
Abstract
Understanding clinical genetic test results in the era of next-generation sequencing has become increasingly complex, necessitating clear and thorough guidelines for sequence variant interpretation. To meet this need the American College of Medical Genetics and Genomics (ACMG) and the Association for Molecular Pathology (AMP) published guidelines for a systematic approach for sequence variant interpretation in 2015. This framework is intended to be adaptable to any Mendelian condition, promoting transparency and consistency in variant interpretation, yet its comprehensive nature yields important challenges and caveats that end users must understand. In this review, we address some of these nuances and discuss the evolving efforts to refine and adapt this framework. We also consider the added complexity of distinguishing between variant-level interpretations and case-level conclusions, particularly in the context of the large gene panel approach to clinical diagnostics.
Similar content being viewed by others

Introduction
Utilizing genetic information for precision medicine requires thorough understanding of sequence variation and causality across all diseases. For complex multifactorial diseases, such as diabetes, many common genetic variants make small contributions to disease risk, in combination with multiple nongenetic factors.1 Multifactorial contributions to disease etiology are interrogated by statistical means (e.g., genome-wide association studies), but the clinical utility of this information is currently limited by its poor predictive power. In contrast, Mendelian or monogenic disorders are characterized by rare variants in a single gene with a high impact on disease risk.2 In general, assertion of variant pathogenicity for a Mendelian disorder implies causality, although this does not always correlate with disease manifestations in a given individual, due to incomplete penetrance and variable expressivity. While some disease mechanisms fall between these categories, arising from a combination of common variants of low effect and rare variants of greater effect, the binary approach (monogenic versus multifactorial) is currently the predominant organizing framework for disease causality.
In lieu of formal statistical approaches, significant efforts have been made to develop guidelines describing the evidence types needed to assess variants implicated in Mendelian diseases.3,4,5 In this review, we focus on the evidence types articulated by the clinical genetics community as providing support for or against pathogenicity of a variant with respect to a monogenic disorder, and the nuances inherent in combining the available evidence to arrive at a clinical interpretation. Accurate variant interpretations often warrant the expertise of a trained molecular geneticist.
Overview of ACMG/AMP sequence variant interpretation guidelines
The American College of Medical Genetics and Genomics (ACMG), together with the Association for Molecular Pathology (AMP), established guidelines for reporting and interpreting sequence variation in an effort to standardize clinical evaluation of genomic information. The original 2000 guidelines established five categories of classifications but provided little guidance on evidence selection and weighting.3 Revision of these guidelines in 2007 incorporated a sixth category of variants: those associated with clinical symptoms, but that are unexpected or unknown to cause disease (e.g., risk variants).4 The 2007 version also recommended that clinical laboratories utilize standardized variant nomenclature and include testing limitations in reports. These initial iterations were qualitative and assigned variants to categories based on certain features (e.g., reported in the literature or observed in other affected individuals).
Variability in the interpretation of variants between laboratories, in the setting of massively increased data generation due to next-generation sequencing, necessitated more thorough guidance and ultimately led to the development of a more structured approach for variant interpretation in 2015 (ref. 5). These updated guidelines establish a 5-tier classification system (pathogenic, likely pathogenic, uncertain significance, likely benign, or benign) and specify lines of evidence necessary for clinical interpretation. Critically, the guidelines include a relative measure of strength (stand-alone, very strong, strong, moderate, or supporting) for each piece of evidence for or against pathogenicity (Fig. 1). Additionally, the 2015 guidelines present rules for combining evidence to make a given assertion, defaulting to variant of uncertain significance (VUS) when these rules are not met or conflicting evidence exists.

American College of Medical Genetics and Genomics/Association for Molecular Pathology (ACMG/AMP) evidence codes for classifying sequence variants as organized in the text by data type and strength. Evidence codes are divided into those that support a benign (B) or pathogenic (P) classification (first letter of code) and given a relative strength (second letter of code): VS very strong, S strong, M moderate, P supporting. See ref. 5 for complete description of codes. The asterisk indicates odds of pathogenicity corresponding to evidence strength, assuming a prior probability of 0.10 as would be anticipated for single-gene analysis (see ref. 40 for details). The plus sign indicates that BA1 is considered a “stand-alone” evidence type and was not included in the Bayesian model used to derive the odds of pathogenicity
The comprehensive nature of these guidelines not only promotes flexibility and adaptability across most Mendelian conditions, but also creates a degree of ambiguity regarding their implementation. The structured format promotes data sharing efforts and aims to minimize inconsistencies in variant classification through transparency in the use of evidence, which allows comparison and conflict resolution.6,7,8,9,10 The National Institutes of Health (NIH) funded endeavors, such as the Clinical Genome Resource (ClinGen)11 and ClinVar,12 are developing curation tools that incorporate the ACMG/AMP guidelines to assist in variant interpretation and data sharing. Below we discuss important challenges and caveats regarding the implementation of these guidelines both in general and with respect to specific criteria. We then address ongoing efforts to improve the guidelines and to provide disease-driven rule specifications.
