
Abstract
The problem of the genetics of related phenotypes is often addressed by analyzing adjusted-model traits, but such traits warrant cautious interpretation. Here, we adopt a joint view of adiposity traits in ~322,154 subjects (GIANT consortium). We classify 159 signals associated with body mass index (BMI), waist-to-hip ratio (WHR), or WHR adjusted for BMI (WHRadjBMI) at P < 5 × 10−8, into four classes based on the direction of their effects on BMI and WHR. Our classes help differentiate adiposity genetics with respect to anthropometry, fat depots, and metabolic health. Class-specific Mendelian randomization reveals that variants associated with both WHR-decrease and BMI increase are linked to metabolically rather favorable adiposity through beneficial hip fat. Class-specific enrichment analyses implicate digestive systems as a pathway in adiposity genetics. Our results demonstrate that WHRadjBMI variants capture relevant effects of “unexpected fat distribution given the BMI” and that a joint view of the genetics underlying related phenotypes can inform on important biology.
Similar content being viewed by others

Introduction
Genome-wide association studies (GWAS) have become a well-established and very successful approach to understand the genetic background of disease phenotypes. However, for our understanding of the underlying mechanisms, it is an important challenge to disentangle the genetics of related phenotypes. Frequently, this is approached by using an adjusted-model trait where the trait Y is adjusted for a covariate Z (YadjZ) in order to separate the genetics of YadjZ from the genetics of Z. However, these adjusted-model traits warrant cautious interpretation: as Aschard and colleagues pointed out, genome scans for traits adjusted for heritable covariates reveal not only genetic factors for the phenotype Y, but also those of the covariate Z to an extent that depends on their correlation1.
We exemplify this issue on adiposity traits that were also utilized by Aschard and colleagues1: BMI and WHR are correlated and capture two aspects of adiposity, overall fat mass, and fat distribution, respectively. Both are independently associated with type 2 diabetes (T2D), coronary artery disease (CAD), and mortality2. The phenotypic correlation between BMI and WHR and the biological mechanisms linking these two measures hamper the distinction of their genetic make-up3,4. Recently, meta-analyses by the GIANT consortium highlighted hundreds of associated loci for BMI, WHR, and WHRadjBMI5,6, whereas BMI and WHRadjBMI loci were shown to depict different biological processes (neuronal versus metabolic), a direct comparison of the loci was lacking.
Aschard and colleagues pointed out that some of the WHRadjBMI lead variants were not completely independent of BMI and showed some effect on BMI in the unexpected direction (WHR increasing allele decreased BMI). This is due to the fact that the genetic effect estimate for WHRadjBMI, bWHRadjBMI, is related to the estimate for WHR, bWHR, and the estimate for BMI, bBMI, by bWHRadjBMI = bWHR – r * bBMI, with r being the observational correlation between BMI and WHR in the analyzed study1. A genome-wide scan on WHRadjBMI will thus not only identify genetic factors for WHR, but will also tend to pick up variants with an additional opposite effect on BMI, or even an effect on BMI only when the sample size is large enough. Aschard and colleagues extended their point by cautioning against potentially false positive signals and biased genetic effect estimates. They propose to examine the potential of the bias by investigating the corrected effect bWHRadjBMI + r * bBMI to ensure that an established WHRadjBMI-association is not biased by the BMI-association.
Therefore, the genome screening of adjusted-model traits in general, and WHRadjBMI in particular, has been criticized1 for its potential to yield biased estimates and spurious associations. As a consequence, it is a current concern whether adjusted-model trait loci like WHRadjBMI loci can reveal meaningful biological information or whether they represent uninterpretable artefacts. We thus investigated the genetic variants that are associated genome-wide with BMI, WHR, or WHRadjBMI in the GIANT data5,6 with regard to their co-association with BMI and WHR and the link of this co-association to metabolic health and pathways. We find that the joint view of the genetic variants across all three of the adiposity traits helps differentiate adiposity subtypes with distinct fat depots and distinct metabolic implications. Furthermore, the joint view helps resolve some of the issues that derive from conducting GWAS on adjusted-model traits.
Results
Little contribution of the WHR genomic screen
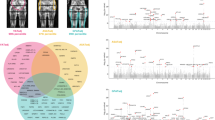
In order to define a set of adiposity-associated variants as the basis of our investigation, we selected variants that showed European ancestry based genome-wide significant association (P < 5 × 10−8) with any of the three adiposity traits, BMI, WHR, and WHRadjBMI from the GIANT consortium (up to N = 322,135, see Methods)5,6. This yielded 159 independent lead variants ( > 500kB or r2 < 0.1): 102, 38, or 53 variants genome-wide significant for BMI, WHR, or WHRadjBMI, respectively. We found a substantial overlap of WHR-derived variants (i.e., variants that are genome-wide significant for WHR) with BMI- or WHRadjBMI-derived variants (genome-wide significant for BMI or WHRadjBMI, respectively), with four being exclusive to the WHR-scan, but no overlap between BMI- and WHRadjBMI-derived variants (Fig. 1, Supplementary Data 1). Thus, the WHRadjBMI-derived variants contributed independently from BMI-derived variants in the GIANT data, whereas the WHR-derived variants contributed little beyond.

Identification of 159 signals from three genomic scans. The Venn diagram shows the number of independent genome-wide significant (P < 5 × 10−8) signals derived from the BMI−, the WHR−, or the WHRadjBMI-scan, respectively, and their overlap. We found no overlap between BMI- and WHRadjBMI-derived variants
WHRadjBMI captures relevant aspects of fat distribution
Whether or not a genetic variant has “an expected effect on WHR given the BMI effect” (i.e., as expected by the phenotypic correlation r, e.g. r = 0.5 in the population-based CoLaus study7) or “an unexpected effect” can be determined by evaluating the variant’s co-association with BMI and WHR: the co-association of the 159 variants is visualized in a plane spanned by the genetic effects on WHR and BMI, i.e., bWHRvs. bBMI (Fig. 2a). Variants with a null effect on WHRadjBMI are those with an observed WHR effect to the extent and direction as expected given the variant’s BMI effect and the phenotypic correlation r (located on the line bWHR = r*bBMI, with r = 0.5, gray dashed line); this is in line with a notion of “an expected change in fat distribution given the change in BMI”. Variants with a non-null effect on WHRadjBMI will be those distant from the WHRadjBMI null line. This includes variants with a WHR effect but no effect on BMI, variants with a WHR effect into the opposite direction as their BMI effect, variants with effects on WHR larger than expected from the BMI effect (“supra-expected”), or even BMI effects with no effect on WHR. All are in line with a notion that the observed WHR effect is unexpected given the variant’s BMI effect. We hypothesized important insights from a detailed view of these variants’ position on the bWHR−bBMI-plane and the link of this position to physiology and pathology.

