion density maximum \({n}_{{{\rm{Li}}}^{+}}(r\, < \, 0.01\ {\rm{mm}})\) seen in Fig. 3e–f at Δt = 40 ps, and maintains its quasi-neutrality. Over the ensuing 1100 ps, this axial peak drops in amplitude and broadens, driven by electrostatic forces. Nevertheless, ne (r > 40 μm) never exceeds 1016 cm−3. Figure 4b shows corresponding refractive index profiles η(r, Δt) (see “Methods”). The index profile does not change noticeably for r > 40 μm throughout the simulated interval. Since the probe pulse turning radius (η − 1 = 10−5, blue dashed line in Fig. 4b) occurs at r ≈ 50 μm in our geometry, the probe does not sense index changes occurring at r < 40 μm (shown in Fig. 4b). Hence, Simulation 1 predicts no change in probe signatures over the interval 100 < Δt < 1200 ps, as shown in Fig. 1d. Quantitative signatures rO(Δt), rB(Δt), and Δz(Δt) remain unchanged over the simulation interval (see open squares in Fig. 2e, f and g, respectively). Simulation 1 encompasses ion motion physics investigated over a tens-of-ps interval in ref. 5, but does not explain longer-term expansion evident here (Figs. 1c and 2e–g).

Comparison of evolution of radial plasma density distributions (left) and corresponding refractive index distributions (right) for the three models used in LCODE simulations. a–b No secondary ionization. c–d Single-step electron and ion-impact ionization from ground state. e–f Single-step plus two-step electron-impact ionization via 2P, 3S, and 3P excited states. Labels on individual curves denote Δt in ps. Although the left-hand column plots only plasma density ne(r), neutral lithium atom (and, for Simulation 3, excited state) distributions are also non-uniform and evolving, and were taken into account in calculating refractive index distributions shown in the right-hand column. Horizontal blue dashed lines in the latter indicate the threshold index η = 1.00001 at which the probe reflects from the plasma column. Panel f has twice the horizontal axis range as other panels.
To capture this continuing long-term expansion, we included impact ionization, induced by energetic electrons and ions streaming radially outward from the directly e-beam-ionized plasma (Fig. 3b). Figure 4c shows evolving ne(r, Δt) profiles when these processes are restricted to single-step ionization from the neutral Li ground state (Simulation 2). The earliest ne(r, Δt = 100 ps) profile shown, and its corresponding η(r, Δt = 100 ps) profile in Fig. 4d, differ only slightly from their counterparts in Simulation 1. By Δt = 400 ps, however, impact ionization has begun to create substantial new plasma in the region 50 < r < 150 μm, which reaches Li vapor density (i.e. ne = na = 8 × 1016 cm−3) by Δt = 1200 ps (see Fig. 4c). At the microscopic level, the simulation shows that energetic electrons, which exit the original plasma first, ionize some neutral Li in this region directly, but inefficiently, since their density and ionization cross-section are small. A moving front of fast ions creates most of the new plasma. Once ions appear at a given location, more electrons come, including lower-energy plasma electrons with high impact-ionization cross-sections. Growth of this electron population triggers near-exponential plasma density growth.
The corresponding η(r, Δt) for Simulation 2 also change substantially at 50 < r < 150 μm (see Fig. 4d). Probe turning radius quadruples from r ≈ 50 μm at Δt = 400 ps to r ≈ 200 μm at Δt = 1300 ps. Consequently, Simulation 2 predicts widening probe shadows (see bottom 4 panels of Fig. 1d) with growing rO(Δt) and rB(Δt) (filled black squares, Fig. 2e, f), bringing Simulation 2 closer to the data than Simulation 1. Nevertheless, simulated rO(Δt) and rB(Δt) still fall well short of observed values (Fig. 2e, f). Moreover, Simulation 2 does not reproduce the observed shift Δz(Δt) in the vertex of the parabolic shadow (see Fig. 2g).