Nuances in the implementation of ACMG/AMP variant interpretation criteria
Application of the 2015 guidelines is intentionally restricted to inherited, Mendelian conditions with relatively high penetrance. The guidelines are not recommended to be used in pharmacogenomics or complex traits/conditions. Notably, caution should be exercised when applying these guidelines in the context of secondary findings, particularly for variants identified in asymptomatic or otherwise healthy individuals. Furthermore, these guidelines are intended for variants in genes with established disease causality, not for novel variants in “candidate” genes. The ClinGen Gene Curation Working Group has developed a framework that can be utilized to determine the strength of evidence supporting gene–disease associations.13
Population data
Population-level minor allele frequency (MAF) data is critical because disease-causing alleles for most Mendelian disorders are expected to be rare, and five ACMG/AMP criteria (BA1, BS1, BS2, PM2, and PS4) utilize these data. It is important to consider disease prevalence, penetrance, and genetic (locus and allelic) heterogeneity when applying any of these criteria, although such information is often unknown or inaccurate due to ascertainment bias. A MAF >5% in any global population is considered a “stand-alone” benign classification (BA1) for the vast majority of Mendelian disorders, with the exception of well-known founder alleles.5 The most frequently applied ACMG/AMP criteria across 99 variants assessed by nine laboratories were PM2 (absent from control populations) and BS1 (MAF higher than expected for disorder).7
To date, ExAC14 and gnomAD are the largest and most ethnically comprehensive datasets of variant allele frequency. However, even these datasets do not represent all populations and it is important to consider population size and error in MAF estimates when assessing thresholds for BS1. Furthermore, inadequate population representation and lack of phenotypic details may cause difficulties in applying BS1 or BS2 (variant for highly penetrant condition seen in healthy individual) criteria. In addition, the data quality of any population allele frequency database should be evaluated for sufficient depth of coverage to ensure accurate MAF estimates. Furthermore, repetitive and low complexity regions of the genome (e.g., paralogous regions) are challenging to correctly sequence with standard technologies and variants in these regions should be interpreted cautiously given their inaccurate representation in these databases. A better understanding of monogenic disorders will allow specification of MAF thresholds for each gene–disease pair as available repositories grow and provide greater statistical power.14,15,16,17
In more prevalent Mendelian conditions, odds ratios (OR) or relative risks can be calculated to assess whether a variant is likely to be associated with a phenotype. Variants with increased prevalence in an affected population compared with controls can be assigned PS4, if the calculated OR >5.0 and the confidence interval does not include 1.0 (ref. 5). The population size used to calculate the OR should be considered when assessing the accuracy and reliability of the study. It may also be possible to calculate an OR using a public MAF repository, such as ExAC, however it is critical to understand the nuances described above when using such databases. Importantly, not all conditions are amenable to statistically compelling case-control studies, therefore the guidelines stipulate that the “prior observation of [very rare] variant[s] in multiple unrelated patients with the same phenotype, and its absence in controls, may be used as moderate level of evidence.”5
Allelic evidence and cosegregation
Due to the Mendelian patterns of inheritance seen in most monogenic disorders, evidence of segregation in family members (or lack thereof) can inform variant interpretation. The ACMG/AMP guidelines include a number of criteria (PS2, PM6, PP1, and BS4) that apply to segregation evidence. The de novo occurrence of a variant is considered strong evidence of pathogenicity (PS2) when (1) maternity and paternity are confirmed, (2) the variant is in a gene associated with a condition consistent with the patient’s phenotype, and (3) there is no past family history of disease (i.e., unaffected parents). When the first criterion is not met, the evidence is considered moderate strength (PM6). The second and third criteria apply for both PS2 and PM6, because all humans are expected to have approximately 44–82 de novo single-nucleotide variants (SNVs) of which 1–2 are expected to be exonic.18 Additionally, improved sequencing techniques are facilitating better detection of mosaic or somatic variants,19 which if applied to the parents of patients with previously reported de novo mutations may reveal that these variants were in fact inherited from a mosaic parent.
When a condition is inherited in a dominant fashion, cosegregation in affected family members is used as supporting evidence in favor of pathogenicity (PP1), with the guidance that strength may be increased when appropriate. This approach promotes a conservative interpretation while allowing discretion and flexibility, but is subject to potential variability between labs with regard to upgrading the strength of segregation evidence. Because the variant under consideration may be in linkage disequilibrium with the “true” pathogenic variant, it is critical to assess the thoroughness of the linkage study. Both the methodology and extent of sequencing merit consideration, in addition to whether all variants within a linkage region have been evaluated for pathogenicity (e.g., a cryptic splice-altering variant deep within the intron). Furthermore, it is important to establish that all other common plausible molecular etiologies have also been ruled out. Conversely, lack of segregation (e.g., variant inherited from the unaffected parent) is considered strong evidence that a variant is benign (BS4). Accurate application of both segregation criteria hinges on thorough phenotypic evaluation of family members, which is not always possible. Phenotypic evaluation and subsequent segregation analysis can be further complicated by issues of penetrance, expressivity, age of onset, and ascertainment bias, therefore, it is generally encouraged to interpret segregation data conservatively.
Aside from de novo occurrence and cosegregation analysis, family studies can also be used to determine phase of two or more heterozygous variants, which applies to three ACMG/AMP criteria (PM3, BP2, and BP5). If a variant occurs in a gene associated with an autosomal recessive condition and is in trans with a pathogenic variant, the PM3 criterion can be applied. However, the guidelines do not address the situation in which the second variant is likely pathogenic, or whether this criterion can be applied (with weaker strength) when phase has not been confirmed (e.g., the pathogenic variant was inherited, but inheritance of the second variant is unknown). If the variant occurs in a gene associated with an autosomal dominant (AD) condition and is in trans with a pathogenic variant, the BP2 criterion can be applied. BP2 also applies when the variant being evaluated is in cis with a pathogenic variant, regardless of inheritance pattern. As with PM3, it is unclear whether BP2 can be applied when the second variant is likely pathogenic. Caution should also be applied in using BP2 in situations where the true “pathogenic” allele might be a complex haplotype that includes more than one change from the reference sequence. For situations in which the variant being evaluated is observed together with another pathogenic variant in a different gene with a more compelling molecular basis for the individual’s phenotype, BP5 should be applied as evidence against pathogenicity. Further caution should be used when applying this criterion because it is possible for an individual’s composite phenotype to result from the rare combination of two different Mendelian disorders.
