
Abstract
This study aims to investigate the role of miR-106b-5p in cervical cancer by performing a comprehensive analysis on its expression and identifying its putative molecular targets and pathways based on The Cancer Genome Atlas (TCGA) dataset, Gene Expression Omnibus (GEO) dataset, and literature review. Significant upregulation of miR-106b-5p in cervical cancer is confirmed by meta-analysis with the data from TCGA, GEO, and literature. Moreover, the expression of miR-106b-5p is significantly correlated with the number of metastatic lymph nodes. Our bioinformatics analyses show that miR-106b could promote cervical cancer progression by modulating the expression of GSK3B, VEGFA, and PTK2 genes. Importantly, these three genes play a crucial role in PI3K-Akt signaling, focal adhesion, and cancer. Both the expression of miR-106b-5p and key genes are upregulated in cervical cancer. Several explanations could be implemented for this upregulation. However, the specific mechanism needs to be investigated further.
Similar content being viewed by others

Introduction
At present, with an increase in morbidity and mortality, cancer has become the leading cause of death and a significant public health problem. There are over 500,000 novel cases and approximately 274,000 deaths estimated for cervical cancer (CC) each year all over the world1. In 2015, the number of new cases and deaths in China was 4,292,000 and 2,814,000, respectively2. CC is the fourth most common cancer in women in the world, and incidence and mortality are still rising3. Although the relationship between persistent high-risk human papillomavirus (HPV) infection and CC has been confirmed4, the specific molecular cellular network mechanism is still unclear.
Genetic mutations lead to cancer by affecting gene expression and protein function in the cells. However, the dysregulation of microRNA (miRNA) expression is detected in a variety of tumors and is considered to be a significant contributor to the development of cancer in recent years5,6. miRNAs are small single-stranded non-coding RNAs that specifically silence gene expression and alter cell or organism phenotypes. Previous studies have confirmed that miRNAs participate in proliferation, apoptosis, morphogenesis7, antiviral defense8, and tumorigenesis9.
Recently, growing evidence reveals that miR-106b-5p plays a critical role in various cancers. Huang and Hu10 showed that the upregulation of miR-106b can be observed in the endometrium and knockdown of miR-106b suppresses proliferation and promotes apoptosis. Shi et al.11 reported that upregulation of miR-106b-5p exhibited a promoting role in hepatocellular carcinoma (HCC) cell properties and migration, whereas downregulation exhibited an opposite effect. Lu et al.12 and Xiang et al.13 submitted that overexpression of miR-106b-5p could promote the proliferation and increase the number of metastatic colonies, whereas inhibition would induce cell cycle arrest, suppress cell proliferation, and promote cell apoptosis in renal cell carcinoma.
For CC, miR-106b, the pre-miRNA of miR-106b-5p, also has a pivotal role in occurrence and development. While constructing a miRNA-mRNA network for CC, Ma et al.14 found that miR-106b was one of the key nodes in the network. Overexpression of miR-106b promoted the migration of HeLa and SiHa cells significantly while inhibition displayed an opposite phenomenon15. However, few studies concern the mechanisms of miR-106b for CC at present. Cheng et al.15 found that DAB2 is identified as a direct target of miR-106b and it is inhibited by TGF-β1 partly through miR-106b and is involved in TGF-β1-induced CC cell migration. Piao et al.16 reported that miR-106 overexpression and DAB2 knockdown induced epithelial to mesenchymal transition (EMT) of CC cells cultured on substrate. As miR-106b plays an essential role in CC, its molecular mechanisms need to be further studied.
The purpose of this study is to investigate the role of miR-106b-5p in CC by performing comprehensive research on its expression and identify its putative molecular targets and pathways based on The Cancer Genome Atlas (TCGA), Gene Expression Omnibus (GEO), and literature review.
Results
Clinical significance of miR-106b-5p
As the expression data of mature miR-106b-5p are absent in TCGA, a comparison of miR-106b between CC and healthy samples is provided. The expression level of miR-106b is higher in CC (Fig. 1) and significantly associated with the number of metastatic lymph nodes (Cor = 24.510, P = 0.006). However, there is no significant correlation in tumor purity, race, pathological M/N/T stage, number of years of birth, histological type, race, radiotherapy, or overall survival (Table 1).

NT normal tissue, TP primary tumor. There are three samples in the NT group and 309 samples in the TP group. Student's t-test is used for the statistical analysis
Meta-analysis of miR-106b-5p expression
Meta-analysis based on TCGA and GEO
A total of 1286 microarrays were obtained from GEO. After careful screening, the three microarrays, GSE86100, GSE19611, and GSE30656, meet the criteria and are included in the analysis (Fig. 2a). The forest plot presents an overall standard mean difference (SMD) of 2.85 (95% confidence interval (CI): 0.89–4.81) with P = 0.0045 and I2 = 88% (random effect used), suggesting that miR-106b-5p is upregulated in CC (Fig. 3a).

