
Abstract
The recent decline in energy, size and complexity scaling of traditional von Neumann architecture has resurrected considerable interest in brain-inspired computing. Artificial neural networks (ANNs) based on emerging devices, such as memristors, achieve brain-like computing but lack energy-efficiency. Furthermore, slow learning, incremental adaptation, and false convergence are unresolved challenges for ANNs. In this article we, therefore, introduce Gaussian synapses based on heterostructures of atomically thin two-dimensional (2D) layered materials, namely molybdenum disulfide and black phosphorus field effect transistors (FETs), as a class of analog and probabilistic computational primitives for hardware implementation of statistical neural networks. We also demonstrate complete tunability of amplitude, mean and standard deviation of the Gaussian synapse via threshold engineering in dual gated molybdenum disulfide and black phosphorus FETs. Finally, we show simulation results for classification of brainwaves using Gaussian synapse based probabilistic neural networks.
Similar content being viewed by others


Introduction
The last five decades have witnessed an unprecedented and exponential growth in computational power, primarily driven by the success of the semiconductor industry. Relentless scaling1 of complementary metal oxide semiconductor (CMOS) technology enabled by breakthroughs in material discovery2, innovation in device physics3, transformation in micro and nanolithography techniques4, and the triumph of von Neumann architecture5 contributed to the computing revolution. Scaling has three characteristic aspects to it. Energy scaling to ensure practically constant computational power budget, size scaling to ensure faster and cheaper computing since more and more transistors can be packed into the same chip area, and complexity scaling to ensure incessant growth in computational power of single on-chip processor. The golden era of metal oxide semiconductor field effect transistor (MOSFET) scaling, also referred to as the Dennard scaling era6, has witnessed concurrent scaling of all three aspects for almost three decades. However, around 2005, the energy scaling ended owing to fundamental thermodynamic limitations at the device physics level, popularly known as the Boltzmann tyranny7. Size scaling continued for another decade albeit with new challenges8 and eventually ended in 2017 owing to limitations at the materials level imposed by quantum mechanics1. Complexity scaling is also on decline owing to the non-scalability of traditional von Neumann computing architecture and the impending “Dark Silicon” era that presents a severe threat to multi-core processor technology9. In order to sustain the growth in computational power, it is imperative that all three aspects of scaling must be reinstated immediately through material rediscovery, device innovations, and advancement in higher complexity computing architectures.
The extraordinarily complex neurobiological architecture of the mammalian nervous system that seamlessly executes diverse and intricate functionalities such as adaption, perception, acquisition of sensory information, learning, memory formation, emotions, cognition, motor action, and many more has inspired computer scientists to think beyond the traditional von Neumann architecture in order to resurrect complexity scaling. The neural architecture deploys billions of information processing units, neurons, which are connected via trillions of synapses in order to accomplish massively parallel, synchronous, coherent, and concurrent computation. This is markedly different from the von Neumann architecture, where the logic and memory units are physically isolated and operate sequentially, i.e., instruction fetch and data operation cannot occur simultaneously. Furthermore, unlike the deterministic digital switches (logic transistors), neural architecture uses probabilistic and analog computational primitives in order to accomplish adaptive functionalities such as pattern recognition and pattern classification, which form the foundation for mammalian problem solving and decision making.
In the above context, IBM’s bioinspired CMOS chip, True North, is a remarkable breakthrough in neuromorphic computing, achieving the complexity of more than 1 million neurons or 256 million synapses while consuming a miniscule 70 mW of power10. Similarly, extensive work by Luca Benini et al. have recently shown that hardware digital neural networks consume comparable or less energy than the human brain for complex tasks, such as, image recognition11. While these are impressive advancements, the inherent scaling challenges associated with the digital CMOS technology can ultimately limit the implementation of very-large-scale artificial neural networks (ANNs), invoking the critical and imminent need for energy efficient analog computing primitives for ANNs. Recent years have, therefore, witnessed innovation in analog devices such as the memristors12,13,14, coupled oscillators15, and various targeted components16,17,18, which can emulate neural spiking, neural transmission, and neural plasticity and hence can be used as computational primitives in ANNs. While these devices do provide some energy benefit at the architectural level for specific applications, they fail to address the intrinsic energy and size scaling needs at the device level, which can ultimately lead to stagnation in complexity scaling. Further challenges associated with ANNs are often overlooked. For example, ANNs deployed for pattern classification problems require optimum training algorithms and learning rules to identify the class statistics with desired accuracy within a short training time. Unfortunately, the most popular and widely used heuristic backpropagation algorithm19, is inherently slow and remains vulnerable to local minima in spite of extensive modifications in recent years using methods such as conjugate gradient, quasi-Newton, and Levenberg–Marquardt (LM) to improve the convergence20. In order to address the slow learning, incremental adaptation, and inherent unreliability of ANNs, novel classification techniques based on statistical principles must be embraced.
In this article, we experimentally demonstrate how a new class of analog devices, namely, Gaussian synapses, based on the heterostructure of novel atomically thin two dimensional (2D) layered semiconductors enables the hardware implementations of probabilistic neural networks (PNNs) and thereby reinstates all three aforementioned quintessential scaling aspects of computing. In short, 2D materials facilitate aggressive size scaling, analog Gaussian synapses offer energy scaling, and PNNs enable complexity scaling. Combined, these new developments can facilitate Exascale Computing and ultimately benefit scientific discovery, national security, energy security, economic security, infrastructure development, and advanced healthcare programs21,22.
Results
Probabilistic neural network
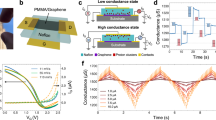
Our overall approach is summarized in Fig. 1a. First, we reintroduce PNN that was proposed by Specht, D. F.23 PNN is derived from Bayesian computing and Kernel density method24. As shown in Fig. 1b, unlike ANNs, which necessitate multiple hidden layers, each with a large number of nodes, PNNs are comprised of a pattern layer and a summation layer and can map any input pattern to any number of output classifications. Furthermore, ANNs use activation functions such as sigmoid, rectified linear unit (ReLU), and their various derivatives for determining pattern statistics. This is often extremely difficult to accomplish with reasonable accuracy for non-linear decision boundaries. PNNs, on the contrary, use parent probability distribution functions (PDFs) approximated by Parzen window25 and a non-parametric function to define the class probability, which in the case of Gaussian kernel is defined by Gaussian distribution as shown in Fig. 1c. PNNs, therefore, facilitate seamless and accurate classification of complex patterns with arbitrarily shaped decision boundaries. Furthermore, PNNs can be extended to map higher dimensional functions since multivariate Gaussian kernels are simply the product of univariate kernels as shown in Fig. 1d.