Computational and predictive criteria
A large number of the ACMG/AMP variant interpretation criteria (PVS1, PS1, PM4, PM5, PP3, BP1, BP3, BP4, and BP7) are categorized as predictive or computational evidence.5 These criteria relate to the type of variant in question and its predicted impact on the protein product based on knowledge about the protein’s function, structure, and evolutionary conservation. Notably, PP2 (missense variant in a gene in which missense changes are rare) and PM1 (mutational hotspot/functional domain), which are categorized as “functional data,” could also be regarded as “predictive” evidence (see Fig. 1). Together, these 11 criteria provide a way to predict variant pathogenicity by extrapolating from what we know about the functional and clinical impact of similar variants, with respect to both variant type and location within a protein. By virtue of the predictive nature of this category, these criteria are most appropriately applied to variants in genes with well-understood molecular mechanism and functional domains.
An important consideration is whether the predicted impact of the variant in question is consistent with the known disease mechanism, such as gain of function (GOF) or loss of function (LOF). Understanding disease mechanism is critical for novel predicted truncating variants (nonsense, frameshift, or canonical splice site), which are classified as likely pathogenic when PVS1 (null variant where LOF is known disease mechanism) and PM2 (absent in population databases) are applied. Unfortunately, disease mechanism is often not well-established. Overly liberal use of PVS1 could result in a potentially erroneous assessment of pathogenicity and consequently have serious implications for patients and family members (e.g., in the context of secondary findings). Population data can be used to evaluate the prevalence of predicted truncating and missense variants in an unselected population,14 approximating how well any given gene tolerates variation and suggesting possible disease mechanism. However, this approach primarily reflects constraint due to reproductive fitness and may not accurately indicate molecular mechanism for any given gene–disease association. Further detailed guidance and expert curation of molecular mechanism across all known Mendelian disease genes is therefore a high priority.
Another potential pitfall when applying the predictive criteria is that several criteria rely on the same basic reasoning to predict pathogenicity. Criteria PM1 (variant in mutational hotspot), PS1 (novel nucleotide change creates same amino acid change as known pathogenic variant), and PM5 (novel missense variant at residue with different pathogenic missense change) similarly argue that variants altering an important region of a protein are likely to be pathogenic and therefore application of either PM1 + PS1 or PM1 + PM5 could artificially bolster the evidence for pathogenicity. The same logic applies to the use of the in silico criteria (PP3 and BP4), because the algorithms used by many in silico pathogenicity predictors rely on protein sequence, structure, and conservation,20 much like many other criteria in the “predictive” category. The current ACMG/AMP guidelines do not restrict the use of certain criteria together, which may inadvertently result in double-counting evidence.
Specific caveats for the use of individual predictive criteria should also be considered. In an early attempt to compare the application of the ACMG/AMP guidelines by the Clinical Sequencing Exploratory Research (CSER) consortium, 8 of the 11 predictive criteria were applied inappropriately or inconsistently, and clarifications to the guidelines were suggested.7 For example, PVS1 (null variant where LOF is known disease mechanism) should not be applied to variants that may escape nonsense-mediated decay, such as premature truncating codons near the 3’ end of the protein21 or noncanonical splice variants. Similarly, PS1, PM1, and PM4 (protein length–changing variant) are all criteria intended for use with specific types of variants; however, each of these criteria were inappropriately used by at least one laboratory due to vague descriptions in the guidelines.7
While in silico predictors have been heralded for the potential to apply high-throughput assessments independent of clinical data,22 laboratories disagree on how to implement these predictors,23 leading to discordant variant interpretations.8,24 The guidelines recommend use of multiple in silico predictors to mitigate the varying strengths and weaknesses of each program and further stipulate that each of the in silico predictions must agree with one another to count as supporting evidence.5 No further guidance is given as to how many and which in silico predictors are most appropriate to use for the consistent application of this criteria. This poses a problem given the varying performance characteristics of the algorithms depending on whether they are tuned for sensitivity to discover potentially damaging variants. Furthermore, the guidelines do not address how to handle “false concordance” arising when predictive tools arrive at a different interpretation from that supported by other available evidence.23
One approach to simplify this issue is to use metapredictors that combine multiple tools into one prediction output. Many of the recently developed metapredictors (e.g., Rare Exome Variant Ensemble Learner [REVEL], VEST3, MetaLR, MetaSVM) demonstrated superior performance in a recent comparison of 25 different algorithms for the prediction of 14,819 benign or pathogenic ClinVar variants.23 For example, REVEL, which considers 13 existing tools to score missense pathogenicity probability from zero to one,25 has a high predictive performance for a variety of diseases, genes, and modes of inheritance23 and is incorporated in the ClinGen Variant Curation Interface (https://curation.clinicalgenome.org). No single threshold exists for BP3/PP3 satisfaction, and we expect that expert panels will define cut-offs based on gene-specific predictive performance.