Searching workflow for the expression of miR-106b-5p between cervical cancer and non-cancerous tissue. a Searching strategy in GEO; bSearching strategy in literature review

a Forest plot of SMD. The expression of miR-106b-5p is significantly higher in cervical cancer tissue; b Funnel plot for four studies that are marked as circles. No significant publication bias is detected (P = 0.5187); c Influence analysis for four studies. No study had an impact on the overall SMD estimation. d Subgroup forest plot based on cancer type. As I2 value is still relatively high, the cancer subtype is not the only source of heterogeneity
A funnel plot of miR-106b-5p expression (Fig. 3b) reveals that no significant publication bias is detected by Egger’s test (P = 0.5187). Sensitivity analysis shows that similar results are obtained for the fixed effects models except for a lower difference (SMD: 2.53, 95%CI: 1.89–3.18, P < 0.0001).
The influence analysis (Fig. 3c) shows that no study had an impact on the overall SMD estimation because the point estimate for any of the studies is not outside the combined analysis CI and there is no significant statistical change.
Except for a decrease in I2 values, similar results are obtained in the subgroup analysis of cancer subtypes (Fig. 3d). The results show that the cancer subtype is not the only source of heterogeneity as the I2 value is still relatively high, but miR-106b-5p continues to be highly expressed in CC tissues.
Meta-analysis based on literature review
The workflow for searching is presented in Fig. 2b. Finally, four studies14,15,17,18 that met the criteria were selected. Consistent with the result of the meta-analysis, a common pattern of upregulation for miR-106b-5p in CC was reported across the included studies (Table 2).
Bioinformatics analyses of miR-106b-5p
Screening of candidate genes
By analyzing the data from Cervical squamous cell carcinoma and endocervical adenocarcinoma (CESC) with the criterion of log|FC| > 1 and FDR < 0.05, 4857 differentially expressed genes (DEGs) were selected, including 4619 upregulated genes and 238 downregulated genes. Meanwhile, predicting using 12 databases in miRWalk, 10,073 target genes that were overlapping in at least five databases were found (Fig. 4a). After merging DEGs and the predicted target genes, 1277 candidate genes were collected (Fig. 4b).

a The number of overlapped genes across 12 databases; 10,073 target genes which overlapped at least five databases are obtained. b Venn plot for the integration between DEGs and predicted target genes of miR-106b-5p
Gene ontology enrichment analysis
The DAVID database was used for Gene Ontology (GO) analysis of the 1277 genes (Fig. 5). Using the criterion of P < 0.001, the results showed that while cellular component (CeC), target genes are mainly involved in “cytoplasm”, “cytosol”, “receptor complex”, “basolateral plasma membrane”, “perinuclear region of cytoplasm”, “ruffle membrane”, “membrane”, “lamellipodium”, “cleavage furrow”, “postsynaptic density”, “membrane raft”, “integral component of plasma membrane”, and “cell cortex”. In terms of biological process (BP), the target genes mainly participate in “protein phosphorylation”, “positive regulation of transcription from RNA polymerase II promoter”, “microtubule cytoskeleton organization”, “epithelial to mesenchymal transition”, “intracellular signal transduction”, “cell migration”, “protein autophosphorylation”, and “positive regulation of protein binding”. With regard to MF, these genes are mainly enriched in “protein binding”, “protein serine/threonine kinase activity”, “ATP binding”, “kinase activity”, “PDZ domain binding”, and “transcription factor activity, sequence-specific DNA binding”.

Values are expressed as −log10 (P-value)
Protein–protein interaction network analysis
The original network contains 668 nodes and 1779 edges. After cleaning the isolated genes, the main network containing 579 nodes and 1716 edges was obtained (Fig. 6a). By extracting the nodes with degree and betweenness which are higher than average, a subnetwork that contains 110 nodes and 404 edges was gained (Fig. 6b; Table 3).

a PPI network of candidate genes; b Subnetwork of PPI for main nodes extracted according to degree and betweenness being higher than average; c Pathway crosstalk analysis of hub genes. The thickness of lines between nodes are represented by the average value of Jaccard coefficient (JC) and overlapping coefficient (OC); d Subnetwork of pathway crosstalk extracted by MCODE; e Comprehensive gene-pathway network constructed by mapping the hub genes to the subnetwork. The arrow direction between gene and pathway is determined by KEGG. Red circle: genes; green square: pathway. f Subnetwork of gene-pathway collected according to the criteria that node’s degree > average
Twelve topological algorithms were applied and the top 20 genes of each method for the subnetwork of PPI were extracted. These selected genes that appeared at least twice are conserved as hub genes (Table 4).
Pathway enrichment and crosstalk analysis
Pathway enrichment analysis was also performed by the DAVID database. The results indicate that the pathways of “Signaling pathways regulating pluripotency of stem cells”, “Neurotrophin signaling pathway”, “Proteoglycans in cancer”, and “Hippo signaling pathway” are significantly enriched.