Classification of 159 signals and overlap by scan. The figure visualizes the classification of the 159 independent signals according to the position on the bWHR-bBMI-plane and their overlap by scan. a The Scatter plot shows the 159 variants on the bWHR-bBMI-plane, where bWHR and bBMI are the variant’s effect on WHR and BMI, respectively. Coloring indicates the four classes: BMI + WHR + (blue, nominal significant effects on BMI and WHR with consistent directions), BMIonly + (green, nominal significant effects on BMI only), WHRonly− (purple, nominal significant effects on WHR only) and BMI + WHR− (red, nominal significant effects on BMI and WHR with opposite directions). Symbols indicate a nominal significance purely for BMI (PBMI < 0.05, PWHR ≥ 0.05, upward triangle), purely for WHR (PBMI ≥ 0.05, PWHR < 0.05, downward triangle), or for both (PBMI < 0.05, PWHR < 0.05, stars). The dashed line indicates a null effect for WHRadjBMI (bWHRadjBMI = 0, estimated as bWHR = r*bBMI, with the correlation between BMI and WHR estimated from the population-based CoLaus study, r = 0.50). b The diagram shows the number of identified signals per class, illustrates the four classes in directed acyclic graphs and shows Venn diagrams per class to distinguish whether the signals were derived with genome-wide-significance by the BMI−, the WHR− or the WHRadjBMI-scan, or by multiple scans. The underlined numbers reflect the 53 genome-wide significant signals identified by the WHRadjBMI-scan
Classifying the 159 adiposity variants
We classified the 159 variants according to their location on the bWHR−bBMI-plane (Fig. 2a). We considered an effect as a non-null effect for BMI or WHR, when the effect was nominally significantly different from zero (PBMI < 0.05, PWHR < 0.05, respectively), corresponding to an uncertainty of beta-estimates given by a 95% confidence interval, and as a null effect otherwise. We defined the following four classes: (1) BMI and WHR effects in the same direction (PBMI < 0.05, PWHR < 0.05; BMI + WHR + ), (2) BMI only effects (PBMI < 0.05, PWHR ≥ 0.05; BMIonly + ), (3) WHR only effects (PWHR < 0.05, PBMI ≥ 0.05; WHRonly−), (4) BMI and WHR effects into opposite directions (PBMI < 0.05, PWHR < 0.05; BMI + WHR−). Of note, the WHR effects that were directionally consistent with the BMI effect, but larger than expected (“supra-expected”) were classified as BMI + WHR + . This classification resulted in 82, 25, 28, or 24 variants for each of the four classes, respectively (Fig. 2a,b).
We found the following: (i) of the 159 variants, the 53 WHRadjBMI-derived variants were all in the BMI + WHR− or WHRonly− class (Fig. 2b, Supplementary Fig. 1), except two variants near ANKRD55 and CALCRL with supra-expected WHR effect (BMI + WHR + class). All 53 WHRadjBMI-derived variants were orthogonally distant from the WHRadjBMI null line and can be considered effects of “unexpected change in fat distribution given the effect on BMI”. (ii) The 102 BMI-derived variants were all in the BMI + WHR + or BMIonly + class (Fig. 2b, Supplementary Fig. 1). They scattered closely around the WHRadjBMI null line with some exceptions in the BMIonly + class and are thus, mostly, in line with a notion of a change in fat distribution that is expected given the effect on BMI. (iii) The 38 WHR-derived variants were spread across the classes BMI + WHR + , WHRonly−, or BMI + WHR− (Fig. 2b, Supplementary Fig. 1); the four variants exclusively identified by the WHR-scan were BMI + WHR + or WHRonly−.
We made further important observations regarding the WHRadjBMI-derived variants: (iv) All 53 WHRadjBMI-derived variants had nominally significant effects on WHR (PWHR < 0.05, i.e., no spurious associations, weakest WHR association observed in GIANT PWHR = 7.5 × 10−3, Supplementary Data 1). (v) Of the 53 WHRadjBMI-derived variants, 27 had no effect on BMI (PBMI ≥ 0.05), 24 had a nominally significant effect on BMI (PBMI < 0.05) into the opposite direction. Therefore, WHRadjBMI-derived variants cannot be considered as “independent of BMI”.
We conducted two types of sensitivity analyses. First, we re-classified the variants based on different P-value thresholds instead of the nominal significance level (Supplementary Data 1). A more stringent threshold at P < 3 × 10−4 ( = 0.05/159, Bonferroni-corrected) resulted in 36 of the 53 WHRadjBMI-derived variants retaining the class, 11 variants changing from BMI + WHR− to WHRonly−, and six just missing the PWHR < 3 × 10−4 in the GIANT data (one with BMI effect PBMI < 3 × 10−4, five without any effect). However, these six variants showed a significant association with WHR in the independent UK Biobank data (PWHR < 3 × 10−4, N = 336,107, PWHR ranging from 9.95 × 10−21 to 6.29 × 10−6, Supplementary Data 2). Of note, all 53 WHRadjBMI-derived variants showed a significant WHR association in the UK Biobank data (PWHR < 3 × 10−4, Supplementary Data 2). This supports the notion that none of the WHRadjBMI-derived variants from the GIANT data was a spurious association without effect on WHR.
Second, as WHRadjBMI is known for sexually dimorphic genetic effects8,9, we also conducted a sensitivity analysis re-classifying the 53 WHRadjBMI variants based on their sex-specific effects on WHR and BMI (i.e., women-specific or men-specific classification). Among those, 11 variants showed significant sex-difference in the genetic effect on WHRadjBMI in our data (PSexdiff < 0.05/53). Among those, the 10 variants with women-specific effects retained class in the women-specific, but not in the men-specific classification; similarly, the one variant with men-specific effect retained class in the men-specific, but not in the women-specific classification. For all other variants there was no remarkable pattern by the re-classification for sex-specific effects (Supplementary Data 3).
Generally, with a few exceptions, our classification resulted in splitting the BMI-derived loci into two groups (BMI + WHR + , BMIonly + ), and splitting the WHRadjBMI-derived loci into two groups (BMI + WHR−, WHRonly−).
Computing WHR effect from observed BMI and WHRadjBMI effects
When bWHRadjBMI and bBMI are given for a variant, bWHR can be computed as bWHRadjBMI + r*bBMI (or bWHRadjBMI as bWHR−r*bBM). We aimed to provide empirical data of how good this computation works by comparing the bWHR estimates computed as described above with the observed bWHR (Fig. 3). When conducting this comparison in one study where we could estimate r directly (interim UK Biobank, N = 116,295, r = 0.44), we found perfect agreement between computed and observed bWHR (Spearman correlation coefficient= 0.98). When conducting this comparison in a meta-analysis setting where r could not be estimated directly (i.e., in GIANT, using r from UK Biobank as a reasonable average across GIANT studies), we found still a strong agreement (Spearman correlation coefficient = 0.88). We were able to improve this agreement even further by using sex-stratified correlation estimates (from UK Biobank, r = 0.46 for women, 0.60 for men, Spearman correlation coefficient > 0.99) and sex-stratified effect estimates (from GIANT, Spearman correlation coefficient = 0.95). Therefore, the formula bWHR = bWHRadjBMI + r*bBMI can very well be used to compute unadjusted estimates from adjusted estimates and BMI estimates; the corresponding standard errors are, however, slightly increased yielding lower power (Supplementary Note 1, Supplementary Fig. 2). As a consequence, for consortia working with obesity traits, such as GIANT5,6, the number of genome-wide traits to be modeled can be limited to two traits as the effect estimate from the third trait can be re-computed with a small loss in precision.