Functional criteria
Data from well-established functional assays showing a deleterious effect (PS3) or no effect (BS3) are considered strong evidence in the ACMG/AMP variant interpretation framework.5 As with in silico tools, functional assays are poised to tackle the reclassification of many rare missense VUSs because they are not dependent on clinical data.22,26 However, lack of guidance on what constitutes a well-established assay has resulted in subjective application of these criteria, and interlaboratory interpretation differences are not always resolved through data sharing.8 Often, assays are performed in research laboratories, which may not meet clinical laboratory standards. For sufficient predictive power, functional assays require extensive reproducibility and experimental rigor, including benchmarking against multiple variants with definitive clinical interpretations as determined by genetic or other evidence.26,27,28,29 An exemplary validated assay is the homology-directed DNA damage repair (HR) assay, which demonstrated 100% sensitivity and specificity for pathogenicity determination.28,29,30
A well-validated functional assay should also provide variant-level evidence of the effect on the gene or gene product to satisfy PS3 or BS3 criteria, whereas assays evaluating biochemical parameters may suggest a specific clinical diagnosis but not pinpoint a causative variant. For example, an in vitro assay of enzyme activity in whole blood from a patient demonstrating impaired enzyme activity implicates the gene encoding the non-functional enzyme, but does not isolate a specific variant’s effect and thus would not meet PS3 criteria. This information might be relevant to the PP4 criteria (patient’s phenotype is highly specific for a disease with a single genetic etiology) but caution is advised in applying this rule, as described below.
For clinical interpretation, a functional assay should also be relevant to disease mechanism and manifestation. Cell-based or cell-free in vitro assays and in vivo organismal studies such as zebrafish or mouse models can be used to probe variant effects, but should be closely related to the known etiology. Cell lines should be disease-relevant and carefully selected; a transformed cell line may not be ideal for isolating a variant’s tumorigenic effects.31 Negative results (equivalent to wild-type function) may support a benign classification, but should be contingent on how thoroughly the assay evaluates gene/protein function. For example, a protein–protein binding assay might evaluate part of a protein’s normal function, but may provide an incomplete assessment if catalytic activity is not evaluated. Multiple assays that comprehensively probe gene function are likely to better reflect clinical significance. Determining the most appropriate functional assay requires gene- and disease-specific knowledge, often beyond the expertise of variant reviewers.8 This underscores the importance of expert consensus on these issues and the adaptation of the ACMG/AMP guidelines for individual genes or diseases.
Other criteria
The remaining criteria (PP4, PP5, and BP6) are not easily classified into the previously discussed categories, but warrant discussion given their potential for misuse. For conditions with a phenotype highly specific to a single gene, PP4 can be applied as supporting evidence of pathogenicity. The ACMG/AMP guidelines stipulate that in addition to a highly specific phenotype, the patient should have a family history consistent with the mode of inheritance, the testing should be highly sensitive, and the gene should have little benign variation. Nevertheless, PP4 was the most inconsistently applied criteria across the nine CSER laboratories evaluating the ACMG/AMP guidelines,7 likely due to the subjectivity in deciding the specificity of a phenotype.
The reputable source criteria (PP5 and BP6) have recently been recommended for removal from the guidelines due to their questionable utility, on the basis that review of the primary evidence is superior to expert opinion and application of this criteria is likely to double count evidence when the criteria used by the reputable source are unknown.32 The ACMG/AMP Interpretation of Sequence Variants Work Group has not yet recommended removal of these criteria,33 therefore laboratories must apply PP5 and BP6 at their own discretion.
Combining rules
A critical feature of the 2015 guidelines is the set of rules for combining individual evidence codes to establish one of the five variant classification assertions (pathogenic, likely pathogenic, VUS, likely benign, or benign). This method allows transparency and promotes consistency amongst laboratories in applying the criteria and arriving at a classification. However, manual tabulation of evidence codes could increase the risk of errors, as evidenced by the early experience of nine CSER laboratories.7 In addition, judgment is required when evidence addressing a particular criterion exists (and can be cited) but is judged to not satisfy an expert’s threshold for utilizing that evidence in the assessment.
In the ACMG/AMP guidelines, a VUS can result from either insufficient evidence or due to conflicting benign/pathogenic evidence. However, determining what constitutes conflicting evidence is challenging. Although not explicitly stated, the ACMG/AMP guidelines imply that the strength of conflicting evidence should be relatively equivalent. The guidelines do not address how to proceed when the strength of conflicting evidence is unbalanced (i.e., weighted more heavily towards pathogenic or benign), and no approved method currently exists for resolving VUS classifications with conflicting evidence.
Efforts in improving variant interpretation guidelines
While the 2017 ACMG/AMP sequence variant interpretation guidelines establish a foundation for uniform and transparent variant analysis, there is still room for improvement and refinement. The guidelines are expected to “evolve as technology and knowledge improve,” and many groups have published their experiences and their critiques and/or modifications to the guidelines.7,8,9,34,35,36,37,38,39 Laboratories within the CSER consortium compared their implementation of the guidelines and identified several criteria that were inconsistently or inappropriately applied and put forth the following recommendations: (1) modify the BA1 stand-alone criteria to be disease-specific, (2) develop quantitative thresholds for segregation analysis, (3) determine which computational algorithms are best in practice, (4) better define “well-established” functional data and establish a database with such data, (5) create a resource for gene–disease mechanism, and (6) develop tools to automate computable aspects of the ACMG/AMP guidelines.7
The ClinGen Consortium has established processes by which Variant Curation Expert Panels can review and specify the interpretation rules for a gene or group of related genes. Important functions of these expert groups are to help define the molecular mechanism of disease and what functional assays qualify as “well-established.” Both the RASopathy and MYH7 expert panels have recently published disease-specific variant interpretation guidelines.38,39 Furthermore, the ClinGen Sequence Variant Interpretation (SVI) group was tasked with making general refinements to the ACMG/AMP guidelines and harmonizing gene-specific refinements proposed by expert panels. Recently, the SVI demonstrated that the combining rules defined in the ACMG/AMP guidelines have a Bayesian nature and are therefore amenable to objective quantification, including incorporation of conflicting evidence into a final probabilistic assessment (Fig. 1) (ref. 40). Finally, ClinGen has a Variant Curation Interface (https://curation.clinicalgenome.org/) and a pathogenicity calculator that automates tabulation of evidence codes.41