For pathway crosstalk analysis, 45 out of 47 pathways that contain more than two genes met the crosstalk analysis criteria and were selected to construct the network (Fig. 6c). The thickness of the edges indicates measurements of the average value of OC and JC. By using MCODE, a major cluster with 33 nodes and 523 edges was identified from the initial network (Fig. 6d).
Comprehensive gene-pathway analysis
After mapping the hub genes into the subnetwork of pathways guided by KEGG, a potential gene-pathway network including 33 essential pathways and 16 hub genes were constructed (Fig. 6e). This network shows that “PIK3R3” and “PIK3CG” participate in most of the pathways. Furthermore, “pathways in cancer” and “focal adhesion” and “proteoglycans in cancer” rank as the top three pathways according to the genes that they involved.
To screen the main factors (including genes and pathways) in the gene-pathway network, those nodes with degree > average were selected (Fig. 6f). It was found that 11 genes (PIK3R3, PIK3CG, MAPK8, GSK3B, ITGB1, CDKN1A, PTK2, VEGFA, PRKACB, RAP1B, and RAP1A) with five pathways (pathways in cancer, focal adhesion, proteoglycans in cancer, PI3K-Akt signaling pathway, and Ras signaling pathway) are involved and considered more likely to play a role as influential agents.
Identification of key genes and pathways
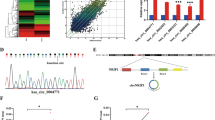
The expression of the main genes was investigated with meta-analysis through nine studies in Oncomine. The results show that all of the main genes are upregulated in CC, among which five genes (GSK3B, VEGFA, PTK2, RAP1B, and PIK3CG) gain significant differences (Fig. 7a). However, the influence analysis indicates that RAP1B and PIK3CG obtain a discrepant result with the meta-analysis for the altering of significance (Table 5). Hence, only GSK3B, VEGFA, and PTK2 are considered to be key genes.

The expression of main genes of cervical cancer across nine studies (a), Venn plot for the interaction between key genes and their pathways (b), and the binding sequence and location between miR-106b-5p and each critical gene (c). Orange square: coding sequence (CDS). Green square: binding site
We merged the pathways that each essential gene participates in order to discover the most important pathways. Three pathways, PI3K-Akt signaling pathway, focal adhesion, and pathways in cancer, which all of the three key genes involved in, were identified (Fig. 7b).
Location and characteristic of the binding site
As presented in Fig. 7c, all of the binding sites for miR-106b-5p are located in 3′UTR of GSK3B, VEGFA, and PTK2. Furthermore, when inspecting the sequence of binding sites, adenine (A) and uracil (U) are occupied in most of the sequence.
Discussion
This study confirms that the expression of miR-106b-5p is significantly upregulated in CC and its expression is highly correlated with the number of metastatic lymph nodes. By using bioinformatics analyses, miR-106b-5p is found to be a key issue in the progression of CC by interacting with three key genes and pathways.
Our results show that miR-106b-5p promotes the progression of CC by targeting GSK3B, VEGFA, and PTK2. GSK3B is dysregulated in a variety of tumor tissues including CC19,20,21,22,23,24, and it participates in the development of CC caused by HPV16 infection by regulating Wnt signaling/β-catenin pathway23,24. In addition, GSK3B exerts antiproliferative effects by promoting APC-dependent phosphorylation and thus promotes protease-mediated degradation of β-catenin which is a transcription factor that positively regulates Myc and cyclin D1 expression21. When referring to VEGFA, its overexpression in CC can enhance the growth and invasion of tumor cells25. More importantly, VEGFA can promote the proliferation and migration of CC cells by activating the PI3K/Akt/mTOR pathway26. In addition, the expression and stability of VEGFA have a close relationship with cellular hypoxia27 and serum VEGFA level can be used as a biomarker for prognosis evaluation28. In terms of PTK2, it is a cytoplasmic protein tyrosine kinase and has an expression in various solid tumors such as ovarian cancer, gastric cancer, and bladder cancer29. It is found that PTK2 is associated with the sensitivity of colon cancer cells to DNA damage therapy30. However, there are few reports of PTK2 in CC.
The results of pathway analyses reveal that all of the three key genes are involved in the pathway of PI3K-Akt signaling pathway, focal adhesion, and Pathways in cancer. With regard to PI3K-Akt signaling pathway, its imbalance in expression is associated with a variety of tumors, including cervical, endometrial, and non-small cell lung cancers31,32,33. It is activated during the G1/S transition of the cell cycle and regulates several key cell cycle regulators34. Tumors associated with HPV infection are closely related to the PI3K/Akt pathway. Activation of this pathway contributes to genetic instability, dysregulation, apoptosis resistance, and altered metabolic properties ultimately leading to the malignant transformation of infected cells. Concerning focal adhesion, this pathway is involved in the invasion and metastasis of many kinds of tumors and is related to the medicine resistance of certain tumors35,36. The decreased expression of focal adhesion kinase (FAK), a key gene involved in the pathway, can inhibit the invasion and migration of CC cells37. Another study reports that targeted FAK therapy makes pancreatic cancer cells more sensitive to immunotherapy38.