Comparison of estimated and computed WHR effect sizes. The figure shows a comparison of effect sizes and standard errors for the 38 genome-wide significant WHR-derived lead variants. Using data from the UK Biobank (UKBB, N = 116,295) as a single large study, we compare estimated overall (sex-combined) WHR effects in UKBB data with a computed WHR effects that were calculated from overall BMI and WHRadjBMI effects in UKBB using the overall correlation between WHR and BMI (r = 0.44, in UKBB); and with b WHR effects that were obtained from meta-analysis of computed sex-specific WHR effects that were calculated from sex-specific BMI and WHRadjBMI effects in UKBB using sex-specific correlations (rM = 0.60, rF = 0.46 in UKBB). Using GIANT meta-analysis summary statistics, we compare meta-analyzed overall WHR effects (resulting from meta-analysis of multiple studies) with c computed WHR effects that were calculated from meta-analyzed overall BMI and WHRadjBMI effects using the overall correlation between WHR and BMI (r = 0.44, in UKBB), and with d WHR effects that were obtained from meta-analysis of computed sex-specific WHR effects that were calculated from meta-analyzed sex-specific BMI and WHRadjBMI effects using sex-specific correlations (rM = 0.60, rF = 0.46 in UKBB)
Anthropometry, fat depots, and cardio-metabolic health
We were interested in whether the four classes characterized meaningful phenotypes with regard to anthropometry, fat depots, and cardio-metabolic health. We thus derived genetic effects of our 159 variants for such measures from genetic consortia and UK Biobank (see Methods, Supplementary Data 4–7). Effects were aligned for BMI-increasing alleles, where appropriate, and for WHR-decreasing alleles for WHRonly− consistent with BMI + WHR− (resulting in an alignment for hip-increasing alleles in all four classes).
First, when evaluating the 159 variants’ co-associations on the components of WHR and BMI, waist and hip circumference, weight, and height (GIANT data, up to N = 253,239), we found a clear separation of the four classes (Fig. 4a–b, Supplementary Data 4). This was supported by enrichment and meta-regression based genetic risk score (GRS) analyses (PBinomial < 3.0 × 10−4, Table 1, PGRS < 8.3 × 10−4, Supplementary Table 1, see Methods). Thus, the variants’ two-dimensional co-association with BMI and WHR effectively summarizes the 2 × 2 co-associations on (height, weight) and (waist circumference, hip circumference). The class-specific view on the variants’ co-association on hip and waist circumference revealed that BMI + WHR + and BMIonly + variants were hip and waist-increasing, WHRonly− variants were enriched for hip increase and waist decrease, and the BMI + WHR− variants were enriched for hip-increasing effects that lacked effects on waist circumference (Table 1). Our results underscore the dual cause for WHR-decreasing effects: decreased waist or increased hip circumference—the role of hip being missed when focusing on “central adiposity” (Supplementary Fig. 3–4; Supplementary Note 2).

Anthropometry, fat depots and cardio-metabolic traits. The figure shows the co-associations for the 159 variants for pairs of traits (from GIANT, DIAGRAM15, GLGC16, MAGIC17, CARDIoGRAMplusC4D18): a waist circumference (WC) and hip circumference (HIP), b weight (WT) and height (HT), c visceral adipose tissues (VAT) and subcutaneous adipose tissue (SAT), d type 2 diabetes (T2D) and coronary artery disease (CAD), e fasting insulin (FI) and triglycerides (TG). Coloring indicates the four classes: BMI + WHR + (blue), BMIonly + (green), WHRonly− (purple), and BMI + WHR− (red). Symbols indicate nominal significance for y axis trait only (downward triangle), the x axis trait only (upward triangle), or both (stars). In a, the dashed line indicates a null effect for WHR (slope estimated as bWC/bHIP = mean(WHR), mean(WHR) = 0.88 from CoLaus); in b, the dashed line indicates the null effect for BMI (slope estimated as bWT/bHT = 2*mean(height)*mean(BMI)*SD(height)/SD(WT) = 0.54, using estimates from CoLaus)
Second, we were interested in the variants’ impact on more elaborate measures of fat depots including centrally stored visceral adipose tissue (VAT), subcutaneous adipose tissue (SAT) that is ubiquitously stored with a preference at hip and thigh10,11,12, and pericardial adipose tissue (PAT), which is a VAT-type fat stored in/around the heart13. We evaluated the 159 genetic variants’ association on measures derived by bioelectrical impedance (body fat, trunk fat, leg fat; UK Biobank, N up to 114,367) or imaging techniques (SAT, VAT, PAT, VAT/SAT ratio; Ectopic Fat Traits consortium14, N up to 18,312; Supplementary Data 5, 6). The visualization of the co-association of VAT and SAT was less conclusive (Fig. 4c), whereas enrichment and GRS analyses elucidated a distinct pattern by class (PBinomial < 3.0 × 10−4, PGRS < 8.3 × 10-4, Table 1, Supplementary Table 1) linking BMI + WHR + to VAT and SAT, BMIonly− and BMI + WHR− only to SAT, and WHRonly− to VAT/SAT ratio.
Third, we evaluated the effects of the 159 variants on eight cardio-metabolic traits (DIAGRAM15, GLGC16, MAGIC17, CARDIoGRAMplusC4D18, up to N = 187,135, Supplementary Data 7). The co-associations on T2D and CAD (Fig. 4d) showed a clear pattern for increasing or decreasing disease risk for the two “extreme” classes BMI + WHR + or BMI + WHR−, respectively, but a rather neutral or inconclusive pattern for BMIonly + (except for the known extreme disease effect of TCF7L2 into the opposite direction as expected by the BMI effect) and WHRonly−. This was supported by enrichment and GRS analyses (PBinomial < 3.0 × 10−4, Table 1, PGRS < 8.3 × 10−4, Supplementary Table 1). The joint impact of the class-specific variants on T2D and CAD was substantial and markedly different: the joint BMI + WHR + alleles increased T2D or CAD risk 2.5- or 1.5-fold, respectively; the joint BMI + WHR− alleles decreased T2D risk to a relative risk of 0.10 and CAD risk to 0.43 (Fig. 5). We found a consistent pattern for fasting insulin, triglycerides, and HDL-cholesterol (HDL-C, BMI + WHR + : adverse, BMI + WHR−: protective, Fig. 4e, Table 1, Supplementary Table 1). Overall, the four classes differentiate genetic adiposity effects into metabolically unfavorable (BMI + WHR + ), metabolically neutral or inconclusive (BMI only, WHR only), and metabolically rather favorable adiposity (BMI + WHR−) with some exceptions.

Different disease implications. Shown are the class-specific variants’ co-associations for BMI and T2D or CAD (from DIAGRAM15and CARDIoGRAMplusC4D18) and the meta-regression line that can be interpreted as the association of the genetic risk score of BMI-increasing alleles (GRS) and disease (slope estimate indicated as “a”, p value as PGRS): a BMI + WHR + variants on T2D, b BMIonly + variants on T2D; c BMI + WHR− variants on T2D; d BMI + WHR + variants on CAD, e BMIonly + variants on CAD; f BMI + WHR− variants on CAD. Although the higher GRS for BMI is significantly associated with increased T2D and CAD risk for BMI + WHR + variants, it is associated with decreased T2D and CAD risk for BMI + WHR− variants
Evidence of gene expression in digestive system tissue
Finally, we explored whether our four classes distinguished the underlying physiological pathways. For this, we used DEPICT19 to search for enriched pathways among the genes overlapping association signals (P < 10−5 for any of BMI, WHR, or WHRadjBMI, excluding metabochip data as done previously5,6, to avoid enriching for known metabolic regions by chip design, see Methods). We applied Data-Driven Expression Prioritized Integration for Complex Traits (DEPICT) for different sets of variants: (i) by the scan that a variant was selected for or (ii) by class. Our scan-specific DEPICT analyses replicated previous findings5,6 (highlighting central nervous system, CNS, for BMI-derived variants and adipose tissue for WHRadjBMI). Previous work had not investigated the WHR-derived variants and we found here that they provided an inconclusive pattern without any significant pathway enrichment (judged at false-discovery rate, FDR, < 5%, Supplementary Fig. 5, Supplementary Data 8, Supplementary Note 3). The lack of enriched pathways for WHR-loci suggests that WHR signals capture less-distinct biology than WHRadjBMI or BMI.