Use of population allele frequencies is a fundamental aspect of variant classification and therefore defining reasonable thresholds for BA1, BS1, and PM2 is critical. The recommended 5% MAF cutoff for BA1 is overly conservative for most rare conditions, but may be too liberal for disorders with known causative variants at high frequencies in some populations (e.g., sickle cell disease) or founder alleles. The ClinGen SVI has identified known exceptions to the BA1 rule (https://www.clinicalgenome.org/site/assets/files/6006/svi_ba1_ashg_10_11_2016_1.pdf). In addition to ClinGen’s disease-specific efforts, two groups have developed general thresholds for the maximum expected MAF for pathogenic variants in various hereditary disorders (referring to BS1) (refs. 42,43). Using the ExAC dataset, Kobayashi and colleagues demonstrated that 97.3% of pathogenic variants in genes associated with a broad spectrum of disorders had MAF < 0.01% and those with higher frequencies were well-characterized in the literature.43 These data suggest that MAF threshold of 0.01% may be an appropriate starting point for the BS1 criteria. Whiffin and colleagues developed a mathematical model that additionally accounts for inheritance pattern, prevalence, heterogeneity, and penetrance, thereby providing an even more stringent MAF threshold.42
Given the potential to quantify segregation data, these criteria (PP1 and BS4) would greatly benefit from a statistical approach to modulate strength based on the number of individuals examined. Because many clinical laboratories do not have genetic statisticians readily available, Jarvik and Browning proposed a simplified calculation to provide thresholds for different strengths of segregation evidence.44 This proposed method is less accurate than previously proposed methods,45,46 but allows for a close approximation without extensive statistical analysis. The ClinGen SVI is developing more granular rules regarding de novo variants and segregation evidence that would be required for supporting, moderate, or strong evidence of pathogenicity (https://www.clinicalgenome.org/site/assets/files/8490/recommendation_ps2_and_pm6_acmgamp_critiera_version_1_0.pdf).
As the sensitivity and specificity of in silico predictors continue to improve, future iterations of these guidelines could be optimized for a more quantitative strength assignment correlated with algorithm accuracy and odds of pathogenicity. While a complete discussion of performance assessments is beyond the scope of this review, the nuances of these considerations should be reviewed for algorithms on a gene-specific basis before broad application and before increasing the weight of computational evidence in the variant interpretation framework.8,23,40,47,48
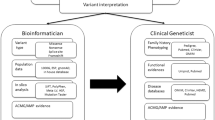
Beyond variant interpretation: challenges in case-level interpretation
One aspect of molecular diagnosis not heavily discussed in the ACMG/AMP guidelines or elsewhere is the distinction between variant-level interpretations and overall case-level (or clinical) conclusions. Although each variant interpretation is critical to an overall case-level conclusion, it is only one necessary component in the final assessment of a case. Acknowledging this distinction, the guidelines explicitly state that “pathogenicity determination [of a variant] should be independent of interpreting the cause of disease in a given patient.”5 The latter necessitates thorough evaluation of the patient’s clinical and family history to assess whether a molecular result is consistent with the patient’s phenotype and the suspected pattern of inheritance. While there is one ACMG/AMP criterion that pertains to phenotypic correlation (PP4), this criteria is intended to be used when a unique phenotype is associated with a single gene (e.g., CFTR).
Beyond the aforementioned challenges associated with variant-level interpretation, case-level interpretation is further complicated by the added complexities of incomplete penetrance, variable expressivity, and phenotypic correlation (including biochemical manifestations).49,50 Variant penetrance and expressivity data is often limited, even for well-established pathogenic variants, and much of the available data is likely to be influenced by ascertainment bias of specific disease manifestations.51 The lack of accurate penetrance and expressivity data is compounded by the difficulty of phenotypic evaluation in the proband and relatives, a subjective process impacted by evolution of symptoms over time. Furthermore, molecular tests can uncover results only partially consistent with the patient’s phenotype and potentially suggestive of an “expanded phenotype”52,53,54,55 or may identify multiple plausible variants, indicating the possible coexistence of two (or more) conditions leading to a “blended phenotype,” rather than a single disease entity.56,57,58,59,60,61
Navigating the nuances of variant-level and case-level interpretation is becoming more challenging because our ability to acquire sequence information far exceeds our current interpretative capacity. Molecular diagnostic laboratories and clinicians must accurately and meaningfully communicate uncertain results to their patients. While the ACMG/AMP variant interpretation guidelines facilitate a systematic characterization of variant-level uncertainty, they do not provide a structured approach for classifying case-level uncertainty. Variability in how laboratories classify their case-level results is illustrated by the range of diagnostic yields from exome analysis across laboratories.62 A standardized classification system to differentiate definitive and inconclusive case-level results might improve comprehension of results and would facilitate better comparison/meta-analysis of published genomic studies, yielding a true assessment of genomic sequencing diagnostic yield. Our experience with exome sequencing in a diverse population led us to propose the case-level classifications outlined in Table 1, where uncertainty can arise from three categories: variant pathogenicity, variant zygosity (e.g., heterozygous variant for AD condition), and phenotypic concordance.63,64
Previously, when single-gene testing dominated the molecular diagnostic arena, the onus was on the clinician to prepare a differential diagnosis, order the appropriate tests, and ultimately interpret the case-level result. As clinicians routinely opt for larger gene panels or even genome-scale diagnostic tests, laboratories will increasingly need to incorporate phenotypic information during variant prioritization. This is particularly important for untargeted genome-scale sequencing, which will uncover many variants unrelated to the diagnostic indication for testing. To fully harness the potential of genome-scale sequencing, clinicians and clinical laboratories must be intentional in establishing collaborative efforts relying on one another’s expertise.51,62,65 This may include developing practical clinical history forms to collect standardized phenotypic terms for use in prioritizing variants, such as those utilized by recent variant prioritization software programs (e.g., OMIM Explorer, Phevor, PHIVE, etc.).66,67 Likewise, clinical laboratories should make every effort to explicitly state their return of results policies and when requested, provide a list of rare variants not meeting the laboratory’s threshold for return.