It has been recognized that miRNA negatively regulates gene expression by guiding the RNA-induced silencing complex (RISC) to silence its target mRNA through degradation or translation repression39. However, it is interesting to observe that both the expression of miR-106b-5p and key genes are upregulated in CC with the binding sites located in 3′UTR of mRNAs. According to previous studies40,41,42,43,44, the mechanisms of miRNA-mediated gene upregulation include (1) the presence of cellular state (G0 or G0-like state) and/or specific factors (AGO1, AGO2, GW182, and FXR1); (2) miRNA directly binds to 5′UTR of RNA and increases its association with 40S and polysome formation or enhances their translation by alleviating their TOP-mediated translational repression during amino acid starvation, respectively; (3) miRNA prevents tristetraprolin (TTP) binding to the AU-rich element (ARE) sites of mRNA and inhibits its degradation by ARE-mediated mRNA decay (AMD) pathway; (4) derepression from miRNA-mediated downregulation in response to cell stresses by HuR (an RNA binding protein that interacts with ARE in 3′UTR of the mRNA). As none of the binding sites are located in 5′UTR in our results, and cells are considered active in cancer tissue, the mechanisms of upregulation for cellular state or binding site in 5′UTR may be less possible.
AREs are found in the 3′UTR of mRNAs that code for proto-oncogenes, nuclear transcription factors, and cytokines45. They can be classified into three types: (1) having dispersed AUUUA motifs within or near U-rich regions; (2) having overlapping AUUUA motifs within or near U-rich regions; (3) a much less well-defined class having a U-rich region but no AUUUA repeats46. Our results reveal that A and U are occupied in most of the binding sequence. To our knowledge, it has been verified that TTP has interactions with GSK3B47 and VEGFA48 whereas there are no reports on PTK2. It is possible that miR-106b-5p prevents TTP from binding to the mRNAs in 3′UTR and therefore regulate their expression, but the specific mechanism needs to be further investigated. In addition, it has been confirmed that HuR can bind to VEGF49 and reverse the repression effect by miR-200b50. This also could be a contributing factor to the upregulation of VEGFA and be adopted for the other key genes.
However, several limitations exist in the present study: (1) Significant heterogeneity can be observed in the meta-analysis. This high heterogeneity may result from population, race, stage, and the type of CC (squamous or adenocarcinoma). Hence, more data from large-scale clinical trials are needed to evaluate the source of the heterogeneity. (2) Parts of genes are removed due to the selection criteria. However, it is possible that these genes might also impact the progression of CC and they also need to be analyzed. (3) As this study is an in silico research, a further experiment is needed for validation. (4) Upregulations of both miR-106-5p and key genes are identified. Despite the fact that several possibilities are analyzed, the specific mechanisms still need to be studied and verified further.
Conclusions
In summary, significant upregulation of miR-106b-5p in CC is confirmed by meta-analysis with the data from TCGA and GEO, and the expression of miR-106b-5p is significantly correlated with the number of metastatic lymph nodes. Furthermore, miR-106b-5p promotes the progression of CC by targeting three key genes (GSK3B, VEGFA, PTK2) through three crucial pathways (PI3K-Akt signaling pathway, focal adhesion, and pathways in cancer). miR-106b-5p might upregulate the key genes by preventing TTP from binding to the mRNAs in 3’UTR with/without the effect of derepression of HuR. However, the specific mechanism needs to be further investigated.
Materials and methods
The workflow of this study is presented in Fig. 8 and this study is performed according to guidelines of MIAME51 and Meta-Analysis of Gene Expression Microarray Datasets52. Firstly, the clinical significance of miR-106b-5p in CC is assessed according to the CESC data from TCGA. Secondly, the expression data of miR-106b-5p from TCGA, GEO, and literature are synthesized by meta-analysis. Thirdly, DEGs from TCGA are screened and 12 databases are used to predict target genes of miR-106b-5p. The overlap genes between DEGs from TCGA and predicted target genes are explored by bioinformatic analyses.

The modules of clinical value evaluation (green), meta-analysis (brown), and bioinformatics analyses (pink) are included
Correlations between the expression of miR-106b-5p and clinical outcomes
To identify the clinical significance of miR-106b-5p in CC, we adopt LinkedOmics53 which is constructed based on TCGA with 309 cancer samples and three normal samples as controls in CESC dataset to explore the correlations between the expression of miR-106b-5p and the clinical outcomes, including the number of metastatic lymph nodes, tumor purity, race, pathology M/N/T stage, years to birth, histological type, ethnicity, radiation therapy, and overall survival.