Our class-specific DEPICT analyses yielded a pattern for CNS and adipose tissue that was similar to the pattern observed previously by Locke et al. and Shungin et al. for three of our four classes5,6 (Supplementary Fig. 6, Supplementary Data 9). WHRonly− variants were not only significantly enriched (at FDR < 5%) for adipocyte-related cells and tissues as reported previously6, but also in physiological systems labeled ‘digestive’ (rectum, cecum, upper GI, esophagus, stomach) and ‘urogenital’ (genitals, uterus, endometrium, myometrium) (Fig. 6a, Supplementary Data 9). This WHRonly- class finding was robust, even more pronounced, after excluding known height loci (to remove effects of the known strong height locus around GDF5 and other height regions), after excluding all five RSPO3 signals (to limit the strong contribution of multiple RSPO3 signals in this class), or after using a wider locus definition treating the RSPO3 signals as a single region in the DEPICT analyses (to limit the contribution of multiple signals like RSPO3, Supplementary Fig. 7, Supplementary Data 10-12).

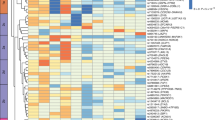
Tissue-specific gene expression for WHRonly− variants. Shown are results of DEPICT and FUMA tissue-specificity analyses based on variants that were selected from GWAS-only meta-analyses of GIANT (P < 10−5) and that were classified as WHRonly−. Significant results within the digestive system are marked with green arrows. a DEPICT results for WHRonly− with significant enrichments highlighted in blue (FDR < 5%). Results are grouped by type and ordered alphabetically by MeSH term within a specific system, cell type, or tissue (details in Supplementary Data 9). Results for the other three classes showed no significance with DEPICT (Supplementary Figure 6). b FUMA results with significant enrichments highlighted in red (adjusted P < 0.05, Bonferroni-corrected, details in Supplementary Data 13). The -log10(Pvalues) in the graph refer to the probability of the hypergeomteric test. Results for the other three classes showed only little enrichment with FUMA (Supplementary Figure 8)
To follow-up this finding, we used FUMA20 to examine data from GTEx21 for tissue-specific enrichments of expression effects of genes overlapping our association results (P < 10−5 for any of BMI, WHR, or WHRadjBMI, excluding metabochip data), again separating the variants by class. Consistent with the class-specific DEPICT analyses, genes harboring WHRonly− variants were significantly enriched (Bonferroni-adjusted P < 0.05) for expression effects in an adipocyte-related tissue (‘Adipose_Subcutaneous’) as well as in digestive tissues (‘Colon_Sigmoid’ and ‘Esophagus_Gastroesophageal_Junction’, Fig. 6b, Supplementary Data 13, Supplementary Fig. 8). In contrast to DEPICT analyses, there was no significant enrichment for expression effects in urogenital tissue in FUMA analyses; there was an additional significant finding for ‘tibial nerve’ in FUnctional Mapping and Annotation (FUMA), which is a tissue not included in DEPICT. We found an overlap of nine genes (BARX1, FOXP2, HOXA13, LAMB1, PCK1, PPARG, RGMA, RSPO3, and VEGFA) that contributed to the significant digestive system results in both DEPICT and FUMA tissue-specificity analyses of WHRonly− class variants.
In summary, we identified the digestive system as a pathway for obesity genetics, which highlights an important biology underlying the WHRonly− class variants.
A wrap-up of the class-specific adiposity phenotypes
When summarizing the results of our data and analysis, we are able to characterize our four adiposity genetics classes with regard to anthropometry, fat depots, metabolic consequences, and implicated pathways (Supplementary Table 2): (i) BMI + WHR + alleles increased waist, hip, SAT, VAT as well as T2D and CAD risk consistent with the observed adverse lipids and insulin profile. This would be in line with a biological model of a CNS-triggered increase in fat mass and a metabolically unfavorable genetic pre-disposition to store fat subcutaneously and viscerally (metabolically unfavorable adiposity, e.g., MC4R and FTO22,23). (ii) BMIonly + alleles presented a similar pattern with increased hip, waist, and SAT, but without VAT storage consistent with an observed neutrality toward T2D or CAD (except TCF7L2, Fig. 4d, Fig. 5b). This would be in line with a CNS-triggered increase in fat mass and a metabolically neutral genetic pre-disposition to store fat subcutaneously rather than viscerally on both belly and lower body (metabolically neutral adiposity). (iii) WHRonly− alleles increased hip, but decreased waist, without any effect on BMI, total fat mass, VAT or SAT, but a decreased VAT/SAT ratio and a tendency toward a favorable metabolic profile (e.g., loci around PPARG, PLXND1, MAP3K1, RSPO3, PLXND1, JUND, Fig. 4d/e). This would be in line with a mechanism of fat redistribution as described for PPARG or RSPO324,25,26 (redistributing adiposity). At least one WHRonly− variant pointed to a different mechanism of enhanced bone growth: the variant near GDF5-UQCC is a known height locus11 and got grasped by WHRonly− due to increased hip probably from bone growth rather than adiposity. For the genes within WHRonly− signals, we found enrichment of expression in digestive systems in DEPICT and FUMA analyses. (iv) BMI + WHR− alleles increased hip and SAT, but had no effect on waist or VAT, and a markedly favorable metabolic profile (metabolically rather favorable adiposity, e.g., GRB14-COBLL1). Our Mendelian Randomization approach27 restricting the instruments to the BMI + WHR− variants showed that their BMI-increasing effect was causally linked to a favorable metabolic profile, particularly decreased risk of T2D and CAD. We also showed that the BMI increase of BMI + WHR− variants was causally linked to increased hip circumference and SAT, but had no effect on waist circumference or VAT. This would be in line with a direct beneficial effect of SAT stored on hip, possibly through adipokines12, for this subtype of adiposity effects.
Discussion
Our investigation demonstrated that a classification of genetic adiposity variants based on their co-association with BMI and WHR characterized distinct anthropometry and different modes of fat deposition. Importantly, our four classes help distinguish metabolically unfavorable (BMI + WHR + ) and metabolically rather favorable adiposity(BMI + WHR−) at high precision that prompted the identification of 16 loci for favorable adiposity including 10 novel compared with previous work24,28. The focus on one of the four classes (WHRonly−) enabled us to reveal the digestive systems as a pathway for obesity genetics that extends upon previous work highlighting neural and adiposite/insulin pathways5,6. Our work has implications for adiposity research and GWAS methodology.