Finally, with the constant discovery of new gene–disease and variant–disease associations,68 variant interpretations (particularly VUSs) are expected to change over time. Reanalysis of genome-scale data can identify a potential diagnosis in 10–36% of previously unsolved cases.61,68,69,70,71 Reanalyzing variants reported in association with hereditary cancer led to reclassification in 3.6% of 1103 cases (predominantly classification downgrades).72 These data emphasize the need for clinical laboratories to reevaluate variant data periodically; however, there are no clear guidelines as to how and when this should happen.73 While reanalysis can potentially impact patient care, it can be onerous, and the ACMG/AMP guidelines recommend that laboratories develop clear policies for variant reanalysis indicating whether a clinician must initiate reanalysis and if there will be an additional charge.5
Conclusion
While the genomic sequencing era has facilitated more efficient identification of potentially disease-causing genomic variants, it has highlighted the need for a systematic, quantitative approach for variant classification to ensure reliable, reproducible results/interpretations for patients. Further refinement of the evidence necessary for variant classification will lead to increasingly quantitative assessments of variant pathogenicity. Widely anticipated implementation of genomic sequencing in an increasingly predictive context will demand thoughtful integration of genomic variant pathogenicity assertions, with consideration of a probabilistic assessment of the likelihood of developing any given condition. Furthermore, increasing complexity in our understanding of genetic contributions to disease (genetic modifiers, oligogenic disorders, etc.) will require laboratorians and clinical practitioners to continually evolve and incorporate new methods for interpreting disease etiology.
References
Manolio TA, Brooks LD, Collins FS. A HapMap harvest of insights into the genetics of common disease. J Clin Invest. 2008;118:1590–1605.
Manolio TA, Collins FS, Cox NJ, et al. Finding the missing heritability of complex diseases. Nature. 2009;461:747–753.
Kazazian HH, Boehm CD, Seltzer WK. ACMG recommendations for standards for interpretation of sequence variations. Genet Med. 2000;2:302–303.
Richards CS, Bale S, Bellissimo DB, et al. ACMG recommendations for standards for interpretation and reporting of sequence variations: revisions 2007. Genet Med. 2008;10:294–300.
Richards S, Aziz N, Bale S, et al. Standards and guidelines for the interpretation of sequence variants: a joint consensus recommendation of the American College of Medical Genetics and Genomics and the Association for Molecular Pathology. Genet Med. 2015;17:405–423.
Pepin MG, Murray ML, Bailey S, et al. The challenge of comprehensive and consistent sequence variant interpretation between clinical laboratories. Genet Med. 2016;18:20–24.
Amendola LM, Jarvik GP, Leo MC, et al. Performance of ACMG-AMP variant-interpretation guidelines among nine laboratories in the Clinical Sequencing Exploratory Research Consortium. Am J Hum Genet. 2016;98:1067–1076.
Harrison SM, Dolinsky JS, Knight Johnson AE, et al. Clinical laboratories collaborate to resolve differences in variant interpretations submitted to ClinVar. Genet Med . 2017;19:1096–1104.
Lincoln SE, Yang S, Cline MS, et al. Consistency of BRCA1 and BRCA2 variant classifications among clinical diagnostic laboratories. JCO Precis Oncol . 2017;1:1–10.
Yang S, Lincoln SE, Kobayashi Y, et al. Sources of discordance among germ-line variant classifications in ClinVar. Genet Med . 2017;19:1118–1126.
Rehm HL, Berg JS, Brooks LD, et al. ClinGen—the Clinical Genome Resource. N Engl J Med . 2015;372:2235–2242.
Landrum MJ, Lee JM, Benson M, et al. ClinVar: public archive of interpretations of clinically relevant variants. Nucleic Acids Res. 2016;44(D1):D862–D868.
Strande NT, Riggs ER, Buchanan AH, et al. Evaluating the clinical validity of gene-disease associations: an evidence-based framework developed by the Clinical Genome Resource. Am J Hum Genet. 2017;100:895–906.
Lek M, Karczewski KJ, Minikel EV, et al. Analysis of protein-coding genetic variation in 60,706 humans. Nature. 2016;536:285–291.
1000 Genomes Project Consortium, Auton A, Brooks LD, et al. A global reference for human genetic variation. Nature. 2015;526:68–74.
Sudmant PH, Rausch T, Gardner EJ, et al. An integrated map of structural variation in 2,504 human genomes. Nature. 2015;526:75–81.
Tennessen JA, Bigham AW, O’Connor TD, et al. Evolution and functional impact of rare coding variation from deep sequencing of human exomes. Science. 2012;337:64–69.
Acuna-Hidalgo R, Veltman JA, Hoischen A. New insights into the generation and role of de novo mutations in health and disease. Genome Biol. 2016;17:241.
Pagnamenta AT, Lise S, Harrison V, et al. Exome sequencing can detect pathogenic mosaic mutations present at low allele frequencies. J Hum Genet. 2012;57:70–72.
Masica DL, Karchin R. Towards increasing the clinical relevance of in silico methods to predict pathogenic missense variants. PLoS Comput Biol . 2016;12:e1004725.