Meta-analysis of miR-106b-5p expression based on TCGA/GEO and literature
A systematic searching in GEO for the miR-106b-5p expression between CC and healthy tissue was performed on 30 March 2018 with the terms and eligibility criteria that are presented in Tables 5 and 6. For adjusting the data to the normal distribution to reduce variation, Log2 scale transformation was applied to all of the expression data. The meta-analysis was conducted by R Version 3.4.154 and meta package55. We pooled SMD using the Mantel–Haenszel formula (fixed-effect model) or the DerSimonian–Laird formula (random effects model) and assessed the heterogeneity using I2 statistics. Random-effect models (P < 0.05 or I2 > 50%) are used when the heterogeneity is considered significant. Otherwise a fixed-effects model would be used.
Funnel plot with Egger’s test56 was utilized to evaluate the publication bias. P < 0.1 was considered to be significant asymmetry for the funnel plot.
To detect the robustness of the pool results, sensitivity analysis was performed by alternating analysis model. In addition, to further evaluate the impact of individual studies on the overall effect estimates, influence analysis was performed and the combined estimates were recalculated by omitting one study at a time.
Furthermore, a full-scale search of miR-106b-5p expression in eight electronic databases (PubMed, Chinese VIP, CNKI, Wanfang Database, Embase, Web of Science, Science Direct, and Wiley Online Library) accompanied with manual searching by screening the references cited in the acquired articles was conducted on 30 March 2018. The searching terms and eligible criteria are also shown in Tables 5 and 6. The data of the publications will be extracted and analyzed, including the author, year of publication, country, number of cancer and control samples, regulations, and testing methods.
Screening of candidate genes for miR-106b-5p
The CESC data were analyzed by the limma package57 to identify DEGs. We determined the significance of the difference in gene expression as Log2 |fold change (FC) | > 1 and False Discovery Rate (FDR) < 0.05. Furthermore, the miR-106b-5p targeted genes are predicted by 12 databases (Microt4, miRWalk, mir-bridge, miRanda, miRDB, miRMap, Pictar2, PITA, miRNAMap, RNAhybrid, RNA22, and Targetscan) in miRWALK version 2.058. To increase prediction accuracy, the genes that are overlapping in at least five databases were selected. Finally, the overlap genes between DEGs and predicted genes were analyzed by upsetR59 and Venn Plot.
GO and pathway enrichment analysis
GO and pathway enrichment analyses were performed by DAVID60 on the overlapping genes. The significantly enriched biological items for CeC, BP, and molecular functions (MF) were identified as P < 0.01.
Protein-protein interaction network analysis
The STRING database61 was used to construct an interaction network between the overlapped genes. To obtain precise results, those nodes in the network would be removed: (a) interaction score < 0.7; (b) not connected to the major network; (3) the value of degree and betweenness is less than average.
CytoHubba62 was used to explore the important nodes by 12 topological algorithms, including Degree, Edge Percolated Component (EPC), Maximum Neighborhood Component (MNC), Density of Maximum Neighborhood Component (DMNC), Maximal Clique Centrality (MCC), and centralities based on shortest paths, such as Bottleneck (BN), EcCentricity, Closeness, Radiality, Betweenness, ClusteringCoefficient, and Stress. The top 20 genes in each topological algorithm were extracted and the duplication of each gene was also calculated. The genes with less than 2 in repetitiveness are excluded for ensuring the genes are closely linked to CC and the rest are considered as hub genes.
Pathway enrichment and crosstalk analysis
For pathway enrichment, the predicted targets were mapped using the Kyoto Gene and Genome Encyclopedia (KEGG) database by online analysis of DAVID. Significant pathways were considered as P < 0.05.
The obtained pathways were recruited for further crosstalk analysis to explore their interactions. The method is based on the assumption that if two pathways share a proportion of genes, they are considered crosstalk63. As described in the previous study64, in order to better measure the overlap between any two pathways, JC (Jaccard coefficient) = | (A ∩ B) / (A ∪ B) | and OC (overlapping coefficient) = (|A ∩ B|) / (min(| A |, | B |)) were adopted, where A and B are the genes contained in the two pathways. As pathways with too few genes may have insufficient biological information, we excluded pathways containing fewer than three genes. Likewise, pairs of pathways with less than two overlapping genes were also removed. After obtaining the network of pathway crosstalk, the plug-in app Molecular Complex Detection (MCODE) in Cytoscape was used to screen the hub subnetwork which had the score >4.
Comprehensive gene-pathway analysis
The hub genes are mapped into the subnetwork of crosstalk to further explore the mechanism by KEGG. To screen the main genes and pathways, the nodes with degree > average are collected for constituting a subnetwork.
Identification of key genes and pathways
To further identify the key genes, we evaluated the expression of main genes between CC and healthy samples with meta-analysis in Oncomine65. P < 0.05 is considered as a significant difference. Moreover, influence analysis was also conducted to access the pool estimates. The pathways that all of the key genes participate in were determined as crucial pathways.