To capture these remaining features we included two-step electron-impact ionization into LCODE (Simulation 3). In these processes, an initial electron impact excited the 2S electron of a ground state Li atom to a 2P, 3S, or 3P state. A subsequent impact within the natural lifetime of these states then ionized the atom. Including such processes increased new plasma production significantly, as ne(r, Δt) plots in Fig. 4e show. Simultaneously they hastened growth of probe turning radius, as η(r, Δt) plots in Fig. 4f show. The partial ion density distributions Ni(r) in Fig. 5a (shades of brown) show that e-impact of excited Li⋆ atoms is, in fact, the dominant source of Li+ ions at Δt = 1200 ps. Figure 5b shows, however, that two-step processes become dominant only at Δt ≳ 400 ps (see brown dotted, orange dot-dashed, red filled circle curves). Simulated probe images (Fig. 1f) widen more than twice as rapidly as for Simulation 2 (Fig. 1e). Moreover, a substantial vertex shift Δz(1200 ps) ≈ 500 μm develops by the end of Simulation 3. Simulated average growth of rO(Δt) and rB(Δt) agrees with observed average growth over the interval 100 < Δt < 1300 ps (see Fig. 2e, f). Finally, simulated and observed probe image lineouts near the beginning (Fig. 2h, i) and end (Fig. 2j, k) of Simulation 3 agree well in width and depth, despite discrepancies in fringe amplitude. Thus Simulation 3 captures all qualitative features of the data, including the vertex shift Δz(Δt) that Simulation 2 missed, as well as some key quantitative features.

a Plot of Li+ ion [(1)–(4)] and Li neutral atom [(5) and (6)] density distributions corresponding to electron density distribution at Δt = 1200 ps in Fig. 4e. Regions (1), (2), and (4) indicate relative contributions of original ions (region 1) and of electron-impact-ionized ground state (2) and excited (4) neutrals, while the barely visible region 3 (black) indicates ion-impact-ionized Li atoms. b Time evolution of indicated impact ionization channels. Ion-impact ionization (solid purple curve) dominates for 50 ≲ Δt ≲ 160 ps; electron-impact ionization (dark-brown dashed, light-brown dotted, orange dot-dashed, red filled-circle curves) dominates for Δt ≳ 160 ps. c Time evolution of indicated energy transport channels. Hot electrons carry ~10% of the energy deposited in the original wake to the walls in the first ~20 ps (region 4). The expanding plasma column retains the rest without noticeable attenuation throughout the remainder of the simulated period. Electrons (2) and fields (3) carry most of the latter energy initially (20 ≲ Δt ≲ 40 ps), but transfer ~85% of it to radial ion motion (1) within 300 ps. The small jumps evident in curves (2)–(4) are nonphysical. They result from occasionally doubling macro-particle size and halving density as ionization increases particle number, in order to speed up the simulation.
Discussion
Nevertheless, some quantitative discrepancies remain. Early in Simulation 3 (100 < Δt < 600 ps), rB(Δt) grows faster (2 × 106 m/s) than observed (1.2 × 106 m/s), resulting in rB values at Δt ~ 600 ps nearly 50% larger than observed. Later (600 < Δt < 1200 ps), on the other hand, rB(Δt) grows more slowly (1.2 × 106 m/s) than observed (1.7 × 106 m/s), yielding rB values at Δt ~ 1200 ps that agree well with observations. Thus, radial expansion of simulated (observed) images decelerates (accelerates) during the simulated (observed) Δt interval.