Popp MW-L, Maquat LE. Organizing principles of mammalian nonsense-mediated mRNA decay. Annu Rev Genet. 2013;47:139–165.
Starita LM, Ahituv N, Dunham MJ, et al. Variant Interpretation: functional assays to the rescue. Am J Hum Genet . 2017;101:315–325.
Ghosh R, Oak N, Plon SE. Evaluation of in silico algorithms for use with ACMG/AMP clinical variant interpretation guidelines. Genome Biol. 2017;18:225.
Grimm DG, Azencott CA, Aicheler F, et al. The evaluation of tools used to predict the impact of missense variants is hindered by two types of circularity. Hum Mutat. 2015;36:513–523.
Ioannidis NM, Rothstein JH, Pejaver V, et al. REVEL: an ensemble method for predicting the pathogenicity of rare missense variants. Am J Hum Genet. 2016;99:877–885.
Millot GA, Carvalho MA, Caputo SM, et al. A guide for functional analysis of BRCA1 variants of uncertain significance. Hum Mutat. 2012;33:1526–1537.
Burd EM. Validation of laboratory-developed molecular assays for infectious diseases. Clin Microbiol Rev. 2010;23:550–576.
Guidugli L, Pankratz VS, Singh N, et al. A classification model for BRCA2 DNA binding domain missense variants based on homology-directed repair activity. Cancer Res. 2013;73:265–275.
Pesaran T, Karam R, Huether R, et al. BeyondDNA: an integrated and functional approach for classifying germline variants in breast cancer genes. Int J Breast Cancer. 2016;2016:1–10.
Guidugli L, Carreira A, Caputo SM, et al. Functional assays for analysis of variants of uncertain significance in BRCA2. Hum Mutat . 2014;35:151–164.
Toland AE, Andreassen PR. DNA repair-related functional assays for the classification of BRCA1 and BRCA2 variants: A critical review and needs assessment. J Med Genet . 2017;54:721–731.
Biesecker LG, Harrison SM The ACMG/AMP reputable source criteria for the interpretation of sequence variants [published online ahead of print March 15, 2018]. Genet Med.
Richards CS, Aziz N, Bale S, et al. Response to Biesecker and Harrison [published online ahead of print March 15, 2018]. Genet Med.
Paludan-Müller C, Ahlberg G, Ghouse J, et al. Integration of 60,000 exomes and ACMG guidelines question the role of catecholaminergic polymorphic ventricular tachycardia-associated variants. Clin Genet. 2017;91:63–72.
Maxwell KN, Hart SN, Vijai J, et al. Evaluation of ACMG-guideline-based variant classification of cancer susceptibility and non-cancer-associated genes in families affected by breast cancer. Am J Hum Genet. 2016;98:801–817.
Chen S, Hu X, Shen Y. Sequence variant interpretation 2.0: perspective on new guidelines for sequence variant classification. Clin Chem. 2015;61:1317–1319.
Karbassi I, Maston GA, Love A, et al. A standardized DNA variant scoring system for pathogenicity assessments in Mendelian disorders. Hum Mutat. 2016;37:127–134.
Kelly MA, Caleshu C, Morales A, et al. Adaptation and validation of the ACMG/AMP variant classification framework for MYH7-associated inherited cardiomyopathies: recommendations by ClinGen’s Inherited Cardiomyopathy Expert Panel. Genet Med. 2018;20:351–359.
Gelb BD, Cavé H, Dillon MW, et al. ClinGen’s RASopathy Expert Panel consensus methods for variant interpretation [published online ahead of print March 15, 2018]. Genet Med.
Tavtigian SV, Greenblatt MS, Harrison SM, et al. Modeling the ACMG/AMP variant classification guidelines as a Bayesian classification framework [published online ahead of print January 4, 2018]. Genet Med.
Patel RY, Shah N, Jackson AR, et al. ClinGen Pathogenicity Calculator: a configurable system for assessing pathogenicity of genetic variants. Genome Med. 2017;9:3.
Whiffin N, Minikel E, Walsh R, et al. Using high-resolution variant frequencies to empower clinical genome interpretation. Genet Med. 2017;19:1151–1158.
Kobayashi Y, Yang S, Nykamp K, et al. Pathogenic variant burden in the ExAC database: an empirical approach to evaluating population data for clinical variant interpretation. Genome Med. 2017;9:13.
Jarvik GP, Browning BL. Consideration of cosegregation in the pathogenicity classification of genomic variants. Am J Hum Genet. 2016;98:1077–1081.
Thompson D, Easton DF, Goldgar DE. A full-likelihood method for the evaluation of causality of sequence variants from family data. Am J Hum Genet. 2003;73:652–655.
Bayrak-Toydemir P, McDonald J, Mao R, et al. Likelihood ratios to assess genetic evidence for clinical significance of uncertain variants: hereditary hemorrhagic telangiectasia as a model. Exp Mol Pathol. 2008;85:45–49.
Leong IUS, Stuckey A, Lai D, et al. Assessment of the predictive accuracy of five in silico prediction tools, alone or in combination, and two metaservers to classify long QT syndrome gene mutations. BMC Med Genet. 2015;16:34
Mahmood K, Jung C, Philip G, et al. Variant effect prediction tools assessed using independent, functional assay-based datasets: implications for discovery and diagnostics. Hum Genomics. 2017;11:10.
Kammenga JE. The background puzzle: how identical mutations in the same gene lead to different disease symptoms. FEBS J. 2017;284:3362–3373.
Schacherer J. Beyond the simplicity of Mendelian inheritance. C R Biol. 2016;339:284–288.
Berg JS. Exploring the importance of case-level clinical information for variant interpretation. Genet Med. 2017;19:3–5.