Possible mechanisms of regulations between miR-106b-5p and key genes
The regulation between miR-106b-5p and the key genes is recognized by their expression. To explore the possible mechanisms of the regulation, we collected the sequence of miR-106b-5p and the three key genes from miRbase66 and NCBI–nucleotide to predict their binding site by RNAhybrid67 with the criteria that mRNA has perfect nucleotide pairing between the second and eighth positions of the 5′ end of miRNA sequences. Furthermore, the character of the binding sequence was also investigated.
Change history
10 July 2019
Due to a technical error, content intended for publication in Volume 4 (2018) published in Volume 5 (2019). The content has been moved into the correct volume, and the citation information was updated accordingly.
References
Torre, L. A. et al. Global Cancer Statistics, 2012. CA Cancer J. Clin. 65, 87–108 (2015).
Chen, W. et al. Cancer Statistics in China. CA Cancer J. Clin. 66, 115–132 (2016).
Siegel, R. L., Miller, K. D. & Jemal, A. Cancer statistics, 2018. CA Cancer J. Clin. 68, 7–30 (2018).
Petry, K. U. HPV and cervical cancer. Scand. J. Clin. Lab. Invest. 74, 59–62 (2014).
Wang, T., Xu, H., Qi, M., Yan, S. & Tian, X. miRNA dysregulation and the risk of metastasis and invasion in papillary thyroid cancer: a systematic review and meta-analysis. Oncotarget 9, 5473–5479 (2018).
Santos, J. M. O., Gil da Costa, R. M. & Medeiros, R. Dysregulation of cellular microRNAs by human oncogenic viruses – Implications for tumorigenesis. Biochim. Biophys. Acta 1861, 95–105 (2018).
Kim, V. N. Small RNAs: classification, biogenesis, and function. Mol. Cells 19, 1–15 (2005).
Lecellier, C.-H. A cellular microRNA mediates antiviral defense in human cells. Science 308, 557–560 (2005).
O’Donnell, K. A., Wentzel, E. A., Zeller, K. I., Dang, C. V. & Mendell, J. T. c-Myc-regulated microRNAs modulate E2F1 expression. Nature 435, 839–843 (2005).
Huang, C. & Hu, G. Shikonin suppresses proliferation and induces apoptosis in endometrioid endometrial cancer cells via modulating miR-106b/PTEN/AKT/mTOR signaling pathway. Biosci. Rep. 0, BSR20171546 (2018).
Shi, D. M., Bian, X. Y., Qin, C. D. & Wu, W. Z. miR-106b-5p promotes stem cell-like properties of hepatocellular carcinoma cells by targeting PTEN via PI3K/Akt pathway. Onco. Targets Ther. 11, 571–585 (2018).
Lu, J. et al. miR-106b-5p promotes renal cell carcinoma aggressiveness and stem-cell-like phenotype by activating Wnt/β-catenin signalling. Oncotarget 8, 21461–21471 (2017).
Xiang, W. et al. miR-106b-5p targets tumor suppressor gene SETD2 to inactive its function in clear cell renal cell carcinoma. Oncotarget 6, 4066–4079 (2015).
Ma, D., Zhang, Y. Y., Guo, Y. L., Li, Z. J. & Geng, L. Profiling of microRNA-mRNA reveals roles of microRNAs in cervical cancer. Chin. Med. J. (Engl.). 125, 4270–4276 (2012).
Cheng, Y. et al. MicroRNA-106b is involved in transforming growth factor β1-induced cell migration by targeting disabled homolog 2 in cervical carcinoma. J. Exp. Clin. Cancer Res. 35, 1–11 (2016).
Piao, J. et al. Substrate stiffness affects epithelial-mesenchymal transition of cervical cancer cells through miR-106b and its target protein DAB2. Int. J. Oncol. 50, 2033–2042 (2017).
Gao, D., Zhang, Y., Zhu, M., Liu, S. & Wang, X. MiRNA expression profiles of HPV-infected patients with cervical cancer in the Uyghur population in China. PLoS ONE 11, 1–12 (2016).
Liu, F. et al. MicroRNA-27b up-regulated by human papillomavirus 16 E7 promotes proliferation and suppresses apoptosis by targeting polo-like kinase2 in cervical cancer. Oncotarget 7, 19666–19679 (2016).
Bauer, L. et al. Expression profiling of stem cell-related genes in neoadjuvant-treated gastric cancer: a NOTCH2, GSK3B and β-catenin gene signature predicts survival. PLoS ONE 7, 1–9 (2012).
Espinosa, I. et al. Gene expression analysis identifies two groups of ovarian high-grade serous carcinomas with different prognosis. Mod. Pathol. 24, 846–854 (2011).