There are several plausible reasons for these discrepancies. First, although incident drive bunches were thoroughly characterized, properties of the bunch after its trailing part focused inside the plasma (Fig. 3b) govern plasma expansion dynamics. Because plasma lensing is nonlinear, small errors in incident bunch properties can lead to large errors in focused bunch properties. For example, simulations assumed axisymmetric drive bunches, whereas ~10% asymmetries between σx and σy, and 10-fold differences between focusing functions βx and βy, were typically present at the plasma entrance, and could have led to asymmetric downstream focusing and plasma expansion. A second probe in an orthogonal plane would help to diagnose such expansion asymmetries, if present. Similarly, deviations in the longitudinal bunch shape from Gaussian, which were not well characterized, sensitively influence the intra-bunch position at which ionization and self-focusing begin, and in turn the fraction of incident bunch charge that drives a nonlinear wake. This can also lead to significant discrepancies between observed and simulated expansion rates.
In the later part of Simulation 3 (600 < Δt < 1200 ps), the radial slope ∂η/∂r of advancing refractive index profiles at the turning point radius shrinks rapidly (see Fig. 4f). As a result, simulated radii rB(Δt ≳ 900 ps) in Fig. 2f become sensitive to small perturbations in η(r) profiles, and by extension to small deviations in the radial profile of the focused drive bunch. Departures of the incident drive bunch radial profile from its assumed Gaussian shape prior to plasma focusing, and depletion or re-shaping of focused drive bunches for z > 30 cm, which are neglected in quasistatic LCODE simulations, are possible sources of such deviations. In addition, neglected drive bunch evolution within the ~100-cm probed region imprints left–right asymmetry onto probe images beyond that currently simulated.
These residual discrepancies indicate that detailed quantitative comparison of simulated and measured ns-scale plasma dynamics will require selected improvements to both experiment and simulation, as noted above. Nevertheless, the broad agreement obtained in the spatial and temporal scale of post-wakefield expansion validates the basic plasma/atomic physics on which Simulation 3 is based. Its output can thus elucidate additional internal properties of the expanding plasma beyond those that were directly observed.
An example is the plasma’s energy budget. According to Simulation 3, the fully focused drive bunch (Fig. 3b) deposits energy into the plasma at rate ~3.5 J/m (see Fig. 5c), in reasonable agreement with the average deposition rate (2.2 J/m) inferred from analysis of the spent drive bunch’s energy spectrum (Supplementary Fig. 2 and Supplementary Methods). The latter rate is expected to be lower than the former, since energy deposition peaks where the bunch fully focuses at z = 31.9 cm, and decreases thereafter as the drive bunch weakens, evolution that is not calculated here. Figure 5c shows additionally the first 0.6 ns of how deposited energy partitions and evolves over 1.3 ns, based on Simulation 3 results. Initially (Δt ≤ 1 ps), beyond the horizontal resolution of Fig. 5, most of the deposited energy is stored in electromagnetic fields of the electron wake, with a minor fraction stored in kinetic energy of coherently moving plasma electrons at the bubble boundary, as is typical for wide bubbles41. After the wave breaks (Δt ~ 1 ps, Fig. 3c), about 10% of deposited energy transforms to kinetic energy of fast electrons (see Fig. 5c, yellow) that diverge radially, some forming a tail wave42 visible in Fig. 3b. As the fastest electrons escape from the plasma, a radial charge separation field appears (see Figs. 3c and 5c, orange) that holds most remaining electrons within the plasma column14. In the first tens of ps (i.e. the range of OSIRIS simulations and the work in ref. 5), electron kinetic energy (light brown) and electric field energy (orange) comprise most of the plasma column’s energy. During the interval 30 < Δt < 300 ps, the charge separation field accelerates ions, which acquire most of the energy by Δt ~ 300 ps (Fig. 5c, dark brown). The fastest ions accelerate beyond 400 keV (i.e. v = 3.6 × 106 m/s). Overall 90% of the initially deposited energy remains in or near the plasma column. Similar confinement is expected for wakes in finite-radius pre-ionized columns. This contrasts with radially unbounded plasmas, in which fast electrons escape the heated region freely, cooling it to sub-keV temperatures within a few hundred wake periods16. Unbounded plasma, however, is impractical for colliders because of the enormous energy cost of producing it over hundreds of stages. Here, plasma energy and its partitioning among plasma species reach steady state for Δt > 300 ps, and change negligibly through the end of the Simulation 3 run at Δt = 1300 ps. This validates the experiment’s premise that the Li blanket records energy transport via ionization without noticeably depleting the energy of the ionizing radiation. It also indicates that the ~106 m/s expansion continues unabated well beyond Δt ≈ 1.3 ns.