With regard to adiposity research, our work links to previous work that separated between BMI-scan identified and WHRadjBMI-scan identified adiposity variants and highlighted differential pathways, neural (BMI) versus adipose/insulin (WHRadjBMI)5,6. Further work used BMI-derived and WHRadjBMI-derived variants to demonstrate a causal relationship of general or central obesity, respectively, with T2D risk via Mendelian Randomization8,22,29. In our approach, we define four classes of adiposity genetics based on the variant’s co-association with BMI and WHR that generally, with some exceptions, split BMI-derived variants into two groups (BMI + WHR + , BMIonly + ) and WHRadjBMI-derived variants into two groups (BMI + WHR−, WHRonly−). Our classification based on nominal significance of BMI and/or WHR association is straightforward and easy to apply. Certainly, there are other methodological approaches for clustering or evaluating multivariate effects worthwhile to be explored in the future30.
Investigating these four classes separately, we find the following aspects of adiposity mechanisms: (i) Our classes BMI + WHR + and BMIonly + differentiate BMI-derived effects between those that involve VAT and increased disease risk from those that do not (with few exceptions). (ii) Our class BMI + WHR− distinguishes effects of pure hip increase (without any effect on waist) from those with altered waist (BMI + WHR + , BMIonly + , WHRonly−). The BMI-increasing alleles of BMI + WHR− variants are all hip-increasing and jointly show a substantial reduction of disease risk (T2D OR = 0.10, CAD OR = 0.43). This finding contributes to the considerable debate on whether the acknowledged importance of SAT stored on the lower body31 stems from its role as a reservoir to avoid fat storage on more detrimental places like VAT32 or from a directly beneficial effect from lower body fat itself33, as the BMI + WHR− variants show no effect on waist circumference, their metabolically beneficial effect can only stem from a directly favorable effect from hip increase, but not from a less-detrimental storage compared with central body fat (then the other allele would be waist-increasing). This also emphasizes the role of WHRadjBMI as a relative measure of lower body fat that is missed when focusing on WHRadjBMI as a measure of central obesity. (iii) For the WHRonly− class, which focuses on a subset of WHRadjBMI variants, significant expression enrichment identifies digestive systems as a pathway for obesity genetics via two independent methods utilizing two independent data sets (FUMA and DEPICT). The fact that this enrichment emerged only when restricting to WHRonly− loci, but not when analysing all WHRadjBMI loci together, suggests that WHRonly− loci capture an adiposity subtype that is diluted in the larger set of WHRadjBMI loci. Still, further data and experiments will be necessary to determine the mechanisms through which these variants can be linked to transcriptional regulation in digestive systems. Altogether, we conclude that our four classes capture distinct anthropometry and fat depots and help distinguish important adiposity mechanisms (Fig. 7) that were missed by the previous separation into only two groups. Although there are exceptions within classes and metabolic implications have to be validated by locus, this differentiation can help prioritize adiposity loci for therapy development pipelines34.

Approach, biological models, and general framework. The figure depicts our joint view on adiposity traits, the resulting hypothesized biological models for adiposity genetics, and a potential general framework
There have been different approaches to capture favorable adiposity. Among the 1124 or 5328 loci previously identified for insulin resistance and put into context with favorable adiposity, 7 or 13 loci, respectively, capture favorable adiposity effects in the here utilized data following a definition where the BMI-increasing allele (PBMI < 0.05) shows decreased risk of T2D or CAD (PT2D or PCAD < 0.05, no increased risk in either). To be comparable, we derived 1 Mb regions around our 159 lead variants resulting in 117 distinct regions. Of these 117 regions, excluding TCF7L2 owing to its extreme T2D risk (and potential index event bias in the BMI-association5,35), 16 regions contained one of our 159 signal variants with a favorable adiposity effect. Of these 16 regions, 10 were novel compared with previous work24,28, 10 were classified as BMI + WHR− including seven novel (Supplementary Data 14). We were thus able to increase the number of loci for favorable adiposity by 50%.
With regard to GWAS methodology, we confirm several points brought up by Aschard and colleagues1: (1) WHRadjBMI effects differ from WHR effects by –r*bBMI (with r being the phenotypic correlation). We provided empirical data that WHR effects can be effectively computed from WHRadjBMI and BMI effects in a single study and in a meta-analysis setting (Fig. 3). (2) WHRadjBMI-derived genetic effects are not necessarily “WHR effects independent of BMI”, as WHRadjBMI-derived variants can have effects on BMI as shown in theory (see (1)) and observed in our data (BMI + WHR−, some in BMI + WHR + ). (3) WHRadjBMI GWAS enrich for WHR effects with simultaneous effects on BMI into the opposite direction, which are exactly the effects in the BMI + WHR− class.
However, there might have been some misconceptions about the implications of these points that we believe our results and approach can help resolve: (a) whereas WHRadjBMI effects are not “independent of BMI”, our WHRadjBMI-derived variants are distinct from BMI-derived variants with regard to their position on the bWHR−bBMI plane (Fig. 2a). With increasing sample sizes, WHRadjBMI− and BMI-derived variants cannot be expected to keep this distinction and several variants will be captured by both screens, which will result in overlapping biology. However, this can be resolved by adopting our joint view and classifying the variants by their position on the bWHR−bBMI plane. (b) WHRadjBMI-derived variants were suspected to yield spurious association. When considering spurious association of WHRadjBMI-derived variants in the sense that such variants end up having no effect on WHR but only on BMI, we found no such alleged spurious association: all of our WHRadjBMI-derived variants showed an effect on WHR in GIANT data (at nominal significance) and in UKBB data at Bonferroni-corrected significance (UKBB N = 336,107, PWHR < 0.05/53, Supplementary Data 2). Even if there were WHRadjBMI-derived variants with an effect only on BMI (and such variants will be detected eventually when GWAS sample size increases), such variants would be part of “adiposity genetics” in a joint view of BMI- and WHRadjBMI-derived variants. (c) When considering spurious association of WHRadjBMI variants in the sense that such variants end up having no effect, neither on WHR nor on BMI, this would be a real concern as these would be variants without adiposity effect. As indicated above (see (b)), there is no such spurious association in the data (all our WHRadjBMI-derived variants have an effect on WHR in GIANT and UKBB) and, in theory (Supplementary Note 4). (d) The “bias-correction” given by Aschard and colleagues is simply an estimation of the WHR effect from WHRadjBMI and BMI effect estimates (see (1) above). However, the term “bias-correction” is misleading as the WHRadjBMI effect sizes are not a nuisance (as effects with bias usually are), but capture the extent to which the observed WHR effect differs from the expected given the variant’s effect on BMI. This is, in the context of adiposity, a relevant quantity as an unexpected change in fat distribution given the change in BMI can mark metabolically relevant conditions (as an extreme, e.g., lipodystrophy) – WHRadjBMI is thus a meaningful phenotype.
We believe that, possibly due to the misinterpretation of the work of Aschard and colleagues, WHRadjBMI GWAS was perceived as treacherous and less useful than a WHR GWAS. However, we have shown that omitting the WHR-scan would have missed only four variants, whereas an omission of the WHRadjBMI-scan—out of a fear of bias and spurious association—would have missed 27 adiposity genetics signals. We have also shown that WHR-derived variants lack any distinct pathway pattern, whereas WHRadjBMI-derived variants are health-relevant (some confer favorable adiposity, some fat redistribution) and pick up important biology (expression in adipose/insulin and digestive systems). We conclude that, in this example of adiposity genetics, the adjusted-model trait GWAS has advantages over the unadjusted trait GWAS. This does not mean that each adjusted-model trait GWAS is useful; this has to be evaluated on a case-by-case basis.