Grassilli, E. et al. Inhibition of GSK3B bypass drug resistance of p53-null colon carcinomas by enabling necroptosis in response to chemotherapy. Clin. Cancer Res. 19, 3820–3831 (2013).
Gürsel, D. B. et al. Tight regulation between cell survival and programmed cell death in GBM stem-like cells by EGFR/GSK3b/PP2A signaling. J. Neurooncol. 121, 19–29 (2015).
Ma, C. et al. GSK3β mediates the carcinogenic effect of HPV16 in cervical cancer. Sci. Rep. 5, 2–10 (2015).
Rath, G., Jawanjal, P., Salhan, S., Nalliah, M. & Dhawan, I. Clinical significance of inactivated glycogen synthase kinase 3β in HPV-associated cervical cancer: relationship with Wnt/β-Catenin pathway activation. Am. J. Reprod. Immunol. 73, 460–478 (2015).
V, B. & G, C. The angiogenic switch in carcinogenesis. Semin. Cancer Biol. 19, 329–337 (2009).
Chen, B., Zhang, C., Dong, P., Guo, Y. & Mu, N. Molecular regulation of cervical cancer growth and invasion by VEGFa. Tumor Biol. 35, 11587–11593 (2014).
Dibbens, J. A. et al. Hypoxic regulation of vascular endothelial growth factor mRNA stability requires the cooperation of multiple RNA elements. Mol. Biol. Cell 10, 907–919 (1999).
Du, K., Gong, H. & Gong, Z. Influence of serum VEGF levels on therapeutic outcome and diagnosis / prognostic value in patients with cervical. Cancer 15, 8793–8796 (2014).
Kong, D., Chen, F. & Sima, N. Focal adhesion kinases crucially regulate TGFβ-induced migration and invasion of bladder cancer cells via Src kinase and E-cadherin. Onco. Targets. Ther. 10, 1783–1792 (2017).
Ma, K. et al. PTK2-mediated degradation of ATG3 impedes cancer cells susceptible to DNA damage treatment. Autophagy 13, 579–591 (2017).
Martini, M., De Santis, M. C., Braccini, L., Gulluni, F. & Hirsch, E. PI3K/AKT signaling pathway and cancer: an updated review. Ann. Med. 46, 372–383 (2014).
Owonikoko, T. K. & Khuri, F. R. Targeting the PI3K/AKT/mTOR pathway: biomarkers of success and tribulation. Am. Soc. Clin. Oncol. Educ. Book 14, (384–399 (2013).
Bai, C. et al. Anti-proliferative effect of RCE-4 from Reineckia carnea on human cervical cancer HeLa cells by inhibiting the PI3K/Akt/mTOR signaling pathway and NF-κB activation. Naunyn Schmiedebergs Arch. Pharmacol. 389, 573–584 (2016).
Liang, J. & Slingerland, J. M. Multiple roles of the PI3K/PKB (Akt) pathway in cell cycle progression. Cell Cycle 2, 336–342 (2003).
Eke, I. & Cordes, N. Focal adhesion signaling and therapy resistance in cancer. Semin. Cancer Biol. 31, 65–75 (2015).
Gari, H. H., DeGala, G. D., Ray, R., Lucia, M. S. & Lambert, J. R. PRL-3 engages the focal adhesion pathway in triple-negative breast cancer cells to alter actin structure and substrate adhesion properties critical for cell migration and invasion. Cancer Lett. 380, 505–512 (2016).
Hao, Z. et al. MicroRNA-7 inhibits metastasis and invasion through targeting focal adhesion kinase in cervical cancer. Int. J. Clin. Exp. Med. 8, 480–487 (2015).
Jiang, H. et al. Targeting focal adhesion kinase renders pancreatic cancers responsive to checkpoint immunotherapy. Nat. Med. 22, 851–860 (2016).
Wahid, F., Shehzad, A., Khan, T. & Kim, Y. Y. MicroRNAs: synthesis, mechanism, function, and recent clinical trials. Biochim. Biophys. Acta 1803, 1231–1243 (2010).
Orang, A. V., Safaralizadeh, R. & Kazemzadeh-Bavili, M. Mechanisms of miRNA-mediated gene regulation from common downregulation to mRNA-specific upregulation. Int. J. Genomics 2014, 1–15 (2014).
Catalanotto, C., Cogoni, C. & Zardo, G. MicroRNA in control of gene expression: an overview of nuclear functions. Int. J. Mol. Sci. 17, 1712–1729 (2016).
Vasudevan, S., Tong, Y. & Steitz, J. A. Switching from repression to activation: microRNAs can up-regulate translation. Science 318, 1931–1934 (2007).
Truesdell, S. S. et al. MicroRNA-mediated mRNA translation activation in quiescent cells and oocytes involves recruitment of a nuclear microRNP. Sci. Rep. 2, 0–11 (2012).
Stevens, K. When microRNAs activate translation. Nat. Methods 5, 122–123 (2008).