In summary, results of this study have identified the principal physical mechanisms, and quantified the dominant dynamical pathways, by which highly nonlinear e-beam-driven wakes in finite-radius ne ~ 1017 cm−3 plasmas release their stored electrostatic energy into the surrounding medium. Time-resolved optical diffractometry measurements of the expanding plasma column, in particular, prompted recognition of the critical, previously unrecognized role of ion-mediated impact ionization in driving the plasma radius outward during the first nanosecond. The results also make clear that the plasma columns internal electrostatic fields, even after the original wake breaks, remain not only the principal propellant of outward ion motion, but the principal force responsible for retaining 90% of the wake’s initially deposited energy within the plasma column for over a nanosecond. The framework hereby established and validated provides a basis for modeling the global thermodynamics of multi-GeV plasma-wakefield accelerators, and for evaluating limits on their repetition rate. Relevant extensions of the experiments and simulations include investigations of laser-driven wakefield accelerators, and the use of varied probe geometries (e.g. larger θ) that will enable space- and time-resolved observation of the plasma column’s evolving internal structure.
Methods
Electron drive bunch characterization
The first 2 km of the SLAC linac delivered e-bunches to the FACET interaction region in sector 20. A series of eight-turn toroidal current transformers along the FACET beamline measured absolute charge of each bunch with 2% accuracy. A pair of stripline beam position monitors, configured to measure bunch charge43, positioned before and after the plasma, measured change in bunch charge with sub-% accuracy. No change was detected. A synchrotron-X-ray-based spectrometer measured the energy spectrum of each incident bunch non-invasively with ~0.1% resolution. An integrated transition radiation monitor and a transverse deflecting cavity, both located just upstream of the FACET interaction region, measured transverse (σx,y) and longitudinal (σz) dimensions, respectively, of bunches entering the plasma with ~10 μm resolution. We measured σx,y for every shot, σz for selected shots. By modeling the beam focusing optics, beam dimensions inside the interaction region were determined with similar accuracy. Beams incident on FACET typically had asymmetric emittance ϵx ≈ 10ϵy, so in order to have round beams with σr ≈ σx ≈ σy ≈ 30 μm at the entrance of the plasma, we focused the beam into the plasma with beta-functions βy ≈ 10βx. See ref. 44 for a detailed overview of FACET beam diagnostics.
Lithium source
Lithium was chosen for the accelerator medium because its low first ionization potential (5.4 eV) allows the drive bunch to singly field-ionize it easily over a 1.5 m path. A heat-pipe oven—consisting of a stainless steel cylindrical tube (length 2 m, inner radius 1.6 cm) heated along its center, and cooled at both ends—generated and confined the lithium gas. The vapor pressure of a melted lithium ingot loaded onto a stainless steel mesh ("wick”) lining the inner wall of the hot center generated gas of temperature-controlled density na. Helium buffer gas concentrated at the cold ends confined it longitudinally. The longitudinal density profile na(z) was deduced from the temperature profile T(z) along the length of the oven, measured by inserting a thermocouple probe into the heat pipe6,20. Thermocouple scans with our normal operating heating power of 1340 W yielded a 1.2-m-long central plateau of density na = 8.0 ± 0.2 × 1016 cm−3, with 0.15 m long density ramps at each end (see Supplementary Fig. 1). With the heat pipe in steady-state operating mode, we controlled overall Li density primarily by adjusting buffer gas pressure, and the length of the central density plateau by adjusting heater power.