Gaussian Synapse based probabilistic neural network (PNN). a Resurrection of three quintessential scaling aspects of computation i.e., complexity scaling through PNNs, size scaling through atomically thin 2D materials and energy scaling through analog Gaussian synapses. b Schematic representation of PNN that comprise of a pattern layer and a summation layer for mapping any input pattern to any number of output classifications. c Gaussian probability density functions (PDFs) facilitating seamless and accurate classification of complex patterns with arbitrarily shaped decision boundaries. d Multivariate Gaussian kernel for mapping higher dimensional functions. e Schematic of two transistor Gaussian synapse based on heterogeneous integration of n-type MoS2 and p-type black phosphorus (BP) back-gated field effect transistors (FETs). The equivalent circuit diagram consists of two variable resistors connected in series. f Transfer characteristics i.e., the drain current (\(I_{\mathrm{D}}\)) versus back-gate voltage (\(V_{\mathrm{G}}\)) of the Gaussian synapse for different drain voltages (\(V_{\mathrm{D}}\)). Clearly, the experimental data (circles) can be modeled by Gaussian distributions (solid). g Transfer characteristics of p-type BP FET. h Transfer characteristics of n-type MoS2 FET
Unfortunately, in spite of the widespread applications and simplicity of PNNs, their hardware implementation is rather sparse. In fact, neither ANNs nor PNNs have been extensively realized using hardware components. While there is growing interest towards the development of devices for the hardware implementation of ANNs, the effort and investment towards the hardware implementation of PNNs are still very limited. One reason is that the hardware implementation of probability functions associated with the PNNs, such as the Gaussian, requires multicomponent digital CMOS circuits that leads to severe area and energy inefficiency. For example, the “Bump” circuit demonstrated by Delbruck, T. uses seven transistors26. Similarly, the Gaussian synapse proposed by Choi, J. et al. consists of a pair of differential amplifiers and several arithmetic computational units27. Madrenas, J. et al. introduced an alternate method to obtain Gaussian function by combining the exponential characteristics of MOSFETs in sub-threshold and square characteristics in inversion28. The circuit was further improved for better symmetry and greater control and tunability by adding more transistors in a floating gate configuration29,30. Another approach is to use a Gilbert Gaussian function, where two sigmoid curves are combined using a differential pair along with a current mirror31,32. Without any extra circuitry to reduce asymmetry, the most compact circuit uses five transistors28. As we will discuss in the following section, our experimental demonstration of Gaussian synapses uses only two transistors, which significantly improves the area and energy efficiency at the device level and provides cascading benefits at the circuit, architecture, and system levels. This will stimulate the much-needed interest in the hardware implementation of PNNs for a wide range of pattern classification problems.
Gaussian synapse
Figure 1e shows the schematic of our proposed two transistor Gaussian synapse based on heterogeneous integration of n-type molybdenum disulfide (MoS2) and p-type black phosphorus (BP) back-gated field effect transistors (FETs). Fig. 1e also shows the equivalent circuit diagram for the Gaussian synapse, which simply consists of two variable resistors in series. The two variable resistors, i.e., RMoS2 and RBP correspond to the MoS2 and BP FETs. Fig. 1f shows the experimentally measured transfer characteristics i.e., the drain current (ID) versus back-gate voltage (VBG) of the Gaussian synapse for different drain voltages (VD). The fabrication process flow and electrical measurement setup for Gaussian synapses are described in the experimental method section. Clearly, the transfer characteristics resemble a Gaussian distribution which can be modeled using the following equation.
Where, \(A, \mu_{\mathrm{V}}\) and \(\sigma _{\mathrm{V}}\) are, respectively, the amplitude, mean, and standard deviation of the Gaussian. For a specific MoS2/BP pair, \(\mu _{\mathrm{V}}\) and σV are found to be constants, whereas, A varies linearly with VD. The emergence of Gaussian transfer characteristics can be explained using the experimentally measured transfer characteristics of its constituents, i.e., the MoS2 FET and the BP FET, as shown in Fig. 1g, h, respectively. MoS2 FETs exhibit unipolar n-type characteristics, irrespective of the choice of contact metal, owing to the phenomenon of metal Fermi level pinning close to the conduction band that facilitates easier electron injection, whereas, BP FETs are predominantly p-type with large work function contact metals such as Ni33,34,35,36. Furthermore, unlike conventional enhancement mode Si FETs used in CMOS circuits, both MoS2 and BP FETs are depletion mode, i.e., they are normally ON without applying any back-gate voltage. Remarkably, this simple difference results in the unique Gaussian transfer characteristics for the MoS2/BP pair in spite of the device structure closely resembling a CMOS logic inverter. From the equivalent circuit diagram, the current (\(I_{\mathrm{D}}\)) through the Gaussian synapse can be written as:
For extreme \(V_{{\mathrm{BG}}}\) values, i.e., large negative (lesser than −30 V) and large positive (greater than 30 V), the MoS2 FET and the BP FET are in their respective OFF states, making the corresponding resistances, i.e., \(R_{{\mathrm{MoS}}_2}\) and \(R_{{\mathrm{BP}}}\) very large (approximately TΩ). This prevents any current conduction between the source and the drain terminal of the Gaussian synapse. However, as the MoS2 FET switches from OFF state to ON state, current conduction begins and increases exponentially with \(V_{{\mathrm{BG}}}\) following the subthreshold characteristics and reaches its peak magnitude determined by \(V_{\mathrm{D}}\). Beyond this peak, the current starts to decrease exponentially following the subthreshold characteristics of the BP FET. As a result, the series connection of the MoS2 and BP FETs exhibits non-monotonic transfer characteristics with exponential tails that mimics a Gaussian distribution.
It must be noted that the Gaussian synapses do not utilize the ON state FET performance and, therefore, are minimally influenced by the carrier mobility values of the n-type and p-type FETs. Instead, the Gaussian synapse exploits the sub-threshold FET characteristics, where the slope is independent of the carrier mobility of the semiconducting channel material. For symmetric Gaussian synapses, it is therefore more desirable to ensure similar sub-threshold slope (SS) values for the respective FETs than the carrier mobility. Ideally, the SS values for both FETs should be 60 mV decade−1. However, presence of a nonzero interface trap capacitance worsens the SS. The SS can be improved by minimizing interface states at the 2D/gate-dielectric interface, as well as by scaling the thickness of the gate dielectric. It is also desirable to have FETs with Ohmic contacts for Gaussian synapses to ensure that the SS is determined by the thermionic emission of carriers in order to reach the minimum theoretical value of 60 mV decade−1 at room temperature. For Schottky contact FETs, the SS can be severely degraded due to tunneling of carriers through the Schottky barrier.
While our proof-of-concept demonstration of Gaussian synapses is based on exfoliated MoS2 and BP flakes, it is well known that the micromechanical exfoliation is not a scalable manufacturing process for large-scale integrated circuits. Therefore, hardware implementation of PNNs using Gaussian synapses will necessitate large-area growth of MoS2 and BP. Fortunately, recent years have seen tremendous progress in wafer-scale growth of high quality MoS2 and BP using chemical vapor deposition (CVD) and metal organic chemical vapor deposition (MOCVD) techniques37,38,39,40,41. Furthermore, while we have used two different 2D materials, MoS2 and BP, for our demonstration of Gaussian synapses owing to their superior performance as n-type and p-type FETs, respectively, there are 2D materials, such as, WSe2, which offer ambipolar transport, i.e., the presence of both electron and hole conduction42 and can be grown over large area using CVD techniques43. However, the performance of WSe2 based n-type and p-type FETs are limited by the presence of large Schottky barriers at the metal/2D contact interfaces36. By resolving the contact resistance related issues36 and improving the quality of large-area synthesized WSe2, it is possible to implement Gaussian synapses based solely on WSe2 as well. Moreover, in recent years several groups have demonstrated p-type MoS2 and n-type BP, by implementing smart contact engineering and/or doping strategies44,45. Therefore, very-large-scale integration of Gaussian synapses based on a CVD grown single 2D material will be possible in the near future for the hardware realization of PNNs. Since the focus of this article is to introduce the novel Gaussian synapse and its benefit as a statistical computing primitive, we avoided material optimization.