Chen, C. Y. A. & Shyu, A. B. AU-rich elements: characterization and importance in mRNA degradation. Trends Biochem. Sci. 20, 465–470 (1995).
Barreau, C., Paillard, L. & Osborne, H. B. AU-rich elements and associated factors: Are there unifying principles? Nucleic Acids Res. 33, 7138–7150 (2005).
Cao, H. & Lin, R. Phosphorylation of recombinant tristetraprolin in vitro. Protein J. 27, 163–169 (2008).
Essafi-Benkhadir, K., Pouysségur, J. & Pagès, G. Implication of the ERK pathway on the post-transcriptional regulation of VEGF mRNA stability. Methods Mol. Biol. 661, 451–469 (2010).
Kurosu, T. et al. HuR keeps an angiogenic switch on by stabilising mRNA of VEGF and COX-2 in tumour endothelium. Br. J. Cancer 104, 819–829 (2011).
Chang, S. H. et al. Antagonistic function of the RNA-binding protein HuR and miR-200b in post-transcriptional regulation of vascular endothelial growth factor-a expression and angiogenesis. J. Biol. Chem. 288, 4908–4921 (2013).
Brazma, A. et al. Minimum information about a microarray experiment (MIAME)-toward standards for microarray data. Nat. Genet. 29, 365–371 (2001).
Ramasamy, A., Mondry, A., Holmes, C. C. & Altman, D. G. Key issues in conducting a meta-analysis of gene expression microarray datasets. PLoS Med. 5, 1320–1332 (2008).
Vasaikar, S. V., Straub, P., Wang, J. & Zhang, B. LinkedOmics: analyzing multi-omics data within and across 32 cancer types. Nucleic Acids Res. 46, D956–D963 (2018).
R. Core Team. R: A Language and Environment for Statistical Computing, Vol. 1 (R Foundation for Statistical Computing, 2017).
Schwarzer, G. meta: An R package for meta-analysis. R. News 7, 40–45 (2007).
Egger, M., Davey Smith, G., Schneider, M. & Minder, C. Bias in meta-analysis detected by a simple, graphical test. BMJ 315, 629–634 (1997).
Ritchie, M. E. et al. Limma powers differential expression analyses for RNA-sequencing and microarray studies. Nucleic Acids Res. 43, e47 (2015).
Dweep, H. & Gretz, N. MiRWalk2.0: a comprehensive atlas of microRNA-target interactions. Nat. Methods 12, 697 (2015).
Conway, J. R., Lex, A. & Gehlenborg, N. UpSetR: an R package for the visualization of intersecting sets and their properties. Bioinformatics 33, 2938–2940 (2017).
Jiao, X. et al. DAVID-WS: a stateful web service to facilitate gene/protein list analysis. Bioinformatics 28, 1805–1806 (2012).
Szklarczyk, D. et al. STRINGv10: protein-protein interaction networks, integrated over the tree of life. Nucleic Acids Res. 43, D447–D452 (2015).
Chin, C. H. et al. cytoHubba: identifying hub objects and sub-networks from complex interactome. BMC Syst. Biol. 8, S11 (2014).
Jia, P., Kao, C.-F., Kuo, P.-H. & Zhao, Z. A comprehensive network and pathway analysis of candidate genes in major depressive disorder. BMC Syst. Biol. 5, S12 (2011).
Hu, Y., Pan, Z., Hu, Y., Zhang, L. & Wang, J. Network and pathway-based analyses of genes associated with Parkinson’s disease. Mol. Neurobiol. 54, 4452–4465 (2017).
Rhodes, D. R. et al. ONCOMINE: A Cancer Microarray Database and Integrated Data-Mining Platform. Neoplasia 6, 1–6 (2004).
Kozomara, A. & Griffiths-Jones, S. MiRBase: annotating high confidence microRNAs using deep sequencing data. Nucleic Acids Res. 42, 68–73 (2014).
Rehmsmeier, M., Steffen, P., Höchsmann, M., Giegerich, R. & Ho, M. Fast and effective prediction of microRNA / target duplexes. RNA 10, 1507–1517(2004).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Edited by: M.V. Niklison Chirou
Electronic supplementary material
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Yi, Y., Liu, Y., Wu, W. et al. The role of miR-106p-5p in cervical cancer: from expression to molecular mechanism. Cell Death Discov. 4, 94 (2018). https://doi.org/10.1038/s41420-018-0096-8
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41420-018-0096-8
This article is cited by
-
Epigenetic regulation in major depression and other stress-related disorders: molecular mechanisms, clinical relevance and therapeutic potential
Signal Transduction and Targeted Therapy (2023)
-
MiR-106b-5p Promotes Malignant Behaviors of Cervical Squamous Cell Carcinoma Cells by Targeting TIMP2
Reproductive Sciences (2022)
-
Cervical cancer development, chemoresistance, and therapy: a snapshot of involvement of microRNA
Molecular and Cellular Biochemistry (2021)