Probe laser and imaging system
Probe pulses (~1 mJ energy, polarized in plane of incidence) were split from the 500 mJ, 50 fs output pulse train of a 10-TW Ti:S laser system24. Transverse probe intensity profiles contained hot spots, which were superposed on single-shot images (see Supplementary Fig. 3 and Supplementary Methods). Since hot-spots varied from shot to shot, while e-beam and plasma structures were comparatively stable, 30-shot averaging removed probe artifacts from the data, while sharpening details of shadow/fringe patterns (Fig. 1c) for quantitative analysis. Probe angle θ = 8 mrad was chosen to highlight the plasma column’s expanding edge, while satisfying space constraints at the ends of the heat-pipe oven, the only optical access to the plasma column. Supplementary Figure 4 compares paths of 0.8 μm wavelength probe rays through an idealized plasma column, similar to the actual one, for θ = 0.008, 0.02, and π/2 rad. For θ = 0.008 rad, probe rays sample only the plasma columns outer edge, as discussed in connection with main text (Fig. 2a–c). For θ = 0.02 rad, they penetrate to the plasma axis, enabling probing of interior structures. For θ = π/2 rad, probe rays are nearly un-deflected, rendering the plasma invisible. Transverse probe pulse width (w0 ≈ 0.4 cm), chosen to ensure nearly constant beam size through the heat pipe, enforced lower limit \({\theta }_{\min }\approx 0.007\) rad to avoid perturbing the e-beam driver with a probe injection mirror of radius πw0/2, and upper limit \({\theta }_{\max }\approx 0.012\) rad to avoid clipping the probe beam on the inner aperture (radius 1.6 cm) of the oven and heat transport pipe. A single-element lens (2-inch diameter, 1 m focal length) imaged probe pulses to 12-bit CCD camera (Allied Vision Technologies Model Manta G-095B, 1292 × 734 pixels, pixel size 4.08 × 4.08 μm).
Simulations
OSIRIS simulations of ionization and wake formation (Fig. 3a, b) used a moving simulation box of dimensions Lr × Lz = 564 × 940 μm, divided into 0.94 × 0.94 μm cells with 12 × 12 particles per cell. The ADK model of Li ionization that these simulations use is strictly valid only up to a critical field Ecrit ≈ 18.7 GV/m45, whereas fields as high as 30 GV/m are reached near the compressed part of the bunch. Nevertheless, the first level of Li is ionized in regions where the field is ≲Ecrit. Thus errors from the ADK approximation are negligible. The field at the boundary of ionized and neutral Li is 13 GV/m. To model ion motion (Fig. 3e) driven by electrostatic energy stored in the nonlinear electron wake (Fig. 3c, d), we switched to a static Lr × Lz = 0.940 × 3.025 mm simulation box in the Li density plateau divided into 0.47 × 1.21 μm cells with 10 × 10 particles per cell. Impact ionization of neutrals is small on a tens-of-ps time scale, and was not included in OSIRIS simulations.
For LCODE simulations, our simulation window extended laterally out to r = 9.4 mm, with grid size 0.19 μm. The initial plasma consisted of 5 × 104 equal-charge macro-particles of each type within a 40 μm radius, corresponding to an average of 250 particles per cell (ppc) per species. Because of cylindrical geometry, the number ranged from ~0 at the axis to ~500 ppc at r = 40 μm. As the plasma expanded and impact ionization proceeded, the number increased to >1000 ppc from r ≈ 80 μm to the plasma edge throughout most of the simulated time interval. These numbers are consistent with those used in convergence tests of other laser-plasma PIC codes32,33. We implemented elastic collisions via the Takizuka-Abe model34 modified to include relativistic particles32. Approximate cross-sections for electron- and ion-impact ionization came from refs. 35 and 36, respectively. Modeling of two-step ionization of lithium neutrals was based on excitation and ionization cross-sections from refs. 37,38. We developed a test to ensure that the Takizuka-Abe model implemented in LCODE accurately simulates deceleration of fast (few keV) electrons in the energy range of interest here (see Supplementary Methods). The test compares simulated average deceleration rate \(\langle{\dot{p}}_{z}\rangle\) with an analytic theoretical formula39 (see Supplementary Eq. (2)) for different probe electron energies Eprobe. Results, shown in Supplementary Fig. 5, show accurate correspondence between simulation and theory.