Our recommendations for future GWAS on adiposity genetics are as follows: (A) if only two GWAS scans (rather than three) are feasible, stick with the BMI- and the WHRadjBMI GWAS, (B) WHR effects can be computed by WHRadjBMI and BMI effects, if not available otherwise, (C) a joint view of BMI- and WHRadjBMI-derived variants on the bBMI−bWHR plane provides a clearer view on the underlying anthropometry than separating between BMI- and WHRadjBMI-derived genetics, and (D) a classification using the variants’ position on the bBMI−bWHR plane can serve to differentiate adiposity mechanisms and metabolic health. Particularly, BMI + WHR− variants can be used effectively to search for favorable adiposity effects. Our approach of joining WHRadjBMI and BMI-derived variants (with or without adding WHR-derived variants), rather than disentangling5,622,23, and linking the variants’ positions on the bBMI−bWHR plane to metabolic implications (Fig. 7) helped resolve some of the appreciable uncertainty about the utility of WHRadjBMI variants’ effects. Our approach can be generalized to a framework for other settings, where two related phenotypes Y and Z are two correlated measures of a latent heritable entity (here: adiposity) and where the adjusted-model trait YadjZ is a meaningful phenotype. An important lesson learned is to view adjusted-model traits and the co-association of related phenotypes as a powerful tool to identify important biology, but to interpret them with great care keeping in mind the underlying biological models.
In summary, our approach and results provide insights into adiposity subtypes and an example for a co-analysis of related phenotypes including adjusted-model traits to help reveal new biology.
Methods
The GIANT consortium data
Our evaluation was based on genome-wide association meta-analysis results for BMI, WHR and WHRadjBMI (from 2015) that are publically available from the GIANT consortium website (www.broadinstitute.org/collaboration/giant)5,6. We used sex-combined, European ancestry meta-analysis results including up to 322,154 persons (114 studies), 212,248 (101 studies), or 210,088 (101 studies) for BMI, WHR, or WHRadjBMI, respectively. In brief, in each study, inverse-normal transformed residuals were calculated from regressing BMI and WHR on age, age2, and other study covariates like principal components—and on BMI to derive WHRadjBMI. The genetic effect estimates on BMI, WHR, and WHRadjBMI were obtained from inverse-variance weighted meta-analyses of study-specific genetic effect estimates on BMI, WHR, or WHRadjBMI, respectively. Genome-wide association studies were either based on Hapmap-imputed SNPs (~2.8 M SNPs) or on genotyped Metabochip SNPs (~190 K SNPs). For further details, see the study descriptive in published literature for BMI5, WHR, and WHRadjBMI6. Informed consent was obtained from all study participants, and study protocols were approved by the local ethics committees.
Integrative genome screen on BMI, WHR, and WHRadjBMI
We excluded SNPs with < 10,000 individuals contributing to the respective meta-analysis and SNPs on sex chromosomes. For each of the three traits, we first selected all variants at genome-wide significance (P < 5 × 10−8). We then combined these three sets of SNPs derived across the three traits yielding a set of 2589 SNPs. We clumped these into 159 non-overlapping, independent regions using a combined distance- and linkage disequilibrium-based criterion ( < 500kB to either side; and r2 > 0.1). The lead SNP of a region was defined as the SNP with the smallest association P-value within the region (no matter from which trait the SNP was derived). The “traits of a region” were defined as the union of traits contributing with genome-wide significance across the SNPs of the respective region. We used PLINK36 and EasyStrata37 for the clumping and for the comparison across traits. Of note, our clumping strategy will yield a different number of independent signals compared with the two GIANT studies that applied a distance-only criterion (no r2 threshold, but consecutive conditional analyses) and used multiple ancestries as well as sex-specific results to select significantly associated variants.
Adiposity traits from the UK Biobank
We used data from the final release of the UK Biobank (N up to 336,107) to follow-up our WHRadjBMI-derived (PWHRadjBMI < 5 × 10−8 in GIANT) for their association with BMI and WHR. The results for WHR and BMI were downloaded from the GeneAtlas9 website (http://geneatlas.roslin.ed.ac.uk/downloads/?traits = 92) and from the Neale Lab website (https://sites.google.com/broadinstitute.org/ukbbgwasresults/), respectively.
For the comparison of estimated and re-computed WHR effects, we used data from the UK biobank interim release (N up to 116,295). For this, we utilized linear regression to obtain residuals of BMI or WHR adjusted for age, age2 (for WHR: additional for BMI), five ancestry principal components, and batch indicators, and used these residuals to derive genetic association (as in GIANT). This was done by sex and results meta-analyzed.
Anthropometric trait lookups from the GIANT consortium
To investigate the identified loci for their effects on waist circumference, hip circumference (HIP), weight (WT), and height (HT), we utilized the publically available meta-analysis summary statistics from the GIANT consortium (www.broadinstitute.org/collaboration/giant): From the 2015 round of meta-analyses, the sex-combined results for WC6 (up to N = 232,083), HIP6 (up to N = 213,028) and HT38 (up to N = 253,239) as well as sex-specific results for BMI5 and WHR6; and from the 2013 round of sex-specific meta-analyses, the sex-specific results for WT8. In order to derive sex-combined meta-analysis results for WT (up to N = 125,943), we conducted a fixed-effect inverse-variance weighted meta-analysis of the two sex-specific WT results. Again, the GIANT consortium results were based on inverse-normal transformed (or standardized for HT) phenotypes in the study-specific analyses.
Fat compartments using impedance measures from UK Biobank
We investigated the effects of the identified variants on impedance-derived measures of body, leg, and trunk fat mass using data from the UK Biobank. We analyzed up to 114,367 unrelated samples of genetically determined European ancestry. Linear regression analyses were applied for the 157 available SNPs including the covariates age, sex, age2, five ancestry principal components, and batch indicators. Sex-stratified analyses were conducted and subsequently meta-analyzed.
Fat compartments using imaging from ectopic fat consortium
We evaluated the effects of the identified variants on computed tomography and magnetic resonance imaging derived measures of ectopic fat volumes as described previously4. This data from the Ectopic fat consortium is publically available (www.nhlbi.nih.gov/research/intramural/researchers/ckdgen). We utilized the meta-analysis summary statistic for (SAT, up to N = 18,206), visceral adipose tissue (VAT, up to N = 18,312) and pericardial adipose tissue (PAT, up to N = 11,616) as well as for the ratio of VAT and SAT (VAT/SAT, up to N = 18,205). For comparison reasons, we computed beta-estimates (assuming a standardized outcome) from the publically available Z scores using beta = Z/sqrt(N * 2* eaf * (1-eaf)), where eaf is the allele frequency of the effect allele, N is the sample size of the meta-analysis and Z the corresponding (and provided) Z score.
Cardio-metabolic traits and diseases lookups
To investigate the identified variants for their effects on other metabolic traits, we utilized publically available meta-analysis summary statistic from several genomic consortia: T2D (up to N = 69,033) from DIAGRAM15 (www.diagram-consortium.org/downloads.html), fasting insulin (FI, up to N = 38,238) and fasting glucose (FG, up to N = 46,186) from MAGIC17 (www.magicinvestigators.org/downloads/), for triglycerides (TG, up to N = 177,829), HDL-C (up to N = 187,135) and LDL-cholesterol (up to N = 173,058) from Global Lipids Genetics Consortium16 (csg.sph.umich.edu/abecasis/public/lipids2013/), and for myocardial infarctions (MI, up to N~170,000) and CAD (up to N~185,000) from the CARDIoGRAMplusC4D18 (www.cardiogramplusc4d.org/data-downloads/). Again, if not available from the downloaded data, we computed beta-estimates (assuming a standardized outcome) from the publically available z scores according to the formula provided before.