Gaussian synapses are inherently low power since they exploit the subthreshold characteristics of the FET devices. In this context, we would like to remind the readers that the total power consumption (\(P_{{\mathrm{total}}}\)) in digital CMOS circuit comprises, primarily, of dynamic switching power (\(P_{{\mathrm{dynamic}}}\)) and static leakage power (\(P_{{\mathrm{static}}}\)) and is given by the following equation:
Note that, \(\eta\) is the activity factor, C is the capacitance of the circuit, f is the switching frequency, and \(V_{{\mathrm{DD}}}\) is the supply voltage. During the Dennard scaling era, the power consumption of the chip was dominated by \(P_{{\mathrm{dynamic}}}\), which was kept constant by scaling the threshold voltage (\(V_{{\mathrm{TH}}}\)) and concurrently the supply voltage (\(V_{{\mathrm{DD}}}\)) of the MOSFET. However, beyond 2005, the voltage scaling stalled since further reduction in \(V_{{\mathrm{TH}}}\) resulted in an exponential increase in the static leakage current (\(I_{{\mathrm{static}}}\)) and hence static power consumption. This is a direct consequence of the non-scalability of the subthreshold swing (SS) to below 60 mV decade−1, as determined by the Boltzmann statistics. In fact, \(P_{{\mathrm{total}}}\) in the present Dark-Si era is mostly dominated by \(P_{{\mathrm{static}}}\). Regardless of whether the dynamic or static power dominates, reinstating \(V_{{\mathrm{DD}}}\) scaling is the only way to escape the Boltzmann tyranny. This is why in recent years, subthreshold logic circuits, which utilize \(V_{{\mathrm{DD}}}\) that is close to or even less than \(V_{{\mathrm{TH}}}\), have received significant attention for ultra-low power applications46,47. New subthreshold logic and memory design methodologies have already been developed and demonstrated on a fast Fourier transform (FFT) processor48, as well as analog VLSI neural systems49.
Note that our proposed Gaussian synapses naturally require operation in subthreshold regime in order to exploit the exponential feature in the transfer characteristics of the n-type and p-type transistors. Furthermore, as shown in Fig. 1f, Gaussian synapses maintain their characteristic features even when the supply voltage (\(V_{{\mathrm{DS}}}\)) is scaled down to 200 mV or beyond. This allows the Gaussian synapses to be inherently low power. For the proof-of-concept demonstration of Gaussian synapses, we have used relatively thicker back-gate and top-gate oxides with respective thicknesses of 285 nm and 120 nm. This necessitates the use of rather large back-gate and top-gate voltages in the range of −50 V to 50 V and −35 V to 35 V, respectively. The power consumption by our proof-of-concept Gaussian synapses will still be high in spite of scaling the supply voltage and exploiting the subthreshold current conduction in the range of nano amperes through the MoS2 and BP FETs. This is because power consumption by Gaussian synapse is simply the area under the \(I_{\mathrm{D}}\) versus \(V_{{\mathrm{BG}}}\) curve. By scaling the thicknesses of both the top and bottom gate dielectrics, it is possible to scale the operating gate voltages and thereby achieve desirable power benefits from the Gaussian synapses. Ultra-thin dielectric materials such as Al2O3 and HfO2, which offer much larger dielectric constants, \(\varepsilon _{{\mathrm{ox}}}\), of ≈9 and 25, respectively, are now routinely used as gate oxides for highly scaled Si FinFETs50. It must also be emphasized that the use of atomically thin 2D materials allows geometric miniaturization of Gaussian synapses without any loss of electrostatic integrity, which aids size scaling. We would like to remind the readers that the scalability of FETs is captured through a simple parameter called the screening length (\(\lambda _{{\mathrm{SC}}} = \sqrt {\frac{{\varepsilon _{{\mathrm{body}}}}}{{\varepsilon _{{\mathrm{ox}}}}}t_{{\mathrm{body}}}t_{{\mathrm{ox}}}}\)), which determines the decay of the potential (band bending) at the source/drain contact interface into the semiconducting channel. In this expression, \(t_{{\mathrm{body}}}\) and \(t_{{\mathrm{ox}}}\) are the thicknesses and \(\varepsilon _{{\mathrm{body}}}\) and \(\varepsilon _{{\mathrm{ox}}}\) are the dielectric constants of the semiconducting channel and the insulating oxide, respectively. As discussed by Frank et al.51, to avoid short channel effects the channel length of an FET (\(L_{{\mathrm{CH}}}\)) has to be at least three times higher than the screening length (\(\lambda _{{\mathrm{SC}}}\)). For atomically thin semiconducting monolayers of 2D materials,\(t_{{\mathrm{body}}}\) is 0.6 nm, which corresponds to \(\lambda _{{\mathrm{SC}}}\) of 1.3 nm, whereas, for the most advanced FinFET technology the thickness of Si fins can be scaled down to only 5 nm without severely increasing the bandgap due to quantum confinement effects and reducing the mobility due to enhanced surface roughness scattering. Nevertheless, the above discussions, clearly articulate how BP/MoS2 2D heterostructure based Gaussian synapses can facilitate effortless hardware realization of PNNs and thereby aid complexity scaling without compromising energy and size scaling.