We simulated probe images (e.g. Fig. 1d–f) by numerically propagating a probe pulse (λ = 800 nm) at angle θ from the axis through a cylindrically symmetric column consisting of a mixture of atomic Li in 2S ground, and 2P, 3S, 3P excited states, plus singly-ionized Li plasma. We calculated the index of refraction ηi = ηi(ω, r, Δt) of atomic Li in each of the four states (i = 1, 2, 3, 4) at probe frequency ω = 2πc/λ, radius r, and time delay Δt from the Lorentz–Lorenz relation
where oscillator strengths fk, damping factors γk, and resonant frequencies ω0k, taken from spectroscopic data in ref. 46, are known with ±0.3% uncertainty. The refractive index of singly-ionized Li plasma was given a Drude form
LCODE simulations output partial density distributions Ni(r, Δt) (see Fig. 5a, b) and ne(r, Δt) (see Fig. 4e) required to finish calculating each index contribution ηi(r, Δt). We combined these, as shown in Supplementary Fig. 6, to obtain composite refractive index distributions
plotted in Fig. 4b, d, f.
Data availability
Experimental data were generated at SLAC’s FACET National User Facility. The authors declare that all data supporting the findings of this study are available within the paper and its Supplementary Information. Reasonable additional inquiries about the data should be directed to the corresponding author.
Code availability
The authors declare that all computer codes supporting the findings of this study are fully documented within the paper, its references, and its Supplementary Information. Information about OSIRIS, including access procedures, is available at https://picksc.idre.ucla.edu/software/software-production-codes/osiris/ and http://epp.tecnico.ulisboa.pt/osiris/. Information about LCODE is available at https://lcode.info/. Reasonable additional inquiries about the codes should be directed to J.V. (on behalf of the OSIRIS consortium) or K.V.L. (LCODE).
References
Tabak, M. et al. Review of progress in fast ignition. Phys. Plasmas 12, 057305 (2005).
Durfee, C. III, Lynch, J. & Milchberg, H. Development of a plasma waveguide for high-intensity laser pulses. Phys. Rev. E 51, 2368–2389 (1995).
Esarey, E., Schroeder, C. B. & Leemans, W. P. Physics of laser-driven plasma-based electron accelerators. Rev. Mod. Phys. 81, 1229–1285 (2009).
Sarkisov, G. S. et al. Self-focusing, channel formation, and high-energy ion generation in interaction of an intense short laser pulse with a He jet. Phys. Rev. E 59, 7042–7054 (1999).
Gilljohann, M. F. et al. Direct observation of plasma waves and dynamics induced by laser-accelerated electron beams. Phys. Rev. X 9, 011046 (2019).
Litos, M. et al. High-efficiency acceleration of an electron beam in a plasma wakefield accelerator. Nature 515, 92–95 (2014).
Corde, S. et al. Multi-gigaelectronvolt acceleration of positrons in a self-loaded plasma wakefield. Nature 524, 442–445 (2015).
Gonsalves, A. J. et al. Petawatt laser guiding and electron beam acceleration to 8 GeV in a laser-heated capillary discharge waveguide. Phys. Rev. Lett. 122, 084801 (2019).
Behnke, T. et al. The international linear collider technical design report - volume 1: Executive summary, EDMS Nr.: D00000001021135 Rev: A Ver: 1,http://ww2.linearcollider.org/ILC/Publications/Technical-Design-Report (2013).
Aicheler, M. et al. A Multi-TeV Linear Collider based on CLIC Technology: CLIC Conceptual Design Report (U.S. Department of Energy Office of Scientific and Technical Information, 2012).