Enrichment analyses
We applied binomial tests to evaluate whether the variants in each class were enriched for nominal significant effects on anthropometric, impedance, ectopic fat, or cardio-metabolic traits. We applied a conservative Bonferroni-corrected significance level to the binomial tests (PBinomial < 0.05/168, corrected for four classes × 21 traits × 2 direction of effects).
Mendelian randomization analysis by class
We also conducted class-specific inverse-variance weighted summary statistic based Mendelian randomization analysis27, in order to explore the causal implication of BMI increase on 20 traits27,29,39 (including anthropometric, fat depot, and metabolic traits) separately by each of the adiposity subtypes. This way we estimated the causal effect of the BMI increase on all 20 traits by restricting the instruments (i.e., the genetic variants) to one class. We excluded the WHRonly− variants, which are no effective instruments for BMI. We applied a conservative Bonferroni-corrected significance level to the meta-regression results (PGRS < 0.05/60, corrected for three classes MR 20 traits).
DEPICT analyses
In order to search for enriched pathways among the genes beneath association signals, there are several tools available, with little evidence, which one is superior. We utilized DEPICT19 to test whether genes harboring associated variants were enriched for genes with expression effects in different tissue, cell type and physiological system. More specifically, DEPICT tests whether the genes in associated regions are highly expressed in any of the 209 MeSH annotations for 37,427 microarrays on the Affymetrix U133 Plus 2.0 Array platform. DEPICT version 1 rel194 was downloaded from https://data.broadinstitute.org and updated using scripts from GitHub (https://github.com/perslab/depict). To prevent bias in the enrichment analysis results owing to the customized design of the Metabochip, we restricted the DEPICT analyses to variants with pronounced association in the GWAS-only meta-analyses (i.e., excluding Metabochip data) as done previously5,6. These data were available to us through our collaboration with GIANT. Our analysis was based on all variants reaching P < 1 × 10−5 in at least one of the GWAS-only meta-analyses for BMI, WHR, or WHRadjBMI. We clumped the GWAS-only variants based on linkage disequilibrium of r² > 0.1 from 1000 Genomes40 data and 500 kb flanking regions to obtain lists of independent SNPs. We conducted DEPICT analyses separately for the loci that were identified with the BMI-scan, the WHR-scan, or the WHRadjBMI-scan (scan-specific pathway analyses). We also conducted the enrichment analysis separately for the variants in each of the four classes BMI + WHR + , BMI only, WHR only, and BMI + WHR− (class-specific pathway analyses) using all at P < 10−5 (GWAS-only) and then classifying variants based on the combined GWAS and Metabochip meta-analysis results. For each DEPICT analysis, the list of utilized SNPs were merged with overlapping genes utilizing precomputed gene regions based on 1000 Genomes project variants. SNPs within the major histocompatibility complex region on chromosome 6, base pairs 25,000,000–35,000,000, were excluded. DEPICT analyses were conducted using the following parameters: 100 repetitions to compute FDR and 1000 permutations based on 500 null GWAS to compute P values adjusted for bias due to gene length. A total of 10,968 reconstituted gene sets were used for the enrichment analysis. Tissue/cell type and Physiological system enrichment plots were generated using R-scripts on the basis of the R-script provided with DEPICT. Sensitivity analyses for the WHRonly- class were conducted that (1) excluded all known height-associated loci from (Wood et al. 2014), (2) excluded variants harboring the RSPO3 gene and (3) utilized a wider locus definition criterion that was based on distance-only ( ± 500 kb).
FUMA analyses
We utilized the FUMA20 web tool (http://fuma.ctglab.nl/) to investigate whether gene sets harboring our class-specific association signals were enriched for genes with expression signals in specific tissues of the GTEx v6 data21. FUMA applies a two-sided t-test to infer whether gene sets are differently expressed (up- or downregulated) in any tissue compared to all others tissues. Differentially expressed gene (DEG) sets are utilized by FUMA that were pre-calculated based on GTEx v6 expression values. DEGs in specific tissues compared with others reflect those gene sets with Bonferroni-corrected enrichment P values ≤ 0.05 and absolute log fold change ≥ 0.58. To prevent from bias through the customized design of the Metabochip, we selected associated variants (P < 10−5 for BMI, WHR, or WHRadjBMI) from GWAS-only meta-analyses (excluding Metabochip studies) of the GIANT consortium. We then utilized GWAS + Metabochip meta-analyses results for the classification, which comprise a larger sample size and thus higher accuracy for the classification. The applied input data sets of association results were identical to the ones that were applied to the DEPICT tissue-specificity analysis. For each class, genes harboring the respective associated regions were tested by FUMA against each of the DEG sets using the hypergeometric test, whereas background genes were those with an average Reads per kilo base per million mapped reads > 1 in at least one of the 53 GTEx tissues and exist in the list of background genes. We included all gene types in the prioritization that were available through FUMA and used default FUMA input values, e.g., r2 < 0.6 to define locus regions around the associated regions.
Data availability
Summary genetic association results that are used as basis for this study are available on the GIANT consortium website (http://portals.broadinstitute.org/collaboration/giant/) for BMI (‘SNP_gwas_mc_merge_nogc.tbl.uniq.gz’)5, WHR (‘GIANT_2015_WHR_COMBINED_EUR.txt.gz’)6, and WHRadjBMI (‘GIANT_2015_WHRadjBMI_COMBINED_EUR.txt.gz’)6. All other data that support the findings of this study are available from the corresponding author upon reasonable request. Our integrative analysis of publically available GIANT data was performed with the open-source R package EasyStrata37. EasyStrata-scripts are available for download from www.genepi-regensburg.de/easystrata.
References
Aschard, H., Vilhjalmsson, B. J., Joshi, A. D., Price, A. L. & Kraft, P. Adjusting for heritable covariates can bias effect estimates in genome-wide association studies. Am. J. Hum. Genet. 96, 329–339 (2015).
Pischon, T. et al. General and abdominal adiposity and risk of death in Europe. N. Engl. J. Med. 359, 2105–2120 (2008).
McCarthy, M. I. Genomics, type 2 diabetes, and obesity. N. Engl. J. Med. 363, 2339–2350 (2010).
Franks, P. W. & McCarthy, M. I. Exposing the exposures responsible for type 2 diabetes and obesity. Science 354, 69–73 (2016).
Locke, A. E. et al. Genetic studies of body mass index yield new insights for obesity biology. Nature 518, 197–206 (2015).
Shungin, D. et al. New genetic loci link adipose and insulin biology to body fat distribution. Nature 518, 187–196 (2015).
Firmann, M. et al. The CoLaus study: a population-based study to investigate the epidemiology and genetic determinants of cardiovascular risk factors and metabolic syndrome. BMC Cardiovasc. Disord. 8, 6 (2008).
Randall, J. C. et al. Sex-stratified genome-wide association studies including 270,000 individuals show sexual dimorphism in genetic loci for anthropometric traits. PLoS. Genet. 9, e1003500 (2013).
Canela-Xandri, O., Rawlik, K. & Tenesa, A. An atlas of genetic associations in UK Biobank. Preprint at bioRxiv: https://www.biorxiv.org/content/early/2017/08/16/176834 (2017).