Reconfigurable Gaussian synapse
For the hardware implementation of Gaussian synapses, it is highly desirable to demonstrate complete tunability of the device transfer function, i.e., \(A,\,\mu _{\mathrm{V}}\), and \(\sigma _{\mathrm{V}}\) of the Gaussian distribution. This could be achieved, seamlessly, in our device structure via threshold engineering through additional gating of either or both MoS2 and BP FETs. Fig. 2a shows the schematic representation of a reconfigurable Gaussian synapse, where, both MoS2 and BP FETs are dual-gated (DG). The top-gate stack was fabricated using hydrogen silsesquioxane (HSQ)52,53 as the top-gate dielectric with nickel/gold (Ni/Au) as the top-gate electrode. The fabrication process flow is described in the experimental method section. Fig. 2b shows the experimentally measured back-gated transfer characteristics of the MoS2 FET at \(V_{\mathrm{D}}\) = 1 V for different top-gate voltages (\(V_{\mathrm{N}}\)). Clearly, \(V_{\mathrm{N}}\) controls the back-gate threshold voltage, \(V_{{\mathrm{TN}}}\) of the MoS2 FET as shown in Fig. 2c. The energy band diagram shown in the inset of Fig. 2c can be used to explain the concept of threshold voltage engineering using gate electrostatics. The top-gate voltage determines the height of the potential barrier for electron injection inside the MoS2 channel, which must be overcome by applying a back-gate voltage to enable current conduction from the source to the drain terminal. Negative top-gate voltages increase the potential barrier for electron injection and hence necessitate larger positive back-gate voltages to achieve similar level of current conduction. As such, \(V_{{\mathrm{TN}}}\) becomes more positive (less negative) for large negative \(V_{\mathrm{N}}\) values. Note that the slope (\(\alpha _{\mathrm{N}}\)) of \(V_{{\mathrm{TN}}}\) versus \(V_{\mathrm{N}}\) in Fig. 2c must be proportional to the ratio of top-gate capacitance (\(C_{{\mathrm{TG}}}\)) to the back-gate capacitance (\(C_{{\mathrm{BG}}}\)). This follows directly from the principle of charge balance, which ensures that the channel charge induced by the top-gate voltage must be compensated by the back-gate voltage at threshold. We extracted the value for \(\alpha _{\mathrm{N}}\) to be 1.91. This is consistent with the theoretical prediction of approximately 1.94, given that the top-gate and back-gate dielectric thicknesses are 120 nm and 285 nm, respectively and the top-gate insulator, HSQ, has a slightly lower dielectric constant (≈3.2) than the back-gate insulator, SiO2 (3.9). Fig. 2d shows the experimentally measured back-gated transfer characteristics of the BP FET at \(V_{\mathrm{D}}\) = 1 V, for different top-gate voltages (\(V_{\mathrm{P}}\)). As expected, \(V_{\mathrm{P}}\) controls the back-gate threshold voltage, \(V_{{\mathrm{TP}}}\) of the BP FET as shown in Fig. 2e. Here, the top-gate voltage influences the height of the potential barrier for hole injection, which is overcome by applying a back-gate voltage, enabling current conduction from the drain to the source terminal. The corresponding energy band diagram is shown in the inset of Fig. 2e. Positive top-gate voltages increase the potential barrier for hole injection and hence necessitate larger negative back-gate voltages to achieve similar level of current conduction. As such, \(V_{{\mathrm{TP}}}\) becomes more negative (less positive) for large positive \(V_{\mathrm{P}}\) values. We also extracted the slope (\(\alpha _{\mathrm{P}}\)) of \(V_{{\mathrm{TP}}}\) versus \(V_{\mathrm{P}}\) in Fig. 2e and, as expected, found a similar value of ≈2.

Reconfigurable Gaussian synapse. a Schematic of a reconfigurable Gaussian synapse involving dual-gated n-type MoS2 FET and p-type BP FET. The top-gate stack was fabricated using hydrogen silsesquioxane (HSQ) as the top-gate dielectric and nickel/gold (Ni/Au) as the top-gate electrode. b Back-gated transfer characteristics of the MoS2 FET at \(V_{\mathrm{D}}\) = 1 V, for different top-gate voltages (\(V_{\mathrm{N}}\)). c Back-gate threshold voltage, \(V_{{\mathrm{TN}}}\) of MoS2 FET as function of \(V_{\mathrm{N}}\) was extracted using the constant current method. Inset shows the band diagram elucidating how \(V_{\mathrm{N}}\) controls \(V_{{\mathrm{TN}}}\) by electrostatically adjusting the height of the thermal energy barrier for electron injection into the MoS2 channel. d Back-gated transfer characteristics of the BP FET at \(V_{\mathrm{D}}\) = 1 V, for different top-gate voltages (\(V_{\mathrm{P}}\)). e Back-gate threshold voltage, \(V_{{\mathrm{TP}}}\) of BP FET as function of \(V_{\mathrm{P}}\). Inset shows the band diagram elucidating how \(V_{\mathrm{P}}\) controls \(V_{{\mathrm{TP}}}\) by electrostatically adjusting the height of the thermal energy barrier for hole injection into the BP channel. As expected the slope (\(\alpha _{\mathrm{N}} = 1.91\)) of \(V_{{\mathrm{TN}}}\) versus \(V_{\mathrm{N}}\) and the slope (\(\alpha _{\mathrm{P}} = 2\)) of \(V_{{\mathrm{TP}}}\) versus \(V_{\mathrm{P}}\) are found to be similar and equal to the ratio of top-gate capacitance (\(C_{{\mathrm{TG}}}\)) to the back-gate capacitance (\(C_{{\mathrm{BG}}}\)), which in our case was ≈1.94. f Transfer characteristics of the Gaussian synapse for different values of \(V_{\mathrm{N}} = V_{\mathrm{P}}\). This configuration allows us to shift the mean (\(\mu _{\mathrm{V}}\)) of the Gaussian synapse without changing the amplitude (A) and the standard deviation (\(\sigma _{\mathrm{V}}\)). g \(\mu _{\mathrm{V}}\) as a function of \(V_{\mathrm{N}} = V_{\mathrm{P}}\). h Transfer characteristics of the Gaussian synapse for different values of \(V_{\mathrm{N}} = - V_{\mathrm{P}}\). This configuration allows us to configure \(\sigma _{\mathrm{V}}\) while keeping \(\mu _{\mathrm{V}}\) constant. i \(\sigma _{\mathrm{V}}\) as a function of \(V_{\mathrm{N}} = - V_{\mathrm{P}}\). However, this configuration also results in an increase in the amplitude (A) of the Gaussian synapse as \(\sigma _{\mathrm{V}}\) increases. This increase can be adjusted by changing the drain voltage (\(V_{\mathrm{D}}\)) since A is linearly proportional to \(V_{\mathrm{D}}\). Nevertheless, by controlling \(V_{\mathrm{N}},V_{\mathrm{P}}\) and VD, it is possible to adjust the mean, standard deviation and amplitude of the Gaussian synapse
The dual-gated MoS2 and BP FETs allow complete control of the shape of the Gaussian synapse. Fig. 2f shows the experimentally measured transfer characteristics of the Gaussian synapse for different values of \(V_{\mathrm{N}} = V_{\mathrm{P}}\). This configuration allows us to shift the mean (\(\mu _{\mathrm{V}}\)) of the Gaussian synapse without changing the amplitude (A) or the standard deviation (\(\sigma _{\mathrm{V}}\)) Fig. 2g shows \(\mu _{\mathrm{V}}\) plotted as a function of \(V_{\mathrm{N}} = V_{\mathrm{P}}\). We are able to do this since the back-gate threshold voltages for both MoS2 and BP FETs shift in the same direction in this configuration. Similarly, Fig. 2h shows the experimentally measured transfer characteristics of the Gaussian synapse for different values of \(V_{\mathrm{N}} = - V_{\mathrm{P}}\). Under this configuration, the back-gate threshold voltages for MoS2 and BP FETs shift in opposite directions. As such the \(\mu _{\mathrm{V}}\) of the Gaussian distribution remains constant, whereas, \(\sigma _{\mathrm{V}}\) keeps increasing. Fig. 2i shows \(\sigma _{\mathrm{V}}\) plotted as a function of \(V_{\mathrm{N}} = - V_{\mathrm{P}}\). However, this configuration also results in an increase in the amplitude (A) of the Gaussian synapse as \(\sigma _{\mathrm{V}}\) increases. This increase can be adjusted by changing the drain voltage (\(V_{\mathrm{D}}\)) since A is linearly proportional to VD. Nevertheless, by controlling \(V_{\mathrm{N}},V_{\mathrm{P}}\), and VD, it is possible to adjust the mean, standard deviation, and amplitude of the Gaussian synapse.