Delahaye, J. P. et al. A beam driven plasma-wakefield linear collider: from Higgs factory to multi-TeV. In Proc. 2014 Internationl Particle Accelarator Conference, Dresden, Germany (2014).
Leemans, W. P. & Esarey, E. Laser-driven plasma-wave electron accelerators. Phys. Today 62, 44–49 (2009).
Gizzi, L. A. et al. Lasers for novel accelerators. J. Phys. Conf. Ser. 1350, 012157 (2019).
Lotov, K. V., Sosedkin, A. P. & Petrenko, A. V. Long-term evolution of broken wakefields in finite-radius plasmas. Phys. Rev. Lett. 112, 194801 (2014).
Vieira, J., Fonseca, R., Mori, W. B. & Silva, L. Ion motion in self-modulated plasma wakefield accelerators. Phys. Rev. Lett. 109, 145005 (2012).
Sahai, A. A. Excitation of a nonlinear plasma ion wake by intense energy sources with applications to the crunch-in regime. Phys. Rev. Accel. Beams 20, 081004 (2017).
De Pontieu, B. et al. The origins of hot plasma in the solar corona. Science 331, 55–58 (2011).
Stanev, T. High Energy Cosmic Rays 2nd edn (Praxis Publishing Ltd, Chichester, 2010).
Hogan, M. J. et al. Plasma wakefield acceleration experiments at FACET. New J. Phys. 12, 055030 (2010).
Muggli, P. et al. Photo-ionized lithium source for plasma accelerator applications. IEEE Trans. Plasma Sci. 27, 791–799 (1999).
Green, S. Z. et al. Plasma wakefield acceleration in self-ionized gas or plasmas. Phys. Rev. E 68, 047401 (2003).
Li, S. Z. et al. Head erosion and emittance growth in PWFA. AIP Conf. Proc. 1507, 582–587 (2012).
Vafaei-Najafabadi, N. et al. Limitation on accelerating gradient of a wakefield excited by an ultrarelativistic electron beam in rubidium plasma. Phys. Rev. Accel. Beams 19, 101303 (2016).
Green, S. Z. et al. Laser ionized preformed plasma at FACET. Plasma Phys. Control. Fusion 56, 084011 (2014).
Deng, A. et al. Electron bunch generation from a plasma photocathode. Nat. Phys. 15, 1156–1160 (2019).
Ralph, J. E. et al. Self-guiding of ultrashort, relativistically intense laser pulses through underdense plasmas in the blowout regime. Phys. Rev. Lett. 102, 175003 (2009).
Abdollahpour, D., Papazoglou, D. G. & Tzortzakis, S. Four-dimensional visualization of single and multiple laser filaments using in-line holographic microscopy. Phys. Rev. A 84, 053809 (2011).
Nye, J. Natural Focusing and Fine Structure of Light: Caustics and Wave Dislocations (IOP Publishing, Bristol and Philadelphia, 1999).
Zel’dovich, Y. B. & Raizer, Y. P. In Physics of Shock Waves and High-Temperature Hydrodynamic Phenomena (eds Hayes, W. C. & Probstein, R. F.) (Academic Press, New York, 1966).
Fonseca, R. A. et al. Exploiting multi-scale parallelism for large scale numerical modeling of laser wakefield accelerators. Plasma Phys. Control. Fusion 55, 124011 (2013).
Sosedkin, A. & Lotov, K. LCODE: a parallel quasistatic code for computationally heavy problems of plasma wakefield acceleration. Nucl. Instrum. Meth. Phys. Res. A 829, 350–352 (2016).
Pérez, F., Gremillet, L., Decoster, A., Drouin, M. & Lefebvre, E. Improved modeling of relativistic collisions and collisional ionization in particle-in-cell codes. Phys. Plasmas 19, 083104 (2012).
Arber, T. D. et al. Contemporary particle-in-cell approach to laser-plasma modeling. Plasma Phys. Control. Fusion 57, 113001 (2015).