Dyment DA, Tétreault M, Beaulieu CL, et al. Whole-exome sequencing broadens the phenotypic spectrum of rare pediatric epilepsy: a retrospective study. Clin Genet . 2015;88:34–40.
Bertola DR, Hsia G, Alvizi L, et al. Richieri-Costa-Pereira syndrome: expanding its phenotypic and genotypic spectrum. Clin Genet. 2018;93:800–811.
Tracewska-Siemiątkowska A, Haer-Wigman L, Bosch D, et al. An expanded multi-organ disease phenotype associated with mutations in YARS. Genes (Basel). 2017;8:381.
Orlova EM, Sozaeva LS, Kareva MA, et al. Expanding the phenotypic and genotypic landscape of autoimmune polyendocrine syndrome type 1. J Clin Endocrinol Metab. 2017;102:3546–3556.
Theunissen TEJ, Sallevelt SCEH, Hellebrekers DMEI, et al. Rapid resolution of blended or composite multigenic disease in infants by whole-exome sequencing. J Pediatr . 2017;182:371–4.e2.
Li Y, Salfelder A, Schwab KO, et al. Against all odds: blended phenotypes of three single-gene defects. Eur J Hum Genet. 2016;24:1274–1279.
Posey JE, Rosenfeld JA, James RA, et al. Molecular diagnostic experience of whole-exome sequencing in adult patients. Genet Med. 2016;18:678–685.
Yang Y, Muzny DM, Xia F, et al. Molecular findings among patients referred for clinical whole-exome sequencing. JAMA. 2014;312:1870–1879.
Balci TB, Hartley T, Xi Y, et al. Debunking Occam’s razor: diagnosing multiple genetic diseases in families by whole-exome sequencing. Clin Genet. 2017;92:281–289.
Eldomery MK, Coban-Akdemir Z, Harel T, et al. Lessons learned from additional research analyses of unsolved clinical exome cases. Genome Med. 2017;9:26.
Strande NT, Berg JS. Defining the clinical value of a genomic diagnosis in the era of next-generation sequencing. Annu Rev Genomics Hum Genet. 2016;17:303–332.
Vora NL, Powell B, Brandt A, et al. Prenatal exome sequencing in anomalous fetuses: new opportunities and challenges. Genet Med. 2017;19:1207–1216.
Skinner D, Roche MI, Weck KE, et al. “Possibly positive or certainly uncertain?”: participants’ responses to uncertain diagnostic results from exome sequencing. Genet Med. 2018;20:313–319.
Schrijver I, Farkas DH, Gibson JS, et al. The evolving role of the laboratory professional in the age of genome sequencing. J Mol Diagn. 2015;17:335–338.
James RA, Campbell IM, Chen ES, et al. A visual and curatorial approach to clinical variant prioritization and disease gene discovery in genome-wide diagnostics. Genome Med . 2016;8:13.
Eilbeck K, Quinlan A, Yandell M. Settling the score: variant prioritization and Mendelian disease. Nat Rev Genet. 2017;18:599–612.
Wenger AM, Guturu H, Bernstein JA, et al. Systematic reanalysis of clinical exome data yields additional diagnoses: implications for providers. Genet Med. 2017;19:209–214.
Wright CF, McRae JF, Clayton S, et al. Making new genetic diagnoses with old data: iterative reanalysis and reporting from genome-wide data in 1,133 families with developmental disorders [published online ahead of print January 11, 2018]. Genet Med.
Nambot S, Thevenon J, Kuentz P, et al. Clinical whole-exome sequencing for the diagnosis of rare disorders with congenital anomalies and/or intellectual disability: substantial interest of prospective annual reanalysis. Genet Med. 2017;20:645–654.
Xiao B, Qiu W, Ji X, et al. Marked yield of re-evaluating phenotype and exome/target sequencing data in 33 individuals with intellectual disabilities. Am J Med Genet A. 2018;176:107–115.
Macklin S, Durand N, Atwal P, et al. Observed frequency and challenges of variant reclassification in a hereditary cancer clinic. Genet Med. 2018;20:346–350.
Rehm HL, Bale SJ, Bayrak-Toydemir P, et al. ACMG clinical laboratory standards for next-generation sequencing. Genet Med. 2013;15:733–747.
Acknowledgements
This work was funded by NIH grants NHGRI U01 HG006487, U01 HG007437, and U41 HG009650; Ms. Brnich was supported by NIH training grants NIGMS T32 GM008719 and T32 GM007092.Ms. Brnich is also a UNC University Cancer Research Fund Scholar. Dr. Berg is a UNC Yang Family Biomedical Scholar.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Disclosure
The authors declare no conflict of interest.
Rights and permissions
About this article

Cite this article
Strande, N.T., Brnich, S.E., Roman, T.S. et al. Navigating the nuances of clinical sequence variant interpretation in Mendelian disease. Genet Med 20, 918–926 (2018). https://doi.org/10.1038/s41436-018-0100-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1038/s41436-018-0100-y
Keywords
This article is cited by
-
Perspective: Application of the American College of Medical Genetics Variant Interpretation Criteria to Common Variable Immunodeficiency Disorders
Clinical Reviews in Allergy & Immunology (2021)
-
Challenges in returning results in a genomic medicine implementation study: the Return of Actionable Variants Empirical (RAVE) study
npj Genomic Medicine (2020)
-
Comparative analysis of functional assay evidence use by ClinGen Variant Curation Expert Panels
Genome Medicine (2019)
-
First Responder to Genomic Information: A Guide for Primary Care Providers
Molecular Diagnosis & Therapy (2019)
-
The histopathological spectrum of malignant hyperthermia and rhabdomyolysis due to RYR1 mutations
Journal of Neurology (2019)