Scaled Gaussian synapses
In order to project the performance of scaled Gaussian synapses, we used the Virtual Source (VS) model that was originally developed by Khakifirooz, A. et al. for short channel Si MOSFETs54. for short channel Si MOSFETs. The Gaussian transfer characteristics (\(I_{\mathrm{D}}\) versus \(V_{\mathrm{G}}\) for different VD) were simulated in the following Eqs. 4, 5, and 6. In the VS model, both the subthreshold and the above threshold behavior is captured through a single semi-empirical and phenomenological relationship that describes the transition in channel charge density from weak to strong inversion (Eq. 5).
Here, RN and RP are the resistances, \(L_{\mathrm{N}}\) and LP are the lengths, \(W_{\mathrm{N}}\) and WP are the widths, μN and μP are the carrier mobility values, and \(Q_{\mathrm{N}}\) and QP are the inversion charges corresponding to the n-type and the p-type 2D-FETs, respectively. The band movement factor m can assumed to be unity for a fully depleted and ultra-thin body 2D-FET with negligible interface trap capacitance. Finally, VTN and VTP are the threshold voltages of the n-type and p-type 2D FETs determined by their respective top-gate voltages VN and VP. Note, that in the subthreshold regime, the inversion charges i.e., \(Q_{\mathrm{N}}\) and \(Q_{\mathrm{P}}\) increase exponentially with \(V_{\mathrm{G}}\), whereas above threshold, the inversion charge is a linear function of VG, which is seamlessly captured through the VS model. Fig. 3a, b show the simulated transfer characteristics of the individual n-type and p-type 2D FETs, respectively, and Fig. 3c shows the transfer characteristics of the Gaussian synapse based on their heterostructure for different combinations of the top-gate voltages, following the VS model, as described above. Furthermore, Fig. 3d–f, respectively, demonstrate the tunability of \(A,\mu _{\mathrm{V}}\), and \(\sigma _{\mathrm{V}}\) of the Gaussian synapse via top-gate voltages \(V_{\mathrm{N}}\) and \(V_{\mathrm{P}}\). More details on the design of Gaussian synapses can be found in the supplementary information section.

Scaled Gaussian Synapses. Simulated back-gated transfer characteristics of (a) n-type and (b) p-type 2D FET for corresponding different top-gate voltages VN and VP, respectively, using the Virtual Source (VS) model. In the VS model, both the subthreshold and the above threshold behavior are captured through a single semi-empirical and phenomenological relationship that describes the transition in channel charge density from weak to strong inversion. c Transfer characteristics, (d) amplitude, (e) mean, and (f) standard deviation of the Gaussian synapse obtained via heterogeneous integration of the n-type and the p-type 2D FETs for different combinations of VN and VP. The following parameters were used for the simulation. \(L_{\mathrm{N}} = L_{\mathrm{P}} = 1\, {{\upmu}} {\mathrm{{m}}}\); \(W_{\mathrm{N}} = W_{\mathrm{P}} = 2\,{{\upmu}} {\mathrm{m}}\);\({\upmu}_{\mathrm{N}} = {\upmu}_{\mathrm{P}} = 20\,{\mathrm{cm}}^2\left( {{\mathrm{Vs}}} \right)^{ - 1}\);\(C_{{\mathrm{BG}}} = 7 \times 10^{ - 3}{\mathrm{F}}\,{\mathrm{m}}^{ - 2}\); M = 1; α = 1; VD = 1 V
Brainwave classification
Next, we show simulation results suggesting that PNNs based on Gaussian synapses can be used for the classification of various neural oscillations, also known as the brainwaves that are fundamental to human awareness, cognition, emotions, and actions. These rhythmic and repetitive oscillations that originate from synchronous and complex firing of neural ensembles are observed throughout the central nervous system and are essential in controlling the neuro-physiological health of any individual. As shown in Fig. 4a, the brainwaves are divided into five frequency bands based on the present understanding and interpretation of their functions. Lower frequency (0.5–3.5 Hz) and higher amplitude delta waves (δ) are generated during deepest meditation and dreamless sleep, suspending all external awareness and facilitating healing and regeneration. Disruptions in δ-wave activity can lead to neurological disorders such as dementia, schizophrenia, parasomnia, epilepsy, and Parkinson’s disease. Low frequency (4–8 Hz) and high amplitude theta waves (θ) originate during sleep or deep meditation with senses withdrawn from the external world and focused within. Normal firing of θ-waves enables learning, memory, intuition, and introspection, while excessive activity can lead to attention-deficit/hyperactivity disorder (ADHD). Mid-frequency (8–14 Hz) and mid-amplitude alpha waves (α) represent the resting state of the brain and facilitate mind/body coordination, mental peace, alertness, and learning. High frequency (16–32 Hz) and low amplitude beta waves (β) dominate the wakeful state of consciousness, direct our concentration towards cognitive tasks such as problem solving and decision-making, and at the same time consume a tremendous amount of energy. In clinical context, β-waves can be used as biomarkers as they indicate the release of gamma aminobutyric acid, the principal inhibitory neurotransmitter in the mammalian nervous system. Finally, gamma waves (γ) are the fastest (32–64 Hz) and quietest brain waves. These waves were dismissed as neural noise until recently, when researchers discovered the connection to greater consciousness and spiritual activity culminating in the state of universal love and altruism55. The above discussion clearly shows the immense importance of brainwaves in regulating our daily experience. Instabilities in brain rhythm can be catastrophic, leading to insomnia, narcolepsy, panic attacks, obsessive-compulsive disorder, agitated depression, hyper-vigilance, and impulsive behaviors. Early diagnosis of abnormal brainwave activity through neural networks can help prevent chronic neuro diseases and mental and emotional disorders.