Janssen, I., Heymsfield, S. B., Allison, D. B., Kotler, D. P. & Ross, R. Body mass index and waist circumference independently contribute to the prediction of nonabdominal, abdominal subcutaneous, and visceral fat. Am. J. Clin. Nutr. 75, 683–688 (2002).
Karpe, F. & Pinnick, K. E. Biology of upper-body and lower-body adipose tissue--link to whole-body phenotypes. Nat. Rev. Endocrinol. 11, 90–100 (2015).
Ryden, M., Andersson, D. P., Bergstrom, I. B. & Arner, P. Adipose tissue and metabolic alterations: regional differences in fat cell size and number matter, but differently: a cross-sectional study. J. Clin. Endocrinol. Metab. 99, E1870–E1876 (2014).
Liu, J. et al. Pericardial adipose tissue, atherosclerosis, and cardiovascular disease risk factors: the Jackson heart study. Diabetes Care. 33, 1635–1639 (2010).
Chu, A. Y. et al. Multiethnic genome-wide meta-analysis of ectopic fat depots identifies loci associated with adipocyte development and differentiation. Nat. Genet. 49, 125–130 (2017).
Morris, A. P. et al. Large-scale association analysis provides insights into the genetic architecture and pathophysiology of type 2 diabetes. Nat. Genet. 44, 981–990 (2012).
Global Lipids Genetics, Willer, C. J. et al. Discovery and refinement of loci associated with lipid levels. Nat. Genet. 45, 1274–1283 (2013).
Dupuis, J. et al. New genetic loci implicated in fasting glucose homeostasis and their impact on type 2 diabetes risk. Nat. Genet. 42, 105–116 (2010).
Nikpay, M. et al. A comprehensive 1,000 Genomes-based genome-wide association meta-analysis of coronary artery disease. Nat. Genet. 47, 1121–1130 (2015).
Pers, T. H. et al. Biological interpretation of genome-wide association studies using predicted gene functions. Nat. Commun. 6, 5890 (2015).
Watanabe, K., Taskesen, E., van Bochoven, A. & Posthuma, D. Functional mapping and annotation of genetic associations with FUMA. Nat. Commun. 8, 1826 (2017).
Consortium, G. T. et al. Genetic effects on gene expression across human tissues. Nature 550, 204–213 (2017).
Emdin, C. A. et al. Genetic association of waist-to-hip ratio with cardiometabolic traits, type 2 diabetes, and coronary heart disease. JAMA 317, 626–634 (2017).
Lyall, D. M. et al. Association of body mass index with cardiometabolic disease in the uk biobank: a mendelian randomization study. JAMA Cardiol. 2, 882–889 (2017).
Yaghootkar, H. et al. Genetic evidence for a link between favorable adiposity and lower risk of type 2 diabetes, hypertension, and heart disease. Diabetes 65, 2448–2460 (2016).
Laplante, M. et al. Mechanisms of the depot specificity of peroxisome proliferator-activated receptor gamma action on adipose tissue metabolism. Diabetes 55, 2771–2778 (2006).
Loh, N. Y. et al. LRP5 regulates human body fat distribution by modulating adipose progenitor biology in a dose- and depot-specific fashion. Cell. Metab. 21, 262–272 (2015).
Burgess, S., Butterworth, A. & Thompson, S. G. Mendelian randomization analysis with multiple genetic variants using summarized data. Genet. Epidemiol. 37, 658–665 (2013).
Lotta, L. A. et al. Integrative genomic analysis implicates limited peripheral adipose storage capacity in the pathogenesis of human insulin resistance. Nat. Genet. 49, 17–26 (2017).
Dastani, Z. et al. Novel loci for adiponectin levels and their influence on type 2 diabetes and metabolic traits: a multi-ethnic meta-analysis of 45,891 individuals. PLoS. Genet. 8, e1002607 (2012).
Schaid, D. J. et al. Statistical methods for testing genetic pleiotropy. Genetics 204, 483–497 (2016).
Vasan, S. K. & Karpe, F. Adipose tissue: Fat, yet fit. Nat. Rev. Endocrinol. 12, 375–376 (2016).
Danforth, E. Jr. Failure of adipocyte differentiation causes type II diabetes mellitus? Nat. Genet. 26, 13 (2000).
Manolopoulos, K. N., Karpe, F. & Frayn, K. N. Gluteofemoral body fat as a determinant of metabolic health. Int. J. Obes. (Lond.). 34, 949–959 (2010).
Nelson, M. R. et al. The genetics of drug efficacy: opportunities and challenges. Nat. Rev. Genet. 17, 197–206 (2016).
Yaghootkar, H. et al. Quantifying the extent to which index event biases influence large genetic association studies. Hum. Mol. Genet. 26, 1018–1030 (2017).
Purcell, S. et al. PLINK: a tool set for whole-genome association and population-based linkage analyses. Am. J. Hum. Genet. 81, 559–575 (2007).
Winkler, T. W. et al. EasyStrata: evaluation and visualization of stratified genome-wide association meta-analysis data. Bioinformatics 31, 259–261 (2015).
Wood, A. R. et al. Defining the role of common variation in the genomic and biological architecture of adult human height. Nat. Genet. 46, 1173–1186 (2014).
Burgess, S., Dudbridge, F. & Thompson, S. G. Combining information on multiple instrumental variables in Mendelian randomization: comparison of allele score and summarized data methods. Stat. Med. 35, 1880–1906 (2016).
Genomes Project, C. et al. A global reference for human genetic variation. Nature 526, 68–74 (2015).
Acknowledgements
This research has been conducted using the UK Biobank Resource. I.M.H. received funding from the Bundesministerium für Bildung und Forschung (BMBF, 01ER1206, 01ER1507) and from the National Institutes of Health (NIH, R01DK075787). Z.K. received financial support from the Swiss National Science Foundation (31003A_169929) and SystemsX.ch (51RTP0_151019). R.J.F.L. received support from the National Institutes of Health (NIH, R01DK107786, R01DK110113, U01HG007417). This work was supported by the German Research Foundation (DFG) within the funding programme Open Access Publishing.
Author information
Authors and Affiliations
Contributions
T.W.W., F.G., S.H., M.E.Z., R.J.F.L., Z.K., and I.M.H. wrote the manuscript; T.W.W., Z.K., and I.M.H. conceived and designed the project; T.W.W. and Z.K. conducted association analyses; T.W.W., S.H., and M.E.Z conducted DEPICT analyses.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Winkler, T.W., Günther, F., Höllerer, S. et al. A joint view on genetic variants for adiposity differentiates subtypes with distinct metabolic implications. Nat Commun 9, 1946 (2018). https://doi.org/10.1038/s41467-018-04124-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41467-018-04124-9
This article is cited by
-
Revealing brain cell-stratified causality through dissecting causal variants according to their cell-type-specific effects on gene expression
Nature Communications (2024)
-
Metabolically healthy obesity: from epidemiology and mechanisms to clinical implications
Nature Reviews Endocrinology (2024)
-
Predicting type 2 diabetes via machine learning integration of multiple omics from human pancreatic islets
Scientific Reports (2024)
-
Association of life course adiposity with risk of incident dementia: a prospective cohort study of 322,336 participants
Molecular Psychiatry (2022)
-
Mendelian randomization prioritizes abdominal adiposity as an independent causal factor for liver fat accumulation and cardiometabolic diseases
Communications Medicine (2022)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