Takizuka, T. & Abe, H. A binary collision model for plasma simulation with a particle code. J. Comp. Phys. 25, 205 (1977).
Younger, S. Electron impact ionization of lithium. J. Res. Natl Bur. Standards 87, 49–51 (1982).
Kaganovich, I. D., Startsev, E. & Davidson, R. C. Scaling and formulary of cross-sections for ion-atom impact ionization. N J. Phys. 8, 278 (2006).
ALADDIN numerical database. IAEA Nuclear Data Section A+M Unit. https://www-amdis.iaea.org/ALADDIN (2019).
Janev, R. K. et al. Atomic collision database for Li beam interaction with fusion plasmas. INDC (NDS)—267 Report (IAEA, Vienna, 1993).
Trubnikov, B. A. Particle interactions in fully ionized plasma. Rev. Plasma Phys. 1, 105–140 (1965).
Ammosov, M. V., Delone, N. B. & Krainov, V. P. Tunnel ionization of complex atoms and of atomic ions in an alternating electric field. Sov. Phys. JETP 64, 1191–1194 (1986).
Lotov, K. V. Blowout regimes of plasma wakefield acceleration. Phys. Rev. E 69, 046405 (2004).
Luo, J. et al. Dynamics of boundary layer electrons around a laser wakefield bubble. Phys. Plasmas 23, 103112 (2016).
Castorina, G. et al. Stripline beam position monitor modeling and simulations for charge measurements. Proc. Sixth International Beam Instrumentation Conference (2017).
Li, S. Z. & Hogan, M. J. Beam diagnostics for FACET. In Proc. 2011 Particle Accelrator Conference, New York, NY (2011).
Bruhwiler, D. L. et al. Particle-in-cell simulations of tunneling ionization effects in plasma-based accelerators. Phys. Plasmas 10, 2022 (2003).
Wiese, W. L. & Fuhr, J. R. Accurate atomic transition probabilities for hydrogen, helium, and lithium. J. Phys. Chem. Ref. Data 38, 565–719 (2009).
Acknowledgements
We acknowledge support from the U.S. Department of Energy (grants DE-SC0011617, DE-SC0014043 and SLAC contract DE-AC02-76SF00515), the U.S. National Science Foundation (grants PHY-1734319 and PHY-2010435), EU Horizon 2020 EuPRAXIA (grant 653782), FCT Portugal (grants PTDC/FIS-PLA/2940/2014 and SFRH/IF/01635/2015), computing time on GCS Supercomputer SuperMUC@LRZ, the Novosibirsk region government, and the Russian Foundation for Basic Research (Project 18-42-540001).
Author information
Authors and Affiliations
Contributions
R.Z. designed and installed the optical probing apparatus, with assistance from Z.L., and acquired and analyzed all experimental data. J.A., S.G., and M.L., under direction of M.J.H. and V.Y., provided logistical support that helped coordinate this experiment with other SLAC-FACET projects. T. S. and J. V. carried out OSIRIS simulations, and A.S., V.K.K. and K.V.L. LCODE simulations, of the experimental results. M.C.D. conceived, led, and acquired funding for the experiment, and wrote the paper in consultation with R.Z., M.J.H. and V.Y., and the simulation teams. All authors discussed the results and commented on the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Peer review information Nature Communications thanks Paul Bolton and the other, anonymous, reviewer(s) for their contribution to the peer review of this work. Peer reviewer reports are available.
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Zgadzaj, R., Silva, T., Khudyakov, V.K. et al. Dissipation of electron-beam-driven plasma wakes. Nat Commun 11, 4753 (2020). https://doi.org/10.1038/s41467-020-18490-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41467-020-18490-w
This article is cited by
-
Recovery of hydrogen plasma at the sub-nanosecond timescale in a plasma-wakefield accelerator
Communications Physics (2024)
-
Recovery time of a plasma-wakefield accelerator
Nature (2022)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