Recognition of Brainwaves using Gaussian Mixture Model (GMM). a Brainwaves are divided into five frequency bands. 0.5–3.5 Hz: Delta waves (δ), 4–8 Hz: Theta waves (θ), 8–14 Hz: Alpha waves (α), 16–32 Hz: Beta waves (β) and 32–64 Hz: Gamma waves (γ). Normalized power spectral density (PSD) as a function of frequency for each type of brainwaves, extracted using the Fast Fourier Transform (FFT) of the time domain Electroencephalography (EEG) data (sequential montage) with increasing sampling times that correspond to sample sizes of (b) N = 512, (c) N = 2560, and (d) N = 6400. As the training set becomes more and more exhaustive, the discrete frequency responses evolve into continuous spectrums. The highly nonlinear functional dependence of the PSDs on frequency for each type of brainwave can be classified using GMM, which is represented as the weighted sum of a finite number of scaled (different variance) and shifted (different mean) normal distributions. e Root mean square error (RMSE) as a function of K, i.e., the number of Gaussian used in the GMMs for each type of brainwave. Clearly, a very limited number of Gaussian synapses are necessary to capture the non-linear decision boundaries
Figure 4b, c, and 4d show the frequency pattern of the normalized power spectral density (PSD) for each type of brainwaves, extracted from the Fast Fourier Transform (FFT) of the time domain Electroencephalography (EEG) data (sequential montage) with increasing sampling times that correspond to sample sizes of N = 512, 2560, and 6400, respectively. Clearly, as the training set becomes more and more exhaustive, the discrete frequency responses corresponding to each type of brainwave evolve into continuous spectrums that show complex patterns. Furthermore, the system is highly nonlinear with functional dependence of the PSDs on frequency being rather complicated for each type of brainwave. As such, classification of brainwave patterns using conventional ANNs, can be challenging56,57,58. In addition, ANNs require optimum training algorithms and extensive feature extraction and preprocessing of the training sample in order to achieve reasonable accuracy. In contrast, as demonstrated in Fig. 4d, the PNN adopts single pass learning by defining the class PDF for each of the brainwave pattern in the frequency domain using Gaussian mixture model (GMM)59,60. GMM is represented as the weighted sum of a finite number of scaled (different variance) and shifted (different mean) normal distributions as described by Eq. 2.
A GMM with K components is parameterized by two types of values, the component weights (\(\psi _i\)) and the component means (\(\mu _i\)) and variances (\(\sigma _i^2\)) with the constraint that \(\mathop {\sum }\limits_{i = 1}^K \psi _i = 1\), so that the total probability distribution normalizes to unity. For each type of brainwave pattern, the GMM parameters for the K component were estimated from the training data corresponding to N = 25,600, using the non-linear least square method. Figure 4e shows root mean square errors (RMSEs) calculated as a function of K, i.e., the number of Gaussian curves used in the corresponding GMMs. Clearly, a very limited number of Gaussian functions are necessary to capture the non-linear decision boundary for each of the brainwaves. This enormously reduces the energy and size constraint for the PNNs based on Gaussian synapses.
Finally, Fig. 5a shows simulation results evaluating the PNN architecture for the detection of new brainwave patterns. The PNN consists of 4 layers: input, pattern, summation, and output. The amplitude of the new FFT data is relayed from the input layer to the pattern layer as the drain voltage (\(V_{\mathrm{D}}\)) of the Gaussian synapses, whereas, the frequency range (0–64 Hz) is mapped to the back-gate voltage (\(V_{\mathrm{G}}\)) range. The summation layer integrates the current over the full swing of VG from the individual pattern blocks and communicates with the winner-takes-it-all (WTA) circuit that allows the output layer to recognize the brainwave patterns. We implemented our PNN architecture on 10 whole-night polysomnographic recordings, obtained from 10 healthy subjects in a sleep laboratory using a digital 32-channel polygraph (details can be found in the method section). The percentage of different brainwave components as recognized by the PNN are shown as a color map in Fig. 5b. As expected, the PNN recognizes the dominant presence of delta and theta waves in the sleep samples. Furthermore, Fig. 5c shows the total power consumption (details can be found in the supplementary information section) by the PNN as a function of the supply voltage (\(V_{{\mathrm{DD}}}\)) and sample volume (N). As expected, the power dissipation scales with N and VDD. Interestingly, even for a large sample volume of N = 2 × 105, corresponding to 8 h of EEG data, the power consumption by the proposed PNN architecture was found to be as frugal as 3 μW for \(V_{{\mathrm{DD}}} = 0.1\,{\mathrm{V}}\), which increases to only 350 μW for \(V_{{\mathrm{DD}}} = 1.0\,{\mathrm{V}}\). A direct comparison of power dissipation with digital CMOS will be premature at this time, especially since the peripheral circuits required for the proposed PNN architecture will add power dissipation overhead. Nevertheless, these preliminary results show that the PNN architectures based on Gaussian synapses can offer extreme energy efficiency.

PNN Architecture for Brainwave Recognition. a The PNN consists of 4 layers: input, pattern, summation, and output. The amplitude of the FFT data is relayed from the input layer to the pattern layer as drain voltage (\(V_{\mathrm{D}}\)) of the Gaussian synapses, whereas, the frequency range (0–64 Hz) is mapped to the back-gate voltage (\(V_{\mathrm{G}}\)) range. The summation layer integrates the current over the full swing of VG from the individual pattern blocks and communicates with the winner-takes-it-all (WTA) circuit that allows the output layer to recognize the brainwave patterns. b Implementation of PNN Architecture: 10 whole-night polysomnographic recordings and the corresponding outcome of the PNN architecture shown using a color map. The PNN recognizes the dominant presence of delta and theta waves in all the sleep samples. c Power Consumption by PNN Architecture: The total power consumption by the PNN as a function of the supply voltage (\(V_{{\mathrm{DD}}}\)) and sample volume (NSAMPLE). As expected, the power dissipation scales with NSAMPLE and VDD
Discussion
In conclusion, we have demonstrated reconfigurable Gaussian synapses based on the heterostructure of atomically thin 2D layered semiconductors as a new class of analog and probabilistic computational primitives that can reinstate both energy and size scaling aspects of computation. Furthermore, we elucidated how Gaussian synapses enable direct hardware realization of PNNs, which offer simple and effective solutions to a wide range of pattern classification problems and thereby resurrect complexity scaling. Finally, we show simulation results suggesting that PNN architecture based on Gaussian synapses is capable of recognizing complex neural oscillations or brainwave patterns from large volumes of EEG data with extreme energy efficiency. We believe that these findings will foster the much-needed interest in hardware implementation of PNNs and ultimately aid high performance and low power computing infrastructure.
Methods
Device fabrication and measurements
MoS2 and BP flakes were micromechanically exfoliated on 285 nm thermally grown SiO2 substrates with highly doped Si as the back-gate electrode. The thicknesses of the MoS2 and BP flakes were in the range of 3–20 nm. MoS2 is a 2D layered material with the lattice parameters a = 3.15 A°, b = 3.15 A°, c = 12.3 A°, α = 90°, β = 90°, and γ = 120°. The layered nature due to van der Waals (vdW) bonding results in a higher value for c. This enables mechanical exfoliation of the material to obtain ultra-thin layers of MoS2. BP exhibits a puckered honeycomb lattice structure. It has phosphorous atoms existing on two parallel planes. The lattice parameters are given by a = 3.31 A°, b = 10.47 A°, c = 4.37 A°, α = 90°, β = 90°, and γ = 90°. The Source/Drain contacts were defined using electron-beam lithography (Vistec EBPG5200). Ni (40 nm) followed by Au (30 nm) was deposited using electron-beam (e-beam) evaporation for the contacts. Both devices were fabricated with a channel length of 1 µm. The width of the MoS2 and BP devices were 0.78 µm and 2 µm, respectively. The top-gated devices were fabricated with hydrogen silsesquioxane (HSQ) as the top-gate dielectric. The top-gate dielectric was deposited by spin coating 6% HSQ in methyl isobutyl ketone (MIBK) (Dow Corning XR-1541–006) at 4000 rpm for 45 s and baked at 80 °C for 4 min. The HSQ was patterned using an e-beam dose of 2000 µC cm−2 and developed at room temperature using 25% tetramethylammonium hydroxide (TMAH) for 30 s following a 90 s rinse in deionized water (DI). Next, the HSQ was cured in air at 180 °C and then 250 °C for 2 min and 3 min, respectively. The thickness of the HSQ layer, used as the top-gate dielectric was 120 nm. Top-gate electrodes with Ni (40 nm) followed by Au (30 nm) were patterned with the same procedure as the source and drain contacts. Given the instability of BP, we took special care to ensure minimal exposure time to the air while fabricating BP devices by storing the material in vacuum chambers between different fabrication steps. In addition, all the three lithography steps involved in the device fabrication were done within a period of 3 days. The electrical characterizations were obtained at room temperature in high vacuum (≈10–6 Torr) a Lake Shore CRX-VF probe station and using a Keysight B1500A parameter analyzer.
EEG data
The data used for our study were obtained from the DREAMS project, which were acquired in a sleep laboratory of a Belgium hospital using a digital 32-channel polygraph (BrainnetTM System of MEDATEC, Brussels, Belgium). They consist of whole-night polysomnographic recordings, coming from healthy subjects. At least two EOG channels (P8—A1, P18—A1), three EEG channels (CZ—A1 or C3—A1, FP1—A1, and O1—A1), and one submental EMG channel were recorded. The standard European Data Format (EDF) was used for storing. The sampling frequency was 200 Hz. These recordings have been specifically selected for their clarity (i.e., that they contain few artifacts) and come from persons, free of any medication, volunteers in other research projects, conducted in the sleep lab.
Data availability
The data that support the plots within this paper and other findings of this study are available from the corresponding authors upon reasonable request.
Code availability
The codes used for data analysis are available from the corresponding authors upon request.
References
Frank, D. J. et al. Device scaling limits of Si MOSFETs and their application dependencies. Proc. IEEE 89, 259–288 (2001).
Thompson, S. E. & Parthasarathy, S. Moore's law: the future of Si microelectronics. Mater. Today 9, 20–25 (2006).
Sze, S. M. & Sze, S. Modern Semiconductor Device Physics. (Wiley, New York, 1998).
Ma, X. & Arce, G. R. Computational Lithography. Vol. 77 (John Wiley & Sons, 2011).
Myers, G. J. Advances in Computer Architecture. (John Wiley & Sons, Inc., 1982).
Dennard, R. H., Gaensslen, F. H., Rideout, V. L., Bassous, E. & LeBlanc, A. R. Design of ion-implanted MOSFET's with very small physical dimensions. IEEE J. Solid-St Circ. 9, 256–268 (1974).
Meindl, J. D., Chen, Q. & Davis, J. A. Limits on silicon nanoelectronics for terascale integration. Science 293, 2044–2049 (2001).
Yu, B. et al. in Electron Devices Meeting. IEDM'02 International. 251–254 (IEEE, 2002).
Esmaeilzadeh, H., Blem, E., Amant, R. S., Sankaralingam, K. & Burger, D. in Computer Architecture (ISCA) 38th Annual International Symposium on ISCA. 365–376 (IEEE, 2011).
Merolla, P. A. et al. A million spiking-neuron integrated circuit with a scalable communication network and interface. Science 345, 668–673 (2014).
Benini, L. & Micheli, Gd System-level power optimization: techniques and tools. ACM Trans. Des. Autom. Electron. Syst. 5, 115–192 (2000).
Pickett, M. D., Medeiros-Ribeiro, G. & Williams, R. S. A scalable neuristor built with Mott memristors. Nat. Mater. 12, 114 (2013).
Prezioso, M. et al. Training and operation of an integrated neuromorphic network based on metal-oxide memristors. Nature 521, 61 (2015).
Wang, Z. et al. Memristors with diffusive dynamics as synaptic emulators for neuromorphic computing. Nat. Mater. 16, 101–108 (2017).
Baldi, P. & Meir, R. Computing with arrays of coupled oscillators: an application to preattentive texture discrimination. Neural Comput. 2, 458–471 (1990).
Arnold, A. J. et al. Mimicking neurotransmitter release in chemical synapses via hysteresis engineering in MoS2 Transistors. ACS Nano 11, 3110–3118 (2017).
Tian, H. et al. Anisotropic black phosphorus synaptic device for neuromorphic applications. Adv. Mater. 28, 4991–4997 (2016).
Jiang, J. et al. 2D MoS2 neuromorphic devices for brain-like computational systems. Small 13, 1700933 (2017).
Dreiseitl, S. & Ohno-Machado, L. Logistic regression and artificial neural network classification models: a methodology review. J. Biomed. Inform. 35, 352–359 (2002).
Hagan, M. T. & Menhaj, M. B. Training feedforward networks with the Marquardt algorithm. IEEE Trans. Neural Netw. 5, 989–993 (1994).
Bergman, K. et al. Exascale computing study: technology challenges in achieving exascale systems. Defense Advanced Research Projects Agency Information Processing Techniques Office (DARPA IPTO), Techical Report 15 (2008).
Reed, D. A. & Dongarra, J. Exascale computing and big data. Commun. ACM 58, 56–68 (2015).
Specht, D. F. Probabilistic neural networks. Neural Netw. 3, 109–118 (1990).
Besag, J., Green, P., Higdon, D. & Mengersen, K. Bayesian computation and stochastic systems. Stat. Sci. 10, 3–41 (1995).
Schløler, H. & Hartmann, U. Mapping neural network derived from the Parzen window estimator. Neural Netw. 5, 903–909 (1992).
Delbruck, T. Bump circuits for computing similarity and dissimilarity of analog voltages. IEEE IJCNN, A475–A479 (1991).
Choi, J., Sheu, B. J. & Chang, J. C. F. A Gaussian synapse circuit for analog vlsi neural networks. 1994 IEEE Int. Symp . Circuits Syst. 6, F483–F486 (1994).
Madrenas, J., Verleysen, M., Thissen, P. & Voz, J. L. A CMOS analog circuit for Gaussian functions. IEEE Trans. Circuits-Ii 43, 70–74 (1996).
Lin, S. Y., Huang, R. J. & Chiueh, T. D. A tunable Gaussian/square function computation circuit for analog neural networks. IEEE Trans. Circuits Syst. Ii-Analog Digit. Signal Process. 45, 441–446 (1998).
Srivastava, R., Singh, U. & Gupta, M. Analog circuits for Gaussian function with improved performance. In Analog circuits for Gaussian function with improved performance 934–938 (IEEE, 2011).
Kang, K. & Shibata, T. An on-chip-trainable Gaussian-Kernel analog support vector machine. IEEE Trans. Circuits-I 57, 1513–1524 (2010).
Wu, N. et al. A real-time and energy-efficient implementation of difference-of-Gaussian with flexible thin-film transistors. IEEE Comp. Soc. Ann. 455–460 https://doi.org/10.1109/Isvlsi.2016.87 (2016).
Das, S., Chen, H. Y., Penumatcha, A. V. & Appenzeller, J. High performance multilayer MoS2 transistors with scandium contacts. Nano Lett. 13, 100–105 (2013).
Das, S., Demarteau, M. & Roelofs, A. Ambipolar phosphorene field effect transistor. ACS nano 8, 11730–11738 (2014).
Das, S., Robinson, J. A., Dubey, M., Terrones, H. & Terrones, M. Beyond graphene: progress in novel two-dimensional materials and van der Waals Solids. Annu Rev. Mater. Res 45, 1–27 (2015).
Schulman, D. S., Arnold, A. J. & Das, S. Contact engineering for 2D materials and devices. Chem. Soc. Rev. 3037–3058 (2018).
Andrzejewski, D. et al. Improved luminescence properties of MoS2 monolayers grown via MOCVD: role of pre-treatment and growth parameters. Nanotechnology 29, 295704 (2018).
Nguyen, T. K. et al. High photoresponse in conformally grown monolayer MoS2 on a rugged substrate. ACS Appl. Mater. Interfaces 10, 40824–40830 (2018).
Smithe, K. K. H., Suryavanshi, S. V., Munoz Rojo, M., Tedjarati, A. D. & Pop, E. Low variability in synthetic monolayer MoS2 devices. ACS Nano 11, 8456–8463 (2017).
Zhang, J. et al. Scalable growth of high-quality polycrystalline MoS(2) monolayers on SiO(2) with tunable grain sizes. ACS Nano 8, 6024–6030 (2014).
Smith, J. B., Hagaman, D. & Ji, H. F. Growth of 2D black phosphorus film from chemical vapor deposition. Nanotechnology 27, 215602 (2016).
Das, S. & Appenzeller, J. WSe2 field effect transistors with enhanced ambipolar characteristics. Appl. Phys. Lett. 103, 103501 (2013).
Zhang, X. et al. Defect-controlled nucleation and orientation of WSe2 on hBN: a route to single-crystal epitaxial monolayers. ACS Nano. https://doi.org/10.1021/acsnano.8b09230 (2019).
Chuang, S. et al. MoS2 p-type transistors and diodes enabled by high work function MoO x contacts. Nano Lett. 14, 1337–1342 (2014).
Perello, D. J., Chae, S. H., Song, S. & Lee, Y. H. High-performance n-type black phosphorus transistors with type control via thickness and contact-metal engineering. Nat. Commun. 6, 7809 (2015).
Wang, A., Calhoun, B. H. & Chandrakasan, A. P. in Sub-threshold Design for Ultra Low-Power Systems (Series on Integrated Circuits and Systems). (Springer-Verlag, 2006).
Hanson, S., Seok, M., Sylvester, D. & Blaauw, D. Nanometer device scaling in subthreshold logic and SRAM. IEEE Trans. Electron Devices 55, 175–185 (2008).
Wang, A. & Chandrakasan, A. A 180-mV subthreshold FFT processor using a minimum energy design methodology. IEEE J. Solid-St. Circ. 40, 310–319 (2005).
Andreou, A. G. et al. Current-mode subthreshold MOS circuits for analog VLSI neural systems. IEEE Trans. Neural Netw. 2, 205–213 (1991).
Wallace, R. M. & Wilk, G. D. High-κ dielectric materials for microelectronics. Crit. Rev. Solid State Mater. Sci. 28, 231–285 (2003).
Frank, D. J., Taur, Y. & Wong, H.-S. P. Generalized scale length for two-dimensional effects in MOSFETs. Electron Device Lett. IEEE 19, 385–387 (1998).
Nasr, J. R. & Das, S. Seamless fabrication and threshold engineering in monolayer MoS2 dual-gated transistors via hydrogen silsesquioxane. Adv. Electron. Mater. 5, 1800888 (2019).
Nasr, J. R., Schulman, D. S., Sebastian, A., Horn, M. W. & Das, S. Mobility deception in nanoscale transistors: an untold contact story. Adv. Mater. 31, 1806020 (2019).
Khakifirooz, A., Nayfeh, O. M. & Antoniadis, D. A simple semiempirical short-channel MOSFET current–voltage model continuous across all regions of operation and employing only physical parameters. IEEE Trans. Electron Devices 56, 1674–1680 (2009).
Rubik, B. Neurofeedback-enhanced gamma brainwaves from the prefrontal cortical region of meditators and non-meditators and associated subjective experiences. J. Altern. Complement. Med. 17, 109–115 (2011).
Nakayama, K., Kaneda, Y. & Hirano, A. A Brain Computer Interface Based on FFT and multilayer neural network - feature extraction and generalization. International Symposium on ISPACS'07 826–829 (IEEE, 2007).
Nakayama, K. & Inagaki, K. A Brain Computer Interface Based on Neural Network with Efficient Pre-Processing. International Symposium on ISPACS'06 673–676 (IEEE, 2006).
Subasi, A. & Ercelebi, E. Classification of EEG signals using neural network and logistic regression. Comput. Methods Prog. Biomed. 78, 87–99 (2005).
Zivkovic, Z. An Improved Moving Object Detection Algorithm Based on Gaussian Mixture Models. Proceedings of the 17th International Conference on Pattern Recognition (ICPR) 28–31 (IEEE, 2004).
Reynolds, D. Gaussian mixture models. Ency. Biometrics 827–832 (2015).
Acknowledgements
The authors would like to acknowledge the contribution of Joseph R Nasr, Harikrishnan Ravichandran, Harikrishnan Jayachandrakurup, and Sarbashis Das for their help in device fabrication. This work was partially supported through Grant Number FA9550–17–1–0018 from Air Force Office of Scientific Research (AFOSR) through the Young Investigator Program.
Author information
Authors and Affiliations
Contributions
S.D. conceived the idea, designed the experiments and wrote the paper. A.S., S.S.R., and A.P. performed the experiments. All authors analyzed the data, discussed the results, agreed on their implications, and contributed to the preparation of the paper.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Peer Review Information Nature Communications thanks Qing Wan, Su-Ting Han and other, anonymous, reviewers for their contribution to the peer review of this work. Peer reviewer reports are available.
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Sebastian, A., Pannone, A., Subbulakshmi Radhakrishnan, S. et al. Gaussian synapses for probabilistic neural networks. Nat Commun 10, 4199 (2019). https://doi.org/10.1038/s41467-019-12035-6
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41467-019-12035-6
This article is cited by
-
Tunable anti-ambipolar vertical bilayer organic electrochemical transistor enable neuromorphic retinal pathway
Nature Communications (2024)
-
Overcoming the Limits of Cross-Sensitivity: Pattern Recognition Methods for Chemiresistive Gas Sensor Array
Nano-Micro Letters (2024)
-
An all 2D bio-inspired gustatory circuit for mimicking physiology and psychology of feeding behavior
Nature Communications (2023)
-
Ultra-low power neuromorphic obstacle detection using a two-dimensional materials-based subthreshold transistor
npj 2D Materials and Applications (2023)
-
A bio-inspired visuotactile neuron for multisensory integration
Nature Communications (2023)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
